#Site Reliability Engineering
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
Tumblr has 16.74 million mobile monthly users in the US.
Text
Netflix's Chaos Monkey: Embracing Failure for Resilience
Chaos Monkey is an innovative tool developed by Netflix as part of their Simian Army suite of testing tools. It deliberately introduces failures into your cloud infrastructure to test system resilience and recovery capabilities. Chaos Monkey works by randomly terminating instances in your production environment. This might sound counterintuitive, but by forcing failures to occur, it helps…
#AWS#chaos engineering#chaos monkey#cloud infrastructure#cloud resilience#devops#disaster recovery#failure injection#fault tolerance#high availability#implementation tutorial#infrastructure automation#infrastructure testing#microservices testing#netflix chaos monkey#netflix open source#netflix technology#production testing#resilience testing#simian army#site reliability engineering#system architecture#system reliability#system resilience
0 notes
Text
SRE Principles and Best Practices
A collection of guidelines and procedures known as site reliability engineering (SRE) are designed to assist you in integrating different facets of software engineering. In addition, it makes it easier to apply them to operational and infrastructure issues to develop software systems that are extremely dependable and scalable.
Irrespective of whether you are just adopting Site Reliability Engineering. or optimizing your current processes, you need to understand these principles and practices first.

0 notes
Text
Why SRE Certification is a must have for IT professionals
In order to guarantee the stability, performance, and dependability of IT systems, the position of SRE foundation certification has grown more and more important. In order to succeed in this ever changing area, IT workers must hold the SRE certification. Here are some reasons why everyone who is serious about an IT profession should get this certification, since it is not only helpful but also necessary.
Let's dive into the primary advantages of acquiring CSERF
1. Understanding the Core Principles of SRE - The SRE Foundation certification offers a thorough comprehension of the fundamental ideas that underpin the SRE certificate field. Site reliability engineering certified professional is a methodology that combines software engineering with IT operations with an emphasis on creating scalable and dependable systems.
2. Bridging the Gap Between Development and Operations - There has always been a major separation in IT between the development and operations teams. Through encouraging cooperation, automation, and shared duties, site reliability engineering certification methods seek to close this gap. IT workers may enhance communication, accelerate deployment cycles, and create more robust systems by learning how to use these principles successfully with the help of the site reliability engineering course.
3. Contributing to Organizational Success -SRE course is about more than simply keeping systems operational; it's about making a positive impact on the company as a whole. The SRE training and certification is a great advantage for both the individual and the business since it gives them the skills and frameworks they need to significantly improve the bottom line of the corporation.
For more information Visit our-
Also visit -
For more inquiries - +91 7796699663.

#SRE certification#SRE certificate#SRE Foundation Certification#site reliability engineering certified professional#site reliability engineering certification#SRE course#site reliability engineering course#site reliability engineer certification#SRE training and certification#site reliability engineering#CSERF.
0 notes
Text
Enhancing Your Business with Site Reliability Engineering Solutions

