#async call in spring boot
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
Tumblr.com rank in the US is 25.
Text
Example of @Async in Spring Boot for Beginners
The @async annotation in Spring Boot allows you to run tasks asynchronously (in the background) without blocking the main thread. This is useful for time-consuming tasks like sending emails, processing large files, or making API calls. ✅ Step-by-Step Guide We will create a Spring Boot app where an API endpoint triggers an async task that runs in the background. 1️⃣ Add Required Dependencies In…
0 notes
Text
hi
java executor service how to use join two collections mongo performance monorepo vs mongotemplate
angular header xml common keys
no sql spring boot
angular authentication header
how to set key …
synchronus vs asynch
resttemplate vs other types
hosted servers
how to produce/consume queue
how many servers where hosted
service goes down
fault tolerance hystrix
producing queue
spring boot microservices async communication
mule connectors
custom policies
resource level policies
convert map to list
call multiple apis
transactional attributes
trasaction progation
spring boot authentication active directory
performance optimization in angular
lazy loading in angular
load dynamic script block
immutable objects
system api vs process api
java optional - Google Search www.google.com 1:10 PM Guide To Java 8 Optional | Baeldung www.baeldung.com
1:09 PM java throws exception order - Google Search www.google.com 1:09 PM Order of throws exceptions in Java - Stack Overflow stackoverflow.com 1:08 PM java exception catch custom - Google Search www.google.com 1:07 PM Implement Custom Exceptions in Java: Why, When and How stackify.com 1:07 PM java exception catch - Google Search www.google.com 1:07 PM AJAX Database www.w3schools.com 1:06 PM ajax call call database - Google Search www.google.com 1:06 PM php - jQuery AJAX call to a database query - Stack Overflow stackoverflow.com 1:05 PM ajax call functionlity - Google Search www.google.com 1:05 PM javascript - jQuery AJAX function call - Stack Overflow stackoverflow.com 1:04 PM ajax javascript - Google Search www.google.com 1:04 PM ajax calls - Google Search www.google.com 1:04 PM rest framework jersey - Google Search www.google.com 1:03 PM REST API with Jersey and Spring | Baeldung www.baeldung.com 1:03 PM dynamic binding vs static binding - Google Search www.google.com 1:02 PM Static vs Dynamic Binding in Java - GeeksforGeeks www.geeksforgeeks.org 1:02 PM hashmap vs hashtable performance - Google Search www.google.com 1:01 PM hashmap vs hashtable - Google Search www.google.com 1:01 PM java stream filter list to set - Google Search www.google.com 1:00 PM Java 8 Filter set based on another set - Stack Overflow stackoverflow.com 1:00 PM list to set java stream - Google Search www.google.com 12:59 PM Convert List to Set in Java | Techie Delight www.techiedelight.com 12:58 PM java stream vs collection - Google Search www.google.com 12:24 AM https://www.fiverr.com/authentications/google/callback?state=a5a6e4b13a8047cda2945fa49094c4d1&code=4%2F0AbUR2VOk1hjoKnGqBip_091Rw0WSlp3HSQ6NuMxD_dxQ8meWw5IIKHv3wPUVunwIEQnwrQ&scope=email+profile+openid+https%3A%2F%2Fwww.googleapis.com%2Fauth%2Fuserinfo.email+https%3A%2F%2Fwww.googleapis.com%2Fauth%2 www.fiverr.com 12:24 AM Sign in - Google Accounts accounts.google.com 12:11 AM
0 notes
Text
Spring Boot Multithreading using Async in Hindi | Complete Tutorial of Multithreading in Spring Boot in HINDI
Full Video Link: https://youtu.be/SSwhctye9jA Hi, a new #video on #springboot #multithreading using #async #annotation is published on #codeonedigest #youtube channel. The complete tutorial guide of multithreading in #spring #boot #project using async
Multithreading in spring boot is achieved using Async annotation and using Task Executor Service class. Multithreading in spring boot is similar to multitasking, except that it allows numerous threads to run concurrently rather than processes. A thread in Java is a sequence of programmed instructions that are managed by the operating system’s scheduler. Threads can be utilized in the background…

View On WordPress
#async call in spring boot#async in spring#async in spring boot#async in spring boot example#async in spring webflux#async processing in spring boot#async rest call in spring boot#enable async in spring boot#how to use multithreading in spring boot#multithreading#multithreading in spring batch#multithreading in spring batch example#multithreading in spring boot#multithreading in spring boot application#multithreading in spring boot example#multithreading in spring boot interview questions#multithreading in spring boot microservices#multithreading in spring boot rest api#multithreading in spring boot using completablefuture#multithreading in spring mvc#spring#Spring boot#spring boot async#spring boot async api#spring boot async completablefuture#spring boot async example#spring boot async method#spring boot async rest api#spring boot async rest api example#spring boot async rest controller
0 notes
Text
Google Analytics (GA) like Backend System Architecture
There are numerous way of designing a backend. We will take Microservices route because the web scalability is required for Google Analytics (GA) like backend. Micro services enable us to elastically scale horizontally in response to incoming network traffic into the system. And a distributed stream processing pipeline scales in proportion to the load.
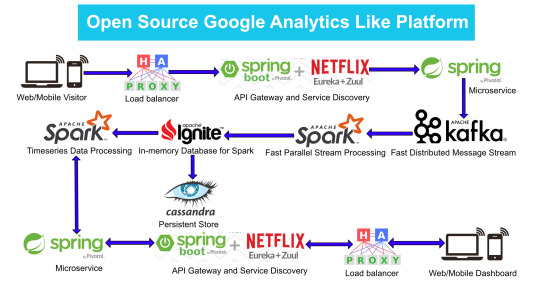
Here is the High Level architecture of the Google Analytics (GA) like Backend System.
Components Breakdown
Web/Mobile Visitor Tracking Code
Every web page or mobile site tracked by GA embed tracking code that collects data about the visitor. It loads an async script that assigns a tracking cookie to the user if it is not set. It also sends an XHR request for every user interaction.
