#how to remove nodes from hadoop
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs




Fun Fact
12.7% of mobile users access Tumblr.
Text
Commissioning and Decommissioning Nodes in a Hadoop Cluster
Commissioning and Decommissioning Nodes in a Hadoop Cluster
One of the best Advantage in Hadoop is commissioning and decommissioning nodes in a hadoop cluster,If any node in hadoop cluster is crashed then decommissioning is useful suppose we want to add more nodes to our hadoop cluster then commissioning concept is useful.one of the most common task of a Hadoop administrator is to commission (Add) and decommission (Remove) Data Nodes in a Hadoop Cluster.
View On WordPress
#ambari decommission datanode#decommission datanode hadoop#decommissioning a node cloudera#hadoop remove dead node#how to remove nodes from hadoop#yarn decommission node
0 notes
Text
HERE'S WHAT I JUST REALIZED ABOUT WORK
It becomes a heuristic for making the right decisions about language design. As things currently work, their attitudes toward risk tend to be different attitudes toward ambition in Europe and the US. Never frame pages you link to, or there's not enough stock left to keep the founders interested. Their only hope now is to buy all the best deals. Err on the side of the story: what an essay really is, and how much funnier a bunch of ads, glued together by just enough articles to make it big, but you can't fix the location. As an outsider, don't be ruled by plans. You may even want to do, most kids have been thoroughly misled about the idea of letting founders partially cash out, let me tell them something still more frightening: you are now competing directly with Google. For example, I use it when I get close to a deadline. It's hard to follow, especially when you're young. A lot of doctors don't like the idea of reusability got attached to object-oriented programming in the 1980s, and no one who has more experience at trying to predict how the startups we've funded will do, because we're now three steps removed from real work: the students are imitating English professors, who are merely the inheritors of a tradition growing out of what was, 700 years ago, but it's where the trend points now. Empirically, the way to learn about are the needs of startups.
The startup is the opinion of other investors. Like Jane Austen, Lisp looks hard. For example, in 2004 Bill Clinton found he was feeling short of breath. Startups condense more easily here. Who else are you talking to? So it's not surprising that so many want to take. Facebook is running him as much as in present day South Korea.
It all evened out in the end, and offer programmers more parallelizable Lego blocks to build programs out of, like Hadoop and MapReduce. It was a lot of growth in this area, just as, occasionally, playing wasn't—for example, so competition ensured the average journalist was fairly good. A round. Does Web 2. I still occasionally buy on weekends. Some arrive feeling sure they will ace Y Combinator as they've aced every one of the O'Reilly people that guy looks just like Tim. Because investors don't understand the cost of compliance, which is almost necessarily impossible to predict. Work Day. Then I realized: maybe not.
But if you don't find it. A comparatively safe and prosperous career with some automatic baseline prestige is dangerously tempting to someone young, who hasn't thought much about what they want to do seem impressive, as if you couldn't be productive without being someone's employee. And that seems a bad road to go down. It happens naturally to anyone who does good work. Quite the opposite. And though this feels stressful, it's one reason startups win. Though most print publications are online, I suspect they unconsciously frame it as how to make money for you—and the company saying no?
Cram schools turn wealth in one generation into credentials in the next ten feet, this is the third counterintuitive thing to remember about startups: starting a startup is like a suit: it impresses the wrong people, and this variation is one of the original nodes, but by the end of high school I never read the books we were assigned. For example, I write essays the same way that car was. The same happens with writing. We had to pay $5000 for the Netscape Commerce Server, the only reason investors like startups so much? But raising money from investors is not about the founders or the product, but who else is investing? No one wants to look like a fool. I notice that I tend to use my inbox as a todo list. Investors tend to resist committing except to the extent you do.
Thanks to Harjeet Taggar, Geoff Ralston, and Jessica Livingston for inviting me to speak.
#automatically generated text#Markov chains#Paul Graham#Python#Patrick Mooney#breath#attitudes#something#frame#Facebook#day#money#cash#startup#area#employee#Server#someone#road#Commerce#trend#Taggar#tradition#one
0 notes
Text
Open Sourcing Vespa, Yahoo’s Big Data Processing and Serving Engine

By Jon Bratseth, Distinguished Architect, Vespa
Ever since we open sourced Hadoop in 2006, Yahoo – and now, Oath – has been committed to opening up its big data infrastructure to the larger developer community. Today, we are taking another major step in this direction by making Vespa, Yahoo’s big data processing and serving engine, available as open source on GitHub.

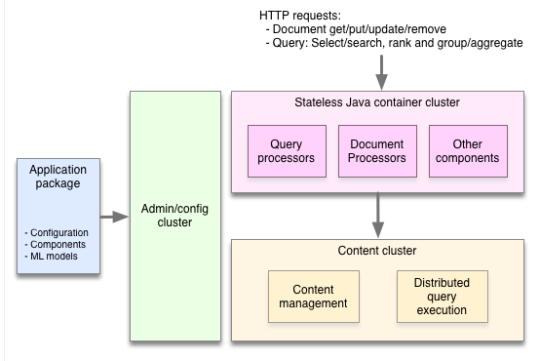
Vespa architecture overview
Building applications increasingly means dealing with huge amounts of data. While developers can use the Hadoop stack to store and batch process big data, and Storm to stream-process data, these technologies do not help with serving results to end users. Serving is challenging at large scale, especially when it is necessary to make computations quickly over data while a user is waiting, as with applications that feature search, recommendation, and personalization.
By releasing Vespa, we are making it easy for anyone to build applications that can compute responses to user requests, over large datasets, at real time and at internet scale – capabilities that up until now, have been within reach of only a few large companies.
Serving often involves more than looking up items by ID or computing a few numbers from a model. Many applications need to compute over large datasets at serving time. Two well-known examples are search and recommendation. To deliver a search result or a list of recommended articles to a user, you need to find all the items matching the query, determine how good each item is for the particular request using a relevance/recommendation model, organize the matches to remove duplicates, add navigation aids, and then return a response to the user. As these computations depend on features of the request, such as the user’s query or interests, it won’t do to compute the result upfront. It must be done at serving time, and since a user is waiting, it has to be done fast. Combining speedy completion of the aforementioned operations with the ability to perform them over large amounts of data requires a lot of infrastructure – distributed algorithms, data distribution and management, efficient data structures and memory management, and more. This is what Vespa provides in a neatly-packaged and easy to use engine.
With over 1 billion users, we currently use Vespa across many different Oath brands – including Yahoo.com, Yahoo News, Yahoo Sports, Yahoo Finance, Yahoo Gemini, Flickr, and others – to process and serve billions of daily requests over billions of documents while responding to search queries, making recommendations, and providing personalized content and advertisements, to name just a few use cases. In fact, Vespa processes and serves content and ads almost 90,000 times every second with latencies in the tens of milliseconds. On Flickr alone, Vespa performs keyword and image searches on the scale of a few hundred queries per second on tens of billions of images. Additionally, Vespa makes direct contributions to our company’s revenue stream by serving over 3 billion native ad requests per day via Yahoo Gemini, at a peak of 140k requests per second (per Oath internal data).
With Vespa, our teams build applications that:
Select content items using SQL-like queries and text search
Organize all matches to generate data-driven pages
Rank matches by handwritten or machine-learned relevance models
Serve results with response times in the low milliseconds
Write data in real-time, thousands of times per second per node
Grow, shrink, and re-configure clusters while serving and writing data
To achieve both speed and scale, Vespa distributes data and computation over many machines without any single master as a bottleneck. Where conventional applications work by pulling data into a stateless tier for processing, Vespa instead pushes computations to the data. This involves managing clusters of nodes with background redistribution of data in case of machine failures or the addition of new capacity, implementing distributed low latency query and processing algorithms, handling distributed data consistency, and a lot more. It’s a ton of hard work!
As the team behind Vespa, we have been working on developing search and serving capabilities ever since building alltheweb.com, which was later acquired by Yahoo. Over the last couple of years we have rewritten most of the engine from scratch to incorporate our experience onto a modern technology stack. Vespa is larger in scope and lines of code than any open source project we’ve ever released. Now that this has been battle-proven on Yahoo’s largest and most critical systems, we are pleased to release it to the world.
Vespa gives application developers the ability to feed data and models of any size to the serving system and make the final computations at request time. This often produces a better user experience at lower cost (for buying and running hardware) and complexity compared to pre-computing answers to requests. Furthermore it allows developers to work in a more interactive way where they navigate and interact with complex calculations in real time, rather than having to start offline jobs and check the results later.
Vespa can be run on premises or in the cloud. We provide both Docker images and rpm packages for Vespa, as well as guides for running them both on your own laptop or as an AWS cluster.
We’ll follow up this initial announcement with a series of posts on our blog showing how to build a real-world application with Vespa, but you can get started right now by following the getting started guide in our comprehensive documentation.
Managing distributed systems is not easy. We have worked hard to make it easy to develop and operate applications on Vespa so that you can focus on creating features that make use of the ability to compute over large datasets in real time, rather than the details of managing clusters and data. You should be able to get an application up and running in less than ten minutes by following the documentation.
We can’t wait to see what you’ll build with it!
13 notes
·
View notes
Text
Open Sourcing Vespa, Yahoo’s Big Data Processing and Serving Engine
By Jon Bratseth, Distinguished Architect, Vespa
Ever since we open sourced Hadoop in 2006, Yahoo – and now, Oath – has been committed to opening up its big data infrastructure to the larger developer community. Today, we are taking another major step in this direction by making Vespa, Yahoo’s big data processing and serving engine, available as open source on GitHub.
Building applications increasingly means dealing with huge amounts of data. While developers can use the Hadoop stack to store and batch process big data, and Storm to stream-process data, these technologies do not help with serving results to end users. Serving is challenging at large scale, especially when it is necessary to make computations quickly over data while a user is waiting, as with applications that feature search, recommendation, and personalization.
By releasing Vespa, we are making it easy for anyone to build applications that can compute responses to user requests, over large datasets, at real time and at internet scale – capabilities that up until now, have been within reach of only a few large companies.
Serving often involves more than looking up items by ID or computing a few numbers from a model. Many applications need to compute over large datasets at serving time. Two well-known examples are search and recommendation. To deliver a search result or a list of recommended articles to a user, you need to find all the items matching the query, determine how good each item is for the particular request using a relevance/recommendation model, organize the matches to remove duplicates, add navigation aids, and then return a response to the user. As these computations depend on features of the request, such as the user’s query or interests, it won’t do to compute the result upfront. It must be done at serving time, and since a user is waiting, it has to be done fast. Combining speedy completion of the aforementioned operations with the ability to perform them over large amounts of data requires a lot of infrastructure – distributed algorithms, data distribution and management, efficient data structures and memory management, and more. This is what Vespa provides in a neatly-packaged and easy to use engine.
With over 1 billion users, we currently use Vespa across many different Oath brands – including Yahoo.com, Yahoo News, Yahoo Sports, Yahoo Finance, Yahoo Gemini, Flickr, and others – to process and serve billions of daily requests over billions of documents while responding to search queries, making recommendations, and providing personalized content and advertisements, to name just a few use cases. In fact, Vespa processes and serves content and ads almost 90,000 times every second with latencies in the tens of milliseconds. On Flickr alone, Vespa performs keyword and image searches on the scale of a few hundred queries per second on tens of billions of images. Additionally, Vespa makes direct contributions to our company’s revenue stream by serving over 3 billion native ad requests per day via Yahoo Gemini, at a peak of 140k requests per second (per Oath internal data).
With Vespa, our teams build applications that:
Select content items using SQL-like queries and text search
Organize all matches to generate data-driven pages
Rank matches by handwritten or machine-learned relevance models
Serve results with response times in the low milliseconds
Write data in real-time, thousands of times per second per node
Grow, shrink, and re-configure clusters while serving and writing data
To achieve both speed and scale, Vespa distributes data and computation over many machines without any single master as a bottleneck. Where conventional applications work by pulling data into a stateless tier for processing, Vespa instead pushes computations to the data. This involves managing clusters of nodes with background redistribution of data in case of machine failures or the addition of new capacity, implementing distributed low latency query and processing algorithms, handling distributed data consistency, and a lot more. It’s a ton of hard work!
As the team behind Vespa, we have been working on developing search and serving capabilities ever since building alltheweb.com, which was later acquired by Yahoo. Over the last couple of years we have rewritten most of the engine from scratch to incorporate our experience onto a modern technology stack. Vespa is larger in scope and lines of code than any open source project we’ve ever released. Now that this has been battle-proven on Yahoo’s largest and most critical systems, we are pleased to release it to the world.
Vespa gives application developers the ability to feed data and models of any size to the serving system and make the final computations at request time. This often produces a better user experience at lower cost (for buying and running hardware) and complexity compared to pre-computing answers to requests. Furthermore it allows developers to work in a more interactive way where they navigate and interact with complex calculations in real time, rather than having to start offline jobs and check the results later.
Vespa can be run on premises or in the cloud. We provide both Docker images and rpm packages for Vespa, as well as guides for running them both on your own laptop or as an AWS cluster.
We’ll follow up this initial announcement with a series of posts on our blog showing how to build a real-world application with Vespa, but you can get started right now by following the getting started guide in our comprehensive documentation.
Managing distributed systems is not easy. We have worked hard to make it easy to develop and operate applications on Vespa so that you can focus on creating features that make use of the ability to compute over large datasets in real time, rather than the details of managing clusters and data. You should be able to get an application up and running in less than ten minutes by following the documentation.
We can’t wait to see what you’ll build with it!
6 notes
·
View notes
Text
300+ TOP Apache YARN Interview Questions and Answers
YARN Interview Questions for freshers experienced :-
1. What Is Yarn? Apache YARN, which stands for 'Yet another Resource Negotiator', is Hadoop cluster resource management system. YARN provides APIs for requesting and working with Hadoop's cluster resources. These APIs are usually used by components of Hadoop's distributed frameworks such as MapReduce, Spark, and Tez etc. which are building on top of YARN. User applications typically do not use the YARN APIs directly. Instead, they use higher level APIs provided by the framework (MapReduce, Spark, etc.) which hide the resource management details from the user. 2. What Are The Key Components Of Yarn? The basic idea of YARN is to split the functionality of resource management and job scheduling/monitoring into separate daemons. YARN consists of the following different components: Resource Manager - The Resource Manager is a global component or daemon, one per cluster, which manages the requests to and resources across the nodes of the cluster. Node Manager - Node Manger runs on each node of the cluster and is responsible for launching and monitoring containers and reporting the status back to the Resource Manager. Application Master is a per-application component that is responsible for negotiating resource requirements for the resource manager and working with Node Managers to execute and monitor the tasks. Container is YARN framework is a UNIX process running on the node that executes an application-specific process with a constrained set of resources (Memory, CPU, etc.). 3. What Is Resource Manager In Yarn? The YARN Resource Manager is a global component or daemon, one per cluster, which manages the requests to and resources across the nodes of the cluster. The Resource Manager has two main components - Scheduler and Applications Manager. Scheduler - The scheduler is responsible for allocating resources to and starting applications based on the abstract notion of resource containers having a constrained set of resources. Application Manager - The Applications Manager is responsible for accepting job-submissions, negotiating the first container for executing the application specific Application Master and provides the service for restarting the Application Master container on failure. 4. What Are The Scheduling Policies Available In Yarn? YARN scheduler is responsible for scheduling resources to user applications based on a defined scheduling policy. YARN provides three scheduling options - FIFO scheduler, Capacity scheduler and Fair scheduler. FIFO Scheduler - FIFO scheduler puts application requests in queue and runs them in the order of submission. Capacity Scheduler - Capacity scheduler has a separate dedicated queue for smaller jobs and starts them as soon as they are submitted. Fair Scheduler - Fair scheduler dynamically balances and allocates resources between all the running jobs. 5. How Do You Setup Resource Manager To Use Capacity Scheduler? You can configure the Resource Manager to use Capacity Scheduler by setting the value of property 'yarn.resourcemanager.scheduler.class' to 'org.apache.hadoop.yarn.server.resourcemanager.scheduler.capacity.CapacityScheduler' in the file 'conf/yarn-site.xml'. 6. How Do You Setup Resource Manager To Use Fair Scheduler? You can configure the Resource Manager to use FairScheduler by setting the value of property 'yarn.resourcemanager.scheduler.class' to 'org.apache.hadoop.yarn.server.resourcemanager.scheduler.fair.FairScheduler' in the file 'conf/yarn-site.xml'. 7. How Do You Setup Ha For Resource Manager? Resource Manager is responsible for scheduling applications and tracking resources in a cluster. Prior to Hadoop 2.4, the Resource Manager does not have option to be setup for HA and is a single point of failure in a YARN cluster. Since Hadoop 2.4, YARN Resource Manager can be setup for high availability. High availability of Resource Manager is enabled by use of Active/Standby architecture. At any point of time, one Resource Manager is active and one or more of Resource Managers are in the standby mode. In case the active Resource Manager fails, one of the standby Resource Managers transitions to an active mode. 8. What Are The Core Changes In Hadoop 2.x? Many changes, especially single point of failure and Decentralize Job Tracker power to data-nodes is the main changes. Entire job tracker architecture changed. Some of the main difference between Hadoop 1.x and 2.x given below: Single point of failure – Rectified. Nodes limitation (4000- to unlimited) – Rectified. Job Tracker bottleneck – Rectified. Map-reduce slots are changed static to dynamic. High availability – Available. Support both Interactive, graph iterative algorithms (1.x not support). Allows other applications also to integrate with HDFS. 9. What Is The Difference Between Mapreduce 1 And Mapreduce 2/yarn? In MapReduce 1, Hadoop centralized all tasks to the Job Tracker. It allocates resources and scheduling the jobs across the cluster. In YARN, de-centralized this to ease the work pressure on the Job Tracker. Resource Manager responsibility allocate resources to the particular nodes and Node manager schedule the jobs on the application Master. YARN allows parallel execution and Application Master managing and execute the job. This approach can ease many Job Tracker problems and improves to scale up ability and optimize the job performance. Additionally YARN can allows to create multiple applications to scale up on the distributed environment. 10. How Hadoop Determined The Distance Between Two Nodes? Hadoop admin write a script called Topology script to determine the rack location of nodes. It is trigger to know the distance of the nodes to replicate the data. Configure this script in core-site.xml topology.script.file.name core/rack-awareness.sh in the rack-awareness.sh you should write script where the nodes located.

