#web scraping tools
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
Tumblr’s website traffic is steadily declining.
Text
Easy way to get job data from Totaljobs
Totaljobs is one of the largest recruitment websites in the UK. Its mission is to provide job seekers and employers with efficient recruitment solutions and promote the matching of talents and positions. It has an extensive market presence in the UK, providing a platform for professionals across a variety of industries and job types to find jobs and recruit staff.
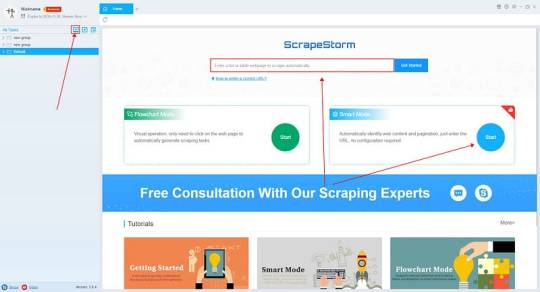
Introduction to the scraping tool
ScrapeStorm is a new generation of Web Scraping Tool based on artificial intelligence technology. It is the first scraper to support both Windows, Mac and Linux operating systems.
Preview of the scraped result
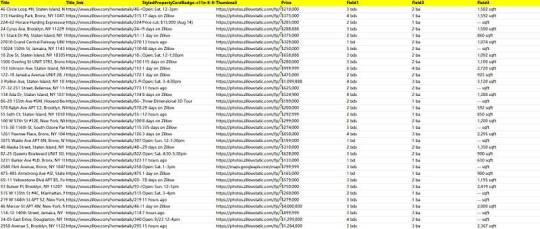
1. Create a task
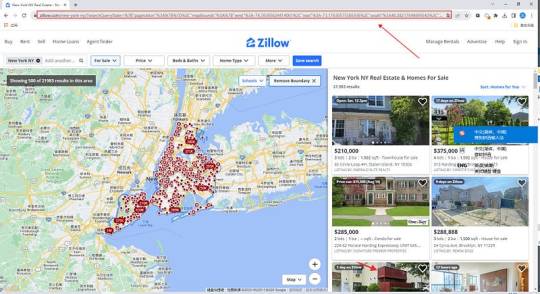
(2) Create a new smart mode task
You can create a new scraping task directly on the software, or you can create a task by importing rules.
How to create a smart mode task
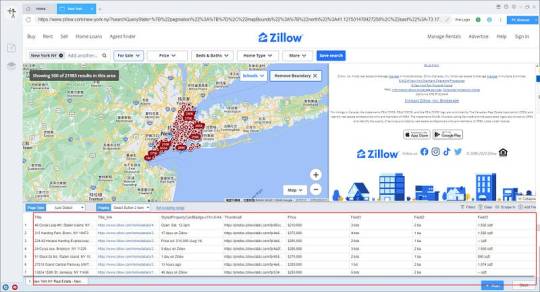
2. Configure the scraping rules
Smart mode automatically detects the fields on the page. You can right-click the field to rename the name, add or delete fields, modify data, and so on.
3. Set up and start the scraping task
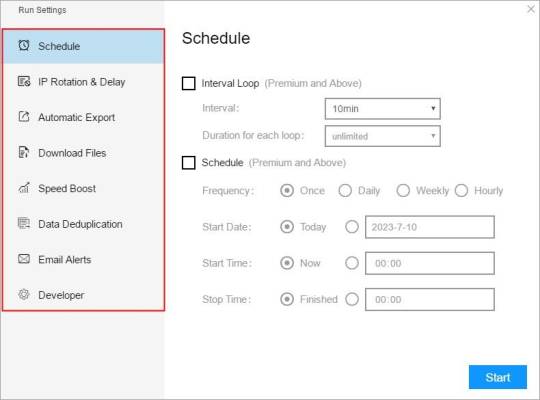
(1) Run settings
Choose your own needs, you can set Schedule, IP Rotation&Delay, Automatic Export, Download Images, Speed Boost, Data Deduplication and Developer.
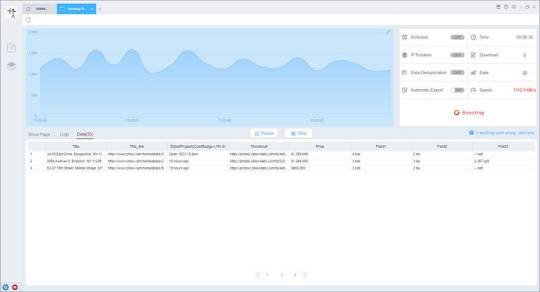
4. Export and view data
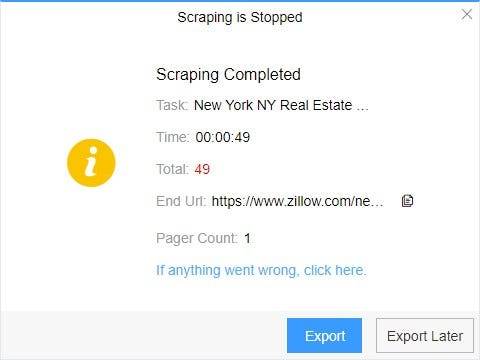
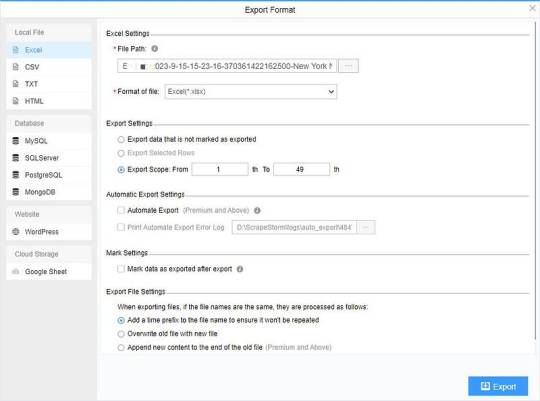
(2) Choose the format to export according to your needs.
ScrapeStorm provides a variety of export methods to export locally, such as excel, csv, html, txt or database. Professional Plan and above users can also post directly to wordpress.
How to view data and clear data
2 notes
·
View notes
Text
done on my mobile app! There may be uses for A.I. (I remain unconvinced): this shit is not it.