HAProxy Load Balancer
HAProxy, which stands for High Availability Proxy, is a popular open source software TCP/HTTP Load Balancer and proxying solution. Its most common use is to improve the performance and reliability of a server environment by distributing the workload across multiple servers. It is used in many high-profile environments, including: GitHub, Imgur, Instagram, and Twitter.
A backend can contain one or many servers in it — generally speaking, adding more servers to your backend will increase your potential load capacity by spreading the load over multiple servers. Increased reliability is also achieved through this manner, in case some of your backend servers become unavailable.
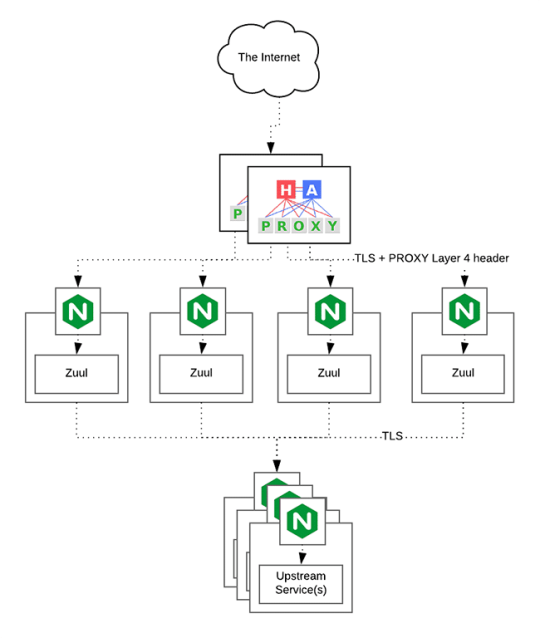
HAProxy routes the requests coming from Web/Mobile Visitor site to the Zuul API Gateway of the solution. Given the nature of a distributed system built for scalability and stateless request and response handling we can distribute the Zuul API gateways spread across geographies. HAProxy performs load balancing (layer 4 + proxy) across our Zuul nodes. High-Availability (HA ) is provided via Keepalived.
Spring Boot & Netflix OSS Eureka + Zuul
Zuul is an API gateway and edge service that proxies requests to multiple backing services. It provides a unified “front door” to the application ecosystem, which allows any browser, mobile app or other user interface to consume services from multiple hosts. Zuul is integrated with other Netflix stack components like Hystrix for fault tolerance and Eureka for service discovery or use it to manage routing rules, filters and load balancing across your system. Most importantly all of those components are well adapted by Spring framework through Spring Boot/Cloud approach.
An API gateway is a layer 7 (HTTP) router that acts as a reverse proxy for upstream services that reside inside your platform. API gateways are typically configured to route traffic based on URI paths and have become especially popular in the microservices world because exposing potentially hundreds of services to the Internet is both a security nightmare and operationally difficult. With an API gateway, one simply exposes and scales a single collection of services (the API gateway) and updates the API gateway’s configuration whenever a new upstream should be exposed externally. In our case Zuul is able to auto discover services registered in Eureka server.
Eureka server acts as a registry and allows all clients to register themselves and used for Service Discovery to be able to find IP address and port of other services if they want to talk to. Eureka server is a client as well. This property is used to setup Eureka in highly available way. We can have Eureka deployed in a highly available way if we can have more instances used in the same pattern.
Spring Boot Microservices
Using a microservices approach to application development can improve resilience and expedite the time to market, but breaking apps into fine-grained services offers complications. With fine-grained services and lightweight protocols, microservices offers increased modularity, making applications easier to develop, test, deploy, and, more importantly, change and maintain. With microservices, the code is broken into independent services that run as separate processes.
Scalability is the key aspect of microservices. Because each service is a separate component, we can scale up a single function or service without having to scale the entire application. Business-critical services can be deployed on multiple servers for increased availability and performance without impacting the performance of other services. Designing for failure is essential. We should be prepared to handle multiple failure issues, such as system downtime, slow service and unexpected responses. Here, load balancing is important. When a failure arises, the troubled service should still run in a degraded functionality without crashing the entire system. Hystrix Circuit-breaker will come into rescue in such failure scenarios.
The microservices are designed for scalability, resilience, fault-tolerance and high availability and importantly it can be achieved through deploying the services in a Docker Swarm or Kubernetes cluster. Distributed and geographically spread Zuul API gateways route requests from web and mobile visitors to the microservices registered in the load balanced Eureka server.
The core processing logic of the backend system is designed for scalability, high availability, resilience and fault-tolerance using distributed Streaming Processing, the microservices will ingest data to Kafka Streams data pipeline.
Apache Kafka Streams
Apache Kafka is used for building real-time streaming data pipelines that reliably get data between many independent systems or applications.
It allows:
Publishing and subscribing to streams of records
Storing streams of records in a fault-tolerant, durable way
It provides a unified, high-throughput, low-latency, horizontally scalable platform that is used in production in thousands of companies.
Kafka Streams being scalable, highly available and fault-tolerant, and providing the streams functionality (transformations / stateful transformations) are what we need — not to mention Kafka being a reliable and mature messaging system.
Kafka is run as a cluster on one or more servers that can span multiple datacenters spread across geographies. Those servers are usually called brokers.
Kafka uses Zookeeper to store metadata about brokers, topics and partitions.
Kafka Streams is a pretty fast, lightweight stream processing solution that works best if all of the data ingestion is coming through Apache Kafka. The ingested data is read directly from Kafka by Apache Spark for stream processing and creates Timeseries Ignite RDD (Resilient Distributed Datasets).
Apache Spark
Spark Streaming is an extension of the core Spark API that enables scalable, high-throughput, fault-tolerant stream processing of live data streams.
It provides a high-level abstraction called a discretized stream, or DStream, which represents a continuous stream of data.
