#also the ip issue is something that could be fixed by training the model on ones own art
Note
AI art isn't real art because there's no human touch. Typing a prompt into a computer doesn't count.
you are severely missing the point. questioning what constitutes as 'art' is counterproductive and does nothing for the actual issue at hand which is abt the ETHICS of it.
art doesnt have to be ethical to be art, but people need to have integrity and good ethics if they want to be respected by others and also if they want to show solidarity with the workers in the art industry
#stop trying to argue whether its art or not art its abt REGULATIONS and if youll believe it. not ip regulations#like youre not supposed to care abt intellectual propertyyyy youre supposed to care abt the capitalist implications of it#and the overcommodification of art. like you cant argue what is and what isnt art#but you CAN argue whether someone should get paid for it or not#also the ip issue is something that could be fixed by training the model on ones own art#the thing with bands and ai generated videos is more a matter of ethics and common decency than it is abt whats art or not#hope that makes sense <3#rb
5 notes
·
View notes
Text
How an Online Game Can Help AI Address Access to Justice (A2J)
youtube
In access to justice discussions it is a truth universally acknowledged, that the majority of those in possession of legal problems, remain in want of solutions. (My apologies to both Jane Austen and the Legal Service Corporation’s Justice Gap Report.) Also, ROBOTS! Ergo, we should throw AI at A2J. There is considerably less consensus, however, on how (or why exactly) this should be done. But don’t worry! There’s an app/game for that, and it lets you train artificial intelligence to help address access-to-justice issues. We’ll get to that in a minute. But first, some background.
Machine Learning & Access to Justice, Together at Last
Machine Learning, the subdiscipline within AI around which the current hype cycle revolves, is good at pattern recognition. Acquaint it with a sufficiently large number of example items, and it can “learn” to find things “like” those items hiding in the proverbial haystack. To accomplish such feats, however, we have to satisfy the machine’s need for data—BIG data. Consequently, AI’s appetite is often a limiting factor when it comes to deploying an AI solution.
Let’s consider two areas where AI’s pattern recognition might have something to offer A2J. Services like ABA’s Free Legal Answers try to match people with legal questions to lawyers offering pro bono limited representation (think free advice “calls” over email). Unfortunately, some questions go unclaimed. In part, that’s because it can be hard to match questions to attorneys with relevant expertise. If I’m a volunteer lawyer with twenty years of health law experience, I probably prefer fielding people’s health law questions while avoiding IP issues.
To get health law questions on my plate and IP questions on someone else’s, a user’s questions need to be (quickly, efficiently, and accurately) labeled and routed to the right folks. Sure, people can do this, but their time and expertise are often better deployed elsewhere, especially if there are lots of questions. Court websites try to match users with the right resources, but it’s hard to search for something when you don’t know what it’s called. After all, you don’t know what you don’t know. Complicating matters further, lawyers don’t use words like everyone else. So it can be hard to match a user’s question with a lawyer’s expertise. Wouldn’t it be great if AI’s knack for pattern recognition could spot areas of law relevant to a person’s needs based on their own words (absent legalese), then direct them to the right guide, tool, template, resource, attorney, or otherwise? That’s what we’re working towards here.
I know what you’re thinking, but we are NOT talking about a robot lawyer. When we say “AI,” think augmented intelligence, not artificial intelligence. What we’re talking about is training models to spot patterns, and it’s worth remembering the sage advice of George Box, “all models are wrong, but some are useful.” Consequently, one must always consider two things before deciding to use a model: First, does the model improve on what came before? Second, is it starting a discussion (not ending it)? Unless the data are pristine and the decision is clear-cut, a model can only inform, not make, the decision.
Something like an automated issue spotter has the potential to improve access to justice simply by making it a little easier to find legal resources. It doesn’t need to answer people’s questions. It just needs to point them in the right direction or bring them to the attention of someone in a position to help. It can get the conversation started by making an educated guess about what someone is looking for and jumping over a few mundane—but often intimidating—first steps.
But at least two problems stand between us and realizing this dream. If we’re going to map lay folks’ questions to issues using machine learning, we’re going to need a list of issues and a boatload of sample questions to train our models. As if this wasn’t enough, those examples need to be tagged or labeled with the right issues. Unfortunately, we are unaware of any appropriately-labeled public dataset. So we’ve decided to help birth one.
Who’s “we” you ask? A collaboration of Suffolk Law School’s Legal Innovation and Technology (LIT) Lab (bringing the data science) and Stanford Law School’s Legal Design Lab (bringing the design chops), with funding from The Pew Charitable Trusts.
Learned Hands: An Introduction to Our Project
Image by Margaret Hagan.
So AI can help address an A2J need but only if someone has the resources and expertise to create a taxonomy, read a bunch of text, and (correctly) label all the legal issues present. This is where you, dear reader, can help.
The Access to Justice & Legal Aid Taxonomy
Stanford’s Legal Design Lab has taken the lead on creating a taxonomy of legal help issues based on existing ones. Eventually, service providers will be able to match their offerings to the list, and AI can pair the general population’s questions with the appropriate label or tag within the taxonomy. Heck, AI could even help service providers match their resources to the taxonomy, serving as a translator on both sides. Either way, the taxonomy will provide a standard nomenclature to help coordinate A2J work across the community. Setting standards is hard, but it’s the sort of foundational work that can pay big dividends. In short, we’re building Version 1.0 and looking for your input. If that appeals to you, give this description of the work/call for input a look and make yourself heard.
Help AI Address Access to Justice
Now we just need tens of thousands of legal questions to feed the machine, and each one must be tagged with items from the taxonomy. Luckily, people publicly post their legal questions all the time. Tens of thousands are available over at r/legaladvice. The moderators and forum rules work to ensure that these posts lack personally identifying information, and all questions are posted with the expectation that they will be published to the front page of the internet, as Reddit calls itself. This makes them unique because, unlike questions posted on sites like ABA Free Legal Answers, their authors understand them to reside in an explicitly public space. Although they haven’t been mapped to our taxonomy, their public nature leaves open the possibility that an army of citizen issue spotters (that’s you) could read through them and label away.
One can download these questions using the Reddit API, but moderators at r/legaladvice were kind enough to share their own repository of nearly 75,000 questions in the hopes they could help jump-start our work. Thanks especially to Ian Pugh and Shane Lidman for facilitating our work with the Reddit Legal Advice community.
The Game: Labeling Texts
To help label our growing collection of texts, we’ve created an online game in the hope that many hands will make light work. So, of course, we call it Learned Hands. (This is wordplay riffing on the name of an eminent American jurist, Learned Hand. I’m sorry I felt compelled to explain the joke, but here we are.)

Logo by Margaret Hagan.
The game presents players with a selection of lay peoples’ questions and asks them to confirm or deny the presence of issues. For example, “Do you see a Health Law issue?” We then combine these “votes” to determine whether or not an issue is present. As you can imagine, deciding when you have a final answer is one of the hard parts. After all, if you ask two lawyers for an opinion, you’ll likely get five different answers.
We decide the final answer using statistical assumptions about the breakdown of voters without requiring a fixed number of votes. Effectively, if everyone agrees on the labeling, we can call the final answer with fewer votes than if there is some disagreement. Consequently, the utility of the next vote changes based on earlier votes. We use this to order the presentation of questions and make sure that the next question someone votes on is the one that’s going to give us the most information/ or move us closest to finalizing a label. This means we don’t waste players’ time by showing them a bunch of undisputed issues.
You earn points based on how many questions you mark (with longer texts garnering more points). Players are ranked based on the points they’ve earned multiplied by their quality score, which reflects how well your markings agree with the final answers. Specifically, we’re using a measure statisticians call the F1 Score.
That’s right. You can compete against your colleagues for bragging rights as the best issue spotter (while training AI to help address A2J issues). After all, we’re trying to have this game go viral. Please tell all your friends! Also, it works on both your desktop and your phone.
Desktop and mobile screenshots.
Eventually, we will make different flavors of the labeled data available to researchers, developers, and entrepreneurs free of charge in the hopes that they can use the data to create useful tools in the service of A2J (for example, we may publish a set where the labels correspond to a 95% confidence level and another where the labels are just the current “best guess”). Not only could such datasets serve to help train new issue spotting models, but ideally, they could serve as a tool for benchmarking (testing) such models. See Want to improve AI for law? Let’s talk about public data and collaboration.
We’re also seeking private data sources for secure in-game labeling by users agreed upon by those providing the data (e.g., their own employees). By including more diverse datasets, we can better train the algorithms, allowing them to better recognize problems beyond those faced by Reddit users. Although we’ll be unable to publicly share labeled private data, we will be able to share the models trained on them, allowing the larger A2J community to benefit while respecting client confidence.
For the record, although this game’s design was a collaboration between the LIT and Legal Design Labs, Metin Eskili (the Legal Design Lab’s technologist) is responsible for the heavy lifting: turning our ideas into functional code. Thanks, Metin.
Active Learning
We will also use a process called active learning. Basically, once we reach a critical mass of questions, we train our machine learning models on the labeled data as it comes in. We then point our models at the unlabeled questions looking for those it’s unsure of. We can then move these questions to the top of the queue. In this way, the models gain insights they need to parse “confusing” examples. Again, the idea is not to do more labeling than necessary. It just makes sense to skip those questions our algorithms are pretty sure about.
Proof of Concept
Here at Suffolk’s LIT Lab, we’ve started training algorithms on a pre-labeled private dataset. The early results are promising, or as I like to say, “not horrible.” As I’ve explained elsewhere, accuracy is often not the best measure of a model’s performance. For example, if you’re predicting something that only happens 5% of the time, your model can be 95% accurate by always guessing that it’s going to happen. It can be hard to say what makes a good model (aside from perfection), but it’s pretty easy to spot when a model’s bad. All you have to do is play through some scenarios. (In practice, one needs to think carefully about the costs of things like false positives and false negatives. Sometimes you’ll have a preference for one over the other, but we’re not going to get that nuanced here.) To keep it simple, we’ll assume a binary prediction (e.g., yes or no).
If a coin flip can beat your predictions, your predictions are horrible. Your accuracy better beat 50%.
If always guessing yes or no can beat your predictions, your predictions are horrible. Your accuracy must be better than the fraction of the majority answer (like in the 95% accuracy example above).
If you’re looking for Xs and you miss most of the Xs in your sample, your predictions are horrible. So your recall has to be greater than 0.5.
If you’re looking for Xs, and less than half of the things you call Xs are actually Xs, your predictions are horrible. So your precision has to be greater than 0.5.
Using these guideposts, we know a classifier is “not horrible” when it beats both a coin flip and always guessing yes or no. If it says something is X, it better be right most of the time, and across the entire dataset, it must correctly identify more than half of the Xs present.
Below, I’ve included some summary statistics for one of our tentative models trained on pre-labeled private data. As you can see, it’s not horrible—accuracy beats always guessing yes or no, and precision and recall beat 0.50. There are some other nice data points in there (like AUC), but we won’t highlight those here (their descriptions are beyond the scope of this post). In the end, “not horrible” is just an extension of the idea that a model should be an improvement on what came before. In this case, “what came before” includes coin flips and always guessing yes or no.
