#distilgpt2
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
Tumblr posted its first advertisements in May 2012 and subsequently earned $13M in revenue.
Text
Trying to build an AI to replace myself
I was suggested (jokingly) to build an AI that will replace me and I decided to give it an actual try. I decided to use GPT-2, it was a model that a couple years ago was regarded as super cool (now we have GPT-3 but its code isn’t released yet and frankly my pc would burst into flames if i tried to use it).
At the time, GPT-2 was considered so good that OpenAI delayed releasing the source code out of fear that if it falls into the wrong hands it would take over the world (jk they just didn’t want spam bots to evade detection with it).
The first lesson I learned while trying to build it was that windows is trash, get linux. The 2nd lesson i learned while trying to build it was that my GPU is trash, and after looking for one of the newest models online...
...I decided I’d just use Google’s GPUs for the training.
There’s 5 models of GPT-2 in total, I tried 4 of them on my pc and it crashed every single time, from the smallest to the biggest it goes
distilGPT2
GPT-2 124M
GPT-2 355M
GPT-2 774M
GPT-2 1.5B
From a little reading around, it turns out that even though 1.5B is better than 774M, its not significantly better, and distilGPT2 isn’t significantly worse than 124M.Every other improvement is significant, so my plan was to use distilGPT2 as a prototype, then to use 774M for an actually decent chatbot.
The prototype
I created a python script that would read the entire message history of a channel and write it down, here’s a sample.
<-USERNAME: froggie -> hug <-USERNAME: froggie -> huh* <-USERNAME: froggie -> why is it all gone <-USERNAME: Nate baka! -> :anmkannahuh: <-USERNAME: froggie -> i miss my old color <-USERNAME: froggie -> cant you make the maid role colorlesss @peds <-USERNAME: Levy -> oh no <-USERNAME: peds -> wasnt my idea <-USERNAME: Levy -> was the chat reset <-USERNAME: SlotBot -> Someone just dropped their wallet in this channel! Hurry and pick it up with `~grab` before someone else gets it!
I decided to use aitextgen as it just seemed like the easiest way and begun training, it was... kinda broken
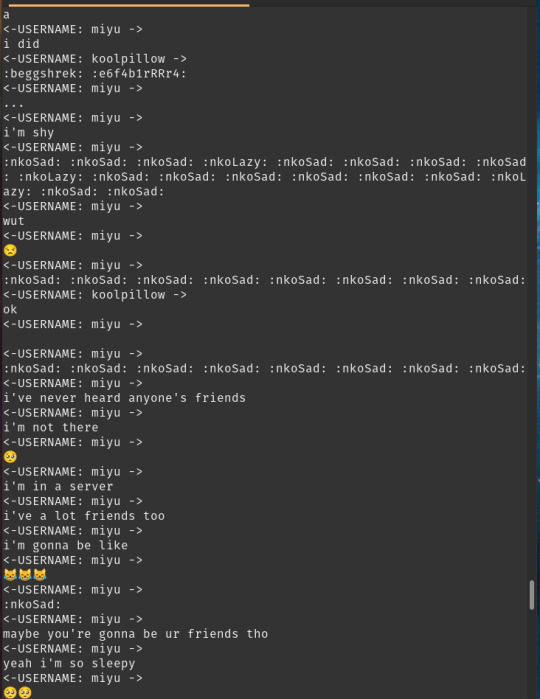
It had the tendency to use the same username over and over again and to repeat the same emote over and over again.
While it is true that most people write multiple messages at a time, one sentence each, and they sometimes write the same emoji multiple times for emphasis, it’s almost never as extreme as the output of GPT2.
But you know what? this IS just a prototype after all, and besides, maybe it only repeats the same name because it needs a prompt with multiple names in it for it to use them in chat, which would be fixed when id implement my bot (just kidding that screenshot is from after i started using prompts with the last 20 messages in the chat history and it still regressed to spam).