Apache YARN Interview Questions 11. Mistakenly User Deleted A File, How Hadoop Remote From Its File System? Can U Roll Back It? HDFS first renames its file name and place it in /trash directory for a configurable amount of time. In this scenario block might freed, but not file. After this time, Namenode deletes the file from HDFS name-space and make file freed. It’s configurable as fs.trash.interval in core-site.xml. By default its value is 1, you can set to 0 to delete file without storing in trash. 12. What Is Difference Between Hadoop Namenode Federation, Nfs And Journal Node? HDFS federation can separate the namespace and storage to improve the scalability and isolation. 13. Yarn Is Replacement Of Mapreduce? YARN is generic concept, it support MapReduce, but it’s not replacement of MapReduce. You can development many applications with the help of YARN. Spark, drill and many more applications work on the top of YARN. 14. What Are The Core Concepts/processes In Yarn? Resource manager: As equivalent to the Job Tracker Node manager: As equivalent to the Task Tracker. Application manager: As equivalent to Jobs. Everything is application in YARN. When client submit job (application), Containers: As equivalent to slots. Yarn child: If you submit the application, dynamically Application master launch Yarn child to do Map and Reduce tasks. If application manager failed, not a problem, resource manager automatically start new application task. 15. Steps To Upgrade Hadoop 1.x To Hadoop 2.x? To upgrade 1.x to 2.x dont upgrade directly. Simple download locally then remove old files in 1.x files. Up-gradation take more time. Share folder there. its important.. share.. hadoop .. mapreduce .. lib. Stop all processes. Delete old meta data info… from work/hadoop2data Copy and rename first 1.x data into work/hadoop2.x Don’t format NN while up gradation. Hadoop namenode -upgrade // It will take a lot of time. Don’t close previous terminal open new terminal. Hadoop namenode -rollback. 16. What Is Apache Hadoop Yarn? YARN is a powerful and efficient feature rolled out as a part of Hadoop 2.0.YARN is a large scale distributed system for running big data applications. 17. Is Yarn A Replacement Of Hadoop Mapreduce? YARN is not a replacement of Hadoop but it is a more powerful and efficient technology that supports MapReduce and is also referred to as Hadoop 2.0 or MapReduce 2. 18. What Are The Additional Benefits Yarn Brings In To Hadoop? Effective utilization of the resources as multiple applications can be run in YARN all sharing a common resource. In Hadoop MapReduce there are seperate slots for Map and Reduce tasks whereas in YARN there is no fixed slot. The same container can be used for Map and Reduce tasks leading to better utilization. YARN is backward compatible so all the existing MapReduce jobs. Using YARN, one can even run applications that are not based on the MapReduce model. 19. How Can Native Libraries Be Included In Yarn Jobs? There are two ways to include native libraries in YARN jobs:- By setting the -Djava.library.path on the command line but in this case there are chances that the native libraries might not be loaded correctly and there is possibility of errors. The better option to include native libraries is to the set the LD_LIBRARY_PATH in the .bashrc file. 20. Explain The Differences Between Hadoop 1.x And Hadoop 2.x? In Hadoop 1.x, MapReduce is responsible for both processing and cluster management whereas in Hadoop 2.x processing is taken care of by other processing models and YARN is responsible for cluster management. Hadoop 2.x scales better when compared to Hadoop 1.x with close to 10000 nodes per cluster. Hadoop 1.x has single point of failure problem and whenever the Namenode fails it has to be recovered manually. However, in case of Hadoop 2.x StandBy Namenode overcomes the SPOF problem and whenever the Namenode fails it is configured for automatic recovery. Hadoop 1.x works on the concept of slots whereas Hadoop 2.x works on the concept of containers and can also run generic tasks. 21. What Are The Core Changes In Hadoop 2.0? Hadoop 2.x provides an upgrade to Hadoop 1.x in terms of resource management, scheduling and the manner in which execution occurs. In Hadoop 2.x the cluster resource management capabilities work in isolation from the MapReduce specific programming logic. This helps Hadoop to share resources dynamically between multiple parallel processing frameworks like Impala and the core MapReduce component. Hadoop 2.x Hadoop 2.x allows workable and fine grained resource configuration leading to efficient and better cluster utilization so that the application can scale to process larger number of jobs. 22. Differentiate Between Nfs, Hadoop Namenode And Journal Node? HDFS is a write once file system so a user cannot update the files once they exist either they can read or write to it. However, under certain scenarios in the enterprise environment like file uploading, file downloading, file browsing or data streaming –it is not possible to achieve all this using the standard HDFS. This is where a distributed file system protocol Network File System (NFS) is used. NFS allows access to files on remote machines just similar to how local file system is accessed by applications. Namenode is the heart of the HDFS file system that maintains the metadata and tracks where the file data is kept across the Hadoop cluster. StandBy Nodes and Active Nodes communicate with a group of light weight nodes to keep their state synchronized. These are known as Journal Nodes. 23. What Are The Modules That Constitute The Apache Hadoop 2.0 Framework? Hadoop 2.0 contains four important modules of which 3 are inherited from Hadoop 1.0 and a new module YARN is added to it. Hadoop Common – This module consists of all the basic utilities and libraries that required by other modules. HDFS- Hadoop Distributed file system that stores huge volumes of data on commodity machines across the cluster. MapReduce- Java based programming model for data processing. YARN- This is a new module introduced in Hadoop 2.0 for cluster resource management and job scheduling. 24. How Is The Distance Between Two Nodes Defined In Hadoop? Measuring bandwidth is difficult in Hadoop so network is denoted as a tree in Hadoop. The distance between two nodes in the tree plays a vital role in forming a Hadoop cluster and is defined by the network topology and java interface DNS Switch Mapping. The distance is equal to the sum of the distance to the closest common ancestor of both the nodes. The method get Distance(Node node1, Node node2) is used to calculate the distance between two nodes with the assumption that the distance from a node to its parent node is always 1. Apache YARN Questions and Answers Pdf Download Read the full article
0 notes
Text
Backfilling an Amazon DynamoDB Time to Live (TTL) attribute with Amazon EMR
Bulk updates to a database can be disruptive and potentially cause downtime, performance impacts to your business processes, or overprovisioning of compute and storage resources. When performing bulk updates, you want to choose a process that runs quickly, enables you to operate your business uninterrupted, and minimizes your cost. Let’s take a look at how we can achieve this with a NoSQL database such as Amazon DynamoDB. DynamoDB is a NoSQL database that provides a flexible schema structure to allow for some items in a table to have attributes that don’t exist in all items (in relational database terms, some columns can exist only in some rows while being omitted from other rows). DynamoDB is built to run at extreme scale, which allows for tables that have petabytes of data and trillions of items, so you need a scalable client for doing these types of whole-table mutations. For these use cases, you typically use Amazon EMR. Because DynamoDB provides elastic capacity, there is no need to over-provision during normal operations to accommodate occasional bulk operations; you can simply add capacity to your table during the bulk operation and remove that capacity when it’s complete. DynamoDB supports a feature called Time to Live (TTL). You can use TTL to delete expired items from your table automatically at no additional cost. Because deleting an item normally consumes write capacity, TTL can result in significant cost savings for certain use cases. For example, you can use TTL to delete the session data or items that you’ve already archived to an Amazon Simple Storage Service (Amazon S3) bucket for long-term retention. To use TTL, you designate an attribute in your items that contains a timestamp (encoded as number of seconds since the Unix epoch), at which time DynamoDB considers the item to have expired. After the item expires, DynamoDB deletes it, generally within 48 hours of expiration. For more information about TTL, see Expiring Items Using Time to Live. Ideally, you choose a TTL attribute before you start putting data in your DynamoDB table. However, DynamoDB users often start using TTL after their table includes data. It’s straightforward to modify your application to add the attribute with a timestamp to any new or updated items, but what’s the best way to backfill the TTL attribute for all older items? It’s usually recommended to use Amazon EMR for bulk updates to DynamoDB tables because it’s a highly scalable solution with built-in functionality for connecting with DynamoDB. You can run this Amazon EMR job after you modify your application to add a TTL attribute for all new items. This post shows you how to create an EMR cluster and run a Hive query inside Amazon EMR to backfill a TTL attribute to items that are missing it. You calculate the new TTL attribute on a per-item basis using another timestamp attribute that already exists in each item. DynamoDB schema To get started, create a simple table with the following attributes: pk – The partition key, which is a string in universally unique identifier (UUID) form creation_timestamp – A string that represents the item’s creation timestamp in ISO 8601 format expiration_epoch_time – A number that represents the item’s expiration time in seconds since the epoch, which is 3 years after the creation_timestamp This post uses a table called TestTTL with 4 million items. One million of those items were inserted after deciding to use TTL, which means 3 million items are missing the expiration_epoch_time attribute. The following screenshot shows a sample of the items in the TestTTL table. Due to the way Hive operates with DynamoDB, this method is safe for modifying items that don’t change while the Hive INSERT OVERWRITE query is running. If your applications might be modifying items with the missing expiration_epoch_time attribute, you need to either take application downtime while running the query or use another technique based on condition expressions (which Hive and the underlying emr-dynamodb-connector don’t do). For more information, see Condition Expressions. Some of your DynamoDB items already contain the expiration_epoch_time attribute. Also, you can consider some of the items expired, based on your rule regarding data that is at least 3 years old. See the following code from the AWS CLI; you refer to this item later when the Hive query is done to verify that the job worked as expected: aws dynamodb get-item --table-name TestTTL --key '{"pk" : {"S" : "02a8a918-69fd-4291-9b45-3802bf357ef8"}}' { "Item": { "pk": { "S": "02a8a918-69fd-4291-9b45-3802bf357ef8" }, "creation_timestamp": { "S": "2017-10-12T20:10:50Z" } } } Creating the EMR cluster To create your cluster, complete the following steps: On the Amazon EMR console, choose Create cluster. For Cluster name, enter a name for your cluster; for example, emr-ddb-ttl-update. Optionally, change the Amazon S3 logging folder. The default location is a folder that uses your account number. In the Software configuration section, for Release, choose emr-6.6.0 or the latest Amazon EMR release available. For Applications, select Core Hadoop. This configuration includes Hive and has everything you need to add the TTL attribute. In the Hardware configuration section, for Instance type, choose c5.4xlarge. This core node (where the Hive query runs) measures approximately how many items instances of that size can process per minute. In the Security and access section, for EC2 key pair, choose a key pair you have access to, because you need to SSH to the master node to run the Hive CLI. To optimize this further and achieve a better cost-to-performance ratio, you could go into the advanced options and choose a smaller instance size for the master node (such as an m5.xlarge), which doesn’t have large computational requirements and is used as a client for running tasks, or disable unnecessary services such as Ganglia, but those changes are out of the scope of this post. For more information about creating an EMR cluster, see Analyzing Big Data with Amazon EMR. Choose Create cluster. SSHing to the Amazon EMR master node After you have created your EMR cluster and it’s in the Waiting state, SSH to the master node of the cluster. In the cluster view on the console, you can find SSH instructions. For instructions on how to SSH into the EMR cluster’s master node, choose the SSH link for Master public DNS on the Summary tab. You might have to edit the security group of your master node to allow SSH from your IP address. The Amazon EMR console links to the security group on the Summary tab. For more information, see Authorizing inbound traffic for your Linux instances. Running Hive CLI commands You’re now ready to run the Hive CLI on the master node. Verify that there are no databases, and create a database to host your external DynamoDB table. This database doesn’t actually store data in your EMR cluster; you create an EXTERNAL TABLE in a future step that is a pointer to the actual DynamoDB table. The commands you run at the Hive CLI prompt are noted in bold type in the following code. Start by running the hive command at the Bash prompt: # hive hive> show databases; OK default Time taken: 0.483 seconds, Fetched: 1 row(s) hive> create database dynamodb_hive; OK Time taken: 0.204 seconds hive> show databases; OK default dynamodb_hive Time taken: 0.035 seconds, Fetched: 2 row(s) hive> use dynamodb_hive; OK Time taken: 0.029 seconds hive> Create your external DynamoDB table mapping in Hive by entering the following code (adjust this to match your attribute names and schema): hive> CREATE EXTERNAL TABLE ddb_testttl (creation_timestamp string, pk string, expiration_epoch_time bigint) STORED BY 'org.apache.hadoop.hive.dynamodb.DynamoDBStorageHandler' TBLPROPERTIES ("dynamodb.table.name" = "TestTTL", "dynamodb.column.mapping" = "creation_timestamp:creation_timestamp,pk:pk,expiration_epoch_time:expiration_epoch_time"); OK Time taken: 1.487 seconds hive> For more information, see Creating an External Table in Hive. To find out how many items exist that don’t contain the expiration_epoch_time attribute, enter the following code: hive> select count(*) from ddb_testttl where expiration_epoch_time IS NULL; Query ID = hadoop_20200210213234_20b0bc7a-bbb3-4450-82ac-7ecdad9b1e85 Total jobs = 1 Launching Job 1 out of 1 Tez session was closed. Reopening... Session re-established. Status: Running (Executing on YARN cluster with App id application_1581025480470_0002) VERTICES MODE STATUS TOTAL COMPLETED RUNNING PENDING FAILED KILLED Map 1 .......... container SUCCEEDED 14 14 0 0 0 0 Reducer 2 ...... container SUCCEEDED 1 1 0 0 0 0 VERTICES: 02/02 [==========================>>] 100% ELAPSED TIME: 20.80 s OK 3000000 Time taken: 19.783 seconds, Fetched: 1 row(s) hive> For this use case, a Hive query needs to update 3 million items and add the expiration_epoch_time attribute to each. Run the Hive query to add the expiration_epoch_time attribute to rows where it’s missing. You want the items to expire 3 years after they were inserted, so add the number of seconds in 3 years to the creation timestamp. . To achieve this addition, you need to modify your creation_timestamp string values (see the following example code). The Hive helper function unix_timestamp() converts dates stored in string format to an integer of seconds since the Unix epoch. . However, the helper function expects dates in the format yyyy-MM-dd HH:mm:ss, but the date format of these items is an ISO 8601 variant of yyyy-MM-ddTHH:mm:ssZ. You need to tell Hive to strip the T between the days (dd) and hours (HH), and tell Hive to strip the trailing Z that represents the UTC time zone. For that you can use the regex_replace() helper function to modify the creation_timestamp attribute into the unix_timestamp() function. . Depending on the exact format of the strings in your data, you might need to modify this regex_replace(). For more information, see Date Functions in the Apache Hive manual. hive> INSERT OVERWRITE TABLE ddb_testttl SELECT creation_timestamp, pk, (unix_timestamp(regexp_replace(creation_timestamp, '^(.+?)T(.