#ScraperAPI
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
The “We are the 99%” Tumblr blog became the slogan for the Occupy Wall Street movement.
Text
Automate The Process Of Textual Data Extraction From Images?

Automate Text Extraction from Images with Ease!
Extracting textual data from images manually can be time-consuming and error-prone. But with automation, businesses can streamline data extraction, enhance accuracy, and boost efficiency!
By leveraging AI-powered Optical Character Recognition (OCR) and advanced data processing techniques, you can convert image-based text into structured, editable formats seamlessly.
0 notes
Text
Scrape Shopee And Lazada Store Data Across Southeast Asia For Tailored Marketing Strategies
Scrape Shopee and Lazada Store Data to gain competitive intelligence, optimize pricing, understand market trends, and make informed decisions for strategic business growth.
Know More: https://www.iwebdatascraping.com/scrape-shopee-and-lazada-store-data-across-southeast-asia.php
#ScrapeShopeeAndLazadaStoreData#ScrapeShopeeproductdata#ScrapeLazadaproductdata#ShopeeProductDataScraper#ShopeeAndLazadaProductDataScraping#LazadaProductDataScraper#Lazada ScraperAPI#ExtractShopeeAndLazadaStoreData#ShopeeAndLazadaStoreDataExtractor
0 notes
Text
What is web scraping and what tools to use for web scraping?
Web scraping is the process of extracting data from websites automatically using software scripts. This technique is widely used for data mining, price monitoring, sentiment analysis, market research and more.
BeautifulSoup
Scrapy
Selenium
Requests & LXML
ScraperAPI
Octoparse
Apify
Data Miner
Web Scraper
Puppeteer
Playwright
1 note
·
View note
Text
Top 10 Rotating Proxies for Web Scraping Without Getting Banned

Web scraping is an essential tool for gathering data from websites, whether for business intelligence, market research, or competitive analysis. However, scraping comes with its own set of challenges, particularly the risk of getting your IP address banned. This is where rotating proxies come into play. In this article, we'll explore the top 10 rotating proxies that help ensure smooth and undetected web scraping. We'll also cover what rotating proxies are, why they're crucial for web scraping, and how to choose the best one for your needs. What are Rotating Proxies? Definition and How They Work Rotating proxies are a type of proxy server that assigns a new IP address from a pool of available IPs for each connection request or at set intervals. This makes it difficult for websites to detect and block your scraping activities since your IP changes regularly, mimicking the behavior of multiple users. Types of Rotating Proxies There are several types of rotating proxies, each suitable for different scraping needs: - Datacenter Proxies: These are hosted on powerful servers in data centers. They are fast but can be easier to detect as non-residential. - Residential Proxies: These proxies use real IP addresses from residential ISPs, making them more difficult to detect but generally slower than datacenter proxies. - Mobile Proxies: These use IPs from mobile carriers, providing a high level of anonymity and are best for avoiding bans but can be more expensive. Why Use Rotating Proxies for Web Scraping? Benefits of Rotating Proxies Rotating proxies provide several benefits when it comes to web scraping: - Avoid IP Bans: By rotating IPs, you reduce the likelihood of being detected and banned by websites. - Improve Anonymity: Rotating proxies help maintain anonymity, making it appear as though requests are coming from different users. - Efficient Data Collection: They allow for continuous scraping without interruptions, maximizing the efficiency of data collection. Avoiding IP Bans and Restrictions Websites often set rate limits or block repeated requests from the same IP address. Rotating proxies can bypass these restrictions by constantly changing IP addresses, making it challenging for websites to identify and block scrapers. Factors to Consider When Choosing Rotating Proxies for Web Scraping Speed and Reliability For efficient web scraping, it's crucial to choose rotating proxies that offer high speed and reliability. Slow proxies can hinder scraping speed, making data collection inefficient. IP Pool Size and Rotation Frequency A large IP pool with frequent rotations is ideal. This helps ensure that IP addresses are not reused too quickly, reducing the chance of detection. Anonymity and Security Features Ensure that the proxy provider offers high anonymity levels, such as no logging policies and strong encryption, to safeguard your scraping activities. Top 10 Rotating Proxies for Web Scraping Without Getting Banned 1. Bright Data (Formerly Luminati) - Features: Massive IP pool, residential and mobile proxies, session control. - Pros and Cons: Highly reliable and versatile but can be expensive. 2. Smartproxy - Features: Affordable, user-friendly dashboard, diverse proxy pool. - Pros and Cons: Excellent for beginners, but lacks some advanced features. 3. ScraperAPI - Features: Handles IP rotation, CAPTCHA solving, and more. - Pros and Cons: Easy integration with code but limited to certain scraping needs. 4. Oxylabs - Features: Large residential and datacenter proxy pool, high performance. - Pros and Cons: Great for enterprise needs, but a higher price point. 5. ProxyMesh - Features: Reliable rotating proxies with regional targeting. - Pros and Cons: Good for small-scale scraping, but not the best for high-volume needs. 6. GeoSurf - Features: Focus on residential proxies, advanced dashboard. - Pros and Cons: High-quality proxies but slightly more expensive. 7. Storm Proxies - Features: Affordable rotating proxies, easy to use. - Pros and Cons: Good for beginners, but IP pool size is limited. 8. NetNut - Features: Offers both static and rotating residential proxies, high speed. - Pros and Cons: Fast and reliable, but requires a minimum commitment. 9. Shifter (Formerly Microleaves) - Features: Large rotating proxy pool, unlimited bandwidth. - Pros and Cons: Suitable for large-scale scraping, but the setup can be complex. 