#mrkeu
Text
Top 5 High Availability Dedicated Server Solutions
What Is a High Availability Dedicated Server?
A typical dedicated server is a powerful computer which is connected to a high-speed Internet connection, and housed in a state-of-the-art remote data center or optimized data facility.
A High Availability dedicated server is an advanced system equipped with redundant power supplies, a fully redundant network, RAID disk towers and backups, ensuring the highest uptime and the full reliability with no single point of failure.
Configuration For High Availability Dedicated Servers
As its name implies, high availability dedicated solutions are scalable and customized hosting solutions, designed to meet the unique needs of any business.
These configurations are carefully designed to provide fail-proof architecture to run the critical applications in your business – those that demand the highest availability.
Possible high availability server configurations might include multiple hosts managed by redundant load balancers and replication hosts. As well as redundant firewalls for added security and reliability.
Why High Availability Server Is Important for Business
Nowadays businesses rely on the Internet. Let’s face it – even the smallest downtime can cause huge losses to business. And not just financial losses. Loss of reputation can be equally devastating.
According to StrategicCompanies more than half of Fortune 500 companies experience a minimum of 1.6 hours of downtime each and every week. That amounts to huge losses of time, profit, and consumer confidence. If your customer can’t reach you online, you might as well be on the moon, as far as they are concerned.
Consider: In the year 2013, 30 minutes of an outage to Amazon.com reportedly cost the company nearly $2 million. That’s $66,240 per minute. Take a moment to drink that in. Even if you’re not Amazon, any unplanned downtime is harmful to your business.
Your regular hosting provider may provide 99% service availability. That might sound good, in theory. But think about that missing 1%… That’s 87 hours (3.62 days) of downtime per year! If the downtime hits during peak periods, the loss to your business can be disastrous.
The best way to prevent downtime and eliminate these losses is to opt for high availability hosting solutions.
Built on a complex architecture of hardware and software, all parts of this system work completely independently of each other. In other words – failure of any single component won’t collapse the entire system.
It can handle very large volume of requests or a sudden surge in traffic. It grows and shrinks with the size and needs of your organization. Your business is flexible, shouldn’t your computer systems be, as well?
Following are some of the best high availability solutions you can use to host your business applications.
1. Ultra High Performance Dedicated Servers
High performance servers are high-end dedicated solutions with larger computing capacity, especially designed to achieve the maximum performance. They are an ideal solution to cater enterprise workloads.
A typical high performance dedicated server will consist of the following:
Single/Dual latest Intel Xeon E3 or E5 series processors.
64 GB to 256 GB RAM
8 to 24 TB SATA II HDD with RAID 10
Energy efficient and redundant power supply & cooling units
Offsite Backups
Note that the list above is just a sample configuration which can be customized/upgraded as per your unique requirements. If you need more power, we can build a setup with 96 drives, 3 TB RAM, and 40+ physical CPU cores.
Real World Applications (Case Study)Customer’s Requirement
One of our existing customers was looking for a high-end game server to host flash games with encoded PHP and MySQL server as a backend.
To achieve the highest availability, they demanded 2 load balancers with failover. Each of them contains 2 web servers and a database server.
Website Statistics
8000-10000 simultaneous players
100% uptime requirement
10 GB+ database size
Solution Proposed by AccuWebHosting
Our capacity planning team designed a fully redundant infrastructure with dual load balancers sitting in front of web and database servers.
This setup consists of 2 VMs with load balancers connected to a group of web servers through a firewall. The database server was built on ultra-fast SSD drives for the fastest disk I/O operations.
For a failover, we set up an exact replica of this architecture with real-time mirroring. Should the primary system fail, the secondary setup will seamlessly take over the workload. That’s right. Zero downtime.
Infrastructure Diagram

2. Load Balanced Dedicated Servers
Load Balancing
The process of distributing incoming web traffic across a group of servers efficiently and without intervention is called Load Balancing.
A hardware or software appliance which provides this load balancing functionality is known as a Load Balancer.
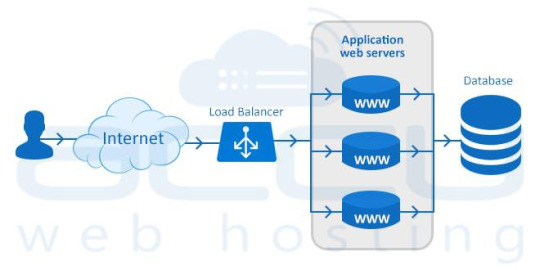
The dedicated servers equipped with a hardware/software load balancer are called Load Balanced Dedicated Servers.
How Load Balancing Works?
A load balancer sits in front of your servers and routes the visitor requests across the servers. It ensures even distribution, i.e., all requests must be fulfilled in a way that it maximizes speed and capacity utilization of all servers and none of them is over or under-utilized.
When your customers visit your website, they are first connected to load balancer and the load balancer routes them to one of the web servers in your infrastructure. If any server goes down, the load balancer instantly redirects the traffic to the remaining online servers.
As web traffic increases, you can add new servers quickly and easily to the existing pool of load-balanced servers. When a new server is added, the load balancer will start sending requests to new server automatically. That’s right – there’s no user-intervention required.
Types Of Load Balancing
Load balancing can be performed with one of the following methods.
Load Balancing Through DNS
Load Balancing Through Hardware
Load Balancing Through Software
Load Balancing With DNS
The DNS service balances the web traffic across the multiple servers. Note that when you perform the traffic load balancing through this method you cannot choose which load balancing algorithm. It always uses the Round Robin algorithm to balance the load.
Load Balancing Through Hardware
This is the most expensive way of load balancing. It uses a dedicated hardware device that handles traffic load balancing.
Most of the hardware based load balancer systems run embedded Linux distribution with a load balancing management tool that allows ease of access and a configuration overview.
Load Balancing Through Software
Software-based load balancing is one of the most reliable methods for distributing the load across servers. In this method, the software balances the incoming requests through a variety of algorithms.
Load Balancing Algorithms
There are a number of algorithms that can be used to achieve load balance on the inbound requests. The choice of load balancing method depends on the service type, load balancing type, network status and your own business requirements.
Typically, for low load systems, simple load balancing methods (i.e., Round Robin) will suffice, whereas, for high load systems, more complex methods should be used. Check out this link for more information on some industry standard Load Balancing Algorithms used by the load balancers.
Setup Load Balancing On Linux
HAProxy (High Availability Proxy) is the best available tool to set up a load balancer on Linux machines (web server, database server, etc).
It is an open-source TCP and HTTP load balancer used by some of the largest websites including Github, StackOverflow, Reddit, Tumblr and Twitter.
It is also used as a fast and lightweight proxy server software with a small memory footprint and low CPU usage.
Following are some excellent tutorials to setup a load balancing on Apache, NGINX and MySQL server.
Setup HAProxy as Load Balancer for Nginx on CentOS 7
Setup High-Availability Load Balancer for Apache with HAProxy
Setup MySQL Load Balancing with HAProxy
Setup Load Balancing On Windows
Check out below the official Microsoft document to setup load balancing with IIS web server.
Setup Load Balancing on IIS
3. Scalable Private Cloud
A scalable private cloud is a cloud-based system that gives you self-service, scalability, and elasticity through a proprietary architecture.
Private clouds are highly scalable that means whenever you need more resources, you can upgrade them, be it memory, storage space, CPU or bandwidth.
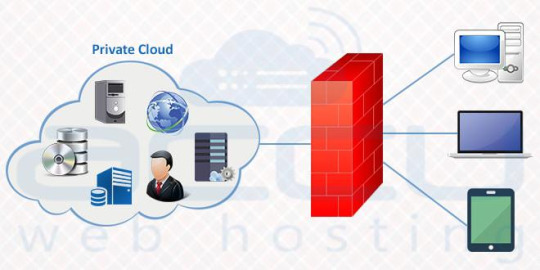
It gives the best level of security and control making it an ideal solution for a larger business. It enables you to customise computer, storage and networking components to best suit custom requirements.
Private Cloud Advantages
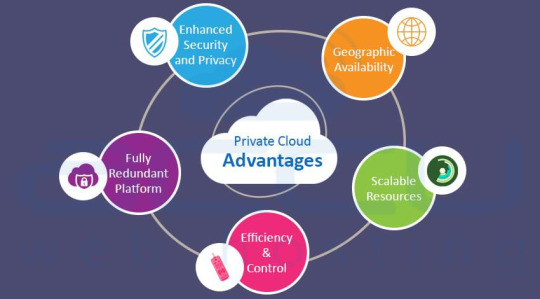
Enhanced Security & Privacy
All your data is stored and managed on dedicated servers with dedicated access. If your Cloud is on-site, the server will be monitored by your internal IT team and if it is at a datacenter, their technicians will monitor it. Thus, physical security is not your concern.
Fully Redundant Platform
A private cloud platform provides a level of redundancy to compensate from multiple failures of the hard drive, processing power etc. When you have a private cloud, you do not have to purchase any physical infrastructure to handle fluctuation in traffic.
Efficiency & Control
Private cloud gives you more control on your data and infrastructure. It has dedicated resources and no one else has access of the server except the owner of the server.
Scalable Resources
Each company has a set of technical and business requirements which usually differ from other companies based on company size, industry and business objectives etc.
A private cloud allows you to customize the server resources as per your unique requirements. It also allows you to upgrade the resources of the server when necessary.
Private Cloud DisadvantagesCost
As compared to the public cloud and simple dedicated server setup, a private cloud is more expensive. Investments in hardware and resources are also required.
You can also rent a private cloud, however the costs will likely be the same or even higher, so this might not be an advantage.
Maintenance
Purchasing or renting a private cloud is only one part of the cost. Obviously, for a purchase, you’ll have a large outlay of cash at the onset. If you are renting you’ll have continuous monthly fees.
But even beyond these costs, you will need to consider maintenance and accessories. Your private cloud will need enough power, cooling facilities, a technician to manage the server and so on.
Under-utilization
Even if you are not utilizing the server resources, you still need to pay the full cost of your private cloud. Whether owning or renting, the cost of capacity under-utilization can be daunting, so scale appropriately at the beginning of the process.
Complex Implementation
If you are not tech savvy, you may face difficulties maintaining a private cloud. You will need to hire a cloud expert to manage your infrastructure, yet another cost.
Linux & Windows Private Cloud Providers
Cloud providers give you an option to select your choice of OS: either Windows or any Linux distribution. Following are some of the private cloud solution providers.
AccuWebHosting
Amazon Web Services
Microsoft Azure
Rackspace
Setting Up Your Own Private Cloud
There are many paid and open source tools available to setup your own private cloud.
OpenStack
VMware vSphere
VMmanager
OnApp
OpenNode Cloud Platform
OpenStack is an open source platform that provides IAAS (Infrastructure As A Service) for both public and private cloud.
Click here to see the complete installation guide on how you can deploy your own private cloud infrastructure with OpenStack on a single node in CentOS or RHEL 7.
4. Failover
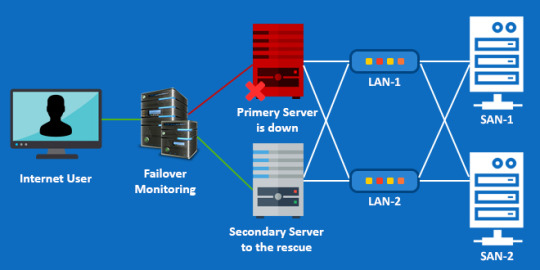
Failover means instantly switching to a standby server or a network upon the failure of the primary server/network.
When the primary host goes down or needs maintenance, the workload will be automatically switched to a secondary host. This should be seamless, with your users completely unaware that it happened.
Failover prevents a single point of failure (SPoF) and hence it is the most suitable option for mission critical applications where the system has to be online without even one second of downtime.
How Failover Works?
Surprisingly, automated failover system is quite easy to set up. A failover infrastructure consists of 2 identical servers, A primary server and a secondary. Both servers will serve the same data.
A third server will be used for monitoring. It continuously monitors the primary server and if it detects a problem, it will automatically update the DNS records for your website so that traffic will be diverted to the secondary server.
Once the primary server starts functioning again, traffic will be routed back to primary server. Most of the time your users won’t even notice a downtime or lag in server response.
Failover TypesCold Failover
A Cold Failover is a redundancy method that involves having one system as a backup for another identical primary system. The Cold Failover system is called upon only on failure of the primary system.
So, Cold Failover means that the second server is only started up after the first one has been shut down. Clearly this means you must be able to tolerate a small amount of downtime during the switch-over.
Hot Failover
Hot Failover is a redundant method in which one system runs simultaneously with an identical primary system.
Upon failure of the primary system, the Hot Failover system immediately takes over, replacing the primary system. However, data is still mirrored in real time ensuring both systems have identical data.
Setup Failover
Checkout the below tutorials to setup and deploy a failover cluster.
Setup Failover Cluster on Windows Server 2012
Configure High Avaliablity Cluster On CentOS
The Complete Guide on Setting up Clustering In Linux
Available Solutions
There are four major providers of failover clusters listed as below.
Microsoft Failover Cluster
RHEL Failover Cluster
VMWare Failover Cluster
Citrix Failover Cluster
Failover Advantages
Failover Server clustering is completely a scalable solution. Resources can be added or removed from the cluster.
If a dedicated server from the cluster requires maintenance, it can be stopped while other servers handle its load. Thus, it makes maintenance easier.
Failover Disadvantages
Failover Server clustering usually requires more servers and hardware to manage and monitor, thus, increases the infrastructure.
Failover Server clustering is not flexible, as not all the server types can be clustered.
There are many applications which are not supported by the clustered design.
It is not a cost-effective solution, as it needs a good server design which can be expensive.
5. High Availability Clusters

