#remote sql dba
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
Celebrities use Tumblr as well.
Text
Elevate Database Management with RalanTech SQL Server Remote DBA Support

https://www.ralantech.com/sqlserver-database-support/ Experience seamless database administration with RalanTech's expert SQL Server Remote DBA support. From performance optimization to maintenance, our dedicated team ensures your databases run smoothly, anytime, anywhere. Boost efficiency and reliability today with RalanTech.
1 note
·
View note
Text
Oracle SQL remains one of the most popular database management systems. There are many oracle DBAs offering outsourcing services, but some are better than others. Understanding the services to expect from good remote Oracle DBAs will ensure you get value for money. Consulting Engagement A good remote DBA should give you at least 3 hours’ consultative engagement. This is the only way your DBA will know exactly what you want. The session will also help you determine if the DBA knows what he is talking about. Solving complex DB problems Some DB problems are quite complex. Examples are engineering of self-learning matching algorithm for more efficient and effective data mining and new daily processes that require the importation of tens or hundreds of millions of records without taking your DB online. A good DBA should have the necessary skills to use advanced DB techniques to fix such complex DB problems. Design of a new DB If you are starting out, you want a remote DBA who will assist you design a new DB. The DBA should come up with a solid architectural blueprint and he/she should work with your team to come up with a DB design that meets your specific business needs. This process should lead to the development of a complete DB schema that is ready to implement. DB architecture review If you have an existing DB that is not performing as it should or that needs to be upgraded for another reason, your DBA should do a comprehensive DB architecture review. This should cover all aspects of the architecture design from details of the data types you are using and DB schema to the overall environment and system architecture configuration. The DBA should then present the findings in a detailed and easy-to-understand report. This report will help you make informed decisions on what is needed. Collaboration with your DBA team If you already have an in-house DBA team that is overstretched with the demands of DB rollout or maintenance, your remote DBA will collaborate with your team, giving valuable technical advice. You could also offload some specific DB-related tasks, such as the reengineering of one of the reporting DBs to your remote DBA so that your team concentrates on the day-to-day running of the DB. Version upgrades and migration from legacy systems If you are planning to upgrade to a new version of Oracle this year or to migrate a legacy application, a remote DBA can assist you. Go for a remote oracle DBA who can do this with minimal business interruption. The DBA should verify compatibility before deployment to minimize interruption. Implementation of a disaster recovery plan A good DBA will ensure there are relevant backups and that the DB design is scalable and high-performance to ensure it performs optimally for a long time. The DBA should always be available, even after the project, for updates and any necessary changes. Monitoring Monitoring a DB is very important because identifying a problem early means quick resolution. Note that your DB may appear to be running smoothly on the surface, but changes are made every hour and these incremental changes sometimes significantly affect the underlying performance characteristics of the system over time and shutdown or degradation can happen suddenly. A good DBA will help you develop processes for monitoring and trending key metrics. Optimization The DB is at the heart of a website. Poor DB performance impacts on operation efficiency and on customer experience, which leads to revenue repercussions. Your DBA should use performance optimization techniques, such as targeted schema and application code optimization for improved performance. DB Security In an increasingly competitive market place, your data might be at risk from competitors who want an edge over you. There is also a risk of people trying to get customer information for criminal purposes (such as identity theft). You should, therefore, ensure your DBA works on securing your DB using the latest Oracle DB security solutions.
Additional services You expect a good DBA to offer other services that will improve your website. A good full-service DBA will offer such services as search engine optimization to ensure your website ranks high in SERPs and responsive web design to ensure your site is mobile-friendly. So, what makes a good DBA? A good DBA will have a good track record and will be part of a team in a reputable firm. Ask for a list of clients served and ask for referrals to ensure the DBA is credible and reliable. You could get tips on credible and reliable DBAs from referrals from people you know, from industry publications, and from online reviews, testimonials, and comments. Longevity in the business is a sign credibility and reliability. Experience is more important than training and even certification. A good DBA will not be an intangible online ghost – he/she should have a physical presence. This helps build trust since you will know where to go in case of any eventuality. Go for a DBA who has good interpersonal and communication skills. This is important because it is only when you understand each other that you will get the exact solution you want. You should note that you expect to pay for quality service and any DBA who charges overly low rates is likely to be fraudulent. Most DBAs have different prices for different packages. Go for a monthly contract since the DBA will be motivated to earn your business in the next month. The DBA should be able to administer your database online (without a GUI). If you were to rely on a GUI, this would mean logistical complications (such as setting up a connection and ensuring one machine is always available) and there would be cost implications and the risk of regular disconnections. Consider hiring a professional for database administration, as this ensures you concentrate on running your core business. You will get professionalism since a DBA will have the training, experience, and tools necessary for the job. You also save money since you will not need a permanent in-house team for the job. Lucy Jones is an Oracle DB expert. She offers everything from DB design to monitoring. She also offers other website optimization services to ensure your site stands out.
0 notes
Text
How to Hire an Oracle Developer: A Complete Guide for Businesses

The right Oracle developer is essential for your SaaS business when you rely on secure and high-performance databases. Oracle is widely adopted for enterprise applications, cloud-based solutions, and complex data management. Whether you need to hire oracle engineers for database administration, PL/SQL programming, or cloud integration, finding the right talent is the key to ensure efficiency and scalability.
Seamless data handling becomes even more crucial when you are operating as a SaaS business. This is why hiring skilled oracle experts can help improve performance and security. Let’s understand this better in the subsequent sections of this article.
Key Steps to Finding the Right Oracle Developer for Your Business Needs
State your business needs
Describe your project needs before you begin the hiring process. Do you need someone to manage an existing database, create an Oracle-based application, or improve performance? Hiring Oracle developers with the appropriate experience will be made easier if you know what you require.
Look for the essential skills
When assessing applicants, consider the following abilities:
Knowledge of PL/SQL, the primary programming language for Oracle databases.
Familiarity with Oracle Database Administration (DBA), which includes database management, security, and optimization.
Knowledge about Oracle Cloud Services: Due to its scalability, Oracle Cloud is being used by many SaaS enterprises.
Knowledge of indexing and performance tweaking ensures quick query execution.
Best practices for security: Preventing breaches of private company information.
Source candidates from the right platforms
There are several ways to discover qualified Oracle developers:
Platforms for freelancers: Websites such as Upwork and Toptal provide skilled Oracle specialists as freelancers. This is an ideal choice if you need project-based or short-term talent.
Both full-time and contract positions are listed on job portals such as Indeed, Glassdoor, and LinkedIn.
IT staffing agencies are companies that specialise in assisting your SaaS business in connecting with Oracle-versed software professionals. Uplers is one such hiring platform with a 1.5M + talent network that offers you the top 3.5% pre-vetted profiles in your inbox within 48 hours.
Conduct interview and technical assessment
To guarantee that you hire qualified Oracle developers, evaluate applicants using:
Technical coding tests: Assess your knowledge of PL/SQL and database optimization.
Problem-solving activities: Evaluate their aptitude for query optimization and troubleshooting.
Review of the portfolio: Examine prior work and customer comments.
Choose between in house vs remote hiring
Choose if you want to hire remote developers or you need a team member on-site.
Oracle Developers on-site pros:
Improved cooperation with internal groups
Full-time availability for current tasks.