They are already selling data to midjourney, and it's very likely your work is already being used to train their models because you have to OPT OUT of this, not opt in. Very scummy of them to roll this out unannounced.
98K notes
·
View notes
Text
How to Rotate Residential IPs Effectively in High-Frequency Tasks
High-frequency tasks like web scraping, ad verification, or multi-account actions need more than speed—they need stealth. Effective residential IP rotation ensures that your requests appear to come from different, legitimate users, helping you bypass detection systems. To rotate smartly, set reasonable intervals, avoid repetitive patterns, and use quality IP pools. This not only protects your operation from being flagged but also boosts success rates across platforms.
1 note
·
View note
Text
Web Scraping 101: Everything You Need to Know in 2025

🕸️ What Is Web Scraping? An Introduction
Web scraping—also referred to as web data extraction—is the process of collecting structured information from websites using automated scripts or tools. Initially driven by simple scripts, it has now evolved into a core component of modern data strategies for competitive research, price monitoring, SEO, market intelligence, and more.
If you’re wondering “What is the introduction of web scraping?” — it’s this: the ability to turn unstructured web content into organized datasets businesses can use to make smarter, faster decisions.
💡 What Is Web Scraping Used For?
Businesses and developers alike use web scraping to:
Monitor competitors’ pricing and SEO rankings
Extract leads from directories or online marketplaces
Track product listings, reviews, and inventory
Aggregate news, blogs, and social content for trend analysis
Fuel AI models with large datasets from the open web
Whether it’s web scraping using Python, browser-based tools, or cloud APIs, the use cases are growing fast across marketing, research, and automation.
🔍 Examples of Web Scraping in Action
What is an example of web scraping?
A real estate firm scrapes listing data (price, location, features) from property websites to build a market dashboard.
An eCommerce brand scrapes competitor prices daily to adjust its own pricing in real time.
A SaaS company uses BeautifulSoup in Python to extract product reviews and social proof for sentiment analysis.
For many, web scraping is the first step in automating decision-making and building data pipelines for BI platforms.
⚖️ Is Web Scraping Legal?
Yes—if done ethically and responsibly. While scraping public data is legal in many jurisdictions, scraping private, gated, or copyrighted content can lead to violations.
To stay compliant:
Respect robots.txt rules
Avoid scraping personal or sensitive data
Prefer API access where possible
Follow website terms of service
If you’re wondering “Is web scraping legal?”—the answer lies in how you scrape and what you scrape.
🧠 Web Scraping with Python: Tools & Libraries
What is web scraping in Python? Python is the most popular language for scraping because of its ease of use and strong ecosystem.
Popular Python libraries for web scraping include:
BeautifulSoup – simple and effective for HTML parsing
Requests – handles HTTP requests
Selenium – ideal for dynamic JavaScript-heavy pages
Scrapy – robust framework for large-scale scraping projects
Puppeteer (via Node.js) – for advanced browser emulation
These tools are often used in tutorials like “Web scraping using Python BeautifulSoup” or “Python web scraping library for beginners.”
⚙️ DIY vs. Managed Web Scraping
You can choose between:
DIY scraping: Full control, requires dev resources
Managed scraping: Outsourced to experts, ideal for scale or non-technical teams
Use managed scraping services for large-scale needs, or build Python-based scrapers for targeted projects using frameworks and libraries mentioned above.
🚧 Challenges in Web Scraping (and How to Overcome Them)
Modern websites often include:
JavaScript rendering
CAPTCHA protection
Rate limiting and dynamic loading
To solve this:
Use rotating proxies
Implement headless browsers like Selenium
Leverage AI-powered scraping for content variation and structure detection
Deploy scrapers on cloud platforms using containers (e.g., Docker + AWS)