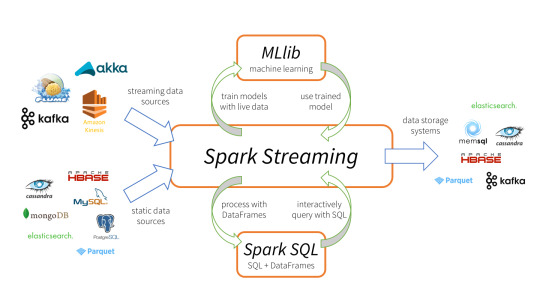
DStreams can be created either from input data streams from sources such as Kafka, Flume, and Kinesis, or by applying high-level operations on other DStreams. Internally, a DStream is represented as a sequence of RDDs (Resilient Distributed Datasets).
Apache Spark is a perfect choice in our case. This is because Spark achieves high performance for both batch and streaming data, using a state-of-the-art DAG scheduler, a query optimizer, and a physical execution engine.
In our scenario Spark streaming process Kafka data streams; create and share Ignite RDDs across Apache Ignite which is a distributed memory-centric database and caching platform.
Apache Ignite
Apache Ignite is a distributed memory-centric database and caching platform that is used by Apache Spark users to:
Achieve true in-memory performance at scale and avoid data movement from a data source to Spark workers and applications.
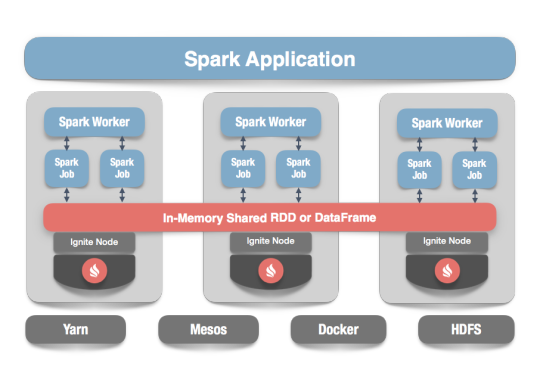
More easily share state and data among Spark jobs.
Apache Ignite is designed for transactional, analytical, and streaming workloads, delivering in-memory performance at scale. Apache Ignite provides an implementation of the Spark RDD which allows any data and state to be shared in memory as RDDs across Spark jobs. The Ignite RDD provides a shared, mutable view of the same data in-memory in Ignite across different Spark jobs, workers, or applications.
The way an Ignite RDD is implemented is as a view over a distributed Ignite table (aka. cache). It can be deployed with an Ignite node either within the Spark job executing process, on a Spark worker, or in a separate Ignite cluster. It means that depending on the chosen deployment mode the shared state may either exist only during the lifespan of a Spark application (embedded mode), or it may out-survive the Spark application (standalone mode).
With Ignite, Spark users can configure primary and secondary indexes that can bring up to 1000x performance gains.
Apache Cassandra
We will use Apache Cassandra as storage for persistence writes from Ignite.
Apache Cassandra is a highly scalable and available distributed database that facilitates and allows storing and managing high velocity structured data across multiple commodity servers without a single point of failure.
The Apache Cassandra is an extremely powerful open source distributed database system that works extremely well to handle huge volumes of records spread across multiple commodity servers. It can be easily scaled to meet sudden increase in demand, by deploying multi-node Cassandra clusters, meets high availability requirements, and there is no single point of failure.
Apache Cassandra has best write and read performance.
Characteristics of Cassandra:
It is a column-oriented database
Highly consistent, fault-tolerant, and scalable
The data model is based on Google Bigtable
The distributed design is based on Amazon Dynamo
Right off the top Cassandra does not use B-Trees to store data. Instead it uses Log Structured Merge Trees (LSM-Trees) to store its data. This data structure is very good for high write volumes, turning updates and deletes into new writes.
In our scenario we will configure Ignite to work in write-behind mode: normally, a cache write involves putting data in memory, and writing the same into the persistence source, so there will be 1-to-1 mapping between cache writes and persistence writes. With the write-behind mode, Ignite instead will batch the writes and execute them regularly at the specified frequency. This is aimed at limiting the amount of communication overhead between Ignite and the persistent store, and really makes a lot of sense if the data being written rapidly changes.
Analytics Dashboard
Since we are talking about scalability, high availability, resilience and fault-tolerance, our analytics dashboard backend should be designed in a pretty similar way we have designed the web/mobile visitor backend solution using HAProxy Load Balancer, Zuul API Gateway, Eureka Service Discovery and Spring Boot Microservices.
The requests will be routed from Analytics dashboard through microservices. Apache Spark will do processing of time series data shared in Apache Ignite as Ignite RDDs and the results will be sent across to the dashboard for visualization through microservices
0 notes
Text
RxJava support 2.0 releases support for Android apps
The RxJava team has released version 2.0 of their reactive Java framework, after an 18 month development cycle. RxJava is part of the ReactiveX family of libraries and frameworks, which is in their words, "a combination of the best ideas from the Observer pattern, the Iterator pattern, and functional programming". The project's "What's different in 2.0" is a good guide for developers already familiar with RxJava 1.x.
RxJava 2.0 is a brand new implementation of RxJava. This release is based on the Reactive Streams specification, an initiative for providing a standard for asynchronous stream processing with non-blocking back pressure, targeting runtime environments (JVM and JavaScript) as well as network protocols.
Reactive implementations have concepts of publishers and subscribers, as well as ways to subscribe to data streams, get the next stream of data, handle errors and close the connection.
The Reactive Streams spec will be included in JDK 9 as java.util.concurrent.Flow. The following interfaces correspond to the Reactive Streams spec. As you can see, the spec is small, consisting of just four interfaces:
· Flow.Processor<T,R>: A component that acts as both a Subscriber and Publisher.
· Flow.Publisher<T>: A producer of items (and related control messages) received by Subscribers.
· Flow.Subscriber<T>: A receiver of messages.
· Flow.Subscription: Message control linking a Flow.Publisher and Flow.Subscriber.
Spring Framework 5 is also going reactive. To see how this looks, refer to Josh Long's Functional Reactive Endpoints with Spring Framework 5.0.
