#non-clustered columnstore index
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
In 2020, Tumblr had 29.4 million users in the US.
Text
Optimizing Column Order for Non-Clustered Columnstore Indexes in SQL Server
Introduction Want to supercharge query performance on your large SQL Server tables? Non-clustered columnstore indexes are a powerful tool for achieving blazing-fast analytics queries. But to get the most benefit, it’s crucial to choose the optimal column order when creating the index. In this post, you’ll learn the key principles for determining the best column order, with concrete examples to…
View On WordPress
0 notes
Text
All About Index In SQL Server 2020
New Post has been published on https://is.gd/1OEPWu
All About Index In SQL Server 2020

In this article you will understand what is Index In SQL Server. How To Create Index and Different Types of Indexes In SQL By Sagar Jaybhay. Also You will leran Unique and Non Unique Index what is the difference between them.
(adsbygoogle = window.adsbygoogle || []).push();
Index In SQL Server
Index is used to find data from the table quickly. An index is created on views and tables. It is similar to the book index.
If you apply index it will improve the query performance drastically. If there is no index then the query engine checks every row from beginning to end and it will require time which is bad and this is called a Table scan.
You can create an index in the SQL server in 2 ways. 1) by Query 2) Graphical Interface.
The index is a special kind of data structures which is associated with table and views by the help of this you can increase the performance of the query.
General Syntax:
Create index index_name on table_name (column_name asc)
Example
create index in_employee on Employee (empid asc)
The above query creates an in_employee index on the Employee table on the empid column.
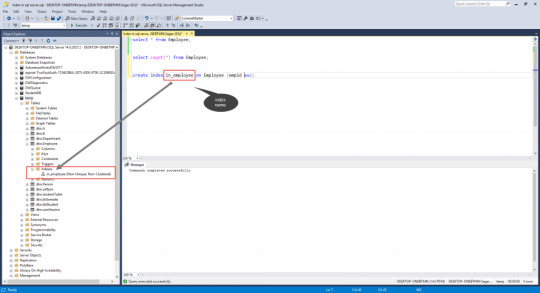
Create Index In SQl Server
To find out all the indexes created on the table using below command
sp_helpindex Employee
In this sp_heplindex is a system stored procedure.
How to drop the index?
Drop index tablename.index_name; -- Example Drop index employee.index_name
There are different types of indexes present in the SQL Server.
Clustered
Non-Clustered
Unique
Filtered
XML
Full text
Spatial
ColumnStore
Index with included column
Index on a computed column
Clustered Index
A clustered index determines the physical order of data in a table. So as it determines the physical order that’s why table can have only one clustered index.
If your column contains primary key constraint and on that table, if you create index then it automatically marks as a Clustered index.
Suppose you create a table in that on a one-column you create a primary key then it will automatically create clustered index on that column for you see below image.

Clustered Index
create table tblEmp ( id int primary key, name varchar(100), salary int, gender varchar(10), city varchar(10) )

sp_helpindex
When your table contains a clustered index it is called a clustered table. If the table has no clustered index then the data rows are stored in an unordered structure which is called a heap.
Clustered index organizes data in a special structure so it is called B-tree.
See below image we insert data in a random manner but when we select this data you able to see it is in an ordered manner.
insert into tblEmp values(10,'sagar',1000,'Male','Pune'),(11,'XYZ',1000,'Female','USA'),(12,'ABC',1000,'Male','JAPAN'),(1,'JAYBHAY',1000,'Male','INDIA'); select * from tblEmp

Clustered Index Example
So it means that clustered index automatically organizes the data in sorted order.
Index or Clustered can contain multiple columns while creating the index. So this index we called as Composite clustered index.
If your column allows null then you not able to create clustered index on that column.
Ex.
Telephone Directory: It is arranged as alphabetical order.
Non-Clustered Index:
It is similar to the index in the book. Non clustered index stored at one place and actual data are stored in another place. This non-clustered index has pointers to the storage location of the data.
As it stores index and data separately you can add multiple indexes on the table.
In the index itself, data is stored in ascending or descending order which doesn’t influence the data store functionality in that table.
You can add as many indexes you can have on the table.
Ex.
A textbook
create nonclustered index indx_Employee on Employee(full_name,gender);

Non Clustered Index
Difference between Clustered and Non-Clustered Index?
Clustered Index Non-Clustered Index Only One Index per table. No restriction on how many indexes you create. It is faster bcoz it is the referred underlying table. Extra lookup is no needed It is not faster as compared to the clustered index. Extra lookup is needed/ No Extra disk storage space needed. Extra disk space is needed. Size of a clustered index is quite larger Size compared to the clustered index is small. Can improve the performance of data retrieval is the main feature. It is generally created on that column on which we took joins.
Unique Index and Non-Unique Index:
Unique Index: It is used to enforce uniqueness of values in the respective column.
By default, the primary key constraints create a unique key or unique clustered index.
If you see the uniqueness is the property of clustered and non clustered index.
create unique nonclustered index indx_Employee on Employee(full_name,gender)
What is the difference between the Unique index and Unique Constraint?
In this, there is no major difference between these 2. When you use a unique constraint the unique index is automatically gets created.
In our employee table, we add unique constraints on the email column. To add a unique constraint we need to alter the table.
alter table Employee add constraint uq_employee unique(email);

Unique And Non Unique in SQL
See above image the while running the query index gets created.
When to Use a unique constraint?
When we required data integrity we need to use unique constraints that automatically created the unique index. Data validation is the same manner whatever you create a unique index or add a unique constraint.
What are the advantages and disadvantages of indexes in SQL?
Advantages:
Indexes are used to find data quickly.
A select, update, delete statement with where clause can benefit from the indexes.
Also, order by clause and group by clause benefit from these indexes.
Disadvantages:
Additional disk space is required: Clustered index does not require additional storage. Every non clustered index required additional space as it stored from a separate table. And the amount of space required for it depends on the size of the table and how many columns you choose to create an index.
Insert, Update, Delete statement become a slow: what it means for delete, update to locate the record time required is much less but when a table is huge and there are multiple indexes then these indexes need to be updated and in this case, too many indexes updates actually hurt the performance.
Covering Query:- suppose you select all the columns from a table in select query and all of these columns are present in the index then there is no lookup but if these columns are not present in the index column then a lookup is required.
(adsbygoogle = window.adsbygoogle || []).push();
0 notes
Link
SQL Server step by step for beginners ##Edx #Beginners #Server #SQL #Step SQL Server step by step for beginners It has 20 labs which covers the below syllabus. Lab 1:- Basic Fundamentals Database, Tables, rows and columns. Lab 2:- Primary key, foreign key, referential integrity and constraints. Lab 3 :- Database Normalization (1st, 2nd and 3rd normal forms). Lab 4: - SQL basics(Select, Insert, Update and Delete) Lab 5 :- DDL (Data definition language) Queries. Lab 6: - ISNULL and Coalesce functions. Lab 7: - Row_Number, Partition, Rank and DenseRank Lab 8: - Triggers, inserted and deleted tables Lab 9: - Instead of and after triggers. Lab 10: - Denormalization, OLTP and OLAP Lab 11: - Understanding Star schema and Snow flake design. Lab 12: - SQL Server 8 kb pages. Lab 13 :- Index and performances Lab 14 :- Page Split and indexes Lab 15 :- Clustered vs non-clustered Lab 16: - Stored procedures and their importance. Lab 17: - Change Data Capture. Lab 18: - Explain Columnstore Indexes? Lab 19: - SQL Server agent Lab 20: - How can we implement Pivot & Unpivot in SQL Server? Who this course is for: Developers who want to become SQL Server developers 👉 Activate Udemy Coupon 👈 Free Tutorials Udemy Review Real Discount Udemy Free Courses Udemy Coupon Udemy Francais Coupon Udemy gratuit Coursera and Edx ELearningFree Course Free Online Training Udemy Udemy Free Coupons Udemy Free Discount Coupons Udemy Online Course Udemy Online Training 100% FREE Udemy Discount Coupons https://www.couponudemy.com/blog/sql-server-step-by-step-for-beginners/
0 notes
Text
Dynamic spatial index for efficient query processing round the cloud
Dynamic spatial index for efficient query processing round the cloud
A spatial index can be a database object to display an info structure made up of keys built according to a number of posts on the table or view and direct for the map that signifies for the storage location in the specified data. Indexes are outfitted for faster retrieval of rows in the table, basically, indexes provide fast data retrieval in the table, which significantly improves query and application performance. Indexes could also be used to be sure the uniqueness of rows in the table, therefore making sure data integrity.
Types of indexes on Clouds:-
Efficient cloud query processing experts from Managed Network plus it Support Derby emphasized round the following types of spatial indexes round the cloud.