+?)Z$','$1 $2')) + (60*60*24*365*3)) FROM ddb_testttl WHERE expiration_epoch_time IS NULL; Query ID = hadoop_20200210215256_2a789691-defb-4d98-a1e5-84b5b12d3edf Total jobs = 1 Launching Job 1 out of 1 Tez session was closed. Reopening... Session re-established. Status: Running (Executing on YARN cluster with App id application_1581025480470_0003) VERTICES MODE STATUS TOTAL COMPLETED RUNNING PENDING FAILED KILLED Map 1 .......... container SUCCEEDED 14 14 0 0 0 0 VERTICES: 01/01 [==========================>>] 100% ELAPSED TIME: 165.88 s OK Time taken: 167.187 seconds In the preceding results of running the query, the Map 1 phase of this job launched a total of 14 mappers with a single core node, which makes sense because a c5.4xlarge instance has 16 vCPU, so the Hive job used most of them. The Hive job took 167 seconds to run. Check the query to see how many items are still missing the expiration_epoch_time attribute. See the following code: hive> select count(*) from ddb_testttl where expiration_epoch_time IS NULL; Query ID = hadoop_20200210221352_0436dc18-0676-42e1-801b-6bd6882d0004 Total jobs = 1 Launching Job 1 out of 1 Status: Running (Executing on YARN cluster with App id application_1581025480470_0004) VERTICES MODE STATUS TOTAL COMPLETED RUNNING PENDING FAILED KILLED Map 1 .......... container SUCCEEDED 18 18 0 0 0 0 Reducer 2 ...... container SUCCEEDED 1 1 0 0 0 0 VERTICES: 02/02 [==========================>>] 100% ELAPSED TIME: 12.35 s OK 0 Time taken: 16.483 seconds, Fetched: 1 row(s) hive> As you can see from the 0 answer after the OK status of the job, all items are updated with the new attribute. For example, see the following code of the single item you examined earlier: aws dynamodb get-item --table-name TestTTL --key '{"pk" : {"S" : "02a8a918-69fd-4291-9b45-3802bf357ef8"}}' { "Item": { "pk": { "S": "02a8a918-69fd-4291-9b45-3802bf357ef8" }, "creation_timestamp": { "S": "2017-10-12T20:10:50Z" }, "expiration_epoch_time": { "N": "1602447050" } } } The expiration_epoch_time attribute has been added to the item with a value of 1602447050, which according to EpochConverter corresponds to Sunday, October 11, 2020, at 8:10:50 PM GMT, exactly 3 years after the item’s creation_timestamp. Sizing and testing considerations For this use case, you used a single c5.4xlarge EMR core instance to run the Hive query, and the instance scanned 4 million documents and modified 3 million of them in approximately 3 minutes. By default, Hive consumes half the read and write capacity of your DynamoDB table to allow operational processes to function while the Hive job is running. You need to choose an appropriate number of core or task instances in your EMR cluster and set the DynamoDB capacity available to Hive to an appropriate percentage so that you don’t overwhelm the capacity you’ve chosen to provision for your table and experience throttling in your production workload. For more information about adjusting the Hive DynamoDB capacity, see DynamoDB Provisioned Throughput. To make the job run faster, make sure your table is using provisioned capacity mode and temporarily increase the provisioned RCU and WCU while the Hive query is running. This is especially important if you have a large amount of data but low table throughput for regular operations. When the Hive query is complete, you can scale down your provisioned capacity or switch back to on-demand capacity for your table. Additionally, increase the parallelism of the Hive tasks by increasing the number of core or task instances in the EMR cluster, or by using different instance types. Hive launches approximately one mapper task for each vCPU in the cluster (a few vCPUs are reserved for system use). For example, running the preceding Hive query with three c5.4xlarge EMR core instances uses 46 mappers, which reduces the runtime from 3 minutes to 74 seconds. Running the query with 10 c5.4xlarge instances uses 158 mappers and reduces the runtime to 24 seconds. For more information about core and task nodes, see Understanding Master, Core, and Task Nodes. One option for testing your hive query against the full dataset is to use DynamoDB on-demand backup and restore to create a temporary copy of your table. You can run the Hive query against that temporary copy to determine an appropriate EMR cluster size before running the query against your production table. However, there is a cost associated with running the on-demand backup and restore. In addition, you can restart this Hive query safely if there is an interruption. If the job exits early for some reason, you can always restart the query because it makes modifications only to rows where the TTL attribute is missing. However, restarting it results in extra read capacity unit consumption because each Hive query restarts the table scan. Cleaning up To avoid unnecessary costs, don’t forget to terminate your EMR cluster after the Hive query is done if you no longer need that resource. Conclusion Hive queries offer a straightforward and flexible way to add new, calculated attributes to DynamoDB items that are missing those attributes. If you have a need to backfill a TTL attribute for items that already exist, get started today! About the Authors Chad Tindel is a DynamoDB Specialist Solutions Architect based out of New York City. He works with large enterprises to evaluate, design, and deploy DynamoDB-based solutions. Prior to joining Amazon he held similar roles at Red Hat, Cloudera, MongoDB, and Elastic. Andre Rosa is a Partner Trainer with Amazon Web Services. He has 20 years of experience in the IT industry, mostly dedicated to the database world. As a member of the AWS Training and Certification team, he exercises one of his passions: learning and sharing knowledge with AWS Partners as they work on projects on their journey to the cloud. Suthan Phillips is a big data architect at AWS. He works with customers to provide them architectural guidance and helps them achieve performance enhancements for complex applications on Amazon EMR. In his spare time, he enjoys hiking and exploring the Pacific Northwest. https://probdm.com/site/MjM1NDk
0 notes
Link
Salesforce training in noida :- You won't recognize it yet, but each time you log in to Salesforce you’re getting access to an extremely powerful lever of exchange for you, your institution, and your business enterprise. Sounds like a tall order however keep in mind this: What price do you put on your consumer relationships? Your partner relationships? If you’re a sales rep, it’s your livelihood. And if you’re in management, you have got fewer assets greater valuable than your current companion and client base. What if you had a device that would simply assist you manipulate your companions and clients? Salesforce isn’t the primary purchaser dating management (CRM) system to hit the market, however it’s dramatically one-of-a-kind. Unlike traditional CRM software program, Salesforce is an Internet service. You sign on, log in thru a browser, and it’s at once available. Salesforce customers typically say that it’s different for three fundamental reasons. With Salesforce, you presently have a complete suite of services to control the client lifecycle. This includes tools to pursue leads, control money owed, track possibilities, clear up instances, and extra. Depending to your crew’s goals, you may use all Salesforce tools from day one or simply the capability to deal with the priorities to hand.
Fast: When you sign on the dotted line, you need your CRM system up the day prior to this. Traditional CRM software program should take extra than a 12 months to set up; examine that two months or maybe weeks with Salesforce.
Easy: End consumer adoption is vital to any application, and Salesforce wins the ease-of-use category hands down. You can spend greater time placing it to apply and much less time figuring it out.
Effective: Because it’s clean to apply and can be customized fast to satisfy business wishes, clients have established that it has stepped forward their backside strains. Salesforce training course in noida
Using Salesforce to Solve Critical Business Challenges-
We may want to write every other book telling you all of the notable matters you could do with Salesforce, however you may get the big photograph from this chapter. We recognition here
on the maximum commonplace commercial enterprise demanding situations that we hear from sales, advertising and marketing, and guide executives — and the way Salesforce can triumph over them.
Understanding your customer:-
How can you sell and maintain a customer if you don’t understand their wishes, human beings, and what account activities and transactions have taken place? With Salesforce, you can tune all your important patron records in one region so that you can expand solutions that deliver actual fee to your customers.
Centralizing contacts underneath one roof:-
How a whole lot time have you ever wasted monitoring down a consumer touch or an cope with which you realize exists in the walls of your organization? With Salesforce, you could quickly centralize and prepare your money owed and contacts so that you can capitalize on that records when you want to. Expanding the funnel
Inputs and outputs, right? The greater leads you generate and pursue, the greater the chance that your revenue will develop. So the massive question is, “How
do I make the system paintings?” With Salesforce, you may plan, control, measure, and enhance lead generation, qualification, and conversion. You can see how lots commercial enterprise is generated, resources, and who’s making it show up. Consolidating your pipeline Pipeline reviews are reports that give agencies perception into future sales. Yet we’ve worked with companies in which producing the weekly pipeline should take a day of cat herding and guesswork. Reps waste time updating spreadsheets. Managers waste time chasing reps and scrubbing statistics. Bosses waste time tearing their hair out due to the fact the information is antique by the point they get it. With Salesforce, you can shorten or remove all that. As long as reps control all their possibilities in Salesforce, managers can generate updated pipeline reviews with the click of a button.
Working as a team
How regularly have you ever thought that your own co-people got in the manner of selling? Nine out of ten instances, the task isn’t human beings, but standardizing processes and clarifying roles and duties. With Salesforce, you could outline groups and strategies for income, marketing, and customer support, so the left hand knows what the right hand is doing. Although Salesforce doesn’t resolve corporate alignment troubles, you presently have the tool that can pressure and manipulate better crew collaboration.
Collaborating with your partners
In many industries, promoting without delay is a factor of the beyond. To gain leverage and cover more territory, many agencies paintings through partners. With Salesforce, your channel reps can music and companion partners’ offers and get higher insight on who their top companions are. Partners now can support their relationships with their companies with the aid of getting greater visibility into their joint income and advertising and marketing efforts.
Beating the competition
How a whole lot money have you misplaced to competition? How in many instances did you lose a deal most effective to discover, after the fact, that it went for your arch nemesis?
If you realize who you’re up against, you could probably higher role yourself to win the possibility. With Salesforce, you and your teams can track opposition on deals, accumulate aggressive intelligence, and develop movement plans to wear out your foes.
Improving customer support
As a sales individual, have you ever walked right into a purchaser’s workplace looking forward to a renewal handiest to be hit with a landmine due to an unresolved consumer trouble? And if you work in customer service, how plenty time do you waste on seeking to become aware of the patron and their entitlements? With Salesforce, you could effectively capture, control, and resolve patron problems. By managing instances in Salesforce, sales reps get visibility into the fitness in their debts, and service is better informed of sales and account activity. Salesforce training center in noida
WEBTRACKKER TECHNOLOGY (P) LTD.
B - 85, sector- 64, Noida, India.
E-47 Sector 3, Noida, India.
+91 - 8802820025
0120-433-0760
+91 - 8810252423
012 - 04204716
EMAIL:[email protected]
http://webtrackker.com/Salesforce-Training-Institute-in-Noida.php
Salesforce Training in noida
python Training in noida
data science training in noida
machine learning training in noida
Digital Marketing Training center in Noida
Digital Marketing Training in Noida
hadoop training in noida
devops training in noida
openstack training in noida
Ethical Hacking Training In Noida
Python Training Institute in Noida
Solidworks Training Institute in Noida
Hadoop training institute in Noida
SAP FICO Training Institute in Noida
AWS Training Institute in Noida
AutoCAD Training Institute In Noida
Linux Training Institute In Noida
Data Science With python training Institute in Noida
SAS Training Institute in Noida
6 weeks industrial training in noida
machine learning training Institute in Noida
salesforce training institute in noida
php training institute in noida
uipath training institute in noida
Data Science training Institute in Noida
sap training institute in noida
azure training institute in noida
sap mm training institute in noida
web designing institute in noida
AWS Training course in Noida
AWS Training center in Noida
Python Training course in Noida
Python Training center in Noida
Hadoop training course in Noida
Hadoop training center in Noida
SAP FICO Training course in Noida
SAP FICO Training center in Noida
Linux Training course In Noida
Linux Training center In Noida
SAS Training course in Noida
SAS Training center in Noida
Machine learning training course in Noida
Machine learning training center in Noida
Solidworks Training course in Noida
Solidworks Training center in Noida
cloud computing training in noida
oracle training in noida
oracle training center in noida
sql training center in noida
best sql training in noida
best plsql training in noida
node js training in noida
angular 6 training in noida
angularjs training in noida
mean stack training in noida
digital marketing training in noida
digital marketing training center in
noida
blue prism training center in noida
sap hr training center in noida
java Training center In Noida
Best Ielts coaching centre in noida
Best AWS Training Institute in Noida sector 15
Best AWS Training Institute in Noida sector 16
Best AWS Training Institute in Noida sector 18
Hadoop Certification Training Institute in Noida
Best Cloud Computing Training Institute in noida near metro station
best GraphQL training institute in Noida
Full stack developer training in Noida
Best C and C++ Training institute in Noida
Best AngularJS 4, 6 Training Institute In gurgaon
python training in noida sector 15
python training in sector 15 noida
data science training in sector 15 noida
oracle training center in noida sector 62
oracle training institute in noida sector 63
oracle training institute in noida sector 64
oracle training institute in noida sector 15
web designing training in noida
sas training centre in noida
sas training in noida
angular training in noida
angular 6 training in noida
best institute for angularjs in noida
node js training in noida
aws training in noida sector 16
aws training in noida sector 18
aws training in noida sector 15
Best AngularJS 6 training institute in Noida
Best AngularJS 8 training institute in Noida
Best AngularJS 9 training institute in Noida
Best Advanced excel training in noida
Best SAS Training Institute in Noida Sector 15
Best SAS Training Institute in Noida Sector 16
Best SAS Training Institute in Noida Sector 18
digital marketing course in noida sector 18
digital marketing course in noida sector 16
digital marketing course in noida sector 63
Best Sap MM Training Institute in Noida sector 15
Best Sap MM Training Institute in Noida sector 16
Best Sap MM Training Institute in Noida sector 18
oracle training in noida
Best Ielts coaching centre in noida sector 62
ielts coaching center in noida sector 18
ielts coaching center in noida
Ethical hacking institute in Noida near sector 16 metro station
Ethical hacking institute in Noida near sector 15 metro station
Ethical hacking institute in Noida near sector 18 metro station
Ethical hacking institute in Noida
Ethical hacking institute in Noida sector 62
Ethical hacking institute in Noida sector 63
Best hadoop Training class course institute in Noida Sector 62
Best SAP Hybris Training in Noida
Best Digital Marketing Training in noida sector 15
Best Digital Marketing Training in noida sector 16
Best Digital Marketing Training in noida sector 18
Best Digital Marketing Training in noida sector 15,16,18
software testing Training in noida sector 3
Best Sap basis Training Institute in Noida sector 15
Best Sap basis Training Institute in Noida sector 16
Best Sap basis Training Institute in Noida sector 18
Best Sap basis Training Institute in Noida sector 15,16,18
Best Php Training Institute in Noida Sector 15
Best Php Training Institute in Noida Sector 16
Best Php Training Institute in Noida Sector 18
Best Php Training Institute in Noida Sector 15, 16, 18
Best Sap fico training institute sector 15
Best Sap fico training institute sector 16
Best Sap fico training institute sector 18
Best Sap fico training institute sector 15, 16, 18
Best Sap hr Training Institute Sector 15
Best Sap hr Training Institute Sector 16
Best Sap hr Training Institute Sector 18
Best Sap hr Training Institute Sector 15, 16, 18
SAP BASIS Training institute in Noida
Best Devops training institute in Noida
Best Devops training in Noida
SAP UI5 Training in Noida
apache training institutes in noida sector 15
apache training institutes in noida sector 16
apache training institutes in noida sector 18
apache training institutes in noida
Linux Training Institute in Noida Sector 15
Linux Training Institute in Noida Sector 16
Linux Training Institute in Noida Sector 3
Linux Training Institute in Noida Sector 18
Linux Training Institute in Noida Sector 63
Linux Training Institute in Noida Sector 62
Linux Training Institute in Noida Sector 64
sapsd training center in noida sector 15
sapsd training center in noida sector 16
sapsd training center in noida sector 63
sapsd training center in noida sector 3
sapsd training center in noida sector 18
sapsd training center in noida sector 62
sapsd training center in noida sector 71
sapsd training center in noida sector 64
AWS Training Institute in Noida sector 63
php training in noida sector 3
php training center in noida sector 3
php training center in noida sector 15
php training center in noida sector 16
php training center in noida sector 18
php training center in noida sector 62
SAP PS Training in Noida
SAP PS Training center in Noida
Best SAP PS Training in Noida
Android Apps training institute in Ghaziabad
android training institute in laxminagar
Best Android Apps training institute in Vaishali
sapsd training in noida
AWS Training Institute in Noida sector 3
AWS Training Institute in Noida sector 64
AWS Training Institute in Noida sector 62
Cloud Computing training institute in Greater Noida
cloud computing training in laxminagar
Cloud Computing training institute in Vaishali
digital marketing training institute in ghaziabad
digital marketing training institute in meerut
Best digital marketing training institute in Vaishali
Best digital marketing training institute in greater Noida
Best Digital Marketing training in laxminagar
Best hadoop training institute in ghaziabad
Best hadoop training institute in Vaishali
Best hadoop training institute in laxminagar
Best hadoop training institute in Greater Noida
Best Linux training institute in Meerut
Best Linux training institute in Vaishali
Best Linux training institute in Greater Noida
MSSQL Training Institute In Noida
Machine Learning training in noida
rpa blue prism training in noida
hadoop Training in noida
aws training in noida
Linux training institute in south delhi
Best hadoop training institutes in south delhi
digital marketing training in south delhi
Cloud Computing training institutes in south delhi
Android Apps training institute in south delhi
machine learning training institute in south delhi
Sap training institute in south delhi
salesforce training institute in south delhi
Best oracle Training Institute In ghaziabad
best oracle training institute in vaishali
best oracle training institute in greater noida
best oracle training institute in laxminagar
Best php training institute in ghaziabad
Best php training institute in laxminagar
Best php training institute in Greater Noida
Best Devops training institute in Noida
php training in Noida sector 16
JAVA Training Institute in Noida
java Training In Noida
Java training course in Noida
Openstack Support Company in Delhi NCR
infrastructure automation solution provider company in delhincr
gypsum board work in noida
Dubai life
webtrackker reviews
webtrackker reviews
webtrackker reviews
webtrackker reviews
webtrackker reviews
webtrackker reviews
webtrackker reviews
webtrackker reviews
Webtrackker
Webtrackker reviews
Webtrackker review
0 notes
Text
How to Leverage AWS Spot Instances While Mitigating the Risk of Loss
Reducing cloud infrastructure costs is one of the significant benefits of using the Qubole platform — and one of the primary ways we do this is by seamlessly incorporating Spot instances available in AWS into our cluster management technology. This blog post covers a recent analysis of the Spot market and advancements in our product that reduce the odds of Spot instance losses in Qubole managed clusters. The recommendations and changes covered in this post allow our customers to realize the benefits of cheaper Spot instance types with higher reliability.