Oracle Developers on-site cons:
Increased expenses (office space, benefits, and salaries).
Oracle developers working remotely pros:
Availability of an international talent pool
Cost-effective hiring options.
Perfect for cloud-based database management for SaaS organisations.
Oracle developers working remotely cons:
Flexible schedules become necessary due to time zone differences, which might hamper communication at times.
Closing Thoughts
For the management of business-critical databases and applications, hiring software developers with appropriate Oracle expertise is crucial. Finding the ideal fit will be made easier if you concentrate on technical knowledge and experience, whether you decide to hire locally or remotely. Securing top Oracle talent guarantees database reliability, performance, and long-term success for SaaS organisations.
#hire oracle developer#hire oracle engineer#Hire software developers#Hire remote developers#IT staffing agencies
0 notes
Text
Ensuring Database Excellence: DBA Support Services by Dizbiztek in Malaysia and Indonesia

In the rapidly evolving digital landscape, maintaining a robust and efficient database system is crucial for business success. Dizbiztek, a leading DBA support agency, offers top-tier DBA support services tailored to meet the unique needs of businesses in Malaysia and Indonesia. With our expertise, your database systems will run smoothly, ensuring optimal performance and security.
Why DBA Support Services are Essential
Database management is a complex task that requires specialized knowledge and continuous monitoring. As businesses grow and data volumes increase, the challenges of managing databases become more pronounced. Here’s where DBA support services come into play. These services ensure your database systems are not only up and running but also optimized for performance and security. Whether it’s routine maintenance, emergency troubleshooting, or performance tuning, a reliable DBA support agency like Dizbiztek is essential.
Remote DBA Support: Flexibility and Efficiency
Dizbiztek offers comprehensive remote DBA support services, providing businesses with the flexibility and expertise they need without the overhead costs of maintaining an in-house team. Our remote DBA support ensures that your databases are monitored and managed round the clock, minimizing downtime and maximizing efficiency. This service is particularly beneficial for small and medium-sized enterprises that need expert DBA support but may not have the resources to maintain a full-time DBA team.
Online DBA Service in Malaysia
In Malaysia, Dizbiztek has established itself as a trusted provider of online DBA services. Our team of experienced DBAs is proficient in handling a variety of database management systems, including Oracle, SQL Server, MySQL, and more. We offer a range of services, from installation and configuration to performance tuning and disaster recovery. By leveraging our online DBA service in Malaysia, businesses can ensure their databases are secure, reliable, and optimized for performance.
Remote DBA Support Services in Indonesia
Indonesia's vibrant business landscape demands robust database management solutions. Dizbiztek’s remote DBA support services in Indonesia are designed to meet these demands. Our team provides proactive monitoring, regular maintenance, and quick resolution of any database issues. This ensures that businesses can focus on their core operations while we take care of their database needs. Our remote DBA support services in Indonesia are tailored to meet the unique challenges faced by businesses in this region, providing them with the peace of mind that their data is in expert hands.
Why Choose Dizbiztek?
Expertise and Experience: Our team comprises highly skilled DBAs with extensive experience in managing complex database environments. Proactive Monitoring: We use advanced monitoring tools to detect and resolve issues before they impact your business. Customized Solutions: We understand that every business is unique, and we tailor our services to meet your specific needs. 24/7 Support: Our remote DBA support services are available round the clock, ensuring your databases are always monitored and managed.
Conclusion
In today’s data-driven world, effective database management is critical. Dizbiztek’s DBA support services in Malaysia and Indonesia provide businesses with the expertise and reliability they need to manage their databases efficiently. Whether you need remote DBA support or online DBA services, our team is here to ensure your database systems are optimized, secure, and always available. Partner with Dizbiztek and experience the peace of mind that comes with knowing your data is in capable hands.
#dba support services#dba support service in malaysia#dba support services in indonesia#dba service provider
0 notes
Text
Upcoming Webinars About SQL Server Monitoring
Learn about the benefits of #SQLServer #database #monitoring with our new webinars in partnership with @SolarWinds. Join us for technical showcases and more. #Microsoft #DBA #SqlDBA #SolarWinds #SQLSentry #Webinar #MadeiraData
Thanks to our productive partnership with SolarWinds as part of our Managed Remote DBA Service, we’ve set up two new webinars in our Data Platform Meetup: More Than Downtime: Elevating Your Business with Database MonitoringTUE, JAN 16, 2024, 11:00 AM IST Target audience: C-level executives (including CTOs and CIOs) wanting to learn about the benefits of SQL Server database monitoring, and…

View On WordPress
0 notes
Text
Compelling Reasons to Consider SQL Server DBA Services with Remote Options
Compelling Reasons to Consider SQL Server DBA Services with Remote Options
For businesses aiming to maintain their SQL Server databases optimally, the inherent value of specialized SQL Server DBA services becomes palpable. Often, possessing an in-depth SQL Server DBA skill set isn't an intrinsic organizational strength. Enter the solution: the potential of harnessing a remote DBA service. When mulling over the decision to outsource SQL server management, many organizations tend to weigh costs foremost. However, here are 9 compelling reasons to weigh the strategic advantages of SQL Server DBA services with remote capabilities: 1. One: Cost-Efficiency in SQL Server DBA Services Remote DBA service costs often tally between 25% to 50% less than maintaining an in-house DBA, as highlighted by Forrester Consulting. 2. Two: Elevated Database Administration Quality Numerous enterprises utilizing SQL Server DBA services note an enhanced capacity to honor service level agreements (SLAs). Additionally, they've reported marked improvement in service quality, as perceived by users. 3. Three: Business-Centric Focus Tapping into a remote SQL Server DBA service enables firms to centralize their attention on primary business objectives and strategies. This shift liberates both technical and managerial bandwidth that was previously dedicated to database management. 4. Four: Empowerment of In-House Resources Leveraging SQL Server DBA services externally allows the in-house IT brigade to pivot away from routine tasks and address unique challenges. This amplifies organizational agility, productivity, and, implicitly, team morale. Furthermore, many SQL Server DBA services extend support beyond standard business hours, enhancing DBA accessibility. 5. Five: Reservoir of Expertise A standout attribute of remote DBA service providers is their roster of seasoned DBAs. The pooled expertise and experience of these teams typically overshadow that of a singular in-house DBA. This collaborative approach often crystallizes into optimal solutions for clientele, ensuring on-tap specialized guidance. 6. Six: Strengthened Database Security A blend of automation and continuous monitoring, underpinned by the robust expertise of a remote SQL Server DBA team, fortifies database security. The added layer of proficiency means that these remote DBA services will adeptly handle tasks such as upgrades, patching, and routine maintenance, mitigating vulnerabilities and ensuring data sanctity.