The Clustered - is certainly a catalog that stores data in the sorted table, by the requirement for the index key form. A table may have only one clustered index since the data is only able to be sorted in one order. If possible, each table should have a clustered index, once the table does not have a clustered index this kind of table is actually a “heap “. A clustered index is created instantly when the PRIMARY KEY (primary key ) and various constraints are created once the clustered index for your table hasn’t yet been defined. In the event you create a clustered index for just about any table (heap), by which you'll find nonclustered indexes, then after creating these need to be reconstructed.
Non-clustered - could be the index that contains the key factor value plus a pointer with a string of knowledge which contains the requirement for that key. A table may have multiple nonclustered indexes. Nonclustered indexes might be created on tables without or having a clustered index. It's mainly the type of index which is often used to boost the performance of generally used queries since nonclustered indexes provide fast search and employ of information by key values.
Filterable - is certainly an improved non-clustered index that employs a filter predicate for indexing areas of the rows inside the table. If it is better to design this sort of index, it might improve query performance, additionally to lessen the cost of maintaining and storing indexes in comparison with full-table indexes.
Unique- is certainly a catalog that ensures the possible lack of duplicate (identical) index key values, therefore guaranteeing the individuality in the strings with this particular key. Both clustered and nonclustered indexes might be unique. In the event you create a unique index on several posts, the index guarantees the individuality of each and every combination of values inside the key. When making a principal KEY or UNIQUE SQL constraint, the server instantly produces a unique index for key posts. A unique index might be created only if the table presently does not have duplicate values for your key posts.
Columnstore- is certainly a catalog based on data storage technology by way of posts. This sort of index might be effectively useful for large data warehouses since it can raise the performance of queries for the storage up to 10 occasions in addition to reduce data size by 10 occasions, since the data inside the Columnstore index is compressed. You'll find both clustered column indexes and non-clustered ones.
Full-text - can be a special type of index that provides effective support for complex searches of words inside the character string data. The whole process of creating and searching following a complete-text index is called “copulating.” You'll find this kind of example filling as full filling and filling based on change tracking. Instantly, the SQL server completely fills the completely new full-text index right after it’s created, however, this may need a ton of sources, with regards to the size up for grabs, so you can postpone full population. Track-based padding may be used to have a complete-text index after it’s initially full.
Spatial - is certainly a catalog that allows for your more efficient usage of specific operations on spatial objects in posts of type geometry or geography data. This sort of index is only able to be created for just about any spatial column, as well as the table the spatial index is decided should have a principal key.
XML - is an additional special type of index that is perfect for posts of knowledge type XML. Due to the XML-index improved query performance for XML posts. There’s 2 kinds of XML index: secondary and first. Primary XML Index-indexes all tags, values, and pathways, stored within an XML column. It might be created only if the table features a clustered index round the primary key. Another XML index might be created only if the table features a primary XML index which is familiar with boost the performance of queries around the particular type of reference to the an XML column. In this connection, there are lots of types of secondary indexes: PATH, VALUE, and PROPERTY.
In line with the experts from Outsourced IT Support Nottingham plus it Support Nottingham, Spatial indexes also are available for the tables that are enhanced for memory (inside the Memory-the OLTP ) for instance hash ( Hash ) indexes and non-clustered indexes, enhanced for memory that’s created to scan a number of checking and orderly.
Operated by: Managed lan
0 notes
Text
Tweeted
How to choose between Clustered Columnstore & Non-Clustered Columnstore index https://t.co/8sGCoyLGXz via SSC
— SQL Joker (@sql_joker) April 27, 2018
0 notes
Link
Indexes are paramount to achieving good database and application performance. Poorly designed indexes and a lack of the same are primary sources of poor SQL Server performance. This article describes an approach for SQL server index optimization to increase query performance.
An index is a copy of information from a table that speeds up retrieval of rows from the table or view. Two main characteristics of an index are:
Smaller than a table – this allows SQL Server to search the index more quickly, so when a query hits a particular column in our table and if that column has an index on it, the SQL Server can choose to search the index rather than searching the entire table because the index is much smaller and therefor it can be scanned faster
Presorted – this also means that search can be performed faster because everything is already presorted, for example, if we’re searching for some string that starts with the letter “Z” the SQL Server is smart enough to start the search from the bottom of an index because it knows where the search criteria is going to be
Available index types
In general, SQL Server supports many types of indexes but in this article, we assume the reader has a general understanding of the index types available in SQL Server and will only list the most used ones that have the greatest impact on SQL Server index optimization. For a general description of all index types, please see Index Types.
Clustered – determines how the data is written to the disk e.g. if a table doesn’t have a clustered index, the data can be written in any order making it hard for SQL Server to access it, however, when present, a clustered index sorts and stores the data rows of the table or view usually in alphabetical on numerical order. So, if we have an identity field with a clustered index on it then the data will be written on the disk based on the number of that identity. There can only be one way in which SQL Server can order the data physically on the disk and therefore we’re only allowed one clustered index per table. One important thing to know is that a clustered index is automatically created with a primary key
Nonclustered – this is the most common type in SQL Server and typically more than one on a single table. The maximum number of nonclustered indexes vary depending on the SQL Server version but the number goes e.g. in SQL Server 2016 as high as 999 per table. Unlike clustered indexes, which actually organize data, the nonclustered index is a bit different. The best analogy would be to think of it as a book. If we go to the very end of a book, usually there is an indexing part that basically has a huge list of topics and it points on which page they’re on. A typical scenario is the reader finds a topic/term and it points e.g. to a chapter on page 256. If the reader goes to that page, the searched information is right there. The point is to find it very fast without the need to go through the entire book searching for the content and this is basically what nonclustered index does
Columnstore – converts data that is normally stored in columns and converts it into rows and in doing so it allows the database engine to search more quickly. They are the standard for storing and querying large data warehousing fact tables
Spatial – this type of index provides the ability to perform certain operations more efficiently on spatial objects like geometry and geography. They are somewhat uncommon outside of specialized GIS systems
XML – as the name applies, this index type is associated with the XML data type and they convert XML data into a tabular format and again this allows them to be searched more quickly. There’re two types: primary and secondary. A primary index is a requirement in order to create secondary
Full-text – provides efficient support for sophisticated word searches and English language queries in character string data. This is the only type of index that allows us to run a different type of query and to find words that sound like each other or different forms of a word, so for example if a singular word search is performed, the index would also return a plural of the specified word
Creating an index
So, now that we gained some basic knowledge and a general idea of what indexes do let’s see a few SQL Server index optimization real-world examples using SQL Server Management Studio (SSMS) to create an index and most importantly take a closer look at some performance benefits of indexes.
First things first, we need to create a testing table and insert some data into it. The following example uses the AdventureWorks2014 database but you’re welcome to use any database also because we’re creating a new table that can be deleted afterward. Execute the code from below to create a brand new copy of the existing Person.Address table:
SELECT * INTO Person.AddressIndexTest FROM Person.Address a;
We just created a new table called Person.AddressIndexTest and by executing the query from above we’ve copied 19614 records into it but unlike the source table the newly creaded one has absolutely no indexes on it:
Because this table has no indexes on it, if we open up ApexSQL Plan and look at the execution plan, it’s going to be a full table scan (scan all rows from the table), row-by-row bringing back the result that is specified in the Select statement:
Now, let’s query the new data in SSMS and see how we can analyze information returned in the results grid. Before analyzing queries and performance testing it’s recommended to use the below code:
CHECKPOINT; GO DBCC DROPCLEANBUFFERS; DBCC FREESYSTEMCACHE('ALL'); GO
The CHECKPOINT and DBCC DROPCLEANBUFFERS are just creating a clean system state. It’s going to remove as much as possible from the cache because when doing performance testing it’s highly advisable to start with a clean state of memory each time. This way we know that any changes in performance weren’t caused by some data being cached that hasn’t been cached on previous runs.