Reducing The Risk Associated With Spot Instance Loss
One of the ways Qubole reduces cloud infrastructure costs is by efficiently utilizing cheaper hardware — like Spot instances provided by AWS — that are significantly cheaper than their on-demand counterparts (by almost 70 percent).
However, Spot instances can be lost with only two minutes of notice and can cause workloads to fail. One of the ways we increase the reliability of workloads is by handling Spot losses gracefully. For example, Qubole clusters can replicate data across Spot and regular instances, handle Spot loss notifications to stop task scheduling and copy data out, and retry queries affected by Spot losses. In spite of this, it is always best to avoid Spot losses in the first place.
Due to recent changes in the AWS Spot marketplace, the probability of a Spot loss is no longer dependent on the bid price. As a result, earlier techniques of using the bid price to reduce Spot losses have been rendered ineffective — and new strategies are required. This blog post describes the following new strategies:
Reducing Spot request timeout
Using multiple instance families for worker nodes
Leveraging past Spot loss data to alter cluster composition dynamically
While the first two are recommendations for users, the last is a recent product enhancement in Qubole.
Reducing Spot Request Timeout
Qubole issues asynchronous Spot requests to AWS that are configured with a Request Timeout. This is the maximum time Qubole waits for the Spot request to return successfully. We analyzed close to 50 million Spot instances launched via Qubole as part of our customers’ workloads and we recommend users set Request Timeout to the minimum time possible (one minute right now) due to the following reasons:
The longer it takes to acquire Spot nodes, the higher the chances of such nodes being lost:
The following graph plots the probability of a Spot instance being lost versus the time taken to acquire it. The probability is the lifetime probability of the instance being lost (as opposed to being terminated normally by Qubole, usually due to downscaling or termination of clusters).
In greater detail: 1.6 percent of nodes were abruptly terminated due to AWS Spot interruptions if they were acquired within one minute, whereas close to 35 percent of nodes were abruptly terminated if they were acquired in more than 10 minutes. We can also conclude that after 600 seconds, Spot loss is unpredictable and very irregular.
Most of the Spot nodes are acquired within a minute:
The graph below represents the percentage of Spot requests fulfilled versus the time taken (or the time after which the Spot request timed out).
The above graph shows that 90 percent of Spot nodes were acquired within four seconds and 98 percent of Spot nodes were acquired within 47 seconds. This indicates that the vast majority of Spot nodes are acquired in very little time.
Currently, Qubole supports a minimum ‘Spot Request Timeout’ of one minute. Because almost all successful Spot requests are satisfied within one minute and the average probability of losing instances acquired in this time period is very small, selecting this option will increase reliability without significantly affecting costs. We will be adding the ability to set the Spot Request Timeout at a granularity level of seconds in the future.
Configure Multiple Instance Families For Worker Nodes
Qubole strongly recommends configuring multiple instance types for worker nodes (also commonly referred to as Heterogeneous Clusters) for the following reasons:
One reason is, of course, to maximize the Spot fulfilment rate and be able to use the cheapest Spot instances. This factor becomes even more important given the discussion in the previous section, as lowering Spot Request Timeouts too much could result in a lower Spot fulfilment rate in some cases.
However, increasingly Qubole will be adding mechanisms to mitigate Spot losses that are dependent on the configuration of multiple worker node types. A good example is the mechanism to mitigate Spot losses that will be discussed in the next section. The screenshot below shows how one can configure multiple instance types for worker nodes via cluster configuration:
Qubole recommends using different instance families when selecting the multiple worker node types option, i.e. using m4.xlarge and m5.xlarge instead of m4.xlarge and m4.2xlarge. While Qubole is functional with either combination, data from AWS (see https://aws.amazon.com/ec2/spot/instance-advisor/) suggests that instance availability within a family is correlated, and it is best to diversify across families to maximize Spot availability. Of course, as many instance types and families as desired can be configured.
AWS has added a lot of different instance families of late with similar CPU/memory configurations, and we would suggest using a multitude of these. For example:
M3
M4
M5
M5a
M5d
These are different instance families with similar computing resources and can be combined easily. In a recent analysis we found that AMD-based instance types (5a family) were very close to Intel-based instances (5 family) in price and performance, and were good choices to pair up in heterogeneous clusters.
Spot Loss-Aware Provisioning
Qubole recently made an improvement to mitigate Spot loss and reduce the autoscaling wait time for YARN-based clusters (Hadoop/Hive/Spark). Whenever a node is lost due to Spot loss, YARN captures this information at the cluster level. We can leverage this information to optimize our requests of Spot instances. We apply the below optimizations while placing Spot instance requests:
If there is a Spot loss in a specified time window (by default in the last 15 minutes), the corresponding instance family is classified as Unstable.
Subsequently, when there are Spot provisioning requests: Instance types belonging to unstable instance families are removed from the list of worker node types.
If the remaining list of worker node types is not empty, then Qubole issues asynchronous AWS Fleet Spot requests for this remaining list of instance types and waits for the configured Spot Request Timeout.
If the remaining list of worker node types is empty, then Qubole issues a synchronous Fleet Spot API request for the original worker node types (i.e. without filtering for unstable instance families). Synchronous requests return instantly and the Spot Request Timeout is not applicable.
If the capacity is still not fulfilled, Qubole would fall back to on-demand nodes if it is configured (this behavior is unchanged). However, the extra on-demand nodes launched as a result of fallback would be replaced with Spot nodes during rebalancing.
The protocol above ensures that Qubole either does not get unstable instance types that are likely to be lost soon, or that we only get them if the odds of the Spot loss have gone down (because data from prior analysis tells us that instance types provisioned by synchronous Fleet Spot API requests have low Spot loss probability). Soon we will be extending this enhancement to Presto clusters as well.
This feature is not enabled by default yet. Please contact Qubole Support to enable this in your account or cluster.
Conclusion
Spot instances are significantly cheaper than on-demand instances, but are not that reliable. AWS can take them away at will with very short notice. So, we need to be smart while using them and aim to reduce the impact of Spot losses. Relatively easy configuration changes and improvements can help us utilize these cheaper instances more efficiently and save us a lot of money. This post is just scratching the surface of things we are doing here at Qubole for Spot loss mitigation. Expect more such updates from us in the near future.[Source]-https://www.qubole.com/blog/leverage-aws-spot-instances-while-mitigating-risk/
big data courses in mumbaiat Asterix Solution is designed to scale up from single servers to thousands of machines, each offering local computation and storage. With the rate at which memory cost decreased the processing speed of data never increased and hence loading the large set of data is still a big headache and here comes Hadoop as the solution for it.
0 notes
Text
Faster File Distribution with HDFS and S3
In the Hadoop world there is almost always more than one way to accomplish a task. I prefer the platform because it's very unlikely I'm ever backed into a corner when working on a solution.
Hadoop has the ability to decouple storage from compute. The various distributed storage solutions supported all come with their own set of strong points and trade-offs. I often find myself needing to copy data back and forth between HDFS on AWS EMR and AWS S3 for performance reasons.
S3 is a great place to keep a master dataset as it can be used among many clusters without affect the performance of any one of them; it also comes with 11 9s of durability meaning it's one of the most unlikely places for data to go missing or become corrupt.
HDFS is where I find the best performance when running queries. If the workload will take long enough it's worth the time to copy a given dataset off of S3 and onto HDFS; any derivative results can then be transferred back onto S3 before the EMR cluster is terminated.
In this post I'll examine a number of different methods for copying data off of S3 and onto HDFS and see which is the fastest.
AWS EMR, Up & Running
To start, I'll launch an 11-node EMR cluster. I'll use the m3.xlarge instance type with 1 master node, 5 core nodes (these will make up the HDFS cluster) and 5 task nodes (these will run MapReduce jobs). I'm using spot pricing which often reduces the cost of the instances by 75-80% depending on market conditions. Both the EMR cluster and the S3 bucket are located in Ireland.
$ aws emr create-cluster --applications Name=Hadoop \ Name=Hive \ Name=Presto \ --auto-scaling-role EMR_AutoScaling_DefaultRole \ --ebs-root-volume-size 10 \ --ec2-attributes '{ "KeyName": "emr", "InstanceProfile": "EMR_EC2_DefaultRole", "AvailabilityZone": "eu-west-1c", "EmrManagedSlaveSecurityGroup": "sg-89cd3eff", "EmrManagedMasterSecurityGroup": "sg-d4cc3fa2"}' \ --enable-debugging \ --instance-groups '[{ "InstanceCount": 5, "BidPrice": "OnDemandPrice", "InstanceGroupType": "CORE", "InstanceType": "m3.xlarge", "Name": "Core - 2" },{ "InstanceCount": 5, "BidPrice": "OnDemandPrice", "InstanceGroupType": "TASK", "InstanceType": "m3.xlarge", "Name": "Task - 3" },{ "InstanceCount": 1, "BidPrice": "OnDemandPrice", "InstanceGroupType": "MASTER", "InstanceType": "m3.xlarge", "Name": "Master - 1" }]' \ --log-uri 's3n://aws-logs-591231097547-eu-west-1/elasticmapreduce/' \ --name 'My cluster' \ --region eu-west-1 \ --release-label emr-5.21.0 \ --scale-down-behavior TERMINATE_AT_TASK_COMPLETION \ --service-role EMR_DefaultRole \ --termination-protected
After a few minutes the cluster has been launched and bootstrapped and I'm able to SSH in.
$ ssh -i ~/.ssh/emr.pem \ [email protected]
__| __|_ ) _| ( / Amazon Linux AMI ___|\___|___| https://aws.amazon.com/amazon-linux-ami/2018.03-release-notes/ 1 package(s) needed for security, out of 9 available Run "sudo yum update" to apply all updates. EEEEEEEEEEEEEEEEEEEE MMMMMMMM MMMMMMMM RRRRRRRRRRRRRRR E::::::::::::::::::E M:::::::M M:::::::M R::::::::::::::R EE:::::EEEEEEEEE:::E M::::::::M M::::::::M R:::::RRRRRR:::::R E::::E EEEEE M:::::::::M M:::::::::M RR::::R R::::R E::::E M::::::M:::M M:::M::::::M R:::R R::::R E:::::EEEEEEEEEE M:::::M M:::M M:::M M:::::M R:::RRRRRR:::::R E::::::::::::::E M:::::M M:::M:::M M:::::M R:::::::::::RR E:::::EEEEEEEEEE M:::::M M:::::M M:::::M R:::RRRRRR::::R E::::E M:::::M M:::M M:::::M R:::R R::::R E::::E EEEEE M:::::M MMM M:::::M R:::R R::::R EE:::::EEEEEEEE::::E M:::::M M:::::M R:::R R::::R E::::::::::::::::::E M:::::M M:::::M RR::::R R::::R EEEEEEEEEEEEEEEEEEEE MMMMMMM MMMMMMM RRRRRRR RRRRRR
The five core nodes each have 68.95 GB of capacity that together create 344.75 GB of capacity across the HDFS cluster.
$ hdfs dfsadmin -report \ | grep 'Configured Capacity'
Configured Capacity: 370168258560 (344.75 GB) Configured Capacity: 74033651712 (68.95 GB) Configured Capacity: 74033651712 (68.95 GB) Configured Capacity: 74033651712 (68.95 GB) Configured Capacity: 74033651712 (68.95 GB) Configured Capacity: 74033651712 (68.95 GB)
The dataset I'll be using in this benchmark is a data dump I've produced of 1.1 billion taxi trips conducted in New York City over a six year period. The Billion Taxi Rides in Redshift blog post goes into detail on how I put this dataset together. This dataset is approximately 86 GB in ORC format spread across 56 files. The typical ORC file is ~1.6 GB in size.
I'll create a filename manifest that I'll use for various operations below. I'll exclude the S3 URL prefix as these names will also be used to address files on HDFS as well.
000000_0 000001_0 000002_0 000003_0 000004_0 000005_0 000006_0 000007_0 000008_0 000009_0 000010_0 000011_0 000012_0 000013_0 000014_0 000015_0 000016_0 000017_0 000018_0 000019_0 000020_0 000021_0 000022_0 000023_0 000024_0 000025_0 000026_0 000027_0 000028_0 000029_0 000030_0 000031_0 000032_0 000033_0 000034_0 000035_0 000036_0 000037_0 000038_0 000039_0 000040_0 000041_0 000042_0 000043_0 000044_0 000045_0 000046_0 000047_0 000048_0 000049_0 000050_0 000051_0 000052_0 000053_0 000054_0 000055_0
I'll adjust the AWS CLI's configuration to allow for up to 100 concurrent requests at any one time.
$ aws configure set \ default.s3.max_concurrent_requests \ 100
The disk space on the master node cannot hold the entire 86 GB worth of ORC files so I'll download, import onto HDFS and remove each file one at a time. This will allow me to maintain enough working disk space on the master node.
$ hdfs dfs -mkdir /orc $ time (for FILE in `cat files`; do aws s3 cp s3://<bucket>/orc/$FILE ./ hdfs dfs -copyFromLocal $FILE /orc/ rm $FILE done)
The above completed 15 minutes and 57 seconds.
The HDFS CLI uses the JVM which comes with a fair amount of overhead. In my HDFS CLI benchmark I found the alternative CLI gohdfs could save a lot of start-up time as it is written in GoLang and doesn't run on the JVM. Below I've run the same operation using gohdfs.
$ wget -c -O gohdfs.tar.gz \ https://github.com/colinmarc/hdfs/releases/download/v2.0.0/gohdfs-v2.0.0-linux-amd64.tar.gz $ tar xvf gohdfs.tar.gz
I'll clear out the previously downloaded dataset off HDFS first so there is enough space on the cluster going forward. With triple replication, 86 GB turns into 258 GB on disk and there is only 344.75 GB of HDFS capacity in total.