A high availability cluster is a group of servers that support server applications which can be utilized with a minimal amount of downtime when any server node fails or experiences overload.
You may require a high availability clusters for any of the reasons like load balancing, failover servers, and backup system. The most common types of Cluster configuration are active-active and active-passive.
Active-Active High Availability Cluster
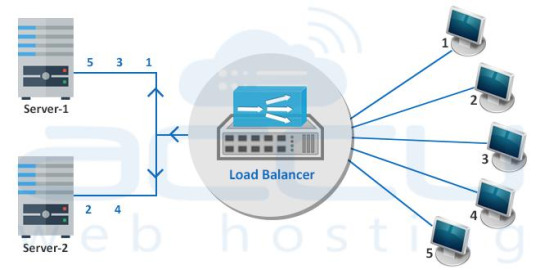
It consists of at least two nodes, both actively running same the service. An active-active cluster is most suitable for achieving true load balancing. The workload is distributed across the nodes. Generally, significant improvement in response time and read/write speed is experienced.
Active-Passive High Availability Cluster
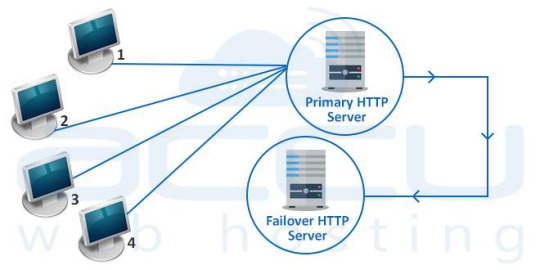
Active-passive also consists of at least two nodes. However, not all nodes remain active simultaneously. The secondary node remains in passive or standby mode. Generally, this cluster is more suitable for a failover cluster environment.
Setup A High Availability Cluster
Here are some excellent tutorials to setup a high availability cluster.
Configuring A High Availability Cluster On CentOS
Configure High-Availability Cluster on CentOS 7 / RHEL 7
Available Solutions
There are very well-known vendors out there, who are experts in high availability services. A few of them are listed below.
Dell Windows High Availability solutions
HP High Availability (HA) Solutions for Microsoft and Linux Clusters
VMware HA Cluster
High Availability Cluster Advantages
Protection Against Downtime
With HA solutions, if any server of a cluster goes offline, all the services are migrated to an active host. The quicker you get your server back online, the quicker you can get back to business. This prevents your business from remaining non-productive.
Optimum Flexibility
High availability solutions offer greater flexibility if your business demands 24×7 availability and security.
Saves Downtime Cost
The quicker you get your server back up online, the quicker you can get back to business.This prevents your business from remaining non-productive.
Easy Customization
With HA solutions, it is a matter of seconds to switch over to the failover server and continue production. You can customize your HA cluster as per your requirement. You can either set data to be up-to-date in minutes or within seconds. Moreover, the data replication scheme, versions can be specified as per your needs.
High Availability Cluster Disadvantages
Continuous Grow in infrastructure
It demands many servers and loads of hardware to deliver a failover and load balancing. This increases your infrastructure.
Application Not Supported!
HA clustering offers much flexibility at the hardware level but not all software applications support clustered environment.
Expensive
HA clustering is not a cost-effective solution, the more sophistication you need, the more money you need to invest.
6. Complex Configuration Built By AccuWebHosting
Customer’s Requirement
An eCommerce website that can handle the peak load of 1000 HTTP requests per second, more than 15,000 visitors per day and 3 times the load in less than 10 seconds. During the peak hours and new product launches, visits count to the website will be multiplied by 2.
Website Statistics
40K products and product related articles
40 GB of static contents (images and videos and website elements)
6 GB of database
Solution We Delivered
We suggested a high availability Cloud Infrastructure, to handle the load and ensure the maximum availability as well. To distribute the load, we mounted 2 load balancer servers in front of the setup with load balanced IP address on top of them.
We deployed a total of 8 web servers, 3 physical dedicated servers, and 5 Cloud instances to absorb the expected traffic. The setup was configured to get synchronized between the various components through the rsync cluster.
The Cloud instances were used in a way that they can be added or removed as per load of the peak traffic without incurring the costs associated with additional physical servers.
Each Cloud instance contained the entire website (40GB of static content) to give the user a smooth website experience.
The 6 GB database was hosted on a master dedicated server, which was replicated on a secondary slave server to take over when the master server fails. Both of these DB servers have SSD disks for better read/write performance.
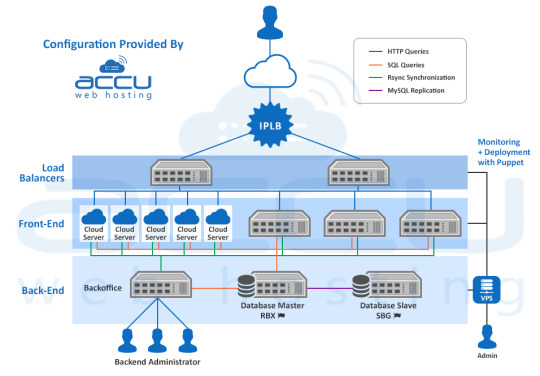
A team of 15 developers and content writers update the content through backoffice servers hosted on a dedicated server. Any changes made by the team are propagated by rsync on the production environment and the database.
The entire infrastructure was monitored by Zabbix, which is installed on a high availability Cloud VPS. Zabbix will monitor the data provided by the infrastructure servers and then generate a series of graphs to depict the RAM usage, load average, disk consumption and network stats. Zabbix will also send an alert when any of the usage reaches its threshold or if any of the services goes down.
0 notes
Text
What Is Load Balancing?
Introduction
Modern websites and applications generate lots of traffic and serve numerous client requests simultaneously. Load balancing helps meet these requests and keeps the website and application response fast and reliable.
In this article, you will learn what load balancing is, how it works, and which different types of load balancing exist.