10. Crawlera by Scrapinghub - Features: Smart proxy rotation, built-in bot detection bypass. - Pros and Cons: Excellent for advanced scraping needs, but has a learning curve. Best Practices for Using Rotating Proxies in Web Scraping Maintaining Anonymity Always use proxies that offer high anonymity and avoid those that log your activity. This is crucial for safe and secure scraping. Optimizing Scraping Speed and Efficiency Select proxies close to the target server's location and ensure you optimize request rates to avoid detection. Respecting Website Terms of Service While scraping is a powerful tool, it’s essential to respect each website's terms of service to avoid legal issues. Pros and Cons of Using Rotating Proxies Advantages - Prevents IP bans and maintains anonymity. - Allows for continuous and efficient data collection. Disadvantages - Can be more expensive than static proxies. - Some providers may have limitations on bandwidth or IP pool size. Frequently Asked Questions (FAQs) What makes rotating proxies better than static proxies for web scraping? Rotating proxies change IPs frequently, making them less likely to be banned compared to static proxies that use a single IP address. How often should IP addresses rotate when scraping data? The rotation frequency depends on the target website’s rate limit and anti-scraping measures, but a typical range is every few seconds to minutes. Are rotating proxies legal to use for web scraping? Yes, rotating proxies are legal, but the legality of scraping depends on the website's terms of service and how you use the data. Can I use free rotating proxies for scraping? Free rotating proxies are available, but they often lack reliability, speed, and security compared to paid options. How can I avoid being detected while using rotating proxies? To avoid detection, use proxies with high anonymity, limit request rates, and mimic human behavior. Conclusion Rotating proxies are invaluable for web scraping, providing a way to avoid IP bans, improve data collection efficiency, and maintain anonymity. This article has covered the top 10 rotating proxies for web scraping, along with their features, pros, and cons. When choosing a proxy, consider factors like speed, IP pool size, and security to find the best fit for your needs. Remember to always scrape responsibly and in accordance with legal guidelines. Read the full article
0 notes
Text
Scrape Google Results - Google Scraping Services

In today's data-driven world, access to vast amounts of information is crucial for businesses, researchers, and developers. Google, being the world's most popular search engine, is often the go-to source for information. However, extracting data directly from Google search results can be challenging due to its restrictions and ever-evolving algorithms. This is where Google scraping services come into play.
What is Google Scraping?
Google scraping involves extracting data from Google's search engine results pages (SERPs). This can include a variety of data types, such as URLs, page titles, meta descriptions, and snippets of content. By automating the process of gathering this data, users can save time and obtain large datasets for analysis or other purposes.
Why Scrape Google?
The reasons for scraping Google are diverse and can include:
Market Research: Companies can analyze competitors' SEO strategies, monitor market trends, and gather insights into customer preferences.
SEO Analysis: Scraping Google allows SEO professionals to track keyword rankings, discover backlink opportunities, and analyze SERP features like featured snippets and knowledge panels.
Content Aggregation: Developers can aggregate news articles, blog posts, or other types of content from multiple sources for content curation or research.
Academic Research: Researchers can gather large datasets for linguistic analysis, sentiment analysis, or other academic pursuits.
Challenges in Scraping Google
Despite its potential benefits, scraping Google is not straightforward due to several challenges:
Legal and Ethical Considerations: Google’s terms of service prohibit scraping their results. Violating these terms can lead to IP bans or other penalties. It's crucial to consider the legal implications and ensure compliance with Google's policies and relevant laws.
Technical Barriers: Google employs sophisticated mechanisms to detect and block scraping bots, including IP tracking, CAPTCHA challenges, and rate limiting.
Dynamic Content: Google's SERPs are highly dynamic, with features like local packs, image carousels, and video results. Extracting data from these components can be complex.
Google Scraping Services: Solutions to the Challenges
Several services specialize in scraping Google, providing tools and infrastructure to overcome the challenges mentioned. Here are a few popular options:
1. ScraperAPI
ScraperAPI is a robust tool that handles proxy management, browser rendering, and CAPTCHA solving. It is designed to scrape even the most complex pages without being blocked. ScraperAPI supports various programming languages and provides an easy-to-use API for seamless integration into your projects.
2. Zenserp
Zenserp offers a powerful and straightforward API specifically for scraping Google search results. It supports various result types, including organic results, images, and videos. Zenserp manages proxies and CAPTCHA solving, ensuring uninterrupted scraping activities.
3. Bright Data (formerly Luminati)
Bright Data provides a vast proxy network and advanced scraping tools to extract data from Google. With its residential and mobile proxies, users can mimic genuine user behavior to bypass Google's anti-scraping measures effectively. Bright Data also offers tools for data collection and analysis.
4. Apify
Apify provides a versatile platform for web scraping and automation. It includes ready-made actors (pre-configured scrapers) for Google search results, making it easy to start scraping without extensive setup. Apify also offers custom scraping solutions for more complex needs.
5. SerpApi
SerpApi is a specialized API that allows users to scrape Google search results with ease. It supports a wide range of result types and includes features for local and international searches. SerpApi handles proxy rotation and CAPTCHA solving, ensuring high success rates in data extraction.
Best Practices for Scraping Google
To scrape Google effectively and ethically, consider the following best practices:
Respect Google's Terms of Service: Always review and adhere to Google’s terms and conditions. Avoid scraping methods that could lead to bans or legal issues.
Use Proxies and Rotate IPs: To avoid detection, use a proxy service and rotate your IP addresses regularly. This helps distribute the requests and mimics genuine user behavior.
Implement Delays and Throttling: To reduce the risk of being flagged as a bot, introduce random delays between requests and limit the number of requests per minute.
Stay Updated: Google frequently updates its SERP structure and anti-scraping measures. Keep your scraping tools and techniques up-to-date to ensure continued effectiveness.
0 notes
Text
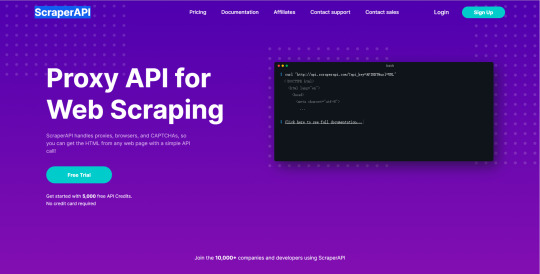
ScraperAPI handles proxy rotation, browsers, and CAPTCHAs so developers can scrape any page with a single API call. Web scraping with 5,000 free API calls!
