#SQL Server Remote DBA support
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
There were a total of 171.5 billion posts on Tumblr in 2019.
Text
Elevate Database Management with RalanTech SQL Server Remote DBA Support

https://www.ralantech.com/sqlserver-database-support/ Experience seamless database administration with RalanTech's expert SQL Server Remote DBA support. From performance optimization to maintenance, our dedicated team ensures your databases run smoothly, anytime, anywhere. Boost efficiency and reliability today with RalanTech.
1 note
·
View note
Text
In today's fast-paced business environment, staying ahead of the competition requires not just hard work, but smart strategies. One area where businesses can gain a significant strategic edge is in their data management. This is where remote DBA (Database Administrator) experts come into play, particularly those specializing in SQL Server consulting.
0 notes
Text
Ensuring Database Excellence: DBA Support Services by Dizbiztek in Malaysia and Indonesia

In the rapidly evolving digital landscape, maintaining a robust and efficient database system is crucial for business success. Dizbiztek, a leading DBA support agency, offers top-tier DBA support services tailored to meet the unique needs of businesses in Malaysia and Indonesia. With our expertise, your database systems will run smoothly, ensuring optimal performance and security.
Why DBA Support Services are Essential
Database management is a complex task that requires specialized knowledge and continuous monitoring. As businesses grow and data volumes increase, the challenges of managing databases become more pronounced. Here’s where DBA support services come into play. These services ensure your database systems are not only up and running but also optimized for performance and security. Whether it’s routine maintenance, emergency troubleshooting, or performance tuning, a reliable DBA support agency like Dizbiztek is essential.
Remote DBA Support: Flexibility and Efficiency
Dizbiztek offers comprehensive remote DBA support services, providing businesses with the flexibility and expertise they need without the overhead costs of maintaining an in-house team. Our remote DBA support ensures that your databases are monitored and managed round the clock, minimizing downtime and maximizing efficiency. This service is particularly beneficial for small and medium-sized enterprises that need expert DBA support but may not have the resources to maintain a full-time DBA team.
Online DBA Service in Malaysia
In Malaysia, Dizbiztek has established itself as a trusted provider of online DBA services. Our team of experienced DBAs is proficient in handling a variety of database management systems, including Oracle, SQL Server, MySQL, and more. We offer a range of services, from installation and configuration to performance tuning and disaster recovery. By leveraging our online DBA service in Malaysia, businesses can ensure their databases are secure, reliable, and optimized for performance.
Remote DBA Support Services in Indonesia
Indonesia's vibrant business landscape demands robust database management solutions. Dizbiztek’s remote DBA support services in Indonesia are designed to meet these demands. Our team provides proactive monitoring, regular maintenance, and quick resolution of any database issues. This ensures that businesses can focus on their core operations while we take care of their database needs. Our remote DBA support services in Indonesia are tailored to meet the unique challenges faced by businesses in this region, providing them with the peace of mind that their data is in expert hands.
Why Choose Dizbiztek?
Expertise and Experience: Our team comprises highly skilled DBAs with extensive experience in managing complex database environments. Proactive Monitoring: We use advanced monitoring tools to detect and resolve issues before they impact your business. Customized Solutions: We understand that every business is unique, and we tailor our services to meet your specific needs. 24/7 Support: Our remote DBA support services are available round the clock, ensuring your databases are always monitored and managed.
Conclusion
In today’s data-driven world, effective database management is critical. Dizbiztek’s DBA support services in Malaysia and Indonesia provide businesses with the expertise and reliability they need to manage their databases efficiently. Whether you need remote DBA support or online DBA services, our team is here to ensure your database systems are optimized, secure, and always available. Partner with Dizbiztek and experience the peace of mind that comes with knowing your data is in capable hands.
#dba support services#dba support service in malaysia#dba support services in indonesia#dba service provider
0 notes
Text
Compelling Reasons to Consider SQL Server DBA Services with Remote Options
Compelling Reasons to Consider SQL Server DBA Services with Remote Options
For businesses aiming to maintain their SQL Server databases optimally, the inherent value of specialized SQL Server DBA services becomes palpable. Often, possessing an in-depth SQL Server DBA skill set isn't an intrinsic organizational strength. Enter the solution: the potential of harnessing a remote DBA service. When mulling over the decision to outsource SQL server management, many organizations tend to weigh costs foremost. However, here are 9 compelling reasons to weigh the strategic advantages of SQL Server DBA services with remote capabilities: 1. One: Cost-Efficiency in SQL Server DBA Services Remote DBA service costs often tally between 25% to 50% less than maintaining an in-house DBA, as highlighted by Forrester Consulting. 2. Two: Elevated Database Administration Quality Numerous enterprises utilizing SQL Server DBA services note an enhanced capacity to honor service level agreements (SLAs). Additionally, they've reported marked improvement in service quality, as perceived by users. 3. Three: Business-Centric Focus Tapping into a remote SQL Server DBA service enables firms to centralize their attention on primary business objectives and strategies. This shift liberates both technical and managerial bandwidth that was previously dedicated to database management. 4. Four: Empowerment of In-House Resources Leveraging SQL Server DBA services externally allows the in-house IT brigade to pivot away from routine tasks and address unique challenges. This amplifies organizational agility, productivity, and, implicitly, team morale. Furthermore, many SQL Server DBA services extend support beyond standard business hours, enhancing DBA accessibility. 5. Five: Reservoir of Expertise A standout attribute of remote DBA service providers is their roster of seasoned DBAs. The pooled expertise and experience of these teams typically overshadow that of a singular in-house DBA. This collaborative approach often crystallizes into optimal solutions for clientele, ensuring on-tap specialized guidance. 6. Six: Strengthened Database Security A blend of automation and continuous monitoring, underpinned by the robust expertise of a remote SQL Server DBA team, fortifies database security. The added layer of proficiency means that these remote DBA services will adeptly handle tasks such as upgrades, patching, and routine maintenance, mitigating vulnerabilities and ensuring data sanctity.

7. Seven: Bolstered Business Continuity Database management plays a pivotal role in ensuring minor system glitches don't magnify into major disruptions. The vigilant oversight provided by SQL Server DBA services, especially with remote monitoring, serves as a proactive shield against such anomalies. 8. Eight: Preservation of Organizational Insight The departure of a pivotal IT personnel, such as a DBA, can erode a significant chunk of institutional expertise. Engaging with a remote DBA service ensures consistent, best-practice handling of your digital ecosystem, minimizing potential hiccups when transitioning personnel. 9. Nine: Pristine Data Integrity Engaging with SQL Server DBA services, especially those offering remote capabilities, often unlocks avenues for data cleansing, facilitating the elimination of redundant or flawed data. This exercise enhances data quality and robustness, serving as a sturdy foundation for informed business decisions. For over two and a half decades, DB Serv has been an industry beacon, offering premier on-site and remote DBA services for SQL Server and other database infrastructures. With our team of certified maestros, we mold our services to fit your needs seamlessly, ranging from handling routine responsibilities to navigating intricate challenges. Engage with DB Serv to elucidate your SQL Server DBA requirements and explore the transformative potential of our remote DBA service. Read the full article
0 notes
Text
Remote Database Support Services -Remote DBA Service - Datapatroltech
Datapatroltech offers the remote database support services to protect company data . Data Patrol’s remote DBA services team includes top expertise in Oracle DBA support, SQL server support, MySQL DBA support, and Postgres DBA support besides others.We have 14 years plus experience in Remote DBA give 24*7 monitoring

1 note
·
View note
Text
Benefits of Remote SQL DBA Services
SQLDBA Experts offers DBA and remote DBA support services without many complexities. Our team of Microsoft certified in SQL ensures services are delivered in every field of remote DBA along with maintaining business essential files and information. For more information, get in touch with us today!
#remote sql dba services#remote sql dba#remote dba support#sql server databases#remote dba services#sql support services#SQL DBA services#database services#database administration services#database assessments service#SQL Database support
0 notes
Text
#SQL Server Database Services#remote database services provide#database managed services#dba support and consulting
0 notes
Text
Which Is The Best PostgreSQL GUI? 2021 Comparison
PostgreSQL graphical user interface (GUI) tools help open source database users to manage, manipulate, and visualize their data. In this post, we discuss the top 6 GUI tools for administering your PostgreSQL hosting deployments. PostgreSQL is the fourth most popular database management system in the world, and heavily used in all sizes of applications from small to large. The traditional method to work with databases is using the command-line interface (CLI) tool, however, this interface presents a number of issues:
It requires a big learning curve to get the best out of the DBMS.
Console display may not be something of your liking, and it only gives very little information at a time.
It is difficult to browse databases and tables, check indexes, and monitor databases through the console.
Many still prefer CLIs over GUIs, but this set is ever so shrinking. I believe anyone who comes into programming after 2010 will tell you GUI tools increase their productivity over a CLI solution.
Why Use a GUI Tool?
Now that we understand the issues users face with the CLI, let’s take a look at the advantages of using a PostgreSQL GUI:
Shortcut keys make it easier to use, and much easier to learn for new users.
Offers great visualization to help you interpret your data.
You can remotely access and navigate another database server.
The window-based interface makes it much easier to manage your PostgreSQL data.
Easier access to files, features, and the operating system.
So, bottom line, GUI tools make PostgreSQL developers’ lives easier.
Top PostgreSQL GUI Tools
Today I will tell you about the 6 best PostgreSQL GUI tools. If you want a quick overview of this article, feel free to check out our infographic at the end of this post. Let’s start with the first and most popular one.
1. pgAdmin
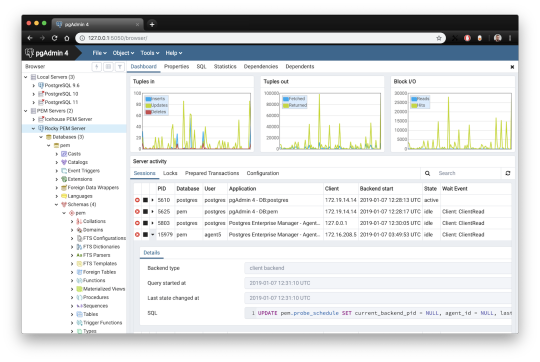
pgAdmin is the de facto GUI tool for PostgreSQL, and the first tool anyone would use for PostgreSQL. It supports all PostgreSQL operations and features while being free and open source. pgAdmin is used by both novice and seasoned DBAs and developers for database administration.
Here are some of the top reasons why PostgreSQL users love pgAdmin:
Create, view and edit on all common PostgreSQL objects.
Offers a graphical query planning tool with color syntax highlighting.
The dashboard lets you monitor server activities such as database locks, connected sessions, and prepared transactions.
Since pgAdmin is a web application, you can deploy it on any server and access it remotely.
pgAdmin UI consists of detachable panels that you can arrange according to your likings.
Provides a procedural language debugger to help you debug your code.
pgAdmin has a portable version which can help you easily move your data between machines.
There are several cons of pgAdmin that users have generally complained about:
The UI is slow and non-intuitive compared to paid GUI tools.
pgAdmin uses too many resources.
pgAdmin can be used on Windows, Linux, and Mac OS. We listed it first as it’s the most used GUI tool for PostgreSQL, and the only native PostgreSQL GUI tool in our list. As it’s dedicated exclusively to PostgreSQL, you can expect it to update with the latest features of each version. pgAdmin can be downloaded from their official website.
pgAdmin Pricing: Free (open source)
2. DBeaver