The other part of the same query will be the Select statement in which we’re returning one column from the table we just created. But wrapped around the Select statement, let’s add the SET STATISTICS IO to display information regarding the amount of disk activity generated by T-SQL statements itself. So, when we execute the statement, it will of course return some data but the interesting part is when we switch over to the Messages tab where we can see how the table was queried under the hood:
As it can be seen, there’re 339 logical reads and the same amount of read-ahead reads. What it’s important here is to know what those two represents:
read-ahead reads – is when the data is read from the disk and then copied into memory (cache) AKA disk activity
logical reads – is when the data is read from the cache AKA memory activity
An easier way to get the same information is to get the actual execution plan of just the Select statement in ApexSQL Plan, and then switch to I/O reads tab. Remember to always clear the cache or you might see zero read-ahead reads. Why? Because we already executed the Select statement once in SSMS and after that SQL Server accesses data from the cache:
Now, let’s create an index on the table and then run the same query again and there should be a lower number of reads. The easiest way to create an index is to go to Object Explorer, locate the table, right-click on it, go to the New index, and then click the Non-Clustered index command:
This will open the New index window in which we can click the Add button on the lower right to add a column to this index:
For this example, we only need one column to be added to the index and that’s the one from the Select statement. So, select the AddressID table column and hit the OK button to proceed:
Back to the new index table, Under the Index key columns tab, there should be the column we just added (if it’s not, switch the page and it will appear). SQL Server has automatically chosen a name for the index and if needed this can be changed but why not go with the defaults. To complete the index creation just hit the OK button one more time:
Once this is done, let’s run the exact same query and look at the I/O reads again:
This time, we got 1 physical, 13 logical, and 11 read-ahead reads which is significantly less than before. Notice that we got the exact same result back with much less disk activity and access to the cache within the addition of a single index and SQL Server fulfilled the request of this query but did significantly less work. Why is that? Well, we can look at a few things to explain this. First, let’s go to Object Explorer, right-click our table and choose Properties:
This will open the table properties window and if we switch over to Storage page, there’s a Data space item which represents the size of the data in the table in megabytes (in this case 2.68 MB) and the first time when we ran the query without the index, SQL Server had to read every row in the table but the index is only 0.367 MB. So, after we created the index, SQL Server could execute the same query by only reading the index because in this case the index is 7.3x smaller than the actual table:
We can also look at the statistics. Statistics play a significant role in the database performance world. Once the index is created, SQL Server automatically creates statistics. Back to Object Explorer, expand the table, expend the Statistics folder and right-click the statistic with the exact same name as previously created index and choose Properties:
Again, this will open the statistics properties window in which we can switch to Details page under which we can see that the index is broken into different ranges:
You’ll see hundreds of these ranges in statistics on tables and because of them, SQL Server knows if values searched for are at the very beginning, middle, or end of an index and therefore it doesn’t need to read the entire index. Usually, it will start at some percentage thru and just read to the end of it.
So, these two factors: an index is usually smaller than a table and the fact that statistics are maintained on an index allows the SQL Server to find the particular data we’re looking for by using fewer resources and more quickly. Bear in mind that the indexes provide for a performance increase when the data is being read from a database but they can also lead to a performance decrease when the data is being written. Why? Simply because when inserting data into a table, SQL Server would have to update both the table and the index values increasing the writing resources. The general rule of thumb is to be aware of how often a table is being read vs how often is written to. Tables that are primarily read-only can have many indexes and tables that are written to often should have fewer indexes.
Columnstore index
A columnstore index is a technology for storing, retrieving and managing data by using a columnar data format, called a columnstore. Creating a columnstore index is similar to creating a regular index. Expand a table in Object Explorer, right-click on the Index folder and there will be two items: Clustered and Non-Clustered Columnstore Index:
Both commands open up the same new index dialog. So, rather than showing the same process of creating another type of indexes let’s look at an existing Columnstore indexes in our sample database. Now, what I like to do is to run a query from below against a targeted database and it will return a list of all indexes for all user tables from that database:
USE AdventureWorks2014 GO SELECT DB_NAME() AS Database_Name, sc.name AS Schema_Name, o.name AS Table_Name, i.name AS Index_Name, i.type_desc AS Index_Type FROM sys.indexes i INNER JOIN sys.objects o ON i.object_id = o.object_id INNER JOIN sys.schemas sc ON o.schema_id = sc.schema_id WHERE i.name IS NOT NULL AND o.type = 'U' ORDER BY o.name, i.type;
The results grid shows the database name, schema name, table name, index name, and most importantly index type. Scrolling down thru the list of indexes find one that says nonclustered columnstore and, as we can see from below example, one is attached to the SalesOrderDetail table:
Next, let’s run a Select query in ApexSQL Plan and again remember to add a checkpoint to clean the buffers:
CHECKPOINT; GO DBCC DROPCLEANBUFFERS; DBCC FREESYSTEMCACHE('ALL'); GO SET STATISTICS IO ON; SELECT sod.SalesOrderID, sod.CarrierTrackingNumber FROM Sales.SalesOrderDetail sod OPTION(IGNORE_NONCLUSTERED_COLUMNSTORE_INDEX); SET STATISTICS IO OFF;
The first time we’ll run it with the option to ignore the columnstore index. The idea behind this is to see what kind of performance we get when we ignore the index and as shown below we got: scan count of 1, 1246 logical reads, 3 physical reads, and 1242 read-ahead reads:
We already know what those I/O reads represent but let’s just comment out the option to ignore the columnstore index and see what happens:
So, this time the index will be used and instead of disk and memory activity we got previously, this time we got 218 lob logical reads, 3 lob physical reads, and 422 lob read-ahead reads:
So, we went down from over 1,200 read-ahead reads to about 400 which means SQL Server is doing 66% less work.
LOB reads – you’ll see those when reading different data types
How does this work? A columnstore index takes data that is typically stored in columns and instead stores it in rows. In this case, we were looking for information stored in two columns: SalesOrderID and CarrierTrackingNumber but the table SalesOrderDetail has 9 additional columns. Without the columnstore index, SQL Server has to read all the details of every row in order to find the two that we specified. But with the columnstore index that data is stored in rows rather than columns and therefore the SQL Server only has to read the appropriate rows and furthermore can ignore a large percentage of the rows which ultimately give us a significant SQL Server index optimization increase by simply causing the SQL Server to do less work.
Explore execution plans
Numbers can be confusing even when we know what they represent. ApexSQL Plan does have a compare option which allows comparing data side-by-side but what I like to do is to explore the execution plans and look at a few things that break things down making it easy to understand what is good and what is bad even for a first-time user.
So, what I’d normally do is edit the Query text and execute two Select statements in one query from which one has the option to exclude the index, and the other one is what SQL Server would normally choose to fulfill the request. This way, if we hover the mouse over first Select statement a tooltip will appear showing T-SQL code. As shown below, this one forces the execution plan to ignore the columnstore index. Furthermore, it shows the total query cost relative to the batch which is 86.4% in this case. Down below we can also see that it’s scanning a clustered index, entirely or only a range:
If we move on to a regular Select statement, notice that query cost is only 13.6% which is a decrease of 84%. Looking at the execution plan, we can also verify that the columnstore index was used this time. Furthermore, if we just look at the bars representing the visual indicator of the total cost, CPU cost, and I/O cost we can see the performance boost on this query within the presence of a single index:
Columnstore indexes were introduced in SQL Server 2014 with a major limitation when adding a columnstore index on a table, in that the table would become read-only. Luckily, Microsoft has removed this limitation in SQL Server 2016 and starting from this version and newer we have the read-write functionality.
I hope this article has been informative for you and I thank you for reading.
For more information about on SQL Server index tuning, please see articles on how to optimize SQL Server query performance – part 1 and part 2
Useful links
Statistics
Indexes
SQL Server Index Design Guide
The post How to create and optimize SQL Server indexes for better performance appeared first on Solution center.