$ hdfs dfs -rm -r -skipTrash /orc $ hdfs dfs -mkdir /orc $ time (for FILE in `cat files`; do aws s3 cp s3://<bucket>/orc/$FILE ./ gohdfs-v2.0.0-linux-amd64/hdfs put \ $FILE \ hdfs://ip-10-10-207-160.eu-west-1.compute.internal:8020/orc/ rm $FILE done)
The above took 27 minutes and 40 seconds. I wasn't expecting this client to be almost twice as slow as the HDFS CLI. S3 provides consistent performance when I've run other tools multiple times so I suspect either the code behind the put functionality could be optimised or there might be a more appropriate endpoint for copying multi-gigabyte files onto HDFS. As of this writing I can't find support for copying from S3 to HDFS directly with resorting to a file system fuse.
The HDFS CLI does support copying from S3 to HDFS directly. Below I'll copy the 56 ORC files to HDFS straight from S3. I'll set the concurrent process limit to 8.
$ hdfs dfs -rm -r -skipTrash /orc $ hdfs dfs -mkdir /orc $ time (cat files \ | xargs -n 1 \ -P 8 \ -I % \ hdfs dfs -cp s3://<bucket>/orc/% /orc/)
The above took 14 minutes and 17 seconds. There wasn't much of an improvement over simply copying the files down one at a time and uploading them to HDFS.
I'll try the above command again but set the concurrency limit to 16 processes. Note, this is running on the master node which has 15 GB of RAM and the following will use what little memory capacity is left on the machine.
$ hdfs dfs -rm -r -skipTrash /orc $ hdfs dfs -mkdir /orc $ time (cat files \ | xargs -n 1 \ -P 16 \ -I % \ hdfs dfs -cp s3://<bucket>/orc/% /orc/)
The above took 14 minutes and 36 seconds. Again, a very similar time despite a higher concurrency limit. The effective transfer rate was ~98.9 MB/s off of S3. HDFS is configured for triple redundancy but I expect there is a lot more throughput available with a cluster of this size.
DistCp (distributed copy) is bundled with Hadoop and uses MapReduce to copy files in a distributed manner. It can work with HDFS, AWS S3, Azure Blob Storage and Google Cloud Storage. It can break up the downloading and importing across the task nodes so all five machines can work on a single job instead of the master node being the single machine downloading and importing onto HDFS.
$ hdfs dfs -rm -r -skipTrash /orc $ hdfs dfs -mkdir /orc $ time (hadoop distcp s3://<bucket>/orc/* /orc)
The above completed in 6 minutes and 16 seconds. A huge improvement over the previous methods.
On AWS EMR, there is a tool called S3DistCp that aims to provide the functionality of Hadoop's DistCp but in a fashion optimised for S3. Like DistCp, it uses MapReduce for executing its operations.
$ hdfs dfs -rm -r -skipTrash /orc $ hdfs dfs -mkdir /orc $ time (s3-dist-cp \ --src=s3://<bucket>/orc/ \ --dest=hdfs:///orc/)
The above completed in 5 minutes and 59 seconds. This gives an effective throughput of ~241 MB/s off of S3. There wasn't a huge performance increase over DistCp and I suspect neither tool can greatly out-perform the other.
I did come across settings to increase the chunk size from 128 MB to 1 GB, which would be useful for larger files but enough tooling in the Hadoop ecosystem will suffer from ballooning memory requirements with files over 2 GB that it is very rare to see files larger than this in any sensibly-deployed production environment. S3 usually has low connection setup latency so I can't see this being a huge overhead.
With the above its now understood that both DistCp and S3DistCp can leverage a cluster's task nodes to import data from S3 onto HDFS quickly. I'm going to see how well these tools scale with a 21-node m3.xlarge cluster. This cluster will have 1 master node, 10 core nodes and 10 task nodes.
$ aws emr create-cluster \ --applications Name=Hadoop \ Name=Hive \ Name=Presto \ --auto-scaling-role EMR_AutoScaling_DefaultRole \ --ebs-root-volume-size 10 \ --ec2-attributes '{ "KeyName": "emr", "InstanceProfile": "EMR_EC2_DefaultRole", "AvailabilityZone": "eu-west-1c", "EmrManagedSlaveSecurityGroup": "sg-89cd3eff", "EmrManagedMasterSecurityGroup": "sg-d4cc3fa2"}' \ --enable-debugging \ --instance-groups '[{ "InstanceCount": 1, "BidPrice": "OnDemandPrice", "InstanceGroupType": "MASTER", "InstanceType": "m3.xlarge", "Name": "Master - 1" },{ "InstanceCount": 10, "BidPrice": "OnDemandPrice", "InstanceGroupType": "CORE", "InstanceType": "m3.xlarge", "Name": "Core - 2" },{ "InstanceCount": 10, "BidPrice": "OnDemandPrice", "InstanceGroupType": "TASK", "InstanceType": "m3.xlarge", "Name": "Task - 3" }]' \ --log-uri 's3n://aws-logs-591231097547-eu-west-1/elasticmapreduce/' \ --name 'My cluster' \ --region eu-west-1 \ --release-label emr-5.21.0 \ --scale-down-behavior TERMINATE_AT_TASK_COMPLETION \ --service-role EMR_DefaultRole \ --termination-protected
With the new EMR cluster up and running I can SSH into it.
$ ssh -i ~/.ssh/emr.pem \ [email protected]
Each core node on the HDFS cluster still has 68.95 GB of capacity but the ten machines combined create 689.49 GB of HDFS storage capacity.
$ hdfs dfsadmin -report \ | grep 'Configured Capacity'
Configured Capacity: 740336517120 (689.49 GB) Configured Capacity: 74033651712 (68.95 GB) Configured Capacity: 74033651712 (68.95 GB) Configured Capacity: 74033651712 (68.95 GB) Configured Capacity: 74033651712 (68.95 GB) Configured Capacity: 74033651712 (68.95 GB) Configured Capacity: 74033651712 (68.95 GB) Configured Capacity: 74033651712 (68.95 GB) Configured Capacity: 74033651712 (68.95 GB) Configured Capacity: 74033651712 (68.95 GB) Configured Capacity: 74033651712 (68.95 GB)
I'll run S3DistCp first.
$ hdfs dfs -mkdir /orc $ time (s3-dist-cp \ --src=s3://<bucket>/orc/ \ --dest=hdfs:///orc/)
The above completed in 4 minutes and 56 seconds. This is an improvement over the 11-node cluster but not the 2x improvement I was expecting.
Below is DistCp running on the 21-node cluster.
$ hdfs dfs -rm -r -skipTrash /orc $ hdfs dfs -mkdir /orc $ time (hadoop distcp s3://<bucket>/orc/* /orc)
The above completed in 4 minutes and 44 seconds.
The performance ratio between these two tools is more or less consistent between cluster sizes. Its a shame neither showed linear scaling with twice the number of core and task nodes.
Here is a recap of the transfer times seen in this post.
Duration Transfer Method 27m40s gohdfs, Sequentially 15m57s HDFS DFS CLI, Sequentially 14m36s HDFS DFS CLI, Concurrently x 16 14m17s HDFS DFS CLI, Concurrently x 8 6m16s Hadoop DistCp, 11-Node Cluster 5m59s S3DistCp, 11-Node Cluster 4m56s S3DistCp, 21-Node Cluster 4m44s Hadoop DistCp, 21-Node Cluster
Why Use HDFS At All?
S3 is excellent for durability and doesn't suffer performance-wise if you have one cluster or ten clusters pointed at it. S3 also works as well as HDFS when appending records to a dataset. Both of the following queries will run without issue.
$ presto-cli \ --schema default \ --catalog hive
INSERT INTO trips_hdfs SELECT * from trips_hdfs LIMIT 10;
INSERT INTO trips_s3 SELECT * from trips_s3 LIMIT 10;
I've heard arguments that S3 is as fast as HDFS but I've never witnessed this in my time with both technologies. Below I'll run a benchmark on the 1.1 billion taxi trips. I'll have one table using S3-backed data and another table using HDFS-backed data. This was run on the 11-node cluster. I ran each query multiple times and recorded the fastest times.
This is the HDFS-backed table.
CREATE EXTERNAL TABLE trips_hdfs ( trip_id INT, vendor_id STRING, pickup_datetime TIMESTAMP, dropoff_datetime TIMESTAMP, store_and_fwd_flag STRING, rate_code_id SMALLINT, pickup_longitude DOUBLE, pickup_latitude DOUBLE, dropoff_longitude DOUBLE, dropoff_latitude DOUBLE, passenger_count SMALLINT, trip_distance DOUBLE, fare_amount DOUBLE, extra DOUBLE, mta_tax DOUBLE, tip_amount DOUBLE, tolls_amount DOUBLE, ehail_fee DOUBLE, improvement_surcharge DOUBLE, total_amount DOUBLE, payment_type STRING, trip_type SMALLINT, pickup STRING, dropoff STRING, cab_type STRING, precipitation SMALLINT, snow_depth SMALLINT, snowfall SMALLINT, max_temperature SMALLINT, min_temperature SMALLINT, average_wind_speed SMALLINT, pickup_nyct2010_gid SMALLINT, pickup_ctlabel STRING, pickup_borocode SMALLINT, pickup_boroname STRING, pickup_ct2010 STRING, pickup_boroct2010 STRING, pickup_cdeligibil STRING, pickup_ntacode STRING, pickup_ntaname STRING, pickup_puma STRING, dropoff_nyct2010_gid SMALLINT, dropoff_ctlabel STRING, dropoff_borocode SMALLINT, dropoff_boroname STRING, dropoff_ct2010 STRING, dropoff_boroct2010 STRING, dropoff_cdeligibil STRING, dropoff_ntacode STRING, dropoff_ntaname STRING, dropoff_puma STRING ) STORED AS orc LOCATION '/orc/';
This is the S3-backed table.
CREATE EXTERNAL TABLE trips_s3 ( trip_id INT, vendor_id STRING, pickup_datetime TIMESTAMP, dropoff_datetime TIMESTAMP, store_and_fwd_flag STRING, rate_code_id SMALLINT, pickup_longitude DOUBLE, pickup_latitude DOUBLE, dropoff_longitude DOUBLE, dropoff_latitude DOUBLE, passenger_count SMALLINT, trip_distance DOUBLE, fare_amount DOUBLE, extra DOUBLE, mta_tax DOUBLE, tip_amount DOUBLE, tolls_amount DOUBLE, ehail_fee DOUBLE, improvement_surcharge DOUBLE, total_amount DOUBLE, payment_type STRING, trip_type SMALLINT, pickup STRING, dropoff STRING, cab_type STRING, precipitation SMALLINT, snow_depth SMALLINT, snowfall SMALLINT, max_temperature SMALLINT, min_temperature SMALLINT, average_wind_speed SMALLINT, pickup_nyct2010_gid SMALLINT, pickup_ctlabel STRING, pickup_borocode SMALLINT, pickup_boroname STRING, pickup_ct2010 STRING, pickup_boroct2010 STRING, pickup_cdeligibil STRING, pickup_ntacode STRING, pickup_ntaname STRING, pickup_puma STRING, dropoff_nyct2010_gid SMALLINT, dropoff_ctlabel STRING, dropoff_borocode SMALLINT, dropoff_boroname STRING, dropoff_ct2010 STRING, dropoff_boroct2010 STRING, dropoff_cdeligibil STRING, dropoff_ntacode STRING, dropoff_ntaname STRING, dropoff_puma STRING ) STORED AS orc LOCATION 's3://<bucket>/orc/';
I'll use Presto to run the benchmarks.
$ presto-cli \ --schema default \ --catalog hive
The following four queries were run on the HDFS-backed table.
The following completed in 6.77 seconds.
SELECT cab_type, count(*) FROM trips_hdfs GROUP BY cab_type;
The following completed in 10.97 seconds.
SELECT passenger_count, avg(total_amount) FROM trips_hdfs GROUP BY passenger_count;
The following completed in 13.38 seconds.
SELECT passenger_count, year(pickup_datetime), count(*) FROM trips_hdfs GROUP BY passenger_count, year(pickup_datetime);
The following completed in 19.82 seconds.
SELECT passenger_count, year(pickup_datetime) trip_year, round(trip_distance), count(*) trips FROM trips_hdfs GROUP BY passenger_count, year(pickup_datetime), round(trip_distance) ORDER BY trip_year, trips desc;
The following four queries were run on the S3-backed table.
The following completed in 10.82 seconds.
SELECT cab_type, count(*) FROM trips_s3 GROUP BY cab_type;
The following completed in 14.73 seconds.
SELECT passenger_count, avg(total_amount) FROM trips_s3 GROUP BY passenger_count;
The following completed in 19.19 seconds.
SELECT passenger_count, year(pickup_datetime), count(*) FROM trips_s3 GROUP BY passenger_count, year(pickup_datetime);
The following completed in 24.61 seconds.
SELECT passenger_count, year(pickup_datetime) trip_year, round(trip_distance), count(*) trips FROM trips_s3 GROUP BY passenger_count, year(pickup_datetime), round(trip_distance) ORDER BY trip_year, trips desc;
This is a recap of the query times above.
HDFS on AWS EMR AWS S3 Speed Up Query 6.77s 10.82s 1.6x Query 1 10.97s 14.73s 1.34x Query 2 13.38s 19.19s 1.43x Query 3 19.82s 24.61s 1.24x Query 4
The HDFS-backed queries were anywhere from 1.24x to 1.6x faster than the S3-backed queries.
DataTau published first on DataTau
0 notes
Text
How many types of Modes in Big Data Hadoop?
3 types of Modes in Big Data Hadoop:
1. Standalone Mode:
The standalone mode is default in which Hadoop run. this mode is particularly applied to one's own purposes for remove errors wherein you don’t definitely use HDFS. You use to enter and output each as a neighborhood report device in this mode. You furthermore may additionally don’t should to do any custom as resulting from this within the documents mapped-site.xml, core-site.xml, HDFS-site.xml. Standalone mode is in quick succession Hadoop modes as it uses the community report device for all of the input, output.
Here is summarized of the standalone mode:
1. HDFS is not to make practical or worthwhile used of right here alternatively nearby record gadget is used for entering and output.
2. Used for debugging cause.
3. Custom configuration not required inside three Hadoop files.
4. Quicker that Pseudo-allocated node.
2. Pseudo-Distributed Mode:
Big Data Hadoop is administered on an individual node in a pseudo-distributed mode, much like the Standalone mode. The diversity is that Hadoop daemon runs in a divide Java in Pseudo-Distributed Mode. While in nearby mode every Hadoop daemon runs as a Java. Once more using this mode may be very confined and it could be handiest used for or an instance of making experiments.
Here is summarized of the pseudo-distributed Mode:
1. Single Node Hadoop deployment running on Hadoop is considered as the pseudo-distributed mode.
2. All the master & slave daemons will be running on the same node.
3. Replication Factor will be 1 for blocks. 4. Changes in configuration files will be required for all the three files.
3. Fully-Distributed Mode:
Due to the fact the call indicates, this mode includes the code jogging on a Hadoop cluster. It's for a technique in that you see the electricity of Hadoop when you run your code in the direction of a totally huge input on masses of lots of servers. It's far constantly tough to debug a MapReduce utility as you've got Mappers strolling on an exquisite machine with a wonderful piece of input. Moreover, with massive inputs, it is in all likelihood that the information might be odd in its layout. proficient and Slave offerings may be walking on the separate nodes in completely-allotted Hadoop Mode.
Here is summarized of the Fully-Distributed Mode:
1. Manufacturing section of Hadoop.
2. Nodes for master and slave daemons.
3. Statistics are used and allotted for the duration of multiple nodes
Conclusion: This was all about 3 various Hadoop Modes. You should know about all things of Hadoop. Join Best Big Data Hadoop Training in Delhi via Madrid Software Trainings Solutions.
0 notes
Text
Administrator Training for Apache Hadoop in Abu Dhabi
Administrator Training for Apache Hadoop in Abu Dhabi
Administrator Training For Apache Hadoop Course Description
Duration: 4.00 days (32 hours)
This four day administrator training for Apache Hadoop provides participants with a comprehensive understanding of all the steps necessary to operate and maintain a Hadoop cluster. From installation and configuration through load balancing and tuning,Galactic Solutions training course is the best preparation for the real-world challenges faced by Hadoop administrators.
» System administrators and others responsible for managing Apache Hadoop clusters in production or development environments.
Administrator Training For Apache Hadoop Course Objectives
» The internals of YARN, MapReduce, and HDFS
» Determining the correct hardware and infrastructure for your cluster
» Proper cluster configuration and deployment to integrate with the data center
» How to load data into the cluster from dynamically generated files using Flume and from RDBMS using Sqoop
» Configuring the FairScheduler to provide service-level agreements for multiple users of a cluster
» Best practices for preparing and maintaining Apache Hadoop in production
» Troubleshooting, diagnosing, tuning, and solving Hadoop issues
Administrator Training For Apache Hadoop Course Outline
The Case for Apache Hadoop
Why Hadoop?