So i made a bot using python again, every time a message is sent
it reads the last 20 messages
stores them into a string
appends <-USERNAME: froggie -> to the string
uses it as a prompt
gets the output and cuts everything after a username besides froggie appears
sends up to 5 of the messages it reads in the output
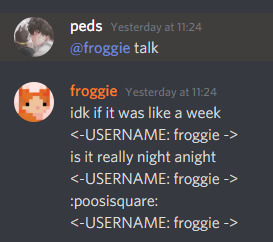
waitwaitwait let me fix that real quick
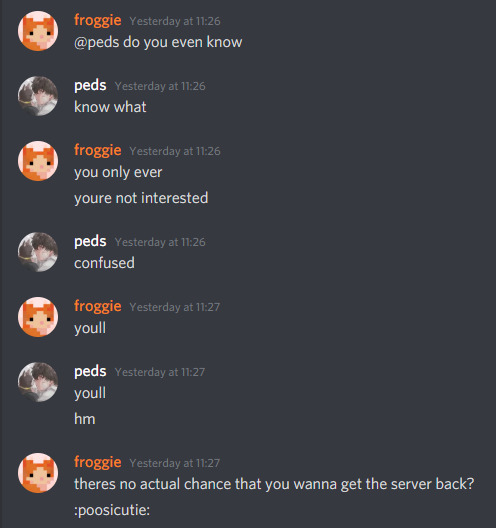
hey, it’s saying words, its sending multiple messages if it has to, it never even reached the limit of 5 i set it to so somehow it doesn’t degrade into spam when i only get the messages with my name on it....

ok that was just one time
but besides the fact that pinging and emoting is broken, (which has nothing to do with the AI) it was a really succesful prototype!
The 774M
The first thing i noticed was that the 774M model was training MUCH slower than the distilGPT, i decided that while it is training i should try to use the default model to see if my computer can even handle it.
It... kinda did..... not really
It took the bot minutes to generate a message and countless distressing errors in the console

>this is bad
This is bad indeed.
With such a huge delay in messages it can’t really have a real-time chat but at least it works, and i was still gonna try it, the model without training seemed to just wanna spam the username line over and over again, but it is untrained after all, surely after hours of training i could open the google colab to find the 774M model generate beautiful realistic conversations, or at least be as good as distilGPT.
(I completely forgot to take a screenshot of it but here is my faithful reenactment)
<-USERNAME froggie -> <-USERNAME froggie -> <-USERNAME froggie -> <-USERNAME miyu -> <-USERNAME miyu -> <-USERNAME levy -> <-USERNAME peds -> <-USERNAME miyu -> <-USERNAME peds ->
It had messages sometimes but 80% of the lines were just username lines.
On the upside it actually seemed to have a better variety of names,
But it still seemed unusable, and that is after 7000 steps, whereas distilGPT seemed usable after its first 1000!
So after seeing how both the ai and my computer are failures i decided I’d just give up, maybe I’ll try this again when I get better hardware and when I’m willing to train AIs for entire days.
So why in the hell is the 774M model worse than distilGPT?
I asked around and most answers i got were links to research papers that I couldn’t understand.
I made a newer version of the script that downloads the chatlogs so that messages by the same person will only have the username line written once, but I didn’t really train an AI with it yet, perhaps it would have helped a bit, but I wanna put this project on hold until I can upgrade my hardware, so hopefully this post will have a part 2 someday.