7. Seven: Bolstered Business Continuity Database management plays a pivotal role in ensuring minor system glitches don't magnify into major disruptions. The vigilant oversight provided by SQL Server DBA services, especially with remote monitoring, serves as a proactive shield against such anomalies. 8. Eight: Preservation of Organizational Insight The departure of a pivotal IT personnel, such as a DBA, can erode a significant chunk of institutional expertise. Engaging with a remote DBA service ensures consistent, best-practice handling of your digital ecosystem, minimizing potential hiccups when transitioning personnel. 9. Nine: Pristine Data Integrity Engaging with SQL Server DBA services, especially those offering remote capabilities, often unlocks avenues for data cleansing, facilitating the elimination of redundant or flawed data. This exercise enhances data quality and robustness, serving as a sturdy foundation for informed business decisions. For over two and a half decades, DB Serv has been an industry beacon, offering premier on-site and remote DBA services for SQL Server and other database infrastructures. With our team of certified maestros, we mold our services to fit your needs seamlessly, ranging from handling routine responsibilities to navigating intricate challenges. Engage with DB Serv to elucidate your SQL Server DBA requirements and explore the transformative potential of our remote DBA service. Read the full article
0 notes
Video
youtube
Benefits of Hiring Remote SQL DBA
Contact SQLDBA Experts today to learn about our remote SQL DBA services and start achieving increased performance, and availability, and enjoy peace of mind knowing that your database is in expert hands. Our remote DBA services cover all aspects of the database including performance tuning, backups, disaster recovery, security, and more.
0 notes
Photo

The Farber Consulting Group has been providing Remote Database Administrator Services since its founding in 1992, and we have developers with over 30 years of experience, having worked on projects with Johnson and Johnson, Avis Car Rental, and Dassault Aircraft Industries.
0 notes
Text
#SQL Server Database Services#remote database services provide#database managed services#dba support and consulting
0 notes
Text
Migrate Your SQL Server Database to Amazon RDS
Amazon RDS is a web service that provides cloud database functionality for developers looking for a cost-effective and simple way to manage databases. If you’re looking to migrate your existing SQL database to RDS, this is the guide for you. RDS offers six database engines: 1. Amazon Aurora 2. Microsoft SQL Server 3. Oracle 4. PostgreSQL 5. MYSQL 6. MariaDB With RDS, there is no need for you to buy any other rack and stack hardware or install any software.The complexity of moving your existing Microsoft SQL Server to Amazon RDS is mostly determined by the size of your database and the types of database objects which you are transferring. For example, migrating a database which has data sets on the order of gigabytes along with stored triggers and procedures is going to be more complex than migrating a modest database with only few megabytes of test data and no stored procedures or triggers. Why You Might Consider Migrating Your SQL Database to Amazon RDS RDS allows developers to set up database instances in the cloud. Developers are relieved of the complexity of managing and maintenance of the database. Instead, they can focus on developing successful products. There’s one issue, however: There is no file system access. Though this is usually not a huge problem, it becomes a concern if you are trying to restore or create an SQL Server backup (.bak) file. This may sound like a daunting task, but it is in fact quite easy. In this post, we have tried to provide you with some easy steps to migrate your SQL Server database to Amazon RDS: 1. The first step would be to take a snapshot of the source RDS instance. 2. Secondly, you will have to disable automatic backups on the origin RDS instance. 3. Now, create your target database by disabling all foreign key constraints and triggers. 4. Import all the logins into the destination database. 5. The next step is creating the schema DDL with the help of the Generate and Publish Scripts Wizard in SSMS. 6. Next, execute the SQL commands on your target DBA to create your schema. 7. You can use either the bulk copy command (cp) or the Import/Export Wizard in SSMS to migrate your data from the origin database to your target database. Migrate Your SQL Server Database to Amazon RDS 8. Clean up the target database by re-enabling the foreign key constraints and triggers. 9. Again re-enable the automatic backups on the source RDS instance. Thankfully, after experimenting with this process many times, we found a better solution not documented in the AWS documentation. SQL Azure Migration Wizard To save time and avoid errors, we have discovered a new and better solution called the SQL Azure Migration Wizard. With SQL Azure Migration Wizard, the process of migrating databases (or anything including views/tablse/stored procedures) in, out, or between RDS instances is much easier and faster. To migrate your SQL database to Amazon RDS using SQL Azure Migration Wizard, follow these easy steps. Step1: Download the SQLAzureMW Tool Download SQL Azure Migration Wizard on CodePlex. Next, you need to extract the SQLAzureMW.exe file. You can utilize SQL Server Management Studio for connecting your local SQL server and Amazon Web Service RDS instance. But, before doing all this, make sure that you have a good connection to these two servers. Step 2: Begin the Migration Double click on the SQLAzureMW.exe file. A page will appear on your screen and what you now need to do is to select Database as an option under the Analyze/Migrate category. Once you do this, click on the Next button. Step 3: Source Database Tasks Now enter your Source SQL Server Database connection details and click on the Connect button. Choose the source database and click on the button that says ‘Next.’ Then select an option named as ‘Script all database objects’.This option can enable to do the complete migration of the database. But if you don’t want to migrate entire database then you select an option that says ‘Select specific database objects.’ Step 4: Create Scripts Create scripts for all selected SQL server objects. You should save the script on local hard drive and the move ahead by hitting a click on a button ‘Next’. Step 5: Destination Database Process Now you have created a script of your database. You will now be required to enter your RDS SQL Server connection credentials and then connect it. Step 6: Select the Target Database Choose the target database that you would like to migrate. If you have not created any database earlier, then create a new one using Create Database option and go next. Be sure to do a quick check to confirm if there are any errors. Step 7: The Grand Finale You can now verify your SQL Server Management Studio and check all the migrated data. As you can see, SQL Azure Migration Wizard saves a lot of time. You will have to modify settings in your corporate firewall if your database is on-premises. In case your database is already hosted on Amazon Web Services, you can also add an entry to your instance’s security group. Next, what you have to do is simple: launch and prepare an Amazon RDS instance running SQL. Then restore the database from the SQL dump and take note of the current log file name. Now you will use the database dump to start the RDS instance. Once the RDS instance is initialized, you will be required to run the replication stored procedures that are supplied as part of the release to configure the RDS instance. Once your RDS instance matches any changes that have taken place, the application configuration can be modified to use it in preference to the existing version. Summary Thus sums up the process on how to migrate a SQL Server database to Amazon RDS. The process of data migration is not a very complicated process but a very easy one indeed. We hope that this post was useful enough in helping all those who want to migrate their SQL Server Database to Amazon RDS.
#database Management services provider#sql server dba service providers#DBA service providers#remote DBA services providers
0 notes
Text
Farber Consulting Group Inc. has been offering Remote Database Administrator Services since its establishment in 1992. Our developers, with over 30 years of experience, have contributed to projects for prominent clients such as Johnson & Johnson, Avis Car Rental, and Dassault Aircraft Industries.
0 notes
Text

Your Trusted Partner for SQL Server Remote DBA Support: RalanTech https://www.ralantech.com/sqlserver-database-support/ Access expert SQL Server Remote DBA support with RalanTech. Our skilled team ensures seamless database management, optimization, and troubleshooting, offering round-the-clock assistance to keep your systems running smoothly and securely. Unlock the full potential of your SQL Server infrastructure.
1 note
·
View note
Text
Which Is The Best PostgreSQL GUI? 2021 Comparison
PostgreSQL graphical user interface (GUI) tools help open source database users to manage, manipulate, and visualize their data. In this post, we discuss the top 6 GUI tools for administering your PostgreSQL hosting deployments. PostgreSQL is the fourth most popular database management system in the world, and heavily used in all sizes of applications from small to large. The traditional method to work with databases is using the command-line interface (CLI) tool, however, this interface presents a number of issues:
It requires a big learning curve to get the best out of the DBMS.