To learn more about RxJava 2.0, InfoQ interviewed main RxJava 2.0 contributor, David Karnok.
InfoQ: First of all, congrats on RxJava 2.0! 18 months in the making, that's quite a feat. What are you most proud of in this release?
David Karnok: Thanks! In some way, I wish it didn't take so long. There was a 10 month pause when Ben Christensen, the original author who started RxJava, left and there was no one at Netflix to push this forward. I'm sure many will contest that things got way better when I took over the lead role this June. I'm proud my research into more advanced and more performant Reactive Streams paid off and RxJava 2 is the proof all of it works.
InfoQ: What’s different in RxJava 2.0 and how does it help developers?
Karnok: There are a lot of differences between version 1 and 2 and it's impossible to list them all here ,but you can visit the dedicated wiki page for a comprehensible explanation. In headlines, we now support the de-facto standard Reactive Streams specification, have significant overhead reduction in many places, no longer allow nulls, have split types into two groups based on support of or lack of backpressure and have explicit interop between the base reactive types.
InfoQ: Where do you see RxJava used the most (e.g. IoT, real-time data processing, etc.)?
Karnok: RxJava is more dominantly used by the Android community, based on the feedback I saw. I believe the server side is dominated by Project Reactor and Akka at the moment. I haven't specifically seen IoT mentioned or use RxJava (it requires Java), but maybe they use some other reactive library available on their platform. For real-time data processing people still tend to use other solutions, most of them not really reactive, and I'm not aware of any providers (maybe Pivotal) who are pushing for reactive in this area.
InfoQ: What benefits does RxJava provide Android more than other environments that would explain the increased traction?
Karnok: As far as I see, Android wanted to "help" their users solving async and concurrent problems with Android-only tools such as AsyncTask, Looper/Handler etc.
Unfortunately, their design and use is quite inconvenient, often hard to understand or predict and generally brings frustration to Android developers. These can largely contribute to callback hell and the difficulty of keeping async operations off the main thread.
RxJava's design (inherited from the ReactiveX design of Microsoft) is dataflow-oriented and orthogonalized where actions execute from when data appears for processing. In addition, error handling and reporting is a key part of the flows. With AsyncTask, you had to manually work out the error delivery pattern and cancel pending tasks, whereas RxJava does that as part of its contract.
In practical terms, having a flow that queries several services in the background and then presents the results in the main thread can be expressed in a few lines with RxJava (+Retrofit) and a simple screen rotation will cancel the service calls promptly.
This is a huge productivity win for Android developers, and the simplicity helps them climb the steep learning curve the whole reactive programming's paradigm shift requires. Maybe at the end, RxJava is so attractive to Android because it reduces the "time-to-market" for individual developers, startups and small companies in the mobile app business.
There was nothing of a comparable issue on the desktop/server side Java, in my opinion, at that time. People learned to fire up ExecutorService's and wait on Future.get(), knew about SwingUtilities.invokeLater to send data back to the GUI thread and otherwise the Servlet API, which is one thread per request only (pre 3.0) naturally favored blocking APIs (database, service calls).
Desktop/server folks are more interested in the performance benefits a non-blocking design of their services offers (rather than how easy one can write a service). However, unlike Android development, having just RxJava is not enough and many expect/need complete frameworks to assist their business logic as there is no "proper" standard for non-blocking web services to replace the Servlet API. (Yes, there is Spring (~Boot) and Play but they feel a bit bandwagon-y to me at the moment).
InfoQ: HTTP is a synchronous protocol and can cause a lot of back pressure when using microservices. Streaming platforms like Akka and Apache Kafka help to solve this. Does RxJava 2.0 do anything to allow automatic back pressure?
Karnok: RxJava 2's Flowable type implements the Reactive Streams interface/specification and does support backpressure. However, the Java level backpressure is quite different from the network level backpressure. For us, backpressure means how many objects to deliver through the pipeline between different stages where these objects can be non uniform in type and size. On the network level one deals with usually fixed size packets, and backpressure manifests via the lack of acknowledgement of previously sent packets. In classical setup, the network backpressure manifests on the Java level as blocking calls that don't return until all pieces of data have been written. There are non-blocking setups, such as Netty, where the blocking is replaced by implicit buffering, and as far as I know there are only individual, non-uniform and non Reactive Streams compatible ways of handling those (i.e., a check for canWrite which one has to spin over/retry periodically). There exist libraries that try to bridge the two worlds (RxNetty, some Spring) with varying degrees of success as I see it.
InfoQ: Do you think reactive frameworks are necessary to handle large amounts of traffic and real-time data?
Karnok: It depends on the problem complexity. For example, if your task is to count the number of characters in a big-data source, there are faster and more dedicated ways of doing that. If your task is to compose results from services on top of a stream of incoming data in order to return something detailed, reactive-based solutions are quite adequate. As far as I know, most libraries and frameworks around Reactive Streams were designed for throughput and not really for latency. For example, in high-frequency trading, the predictable latency is very important and can be easily met by Aeron but not the main focus for RxJava due to the unpredictable latency behavior.
InfoQ: Does HTTP/2 help solve the scalability issues that HTTP/1.1 has?
Karnok: This is not related to RxJava and I personally haven't played with HTTP/2 but only read the spec. Multiplexing over the same channel is certainly a win in addition to the support for explicit backpressure (i.e., even if the network can deliver, the client may still be unable to process the data in that volume) per stream. I don't know all the technical details but I believe Spring Reactive Web does support HTTP/2 transport if available but they hide all the complexity behind reactive abstractions so you can express your processing pipeline in RxJava 2 and Reactor 3 terms if you wish.
InfoQ: Java 9 is projected to be featuring some reactive functionality. Is that a complete spec?
Karnok: No. Java 9 will only feature 4 Java interfaces with 7 methods total. No stream-like or Rx-like API on top of that nor any JDK features built on that.
InfoQ: Will that obviate the need for RxJava if it is built right into the JDK?