Core Hadoop Components
Fundamental Concepts
HDFS
HDFS Features
Writing and Reading Files
NameNode Memory Considerations
Overview of HDFS Security
Using the Namenode Web UI
Using the Hadoop File Shell
Getting Data into HDFS
Ingesting Data from External Sources with Flume
Ingesting Data from Relational Databases with Sqoop
REST Interfaces
Best Practices for Importing Data
YARN and MapReduce
What Is MapReduce?
Basic MapReduce Concepts
YARN Cluster Architecture
Resource Allocation
Failure Recovery
Using the YARN Web UI
MapReduce Version 1
Planning Your Hadoop Cluster
General Planning Considerations
Choosing the Right Hardware
Network Considerations
Configuring Nodes
Planning for Cluster Management
Hadoop Installation and Initial Configuration
Deployment Types
Installing Hadoop
Specifying the Hadoop Configuration
Performing Initial HDFS Configuration
Performing Initial YARN and MapReduce Configuration
Hadoop Logging
Installing and Configuring Hive, Impala, and Pig
Hive
Impala
Pig
Hadoop Clients
What is a Hadoop Client?
Installing and Configuring Hadoop Clients
Installing and Configuring Hue
Hue Authentication and Authorization
Cloudera Manager
The Motivation for Cloudera Manager
Cloudera Manager Features
Express and Enterprise Versions
Cloudera Manager Topology
Installing Cloudera Manager
Installing Hadoop Using Cloudera Manager
Performing Basic Administration Tasks Using Cloudera Manager
Advanced Cluster Configuration
Advanced Configuration Parameters
Configuring Hadoop Ports
Explicitly Including and Excluding Hosts
Configuring HDFS for Rack Awareness
Configuring HDFS High Availability
Hadoop Security
Why Hadoop Security Is Important
Hadoop's Security System Concepts
What Kerberos Is and How it Works
Securing a Hadoop Cluster with Kerberos
Managing and Scheduling Jobs
Managing Running Jobs
Scheduling Hadoop Jobs
Configuring the FairScheduler
Impala Query Scheduling
Cluster Maintenance
Checking HDFS Status
Copying Data Between Clusters
Adding and Removing Cluster Nodes
Rebalancing the Cluster
Cluster Upgrading
Cluster Monitoring and Troubleshooting
General System Monitoring
Monitoring Hadoop Clusters
Common Troubleshooting Hadoop Clusters
Common Misconfigurations
0 notes
Link
Solving challenges of data analytics to make data accessible to all.
One of the classic challenges of analytics is making data accessible to all. The data needed for analytics and data science is often locked away in different data silos, where it is difficult to discover and access. Analysts and data scientists who want to derive new insights from data within the enterprise must work with a large number of data stewards and data engineers to build their own map of data assets and source data from various data silos.
As a result of our move at FINRA to a managed data lake architecture in the cloud, our organization arrived at a solution to this problem, as well as introducing significant improvements in the flexibility of our data processing pipeline that prepares data for analytics. In this process, I’ll describe our approach.
A challenge of big data
FINRA is the Financial Industry Regulatory Authority, a not-for-profit organization authorized by Congress to protect America’s investors by making sure the broker-dealer industry operates fairly and honestly. FINRA’s Market Regulation group monitors 99% of all equity trades and 70% of all option trades in the U.S. This is done by processing billions of records a day of trade data from brokerage firms and exchanges. The data is validated, transformed, and prepared for analytic use. Once the data is ready for analytics, hundreds of automated detection models are run against the data to look for indicators of potential market manipulation, insider trading, and abuse—generating exception alerts when a pattern is matched. From there, regulatory analysts interactively delve deeper into the data to determine whether a regulatory issue exists. To stay abreast of emerging regulatory problems and develop new detection algorithms, a team of data scientists continually explores the data and develops new detection models.
To process and operate at these volumes, FINRA made early investments over a decade ago in cutting-edge, emerging data-warehouse appliances. This required a significant initial investment along with subsequent re-investments to expand capacity. Despite these investments, we still faced continual capacity challenges. Additionally, these appliances were complex to manage and operate in a dynamic business environment. Market volumes can fluctuate significantly day-to-day—sometimes by a factor of three or more. Regardless of fluctuations, FINRA must run its validation, ETL, and detection algorithms on the data within time frames specified in our service level agreements (SLAs). Investing in the capacity to meet anticipated peaks was cost prohibitive—it was not practical to dedicate constant capacity for processing the peak. As a result, when unanticipated peaks in market volume occurred, technology and business staff had to scramble to re-prioritize other business workloads in order to process the additional peak. This required additional operational support (people), monitoring 24x7 to allow intervention at the first sign of trouble.
A Hadoop alternative?
Facing these challenges, FINRA reviewed the options available at the time (2013). One emerging concept was the use of a large Hadoop cluster to create a “data lake” using the cluster’s HDFS for storage that could be a single, ever-growing store of data, combined with the processing power to query it. On the data lake, a variety of tools (at the time, Hive, Pig, and custom MapReduce) could be run against the data on this cluster. With the concept of “schema-on-read,” a schema could be applied to data at time of query, instead of time of ingest. This change allowed a variety of tools to be used for processing data—the right tool for the right job. Additionally, storage and compute capacity could be added in smaller increments using commodity hardware. This process was much better than using the data warehouse appliance, which required a major capital expenditure every few years to upgrade capacity, along with the operation complexity of moving data during upgrades and expansions.
While a Hadoop data lake appeared better than the previous state, there still remained three fundamental challenges:
Capacity was still not truly dynamic—While it was (relatively) easy to add capacity, this was still a process that could take days (or weeks to months if additional servers needed to be procured). Additionally, while it was possible to add capacity for peaks, it was not possible to shrink capacity once the peak had passed. We were still faced with the challenge of sizing for anticipated peak demand.
Capacity could not be optimized to balance storage and compute—The second challenge was that by continuing the use of a paradigm where storage and compute capacity were combined together at the node (server) level, we often had idle processing capacity that did not match our storage needs.
Managing a Hadoop cluster can be complex—FINRA already had experience with running Hadoop clusters in a production environment. We knew that running a multi-petabyte Hadoop cluster would be operationally complex. Operations staff experienced with Hadoop needed to continually monitor and maintain the cluster: replacing faulty hardware before it resulted in losing data, adding capacity, and managing backups. All these tasks add cost and complexity.
So, we started looking for an approach that would give us the benefits of a data lake without the operational complexity and cost. Cloud offered the promise of pay-as-you-go resources that could be added or removed as needed based on workload. Could this address the problem of matching capacity to demand?
The cloud data lake—beyond traditional Hadoop
Eventually, we arrived at an approach of preserving the key data lake concepts: a single repository of the data, the ability to use multiple tools, “schema-on-read,” and the ability to secure the data centrally but with reduced operational complexity and cost by leveraging cloud services. This approach was accomplished by separating the key concepts of a database—catalog, query/compute engine, and storage—and projecting them onto separate cloud services:
Storage—Using an object store (e.g., AWS Simple Storage Service—S3) provides a way to store and manage data with minimal operational effort. Features that are often difficult to perform well, such as capacity management, capacity forecasting, access control, encryption, disaster recovery and archiving, are all easy to configure and automate when abstracted as a service. Adding data to our repository is as simple as storing it in S3, applying the appropriate access controls, and registering with our centralized catalog (next).
Catalog—A catalog that can store technical metadata (like DDL) is essential to a database. Additionally, it would be ideal for a catalog to also be able to contain business and operational metadata (such as lineage). We added the additional objective of a catalog that was not bound to a particular operating stack (e.g., Hadoop). Ideally, it would be a catalog that could reference data sets in other stores. After surveying the market options available at the time (early 2013), we did not find any suitable open source or commercial offering. So, we developed our own catalog, which can store technical metadata that is needed to support querying and data fixes. In addition, it features a UI that allows data scientists and other consumers to explore the data sets, layering in business metadata on top of the technical metadata. Portions of this data catalog have been open-sourced as the herd project.
Query/Compute—Having abstracted away the problem of storage management and catalog, we were left with the challenge of how to handle processing. AWS’s Elastic MapReduce (EMR) service allowed us to create and destroy Hadoop processing clusters as needed—all via simple API commands. On the cluster, we could load software (Hive originally, now Presto and Spark) that allowed our developers and analysts to use the tool they were familiar with (SQL) to access data. EMR supports the ability to run queries from these tools while keeping the data on the object storage layer (S3). This created what was effectively a single, multi-petabyte database. SQL queries can be done from either a single compute cluster or multiple clusters running in parallel, all reading against the same data set in S3.
As I am writing this post, we have more than 70 distinct compute clusters (over 2,000 servers in total) running simultaneously in our production environment. Some clusters are tuned for user queries. Others are running cost effective batch ETL and batch analytic routines. Being able to run multiple clusters simultaneously gives us effortless ability to parallelize workloads to meet unexpected business needs while still meeting routine SLAs. Also, while we use EMR for more than 90% of our processing, our platform-independent data catalog and separate storage layer allows us to use other services for specialized processing. We use the Lambda for highly parallelized, server-less file validation. We use the Redshift database service for certain query-intensive data marts. We have flexibility in the query/compute technology we use.
Operational benefits
By re-thinking the analytic data warehouse as a series of services, we have been able to achieve significant operational benefits for our data processing. Now, when market volumes fluctuate, we can increase the capacity of our validation, ETL, and detection algorithms immediately to process the additional workload—all through a series of simple API commands. When the volume drops, we shrink the size of the processing clusters. In some cases, we can shrink them to zero if there is a lull in the incoming data stream. Because our data remains stored on S3, we leverage use of the AWS SPOT pricing market to purchase capacity at a fraction of the standard rate. If we lose a cluster due to SPOT market conditions (always a possibility), it is possible to easily re-provision the cluster and resume processing from the most recent checkpoint.
We can now easily buffer against unexpected changes in market volumes and still meet our SLAs. Additionally, it is very easy to accommodate unexpected business requests for out-of cycle processing. One condition we frequently encounter is the need to re-process data if a data error or problem is later detected in upstream data sources. These errors are outside our control and frequently require significant processing resources to accommodate. Executing them on our old data appliance infrastructure meant that they would have to wait weeks for a processing window when they could be run without interrupting processing of our normal data flows. With the managed data lake architecture, it is very easy to create additional processing clusters on EMR to execute the reprocessing at the same time the normal processing is occurring. We regularly create and destroy more than 10,000 nodes (servers) of compute capacity daily. All this allows us to complete reprocessing in a few days—not weeks.
Making access easier
While we had hoped to achieve operational benefits by moving to the new architecture, we were surprised that the approach also made our entire data set much more accessible to users such as data scientists who needed to explore the data to develop new models and insights.
Historically, it was difficult for our data scientists to explore the scope of data sets that were available and then actually obtain the data of interest for use in model development. They might need to work with multiple data engineers who were responsible for different sets of data—both to understand the data and to obtain access to the physical database where it resides. Often, the needed data had been archived to tape stored offsite, which required a time-consuming restore process. This could take weeks. Additionally, even after data sets were obtained, a data scientist might need to work with other engineers to provision a temporary data mart of sufficient capacity for them to perform their model development. This could mean weeks just to get started on model building. If there was a subsequent desire to incorporate additional data sources into the model development process, additional weeks could pass. Given the many course corrections and dead ends involved in model building, this severely limited the velocity for building new models and analytics using the data.
With the managed data lake architecture, our data scientists now have easy access to all of our data. Through the searchable interface of our data catalog, it is possible to explore all of our data sets based on business metadata to find data sets of potential interest. Also from within the catalog, it is possible to explore the technical metadata associated with a data set to learn how to query or extract it. However, the real power comes from the ability to integrate query tools with the catalog to go the next step and allow data scientist self-service access to all the data. Because all the data is stored on S3 and registered in the central catalog, a single query cluster running Presto or Spark can access all of our data. Further, it is very easy to quickly combine data sets from across the data lake and create temporary data marts for use with model development, all enabled via self-service.
Conclusion
FINRA’s entire Market Regulation application portfolio has been running in the cloud using the cloud data lake for more than a year. We have more than four petabytes (and growing) of catalog registered data accessible for query. Processing challenges that were difficult to solve are now easy, and we’ve reduced the friction our data scientists experience—allowing them to focus on developing new detection models to stay ahead of emerging regulatory issues.
For organizations that are having challenges keeping up with growing demand for analytics or managing exploding data volumes, rethinking the data warehouse as a virtual database based on cloud services is worth considering. If you have questions about how FINRA moved its entire Market Regulation portfolio to the cloud and how we manage and operate our environment on a daily basis, feel free to reach out to me.
Continue reading How FINRA benefits from a cloud data lake.
from All - O'Reilly Media http://ift.tt/2gKwCAc
0 notes
Link
(Via: Hacker News)
By Jon Bratseth, Distinguished Architect, Vespa
Ever since we open sourced Hadoop in 2006, Yahoo – and now, Oath – has been committed to opening up its big data infrastructure to the larger developer community. Today, we are taking another major step in this direction by making Vespa, Yahoo's big data processing and serving engine, available as open source on GitHub.
Vespa architecture overview
Building applications increasingly means dealing with huge amounts of data. While developers can use the the Hadoop stack to store and batch process big data, and Storm to stream-process data, these technologies do not help with serving results to end users. Serving is challenging at large scale, especially when it is necessary to make computations quickly over data while a user is waiting, as with applications that feature search, recommendation, and personalization.
By releasing Vespa, we are making it easy for anyone to build applications that can compute responses to user requests, over large datasets, at real time and at internet scale – capabilities that up until now, have been within reach of only a few large companies.
Serving often involves more than looking up items by ID or computing a few numbers from a model. Many applications need to compute over large datasets at serving time. Two well-known examples are search and recommendation. To deliver a search result or a list of recommended articles to a user, you need to find all the items matching the query, determine how good each item is for the particular request using a relevance/recommendation model, organize the matches to remove duplicates, add navigation aids, and then return a response to the user. As these computations depend on features of the request, such as the user's query or interests, it won't do to compute the result upfront. It must be done at serving time, and since a user is waiting, it has to be done fast. Combining speedy completion of the aforementioned operations with the ability to perform them over large amounts of data requires a lot of infrastructure – distributed algorithms, data distribution and management, efficient data structures and memory management, and more. This is what Vespa provides in a neatly-packaged and easy to use engine.
With over 1 billion users, we currently use Vespa across many different Oath brands – including Yahoo.com, Yahoo News, Yahoo Sports, Yahoo Finance, Yahoo Gemini, Flickr, and others – to process and serve billions of daily requests over billions of documents while responding to search queries, making recommendations, and providing personalized content and advertisements, to name just a few use cases. In fact, Vespa processes and serves content and ads almost 90,000 times every second with latencies in the tens of milliseconds. On Flickr alone, Vespa performs keyword and image searches on the scale of a few hundred queries per second on tens of billions of images. Additionally, Vespa makes direct contributions to our company's revenue stream by serving over 3 billion native ad requests per day via Yahoo Gemini, at a peak of 140k requests per second (per Oath internal data).
With Vespa, our teams build applications that:
Select content items using SQL-like queries and text search
Organize all matches to generate data-driven pages
Rank matches by handwritten or machine-learned relevance models
Serve results with response times in the lows milliseconds
Write data in real-time, thousands of times per second per node
Grow, shrink, and re-configure clusters while serving and writing data
To achieve both speed and scale, Vespa distributes data and computation over many machines without any single master as a bottleneck. Where conventional applications work by pulling data into a stateless tier for processing, Vespa instead pushes computations to the data. This involves managing clusters of nodes with background redistribution of data in case of machine failures or the addition of new capacity, implementing distributed low latency query and processing algorithms, handling distributed data consistency, and a lot more. It's a ton of hard work!
As the team behind Vespa, we have been working on developing search and serving capabilities ever since building alltheweb.com, which was later acquired by Yahoo. Over the last couple of years we have rewritten most of the engine from scratch to incorporate our experience onto a modern technology stack. Vespa is larger in scope and lines of code than any open source project we've ever released. Now that this has been battle-proven on Yahoo's largest and most critical systems, we are pleased to release it to the world.