Load Balancing Definition
Load balancing distributes high network traffic across multiple servers, allowing organizations to scale horizontally to meet high-traffic workloads. Load balancing routes client requests to available servers to spread the workload evenly and improve application responsiveness, thus increasing website availability.
Load balancing applies to layers 4-7 in the seven-layer Open System Interconnection (OSI) model. Its capabilities are:
L4. Directing traffic based on network data and transport layer protocols, e.g., IP address and TCP port.
L7. Adds content switching to load balancing, allowing routing decisions depending on characteristics such as HTTP header, uniform resource identifier, SSL session ID, and HTML form data.
GSLB. Global Server Load Balancing expands L4 and L7 capabilities to servers in different sites.
Why Is Load Balancing Important?
Load balancing is essential to maintain the information flow between the server and user devices used to access the website (e.g., computers, tablets, smartphones).
There are several load balancing benefits:
Reliability. A website or app must provide a good UX even when traffic is high. Load balancers handle traffic spikes by moving data efficiently, optimizing application delivery resource usage, and preventing server overloads. That way, the website performance stays high, and users remain satisfied.
Availability. Load balancing is important because it involves periodic health checks between the load balancer and the host machines to ensure they receive requests. If one of the host machines is down, the load balancer redirects the request to other available devices.
Load balancers also remove faulty servers from the pool until the issue is resolved. Some load balancers even create new virtualized application servers to meet an increased number of requests.
Security. Load balancing is becoming a requirement in most modern applications, especially with the added security features as cloud computing evolves. The load balancer's off-loading function protects from DDoS attacks by shifting attack traffic to a public cloud provider instead of the corporate server.
Predictive Insight. Load balancing includes analytics that can predict traffic bottlenecks and allow organizations to prevent them. The predictive insights boost automation and help organizations make decisions for the future.
How Does Load Balancing Work?
Load balancers sit between the application servers and the users on the internet. Once the load balancer receives a request, it determines which server in a pool is available and then routes the request to that server.

By routing the requests to available servers or servers with lower workloads, load balancing takes the pressure off stressed servers and ensures high availability and reliability.
Load balancers dynamically add or drop servers in case of high or low demand. That way, it provides flexibility in adjusting to demand.
Load balancing also provides failover in addition to boosting performance. The load balancer redirects the workload from a failed server to a backup one, mitigating the impact on end-users.
Types of Load Balancing
Load balancers vary in storage type, balancer complexity, and functionality. The different types of load balancers are explained below.
Hardware-Based
A hardware-based load balancer is dedicated hardware with proprietary software installed. It can process large amounts of traffic from various application types.
Hardware-based load balancers contain in-built virtualization capabilities that allow multiple virtual load balancer instances on the same device.
Software-Based
A software-based load balancer runs on virtual machines or white box servers, usually incorporated into ADC (application delivery controllers). Virtual load balancing offers superior flexibility compared to the physical one.
Software-based load balancers run on common hypervisors, containers, or as Linux processes with negligible overhead on a bare metal server.
Virtual
A virtual load balancer deploys the proprietary load balancing software from a dedicated device on a virtual machine to combine the two above-mentioned types. However, virtual load balancers cannot overcome the architectural challenges of limited scalability and automation.
Cloud-Based
Cloud-based load balancing utilizes cloud infrastructure. Some examples of cloud-based load balancing are:
Network Load Balancing. Network load balancing relies on layer 4 and takes advantage of network layer information to determine where to send network traffic. Network load balancing is the fastest load balancing solution, but it lacks in balancing the distribution of traffic across servers.
HTTP(S) Load Balancing. HTTP(S) load balancing relies on layer 7. It is one of the most flexible load balancing types, allowing administrators to make traffic distribution decisions based on any information that comes with an HTTP address.
Internal Load Balancing. Internal load balancing is almost identical to network load balancing, except it can balance distribution in internal infrastructure.
Load Balancing Algorithms
Different load balancing algorithms offer different benefits and complexity, depending on the use case. The most common load balancing algorithms are:
Round Robin
Distributes requests sequentially to the first available server and moves that server to the end of the queue upon completion. The Round Robin algorithm is used for pools of equal servers, but it doesn't consider the load already present on the server.

Least Connections
The Least Connections algorithm involves sending a new request to the least busy server. The least connection method is used when there are many unevenly distributed persistent connections in the server pool.

Least Response Time
Least Response Time load balancing distributes requests to the server with the fewest active connections and with the fastest average response time to a health monitoring request. The response speed indicates how loaded the server is.

Hash
The Hash algorithm determines where to distribute requests based on a designated key, such as the client IP address, port number, or the request URL. The Hash method is used for applications that rely on user-specific stored information, for example, carts on e-commerce websites.

Custom Load
The Custom Load algorithm directs the requests to individual servers via SNMP (Simple Network Management Protocol). The administrator defines the server load for the load balancer to take into account when routing the query (e.g., CPU and memory usage, and response time).

0 notes
Text
Shared Nothing Architecture Explained
Introduction
Why are companies such as Google and Facebook using the Shared Nothing Architecture, and how does it differ from other models?
Read on to learn what Shared Nothing is, how it compares to other architectures, and its advantages and disadvantages.

What Is Shared Nothing Architecture?
Shared Nothing Architecture (SNA) is a distributed computing architecture that consists of multiple separated nodes that don’t share resources. The nodes are independent and self-sufficient as they have their own disk space and memory.
In such a system, the data set/workload is split into smaller sets (nodes) distributed into different parts of the system. Each node has its own memory, storage, and independent input/output interfaces. It communicates and synchronizes with other nodes through a high-speed interconnect network. Such a connection ensures low latency, high bandwidth, as well as high availability (with a backup interconnect available in case the primary fails).
Since data is horizontally partitioned, the system supports incremental growth. You can add new nodes to scale the distributed system horizontally and increase the transmission capacity.
Shared Nothing Architecture Diagram
The best way to understand the architecture of the shared-nothing model is to see it side by side with other types of architectures.
Below you see the difference in shared vs. non-shared components in different models - Shared Everything, Shared Storage, and Shared Nothing.
Unlike the others, SNA has no shared resources. The only thing connecting the nodes is the network layer, which manages the system and communication among nodes.

Other Shared Architecture Types Explained
The concept of “shared nothing” was first introduced by Michael Stonebraker in his 1986 research paper, in which he contrasted shared disk and shared memory architecture. While comparing these two options, Stonebraker included the possibility of creating a system in which neither memory nor storage is shared.
When deciding whether SNA is the solution for your use case, it is best to compare it with other cluster types. Alternative options include:
Shared Disk Architecture
Shared Memory Architecture
Shared Everything Architecture
Shared-Disk Architecture
Shared disk is a distributed computing architecture in which all the nodes in the system are linked to the same disk device but have their own private memory. The shared data is accessible from all cluster nodes and usually represents a shared disk (such as a database) or a shared filesystem (like a storage area network or network-attached storage). The shared disk architecture is best for use cases in which data partitioning isn’t an option. Compared to SNA, it is far less scalable.

