#file handling methods in python
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
In 2020, 44% of users from Denmark used Tumblr daily.
Text
Concept of File Handling in Python
Hello dear visitor !!! You all the again most welcome to this domain bittutech.com . Today we are going to discus about most important concept of Python Programming Language which is File Handling including What is file?, Types of files, Modes of files, Opening and Closing of file, Working with files… and many more. So let’s dive in this amazing concept 👍. Most of the programming languages…
#file handling#file handling in python#file handling methods in python#what is file handling#what is file handling in programming language
0 notes
Text
piece of code I thought was going to be hellish to write turned out to be relatively simple and actually kinda fun! peace and love on fucking planet earth
#turns out file handling in python isn't a super headache at all#also the built in string methods worked great to handle the lines of said file#now hopefully I've got the info I need to actually get this project done#still much to do but that's a major headache cleared#tales from the phd#chattering
6 notes
·
View notes
Text
shitGPT
for uni im going to be coding with a chatGPT user, so i decided to see how good it is at coding (sure ive heard it can code, but theres a massive difference between being able to code and being able to code well).
i will complain about a specific project i asked it to make and improve on under the cut, but i will copy my conclusion from the bottom of the post and paste it up here.
-
conclusion: it (mostly) writes code that works, but isnt great. but this is actually a pretty big problem imo. as more and more people are using this to learn how to code, or getting examples of functions, theyre going to be learning from pretty bad code. and then theres what im going to be experiencing, coding with someone who uses this tool. theres going to be easily improvable code that the quote unquote writer wont fully understand going into a codebase with my name of it - a codebase which we will need present for our degree. even though the code is not the main part of this project (well, the quality of the code at least. you need it to be able to run and thats about it) its still a shitty feeling having my name attached to code of this quality.
and also it is possible to get it to write good (readable, idiomatic, efficient enough) code, but only if you can write this code yourself (and are willing to spend more time arguing with the AI than you would writing the code.) most of the things i pointed out to the AI was stuff that someone using this as a learning resource wont know about. if it never gives you static methods, class methods, ABCs, coroutines, type hints, multi-file programs, etc without you explicitly asking for them then its use is limited at best. and people who think that its a tool that can take all the info they need, and give it back to them in a concise, readable way (which is a surprising lot of people) will be missing out without even knowing about it.
i got it to write tic-tac-toe (the standard babee) in python (the lang i have to use for uni ;-; (held at gunpoint here)). my specific prompt was "write me a python program for tictactoe that is written in an object oriented way and allows for future expansion via multiple files"
it separated it into three files below (which i think would run, but i never actually ran any of this code. just reading and judging)



why does board use display instead of __str__ and __repr__?
why is the board stored as 1d instead of 2d? thats just confusing
why does it never early return aside from check_winner? (not a big issue here but kept on choosing to never early return when i asked it to add more methods)
why is there no handling of non-number user inputs?
why are non-int inputs truncated instead of telling the user that they should input ints only?
why is display implemented like that?
why are so many lines so bloody long (wide)?
why is there a redundant self.check_winner() after the while loop in TicTaacToe.play()? and if it wasnt redundant then you could finish the game without there being anything printed telling you that the game is finished?
why is the only comment useless? (this comment wouldnt be useless if it was a doc comment tho, but it aint a doc comment. speaking of, why is there no doc comments?)
these are the more immediate things i saw, but there are other things that are bad here.
whenever i write * this is where it updated the api without changing any usage of the api.
so i ask it to change board.display into __str__ and __repr__, it changes it to __str__*, it does not add a __repr__. asking it to add a __repr__ 1) removes the __str__ and 2) gives me this (the other methods are unchanged)
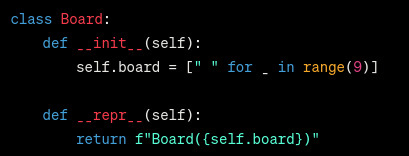
what. the. fuck. this would imply that board takes in an argument for the boardstate, but it clearly doesnt. after 4 more asks it finally has both __str__ and __repr__, without fixing the fact its implying board takes an optional arg, so i get it to add this arg. anything that needs to print the board still calls display btw.
the reasoning it gave for using display over the repr and str magics was this
While using __str__ and __repr__ is a more idiomatic approach in Python, choosing to have a separate display method can still be a valid choice, especially if the display logic is more complex or if you want to keep the __str__ method for a more concise or formal representation of the object.
which, erm what? why would __str__ be for a concise or formal repr when thats what __repr__ is for? who cares about how complex the logic is. youre calling this every time you print, so move the logic into __str__. it makes no difference for the performance of the program (if you had a very expensive func that prints smth, and you dont want it to run every time you try to print the obj then its understandable to implement that alongside str and repr)
it also said the difference between __str__ and __repr__ every damn time, which if youre asking it to implement these magics then surely you already know the difference?
but okay, one issue down and that took what? 5-10 minutes? and it wouldve taken 1 minute tops to do it yourself?
okay next implementing a tic-tac-toe board as a 1d array is fine, but kinda weird when 2d arrays exist. this one is just personal preference though so i got it to change it to a 2d list*. it changed the init method to this

tumblr wont let me add alt text to this image so:
[begin ID: Python code that generates a 2D array using nested list comprehensions. end ID]
which works, but just use [[" "] * 3 for _ in range(3)]. the only advantage listcomps have here over multiplying is that they create new lists, instead of copying the pointers. but if you update a cell it will change that pointer. you only need listcomps for the outermost level.
again, this is mainly personal preference, nothing major. but it does show that chatgpt gives u sloppy code
(also if you notice it got rid of the board argument lol)
now i had to explicitly get it to change is_full and make_move. methods in the same damn class that would be changed by changing to a 2d array. this sorta shit should be done automatically lol
it changed make_move by taking row and col args, which is a shitty decision coz it asks for a pos 1-9, so anything that calls make_move would have to change this to a row and col. so i got it to make a func thatll do this for the board class
what i was hoping for: a static method that is called inside make_move
what i got: a standalone function that is not inside any class that isnt early exited

the fuck is this supposed to do if its never called?
so i had to tell it to put it in the class as a static method, and get it to call it. i had to tell it to call this function holy hell
like what is this?
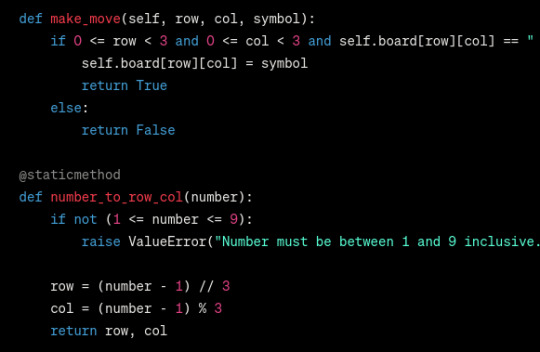
i cant believe it wrote this method without ever calling it!
and - AND - theres this code here that WILL run when this file is imported
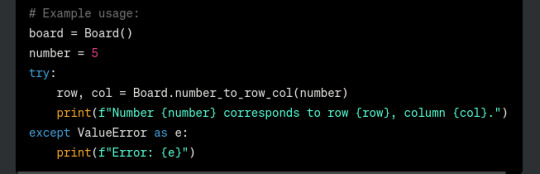
which, errrr, this files entire point is being imported innit. if youre going to have example usage check if __name__ = "__main__" and dont store vars as globals
now i finally asked it to update the other classes not that the api has changed (hoping it would change the implementation of make_move to use the static method.) (it didnt.)
Player.make_move is now defined recursively in a way that doesnt work. yippe! why not propagate the error ill never know.
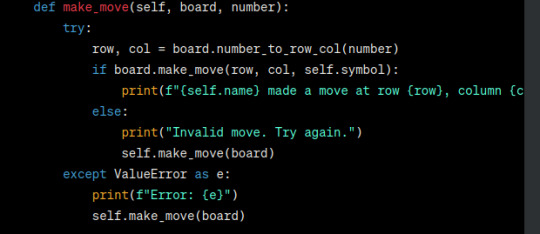
also why is there so much shit in the try block? its not clear which part needs to be error checked and it also makes the prints go offscreen.
after getting it to fix the static method not being called, and the try block being overcrowded (not getting it to propagate the error yet) i got it to add type hints (if u coding python, add type hints. please. itll make me happy)
now for the next 5 asks it changed 0 code. nothing at all. regardless of what i asked it to do. fucks sake.
also look at this type hint

what
the
hell
is
this
?
why is it Optional[str]???????? the hell??? at no point is it anything but a char. either write it as Optional[list[list[char]]] or Optional[list[list]], either works fine. just - dont bloody do this
also does anything look wrong with this type hint?

a bloody optional when its not optional
so i got it to remove this optional. it sure as hell got rid of optional
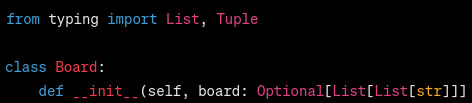
it sure as hell got rid of optional
now i was just trying to make board.py more readable. its been maybe half an hour at this point? i just want to move on.
it did not want to write PEP 8 code, but oh well. fuck it we ball, its not like it again decided to stop changing any code

(i lied)
but anyway one file down two to go, they were more of the same so i eventually gave up (i wont say each and every issue i had with the code. you get the gist. yes a lot of it didnt work)
conclusion: as you probably saw, it (mostly) writes code that works, but isnt great. but this is actually a pretty big problem imo. as more and more people are using this to learn how to code, or getting examples of functions, theyre going to be learning from pretty bad code. and then theres what im going to be experiencing, coding with someone who uses this tool. theres going to be easily improvable code that the quote unquote writer wont fully understand going into a codebase with my name of it - a codebase which we will need present for our degree. even though the code is not the main part of this project (well, the quality of the code at least. you need it to be able to run and thats about it) its still a shitty feeling having my name attached to code of this quality.
and also it is possible to get it to write good (readable, idiomatic, efficient enough) code, but only if you can write this code yourself (and are willing to spend more time arguing with the AI than you would writing the code.) most of the things i pointed out to the AI was stuff that someone using this as a learning resource wont know about. if it never gives you static methods, class methods, ABCs, coroutines, type hints, multi-file programs, etc without you explicitly asking for them then its use is limited at best. and people who think that its a tool that can take all the info they need, and give it back to them in a concise, readable way (which is a surprising lot of people) will be missing out without even knowing about it.
#i speak i ramble#effortpost#long post#progblr#codeblr#python#chatgpt#tried to add IDs in as many alts as possible. some didnt let me and also its hard to decide what to put in the IDs for code.#like sometimes you need implementation details but others just the broad overview is good enough yknow?#and i also tried to write in a way where you dont need the IDs to follow along. (but with something like this it is hard yknow?)#id in alt#aside from that one where i got cockblocked#codeblocked?#codeblocked.
40 notes
·
View notes
Text
UNLOCKING THE POWER OF AI WITH EASYLIBPAL 2/2