Console display may not be something of your liking, and it only gives very little information at a time.
It is difficult to browse databases and tables, check indexes, and monitor databases through the console.
Many still prefer CLIs over GUIs, but this set is ever so shrinking. I believe anyone who comes into programming after 2010 will tell you GUI tools increase their productivity over a CLI solution.
Why Use a GUI Tool?
Now that we understand the issues users face with the CLI, let’s take a look at the advantages of using a PostgreSQL GUI:
Shortcut keys make it easier to use, and much easier to learn for new users.
Offers great visualization to help you interpret your data.
You can remotely access and navigate another database server.
The window-based interface makes it much easier to manage your PostgreSQL data.
Easier access to files, features, and the operating system.
So, bottom line, GUI tools make PostgreSQL developers’ lives easier.
Top PostgreSQL GUI Tools
Today I will tell you about the 6 best PostgreSQL GUI tools. If you want a quick overview of this article, feel free to check out our infographic at the end of this post. Let’s start with the first and most popular one.
1. pgAdmin
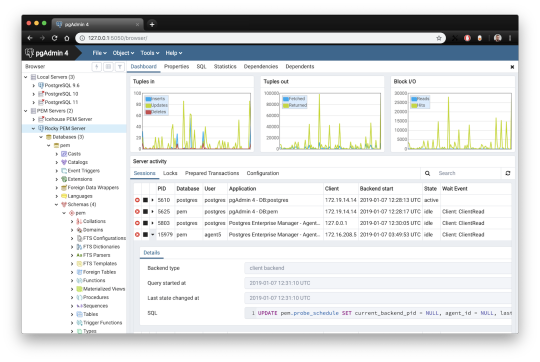
pgAdmin is the de facto GUI tool for PostgreSQL, and the first tool anyone would use for PostgreSQL. It supports all PostgreSQL operations and features while being free and open source. pgAdmin is used by both novice and seasoned DBAs and developers for database administration.
Here are some of the top reasons why PostgreSQL users love pgAdmin:
Create, view and edit on all common PostgreSQL objects.
Offers a graphical query planning tool with color syntax highlighting.
The dashboard lets you monitor server activities such as database locks, connected sessions, and prepared transactions.
Since pgAdmin is a web application, you can deploy it on any server and access it remotely.
pgAdmin UI consists of detachable panels that you can arrange according to your likings.
Provides a procedural language debugger to help you debug your code.
pgAdmin has a portable version which can help you easily move your data between machines.
There are several cons of pgAdmin that users have generally complained about:
The UI is slow and non-intuitive compared to paid GUI tools.
pgAdmin uses too many resources.
pgAdmin can be used on Windows, Linux, and Mac OS. We listed it first as it’s the most used GUI tool for PostgreSQL, and the only native PostgreSQL GUI tool in our list. As it’s dedicated exclusively to PostgreSQL, you can expect it to update with the latest features of each version. pgAdmin can be downloaded from their official website.
pgAdmin Pricing: Free (open source)
2. DBeaver

DBeaver is a major cross-platform GUI tool for PostgreSQL that both developers and database administrators love. DBeaver is not a native GUI tool for PostgreSQL, as it supports all the popular databases like MySQL, MariaDB, Sybase, SQLite, Oracle, SQL Server, DB2, MS Access, Firebird, Teradata, Apache Hive, Phoenix, Presto, and Derby – any database which has a JDBC driver (over 80 databases!).
Here are some of the top DBeaver GUI features for PostgreSQL:
Visual Query builder helps you to construct complex SQL queries without actual knowledge of SQL.
It has one of the best editors – multiple data views are available to support a variety of user needs.
Convenient navigation among data.
In DBeaver, you can generate fake data that looks like real data allowing you to test your systems.
Full-text data search against all chosen tables/views with search results shown as filtered tables/views.
Metadata search among rows in database system tables.
Import and export data with many file formats such as CSV, HTML, XML, JSON, XLS, XLSX.
Provides advanced security for your databases by storing passwords in secured storage protected by a master password.
Automatically generated ER diagrams for a database/schema.
Enterprise Edition provides a special online support system.
One of the cons of DBeaver is it may be slow when dealing with large data sets compared to some expensive GUI tools like Navicat and DataGrip.
You can run DBeaver on Windows, Linux, and macOS, and easily connect DBeaver PostgreSQL with or without SSL. It has a free open-source edition as well an enterprise edition. You can buy the standard license for enterprise edition at $199, or by subscription at $19/month. The free version is good enough for most companies, as many of the DBeaver users will tell you the free edition is better than pgAdmin.
DBeaver Pricing
: Free community, $199 standard license
3. OmniDB
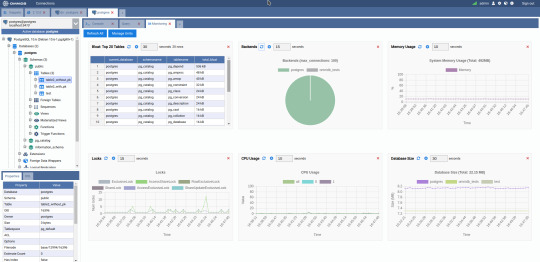
The next PostgreSQL GUI we’re going to review is OmniDB. OmniDB lets you add, edit, and manage data and all other necessary features in a unified workspace. Although OmniDB supports other database systems like MySQL, Oracle, and MariaDB, their primary target is PostgreSQL. This open source tool is mainly sponsored by 2ndQuadrant. OmniDB supports all three major platforms, namely Windows, Linux, and Mac OS X.
There are many reasons why you should use OmniDB for your Postgres developments:
You can easily configure it by adding and removing connections, and leverage encrypted connections when remote connections are necessary.
Smart SQL editor helps you to write SQL codes through autocomplete and syntax highlighting features.
Add-on support available for debugging capabilities to PostgreSQL functions and procedures.
You can monitor the dashboard from customizable charts that show real-time information about your database.
Query plan visualization helps you find bottlenecks in your SQL queries.
It allows access from multiple computers with encrypted personal information.
Developers can add and share new features via plugins.
There are a couple of cons with OmniDB:
OmniDB lacks community support in comparison to pgAdmin and DBeaver. So, you might find it difficult to learn this tool, and could feel a bit alone when you face an issue.
It doesn’t have as many features as paid GUI tools like Navicat and DataGrip.
OmniDB users have favorable opinions about it, and you can download OmniDB for PostgreSQL from here.
OmniDB Pricing: Free (open source)
4. DataGrip

DataGrip is a cross-platform integrated development environment (IDE) that supports multiple database environments. The most important thing to note about DataGrip is that it’s developed by JetBrains, one of the leading brands for developing IDEs. If you have ever used PhpStorm, IntelliJ IDEA, PyCharm, WebStorm, you won’t need an introduction on how good JetBrains IDEs are.
There are many exciting features to like in the DataGrip PostgreSQL GUI:
The context-sensitive and schema-aware auto-complete feature suggests more relevant code completions.
It has a beautiful and customizable UI along with an intelligent query console that keeps track of all your activities so you won’t lose your work. Moreover, you can easily add, remove, edit, and clone data rows with its powerful editor.
There are many ways to navigate schema between tables, views, and procedures.
It can immediately detect bugs in your code and suggest the best options to fix them.
