#Web Scraping MercadoLibre
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
The Tumblr app for Google Glass was released on May 16, 2013.
Text
How to Scrape Data from Chinese Sellers on MercadoLibre MX FBM
Introduction
The eCommerce industry in Latin America has seen massive growth, with MercadoLibre Mexico emerging as one of the largest online marketplaces. Among the various sellers operating on the platform, Chinese Sellers on MercadoLibre Mexico have gained a significant market share due to their competitive pricing, diverse product offerings, and strategic use of FBM (Fulfillment by Merchant). These sellers bypass local fulfillment centers, shipping products directly from China, allowing them to maintain lower costs and high-profit margins.
With this increasing competition, businesses need Web Scraping MercadoLibre Mexico Sellers to track seller data, pricing trends, and inventory insights. Extracting real-time marketplace data helps brands, retailers, and competitors stay ahead by understanding product availability, discount strategies, and customer preferences.
This blog explores how to Scrape Data from Chinese Sellers on MercadoLibre, why businesses should monitor seller trends, and how MercadoLibre FBM Web Scraping can help in gathering actionable insights.
Growing Presence of Chinese Sellers on MercadoLibre Mexico
The eCommerce landscape in Latin America has witnessed a surge in international sellers, with Chinese vendors dominating a significant portion of MercadoLibre Mexico. Due to the platform’s vast customer base and cross-border selling opportunities, more Chinese businesses are leveraging MercadoLibre FBM (Fulfillment by Merchant) to ship products directly from their warehouses. This strategy helps them avoid local fulfillment costs and maintain competitive pricing. According to 2025 statistics, over 40% of new electronics and gadget listings on MercadoLibre MX come from Chinese sellers. Their competitive pricing, fast shipping partnerships, and broad product variety have made them major players in Mexico’s online retail market

Importance of MercadoLibre FBM Web Scraping for Tracking Seller Data
With the rising competition in the Latin American eCommerce market, businesses must leverage MercadoLibre FBM Web Scraping to track Chinese seller activities, pricing trends, and inventory strategies. Web Scraping MercadoLibre Mexico Sellers allows companies to extract critical insights such as:
Product Listings – Track new product additions and category trends.
Pricing Strategies – Analyze price fluctuations and discount offers.
Seller Ratings & Feedback – Understand customer sentiment and service quality.
Shipping & Delivery – Monitor estimated delivery times and logistics efficiency.
By implementing Scrape Data from Chinese Sellers on MercadoLibre, businesses can make data-backed decisions, optimize pricing strategies, and enhance their marketplace performance.

How Businesses Can Benefit from Extracting Accurate and Real-Time Marketplace Insights?
By using Extract MercadoLibre Seller Information, businesses can unlock crucial insights to improve sales strategies and outperform competitors. Key benefits include:
A. Competitive Pricing Strategies
Track Chinese seller pricing and adjust prices accordingly.
Identify seasonal discount patterns and promotional campaigns.
Use Track Chinese Seller Prices on MercadoLibre to maintain a competitive edge.
B. Trend Analysis & Market Research
Discover top-selling categories and emerging trends.
Analyze product demand based on customer preferences.
Scrape MercadoLibre Product Listings to monitor newly launched items.
C. Inventory & Stock Optimization
Monitor product availability and restocking patterns.
Identify potential stock shortages and supply chain issues.
Ensure optimal inventory levels to meet market demand.

How to Scrape Data from Chinese Sellers on MercadoLibre?
Businesses can leverage Web Scraping for Cross-Border eCommerce Data to gain critical marketplace insights and stay competitive. By extracting data from global marketplaces, companies can track pricing trends, monitor competitors, and optimize their sales strategy.
Key Steps in Web Scraping for eCommerce Insights
Identifying Targeted Seller Data – Businesses can collect essential details such as product names, prices, ratings, and reviews from various online platforms. This data helps in understanding competitor pricing strategies and customer preferences.
Setting Up Automated Scrapers – Utilizing advanced web scraping tools, businesses can efficiently extract structured data without manual effort. Automation ensures consistency and scalability, making data collection seamless.