A snapshot of private data testing results.
As you’d expect, our models are getting better with more data. So we’re really excited to see what happens when a bunch of folks start labeling. Also, it’s worth noting that we are starting with high-level labels (e.g., family law and housing). Over time, we will be including more granular labels (e.g., divorce and eviction).
How Does This All Work? (A Slightly-Technical Description)
Text classification isn’t as complicated as you might think. That’s mostly because the algorithms aren’t really reading the texts (at least not the way you do). To oversimplify a common text-classification method called bag-of-words, one creates a list of words found across all texts and then represents each document as a count of words found in that document. Each word counts is treated as a dimension in a vector (think “column in a list of numbers”). After looking at all the data, one might notice that questions about divorce always have a value greater than or equal to three for the dimension associated with the word “divorce.” In other words, divorce-related questions always contain the word “divorce” at least three times. So it is possible to describe questions about divorce by referring to their vectors.
Put another way, every text with vectors whose divorce dimension is on either side of three goes into either the divorce or not-divorce categories. This isn’t a very realistic example, though, because document types aren’t often like Beetlejuice (say the magic word three times and they appear). Still, it is reasonable to assume there is a constellation of keywords that help define a document type. For example, maybe the chance that a question is housing-related goes up when the query uses words like landlord, tenant, or roommate. Larger values across those dimensions, then, are correlated with housing questions. You can (of course) get more nuanced and start looking for n-grams (couplings of two, three, or words) like best interest while ignoring common words like and. But the general method remains the same: we throw the words into a bag and count them.
More sophisticated approaches—like word2vec—employ different methods for converting text to vectors, but without getting too far in the weeds we can generalize the process of text-classification. First, you turn texts into numbers embedded in some multi-dimensional space. Then you look for surfaces in that space that define borders between different text groupings with different labels. This, of course, relies on different text types occupying different regions in the space after they are embedded. Whether or not these groupings exist is an empirical question (which is why it’s nice to see not horrible output above). The data help us think success is an option.
Google’s Machine Learning Crash Course on Text Classification provides a good high-level introduction for those interested in the technology. Our workflow tracks with much of their description, although there are some differences. For example, we’re using over- and under-sampling for unbalanced classes and stacking various models. Don’t worry, we’ll eventually write everything up in detail. Here’s the point, though: we aren’t pushing the state of the art with these classifiers. We’re sticking with time-tested methods and producing a publicly-labeled dataset. We’d love to see this labeled dataset feeding some cutting-edge work down the road, and if you can make a compelling demonstration for how your novel method could make better predictions, we’re open to taking your model in-house and training it on our private datasets (assuming you commit to making the trained model-free and publicly available). After all, many hands make light work. Tell your friends! Heck, let’s make it super simple. Just share this tweet as often as you can:
Compete against your colleagues for bragging rights as the best legal issue spotter (while training #AI to help address #A2J issues), a collaboration between @SuffolkLITLab & @LegalDesignLab. Play on your ?or ??. https://t.co/PgL99vONro
— Suffolk LIT Lab (@SuffolkLITLab) October 16, 2018
And don’t forget to play Learned Hands during your commute, over lunch, or while waiting in court.
Originally published 2018-10-18. Republished 2020-02-17.
The post How an Online Game Can Help AI Address Access to Justice (A2J) appeared first on Lawyerist.
from Law and Politics https://lawyerist.com/blog/learned-hands-launch/
via http://www.rssmix.com/
0 notes
Text
How to Get Best Printing Services in North York

Are you planning for printing something in bulk and you haven't done any research on the Print Shop in North York, Toronto Canada. I know it could be hard sometime but it's important that your work, money must be spent on a good place where you can get the trust that you will get the best quality product at the best price within a most reasonable time.
Here we are with all the packed research Best shop with their best Printing Services North York.
Some Benefits of Printing Services North York
Save time and improve efficiency
Reduce costs and save money
Improve productivity in your organization
Reduce capital expenditure and improve cash flow
Reduce your environmental footprint
Be more agile
Improve your information security
Save Time and Improve Efficiency
The amount of time employees spend on printer-related tasks can be frustrating. The process of printing, scanning, copying or faxing documents on old hardware or poorly configured software is just the start. There is also the time spent fixing device malfunctions and replacing ink cartridges and toners to consider too.
A Print Shop in North York, Canada should identify such obstacles and include plans to reduce the hidden waste of employees’ time incurred on print-related tasks. This saves a lot of time to focus on other important actions, as opposed to day-to-day maintenance tasks.
Enable print security
Deliver on the mobility issues
Implement cost accounting initiatives
Reduce Costs and Your Save Money
An uncommon approach to your organization’s print setup can lead to inefficiencies in a number of areas. First and foremost, there are maintenance costs. Maintaining individual devices one at a time is costlier than having an automated, cloud-based system for doing so at scale.
Print Shop in North very often combine with all devices to one monitor system to make is quicker just in time delivery of replacement toners and repairs. This makes better use of economies of scale by allowing you to bulk buy supplies at a discount. It also reduces the cost associated with stockpiling unused inventory.
The total print audit and assessment can also classify in such a way to connect your hardware. After all, having too many devices scattered around your organization will cost more to maintain and use up space and electricity. A print expert will have the ability to calculate the true cost of an ad-hoc approach and identify ways to make savings.
Improve Productivity
The printing needs of various departments within an organization can vary. After an initial assessment of an organization’s current and future needs, the MPS a provider should be able to recommend a tailored program for these departments.
This also includes printing from mobile devices or off-site
"for example, or the need to print special types of document sizes and formats which you use regularly"
There's a plus point comes in the form of frequent hardware upgrades, giving you access to cutting edge technology when it’s release. The best Printing Services Toronto, North York usually involves staff training too, which will help get your colleagues up to speed with new hardware and workflows.
Reduce capital expenditure and improve cash flow
Cost of buying an entire line of devices can be tough, but Managed Print Services typically offer flexible payment options. Pay-per-page print models with leased hardware are perfect for companies who balk at the idea of a huge one-off bill for hardware every five to ten years. You can enjoy real-time mode dashboards and forecasting tools for your network of devices. This leaves you in a better position to manage your budget.
Reduce your environmental footprint
Reducing the amount of paper, electricity and print consumables you use is all part of being a responsible corporate citizen. With a monitoring system in place as part of your MPS package, you should be able to identify and track levels of print usage. That way, you’ll in a better position to intervene and reduce your environmental footprint. And once you’ve done so, you can show the results of your paper saving efforts in your Corporate Social Responsibility report.
Be more agile
The most successful organizations look to continuously improve their processes to stay ahead. In the 2015 Computing survey, we saw this in action. Take a look at the sheer number and variety of workplace technology projects IT Managers had planned over the following 24 months in the chart above. North York Print Shop your side, you’ll receive ongoing advice and strategic support from experts in the field of workplace technology.
Improve Your Information Security
Print Shop in North print assessment which comes with a Managed Print Service can identify print and IP security risks your organization faces. The subsequent MPS program should help mitigate those risks with a tailored print security plan. This might include recommending printer sign-in procedures to minimize documents being stolen from output trays. It could involve waste disposal and document management facilities. It could also include installing multifunctional printers with automatic hard drive wiping functionality and network-level solutions to reduce the risk of information being retrieved by hackers.
You Can One Of The Best For You Print Shop in North York
CanStarPrinting provides you most affordable Printing Services in North York for business and all kind of customers. They have trained and dedicated team to complete their work within the time.
0 notes
Text
Dealing with Printer Issues in a Minute Together with the Appropriate Download Canon PixmaIp Driver Update
To start with, we really have to take a look at just what the printer is really before we can easily really analyze something about obtaining the appropriate Canon Printer driver revise for your self. In the long run throughout the day, whatever the company in the printer is, the outcome, as well as the issues, are generally virtually a similar, and when you find yourself achieving this, you need to know how to proceed and the way to practice it.

Just before we really proceed to these methods that one could fix all of your printer issues, we should be looking at what computer printers are and what kinds of ink jet printers you have out there. In info processor chips, a printer is a sheet of equipment that allows textual content and vivid output from your info finalizing system and transfers the information to document, typically to common sized sheets of document. Ink jet printers are occasionally handled computers devices, but far more often are acquired alone. Printers diverge in dimensions, acceleration, class, and expense. Typically, more costly ink jet printers are used for greater-solution color stamping.
Pc computer printers could be acknowledged as an effect or no-effect publishing models. Earlier effect printing equipment processed something such as a mechanistic typewriter, using a crucial hitting an tattooed depression symptoms on paper for each published sort. The download canon pixma ip driver dot-matrix generating machine was a favorite inexpensive private computers device stamping equipment. It's a positive change printer that affects the pieces of paper a training course at any given time. The very best-acknowledged no-affect printers will be the inkjet printer, an illustration getting particular distinctive models of low-price color laser printers, along with the more complex laser computer printers. Inkjet ink jet printers operate by getting the inkjet to apply printer coming from a printer cartridge in an incredibly close level against the paper since the roller rolls it using.
The laser printer utilizes a laser beam mirrored from a mirror to get ink cartridge (that is also referred to as toner) to pick out papers regions like a page rolls more than a tire. Now so how exactly does the software program part of this can be purchased in and why do we should know a great deal concerning this. Eventually through the day, the Operating system within your body must speak with the printer in order to give the data back and forth and just how this can be done is by making use of a computer software driver, which is essentially just like a middleman that communicates the info between the personal computer and also the printer.
The problems that can occur following that is actually how the driver becomes corrupted, or you will discover an issue each time a computer software turmoil comes about. Something you have to know is how to troubleshoot these types of troubles and when you need to, all that you should do happens to be to upgrade the program in the driver or install some clean ones. Anything previously mentioned that will require that you merely really make contact with the maker or maybe solicit the help of your neighborhood technician skilled. Eventually, through the day, all products and gizmos are constructed to at some point fail, so take it plus your best defend are driver upgrades.
Click The Link to download Driver Scan at no cost and immediately resolve Canon Printer Driver problems. Logan Albright is undoubtedly an authority on problem-solving car owners problems at Driverscan.org, and it has really helped several to optimize their pcs for top performance.
1 note
·
View note
Text
Divest From the Video Games Industry! by Marina Kittaka
https://medium.com/@even_kei/divest-from-the-video-games-industry-814a1381092d
This piece seeks to contextualize the problems of the video games industry within its own mythology, and from there, to imagine and celebrate new directions through a lens of anti-capitalist and embodied compassion.
My name is Marina Ayano Kittaka (she/her), I’m a 4th gen Japanese American trans woman from middle class background. I work in a variety of different art forms but my bread and butter are the video games I make with my friend Melos Han-Tani, e.g. the Anodyne series.