0 notes
Photo

Scraperapi Voucher Codes & Coupons. Get The Lowest Price
As more of our lives are being lived online, the need for tools to manage what information we spread and to protect our anonymity while browsing is becoming increasingly important. Proxies have been with us for some time and are commonly used tools to keep web scrapers and users’ browsing activities private.
While there is a wide class of different proxy tools, residential proxies are some of the most powerful. This type of proxy can deliver higher levels of reliability and security for web scrapers looking to extract data from difficult to scrape sites. So that, ScraperAPI is proud of supplying the quality proxy tools for customers.
Don't hesitate to use exclusive codes here: https://www.couponupto.com/coupons/scraperapi
0 notes
Text
Cómo conseguir generación de leads con web scraping
La tecnología está cambiando el rostro del mundo empresarial y haciendo que las tácticas de marketing críticas y la información empresarial sean de fácil acceso. Una de esas tácticas que ha estado circulando por la generación de leads de calidad es el web scraping.
El web scraping no es más que recopilar información valiosa de páginas web y reunirlas todas para el uso futuro. Si alguna vez has copiado contenido de palabras de un sitio web y luego lo has utilizado para tu propósito, tú, también has utilizado el proceso de raspado web, aunque a un nivel minúsculo. Este artículo habla en detalle sobre el proceso de web scraping y su impacto en la generación de leads de calidad de alto-valor.
Tabla de contenido
1. Introducción al web scraping
Conceptos básicos del web scraping
Procesos de web scraping
Industrias beneficiadas por el web scraping
2. Cómo generar leads con Web Scraping
3. Otros beneficios de Web Scraping
4. Conclusiones
Introducción al web scraping
Conceptos básicos del web scraping
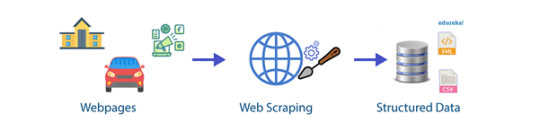
El flujo básico de los procesos de web scraping
¿Qué es?
Web scraping, también conocido como Recolección en la Web y Extracción de datos web, es el proceso de extraer o copiar datos específicos o información valiosa de sitios web y depositarlos en una base de datos central u hoja de cálculo para investigación, análisis o generación de prospectos más adelante. Si bien el web scraping también se puede realizar manualmente, las empresas utilizan cada vez más bots o rastreadores web para implementar un proceso automatizado.
#Tip: Yellow Pages es uno de los directorios de empresas más grandes de la web, especialmente en los EE. UU. Es la mejor vía para scrapear contactos como nombres, direcciones, números de teléfono y correos electrónicos para la generación de clientes potenciales.
Procesos de web scraping
Web Scraping es un proceso extremadamente simple e involucra solo dos componentes- un web crawler(rastreador web) y un web scraper(raspador web). Y gracias a la tecnología ninja, estos los realizan por bots de IA con una intervención manual mínima o nula. Mientras que el crawler, generalmente llamado un "spider(araña)", explora varias páginas web para indexar y buscar contenido siguiendo los enlaces, el scraper extrae rápidamente la información exacta.
El proceso comienza cuando el crawler accede a la World Wide Web directamente a través de un navegador y recupera las páginas descargándolas. El segundo proceso incluye la extracción en la que el web scraper copia los datos en una hoja de cálculo y los formatea en segmentos que no se pueden procesar para su posterior procesamiento.
El diseño y el uso de los raspadores web varían ampliamente, depende del proyecto y su propósito.
Industrias beneficiadas por el web scraping
Reclutamiento
Comercio electrónico
Industria minorista
Entretenimiento
Belleza y estilo de vida
Bienes raíces
Ciencia de los datos
Finanzas
Los minoristas de moda informan a los diseñadores sobre las próximas tendencias basándose en información extraída, los inversores cronometran sus posiciones en acciones y los equipos de marketing abruman a la competencia con información detallada. Un ejemplo generalizado de web scraping es extraer nombres, números de teléfono, ubicaciones e ID de correo electrónico de los sitios de publicación de trabajos por parte de los reclutadores de recursos humanos.
#Tip: Después de COVID 19, la generación de datos en el sector de la salud se ha multiplicado exponencialmente, debido a que el web scraping en la industria de la salud y farmacéutica relacionada ha aumentado en un 57%. Las empresas están analizando datos para diseñar nuevas políticas, desarrollar vacunas, ofrecer mejores soluciones de salud pública, etc. para transformar las oportunidades comerciales.
Web Scraping y Generación de Leads
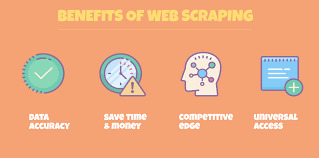
Beneficios de Web Scraping para la generación de leads
#Realidad: 79% de los especialistas en marketing ven el web scraping como una fuente muy beneficiosa de generación de leads.
Los analistas de datos y los expertos en negocios coinciden unánimemente en el hecho de que utilizar Web Scraping mediante la aplicación de proxies residenciales (los proxies residenciales le permiten elegir una ubicación específica y navegar por la web como un usuario real en esa área) es una de las formas más beneficiosas de generar clientes potenciales calificados de ventas para tu negocio. Diseñar un raspador de clientes potenciales único para generar clientes potenciales puede ser mucho más rentable y rentable para generar rápidamente clientes potenciales de calidad.