DBeaver is a major cross-platform GUI tool for PostgreSQL that both developers and database administrators love. DBeaver is not a native GUI tool for PostgreSQL, as it supports all the popular databases like MySQL, MariaDB, Sybase, SQLite, Oracle, SQL Server, DB2, MS Access, Firebird, Teradata, Apache Hive, Phoenix, Presto, and Derby – any database which has a JDBC driver (over 80 databases!).
Here are some of the top DBeaver GUI features for PostgreSQL:
Visual Query builder helps you to construct complex SQL queries without actual knowledge of SQL.
It has one of the best editors – multiple data views are available to support a variety of user needs.
Convenient navigation among data.
In DBeaver, you can generate fake data that looks like real data allowing you to test your systems.
Full-text data search against all chosen tables/views with search results shown as filtered tables/views.
Metadata search among rows in database system tables.
Import and export data with many file formats such as CSV, HTML, XML, JSON, XLS, XLSX.
Provides advanced security for your databases by storing passwords in secured storage protected by a master password.
Automatically generated ER diagrams for a database/schema.
Enterprise Edition provides a special online support system.
One of the cons of DBeaver is it may be slow when dealing with large data sets compared to some expensive GUI tools like Navicat and DataGrip.
You can run DBeaver on Windows, Linux, and macOS, and easily connect DBeaver PostgreSQL with or without SSL. It has a free open-source edition as well an enterprise edition. You can buy the standard license for enterprise edition at $199, or by subscription at $19/month. The free version is good enough for most companies, as many of the DBeaver users will tell you the free edition is better than pgAdmin.
DBeaver Pricing
: Free community, $199 standard license
3. OmniDB
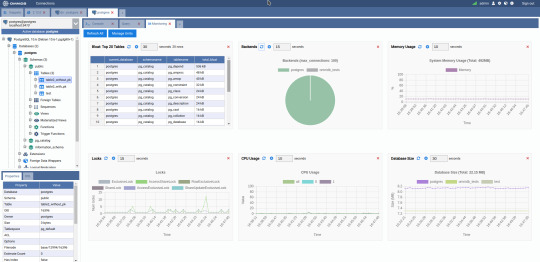
The next PostgreSQL GUI we’re going to review is OmniDB. OmniDB lets you add, edit, and manage data and all other necessary features in a unified workspace. Although OmniDB supports other database systems like MySQL, Oracle, and MariaDB, their primary target is PostgreSQL. This open source tool is mainly sponsored by 2ndQuadrant. OmniDB supports all three major platforms, namely Windows, Linux, and Mac OS X.
There are many reasons why you should use OmniDB for your Postgres developments:
You can easily configure it by adding and removing connections, and leverage encrypted connections when remote connections are necessary.
Smart SQL editor helps you to write SQL codes through autocomplete and syntax highlighting features.
Add-on support available for debugging capabilities to PostgreSQL functions and procedures.
You can monitor the dashboard from customizable charts that show real-time information about your database.
Query plan visualization helps you find bottlenecks in your SQL queries.
It allows access from multiple computers with encrypted personal information.
Developers can add and share new features via plugins.
There are a couple of cons with OmniDB:
OmniDB lacks community support in comparison to pgAdmin and DBeaver. So, you might find it difficult to learn this tool, and could feel a bit alone when you face an issue.
It doesn’t have as many features as paid GUI tools like Navicat and DataGrip.
OmniDB users have favorable opinions about it, and you can download OmniDB for PostgreSQL from here.
OmniDB Pricing: Free (open source)
4. DataGrip

DataGrip is a cross-platform integrated development environment (IDE) that supports multiple database environments. The most important thing to note about DataGrip is that it’s developed by JetBrains, one of the leading brands for developing IDEs. If you have ever used PhpStorm, IntelliJ IDEA, PyCharm, WebStorm, you won’t need an introduction on how good JetBrains IDEs are.
There are many exciting features to like in the DataGrip PostgreSQL GUI:
The context-sensitive and schema-aware auto-complete feature suggests more relevant code completions.
It has a beautiful and customizable UI along with an intelligent query console that keeps track of all your activities so you won’t lose your work. Moreover, you can easily add, remove, edit, and clone data rows with its powerful editor.
There are many ways to navigate schema between tables, views, and procedures.
It can immediately detect bugs in your code and suggest the best options to fix them.
It has an advanced refactoring process – when you rename a variable or an object, it can resolve all references automatically.
DataGrip is not just a GUI tool for PostgreSQL, but a full-featured IDE that has features like version control systems.
There are a few cons in DataGrip:
The obvious issue is that it’s not native to PostgreSQL, so it lacks PostgreSQL-specific features. For example, it is not easy to debug errors as not all are able to be shown.
Not only DataGrip, but most JetBrains IDEs have a big learning curve making it a bit overwhelming for beginner developers.
It consumes a lot of resources, like RAM, from your system.
DataGrip supports a tremendous list of database management systems, including SQL Server, MySQL, Oracle, SQLite, Azure Database, DB2, H2, MariaDB, Cassandra, HyperSQL, Apache Derby, and many more.
DataGrip supports all three major operating systems, Windows, Linux, and Mac OS. One of the downsides is that JetBrains products are comparatively costly. DataGrip has two different prices for organizations and individuals. DataGrip for Organizations will cost you $19.90/month, or $199 for the first year, $159 for the second year, and $119 for the third year onwards. The individual package will cost you $8.90/month, or $89 for the first year. You can test it out during the free 30 day trial period.
DataGrip Pricing
: $8.90/month to $199/year
5. Navicat