I am not an authority on any of these topics, and it’s not my intention to speak over anyone else or offer comprehensive solutions, only to be one small piece of a larger conversation and movement. I use declarative and imperative sentences for clarity, not certainty.
I seek to follow the leadership of BIPOC abolitionist thinkers such as Ejeris Dixon, Leah Lakshmi Piepzna-Samarasinha, adrienne maree brown and Ruth Wilson Gilmore, along with the work of local (to me) groups like Black Visions Collective and MPD150. I welcome feedback, especially if you believe that something I’ve said is harmful.
This piece is inspired by the latest wave of survivors bravely sharing their stories (it is June 2020, during the Covid-19 pandemic and global uprising against anti-Black racism and the unjust institution of police). I believe and stand with survivors.
The Problems
The video games industry has many deep, tragic, and intertwining problems. It’s beyond the scope of this piece to examine the entirety of games culture (I will focus on development and, to a lesser degree, distribution). It’s also beyond the scope of this piece to convince anyone that these problems exist, but I’ll be moving forward with the assumption that we agree that they do. Here is an incomplete list:
Pervasive sexual abuse
Workplace abuse, bullying, crunch, burnout, generally exploitative labor conditions
Sexism, racism, and other bigotry — the above abuses are accentuated along these intersections (e.g. the sexual abuse of marginalized genders or the exclusion of racial minorities).
Supply chain problems including conflict minerals and exploitative factory conditions
Heavy environmental impacts
Non-Judgement
This conversation may spark hurt or defensive feelings. I want to address this directly. Many people love video games, and not only that, but are deeply invested in the world of games. I’m particularly sensitive to marginalized creators who have fought hard to find a foothold in the games industry and deserve to follow their dreams. I exist more on the periphery of the games industry and my goal is not to center my personal anger or disdain — but instead to push toward a world with better games, played by happier audiences, made by creators who feel safe and appreciated.
Additionally, this conversation is not about the merits of any individual AAA (large studio) game. It’s not about creating strict rules about media consumption. It’s not about shaming people into certain beliefs or behaviors. When we try to act like our personal tastes must align with our most high-minded ideals, we encourage shame or denial — things that distance us from others.
Nor is this exclusively about AAA. This is about any situation where the power becomes the point. There can be gradations of industrial complexes and power complexes existing from the smallest micro-communities to the largest corporations. We can divest on all levels.
The Industry Promise
I believe that many of us as game creators and audiences have (consciously or not) bought into the idea that happiness and wonder are scarce and fragile commodities — precious gems mined via arcane and costly processes. Life can often be isolating, alienating, and traumatic, and many of us cope by numbing some parts of ourselves¹. The poignance and pleasure of simply feeling becomes rare.
In answer to this perceived scarcity, The Industry swoops in with a promise that technological and design mastery can “make” people feel. It does this not only blatantly in marketing copy or developer interviews, but also in unwieldy assertions that games can make you empathic, or through the widespread notion that games are an exceptionally “immersive” art form due to “interactivity”. Embedded in this promise is the ever-alluring assumption that technological progress is linear: games overall must be getting better, more beautiful, more moving, because that is simply how technology works! Or perhaps it is the progress itself that is beautiful — each impressive jump towards photorealism delivering the elusive sense of wonder that we crave.
At this point, I could argue that the benefits are not worth the cost, that the aforementioned Problems outweigh even this idealized vision of what games provide. But I’m guessing many of you might find that unsatisfying, right? Why don’t we simply reform the system? Spread awareness and training about sexism and racism, create more art that engenders empathy, encourage diversity? Isn’t it throwing the baby out with the bathwater to “halt” technological progress in order to fix some issues of bad leadership here or abusive superstar there?
Here we come to my main purpose in writing this piece: to expand the imaginative space around video games by tearing out The Industry Promise at its roots. If wonder is not scarce and progress is not linear, then the world that rises from the ashes of the Video Games Industry can be more exciting and more technologically vibrant than ever before.
Precious Gems
Take a deep breath and picture some of the happy moments of your life. Maybe some of them look like this:
Staying up late and getting slaphappy with a friend; looking out over a beautiful landscape; a passionate kiss; collaborating with friends in a session of DnD or Minecraft; a thoughtful gift from someone you admire; a cool drink on a hot summer day; making a new friend who feels like they really see you; singing a song; a hug from someone who smells nice; getting junk food late at night and feeling naughty about it; the vivid colors and sounds of a rainy city evening; drifting to sleep in the cottony silence of a smalltown homestead; getting a crew together to see a new movie; the scent of the air at sunrise; having a meaningful conversation with a nonverbal baby.
Picture the games you loved most as a child, the games that felt full of possibility and mystery and fun. Were they all the most technologically advanced? The most critically revered?
Maybe your happy moments look nothing like this. Or maybe you can’t recall feeling happy and that’s the whole problem. But my point is that happiness, joy, fun… these things are at their core fluid, social, narrative, contextual, chemical. In both its best and most common incarnations, happiness is not shoved into your passive body by the objective “high quality” of an experience. Both recent psychological research and traditions from around the world (e.g. Buddhist monks) suggest that happiness and well-being are growable skills rooted in compassion.
Think of all the billions of people who have ever lived, across time, across cultures, with video games and without, living nomadically or settling in cities or jungles. In every moment there are infinite reasons to suffer and infinite reasons to be happy². Giant industry’s monopolistic claims to “art” or “entertainment” have always been a capitalist lie, nonsensical yet inescapable.
The Narrative of Technology and Progress
Is this an anti-technology screed? Am I suggesting we must all go outside like in the good old days and play “hoop and stick” until the end of time? Let’s start by unpacking what we mean when we say “technology”. Here’s one definition:
Technology is the sum of techniques, skills, methods, and processes used in the production of goods or services or in the accomplishment of objectives.
— Wikipedia
Honestly, technology is such a vague and broad concept that nearly anything anyone ever does could be considered technological! As such, how we use the term in practice is very revealing of our cultural values. Computing power, massive scale, photorealistic graphics, complex AI, VR experiences that attempt to recreate the visual and aural components of a real or imagined situation… certainly these are all technologies that can and have grown in sophistication over time. But what The Industry considers technological progress actually consists of fairly niche goals that have been artificially inflated because capitalists have figured out they can make money this way. Notably, I don’t use “niche” here as an insult — aren’t many of the most fascinating things intrinsically niche? But when one restrictive narrative sucks all the air out of the room and leaves a swath of emotional and physical devastation in its wake… isn’t it time to question it?
What if humans having basic needs met is “technological progress”? What if indigenous models of sustainable living are “hi-tech”? What if creating a more accessible world where people have freedom of movement opens up numerous high-fidelity multisensory experiences? These questions go far beyond the scope of the video games industry, sure, but in the words of adrienne maree brown, “what we practice at the small scale sets the patterns for the whole system”³.
What We Hope to Gain
The kneejerk reaction to dismantling an existing structure tends to be a subtractive vision. Here we are, living in the exact same world, but all blockbuster video games have been magically snapped out of existence… only hipster indie games remain! Missing from this vision is the understanding that our current existence is itself subtractive — what we cling to now comes at the expense of so much good. The loss of maturing vision and skill when people leave the industry due to burnout, sexual assault, and racist belittlement. Corporate IP laws and progress narratives that disincentivize preservation and rob us of our rich and fertile history. The ad-centric, sanitized, and consolidated internet that chokes out democratized community spaces. The fighting-for-scraps mentality that the larger industry places on small creators with its sparing and self-interested investment. Our current value system limits not only what AAA games are but also what everything else has the capacity to be.
Utopia does not have an aesthetic. We don’t need to prescribe the correct “alt” taste. Games can be high and low, sacred and profane, cute and ugly, left brain and right. Destroying the games industry does not mean picking an alternate niche to replace it. Instead, we seek to open the floodgates to a world in which countless decentralized, intimate, and overlapping niches might thrive.
When we decentralize power, we not only create the conditions for more and better games, we also diminish the conditions under which abuse can flourish. Many of the stories of abuse hinge on the abuser wielding the power to dramatically help or harm the careers of others. The consolidation of this power is enhanced by our collective investment in The Industry Promise (not forgetting the wider cultural intersections of oppression). Mythologized figures ascend along a linear axis of greatness, shielded by the horrifying notion that they are less replaceable than others because their ranking in The Industry evidences their mystical importance.
What’s Next?
Here is a fundamental truth: we do not need video games. Paradoxically, this truth opens up the world of video games to be as full and varied and strange and contradictory as life itself.
So. Say you agree with all or part of my assertions that collectively we may proceed to end the video games industry by divesting our attention, time, and money, and building something new with each other. But what does that look like in practice? I don’t have all the answers. I find community very difficult due to my own trauma. Nonetheless, I’ll do some brainstorming. Skim this and read what speaks to you personally, or do your own brainstorming!
Center BIPOC/queer leadership
I.e. people who have been often forcibly divested from the majority culture and have experience in creating alternatives. Draw on influences outside of media e.g. transformative justice, police abolition, and prison abolition. Books like Beyond Survival and Emergent Strategy are based in far deeper understanding of organizing than anything written here, and are much more relevant to the direct and immediate issues of things like responding to sexual assault in our communities.
Divest from celebrity/authority
Many people will tell you that their most rewarding artistic relationships are with peers, not mentors and certainly not idols. Disengage from social media-as-spectator sport where larger-than-life personalities duke it out via hot take. Question genius narratives wherever they arise. Cultivate your own power and the power of those adjacent to you. If you feel yourself becoming a celebrity: take a step back, recognize the power that you wield over others, redirect opportunities to marginalized creators whose work you respect, invest in completely unrelated areas of your life, go to therapy.
Divest from video games exceptionalism
Academics have delved into video games’ inferiority complex and the topic of “video games exceptionalism”, which is tied into what I frame as The Industry Promise above — the idea that video games as a technological vanguard are brimming with inherent value due to all the things they can do that other forms of media cannot. This ensures that gobs of money get thrown around, but it’s an ahistorical and isolating notion that does nothing to actually advance our understanding of games as a form (Interesting discussion on this here, which reminds me of Richard Terrell’s work regarding vocabulary).
Reimagine scale
Rigorously question the notion that “bigger is better” at every turn. With regards to projects, studios, events, continually ask “why?” in the face of any pressure to make something bigger, and then try to determine what might be lost as well as what might be gained. Compromising on values tends to be inevitable at scale, workplace abuse or deals with questionable entities. For me this calls to mind the research led by psychologist Daniel Kahneman suggesting that the happiness benefits of wealth taper off dramatically once a comfortable standard of living is reached. Anyone who’s ever had a tweet go viral can tell you that it’s fun at first and then it just becomes annoying. Living in a conglomerated, global world, we regularly have to face and process social metrics that are completely incomprehensible to the way our social brains are programmed, and the results are messy. Are there ever legitimate uses for a huge team working on a project for many years? Sure, probably, but the idea that this is some sort of ideal normal situation that everyone should strive for is based on nothing but propaganda.