Filtering & Analyzing Data – Once data is extracted, it is essential to organize and analyze it for competitor benchmarking and pricing analysis. This helps businesses adjust their pricing strategies and enhance product offerings based on real market trends.
Monitoring Real-Time Updates – The eCommerce landscape is dynamic, requiring businesses to stay updated. Automated scrapers can be set to perform daily or weekly data extraction to track changing trends, stock availability, and price fluctuations.
MercadoLibre FBM Web Scraping for Enhanced Market Intelligence
For businesses targeting Latin American markets, MercadoLibre FBM Web Scraping is a game-changer. By automating data collection from MercadoLibre, companies can gain real-time insights into competitor pricing, top-selling products, and customer sentiment. This ensures accurate and up-to-date marketplace intelligence, enabling data-driven decision-making.

Challenges in Scraping MercadoLibre & How to Overcome Them
While Extracting MercadoLibre Seller Information offers valuable insights, businesses face challenges such as:
CAPTCHAs & Anti-Scraping Mechanisms – Implement Web Scraping API Services for seamless data extraction.
Large Data Volumes – Use Automated Data Extraction from MercadoLibre for scalability.
Dynamic Pricing & Real-Time Updates – Ensure frequent data collection to track price fluctuations accurately.

How Actowiz Solutions Can Help?
Actowiz Solutions specializes in MercadoLibre Seller Analytics with Web Scraping, providing:
Custom Web Scraping Solutions – Tailored tools for tracking seller data.
Real-Time Price & Inventory Monitoring – Keep up with market changes.
Competitor Benchmarking – Compare pricing strategies and product listings.
Scalable & Automated Scraping – Extract large datasets without restrictions.
Our expertise in Scrape Data from Chinese Sellers on MercadoLibre ensures accurate, real-time insights that drive business growth.
Conclusion
The increasing presence of Chinese Sellers on MercadoLibre Mexico presents both opportunities and challenges for businesses. To stay competitive, companies must leverage Web Scraping MercadoLibre Mexico Sellers for data-driven insights on pricing, inventory, and seller strategies. By implementing MercadoLibre FBM Web Scraping, businesses can optimize pricing, track competitors, and enhance their overall marketplace performance.
Ready to extract real-time data from MercadoLibre? Contact Actowiz Solutions for powerful Web Scraping Services today!
Learn More
#Web Scraping MercadoLibre#Web Scraping to track Chinese seller#web scraping tools#Web Scraping API Services
0 notes
Text
Los 30 Mejores Software Gratuitos de Web Scraping en 2021
El Web scraping (también denominado extracción datos de una web, web crawler, web scraper o web spider) es una web scraping técnica para extraer datos de una página web . Convierte datos no estructurados en datos estructurados que pueden almacenarse en su computadora local o en database.
Puede ser difícil crear un web scraping para personas que no saben nada sobre codificación. Afortunadamente, hay herramientas disponibles tanto para personas que tienen o no habilidades de programación. Aquí está nuestra lista de las 30 herramientas de web scraping más populares, desde bibliotecas de código abierto hasta extensiones de navegador y software de escritorio.
Tabla de Contenido
Beautiful Soup
Octoparse
Import.io
Mozenda
Parsehub
Crawlmonster
Connotate
Common Crawl
Crawly
Content Grabber
Diffbot
Dexi.io
DataScraping.co
Easy Web Extract
FMiner
Scrapy
Helium Scraper
Scrape.it
Scrapinghub
Screen-Scraper
Salestools.io
ScrapeHero
UniPath
Web Content Extractor
WebHarvy
Web Scraper.io
Web Sundew
Winautomation
Web Robots
1. Beautiful Soup
Para quién sirve: desarrolladores que dominan la programación para crear un web spider/web crawler.
Por qué deberías usarlo:Beautiful Soup es una biblioteca de Python de código abierto diseñada para scrape archivos HTML y XML. Son los principales analizadores de Python que se han utilizado ampliamente. Si tienes habilidades de programación, funciona mejor cuando combina esta biblioteca con Python.