Navicat is an easy-to-use graphical tool that targets both beginner and experienced developers. It supports several database systems such as MySQL, PostgreSQL, and MongoDB. One of the special features of Navicat is its collaboration with cloud databases like Amazon Redshift, Amazon RDS, Amazon Aurora, Microsoft Azure, Google Cloud, Tencent Cloud, Alibaba Cloud, and Huawei Cloud.
Important features of Navicat for Postgres include:
It has a very intuitive and fast UI. You can easily create and edit SQL statements with its visual SQL builder, and the powerful code auto-completion saves you a lot of time and helps you avoid mistakes.
Navicat has a powerful data modeling tool for visualizing database structures, making changes, and designing entire schemas from scratch. You can manipulate almost any database object visually through diagrams.
Navicat can run scheduled jobs and notify you via email when the job is done running.
Navicat is capable of synchronizing different data sources and schemas.
Navicat has an add-on feature (Navicat Cloud) that offers project-based team collaboration.
It establishes secure connections through SSH tunneling and SSL ensuring every connection is secure, stable, and reliable.
You can import and export data to diverse formats like Excel, Access, CSV, and more.
Despite all the good features, there are a few cons that you need to consider before buying Navicat:
The license is locked to a single platform. You need to buy different licenses for PostgreSQL and MySQL. Considering its heavy price, this is a bit difficult for a small company or a freelancer.
It has many features that will take some time for a newbie to get going.
You can use Navicat in Windows, Linux, Mac OS, and iOS environments. The quality of Navicat is endorsed by its world-popular clients, including Apple, Oracle, Google, Microsoft, Facebook, Disney, and Adobe. Navicat comes in three editions called enterprise edition, standard edition, and non-commercial edition. Enterprise edition costs you $14.99/month up to $299 for a perpetual license, the standard edition is $9.99/month up to $199 for a perpetual license, and then the non-commercial edition costs $5.99/month up to $119 for its perpetual license. You can get full price details here, and download the Navicat trial version for 14 days from here.
Navicat Pricing
: $5.99/month up to $299/license
6. HeidiSQL
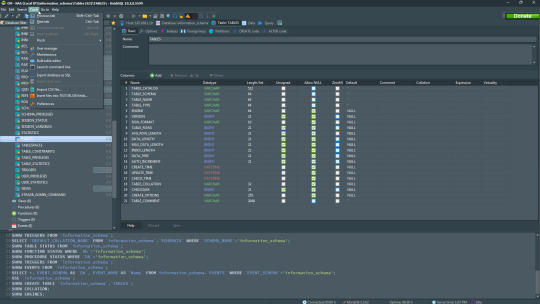
HeidiSQL is a new addition to our best PostgreSQL GUI tools list in 2021. It is a lightweight, free open source GUI that helps you manage tables, logs and users, edit data, views, procedures and scheduled events, and is continuously enhanced by the active group of contributors. HeidiSQL was initially developed for MySQL, and later added support for MS SQL Server, PostgreSQL, SQLite and MariaDB. Invented in 2002 by Ansgar Becker, HeidiSQL aims to be easy to learn and provide the simplest way to connect to a database, fire queries, and see what’s in a database.
Some of the advantages of HeidiSQL for PostgreSQL include:
Connects to multiple servers in one window.
Generates nice SQL-exports, and allows you to export from one server/database directly to another server/database.
Provides a comfortable grid to browse and edit table data, and perform bulk table edits such as move to database, change engine or ollation.
You can write queries with customizable syntax-highlighting and code-completion.
It has an active community helping to support other users and GUI improvements.
Allows you to find specific text in all tables of all databases on a single server, and optimize repair tables in a batch manner.
Provides a dialog for quick grid/data exports to Excel, HTML, JSON, PHP, even LaTeX.
There are a few cons to HeidiSQL:
Does not offer a procedural language debugger to help you debug your code.
Built for Windows, and currently only supports Windows (which is not a con for our Windors readers!)
HeidiSQL does have a lot of bugs, but the author is very attentive and active in addressing issues.
If HeidiSQL is right for you, you can download it here and follow updates on their GitHub page.
HeidiSQL Pricing: Free (open source)
Conclusion
Let’s summarize our top PostgreSQL GUI comparison. Almost everyone starts PostgreSQL with pgAdmin. It has great community support, and there are a lot of resources to help you if you face an issue. Usually, pgAdmin satisfies the needs of many developers to a great extent and thus, most developers do not look for other GUI tools. That’s why pgAdmin remains to be the most popular GUI tool.
If you are looking for an open source solution that has a better UI and visual editor, then DBeaver and OmniDB are great solutions for you. For users looking for a free lightweight GUI that supports multiple database types, HeidiSQL may be right for you. If you are looking for more features than what’s provided by an open source tool, and you’re ready to pay a good price for it, then Navicat and DataGrip are the best GUI products on the market.
Ready for some PostgreSQL automation?
See how you can get your time back with fully managed PostgreSQL hosting. Pricing starts at just $10/month.
While I believe one of these tools should surely support your requirements, there are other popular GUI tools for PostgreSQL that you might like, including Valentina Studio, Adminer, DB visualizer, and SQL workbench. I hope this article will help you decide which GUI tool suits your needs.
Which Is The Best PostgreSQL GUI? 2019 Comparison
Here are the top PostgreSQL GUI tools covered in our previous 2019 post:
pgAdmin
DBeaver
Navicat
DataGrip
OmniDB
Original source: ScaleGrid Blog
3 notes
·
View notes
Text
MySQL NDB Cluster Backup & Restore In An Easy Way
In this post, we will see, how easily user can take NDB Cluster backup and then restore it. NDB cluster supports online backups, which are taken while transactions are modifying the data being backed up. In NDB Cluster, each backup captures all of the table content stored in the cluster. User can take backup in the following states: When the cluster is live and fully operational When the cluster is live, but in a degraded state: Some data nodes are down Some data nodes are restarting During read and write transactions Users can restore backups in the following cluster environments: Restore to the same physical cluster Restore into a different physical cluster Restore into a different configuration cluster i.e. backup taken from a 4 nodes cluster and restore into 8 data nodes cluster Restore into a different cluster version Backups can be restored flexibly: Restore can be run locally or remotely w.r.t the data nodes Restore can be run in parallel across data nodes Can restore a partial set of the tables captured in the backup Use cases of Backup & Restore: Disaster recovery - setting up a cluster from scratch Setup NDB Cluster asynchronous replication Recovery from user/DBA accidents like dropping of a table/database/schema changes etc During NDB Cluster software upgrade Limitations: Schemas and table data for tables stored using the NDB Cluster engine are backed up Views, stored procedure, triggers and tables/schemas from other storage engine like Innodb are not backed up. Users need to use other MySQL backup tools like mysqldump/mysqlpump etc to capture these Support for only full backup. No incremental or partial backup supported. NDB Cluster Backup & Restore concept in brief: In NDB Cluster, tables are horizontally partitioned into a set of partitions, which are then distributed across the data nodes in the cluster. The data nodes are logically grouped into nodegroups. All data nodes in a nodegroup (up to four) contain the same sets of partitions, kept in sync at all times. Different nodegroups contain different sets of partitions. At any time, each partition is logically owned by just one node in one nodegroup, which is responsible for including it in a backup.When a backup starts, each data node scans the set of table partitions it owns, writing their records to its local disk. At the same time, a log of ongoing changes is also recorded. The scanning and logging are synchronised so that the backup is a snapshot at a single point in time. Data is distributed across all the data nodes, and the backup occurs in parallel across all nodes, so that all data in the cluster is captured. At the end of a backup, each data node has recorded a set of files (*.data, *.ctl, *.log), each containing a subset of cluster data.During restore, each set of files will be restored [in parallel] to bring the cluster to the snapshot state. The CTL file is used to restore the schema, the DATA file is used to restore most of the data, and the LOG file is used to ensure snapshot consistency.Let’s look at NDB Cluster backup and restore feature through an example:To demonstrate this feature, let’s create a NDB Cluster with below environment.NDB Cluster 8.0.22 version 2 Management servers 4 Data nodes servers 2 Mysqld servers 6 API nodes NoOfReplicas = 2 If you are wondering how to setup a NDB Cluster, then please look into my previous blog here. Step 1:Before we start the cluster, let’s modify the cluster config file (config.ini) for backup. When backup starts, it create 3 files (BACKUP-backupid.nodeid.Data, BACKUP-backupid.nodeid.ctl, BACKUP-backupid.nodeid.log) under a directory named BACKUP. By default, this directory BACKUP created under each data node data directory. It is advisable to create this BACKUP directory outside the data directory. This can be done by adding a config variable ‘BackupDataDir’ to cluster configuration file i.e. config.iniIn the below example, I have assigned a path to ‘BackupDataDir‘ in config.ini:BackupDataDir=/export/home/saroj/mysql-tree/8.0.22/ndbd/node1/data4Step 2: Let’s look at the cluster from the management client (bin/ndb_mgm): Step 3: As cluster is up and running so let’s create a database, a table and do some transactions on it. Let’s insert rows into table ‘t1’ either thru sql or thru any tools. Let’s continue the rows insertion thru sql to have a significant amount of datas in the cluster. Let’s check the rows count from table ‘t1’. From the below image, we can see that table 't1' has ‘396120’ rows in it. Step 4: Now issue a backup command from the management client (bin/ndb_mgm) while some transactions on the table ‘t1’ was going on. We will delete rows from table ‘t1’ and issue a backup command in parallel. While delete ops is going on, issue a backup command from the management client: Let’s check the new row count from table ‘t1’ after all the delete ops finished. From the below image, we can see that now the table ‘t1’ has ‘306120’ rows. Let’s look at the files backup created. As we have assigned a path to backup files so let’s discuss about these files in brief. From the above image, we can see that, for each backup, one backup directory is created (BACKUP-backupid) and under each backup directory, 3 files are created. These are:BACKUP-backupid-0.node_id.Data (BACKUP-1-0.1.Data):The above file contains most of the data stored in the table fragments owned by this node. In the above example, 1 is the backupid, 0 is a hardcoded value for future use. 1 is node_id of the data node 1. BACKUP-backupid.node_id.ctl (BACKUP-1.1.ctl): The above file contains table meta data i.e. table definitions, index definitions.BACKUP-backupid.node_id.log (BACKUP-1.1.log):This file contains all the row changes that happened to the tables while the backup was in progress. These logs will execute during restore either as roll forward or roll back depends on whether the backup is snapshot start or snapshot end. Note:User can restore from anywhere i.e. doesn’t have to be from any particular data node. ndb_restore is an NDB API client program, so can run anywhere that can access the cluster. Step 5: Upon successfully completion of a backup, the output will looks like below: From the above image, Node 1 is the master node who initiate the backup, node 254 is the management node on which the START BACKUP command was issued, and Backup 1 is the 1st backup taken. #LogRecords ‘30000’ indicate that while backup was in progress some transaction was also running on the same table. #Records shows the number of records captured across the cluster. User can see the backup status also from the “cluster log” as shown below:2021-01-12 15:00:04 [MgmtSrvr] INFO -- Node 1: Backup 1 started from node 2542021-01-12 15:01:18 [MgmtSrvr] INFO -- Node 1: Backup 1 started from node 254 completed. StartGCP: 818 StopGCP: 855 #Records: 306967 #LogRecords: 30000 Data: 5950841732 bytes Log: 720032 bytesSo this concludes our NDB Cluster backup procedure. Step 6:We will now try to restore the data from the backup taken above. Let’s shutdown the cluster, cleanup all the files except the backup files and then start the cluster with initial (with no data).Let’s restore the backup to a different cluster. From the below image, we can see that data node Id’s are different from the cluster where backup was taken. Now let’s see if our database ‘test1’ is exist in the cluster or not after initial start. From the above image, we can see that, database ‘test1’ is not present. Now let’s start our restore process from the backup image #1 (BACKUP-1). The NDB restore works in this flow: It first restore the meta data from the *.ctl file so that all the tables/indexes can be recreated in the database. Then it restore the data files (*.Data) i.e. inserts all the records into the tables in the database. At the end, it executes all the transaction logs (*.log) rollback or roll forward to make the database consistent. Since restore will fail while restoring unique and foreign key constraints that are taken from the backup image so user must disable the index at the beginning and once restore is finished, again user need to rebuild the index. Step 7:Let’s start the restoration of meta data.Meta data restore, disable index and data restore can execute at one go, or can be done in serial. This restore command can be issued from any data node or can be from a non-data node as well.In this example, I am issuing meta data restore and disable index from Data Node 1 only for once. Upon successful completion, I will issue the data restore.Data Node 1: shell> bin/ndb_restore -n node_id -b backup_id -m --disable-indexes --ndb-connectstring=cluster-test01:1186,cluster-test02:1186 –backup_path=/path/to/backup directory -n: node id of the data node from where backup was taken. Do not confuse with the data node id of the new cluster.-b: backup id (we have taken backup id as ‘1’)-m: meta data restoration (recreate table/indexes)--disable-indexes: disable restoration of indexes during restore of data--ndb-connectstring (-c): Connection to the management nodes of the cluster.--backup_path: path to the backup directory where backup files exist. The results of above meta restore from data node 1 is shown below: Let’s start the data restore on the Data Node 1. Data Node 1:shell> bin/ndb_restore -n node_id -b backup_id -r --ndb-connectstring=cluster-test01:1186,cluster-test02:1186 –backup_path=/path/to/backup directory Below, I am trying to capture the logs from the data restore run results as it started and then at the end. From the above image, we can see that restore went successful. Restore skips restoration of system table data. System tables referred to here are tables used internally by NDB Cluster. Thus these tables should not be overwritten by the data from a backup. Backup data is restored in fragments, so whenever a fragment is found, ndb_restore checks if it belongs to a system table. If it does belong to a system table, ndb_restore decides to skip restoring it and prints a 'Skipping fragment' log message.Let’s finish all the remaining data restore from the other data nodes. These data restore can be run in parallel to minimise the restore time. Here, we don’t have to pass -m, --disable-indexes again to restore command as we need to do it only once. With the first restore completion, it has already created tables, indexes etc so no need to recreate it again and will also fail. Once all the data are restored into the table(s), we will enable the indexes and constraints again using the –rebuild-indexes option. Note that rebuilding the indexes and constraints like this ensures that they are fully consistent when the restore completes.Data Node 2:shell> bin/ndb_restore -n node_id -b backup_id -r --ndb-connectstring=cluster-test01:1186,cluster-test02:1186 –backup_path=/path/to/backup directoryData Node 3:shell> bin/ndb_restore -n node_id -b backup_id -r --ndb-connectstring=cluster-test01:1186,cluster-test02:1186 –backup_path=/path/to/backup directoryData Node 4:shell> bin/ndb_restore -n node_id -b backup_id -r --ndb-connectstring=cluster-test01:1186,cluster-test02:1186 –backup_path=/path/to/backup directory Ndb restore (ndb_restore) is an API, it needs API slots to connect to cluster. Since we have initiated 3 ndb_restore programme in parallel from Data node ID 4, 5 and 6 so we can see from the below image that ndb_restore took API ID: 47, 48 and 49. Let’s see the results from the remaining data nodes. Since all the ndb_restore API finished successfully, we can see that the API ID that it had taken to connect the cluster has been released. The last step is to rebuild the index. This can also done from any data nodes or from any non-data nodes but only once.Data Node 1:shell> bin/ndb_restore -n node_id -b backup_id --rebuild-indexes --ndb-connectstring=cluster-test01:1186,cluster-test02:1186 –backup_path=/path/to/backup directory--rebuild-indexes: It enables rebuilding of ordered indexes and foreign key constraints. Step 8:So we have finished our restoration steps. Let’s check the database, table, rows count in table etc .. So database ‘test1’ is already created. Now we can see that table ‘t1’ has been created and the row count#306120 which is also matching with our backup image (look at Step# 4).So this concludes our NDB Cluster backup and restore feature. There are many more options user can pass to both backup (START BACKUP) and restore (ndb_restore) programme based on the requirements. In the above example, I have selected the basic minimum options user might need for backup and restore. For more information on these options, please refer to NDB Cluster reference manual here. https://clustertesting.blogspot.com/2021/01/mysql-ndb-cluster-backup-restore-in.html
1 note
·
View note
Text
Sql Tools For Mac