0 notes
Text
20464: Developing Microsoft SQL Server Databases (SQL Server 2014 Update)thailand
20464: Developing Microsoft SQL Server Databases (SQL Server 2014 Update) 20464: Developing Microsoft SQL Server Databases (SQL Server 2014 Update) Course DescriptionDuratio: 5.00 days (40 hours).This 5-day instructor-led course introduces SQL Server 2014 and describes logical table design, indexing and query plans. It also focusses on the creation of database objects including views, stored procedures, along with parameters, and functions. Other common aspects of procedure coding, such as indexes, concurrency, error handling, and triggers are also covered in this course. Also this course helps you prepare for the Exam 70-464.Note: This course is designed for customers who are interested in learning SQL Server 2012 or SQL Server 2014. It covers the new features in SQL Server 2014, but also the important capabilities across the SQL Server data platform.Intended Audience For This 20464: Developing Microsoft SQL Server Databases (SQL Server 2014 Update) Course » The primary audience for this course is IT Professionals who want to become skilled on SQL Server 2014 product features and technologies for implementing a database.20464: Developing Microsoft SQL Server Databases (SQL Server 2014 Update) Course Objectives » Introduce the entire SQL Server platform and its major tools. It will cover editions, versions, basics of network listeners, and concepts of services and service accounts.» Determine appropriate data types to be used when designing tables, convert data between data types, and create alias data types.» Be aware of good design practices regarding SQL Server tables and be able to create tables using T-SQL. (Note: partitioned tables are not covered).» Implement PRIMARY KEY, FOREIGN KEY, DEFAULT, CHECK and UNIQUE constraints, and investigate cascading FOREIGN KEY constraints.» Determine appropriate single column and composite indexes strategies.» Create tables as heaps and tables with clustered indexes. Also consider the design of a table and suggest an appropriate structure.» Read and interpret details of common elements from execution plans.» Design effective non-clustered indexes.» Design and implement views» Design and implement stored procedures.» Work with table types, table valued parameters and use the MERGE statement to create stored procedures that update data warehouses.» Design and implement functions, both scalar and table-valued. (Also describe where they can lead to performance issues).» Perform basic investigation of a deadlock situation and learn how transaction isolation levels affect application concurrency.» Use both traditional T-SQL error handling code and structured exception handling.» Design and implement DML triggers» Learn appropriate uses for SQL CLR integration and implement an existing .NET assembly within SQL Server.» Store XML data and schemas in SQL Server.» Perform basic queries on XML data in SQL Server20464: Developing Microsoft SQL Server Databases (SQL Server 2014 Update) Course Outline Module 1: Introduction to Database DevelopmentIntroduction to the SQL Server PlatformSQL Server Database Development TasksLab : Introduction to Database DevelopmentModule 2: Designing and Implementing TablesDesigning TablesData TypesWorking with SchemasCreating and Altering TablesPartitioning DataCompressing DataLab : Designing and Implementing TablesModule 3: Ensuring Data Integrity through ConstraintsEnforcing Data IntegrityImplementing Domain IntegrityImplementing Entity and Referential IntegrityLab : Ensuring Data Integrity through ConstraintsModule 4: Introduction to IndexingCore Indexing ConceptsData Types and IndexesSingle Column and Composite IndexesLab : Implementing IndexesModule 5: Designing Optimized Index StrategiesCovering IndexesManaging IndexesWorking with Execution PlansUsing the DTELab : Designing Optimized Index StrategiesModule 6: Columnstore IndexesIntroduction to Columnstore indexesCreating Columnstore IndexesWorking with Columnstore IndexesLab : Using Columnstore IndexesModule 7: Designing and Implementing ViewsIntroduction to ViewsCreating and Managing ViewsPerformance Considerations for ViewsLab : Designing and Implementing ViewsModule 8: Designing and Implementing Stored ProceduresIntroduction to Stored ProceduresWorking With Stored ProceduresImplementing Parameterized Stored ProceduresControlling Execution ContextLab : Designing and Implementing Stored ProceduresModule 9: Designing and Implementing User-Defined FunctionsOverview of FunctionsDesigning and Implementing Scalar FunctionsDesigning and Implementing Table-Valued FunctionsImplementation Considerations for FunctionsAlternatives to FunctionsLab : Designing and Implementing User-Defined FunctionsModule 10: Responding to Data Manipulation via TriggersDesigning DML TriggersImplementing DML TriggersAdvanced Trigger ConceptsLab : Responding to Data Manipulation via TriggersModule 11: Using In-Memory TablesIn-Memory TablesNative Stored ProceduresLab : In-Memory OLTPModule 12: Implementing Managed Code in SQL Server 2014Introduction to SQL CLR IntegrationImporting and Configuring AssembliesImplementing SQL CLR IntegrationLab : Implementing Managed Code in SQL Server 2014Module 13: Storing and Querying XML Data in SQL ServerIntroduction to XML and XML SchemasStoring XML Data and Schemas in SQL ServerImplementing the XML Data TypeUsing the T-SQL FOR XML StatementGetting Started with XQueryLab : Storing and Querying XML Data in SQL Server 2014Module 14: Working with SQL Server 2014 Spatial DataIntroduction to Spatial DataWorking with SQL Server Spatial Data TypesUsing Spatial Data in ApplicationsLab : Working with SQL Server Spatial DataModule 15: Incorporating Data Files into DatabasesQuerying Data with Stored ProceduresImplementing FILESTREAM and File TablesSearching Data FilesLab : Implementing a Solution for Storing Data Files
0 notes
Photo

Improving Azure SQL Database Performance using In-Memory Technologies In late 2016, Microsoft announced the general availability of Azure SQL Database In-Memory technologies. In-Memory processing is only available in Azure Premium database tiers and provides performance improvements for On-line Analytical Processing (OLTP), Clustered Columnstore Indexes and Non-clustered Columnstore Indexes for Hybrid Transactional and Analytical Processing (HTAP) scenarios. By Kent Weare
0 notes
Text
The Impact of Modern Fast Storage on Clustered Columnstore Index Fragmentation in SQL Server
Introduction Recent advancements in storage technology have greatly enhanced database performance. This raises an important question: Does the fragmentation of clustered columnstore indexes have the same minimal impact as the fragmentation of non-clustered indexes in SQL Server, especially with today’s high-speed storage options? We will delve deeper into this subject to understand it…
View On WordPress
0 notes
Text
20464: Developing Microsoft SQL Server Databases (SQL Server 2014 Update)thailand
20464: Developing Microsoft SQL Server Databases (SQL Server 2014 Update)
20464: Developing Microsoft SQL Server Databases (SQL Server 2014 Update) Course Description
Duration: 5.00 days (40 hours).
This 5-day instructor-led course introduces SQL Server 2014 and describes logical table design, indexing and query plans. It also focusses on the creation of database objects including views, stored procedures, along with parameters, and functions. Other common aspects of procedure coding, such as indexes, concurrency, error handling, and triggers are also covered in this course. Also this course helps you prepare for the Exam 70-464.
Note: This course is designed for customers who are interested in learning SQL Server 2012 or SQL Server 2014. It covers the new features in SQL Server 2014, but also the important capabilities across the SQL Server data platform.
Intended Audience For This 20464: Developing Microsoft SQL Server Databases (SQL Server 2014 Update) Course
» The primary audience for this course is IT Professionals who want to become skilled on SQL Server 2014 product features and technologies for implementing a database.
20464: Developing Microsoft SQL Server Databases (SQL Server 2014 Update) Course Objectives
» Introduce the entire SQL Server platform and its major tools. It will cover editions, versions, basics of network listeners, and concepts of services and service accounts.
» Determine appropriate data types to be used when designing tables, convert data between data types, and create alias data types.
» Be aware of good design practices regarding SQL Server tables and be able to create tables using T-SQL. (Note: partitioned tables are not covered).
» Implement PRIMARY KEY, FOREIGN KEY, DEFAULT, CHECK and UNIQUE constraints, and investigate cascading FOREIGN KEY constraints.
» Determine appropriate single column and composite indexes strategies.
» Create tables as heaps and tables with clustered indexes. Also consider the design of a table and suggest an appropriate structure.
» Read and interpret details of common elements from execution plans.
» Design effective non-clustered indexes.
» Design and implement views
» Design and implement stored procedures.
» Work with table types, table valued parameters and use the MERGE statement to create stored procedures that update data warehouses.
» Design and implement functions, both scalar and table-valued. (Also describe where they can lead to performance issues).
» Perform basic investigation of a deadlock situation and learn how transaction isolation levels affect application concurrency.
» Use both traditional T-SQL error handling code and structured exception handling.
» Design and implement DML triggers
» Learn appropriate uses for SQL CLR integration and implement an existing .NET assembly within SQL Server.
» Store XML data and schemas in SQL Server.