Shared-Memory Architecture
Shared memory is an architectural model in which nodes within the system use one shared memory resource. This setup offers simplicity and load balancing as it includes point-to-point connections between devices and the main memory. Fast and efficient communication among processors is key to ensure efficient transmission of data and to avoid redundancy. Such communication is carried out through an interconnection network and managed by a single operating system.
Shared-Everything Architecture
On the opposite side of the spectrum, there is the shared everything architecture. This architectural model consists of nodes that share all resources within the system. Each node has access to the same computing resources and shared storage. The main idea behind such a system is maximizing resource utilization. The disadvantage is that shared resources also lead to reduced performance due to contention.

Advantages and Disadvantages of Shared Nothing Architecture
When compared to different shared architectures mentioned above, it is clear the Shared Nothing Architecture comes with many benefits. Take a look at some of the advantages, as well as disadvantages of such a model.
Advantages
There are many advantages of SNA, the main ones being scalability, fault tolerance, and less downtime.
Easier to Scale
There is no limit when it comes to scaling in the shared-nothing model. Unlimited scalability is one of the best features of this type of architecture. Since nodes are independent and don’t share resources, scaling up your application won’t disrupt the entire system or lead to resource contention.
Eliminates Single Points of Failure
If one of the nodes in the application fails, it doesn’t affect the functionality of others as each node is self-reliant. Although node failure can impact performance, it doesn’t disrupt the overall behavior of the app as a whole.
Simplifies Upgrades and Prevents Downtime
There is no need to shut down the system while working on or upgrading individual nodes. Thanks to redundancy, upgrading one node at a time doesn’t impact the effectiveness of others. What’s more, having redundant copies of data on different nodes prevents unexpected downtime caused by disk failure or data loss.
Disadvantages
Once you considered the benefits of SNA, take a look at a couple of disadvantages that can help you decide whether it is the best option for you.
Cost
A node consists of its individual processor, memory, and disk. Having dedicated resources essentially means higher costs when it comes to setting up the system. Additionally, transmitting data that requires software interaction is more expensive compared to architectures with shared disk space and/or memory.
Decreased Performance
Scaling up your system can eventually affect the overall performance if the cross-communication layer isn’t set up correctly.
Conclusion
After reading this article, you should have a better understanding of Shared Nothing Architecture and how it works. Take into account all the advantages and disadvantages of the model before deciding on the architecture for your application.
0 notes
Text
What is High Availability Architecture?
High Availability Definition
A highly available architecture involves multiple components working together to ensure uninterrupted service during a specific period. This also includes the response time to users’ requests. Namely, available systems have to be not only online, but also responsive.
Implementing a cloud computing architecture that enables this is key to ensuring the continuous operation of critical applications and services. They stay online and responsive even when various component failures occur or when a system is under high stress.
Highly available systems include the capability to recover from unexpected events in the shortest time possible. By moving the processes to backup components, these systems minimize downtime or eliminate it. This usually requires constant maintenance, monitoring, and initial in-depth tests to confirm that there are no weak points.
High availability environments include complex server clusters with system software for continuous monitoring of the system’s performance. The top priority is to avoid unplanned equipment downtime. If a piece of hardware fails, it must not cause a complete halt of service during the production time.
Staying operational without interruptions is especially crucial for large organizations. In such settings, a few minutes lost can lead to a loss of reputation, customers, and thousands of dollars. Highly available computer systems allow glitches as long as the level of usability does not impact business operations.
A highly available infrastructure has the following traits:
Hardware redundancy
Software and application redundancy
Data redundancy
The single points of failure eliminated
How To Calculate High Availability Uptime Percentage?
Availability is measured by how much time a specific system stays fully operational during a particular period, usually a year.
It is expressed as a percentage. Note that uptime does not necessarily have to mean the same as availability. A system may be up and running, but not available to the users. The reasons for this may be network or load balancing issues.
The uptime is usually expressed by using the grading with five 9’s of availability.
If you decide to go for a hosted solution, this will be defined in the Service Level Agreement (SLA). A grade of “one nine” means that the guaranteed availability is 90%. Today, most organizations and businesses require having at least “three nines,” i.e., 99.9% of availability.
Businesses have different availability needs. Those that need to remain operational around the clock throughout the year will aim for “five nines,” 99.999% of uptime. It may seem like 0.1% does not make that much of a difference. However, when you convert this to hours and minutes, the numbers are significant.
Refer to the table of nines to see the maximum downtime per year every grade involves:

As the table shows, the difference between 99% and 99.9% is substantial.
Note that it is measured in days per year, not hours or minutes. The higher you go on the scale of availability, the cost of the service will increase as well.
How to calculate downtime? It is essential to measure downtime for every component that may affect the proper functioning of a part of the system, or the entire system. Scheduled system maintenance must be a part of the availability measurements. Such planned downtimes also cause a halt to your business, so you should pay attention to that as well when setting up your IT environment.
As you can tell, 100% availability level does not appear in the table.
Simply put, no system is entirely failsafe. Additionally, the switch to backup components will take some period, be that milliseconds, minutes, or hours.
How to Achieve High Availability
Businesses looking to implement high availability solutions need to understand multiple components and requirements necessary for a system to qualify as highly available. To ensure business continuity and operability, critical applications and services need to be running around the clock. Best practices for achieving high availability involve certain conditions that need to be met. Here are 4 Steps to Achieving 99.999% Reliability and Uptime.
1. Eliminate Single Points of Failure High Availability vs. Redundancy
The critical element of high availability systems is eliminating single points of failure by achieving redundancy on all levels. No matter if there is a natural disaster, a hardware or power failure, IT infrastructures must have backup components to replace the failed system.
There are different levels of component redundancy. The most common of them are:
The N+1 model includes the amount of the equipment (referred to as ‘N’) needed to keep the system up. It is operational with one independent backup component for each of the components in case a failure occurs. An example would be using an additional power supply for an application server, but this can be any other IT component. This model is usually active/passive. Backup components are on standby, waiting to take over when a failure happens. N+1 redundancy can also be active/active. In that case, backup components are working even when primary components function correctly. Note that the N+1 model is not an entirely redundant system.
The N+2 model is similar to N+1. The difference is that the system would be able to withstand the failure of two same components. This should be enough to keep most organizations up and running in the high nines.
The 2N model contains double the amount of every individual component necessary to run the system. The advantage of this model is that you do not have to take into consideration whether there was a failure of a single component or the whole system. You can move the operations entirely to the backup components.
The 2N+1 model provides the same level of availability and redundancy as 2N with the addition of another component for improved protection.
The ultimate redundancy is achieved through geographic redundancy.
That is the only mechanism against natural disasters and other events of a complete outage. In this case, servers are distributed over multiple locations in different areas.
The sites should be placed in separate cities, countries, or even continents. That way, they are entirely independent. If a catastrophic failure happens in one location, another would be able to pick up and keep the business running.
This type of redundancy tends to be extremely costly. The wisest decision is to go for a hosted solution from one of the providers with data centers located around the globe.
Next to power outages, network failures represent one of the most common causes of business downtime.
For that reason, the network must be designed in such a way that it stays up 24/7/365. To achieve 100% network service uptime, there have to be alternate network paths. Each of them should have redundant enterprise-grade switches and routers.
2. Data Backup and recovery
Data safety is one of the biggest concerns for every business. A high availability system must have sound data protection and disaster recovery plans.
An absolute must is to have proper backups. Another critical thing is the ability to recover in case of a data loss quickly, corruption, or complete storage failure. If your business requires low RTOs and RPOs and you cannot afford to lose data, the best option to consider is using data replication. There are many backup plans to choose from, depending on your business size, requirements, and budget.
Data backup and replication go hand in hand with IT high availability. Both should be carefully planned. Creating full backups on a redundant infrastructure is vital for ensuring data resilience and must not be overlooked.