Enhancing your business with Site Reliability Engineering solutions ensures optimal performance, reliability, and scalability of your systems. By integrating SRE practices, you can minimize downtime, improve user experience, and accelerate innovation. Leverage automation, monitoring, and incident management to achieve higher efficiency and resilience, empowering your business to thrive in a competitive landscape.
0 notes
Text
In today's rapidly evolving digital landscape, organizations are increasingly adopting cloud-native technologies to gain agility, scalability, and cost-effectiveness. With this shift, the role of Site Reliability Engineering (SRE) has become more critical than ever. SRE is evolving to meet the challenges of the cloud-native era. Learn about the key trends in the future of SRE, including reliability, performance, scalability, and security of software systems.
0 notes
Text
He signed executive orders for all of those things, actually. And real politics isn't as simple as anonymous keyboard warriors claim it is.
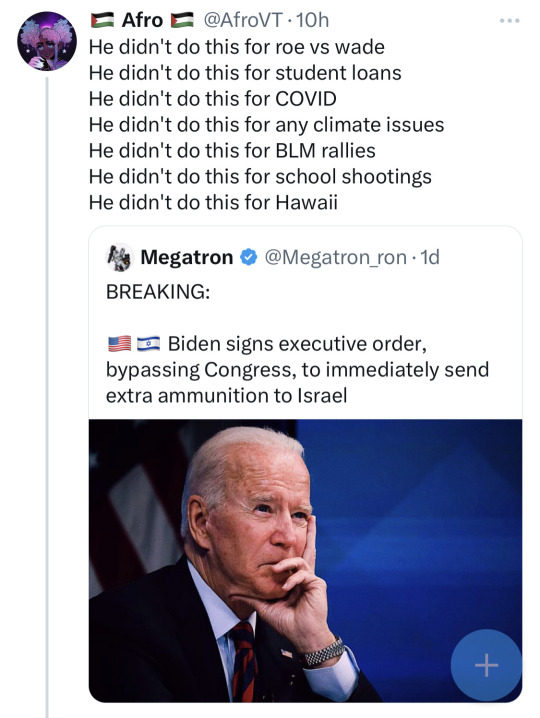
#I checked and the weapon sales seem to be legit#but it's interesting that none of the trustworthy news sites were at the top of any of my search engines#Are you going to say *that's* a conspiracy next? And that uhh Megatron is more reliable?#current affairs
63K notes
·
View notes
Text
SRE Online Training | Site Reliability Engineering Training
The Concept of "Retry, Timeout, and Circuit Breaker" patterns