Download SQL Server Data Tools (SSDT) for Visual Studio.; 6 minutes to read +32; In this article. APPLIES TO: SQL Server Azure SQL Database Azure Synapse Analytics (SQL Data Warehouse) Parallel Data Warehouse SQL Server Data Tools (SSDT) is a modern development tool for building SQL Server relational databases, databases in Azure SQL, Analysis Services (AS) data models, Integration. SQLite's code is in the public domain, which makes it free for commercial or private use. I use MySQL GUI clients mostly for SQL programming, and I often keep SQL in files. My current favorites are: DBVisualizer Not free but I now use. Oracle SQL Developer is a free, development environment that simplifies the management of Oracle Database in both traditional and Cloud deployments. It offers development of your PL/SQL applications, query tools, a DBA console, a reports interface, and more.
Full MySQL Support
Sequel Pro is a fast, easy-to-use Mac database management application for working with MySQL databases.
Perfect Web Development Companion
Whether you are a Mac Web Developer, Programmer or Software Developer your workflow will be streamlined with a native Mac OS X Application!
Flexible Connectivity
Sequel Pro gives you direct access to your MySQL Databases on local and remote servers.
Easy Installation
Simply download, and connect to your database. Use these guides to get started:
Get Involved
Sequel Pro is open source and built by people like you. We’d love your input – whether you’ve found a bug, have a suggestion or want to contribute some code.
Get Started
New to Sequel Pro and need some help getting started? No problem.
-->
APPLIES TO: SQL Server Azure SQL Database Azure Synapse Analytics (SQL Data Warehouse) Parallel Data Warehouse
SQL Server Data Tools (SSDT) is a modern development tool for building SQL Server relational databases, databases in Azure SQL, Analysis Services (AS) data models, Integration Services (IS) packages, and Reporting Services (RS) reports. With SSDT, you can design and deploy any SQL Server content type with the same ease as you would develop an application in Visual Studio.
SSDT for Visual Studio 2019
Changes in SSDT for Visual Studio 2019
The core SSDT functionality to create database projects has remained integral to Visual Studio.
With Visual Studio 2019, the required functionality to enable Analysis Services, Integration Services, and Reporting Services projects has moved into the respective Visual Studio (VSIX) extensions only.
Note
There's no SSDT standalone installer for Visual Studio 2019.
Install SSDT with Visual Studio 2019
If Visual Studio 2019 is already installed, you can edit the list of workloads to include SSDT. If you don’t have Visual Studio 2019 installed, then you can download and install Visual Studio 2019 Community.
To modify the installed Visual Studio workloads to include SSDT, use the Visual Studio Installer.

Launch the Visual Studio Installer. In the Windows Start menu, you can search for 'installer'.
In the installer, select for the edition of Visual Studio that you want to add SSDT to, and then choose Modify.
Select SQL Server Data Tools under Data storage and processing in the list of workloads.