3. Automatic failover with Failure Detection
In a highly available, redundant IT infrastructure, the system needs to instantly redirect requests to a backup system in case of a failure. This is called failover. Early failure detections are essential for improving failover times and ensuring maximum systems availability.
One of the software solutions we recommend for high availability is Carbonite Availability. It is suitable for any infrastructure, whether it is virtual or physical.
For fast and flexible cloud-based infrastructure failover and failback, you can turn to Cloud Replication for Veeam. The failover process applies to either a whole system or any of its parts that may fail. Whenever a component fails or a web server stops responding, failover must be seamless and occur in real-time.
The process looks like this:
There is Machine 1 with its clone Machine 2, usually referred to as Hot Spare.
Machine 2 continually monitors the status of Machine 1 for any issues.
Machine 1 encounters an issue. It fails or shuts down due to any number of reasons.
Machine 2 automatically comes online. Every request is now routed to Machine 2 instead of Machine 1. This happens without any impact to end users. They are not even aware there are any issues with Machine 1.
When the issue with the failed component is fixed, Machine 1 and Machine 2 resume their initial roles
The duration of the failover process depends on how complicated the system is. In many cases, it will take a couple of minutes. However, it can also take several hours.
Planning for high availability must be based on all these considerations to deliver the best results. Each system component needs to be in line with the ultimate goal of achieving 99.999 percent availability and improve failover times.
4. Load Balancing
A load balancer can be a hardware device or a software solution. Its purpose is to distribute applications or network traffic across multiple servers and components. The goal is to improve overall operational performance and reliability.
It optimizes the use of computing and network resources by efficiently managing loads and continuously monitoring the health of the backend servers.
How does a load balancer decide which server to select?
Many different methods can be used to distribute load across a server pool. Choosing the one for your workloads will depend on multiple factors. Some of them include the type of application that is served, the status of the network, and the status of the backend servers. A load balancer decides which algorithm to use according to the current amount of incoming requests.
Some of the most common load balancing algorithms are:
Round Robin. With Round Robin, the load balancer directs requests to the first server in line. It will move down the list to the last one and then start from the beginning. This method is easy to implement, and it is widely used. However, it does not take into consideration if servers have different hardware configurations and if they can overload faster.
Least Connection. In this case, the load balancer will select the server with the least number of active connections. When a request comes in, the load balancer will not assign a connection to the next server on the list, as is the case with Round Robin. Instead, it will look for one with the least current connections. Least connection method is especially useful to avoid overloading your web servers in cases where sessions last for a long time.
Source IP hash. This algorithm will determine which server to select according to the source IP address of the request. The load balancer creates a unique hash key using the source and destination IP address. Such a key enables it always to direct a user’s request to the same server.
Load balancers indeed play a prominent role in achieving a highly available infrastructure. However, merely having a load balancer does not mean that you have a high system availability.
If a configuration with a load balancer only routes the traffic to decrease the load on a single machine, that does not make a system highly available.
By implementing redundancy for the load balancer itself, you can eliminate it as a single point of failure.
In Closing: Implement High Availability Architecture
No matter what size and type of business you run, any kind of service downtime can be costly without a cloud disaster recovery solution.
Even worse, it can bring permanent damage to your reputation. By applying a series of best practices listed above, you can reduce the risk of losing your data. You also minimize the possibilities of having production environment issues.
Your chances of being offline are higher without a high availability system.
From that perspective, the cost of downtime dramatically surpasses the costs of a well-designed IT infrastructure. In recent years, hosted and cloud computing solutions have become more popular than in-house solutions support. The main reason for this is the fact it reduces IT costs and adds more flexibility.
No matter which solution you go for, the benefits of a high availability system are numerous:
You save money and time as there is no need to rebuild lost data due to storage or other system failures. In some cases, it is impossible to recover your data after an outage. That can have a disastrous impact on your business.
Less downtime means less impact on users and clients. If your availability is measured in five nines, that means almost no service disruption. This leads to better productivity of your employees and guarantees customer satisfaction.
The performance of your applications and services will be improved.
You will avoid fines and penalties if you do not meet the contract SLAs due to a server issue.
0 notes
Text
vCloud Availability for Cloud-to-Cloud DR 1.5 Reference Architecture
Overview
The vCloud Availability Cloud-to-Cloud DR solution provides replication and failover capabilities for vCloud Director workloads at both VM and vApp level.

VMware vCloud Availability for Cloud-to-Cloud DR Reference Architecture (PDF format here)
This blog demonstrates the reference architecture of vCloud Availability for Cloud-to-Cloud Disaster Recovery 1.5, VMware vCloud Availability for Cloud-to-Cloud DR 1.5 allows tenant and service provider users to protect vApps between different virtual data centers within a vCloud Director environment and across different vCloud Director based clouds.
The architecture diagram illustrates the needed solution components between cloud provider’s two data centers which are backed by different vCloud Director cloud management platform, it also shows the network flow directions and port number required for communication among components in the vCloud Availability for Cloud-to-Cloud DR solution. Architecture supports symmetrical replication operations between cloud environments.
The service operates through a VMware Cloud Provider Program, and each installation provides recovery for multiple cloud environments. The vCloud Availability for Cloud-to-Cloud DR provides:
Self-service protection and failover workflows per virtual machine (VM).
Single installation package as a Photon-based virtual appliance.
The capability of each deployment to serve as both source and recovery vCloud Director instance (site). There are no dedicated source and destination sites.
Symmetrical replication flow that can be started from either the source or the recovery vCloud Director site.
Replication and recovery of vApps and VMs between vCloud Director sites.
Using a single-site vCloud Availability for Cloud-to-Cloud DR installation, you can migrate vApps and VMs between Virtual Data Centers that belong to a single vCloud Director Organization.
Secure Tunneling through a TCP proxy.
Integration with existing vSphere environments.
Multi-tenant support.
Built-in encryption or encryption and compression of replication traffic.
Support for multiple vCenter Server and ESXi versions.
Architecture Explained
When you implement this solution from the ova file in your production environment, make sure you are not choosing the “Combined” configuration type, instead you need to choose the “Manager node with vCloud Director Support’ configuration (icon # 6 in the RA), you’ll see the configuration description showing “The H4 Management Node. Deploy one of these if you need to configure replications to/from vCD”, H4 represents the vCloud Availability Replicator or Manager (C4 is for vCloud Availability vApp Replication Service or Manager), by selecting this configuration type, the ova will install three vCAV components all together in a single appliance:
1. vCloud Availability Cloud-to-Cloud DR Portal (icon # 5 in the RA)
2. vCloud Availability vAPP Replication Manager (icon # 4 in the RA)
3. vCloud Availability Replication Manager (icon # 3 in the RA)
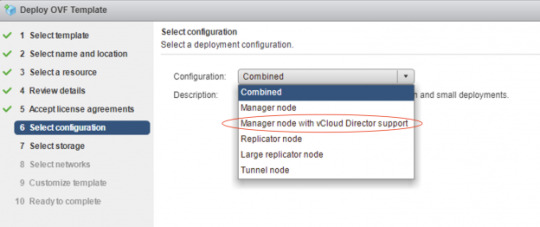