It has an advanced refactoring process – when you rename a variable or an object, it can resolve all references automatically.
DataGrip is not just a GUI tool for PostgreSQL, but a full-featured IDE that has features like version control systems.
There are a few cons in DataGrip:
The obvious issue is that it’s not native to PostgreSQL, so it lacks PostgreSQL-specific features. For example, it is not easy to debug errors as not all are able to be shown.
Not only DataGrip, but most JetBrains IDEs have a big learning curve making it a bit overwhelming for beginner developers.
It consumes a lot of resources, like RAM, from your system.
DataGrip supports a tremendous list of database management systems, including SQL Server, MySQL, Oracle, SQLite, Azure Database, DB2, H2, MariaDB, Cassandra, HyperSQL, Apache Derby, and many more.
DataGrip supports all three major operating systems, Windows, Linux, and Mac OS. One of the downsides is that JetBrains products are comparatively costly. DataGrip has two different prices for organizations and individuals. DataGrip for Organizations will cost you $19.90/month, or $199 for the first year, $159 for the second year, and $119 for the third year onwards. The individual package will cost you $8.90/month, or $89 for the first year. You can test it out during the free 30 day trial period.
DataGrip Pricing
: $8.90/month to $199/year
5. Navicat

Navicat is an easy-to-use graphical tool that targets both beginner and experienced developers. It supports several database systems such as MySQL, PostgreSQL, and MongoDB. One of the special features of Navicat is its collaboration with cloud databases like Amazon Redshift, Amazon RDS, Amazon Aurora, Microsoft Azure, Google Cloud, Tencent Cloud, Alibaba Cloud, and Huawei Cloud.
Important features of Navicat for Postgres include:
It has a very intuitive and fast UI. You can easily create and edit SQL statements with its visual SQL builder, and the powerful code auto-completion saves you a lot of time and helps you avoid mistakes.
Navicat has a powerful data modeling tool for visualizing database structures, making changes, and designing entire schemas from scratch. You can manipulate almost any database object visually through diagrams.
Navicat can run scheduled jobs and notify you via email when the job is done running.
Navicat is capable of synchronizing different data sources and schemas.
Navicat has an add-on feature (Navicat Cloud) that offers project-based team collaboration.
It establishes secure connections through SSH tunneling and SSL ensuring every connection is secure, stable, and reliable.
You can import and export data to diverse formats like Excel, Access, CSV, and more.
Despite all the good features, there are a few cons that you need to consider before buying Navicat:
The license is locked to a single platform. You need to buy different licenses for PostgreSQL and MySQL. Considering its heavy price, this is a bit difficult for a small company or a freelancer.
It has many features that will take some time for a newbie to get going.
You can use Navicat in Windows, Linux, Mac OS, and iOS environments. The quality of Navicat is endorsed by its world-popular clients, including Apple, Oracle, Google, Microsoft, Facebook, Disney, and Adobe. Navicat comes in three editions called enterprise edition, standard edition, and non-commercial edition. Enterprise edition costs you $14.99/month up to $299 for a perpetual license, the standard edition is $9.99/month up to $199 for a perpetual license, and then the non-commercial edition costs $5.99/month up to $119 for its perpetual license. You can get full price details here, and download the Navicat trial version for 14 days from here.
Navicat Pricing
: $5.99/month up to $299/license
6. HeidiSQL
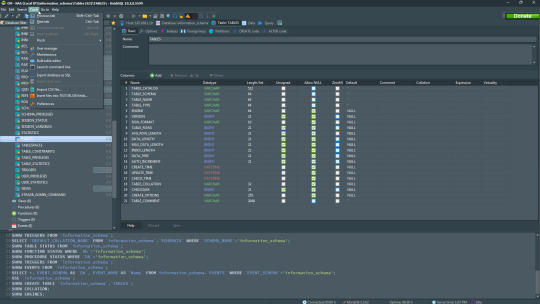
HeidiSQL is a new addition to our best PostgreSQL GUI tools list in 2021. It is a lightweight, free open source GUI that helps you manage tables, logs and users, edit data, views, procedures and scheduled events, and is continuously enhanced by the active group of contributors. HeidiSQL was initially developed for MySQL, and later added support for MS SQL Server, PostgreSQL, SQLite and MariaDB. Invented in 2002 by Ansgar Becker, HeidiSQL aims to be easy to learn and provide the simplest way to connect to a database, fire queries, and see what’s in a database.
Some of the advantages of HeidiSQL for PostgreSQL include:
Connects to multiple servers in one window.
Generates nice SQL-exports, and allows you to export from one server/database directly to another server/database.
Provides a comfortable grid to browse and edit table data, and perform bulk table edits such as move to database, change engine or ollation.
You can write queries with customizable syntax-highlighting and code-completion.
It has an active community helping to support other users and GUI improvements.
Allows you to find specific text in all tables of all databases on a single server, and optimize repair tables in a batch manner.
Provides a dialog for quick grid/data exports to Excel, HTML, JSON, PHP, even LaTeX.
There are a few cons to HeidiSQL:
Does not offer a procedural language debugger to help you debug your code.
Built for Windows, and currently only supports Windows (which is not a con for our Windors readers!)
HeidiSQL does have a lot of bugs, but the author is very attentive and active in addressing issues.
If HeidiSQL is right for you, you can download it here and follow updates on their GitHub page.
HeidiSQL Pricing: Free (open source)
Conclusion
Let’s summarize our top PostgreSQL GUI comparison. Almost everyone starts PostgreSQL with pgAdmin. It has great community support, and there are a lot of resources to help you if you face an issue. Usually, pgAdmin satisfies the needs of many developers to a great extent and thus, most developers do not look for other GUI tools. That’s why pgAdmin remains to be the most popular GUI tool.
If you are looking for an open source solution that has a better UI and visual editor, then DBeaver and OmniDB are great solutions for you. For users looking for a free lightweight GUI that supports multiple database types, HeidiSQL may be right for you. If you are looking for more features than what’s provided by an open source tool, and you’re ready to pay a good price for it, then Navicat and DataGrip are the best GUI products on the market.
Ready for some PostgreSQL automation?
See how you can get your time back with fully managed PostgreSQL hosting. Pricing starts at just $10/month.
While I believe one of these tools should surely support your requirements, there are other popular GUI tools for PostgreSQL that you might like, including Valentina Studio, Adminer, DB visualizer, and SQL workbench. I hope this article will help you decide which GUI tool suits your needs.