Redefine niche
Above I suggest that AAA is niche. I believe it’s true broadly, but that it’s definitely true relative to their budgets. What do I mean by this? AAA marketing budgets are reported to be an additional 75–100% relative to development costs (possibly even higher in some cases). Isn’t this mindblowing? If a game naturally appealed to proportionately mass numbers of people by virtue of its High Quality or Advanced Technology, then would we really need to spend tens or hundreds of millions of dollars just to convince people to play it? For contrast, Melos estimates that our marketing budget for Anodyne 2 was an added 10% of development costs and it was a modest commercial success. Certainly marketing is a complex field that can be ethical, but to me, there is something deeply unhealthy about the capacity of large studios to straight up purchase their own relevance (according to some research, marketing influences game revenue three times more than high review scores).
On a separate but related note, I don’t buy that all the perceived benefits of AAA such as advancements in photorealism will vanish without the machine of The Industry to back them. People are astonishing and passionate! It won’t always necessarily look like a 60 hour adventure world, but it will be a niche that we can support like any other.
Ground yourself in your body
Self-compassion, mindfulness, meditation, exercise, breathing, nature, inter-being. There are many ways to build your capacity to experience joy, wonder, and happiness. One of the difficult things about this process though is that if you approach these topics head on, you’ll often be overwhelmed with Extremely Specific Aesthetics that might not fit you (e.g. New Agey or culturally appropriative). My advice is to 1) be open to learning from practices that don’t fit your brand while also 2) being able to adapt the spirit of advice into something that actually works for you. The benefit of locating our capacity for joy internally is that it reveals that The Industry is fundamentally superfluous and so we are free to take what we want and throw the rest in the compost pile.
As a side note, some artists (who otherwise have structural access to things like mental health services) fear becoming healthy, because they’re worried that they will lose the spark and no longer make good art. Speaking as an artist whose creative capacity has consistently increased with my mental health, there are multiple reasons why I don’t think people should worry about this.
You carry your past selves within you, even as you change. “Our bodies are neural and physiological reservoirs of all our significant experiences starting in our prenatal past to the present.”⁴
You can lose a spark and gain another. You can gain 6 sparks in place of the one you lost.
What is it that you ultimately seek from being “good at art”? Ego satisfaction? Human connection? Self-respect? All of these things would be easier to come by in the feared scenario in which you are so happy and healthy that you can no longer make art. Cut out the middleman! Art is for nerds!
Invest outside of games
Games culture often encourages a total identification with video games. This pressures developers into working and audiences into buying, conveniently benefitting executives and shareholders to everyone else’s detriment. Investing in interests wholly unrelated to video games is beneficial in many ways and there’s something for everyone! Personally, I love books. A novel is “low-tech” in nearly every way that a AAA game is “high-tech”, and yet books are affordable, data-light, easy-to-preserve, stimulating, challenging, immersive, and entertaining. What is technology, again?
Another pertinent thought: while there’s nothing inherently wrong with dating a fellow game developer, you should not enter industry/work spaces or events looking for romantic connection. Particularly if you have any sort of institutional power, you will inevitably put others in uncomfortable situations and prime yourself to commit abuse. If you want sex, relationships, etc, find other outlets, shared interests, and dating pools.
Work towards a more accessible world
In the context of an often systemically ableist world, video games can — at their best — be fun, valuable, and accessible experiences for disabled audiences. Consequently, when I say “divest from the video games industry”, I don’t want to gloss over the fact that divestment comes with a different cost for different people. Certainly accessibility within video games continues to be as important as ever, but if I’m asking, e.g., for people to “invest outside of games”, then a commitment to a more accessible out-of-game world is also extremely vital. For instance, non-disabled people can be attuned during this particular moment to the unique perspectives and leadership of disabled people regarding Covid lockdowns and widespread work-from-home, and be wary as we gradually lift restrictions of reverting to a selective and hypocritical approach to accommodations.
Invest in alternative technological advancements
What might we have the resources, attention, and energy to grow if our industry weren’t so laser focused on a constricted definition of technological advancement? For example, audio-only games appear to me an incredibly fertile area for technological advancement that has been under-resourced. How about further advancements towards biodegradable/recyclable microchips and batteries? A fundamental rethinking of the “home console” model in which each successive generation strives to obsolete the last and sell tens of millions new hardware units? Something like an arcade or those gaming lounges (but do they all have to have the same aggressive aesthetics?). The success of Pokemon GO seems to gesture at potential for social, non-remote video game experiences with broader demographic/aesthetic appeal. At the Portland (Maine) Public Library, there’s a console setup in the teen section where local kids would play and they also had a selection of console games for checkout — that was really cool! Local game dev organizations like GLITCH creating events where local devs show and playtest games with the public…
Look to small tools
Small tools such as hobbyist-centered game engines very naturally and successfully act as springboards to community. Look at ZZT, early Game Maker (e.g. gamemakergames), OHRRPGCE. Look at bitsy, PuzzleScript, Pico-8! Look at Electric Zine Maker by Nathalie Lawhead as well as this post they wrote on small tools. Small tools, by virtue of their limitations, tend to lend themselves to particular aesthetics and goals. Whether you’re ultimately playing to or against the core gravitational pull of a small tool, I think it grounds you within a certain design conversation that is conducive to community. Participating in these communities as a child (even though I rarely interacted directly) fundamentally instilled in me ideas like: people make their own fun; wonder is uncorrelated with budget; being strangely specific has value. Can other structures learn from small tools? Events, meetings, parties… what happens if we think of these as communal “engines” — structures built around a conversational core that people can use to create things or express themselves…?
Something that crosses my mind often is that it may be fundamentally healthy for us all to be “big fish in small ponds” in one way or another. The idea that there exists One True Big Pond that reflects all of our collective values simultaneously is a harmful myth that serves to direct all admiration and energy towards corporate interests and robs the rest of us of our accomplishments.
Sucking as praxis
“Professional artistry” as the capacity to maintain the shared illusion that there are indisputable measures of beauty and worth. When you allow the illusion to fail — often against your will — 1) capitalist powers will be disappointed in their inability to wield you with proper efficiency and 2) fellow small creators will be heartened because you bypassed the illusion and still offered something worthy. Failure in a backwards system can be strength. Growing as an artist can be a gloriously paradoxical affair.
Fight for history
We miss out on so much when history is lost to us, and video games are extraordinarily susceptible due to their technical dependencies on ever-shifting hardware. The Industry’s current incarnation goes beyond history-apathy to a downright historical hostility. Sustaining the narrative of linear technological progress inevitably involves shitting on the past (there are a chosen few old games that are kept accessible, but they feel like exceptions proving the rule). Emulation is a vital resource, ever on the verge of outlaw (See Nintendo’s legal actions), Internet Archive is under attack, and Disney warps copyright laws to keep their stranglehold on media intact. Overviews and longplays of difficult-to-play older games are incredibly valuable and I’m truly grateful for people who do this vital work. Off the top of my head, I’ve enjoyed Nitro Rad’s comprehensive work in 3D platformers, and Cannot Be Tamed’s retro reviews. See also: the Video Game History Foundation.
Public libraries could be a vital ally in this cause. What if libraries had access to legacy tech or specialized emulation software that made playing, researching, or recording from old video games more feasible? What if small creators or defunct small studios could get grants or support in preserving their own old work? Would disappointing institutional responses to Gamergate have played out differently if knowledge of and respect for the ongoing historic contributions of BIPOC, female, and/or queer developers were built into the core fabric of video games spaces? Would it be so easy to accept the AAA model as the pinnacle of technology if we contextualized the astounding complexity of past games like Dwarf Fortress, or the Wizardry or Ultima series — technological complexity that would not have been possible had the games been beholden to modern AAA priorities? (Talking out of my ass here, as I have never played these games. See also: modern work on Dwarf Fortress). See also: The Spriter’s Resource and it’s affiliate sites.
Expand government arts funding
I don’t know a lot about this, but… there should be more of it! I see it happening more in other countries besides the US.
Labor organizing
We can look into studio structures like co-ops. We can join unions. Those unions must be intersectional to the core (see recent events regarding GWU international). How about dual power? Many small studios could combine in overlapping networks of varying formality. They could integrate their audiences, cross-promote, build collective power so as to not be totally beholden to the will of corporations. I’m not an expert on labor though, look to others who know more.
Collaborative / open source resources
E.g. The Open Source Afro Hair Library, Open Game Art, Rrrrrose Azerty’s prolific CC0 music and the broader Free Music Archive community.
Give money
Normalize mutual aid. Normalize buying small games. Contribute to things like Galaxy Fund.
Just Play!
Play something totally random on itch.io (or another community-oriented site) with no outside recommendation. Compliment and/or pay the developer if you like something about it!
Conclusion
Thank you for engaging with these thoughts! I hope that they spark thoughts for you, and that we can all learn from each other. Feel free to reach out to me on twitter or via email: [email protected]
[Edit: at 11:20PM CDT, 6/25/20, I changed the audio games link from a wikipedia article to the more relevant-seeming: https://audiogames.net/]
0 notes
Text
How an Online Game Can Help AI Address Access to Justice (A2J)
youtube
In access to justice discussions it is a truth universally acknowledged, that the majority of those in possession of legal problems, remain in want of solutions. (My apologies to both Jane Austen and the Legal Service Corporation’s Justice Gap Report.) Also, ROBOTS! Ergo, we should throw AI at A2J. There is considerably less consensus, however, on how (or why exactly) this should be done. But don’t worry! There’s an app/game for that, and it lets you train artificial intelligence to help address access-to-justice issues. We’ll get to that in a minute. But first, some background.
Machine Learning & Access to Justice, Together at Last
Machine Learning, the subdiscipline within AI around which the current hype cycle revolves, is good at pattern recognition. Acquaint it with a sufficiently large number of example items, and it can “learn” to find things “like” those items hiding in the proverbial haystack. To accomplish such feats, however, we have to satisfy the machine’s need for data—BIG data. Consequently, AI’s appetite is often a limiting factor when it comes to deploying an AI solution.
Let’s consider two areas where AI’s pattern recognition might have something to offer A2J. Services like ABA’s Free Legal Answers try to match people with legal questions to lawyers offering pro bono limited representation (think free advice “calls” over email). Unfortunately, some questions go unclaimed. In part, that’s because it can be hard to match questions to attorneys with relevant expertise. If I’m a volunteer lawyer with twenty years of health law experience, I probably prefer fielding people’s health law questions while avoiding IP issues.
To get health law questions on my plate and IP questions on someone else’s, a user’s questions need to be (quickly, efficiently, and accurately) labeled and routed to the right folks. Sure, people can do this, but their time and expertise are often better deployed elsewhere, especially if there are lots of questions. Court websites try to match users with the right resources, but it’s hard to search for something when you don’t know what it’s called. After all, you don’t know what you don’t know. Complicating matters further, lawyers don’t use words like everyone else. So it can be hard to match a user’s question with a lawyer’s expertise. Wouldn’t it be great if AI’s knack for pattern recognition could spot areas of law relevant to a person’s needs based on their own words (absent legalese), then direct them to the right guide, tool, template, resource, attorney, or otherwise? That’s what we’re working towards here.