EXPANDED COMPONENTS AND DETAILS OF EASYLIBPAL:
1. Easylibpal Class: The core component of the library, responsible for handling algorithm selection, model fitting, and prediction generation
2. Algorithm Selection and Support:
Supports classic AI algorithms such as Linear Regression, Logistic Regression, Support Vector Machine (SVM), Naive Bayes, and K-Nearest Neighbors (K-NN).
and
- Decision Trees
- Random Forest
- AdaBoost
- Gradient Boosting
3. Integration with Popular Libraries: Seamless integration with essential Python libraries like NumPy, Pandas, Matplotlib, and Scikit-learn for enhanced functionality.
4. Data Handling:
- DataLoader class for importing and preprocessing data from various formats (CSV, JSON, SQL databases).
- DataTransformer class for feature scaling, normalization, and encoding categorical variables.
- Includes functions for loading and preprocessing datasets to prepare them for training and testing.
- `FeatureSelector` class: Provides methods for feature selection and dimensionality reduction.
5. Model Evaluation:
- Evaluator class to assess model performance using metrics like accuracy, precision, recall, F1-score, and ROC-AUC.
- Methods for generating confusion matrices and classification reports.
6. Model Training: Contains methods for fitting the selected algorithm with the training data.
- `fit` method: Trains the selected algorithm on the provided training data.
7. Prediction Generation: Allows users to make predictions using the trained model on new data.
- `predict` method: Makes predictions using the trained model on new data.
- `predict_proba` method: Returns the predicted probabilities for classification tasks.
8. Model Evaluation:
- `Evaluator` class: Assesses model performance using various metrics (e.g., accuracy, precision, recall, F1-score, ROC-AUC).
- `cross_validate` method: Performs cross-validation to evaluate the model's performance.
- `confusion_matrix` method: Generates a confusion matrix for classification tasks.
- `classification_report` method: Provides a detailed classification report.
9. Hyperparameter Tuning:
- Tuner class that uses techniques likes Grid Search and Random Search for hyperparameter optimization.
10. Visualization:
- Integration with Matplotlib and Seaborn for generating plots to analyze model performance and data characteristics.
- Visualization support: Enables users to visualize data, model performance, and predictions using plotting functionalities.
- `Visualizer` class: Integrates with Matplotlib and Seaborn to generate plots for model performance analysis and data visualization.
- `plot_confusion_matrix` method: Visualizes the confusion matrix.
- `plot_roc_curve` method: Plots the Receiver Operating Characteristic (ROC) curve.
- `plot_feature_importance` method: Visualizes feature importance for applicable algorithms.
11. Utility Functions:
- Functions for saving and loading trained models.
- Logging functionalities to track the model training and prediction processes.
- `save_model` method: Saves the trained model to a file.
- `load_model` method: Loads a previously trained model from a file.
- `set_logger` method: Configures logging functionality for tracking model training and prediction processes.
12. User-Friendly Interface: Provides a simplified and intuitive interface for users to interact with and apply classic AI algorithms without extensive knowledge or configuration.
13.. Error Handling: Incorporates mechanisms to handle invalid inputs, errors during training, and other potential issues during algorithm usage.
- Custom exception classes for handling specific errors and providing informative error messages to users.
14. Documentation: Comprehensive documentation to guide users on how to use Easylibpal effectively and efficiently
- Comprehensive documentation explaining the usage and functionality of each component.
- Example scripts demonstrating how to use Easylibpal for various AI tasks and datasets.
15. Testing Suite:
- Unit tests for each component to ensure code reliability and maintainability.
- Integration tests to verify the smooth interaction between different components.
IMPLEMENTATION EXAMPLE WITH ADDITIONAL FEATURES:
Here is an example of how the expanded Easylibpal library could be structured and used:
```python
import numpy as np
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from easylibpal import Easylibpal, DataLoader, Evaluator, Tuner
# Example DataLoader
class DataLoader:
def load_data(self, filepath, file_type='csv'):
if file_type == 'csv':
return pd.read_csv(filepath)
else:
raise ValueError("Unsupported file type provided.")
# Example Evaluator
class Evaluator:
def evaluate(self, model, X_test, y_test):
predictions = model.predict(X_test)
accuracy = np.mean(predictions == y_test)
return {'accuracy': accuracy}
# Example usage of Easylibpal with DataLoader and Evaluator
if __name__ == "__main__":
# Load and prepare the data
data_loader = DataLoader()
data = data_loader.load_data('path/to/your/data.csv')
X = data.iloc[:, :-1]
y = data.iloc[:, -1]
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# Scale features
scaler = StandardScaler()
X_train_scaled = scaler.fit_transform(X_train)
X_test_scaled = scaler.transform(X_test)
# Initialize Easylibpal with the desired algorithm
model = Easylibpal('Random Forest')
model.fit(X_train_scaled, y_train)
# Evaluate the model
evaluator = Evaluator()
results = evaluator.evaluate(model, X_test_scaled, y_test)
print(f"Model Accuracy: {results['accuracy']}")
# Optional: Use Tuner for hyperparameter optimization
tuner = Tuner(model, param_grid={'n_estimators': [100, 200], 'max_depth': [10, 20, 30]})
best_params = tuner.optimize(X_train_scaled, y_train)
print(f"Best Parameters: {best_params}")
```
This example demonstrates the structured approach to using Easylibpal with enhanced data handling, model evaluation, and optional hyperparameter tuning. The library empowers users to handle real-world datasets, apply various machine learning algorithms, and evaluate their performance with ease, making it an invaluable tool for developers and data scientists aiming to implement AI solutions efficiently.
Easylibpal is dedicated to making the latest AI technology accessible to everyone, regardless of their background or expertise. Our platform simplifies the process of selecting and implementing classic AI algorithms, enabling users across various industries to harness the power of artificial intelligence with ease. By democratizing access to AI, we aim to accelerate innovation and empower users to achieve their goals with confidence. Easylibpal's approach involves a democratization framework that reduces entry barriers, lowers the cost of building AI solutions, and speeds up the adoption of AI in both academic and business settings.
Below are examples showcasing how each main component of the Easylibpal library could be implemented and used in practice to provide a user-friendly interface for utilizing classic AI algorithms.
1. Core Components
Easylibpal Class Example:
```python
class Easylibpal:
def __init__(self, algorithm):
self.algorithm = algorithm
self.model = None
def fit(self, X, y):
# Simplified example: Instantiate and train a model based on the selected algorithm
if self.algorithm == 'Linear Regression':
from sklearn.linear_model import LinearRegression
self.model = LinearRegression()
elif self.algorithm == 'Random Forest':
from sklearn.ensemble import RandomForestClassifier
self.model = RandomForestClassifier()
self.model.fit(X, y)
def predict(self, X):
return self.model.predict(X)
```
2. Data Handling
DataLoader Class Example:
```python
class DataLoader:
def load_data(self, filepath, file_type='csv'):
if file_type == 'csv':
import pandas as pd
return pd.read_csv(filepath)
else:
raise ValueError("Unsupported file type provided.")
```
3. Model Evaluation
Evaluator Class Example:
```python
from sklearn.metrics import accuracy_score, classification_report
class Evaluator:
def evaluate(self, model, X_test, y_test):
predictions = model.predict(X_test)
accuracy = accuracy_score(y_test, predictions)
report = classification_report(y_test, predictions)
return {'accuracy': accuracy, 'report': report}
```
4. Hyperparameter Tuning
Tuner Class Example:
```python
from sklearn.model_selection import GridSearchCV
class Tuner:
def __init__(self, model, param_grid):
self.model = model
self.param_grid = param_grid
def optimize(self, X, y):
grid_search = GridSearchCV(self.model, self.param_grid, cv=5)
grid_search.fit(X, y)
return grid_search.best_params_
```
5. Visualization
Visualizer Class Example:
```python
import matplotlib.pyplot as plt
class Visualizer:
def plot_confusion_matrix(self, cm, classes, normalize=False, title='Confusion matrix'):
plt.imshow(cm, interpolation='nearest', cmap=plt.cm.Blues)
plt.title(title)
plt.colorbar()
tick_marks = np.arange(len(classes))
plt.xticks(tick_marks, classes, rotation=45)
plt.yticks(tick_marks, classes)
plt.ylabel('True label')
plt.xlabel('Predicted label')
plt.show()
```
6. Utility Functions
Save and Load Model Example:
```python
import joblib
def save_model(model, filename):
joblib.dump(model, filename)
def load_model(filename):
return joblib.load(filename)
```
7. Example Usage Script
Using Easylibpal in a Script:
```python
# Assuming Easylibpal and other classes have been imported
data_loader = DataLoader()
data = data_loader.load_data('data.csv')
X = data.drop('Target', axis=1)
y = data['Target']
model = Easylibpal('Random Forest')
model.fit(X, y)
evaluator = Evaluator()
results = evaluator.evaluate(model, X, y)
print("Accuracy:", results['accuracy'])
print("Report:", results['report'])
visualizer = Visualizer()
visualizer.plot_confusion_matrix(results['cm'], classes=['Class1', 'Class2'])
save_model(model, 'trained_model.pkl')
loaded_model = load_model('trained_model.pkl')
```
These examples illustrate the practical implementation and use of the Easylibpal library components, aiming to simplify the application of AI algorithms for users with varying levels of expertise in machine learning.
EASYLIBPAL IMPLEMENTATION:
Step 1: Define the Problem
First, we need to define the problem we want to solve. For this POC, let's assume we want to predict house prices based on various features like the number of bedrooms, square footage, and location.
Step 2: Choose an Appropriate Algorithm
Given our problem, a supervised learning algorithm like linear regression would be suitable. We'll use Scikit-learn, a popular library for machine learning in Python, to implement this algorithm.
Step 3: Prepare Your Data
We'll use Pandas to load and prepare our dataset. This involves cleaning the data, handling missing values, and splitting the dataset into training and testing sets.
Step 4: Implement the Algorithm
Now, we'll use Scikit-learn to implement the linear regression algorithm. We'll train the model on our training data and then test its performance on the testing data.
Step 5: Evaluate the Model
Finally, we'll evaluate the performance of our model using metrics like Mean Squared Error (MSE) and R-squared.
Python Code POC
```python
import numpy as np
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LinearRegression
from sklearn.metrics import mean_squared_error, r2_score
# Load the dataset
data = pd.read_csv('house_prices.csv')
# Prepare the data
X = data'bedrooms', 'square_footage', 'location'
y = data['price']
# Split the data into training and testing sets
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# Create and train the model
model = LinearRegression()
model.fit(X_train, y_train)
# Make predictions
predictions = model.predict(X_test)
# Evaluate the model
mse = mean_squared_error(y_test, predictions)
r2 = r2_score(y_test, predictions)
print(f'Mean Squared Error: {mse}')
print(f'R-squared: {r2}')
```
Below is an implementation, Easylibpal provides a simple interface to instantiate and utilize classic AI algorithms such as Linear Regression, Logistic Regression, SVM, Naive Bayes, and K-NN. Users can easily create an instance of Easylibpal with their desired algorithm, fit the model with training data, and make predictions, all with minimal code and hassle. This demonstrates the power of Easylibpal in simplifying the integration of AI algorithms for various tasks.
```python
# Import necessary libraries
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.linear_model import LinearRegression
from sklearn.linear_model import LogisticRegression
from sklearn.svm import SVC
from sklearn.naive_bayes import GaussianNB
from sklearn.neighbors import KNeighborsClassifier
class Easylibpal:
def __init__(self, algorithm):
self.algorithm = algorithm
def fit(self, X, y):
if self.algorithm == 'Linear Regression':
self.model = LinearRegression()
elif self.algorithm == 'Logistic Regression':
self.model = LogisticRegression()
elif self.algorithm == 'SVM':
self.model = SVC()
elif self.algorithm == 'Naive Bayes':
self.model = GaussianNB()
elif self.algorithm == 'K-NN':
self.model = KNeighborsClassifier()
else:
raise ValueError("Invalid algorithm specified.")
self.model.fit(X, y)
def predict(self, X):
return self.model.predict(X)
# Example usage:
# Initialize Easylibpal with the desired algorithm
easy_algo = Easylibpal('Linear Regression')
# Generate some sample data
X = np.array([[1], [2], [3], [4]])
y = np.array([2, 4, 6, 8])
# Fit the model
easy_algo.fit(X, y)
# Make predictions
predictions = easy_algo.predict(X)
# Plot the results
plt.scatter(X, y)
plt.plot(X, predictions, color='red')
plt.title('Linear Regression with Easylibpal')
plt.xlabel('X')
plt.ylabel('y')
plt.show()
```
Easylibpal is an innovative Python library designed to simplify the integration and use of classic AI algorithms in a user-friendly manner. It aims to bridge the gap between the complexity of AI libraries and the ease of use, making it accessible for developers and data scientists alike. Easylibpal abstracts the underlying complexity of each algorithm, providing a unified interface that allows users to apply these algorithms with minimal configuration and understanding of the underlying mechanisms.
ENHANCED DATASET HANDLING
Easylibpal should be able to handle datasets more efficiently. This includes loading datasets from various sources (e.g., CSV files, databases), preprocessing data (e.g., normalization, handling missing values), and splitting data into training and testing sets.
```python
import os
from sklearn.model_selection import train_test_split
class Easylibpal:
# Existing code...
def load_dataset(self, filepath):
"""Loads a dataset from a CSV file."""
if not os.path.exists(filepath):
raise FileNotFoundError("Dataset file not found.")
return pd.read_csv(filepath)
def preprocess_data(self, dataset):
"""Preprocesses the dataset."""
# Implement data preprocessing steps here
return dataset
def split_data(self, X, y, test_size=0.2):
"""Splits the dataset into training and testing sets."""
return train_test_split(X, y, test_size=test_size)
```
Additional Algorithms
Easylibpal should support a wider range of algorithms. This includes decision trees, random forests, and gradient boosting machines.
```python
from sklearn.tree import DecisionTreeClassifier
from sklearn.ensemble import RandomForestClassifier
from sklearn.ensemble import GradientBoostingClassifier
class Easylibpal:
# Existing code...
def fit(self, X, y):
# Existing code...
elif self.algorithm == 'Decision Tree':
self.model = DecisionTreeClassifier()
elif self.algorithm == 'Random Forest':
self.model = RandomForestClassifier()
elif self.algorithm == 'Gradient Boosting':
self.model = GradientBoostingClassifier()
# Add more algorithms as needed
```
User-Friendly Features
To make Easylibpal even more user-friendly, consider adding features like:
- Automatic hyperparameter tuning: Implementing a simple interface for hyperparameter tuning using GridSearchCV or RandomizedSearchCV.
- Model evaluation metrics: Providing easy access to common evaluation metrics like accuracy, precision, recall, and F1 score.
- Visualization tools: Adding methods for plotting model performance, confusion matrices, and feature importance.
```python
from sklearn.metrics import accuracy_score, classification_report
from sklearn.model_selection import GridSearchCV
class Easylibpal:
# Existing code...
def evaluate_model(self, X_test, y_test):
"""Evaluates the model using accuracy and classification report."""
y_pred = self.predict(X_test)
print("Accuracy:", accuracy_score(y_test, y_pred))
print(classification_report(y_test, y_pred))
def tune_hyperparameters(self, X, y, param_grid):
"""Tunes the model's hyperparameters using GridSearchCV."""
grid_search = GridSearchCV(self.model, param_grid, cv=5)
grid_search.fit(X, y)
self.model = grid_search.best_estimator_
```
Easylibpal leverages the power of Python and its rich ecosystem of AI and machine learning libraries, such as scikit-learn, to implement the classic algorithms. It provides a high-level API that abstracts the specifics of each algorithm, allowing users to focus on the problem at hand rather than the intricacies of the algorithm.
Python Code Snippets for Easylibpal
Below are Python code snippets demonstrating the use of Easylibpal with classic AI algorithms. Each snippet demonstrates how to use Easylibpal to apply a specific algorithm to a dataset.
# Linear Regression
```python
from Easylibpal import Easylibpal
# Initialize Easylibpal with a dataset
Easylibpal = Easylibpal(dataset='your_dataset.csv')
# Apply Linear Regression
result = Easylibpal.apply_algorithm('linear_regression', target_column='target')
# Print the result
print(result)
```
# Logistic Regression
```python
from Easylibpal import Easylibpal
# Initialize Easylibpal with a dataset
Easylibpal = Easylibpal(dataset='your_dataset.csv')
# Apply Logistic Regression
result = Easylibpal.apply_algorithm('logistic_regression', target_column='target')
# Print the result
print(result)
```
# Support Vector Machines (SVM)
```python
from Easylibpal import Easylibpal
# Initialize Easylibpal with a dataset
Easylibpal = Easylibpal(dataset='your_dataset.csv')
# Apply SVM
result = Easylibpal.apply_algorithm('svm', target_column='target')
# Print the result
print(result)
```
# Naive Bayes
```python
from Easylibpal import Easylibpal
# Initialize Easylibpal with a dataset
Easylibpal = Easylibpal(dataset='your_dataset.csv')
# Apply Naive Bayes
result = Easylibpal.apply_algorithm('naive_bayes', target_column='target')
# Print the result
print(result)
```
# K-Nearest Neighbors (K-NN)
```python
from Easylibpal import Easylibpal
# Initialize Easylibpal with a dataset
Easylibpal = Easylibpal(dataset='your_dataset.csv')
# Apply K-NN
result = Easylibpal.apply_algorithm('knn', target_column='target')
# Print the result
print(result)
```
ABSTRACTION AND ESSENTIAL COMPLEXITY
- Essential Complexity: This refers to the inherent complexity of the problem domain, which cannot be reduced regardless of the programming language or framework used. It includes the logic and algorithm needed to solve the problem. For example, the essential complexity of sorting a list remains the same across different programming languages.
- Accidental Complexity: This is the complexity introduced by the choice of programming language, framework, or libraries. It can be reduced or eliminated through abstraction. For instance, using a high-level API in Python can hide the complexity of lower-level operations, making the code more readable and maintainable.
HOW EASYLIBPAL ABSTRACTS COMPLEXITY
Easylibpal aims to reduce accidental complexity by providing a high-level API that encapsulates the details of each classic AI algorithm. This abstraction allows users to apply these algorithms without needing to understand the underlying mechanisms or the specifics of the algorithm's implementation.
- Simplified Interface: Easylibpal offers a unified interface for applying various algorithms, such as Linear Regression, Logistic Regression, SVM, Naive Bayes, and K-NN. This interface abstracts the complexity of each algorithm, making it easier for users to apply them to their datasets.
- Runtime Fusion: By evaluating sub-expressions and sharing them across multiple terms, Easylibpal can optimize the execution of algorithms. This approach, similar to runtime fusion in abstract algorithms, allows for efficient computation without duplicating work, thereby reducing the computational complexity.
- Focus on Essential Complexity: While Easylibpal abstracts away the accidental complexity; it ensures that the essential complexity of the problem domain remains at the forefront. This means that while the implementation details are hidden, the core logic and algorithmic approach are still accessible and understandable to the user.
To implement Easylibpal, one would need to create a Python class that encapsulates the functionality of each classic AI algorithm. This class would provide methods for loading datasets, preprocessing data, and applying the algorithm with minimal configuration required from the user. The implementation would leverage existing libraries like scikit-learn for the actual algorithmic computations, abstracting away the complexity of these libraries.
Here's a conceptual example of how the Easylibpal class might be structured for applying a Linear Regression algorithm:
```python
class Easylibpal:
def __init__(self, dataset):
self.dataset = dataset
# Load and preprocess the dataset
def apply_linear_regression(self, target_column):
# Abstracted implementation of Linear Regression
# This method would internally use scikit-learn or another library
# to perform the actual computation, abstracting the complexity
pass
# Usage
Easylibpal = Easylibpal(dataset='your_dataset.csv')
result = Easylibpal.apply_linear_regression(target_column='target')
```
This example demonstrates the concept of Easylibpal by abstracting the complexity of applying a Linear Regression algorithm. The actual implementation would need to include the specifics of loading the dataset, preprocessing it, and applying the algorithm using an underlying library like scikit-learn.
Easylibpal abstracts the complexity of classic AI algorithms by providing a simplified interface that hides the intricacies of each algorithm's implementation. This abstraction allows users to apply these algorithms with minimal configuration and understanding of the underlying mechanisms. Here are examples of specific algorithms that Easylibpal abstracts:
To implement Easylibpal, one would need to create a Python class that encapsulates the functionality of each classic AI algorithm. This class would provide methods for loading datasets, preprocessing data, and applying the algorithm with minimal configuration required from the user. The implementation would leverage existing libraries like scikit-learn for the actual algorithmic computations, abstracting away the complexity of these libraries.
Here's a conceptual example of how the Easylibpal class might be structured for applying a Linear Regression algorithm:
```python
class Easylibpal:
def __init__(self, dataset):
self.dataset = dataset
# Load and preprocess the dataset
def apply_linear_regression(self, target_column):
# Abstracted implementation of Linear Regression
# This method would internally use scikit-learn or another library
# to perform the actual computation, abstracting the complexity
pass
# Usage
Easylibpal = Easylibpal(dataset='your_dataset.csv')
result = Easylibpal.apply_linear_regression(target_column='target')
```
This example demonstrates the concept of Easylibpal by abstracting the complexity of applying a Linear Regression algorithm. The actual implementation would need to include the specifics of loading the dataset, preprocessing it, and applying the algorithm using an underlying library like scikit-learn.
Easylibpal abstracts the complexity of feature selection for classic AI algorithms by providing a simplified interface that automates the process of selecting the most relevant features for each algorithm. This abstraction is crucial because feature selection is a critical step in machine learning that can significantly impact the performance of a model. Here's how Easylibpal handles feature selection for the mentioned algorithms:
To implement feature selection in Easylibpal, one could use scikit-learn's `SelectKBest` or `RFE` classes for feature selection based on statistical tests or model coefficients. Here's a conceptual example of how feature selection might be integrated into the Easylibpal class for Linear Regression:
```python
from sklearn.feature_selection import SelectKBest, f_regression
from sklearn.linear_model import LinearRegression
class Easylibpal:
def __init__(self, dataset):
self.dataset = dataset
# Load and preprocess the dataset
def apply_linear_regression(self, target_column):
# Feature selection using SelectKBest
selector = SelectKBest(score_func=f_regression, k=10)
X_new = selector.fit_transform(self.dataset.drop(target_column, axis=1), self.dataset[target_column])
# Train Linear Regression model
model = LinearRegression()
model.fit(X_new, self.dataset[target_column])
# Return the trained model
return model
# Usage
Easylibpal = Easylibpal(dataset='your_dataset.csv')
model = Easylibpal.apply_linear_regression(target_column='target')
```
This example demonstrates how Easylibpal abstracts the complexity of feature selection for Linear Regression by using scikit-learn's `SelectKBest` to select the top 10 features based on their statistical significance in predicting the target variable. The actual implementation would need to adapt this approach for each algorithm, considering the specific characteristics and requirements of each algorithm.
To implement feature selection in Easylibpal, one could use scikit-learn's `SelectKBest`, `RFE`, or other feature selection classes based on the algorithm's requirements. Here's a conceptual example of how feature selection might be integrated into the Easylibpal class for Logistic Regression using RFE:
```python
from sklearn.feature_selection import RFE
from sklearn.linear_model import LogisticRegression
class Easylibpal:
def __init__(self, dataset):
self.dataset = dataset
# Load and preprocess the dataset
def apply_logistic_regression(self, target_column):
# Feature selection using RFE
model = LogisticRegression()
rfe = RFE(model, n_features_to_select=10)
rfe.fit(self.dataset.drop(target_column, axis=1), self.dataset[target_column])