Esta tabla resume las ventajas y desventajas de cada parser:-
ParserUso estándarVentajasDesventajas
html.parser (puro)BeautifulSoup(markup, "html.parser")
Pilas incluidas
Velocidad decente
Leniente (Python 2.7.3 y 3.2.)
No es tan rápido como lxml, es menos permisivo que html5lib.
HTML (lxml)BeautifulSoup(markup, "lxml")
Muy rápido
Leniente
Dependencia externa de C
XML (lxml)
BeautifulSoup(markup, "lxml-xml") BeautifulSoup(markup, "xml")
Muy rápido
El único parser XML actualmente soportado
Dependencia externa de C
html5lib
BeautifulSoup(markup, "html5lib")
Extremadamente indulgente
Analizar las páginas de la misma manera que lo hace el navegador
Crear HTML5 válido
Demasiado lento
Dependencia externa de Python
2. Octoparse
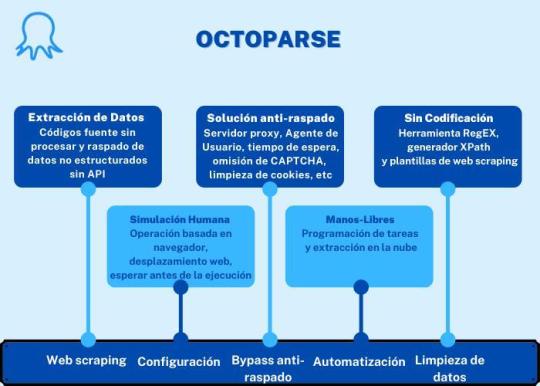
Para quién sirve: Las empresas o las personas tienen la necesidad de captura estos sitios web: comercio electrónico, inversión, criptomoneda, marketing, bienes raíces, etc. Este software no requiere habilidades de programación y codificación.
Por qué deberías usarlo: Octoparse es una plataforma de datos web SaaS gratuita de por vida. Puedes usar para capturar datos web y convertir datos no estructurados o semiestructurados de sitios web en un conjunto de datos estructurados sin codificación. También proporciona task templates de los sitios web más populares de países hispanohablantes para usar, como Amazon.es, Idealista, Indeed.es, Mercadolibre y muchas otras. Octoparse también proporciona servicio de datos web. Puedes personalizar tu tarea de crawler según tus necesidades de scraping.
PROS
Interfaz limpia y fácil de usar con un panel de flujo de trabajo simple
Facilidad de uso, sin necesidad de conocimientos especiales
Capacidades variables para el trabajo de investigación
Plantillas de tareas abundantes
Extracción de nubes
Auto-detección
CONS
Se requiere algo de tiempo para configurar la herramienta y comenzar las primeras tareas
3. Import.io
Para quién sirve: Empresa que busca una solución de integración en datos web.
Por qué deberías usarlo: Import.io es una plataforma de datos web SaaS. Proporciona un software de web scraping que le permite extraer datos de una web y organizarlos en conjuntos de datos. Pueden integrar los datos web en herramientas analíticas para ventas y marketing para obtener información.
PROS
Colaboración con un equipo
Muy eficaz y preciso cuando se trata de extraer datos de grandes listas de URL
Rastrear páginas y raspar según los patrones que especificas a través de ejemplos
CONS
Es necesario reintroducir una aplicación de escritorio, ya que recientemente se basó en la nube
Los estudiantes tuvieron tiempo para comprender cómo usar la herramienta y luego dónde usarla.
4. Mozenda
Para quién sirve: Empresas y negocios hay necesidades de fluctuantes de datos/datos en tiempo real.
Por qué deberías usarlo: Mozenda proporciona una herramienta de extracción de datos que facilita la captura de contenido de la web. También proporcionan servicios de visualización de datos. Elimina la necesidad de contratar a un analista de datos.
PROS
Creación dinámica de agentes
Interfaz gráfica de usuario limpia para el diseño de agentes
Excelente soporte al cliente cuando sea necesario
CONS
La interfaz de usuario para la gestión de agentes se puede mejorar
Cuando los sitios web cambian, los agentes podrían mejorar en la actualización dinámica
Solo Windows
5. Parsehub
Para quién sirve: analista de datos, comercializadores e investigadores que carecen de habilidades de programación.