I know what you’re thinking, but we are NOT talking about a robot lawyer. When we say “AI,” think augmented intelligence, not artificial intelligence. What we’re talking about is training models to spot patterns, and it’s worth remembering the sage advice of George Box, “all models are wrong, but some are useful.” Consequently, one must always consider two things before deciding to use a model: First, does the model improve on what came before? Second, is it starting a discussion (not ending it)? Unless the data are pristine and the decision is clear-cut, a model can only inform, not make, the decision.
Something like an automated issue spotter has the potential to improve access to justice simply by making it a little easier to find legal resources. It doesn’t need to answer people’s questions. It just needs to point them in the right direction or bring them to the attention of someone in a position to help. It can get the conversation started by making an educated guess about what someone is looking for and jumping over a few mundane—but often intimidating—first steps.
But at least two problems stand between us and realizing this dream. If we’re going to map lay folks’ questions to issues using machine learning, we’re going to need a list of issues and a boatload of sample questions to train our models. As if this wasn’t enough, those examples need to be tagged or labeled with the right issues. Unfortunately, we are unaware of any appropriately-labeled public dataset. So we’ve decided to help birth one.
Who’s “we” you ask? A collaboration of Suffolk Law School’s Legal Innovation and Technology (LIT) Lab (bringing the data science) and Stanford Law School’s Legal Design Lab (bringing the design chops), with funding from The Pew Charitable Trusts.
Learned Hands: An Introduction to Our Project
Image by Margaret Hagan.
So AI can help address an A2J need but only if someone has the resources and expertise to create a taxonomy, read a bunch of text, and (correctly) label all the legal issues present. This is where you, dear reader, can help.
The Access to Justice & Legal Aid Taxonomy
Stanford’s Legal Design Lab has taken the lead on creating a taxonomy of legal help issues based on existing ones. Eventually, service providers will be able to match their offerings to the list, and AI can pair the general population’s questions with the appropriate label or tag within the taxonomy. Heck, AI could even help service providers match their resources to the taxonomy, serving as a translator on both sides. Either way, the taxonomy will provide a standard nomenclature to help coordinate A2J work across the community. Setting standards is hard, but it’s the sort of foundational work that can pay big dividends. In short, we’re building Version 1.0 and looking for your input. If that appeals to you, give this description of the work/call for input a look and make yourself heard.
Help AI Address Access to Justice
Now we just need tens of thousands of legal questions to feed the machine, and each one must be tagged with items from the taxonomy. Luckily, people publicly post their legal questions all the time. Tens of thousands are available over at r/legaladvice. The moderators and forum rules work to ensure that these posts lack personally identifying information, and all questions are posted with the expectation that they will be published to the front page of the internet, as Reddit calls itself. This makes them unique because, unlike questions posted on sites like ABA Free Legal Answers, their authors understand them to reside in an explicitly public space. Although they haven’t been mapped to our taxonomy, their public nature leaves open the possibility that an army of citizen issue spotters (that’s you) could read through them and label away.
One can download these questions using the Reddit API, but moderators at r/legaladvice were kind enough to share their own repository of nearly 75,000 questions in the hopes they could help jump-start our work. Thanks especially to Ian Pugh and Shane Lidman for facilitating our work with the Reddit Legal Advice community.
The Game: Labeling Texts
To help label our growing collection of texts, we’ve created an online game in the hope that many hands will make light work. So, of course, we call it Learned Hands. (This is wordplay riffing on the name of an eminent American jurist, Learned Hand. I’m sorry I felt compelled to explain the joke, but here we are.)
Logo by Margaret Hagan.
The game presents players with a selection of lay peoples’ questions and asks them to confirm or deny the presence of issues. For example, “Do you see a Health Law issue?” We then combine these “votes” to determine whether or not an issue is present. As you can imagine, deciding when you have a final answer is one of the hard parts. After all, if you ask two lawyers for an opinion, you’ll likely get five different answers.
We decide the final answer using statistical assumptions about the breakdown of voters without requiring a fixed number of votes. Effectively, if everyone agrees on the labeling, we can call the final answer with fewer votes than if there is some disagreement. Consequently, the utility of the next vote changes based on earlier votes. We use this to order the presentation of questions and make sure that the next question someone votes on is the one that’s going to give us the most information/ or move us closest to finalizing a label. This means we don’t waste players’ time by showing them a bunch of undisputed issues.
You earn points based on how many questions you mark (with longer texts garnering more points). Players are ranked based on the points they’ve earned multiplied by their quality score, which reflects how well your markings agree with the final answers. Specifically, we’re using a measure statisticians call the F1 Score.
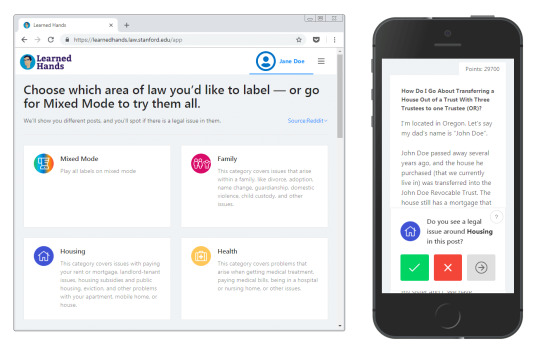
That’s right. You can compete against your colleagues for bragging rights as the best issue spotter (while training AI to help address A2J issues). After all, we’re trying to have this game go viral. Please tell all your friends! Also, it works on both your desktop and your phone.
Desktop and mobile screenshots.
Eventually, we will make different flavors of the labeled data available to researchers, developers, and entrepreneurs free of charge in the hopes that they can use the data to create useful tools in the service of A2J (for example, we may publish a set where the labels correspond to a 95% confidence level and another where the labels are just the current “best guess”). Not only could such datasets serve to help train new issue spotting models, but ideally, they could serve as a tool for benchmarking (testing) such models. See Want to improve AI for law? Let’s talk about public data and collaboration.
We’re also seeking private data sources for secure in-game labeling by users agreed upon by those providing the data (e.g., their own employees). By including more diverse datasets, we can better train the algorithms, allowing them to better recognize problems beyond those faced by Reddit users. Although we’ll be unable to publicly share labeled private data, we will be able to share the models trained on them, allowing the larger A2J community to benefit while respecting client confidence.
For the record, although this game’s design was a collaboration between the LIT and Legal Design Labs, Metin Eskili (the Legal Design Lab’s technologist) is responsible for the heavy lifting: turning our ideas into functional code. Thanks, Metin.
Active Learning
We will also use a process called active learning. Basically, once we reach a critical mass of questions, we train our machine learning models on the labeled data as it comes in. We then point our models at the unlabeled questions looking for those it’s unsure of. We can then move these questions to the top of the queue. In this way, the models gain insights they need to parse “confusing” examples. Again, the idea is not to do more labeling than necessary. It just makes sense to skip those questions our algorithms are pretty sure about.
Proof of Concept
Here at Suffolk’s LIT Lab, we’ve started training algorithms on a pre-labeled private dataset. The early results are promising, or as I like to say, “not horrible.” As I’ve explained elsewhere, accuracy is often not the best measure of a model’s performance. For example, if you’re predicting something that only happens 5% of the time, your model can be 95% accurate by always guessing that it’s going to happen. It can be hard to say what makes a good model (aside from perfection), but it’s pretty easy to spot when a model’s bad. All you have to do is play through some scenarios. (In practice, one needs to think carefully about the costs of things like false positives and false negatives. Sometimes you’ll have a preference for one over the other, but we’re not going to get that nuanced here.) To keep it simple, we’ll assume a binary prediction (e.g., yes or no).
If a coin flip can beat your predictions, your predictions are horrible. Your accuracy better beat 50%.
If always guessing yes or no can beat your predictions, your predictions are horrible. Your accuracy must be better than the fraction of the majority answer (like in the 95% accuracy example above).
If you’re looking for Xs and you miss most of the Xs in your sample, your predictions are horrible. So your recall has to be greater than 0.5.
If you’re looking for Xs, and less than half of the things you call Xs are actually Xs, your predictions are horrible. So your precision has to be greater than 0.5.
Using these guideposts, we know a classifier is “not horrible” when it beats both a coin flip and always guessing yes or no. If it says something is X, it better be right most of the time, and across the entire dataset, it must correctly identify more than half of the Xs present.
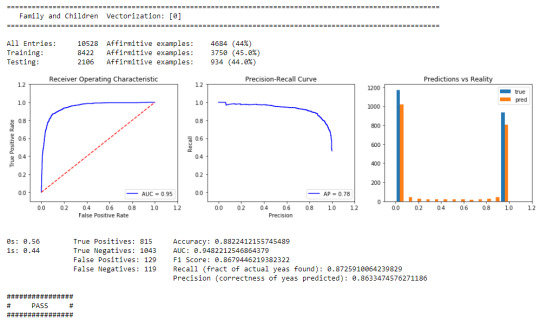
Below, I’ve included some summary statistics for one of our tentative models trained on pre-labeled private data. As you can see, it’s not horrible—accuracy beats always guessing yes or no, and precision and recall beat 0.50. There are some other nice data points in there (like AUC), but we won’t highlight those here (their descriptions are beyond the scope of this post). In the end, “not horrible” is just an extension of the idea that a model should be an improvement on what came before. In this case, “what came before” includes coin flips and always guessing yes or no.
A snapshot of private data testing results.
As you’d expect, our models are getting better with more data. So we’re really excited to see what happens when a bunch of folks start labeling. Also, it’s worth noting that we are starting with high-level labels (e.g., family law and housing). Over time, we will be including more granular labels (e.g., divorce and eviction).
How Does This All Work? (A Slightly-Technical Description)
Text classification isn’t as complicated as you might think. That’s mostly because the algorithms aren’t really reading the texts (at least not the way you do). To oversimplify a common text-classification method called bag-of-words, one creates a list of words found across all texts and then represents each document as a count of words found in that document. Each word counts is treated as a dimension in a vector (think “column in a list of numbers”). After looking at all the data, one might notice that questions about divorce always have a value greater than or equal to three for the dimension associated with the word “divorce.” In other words, divorce-related questions always contain the word “divorce” at least three times. So it is possible to describe questions about divorce by referring to their vectors.
Put another way, every text with vectors whose divorce dimension is on either side of three goes into either the divorce or not-divorce categories. This isn’t a very realistic example, though, because document types aren’t often like Beetlejuice (say the magic word three times and they appear). Still, it is reasonable to assume there is a constellation of keywords that help define a document type. For example, maybe the chance that a question is housing-related goes up when the query uses words like landlord, tenant, or roommate. Larger values across those dimensions, then, are correlated with housing questions. You can (of course) get more nuanced and start looking for n-grams (couplings of two, three, or words) like best interest while ignoring common words like and. But the general method remains the same: we throw the words into a bag and count them.