Karnok: No and I believe there's going to be more need for a true and proven library such as RxJava. Once the toolchains grow up to Java 9, we will certainly provide adapters and we may convert (or rewrite) RxJava 3 on top of Java 9's features (VarHandles).
One of my fears is that once Java 9 is out, many will try to write their own libraries (individuals, companies) and the "market" gets diluted with big branded-low quality solutions, not to mention the increased amount of "how does RxJava differ from X" questions.
My personal opinion is that this is already happening today around Reactive Streams where certain libraries and frameworks advertise themselves as RS but fail to deliver based on it. My (likely biased) conjecture is that RxJava 2 is the closest library/technology to an optimal Reactive Streams-based solution that can be.
InfoQ: What's next for RxJava?
Karnok: We had fantastic reviewers, such as Jake Wharton, during the development of RxJava 2. Unfortunately, the developer previews and release candidates didn't generate enough attention and despite our efforts, small problems and oversights slipped into the final release. I don't expect major issues in the coming months but we will keep fixing both version 1 and 2 as well as occasionally adding new operators to support our user base. A few companion libraries, such as RxAndroid, now provide RxJava 2 compatible versions, but the majority of the other libraries don't yet or haven't yet decided how to go forward. In terms of RxJava, I plan to retire RxJava 1 within six months (i.e., only bugfixes then on), partly due to the increasing maintenance burden on my "one man army" for some time now; partly to "encourage" the others to switch to the RxJava 2 ecosystem. As for RxJava 3, I don't have any concrete plans yet. There are ongoing discussions about splitting the library along types or along backpressure support as well as making the so-called operator-fusion elements (which give a significant boost to our performance) a standard extension of the Reactive Streams specification.
1 note
·
View note
Text
RX JAVA 2.0 releases support for Android
The RxJava team has released version 2.0 of their reactive Java framework, after an 18 month development cycle. RxJava is part of the ReactiveX family of libraries and frameworks, which is in their words, "a combination of the best ideas from the Observer pattern, the Iterator pattern, and functional programming". The project's "What's different in 2.0" is a good guide for developers already familiar with RxJava 1.x.
RxJava 2.0 is a brand new implementation of RxJava. This release is based on the Reactive Streams specification, an initiative for providing a standard for asynchronous stream processing with non-blocking back pressure, targeting runtime environments (JVM and JavaScript) as well as network protocols.
Reactive implementations have concepts of publishers and subscribers, as well as ways to subscribe to data streams, get the next stream of data, handle errors and close the connection.
The Reactive Streams spec will be included in JDK 9 as java.util.concurrent.Flow. The following interfaces correspond to the Reactive Streams spec. As you can see, the spec is small, consisting of just four interfaces:
· Flow.Processor<T,R>: A component that acts as both a Subscriber and Publisher.
· Flow.Publisher<T>: A producer of items (and related control messages) received by Subscribers.
· Flow.Subscriber<T>: A receiver of messages.
· Flow.Subscription: Message control linking a Flow.Publisher and Flow.Subscriber.
Spring Framework 5 is also going reactive. To see how this looks, refer to Josh Long's Functional Reactive Endpoints with Spring Framework 5.0.
To learn more about RxJava 2.0, InfoQ interviewed main RxJava 2.0 contributor, David Karnok.
InfoQ: First of all, congrats on RxJava 2.0! 18 months in the making, that's quite a feat. What are you most proud of in this release?
David Karnok: Thanks! In some way, I wish it didn't take so long. There was a 10 month pause when Ben Christensen, the original author who started RxJava, left and there was no one at Netflix to push this forward. I'm sure many will contest that things got way better when I took over the lead role this June. I'm proud my research into more advanced and more performant Reactive Streams paid off and RxJava 2 is the proof all of it works.
InfoQ: What’s different in RxJava 2.0 and how does it help developers?
Karnok: There are a lot of differences between version 1 and 2 and it's impossible to list them all here ,but you can visit the dedicated wiki page for a comprehensible explanation. In headlines, we now support the de-facto standard Reactive Streams specification, have significant overhead reduction in many places, no longer allow nulls, have split types into two groups based on support of or lack of backpressure and have explicit interop between the base reactive types.
InfoQ: Where do you see RxJava used the most (e.g. IoT, real-time data processing, etc.)?
Karnok: RxJava is more dominantly used by the Android community, based on the feedback I saw. I believe the server side is dominated by Project Reactor and Akka at the moment. I haven't specifically seen IoT mentioned or use RxJava (it requires Java), but maybe they use some other reactive library available on their platform. For real-time data processing people still tend to use other solutions, most of them not really reactive, and I'm not aware of any providers (maybe Pivotal) who are pushing for reactive in this area.
InfoQ: What benefits does RxJava provide Android more than other environments that would explain the increased traction?
Karnok: As far as I see, Android wanted to "help" their users solving async and concurrent problems with Android-only tools such as AsyncTask, Looper/Handler etc.
Unfortunately, their design and use is quite inconvenient, often hard to understand or predict and generally brings frustration to Android developers. These can largely contribute to callback hell and the difficulty of keeping async operations off the main thread.
RxJava's design (inherited from the ReactiveX design of Microsoft) is dataflow-oriented and orthogonalized where actions execute from when data appears for processing. In addition, error handling and reporting is a key part of the flows. With AsyncTask, you had to manually work out the error delivery pattern and cancel pending tasks, whereas RxJava does that as part of its contract.
In practical terms, having a flow that queries several services in the background and then presents the results in the main thread can be expressed in a few lines with RxJava (+Retrofit) and a simple screen rotation will cancel the service calls promptly.
This is a huge productivity win for Android developers, and the simplicity helps them climb the steep learning curve the whole reactive programming's paradigm shift requires. Maybe at the end, RxJava is so attractive to Android because it reduces the "time-to-market" for individual developers, startups and small companies in the mobile app business.
There was nothing of a comparable issue on the desktop/server side Java, in my opinion, at that time. People learned to fire up ExecutorService's and wait on Future.get(), knew about SwingUtilities.invokeLater to send data back to the GUI thread and otherwise the Servlet API, which is one thread per request only (pre 3.0) naturally favored blocking APIs (database, service calls).