0 notes
Text
python fine tune a distilgpt llm model using attention matrix pruning, low-rank approximation and low-rank adaptation (lora)
# fine tune a model with attention matrices pruned and low-rank approximation/adaptation # https://pythonprogrammingsnippets.tumblr.com import torch from transformers import AutoTokenizer, AutoModelForCausalLM import os # load the pretrained model if it exists in _MODELS/lora_attention # otherwise load the pretrained model from huggingface if os.path.exists("_MODELS/lora_attention"): print("loading trained model") # Load the tokenizer tokenizer = AutoTokenizer.from_pretrained("_MODELS/lora_attention") # Load the pre-trained DistilGPT2 model model = AutoModelForCausalLM.from_pretrained("_MODELS/lora_attention") else: print("Downloading pretrained model from huggingface") # Load the tokenizer tokenizer = AutoTokenizer.from_pretrained("distilgpt2") # Load the pre-trained DistilGPT2 model model = AutoModelForCausalLM.from_pretrained("distilgpt2") # set padding token tokenizer.pad_token = tokenizer.eos_token # Define the training data from _DATASETS/data.txt with one sentence per line # now train with the train_data from the file _DATASETS/data.txt with one sentence per line. with open("_DATASETS/data.txt") as f: data = f.read() # now split data by \n train_data = data.split( '\n' ) # shuffle the data import random random.shuffle(train_data) # define the function for pruning the attention matrices def prune_attention_matrices(model, threshold): for name, param in model.named_parameters(): if "attention" in name and "weight" in name: data = param.data data[torch.abs(data) < threshold] = 0 param.data = data # define the function for low-rank approximation of the attention matrices def low_rank_approximation(model, rank): for name, param in model.named_parameters(): if "attention" in name and "weight" in name: data = param.data u, s, v = torch.svd(data) data = torch.mm(u[:, :rank], torch.mm(torch.diag(s[:rank]), v[:, :rank].t())) param.data = data # define the function for low-rank adaptation def low_rank_adaptation(model, train_data, tokenizer, rank, num_epochs, lr): # Define the optimizer and loss function optimizer = torch.optim.Adam(model.parameters(), lr=lr) loss_fn = torch.nn.CrossEntropyLoss() # Tokenize the training data input_ids = tokenizer(train_data, padding=True, truncation=True, return_tensors="pt")["input_ids"] # Perform low-rank adaptation fine-tuning for epoch in range(num_epochs): # Zero the gradients optimizer.zero_grad() # Get the model outputs outputs = model(input_ids=input_ids, labels=input_ids) # Get the loss loss = outputs.loss # Backpropagate the loss loss.backward() # Update the parameters optimizer.step() # Print the loss print("Epoch: {}, Loss: {}".format(epoch, loss.item())) # Low-rank approximation low_rank_approximation(model, rank) # prune the attention matrices prune_attention_matrices(model, 0.1) # low-rank approximation low_rank_approximation(model, 32) # low-rank adaptation low_rank_adaptation(model, train_data, tokenizer, 32, 5, 5e-5) # now train # Define the optimizer and loss function optimizer = torch.optim.Adam(model.parameters(), lr=5e-5) loss_fn = torch.nn.CrossEntropyLoss() # Tokenize the training data input_ids = tokenizer(train_data, padding=True, truncation=True, return_tensors="pt")["input_ids"] # Perform fine-tuning for epoch in range(5): # Zero the gradients optimizer.zero_grad() # Get the model outputs outputs = model(input_ids=input_ids, labels=input_ids) # Get the loss loss = outputs.loss # Backpropagate the loss loss.backward() # Update the parameters optimizer.step() # Print the loss print("Epoch: {}, Loss: {}".format(epoch, loss.item())) # save the model model.save_pretrained("_MODELS/lora_attention") # save the tokenizer tokenizer.save_pretrained("_MODELS/lora_attention") ## # load the model model = AutoModelForCausalLM.from_pretrained("_MODELS/lora_attention") # load the tokenizer tokenizer = AutoTokenizer.from_pretrained("_MODELS/lora_attention") # define the function for generating text def generate_text(model, tokenizer, prompt, max_length): # Tokenize the prompt input_ids = tokenizer(prompt, return_tensors="pt")["input_ids"] # Generate the text output_ids = model.generate(input_ids, max_length=max_length, do_sample=True, top_k=50, top_p=0.95, temperature=0.5, num_return_sequences=1) # Decode the text output_text = tokenizer.decode(output_ids[0], skip_special_tokens=True) # Print the text print(output_text) # generate text generate_text(model, tokenizer, "quick brown", 125)
#python#LoRa#low-rank adaptation#low-rank approximation#adaptation#approximation#attention pruning#attention matrices#attention matrix#attention#matrices#matrix#gpt#distilgpt#generative pretrained transformer#pretrained#transformers#transformer#pre-trained#optimizer#torch#pytorch#huggingface#chatgpt#deep learning#ml#machine learning#ai#fine tuning
0 notes