The above three components are located in a white-colored rectangle box (icon # 6) in the reference architecture diagram, all the communications between those three components are happened internally and will never route through outside this appliance, for example, vCloud Availability vAPP Replication Manager will use REST API calls to vCloud Availability Replication Manager in order to perform required replication tasks.
vCloud DirectorWith the vCloud Director, cloud provider can build secure, multi-tenant private clouds by pooling infrastructure resources into virtual data centers and exposing them to users through Web- based portals and programmatic interfaces as fully automated, catalog-based services.
vCloud Availability Replicator Appliance
For production deployments, You deploy and configure dedicated vCloud Availability Replicator appliance or appliances, it exposes the low-level HBR primitives as REST APIs.
vCloud Availability Replicator ManagerA management service operating on the vCenter Server level. It understands the vCenter Server level concepts for starting the replication workflow for the virtual machines. It must have TCP access to the Lookup Service and all the vCloud Availability Replicator appliances in both local, and remote sites.
vCloud Availability vApp Replication ManagerProvides the main interface for the Cloud-to-Cloud replication operations. It understands the vCloud Director level concepts and works with vApps and virtual machines using vCD API calls.
vCloud Availability C2C DR PortalIt provides tenants and service providers with a graphic user interface to facilitate the management of the vCloud Availability for Cloud-to-Cloud DR solution. It also provides overall system and workload information.
Manager node with vCloud Director Support
Single appliance that contains the following services:vCloud Availability Cloud-to-Cloud DR Portal
vCloud Availability vAPP Replication Manager
vCloud Availability Replication Manager
vCenter Server with Platform Services ControllerThe PSC provides common infrastructure services to the vSphere environment. Services include licensing, certificate management, and authentication with VMware vCenter Single Sign-On.
vCloud Availability Tunnel ApplianceThis solution requires that each component on a local site has bidirectional TCP connectivity to each component on the remote site, If bidirectional connections between sites are a problem, you configure Cloud-to-Cloud Tunneling, you must provide connectivity between the vCloud Availability Tunnel appliances on each site. It simplifies provider networking setup by channeling all incoming and outgoing traffic for a site through a single point.
Network Address TranslationYou must set an IP and port in the local site that is reachable for remote sites and forward it to the private address of the vCloud Availability Tunnel appliance, port 8048, for example, by using destination network address translation (DNAT).
Coexistence
Based on the product release nodes, vCloud Availability for Cloud-to-Cloud DR 1.5 and vCloud Availability for vCloud Director 2.X can be installed and can operate together in the same vCloud Director environment. You can protect virtual machines either by using vCloud Availability for Cloud-to-Cloud DR 1.5 or vCloud Availability for vCloud Director 2.X.
vCloud Availability for Cloud-to-Cloud DR 1.5 and vCloud Director Extender 1.1.X can be installed and can operate together in the same vCloud Director environment. You can migrate virtual machines either by using vCloud Availability for Cloud-to-Cloud DR 1.5 or vCloud Director Extender 1.1.X.
Interoperability
vSphere Hypervisor (ESXi) – 5.5 and above
vCenter Server – 6.0, 6.5 and 6.7
vCloud Director for Service Providers – 8.20, 9.0, 9.1 and 9.5
* Please visit VMware Product Interoperability Matrices website to check the latest support products version.
Notes
There’s a comprehensive vCloud Availability Cloud-to-Cloud DR Design and Deploy Guide available here, which was published by my colleague, Avnish Tripathi, you can find detail design guidelines for this solution.
VMware official vCloud Availability for Cloud-to-Cloud DR Documentation is here.
0 notes
Text
Deep Dive Architecture Comparison of DaaS & VDI, Part 2
In part 1 of this blog series, I discussed the Horizon 7 architecture and a typical single-tenant deployment using Pods and Blocks. In this post I will discuss the Horizon DaaS platform architecture and how this offers massive scale for multiple tenants in a service provider environment.
Horizon DaaS Architecture
The fundamental difference with the Horizon DaaS platform is multi-tenancy architecture. There are no Connection or Security servers, but there are some commonalities. I mentioned Access Point previously, this was originally developed for Horizon Air, and is now a key component for both Horizon 7 and DaaS for remote access.
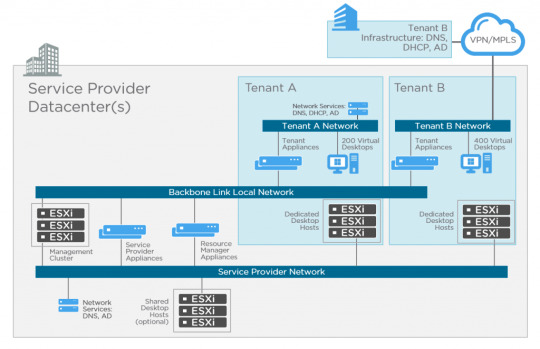
If you take a look at the diagram above you’ll see these key differences. Let’s start with the management appliances.
There are five virtual appliances (OVA) used for Horizon DaaS; Service Provider, Tenant, Desktop Manager, Resource Manager and Access Point. When these appliances are deployed, they are always provisioned as an HA pair (master/slave), except for Access Point which is active/active across multiple appliances. No load-balancer is required, only for multiple Access Point appliances. The remaining virtual appliances use a virtual IP in the master/slave configuration. There is only a single OVA (template), and upon initial installation, the bootstrap process uses this template as a base for each of the virtual appliance types.
I’ve already introduced Access Point with the Horizon 7 architecture previously, but it’s worth mentioning that this is a recent addition. Previously with the original Desktone product and subsequent versions of Horizon DaaS platform, remote access was provided using dtRAM (Desktone Remote Access Manager). The dtRAM is also a virtual appliance (based on FreeBSD and pfSense) and still available, but I would now recommend using Access Point for the latest features.
Service Provider
The service provider has two different types of virtual appliance (HA pair); the Service Provider and Resource Manager.
The Service Provider appliance provides the Service Center portal where the provider can perform a number of activities including Desktop Model management, Tenant management, monitoring and discovery of infrastructure resources. This appliance also contains a Resource Manager service which targets and deploys other management virtual appliances. For example, when a Tenant Appliance pair is created, it’s name, networks, IP address, and so on, are stored in the FDB (Fabric Database). The Service Provider appliance then instructs the resource manager service to clone a tenant appliance.
Resource Manager
The Resource Manager virtual appliance communicates with the infrastructure (vCenter) to carry out desktop provisioning, and provides management of all desktops for tenants. Unlike Horizon 7 that can provision View Composer linked clones, Instant Clones or full clones, only full clones are currently supported with Horizon DaaS. Resources are assigned to tenants so they can consume compute, storage and network for virtual desktops.
It’s important to note that Resource Manager appliances are tied to the service provider, and not the tenant.
Tenant
The tenant also has two different types of virtual appliance (HA pair); Tenant and Desktop Manager virtual appliance.
The Tenant appliance provides a web-based UI (Enterprise Center) for both the tenant end-user and IT administrator. End-users can manage their own virtual desktops, and the administrator functions allow for creation and management of the tenant desktops.
Other tenant operations provided by Enterprise Center, include:
Domain registration
Gold pattern conversion
Desktop pool creation
AD user and group assignment to virtual desktops
The Tenant virtual appliance also contains a Desktop Manager component which brokers connections to tenant virtual desktops. Each Desktop Manager supports up to 5,000 virtual desktops. If more are required then a HA-pair of Desktop Manager virtual appliances can be deployed.
Desktop Manager
The Desktop Manager virtual appliance is the same as the Tenant appliance, but does not include the brokering or Enterprise Center portal. You can deploy Desktop Manager appliances to scale beyond the 5,000 virtual desktop limit.
Resources are assigned to the Desktop Manager for consumption by the tenant. In some cases you may have a vSphere cluster dedicated for 3D workloads with vDGA pass-through. These 3D specific resources would be dedicated to a Desktop Manager virtual appliance pair.
Each virtual desktop is installed with the DaaS Agent which sends heartbeats to the Desktop Manager in order to keep track of it’s state.
Networking
As shown in the above diagram, there are three networks associated with Horizon DaaS; Backbone Link Local network, Service Provider network, and tenant networks.
The Backbone Link Local network is a private network that is dedicated for all virtual appliances. Although the Tenant virtual appliances are connected to this network, there is no access from the tenant network.
The Service Provider management network provides access for service provider administration of the Service Provider appliances, and vSphere infrastructure.
The Tenant network (per tenant) is dedicated for virtual desktops. This also has IP connectivity to the tenants supporting infrastructure such as Active Directory, DNS, NTP, and file servers.
Horizon DaaS Terminology

Conclusion
VMware Horizon® is a family of desktop and application virtualization solutions that has matured significantly over the past few years. vCloud Air Network service providers can provide customers with either a managed Horizon 7 platform, or Desktop as a Service with Horizon DaaS.
Both Horizon 7 and Horizon DaaS offer virtual desktops and applications, and used in combination with App Volumes, applications can be delivered in near real-time to end-users.
Access Point provides remote access to both Horizon 7 and Horizon DaaS which provide many advantages to the service provider. With their active/active scalable deployment, and hardened Linux platform, service providers and customers can benefit from multiple authentication and access methods from any device and any location.
For both Horizon solutions, RDSH continues to be an attractive choice for delivering desktop or application sessions. These can either be presented to the user with the Horizon Client, or with integration with Workspace ONE and Identity Manager.
Finally, the vCloud Air Network is a global ecosystem of service providers that are uniquely positioned to supply modern enterprises with the ideal VMware-based solutions they need to grow their businesses. Built on the foundation of existing VMware technology, vCloud Air Network Service Providers deliver a seamless entry into the cloud. You can learn more about the vCloud Air Network, or search for a vCAN service provider here: http://vcloudproviders.vmware.com
0 notes
Text