# Train Logistic Regression model
model.fit(self.dataset.drop(target_column, axis=1), self.dataset[target_column])
# Return the trained model
return model
# Usage
Easylibpal = Easylibpal(dataset='your_dataset.csv')
model = Easylibpal.apply_logistic_regression(target_column='target')
```
This example demonstrates how Easylibpal abstracts the complexity of feature selection for Logistic Regression by using scikit-learn's `RFE` to select the top 10 features based on their importance in the model. The actual implementation would need to adapt this approach for each algorithm, considering the specific characteristics and requirements of each algorithm.
EASYLIBPAL HANDLES DIFFERENT TYPES OF DATASETS
Easylibpal handles different types of datasets with varying structures by adopting a flexible and adaptable approach to data preprocessing and transformation. This approach is inspired by the principles of tidy data and the need to ensure data is in a consistent, usable format before applying AI algorithms. Here's how Easylibpal addresses the challenges posed by varying dataset structures:
One Type in Multiple Tables
When datasets contain different variables, the same variables with different names, different file formats, or different conventions for missing values, Easylibpal employs a process similar to tidying data. This involves identifying and standardizing the structure of each dataset, ensuring that each variable is consistently named and formatted across datasets. This process might include renaming columns, converting data types, and handling missing values in a uniform manner. For datasets stored in different file formats, Easylibpal would use appropriate libraries (e.g., pandas for CSV, Excel files, and SQL databases) to load and preprocess the data before applying the algorithms.
Multiple Types in One Table
For datasets that involve values collected at multiple levels or on different types of observational units, Easylibpal applies a normalization process. This involves breaking down the dataset into multiple tables, each representing a distinct type of observational unit. For example, if a dataset contains information about songs and their rankings over time, Easylibpal would separate this into two tables: one for song details and another for rankings. This normalization ensures that each fact is expressed in only one place, reducing inconsistencies and making the data more manageable for analysis.
Data Semantics
Easylibpal ensures that the data is organized in a way that aligns with the principles of data semantics, where every value belongs to a variable and an observation. This organization is crucial for the algorithms to interpret the data correctly. Easylibpal might use functions like `pivot_longer` and `pivot_wider` from the tidyverse or equivalent functions in pandas to reshape the data into a long format, where each row represents a single observation and each column represents a single variable. This format is particularly useful for algorithms that require a consistent structure for input data.
Messy Data
Dealing with messy data, which can include inconsistent data types, missing values, and outliers, is a common challenge in data science. Easylibpal addresses this by implementing robust data cleaning and preprocessing steps. This includes handling missing values (e.g., imputation or deletion), converting data types to ensure consistency, and identifying and removing outliers. These steps are crucial for preparing the data in a format that is suitable for the algorithms, ensuring that the algorithms can effectively learn from the data without being hindered by its inconsistencies.
To implement these principles in Python, Easylibpal would leverage libraries like pandas for data manipulation and preprocessing. Here's a conceptual example of how Easylibpal might handle a dataset with multiple types in one table:
```python
import pandas as pd
# Load the dataset
dataset = pd.read_csv('your_dataset.csv')
# Normalize the dataset by separating it into two tables
song_table = dataset'artist', 'track'.drop_duplicates().reset_index(drop=True)
song_table['song_id'] = range(1, len(song_table) + 1)
ranking_table = dataset'artist', 'track', 'week', 'rank'.drop_duplicates().reset_index(drop=True)
# Now, song_table and ranking_table can be used separately for analysis
```
This example demonstrates how Easylibpal might normalize a dataset with multiple types of observational units into separate tables, ensuring that each type of observational unit is stored in its own table. The actual implementation would need to adapt this approach based on the specific structure and requirements of the dataset being processed.
CLEAN DATA
Easylibpal employs a comprehensive set of data cleaning and preprocessing steps to handle messy data, ensuring that the data is in a suitable format for machine learning algorithms. These steps are crucial for improving the accuracy and reliability of the models, as well as preventing misleading results and conclusions. Here's a detailed look at the specific steps Easylibpal might employ:
1. Remove Irrelevant Data
The first step involves identifying and removing data that is not relevant to the analysis or modeling task at hand. This could include columns or rows that do not contribute to the predictive power of the model or are not necessary for the analysis .
2. Deduplicate Data
Deduplication is the process of removing duplicate entries from the dataset. Duplicates can skew the analysis and lead to incorrect conclusions. Easylibpal would use appropriate methods to identify and remove duplicates, ensuring that each entry in the dataset is unique.
3. Fix Structural Errors
Structural errors in the dataset, such as inconsistent data types, incorrect values, or formatting issues, can significantly impact the performance of machine learning algorithms. Easylibpal would employ data cleaning techniques to correct these errors, ensuring that the data is consistent and correctly formatted.
4. Deal with Missing Data
Handling missing data is a common challenge in data preprocessing. Easylibpal might use techniques such as imputation (filling missing values with statistical estimates like mean, median, or mode) or deletion (removing rows or columns with missing values) to address this issue. The choice of method depends on the nature of the data and the specific requirements of the analysis.
5. Filter Out Data Outliers
Outliers can significantly affect the performance of machine learning models. Easylibpal would use statistical methods to identify and filter out outliers, ensuring that the data is more representative of the population being analyzed.
6. Validate Data
The final step involves validating the cleaned and preprocessed data to ensure its quality and accuracy. This could include checking for consistency, verifying the correctness of the data, and ensuring that the data meets the requirements of the machine learning algorithms. Easylibpal would employ validation techniques to confirm that the data is ready for analysis.
To implement these data cleaning and preprocessing steps in Python, Easylibpal would leverage libraries like pandas and scikit-learn. Here's a conceptual example of how these steps might be integrated into the Easylibpal class:
```python
import pandas as pd
from sklearn.impute import SimpleImputer
from sklearn.preprocessing import StandardScaler
class Easylibpal:
def __init__(self, dataset):
self.dataset = dataset
# Load and preprocess the dataset
def clean_and_preprocess(self):
# Remove irrelevant data
self.dataset = self.dataset.drop(['irrelevant_column'], axis=1)
# Deduplicate data
self.dataset = self.dataset.drop_duplicates()
# Fix structural errors (example: correct data type)
self.dataset['correct_data_type_column'] = self.dataset['correct_data_type_column'].astype(float)
# Deal with missing data (example: imputation)
imputer = SimpleImputer(strategy='mean')
self.dataset['missing_data_column'] = imputer.fit_transform(self.dataset'missing_data_column')
# Filter out data outliers (example: using Z-score)
# This step requires a more detailed implementation based on the specific dataset
# Validate data (example: checking for NaN values)
assert not self.dataset.isnull().values.any(), "Data still contains NaN values"
# Return the cleaned and preprocessed dataset
return self.dataset
# Usage
Easylibpal = Easylibpal(dataset=pd.read_csv('your_dataset.csv'))
cleaned_dataset = Easylibpal.clean_and_preprocess()
```
This example demonstrates a simplified approach to data cleaning and preprocessing within Easylibpal. The actual implementation would need to adapt these steps based on the specific characteristics and requirements of the dataset being processed.
VALUE DATA
Easylibpal determines which data is irrelevant and can be removed through a combination of domain knowledge, data analysis, and automated techniques. The process involves identifying data that does not contribute to the analysis, research, or goals of the project, and removing it to improve the quality, efficiency, and clarity of the data. Here's how Easylibpal might approach this:
Domain Knowledge
Easylibpal leverages domain knowledge to identify data that is not relevant to the specific goals of the analysis or modeling task. This could include data that is out of scope, outdated, duplicated, or erroneous. By understanding the context and objectives of the project, Easylibpal can systematically exclude data that does not add value to the analysis.
Data Analysis
Easylibpal employs data analysis techniques to identify irrelevant data. This involves examining the dataset to understand the relationships between variables, the distribution of data, and the presence of outliers or anomalies. Data that does not have a significant impact on the predictive power of the model or the insights derived from the analysis is considered irrelevant.
Automated Techniques
Easylibpal uses automated tools and methods to remove irrelevant data. This includes filtering techniques to select or exclude certain rows or columns based on criteria or conditions, aggregating data to reduce its complexity, and deduplicating to remove duplicate entries. Tools like Excel, Google Sheets, Tableau, Power BI, OpenRefine, Python, R, Data Linter, Data Cleaner, and Data Wrangler can be employed for these purposes .
Examples of Irrelevant Data
- Personal Identifiable Information (PII): Data such as names, addresses, and phone numbers are irrelevant for most analytical purposes and should be removed to protect privacy and comply with data protection regulations .
- URLs and HTML Tags: These are typically not relevant to the analysis and can be removed to clean up the dataset.
- Boilerplate Text: Excessive blank space or boilerplate text (e.g., in emails) adds noise to the data and can be removed.
- Tracking Codes: These are used for tracking user interactions and do not contribute to the analysis.
To implement these steps in Python, Easylibpal might use pandas for data manipulation and filtering. Here's a conceptual example of how to remove irrelevant data:
```python
import pandas as pd
# Load the dataset
dataset = pd.read_csv('your_dataset.csv')
# Remove irrelevant columns (example: email addresses)
dataset = dataset.drop(['email_address'], axis=1)
# Remove rows with missing values (example: if a column is required for analysis)
dataset = dataset.dropna(subset=['required_column'])
# Deduplicate data
dataset = dataset.drop_duplicates()
# Return the cleaned dataset
cleaned_dataset = dataset
```
This example demonstrates how Easylibpal might remove irrelevant data from a dataset using Python and pandas. The actual implementation would need to adapt these steps based on the specific characteristics and requirements of the dataset being processed.
Detecting Inconsistencies
Easylibpal starts by detecting inconsistencies in the data. This involves identifying discrepancies in data types, missing values, duplicates, and formatting errors. By detecting these inconsistencies, Easylibpal can take targeted actions to address them.
Handling Formatting Errors
Formatting errors, such as inconsistent data types for the same feature, can significantly impact the analysis. Easylibpal uses functions like `astype()` in pandas to convert data types, ensuring uniformity and consistency across the dataset. This step is crucial for preparing the data for analysis, as it ensures that each feature is in the correct format expected by the algorithms.
Handling Missing Values
Missing values are a common issue in datasets. Easylibpal addresses this by consulting with subject matter experts to understand why data might be missing. If the missing data is missing completely at random, Easylibpal might choose to drop it. However, for other cases, Easylibpal might employ imputation techniques to fill in missing values, ensuring that the dataset is complete and ready for analysis.
Handling Duplicates
Duplicate entries can skew the analysis and lead to incorrect conclusions. Easylibpal uses pandas to identify and remove duplicates, ensuring that each entry in the dataset is unique. This step is crucial for maintaining the integrity of the data and ensuring that the analysis is based on distinct observations.
Handling Inconsistent Values
Inconsistent values, such as different representations of the same concept (e.g., "yes" vs. "y" for a binary variable), can also pose challenges. Easylibpal employs data cleaning techniques to standardize these values, ensuring that the data is consistent and can be accurately analyzed.
To implement these steps in Python, Easylibpal would leverage pandas for data manipulation and preprocessing. Here's a conceptual example of how these steps might be integrated into the Easylibpal class:
```python
import pandas as pd
class Easylibpal:
def __init__(self, dataset):
self.dataset = dataset
# Load and preprocess the dataset
def clean_and_preprocess(self):
# Detect inconsistencies (example: check data types)
print(self.dataset.dtypes)
# Handle formatting errors (example: convert data types)
self.dataset['date_column'] = pd.to_datetime(self.dataset['date_column'])
# Handle missing values (example: drop rows with missing values)
self.dataset = self.dataset.dropna(subset=['required_column'])
# Handle duplicates (example: drop duplicates)
self.dataset = self.dataset.drop_duplicates()
# Handle inconsistent values (example: standardize values)
self.dataset['binary_column'] = self.dataset['binary_column'].map({'yes': 1, 'no': 0})
# Return the cleaned and preprocessed dataset
return self.dataset
# Usage
Easylibpal = Easylibpal(dataset=pd.read_csv('your_dataset.csv'))
cleaned_dataset = Easylibpal.clean_and_preprocess()
```
This example demonstrates a simplified approach to handling inconsistent or messy data within Easylibpal. The actual implementation would need to adapt these steps based on the specific characteristics and requirements of the dataset being processed.
Statistical Imputation
Statistical imputation involves replacing missing values with statistical estimates such as the mean, median, or mode of the available data. This method is straightforward and can be effective for numerical data. For categorical data, mode imputation is commonly used. The choice of imputation method depends on the distribution of the data and the nature of the missing values.
Model-Based Imputation
Model-based imputation uses machine learning models to predict missing values. This approach can be more sophisticated and potentially more accurate than statistical imputation, especially for complex datasets. Techniques like K-Nearest Neighbors (KNN) imputation can be used, where the missing values are replaced with the values of the K nearest neighbors in the feature space.
Using SimpleImputer in scikit-learn
The scikit-learn library provides the `SimpleImputer` class, which supports both statistical and model-based imputation. `SimpleImputer` can be used to replace missing values with the mean, median, or most frequent value (mode) of the column. It also supports more advanced imputation methods like KNN imputation.
To implement these imputation techniques in Python, Easylibpal might use the `SimpleImputer` class from scikit-learn. Here's an example of how to use `SimpleImputer` for statistical imputation:
```python
from sklearn.impute import SimpleImputer
import pandas as pd
# Load the dataset
dataset = pd.read_csv('your_dataset.csv')
# Initialize SimpleImputer for numerical columns
num_imputer = SimpleImputer(strategy='mean')
# Fit and transform the numerical columns
dataset'numerical_column1', 'numerical_column2' = num_imputer.fit_transform(dataset'numerical_column1', 'numerical_column2')
# Initialize SimpleImputer for categorical columns
cat_imputer = SimpleImputer(strategy='most_frequent')
# Fit and transform the categorical columns
dataset'categorical_column1', 'categorical_column2' = cat_imputer.fit_transform(dataset'categorical_column1', 'categorical_column2')
# The dataset now has missing values imputed
```
This example demonstrates how to use `SimpleImputer` to fill in missing values in both numerical and categorical columns of a dataset. The actual implementation would need to adapt these steps based on the specific characteristics and requirements of the dataset being processed.
Model-based imputation techniques, such as Multiple Imputation by Chained Equations (MICE), offer powerful ways to handle missing data by using statistical models to predict missing values. However, these techniques come with their own set of limitations and potential drawbacks:
1. Complexity and Computational Cost
Model-based imputation methods can be computationally intensive, especially for large datasets or complex models. This can lead to longer processing times and increased computational resources required for imputation.
2. Overfitting and Convergence Issues
These methods are prone to overfitting, where the imputation model captures noise in the data rather than the underlying pattern. Overfitting can lead to imputed values that are too closely aligned with the observed data, potentially introducing bias into the analysis. Additionally, convergence issues may arise, where the imputation process does not settle on a stable solution.
3. Assumptions About Missing Data
Model-based imputation techniques often assume that the data is missing at random (MAR), which means that the probability of a value being missing is not related to the values of other variables. However, this assumption may not hold true in all cases, leading to biased imputations if the data is missing not at random (MNAR).
4. Need for Suitable Regression Models
For each variable with missing values, a suitable regression model must be chosen. Selecting the wrong model can lead to inaccurate imputations. The choice of model depends on the nature of the data and the relationship between the variable with missing values and other variables.
5. Combining Imputed Datasets
After imputing missing values, there is a challenge in combining the multiple imputed datasets to produce a single, final dataset. This requires careful consideration of how to aggregate the imputed values and can introduce additional complexity and uncertainty into the analysis.
6. Lack of Transparency
The process of model-based imputation can be less transparent than simpler imputation methods, such as mean or median imputation. This can make it harder to justify the imputation process, especially in contexts where the reasons for missing data are important, such as in healthcare research.
Despite these limitations, model-based imputation techniques can be highly effective for handling missing data in datasets where a amusingness is MAR and where the relationships between variables are complex. Careful consideration of the assumptions, the choice of models, and the methods for combining imputed datasets are crucial to mitigate these drawbacks and ensure the validity of the imputation process.
USING EASYLIBPAL FOR AI ALGORITHM INTEGRATION OFFERS SEVERAL SIGNIFICANT BENEFITS, PARTICULARLY IN ENHANCING EVERYDAY LIFE AND REVOLUTIONIZING VARIOUS SECTORS. HERE'S A DETAILED LOOK AT THE ADVANTAGES:
1. Enhanced Communication: AI, through Easylibpal, can significantly improve communication by categorizing messages, prioritizing inboxes, and providing instant customer support through chatbots. This ensures that critical information is not missed and that customer queries are resolved promptly.
2. Creative Endeavors: Beyond mundane tasks, AI can also contribute to creative endeavors. For instance, photo editing applications can use AI algorithms to enhance images, suggesting edits that align with aesthetic preferences. Music composition tools can generate melodies based on user input, inspiring musicians and amateurs alike to explore new artistic horizons. These innovations empower individuals to express themselves creatively with AI as a collaborative partner.
3. Daily Life Enhancement: AI, integrated through Easylibpal, has the potential to enhance daily life exponentially. Smart homes equipped with AI-driven systems can adjust lighting, temperature, and security settings according to user preferences. Autonomous vehicles promise safer and more efficient commuting experiences. Predictive analytics can optimize supply chains, reducing waste and ensuring goods reach users when needed.
4. Paradigm Shift in Technology Interaction: The integration of AI into our daily lives is not just a trend; it's a paradigm shift that's redefining how we interact with technology. By streamlining routine tasks, personalizing experiences, revolutionizing healthcare, enhancing communication, and fueling creativity, AI is opening doors to a more convenient, efficient, and tailored existence.
5. Responsible Benefit Harnessing: As we embrace AI's transformational power, it's essential to approach its integration with a sense of responsibility, ensuring that its benefits are harnessed for the betterment of society as a whole. This approach aligns with the ethical considerations of using AI, emphasizing the importance of using AI in a way that benefits all stakeholders.
In summary, Easylibpal facilitates the integration and use of AI algorithms in a manner that is accessible and beneficial across various domains, from enhancing communication and creative endeavors to revolutionizing daily life and promoting a paradigm shift in technology interaction. This integration not only streamlines the application of AI but also ensures that its benefits are harnessed responsibly for the betterment of society.
USING EASYLIBPAL OVER TRADITIONAL AI LIBRARIES OFFERS SEVERAL BENEFITS, PARTICULARLY IN TERMS OF EASE OF USE, EFFICIENCY, AND THE ABILITY TO APPLY AI ALGORITHMS WITH MINIMAL CONFIGURATION. HERE ARE THE KEY ADVANTAGES:
- Simplified Integration: Easylibpal abstracts the complexity of traditional AI libraries, making it easier for users to integrate classic AI algorithms into their projects. This simplification reduces the learning curve and allows developers and data scientists to focus on their core tasks without getting bogged down by the intricacies of AI implementation.
- User-Friendly Interface: By providing a unified platform for various AI algorithms, Easylibpal offers a user-friendly interface that streamlines the process of selecting and applying algorithms. This interface is designed to be intuitive and accessible, enabling users to experiment with different algorithms with minimal effort.
- Enhanced Productivity: The ability to effortlessly instantiate algorithms, fit models with training data, and make predictions with minimal configuration significantly enhances productivity. This efficiency allows for rapid prototyping and deployment of AI solutions, enabling users to bring their ideas to life more quickly.
- Democratization of AI: Easylibpal democratizes access to classic AI algorithms, making them accessible to a wider range of users, including those with limited programming experience. This democratization empowers users to leverage AI in various domains, fostering innovation and creativity.
- Automation of Repetitive Tasks: By automating the process of applying AI algorithms, Easylibpal helps users save time on repetitive tasks, allowing them to focus on more complex and creative aspects of their projects. This automation is particularly beneficial for users who may not have extensive experience with AI but still wish to incorporate AI capabilities into their work.
- Personalized Learning and Discovery: Easylibpal can be used to enhance personalized learning experiences and discovery mechanisms, similar to the benefits seen in academic libraries. By analyzing user behaviors and preferences, Easylibpal can tailor recommendations and resource suggestions to individual needs, fostering a more engaging and relevant learning journey.
- Data Management and Analysis: Easylibpal aids in managing large datasets efficiently and deriving meaningful insights from data. This capability is crucial in today's data-driven world, where the ability to analyze and interpret large volumes of data can significantly impact research outcomes and decision-making processes.
In summary, Easylibpal offers a simplified, user-friendly approach to applying classic AI algorithms, enhancing productivity, democratizing access to AI, and automating repetitive tasks. These benefits make Easylibpal a valuable tool for developers, data scientists, and users looking to leverage AI in their projects without the complexities associated with traditional AI libraries.
2 notes
·
View notes
Text
Introduction: The Evolution of Web Scraping
Traditional Web Scraping involves deploying scrapers on dedicated servers or local machines, using tools like Python, BeautifulSoup, and Selenium. While effective for small-scale tasks, these methods require constant monitoring, manual scaling, and significant infrastructure management. Developers often need to handle cron jobs, storage, IP rotation, and failover mechanisms themselves. Any sudden spike in demand could result in performance bottlenecks or downtime. As businesses grow, these challenges make traditional scraping harder to maintain. This is where new-age, cloud-based approaches like Serverless Web Scraping emerge as efficient alternatives, helping automate, scale, and streamline data extraction.