» Perform basic queries on XML data in SQL Server
20464: Developing Microsoft SQL Server Databases (SQL Server 2014 Update) Course Outline
Module 1: Introduction to Database Development
Introduction to the SQL Server Platform
SQL Server Database Development Tasks
Lab : Introduction to Database Development
Module 2: Designing and Implementing Tables
Designing Tables
Data Types
Working with Schemas
Creating and Altering Tables
Partitioning Data
Compressing Data
Lab : Designing and Implementing Tables
Module 3: Ensuring Data Integrity through Constraints
Enforcing Data Integrity
Implementing Domain Integrity
Implementing Entity and Referential Integrity
Lab : Ensuring Data Integrity through Constraints
Module 4: Introduction to Indexing
Core Indexing Concepts
Data Types and Indexes
Single Column and Composite Indexes
Lab : Implementing Indexes
Module 5: Designing Optimized Index Strategies
Covering Indexes
Managing Indexes
Working with Execution Plans
Using the DTE
Lab : Designing Optimized Index Strategies
Module 6: Columnstore Indexes
Introduction to Columnstore indexes
Creating Columnstore Indexes
Working with Columnstore Indexes
Lab : Using Columnstore Indexes
Module 7: Designing and Implementing Views
Introduction to Views
Creating and Managing Views
Performance Considerations for Views
Lab : Designing and Implementing Views
Module 8: Designing and Implementing Stored Procedures
Introduction to Stored Procedures
Working With Stored Procedures
Implementing Parameterized Stored Procedures
Controlling Execution Context
Lab : Designing and Implementing Stored Procedures
Module 9: Designing and Implementing User-Defined Functions
Overview of Functions
Designing and Implementing Scalar Functions
Designing and Implementing Table-Valued Functions
Implementation Considerations for Functions
Alternatives to Functions
Lab : Designing and Implementing User-Defined Functions
Module 10: Responding to Data Manipulation via Triggers
Designing DML Triggers
Implementing DML Triggers
Advanced Trigger Concepts
Lab : Responding to Data Manipulation via Triggers
Module 11: Using In-Memory Tables
In-Memory Tables
Native Stored Procedures
Lab : In-Memory OLTP
Module 12: Implementing Managed Code in SQL Server 2014
Introduction to SQL CLR Integration
Importing and Configuring Assemblies
Implementing SQL CLR Integration
Lab : Implementing Managed Code in SQL Server 2014
Module 13: Storing and Querying XML Data in SQL Server
Introduction to XML and XML Schemas
Storing XML Data and Schemas in SQL Server
Implementing the XML Data Type
Using the T-SQL FOR XML Statement
Getting Started with XQuery
Lab : Storing and Querying XML Data in SQL Server 2014
Module 14: Working with SQL Server 2014 Spatial Data
Introduction to Spatial Data
Working with SQL Server Spatial Data Types
Using Spatial Data in Applications
Lab : Working with SQL Server Spatial Data
Module 15: Incorporating Data Files into Databases
Querying Data with Stored Procedures
Implementing FILESTREAM and File Tables
Searching Data Files
Lab : Implementing a Solution for Storing Data Files
0 notes
Text
20464: Developing Microsoft SQL Server Databases (SQL Server 2014 Update)taiwan
20464: Developing Microsoft SQL Server Databases (SQL Server 2014 Update)20464: Developing Microsoft SQL Server Databases (SQL Server 2014 Update) Course DescriptionDuration: 5.00 days (40 hours).
This 5-day instructor-led course introduces SQL Server 2014 and describes logical table design, indexing and query plans. It also focusses on the creation of database objects including views, stored procedures, along with parameters, and functions. Other common aspects of procedure coding, such as indexes, concurrency, error handling, and triggers are also covered in this course. Also this course helps you prepare for the Exam 70-464.
Note: This course is designed for customers who are interested in learning SQL Server 2012 or SQL Server 2014. It covers the new features in SQL Server 2014, but also the important capabilities across the SQL Server data platform.
Intended Audience For This 20464: Developing Microsoft SQL Server Databases (SQL Server 2014 Update) Course
» The primary audience for this course is IT Professionals who want to become skilled on SQL Server 2014 product features and technologies for implementing a database.
20464: Developing Microsoft SQL Server Databases (SQL Server 2014 Update) Course Objectives
» Introduce the entire SQL Server platform and its major tools. It will cover editions, versions, basics of network listeners, and concepts of services and service accounts.
» Determine appropriate data types to be used when designing tables, convert data between data types, and create alias data types.
» Be aware of good design practices regarding SQL Server tables and be able to create tables using T-SQL. (Note: partitioned tables are not covered).
» Implement PRIMARY KEY, FOREIGN KEY, DEFAULT, CHECK and UNIQUE constraints, and investigate cascading FOREIGN KEY constraints.
» Determine appropriate single column and composite indexes strategies.
» Create tables as heaps and tables with clustered indexes. Also consider the design of a table and suggest an appropriate structure.
» Read and interpret details of common elements from execution plans.
» Design effective non-clustered indexes.
» Design and implement views
» Design and implement stored procedures.
» Work with table types, table valued parameters and use the MERGE statement to create stored procedures that update data warehouses.
» Design and implement functions, both scalar and table-valued. (Also describe where they can lead to performance issues).
» Perform basic investigation of a deadlock situation and learn how transaction isolation levels affect application concurrency.
» Use both traditional T-SQL error handling code and structured exception handling.
» Design and implement DML triggers
» Learn appropriate uses for SQL CLR integration and implement an existing .NET assembly within SQL Server.
» Store XML data and schemas in SQL Server.
» Perform basic queries on XML data in SQL Server
20464: Developing Microsoft SQL Server Databases (SQL Server 2014 Update) Course Outline
Module 1: Introduction to Database Development
Module 2: Designing and Implementing Tables
Module 3: Ensuring Data Integrity through Constraints
Module 4: Introduction to Indexing
Module 5: Designing Optimized Index Strategies
Module 6: Columnstore Indexes
Module 7: Designing and Implementing Views
Module 8: Designing and Implementing Stored Procedures
Module 9: Designing and Implementing User-Defined Functions
Module 10: Responding to Data Manipulation via Triggers
Module 11: Using In-Memory Tables
Module 12: Implementing Managed Code in SQL Server 2014
Module 13: Storing and Querying XML Data in SQL Server
Module 14: Working with SQL Server 2014 Spatial Data
Module 15: Incorporating Data Files into Databases
Introduction to the SQL Server Platform
SQL Server Database Development Tasks
Lab : Introduction to Database Development
Designing Tables
Data Types
Working with Schemas
Creating and Altering Tables
Partitioning Data
Compressing Data
Lab : Designing and Implementing Tables
Enforcing Data Integrity
Implementing Domain Integrity
Implementing Entity and Referential Integrity
Lab : Ensuring Data Integrity through Constraints
Core Indexing Concepts
Data Types and Indexes
Single Column and Composite Indexes
Lab : Implementing Indexes
Covering Indexes
Managing Indexes
Working with Execution Plans
Using the DTE
Lab : Designing Optimized Index Strategies
Introduction to Columnstore indexes
Creating Columnstore Indexes
Working with Columnstore Indexes
Lab : Using Columnstore Indexes
Introduction to Views
Creating and Managing Views
Performance Considerations for Views
Lab : Designing and Implementing Views
Introduction to Stored Procedures
Working With Stored Procedures
Implementing Parameterized Stored Procedures
Controlling Execution Context
Lab : Designing and Implementing Stored Procedures
Overview of Functions
Designing and Implementing Scalar Functions
Designing and Implementing Table-Valued Functions
Implementation Considerations for Functions
Alternatives to Functions
Lab : Designing and Implementing User-Defined Functions
Designing DML Triggers
Implementing DML Triggers
Advanced Trigger Concepts
Lab : Responding to Data Manipulation via Triggers
In-Memory Tables
Native Stored Procedures
Lab : In-Memory OLTP
Introduction to SQL CLR Integration
Importing and Configuring Assemblies
Implementing SQL CLR Integration
Lab : Implementing Managed Code in SQL Server 2014
Introduction to XML and XML Schemas
Storing XML Data and Schemas in SQL Server
Implementing the XML Data Type
Using the T-SQL FOR XML Statement
Getting Started with XQuery
Lab : Storing and Querying XML Data in SQL Server 2014
Introduction to Spatial Data
Working with SQL Server Spatial Data Types
Using Spatial Data in Applications
Lab : Working with SQL Server Spatial Data
Querying Data with Stored Procedures
Implementing FILESTREAM and File Tables
Searching Data Files
Lab : Implementing a Solution for Storing Data Files
0 notes
Text
20464: Developing Microsoft SQL Server Databases (SQL Server 2014 Update), riyadh,saudi arabia
20464: Developing Microsoft SQL Server Databases (SQL Server 2014 Update)20464: Developing Microsoft SQL Server Databases (SQL Server 2014 Update) Course DescriptionDuration: 5.00 days (40 hours).
This 5-day instructor-led course introduces SQL Server 2014 and describes logical table design, indexing and query plans. It also focusses on the creation of database objects including views, stored procedures, along with parameters, and functions. Other common aspects of procedure coding, such as indexes, concurrency, error handling, and triggers are also covered in this course. Also this course helps you prepare for the Exam 70-464.
Note: This course is designed for customers who are interested in learning SQL Server 2012 or SQL Server 2014. It covers the new features in SQL Server 2014, but also the important capabilities across the SQL Server data platform.
Galactic Solutions.
Intended Audience For This 20464: Developing Microsoft SQL Server Databases (SQL Server 2014 Update) Course
» The primary audience for this course is IT Professionals who want to become skilled on SQL Server 2014 product features and technologies for implementing a database.
20464: Developing Microsoft SQL Server Databases (SQL Server 2014 Update) Course Objectives
» Introduce the entire SQL Server platform and its major tools. It will cover editions, versions, basics of network listeners, and concepts of services and service accounts.
» Determine appropriate data types to be used when designing tables, convert data between data types, and create alias data types.
» Be aware of good design practices regarding SQL Server tables and be able to create tables using T-SQL. (Note: partitioned tables are not covered).
» Implement PRIMARY KEY, FOREIGN KEY, DEFAULT, CHECK and UNIQUE constraints, and investigate cascading FOREIGN KEY constraints.