Ngõ nhỏ nghiêng nghiêng hàng gạch đỏ
Cửa gỗ xếp chồng gác liêu xiêu
Tường rêu loang lổ vài tia nắng
Tiếng bước chân xưa đã vắng rồi…
0 notes
Text
NHỮNG ĐIỀU CẦN BIẾT ĐỂ THI CHỨNG CHỈ PMP
Bạn đã biết về giá trị của việc sở hữu Chứng chỉ PMP – chứng chỉ quản lý dự án quốc tế được công nhận rộng rãi nhất hiện nay?
Việc sở hữu PMP không chỉ dừng lại ở việc chứng minh năng lực mà còn là cơ hội cho con đường thăng tiến trong sự nghiệp. Theo nghiên cứu lương hàng năm của PMI, người sở hữu PMP có thu nhập trung bình cao hơn 25% so với người chưa có chứng chỉ.
Vậy bằng cách nào bạn có thể đăng ký thi và sở hữu PMP một cách dễ dàng? Đáp án đã có trong Project Management Professional (PMP) Handbook (Sổ tay Quản lý dự án chuyên nghiệp) - cung cấp cái nhìn tổng quan về quá trình thi lấy chứng chỉ PMP.
Hãy cùng MrKeu tìm hiểu toàn bộ thông tin về quy trình, thủ tục cần thiết khi đăng ký dự thi chứng chỉ Project Management Professional (PMP) để việc sở hữu PMP trở nên rõ ràng và trong tầm tay bạn.
Giới thiệu chứng chỉ PMP là gì
Lĩnh vực Quản lý dự án có nhiều loại chứng chỉ cũng như nhiều tổ chức cấp chứng chỉ. Tuy nhiên, thông dụng nhất hiện nay là chứng chỉ PMP (Project Management Professional) của Viện quản lý dự án Hoa Kỳ PMI (Project Management Institute). Chứng chỉ PMP ra đời từ năm 1984 do PMI cung cấp và có giá trị toàn cầu. Từ lâu, PMP đã được công nhận là thước đo chuẩn mực về Quản lý dự án chuyên nghiệp.
Trong thực tế, chứng chỉ PMP được cấp cho các chuyên gia quản lý dự án đa ngành nghề như CNTT, xây dựng, ngân hàng, công nghiệp, sản xuất,… Để đạt được chứng chỉ này, các ứng viên cần phải đáp ứng rất nhiều điều kiện khắt khe và vượt qua quy trình đánh giá, xét duyệt hồ sơ không hề đơn giản.
Vì vậy, PMI đã ra mắt ấn phẩm PMI Project Management Handbook nhằm mục đích định hướng quy trình và các thủ tục thi; hỗ trợ thí sinh thuận tiện hơn trong quá trình lấy chứng chỉ.
Điều kiện dự thi PMP là gì
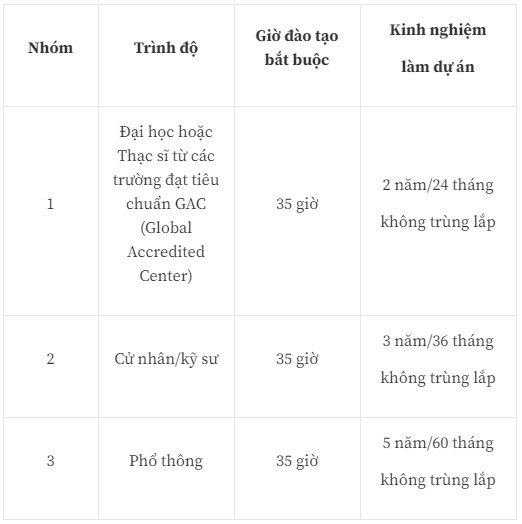
Để được dự thi PMP, bạn phải thỏa mãn những yêu cầu sau:
Trong đó:
Điều kiện về giờ đào tạo: là số giờ học về quản lý dự án bạn phải thực hiện trước khi thi PMP. Bạn có thể lấy chứng nhận đảm bảo điều kiện này bằng cách tham dự các khóa học, hội thảo chuyên đề, khóa đào tạo của các chuyên gia, trung tâm, chương trình, đơn vị đủ quyền hạn (Xem chi tiết ở trang 11 của PMP Handbook). Chứng nhận 35 giờ đào tạo này có giá trị chứng minh thí sinh đã đáp ứng yêu cầu, tiếp thu đầy đủ kiến thức Quản lý dự án theo đúng chuẩn PMI để dự thi PMP.
Điều kiện về kinh nghiệm làm project tasks: Project tasks là những công việc, process trong quản lý dự án theo tiêu chuẩn của PMP. Bạn phải chứng minh đã từng trải qua số giờ làm thực tế với những project task đó. Nếu bạn đã có bằng cử nhân và có đủ 3 năm kinh nghiệm làm quản lý dự án nhưng chỉ có kinh nghiệm làm việc ở hai nhóm quy trình của dự án là khởi tạo và kết thúc dự án chẳng hạn thì cũng không được chấp nhận.
Số năm/tháng kinh nghiệm: số năm/tháng tối thiểu bạn đã làm ở vị trí quản lý dự án phân theo nhóm. Nhóm thạc sĩ yêu cầu 2 năm/24 tháng kinh nghiệm. Nhóm cử nhân, kỹ sư yêu cầu 3 năm/36 tháng kinh nghiệm. Còn nhóm phổ thông yêu cầu 5 năm/60 tháng kinh nghiệm.
Lưu ý: Nếu bạn tốt nghiệp từ các chương trình của trường đạt tiêu chuẩn GAC (Global Accredited Center), bạn sẽ nhận được tín chỉ 12 tháng về yêu cầu kinh nghiệm làm việc. Ngoài ra, bạn có thể sử dụng kết quả học từ chương trình đào tạo GAC để đáp ứng yêu cầu 35 giờ đào tạo.
Lưu ý: Nếu bạn đã sở hữu chứng chỉ CAPM, bạn không cần cung cấp 35 giờ đào tạo bắt buộc. Nói cách khác, bạn được mặc định đã đáp ứng đủ số giờ đào tạo về quản lý dự án.
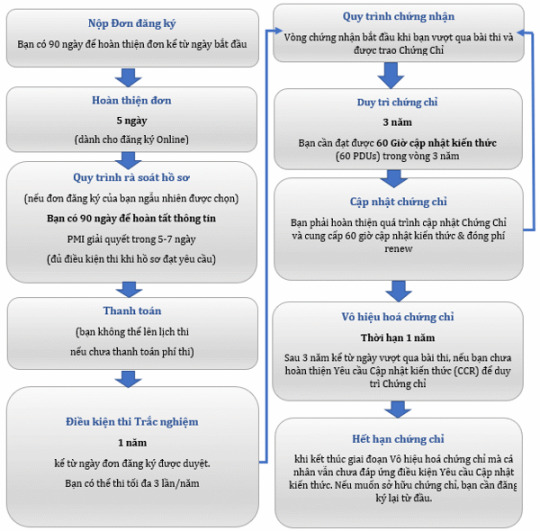
Hồ sơ dự thi PMP
Hồ sơ dự thi của bạn sẽ gồm có:
Bằng cử nhân/kỹ sư (nếu bạn thuộc nhóm 1) - CHỈ cần nộp nếu bạn bị chọn audit hồ sơ.
Hồ sơ mô tả 2 năm/24 tháng kinh nghiệm làm quản lý dự án với nhóm 1, 3 năm/36 tháng kinh nghiệm làm quản lý dự án đối với nhóm 2 và 5 năm/60 tháng kinh nghiệm với nhóm 3.
Chứng nhận đã có 35 giờ học về quản lý dự án.
Đăng ký thi PMP
Bạn đăng ký dự thi tại website của PMI. Cần cung cấp đầy đủ các thông tin sau:
Địa chỉ nhà, cơ quan hoặc công ty
Thông tin liên hệ
Trình độ học vấn, tên trường, địa chỉ, năm tốt nghiệp, chuyên ngànhKinh nghiệm quản lý dự án (theo từng dự án)
Tham gia học về quản lý dự án
Chứng chỉ: Họ tên đầy đủ để in lên chứng chỉ
Lưu ý: Sau khi đăng ký, PMI có thể kiểm tra ngẫu nhiên để xác nhận thông tin (audit). Trong trường hợp đó, bạn sẽ được yêu cầu cung cấp thêm các thông tin, bằng chứng, người liên quan để đối chiếu.