Challenges of Manual Scraper Deployment (Scaling, Infrastructure, Cost)
Manual scraper deployment comes with numerous operational challenges. Scaling scrapers to handle large datasets or traffic spikes requires robust infrastructure and resource allocation. Managing servers involves ongoing costs, including hosting, maintenance, load balancing, and monitoring. Additionally, handling failures, retries, and scheduling manually can lead to downtime or missed data. These issues slow down development and increase overhead. In contrast, Serverless Web Scraping removes the need for dedicated servers by running scraping tasks on platforms like AWS Lambda, Azure Functions, and Google Cloud Functions, offering auto-scaling and cost-efficiency on a pay-per-use model.
Introduction to Serverless Web Scraping as a Game-Changer

What is Serverless Web Scraping?
Serverless Web Scraping refers to the process of extracting data from websites using cloud-based, event-driven architecture, without the need to manage underlying servers. In cloud computing, "serverless" means the cloud provider automatically handles infrastructure scaling, provisioning, and resource allocation. This enables developers to focus purely on writing the logic of Data Collection, while the platform takes care of execution.
Popular Cloud Providers like AWS Lambda, Azure Functions, and Google Cloud Functions offer robust platforms for deploying these scraping tasks. Developers write small, stateless functions that are triggered by events such as HTTP requests, file uploads, or scheduled intervals—referred to as Scheduled Scraping and Event-Based Triggers. These functions are executed in isolated containers, providing secure, cost-effective, and on-demand scraping capabilities.
The core advantage is Lightweight Data Extraction. Instead of running a full scraper continuously on a server, serverless functions only execute when needed—making them highly efficient. Use cases include:
Scheduled Scraping (e.g., extracting prices every 6 hours)
Real-time scraping triggered by user queries
API-less extraction where data is not available via public APIs
These functionalities allow businesses to collect data at scale without investing in infrastructure or DevOps.
Key Benefits of Serverless Web Scraping
Scalability on Demand
One of the strongest advantages of Serverless Web Scraping is its ability to scale automatically. When using Cloud Providers like AWS Lambda, Azure Functions, or Google Cloud Functions, your scraping tasks can scale from a few requests to thousands instantly—without any manual intervention. For example, an e-commerce brand tracking product listings during flash sales can instantly scale their Data Collection tasks to accommodate massive price updates across multiple platforms in real time.
Cost-Effectiveness (Pay-as-You-Go Model)
Traditional Web Scraping involves paying for full-time servers, regardless of usage. With serverless solutions, you only pay for the time your code is running. This pay-as-you-go model significantly reduces costs, especially for intermittent scraping tasks. For instance, a marketing agency running weekly Scheduled Scraping to track keyword rankings or competitor ads will only be billed for those brief executions—making Serverless Web Scraping extremely budget-friendly.
Zero Server Maintenance
Server management can be tedious and resource-intensive, especially when deploying at scale. Serverless frameworks eliminate the need for provisioning, patching, or maintaining infrastructure. A developer scraping real estate listings no longer needs to manage server health or uptime. Instead, they focus solely on writing scraping logic, while Cloud Providers handle the backend processes, ensuring smooth, uninterrupted Lightweight Data Extraction.
Improved Reliability and Automation
Using Event-Based Triggers (like new data uploads, emails, or HTTP calls), serverless scraping functions can be scheduled or executed automatically based on specific events. This guarantees better uptime and reduces the likelihood of missing important updates. For example, Azure Functions can be triggered every time a CSV file is uploaded to the cloud, automating the Data Collection pipeline.
Environmentally Efficient
Traditional servers consume energy 24/7, regardless of activity. Serverless environments run functions only when needed, minimizing energy usage and environmental impact. This makes Serverless Web Scraping an eco-friendly option. Businesses concerned with sustainability can reduce their carbon footprint while efficiently extracting vital business intelligence.