🔐 Ethical and Legal Best Practices
Scraping must balance business innovation with user privacy and legal integrity. Ethical scraping includes:
Minimal server load
Clear attribution
Honoring opt-out mechanisms
This ensures long-term scalability and compliance for enterprise-grade web scraping systems.
🔮 The Future of Web Scraping
As demand for real-time analytics and AI training data grows, scraping is becoming:
Smarter (AI-enhanced)
Faster (real-time extraction)
Scalable (cloud-native deployments)
From developers using BeautifulSoup or Scrapy, to businesses leveraging API-fed dashboards, web scraping is central to turning online information into strategic insights.
📘 Summary: Web Scraping 101 in 2025
Web scraping in 2025 is the automated collection of website data, widely used for SEO monitoring, price tracking, lead generation, and competitive research. It relies on powerful tools like BeautifulSoup, Selenium, and Scrapy, especially within Python environments. While scraping publicly available data is generally legal, it's crucial to follow website terms of service and ethical guidelines to avoid compliance issues. Despite challenges like dynamic content and anti-scraping defenses, the use of AI and cloud-based infrastructure is making web scraping smarter, faster, and more scalable than ever—transforming it into a cornerstone of modern data strategies.
🔗 Want to Build or Scale Your AI-Powered Scraping Strategy?
Whether you're exploring AI-driven tools, training models on web data, or integrating smart automation into your data workflows—AI is transforming how web scraping works at scale.
👉 Find AI Agencies specialized in intelligent web scraping on Catch Experts,
📲 Stay connected for the latest in AI, data automation, and scraping innovation:
💼 LinkedIn
🐦 Twitter
📸 Instagram
👍 Facebook
▶️ YouTube
#web scraping#what is web scraping#web scraping examples#AI-powered scraping#Python web scraping#web scraping tools#BeautifulSoup Python#web scraping using Python#ethical web scraping#web scraping 101#is web scraping legal#web scraping in 2025#web scraping libraries#data scraping for business#automated data extraction#AI and web scraping#cloud scraping solutions#scalable web scraping#managed scraping services#web scraping with AI
0 notes
Text
How to Scrape Data from Chinese Sellers on MercadoLibre MX FBM
Introduction
The eCommerce industry in Latin America has seen massive growth, with MercadoLibre Mexico emerging as one of the largest online marketplaces. Among the various sellers operating on the platform, Chinese Sellers on MercadoLibre Mexico have gained a significant market share due to their competitive pricing, diverse product offerings, and strategic use of FBM (Fulfillment by Merchant). These sellers bypass local fulfillment centers, shipping products directly from China, allowing them to maintain lower costs and high-profit margins.
With this increasing competition, businesses need Web Scraping MercadoLibre Mexico Sellers to track seller data, pricing trends, and inventory insights. Extracting real-time marketplace data helps brands, retailers, and competitors stay ahead by understanding product availability, discount strategies, and customer preferences.
This blog explores how to Scrape Data from Chinese Sellers on MercadoLibre, why businesses should monitor seller trends, and how MercadoLibre FBM Web Scraping can help in gathering actionable insights.
Growing Presence of Chinese Sellers on MercadoLibre Mexico
The eCommerce landscape in Latin America has witnessed a surge in international sellers, with Chinese vendors dominating a significant portion of MercadoLibre Mexico. Due to the platform’s vast customer base and cross-border selling opportunities, more Chinese businesses are leveraging MercadoLibre FBM (Fulfillment by Merchant) to ship products directly from their warehouses. This strategy helps them avoid local fulfillment costs and maintain competitive pricing. According to 2025 statistics, over 40% of new electronics and gadget listings on MercadoLibre MX come from Chinese sellers. Their competitive pricing, fast shipping partnerships, and broad product variety have made them major players in Mexico’s online retail market