Por qué deberías usarlo: ParseHub es un software visual de web scrapinng que puede usar para obtener datos de la web. Puede extraer los datos haciendo clic en cualquier campo del sitio web. También tiene una rotación de IP que ayudaría a cambiar su dirección IP cuando se encuentre con sitios web agresivos con una técnica anti-scraping.
PROS
Tener un excelente boaridng que te ayude a comprender el flujo de trabajo y los conceptos dentro de las herramientas
Plataforma cruzada, para Windows, Mac y Linux
No necesita conocimientos básicos de programación para comenzar
Soporte al usuario de muy alta calidad
CONS
No se puede importar / exportar la plantilla
Tener una integración limitada de javascript / regex solamente
6. Crawlmonster
Para quién sirve: SEO y especialistas en marketing
Por qué deberías usarlo: CrawlMonster es un software de web scraping gratis. Te permite escanear sitios web y analizar el contenido de tu sitio web, el código fuente, el estado de la página y muchos otros.
PROS
Facilidad de uso
Atención al cliente
Resumen y publicación de datos
Escanear el sitio web en busca de todo tipo de puntos de datos
CONS
Funcionalidades no son tan completas
7. Connotate
Para quién sirve: Empresa que busca una solución de integración en datos web.
Por qué deberías usarlo: Connotate ha estado trabajando junto con Import.io, que proporciona una solución para automatizar el scraping de datos web. Proporciona un servicio de datos web que puede ayudarlo a scrapear, recopilar y manejar los datos.
PROS
Fácil de usar, especialmente para no programadores
Los datos se reciben a diario y, por lo general, son bastante limpios y fáciles de procesar
Tiene el concepto de programación de trabajos, que ayuda a obtener datos en tiempos programados
CONS
Unos cuantos glitches con cada lanzamiento de una nueva versión provocan cierta frustración
Identificar las faltas y resolverlas puede llevar más tiempo del que nos gustaría
8. Common Crawl
Para quién sirve: Investigador, estudiantes y profesores.
Por qué deberías usarlo: Common Crawl se basa en la idea del código abierto en la era digital. Proporciona conjuntos de datos abiertos de sitios web rastreados. Contiene datos sin procesar de la página web, metadatos extraídos y extracciones de texto.
Common Crawl es una organización sin fines de lucro 501 (c) (3) que rastrea la web y proporciona libremente sus archivos y conjuntos de datos al público.
9. Crawly
Para quién sirve: Personas con requisitos de datos básicos sin hababilidad de codificación.
Por qué deberías usarlo: Crawly proporciona un servicio automático que scrape un sitio web y lo convierte en datos estructurados en forma de JSON o CSV. Pueden extraer elementos limitados en segundos, lo que incluye: Texto del título. HTML, comentarios, etiquetas de fecha y entidad, autor, URL de imágenes, videos, editor y país.
Características
Análisis de demanda
Investigación de fuentes de datos
Informe de resultados
Personalización del robot
Seguridad, LGPD y soporte
10. Content Grabber
Para quién sirve: Desarrolladores de Python que son expertos en programación.
Por qué deberías usarlo: Content Grabber es un software de web scraping dirigido a empresas. Puede crear sus propios agentes de web scraping con sus herramientas integradas de terceros. Es muy flexible en el manejo de sitios web complejos y extracción de datos.
PROS
Fácil de usar, no requiere habilidades especiales de programación
Capaz de raspar sitios web de datos específicos en minutos
Debugging avanzado
Ideal para raspados de bajo volumen de datos de sitios web
CONS
No se pueden realizar varios raspados al mismo tiempo
Falta de soporte
11. Diffbot
Para quién sirve: Desarrolladores y empresas.
Por qué deberías usarlo: Diffbot es una herramienta de web scraping que utiliza aprendizaje automático y algoritmos y API públicas para extraer datos de páginas web (web scraping). Puede usar Diffbot para el análisis de la competencia, el monitoreo de precios, analizar el comportamiento del consumidor y muchos más.