» Determine appropriate single column and composite indexes strategies.
» Create tables as heaps and tables with clustered indexes. Also consider the design of a table and suggest an appropriate structure.
» Read and interpret details of common elements from execution plans.
» Design effective non-clustered indexes.
» Design and implement views
» Design and implement stored procedures.
» Work with table types, table valued parameters and use the MERGE statement to create stored procedures that update data warehouses.
» Design and implement functions, both scalar and table-valued. (Also describe where they can lead to performance issues).
» Perform basic investigation of a deadlock situation and learn how transaction isolation levels affect application concurrency.
» Use both traditional T-SQL error handling code and structured exception handling.
» Design and implement DML triggers
» Learn appropriate uses for SQL CLR integration and implement an existing .NET assembly within SQL Server.
» Store XML data and schemas in SQL Server.
» Perform basic queries on XML data in SQL Server
20464: Developing Microsoft SQL Server Databases (SQL Server 2014 Update) Course Outline
Module 1: Introduction to Database Development
Module 2: Designing and Implementing Tables
Module 3: Ensuring Data Integrity through Constraints
Module 4: Introduction to Indexing
Module 5: Designing Optimized Index Strategies
Module 6: Columnstore Indexes
Module 7: Designing and Implementing Views
Module 8: Designing and Implementing Stored Procedures
Module 9: Designing and Implementing User-Defined Functions
Module 10: Responding to Data Manipulation via Triggers
Module 11: Using In-Memory Tables
Module 12: Implementing Managed Code in SQL Server 2014
Module 13: Storing and Querying XML Data in SQL Server
Module 14: Working with SQL Server 2014 Spatial Data
Module 15: Incorporating Data Files into Databases
Introduction to the SQL Server Platform
SQL Server Database Development Tasks
Lab : Introduction to Database Development
Designing Tables
Data Types
Working with Schemas
Creating and Altering Tables
Partitioning Data
Compressing Data
Lab : Designing and Implementing Tables
Enforcing Data Integrity
Implementing Domain Integrity
Implementing Entity and Referential Integrity
Lab : Ensuring Data Integrity through Constraints
Core Indexing Concepts
Data Types and Indexes
Single Column and Composite Indexes
Lab : Implementing Indexes
Covering Indexes
Managing Indexes
Working with Execution Plans
Using the DTE
Lab : Designing Optimized Index Strategies
Introduction to Columnstore indexes
Creating Columnstore Indexes
Working with Columnstore Indexes
Lab : Using Columnstore Indexes
Introduction to Views
Creating and Managing Views
Performance Considerations for Views
Lab : Designing and Implementing Views
Introduction to Stored Procedures
Working With Stored Procedures
Implementing Parameterized Stored Procedures
Controlling Execution Context
Lab : Designing and Implementing Stored Procedures
Overview of Functions
Designing and Implementing Scalar Functions
Designing and Implementing Table-Valued Functions
Implementation Considerations for Functions
Alternatives to Functions
Lab : Designing and Implementing User-Defined Functions
Designing DML Triggers
Implementing DML Triggers
Advanced Trigger Concepts
Lab : Responding to Data Manipulation via Triggers
In-Memory Tables
Native Stored Procedures
Lab : In-Memory OLTP
Introduction to SQL CLR Integration
Importing and Configuring Assemblies
Implementing SQL CLR Integration
Lab : Implementing Managed Code in SQL Server 2014
Introduction to XML and XML Schemas
Storing XML Data and Schemas in SQL Server
Implementing the XML Data Type
Using the T-SQL FOR XML Statement
Getting Started with XQuery
Lab : Storing and Querying XML Data in SQL Server 2014
Introduction to Spatial Data
Working with SQL Server Spatial Data Types
Using Spatial Data in Applications
Lab : Working with SQL Server Spatial Data
Querying Data with Stored Procedures
Implementing FILESTREAM and File Tables
Searching Data Files
Lab : Implementing a Solution for Storing Data Files
0 notes
Text
20464: Developing Microsoft SQL Server Databases (SQL Server 2014 Update),Doha-Qatar
20464: Developing Microsoft SQL Server Databases (SQL Server 2014 Update)20464: Developing Microsoft SQL Server Databases (SQL Server 2014 Update) Course DescriptionDuration: 5.00 days (40 hours),
This 5-day instructor-led course introduces SQL Server 2014 and describes logical table design, indexing and query plans. It also focusses on the creation of database objects including views, stored procedures, along with parameters, and functions. Other common aspects of procedure coding, such as indexes, concurrency, error handling, and triggers are also covered in this course. Also this course helps you prepare for the Exam 70-464.
Note: This course is designed for customers who are interested in learning SQL Server 2012 or SQL Server 2014. It covers the new features in SQL Server 2014, but also the important capabilities across the SQL Server data platform.
Intended Audience For This 20464: Developing Microsoft SQL Server Databases (SQL Server 2014 Update) Course
» The primary audience for this course is IT Professionals who want to become skilled on SQL Server 2014 product features and technologies for implementing a database.
20464: Developing Microsoft SQL Server Databases (SQL Server 2014 Update) Course Objectives
» Introduce the entire SQL Server platform and its major tools. It will cover editions, versions, basics of network listeners, and concepts of services and service accounts.
» Determine appropriate data types to be used when designing tables, convert data between data types, and create alias data types.
» Be aware of good design practices regarding SQL Server tables and be able to create tables using T-SQL. (Note: partitioned tables are not covered).
» Implement PRIMARY KEY, FOREIGN KEY, DEFAULT, CHECK and UNIQUE constraints, and investigate cascading FOREIGN KEY constraints.
» Determine appropriate single column and composite indexes strategies.
» Create tables as heaps and tables with clustered indexes. Also consider the design of a table and suggest an appropriate structure.
» Read and interpret details of common elements from execution plans.
» Design effective non-clustered indexes.
» Design and implement views
» Design and implement stored procedures.
» Work with table types, table valued parameters and use the MERGE statement to create stored procedures that update data warehouses.
» Design and implement functions, both scalar and table-valued. (Also describe where they can lead to performance issues).
» Perform basic investigation of a deadlock situation and learn how transaction isolation levels affect application concurrency.
» Use both traditional T-SQL error handling code and structured exception handling.
» Design and implement DML triggers
» Learn appropriate uses for SQL CLR integration and implement an existing .NET assembly within SQL Server.
» Store XML data and schemas in SQL Server.
» Perform basic queries on XML data in SQL Server
20464: Developing Microsoft SQL Server Databases (SQL Server 2014 Update) Course Outline
Module 1: Introduction to Database Development
Module 2: Designing and Implementing Tables
Module 3: Ensuring Data Integrity through Constraints
Module 4: Introduction to Indexing
Module 5: Designing Optimized Index Strategies
Module 6: Columnstore Indexes
Module 7: Designing and Implementing Views
Module 8: Designing and Implementing Stored Procedures
Module 9: Designing and Implementing User-Defined Functions
Module 10: Responding to Data Manipulation via Triggers
Module 11: Using In-Memory Tables
Module 12: Implementing Managed Code in SQL Server 2014
Module 13: Storing and Querying XML Data in SQL Server
Module 14: Working with SQL Server 2014 Spatial Data
Module 15: Incorporating Data Files into Databases
Introduction to the SQL Server Platform
SQL Server Database Development Tasks
Lab : Introduction to Database Development
Designing Tables
Data Types
Working with Schemas
Creating and Altering Tables
Partitioning Data
Compressing Data
Lab : Designing and Implementing Tables
Enforcing Data Integrity
Implementing Domain Integrity
Implementing Entity and Referential Integrity
Lab : Ensuring Data Integrity through Constraints
Core Indexing Concepts
Data Types and Indexes
Single Column and Composite Indexes
Lab : Implementing Indexes
Covering Indexes
Managing Indexes
Working with Execution Plans
Using the DTE
Lab : Designing Optimized Index Strategies
Introduction to Columnstore indexes
Creating Columnstore Indexes
Working with Columnstore Indexes
Lab : Using Columnstore Indexes
Introduction to Views
Creating and Managing Views
Performance Considerations for Views
Lab : Designing and Implementing Views
Introduction to Stored Procedures
Working With Stored Procedures
Implementing Parameterized Stored Procedures
Controlling Execution Context
Lab : Designing and Implementing Stored Procedures
Overview of Functions
Designing and Implementing Scalar Functions
Designing and Implementing Table-Valued Functions
Implementation Considerations for Functions
Alternatives to Functions
Lab : Designing and Implementing User-Defined Functions
Designing DML Triggers
Implementing DML Triggers
Advanced Trigger Concepts
Lab : Responding to Data Manipulation via Triggers
In-Memory Tables
Native Stored Procedures
Lab : In-Memory OLTP
Introduction to SQL CLR Integration
Importing and Configuring Assemblies
Implementing SQL CLR Integration
Lab : Implementing Managed Code in SQL Server 2014
Introduction to XML and XML Schemas
Storing XML Data and Schemas in SQL Server
Implementing the XML Data Type
Using the T-SQL FOR XML Statement
Getting Started with XQuery
Lab : Storing and Querying XML Data in SQL Server 2014
Introduction to Spatial Data
Working with SQL Server Spatial Data Types
Using Spatial Data in Applications
Lab : Working with SQL Server Spatial Data
Querying Data with Stored Procedures
Implementing FILESTREAM and File Tables
Searching Data Files
Lab : Implementing a Solution for Storing Data Files
0 notes
Text
20464: Developing Microsoft SQL Server Databases (SQL Server 2014 Update), Manila-Philippines
20464: Developing Microsoft SQL Server Databases (SQL Server 2014 Update)20464: Developing Microsoft SQL Server Databases (SQL Server 2014 Update) Course DescriptionDuration: 5.00 days (40 hours),
This 5-day instructor-led course introduces SQL Server 2014 and describes logical table design, indexing and query plans. It also focusses on the creation of database objects including views, stored procedures, along with parameters, and functions. Other common aspects of procedure coding, such as indexes, concurrency, error handling, and triggers are also covered in this course. Also this course helps you prepare for the Exam 70-464.