Desktop/server folks are more interested in the performance benefits a non-blocking design of their services offers (rather than how easy one can write a service). However, unlike Android development, having just RxJava is not enough and many expect/need complete frameworks to assist their business logic as there is no "proper" standard for non-blocking web services to replace the Servlet API. (Yes, there is Spring (~Boot) and Play but they feel a bit bandwagon-y to me at the moment).
InfoQ: HTTP is a synchronous protocol and can cause a lot of back pressure when using microservices. Streaming platforms like Akka and Apache Kafka help to solve this. Does RxJava 2.0 do anything to allow automatic back pressure?
Karnok: RxJava 2's Flowable type implements the Reactive Streams interface/specification and does support backpressure. However, the Java level backpressure is quite different from the network level backpressure. For us, backpressure means how many objects to deliver through the pipeline between different stages where these objects can be non uniform in type and size. On the network level one deals with usually fixed size packets, and backpressure manifests via the lack of acknowledgement of previously sent packets. In classical setup, the network backpressure manifests on the Java level as blocking calls that don't return until all pieces of data have been written. There are non-blocking setups, such as Netty, where the blocking is replaced by implicit buffering, and as far as I know there are only individual, non-uniform and non Reactive Streams compatible ways of handling those (i.e., a check for canWrite which one has to spin over/retry periodically). There exist libraries that try to bridge the two worlds (RxNetty, some Spring) with varying degrees of success as I see it.
InfoQ: Do you think reactive frameworks are necessary to handle large amounts of traffic and real-time data?
Karnok: It depends on the problem complexity. For example, if your task is to count the number of characters in a big-data source, there are faster and more dedicated ways of doing that. If your task is to compose results from services on top of a stream of incoming data in order to return something detailed, reactive-based solutions are quite adequate. As far as I know, most libraries and frameworks around Reactive Streams were designed for throughput and not really for latency. For example, in high-frequency trading, the predictable latency is very important and can be easily met by Aeron but not the main focus for RxJava due to the unpredictable latency behavior.
InfoQ: Does HTTP/2 help solve the scalability issues that HTTP/1.1 has?
Karnok: This is not related to RxJava and I personally haven't played with HTTP/2 but only read the spec. Multiplexing over the same channel is certainly a win in addition to the support for explicit backpressure (i.e., even if the network can deliver, the client may still be unable to process the data in that volume) per stream. I don't know all the technical details but I believe Spring Reactive Web does support HTTP/2 transport if available but they hide all the complexity behind reactive abstractions so you can express your processing pipeline in RxJava 2 and Reactor 3 terms if you wish.
InfoQ: Java 9 is projected to be featuring some reactive functionality. Is that a complete spec?
Karnok: No. Java 9 will only feature 4 Java interfaces with 7 methods total. No stream-like or Rx-like API on top of that nor any JDK features built on that.
InfoQ: Will that obviate the need for RxJava if it is built right into the JDK?
Karnok: No and I believe there's going to be more need for a true and proven library such as RxJava. Once the toolchains grow up to Java 9, we will certainly provide adapters and we may convert (or rewrite) RxJava 3 on top of Java 9's features (VarHandles).
One of my fears is that once Java 9 is out, many will try to write their own libraries (individuals, companies) and the "market" gets diluted with big branded-low quality solutions, not to mention the increased amount of "how does RxJava differ from X" questions.
My personal opinion is that this is already happening today around Reactive Streams where certain libraries and frameworks advertise themselves as RS but fail to deliver based on it. My (likely biased) conjecture is that RxJava 2 is the closest library/technology to an optimal Reactive Streams-based solution that can be.
InfoQ: What's next for RxJava?
Karnok: We had fantastic reviewers, such as Jake Wharton, during the development of RxJava 2. Unfortunately, the developer previews and release candidates didn't generate enough attention and despite our efforts, small problems and oversights slipped into the final release. I don't expect major issues in the coming months but we will keep fixing both version 1 and 2 as well as occasionally adding new operators to support our user base. A few companion libraries, such as RxAndroid, now provide RxJava 2 compatible versions, but the majority of the other libraries don't yet or haven't yet decided how to go forward. In terms of RxJava, I plan to retire RxJava 1 within six months (i.e., only bugfixes then on), partly due to the increasing maintenance burden on my "one man army" for some time now; partly to "encourage" the others to switch to the RxJava 2 ecosystem. As for RxJava 3, I don't have any concrete plans yet. There are ongoing discussions about splitting the library along types or along backpressure support as well as making the so-called operator-fusion elements (which give a significant boost to our performance) a standard extension of the Reactive Streams specification.
0 notes
Text
The RxJava team has released version 2.0 of their reactive Java framework
The RxJava team has released version 2.0 of their reactive Java framework, after an 18 month development cycle. RxJava is part of the ReactiveX family of libraries and frameworks, which is in their words, "a combination of the best ideas from the Observer pattern, the Iterator pattern, and functional programming". The project's "What's different in 2.0" is a good guide for developers already familiar with RxJava 1.x.
RxJava 2.0 is a brand new implementation of RxJava. This release is based on the Reactive Streams specification, an initiative for providing a standard for asynchronous stream processing with non-blocking back pressure, targeting runtime environments (JVM and JavaScript) as well as network protocols.
Reactive implementations have concepts of publishers and subscribers, as well as ways to subscribe to data streams, get the next stream of data, handle errors and close the connection.
The Reactive Streams spec will be included in JDK 9 as java.util.concurrent.Flow. The following interfaces correspond to the Reactive Streams spec. As you can see, the spec is small, consisting of just four interfaces:
· Flow.Processor<T,R>: A component that acts as both a Subscriber and Publisher.
· Flow.Publisher<T>: A producer of items (and related control messages) received by Subscribers.
· Flow.Subscriber<T>: A receiver of messages.
· Flow.Subscription: Message control linking a Flow.Publisher and Flow.Subscriber.