More sophisticated approaches—like word2vec—employ different methods for converting text to vectors, but without getting too far in the weeds we can generalize the process of text-classification. First, you turn texts into numbers embedded in some multi-dimensional space. Then you look for surfaces in that space that define borders between different text groupings with different labels. This, of course, relies on different text types occupying different regions in the space after they are embedded. Whether or not these groupings exist is an empirical question (which is why it’s nice to see not horrible output above). The data help us think success is an option.
Google’s Machine Learning Crash Course on Text Classification provides a good high-level introduction for those interested in the technology. Our workflow tracks with much of their description, although there are some differences. For example, we’re using over- and under-sampling for unbalanced classes and stacking various models. Don’t worry, we’ll eventually write everything up in detail. Here’s the point, though: we aren’t pushing the state of the art with these classifiers. We’re sticking with time-tested methods and producing a publicly-labeled dataset. We’d love to see this labeled dataset feeding some cutting-edge work down the road, and if you can make a compelling demonstration for how your novel method could make better predictions, we’re open to taking your model in-house and training it on our private datasets (assuming you commit to making the trained model-free and publicly available). After all, many hands make light work. Tell your friends! Heck, let’s make it super simple. Just share this tweet as often as you can:
Compete against your colleagues for bragging rights as the best legal issue spotter (while training #AI to help address #A2J issues), a collaboration between @SuffolkLITLab & @LegalDesignLab. Play on your ?or ??. https://t.co/PgL99vONro
— Suffolk LIT Lab (@SuffolkLITLab) October 16, 2018
And don’t forget to play Learned Hands during your commute, over lunch, or while waiting in court.
Originally published 2018-10-18. Republished 2020-02-17.
The post How an Online Game Can Help AI Address Access to Justice (A2J) appeared first on Lawyerist.
from Law https://lawyerist.com/blog/learned-hands-launch/
via http://www.rssmix.com/
0 notes
Text
Highlights for Agile Application Security
Don’t wait for the perfect time, tool or training course to get started. Just do something.
Lean as a methodology prioritises the principle cycle of “Build” → “Measure” → “Learn”.
Many security professionals have a hard time adapting their existing practices to a world where requirements can change every few weeks, or where they are never written down at all. Where design and risk management decisions are made by the team just in time, instead of being planned out and directed from top down. And where manual testing and compliance checking cannot possibly keep up with the speed of delivery.
Agile practitioners argue that while this rule is broadly speaking true, catching a defect later is more expensive than catching one earlier, the solution is not to attempt the impossible task of catching all defects earlier, but instead to focus on reducing the cost of fixing defects by making change safer and easier.
instead you need to be thinking about secure service design, trust modeling, and secure architecture patterns.
The design team should have access to security training or security expertise to ensure that the service they are designing enables security through the user experience.
Security teams should be providing tooling, processes and guidance that helps product managers, architects and developers follow good security practice while designing a new system.
Security checks that happen at this stage need to be automatable, reliable, repeatable and understandable in order for a team to adopt them.
The security team should do everything that they can to ensure that the easiest way to build something inside the organisation is the safe and secure way, by providing teams with secure headers, hardened run-time configuration recipes and playbooks, and vetted third party libraries and images that are free from vulnerabilities which teams can grab and use right away.
When security stops being the team that says no, and becomes the team that enables reliable code to ship, then that’s true agile security.
Truly agile security teams measure themselves on what they can enable to happen, rather than the security issues they have blocked from going out of the door.
or they could be taken care of by training the team in secure coding so that they know know how to do things properly from the start.
Another way to include security in requirements is through attacker stories or misuse cases (instead of use cases). In these stories the team spends some time thinking through how a feature could be misused by an attacker or by another malicious – or even a careless – user.
We’ve had experience in at least one company where the attack trees are stored electronically in a wiki, and all of the controls are linked to the digital story cards, so the status of each story is recorded in a live view. This shows the security team the current state of the threat tree, any planned work that might affect it, and allows compliance officers to trace back from a work order to find out why it was requested and when it was completed.
this kind of interlinking is very valuable for high performing and fast moving teams to give them situational awareness to help in making decisions.
As we’ve seen throughout this book, the speed of agile development creates new security risks and problems. But this speed and efficiency can also offer an important edge against attackers, a way to close vulnerability windows much faster.
Security should be about enabling the organisation to carry out its goals in the most safe and secure manner possible. This means that an effective risk management process should be about enabling people in the organisation to take appropriate risks in an informed manner. The key here being informed: risk management is not all about avoidance but the mindful understanding, reduction, sharing and acceptance of risk as appropriate.
But with an agile team continuously changing the system in response to new information, the context in which a risk is accepted can change dramatically in a fairly short time.
Common change control practices, such as specified by ITIL or COBIT, are designed to deal with waterfall projects that push large change sets a handful of times per year, and cannot possibly keep up with Continuous Delivery or Continuous Deployment approaches.
This means that unlike in some more traditional software engineering shops, Agile teams may resist or avoid review boards, design authorities and other control mechanisms imposed from outside if they believe that these outside forces will get in the way of delivery. This is a problem for security professionals who are used to working with architecture review boards and other central authorities to set guiding principles and rules to ensure the security of all systems.
In a traditional software development lifecycle, risk assessment is done based on the system requirements and design specifications and models created up front. A risk analyst uses those documents to identify the risks that will reside in the system, and puts together a plan to monitor and mitigate these risks. Then audits are done to ensure that the system built matches the documented design specifications and that the risk management plan is still valid.
Nation state attack teams looking to steal data or IP, or conducting reconnaissance or sabotage for cyber warfare (for a vast majority of situations these will be well outside of your threat model and would not be something you would likely be able to discover or prevent).
There are different sources of information about threats to help you understand threat actors and the risks that they pose to your organization. While this is an area of the security industry that is widely considered to be over-hyped and to have not returned on the promises of value that have been made (See Threaty Threats boxout), it can still have a place in your security program.
Some platforms for reporting, detecting, collecting and aggregating threat intelligence include: Open Threat Exchange (https://ift.tt/1CNn9q6) Open TPX (https://ift.tt/1Wd1EOd) Passive Total (https://ift.tt/1wqFz2w) Critical Stack (https://ift.tt/15mr8Re) Facebook’s Threat Exchange (https://ift.tt/1BbkckQ)
Does a change fundamentally change the architecture or alter a tryst boundary? These types of changes should trigger a risk review (in design or code or both) and possibly some kind of compliance checks.
Quick and dirty threat modelling done often is much better than no threat modelling at all.
Each time that you come back again to look at the design and how it has been changed, you’ll have a new focus, new information and more experience, which means that you may ask new questions and find problems that you didn’t see before.
Because the attack surface is continuously changing, you need to do threat modeling on a continuous basis. Threat modeling has to be done a lightweight, incremental and iterative way.
People (including attackers) are like water when it comes to protective controls that get in their way. They will work around them and come up with pragamtic solutions to get themselves moving again.
You can’t secure what you don’t understand Bruce Schneier
A clean architecture with well-defined interfaces and a minimal feature set is not the same as a simplistic and incomplete design that focuses only on implementing features quickly, without dealing with data safety and confidentiality, or providing defense against run-time failures and attacks.
In many environments, enforcing code reviews upfront is the only way to ensure that reviews get done at all: it can be difficult to convince developers to make code changes after they have already checked code in and moved on to another piece of work.
Probably the best reference for a security code review checklist is OWASP’s ASVS project.
Acceptance tests may also be done manually, in demos with the customer, especially where the tests are expensive or inconvenient to automate.
The advantages to an agile development team of being able to self-provision development and test environments like this are obvious. They get control over how their environments are set up and when it gets done. They don’t have to wait days or weeks to hear back from ops.
Before adding security testing into your pipeline, make sure that the pipeline is set up correctly, and that the team is using it correctly and consistently. all changes are checked into the code repository team members check in frequently automated tests run consistently and quickly when tests fail, the team stops and fix problems imemdiately before making more changes
But instead of treating pen testing as a gate, think of it more as a validation and a valuable learning experience for the entire team.
OpenSCAP (https://ift.tt/1J1dLZ7) scans specific Linux platforms and other software against hardening policies based on PCI DSS, STIG, and USGCB and helps with automatically correcting any deficiencies that are found. Lynis (https://ift.tt/1GxO8Na) is an open source scanner for Linux and Unix systems that will check configurations against CIS, NIST and NSA hardening specs, as well as vendor-supplied guidelines and general best practices.
One of the best examples is Dev-Sec (https://ift.tt/1tthojx), a set of open source hardening templates originally created at Deutsche Telekom, and now maintained by contributors from many organizations.
Security Monkey (https://ift.tt/1qrdOCQ) automatically checks for insecure policies, and records the history of policy changes
Conformity Monkey (https://ift.tt/1nSNi0A) automatically checks configuration of a run-time instance against pre-defined rules and alerts the owner (and security team) of any violations
build chains can become highly customized and fragile over time.
6.5 train the development team in secure coding at least annually, and provide them with secure coding guidelines.
Many of the ideas about automating compliance in this chapter are based on the DevOps Audit Defense Toolkit, a free, community-built process framework written by compliance and IT governance experts James DeLuccia IV, Jeff Gallimore, Gene Kim, and Byron Miller.
Reviewers follow checklists to ensure that all code meets the team’s standards and guidelines, and to watch out for unsafe coding practices. Management periodically audits to make sure that reviews are done consistently, and that engineers aren’t rubber stamping each other’s work.
While ITIL change management is designed to deal with infrequent, high-risk “big bang” changes, most changes by Agile and DevOps teams are small and low-risk, and can flow under the bar. They can be treated as standard or routine changes that have been preapproved by management, and that don’t require a heavyweight change review meeting.
Auditors like this a lot. Look at all of the clear, documented hand offs and reviews and approvals, all of the double checks and opportunities to catch mistakes and malfeasance. But look at all the unnecessary delays and overhead costs, and the many chances for misunderstandings and miscommunication. This is why almost nobody builds and delivers systems this way any more.
For teams, compliance should – and has to – build on top of the team’s commitment to doing things right and delivering working software. Teams that are already working towards zero defect tolerance, and teams that are following good technical practices including Continuous Integration should be more successful in meeting compliance.
‘Effective security teams should measure themselves by what they enable, not by what they block’
Lazy security teams default to No as it is a get out of jail free card for any future negative impact that may come from the project they opposed. Ineffective security teams want the risk profile of a company to stay the same so that they do not have to make hard choices between security and innovation.
A security team who can default to openness and only restrict as the exception will do a far better job at spreading knowledge about what they do, and most importantly, why they are doing it.
via English – alper.nl https://ift.tt/2NkGmiq
0 notes
Link
So recently Tenant Dial Plans came into Preview in Skype for Business Online and Microsoft published a Skype Academy presents video on Skype Operation frameworks in their technical product training. Below is a summary and the key points i found on watching the video below.