Introduction:
Site Reliability engineering software systems, resilience and fault tolerance are crucial for ensuring smooth user experiences and optimal system performance. Among the key strategies for improving reliability, Retry, Timeout, and Circuit Breaker patterns stand out as essential techniques for handling failures and improving system robustness. These patterns help prevent cascading failures, reduce downtime, and enhance the overall reliability of applications. By understanding how these patterns work, developers can design systems that can gracefully recover from errors and continue providing service to users. Site Reliability Engineering Online Training
What Are Retry, Timeout, and Circuit Breaker Patterns?
At their core, Retry, Timeout, and Circuit Breaker patterns aim to ensure that software systems remain operational even in the face of transient or unexpected failures. Each pattern has a distinct role and can be used independently or together depending on the complexity of the system being developed.
Retry Pattern: The Retry pattern is employed when a request fails due to temporary issues like network instability or service unavailability. The idea is simple—rather than immediately returning an error, the system attempts the request again after a brief delay. This pattern is particularly useful for addressing intermittent failures in remote services, APIs, or external dependencies.
Timeout Pattern: The Timeout pattern focuses on avoiding endless waits in case of service delays or failures. When a system makes a request, it sets a predefined period for the operation to complete. If the request doesn’t respond within the specified time, it is aborted and an error is returned. This pattern helps prevent the system from getting stuck and ensures that users aren't left waiting for an unreasonable amount of time.
Circuit Breaker Pattern: The Circuit Breaker pattern protects the system from being overwhelmed by continuous failures. When a certain threshold of consecutive failed attempts is reached, the circuit breaker trips and the system stops making calls to the failing service for a predefined "cool-off" period. This allows the service to recover, preventing it from being flooded with requests and improving overall system stability.
How Do Retry, Timeout, and Circuit Breaker Patterns Improve System Resilience?
These three patterns work together to create a more resilient and fault-tolerant system. By implementing Retry, Timeout, and Circuit Breaker patterns, developers can handle failures more effectively, resulting in a better user experience and a more reliable application.
1. Reducing the Impact of Temporary Failures with Retry
The Retry pattern is designed to address temporary failures that are often caused by external systems or services. When a request fails, such as during network timeouts or when a service is momentarily unavailable, the system does not immediately report an error to the user. Instead, it retries the operation after a brief pause, increasing the likelihood that the request will succeed if the failure is only transient.
In some cases, the system can implement exponential back off, where the time between retries gradually increases. This strategy helps avoid overwhelming the failing service with too many requests in a short period, giving the service time to recover.
2. Preventing Endless Waits with Timeout
While retries help with temporary failures, there are situations where an operation may take too long to complete due to persistent issues. The Timeout pattern ensures that the system doesn't waste resources waiting for an operation that isn't responding within a reasonable period.
For instance, if a request is made to an external service, but the service is down or experiencing heavy load, the Timeout pattern ensures that the system doesn't continue to wait indefinitely. By setting an appropriate timeout value, developers can avoid slow performance and ensure that users receive a response within an acceptable timeframe. SRE Course
3. Protecting Systems from Cascading Failures with Circuit Breaker
The Circuit Breaker pattern is especially critical when dealing with failures that could lead to cascading issues across the system. When one part of the system fails repeatedly, it can put excessive strain on other components that depend on it. This could lead to a complete system failure, which is where the Circuit Breaker comes into play.
Once the circuit breaker detects a certain number of consecutive failures, it "trips," halting further attempts to interact with the failing service. The system enters a "half-open" state where it periodically tests the health of the service. If the service is functioning properly, the circuit breaker is reset and normal operation resumes. However, if the service continues to fail, the system remains "closed", and no further requests are made.
By implementing this pattern, a system can avoid overloading a failing service and give it time to recover. This prevents a localized failure from escalating into a system-wide breakdown, improving overall resilience.
Key Benefits of Using Retry, Timeout, and Circuit Breaker Patterns
Each of these patterns brings unique advantages to a software system. Here are some key benefits of implementing Retry, Timeout, and Circuit Breaker patterns in your applications:
Increased Fault Tolerance: By incorporating these patterns, systems can better handle errors, ensuring that they continue functioning even when failures occur.
Improved User Experience: These patterns reduce downtime and ensure that users experience fewer interruptions, even in the event of service failures.
System Stability: With a combination of retries, timeouts, and circuit breakers, systems can maintain their stability by preventing cascading failures and overloading.
Faster Recovery: In the event of a failure, these patterns allow systems to recover more quickly, ensuring a more reliable and efficient service.
Best Practices for Implementing Retry, Timeout, and Circuit Breaker Patterns
To effectively implement these patterns, there are several best practices to follow:
Tune Retry Settings: While retries can help with temporary issues, setting too many retries or insufficient wait times can cause further problems. It's crucial to find a balance between retry attempts and back-off times to prevent unnecessary strain on the system.
Set Appropriate Timeout Values: The timeout values should be set by the expected response time of the external services. Short timeouts may lead to premature failures, while long timeouts may cause delays in the system.
Monitor Circuit Breaker States: Regular monitoring of the circuit breaker states is essential to ensure that services are properly recovering after failures. Metrics and logs can help track the health of services and adjust the configuration as necessary.
Implement Fullback Strategies: In conjunction with the Circuit Breaker pattern, fall back mechanisms should be put in place. This could include providing default responses when the service is unavailable or offering a reduced level of functionality. SRE Certification Course
Conclusion
In conclusion, Retry, Timeout, and Circuit Breaker patterns are indispensable tools for building resilient software systems. These patterns work together to enhance the fault tolerance, stability, and user experience of modern applications. By carefully implementing these patterns, developers can create systems that gracefully handle failures, recover quickly, and ensure continuous service even in the face of errors. Their strategic use helps safeguard against cascading failures, prevents unnecessary delays, and ensures the long-term reliability of software systems.
Visualpath is the Best Software Online Training Institute in Hyderabad. Avail complete Site Reliability Engineering (SRE) worldwide. You will get the best course at an affordable cost.
Attend Free Demo
Call on - +91-9989971070.
WhatsApp: https://www.whatsapp.com/catalog/919989971070/
Visit Blog: https://sitereliabilityengineering123.blogspot.com/
Visit: https://www.visualpath.in/online-site-reliability-engineering-training.html
#Site Reliability Engineering Training#SRE Course#Site Reliability Engineering Online Training#SRE Training Online#Site Reliability Engineering Training in Hyderabad#SRE Online Training in Hyderabad#SRE Courses Online#SRE Certification Course
0 notes
Text