Spring Framework 5 is also going reactive. To see how this looks, refer to Josh Long's Functional Reactive Endpoints with Spring Framework 5.0.
To learn more about RxJava 2.0, InfoQ interviewed main RxJava 2.0 contributor, David Karnok.
InfoQ: First of all, congrats on RxJava 2.0! 18 months in the making, that's quite a feat. What are you most proud of in this release?
David Karnok: Thanks! In some way, I wish it didn't take so long. There was a 10 month pause when Ben Christensen, the original author who started RxJava, left and there was no one at Netflix to push this forward. I'm sure many will contest that things got way better when I took over the lead role this June. I'm proud my research into more advanced and more performant Reactive Streams paid off and RxJava 2 is the proof all of it works.
InfoQ: What’s different in RxJava 2.0 and how does it help developers?
Karnok: There are a lot of differences between version 1 and 2 and it's impossible to list them all here ,but you can visit the dedicated wiki page for a comprehensible explanation. In headlines, we now support the de-facto standard Reactive Streams specification, have significant overhead reduction in many places, no longer allow nulls, have split types into two groups based on support of or lack of backpressure and have explicit interop between the base reactive types.
InfoQ: Where do you see RxJava used the most (e.g. IoT, real-time data processing, etc.)?
Karnok: RxJava is more dominantly used by the Android community, based on the feedback I saw. I believe the server side is dominated by Project Reactor and Akka at the moment. I haven't specifically seen IoT mentioned or use RxJava (it requires Java), but maybe they use some other reactive library available on their platform. For real-time data processing people still tend to use other solutions, most of them not really reactive, and I'm not aware of any providers (maybe Pivotal) who are pushing for reactive in this area.
InfoQ: What benefits does RxJava provide Android more than other environments that would explain the increased traction?
Karnok: As far as I see, Android wanted to "help" their users solving async and concurrent problems with Android-only tools such as AsyncTask, Looper/Handler etc.
Unfortunately, their design and use is quite inconvenient, often hard to understand or predict and generally brings frustration to Android developers. These can largely contribute to callback hell and the difficulty of keeping async operations off the main thread.
RxJava's design (inherited from the ReactiveX design of Microsoft) is dataflow-oriented and orthogonalized where actions execute from when data appears for processing. In addition, error handling and reporting is a key part of the flows. With AsyncTask, you had to manually work out the error delivery pattern and cancel pending tasks, whereas RxJava does that as part of its contract.
In practical terms, having a flow that queries several services in the background and then presents the results in the main thread can be expressed in a few lines with RxJava (+Retrofit) and a simple screen rotation will cancel the service calls promptly.
This is a huge productivity win for Android developers, and the simplicity helps them climb the steep learning curve the whole reactive programming's paradigm shift requires. Maybe at the end, RxJava is so attractive to Android because it reduces the "time-to-market" for individual developers, startups and small companies in the mobile app business.
There was nothing of a comparable issue on the desktop/server side Java, in my opinion, at that time. People learned to fire up ExecutorService's and wait on Future.get(), knew about SwingUtilities.invokeLater to send data back to the GUI thread and otherwise the Servlet API, which is one thread per request only (pre 3.0) naturally favored blocking APIs (database, service calls).
Desktop/server folks are more interested in the performance benefits a non-blocking design of their services offers (rather than how easy one can write a service). However, unlike Android development, having just RxJava is not enough and many expect/need complete frameworks to assist their business logic as there is no "proper" standard for non-blocking web services to replace the Servlet API. (Yes, there is Spring (~Boot) and Play but they feel a bit bandwagon-y to me at the moment).
InfoQ: HTTP is a synchronous protocol and can cause a lot of back pressure when using microservices. Streaming platforms like Akka and Apache Kafka help to solve this. Does RxJava 2.0 do anything to allow automatic back pressure?
Karnok: RxJava 2's Flowable type implements the Reactive Streams interface/specification and does support backpressure. However, the Java level backpressure is quite different from the network level backpressure. For us, backpressure means how many objects to deliver through the pipeline between different stages where these objects can be non uniform in type and size. On the network level one deals with usually fixed size packets, and backpressure manifests via the lack of acknowledgement of previously sent packets. In classical setup, the network backpressure manifests on the Java level as blocking calls that don't return until all pieces of data have been written. There are non-blocking setups, such as Netty, where the blocking is replaced by implicit buffering, and as far as I know there are only individual, non-uniform and non Reactive Streams compatible ways of handling those (i.e., a check for canWrite which one has to spin over/retry periodically). There exist libraries that try to bridge the two worlds (RxNetty, some Spring) with varying degrees of success as I see it.
InfoQ: Do you think reactive frameworks are necessary to handle large amounts of traffic and real-time data?
Karnok: It depends on the problem complexity. For example, if your task is to count the number of characters in a big-data source, there are faster and more dedicated ways of doing that. If your task is to compose results from services on top of a stream of incoming data in order to return something detailed, reactive-based solutions are quite adequate. As far as I know, most libraries and frameworks around Reactive Streams were designed for throughput and not really for latency. For example, in high-frequency trading, the predictable latency is very important and can be easily met by Aeron but not the main focus for RxJava due to the unpredictable latency behavior.
InfoQ: Does HTTP/2 help solve the scalability issues that HTTP/1.1 has?
Karnok: This is not related to RxJava and I personally haven't played with HTTP/2 but only read the spec. Multiplexing over the same channel is certainly a win in addition to the support for explicit backpressure (i.e., even if the network can deliver, the client may still be unable to process the data in that volume) per stream. I don't know all the technical details but I believe Spring Reactive Web does support HTTP/2 transport if available but they hide all the complexity behind reactive abstractions so you can express your processing pipeline in RxJava 2 and Reactor 3 terms if you wish.
InfoQ: Java 9 is projected to be featuring some reactive functionality. Is that a complete spec?
Karnok: No. Java 9 will only feature 4 Java interfaces with 7 methods total. No stream-like or Rx-like API on top of that nor any JDK features built on that.