For Analysis Services, Integration Services, or Reporting Services projects, you can install the appropriate extensions from within Visual Studio with Extensions > Manage Extensions or from the Marketplace.
SSDT for Visual Studio 2017
Changes in SSDT for Visual Studio 2017
Sql Server Data Tools For Mac
Starting with Visual Studio 2017, the functionality of creating Database Projects has been integrated into the Visual Studio installation. There's no need to install the SSDT standalone installer for the core SSDT experience.
Now to create Analysis Services, Integration Services, or Reporting Services projects, you still need the SSDT standalone installer.
Install SSDT with Visual Studio 2017
To install SSDT during Visual Studio installation, select the Data storage and processing workload, and then select SQL Server Data Tools.
Sql Management Studio For Mac
If Visual Studio is already installed, use the Visual Studio Installer to modify the installed workloads to include SSDT.
Launch the Visual Studio Installer. In the Windows Start menu, you can search for 'installer'.
In the installer, select for the edition of Visual Studio that you want to add SSDT to, and then choose Modify.
Select SQL Server Data Tools under Data storage and processing in the list of workloads.
Install Analysis Services, Integration Services, and Reporting Services tools
To install Analysis Services, Integration Services, and Reporting Services project support, run the SSDT standalone installer.
The installer lists available Visual Studio instances to add SSDT tools. If Visual Studio isn't already installed, selecting Install a new SQL Server Data Tools instance installs SSDT with a minimal version of Visual Studio, but for the best experience, we recommend using SSDT with the latest version of Visual Studio.
SSDT for VS 2017 (standalone installer)
Important
Before installing SSDT for Visual Studio 2017 (15.9.6), uninstall Analysis Services Projects and Reporting Services Projects extensions if they are already installed, and close all VS instances.
Removed the inbox component Power Query Source for SQL Server 2017. Now we have announced Power Query Source for SQL Server 2017 & 2019 as out-of-box component, which can be downloaded here.
To design packages using Oracle and Teradata connectors and targeting an earlier version of SQL Server prior to SQL 2019, in addition to the Microsoft Oracle Connector for SQL 2019 and Microsoft Teradata Connector for SQL 2019, you need to also install the corresponding version of Microsoft Connector for Oracle and Teradata by Attunity.
Release Notes
For a complete list of changes, see Release notes for SQL Server Data Tools (SSDT).
System requirements
Microsoft Sql Tools For Mac
SSDT for Visual Studio 2017 has the same system requirements as Visual Studio.
Available Languages - SSDT for VS 2017
Sql Server Tools For Mac
This release of SSDT for VS 2017 can be installed in the following languages:
Considerations and limitations
You can’t install the community version offline
To upgrade SSDT, you need to follow the same path used to install SSDT. For example, if you added SSDT using the VSIX extensions, then you must upgrade via the VSIX extensions. If you installed SSDT via a separate install, then you need to upgrade using that method.
Offline install
To install SSDT when you’re not connected to the internet, follow the steps in this section. For more information, see Create a network installation of Visual Studio 2017.
First, complete the following steps while online:
Download the SSDT standalone installer.
Download vs_sql.exe.
While still online, execute one of the following commands to download all the files required for installing offline. Using the --layout option is the key, it downloads the actual files for the offline installation. Replace <filepath> with the actual layouts path to save the files.
For a specific language, pass the locale: vs_sql.exe --layout c:<filepath> --lang en-us (a single language is ~1 GB).
For all languages, omit the --lang argument: vs_sql.exe --layout c:<filepath> (all languages are ~3.9 GB).
After completing the previous steps, the following steps below can be done offline:
Run vs_setup.exe --NoWeb to install the VS2017 Shell and SQL Server Data Project.
From the layouts folder, run SSDT-Setup-ENU.exe /install and select SSIS/SSRS/SSAS.a. For an unattended installation, run SSDT-Setup-ENU.exe /INSTALLALL[:vsinstances] /passive.
For available options, run SSDT-Setup-ENU.exe /help
Note
If using a full version of Visual Studio 2017, create an offline folder for SSDT only, and run SSDT-Setup-ENU.exe from this newly created folder (don’t add SSDT to another Visual Studio 2017 offline layout). If you add the SSDT layout to an existing Visual Studio offline layout, the necessary runtime (.exe) components are not created there.
Supported SQL versions
Project TemplatesSQL Platforms SupportedRelational databasesSQL Server 2005* - SQL Server 2017 (use SSDT 17.x or SSDT for Visual Studio 2017 to connect to SQL Server on Linux) Azure SQL Database Azure Synapse Analytics (supports queries only; database projects aren't yet supported) * SQL Server 2005 support is deprecated, move to an officially supported SQL versionAnalysis Services models Reporting Services reportsSQL Server 2008 - SQL Server 2017Integration Services packagesSQL Server 2012 - SQL Server 2019
DacFx
SSDT for Visual Studio 2015 and 2017 both use DacFx 17.4.1: Download Data-Tier Application Framework (DacFx) 17.4.1.
Previous versions
Unix Tools For Mac
To download and install SSDT for Visual Studio 2015, or an older version of SSDT, see Previous releases of SQL Server Data Tools (SSDT and SSDT-BI).
See Also
Next steps
After installing SSDT, work through these tutorials to learn how to create databases, packages, data models, and reports using SSDT.
Get help
1 note
·
View note
Text
TOP 10 IT COURSES IN 2020
The relationship between businesses and technologies are emerging day by day. New technologies have been launching in the market, and companies are looking for those candidates who are certified in those technologies, and who are skilled enough in their platform IT Courses. Even if you are a fresher and looking to work on new technology, you can get certified and get a good job in top companies. Here are the top 10 technologies which are currently ruling the IT market. They are:
1. Cloud Computing Technology:-
One of the most trending technologies in the IT Courses industry is Cloud Computing Technology. We’re now utilizing many cloud-based administrations, for example, from Google, Amazon, Microsoft, HP, and others. Cloud computing is around the “On-demand service” design which enables clients to acquire, design, and deploy cloud administrations themselves utilizing cloud administration inventories, without requiring its help.
Generally, individuals and Corporates would purchase programming and introduce them to their PCs for use. With the coming of the Internet, a wide range of projects got accessible on a ‘Cloud’. Cloud computing clients don’t claim the servers and other physical foundation that stores these projects. Rather, they lease the projects — or the utilization of the projects — from a specialist co-op/provider. This helps spare assets since the client pays just for the assets that the individual uses. Huge advancements in virtualization and dispersed figuring, just as improved access to the rapid Internet and a frail economy, have quickened corporate enthusiasm for Cloud registering IT Courses.
Some popular and important subject in cloud computing is
· Infrastructure as a service (IaaS)
· Platform as a service (PaaS)
· Software as a service (SaaS)
· Network as a service (NaaS)
· Database as a service (DBaaS) and few more services.
The fast improvement of information being produced progress in virtualization, and cloud computing, and the combination of server centers frameworks are making popularity for talented IT Courses experts. Qualification: Anyone with fundamental information on PCs and the Internet can begin with the underlying modules of cloud-based courses. Individuals with programming aptitudes in.NET or J2EE may straightforwardly choose the further developed modules in cloud processing. Microsoft’s cloud computing service, Windows Azure is one of the reliable course alternatives.
2. Database Administrators (DBA):-
Some popular DBA is (Oracle, DB2, MySQL, SQL Server).
In an extremely unique and dynamic Software/IT industry, the one course which you can depend on for a steady profession is Database Administration (DBA). DBA is all about creating, managing and keeping up large information records; and from the few database flavors accessible in the market, Oracle can be your most solid option. Others are famous, however, once you are through with Oracle, the ones like MySQL and DB2 can be effectively adapted later on in a lot shorter period.
To move to further develop levels, courses like Data Warehousing can be sought after further. Again likewise with numerous Software/IT courses, there is no least eligibility to learn DBA, yet a customary recognition/graduation in PCs keeps on being favored from an occupation point of view.
To improve your profile, you should search for certifications (after fulfillment of course or self-learning) like from Oracle or IBM. Interest in DBA will stay positive as there’s no task in Software/IT Courses that doesn’t utilize a database, regardless of the size of the undertaking. So in case, you’re vigilant for a stable employment choice and information support (automatically) charms you, at that point a DBA course is the best approach!
3. JAVA – J2EE and it’s Frameworks:-
The most generally utilized innovation by practically all the regarded organizations crosswise over a domain around the globe is only Java. What’s more, with regard to what precisely you should realize, Java keeps on being an unending sea where you should concentrate on boosting your core portion of it, however, much as could reasonably be expected. Hopefuls regularly lose control with the appeal of JSP and Servlets, yet that murders you like sweet toxic substance over the long haul. There are a few things you should focus on when you are learning JAVA. They are
· J2SE — Core or primary Portion.
· J2EE — Java server pages (JSP) and Servlets along with Enterprise JAVA Beans (EJB).
· Struts — Framework for Java.
· SPRING or potentially HIBERNATE (For increasingly complex and propelled applications).
There are numerous frameworks and supporting advancements for Java hopefuls Yet, the over ones are an absolute necessity and most on-demand ones in the Software/IT Courses showcase.
To learn Java, there is no qualification all things considered, yet on the off chance that you’re focusing on a tolerable activity, at that point you will require a Bachelor/Master’s certificate in computer field alongside it. So if a vocation in any of the above significant areas premiums you and the enthusiasm for relentless coding satisfy your spirit, at that point look no more remote than learning Java.
4. Software Testing:-
A profession choice regularly involved (or for the most part disagreeable/disregarded) to an industry fresher is Software Testing. While the reality of any medium or huge scale venture is that it’s inadequate without the Testing groups. An untested application is consistently the most unsafe one and suspected to worsen in the longer run. Testing is a procedure used to help specify the accuracy, fulfillment, and nature of the developed programs. Because of that, testing can never totally set up the accuracy of the programs.
Testing helps in checking and approving if the product or software is working as it is proposed to work. This includes utilizing static and dynamic viewpoints to test the application. Testing should regularly open different classes of errors in the least amount of time and with the smallest amount of effort. An extra advantage of testing is that it shows that the product or software seems, by all reports to be functioning as expressed in the specifications.