El web scraping juega un papel importante en la generación de leads mediante dos pasos:
Identificar fuentes
El primer paso para todas las empresas en la generación de leads es agilizar el proceso. ¿Qué fuentes vas a utilizar? ¿Quién es tu público objetivo? ¿A qué ubicación geográfica vas a apuntar? ¿Cuál es tu presupuesto de marketing? ¿Cuáles son los objetivos de tu marca? ¿Qué imagen quieres establecer a través de tu marca? ¿Qué tipo de marketing quieres seguir? ¿Quiénes son tus competidores?
Decodificar la respuesta a estas preguntas fundamentales y diseñar un bot raspador específicamente para cumplir con tus requisitos te llevará a extraer y acceder a información relativa de alta-calidad.
Tip: Si la información de los clientes de tus competidores está disponible públicamente, puedes raspar sus sitios web para su demografía. Esto te daría una buena visualización de quiénes son tus clientes potenciales y qué ofrecen actualmente.
Extraer datos
Después de descubrir las preguntas fundamentales para administrar un negocio exitoso, el siguiente paso es extraer los datos más relevantes, en tiempo real, procesables y de alto rendimiento para diseñar campañas de estratégicas de marketing para obtener el máximo beneficio. Sin embargo, hay dos formas posibles de hacerlo-
A) Optar por una herramienta de generación de leads
Uno de los proveedores de datos B2B más comunes, DataCaptive, ofrece un servicio de generación de lead y otras soluciones de marketing para brindar un soporte incomparable a tu negocio y aumentar el ROI por 4.
B) Usar herramientas de scraping
Octoparse es uno de los proveedores de herramientas de scraping más destacados que te proporciona información valiosa para maximizar el proceso de generación de clientes potenciales. Nuestra flexibilidad y escalabilidad de web scraping aseguran cumplir con los parámetros de tu proyecto con facilidad.
Nuestro proceso de raspado web de tres pasos incluye-
En el primer paso, personalizamos los raspadores que son únicos y complementan los requisitos de tu proyecto para identificar y extraer datos exactos que darán los resultados más beneficiosos. También puedes registrar el sitio web o las páginas web que deseas raspar específicamente.
Los raspadores recuperan los datos en formato HTML. A continuación, eliminamos lo que rodea a los datos y los analizamos para extraer los datos que desees. Los datos pueden ser simples o complejos, según el proyecto y su demanda.
En el tercer y último proceso, los datos se formatean según la demanda exacta del proyecto y se almacenan en consecuencia.
Otros beneficios de Web Scraping
Comparación de precios
Tener acceso al precio actual y en tiempo real de los servicios relacionados ofrecidos por tus competidores puede revolucionar tus procedimientos comerciales diarios y aumentar la visibilidad de tu marca. El web scraping es la solución de un solo paso para determinar soluciones de precios automáticas y analizar perspectivas rentables.
Analizar sentimiento / psicología del comprador
El análisis de sentimientos o persona del comprador ayuda a las marcas a comprender a su clientela mediante el análisis de su comportamiento de compra, historial de navegación y participación en línea. Los datos extraídos de la Web desempeñan un papel clave en la erradicación de interpretaciones sesgadas mediante la recopilación y el análisis de datos de compradores relevantes y perspicaces.
Marketing- contenido, redes sociales y otros medios digitales
El raspado web es la solución definitiva para monitorear, agregar y analizar las historias más críticas de tu industria y generar contenido a tu alrededor para obtener respuestas más impactantes.
Inversión de las empresas
Datos web diseñados explícitamente para que los inversores estimen los fundamentos de la empresa y el gobierno y analicen las perspectivas de las presentaciones ante la SEC y comprendan los escenarios del mercado para tomar decisiones de inversión sólidas.
Investigación de mercado
El web scraping está haciendo que el proceso de investigación de mercado e inteligencia empresarial sea aún más crítico en todo el mundo al proporcionar datos de alta calidad, gran volumen y muy perspicaz de todas las formas y tamaños.
Conclusiones
Web scraping es el proceso de seleccionar páginas web en busca de contenido relevante y descargarlas en una hoja de cálculo para el uso posterior con un rastreador web y un raspador web.
Las industrias más destacadas para practicar el web scraping para generar lead e impulsar las ventas son la ciencia de datos, bienes raíces, el marketing digital, el entretenimiento, la educación, el comercio minorista, reclutamiento y la belleza y estilo de vida, entre muchas otras.
Después de la pandemia de COVD 19, la industria farmacéutica y de la salud ha sido testigo de un aumento significativo en su porcentaje de raspado web debido a su aumento continuo y exponencial en la generación de datos.
Además de la generación de leads, el web scraping también es beneficioso para la investigación de mercado, la creación de contenido, la planificación de inversiones, el análisis de la competencia, etc.
Algunas de las mejores y más utilizadas herramientas de raspado web o proveedores de herramientas son Octoparse, ScraperAPI, ScrapeSimple, Parsehub, Scrappy, Diffbot y Cheerio.
1 note
·
View note
Text
Free data extractor

FREE DATA EXTRACTOR MANUAL
FREE DATA EXTRACTOR CODE
The best part is that their platform is self-service, so you can benefit from their development resources. They have an easy solution that has been worked on by their developers for a long time, which means that they have done all the hard work on their end so that you can make the most of a streamlined service on yours.