PROS
Información precisa actualizada
API confiable
Integración de Diffbot
CONS
La salida inicial fue en general bastante complicada, lo que requirió mucha limpieza antes de ser utilizable
12. Dexi.io
Para quién sirve: Personas con habilidades de programación y cotificación.
Por qué deberías usarlo: Dexi.io es un web spider basado en navegador. Proporciona tres tipos de robots: extractor, rastreador y tuberías. PIPES tiene una función de robot maestro donde 1 robot puede controlar múltiples tareas. Admite muchos servicios de terceros (solucionadores de captcha, almacenamiento en la nube, etc.) que puede integrar fácilmente en sus robots.
PROS
Fácil de empezar
El editor visual hace que la automatización web sea accesible para las personas que no están familiarizadas con la codificación
Integración con Amazon S3
CONS
La página de ayuda y soporte del sitio no cubre todo
Carece de alguna funcionalidad avanzada
13. DataScraping.co
Para quién sirve: Analista de datos, comercializadores e investigadores que carecen de habilidades de programación.
Por qué deberías usarlo: Data Scraping Studio es un software web scraping gratis para recolectar datos de páginas web, HTML, XML y pdf.
PROS
Una variedad de plataformas, incluidas en línea / basadas en la web, Windows, SaaS, Mac y Linux
14. Easy Web Extract
Para quién sirve: Negocios con necesidades limitadas de datos, especialistas en marketing e investigadores que carecen de habilidades de programación.
Por qué deberías usarlo: Easy Web Extract es un software visual de scraping y crawling para fines comerciales. Puede extraer el contenido (texto, URL, imagen, archivos) de las páginas web y transformar los resultados en múltiples formatos.
Características
Agregación y publicación de datos
Extracción de direcciones de correo electrónico
Extracción de imágenes
Extracción de dirección IP
Extracción de número de teléfono
Extracción de datos web
15. FMiner
Para quién sirve: Analista de datos, comercializadores e investigadores que carecen de habilidades de programación.
Por qué deberías usarlo: FMiner es un software de web scraping con un diseñador de diagramas visuales, y le permite construir un proyecto con una grabadora de macros sin codificación. La característica avanzada le permite scrapear desde sitios web dinámicos usando Ajax y Javascript.
PROS
Herramienta de diseño visual
No se requiere codificación
Características avanzadas
Múltiples opciones de navegación de rutas de rastreo
Listas de entrada de palabras clave
CONS
No ofrece formación
16. Scrapy
Para quién sirve: Desarrollador de Python con habilidades de programación y scraping
Por qué deberías usarlo: Scrapy se usa para desarrollar y construir una araña web. Lo bueno de este producto es que tiene una biblioteca de red asincrónica que le permitirá avanzar en la siguiente tarea antes de que finalice.
PROS
Construido sobre Twisted, un marco de trabajo de red asincrónico
Rápido, las arañas scrapy no tienen que esperar para hacer solicitudes una a la vez
CONS
Scrapy es solo para Python 2.7. +
La instalación es diferente para diferentes sistemas operativos
17. Helium Scrape
Para quién sirve: Analista de datos, comercializadores e investigadores que carecen de habilidades de programación.
Por qué deberías usarlo: Helium Scraper es un software visual de scraping de datos web que funciona bastante bien, especialmente eficaz para elementos pequeños en el sitio web. Tiene una interfaz fácil de apuntar y hacer clic, lo que facilita su uso.
Características:
Extracción rápida. Realizado por varios navegadores web Chromium fuera de la pantalla
Capturar datos complejos
Extracción rápida
Capturar datos complejos
Extracción rápida
Flujo de trabajo simple
Capturar datos complejos
18. Scrape.it
Para quién sirve: Personas que necesitan datos escalables sin codificación.
Por qué deberías usarlo: Permite que los datos raspados se almacenen en tu disco local que autorizas. Puede crear un Scraper utilizando su lenguaje de web scraping (WSL), que tiene una curva de aprendizaje baja y no tiene que estudiar codificación. Es una buena opción y vale la pena intentarlo si está buscando una herramienta de web scraping segura.