InfoQ: Will that obviate the need for RxJava if it is built right into the JDK?
Karnok: No and I believe there's going to be more need for a true and proven library such as RxJava. Once the toolchains grow up to Java 9, we will certainly provide adapters and we may convert (or rewrite) RxJava 3 on top of Java 9's features (VarHandles).
One of my fears is that once Java 9 is out, many will try to write their own libraries (individuals, companies) and the "market" gets diluted with big branded-low quality solutions, not to mention the increased amount of "how does RxJava differ from X" questions.
My personal opinion is that this is already happening today around Reactive Streams where certain libraries and frameworks advertise themselves as RS but fail to deliver based on it. My (likely biased) conjecture is that RxJava 2 is the closest library/technology to an optimal Reactive Streams-based solution that can be.
InfoQ: What's next for RxJava?
Karnok: We had fantastic reviewers, such as Jake Wharton, during the development of RxJava 2. Unfortunately, the developer previews and release candidates didn't generate enough attention and despite our efforts, small problems and oversights slipped into the final release. I don't expect major issues in the coming months but we will keep fixing both version 1 and 2 as well as occasionally adding new operators to support our user base. A few companion libraries, such as RxAndroid, now provide RxJava 2 compatible versions, but the majority of the other libraries don't yet or haven't yet decided how to go forward. In terms of RxJava, I plan to retire RxJava 1 within six months (i.e., only bugfixes then on), partly due to the increasing maintenance burden on my "one man army" for some time now; partly to "encourage" the others to switch to the RxJava 2 ecosystem. As for RxJava 3, I don't have any concrete plans yet. There are ongoing discussions about splitting the library along types or along backpressure support as well as making the so-called operator-fusion elements (which give a significant boost to our performance) a standard extension of the Reactive Streams specification.
0 notes
Text
jj
javascript event loop concurrency store value - Google Search
www.google.com
Sep 10, 2020
TypeScript: Playground - An online editor for exploring TypeScript and JavaScript
www.typescriptlang.org
Sep 10, 2020
TypeScript: Playground - An online editor for exploring TypeScript and JavaScript
www.typescriptlang.org
JavaScript Concurrency Model and Event Loop
www.freecodecamp.org
javascript null vs undefined - Google Search
www.google.com
Sep 17, 2020
javascript event loop concurrency - Google Search
www.google.com
Sep 17, 2020
javascript event loop async - Google Search
www.google.com
javascript inheritance - Google Search
www.google.com
Sep 17, 2020
Inheritance
www.tutorialsteacher.com
Sep 17, 2020
javascript closure concurrency - Google Search
www.google.com
Sep 17, 2020
Concurrency model and the event loop - JavaScript | MDN
developer.mozilla.org
Sep 17, 2020
javascript closure - Google Search
www.google.com
Sep 17, 2020
Closures - JavaScript | MDN
developer.mozilla.org
Sep 17, 2020
JavaScript Function Closures
www.w3schools.com
javascript event loop concurrency - Google Search
www.google.com
Sep 17, 2020
javascript event loop - Google Search
www.google.com
Sep 17, 2020
javascript var vs let vs const - Google Search
www.google.com
AngularJS - Component vs Controller based design - Proficient Blog
proficientblog.com
Sep 17, 2020
angular spa example - Google Search
www.google.com
Sep 17, 2020
Build Single Page Application Using AngularJS (Tutorial with Example)
www.softwaretestinghelp.com
Sep 17, 2020
angular ng rx - Google Search
www.google.com
Sep 17, 2020
AngularJS - Controllers - Tutorialspoint
www.tutorialspoint.com
Sep 17, 2020
AngularJS Tutorial - Tutorialspoint
www.tutorialspoint.com
Sep 17, 2020
angular js tutorialspoint - Google Search
www.google.com
javascript var vs let - Google Search
www.google.com
javascript null vs undefined - Google Search
www.google.com
ChronoUnit (Java Platform SE 8 )
docs.oracle.com
Sep 16, 2020
41. Testing
docs.spring.io
Sep 16, 2020
Example ex04_1: HTTP Method Extension | RESTful Java with JAX-RS 2.0 (Second Edition)
dennis-xlc.gitbooks.io
Sep 16, 2020
JAX-RS - Client and ClientBuilder Examples
www.logicbig.com
What is the difference between null and undefined in JavaScript?
www.tutorialspoint.com
Sep 17, 2020
javascript data types - Google Search
www.google.com
Sep 17, 2020
Data types
javascript.info
Sep 17, 2020
JavaScript Data Types
www.w3schools.com
hat’s the difference between AngularJS and Angular? | Gorrion's Blog
gorrion.io
Sep 17, 2020
What’s the difference between AngularJS and Angular? | Gorrion's Blog
gorrion.io
Sep 18, 2020
Full Stack Development Using Spring Boot Angular and React | Udemy
www.udemy.com
Sep 17, 2020
Full Stack Development Using Spring Boot Angular and React | Udemy
www.udemy.com
Sep 17, 2020
Full Stack Development Using Spring Boot Angular and React | Udemy
www.udemy.com
Sep 17, 2020
angular ngrx - Google Search
www.google.com
Sep 17, 2020
angular to web api call - Google Search
www.google.com
Sep 17, 2020
Call REST-full API’s | Web services using Angular and RxJS. | by Ankit Maheshwari | Medium
medium.com
Sep 17, 2020
Angular - Communicating with backend services using HTTP
angular.io
Sep 17, 2020
angular component lifecycle - Google Search
www.google.com
Sep 17, 2020
Angular 6, Part 3: Lifecycle of a Component - DZone Web Dev
dzone.com
Sep 17, 2020
Angular - Hooking into the component lifecycle
angular.io
Sep 17, 2020
angular 2 vs angular 6 - Google Search
www.google.com
Sep 17, 2020
angularjs vs angular - Google Search
www.google.com
Sep 17, 2020
angular controller vs component - Google Search
www.google.com
Building a Reactive Application with Ngrx and Angular 2 | Toptal
0 notes