Any Testing course should cover these minimum topics as mentioned below Static Testing, Dynamic Testing, Load Testing, Black box Testing, White Box Testing, Unit Testing, Regression Testing (Software), Web Regression Testing, Automated Regression Testing, etc.
A software tester appreciates a similarly quicker and simpler arch to the development in IT Courses companies.
5. Data Analysis:-
The market wildly needs a master’s or expert’s in the data Analysis. Because of an exceptional increment in the measure of data, the ability to prepare and understanding it has gotten vital. Specifically, everyone has attracted up for estimating and following everything, and the understanding of how to manage the hard outcomes accomplished will be the most likely requested.
For this situation, the procedure to depend on computer’s isn’t compelling, since the best business results can be accomplished by planning an intelligent way to deal with data information and analysis.
There are Kinds of Data Analysis available in the market. They are
· Data Mining
· Statistical Analysis
· Business Intelligence
· Content Analytics
· Predictive Analytics
Therefore, a position to make spot designs, uncover the patterns and estimate probabilities is definitely the expertise of things to come in the IT circle.
6. System Administration:-
For the ones who are attached to installation and computer organization exercises like User Management, framework security, chance administration, bundle establishments – System administration can be a captivating decision.
Likewise, with CISCO innovations, framework organization is additionally widespread as a course among non-IT applicants. You have to have done 10+2 or legitimate recognition/graduation (IT or non-IT) to begin with this course and afterward show up for the confirmation tests or certification exams.
Except if you hold an ordinary IT graduation, the certifications are practically necessary for you if picking this organization course. There are different choices in certifications from Red Hat, VMware, and Solaris.
system administration is all around considered a normal pay getting profile, however, yes there are lots of special cases to it and the individuals who hold 4-year graduation in software engineering are at a preferred position to draw greater pay scales. Similarly, non-IT competitors should be somewhat patient and spotlight on picking up the underlying 4-5 years of experience.
7. Statistical Analysis System (SAS):-
Data Analytics is presently a quickly developing field thus this Business Intelligence area has risen as the most worthwhile choice among its present type graduates.
SAS means statistical analysis system is a coordinated arrangement of programming items gave by SAS Institute, to perform information passage, recovery, the executives, mining, report composing, and illustrations.
Some unequivocal advantages are as under:
· Generally used for business arranging, gauging, and choice help for its exact outcomes.
· Widely used for activities research and task the board.
· The best device for quality improvement and applications advancement.
· Gives Data warehousing (separate, change, and burden)
· Extra advantages of platform license, and remote computing capacity.
· SAS business arrangements aid regions, for example, human asset the executives, money related administration, business knowledge, client relationship the board and the sky is the limit from there.
· Used in the examination of results and report generation in clinical paths in the pharmaceutical business SAS contains multi-motor engineering for a better data management and publishing.
SAS preparing gets ready students for fulfilling, and very well paying professions as SAS examiner, software engineer, designer or consultant. Anybody can get familiar with this course and show up for the confirmation tests, yet for the most part, the ones who hold substantial graduation in Computers/IT Courses, are liked. The SAS Certified Professional Program was propelled by SAS Institute, Inc. in 1999 to observe clients who can exhibit an inside and out comprehension of SAS programming. The program consists of five confirmations crosswise over various areas. A few SAS courses get ready clients for the certification exams.
To date numerous developers have taken these courses, some accomplished clients simply take the tests, and numerous SAS experts are experienced however not SAS certified. According to some ongoing reviews, around 60,000 SAS Analysts and developers will be required in the following couple of years. Also, SAS consultants are paid with a good package when differentiated with other software engineers.
8. Blockchain Technology:-
Many people consider Blockchain innovation in connection to digital forms of money, for example, Bitcoin, Blockchain offers security that is helpful from numerous points of view. In the least difficult of terms, Blockchain can be represented as data you can just add to, not divert from or change. Consequently, the expression, “chain” since you’re making a chain of data. Not having the option to change the past intersections is the thing that makes it so secure.
Moreover, Blockchain is agreement driven, so nobody substance can assume responsibility for the data. With Blockchain, you needn’t bother with a trusted in an outsider to control or approve exchanges. A few enterprises are including and actualizing Blockchain, and as the utilization of Blockchain innovation gains, so too does the interest in gifted experts. In such a manner, we are as of now behind.
As per the survey, Blockchain-related jobs are the second-quickest developing classification of employments, with 12 employment opportunities for each one Blockchain designer. A Blockchain designer spends significant time in creating and executing engineering and designs using Blockchain innovation. The normal yearly compensation of a Blockchain engineer is $145,000.
In the event that you are captivated by Blockchain and its applications, and need to make your career in this quickly developed industry, at that point this is the perfect time to learn Blockchain and apparatus up for an energizing future.
Just go for Blockchain demo you can know more: https://itcources.com/blockchain-training/
9. Artificial Intelligence (AI):-
Artificial intelligence or AI, has just gotten a great deal of buzz as of late, yet, it keeps on being a pattern to watch since its impacts on how do we live, work and play are just in the beginning periods. Moreover, different parts of AI has created, including Machine Learning, which we will go into beneath.
AI relates to computer systems worked to copy human insight, and perform undertakings, for example, acknowledgment of pictures, discourse or example, and basic leadership. AI can carry out these responsibilities quicker and more precisely than people. Five out of six Americans use AI benefits in some structures each day, including navigation applications, streaming services, cell phone individual assistance, ride-sharing applications, home individual assistance, etc.
Notwithstanding customer use, AI is used to plan trains, survey business hazards, divine maintenance, and improve vitality productivity, among numerous other cash saving undertakings. Artificial intelligence is one part of what we allude to comprehensively as automation, and automation is an interesting issue due to potential work loss.
Specialists state that automation will wipe out 73 million additional employments by 2030. In any case, automation is making occupations just as disposing of them, particularly in the field of AI. Employments will be made being developed, programming, testing, backing, and support, to give some examples. AI architect is one such work. Some say it will quickly challenge data scientists in demand of experienced specialists.
Just go for AI demo you know more: https://itcources.com/artificial-intelligence-training/
10. Internet of Things (IoT):-
Many “things” are presently being worked with Wi-Fi availability, which means they can be associated with the Internet and to one another. Henceforth, the Internet of Things, or IoT.
The Internet of Things is the future and has just empowered gadgets, home devices, vehicles and substantially more to be associated with and trade information over the Internet. What’s more, we’re just in the first place phases of IoT: the quantity of IoT gadgets arrived at 7.4 billion in 2017 is relied upon to arrive at 33 billion gadgets by 2020. As purchasers, we’re now using and profiting by IoT. We can bolt our doors remotely on the off chance that we neglect to when we leave for work and preheat our stoves on our route home from work, all while following our wellness on our Fit bits, and hailing a ride with Lyft. In any case, organizations additionally have a lot to pick up now, and sooner rather than later.
The IoT can empower better security, effectiveness and basic leadership for organizations as information is gathered and investigated. It can empower cautious support, accelerate healthful consideration, improve client assistance, and offer advantages we haven’t thought at this point. Be that as it may, in spite of this shelter in the advancement and selection of IoT, specialists state insufficient IT experts are landing prepared for IoT positions.
For somebody keens on a profession in IoT, that implies simple passage into the field in case you’re encouraged, with a scope of choices for the beginning. Abilities required to include IoT security, cloud computing information, data analytics, automation, knowledge of embedded systems, device information to give some examples. All things considered, it’s the Internet of Things, and those things are numerous and differed, which means the abilities required are too.
Just go for IOT Demo you can know more: https://itcources.com/iot-training/
DevOps:
DevOps certification online training provided by ITcources.com will aid you to become a master in DevOps and its latest methodologies. In this training class, you’ll be able to implement DevOps software development lifecycle. The training is being provided by Industry professionals to make you understand the real-time IT scenarios and problems.
Just go for DevOps Demo you can know more: https://itcources.com/devops-training/
Data Science:
A Data Analyst, as a rule, clarifies what is happening by preparing a history of the information. Then again, Data Scientist not exclusively does the exploratory examination to find experiences from it, yet in addition, utilizes different propelled AI calculations to recognize the event of a specific occasion later on. A Data Scientist will take a gander at the information from numerous edges, once in a while edges not known before. Information Science is a mixture of various devices, calculations, and AI standards with the objective to find concealed examples from the crude data. How is this not the same as what analysts have been getting along for a particular amount of time? The appropriate response lies in the contrast among clarifying and anticipating. ITcources.com provides you the best Data Science online training or online classes in the Bangalore for the certification.
Just go for Data Science Demo you can know more: https://itcources.com/data-science-training/
Final Conclusion:-
The interest for IT Courses expert’s methods higher remunerations and wages expanded speculations by corporations to pay more for qualified and certified IT Courses experts, and more motivations to enlist contract or temporary experts to fill those IT jobs.
Note:-
Adding to your abilities, having a training certification from one of the main innovation training platforms like “ITcources” is an additional preferred advantage. Don’t hesitate to view leading technology courses and get certified to promote your profession or career in your attracted and on-demand IT field at our website “www.itcources.com”
1 note
·
View note
Text