FREE DATA EXTRACTOR CODE
This way, you can get quality data in just a couple of minutes from any public website, and the best part is that you can collect it by yourself, and don’t need a code to do so. With their data collection strategies, you can automate and streamline your data collection with maximum flexibility, and zero infrastructure. They can also help you with proxy infrastructure, so you can virtually do everything that you need to under one roof. They say they can help their clients with pre-made data sets, as well as data collection, so that you can collect all of the public web data that your company needs, without worrying about whether your competition has caught onto your business strategies are not. There are many reasons why you would want to use Bright Data for your web scraping, especially the fact that they are the world’s number one when it comes to being a massive web data platform. In addition, it is very affordable and only charges for successful requests. This allows you to have unlimited access to the data that interests you. ScraperAPI was designed to protect against scraping and bot systems. All you need to do is to parse and process the data.Īlthough it is not an automated tool, it takes care of an essential part of scraping. This makes it easy to access data from social media sites with difficult to scrap. It handles headless browsers, bypasses Captchas, and provides proxies. ScraperAPI is a proxy API that allows web scraping. Phantombuster can also accept requests and interact with prospects to increase their visibility on the internet. Phantombuster is a data extraction and social media scraping tool that helps sales and marketing teams of all sizes to collect information from LinkedIn and Instagram.Īdministrators can also schedule and automate actions like following profiles, liking posts, and sending customized messages. Here’s a quick look at the best social media scraper tools: Our top social media scraper list has been independently tested and carefully selected based on past users’ experience and effectiveness in data extraction. So that you have a complete list of the best, we will be discussing only the tried and tested. Many social media scraping tools are on the market for sites like Facebook, Twitter, and Instagram. We will be sharing the best social media scraping tools that you can use to scrape social media sites in this article.ĥ.1) Related Reading Best Social Media Scraping Tools 2022 Web scrapers that support social media platforms will be the best.
FREE DATA EXTRACTOR MANUAL
This is relevant not only to marketing research and social studies but also for research.Īlthough social media platforms are very important sources of data, particularly when it comes to human-generated content, extracting data from these platforms can be difficult, especially if you need to access large amounts of data that would not be possible with manual data extraction methods. Some websites that provide big data on human-generated content are social media sites. With the internet’s advent, data has become so readily available that it is difficult for people to know what to do. Unfortunately, it will be necessary to spend large sums of money to access data for your research and business in many cases. The availability of data was a major issue in research in the past. Here you can find the best social media scraping tools on the market. The best social media scraper tool in 2022, as found in our independent testing, is Phantombuster!
1 note
·
View note
Text
データ集録をより便利に:10の一般的なデータ集録ツール
今日の急速に発展するネットワーク時代には、情報を検索するだけでなく、必要なデータ情報を迅速に収集し、Web サイト、データベース、オンライン ショップ、ドキュメントなど、インターネット情報に対する新たな需要を生み出しています。 データを必要とするのは、データ利用に対する強い需要がデータ集録ツールの生成につながっているところです。
では、今日の市場では、どのような信頼できるデータ集録ツールがあるのでしょうか。 この記事では、詳細な紹介を行います。
1. ScrapeStorm
ポストキャプチャは、人工知能技術に基づいて、元Google検索技術チームによって開発された次世代のWebキャプチャソフトウェアです。 強力で操作しやすいソフトウェアは、プログラミングベースのない製品、運用、販売、金融、ニュース、電子商取引、データ分析の実務家だけでなく、政府機関や学術研究などのユーザーに合わせた製品です。 これは、フローチャートモードとインテリジェントモードの2種類に分けら��、フローチャートモードは、単にソフトウェアプロンプトに従ってページ内のクリック操作を行い、完全にWebブラウジングの考え方に完全に準拠し、複雑な収集ルールを生成するために簡単なステップ、インテリジェント識別アルゴリズムと組み合わせることで、任意のWebページのデータを簡単に収集することができます。 インテリジェントモードは人工知能アルゴリズムに基づいて構築され、リストデータ、テーブルデータ、ページングボタンをインテリジェントに識別するためにURLを入力するだけで、ワンクリックで取得ルールを設定する必要はありません。
2. Octoparse
Octoparseは、京東、天猫、フォルクスワーゲンレビューなどの人気収集サイトに組み込まれ、テンプレート設定パラメータを参照して、ウェブサイト公開データを取得することができます。 さらに、8 爪の魚 API を使用すると、リモート コントロール タスクの開始と停止など、8 爪の魚のタスク情報と収集されたデータを取得し、データ収集とアーカイブを実現できます。 また、ビジネスを自動化するために、社内のさまざまな管理プラットフォームとつながることもできます。
3. ScraperAPI
ScraperAPI を使用すると、取得する URL が API キーと共に API に送信され、API がクロールする URL から HTML 応答を返すだけで、手に入れるのは困難です。 同時に、ScraperAPIはBeautifulSoupクローラコードベースの多くの機能を統合し、プロキシ、クッキー設定、確認コード認識などの機能の数十万を提供し、ユーザーはURLを渡すだけで、パラメータはいくつかの関連する設定に関連し、残りはユーザーを助けるために彼によって行われます。 彼はパッケージ化された集録コンポーネントのようなものです。
4. Apify
Apify プラットフォームは、大規模で高性能な Web クロールと自動化のニーズを満たすように設計されています。 コンソール Web インターフェイス、Apify の API、または JavaScript および Python API クライアントを介して、コンピューティング インスタンス、便利な要求と結果ストア、プロキシ、スケジューリング、Webhook などに簡単にアクセスできます。
5. ParseHub
ParseHubは無料のウェブグラブツールです。 ParseHub を使用すると、Web グラブ スクリプトの障壁なしに、オンラインの e コマース プラットフォームからデータを簡単に取得できます。 適切なメトリックを解決することで、カテゴリ レベルまたはサブカテゴリ レベルでスコープをドリルダウンして、企業が競合企業と比較したポートフォリオを評価するのに役立ちます。 また、ユーザーがブラウザ上のすべての操作を実装するのに役立ちますが、ユーザーのデータ量が少ない場合や、クラウド ホスティングなどの機能を必要としない場合は、非常に適しています。
1 note
·
View note
Text

Scrape Shopee And Lazada Store Data Across Southeast Asia For Tailored Marketing Strategies
Scrape Shopee and Lazada Store Data to gain competitive intelligence, optimize pricing, understand market trends, and make informed decisions for strategic business growth.