Lệ phí thi PMP
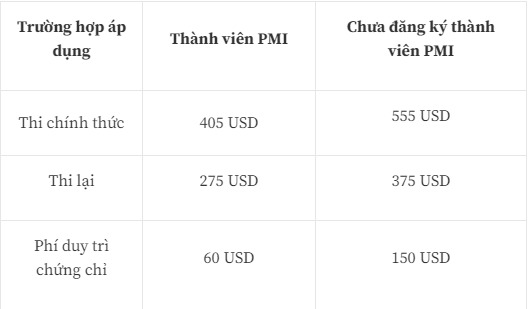
Tips dành cho bạn thi PMP là gì:
Đăng ký làm thành viên PMI trước khi đăng ký thi sẽ tiết kiệm được 11 USD. Cụ thể như sau:
- Non-member: phí thi 555 USD
- Member: phí thi 405 USD. Phí member 129 USD. Phí admin 10 USD. Tổng cộng là 544 USD.
Lợi ích khi là thành viên PMI, bạn có thể tích lũy PDUs miễn phí trong một năm khi bạn truy cập vào Projectmanagement.com. Bạn cần truy cập vào website này bằng tài khoản PMI và việc lấy PDUs thông qua trang này sẽ được đồng bộ hóa tự động vào tài khoản của bạn trên trang pmi.org mà không cần bất cứ thao tác nào của bạn. Bên cạnh đó, thành viên PMI có thể tiết kiệm chi phí trong trường hợp phải thi lại (trong trường hợp xấu nhất) hoặc duy trì chứng chỉ trong vòng 03 năm.
- Bạn lưu ý đăng ký thành viên PMI thành công trước khi đăng ký nộp phí thi PMP thì mới có hiệu lực và ưu đãi về phí thi nhé.
Cấu trúc bài thi PMP
Bài thi PMP diễn ra trong 230 phút, có format như sau:
Gồm 180 câu hỏi. Các câu hỏi sẽ sự kết hợp của nhiều lựa chọn, nhiều câu trả lời, đối sánh, điểm phát sóng và giới hạn điền vào chỗ trống. Xem thêm tài liệu PMP2021 (PMI® Authorized PMP® Exam Prep) - Tài liệu luyện thi PMP chính thức từ PMI.
Trong 180 câu, có 175 câu được tính điểm, 5 câu chỉ nhằm mục đích thống kê của PMI. Khi thi không biết câu nào không tính điểm, câu nào được tính điểm.
Có tổng cộng 2 lần nghỉ giải lao 10 phút.
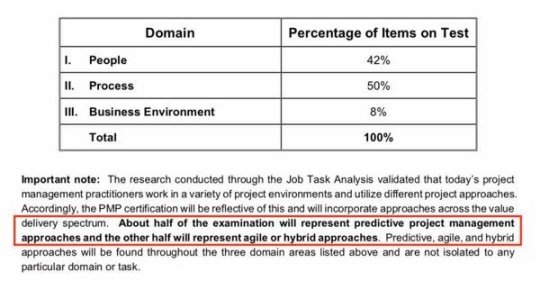
Kỳ thi PMP® từ ngày 02/01/2021 sẽ tập trung vào ba lĩnh vực:PEOPLE (CON NGƯỜI) - nhấn mạnh các kỹ năng và hoạt động liên quan đến việc lãnh đạo một nhóm dự án hiệu quả
PROCESS (QUY TRÌNH) - củng cố các khía cạnh kỹ thuật trong việc quản lý dự án
BUSINESS ENVIRONMENT (MÔI TRƯỜNG KINH DOANH) - nêu bật sự kết nối giữa các dự án và chiến lược tổ chức
Nội dung mở rộng phổ giá trị, bao gồm các cách tiếp cận có thể dự đoán (predictive), agile, và lai (hybrid), sẽ được bao gồm trong ba lĩnh vực kiểm tra. Cách tốt nhất để hiểu những gì được bao gồm trong bài kiểm tra là xem lại Nội dung bài kiểm tra PMP® MỚI | Updated PMP® Exam Content Outline.
Hỗ trợ ngôn ngữ
PMI có hỗ trợ ngôn ngữ nếu Tiếng Anh không phải là ngôn ngữ chính của thí sinh. Danh sách các ngôn ngữ được hỗ trợ gồm có: Arabic, Bahasa Indonesian, Turkish, Polish, Hebrew, Brazilian Portuguese, Italian, Japanese, Chinese (Simplified), Chinese (Traditional), Korean, French, Russian, German, Spanish. Rất tiếc trong danh sách hỗ trợ ngôn ngữ không có tiếng Việt. Tuy nhiên, theo chia sẻ về kinh nghiệm dự thi, rào cản ngôn ngữ không phải là vấn đề quá lớn với các anh/chị đã từng thi PMP. Điều khó khăn ở đây là hoàn thiện kiến thức theo khung chuẩn của PMI nhằm khoanh vùng câu trả lời đúng.
Địa điểm thi PMP OFFLINE
Theo thông báo mới nhất, PMI đã đổi đơn vị khảo thí từ Prometric sang Pearson VUE. Cụ thể:
Thông báo: PMI Chuyển đổi trung tâm khảo thí
Cập nhật danh sách địa điểm thi ở Pearson VUE
Như vậy, các thí sinh đăng ký thi chứng chỉ PMI sau ngày 1/7/2019 sẽ thi tại địa điểm của Pearson VUE như đã thông báo. Ở Việt Nam thì hiện nay có 3 trung tâm thi OFFLINE:
HÀ NỘI
- IPMAC Information Technology Joint Stock Company
Tầng 6, Tòa nhà Kim Ánh, ngõ 78, phố Duy Tân, Q.Cầu Giấy, Hà Nội
(+84) 2437 710 679
TP. HCM
- VIET Professional Co Ltd
149/1D Ung Văn Khiêm, P.25, Q.Bình Thạnh, TP. HCM
(+84) 2835 124 257
- International Talent Development Academy
Tầng 5, Toà nhà Minh Phú, 21 Lê Quý Đôn, Phường 6, Quận 3, Thành phố Hồ Chí Minh
(+84) 906 906 429
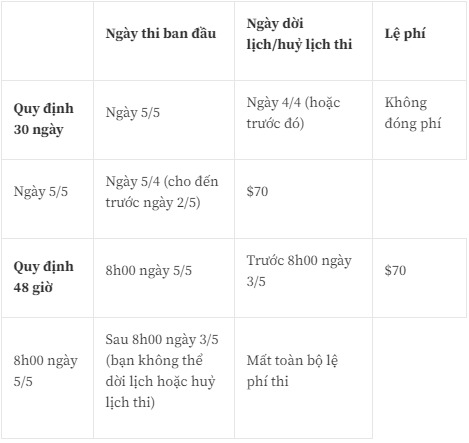
Dời/huỷ lịch thi đã đăng ký
Sớm hơn quá 30 ngày so với ngày thi thì có thể reschedule mà không mất phí
Trong vòng 30 ngày trước ngày thi thì có thể reschedule và tốn 70usd
Trong vòng 48 giờ trước ngày thi thì không thể reschedule và sẽ mất toàn bộ phí thi đã đóng
Lưu ý: Một số thời điểm cụ thể có thể không mất phí dời/hủy lịch thi, ví dụ lúc dịch covid-19
Ví dụ:
Duy trì chứng chỉ PMP sau khi Pass
Sau khi Pass chứng chỉ PMP, bạn phải tham gia vào chương trình “Yêu cầu duy trì chứng chỉ” – Continuing Certification Requirements (CCR) của PMI. Chứng chỉ PMP có giá trị trong thời hạn 3 năm. Trong 3 năm này, bạn phải tham gia các hoạt động và lấy được ít nhất 60 PDUs – Professional Development Units. Nói cách khác, để duy trì chứng chỉ PMP, bạn cần tích lũy 60 PDUs (Professional Development Units) mỗi 3 năm và đóng phí gia hạn.
Thi PMP bằng hình thức ONLINE PROCTORED
Hình thức thi PMP ONLINE đã được PMI thông qua vào ngày 15/04/2020. Học viên có thể thi ONLINE PROCTOR ở bất kỳ đâu có kết nối internet, từ đó thoải mái lựa chọn địa điểm thi ở nhà, ở văn phòng công ty... Đồng thời số slot thi ONLINE là cực nhiều, hầu như mỗi 15 phút là có slot thi (chứ không bị giới hạn số lượng slot ít ỏi như khi thi offline ở Hà Nội hoặc Sài Gòn). Tìm hiểu thêm thông tin tại Tin chính thức từ PMI – thi PMP® bằng hình thức Online Proctor
Lời kết
Những thông tin trên được chia sẻ từ PMP Handbook, từ tổng hợp nhiều nguồn hữu ích, và đều có liên quan đến quy trình đăng ký thi chứng chỉ PMP. Tuy nhiên, sở hữu PMP chỉ là khởi đầu. Quá trình làm việc liên tục để cập nhật kiến thức, vận dụng các khung chuẩn vào thực tế và đóng góp cho cộng đồng mới thực sự khẳng định giá trị của một PM chuyên nghiệp trên con đường sự nghiệp lâu dài.
Chúc quý anh chị em ngày càng gặt hái nhiều thành công!
0 notes
Text









- Cô ấy nói tôi bỏ game, tôi bỏ game.
- Cô ấy nói tôi bỏ rượu bia, tôi bỏ rượu bia.
- Cô ấy nói tôi bỏ chụp mẫu, tôi chuyển qua chụp cảnh.
- Cô ấy nói tôi bỏ thức đêm cày cuốc, tôi ngủ từ 9h tối cho cô ấy sợ.
- Cô ấy nói tôi bỏ thịt chó, ok tôi chuyển qua ăn giả cầy.
- Và cô ấy bảo tôi bỏ Hà Nội theo cô ấy đi vùng khác.
....
Tôi bỏ cô ấy!
Và tôi lại quay về như cũ, mỗi cái thêm một tí nó lại rực rỡ hơn 😱
_____
📷 ME
0 notes
Last Seen Blogs

wzoryfaktury2151
wzory inne 9593

indrani-maharaj
Books, dogs and photography♥️

cuniuscumbias
Ale Cast

midnightraptor
say it again

choli-hsnz
Choli