PROS
Soporte móvil
Agregación y publicación de datos
Automatizará todo el sitio web para ti
CONS
El precio es un poco alto
19. ScraperWiki
Para quién sirve: Un entorno de análisis de datos Python y R, ideal para economistas, estadísticos y administradores de datos que son nuevos en la codificación.
Por qué deberías usarlo: ScraperWiki tiene dos nombres
QuickCode: es el nuevo nombre del producto ScraperWiki original. Le cambian el nombre, ya que ya no es un wiki o simplemente para rasparlo. Es un entorno de análisis de datos de Python y R, ideal para economistas, estadísticos y administradores de datos que son nuevos en la codificación.
The Sensible Code Company: es el nuevo nombre de su empresa. Diseñan y venden productos que convierten la información desordenada en datos valiosos.
20. Zyte (anteriormente Scrapinghub)
Para quién sirve: Python/Desarrolladores de web scraping
Por qué deberías usarlo: Zyte es una plataforma web basada en la nube. Tiene cuatro tipos diferentes de herramientas: Scrapy Cloud, Portia, Crawlera y Splash. Es genial que Zyte ofrezca una colección de direcciones IP cubiertas en más de 50 países, que es una solución para los problemas de prohibición de IP.
PROS
La integración (scrapy + scrapinghub) es realmente buena, desde una simple implementación a través de una biblioteca o un docker lo hace adecuado para cualquier necesidad
El panel de trabajo es fácil de entender
La efectividad
CONS
No hay una interfaz de usuario en tiempo real que pueda ver lo que está sucediendo dentro de Splash
No hay una solución simple para el rastreo distribuido / de gran volumen
Falta de monitoreo y alerta.
21. Screen-Scraper
Para quién sirve: Para los negocios se relaciona con la industria automotriz, médica, financiera y de comercio electrónico.
Por qué deberías usarlo: Screen Scraper puede proporcionar servicios de datos web para las industrias automotriz, médica, financiera y de comercio electrónico. Es más conveniente y básico en comparación con otras herramientas de web scraping como Octoparse. También tiene un ciclo de aprendizaje corto para las personas que no tienen experiencia en el web scraping.
PROS
Sencillo de ejecutar - se puede recopilar una gran cantidad de información hecha una vez
Económico - el raspado brinda un servicio básico que requiere poco o ningún esfuerzo
Precisión - los servicios de raspado no solo son rápidos, también son exactos
CONS
Difícil de analizar - el proceso de raspado es confuso para obtenerlo si no eres un experto
Tiempo - dado que el software tiene una curva de aprendizaje
Políticas de velocidad y protección - una de las principales desventajas del rastreo de pantalla es que no solo funciona más lento que las llamadas a la API, pero también se ha prohibido su uso en muchos sitios web
22. Salestools.io
Para quién sirve: Comercializador y ventas.
Por qué deberías usarlo: Salestools.io proporciona un software de web scraping que ayuda a los vendedores a recopilar datos en redes profesionales como LinkedIn, Angellist, Viadeo.
PROS
Crear procesos de seguimiento automático en Pipedrive basados en los acuerdos creados
Ser capaz de agregar prospectos a lo largo del camino al crear acuerdos en el CRM
Ser capaz de integrarse de manera eficiente con CRM Pipedrive
CONS
La herramienta requiere cierto conocimiento de las estrategias de salida y no es fácil para todos la primera vez
El servicio necesita bastantes interacciones para obtener el valor total
23. ScrapeHero
Para quién sirve: Para inversores, Hedge Funds, Market Analyst es muy útil.
Por qué deberías usarlo: ScrapeHero como proveedor de API le permite convertir sitios web en datos. Proporciona servicios de datos web personalizados para empresas y empresas.
PROS
La calidad y consistencia del contenido entregado es excelente
Buena capacidad de respuesta y atención al cliente
Tiene buenos analizadores disponibles para la conversión de documentos a texto
CONS
Limited functionality in terms of what it can do with RPA, it is difficult to implement in use cases that are non traditional
Los datos solo vienen como un archivo CSV
24. UniPath
Para quién sirve: Negocios con todos los tamaños
Por qué deberías usarlo: UiPath es un software de automatización de procesos robótico para el web scraping gratuito. Permite a los usuarios crear, implementar y administrar la automatización en los procesos comerciales. Es una gran opción para los usuarios de negocios, ya que te hace crear reglas para la gestión de datos.