Know More: https://www.iwebdatascraping.com/scrape-shopee-and-lazada-store-data-across-southeast-asia.php
#ScrapeShopeeAndLazadaStoreData#ScrapeShopeeproductdata#ScrapeLazadaproductdata#ShopeeProductDataScraper#ShopeeAndLazadaProductDataScraping#LazadaProductDataScraper#Lazada ScraperAPI#ExtractShopeeAndLazadaStoreData
0 notes
Text
Web Scraping API Services | Gather Data in Real-Time | iWeb Scraping USA
Use real-time web data scraping API Services in USA, UK, UAE from iWeb Scraping to access data from finance, e-commerce, and stock websites to get clean & well-structured data.
1 note
·
View note
Text
Scrape Shopee And Lazada Store Data Across Southeast Asia For Tailored Marketing Strategies
Scrape Shopee And Lazada Store Data Across Southeast Asia For Tailored Marketing Strategies

In the ever-evolving Southeast Asian e-commerce sphere, securing a competitive advantage demands profound insights into market trends, competitor tactics, and consumer preferences. For enterprises navigating the markets of Singapore, Malaysia, Thailand, the Philippines, and Indonesia, leveraging data through web scraping has emerged as an indispensable asset. This article delves into the crucial advantages and importance of extracting Shopee and Lazada store data within these regions. By harnessing the power of web scraping, businesses can gain a strategic edge by staying informed about pricing dynamics, product availability, and emerging market trends. Analyzing and interpreting this data proves invaluable, allowing companies to tailor their strategies and offerings to the unique demands of each Southeast Asian market, ultimately fostering success in this dynamic and diverse e-commerce landscape
List of Data Fields
Product Name
Product Description
SKU
Brand
Category
Sub Category
Product Images
Price
Stock Levels
Seller Details
Reviews
Ratings
Trends and Analytics
Competitor Analysis
About Shopee and Lazada
About Shopee
Shopee, launched in 2015 by Sea Limited, is a leading e-commerce platform in Southeast Asia. Boasting a user-friendly interface and a diverse product range, Shopee operates across multiple countries, including Singapore, Malaysia, Thailand, Indonesia, and the Philippines. Known for its mobile-centric approach, frequent promotions, and secure payment options, Shopee has become a pivotal player in the region's online retail landscape, offering a dynamic marketplace for individual sellers and established businesses. Scrape Shopee product data to gain comprehensive insights into pricing trends, product availability, and customer reviews, enabling businesses to make informed decisions and stay competitive in the dynamic e-commerce landscape of Southeast Asia.
About Lazada
Lazada, established in 2012, is a prominent e-commerce platform in Southeast Asia. As part of the Alibaba Group, it serves countries such as Singapore, Malaysia, Thailand, Indonesia, and the Philippines. Lazada provides a diverse marketplace for sellers, offering various products from electronics and fashion to household goods. Known for its regular promotions and secure payment options, Lazada has become a key player in the region's online retail scene, contributing to the growth of e-commerce by providing a convenient and accessible platform for buyers and sellers alike. Scrape Lazada product data to unlock valuable insights into market trends, competitor strategies, and consumer preferences across Southeast Asia. Analyzing pricing dynamics, product availability, and customer reviews enables businesses to refine their strategies, optimize product offerings, and stay ahead in the highly competitive e-commerce landscape.
Market Dynamics in Singapore: Navigating E-commerce Trends
For businesses operating in Singapore, the strategic scraping of Shopee and Lazada data reveals crucial insights into the local e-commerce landscape. By delving into consumer preferences, identifying popular products, and understanding pricing dynamics, businesses can refine their strategies to optimize offerings and maintain a competitive edge in this dynamic market.
Navigating the Evolving Malaysian E-commerce Terrain
In Malaysia, the e-commerce market is undergoing rapid evolution. Employing e-commerce data scraping techniques on platforms like Shopee and Lazada allows businesses to track competitors, closely monitor pricing fluctuations, and pinpoint growth opportunities. This valuable insight proves instrumental in adapting marketing strategies to align with the unique demands of Malaysian consumers.
Tapping into Thriving E-commerce Trends in Thailand
Thailand's e-commerce sector is experiencing a significant boom, giving businesses growth opportunities. Leveraging scraped data using an e-commerce data scraper provides a comprehensive understanding of the market dynamics. It includes analyzing customer reviews, tracking product availability, and monitoring promotions on Shopee and Lazada. These insights contribute to a strategic approach tailored to the dynamic nature of the Thai market.
Philippines: A Growing E-commerce Hub

With the Philippines witnessing a surge in online shopping, staying informed about market dynamics is crucial for businesses. Scraping Shopee and Lazada data offers valuable information on shifting consumer preferences. Businesses can tailor their offerings to meet the evolving needs of Filipino shoppers, ensuring relevance and competitiveness in this burgeoning e-commerce hub.
Insights into Indonesia's Diverse E-commerce Landscape
Indonesia's expansive and diverse market demands businesses to stay agile and well-informed. Collecting data using e-commerce data scraping services proves invaluable in understanding regional preferences, analyzing competitor strategies, and identifying potential areas for expansion. This detailed insight allows businesses to navigate Indonesia's diverse e-commerce landscape precisely, ensuring a strategic and adaptive market approach.
Why Scrape Shoppe and Lazada Store Data?

Competitive Intelligence: By scraping Shopee and Lazada store data, businesses gain valuable insights into competitors' strategies. It includes pricing structures, product offerings, and promotional tactics, empowering companies to adjust their strategies for greater competitiveness.
Market Trend Analysis: The scraped data provides a real-time pulse of market trends. It includes popular products, emerging categories, and shifting consumer preferences, allowing businesses to adapt and capitalize on evolving market dynamics.
Pricing Optimization: Scrutinizing pricing data using Shopee Product Data Scraper helps businesses optimize their pricing strategies. It involves understanding how competitors price similar products, identifying opportunities for discounts, and ensuring that prices align with market expectations.