Vespa gives application developers the ability to feed data and models of any size to the serving system and make the final computations at request time. This often produces a better user experience at lower cost (for buying and running hardware) and complexity compared to pre-computing answers to requests. Furthermore it allows developers to work in a more interactive way where they navigate and interact with complex calculations in real time, rather than having to start offline jobs and check the results later.
Vespa can be run on premises or in the cloud. We provide both Docker images and rpm packages for Vespa, as well as guides for running them both on your own laptop or as an AWS cluster.
We'll follow up this initial announcement with a series of posts on our blog showing how to build a real-world application with Vespa, but you can get started right now by following the getting started guide in our comprehensive documentation.
Managing distributed systems is not easy. We have worked hard to make it easy to develop and operate applications on Vespa so that you can focus on creating features that make use of the ability to compute over large datasets in real time, rather than the details of managing clusters and data. You should be able to get an application up and running in less than ten minutes by following the documentation.
We can't wait to see what you build with it!
0 notes
Text
75% off #Projects in Hadoop and Big Data – Learn by Building Apps – $10
A Practical Course to Learn Big Data Technologies While Developing Professional Projects
Intermediate Level, – 10 hours, 43 lectures
Average rating 3.7/5 (3.7 (97 ratings) Instead of using a simple lifetime average, Udemy calculates a course’s star rating by considering a number of different factors such as the number of ratings, the age of ratings, and the likelihood of fraudulent ratings.)
Course requirements:
Working knowledge of Hadoop is expected before starting this course Basic programming knowledge of Java and Python will be great
Course description:
The most awaited Big Data course on the planet is here. The course covers all the major big data technologies within the Hadoop ecosystem and weave them together in real life projects. So while doing the course you not only learn the nuances of the hadoop and its associated technologies but see how they solve real world problems and how they are being used by companies worldwide.
This course will help you take a quantum jump and will help you build Hadoop solutions that will solve real world problems. However we must warn you that this course is not for the faint hearted and will test your abilities and knowledge while help you build a cutting edge knowhow in the most happening technology space. The course focuses on the following topics
Add Value to Existing Data – Learn how technologies such as Mapreduce applies to Clustering problems. The project focus on removing duplicate or equivalent values from a very large data set with Mapreduce.
Hadoop Analytics and NoSQL – Parse a twitter stream with Python, extract keyword with apache pig and map to hdfs, pull from hdfs and push to mongodb with pig, visualise data with node js . Learn all this in this cool project.
Kafka Streaming with Yarn and Zookeeper – Set up a twitter stream with Python, set up a Kafka stream with java code for producers and consumers, package and deploy java code with apache samza.
Real-Time Stream Processing with Apache Kafka and Apache Storm – This project focus on twitter streaming but uses Kafka and apache storm and you will learn to use each of them effectively.
Big Data Applications for the Healthcare Industry with Apache Sqoop and Apache Solr – Set up the relational schema for a Health Care Data dictionary used by the US Dept of Veterans Affairs, demonstrate underlying technology and conceptual framework. Demonstrate issues with certain join queries that fail on MySQL, map technology to a Hadoop/Hive stack with Scoop and HCatalog, show how this stack can perform the query successfully.
Log collection and analytics with the Hadoop Distributed File System using Apache Flume and Apache HCatalog – Use Apache Flume and Apache HCatalog to map real time log stream to hdfs and tail this file as Flume event stream. , Map data from hdfs to Python with Pig, use Python modules for analytic queries
Data Science with Hadoop Predictive Analytics – Create structured data with Mapreduce, Map data from hdfs to Python with Pig, run Python Machine Learning logistic regression, use Python modules for regression matrices and supervise training
Visual Analytics with Apache Spark on Yarn – Create structured data with Mapreduce, Map data from hdfs to Python with Spark, convert Spark dataframes and RDD’s to Python datastructures, Perform Python visualisations
Customer 360 degree view, Big Data Analytics for e-commerce – Demonstrate use of EComerce tool ‘Datameer’ to perform many fof the analytic queries from part 6,7 and 8. Perform queries in the context of Senitment analysis and Twiteer stream.
Putting it all together Big Data with Amazon Elastic Map Reduce – Rub clustering code on AWS Mapreduce cluster. Using AWS Java sdk spin up a Dedicated task cluster with the same attributes.
So after this course you can confidently built almost any system within the Hadoop family of technologies. This course comes with complete source code and fully operational Virtual machines which will help you build the projects quickly without wasting too much time on system setup. The course also comes with English captions. So buckle up and join us on our journey into the Big Data.
Full details Understand the Hadoop Ecosystem and Associated Technologies Learn Concepts to Solve Real World Problems Learn the Updated Changes in Hadoop Use Code Examples Present Here to Create Your own Big Data Services Get fully functional VMs fine tuned and created specifically for this course.
Full details Students who want to use Hadoop and Big Data in their Workplac
Reviews:
“This course is very polished, straightforward, and fun!” (Rozar)
“Don’t feel very engaged with the course, hopefully this will change after I start doing assignments and projects” (Mohamed El-Kholy)
“Would have been better if the instructor showed us how to set up all these projects instead of just reading through the code.” (Sampson Adu-Poku)
About Instructor:
Eduonix Learning Soultions Eduonix-Tech . Eduonix Support
Eduonix creates and distributes high quality technology training content. Our team of industry professionals have been training manpower for more than a decade. We aim to teach technology the way it is used in industry and professional world. We have professional team of trainers for technologies ranging from Mobility, Web to Enterprise and Database and Server Administration.
Instructor Other Courses:
Linux For Absolute Beginners Eduonix Learning Soultions, 1+ Million Students Worldwide | 200+ Courses (22) $10 $30 Projects In ReactJS – The Complete React Learning Course Eduonix Learning Soultions, 1+ Million Students Worldwide | 200+ Courses (16) $10 $40 Implementing and Managing Hyper-V in Windows Server 2016 Eduonix Learning Soultions, 1+ Million Students Worldwide | 200+ Courses (1) $10 $20 Become An AWS Certified Solutions Architect – Associate Learn to build an Auth0 App using Angular 2 Youtube: Beginners Guide To A Successful Channel The Developers Guide to Python 3 Programming Learn To Build A Google Map App Using Angular 2 Learn Web Development Using VueJS …………………………………………………………… Eduonix Learning Soultions Eduonix-Tech . Eduonix Support coupons Development course coupon Udemy Development course coupon Software Engineering course coupon Udemy Software Engineering course coupon Projects in Hadoop and Big Data – Learn by Building Apps Projects in Hadoop and Big Data – Learn by Building Apps course coupon Projects in Hadoop and Big Data – Learn by Building Apps coupon coupons
The post 75% off #Projects in Hadoop and Big Data – Learn by Building Apps – $10 appeared first on Udemy Cupón/ Udemy Coupon/.
from Udemy Cupón/ Udemy Coupon/ http://coursetag.com/udemy/coupon/75-off-projects-in-hadoop-and-big-data-learn-by-building-apps-10/ from Course Tag https://coursetagcom.tumblr.com/post/155983197388
0 notes
Text
300+ TOP Apache YARN Interview Questions and Answers
YARN Interview Questions for freshers experienced :-
1. What Is Yarn? Apache YARN, which stands for 'Yet another Resource Negotiator', is Hadoop cluster resource management system. YARN provides APIs for requesting and working with Hadoop's cluster resources. These APIs are usually used by components of Hadoop's distributed frameworks such as MapReduce, Spark, and Tez etc. which are building on top of YARN. User applications typically do not use the YARN APIs directly. Instead, they use higher level APIs provided by the framework (MapReduce, Spark, etc.) which hide the resource management details from the user. 2. What Are The Key Components Of Yarn? The basic idea of YARN is to split the functionality of resource management and job scheduling/monitoring into separate daemons. YARN consists of the following different components: Resource Manager - The Resource Manager is a global component or daemon, one per cluster, which manages the requests to and resources across the nodes of the cluster. Node Manager - Node Manger runs on each node of the cluster and is responsible for launching and monitoring containers and reporting the status back to the Resource Manager. Application Master is a per-application component that is responsible for negotiating resource requirements for the resource manager and working with Node Managers to execute and monitor the tasks. Container is YARN framework is a UNIX process running on the node that executes an application-specific process with a constrained set of resources (Memory, CPU, etc.). 3. What Is Resource Manager In Yarn? The YARN Resource Manager is a global component or daemon, one per cluster, which manages the requests to and resources across the nodes of the cluster. The Resource Manager has two main components - Scheduler and Applications Manager. Scheduler - The scheduler is responsible for allocating resources to and starting applications based on the abstract notion of resource containers having a constrained set of resources. Application Manager - The Applications Manager is responsible for accepting job-submissions, negotiating the first container for executing the application specific Application Master and provides the service for restarting the Application Master container on failure. 4. What Are The Scheduling Policies Available In Yarn? YARN scheduler is responsible for scheduling resources to user applications based on a defined scheduling policy. YARN provides three scheduling options - FIFO scheduler, Capacity scheduler and Fair scheduler. FIFO Scheduler - FIFO scheduler puts application requests in queue and runs them in the order of submission. Capacity Scheduler - Capacity scheduler has a separate dedicated queue for smaller jobs and starts them as soon as they are submitted. Fair Scheduler - Fair scheduler dynamically balances and allocates resources between all the running jobs. 5. How Do You Setup Resource Manager To Use Capacity Scheduler? You can configure the Resource Manager to use Capacity Scheduler by setting the value of property 'yarn.resourcemanager.scheduler.class' to 'org.apache.hadoop.yarn.server.resourcemanager.scheduler.capacity.CapacityScheduler' in the file 'conf/yarn-site.xml'. 6. How Do You Setup Resource Manager To Use Fair Scheduler? You can configure the Resource Manager to use FairScheduler by setting the value of property 'yarn.resourcemanager.scheduler.class' to 'org.apache.hadoop.yarn.server.resourcemanager.scheduler.fair.FairScheduler' in the file 'conf/yarn-site.xml'. 7. How Do You Setup Ha For Resource Manager? Resource Manager is responsible for scheduling applications and tracking resources in a cluster. Prior to Hadoop 2.4, the Resource Manager does not have option to be setup for HA and is a single point of failure in a YARN cluster. Since Hadoop 2.4, YARN Resource Manager can be setup for high availability. High availability of Resource Manager is enabled by use of Active/Standby architecture. At any point of time, one Resource Manager is active and one or more of Resource Managers are in the standby mode. In case the active Resource Manager fails, one of the standby Resource Managers transitions to an active mode. 8. What Are The Core Changes In Hadoop 2.x? Many changes, especially single point of failure and Decentralize Job Tracker power to data-nodes is the main changes. Entire job tracker architecture changed. Some of the main difference between Hadoop 1.x and 2.x given below: Single point of failure – Rectified. Nodes limitation (4000- to unlimited) – Rectified. Job Tracker bottleneck – Rectified. Map-reduce slots are changed static to dynamic. High availability – Available. Support both Interactive, graph iterative algorithms (1.x not support). Allows other applications also to integrate with HDFS. 9. What Is The Difference Between Mapreduce 1 And Mapreduce 2/yarn? In MapReduce 1, Hadoop centralized all tasks to the Job Tracker. It allocates resources and scheduling the jobs across the cluster. In YARN, de-centralized this to ease the work pressure on the Job Tracker. Resource Manager responsibility allocate resources to the particular nodes and Node manager schedule the jobs on the application Master. YARN allows parallel execution and Application Master managing and execute the job. This approach can ease many Job Tracker problems and improves to scale up ability and optimize the job performance. Additionally YARN can allows to create multiple applications to scale up on the distributed environment. 10. How Hadoop Determined The Distance Between Two Nodes? Hadoop admin write a script called Topology script to determine the rack location of nodes. It is trigger to know the distance of the nodes to replicate the data. Configure this script in core-site.xml topology.script.file.name core/rack-awareness.sh in the rack-awareness.sh you should write script where the nodes located.

Apache YARN Interview Questions 11. Mistakenly User Deleted A File, How Hadoop Remote From Its File System? Can U Roll Back It? HDFS first renames its file name and place it in /trash directory for a configurable amount of time. In this scenario block might freed, but not file. After this time, Namenode deletes the file from HDFS name-space and make file freed. It’s configurable as fs.trash.interval in core-site.xml. By default its value is 1, you can set to 0 to delete file without storing in trash. 12. What Is Difference Between Hadoop Namenode Federation, Nfs And Journal Node? HDFS federation can separate the namespace and storage to improve the scalability and isolation. 13. Yarn Is Replacement Of Mapreduce? YARN is generic concept, it support MapReduce, but it’s not replacement of MapReduce. You can development many applications with the help of YARN. Spark, drill and many more applications work on the top of YARN. 14. What Are The Core Concepts/processes In Yarn? Resource manager: As equivalent to the Job Tracker Node manager: As equivalent to the Task Tracker. Application manager: As equivalent to Jobs. Everything is application in YARN. When client submit job (application), Containers: As equivalent to slots. Yarn child: If you submit the application, dynamically Application master launch Yarn child to do Map and Reduce tasks. If application manager failed, not a problem, resource manager automatically start new application task. 15. Steps To Upgrade Hadoop 1.x To Hadoop 2.x? To upgrade 1.x to 2.x dont upgrade directly. Simple download locally then remove old files in 1.x files. Up-gradation take more time. Share folder there. its important.. share.. hadoop .. mapreduce .. lib. Stop all processes. Delete old meta data info… from work/hadoop2data Copy and rename first 1.x data into work/hadoop2.x Don’t format NN while up gradation. Hadoop namenode -upgrade // It will take a lot of time. Don’t close previous terminal open new terminal. Hadoop namenode -rollback. 16. What Is Apache Hadoop Yarn? YARN is a powerful and efficient feature rolled out as a part of Hadoop 2.0.YARN is a large scale distributed system for running big data applications. 17. Is Yarn A Replacement Of Hadoop Mapreduce? YARN is not a replacement of Hadoop but it is a more powerful and efficient technology that supports MapReduce and is also referred to as Hadoop 2.0 or MapReduce 2. 18. What Are The Additional Benefits Yarn Brings In To Hadoop? Effective utilization of the resources as multiple applications can be run in YARN all sharing a common resource. In Hadoop MapReduce there are seperate slots for Map and Reduce tasks whereas in YARN there is no fixed slot. The same container can be used for Map and Reduce tasks leading to better utilization. YARN is backward compatible so all the existing MapReduce jobs. Using YARN, one can even run applications that are not based on the MapReduce model. 19. How Can Native Libraries Be Included In Yarn Jobs? There are two ways to include native libraries in YARN jobs:- By setting the -Djava.library.path on the command line but in this case there are chances that the native libraries might not be loaded correctly and there is possibility of errors. The better option to include native libraries is to the set the LD_LIBRARY_PATH in the .bashrc file. 20. Explain The Differences Between Hadoop 1.x And Hadoop 2.x? In Hadoop 1.x, MapReduce is responsible for both processing and cluster management whereas in Hadoop 2.x processing is taken care of by other processing models and YARN is responsible for cluster management. Hadoop 2.x scales better when compared to Hadoop 1.x with close to 10000 nodes per cluster. Hadoop 1.x has single point of failure problem and whenever the Namenode fails it has to be recovered manually. However, in case of Hadoop 2.x StandBy Namenode overcomes the SPOF problem and whenever the Namenode fails it is configured for automatic recovery. Hadoop 1.x works on the concept of slots whereas Hadoop 2.x works on the concept of containers and can also run generic tasks. 21. What Are The Core Changes In Hadoop 2.0? Hadoop 2.x provides an upgrade to Hadoop 1.x in terms of resource management, scheduling and the manner in which execution occurs. In Hadoop 2.x the cluster resource management capabilities work in isolation from the MapReduce specific programming logic. This helps Hadoop to share resources dynamically between multiple parallel processing frameworks like Impala and the core MapReduce component. Hadoop 2.x Hadoop 2.x allows workable and fine grained resource configuration leading to efficient and better cluster utilization so that the application can scale to process larger number of jobs. 22. Differentiate Between Nfs, Hadoop Namenode And Journal Node? HDFS is a write once file system so a user cannot update the files once they exist either they can read or write to it. However, under certain scenarios in the enterprise environment like file uploading, file downloading, file browsing or data streaming –it is not possible to achieve all this using the standard HDFS. This is where a distributed file system protocol Network File System (NFS) is used. NFS allows access to files on remote machines just similar to how local file system is accessed by applications. Namenode is the heart of the HDFS file system that maintains the metadata and tracks where the file data is kept across the Hadoop cluster. StandBy Nodes and Active Nodes communicate with a group of light weight nodes to keep their state synchronized. These are known as Journal Nodes. 23. What Are The Modules That Constitute The Apache Hadoop 2.0 Framework? Hadoop 2.0 contains four important modules of which 3 are inherited from Hadoop 1.0 and a new module YARN is added to it. Hadoop Common – This module consists of all the basic utilities and libraries that required by other modules. HDFS- Hadoop Distributed file system that stores huge volumes of data on commodity machines across the cluster. MapReduce- Java based programming model for data processing. YARN- This is a new module introduced in Hadoop 2.0 for cluster resource management and job scheduling. 24. How Is The Distance Between Two Nodes Defined In Hadoop? Measuring bandwidth is difficult in Hadoop so network is denoted as a tree in Hadoop. The distance between two nodes in the tree plays a vital role in forming a Hadoop cluster and is defined by the network topology and java interface DNS Switch Mapping. The distance is equal to the sum of the distance to the closest common ancestor of both the nodes. The method get Distance(Node node1, Node node2) is used to calculate the distance between two nodes with the assumption that the distance from a node to its parent node is always 1. Apache YARN Questions and Answers Pdf Download Read the full article
0 notes
Text
A Book Review of "Architecting Modern Data Platforms"
In December O'Reilly published Architecting Modern Data Platforms, a 636-page guide to implementing Hadoop projects in enterprise environments. The book was written by four authors, Lars George, Jan Kunigk, Paul Wilkinson and Ian Buss, all of whom either have worked or are currently working at Cloudera.