Ideal Use Cases for Serverless Web Scraping
1. Market and Price Monitoring
Serverless Web Scraping enables retailers and analysts to monitor competitor prices in real-time using Scheduled Scraping or Event-Based Triggers.
Example:
A fashion retailer uses AWS Lambda to scrape competitor pricing data every 4 hours. This allows dynamic pricing updates without maintaining any servers, leading to a 30% improvement in pricing competitiveness and a 12% uplift in revenue.
2. E-commerce Product Data Collection
Collect structured product information (SKUs, availability, images, etc.) from multiple e-commerce platforms using Lightweight Data Extraction methods via serverless setups.
Example:
An online electronics aggregator uses Google Cloud Functions to scrape product specs and availability across 50+ vendors daily. By automating Data Collection, they reduce manual data entry costs by 80%.
3. Real-Time News and Sentiment Tracking
Use Web Scraping to monitor breaking news or updates relevant to your industry and feed it into dashboards or sentiment engines.
Example:
A fintech firm uses Azure Functions to scrape financial news from Bloomberg and CNBC every 5 minutes. The data is piped into a sentiment analysis engine, helping traders act faster based on market sentiment—cutting reaction time by 40%.
4. Social Media Trend Analysis
Track hashtags, mentions, and viral content in real time across platforms like Twitter, Instagram, or Reddit using Serverless Web Scraping.
Example:
A digital marketing agency leverages AWS Lambda to scrape trending hashtags and influencer posts during product launches. This real-time Data Collection enables live campaign adjustments, improving engagement by 25%.
5. Mobile App Backend Scraping Using Mobile App Scraping Services
Extract backend content and APIs from mobile apps using Mobile App Scraping Services hosted via Cloud Providers.
Example:
A food delivery startup uses Google Cloud Functions to scrape menu availability and pricing data from a competitor’s app every 15 minutes. This helps optimize their own platform in real-time, improving response speed and user satisfaction.
Technical Workflow of a Serverless Scraper
In this section, we’ll outline how a Lambda-based scraper works and how to integrate it with Web Scraping API Services and cloud triggers.
1. Step-by-Step on How a Typical Lambda-Based Scraper Functions
A Lambda-based scraper runs serverless functions that handle the data extraction process. Here’s a step-by-step workflow for a typical AWS Lambda-based scraper:
Step 1: Function Trigger
Lambda functions can be triggered by various events. Common triggers include API calls, file uploads, or scheduled intervals.
For example, a scraper function can be triggered by a cron job or a Scheduled Scraping event.
Example Lambda Trigger Code:
Lambda functionis triggered based on a schedule (using EventBridge or CloudWatch).
requests.getfetches the web page.
BeautifulSoupprocesses the HTML to extract relevant data.
Step 2: Data Collection
After triggering the Lambda function, the scraper fetches data from the targeted website. Data extraction logic is handled in the function using tools like BeautifulSoup or Selenium.
Step 3: Data Storage/Transmission
After collecting data, the scraper stores or transmits the results:
Save data to AWS S3 for storage.
Push data to an API for further processing.
Store results in a database like Amazon DynamoDB.
2. Integration with Web Scraping API Services
Lambda can be used to call external Web Scraping API Services to handle more complex scraping tasks, such as bypassing captchas, managing proxies, and rotating IPs.
For instance, if you're using a service like ScrapingBee or ScraperAPI, the Lambda function can make an API call to fetch data.
Example: Integrating Web Scraping API Services
In this case, ScrapingBee handles the web scraping complexities, and Lambda simply calls their API.
3. Using Cloud Triggers and Events
Lambda functions can be triggered in multiple ways based on events. Here are some examples of triggers used in Serverless Web Scraping:
Scheduled Scraping (Cron Jobs Cron Jobs):
You can use AWS EventBridge or CloudWatch Events to schedule your Lambda function to run at specific intervals (e.g., every hour, daily, or weekly).
Example: CloudWatch Event Rule (cron job) for Scheduled Scraping:
This will trigger the Lambda function to scrape a webpage every hour.
File Upload Trigger (Event-Based):
Lambda can be triggered by file uploads in S3. For example, after scraping, if the data is saved as a file, the file upload in S3 can trigger another Lambda function for processing.
Example: Trigger Lambda on S3 File Upload:
By leveraging Serverless Web Scraping using AWS Lambda, you can easily scale your web scraping tasks with Event-Based Triggers such as Scheduled Scraping, API calls, or file uploads. This approach ensures that you avoid the complexity of infrastructure management while still benefiting from scalable, automated data collection. Learn More
#LightweightDataExtraction#AutomatedDataExtraction#StreamlineDataExtraction#ServerlessWebScraping#DataMining
0 notes
Text
Is Python Training Certification Worth It? A Complete Breakdown
Introduction: Why Python, Why Now?
In today's digital-first world, learning Python is more than a tech trend it's a smart investment in your career. Whether you're aiming for a job in data science, web development, automation, or even artificial intelligence, Python opens doors across industries. But beyond just learning Python, one big question remains: Is getting a Python certification truly worth it? Let’s break it all down for you.
This blog gives a complete and easy-to-understand look at what Python training certification involves, its real-world value, the skills you’ll gain, and how it can shape your future in the tech industry.

What Is a Python Certification Course?
A Python certification course is a structured training program that equips you with Python programming skills. Upon completion, you receive a certificate that validates your knowledge. These programs typically cover:
Core Python syntax
Data structures (lists, tuples, sets, dictionaries)
Functions and modules
Object-oriented programming
File handling
Exception handling
Real-world projects and coding tasks
Many certification programs also dive into specialized areas like data analysis, machine learning, and automation.
Why Choose Python Training Online?
Python training online offers flexibility, accessibility, and practical experience. You can learn at your own pace, access pre-recorded sessions, and often interact with instructors or peers through discussion boards or live sessions.
Key Benefits of Online Python Training:
Learn from anywhere at any time
Save time and commute costs
Access recorded lessons and code examples
Practice real-world problems in sandbox environments
Earn certificates that add credibility to your resume
What You’ll Learn in a Python Certification Course
A typical Python certification course builds a solid foundation while preparing you for real-world applications. Here’s a step-by-step breakdown of the topics generally covered:
1. Python Basics
Installing Python
Variables and data types
Input/output operations
Basic operators and expressions
2. Control Flow
Conditional statements (if, elif, else)
Loops (for, while)
Loop control (break, continue, pass)
3. Data Structures
Lists, Tuples, Sets, Dictionaries
Nested structures
Built-in methods
4. Functions
Defining and calling functions
Arguments and return values
Lambda and anonymous functions
5. Object-Oriented Programming (OOP)
Classes and objects
Inheritance and polymorphism
Encapsulation and abstraction
6. Modules and Packages
Creating and importing modules
Built-in modules
Using packages effectively
7. File Handling
Reading and writing text and binary files
File methods and context managers
8. Error and Exception Handling
Try-except blocks
Raising exceptions
Custom exceptions
9. Hands-On Projects
Calculator, contact manager, data scraper
Mini web applications or automation scripts
Each section ends with assessments or projects to apply what you’ve learned.
Real-World Value: Is It Worth It?
Yes. A Python training certification proves your ability to code, solve problems, and think logically using one of the most in-demand languages in the world.
Here’s how it adds value:
Resume Booster: Employers look for certifications to confirm your skills.
Interview Confidence: It helps you discuss concepts and projects fluently.
Skill Validation: Certification shows structured learning and consistent practice.
Career Mobility: Useful across fields like automation, finance, healthcare, education, and cloud computing.
Industry Demand for Python Skills:
Python is the #1 programming language according to multiple tech industry surveys.
Data shows that Python developers earn an average of $110,000/year in the U.S.
Job postings mentioning Python have grown by over 30% annually in tech job boards.
Who Should Take Python Training?
Python is beginner-friendly and ideal for:
Career switchers moving into tech
Recent graduates seeking to upskill
IT professionals expanding their language toolkit
Data analysts looking to automate reports
Web developers wanting to integrate back-end logic
QA testers or manual testers automating test cases
No prior coding background? No problem. The syntax and logic of Python are easy to learn, making it perfect for newcomers.
Top Online Python Courses: What Makes Them Stand Out?
A good online certification in Python includes:
Clear learning paths (Beginner to Advanced)
Project-based learning
Regular assignments and quizzes
Instructor-led sessions
Code-along demos
Interview prep support
You’ll also benefit from industry-expert guidance and hands-on practice that aligns with job roles like:
Python Developer
Automation Engineer
Data Analyst
Machine Learning Engineer
DevOps Support Engineer
How a Certified Python Skillset Helps in the Job Market
Certified Python professionals can confidently step into roles across multiple domains. Here are just a few examples:
Industry
Use of Python
Finance
Automating calculations, data modeling, trading bots
Healthcare
Analyzing patient records, diagnostics, imaging
E-commerce
Building web apps, handling user data, recommendations
Education
Online tutoring platforms, interactive content
Media & Gaming
Scripting, automation, content generation
Python certification helps you stand out and back your resume with verified skills.
Common Python Program Ideas to Practice
Practicing real-world Python program ideas will sharpen your skills. Some examples:
Web scraper: Pull news headlines automatically.
To-do list app: Store and edit tasks using files or databases.
Weather app: Use APIs to show forecasts.
Quiz app: Build a console-based quiz game.
Data visualizer: Create graphs with user input.
These ideas not only test your knowledge but also help you build a portfolio.
How Certification Enhances Your Career Growth
Getting a Python certification course helps in:
Job Placements: Certification shows employers you’re job-ready.
Career Transition: It bridges the gap between your current role and tech jobs.
Higher Salaries: Certified professionals often get better salary offers.
Freelance Opportunities: Certification builds trust for independent work.
Continued Learning: Prepares you for specialized tracks like AI, ML, or full-stack development.
Sample Python Code: A Glimpse into Real-World Logic
Here’s a simple example of file handling in Python:
python
def write_to_file(filename, data):
with open(filename, 'w') as file:
file.write(data)
def read_from_file(filename):
with open(filename, 'r') as file:
return file.read()
write_to_file('sample.txt', 'Learning Python is rewarding!')
print(read_from_file('sample.txt'))
This simple project covers file handling, function usage, and string operations key concepts in any Python training online course.
Things to Consider Before Choosing a Course
To make your online certification in Python truly worth it, ensure the course offers:
Well-structured syllabus
Projects that simulate real-world use
Active instructor feedback
Placement or job-readiness training
Lifetime access or resources
Test simulations or quizzes
Summary: Is It Worth the Time and Money?
In short, yes a Python certification is worth it.
Whether you're just starting out or looking to grow your tech skills, Python is a powerful tool that opens many doors. A certification not only helps you learn but also proves your commitment and ability to apply these skills in real scenarios.
Final Thoughts
Python is no longer optional, it’s essential. A Python certification course gives you structure, credibility, and a roadmap to professional success. It’s one of the smartest ways to future-proof your career in tech.
Start your learning journey with H2K Infosys today. Enroll now for hands-on Python training and expert-led certification support that prepares you for the real tech world.
#pythoncertification#pythononlinecoursecertification#pythoncertificationcourse#pythontraining#pythononlinetraining#pythonbasicstraining#pythontraininginstitute#pythontrainingcourse
0 notes
Text
Sweep AI: The Future of Automated Code Refactoring
Introduction to Sweep AI
In today’s digital age, writing and maintaining clean code can wear developers down. Deadlines pile up, bugs pop in, and projects often fall behind. That’s where Sweep AI steps in. It acts as a reliable coding assistant that saves time, boosts productivity, and supports developers by doing the heavy lifting in coding tasks.
This article breaks down everything about Sweep AI, how it helps with code automation, and why many developers choose it as their go-to AI tool.
Understanding Sweep AI
Sweep AI is an open-source AI-powered tool that behaves like a junior developer. It listens to your needs, reads your code, and writes or fixes it accordingly. It can turn bug reports into actual code fixes without needing constant manual guidance.
More importantly, Sweep AI does not cost a dime to start. It’s ideal for teams and solo developers who want to move fast without sacrificing code quality.
How Sweep AI Works
Sweep AI works in a simple yet powerful way. Once a developer writes a feature request or a bug report, the AI jumps into action. Here’s what it usually does:
Reads the existing code
Plans the changes intelligently
Writes pull requests automatically
Updates based on comments or suggestions
Sweep AI also uses popularity ranking to understand which parts of your repository matter the most. It responds to feedback and works closely with developers throughout the code improvement process.
Types of Refactoring Sweeps AI Can Handle
Sweeps AI does not just work on surface-level improvements. It digs deep into the code. Some of its main capabilities include:
Function extraction: breaking large functions into smaller, clearer ones
Renaming variables: making names more meaningful
Removing dead code: getting rid of unused blocks
Code formatting: applying consistent style and spacing
It can also detect complex issues like duplicate logic across files, risky design patterns, and nested loops that slow down performance.
Why Developers Are Turning to Sweeps AI
Many developers use Sweeps AI because it:
Saves time
Reduces human error
Maintains consistent coding standards
Improves software quality
Imagine a junior developer who must refactor 500 lines of spaghetti code. That person might take hours or even days to clean it up. With Sweeps AI, the job could be done in minutes.
Step-by-Step Guide to Start Using Sweep AI
You don’t need to be a tech wizard to get started with Sweep AI. Here are two easy methods:
Install the Sweep AI GitHub App Connects to your repository and starts working almost immediately.
Self-host using Docker Ideal for developers who want more control or need to run it privately.
Sweep AI also shares helpful guides, video tutorials, and documentation to walk users through each step.
The Present and the Future
Right now, Sweeps AI already supports languages like Python, JavaScript, TypeScript, and Java. But the roadmap includes support for C++, PHP, and even legacy languages like COBOL. That shows just how ambitious the project is.
In the coming years, we might see Sweeps AI integrated into platforms like GitHub, VS Code, and JetBrains IDES by default. That means you won’t need to go out of your way to use it will be part of your everyday coding workflow.
How Much Does Sweep AI Cost?
Sweep AI offers a flexible pricing model:
Free Tier – Unlimited GPT-3.5 tickets for all users.
Plus Plan – $120/month includes 30 GPT-4 tickets for more advanced tasks.
GPT-4 Access – Requires users to connect their own Openai API key (charges may apply).
Whether you’re working on a startup project or a large codebase, there’s a plan that fits.
Is Sweep AI Worth It?
Absolutely. Sweep AI is more than just another coding assistant it’s a valuable teammate. It understands what you need, helps you fix problems faster, and lets you focus on what really matters: building great products.
Thanks to its smart features and developer-friendly design, Sweep AI stands out as one of the top AI tools for modern software teams. So, if you haven’t tried it yet, now’s a good time to dive in and take advantage of what it offers.
Frequently Asked Questions
Q: Who is the founder of Sweep AI?
Sweep AI was co-founded by William Suryawan and Kevin Luo, two AI engineers focused on making AI useful for developers by automating common tasks in GitHub.
Q: Is there another AI like Chatgpt?
Yes, there are several AIS similar to Chatgpt, including Claude, Gemini (by Google), Cohere, and Anthropic’s Claude. However, Sweep AI is more focused on code generation and GitHub integrations.
Q: Which AI solves GitHub issues?
Sweep AI is one of the top tools for automatically solving GitHub issues by generating pull requests based on bug reports or feature requests. It acts like a junior developer who understands your project.
Q: What is an AI agent, and how does it work?
An AI agent is a software program that performs tasks autonomously using artificial intelligence. It receives input (like code requests), makes decisions, and performs actions (like fixing bugs or writing code) based on logic and data.
Q: Who is the CEO of Sweep.io?
As of the latest information, Kevin Luo serves as the CEO of Sweep.io, focusing on making AI development tools smarter and more accessible.
0 notes
Text
Find the Best C++ Course Online with Certification and Easy to Follow Lessons