Características:
Conversión del valor FPKM de expresión génica en valor P
Combinación de valores P
Ajuste de valores P
ATAC-seq de celda única
Puntuaciones de accesibilidad global
Conversión de perfiles scATAC-seq en puntuaciones de enriquecimiento de la vía
25. Web Content Extractor
Para quién sirve: Analista de datos, comercializadores e investigadores que carecen de habilidades de programación.
Por qué deberías usarlo: Web Content Extractor es un software de web scraping fácil de usar para fines privados o empresariales. Es muy fácil de aprender y dominar. Tiene una prueba gratuita de 14 días.
PROS
Fácil de usar para la mayoría de los casos que puede encontrar en web scraping
Raspar un sitio web con un simple clic y obtendrá tus resultados de inmediato
Su soporte responderá a tus preguntas relacionadas con el software
CONS
El tutorial de youtube fue limitado
26. Webharvy
Para quién sirve: Analista de datos, comercializadores e investigadores que carecen de habilidades de programación.
Por qué deberías usarlo: WebHarvy es un web scraping software de apuntar y hacer clic. Está diseñado para no programadores. El extractor no le permite programar. Tienen tutoriales de web scraping que son muy útiles para la mayoría de los usuarios principiantes.
PROS
Webharvey es realmente útil y eficaz. Viene con una excelente atención al cliente
Perfecto para raspar correos electrónicos y clientes potenciales
La configuración se realiza mediante una GUI que facilita la instalación inicialmente, pero las opciones hacen que la herramienta sea aún más poderosa
CONS
A menudo no es obvio cómo funciona una función
Tienes que invertir mucho esfuerzo en aprender a usar el producto correctamente
27. Web Scraper.io
Para quién sirve: Analista de datos, comercializadores e investigadores que carecen de habilidades de programación.
Por qué deberías usarlo: Web Scraper es una extensión de navegador Chrome creada para extraer datos en la web. Es un software gratuito de web scraping para descargar páginas web dinámicas.
PROS
Los datos que se raspan se almacenan en el almacenamiento local y, por lo tanto, son fácilmente accesibles
Funciona con una interfaz limpia y sencilla
El sistema de consultas es fácil de usar y es coherente con todos los proveedores de datos
CONS
Tiene alguna curva de aprendizaje
No para organizaciones
28. Web Sundew
Para quién sirve: Empresas, comercializadores e investigadores.
Por qué deberías usarlo: WebSundew es una herramienta de crawly web scraper visual que funciona para el raspado estructurado de datos web. La edición Enterprise le permite ejecutar el scraping en un servidor remoto y publicar los datos recopilados a través de FTP.
Caraterísticas:
Interfaz fácil de apuntar y hacer clic
Extraer cualquier dato web sin una línea de codificación
Desarrollado por Modern Web Engine
Software de plataforma agnóstico
29. Winautomation
Para quién sirve: Desarrolladores, líderes de operaciones comerciales, profesionales de IT
Por qué deberías usarlo: Winautomation es una herramienta de web scraper parsers de Windows que le permite automatizar tareas de escritorio y basadas en la web.
PROS
Automatizar tareas repetitivas
Fácil de configurar
Flexible para permitir una automatización más complicada
Se notifica cuando un proceso ha fallado
CONS
Podría vigilar y descartar actualizaciones de software estándar o avisos de mantenimiento
La funcionalidad FTP es útil pero complicada
Ocasionalmente pierde la pista de las ventanas de la aplicación
30. Web Robots
Para quién sirve: Analista de datos, comercializadores e investigadores que carecen de habilidades de programación.
Por qué deberías usarlo: Web Robots es una plataforma de web scraping basada en la nube para scrape sitios web dinámicos con mucho Javascript. Tiene una extensión de navegador web, así como un software de escritorio que es fácil para las personas para extraer datos de los sitios web.