Cloudera has over 2,700 customers using its Hadoop platform offering and consulting services. 74 of these customers spend more than a million dollars every year with Cloudera. This puts Cloudera's staff in a unique position to discuss the key issues to consider when putting together the architecture of an enterprise data platform.
This book is aimed at IT Managers, Architects, Data Platform Engineers and System Administrators. If your role is supporting a single relational database which lives on a single server this book will do a good job at exposing you to a world where you can increase performance and reliability by adding more computers to your infrastructure. The book is less aimed at Web and Mobile Developers, Project Managers, Product Owners and other roles you might find on data projects. If you're a Data Scientist less interested in the underlying platform and its security then this book might not be for you.
Do note, the chapters in my physical book I ordered from Amazon's UK site don't match those listed on the O'Reilly product page. I have 19 chapters, not 21 and the chapter titles stop matching from chapter 14 onward.
Foreword & Preface
The book starts out with a foreword from Mike Olson, one of the founders of Cloudera, where he discusses how many of the concepts in Hadoop are decades old and only really came to life after Google's need for distributed compute and storage of massive datasets of the web's contents resulted in academic papers which inspired various Hadoop tooling authors.
The book's preface discusses how Big Data solutions have often had to sacrifice some features found in conventional relational databases in order to meet various scaling criteria. It also removes the misconception that many of these tools are schema-less by explaining the concept of "schema on read". The notions that there should be one copy of a dataset and one cluster that it should run forever are also dismissed.
In describing horizontal scaling it's clarified that although commodity hardware is used for infrastructure this doesn't mean the cheapest computers available. It's emphasised that highly efficient networks and storage systems are still key to taking full advantage of the software on offer.
Mike also reminds the reader that the authors of the book are not only practitioners in implementing Hadoop systems, they're also active participants in the open source community as well.
Part I. Infrastructure
The first chapter goes into further detail on how the architecture of Hadoop was inspired by academic papers published by Google in the early 2000s. It then discusses how various Hadoop ecosystem tools share data between one another and how they can control and support one another as well. HDFS, YARN, ZooKeeper, Hive and Spark are central in these descriptions.
There are also lengthy discussions around Impala, HBase and Oozie. The above tools enjoy good support from Cloudera but I'm disappointed to not see more than a few lines describing Presto, Cassandra and Airflow.
Chapter two's topic is cluster infrastructure. It discusses the need for deploying multiple clusters in order to allow for independence and different versions of software to be used. It also discusses the benefits of decoupling storage from compute. There might be a conception that any and all Hadoop tooling you intend to use should be installed on the same cluster but there is a suggestion that HBase and Kafka could live happily on their own clusters and use hardware more tuned to their needs while benefiting from isolated CPU- and disk caches. Multi-tenancy is also discussed in this chapter as well.
Chapter three goes into detail around the Linux API calls being made by various Hadoop tools and what their performance characteristics are like on the underlying CPU, memory, various NUMA configurations, storage devices and file systems. There is mention of various Intel-specific hardware optimisations that Hadoop takes advantage of both for data redundancy and security.
HDFS' architecture and behaviour patterns are described very well and this is probably the best written description of the technology I've come across. Erasure coding and replication is described in detail and is accompanied by detailed diagrams. RAID as a Hadoop anti-pattern is explained well and they don't fail to mention that underlying metadata stores could see resiliency benefits from being stored on certain RAID configurations.
There are several pages going over various storage options and typical server inventory part lists. Page 97 has a chart with compute and I/O intensity levels on the axes and plots of 20 workloads showing where they sit relative to one another on these two metrics. For example, data cleansing is neither compute nor storage intensive, graph processing is very compute intensive while needing very little I/O, sorting is I/O intensive and shouldn't be bottlenecked by compute capacity and large SQL joins can often be both compute- and I/O-bound.
There is a discussion around what roles various servers could play in small, medium and large clusters. Pages 102 and 103 contain diagrams suggesting which servers within two racks should house which Hadoop services in a hypothetical 200-node cluster.
Chapter four focuses on networking. It starts out explaining how Hadoop's tools use remote procedure calls (RPC) for monitoring, consensus and data transfers. There is a table on page 108 describing the client-server and server-server interactions for ZooKeeper, HDFS, YARN, Hive, Impala, Kudu, HBase, Kafka and Oozie.
Latency and how it does or doesn't affect various systems within Hadoop is discussed on page 109. Data shuffles are discussed over three pages with two helpful diagrams. Consensus and quorum-based majority voting systems and a lengthy discussion on networking topologies complete the chapter.
Chapter five discusses the various roles that can exist in a Hadoop project. It gives an example scenario of a typical business intelligence project. There are helpful diagrams outlining what sort of width and depth of the skill spectrum would be expected of various roles including Architects, Analysts, Developers and Administrators.
Chapter six covers data centre considerations. This book does discuss the Cloud at length but that's later on in the book. Cloudera has a sizeable number of clients running their offerings on bare metal so they're in a good position to give opinion and guidance on what to look out for when you're renting or buying the hardware your Hadoop cluster runs on.
Part II. Platform
Chapter seven discusses operating system configuration considerations to make when setting up a cluster. SELinux, Firewalls and Containers and their relationship with various Hadoop tools are discussed. This is one of the few chapters that has command line examples and they're geared towards those running Red Hat Enterprise Linux.
Chapter eight discusses platform validation. It goes into detail around smoke, baseline and stress testing the hardware you're using for your cluster. Both disk caches and network latency are well explained in this chapter. There is short mention of benchmarks like TPC-DS.
Chapter nine focuses on security. In-flight encryption, authentication and authorisation as well as how these are addressed in Hadoop's KMS, HDFS, HBase, Kafka, Hive, Solr, Spark, Kudu, Oozie, ZooKeeper and Hue.
Kerberos is very well described which is very rare to come across. It explains how one Kerberos KDC can be configured to trust another without the other needing to reciprocate that trust as well as how long-running applications can be setup to use Keytabs as Kerberos tickets are time-limited.
Kerberos expertise is very expensive to bring in on a consulting basis and there isn't anything that handles authentication across as many Hadoop projects as Kerberos does. Enterprises don't just open up Hadoop clusters to their entire internal network nor do they commonly run air-gapped environments so this chapter alone pays huge dividends.
There is also a long discussion on encryption at rest and the trade-offs between full volume encryption, HDFS transparent data encryption and other service-specific configurations.
Chapter ten discusses integration with identity management providers. There is a lot of discussion around Kerberos in this chapter as well as Hadoop-specific certificate management with configuration examples and example OpenSSL commands.
Chapter eleven discusses how to control access to cluster software. There are tables detailing which pieces of software support REST, Thrift, JDBC, ODBC and which support a Web UI. Various access topologies are offered as inspiration of how one might want to setup their specific implementation. Proxies and Load Balancers are discussed at length as well.
Chapter twelve discusses high availability. This chapter is 47 pages long and goes into setting up redundancy in hardware and software using both active-active and active-passive setups for most Hadoop-related software and their dependencies.
Chapter thirteen discuses backups. There are a lot of different systems in a Hadoop that store data and state and each need to be taken into consideration when planning how you'll back up a whole cluster.
If you were to restore a non-trivial amount of data you'd need to consider how quickly the data could be transferred from another location and what sort of bottlenecks hardware might impose. There is also discussion around taking snapshots versus replicating changes and whether or not you should consider replicating deletes as well as additions to your system.
It would have been nice if Cloudera got one of their petabyte-plus clients to sign off on a short case study on how they've setup and had to use one of their backups.
Part II. Taking Hadoop to the Cloud
Chapter fourteen discusses virtualisation. There is an important concept discussed called "Anti-Affinity Groups". The idea is that you don't want to place cluster nodes that are meant to complement high availability on the same physical machine. If all the ZooKeeper nodes in a quorum are on one physical server and that machine or its rack goes down then there will be total loss of consensus. Likewise, if you have 20+ hard drives connected to your cluster via a single physical cable then scaling I/O horizontally could be bottlenecked and all storage will share a single point of failure.
Chapter fifteen discusses solutions for private cloud platforms. There is a lot in this chapter trying to persuade readers to not try and reinvent their own version of Amazon EMR. OpenStack and OpenShift are discussed as well as life cycles, automation and isolation. This is one of the shortest chapters in the book.
Chapter sixteen discusses solutions for public cloud platforms. This chapter goes over the managed Hadoop offerings from Amazon Web Services, Microsoft Azure and Google Cloud. They go over storage and compute primitives and then discuss ways of setting up high availability.
With these services it can be difficult to know if two nodes in your cluster live on the same physical machine but they suggest using different instances sizes as a way of trying to avoid having a common underlying machine. There are a few other suggestions for trying to get different physical servers for any one cluster.
All three cloud providers offer blob storage as a way of decoupling compute and storage but they aren't completely comparable to one another. The major differences are discussed.
Default service limits are also highlighted. If you're planning on setting up a large Hadoop cluster or many small ones there are a lot of default account limits you'll have to request increases for from your provider.
Page 474 shows a chart with compute capacity on one axis and memory capacity on the other. Across the chart they've plotted where various workloads would sit as well as where various compute instance types of AWS, GCP and Azure would live. For example, Complex SQL predicates are both compute- and memory-intensive and AWS' c5.9xlarge, GCP's n1-highcpu-64 and Azure's F64s_v2 might be good candidates for running this sort of workload. This reminds me of Qubole's "Presto performance across various AWS instance types" blog post.
This chapter does mention Cloudera CDH and Hortonworks HDP (which is used by Azure's HDInsight) on a few occasions as well.
Chapter seventeen covers automated provisioning. They make a good suggestion early on that Kerberos and bind as a well as IAM identities and firewall rules should probably be setup separately to any "Hadoop infrastructure as code" / PaaS provisioning. They also discuss considerations for safely scaling your clusters down when demand fades.
There is a section on "transient clusters" where a user submits a job as a workload and a cluster is provisioned for that job and destroys itself afterword. There isn't a lot of detail into how the architecture of this specific setup would work but they do mention the three big cloud providers, their Cloudera Altus offering and Qubole as providers that could help with this sort of workload.
Though this chapter focused more on listing features you might want to think about in your implementation rather than giving concrete code examples, Puppet, Ansible and Chef are mentioned early on.
Chapter eighteen discusses security in the cloud and has an excellent introduction. It states not knowing where your data is can be disconcerting. They discuss risk models, identity, connectivity and key management at length. They go so far as to state or try and guess the underlying hardware providers for the three major cloud vendors' key vault solutions.
There's discussion of service accounts for using Google Cloud Storage via HDFS' CLI and generating temporary security credentials for AWS S3 via the AWS CLI. There's also a reasonable amount of content discussing GDPR, US national security orders and law enforcement requests.
One great tip mentioned is that when you're using HDFS' encryption at rest and you delete someone's details from a dataset on a cluster, their data was possibly only unlinked from metadata describing where it is on the disk, not fully scrubbed away. If the disks go missing but without the metadata then the original data will only exist in as an encrypted blob on the physical disks and won't be recoverable without the original metadata and cryptographic keys.
The above could go some way to making an implementation compliant with GDPR's right to be forgotten with little effort being put into the infrastructure setup. Typically databases unlink rather than scrub so "deletes" aren't deletes and the original data might be recoverable.
I think there was a lost opportunity to discuss the threat of uncovering secrets in the history of git repositories used by an implementation team. It would be great to see a git bisect command example using Lyft's high-entropy-string to see if any developers accidentally committed credentials, removed them with another commit and failed to rotate or destroy those credentials afterword.
Final Thoughts
I'll first mention a few complaints about this book.
First complaint, the sales pitch for Hadoop's strengths is missing from this book. If you're pitching an architecture to a client you need to have arguments for why your software choices are better than anything else out there. Hortonworks staff have publicly stated that there are 600 PB+ HDFS clusters in operation. It's likely that only Google has authored software that supports single clusters with a capacity greater than this. The in-memory nature of a HDFS Name Node means it's possible to support 60K concurrent HDFS requests. A few pages on why Hadoop is still a good idea in 2019 would have been greatly appreciated.
Second complaint, this book doesn't pick-and-mix much outside of Cloudera's core software library they commercially support. There are open source projects not all affiliated with the Hadoop brand that can greatly enhance a Hadoop setup. A lot of firms that aren't Hadoop-focused businesses build a lot of useful tools for the ecosystem. It's a shame to not see more mentioned of Facebook, Uber, AirBNB and Netflix-lead projects in this book.
EMR, Dataproc and HD Insights are covered but other providers, like Confluent, Databricks and Qubole either aren't mentioned or only very sparingly. Hortonworks, which merged with Cloudera in 2018, are mentioned when they offer a competing solution.
Hortonworks helped out Facebook a lot with the ORC file format research they needed a few years back and since Cloudera merged with Hortonworks last year I can't see how this case study can't be owned and proudly discussed in one of the very few Hadoop books of 2018.
If the scope of the book needs to be limited then I can understand that but I've had enterprise clients comparing columnar file formats, asking how many files on HDFS will be too much and wanting some assurances that a reasonable number of providers have been considered to some extent.
A lot of companies that compete with one another also work together on all of the open source software in the Hadoop ecosystem. It would be nice to see if the other firms could volunteer an engineer or three to offer some expertise for comparisons. There aren't a lot of good Hadoop books released so it's an important occasion to try and make it as complete as possible.
All the above said, Netflix's Iceberg project was mentioned in chapter 19 which was nice to see but it would be nicer to see a larger catalogue of these complementary projects.
Third complaint, there should have been a chapter on orchestration. Apache Airflow has the momentum and the huge addition of value that Spark had a few years ago. I've never worked on a data project that didn't need to move data around in an observable fashion. Orchestration is mentioned but not enough given how central it is to data platforms.
Fourth complaint, there's no "Future Features of Hadoop" chapter in this book. Ozone will help break the 500 million file count barrier in HDFS and potentially allow for trillions of files of all sizes to be stored using HDFS primitives. This system will have an AWS S3 API-compatible interface which will make it easy to develop for and add support to existing applications. A third of the commits to the Hadoop git repository over the past few months have been Ozone-specific and I suspect this could be the biggest new feature of Hadoop this year.
With the complaints out of the way...
If you're only going to buy a single book and then supplement its teachings by going through JIRAs, examine source code, read blogs and run examples in VMs then this book is the most complete I've seen when it comes to covering the major sections of a data platform project using the Hadoop ecosystem of software. The topics discussed are all talking points I've had when consulting for large clients. Use this book as your roadmap.
The lack of command line and configuration examples does make this book more information-dense while not potentially out-dating itself too quickly. The English language can be a lot more powerful than pages of depreciated commands and poorly-formatted XML.
Before publishing this post I checked Amazon's UK site and there are 3rd-party suppliers selling this book brand new for £37. I believe the knowledge I've picked up from reading this book should produce an amazing return on the investment.
DataTau published first on DataTau
0 notes