very good, peer-reviewed tags via @a-commas-a-pause
the amount of people my age (i think im an older gen z though ive been called millennial so ¯\_(ツ)_/¯) or younger who trust the first search result on google is terrifying.
and the volume of them who trust the information from a tiktok with no sources or citations even mentioned let alone linked is even worse.
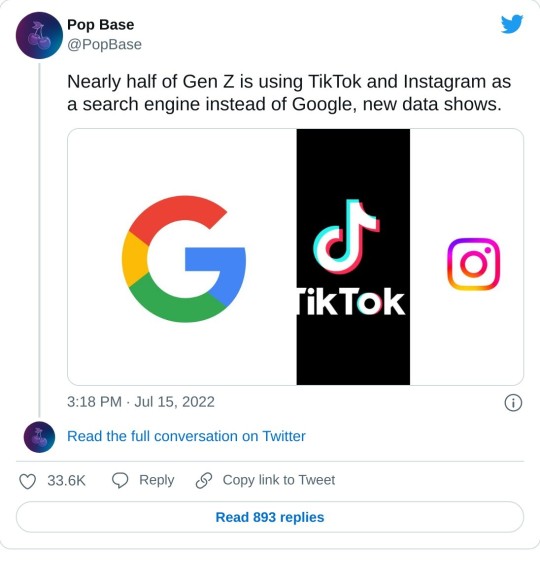

[ID: A tweet by Popbase that reads, "Nearly half of Gen Z is using TikTok and Instagram as a search engine instead of Google, new data shows.". Below the tweet is a pic of a poorly drawn Goomba from Super Mario Bros with text below him that reads "are you out of your fucking mind".]
#im begging these people#please look for a source when you encounter new information#and thats not just finding the first website that corroborates it or another tiktok saying it#its looking at various different sites or free-to-read papers or news articles to get a good grasp on that topic#and use different search engines PLEASE#theres bing or ecosia or duckduckgo#and if youre making any kind of informational post#PROVIDE GODDAMN SOURCES#it can take me hours to make an informational post because im just trying to ensure the information is correct and the sources are reliable#and not written by a crank or grifter
66K notes
·
View notes
Text
Jira Change and Incident Management Implementation Services
Organizations must operate efficiently and stay agile to remain competitive in today's fast-paced business environment. Managing tasks, projects, and teams can be challenging, especially as businesses scale.
PDF: https://www.slideshare.net/slideshow/jira-administrator-projects-in-philadelphia-pdf/272650805
#best jira training#azure devops training#agile maturity assessment#jira assessment#site reliability engineering training#jira administrator projects
0 notes
Text
everytime there's new fanwork of re:kinder an angel gains it's wings it fills me with such joy everytime
#i talk!!!#i know this sounds silly but i MAYYYY OR NOTTTT search up rekinder on every social media i can think of daily#mainly twitter and tumblr#because really any other art plataform has really fallen off on their search engines and its hard to find anything recent in them.#twitter is.... i make it work?😭😭 tumblr is the most reliable MOST OF THE TIME#the ways to find recent art of a certain thing in the biggest platforms for art over the recent years has been A MESS but i do what i can😊#theres a few exceptions of sites i am not putting my foot on so honestly there may be more recent art coming out that i dont know about#OBVIOUSLY IM EXCLDUING MYSELF FROM THIS WHOLE THING as much as drawing it gives me joy#is it the same joy of seeing others draw it and share mutual glee for the game...#every time theres a new drawing. no matter what is going on in my life I WILL BE FILLED WITH JOY and an angel gains its wings#love to see how everyone draws the sillies ... i wish i could paste it all on my wall but i dun have a printer#i wish i could have a magic radar in my brain that told me when new recent fanwork is made and where to find it everytime#that way i could never miss it because of strange. search engine algorithm of the big platforms and social media nowadays
0 notes
Text
WP Engine is a well-known managed WordPress hosting provider.
It offers a range of features and services tailored specifically for WordPress websites, making it a popular choice among businesses, bloggers, and developers who seek reliable, high-performance hosting solutions.