If you want to learn computer programming from the very beginning, then doing a C++ programming course can be a really good step. C++ is one of those programming languages that has been around for a long time and is still used in many areas like making computer software, designing games, and even building robots.
In this blog, you will get to know everything in detail about the C++ course — why it is useful, what topics you will study in it, what job options are available after learning it, and how you can begin learning it using the right tools and support.
What is a C++ Programming Course?
A C++ programming course is a learning program that helps you understand how to create computer programs using the C++ language. It is specially made for those who are new to programming or those who already know a little and want to learn more.
In this course, you will be taught how to write simple codes, find solutions to programming problems, and understand the basic ideas of how object-based programming works — which is a way of building programs by using small blocks called “objects.”
Why should you learn C++ in 2025?
Choosing to learn C++ in 2025 is a really good idea for several simple reasons. C++ is still used a lot by many companies. Big companies pick C++ when they want to make software that works quickly and does not break easily. If you want a job in IT, making software, or even working with artificial intelligence, knowing C++ will help you stand out. Also, C++ is the starting point for many other programming languages. After you learn C++, it becomes much simpler to pick up other languages like Java or Python.
Who can join a C++ Programming Course?
If you like computers or want to learn about technology, you can join a C++ programming course. You do not need to be a computer expert or have any special background. Many students take a C++ course after finishing class 12 because it helps them start learning programming early. People who already have jobs but want to learn new things or change their career can also join a C++ course.
If you are a student, you can find C++ courses made just for students, so learning is easy for you. There are also many good C++ courses online in 2025 for all levels, whether you are just starting or already know some programming.
What Will You Learn in a C++ Course? (Syllabus Overview)
When you join a C++ course made for beginners, you will learn all the main things that help you start coding easily. Here’s what is usually taught in such a course:
A simple explanation of what C++ is and where it came from
How to install and start using the C++ software on your computer
Writing your first basic program in C++
Learning about variables, data types, and math symbols (operators)
How to use loops and “if-else” conditions to make decisions in code
What functions are, and how to use them in different programs
Understanding arrays, how to use strings, and what pointers do
Learning the basics of object oriented programming in C++, like how classes and objects work, and things like inheritance and polymorphism
How to work with files, and how to handle errors in programs
Doing small projects and exercises to check what you’ve learned
Most C++ courses also come with a C++ programming tutorial step by step, which means you don’t just read — you also practice. This kind of hands-on method helps you remember and understand better.
Career Opportunities After Learning C++
When you finish a C++ programming course, you will have many job options. C++ is used in lots of different fields, so you can find work in many kinds of jobs. Some common jobs you can get are:
Software Developer
Game Developer
System Programmer
Embedded Systems Engineer
Data Analyst
Robotics Programmer
Having a job in C++ programming is safe and can help you grow in your career. Many companies want people who know C++. You can also choose to work for yourself as a freelancer or even start your own software business.
C++ Course Duration and Fees
How long a C++ course takes and how much it costs depends on where you study and which course you pick. Most beginner courses are between 1 and 3 months long. If you go for a bigger or more advanced course, it might take more time. The fees are different for each course. Some websites let you learn the full C++ course in English for free, but some may ask for a small payment for a C++ certification course.
It is smart to look at different courses and see which one is best for your budget and the way you like to learn. Many places also give discounts or scholarships to students.
Best Tools and Software for Practicing C++
If you want to practice C++, you should use some good tools. Here are some well-known choices:
Code::Blocks: This tool is friendly for people who are just starting. It is not hard to use.
Dev C++: This one is simple and does not use much space on your computer.
Visual Studio: This software is strong and many experts use it for their work.
Online compilers: There are websites like Online GDB and Repl.it where you can write and check your C++ code online. You do not have to put any software on your computer to use these sites.
With these tools, you can easily learn from a C++ programming tutorial step by step and practice everything you study.
Expected Salary After Completing a C++ Course
A big reason many people pick a C++ programming course is because they can get a good salary. After you finish your course, your starting pay is often more than many other jobs. In India, if you are new, you can earn about ₹3 to ₹6 lakhs each year. If you have more experience, you can get paid even more.
If you get a job in another country, your salary can be much higher. As you keep working and learning, your pay will go up when you get bigger and better jobs. After a C++ course, you can find jobs in both private companies and government offices.
Tips and Resources to Learn C++ Easily
If you want to learn C++ in a simple way, try these tips:
- Try to write code every day, even if you only have 30 minutes. - Watch simple video lessons and do the steps shown in the videos. - Join online groups or forums where you can ask questions and talk about what you are learning. - Work on small, easy projects to use what you have learned. - Do quizzes and small tests to see how much you understand.
There are lots of helpful things online, like a C++ full course in English, video lessons, and e-books. You can also learn C++ online for free and get a certificate from good websites.
How to Join a C++ Programming Course with IID
If you want to start learning C++ and are searching for a good place, the Institute for Industrial Development (IID) is a very good option. IID has a C++ certification course that is made for beginners and teaches you all the important things you need to know. You can sign up for the course online, join live classes, and get help from expert teachers. IID gives you study materials, assignments to practice, and a certificate that is recognized when you finish the course. You can learn at your own speed with IID, and if you ever have questions or need help, support is always available. This makes learning C++ with IID easy and comfortable.
Conclusion
In 2025, taking a C++ programming course is still a great way to begin a career in technology. C++ is not hard to learn, many companies need people who know it, and it can help you get many different jobs. It does not matter if you are a student, someone working, or just interested in programming-learning C++ will give you a strong base for your future. There are lots of resources and online courses you can use, so now is the perfect time to start learning C++. Take the first step, join a course, and open up many new opportunities for yourself with C++.
#c++#c++ programming#programming languages#c language#learningc++#prgrammingcourse#career#industrialcourse#businesscourses#businesscouse#professionalcourses#entrepreneurcourse#iidcourses#onlinecourse#onlinecourses#professionalcourse
0 notes
Text
Top 10 Free Coding Tutorials on Coding Brushup You Shouldn’t Miss
If you're passionate about learning to code or just starting your programming journey, Coding Brushup is your go-to platform. With a wide range of beginner-friendly and intermediate tutorials, it’s built to help you brush up your skills in languages like Java, Python, and web development technologies. Best of all? Many of the tutorials are absolutely free.