Which Is The Best PostgreSQL GUI? 2019 Comparison
Here are the top PostgreSQL GUI tools covered in our previous 2019 post:
pgAdmin
DBeaver
Navicat
DataGrip
OmniDB
Original source: ScaleGrid Blog
3 notes
·
View notes
Text
MySQL NDB Cluster Backup & Restore In An Easy Way
In this post, we will see, how easily user can take NDB Cluster backup and then restore it. NDB cluster supports online backups, which are taken while transactions are modifying the data being backed up. In NDB Cluster, each backup captures all of the table content stored in the cluster. User can take backup in the following states: When the cluster is live and fully operational When the cluster is live, but in a degraded state: Some data nodes are down Some data nodes are restarting During read and write transactions Users can restore backups in the following cluster environments: Restore to the same physical cluster Restore into a different physical cluster Restore into a different configuration cluster i.e. backup taken from a 4 nodes cluster and restore into 8 data nodes cluster Restore into a different cluster version Backups can be restored flexibly: Restore can be run locally or remotely w.r.t the data nodes Restore can be run in parallel across data nodes Can restore a partial set of the tables captured in the backup Use cases of Backup & Restore: Disaster recovery - setting up a cluster from scratch Setup NDB Cluster asynchronous replication Recovery from user/DBA accidents like dropping of a table/database/schema changes etc During NDB Cluster software upgrade Limitations: Schemas and table data for tables stored using the NDB Cluster engine are backed up Views, stored procedure, triggers and tables/schemas from other storage engine like Innodb are not backed up. Users need to use other MySQL backup tools like mysqldump/mysqlpump etc to capture these Support for only full backup. No incremental or partial backup supported. NDB Cluster Backup & Restore concept in brief: In NDB Cluster, tables are horizontally partitioned into a set of partitions, which are then distributed across the data nodes in the cluster. The data nodes are logically grouped into nodegroups. All data nodes in a nodegroup (up to four) contain the same sets of partitions, kept in sync at all times. Different nodegroups contain different sets of partitions. At any time, each partition is logically owned by just one node in one nodegroup, which is responsible for including it in a backup.When a backup starts, each data node scans the set of table partitions it owns, writing their records to its local disk. At the same time, a log of ongoing changes is also recorded. The scanning and logging are synchronised so that the backup is a snapshot at a single point in time. Data is distributed across all the data nodes, and the backup occurs in parallel across all nodes, so that all data in the cluster is captured. At the end of a backup, each data node has recorded a set of files (*.data, *.ctl, *.log), each containing a subset of cluster data.During restore, each set of files will be restored [in parallel] to bring the cluster to the snapshot state. The CTL file is used to restore the schema, the DATA file is used to restore most of the data, and the LOG file is used to ensure snapshot consistency.Let’s look at NDB Cluster backup and restore feature through an example:To demonstrate this feature, let’s create a NDB Cluster with below environment.NDB Cluster 8.0.22 version 2 Management servers 4 Data nodes servers 2 Mysqld servers 6 API nodes NoOfReplicas = 2 If you are wondering how to setup a NDB Cluster, then please look into my previous blog here. Step 1:Before we start the cluster, let’s modify the cluster config file (config.ini) for backup. When backup starts, it create 3 files (BACKUP-backupid.nodeid.Data, BACKUP-backupid.nodeid.ctl, BACKUP-backupid.nodeid.log) under a directory named BACKUP. By default, this directory BACKUP created under each data node data directory. It is advisable to create this BACKUP directory outside the data directory. This can be done by adding a config variable ‘BackupDataDir’ to cluster configuration file i.e. config.iniIn the below example, I have assigned a path to ‘BackupDataDir‘ in config.ini:BackupDataDir=/export/home/saroj/mysql-tree/8.0.22/ndbd/node1/data4Step 2: Let’s look at the cluster from the management client (bin/ndb_mgm): Step 3: As cluster is up and running so let’s create a database, a table and do some transactions on it. Let’s insert rows into table ‘t1’ either thru sql or thru any tools. Let’s continue the rows insertion thru sql to have a significant amount of datas in the cluster. Let’s check the rows count from table ‘t1’. From the below image, we can see that table 't1' has ‘396120’ rows in it. Step 4: Now issue a backup command from the management client (bin/ndb_mgm) while some transactions on the table ‘t1’ was going on. We will delete rows from table ‘t1’ and issue a backup command in parallel. While delete ops is going on, issue a backup command from the management client: Let’s check the new row count from table ‘t1’ after all the delete ops finished. From the below image, we can see that now the table ‘t1’ has ‘306120’ rows. Let’s look at the files backup created. As we have assigned a path to backup files so let’s discuss about these files in brief. From the above image, we can see that, for each backup, one backup directory is created (BACKUP-backupid) and under each backup directory, 3 files are created. These are:BACKUP-backupid-0.node_id.Data (BACKUP-1-0.1.Data):The above file contains most of the data stored in the table fragments owned by this node. In the above example, 1 is the backupid, 0 is a hardcoded value for future use. 1 is node_id of the data node 1. BACKUP-backupid.node_id.ctl (BACKUP-1.1.ctl): The above file contains table meta data i.e. table definitions, index definitions.BACKUP-backupid.node_id.log (BACKUP-1.1.log):This file contains all the row changes that happened to the tables while the backup was in progress. These logs will execute during restore either as roll forward or roll back depends on whether the backup is snapshot start or snapshot end. Note:User can restore from anywhere i.e. doesn’t have to be from any particular data node. ndb_restore is an NDB API client program, so can run anywhere that can access the cluster. Step 5: Upon successfully completion of a backup, the output will looks like below: From the above image, Node 1 is the master node who initiate the backup, node 254 is the management node on which the START BACKUP command was issued, and Backup 1 is the 1st backup taken. #LogRecords ‘30000’ indicate that while backup was in progress some transaction was also running on the same table. #Records shows the number of records captured across the cluster. User can see the backup status also from the “cluster log” as shown below:2021-01-12 15:00:04 [MgmtSrvr] INFO -- Node 1: Backup 1 started from node 2542021-01-12 15:01:18 [MgmtSrvr] INFO -- Node 1: Backup 1 started from node 254 completed. StartGCP: 818 StopGCP: 855 #Records: 306967 #LogRecords: 30000 Data: 5950841732 bytes Log: 720032 bytesSo this concludes our NDB Cluster backup procedure. Step 6:We will now try to restore the data from the backup taken above. Let’s shutdown the cluster, cleanup all the files except the backup files and then start the cluster with initial (with no data).Let’s restore the backup to a different cluster. From the below image, we can see that data node Id’s are different from the cluster where backup was taken. Now let’s see if our database ‘test1’ is exist in the cluster or not after initial start. From the above image, we can see that, database ‘test1’ is not present. Now let’s start our restore process from the backup image #1 (BACKUP-1). The NDB restore works in this flow: It first restore the meta data from the *.ctl file so that all the tables/indexes can be recreated in the database. Then it restore the data files (*.Data) i.e. inserts all the records into the tables in the database. At the end, it executes all the transaction logs (*.log) rollback or roll forward to make the database consistent. Since restore will fail while restoring unique and foreign key constraints that are taken from the backup image so user must disable the index at the beginning and once restore is finished, again user need to rebuild the index. Step 7:Let’s start the restoration of meta data.Meta data restore, disable index and data restore can execute at one go, or can be done in serial. This restore command can be issued from any data node or can be from a non-data node as well.In this example, I am issuing meta data restore and disable index from Data Node 1 only for once. Upon successful completion, I will issue the data restore.Data Node 1: shell> bin/ndb_restore -n node_id -b backup_id -m --disable-indexes --ndb-connectstring=cluster-test01:1186,cluster-test02:1186 –backup_path=/path/to/backup directory -n: node id of the data node from where backup was taken. Do not confuse with the data node id of the new cluster.