#Managed WordPress Hosting:#security#and reliability.#automated updates#and staging environments.#Genesis Framework and StudioPress Themes:#Access to the Genesis Framework for building fast#secure#and SEO-friendly websites.#Includes over 35 StudioPress themes for customization and design flexibility.#Global Edge Security:#Advanced security features including DDoS protection and Web Application Firewall (WAF).#Managed threat detection and prevention.#Content Performance:#Tools and analytics to measure and optimize content performance.#Helps improve site speed and SEO rankings.#Dev#Stage#Prod Environments:#Separate development#staging#and production environments for better workflow management.#Allows for testing changes before pushing them live.#Automated Migrations:#Easy migration tools to transfer existing WordPress sites to WP Engine.#Assisted migrations for a smoother transition.#24/7 Customer Support:
0 notes
Text

The Site Reliability Engineering Certification offered by GSDC is a testament to the skills and expertise of an SRE. It demonstrates that the candidate has a comprehensive understanding of SRE principles, practices, and methodologies and can apply them to real-world scenarios. The SRE Certification is important for professionals who want to enhance their job prospects and advance their careers in the field of Site Reliability Engineering. It provides a competitive edge in the job market and shows that the candidate is committed to ongoing learning and development. Organizations that wish to be sure that their SREs have the ability to manage and maintain complex systems can also benefit from the certification.It assures that the candidate can design, build, and operate reliable systems that meet or exceed the required service level objectives.
#site reliability engineering certification#site reliability engineer certification#sre course#site reliability engineer foundation certification#site reliability engineering certification online#sre foundation certificaiton
0 notes
Text

Embark on a journey to mastery with our Site Reliability Engineering (SRE) Certification Program. This comprehensive course offers participants an in-depth exploration of SRE principles, methodologies, and tools. Designed by industry experts, the curriculum delves into the core tenets of ensuring large-scale system reliability and efficiency
#sre certifications#SRE Foundation#site reliability engineering certification#sre certification cost
0 notes
Text
Elevate Your IT Career: Achieve SRE Foundation Certification!
It is a compelling call to action for professionals seeking to enhance their expertise in the field of site reliability engineering. This headline emphasizes the transformative impact that the SRE Foundation Certification can have on an individual's career in IT. The SRE Certification is not just a testament to one's skills in maintaining reliable and efficient systems; it's a stepping stone towards becoming a leader in the rapidly evolving tech landscape. The Site Reliability Engineering Certification, often referred to as the SRE Foundation Certification, is designed to equip IT professionals with the principles and practices essential for ensuring system reliability and efficiency.

#sre certification#site reliability engineering certification#SRE Foundation Certification#sre certification cost
0 notes
Text
In software engineering and development, the ability to make adjustments is essential. There’s always a chance that some bugs went unnoticed by the QA, and urgent patching is needed.
In this scenario, the development team must balance the desire to add new code into the system as quickly as possible and not compromise its reliability. There are many techniques that allow automating the Software Development Life Cycle while maintaining the emphasis on product quality. One of them is Site Reliability Engineering, or SRE, which we will discuss today.
#outsourcing#web development#software development#staff augmentation#custom software development#it staff augmentation#custom software solutions#it staffing company#it staff offshoring#custom software#site reliability engineering certification
0 notes
Text
What is site reliability in SRE foundation
For scalable, dependable software systems, Site Reliability Engineering (SRE) integrates system administration with software engineering. SREs guarantee the security, performance, and reliability of systems. SRE fundamentals are covered in the SRE Foundation certification. SLOs, monitoring, alerting, labor minimization, and simplicity are all covered.
For more information visit: https://www.novelvista.com/in/sre-foundation-training-certification
1 note
·
View note