Consumer Behavior Understanding: Analyzing customer reviews, ratings, and product preferences from Shopee and Lazada enables businesses to understand consumer behavior. This knowledge helps in tailoring products and marketing strategies to meet the specific needs and expectations of the target audience.
Supply Chain Management: Scraping data regarding product availability and stock levels assists in efficient supply chain management. Businesses can ensure they have adequate stock to meet demand, avoid stockouts, and optimize inventory levels based on market demand.
Strategic Marketing: Insights into trending products and popular categories using Lazada Product Data Scraper guide businesses in crafting targeted marketing campaigns. Whether leveraging popular keywords or aligning promotions with high-demand items, scraping data helps in strategic and practical marketing efforts.
Enhanced Customer Experience: Understanding customer reviews and feedback helps identify improvement areas. Businesses can address concerns, enhance product features, and tailor their services to provide a superior customer experience, fostering brand loyalty.
Adaptation to Regulatory Changes: Monitoring platform policies and updates through scraped data ensures businesses comply with regulatory changes. This adaptability is crucial for maintaining a stable and legal operation within the e-commerce ecosystem.
Expansion Opportunities: Scraping data aids in identifying potential areas for business expansion. Insights into regional preferences, competitor presence, and market gaps assist in making informed decisions about entering new markets or diversifying product offerings.
Dynamic Pricing Strategies: Real-time pricing information from Shopee and Lazada allows businesses to implement dynamic pricing strategies. It could involve adjusting prices based on demand, competitor actions, or seasonal trends to maximize revenue and stay agile in the market.
Early Warning System: The ability to monitor stock levels, pricing changes, and customer sentiments provides an early warning system for potential challenges. Businesses can proactively address issues like stock shortages or negative reviews before they escalate.
Data-Driven Decision-Making: Scraping Shopee and Lazada store data empowers businesses to make informed, data-driven decisions. From marketing and sales strategies to inventory management, this data is a foundational element for strategic planning and execution.
Conclusion:
Scraping Shopee and Lazada store data across Southeast Asia is a strategic move for businesses aiming to thrive in the competitive e-commerce landscape. With insights into market trends, consumer behavior, and competitor strategies, businesses can make informed decisions and position themselves for success in these dynamic markets.
Know More: https://www.iwebdatascraping.com/scrape-shopee-and-lazada-store-data-across-southeast-asia.php
#ScrapeShopeeAndLazadaStoreData#ScrapeShopeeproductdata#ScrapeLazadaproductdata#ShopeeProductDataScraper#ShopeeAndLazadaProductDataScraping#LazadaProductDataScraper#Lazada ScraperAPI#ExtractShopeeAndLazadaStoreData#ShopeeAndLazadaStoreDataExtractor
0 notes
Text
Which are The Best Scraping Tools For Amazon Web Data Extraction?

Web scraping is the method of extracting data from the internet. You'll usually want to analyze, evaluate, reformat, or transfer data into a worksheet after you have it.
Web extracting has numerous applications, but we'll emphasize just a couple today: obtaining service and product information from markets. Retailers utilize this information to gain a better understanding of the business and its competitors.
In reality, the benefits can be enormous. To oppose your competitor's approach, you must first understand the concept. Knowing their rates, for instance, can provide you an advantage in sales by offering a special offer or selling at low rate. Amazon is one of the most popular online shopping destinations. People use it to order groceries, books, laptops, or even hosting plan solutions daily.
Amazon has the largest database for items, reviews, retailers, and market dynamics as a prominent e-commerce site. It's a gold mine for website data scrapers.
We'll look at the top APIs for scraping Amazon data without getting prohibited. This blog will save your precious time if you're looking for the finest tool to extract data from Amazon.
Let's get started!
Reasons Behind Scraping Amazon Data
If you try to sell any product online, some of the necessary steps are:
Competitor Analysis
Enhancing Your Product And Value Proposal
Learning Market Tendencies And Manipulating Them.
By extracting amazon data, you can simply collect, compare and monitor competitive product details, such as pricing, ratings, and availability. You cannot only assess their cost management, but can also uncover amazing offers for resale.
In the blog, we are providing few web scraping tools for scraping amazon data.
Why Use Web Scraping API?
Amazon is among the biggest online stores in history. As a result, Amazon has one of the largest databases of information about customers, items, ratings, sellers, market dynamics, and even user temperament.
Before we learn the specifics of data extraction, it's worth noting that Amazon does not support internet scraping. This is because the page structure differs depending on the product categories. Simple anti-scraping techniques are in place on the website, which may prevent you from gathering the information you seek. Aside from that, Amazon can tell whether you're scraping it with a scraper. Besides that, Amazon can detect if you are scraping it with a bot and will immediately block your IP address.
Amazon Web Scraping Tools For The Job
We'll scrape using a terminal and some curl requests to get the job done as quickly as possible even without the need to create a new project for each application we test. To test out, we've chosen five promising web scraping APIs.
Let us take each of them for a test and search out which is the best web scraping tool for amazon data scraping.
1. Web Scraping API
Web Scraping API is a program that enables us to scrape any web resource. It uses a simple API to extract HTML from any web page and returns ready-to-process data. It's useful for extracting product data, processing real estate, HR, or financial data, and even tracking market data. We can get all the information we need from a specific Amazon product page using Web Scraping API.
For instance, find an exciting product on the Amazon market.
The product page seen in the image above will be scraped.
Secondly, let’s get the product’s page
URL:https://www.amazon.co.uk/dp/B088CZW8XC/ref=gw_uk_desk_h1_vicc_sh_cto_kif0321?pf_rd_r=RYXBGN8C757Y9BD6W38B
We will be taken to the application's dashboard after creating a new Web Scraping API account. To test the application, Web Scraping API offers a free plan with 1000 requests. For what we're going to do, that's more than enough.
We'll go to the dashboard page and click the "Use API Playground" button. We can see the complete curl command here, which will assist us in scraping the Amazon product page.