Importance of MercadoLibre FBM Web Scraping for Tracking Seller Data
With the rising competition in the Latin American eCommerce market, businesses must leverage MercadoLibre FBM Web Scraping to track Chinese seller activities, pricing trends, and inventory strategies. Web Scraping MercadoLibre Mexico Sellers allows companies to extract critical insights such as:
Product Listings – Track new product additions and category trends.
Pricing Strategies – Analyze price fluctuations and discount offers.
Seller Ratings & Feedback – Understand customer sentiment and service quality.
Shipping & Delivery – Monitor estimated delivery times and logistics efficiency.
By implementing Scrape Data from Chinese Sellers on MercadoLibre, businesses can make data-backed decisions, optimize pricing strategies, and enhance their marketplace performance.

How Businesses Can Benefit from Extracting Accurate and Real-Time Marketplace Insights?
By using Extract MercadoLibre Seller Information, businesses can unlock crucial insights to improve sales strategies and outperform competitors. Key benefits include:
A. Competitive Pricing Strategies
Track Chinese seller pricing and adjust prices accordingly.
Identify seasonal discount patterns and promotional campaigns.
Use Track Chinese Seller Prices on MercadoLibre to maintain a competitive edge.
B. Trend Analysis & Market Research
Discover top-selling categories and emerging trends.
Analyze product demand based on customer preferences.
Scrape MercadoLibre Product Listings to monitor newly launched items.
C. Inventory & Stock Optimization
Monitor product availability and restocking patterns.
Identify potential stock shortages and supply chain issues.
Ensure optimal inventory levels to meet market demand.

How to Scrape Data from Chinese Sellers on MercadoLibre?
Businesses can leverage Web Scraping for Cross-Border eCommerce Data to gain critical marketplace insights and stay competitive. By extracting data from global marketplaces, companies can track pricing trends, monitor competitors, and optimize their sales strategy.
Key Steps in Web Scraping for eCommerce Insights
Identifying Targeted Seller Data – Businesses can collect essential details such as product names, prices, ratings, and reviews from various online platforms. This data helps in understanding competitor pricing strategies and customer preferences.
Setting Up Automated Scrapers – Utilizing advanced web scraping tools, businesses can efficiently extract structured data without manual effort. Automation ensures consistency and scalability, making data collection seamless.
Filtering & Analyzing Data – Once data is extracted, it is essential to organize and analyze it for competitor benchmarking and pricing analysis. This helps businesses adjust their pricing strategies and enhance product offerings based on real market trends.
Monitoring Real-Time Updates – The eCommerce landscape is dynamic, requiring businesses to stay updated. Automated scrapers can be set to perform daily or weekly data extraction to track changing trends, stock availability, and price fluctuations.
MercadoLibre FBM Web Scraping for Enhanced Market Intelligence
For businesses targeting Latin American markets, MercadoLibre FBM Web Scraping is a game-changer. By automating data collection from MercadoLibre, companies can gain real-time insights into competitor pricing, top-selling products, and customer sentiment. This ensures accurate and up-to-date marketplace intelligence, enabling data-driven decision-making.