-b: backup id (we have taken backup id as ‘1’)-m: meta data restoration (recreate table/indexes)--disable-indexes: disable restoration of indexes during restore of data--ndb-connectstring (-c): Connection to the management nodes of the cluster.--backup_path: path to the backup directory where backup files exist. The results of above meta restore from data node 1 is shown below: Let’s start the data restore on the Data Node 1. Data Node 1:shell> bin/ndb_restore -n node_id -b backup_id -r --ndb-connectstring=cluster-test01:1186,cluster-test02:1186 –backup_path=/path/to/backup directory Below, I am trying to capture the logs from the data restore run results as it started and then at the end. From the above image, we can see that restore went successful. Restore skips restoration of system table data. System tables referred to here are tables used internally by NDB Cluster. Thus these tables should not be overwritten by the data from a backup. Backup data is restored in fragments, so whenever a fragment is found, ndb_restore checks if it belongs to a system table. If it does belong to a system table, ndb_restore decides to skip restoring it and prints a 'Skipping fragment' log message.Let’s finish all the remaining data restore from the other data nodes. These data restore can be run in parallel to minimise the restore time. Here, we don’t have to pass -m, --disable-indexes again to restore command as we need to do it only once. With the first restore completion, it has already created tables, indexes etc so no need to recreate it again and will also fail. Once all the data are restored into the table(s), we will enable the indexes and constraints again using the –rebuild-indexes option. Note that rebuilding the indexes and constraints like this ensures that they are fully consistent when the restore completes.Data Node 2:shell> bin/ndb_restore -n node_id -b backup_id -r --ndb-connectstring=cluster-test01:1186,cluster-test02:1186 –backup_path=/path/to/backup directoryData Node 3:shell> bin/ndb_restore -n node_id -b backup_id -r --ndb-connectstring=cluster-test01:1186,cluster-test02:1186 –backup_path=/path/to/backup directoryData Node 4:shell> bin/ndb_restore -n node_id -b backup_id -r --ndb-connectstring=cluster-test01:1186,cluster-test02:1186 –backup_path=/path/to/backup directory Ndb restore (ndb_restore) is an API, it needs API slots to connect to cluster. Since we have initiated 3 ndb_restore programme in parallel from Data node ID 4, 5 and 6 so we can see from the below image that ndb_restore took API ID: 47, 48 and 49. Let’s see the results from the remaining data nodes. Since all the ndb_restore API finished successfully, we can see that the API ID that it had taken to connect the cluster has been released. The last step is to rebuild the index. This can also done from any data nodes or from any non-data nodes but only once.Data Node 1:shell> bin/ndb_restore -n node_id -b backup_id --rebuild-indexes --ndb-connectstring=cluster-test01:1186,cluster-test02:1186 –backup_path=/path/to/backup directory--rebuild-indexes: It enables rebuilding of ordered indexes and foreign key constraints. Step 8:So we have finished our restoration steps. Let’s check the database, table, rows count in table etc .. So database ‘test1’ is already created. Now we can see that table ‘t1’ has been created and the row count#306120 which is also matching with our backup image (look at Step# 4).So this concludes our NDB Cluster backup and restore feature. There are many more options user can pass to both backup (START BACKUP) and restore (ndb_restore) programme based on the requirements. In the above example, I have selected the basic minimum options user might need for backup and restore. For more information on these options, please refer to NDB Cluster reference manual here. https://clustertesting.blogspot.com/2021/01/mysql-ndb-cluster-backup-restore-in.html
1 note
·
View note
Text
Sql Tools For Mac

Download SQL Server Data Tools (SSDT) for Visual Studio.; 6 minutes to read +32; In this article. APPLIES TO: SQL Server Azure SQL Database Azure Synapse Analytics (SQL Data Warehouse) Parallel Data Warehouse SQL Server Data Tools (SSDT) is a modern development tool for building SQL Server relational databases, databases in Azure SQL, Analysis Services (AS) data models, Integration. SQLite's code is in the public domain, which makes it free for commercial or private use. I use MySQL GUI clients mostly for SQL programming, and I often keep SQL in files. My current favorites are: DBVisualizer Not free but I now use. Oracle SQL Developer is a free, development environment that simplifies the management of Oracle Database in both traditional and Cloud deployments. It offers development of your PL/SQL applications, query tools, a DBA console, a reports interface, and more.
Full MySQL Support
Sequel Pro is a fast, easy-to-use Mac database management application for working with MySQL databases.
Perfect Web Development Companion
Whether you are a Mac Web Developer, Programmer or Software Developer your workflow will be streamlined with a native Mac OS X Application!
Flexible Connectivity
Sequel Pro gives you direct access to your MySQL Databases on local and remote servers.
Easy Installation
Simply download, and connect to your database. Use these guides to get started:
Get Involved
Sequel Pro is open source and built by people like you. We’d love your input – whether you’ve found a bug, have a suggestion or want to contribute some code.
Get Started
New to Sequel Pro and need some help getting started? No problem.
-->
APPLIES TO: SQL Server Azure SQL Database Azure Synapse Analytics (SQL Data Warehouse) Parallel Data Warehouse
SQL Server Data Tools (SSDT) is a modern development tool for building SQL Server relational databases, databases in Azure SQL, Analysis Services (AS) data models, Integration Services (IS) packages, and Reporting Services (RS) reports. With SSDT, you can design and deploy any SQL Server content type with the same ease as you would develop an application in Visual Studio.
SSDT for Visual Studio 2019
Changes in SSDT for Visual Studio 2019
The core SSDT functionality to create database projects has remained integral to Visual Studio.
With Visual Studio 2019, the required functionality to enable Analysis Services, Integration Services, and Reporting Services projects has moved into the respective Visual Studio (VSIX) extensions only.
Note
There's no SSDT standalone installer for Visual Studio 2019.
Install SSDT with Visual Studio 2019
If Visual Studio 2019 is already installed, you can edit the list of workloads to include SSDT. If you don’t have Visual Studio 2019 installed, then you can download and install Visual Studio 2019 Community.
To modify the installed Visual Studio workloads to include SSDT, use the Visual Studio Installer.

Launch the Visual Studio Installer. In the Windows Start menu, you can search for 'installer'.
In the installer, select for the edition of Visual Studio that you want to add SSDT to, and then choose Modify.
Select SQL Server Data Tools under Data storage and processing in the list of workloads.

For Analysis Services, Integration Services, or Reporting Services projects, you can install the appropriate extensions from within Visual Studio with Extensions > Manage Extensions or from the Marketplace.
SSDT for Visual Studio 2017
Changes in SSDT for Visual Studio 2017
Sql Server Data Tools For Mac
Starting with Visual Studio 2017, the functionality of creating Database Projects has been integrated into the Visual Studio installation. There's no need to install the SSDT standalone installer for the core SSDT experience.
Now to create Analysis Services, Integration Services, or Reporting Services projects, you still need the SSDT standalone installer.
Install SSDT with Visual Studio 2017
To install SSDT during Visual Studio installation, select the Data storage and processing workload, and then select SQL Server Data Tools.
Sql Management Studio For Mac
If Visual Studio is already installed, use the Visual Studio Installer to modify the installed workloads to include SSDT.
Launch the Visual Studio Installer. In the Windows Start menu, you can search for 'installer'.
In the installer, select for the edition of Visual Studio that you want to add SSDT to, and then choose Modify.
Select SQL Server Data Tools under Data storage and processing in the list of workloads.
Install Analysis Services, Integration Services, and Reporting Services tools
To install Analysis Services, Integration Services, and Reporting Services project support, run the SSDT standalone installer.