Your Trusted Partner for SQL Server Remote DBA Support: RalanTech https://www.ralantech.com/sqlserver-database-support/ Access expert SQL Server Remote DBA support with RalanTech. Our skilled team ensures seamless database management, optimization, and troubleshooting, offering round-the-clock assistance to keep your systems running smoothly and securely. Unlock the full potential of your SQL Server infrastructure.
1 note
·
View note



Text
Oimerp Driver Download


Oimerp Driver Download Pc

Oimerp Driver Download Torrent
In reply to Omer Coskun's post on August 25, 2010 I installed it and can see it in add/remove programs but devive manager still has a yellow question mark. I tried to reintall driver tab but got a message one cound not be found. Omer Faruk free download - Omer Reminder, OMeR X, Omer Counter, and many more programs. Download Chrome For Windows 10/8.1/8/7 32-bit. For Windows 10/8.1/8/7 64-bit. This computer will no longer receive Google Chrome updates because Windows XP and Windows Vista are no longer. View & download of more than 498 Cerwin-Vega PDF user manuals, service manuals, operating guides. Speakers, Subwoofer user manuals, operating guides & specifications.
Aarp Safe Driver
Object TypeActionsViewersCatalogs
Create Database Catalogs CatalogReferences, Tables SchemasCreate Schema Schemas SchemaExport Schema, Drop Schema References, Tables TablesCreate Table, Import Table DataReferences, Tables TableAlter Table, Create Trigger, Export Table, Import Table Data, Add Extended Property, Create Index, Delete Extended Property, Drop Table, Edit Extended Property, Empty Table, Rename Table, Script: Script Table Navigator1, References, Data, Columns, DDL, Extended Properties, Grants, Indexes, Indexes2, Info, Primary Key, Row Count, Row Id, Triggers HistoryTable3 Extended Properties, Grants, Indexes, Info Columns Columns, Extended Properties ColumnAdd Extended Property, Delete Extended Property, Edit Extended Property, Rename Column Column, Extended Properties Indexes Indexes IndexDrop Index, Rebuild Index4, Rename Index DDL4, Index Triggers Triggers TriggerExport Trigger, Disable Trigger, Drop Trigger, Enable Trigger, Rename Trigger Trigger Editor, Info Views Views ViewExport View, Add Extended Property, Create Trigger, Delete Extended Property, Drop View, Edit Extended Property, Rename View, Script: Script View Data, Columns, DDL, Extended Properties, Indexes, Info, Row Count Columns Columns, Extended Properties ColumnAdd Extended Property, Delete Extended Property, Edit Extended Property, Rename Column Column, Extended Properties Triggers Triggers TriggerExport Trigger, Disable Trigger, Drop Trigger, Enable Trigger, Rename Trigger Trigger Editor, Info SynonymsCreate Synonym Synonyms SynonymDrop Synonym Info Indexes Indexes IndexDrop Index, Rebuild Index4, Rename Index DDL4, Index Sequences5Create Sequence Sequences SequenceDrop Sequence Info Types User Defined Data Types Triggers Triggers TriggerExport Trigger, Disable Trigger, Drop Trigger, Enable Trigger, Rename Trigger Trigger Editor, Info ProceduresCreate Procedure Procedures ProcedureExport Procedure, Drop Procedure, Rename Procedure, Script: Script Procedure Procedure Editor, Interface FunctionsCreate Function Functions FunctionExport Function, Drop Function, Rename Function, Script: Script Function Function Editor, Interface Users6 Users Roles Roles Role Info, Users6LinkedServers7Create Linked Server1 Linked Servers LinkedServerAdd Login, Drop Linked Server Login, Drop Linked Server1, Enable/Disable Options, Set Remote Collation, Set Timeout Options, Test Connection1 Info LinkedServerCatalogs Catalogs LinkedServerCatalogLinkedServerSchemas Schemas LinkedServerSchemaLinkedServerTables Tables LinkedServerTableData, Columns, Foreign Keys, Grants, Info, Primary Key, Row Count LinkedServerColumns Columns LinkedServerColumn Column LinkedServerViews Views LinkedServerViewData, Columns, Info, Row Count LinkedServerColumns Columns LinkedServerColumn Column LinkedServerSynonyms Synonyms LinkedServerSynonym Column DBA DBA ServerInfo Latest Error Log6, Server Info Logins6 Logins Devices6 Database Devices Processes6 Processes ServerRoles6 Roles ServerRole Info, Users ServerAgent8 Latest Error Log, Sql Server Agent JobsCreate Job Jobs JobCreate Step, Delete Job, Edit, Edit Notifications, Enable/Disable Job, Start the job Alerts, History, Steps, info JobStepCopy Step, Delete Job Step, Edit Step info JobSchedulesAttach Schedule Schedules JobScheduleDetach Schedule, Enable/Disable Schedule Schedules JobServersAdd Server Servers JobServerDelete Server Server SchedulerSchedulesAdd Recurring Daily, Add Recurring Monthly, Add Recurring Weekly, Add one time, Add other Schedules SchedulerScheduleDelete Schedule, Enable/Disable Schedule Jobs, Schedules Alerts Alerts Alert Alert, Operators Operators Operators Operator Alerts, Info, Jobs Locks6 Locks 1)DbVisualizer Pro 2)Version 10 and later 3)Version 13 and later 4)Version 9 and later 5)Version 11 and later 6)Not Azure SQL Database 7)Version 10 and when linked servers is supported 8)Version 9 and not Azure SQL Database
0 notes
Photo