PROS
Ejecutarse en tu navegador Chrome o Edge como extensión
Localizar y extraer automáticamente datos de páginas web
SLA garantizado y excelente servicio al cliente
Puedes ver datos, código fuente, estadísticas e informes en el portal del cliente
CONS
Solo en la nube, SaaS, basado en web
Falta de tutoriales, no tiene videos
1 note
·
View note
Text
How To Scrape MercadoLibre With Python And Beautiful Soup?
The blog aims is to be up-to-date and you will get every particular result in real-time.
First, you need to install Python 3. If not, you can just get Python 3 and get it installed before you proceed. Then you need to install beautiful soup with pip3 install beautifulsoup4.
We will require the library’s requests, soupsieve, and lxml to collect data, break it down to XML, and use CSS selectors. Install them using.
pip3 install requests soupsieve lxml
Once installed, open an editor and type in.
# -*- coding: utf-8 -*- from bs4 import BeautifulSoup import requests
Now let’s go to the MercadoLibre search page and inspect the data we can get
This is how it looks.
Back to our code now. Let’s try and get this data by pretending we are a browser like this.
# -*- coding: utf-8 -*- from bs4 import BeautifulSoup import requestsheaders = {'User-Agent':'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_11_2) AppleWebKit/601.3.9 (KHTML, like Gecko) Version/9.0.2 Safari/601.3.9'} url='https://listado.mercadolibre.com.mx/phone#D[A:phone]' response=requests.get(url,headers=headers) print(response)
Save this as scrapeMercado.py.
If you run it
python3 scrapeMercado.py
You will see the whole HTML page.
Now, let’s use CSS selectors to get to the data we want. To do that, let’s go back to Chrome and open the inspect tool. We now need to get to all the articles. We notice that class ‘.results-item.’ holds all the individual product details together.
If you notice that the article title is contained in an element inside the results-item class, we can get to it like this.
# -*- coding: utf-8 -*- from bs4 import BeautifulSoup import requests headers = {'User-Agent':'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_11_2) AppleWebKit/601.3.11 (KHTML, like Gecko) Version/9.0.2 Safari/601.3.9', 'Accept-Encoding': 'identity' } #'Accept-Encoding': 'identity'url = 'https://listado.mercadolibre.com.mx/phone#D[A:phone]' response=requests.get(url,headers=headers) #print(response.content) soup=BeautifulSoup(response.content,'lxml') for item in soup.select('.results-item'): try: print('---------------------------') print(item.select('h2')[0].get_text()) except Exception as e: #raise e print('')
This selects all the pb-layout-item article blocks and runs through them, looking for the element and printing its text.
So when you run it, you get the product title
Now with the same process, we get the class names of all the other data like product image, the link, and price.
# -*- coding: utf-8 -*- from bs4 import BeautifulSoup import requests headers = {'User-Agent':'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_11_2) AppleWebKit/601.3.11 (KHTML, like Gecko) Version/9.0.2 Safari/601.3.9', 'Accept-Encoding': 'identity' } #'Accept-Encoding': 'identity' url = 'https://listado.mercadolibre.com.mx/phone#D[A:phone]' response=requests.get(url,headers=headers) #print(response.content) soup=BeautifulSoup(response.content,'lxml') for item in soup.select('.results-item'): try: print('---------------------------') print(item.select('h2')[0].get_text()) print(item.select('h2 a')[0]['href']) print(item.select('.price__container .item__price')[0].get_text()) print(item.select('.image-content a img')[0]['data-src']) except Exception as e: #raise e print('')
What we run, should print everything we need from each product like this.
If you need to utilize this in production and want to scale to thousands of links, then you will get that you will get IP blocked rapidly by MercadoLibre. In this scenario, using a rotating proxy service to rotate IPs is a must. You can use a service like Proxies API to route your calls through a pool of millions of residential proxies.
If you need to scale the crawling speed and don’t want to set up your infrastructure, you can utilize our Cloud-based crawler by Web Screen Scraping to easily crawl thousands of URLs at high speed from our network of crawlers.
If you are looking for the best MercadoLibre with Python and Beautiful Soup, then you can contact Web Screen Scraping for all your requirements.
0 notes