Let's copy and paste the product's URL into the URL field. The preview of the URL command on the right will alter as a result of this.
After you've finished this step, copy the curl command and copy this into a new terminal session. If you follow the above procedure, you should have something similar to this:
When we press enter, Web Scraping API will return the product's page in HTML format.
According to our results, Web Scraping API was able to successfully obtain the required information in 99.7 percent of the situations, with a success rate of 997 out of 1000 queries and a 1-second latency.
2. ScrapingBee
ScrapingBee allows you to scrape without even being blocked using both traditional and premium proxies. It concentrates on collecting all the required data for rendering websites in a real browser (Chrome). Developers and businesses can scrape without worrying about proxies or headless browsers thanks to their vast proxy pool.
Let's try scraping the same Amazon page we scraped earlier. Make a new ScrapingBee account, browse to the app's dashboard, and paste the previous URL in the URL input.
In the "Request Builder" area, click the "Copy to clipboard" button. Open a terminal window and paste the copied code and hit “ENTER”.
With this command, we'll scrape the same page on the Amazon marketplace so that we can compare the results from each API.
According to our investigation, ScrapingBee was able to correctly obtain information in 92.5 percent of the situations with a rather large latency of 6 seconds.
3. Scraper API
Web scraper API is a development tool for web scrapers or a tool that extracts any data using a simple API call. The web service will manage proxies, browsers, and CAPTCHAs, allowing developers to achieve raw HTML from any website. Furthermore, the product will achieve a balance in functionality, dependability, and use.
We'll create a fresh account on Web Scraper API and use 1000 free requests for evaluating their crawling technology, exactly like we did before. We will be forwarded to the following page once we have completed the registration process:
ScraperAPI does not appear to offer the ability to change the curl query by writing the new URL at the first sight. This isn't a large deal. We'll start a new terminal window and paste the code from the "Sample API Code" field.
As we can see, the default URL that it’s being scraped is “http:/httpbin.org/ip”. We are going to change it to the escaped version of the product’s page URL presented at the top of the section. Change the previously presented link with the following one:
The final command should look something like this:
After pressing enter, the HTML code for the product's page will be shown. Of course, you can manipulate the generated data structure with Cheerio or any other markup parser.
ScraperAPI appears to be the finest option, with a success rate of 100% and a latency of less than one second.
4. Zenscrape
Zenscrape is a web scraping API of sorts that will return the HTML of any website, allowing developers to collect data faster and efficiently. By solving Javascript rendering or CHAPTCHAs, the program will allow you to fetch the website content seamlessly and reliably.
Once we complete the registration process as before, we will be readdressed to the dashboard page.
Copy and paste the product’s page URL in the URL input.
Scroll down to the middle of a page to get the curl command we need to scrape the Amazon data. Copy it to the clipboard by clicking the “Copy to Clipboard” button, then paste it into a new terminal window. It should look like this:
Unlike other web scraping tools, the result that will be displayed would be in HTML page format.
According to our analysis, Zenscrape has a 98 percent success rate, with 98 successful requests out of 100 and a latency of 1.4 seconds. This ranks it lesser than the preceding tools, but it has one of the most intuitive and elegant user interfaces, and it gets the job done.
5. ScrapingAnt
ScrapingAnt is a web harvesting and scraping solution that offers its users a complete online gathering and scraping experience. It is a facility that manages Javascript processing, the headless browser informs the management, proxy variation and rotation, and proxy diversity and rotation. This scraping API has the high availability, dependability, and feature flexibility to meet the needs of any organization.
As before, we go through the same process, initially, create an account on Scraping Ant and make use of its 1000 free requests for scraping amazon product data.
Replace our URL in the URL input field, copy the curl command to a new terminal window, and hit ENTER.
This will yield an HTML structure that we can parse using Cheerio or another markup parser. ScrapingAnt's key features include Chrome page rendering, output preprocessing, and scraping requests with a low risk of CAPTCHA check triggering.
According to our analysis, ScrapingAnt has a success rate of 100 percent and a latency of three full seconds. Although has one of the highest success percentages on this list, the 3-second latency is a major issue when scraping a large amount of Amazon product data.
Final Thoughts
We sought to figure out what the effective tool for the occupation was during this process. We were able to examine and analyze five scrapers and discovered that the outcomes were not that dissimilar. They're all capable of getting the job done in the end. Each scraper's delay, rate of success, amount of free requests, and pricing makes a difference. When it comes to scraping Amazon data, Web Scraping API is a good choice because it has one of the smallest latency (1 second) and a near-100 percent success rate. It has a free tier for those who don't need to make a lot of requests, as well as 1000 free inquiries if you just want to play about with it.
AScrapingBee is another web scraper we certify, however, the results are unsatisfactory. We have a hard time getting the information we needed on our Amazon goods with a success rate of only 92.5 percent and a somewhat long latency.
ScraperAPI is also one of the fastest scrapers we've come across. It has better effects in the level of technical criteria, with only a 1-second delay and a 100% success rate. Its disadvantage is the user interface, which appears to be the most basic. Another flaw is the price plan, which does not have a free tier.
Zenscrape features the most user-friendly interfaces of any scraper we have evaluated. WebScrapingAPI is the only one that comes close. Zenscrape has a 1.4-second latency and a 98 percent success rate.
ScrapingAnt is the most recent scraper we tested. It's an excellent option for extracting the Amazon information we require, but it's a little slow, with such a latency of around 3 seconds and a rate of success of 100%.
Finally, when it collects Amazon product information, all of the web scrapers we examined perform admirably.
Instead of trying yourselves, we recommend contacting iWeb Scraping services for genuine amazon data scraping delivery.
We are always available to deliver the best services.
https://www.iwebscraping.com/which-are-the-best-scraping-tools-for-amazon-web-data-extraction.php
1 note
·
View note