Note: This course is designed for customers who are interested in learning SQL Server 2012 or SQL Server 2014. It covers the new features in SQL Server 2014, but also the important capabilities across the SQL Server data platform.
Intended Audience For This 20464: Developing Microsoft SQL Server Databases (SQL Server 2014 Update) Course
» The primary audience for this course is IT Professionals who want to become skilled on SQL Server 2014 product features and technologies for implementing a database.
20464: Developing Microsoft SQL Server Databases (SQL Server 2014 Update) Course Objectives
» Introduce the entire SQL Server platform and its major tools. It will cover editions, versions, basics of network listeners, and concepts of services and service accounts.
» Determine appropriate data types to be used when designing tables, convert data between data types, and create alias data types.
» Be aware of good design practices regarding SQL Server tables and be able to create tables using T-SQL. (Note: partitioned tables are not covered).
» Implement PRIMARY KEY, FOREIGN KEY, DEFAULT, CHECK and UNIQUE constraints, and investigate cascading FOREIGN KEY constraints.
» Determine appropriate single column and composite indexes strategies.
» Create tables as heaps and tables with clustered indexes. Also consider the design of a table and suggest an appropriate structure.
» Read and interpret details of common elements from execution plans.
» Design effective non-clustered indexes.
» Design and implement views
» Design and implement stored procedures.
» Work with table types, table valued parameters and use the MERGE statement to create stored procedures that update data warehouses.
» Design and implement functions, both scalar and table-valued. (Also describe where they can lead to performance issues).
» Perform basic investigation of a deadlock situation and learn how transaction isolation levels affect application concurrency.
» Use both traditional T-SQL error handling code and structured exception handling.
» Design and implement DML triggers
» Learn appropriate uses for SQL CLR integration and implement an existing .NET assembly within SQL Server.
» Store XML data and schemas in SQL Server.
» Perform basic queries on XML data in SQL Server
20464: Developing Microsoft SQL Server Databases (SQL Server 2014 Update) Course Outline
Module 1: Introduction to Database Development
Module 2: Designing and Implementing Tables
Module 3: Ensuring Data Integrity through Constraints
Module 4: Introduction to Indexing
Module 5: Designing Optimized Index Strategies
Module 6: Columnstore Indexes
Module 7: Designing and Implementing Views
Module 8: Designing and Implementing Stored Procedures
Module 9: Designing and Implementing User-Defined Functions
Module 10: Responding to Data Manipulation via Triggers
Module 11: Using In-Memory Tables
Module 12: Implementing Managed Code in SQL Server 2014
Module 13: Storing and Querying XML Data in SQL Server
Module 14: Working with SQL Server 2014 Spatial Data
Module 15: Incorporating Data Files into Databases
Introduction to the SQL Server Platform
SQL Server Database Development Tasks
Lab : Introduction to Database Development
Designing Tables
Data Types
Working with Schemas
Creating and Altering Tables
Partitioning Data
Compressing Data
Lab : Designing and Implementing Tables
Enforcing Data Integrity
Implementing Domain Integrity
Implementing Entity and Referential Integrity
Lab : Ensuring Data Integrity through Constraints
Core Indexing Concepts
Data Types and Indexes
Single Column and Composite Indexes
Lab : Implementing Indexes
Covering Indexes
Managing Indexes
Working with Execution Plans
Using the DTE
Lab : Designing Optimized Index Strategies
Introduction to Columnstore indexes
Creating Columnstore Indexes
Working with Columnstore Indexes
Lab : Using Columnstore Indexes
Introduction to Views
Creating and Managing Views
Performance Considerations for Views
Lab : Designing and Implementing Views
Introduction to Stored Procedures
Working With Stored Procedures
Implementing Parameterized Stored Procedures
Controlling Execution Context
Lab : Designing and Implementing Stored Procedures
Overview of Functions
Designing and Implementing Scalar Functions
Designing and Implementing Table-Valued Functions
Implementation Considerations for Functions
Alternatives to Functions
Lab : Designing and Implementing User-Defined Functions
Designing DML Triggers
Implementing DML Triggers
Advanced Trigger Concepts
Lab : Responding to Data Manipulation via Triggers
In-Memory Tables
Native Stored Procedures
Lab : In-Memory OLTP
Introduction to SQL CLR Integration
Importing and Configuring Assemblies
Implementing SQL CLR Integration
Lab : Implementing Managed Code in SQL Server 2014
Introduction to XML and XML Schemas
Storing XML Data and Schemas in SQL Server
Implementing the XML Data Type
Using the T-SQL FOR XML Statement
Getting Started with XQuery
Lab : Storing and Querying XML Data in SQL Server 2014
Introduction to Spatial Data
Working with SQL Server Spatial Data Types
Using Spatial Data in Applications
Lab : Working with SQL Server Spatial Data
Querying Data with Stored Procedures
Implementing FILESTREAM and File Tables
Searching Data Files
Lab : Implementing a Solution for Storing Data Files
0 notes
Text
20464: Developing Microsoft SQL Server Databases (SQL Server 2014 Update), muscat,oman
20464: Developing Microsoft SQL Server Databases (SQL Server 2014 Update)20464: Developing Microsoft SQL Server Databases (SQL Server 2014 Update) Course DescriptionDuration: 5.00 days (40 hours),
This 5-day instructor-led course introduces SQL Server 2014 and describes logical table design, indexing and query plans. It also focusses on the creation of database objects including views, stored procedures, along with parameters, and functions. Other common aspects of procedure coding, such as indexes, concurrency, error handling, and triggers are also covered in this course. Also this course helps you prepare for the Exam 70-464.
Note: This course is designed for customers who are interested in learning SQL Server 2012 or SQL Server 2014. It covers the new features in SQL Server 2014, but also the important capabilities across the SQL Server data platform.
Intended Audience For This 20464: Developing Microsoft SQL Server Databases (SQL Server 2014 Update) Course
» The primary audience for this course is IT Professionals who want to become skilled on SQL Server 2014 product features and technologies for implementing a database.
20464: Developing Microsoft SQL Server Databases (SQL Server 2014 Update) Course Objectives
» Introduce the entire SQL Server platform and its major tools. It will cover editions, versions, basics of network listeners, and concepts of services and service accounts.
» Determine appropriate data types to be used when designing tables, convert data between data types, and create alias data types.
» Be aware of good design practices regarding SQL Server tables and be able to create tables using T-SQL. (Note: partitioned tables are not covered).
» Implement PRIMARY KEY, FOREIGN KEY, DEFAULT, CHECK and UNIQUE constraints, and investigate cascading FOREIGN KEY constraints.
» Determine appropriate single column and composite indexes strategies.
» Create tables as heaps and tables with clustered indexes. Also consider the design of a table and suggest an appropriate structure.
» Read and interpret details of common elements from execution plans.
» Design effective non-clustered indexes.
» Design and implement views
» Design and implement stored procedures.
» Work with table types, table valued parameters and use the MERGE statement to create stored procedures that update data warehouses.
» Design and implement functions, both scalar and table-valued. (Also describe where they can lead to performance issues).
» Perform basic investigation of a deadlock situation and learn how transaction isolation levels affect application concurrency.
» Use both traditional T-SQL error handling code and structured exception handling.
» Design and implement DML triggers
» Learn appropriate uses for SQL CLR integration and implement an existing .NET assembly within SQL Server.