In this blog, we’ll highlight the top 10 free coding tutorials on Coding BrushUp that you simply shouldn’t miss. Whether you're aiming to master the basics or explore real-world projects, these tutorials will give you the knowledge boost you need.
1. Introduction to Python Programming – Coding BrushUp Python Tutorial
Python is one of the most beginner-friendly languages, and the Coding BrushUp Python Tutorial series starts you off with the fundamentals. This course covers:
● Setting up Python on your machine
● Variables, data types, and basic syntax
● Loops, functions, and conditionals
● A mini project to apply your skills
Whether you're a student or an aspiring data analyst, this free tutorial is perfect for building a strong foundation.
📌 Try it here: Coding BrushUp Python Tutorial
2. Java for Absolute Beginners – Coding BrushUp Java Tutorial
Java is widely used in Android development and enterprise software. The Coding BrushUp Java Tutorial is designed for complete beginners, offering a step-by-step guide that includes:
● Setting up Java and IntelliJ IDEA or Eclipse
● Understanding object-oriented programming (OOP)
● Working with classes, objects, and inheritance
● Creating a simple console-based application
This tutorial is one of the highest-rated courses on the site and is a great entry point into serious backend development.
📌 Explore it here: Coding BrushUp Java Tutorial
3. Build a Personal Portfolio Website with HTML & CSS
Learning to create your own website is an essential skill. This hands-on tutorial walks you through building a personal portfolio using just HTML and CSS. You'll learn:
● Basic structure of HTML5
● Styling with modern CSS3
● Responsive layout techniques
● Hosting your portfolio online
Perfect for freelancers and job seekers looking to showcase their skills.
4. JavaScript Basics: From Zero to DOM Manipulation
JavaScript powers the interactivity on the web, and this tutorial gives you a solid introduction. Key topics include:
● JavaScript syntax and variables
● Functions and events
● DOM selection and manipulation
● Simple dynamic web page project
By the end, you'll know how to create interactive web elements without relying on frameworks.
5. Version Control with Git and GitHub – Beginner’s Guide
Knowing how to use Git is essential for collaboration and managing code changes. This free tutorial covers:
● Installing Git
● Basic Git commands: clone, commit, push, pull
● Branching and merging
● Using GitHub to host and share your code
Even if you're a solo developer, mastering Git early will save you time and headaches later.
6. Simple CRUD App with Java (Console-Based)
In this tutorial, Coding BrushUp teaches you how to create a simple CRUD (Create, Read, Update, Delete) application in Java. It's a great continuation after the Coding Brushup Java Course Tutorial. You'll learn:
● Working with Java arrays or Array List
● Creating menu-driven applications
● Handling user input with Scanner
● Structuring reusable methods
This project-based learning reinforces core programming concepts and logic building.
7. Python for Data Analysis: A Crash Course
If you're interested in data science or analytics, this Coding Brushup Python Tutorial focuses on:
● Using libraries like Pandas and NumPy
● Reading and analyzing CSV files
● Data visualization with Matplotlib
● Performing basic statistical operations
It’s a fast-track intro to one of the hottest career paths in tech.
8. Responsive Web Design with Flexbox and Grid
This tutorial dives into two powerful layout modules in CSS:
● Flexbox: for one-dimensional layouts
● Grid: for two-dimensional layouts
You’ll build multiple responsive sections and gain experience with media queries, making your websites look great on all screen sizes.
9. Java Object-Oriented Concepts – Intermediate Java Tutorial
For those who’ve already completed the Coding Brushup Java Tutorial, this intermediate course is the next logical step. It explores:
● Inheritance and polymorphism
● Interfaces and abstract classes
● Encapsulation and access modifiers
● Real-world Java class design examples
You’ll write cleaner, modular code and get comfortable with real-world Java applications.
10. Build a Mini Calculator with Python (GUI Version)
This hands-on Coding BrushUp Python Tutorial teaches you how to build a desktop calculator using Tkinter, a built-in Python GUI library. You’ll learn:
● GUI design principles
● Button, entry, and event handling
● Function mapping and error checking
● Packaging a desktop application
A fun and visual way to practice Python programming!
Why Choose Coding BrushUp?
Coding BrushUp is more than just a collection of tutorials. Here’s what sets it apart:
✅ Clear Explanations – All lessons are written in plain English, ideal for beginners. ✅ Hands-On Projects – Practical coding exercises to reinforce learning. ✅ Progressive Learning Paths – Start from basics and grow into advanced topics. ✅ 100% Free Content – Many tutorials require no signup or payment. ✅ Community Support – Comment sections and occasional Q&A features allow learner interaction.
Final Thoughts
Whether you’re learning to code for career advancement, school, or personal development, the free tutorials at Coding Brushup offer valuable, structured, and practical knowledge. From mastering the basics of Python and Java to building your first website or desktop app, these resources will help you move from beginner to confident coder.
👉 Start learning today at Codingbrushup.com and check out the full Coding BrushUp Java Tutorial and Python series to supercharge your programming journey.
0 notes
Text
Pandas DataFrame Tutorial: Ways to Create and Manipulate Data in Python Are you diving into data analysis with Python? Then you're about to become best friends with pandas DataFrames. These powerful, table-like structures are the backbone of data manipulation in Python, and knowing how to create them is your first step toward becoming a data analysis expert. In this comprehensive guide, we'll explore everything you need to know about creating pandas DataFrames, from basic methods to advanced techniques. Whether you're a beginner or looking to level up your skills, this tutorial has got you covered. Getting Started with Pandas Before we dive in, let's make sure you have everything set up. First, you'll need to install pandas if you haven't already: pythonCopypip install pandas Then, import pandas in your Python script: pythonCopyimport pandas as pd 1. Creating a DataFrame from Lists The simplest way to create a DataFrame is using Python lists. Here's how: pythonCopy# Creating a basic DataFrame from lists data = 'name': ['John', 'Emma', 'Alex', 'Sarah'], 'age': [28, 24, 32, 27], 'city': ['New York', 'London', 'Paris', 'Tokyo'] df = pd.DataFrame(data) print(df) This creates a clean, organized table with your data. The keys in your dictionary become column names, and the values become the data in each column. 2. Creating a DataFrame from NumPy Arrays When working with numerical data, NumPy arrays are your friends: pythonCopyimport numpy as np # Creating a DataFrame from a NumPy array array_data = np.random.rand(4, 3) df_numpy = pd.DataFrame(array_data, columns=['A', 'B', 'C'], index=['Row1', 'Row2', 'Row3', 'Row4']) print(df_numpy) 3. Reading Data from External Sources Real-world data often comes from files. Here's how to create DataFrames from different file formats: pythonCopy# CSV files df_csv = pd.read_csv('your_file.csv') # Excel files df_excel = pd.read_excel('your_file.xlsx') # JSON files df_json = pd.read_json('your_file.json') 4. Creating a DataFrame from a List of Dictionaries Sometimes your data comes as a list of dictionaries, especially when working with APIs: pythonCopy# List of dictionaries records = [ 'name': 'John', 'age': 28, 'department': 'IT', 'name': 'Emma', 'age': 24, 'department': 'HR', 'name': 'Alex', 'age': 32, 'department': 'Finance' ] df_records = pd.DataFrame(records) print(df_records) 5. Creating an Empty DataFrame Sometimes you need to start with an empty DataFrame and fill it later: pythonCopy# Create an empty DataFrame with defined columns columns = ['Name', 'Age', 'City'] df_empty = pd.DataFrame(columns=columns) # Add data later new_row = 'Name': 'Lisa', 'Age': 29, 'City': 'Berlin' df_empty = df_empty.append(new_row, ignore_index=True) 6. Advanced DataFrame Creation Techniques Using Multi-level Indexes pythonCopy# Creating a DataFrame with multi-level index arrays = [ ['2023', '2023', '2024', '2024'], ['Q1', 'Q2', 'Q1', 'Q2'] ] data = 'Sales': [100, 120, 150, 180] df_multi = pd.DataFrame(data, index=arrays) print(df_multi) Creating Time Series DataFrames pythonCopy# Creating a time series DataFrame dates = pd.date_range('2024-01-01', periods=6, freq='D') df_time = pd.DataFrame(np.random.randn(6, 4), index=dates, columns=['A', 'B', 'C', 'D']) Best Practices and Tips Always Check Your Data Types pythonCopy# Check data types of your DataFrame print(df.dtypes) Set Column Names Appropriately Use clear, descriptive column names without spaces: pythonCopydf.columns = ['first_name', 'last_name', 'email'] Handle Missing Data pythonCopy# Check for missing values print(df.isnull().sum()) # Fill missing values df.fillna(0, inplace=True) Common Pitfalls to Avoid Memory Management: Be cautious with large datasets. Use appropriate data types to minimize memory usage:
pythonCopy# Optimize numeric columns df['integer_column'] = df['integer_column'].astype('int32') Copy vs. View: Understand when you're creating a copy or a view: pythonCopy# Create a true copy df_copy = df.copy() Conclusion Creating pandas DataFrames is a fundamental skill for any data analyst or scientist working with Python. Whether you're working with simple lists, complex APIs, or external files, pandas provides flexible and powerful ways to structure your data. Remember to: Choose the most appropriate method based on your data source Pay attention to data types and memory usage Use clear, consistent naming conventions Handle missing data appropriately With these techniques in your toolkit, you're well-equipped to handle any data manipulation task that comes your way. Practice with different methods and explore the pandas documentation for more advanced features as you continue your data analysis journey. Additional Resources Official pandas documentation Pandas cheat sheet Python for Data Science Handbook Real-world pandas examples on GitHub Now you're ready to start creating and manipulating DataFrames like a pro. Happy coding!
0 notes
Text
Level Up Data Science Skills with Python: A Full Guide
Data science is one of the most in-demand careers in the world today, and Python is its go-to language. Whether you're just starting out or looking to sharpen your skills, mastering Python can open doors to countless opportunities in data analytics, machine learning, artificial intelligence, and beyond.
In this guide, we’ll explore how Python can take your data science abilities to the next level—covering core concepts, essential libraries, and practical tips for real-world application.
Why Python for Data Science?
Python’s popularity in data science is no accident. It’s beginner-friendly, versatile, and has a massive ecosystem of libraries and tools tailored specifically for data work. Here's why it stands out:
Clear syntax simplifies learning and ensures easier maintenance.
Community support means constant updates and rich documentation.
Powerful libraries for everything from data manipulation to visualization and machine learning.
Core Python Concepts Every Data Scientist Should Know
Establish a solid base by thoroughly understanding the basics before advancing to more complex methods:
Variables and Data Types: Get familiar with strings, integers, floats, lists, and dictionaries.
Control Flow: Master if-else conditions, for/while loops, and list comprehensions through practice.
Functions and Modules: Understand how to create reusable code by defining functions.
File Handling: Leverage built-in functions to handle reading from and writing to files.
Error Handling: Use try-except blocks to write robust programs.
Mastering these foundations ensures you can write clean, efficient code—critical for working with complex datasets.
Must-Know Python Libraries for Data Science
Once you're confident with Python basics, it’s time to explore the libraries that make data science truly powerful:
NumPy: For numerical operations and array manipulation. It forms the essential foundation for a wide range of data science libraries.
Pandas: Used for data cleaning, transformation, and analysis. DataFrames are essential for handling structured data.
Matplotlib & Seaborn: These libraries help visualize data. While Matplotlib gives you control, Seaborn makes it easier with beautiful default styles.
Scikit-learn: Perfect for building machine learning models. Features algorithms for tasks like classification, regression, clustering, and additional methods.
TensorFlow & PyTorch: For deep learning and neural networks. Choose one based on your project needs and personal preference.
Real-World Projects to Practice
Applying what you’ve learned through real-world projects is key to skill development. Here are a few ideas:
Data Cleaning Challenge: Work with messy datasets and clean them using Pandas.
Exploratory Data Analysis (EDA): Analyze a dataset, find patterns, and visualize results.
Build a Machine Learning Model: Use Scikit-learn to create a prediction model for housing prices, customer churn, or loan approval.
Sentiment Analysis: Use natural language processing (NLP) to analyze product reviews or tweets.
Completing these projects can enhance your portfolio and attract the attention of future employers.
Tips to Accelerate Your Learning
Join online courses and bootcamps: Join Online Platforms
Follow open-source projects on GitHub: Contribute to or learn from real codebases.
Engage with the community: Join forums like Stack Overflow or Reddit’s r/datascience.
Read documentation and blogs: Keep yourself informed about new features and optimal practices.
Set goals and stay consistent: Data science is a long-term journey, not a quick race.
Python is the cornerstone of modern data science. Whether you're manipulating data, building models, or visualizing insights, Python equips you with the tools to succeed. By mastering its fundamentals and exploring its powerful libraries, you can confidently tackle real-world data challenges and elevate your career in the process. If you're looking to sharpen your skills, enrolling in a Python course in Gurgaon can be a great way to get expert guidance and hands-on experience.
DataMites Institute stands out as a top international institute providing in-depth education in data science, AI, and machine learning. We provide expert-led courses designed for both beginners and professionals aiming to boost their careers.
Python vs R - What is the Difference, Pros and Cons
youtube
#python course#python training#python institute#learnpython#python#pythoncourseingurgaon#pythoncourseinindia#Youtube
0 notes
Text
Development // Mall Level (Part 2)

Now that all of the layout and modelling is done, I plan to use the Quixel mega scans library to have access to have a range of materials to use. I also found a free pack that contains assets for a down town area, which will be useful when it comes to models and materials for the mall.

Now a issue that I came across was that I used cube grid to extend parts of my wall. Causing the mesh to require two materials which gets annoying to have to do for every mesh.


My first solution was to go into the modelling mode, then to delete all of the materials. After that creating a new material which would in theory make it so that the mesh uses it.


I decided before anything else, I would double check and improve the meshes around the mall. Having it so that the UV maps are more consistent so that textures tile properly.

Now another issue that I came across is that: I couldn't easily scale materials so that they tile a certain amount of times. This would makes materials not look good which is what I wanted to avoid.
youtube



I watched this youtube video to see if I could find a solution to this. I closely followed the tutorial and tried to adapt the solution to how mega scans have their materials. (One giant material that handles everything). Then in the comments I found a suggestion that would make this method easier for other materials. Which was to have a parameter that would change the scale of the texture cord.

With this issue fixed I started out by downloading and applying: A side walk material to the floor, a concrete/plaster material for the walls, and a brick material for the stairs.

After doing more searching a found a better material for the walls. Now my next step is fixing the double material issue before I start doing anything else.


Since the first solution didn't work, I had a different idea in mind: which was to edit the materials in a 3rd party application like blender. So I started out by separating all of the meshes that are being used with the unused ones. As I don't want to edit the materials of meshes that I am not using in the first place. I placed the used meshes in a separate folder while deleting all of the unused ones.

Next up, I took all of the meshes and enabled nanite on all of them. Nanite is a system inside of unreal engine that can basically provides a lot of benefits when it comes to meshes, such as optimisations that improve frame rate.

Next, I exported all of the meshes outside of unreal engine, so that I can start fixing the materials. Another reason to export them is that unreal engine doesn't allow me to make changes to them, in 3rd party applications without exporting. As well as not being able to reimport them in the case that I make any changes.

Inside of blender, I imported all of the meshes at once. This is because I plan to make a script that automatically does what I need to do to fix. The problems I am having with the materials.

Blender has support for python scripting. Allowing people to write code to do actions inside of blender. Such as in this case removing the materials.
The code simply imports the things it needs to make changes inside of blender. Then it goes through every material inside of the files and removes it. It also unlinks it from the mesh it is associated to. Then it loops through every object in the scene and then clears out all of the material slots. Lastly, the objects are looped through again and this time a new material is created with the same name as the object. This effectively fixes the issues with materials not working on the meshes.
I used snippets of code on these forum posts, when it came to writing mine. As I haven’t had experience making python scripts before let alone how blender and python interact.

Lastly for blender, I exported all of the meshes as one file to make it easier to import into unreal engine. I made sure to only export out the meshes as I don't need the materials that were created.


Now as for importing the meshes back into unreal, I simply had to make sure that I ticked off combine static meshes. Creating new static meshes instead of having one giant static mesh with everything. I also made sure to also tick off import meshes as I don't need the materials that were generated by blender. I simply used blender to fix the assignment of materials and how they work.
youtube
I used this video when it came down to importing all of the meshes inside of unreal. It helps me figure out what I had to make sure to toggle off to avoid having issues.

Now another issues appears, because I couldn't reimport the meshes that were generated by unreal. I now have two folders of meshes one being the ones generated by unreal which are broken and the ones that have been fixed. Issue being that I now would have to manually replace every single broken mesh in use to fix the previous issues. Which was something I wanted to avoid since it would have been extremely tedious.

So because unreal engine also supports python scripting, I created a python script that would do the replacing for me. This script basically takes in two variables the source folder which is everything that I want to replace, and the target folder which contains what I want to replace the source folder with. Next, I made a bunch of variables that give me the methods that I need for the replacing part.
After that, I get every single asset inside of the source folder and loop through it. I get the asset name and using that I can find the mesh inside of the target folder.
Next, I check if that mesh exists if it does then it gets loaded in to avoid any issues. This also returns a object that I will use in the final part of the code. Then I get the object that is to be replaced simply using get asset.
I create a array for the objects that need to be replaced and I place that object inside. I needed to do this because the method/function I needed to use to replace the object needs this to be a array for some reason.
Lastly, using the 'EditorAssetLibrary' I consolidate the assets to replace them with their respective new versions.
This fixes the tedious process of having to replace every single one. One by one. (Although I'm pretty sure if I did it manually it would have been faster than taking the time to write the script but oh well new learning opportunity :P)
With this every single mesh has been replaced with ones that work with materials.
Throughout this whole process of writing this script, I heavily relied on Unreal's Python API Documentation. Which provided pointers on what I needed to provide for certain functions.

I wanted to improve the store front meshes more so, I created a open hole on either side of them. This will allow me to add windows to make it so that you can look inside of the stores. Giving the mall more full look and not having full concrete walls everywhere.

Using a material from the down-town pack, I created a new mesh that will be the window itself. I used a glass material from the down-town pack to make it look more realistic.

From the same pack, I found this fountain blueprint that has a water particles setup. I decided to use this to save time from having to make my own fountain mesh and particles.

Now because of the way that some of the meshes are scaled. I needed to be able to put different materials on different sides of the mesh. This was simply done inside of the modelling mode and using the edit material took and selecting the top faces. Then creating a new material slot, setting it as the active material slot and pressing "assign active material".

I looked more into the Quixel library and also found a office roof tile material. I decided to use this material for the roof of the mall and stores.