Challenges in Scraping MercadoLibre & How to Overcome Them
While Extracting MercadoLibre Seller Information offers valuable insights, businesses face challenges such as:
CAPTCHAs & Anti-Scraping Mechanisms – Implement Web Scraping API Services for seamless data extraction.
Large Data Volumes – Use Automated Data Extraction from MercadoLibre for scalability.
Dynamic Pricing & Real-Time Updates – Ensure frequent data collection to track price fluctuations accurately.

How Actowiz Solutions Can Help?
Actowiz Solutions specializes in MercadoLibre Seller Analytics with Web Scraping, providing:
Custom Web Scraping Solutions – Tailored tools for tracking seller data.
Real-Time Price & Inventory Monitoring – Keep up with market changes.
Competitor Benchmarking – Compare pricing strategies and product listings.
Scalable & Automated Scraping – Extract large datasets without restrictions.
Our expertise in Scrape Data from Chinese Sellers on MercadoLibre ensures accurate, real-time insights that drive business growth.
Conclusion
The increasing presence of Chinese Sellers on MercadoLibre Mexico presents both opportunities and challenges for businesses. To stay competitive, companies must leverage Web Scraping MercadoLibre Mexico Sellers for data-driven insights on pricing, inventory, and seller strategies. By implementing MercadoLibre FBM Web Scraping, businesses can optimize pricing, track competitors, and enhance their overall marketplace performance.
Ready to extract real-time data from MercadoLibre? Contact Actowiz Solutions for powerful Web Scraping Services today!
Learn More
#Web Scraping MercadoLibre#Web Scraping to track Chinese seller#web scraping tools#Web Scraping API Services
0 notes
Text
What Is Web Scraping? An In-Depth Guide by WebDataGuru Curious about web scraping and its potential? Discover how web scraping works, its key applications, and how WebDataGuru expert solutions can help you unlock valuable insights from online data. Dive into the essentials of web scraping and understand why it’s transforming industries by enabling real-time data access and analysis.
0 notes
Text
Large-Scale Web Scraping: An Ultimate Guide offers comprehensive insights into automating massive data extraction. Learn about tools, techniques, and best practices to efficiently gather and process web data at scale.
#Large-Scale Web Scraping#Web Scraping Tools#Web Scraping Services#Python Web Scraping#Web Scraping API
0 notes
Text
How Businesses Use Web Scraping Services?

In today's digital era, businesses are always on the lookout for ways to stay ahead of the competition. One way they do this is by harnessing the power of data. Web scraping services have become indispensable tools in this pursuit, providing businesses with the means to gather, analyze, and act upon large quantities of data from the internet. Let's explore how businesses use web scraping services and the benefits they offer.
What Is Web Scraping?
Web scraping is a method of extracting data from websites. It involves using scripts or automated tools to retrieve specific data from web pages, which is then stored and organized for further analysis. Web scraping services offer a systematic way to obtain this data, enabling businesses to gather information about competitors, customers, market trends, and more.
How Businesses Use Web Scraping Services
Competitor Analysis:
Businesses use web scraping to monitor competitors' websites, including pricing, product information, and marketing strategies.
By tracking competitors' actions, companies can adapt their strategies, develop competitive pricing models, and enhance their product offerings.
Market Research:
Web scraping allows businesses to collect data on market trends and customer preferences by analyzing product reviews, ratings, and forums.
This insight helps businesses make informed decisions regarding product development, marketing strategies, and customer engagement.
Lead Generation:
Companies can scrape data from websites and social media platforms to identify potential leads.
Contact information, demographics, and other relevant data can be gathered, allowing businesses to tailor their outreach efforts more effectively.
Brand Monitoring:
Web scraping services enable businesses to track online mentions of their brand, products, or services.
This helps companies gauge their brand reputation, understand customer sentiment, and quickly address any issues that may arise.
Price Optimization:
Retailers use web scraping to monitor competitors' pricing in real time.
By understanding current market prices, businesses can optimize their own pricing strategies to remain competitive and maximize profits.
Content Aggregation:
Media and news organizations often use web scraping to gather content from multiple sources.
This allows them to curate and present a wide range of information to their audience, enhancing their own content offerings.
Financial Data Analysis:
Financial institutions and analysts use web scraping to collect data on stock prices, economic indicators, and other financial metrics.
This data helps inform investment strategies and market predictions.
The Benefits of Using Web Scraping Services
Time and Cost Savings:
Manual data collection is time-consuming and labor-intensive. Web scraping automates this process, saving businesses time and resources.
Data Accuracy:
Automated web scraping services can retrieve data more consistently and accurately than manual methods, reducing the risk of human error.
Real-Time Data:
Businesses can access real-time data, allowing them to make more agile and informed decisions.
Customizable Data Collection:
Web scraping services can be tailored to target specific data points, ensuring businesses get the exact information they need.
Actionable Insights:
By analyzing the data collected through web scraping, businesses can gain valuable insights into customer behavior, market trends, and industry shifts.
Legal and Ethical Considerations
While web scraping offers numerous benefits, businesses must also be mindful of the legal and ethical implications of using these services. Scraping data without permission from the website owner may violate terms of service or intellectual property rights. Therefore, it is crucial to adhere to the legal boundaries and ethical guidelines surrounding data collection.
Conclusion
Web scraping services have become essential tools for businesses across various industries. By leveraging these services, companies can gain access to valuable data, allowing them to make better decisions and maintain a competitive edge. However, it is important to use web scraping responsibly, respecting legal and ethical considerations. With the right approach, businesses can harness the full potential of web scraping services to drive growth and success.
0 notes
Text
How To Scrape Threads Data For Insights?