This has for me been a long awaited feature where we can now have custom dial plans as we can do with on premises Skype for Business and Lync Server deployments. Previously SfB Online users have had dial plans assigned automatically by Microsoft which are not customisable and for basic dialling such as calling local, domestic and internationally numbers, no custom normalisation was possible which with users moving from old PBX where this was possible was being seen as a step back and being a potentially roadblock to moving to SfB Online.
What are dial plans ?
A dial plan is a named set of normalization rules that translate dialled telephone numbers by a user into E.164 (Recommended) or can be other number formats but i would always stick to E.164.
Dial Plans themselves are made up of one or more normalization rules which define how phone numbers are translated into an alternate format. Dial Plans can be assigned at given levels for on premises these can be global, site, pool and user. Looks like Online is different with merged dial plans so take note of this.
For example a user will have a dialplan and in that dial plan will be a number of normalization rules that are in affect in the SfB client when a user dials. If a user dials 01782 123456 for UK landline now SfB Online already will normalize this to +441782123456 with the default UK dial plan. Tenant Dial plans for allows SfB Online users to have more flexibility and they can define custom dial plans with custom normalization for extension dialling or local number dialling etc. I feel a very awaited feature !
Link to Video from Skype academy here
Lets go!
Great use of a scenario using Garth who plays a part throughout the video.
Garth works for Contoso
Contoso move from PBX to SfB Online
Garth comes into the Office Monday morning, signs into SfB client and dials 5551234 as he did previously with his PBX desk phone last week.
SfB Client ahs incorrectly normalized this
Gareth hits enter and dials and it fails
Garth listens to Diagnostic announcement service which lets him know they have dialled a number incorrectly.
Garth dialled correctly as he was used to with his PBX but the number was normalized incorrectly, a user wouldn’t and shouldn’t have to know about really as its done for them in the background.
Summed up below Garth is SAD and he wished he could dial number like he used to. He’s moved from old legacy PBX phone to SfB and he cant dial like he used which gives a poor user experience from day one
SO we need to make Garth happy again here comes Tenant Dial Plans !! Wohoo !
3 Simple things to take away for this session.
Tenant Dial Plans creates support for tenant based custom dial plans in Sfb Online, these rules and dial plans, create custom normalization rules and applicable to specific USER or ENTIRE tenant.
Custom Dial Plans are still in PREVIEW and subject to change as noted below so set expectations on custom dial plans from day one with users if you are using them during the preview. This training is Feb 2017 and current at this time only.
Any Issue please log in Office 365 support portal.
Sign up for Tenant Dial Plans here and requirements to join the preview are below as well.
http://ift.tt/1INEPVf
Tenant Dial Plans and SOF
Break into Plan, Deliver and Operations Phases of SOF.
Plan Phase
What are Tenant Dial Plans??
Based on overwhelming customer feedback, single county specific dial plans are not enough and customers want dial plan customisation that they have or had with on premise deployment for SfB Server in SfB Online. End user experience was impacted when migrated, users felt they had lost out on functionality by moving from PBX to Cloud PBX which isnt good.
KEY POINT
LIMIT of 25 Normalization rules per dial plan – Key for planning !
Applies to Cloud PBX and Hybrid users using CCE and dial out for Cloud PSTN Conferencing !
No changes in routing / PSTN usages
Before Tenant Dial Plans
Very basic normalisation rules
Dial plans has always existed but were basic
Now there are two types of dial plans
Service – Always existed and has always been applied – CAN NOT be changed
Tenant – with two subset types. Default applied to all Office 365 tenants.
Tenant dial plans can be scoped in two different ways:
Tenant – Global – applies to all users in tenant
Tenant – User – applies to specific subset of users who have been granted this.
How these Dial Plans now work together
Dial plan scope / Hierarchy
Key Point – Hierarchy of Dial Plans works differently to Lync / SfB Server on premises ! Global Site Pool and User, you would apply the lowest level.
If you applied pool level and site to a user then the Pool level would apply, site is ignored completely.
MERGED DIAL PLANS
For Tenant Dial plans these are merged together to come up with affective dial plans. Three different categories
1 – No tenant global plans , no user dial plan – only dial plan dialled is service country dial plan
2 – Tenant global , no user level dial plan – Merge Service level and tenant global
3 – Tenant user dial plan – ignore tenant global dial plan and merge tenant user and service country
Found this information as well taken from here
The following is the inheritance model of dial plans in Skype for Business Online.
The following are the possible effective dial plans:
Service Country If no tenant scoped dial plan is defined and no tenant user scoped dial plan is assigned to the provisioned user – the user will receive an effective dial plan mapped to the service country associated with their Office 365 Usage Location.
Tenant Global – Service Country If a tenant user dial plan is defined but not assigned to a user – the provisioned user will receive an effective dial plan consisting of a merged tenant dial plan and the service country dial plan associated with their Office 365 Usage Location.
Tenant User – Service Country If a tenant user dial plan is defined and assigned to a user – the provisioned user will receive an effective dial plan consisting of the merged tenant user dial plan and the service country dial plan associated with their Office 365 Usage Location.
Planning Steps
First off Are custom rules required ? Majority of cases this will be required as Service Country as very basic.
Can you use tenant global dial plan for all users and keep it simple or do you need user specific ?
No details on creating number plans recommends to look online for other content, ill added some references at the bottom of this post.
Recommendation to maintain consistency on tenant dial plan names !! Key to have a naming standard makes it easier for admins! Same with on premises. Keep it simple !
Also checkout Skype optimizer for all your Dial Plan needs and Tenant Dial plans are coming here to http://ift.tt/2cnhJgK
Have on premise deployed already then check what’s in place and also check if these are actually required or not ? Only use what you need ?
Export from on premises and import to SfB Online
Migration from legacy PBX have a look at old system and add to file to import
Tenant Dial Plans are cmdlet only (Make sure you know how to connect to your Tenant Via PowerShell) Link here
Enable UI in couple of months
Not currently supported with current Cloud PBX Certified IP Phones ! No support was required when qualifying IP Phones as tenant dial plans didn’t exist. This is being looked at in the future.
Working with Tenant Dial Plans
Table displaying scenario and cmdlets to use.
Note – using variables in the cmdlets
7 digits dialled and append +142 infront (Goes back to Garth)
Using Get-csEffectiveTenantDialPlan is a good way to check merged dial plans for users and also testing your rules using –dialledNumber
UseOnPremDialPlan must be set to False if you want Cloud PBX users to use Tenant Dial Plans.
For the PowerShell cmdlets and scripts head over to here for examples from Microsoft you can copy and paste and also details on how to connect via PowerShell to your tenant which is key as there is currently no GUI for tenant dial plans.
http://ift.tt/2kmrcdH
In action – Back to Garth
Garth is happy and his normalization is fixed
Changing Tenant Dial Plan
First we look at deleting a dial plan using remove-cstenantdialplan specify the identity and apply force. Forces removal even if assigned to users. without –force you will have to ungrant it from users first (Recommended way) try not to use –force if possible.
Create input CSV, example above shows example CSV file for importing.
Use CSV in script below
There’s also an example for exporting on premises here which instead of using a CSV it uses XML. Again before exporting and just importing please review if all normalization are actually required ? also remember the 25 normalization rule limit in online as well.
Operate SOF Phase
Some useful troubleshooting information.
What to look for when troubleshooting
Run cmdlet – Get-cseffectivetenantdialplan
Open Client log file with Snooper > Search for LocationProfileDescription
Before – He was assigned Service / Country Dial plan for region
After – Dial Plan has been assigned. Effective dial plan that is combined with Service and Tenant Global. The numbers don’t match as they are merged but the start of the dial plan string is the same.
Recap
Key parts for me were
Merged dial plans – this is something to remember
Limit of 25 normalization rule per dial plan
New cmdlets – Using get-cseffectivedialplan is great for troubleshooting
No Dial plan UI currently
IP Phone doesn’t support tenant dial plans
Dial plan naming is as key online as well as on premise
More Details
Planning
http://ift.tt/2kCJt5b
Create and Manage
http://ift.tt/2kCJt5b
Skype Optimizer – Tenant Dial Plans coming soon
http://ift.tt/2cnhJgK
0 notes
Text
How an Online Game Can Help AI Address Access to Justice (A2J)
TL;DR: If you like issue spotting, play this “game” to help AI improve access to justice by training algorithms to help connect folks with legal services.
It is a truth universally acknowledged, that the majority of those in possession of legal problems, remain in want of solutions.1 Also, ROBOTS! Ergo, we should throw AI at A2J. There is considerably less consensus, however, on how (or why exactly) this should be done. But don’t worry! There’s an app/game for that, and it let’s you train artificial intelligence to help address access-to-justice issues. We’ll get to that in a minute. But first, some background.
Machine Learning & Access to Justice, Together at Last
Machine Learning, the subdiscipline within AI around which the current hype cycle revolves, is good at pattern recognition. Acquaint it with a sufficiently large number of example items, and it can “learn” to find things “like” those items hiding in the proverbial haystack. To accomplish such feats, however, we have to satisfy the machine’s need for data—BIG data. Consequently, AI’s appetite is often a limiting factor when it comes to deploying an AI solution.
Image: “The Supreme Court” by Tim Sackton is licensed CC BY-SA 2.0. The image has been modified to include “big Data,” with inspiration from Josh Lee.
Let’s consider two areas where AI’s pattern recognition might have something to offer A2J. Services like ABA’s Free Legal Answers try to match people with legal questions to lawyers offering pro bono limited representation (think free advice “calls” over email). Unfortunately, some questions go unclaimed. In part, that’s because it can be hard to match questions to attorneys with relevant expertise. If I’m a volunteer lawyer with twenty years of health law experience, I probably prefer fielding people’s health law questions while avoiding IP issues.
To get health law questions on my plate and IP questions on someone else’s, a user’s questions need to be (quickly, efficiently, and accurately) labeled and routed to the right folks. Sure, people can do this, but their time and expertise are often better deployed elsewhere, especially if there are lots of questions. Court websites try to match users with the right resources, but it’s hard to search for something when you don’t know what it’s called. After all, you don’t know what you don’t know. Complicating matters further, lawyers don’t use words like everyone else. So it can be hard to match a user’s question with a lawyer’s expertise. Wouldn’t it be great if AI’s knack for pattern recognition could spot areas of law relevant to a person’s needs based on their own words (absent legalese), then direct them to the right guide, tool, template, resource, attorney, or otherwise? That’s what we’re working towards here.
I include a version of this slide in just about every data science talk I give. You can find the map background image here.
I know what you’re thinking, but we are NOT talking about a robot lawyer. When we say “AI,” think augmented intelligence, not artificial intelligence. What we’re talking about is training models to spot patterns, and it’s worth remembering the sage advice of George Box, “all models are wrong, but some are useful.” Consequently, one must always consider two things before deciding to use a model: First, does the model improve on what came before? Second, is it starting a discussion (not ending it)? Unless the data are pristine and the decision is clear-cut, a model can only inform, not make, the decision.