Lastly, for the bathrooms I found a white tile material from the Quixel library. I downloaded it and placed it inside of where the bathrooms are. Matching up more with the common texture that I saw inside of my pool rooms mood board.
0 notes
Text
Understanding Web Scraping: Techniques, Ethics & Professional Guidance

Web scraping is a widely-used method for automatically extracting information from websites. It allows users to programmatically gather large volumes of data without manual copying and pasting. This technology has become essential for professionals in fields like market research, journalism, and e-commerce. In this blog, we’ll explore what web scraping is, how it works, and why practicing it ethically matters—along with how partnering with experts in web development can enhance your data strategy.
What Is Web Scraping?
At its core, web scraping is a digital technique that simulates human browsing to extract useful information from websites. It involves writing scripts that send requests to web pages, parse the HTML code, and organize extracted content—such as prices, reviews, or contact info—into structured formats like spreadsheets or databases.
Many developers choose languages like Python for web scraping due to its clean syntax and powerful libraries like Beautiful Soup and Scrapy. These tools make it easier to navigate and extract data from complex websites efficiently.
Common Applications of Web Scraping
Web scraping serves a wide variety of purposes across different industries:
Market Research: Businesses collect consumer feedback and competitor pricing to understand market trends.
E-commerce Monitoring: Online stores track product availability and prices across multiple platforms.
News & Journalism: Reporters gather public data or breaking information to support their stories.
Academic Research: Analysts compile datasets for large-scale studies or surveys.
By leveraging these insights, companies can fine-tune their strategies and stay ahead of the competition.
Why Ethical Web Scraping Matters
While web scraping can be incredibly useful, it must be done responsibly. Key ethical considerations include:
Respect for Consent: Many websites specify in their terms of service whether scraping is allowed. Ignoring these terms may result in legal issues or damage to your reputation.
Robots.txt Compliance: Most websites use a file called robots.txt to control which parts of their site are accessible to bots. Ethical scrapers always check and follow these rules.
Data Usage Responsibility: Scraped data must be handled with care, especially if it contains personal or sensitive information. It should never be exposed or misused.
Maintaining an ethical stance helps preserve trust across the digital ecosystem and ensures long-term viability of web scraping as a business tool.
How to Practice Ethical Web Scraping
To make your web scraping efforts both effective and ethical, consider the following best practices:
Review Website Policies: Always check the site’s terms of service and robots.txt file before scraping.
Limit Request Frequency: Sending too many requests at once can overload a website’s server. Adding delays between requests is a respectful practice.
Anonymize Sensitive Data: If your project involves sharing scraped data, make sure it does not expose personal information.
Use Reliable Tools and Secure Platforms: Implement scraping on well-developed systems that adhere to best practices in coding and data security.
Get Professional Help with Ethical Web Development
While scraping tools are powerful, integrating them into a secure and compliant workflow requires professional expertise. That’s where a reliable partner like Dzinepixel comes in. As a leading web development company in India, Dzinepixel has worked with a wide range of businesses to create customized, secure, and ethical digital solutions.
Whether you need assistance building an efficient scraping tool or a full-fledged data dashboard, their expert developers can help you:
Create scalable and secure backend systems
Ensure compliance with data protection laws
Develop user-friendly interfaces for visualizing scraped data
Build APIs and data integration pipelines
By relying on an experienced web development team, you can streamline your scraping workflows while avoiding legal or technical pitfalls.
Final Thoughts
Web scraping is a valuable technique that helps individuals and organizations access critical data quickly and efficiently. However, it’s essential to approach it with caution and ethics. By understanding how scraping works, respecting website policies, and managing data responsibly, you ensure long-term success and sustainability.
If you're considering a web scraping project, or if you want to build a robust and secure platform for your business, explore the services offered by Dzinepixel’s web development team. Their expertise in building high-performance digital systems can give you a competitive edge while staying compliant with all ethical and legal standards.
Start small—review a website’s policies, test your scraping tool responsibly, or consult a professional. The right foundation today ensures scalable, secure success tomorrow.
#best web development agencies india#website design and development company in india#website development company in india#web design company india#website designing company in india#digital marketing agency india
0 notes
Text
Here is the python code for an ip address html dirrect message box to a server console message! :
import socket from http.server import HTTPServer, BaseHTTPRequestHandler import argparse import threading import webbrowser import urllib.parse
class HTMLHandler(BaseHTTPRequestHandler): """Handles HTTP requests and serves HTML from input."""def do_GET(self): """Handles GET requests.""" if self.path.startswith('/'): if '?' in self.path: query = urllib.parse.urlsplit(self.path).query query_components = urllib.parse.parse_qs(query) if 'myTextbox' in query_components: text_input = query_components['myTextbox'][0] print(f"Text box input: {text_input}") # Print to console self.send_response(200) self.send_header('Content-type', 'text/html') self.end_headers() html_with_textbox = self.server.html_content + """ <br><br> <form action="/" method="GET"> <input type="text" id="myTextbox" name="myTextbox" placeholder="Type here..."> <input type="submit" value="Submit"> </form> """ self.wfile.write(html_with_textbox.encode('utf-8')) else: self.send_response(404) self.end_headers()
def run_server(ip_address, port, html_content): """Starts an HTTP server with dynamic HTML content.""" try: server = HTTPServer((ip_address, port), HTMLHandler) server.html_content = html_content print(f"Serving dynamic HTML on http://{ip_address}:{port}") server.serve_forever() except OSError as e: if e.errno == 98: print(f"Error: Address {ip_address}:{port} is already in use.") else: print(f"An unexpected Error occurred: {e}") except KeyboardInterrupt: print("\nStopping server…") server.shutdown() print("Server stopped.")
if name == "main": parser = argparse.ArgumentParser(description="Serve dynamic HTML from input.") parser.add_argument("-p", "--port", type=int, default=8000, help="Port number to listen on.") parser.add_argument("-i", "--ip", type=str, default="127.0.0.1", help="IP address to listen on.") parser.add_argument("-o", "--open", action="store_true", help="Open the webpage in a browser automatically.") parser.add_argument("-f", "--file", type=str, help="Read HTML content from a file.") parser.add_argument("html_content", nargs="*", help="HTML content to serve (as command-line arguments).")args = parser.parse_args() html_content = "" if args.file: try: with open(args.file, 'r') as f: html_content = f.read() except FileNotFoundError: print(f"Error: File '{args.file}' not found.") exit(1) elif args.html_content: html_content = " ".join(args.html_content) else: html_content = input("Enter HTML content: ") server_thread = threading.Thread(target=run_server, args=(args.ip, args.port, html_content)) server_thread.daemon = True server_thread.start() if args.open: webbrowser.open(f"http://{args.ip}:{args.port}") server_thread.join()
0 notes
Text
```markdown
Cryptocurrency SERP Data Scraping: Unveiling Insights from the Digital Frontier
In the ever-evolving landscape of digital currencies, understanding how cryptocurrencies are perceived and discussed online is crucial. One powerful tool for gaining these insights is through scraping Search Engine Results Pages (SERP) data. This method allows us to analyze trends, sentiment, and popular queries related to cryptocurrencies, providing a comprehensive view of the market's pulse.
Why SERP Data Matters in Cryptocurrency Analysis
1. Trend Identification: By analyzing SERP data, we can identify emerging trends in cryptocurrency discussions. This includes spotting new coins or technologies that are gaining traction among users.
2. Sentiment Analysis: Understanding the sentiment behind search queries can help gauge public opinion on specific cryptocurrencies. Is there a surge in negative sentiment around a particular coin? Are people more curious about regulatory news?
3. Competitive Intelligence: For businesses operating in the crypto space, monitoring SERP data can provide valuable competitive intelligence. It helps in understanding what competitors are doing right and where there might be gaps in the market.
How to Conduct Effective SERP Data Scraping
Tools and Techniques
Web Scraping Libraries: Python libraries like BeautifulSoup and Scrapy are essential for extracting data from web pages efficiently.
APIs: Some search engines offer APIs that allow developers to programmatically access their search results. Google’s Custom Search API is one such example.
Automation: Setting up automated scripts to scrape data regularly ensures that you always have the most up-to-date information.
Best Practices
Ethical Considerations: Always ensure that your scraping activities comply with the terms of service of the websites you are scraping. Respect robots.txt files and avoid overloading servers.
Data Privacy: Be mindful of privacy concerns when handling scraped data. Ensure that any personal information is anonymized and handled securely.
Case Study: Analyzing Bitcoin Trends
Let’s consider a hypothetical case study where we analyze Bitcoin-related searches over the past year. By looking at the volume of searches, we can see spikes corresponding to major events in the cryptocurrency world. For instance, a significant increase in searches around "Bitcoin halving" could indicate heightened interest during this event.
Conclusion and Discussion Points
Scraping SERP data offers a wealth of information for anyone interested in the cryptocurrency market. However, it also raises important questions about data ethics and privacy. As we continue to explore this digital frontier, it’s crucial to balance the benefits of data analysis with responsible practices.
What do you think are the most promising applications of SERP data in the cryptocurrency space? Share your thoughts and experiences below!
```
加飞机@yuantou2048

ETPU Machine
谷歌留痕
0 notes
Text
Top 20 Web Designing Interview Questions & Answers
Web designing is one of the most sought-after professions across various industries. This dynamic field evolves continuously with advancements in technology. To build a successful career in web designing, mastering the basics is essential. A comprehensive web designing course typically covers fundamental concepts like the box model, color theory, typography, positioning, and much more. Below, you'll find a collection of essential web designing interview questions and answers to help you excel in your career journey.
Web Designing Interview Questions & Answers
Which languages and platforms are most commonly used in website design?
Web designing can be learnt from the scratch
CSS and HTML basic learning
Web designing on trend and development
Web development debugging design inside
Create website portfolio
This course is ideal for both beginners and individuals with limited knowledge of web design. It opens up greater opportunities for web developers and those who are pursuing or aspiring to pursue careers as graphic designers.
Web design and development involve various languages, but JavaScript and Java are among the most prominent, with Python also playing a significant role.
These languages are versatile and can handle various tasks, such as controlling browsers, editing content, executing client-side scripts to interact with users, and enabling asynchronous communication.
What is HTML?
Hypertext Markup Language (HTML) is the standard tool for creating documents that can be displayed in a web browser. It structures documents by defining structural semantics to format text elements such as headings, lists, links, paragraphs, quotes, and more.
Here are the most commonly used tags in HTML:
HTML tag which is considered to be the the basic or the foundation of the HTML document
Head tag which has all kinds of head elements like title, style, meta in the HTML file
Body tag defines the HTML document body contains image, lists, tables
Title tag which defines the HTML document title
Empty or non container tags
Tables tags
Inputs tag, form tag, submit input tag, drop down option tag
What role does CSS play in web design?
CSS is used for the presentation of web pages, including elements like colors, layout, and fonts. It enables the presentation to adapt to various devices, such as screens, printers, or smaller screens. CSS is an independent language from HTML and is often used in XML-based markup languages.
What is an external stylesheet, and how is it linked?
An external stylesheet is a separate file linked to an HTML web page. It typically has a .CSS file extension and contains all the styles used throughout the website. This method is a valuable tool for webmasters, as it allows for centralized management of styles across multiple pages.
6. Explain how can you integrate CSS file to your webpage?
There are three ways to set CSS into the web pages
The external file should be linked into the webpage which can be done with the input method of old browsers like Netscape 4.0
Create the CSS block in the web page which typically gets most at the webpage top this happens in between the the head and head tax
Embed or insert the right CSS code with the tag itself
7. How do you differentiate between HTML tags and elements?
An HTML element refers to a fundamental component of a document. It consists of a start tag and an end tag, with the content placed between them, conveying the meaning of the element.
An HTML tag is used to define the beginning or end of an element. The terms "tag" and "element" are often used interchangeably, meaning an element is essentially a tag, and vice versa.
8. Here are some commonly used jQuery functions for webpage design:
This application is highly efficient, offering numerous functions that streamline tasks and accelerate processes. The framework plays a crucial role in building JavaScript, making development faster and more effective.
It can be used in local installation to include in the HTML cord.
Cdn best version can be included in the jQuery library.
Helps in developing ajax based applications.
Create quotes simple, reusable and precise.
The process gets simplified because of the html.com traverse.
Helps in handling events create animation with ajax support.
9. How can you set an image as a fixed background?
To fix or position a background image, CSS is essential. The background property in CSS is used to define background settings, and it allows for customization of the image placement. CSS2 provides functionality to fix the background, while CSS3 introduces values that enable fixing the background within a containing block.
10. What is an external stylesheet?
An external stylesheet is a separate file with a .CSS extension that contains all the CSS definitions for an HTML page. It is typically named something like "styles.css" and holds all the necessary styles for the HTML document.
11. What is doctype?
The DOCTYPE declaration is an instruction that associates a document with a specific SGML (Standard Generalized Markup Language) document type for XML. It is part of the document and defines the markup language in a concise string, ensuring it adheres to a specific syntax.
12. Explain the difference between Standard Mode and Quirks Mode.
In Quirks Mode, the page design behaves like non-standard rendering, a feature that originated with early versions of Microsoft Internet Explorer and Netscape Navigator.
In contrast, Standard Mode follows the HTML and CSS specifications for proper design behavior. Standard Mode is the preferred mode, as it adheres to the latest web standards, unlike the older Quirks Mode.
13. How would you scale route in Mobile Screens?
Online business transactions via mobile devices continue to grow each year, making mobile optimization increasingly important. This trend encourages companies to focus on creating websites and e-commerce platforms tailored for mobile users. The primary reasons for this shift include the diverse behaviors across different platforms, which drive the need for efficient website development and enhancement.
Web pages have different parameters like header, footer, main content, forms, videos images, tables, the screen dimensions in the devices, changing screen solutions to determine the pixel density and also work accordingly on the operating system.
These kinds of changes highly focus to the enhanced performance of the devices. It is mandatory that the sides have to be according to the adaptation of different devices, so the mobile first approach should be taken and produced matching the features.
14. When should you use the CSS float property?
The CSS float property is used to position an element to the left or right of its container, allowing text and inline elements to wrap around it. It is commonly used when you want to align an image and have text flow around it.
15. How do you insert comments into HTML code without text being picked up?
HTML commands are using different quotes in the browser the comment starts with “<*!—and end with”-->”
16. How many HTML tags are typically used for a basic web page design?
The number of HTML tags used for a web page depends on the specific design and functionality required. Below are some common tags that can be used to create a basic webpage.
IMG
Paragraph
DIV
SPAN
OL and UL
Anchor tag
Button
Input
Select
17. What do you mean by the prompt box?
The method called prompt exhibits the dialogue box which allows the visitor for inputs. It is used whenever the user wants to provide value before getting inside the page. This also returns the input value once the user tries to click the option “ok”.
18. Is CSS case sensitive?
The entire style sheets of CSS are case insensitive where certain parts are completely not under the CSS control. The HTML attributes like “id” and “class” are case sensitivity which comes under the category of font names and URIs. They are out of the specifications.
19. What are the elements that have been disappeared?
During the page creation many have noticed the disappearance of elements like the text, colour, text visibility, block visibility, block size, block position, font size and overlay.
20. For what purpose NaN functioning used?
This is a library function which gets the NaN value determining whether it actually a number or not. NaN expansion is not a number it comes back if it’s not true. If it is cancelled then it returns as null.
0 notes