In today's digital world, the voices echoing online forums and discussions are more influential than ever. Platforms like Threads are woven with opinions, conversations, insights, and experiences for data enthusiasts, researchers and analysts. But how do we collect and make the best use of this data available before it disappears? That's when scraping helps. Scraping Threads can not only navigate you through the valuable user-generated content. Still, they can also be the treasure you might be looking for to bolster customer understanding and spark innovative ideas. In this blog, let's explore how to extract valuable insights from Threads and how to put the data to better use while considering ethical practices.
What is Threads and Scraping in the context of Threads?
Threads, created by Meta (formerly Facebook), is a social networking platform focused on fleeting photo and video sharing. Users close to each other on Instagram can create "threads" – temporary group chats where the content disappears after 24 hours or upon exiting the chat. This impermanent nature adds a layer of intrigue and authenticity to interactions.
Scraping, in the context of social media, refers to extracting data from a platform. Thread scraping involves collecting publicly available information from the app, such as Usernames, Captions, Comments, and Engagement Metrics.
Why Scrape Threads Data?

Threads is about sharing short-lived posts with close friends, giving us a unique look at trends and how users act. Let's explore why collecting data from Threads can be useful:
Capturing Fleeting Trends
Unlike public posts on platforms like Instagram, Thread's content disappears after 24 hours. This can be particularly valuable for:
Identifying Emerging Trends
Unearthing trending topics, hashtags, and visual styles before they explode into the mainstream.
Analyzing Real-Time Sentiment
Getting a clear view of what people think and feel about events or issues as they happen, providing important insights instantly.
Understanding Unfiltered Opinions
Threads foster a more candid environment with its disappearing content and close friend circles. You can understand the honest opinions and talks happening in tight-knit groups by collecting public information like captions and comments. This can be particularly useful for:
Market Research
Understanding how close friends talk about brands, products, or services can provide valuable insights into real-world user preferences and pain points.
Social Listening
Identifying emerging trends or concerns related to specific topics, events, or social issues can help organizations stay ahead of the curve and effectively address public sentiment.
Fueling Content Creation Strategies
Knowing what your audience likes is key to making interesting content. Collecting data from Threads lets you see what kinds of posts, pictures, and topics get the most attention in close friend groups. This information can guide you in making content your audience will enjoy, even beyond the Threads app.
How to Scrape Threads?
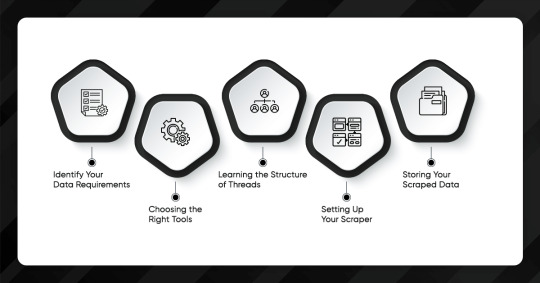
Before we dive into the how-to, we must understand the legal and ethical considerations of scraping. You must always comply with the Terms of Service (ToS) of the website you're scraping. Many sites explicitly prohibit scraping in their ToS, and scraping such sites without permission may subject you to legal action.
Also, consider the ethical implications – you should respect users' privacy and not misuse the data. Always aim for anonymized data that removes personal indicators whenever possible.
Identify Your Data Requirements
First, be clear on what information you need. Is it the thread text, user interactions, timestamps, or maybe the number of views and replies? The more specific you are, the more effective your scraping operation will be.
Choosing the Right Tools
Next, you need to equip yourself with the right tools. There are numerous web scraping tools and libraries available, such as:
BeautifulSoup and Requests for Python
Great for beginners and perfect for static content, but might stumble on JavaScript-heavy sites.
Scrapy
An open-source and collaborative framework for extracting the data you need from websites. It's built on Twisted, an asynchronous networking framework, which means it can handle larger amounts of data and more complex scraping tasks.