Something like an automated issue spotter has the potential to improve access to justice simply by making it a little easier to find legal resources. It doesn’t need to answer people’s questions. It just needs to point them in the right direction or bring them to the attention of someone in a position to help. It can get the conversation started by making an educated guess about what someone is looking for and jumping over a few mundane—but often intimidating—first steps.
But at least two problems stand between us and realizing this dream. If we’re going to map lay folks’ questions to issues using machine learning, we’re going to need a list of issues and a boatload of sample questions to train our models. As if this wasn’t enough, those examples need to be tagged or labeled with the right issues. Unfortunately, we are unaware of any appropriately-labeled public dataset. So we’ve decided to help birth one.
Who’s “we” you ask? A collaboration of Suffolk Law School’s Legal Innovation and Technology (LIT) Lab (bringing the data science) and Stanford Law School’s Legal Design Lab (bringing the design chops), with funding from The Pew Charitable Trusts.
Learned Hands: An Introduction to Our Project
Image by Margaret Hagan.
So AI can help address an A2J need but only if someone has the resources and expertise to create a taxonomy, read a bunch of text, and (correctly) label all the legal issues present. This is where you, dear reader, can help.
The Access to Justice & Legal Aid Taxonomy
Stanford’s Legal Design Lab has taken the lead on creating a taxonomy of legal help issues based on existing ones. Eventually, service providers will be able to match their offerings to the list, and AI can pair the general population’s questions with the appropriate label or tag within the taxonomy. Heck, AI could even help service providers match their resources to the taxonomy, serving as a translator on both sides. Either way, the taxonomy will provide a standard nomenclature to help coordinate A2J work across the community. Setting standards is hard, but it’s the sort of foundational work that can pay big dividends. In short, we’re building Version 1.0 and looking for your input. If that appeals to you, give this description of the work/call for input a look and make yourself heard.
Help AI Address Access to Justice
Now we just need tens of thousands of legal questions to feed the machine, and each one must be tagged with items from the taxonomy. Luckily, people publicly post their legal questions all the time. Tens of thousands are available over at r/legaladvice. The moderators and forum rules work to ensure that these posts lack personally identifying information, and all questions are posted with the expectation that they will be published to the front page of the internet, as Reddit calls itself. This makes them unique because, unlike questions posted on sites like ABA Free Legal Answers, their authors understand them to reside in an explicitly public space. Although they haven’t been mapped to our taxonomy, their public nature leaves open the possibility that an army of citizen issue spotters (that’s you) could read through them and label away.
One can download these questions using the Reddit API, but moderators at r/legaladvice were kind enough to share their own repository of nearly 75,000 questions in the hopes they could help jump-start our work. Thanks especially to Ian Pugh and Shane Lidman for facilitating our work with the Reddit Legal Advice community.
The Game: Labeling Texts
To help label our growing collection of texts, we’ve created an online game in the hope that many hands will make light work. So, of course, we call it Learned Hands.2
Logo by Margaret Hagan.
The game presents players with a selection of lay peoples’ questions and asks them to confirm or deny the presence of issues. For example, “Do you see a Health Law issue?” We then combine these “votes” to determine whether or not an issue is present. As you can imagine, deciding when you have a final answer is one of the hard parts. After all, if you ask two lawyers for an opinion, you’ll likely get five different answers.
We decide the final answer using statistical assumptions about the breakdown of voters without requiring a fixed number of votes. Effectively, if everyone agrees on the labeling, we can call the final answer with fewer votes than if there is some disagreement. Consequently, the utility of the next vote changes based on earlier votes. We use this to order the presentation of questions and make sure that the next question someone votes on is the one that’s going to give us the most information/ or move us closest to finalizing a label. This means we don’t waste players’ time by showing them a bunch of undisputed issues.
You earn points based on how many questions you mark (with longer texts garnering more points). Players are ranked based on the points they’ve earned multiplied by their quality score, which reflects how well your markings agree with the final answers. Specifically, we’re using a measure statisticians call the F1 Score.
That’s right. You can compete against your colleagues for bragging rights as the best issue spotter (while training AI to help address A2J issues). After all, we’re trying to have this game go viral. Please tell all your friends! Also, it works on both your desktop and your phone.
Desktop and mobile screenshots.
Eventually, we will make different flavors of the labeled data available to researchers, developers, and entrepreneurs free of charge in the hopes that they can use the data to create useful tools in the service of A2J (for example, we may publish a set where the labels correspond to a 95% confidence level and another were the labels are just the current “best guess”). Not only could such datasets serve to help train new issue spotting models, but ideally, they could serve as a tool for benchmarking (testing) such models. See Want to improve AI for law? Let’s talk about public data and collaboration.
We’re also seeking private data sources for secure in-game labeling by users agreed upon by those providing the data (e.g., their own employees). By including more diverse datasets, we can better train the algorithms, allowing them to better recognize problems beyond those faced by Reddit users. Although we’ll be unable to publicly share labeled private data, we will be able to share the models trained on them, allowing the larger A2J community to benefit while respecting client confidence.
For the record, although this game’s design was a collaboration between the LIT and Legal Design Labs, Metin Eskili (the Legal Design Lab’s technologist) is responsible for the heavy lifting: turning our ideas into functional code. Thanks Metin.
Active Learning
We will also use a process called active learning. Basically, once we reach a critical mass of questions, we train our machine learning models on the labeled data as it comes in. We then point our models at the unlabeled questions looking for those it’s unsure of. We can then move these questions to the top of the queue. In this way, the models gain insights they need to parse “confusing” examples. Again, the idea is not to do more labeling than necessary. It just makes sense to skip those questions our algorithms are pretty sure about.
Proof of Concept
Here at Suffolk’s LIT Lab, we’ve started training algorithms on a pre-labeled private dataset. The early results are promising, or as I like to say, “not horrible.” As I’ve explained elsewhere, accuracy is often not the best measure of a model’s performance. For example, if you’re predicting something that only happens 5% of the time, your model can be 95% accurate by always guessing that it’s going to happen. It can be hard to say what makes a good model (aside from perfection), but it’s pretty easy to spot when a model’s bad. All you have to do is play through some scenarios.3 To keep it simple, we’ll assume a binary prediction (e.g., yes or no).
If a coin flip can beat your predictions, your predictions are horrible. Your accuracy better beat 50%.
If always guessing yes or no can beat your predictions, your predictions are horrible. Your accuracy must be better than the fraction of the majority answer (like in the 95% accuracy example above).
If you’re looking for Xs and you miss most of the Xs in your sample, your predictions are horrible. So your recall has to be greater than 0.5.
If you’re looking for Xs, and less than half of the things you call Xs are actually Xs, your predictions are horrible. So your precision has to be greater than 0.5.
Using these guideposts, we know a classifier is “not horrible” when it beats both a coin flip and always guessing yes or no. If it says something is X, it better be right most of the time, and across the entire dataset, it must correctly identify more than half of the Xs present.
Below, I’ve included some summary statistics for one of our tentative models trained on pre-labeled private data. As you can see, it’s not horrible—accuracy beats always guessing yes or no, and precision and recall beat 0.50. There are some other nice data points in there (like AUC), but we won’t highlight those here (their descriptions are beyond the scope of this post). In the end, “not horrible” is just an extension of the idea that a model should be an improvement on what came before. In this case, “what came before” includes coin flips and always guessing yes or no.
A snapshot of private data testing results.
As you’d expect, our models are getting better with more data. So we’re really excited to see what happens when a bunch of folks start labeling. Also, it’s worth noting that we are starting with high-level labels (e.g., family law and housing). Over time, we will be including more granular labels (e.g., divorce and eviction).
How Does This All Work? (A Slightly-Technical Description)
Text classification isn’t as complicated as you might think. That’s mostly because the algorithms aren’t really reading the texts (at least not the way you do). To oversimplify a common text-classification method called bag-of-words, one creates a list of words found across all texts and then represents each document as a count of words found in that document. Each word counts is treated as a dimension in a vector (think “column in a list of numbers”). After looking at all the data, one might notice that questions about divorce always have a value greater than or equal to three for the dimension associated with the word “divorce.” In other words, divorce-related questions always contain the word “divorce” at least three times. So it is be possible to describe questions about divorce by referring to their vectors.
Put another way, every text with vectors whose divorce dimension is on either side of three goes into either the divorce or not-divorce categories. This isn’t a very realistic example, though, because document types aren’t often like Beetlejuice (say the magic word three times and they appear). Still it is reasonable to assume there is a constellation of keywords that help define a document type. For example, maybe the chance that a question is housing related goes up when the query uses words like landlord, tenant, or roommate. Larger values across those dimensions, then, are correlated with housing questions. You can (of course) get more nuanced and start looking for n-grams (couplings of two, three, or n words) like best interest, while ignoring common words like and. But the general method remains the same: we throw the words into a bag and count them.
More sophisticated approaches—like word2vec—employ different methods for converting text to vectors, but without getting too far in the weeds we can generalize the the process of text-classification. First, you turn texts into numbers embedded in some multi-dimensional space. Then you look for surfaces in that space that define borders between different text groupings with different labels. This, of course, relies on different text types occupying different regions in the space after they are embedded. Whether or not these groupings exist is an empirical question (which is why it’s nice to see not horrible output above). The data help us think success is an option.
Google’s Machine Learning Crash Course on Text Classification provides a good high-level introduction for those interested in the technology. Our workflow tracks with much of their description, although there are some differences. For example, we’re using over- and under-sampling for unbalanced classes and stacking various models. Don’t worry, we’ll eventually write everything up in detail. Here’s the point, though: we aren’t pushing the state of the art with these classifiers. We’re sticking with time-tested methods and producing a publicly-labeled dataset. We’d love to see this labeled dataset feeding some cutting-edge work down the road, and if you can make a compelling demonstration for how your novel method could make better predictions, we’re open to taking your model in-house and training it on our private datasets (assuming you commit to making the trained model free and publicly available). After all, many hands make light work. Tell your friends! Heck, let’s make its super simple. Just share this tweet as often as you can:
Compete against your colleagues for bragging rights as the best legal issue spotter (while training #AI to help address #A2J issues), a collaboration between @SuffolkLITLab & @LegalDesignLab. Play on your ?or ??. https://t.co/PgL99vONro
— Suffolk LIT Lab (@SuffolkLITLab) October 16, 2018
And don’t forget to play Learned Hands during your commute, over lunch, or while waiting in court.
My apologies to both Jane Austin and the Legal Service Corporation’s 2017 Justice Gap Report. ↩
This is wordplay riffing on the name of an eminent American jurist, Learned Hand. I’m sorry I felt compelled to explain the joke, but here we are… in a footnote. :/ ↩
In practice, one needs to think carefully about the costs of things like false positives and false negatives. Sometimes you’ll have a preference for one over the other, but we’re not going to get that nuanced here. ↩
The post How an Online Game Can Help AI Address Access to Justice (A2J) appeared first on Lawyerist.com.
from Law https://lawyerist.com/learned-hands-launch/
via http://www.rssmix.com/
0 notes
Last Seen Blogs