» Store XML data and schemas in SQL Server.
» Perform basic queries on XML data in SQL Server
20464: Developing Microsoft SQL Server Databases (SQL Server 2014 Update) Course Outline
Module 1: Introduction to Database Development
Module 2: Designing and Implementing Tables
Module 3: Ensuring Data Integrity through Constraints
Module 4: Introduction to Indexing
Module 5: Designing Optimized Index Strategies
Module 6: Columnstore Indexes
Module 7: Designing and Implementing Views
Module 8: Designing and Implementing Stored Procedures
Module 9: Designing and Implementing User-Defined Functions
Module 10: Responding to Data Manipulation via Triggers
Module 11: Using In-Memory Tables
Module 12: Implementing Managed Code in SQL Server 2014
Module 13: Storing and Querying XML Data in SQL Server
Module 14: Working with SQL Server 2014 Spatial Data
Module 15: Incorporating Data Files into Databases
Introduction to the SQL Server Platform
SQL Server Database Development Tasks
Lab : Introduction to Database Development
Designing Tables
Data Types
Working with Schemas
Creating and Altering Tables
Partitioning Data
Compressing Data
Lab : Designing and Implementing Tables
Enforcing Data Integrity
Implementing Domain Integrity
Implementing Entity and Referential Integrity
Lab : Ensuring Data Integrity through Constraints
Core Indexing Concepts
Data Types and Indexes
Single Column and Composite Indexes
Lab : Implementing Indexes
Covering Indexes
Managing Indexes
Working with Execution Plans
Using the DTE
Lab : Designing Optimized Index Strategies
Introduction to Columnstore indexes
Creating Columnstore Indexes
Working with Columnstore Indexes
Lab : Using Columnstore Indexes
Introduction to Views
Creating and Managing Views
Performance Considerations for Views
Lab : Designing and Implementing Views
Introduction to Stored Procedures
Working With Stored Procedures
Implementing Parameterized Stored Procedures
Controlling Execution Context
Lab : Designing and Implementing Stored Procedures
Overview of Functions
Designing and Implementing Scalar Functions
Designing and Implementing Table-Valued Functions
Implementation Considerations for Functions
Alternatives to Functions
Lab : Designing and Implementing User-Defined Functions
Designing DML Triggers
Implementing DML Triggers
Advanced Trigger Concepts
Lab : Responding to Data Manipulation via Triggers
In-Memory Tables
Native Stored Procedures
Lab : In-Memory OLTP
Introduction to SQL CLR Integration
Importing and Configuring Assemblies
Implementing SQL CLR Integration
Lab : Implementing Managed Code in SQL Server 2014
Introduction to XML and XML Schemas
Storing XML Data and Schemas in SQL Server
Implementing the XML Data Type
Using the T-SQL FOR XML Statement
Getting Started with XQuery
Lab : Storing and Querying XML Data in SQL Server 2014
Introduction to Spatial Data
Working with SQL Server Spatial Data Types
Using Spatial Data in Applications
Lab : Working with SQL Server Spatial Data
Querying Data with Stored Procedures
Implementing FILESTREAM and File Tables
Searching Data Files
Lab : Implementing a Solution for Storing Data Files
0 notes
Text
20464: Developing Microsoft SQL Server Databases (SQL Server 2014 Update),Kuwait city, kuwait
20464: Developing Microsoft SQL Server Databases (SQL Server 2014 Update)20464: Developing Microsoft SQL Server Databases (SQL Server 2014 Update) Course DescriptionThis 5-day instructor-led course introduces SQL Server 2014 and describes logical table design, indexing and query plans. It also focusses on the creation of database objects including views, stored procedures, along with parameters, and functions. Other common aspects of procedure coding, such as indexes, concurrency, error handling, and triggers are also covered in this course. Also this course helps you prepare for the Exam 70-464.
Note: This course is designed for customers who are interested in learning SQL Server 2012 or SQL Server 2014. It covers the new features in SQL Server 2014, but also the important capabilities across the SQL Server data platform.
Intended Audience For This 20464: Developing Microsoft SQL Server Databases (SQL Server 2014 Update) Course
» The primary audience for this course is IT Professionals who want to become skilled on SQL Server 2014 product features and technologies for implementing a database.
20464: Developing Microsoft SQL Server Databases (SQL Server 2014 Update) Course Objectives
» Introduce the entire SQL Server platform and its major tools. It will cover editions, versions, basics of network listeners, and concepts of services and service accounts.
» Determine appropriate data types to be used when designing tables, convert data between data types, and create alias data types.
» Be aware of good design practices regarding SQL Server tables and be able to create tables using T-SQL. (Note: partitioned tables are not covered).
» Implement PRIMARY KEY, FOREIGN KEY, DEFAULT, CHECK and UNIQUE constraints, and investigate cascading FOREIGN KEY constraints.
» Determine appropriate single column and composite indexes strategies.
» Create tables as heaps and tables with clustered indexes. Also consider the design of a table and suggest an appropriate structure.
» Read and interpret details of common elements from execution plans.
» Design effective non-clustered indexes.
» Design and implement views
» Design and implement stored procedures.
» Work with table types, table valued parameters and use the MERGE statement to create stored procedures that update data warehouses.
» Design and implement functions, both scalar and table-valued. (Also describe where they can lead to performance issues).
» Perform basic investigation of a deadlock situation and learn how transaction isolation levels affect application concurrency.
» Use both traditional T-SQL error handling code and structured exception handling.
» Design and implement DML triggers
» Learn appropriate uses for SQL CLR integration and implement an existing .NET assembly within SQL Server.
» Store XML data and schemas in SQL Server.
» Perform basic queries on XML data in SQL Server
20464: Developing Microsoft SQL Server Databases (SQL Server 2014 Update) Course Outline
Module 1: Introduction to Database Development
Module 2: Designing and Implementing Tables
Module 3: Ensuring Data Integrity through Constraints
Module 4: Introduction to Indexing
Module 5: Designing Optimized Index Strategies
Module 6: Columnstore Indexes
Module 7: Designing and Implementing Views
Module 8: Designing and Implementing Stored Procedures
Module 9: Designing and Implementing User-Defined Functions
Module 10: Responding to Data Manipulation via Triggers
Module 11: Using In-Memory Tables
Module 12: Implementing Managed Code in SQL Server 2014
Module 13: Storing and Querying XML Data in SQL Server
Module 14: Working with SQL Server 2014 Spatial Data
Module 15: Incorporating Data Files into Databases
Introduction to the SQL Server Platform
SQL Server Database Development Tasks
Lab : Introduction to Database Development
Designing Tables
Data Types
Working with Schemas
Creating and Altering Tables
Partitioning Data
Compressing Data
Lab : Designing and Implementing Tables
Enforcing Data Integrity
Implementing Domain Integrity
Implementing Entity and Referential Integrity
Lab : Ensuring Data Integrity through Constraints
Core Indexing Concepts
Data Types and Indexes
Single Column and Composite Indexes
Lab : Implementing Indexes
Covering Indexes
Managing Indexes
Working with Execution Plans
Using the DTE
Lab : Designing Optimized Index Strategies
Introduction to Columnstore indexes
Creating Columnstore Indexes
Working with Columnstore Indexes
Lab : Using Columnstore Indexes
Introduction to Views
Creating and Managing Views
Performance Considerations for Views
Lab : Designing and Implementing Views
Introduction to Stored Procedures
Working With Stored Procedures
Implementing Parameterized Stored Procedures
Controlling Execution Context
Lab : Designing and Implementing Stored Procedures
Overview of Functions
Designing and Implementing Scalar Functions
Designing and Implementing Table-Valued Functions
Implementation Considerations for Functions
Alternatives to Functions
Lab : Designing and Implementing User-Defined Functions
Designing DML Triggers
Implementing DML Triggers
Advanced Trigger Concepts
Lab : Responding to Data Manipulation via Triggers
In-Memory Tables
Native Stored Procedures
Lab : In-Memory OLTP
Introduction to SQL CLR Integration
Importing and Configuring Assemblies
Implementing SQL CLR Integration
Lab : Implementing Managed Code in SQL Server 2014
Introduction to XML and XML Schemas
Storing XML Data and Schemas in SQL Server
Implementing the XML Data Type
Using the T-SQL FOR XML Statement
Getting Started with XQuery
Lab : Storing and Querying XML Data in SQL Server 2014
Introduction to Spatial Data
Working with SQL Server Spatial Data Types
Using Spatial Data in Applications
Lab : Working with SQL Server Spatial Data
Querying Data with Stored Procedures
Implementing FILESTREAM and File Tables
Searching Data Files
Lab : Implementing a Solution for Storing Data Files
0 notes