Selenium
Ideal for dynamic content that requires interacting with the web page, like clicking buttons to load more thread content.
Puppeteer or Playwright
Headless browsers that can control web pages with a JavaScript API, perfect for scraping single-page applications.
Learning the Structure of Threads
Threads are typically structured in a nested manner. There may be a main post followed by replies, each with its own sub-replies. Understanding this structure is essential to ensuring your scraper navigates the thread accurately.
Setting Up Your Scraper
Use the inspect tool in your browser to understand the page's HTML structure. Write the code and run the scraper to collect the data. Ensure you include error handling and respect the site's robots.txt and rate limiting to avoid blocking your IP.
Storing Your Scraped Data
It's good practice to store data in a structured format as you scrape it. For simpler needs, a JSON or CSV file might suffice.
Approaches to Scrape Threads data
There are multiple approaches to scraping Threads data, each with its own advantages and limitations
Manual Scraping
This is the simplest form, where you manually visit forums or Threads and copy-paste the needed information. While straightforward, it's time-consuming and not efficient for large-scale data collection.
Using APIs
Many platforms offer Application Programming Interfaces (APIs) that allow you to access and collect data legally in a structured manner. Using an API facilitates gathering large amounts of data while respecting the platform's data use policies.
Web Scraping Tools
There are numerous web scraping tools and software available that can automate the data collection process. These tools navigate websites, extract specified data, and store it for further analysis. Some popular tools include Beautiful Soup (for Python users), Scrapy, and Octoparse.
Custom Web Scrapers
Developing custom web scrapers using programming languages like Python is a viable approach for more specific needs or for gathering data from platforms without an API. This involves writing scripts that send requests to the website, parse the HTML content, and extract the desired information.
Browser Extensions
Browser extensions designed for scraping data from web pages with minimal effort exist. These extensions can be particularly useful for quick, one-off scraping tasks or when dealing with a small volume of data.
Outsourcing to Scraping Services
If you lack the technical skills or resources, outsourcing data collection to a specialized scraping service is an option. Many companies offer tailored services to scrape and deliver data according to your specifications.
Considerations for Ethical Scraping
Respect robots.txt
This specifies the areas that should not be scraped. Respecting these rules is crucial for ethical scraping.
Rate Limiting
Implement delays between your scraping requests to avoid overwhelming the server.
User Privacy
Be mindful of personal data and comply with regulations like GDPR or CCPA to protect user privacy.
Terms of Service
Adhere to the website's terms of service, which often include clauses about data scraping.
Conclusion
Scraping Threads data can provide valuable insights into user behaviour, trends, and opinions. However, your chosen approach should balance your data needs, technical capabilities, and ethical considerations. Whether through APIs, web scraping tools, or custom scripts, data scraping, when done responsibly, can be a powerful tool for research, marketing, and strategic decision-making.
Scraping service providers like Web Screen Scraping transform the extracted data into actionable insights. We offer custom data analysis solutions and scraping services to businesses of all sizes. Using the latest technologies and the expertise of our team, we provide well-structured data from the source.
Article Source : https://www.webscreenscraping.com/how-to-scrape-threads-data-for-insights.php
1 note
·
View note
Text
How combining AI and RPA can help your businesses
Explore the transformative potential of integrating Artificial Intelligence (AI) with Robotic Process Automation (RPA) to optimize your business processes. Read more https://scrape.works/blog/how-combining-ai-and-rpa-can-help-your-businesses/