The installer lists available Visual Studio instances to add SSDT tools. If Visual Studio isn't already installed, selecting Install a new SQL Server Data Tools instance installs SSDT with a minimal version of Visual Studio, but for the best experience, we recommend using SSDT with the latest version of Visual Studio.
SSDT for VS 2017 (standalone installer)
Important
Before installing SSDT for Visual Studio 2017 (15.9.6), uninstall Analysis Services Projects and Reporting Services Projects extensions if they are already installed, and close all VS instances.
Removed the inbox component Power Query Source for SQL Server 2017. Now we have announced Power Query Source for SQL Server 2017 & 2019 as out-of-box component, which can be downloaded here.
To design packages using Oracle and Teradata connectors and targeting an earlier version of SQL Server prior to SQL 2019, in addition to the Microsoft Oracle Connector for SQL 2019 and Microsoft Teradata Connector for SQL 2019, you need to also install the corresponding version of Microsoft Connector for Oracle and Teradata by Attunity.
Release Notes
For a complete list of changes, see Release notes for SQL Server Data Tools (SSDT).
System requirements
Microsoft Sql Tools For Mac
SSDT for Visual Studio 2017 has the same system requirements as Visual Studio.
Available Languages - SSDT for VS 2017
Sql Server Tools For Mac
This release of SSDT for VS 2017 can be installed in the following languages:
Considerations and limitations
You can’t install the community version offline
To upgrade SSDT, you need to follow the same path used to install SSDT. For example, if you added SSDT using the VSIX extensions, then you must upgrade via the VSIX extensions. If you installed SSDT via a separate install, then you need to upgrade using that method.
Offline install
To install SSDT when you’re not connected to the internet, follow the steps in this section. For more information, see Create a network installation of Visual Studio 2017.
First, complete the following steps while online:
Download the SSDT standalone installer.
Download vs_sql.exe.
While still online, execute one of the following commands to download all the files required for installing offline. Using the --layout option is the key, it downloads the actual files for the offline installation. Replace <filepath> with the actual layouts path to save the files.
For a specific language, pass the locale: vs_sql.exe --layout c:<filepath> --lang en-us (a single language is ~1 GB).
For all languages, omit the --lang argument: vs_sql.exe --layout c:<filepath> (all languages are ~3.9 GB).
After completing the previous steps, the following steps below can be done offline:
Run vs_setup.exe --NoWeb to install the VS2017 Shell and SQL Server Data Project.
From the layouts folder, run SSDT-Setup-ENU.exe /install and select SSIS/SSRS/SSAS.a. For an unattended installation, run SSDT-Setup-ENU.exe /INSTALLALL[:vsinstances] /passive.
For available options, run SSDT-Setup-ENU.exe /help
Note
If using a full version of Visual Studio 2017, create an offline folder for SSDT only, and run SSDT-Setup-ENU.exe from this newly created folder (don’t add SSDT to another Visual Studio 2017 offline layout). If you add the SSDT layout to an existing Visual Studio offline layout, the necessary runtime (.exe) components are not created there.
Supported SQL versions
Project TemplatesSQL Platforms SupportedRelational databasesSQL Server 2005* - SQL Server 2017 (use SSDT 17.x or SSDT for Visual Studio 2017 to connect to SQL Server on Linux) Azure SQL Database Azure Synapse Analytics (supports queries only; database projects aren't yet supported) * SQL Server 2005 support is deprecated, move to an officially supported SQL versionAnalysis Services models Reporting Services reportsSQL Server 2008 - SQL Server 2017Integration Services packagesSQL Server 2012 - SQL Server 2019
DacFx
SSDT for Visual Studio 2015 and 2017 both use DacFx 17.4.1: Download Data-Tier Application Framework (DacFx) 17.4.1.
Previous versions
Unix Tools For Mac
To download and install SSDT for Visual Studio 2015, or an older version of SSDT, see Previous releases of SQL Server Data Tools (SSDT and SSDT-BI).
See Also
Next steps
After installing SSDT, work through these tutorials to learn how to create databases, packages, data models, and reports using SSDT.
Get help
1 note
·
View note
Text
Universal remote Database Administration Service Could Solve Your Needs
The internationalization has taken place, and the outsourcing techniques and IT operation has become ubiquitous. The term outsourcing indicates a procedure through which the project could be relocated outside the boundary from the corporate culture. Generally the idea deals with a third-party service provider. In today's economy, the companies want to curtail cost, justify the operations and get competitive advantages. Many businesses are concentrating on management, hr, capital and the other solutions, and they emphasize on freelancing to have the maximum benefits from their very own business operation. Cloud Computing
The data source which provide a suitable safe-keeping facilities for the vast array of data help you store, search watch and manipulate information good business vision, mission along with goals. The basic job outline of a data base officer can be monitoring, backup, tackling and troubleshooting consistently. The truly great demand of the uptime and also the downtime of the dangers of the actual database make involve while using database outsourcing and the probable growth of remote database government has taken place.
The data bank administrators are dealing with all these factors in an implausible pressure. DBA is utilizing these people in more strategically. The global financial system and the business is modifying rapidly, and this trend is usually moving towards the Remote Data bank Administration to protect burnout, in addition to staff turnover of DBA, besides they concentrate on decline of the system weakness as well as increasing the productivity. When considering Oracle database assistance, it can come to our grasp that Oracle is one of the almost all stylish Relational Database Operations Systems, RDBMS. The Oracle is fully platform 3rd party, variable, secured, fast and also dependable for dealing with OLTP, On the web Transaction Processing techniques. It is a real enterprise solution.

Even so the Oracle database can be dangerous and all the operation may be stopped. It happens due to distinct causes including the failure in the storage media or the crime of the system. Generally the people have to have various corrective approaches to overcome this debacle in order to recover the Oracle databases. If this system does not retain, the users go for third-party Oracle database recovery software to solve the Oracle database.
Typically the Remote Database Administrators assist remotely. RDBA solves bothersome database issues involving using structural scale, programming and also security. The monthly provider includes remote database assistance for twenty four hours a day along with seven days a week. This support also includes a friction involving cost of a full time, the particular in house resource, the best remote control management services and the THE IDEA practices. The merits on the RDBA, Remote Data Bottom part Administrator can be the expert data source implementation, the reduced investment and ongoing spending, as well as the return of investment consisting of immediate and tangible go back.
The consideration of the distant DBA program can be the cost-effective as remote data bottom part administrator pacifies the risk and the on-shore support. Also you can have the dedicated senior DBA resources, immediate contact, keeping track of tools and analytics with the third parties, trailing the circumstances and daily proactive technique audits. Usually the agencies move towards remote Files base Administration to gain help of remote DBA. And this also monitors MS SQL, MySwl, Sybase, DB2, Enterprise DB and the all other Platforms. It may help emphasize on core skills, uphold the institutional reliability and decrease the computing price of the enterprise.
Auburn IT has developed a comprehensive services suite that gives customers complete peace of mind when it comes to their business. We offer remote monitoring and management, proactive maintenance, security, data backup, and first-rate tech support all within our managed IT service plans. These plans have no lock-in contracts and no minimums; we believe in the quality of our work and we believe you will be satisfied with the service we provide.
References Technology
1 note
·
View note