0 notes
Text
If you’re as obsessed with data, tech, and the endless possibilities of the internet as I am, you’re going to want to hear about ProxyJet. This platform is not just changing the game; it’s completely revolutionizing how we approach data collection. Let me break down why ProxyJet is the MVP of proxy services.
Why ProxyJet is a Game-Changer:
Speed is Key: Imagine getting your proxy setup done in less than 20 seconds. With ProxyJet, that’s not a dream—it’s reality. This means more time diving into the data that matters most to you, and less time waiting around.
A Proxy for Every Purpose: Whether you’re into web scraping, protecting your privacy, or just exploring the digital world, ProxyJet has a type of proxy for you. Rotating Residential, Static Residential, Mobile, Datacenter—take your pick. Each one is tailored to specific needs and challenges.
Worldwide Reach: Access over 75M+ IPs across the globe. This isn’t just about being able to scrape or access data—it’s about breaking down geographical barriers and unlocking a world of information.
Pricing that Makes Sense: Starting from $0.25/GB, ProxyJet offers flexible pricing that ensures you’re only paying for what you need. It’s like having your cake and eating it too, but with data.
The Technical Stuff: We’re talking a 99.9% success rate, people. This platform is reliable, efficient, and designed to make your data collection as seamless as possible.
Why I’m All In:
In a world where data is gold, having the right tools to mine that gold is crucial. ProxyJet isn’t just another tool; it’s the Swiss Army knife for anyone looking to harness the power of the internet. Whether you’re a seasoned developer, a marketer, or just someone curious about the digital landscape, ProxyJet is your gateway to exploring the vast, uncharted territories of the web.
So, What’s Next?
If you’re ready to level up your data game, take a leap into ProxyJet. It’s not just about collecting data; it’s about unlocking potential, discovering new horizons, and empowering your online adventures.
Dive in, explore, and let’s revolutionize the way we interact with the digital world together. Check out ProxyJet at https://proxyjet.io/ and start your journey.
#ai scraping#data scraping#proxy#scraping#web scraping api#web scraping services#web scraping tools#proxy server
1 note
·
View note
Text
Extract ticket data from TicketNetwork using ScrapeStorm
TicketNetwork is a well-known online ticketing platform dedicated to providing tickets for a variety of sports games, concerts, theater, entertainment events and other special events.
Introduction to the scraping tool
ScrapeStorm is a new generation of Web Scraping Tool based on artificial intelligence technology. It is the first scraper to support both Windows, Mac and Linux operating systems.
Preview of the scraped result
Export to Excel:

This is the demo task:
1. Create a task
(1) Copy the URL

(2) Create a new smart mode task
You can create a new scraping task directly on the software, or you can create a task by importing rules.
How to create a smart mode task

2. Configure the scraping rules
Smart mode automatically detects the fields on the page. You can right-click the field to rename the name, add or delete fields, modify data, and so on.

3. Set up and start the scraping task
(1) Run settings
Choose your own needs, you can set Schedule, IP Rotation&Delay, Automatic Export, Download Images, Speed Boost, Data Deduplication and Developer.

(2)Wait a moment, you will see the data being scraped.

4. Export and view data

(2) Choose the format to export according to your needs.
ScrapeStorm provides a variety of export methods to export locally, such as excel, csv, html, txt or database. Professional Plan and above users can also post directly to wordpress.
How to view data and clear data

0 notes
Text
https://www.webrobot.eu/travel-data-scraper-benefits-hospitality-tourism

The travel industry faces several challenges when using travel data. Discover how web scraping technology can help your tourism business solve these issues.
#travel#tourism#big data#web scraping tools#data extraction#hospitality#data analytics#datasets#webrobot#data mining#no code#ai tools
1 note
·
View note
Text
#scrapper tool#scraper tool#web scraper#web automation#web scraping tools#web scraper tools 2024#scraping tools 2024
0 notes