The Farber Consulting Group provides database services such as: SQL Consulting and Remote DBA services. Some of our consultants have more than 30 years of experience including MS MVP. See some of our services that we provide to our clients and some case studies to support that in the below article. https://www.dfarber.com/ms-sql-server-solutions/remote-dba-for-ms-sql-mysql-oracle-and-use-it-only-when-you-need-it/
0 notes
Text
Federated query support for Amazon Aurora PostgreSQL and Amazon RDS for PostgreSQL
PostgreSQL is one of the most widely used database engines and is supported by a very large and active community. It’s a viable open-source option to use compared to many commercial databases, which require heavy license costs. Amazon RDS for PostgreSQL and Amazon Aurora PostgreSQL are AWS managed offerings that take away the heavy lifting required for setting up the platform, configuring high availability, monitoring, and much more. This allows DBAs to spend more time on business-critical problems like doing schema design early on or query tuning. In 2003, a new specification called SQL/MED (“SQL Management of External Data”) was added to the SQL standard. It’s a standardized way of handling access to remote objects from SQL databases. In 2011, PostgreSQL 9.1 was released with read-only support of this standard, and in 2013, write support was added with PostgreSQL 9.3. The implementation of this concept in PostgreSQL was called foreign data wrappers (FDW). Several FDWs are available that help connect PostgreSQL Server to different remote data stores, ranging from other SQL database engines to flat files. However, most FDWs are independent open-source projects implemented as Postgres extensions, and not officially supported by the PostgreSQL Global Development Group. In this post, we discuss one FDW implementation that comes with PostgreSQL source as a contrib extension module called postgres_fdw. postgres_fdw allows you to implement federated query capability to interact with any remote PostgreSQL-based database, both managed and self-managed on Amazon Elastic Compute Cloud (Amazon EC2) or on premises. This is available in all present versions supported for Amazon RDS for PostgreSQL and Aurora PostgreSQL. The following diagram illustrates this architecture. Use cases In this post, we primarily focus on two use cases to give an overview on the capability. However, you can easily extended the solution for other federated query use cases. When working with independent software vendors (ISVs), we occasionally see them offering Amazon RDS for PostgreSQL and Aurora PostgreSQL in a multi-tenant setup in which they use one database per customer and a shared database within a single instance. Federated query capability implemented via FDW allows you to pull data from a shared database to other databases as needed. An organization could have multiple systems catering to different departments. For example, a payroll database has employee salary information. This data maybe required by the HR and tax systems to calculate hike or decide tax incurred, respectively. One solution for such a problem is to copy the salary information in both the HR and Tax systems. However, this kind of duplication may lead to problems, like ensuring data accuracy, extra storage space incurred, or double writes. FDWs avoid duplication while providing access to required data that resides in a different foreign database. The following diagram illustrates this architecture. Furthermore, in today’s world of purpose-built databases you host hot or active data in Amazon RDS for PostgreSQL and Aurora PostgreSQL, you have separate data warehouse solutions like Amazon Redshift for data archival. Without federated query support from an active database, you have to stream the active data to the data warehouse on an almost near-real-time basis to run analytical queries, which requires extra efforts and costs to set up a data pipeline and an additional overhead to the data warehouse. With federated query capability, you can derive insights while joining data at the transactional database from within itself as well as a data warehouse like Amazon Redshift. The following diagram illustrates this architecture. For more information about querying data in your Aurora PostgreSQL or Amazon RDS for PostgreSQL remote server from Amazon Redshift as the primary database, see Querying data with federated queries in Amazon Redshift. Prerequisites Before getting started, make sure you have the following prerequisites: A primary Aurora PostgreSQL or Amazon RDS for PostgreSQL instance as your source machine. A remote PostgreSQL-based instance with information like username, password, and database name. You can use any of the following databases: Aurora PostgreSQL Amazon RDS for PostgreSQL Amazon Redshift Self-managed PostgreSQL on Amazon EC2 On-premises PostgreSQL database Network connectivity between the primary and remote database. The remote database can be a different database within the same primary database instance, a separate database instance, Amazon Redshift cluster within the same or different Amazon Virtual Private Cloud (Amazon VPC), or even on-premises PostgreSQL-based database servers that can be reached using VPC peering or AWS managed VPN or AWS Direct Connect. The remote PostgreSQL-based database instance or Amazon Redshift cluster can be in a same or different AWS account with established network connectivity in place. For more information, see How can I troubleshoot connectivity to an Amazon RDS DB instance that uses a public or private subnet of a VPC? Tables that you query in the foreign (remote) server. For this post, we create one table in source database pdfdwsource and one table in target database pdfdwtarget. For pdfdwsource, create a salary table with the columns emailid and salary with dummy content. See the following code: [ec2-user@ip-172-31-15-24 ~]$ psql -h pgfdwsource.xxxx.us-west-2.rds.amazonaws.com -d pgfdwsource -U pgfdwsource -w SET Expanded display is on. SSL connection (protocol: TLSv1.2, cipher: ECDHE-RSA-AES256-GCM-SHA384, bits: 256, compression: off) Type "help" for help pgfdwsource=> create table salary(emailid varchar, salary int); CREATE TABLE pgfdwsource=> insert into salary values('[email protected]',10000); INSERT 0 1 pgfdwsource=> insert into salary values('[email protected]',100000); INSERT 0 1 pgfdwsource=> insert into salary values('[email protected]',1000000); INSERT 0 1 pgfdwsource=> d salary Table "public.salary" Column | Type | Modifiers ---------+-------------------+----------- emailid | character varying | salary | integer | pgfdwsource=> select * from salary; emailid | salary ---------------------+--------- [email protected] | 10000 [email protected] | 100000 [email protected] | 1000000 For pdfdwtarget, create a table corresponding to customer1 with the columns id, name, emailid, projectname, and contactnumber with dummy content. See the following code: [ec2-user@ip-172-31-15-24 ~]$ psql -h pgfdwtarget.xxxx.us-west-2.rds.amazonaws.com -d pgfdwtarget -U pgfdwtarget SET SSL connection (protocol: TLSv1.2, cipher: ECDHE-RSA-AES256-GCM-SHA384, bits: 256, compression: off) Type "help" for help. pgfdwtarget=> create table customer1( id int, name varchar, emailid varchar, projectname varchar, contactnumber bigint); CREATE TABLE pgfdwtarget=> insert into customer1 values(1,'Tom','[email protected]','Customer1.migration',328909432); INSERT 0 1 pgfdwtarget=> insert into customer1 values(2,'Harry','[email protected]','Customer1.etl',2328909432); INSERT 0 1 pgfdwtarget=> insert into customer1 values(3,'Jeff','[email protected]','Customer1.infra',328909432); INSERT 0 1 pgfdwtarget=> d customer1 Table "public.customer1" Column | Type | Modifiers ---------------+-------------------+----------- id | integer | name | character varying | emailid | character varying | projectname | character varying | contactnumber | bigint | pgfdwtarget=> select * from customer1; id | name | emailid | projectname | contactnumber ----+-------+---------------------+---------------------+--------------- 1 | Tom | [email protected] | Customer1.migration | 328909432 2 | Harry | [email protected] | Customer1.etl | 2328909432 3 | Jeff | [email protected] | Customer1.infra | 328909432 (3 rows) In both tables, the column emailid is common and can be used to derive insights into salary corresponding to customer1 employee information. Now let’s see this in action. Configuring your source instance, foreign server, user mapping, and foreign table All the steps in this section are performed after logging in with the role pgfdwsource into the primary database instance pgfdwsource. Connecting to the source instance You connect to your source instance with a master user or via a normal user that has rds_superuser permissions. You can use client tools like psql or pgAdmin. For more information, see Connecting to a DB instance running the PostgreSQL database engine. Create the extension postgres_fdw with CREATE EXTENSION: pgfdwsource=> conninfo You are connected to database "pgfdwsource" as user "pgfdwsource" on host "pgfdwsource.xxxx.us-west-2.rds.amazonaws.com" at port "5432". SSL connection (protocol: TLSv1.2, cipher: ECDHE-RSA-AES256-GCM-SHA384, bits: 256, compression: off) pgfdwsource=> du pgfdwsource List of roles Role name | Attributes | Member of -------------+-------------------------------+----------------- pgfdwsource | Create role, Create DB +| {rds_superuser} | Password valid until infinity | pgfdwsource=> create extension postgres_fdw; CREATE EXTENSION pgfdwsource=> dx List of installed extensions Name | Version | Schema | Description --------------+---------+------------+---------------------------------------------------- plpgsql | 1.0 | pg_catalog | PL/pgSQL procedural language postgres_fdw | 1.0 | public | foreign-data wrapper for remote PostgreSQL servers (2 rows) Creating a foreign server We use CREATE SERVER to create our foreign (remote) server mapping as the PostgreSQL-based server from which we pull the data. A foreign server typically encapsulates connection information that an FDW uses to access an external data resource. It uses the same connection options as libpq. SSLMODE ‘require’ makes sure that the data is encrypted in transit. See the following code: pgfdwsource=> create server my_fdw_target Foreign Data Wrapper postgres_fdw OPTIONS (DBNAME 'pgfdwtarget', HOST 'pgfdwtarget.xxxx.us-west-2.rds.amazonaws.com', SSLMODE 'require'); CREATE SERVER If the master user (or user with rds_superuser) is creating the foreign server, then other users need usage access to this server. See the following code: GRANT USAGE ON FOREIGN SERVER my_fdw_target TO normal_user; If you want to grant access to normal users to create a foreign server, you need to grant usage on the extension itself from the master user: GRANT USAGE ON FOREIGN DATA WRAPPER postgres_fdw TO normal_user; Creating user mapping CREATE USER MAPPING defines a mapping of a user to a foreign server. In the following code, when the user pgfdwsource is connecting to the server my_fdw_target (remote database), they use the login information provided in the user mapping. Therefore, postgres_fdw uses the user pgfdwtarget to connect to the remote database. pgfdwsource=> CREATE USER MAPPING FOR pgfdwsource SERVER my_fdw_target OPTIONS (user 'pgfdwtarget', password 'test1234'); CREATE USER MAPPING Creating a foreign table CREATE FOREIGN TABLE creates a foreign table in the source database that is mapped to the table in the foreign server. It creates a table reference in the local database of a table residing in the remote database. The name of this table reference is defined as the foreign table. For example, in the following code, foreign table customer1_fdw points to the table customer1, which resides in the remote database. Now, whenever you need to query data from table customer1 in the remote database, the user in local database queries using the foreign table customer1_fdw. pgfdwsource=> create foreign table customer1_fdw( id int, name varchar, emailid varchar, projectname varchar, contactnumber bigint) server my_fdw_target OPTIONS( TABLE_NAME 'customer1'); CREATE FOREIGN TABLE Furthermore, the name of the foreign table or table reference can be different from the name of the table in the remote database. This flexibility can be useful when you want to mask the name of the table in remote database. Running federated queries with a PostgreSQL FDW FDWs (postgres_fdw) allow you to query (SELECT, INSERT, UPDATE, and DELETE) a remote PostgreSQL-based database (Amazon RDS for PostgreSQL, Aurora PostgreSQL, or Amazon Redshift). For this post, we focus on the SELECT query functionality. With the preceding steps complete, you can now query the table customer1, which resides in the Amazon RDS for PostgreSQL or Aurora PostgreSQL instance pgfdwtarget.xxxx.us-west-2.rds.amazonaws.com in the database pgfdwtarget, from within the instance pgfdwsource.xxxx.us-west-2.rds.amazonaws.com without the need for replication or any kind of pipeline. You can also run join queries to perform aggregates (and more) to derive insights. See the following code: pgfdwsource=> conninfo You are connected to database "pgfdwsource" as user "pgfdwsource" on host "pgfdwsource.xxxx.us-west-2.rds.amazonaws.com" at port "5432". SSL connection (protocol: TLSv1.2, cipher: ECDHE-RSA-AES256-GCM-SHA384, bits: 256, compression: off) -- running select * on foreign table customer1 mapped to name customer1_fdw in source instance. pgfdwsource=> select * from customer1_fdw; id | name | emailid | projectname | contactnumber ----+-------+---------------------+---------------------+--------------- 1 | Tom | [email protected] | Customer1.migration | 328909432 2 | Harry | [email protected] | Customer1.etl | 2328909432 3 | Jeff | [email protected] | Customer1.infra | 328909432 (3 rows) -- running select * on foreign table customer1 mapped to name customer1_fdw in source instance while joining it with salary table to derive salary insights. pgfdwsource=> select * from salary s inner join customer1_fdw c on s.emailid=c.emailid; emailid | salary | id | name | emailid | projectname | contactnumber ---------------------+---------+----+-------+---------------------+---------------------+--------------- [email protected] | 10000 | 1 | Tom | [email protected] | Customer1.migration | 328909432 [email protected] | 100000 | 2 | Harry | [email protected] | Customer1.etl | 2328909432 [email protected] | 1000000 | 3 | Jeff | [email protected] | Customer1.infra | 328909432 (3 rows) In the following code, only the data for a particular project is queried. The project name details are stored in the remote server. In the explain plan of the query, the WHERE clause has been pushed down to the remote server. This makes sure that only the data required to realize the result of the query is retrieved from the remote server and not the entire table. This is one of the optimizations that postgres_fdw offers. pgfdwsource=> select * from salary s inner join customer1_fdw c on s.emailid=c.emailid where c.projectname like 'Customer1.etl'; emailid | salary | id | name | emailid | projectname | contactnumber ---------------------+--------+----+-------+---------------------+---------------+--------------- [email protected] | 100000 | 2 | Harry | [email protected] | Customer1.etl | 2328909432 (1 row) pgfdwsource=> explain verbose select * from salary s inner join customer1_fdw c on s.emailid=c.emailid where c.projectname like 'Customer1.etl'; QUERY PLAN ----------------------------------------------------------------------------------------------------------------------------------------------------- Nested Loop (cost=100.00..118.98 rows=1 width=144) Output: s.emailid, s.salary, c.id, c.name, c.emailid, c.projectname, c.contactnumber Join Filter: ((s.emailid)::text = (c.emailid)::text) -> Seq Scan on public.salary s (cost=0.00..1.03 rows=3 width=36) Output: s.emailid, s.salary -> Materialize (cost=100.00..117.83 rows=3 width=108) Output: c.id, c.name, c.emailid, c.projectname, c.contactnumber -> Foreign Scan on public.customer1_fdw c (cost=100.00..117.81 rows=3 width=108) Output: c.id, c.name, c.emailid, c.projectname, c.contactnumber Remote SQL: SELECT id, name, emailid, projectname, contactnumber FROM public.customer1 WHERE ((projectname ~~ 'Customer1.etl'::text)) (10 rows) You can pull data from a different database within the same instance or from a different instance, as seen in the preceding examples. You can also pull data from your PostgreSQL-based data warehouse like Amazon Redshift for a quick query on archived data. Because the data is pulled in real time from a foreign database, you can achieve this without needing to set up any kind of replication or reserving space in the source database. Cleaning up You can follow the steps in this section to clean up the resources created in previous steps: Drop the foreign table customer1_fdw: pgfdwsource=> drop foreign table customer1_fdw; DROP FOREIGN TABLE Drop the user mapping that maps the database user to the foreign server user: pgfdwsource=> drop user mapping for pgfdwsource SERVER my_fdw_target; DROP USER MAPPING Drop the foreign server definition that provides the local PostgreSQL server with the foreign (remote) server connection information: pgfdwsource=> drop server my_fdw_target; DROP SERVER Drop the extension postgres_fdw: pgfdwsource=> drop extension postgres_fdw; DROP EXTENSION Common error messages As is the case with any other setup, you may encounter some common issues while setting up postgres_fdw, like connection problems or permission issues. The following section lists some common error messages that you may encounter and also suggests common culprits for those errors, which should point you in the right direction to mitigate them. Network connectivity – The following error message can appear when trying to query the foreign table customer1_fdw from the source database. A connection timed out error message appears when there is no network connectivity between the source and target databases. Common culprits are incorrectly configured security groups, Network Access Control List (NACL), or route table. pgfdwsource=> select * from customer1_fdw; ERROR: could not connect to server "my_fdw_target" DETAIL: could not connect to server: Connection timed out Is the server running on host "pgfdwtarget.xxxx.us-west-2.rds.amazonaws.com" (172.31.30.166) and accepting TCP/IP connections on port 5432? DNS resolution – The following error message may appear when trying to query the foreign table customer1_fdw from the source database. This is a classic case of DNS resolution failure (issues in /etc/resolv.conf) for the endpoint. The culprit is the incorrect endpoint entered while creating the foreign server. pgfdwsource=> select * from customer1_fdw; ERROR: could not connect to server "my_fdw_target" DETAIL: could not translate host name "pgfdwtarget.xx.us-west-2.rds.amazonaws.com" to address: Name or service not known Table not present – In this scenario, the table notpresent was not in the target database instance. Therefore, the error message ERROR: relation "public.notpresent" does not exist The common culprit is a non-existent or dropped table. pgfdwsource=> create foreign table customer2_fdw( id int, name varchar, emailid varchar, projectname varchar, contactnumber bigint) server my_fdw_target OPTIONS( TABLE_NAME 'notpresent'); CREATE FOREIGN TABLE pgfdwsource=> select * from customer2_fdw; ERROR: relation "public.notpresent" does not exist CONTEXT: remote SQL command: SELECT id, name, emailid, projectname, contactnumber FROM public.notpresent User permission – In this scenario, a permission denied error occurs when setting up user mapping, saying that you don’t have permission over the schema test. Common culprits are lack of select permission on the schema or table for the user specified in user mappings. pgfdwsource=> create foreign table customer1_fdw( id int, name varchar, emailid varchar, projectname varchar, contactnumber bigint) server my_fdw_target OPTIONS( SCHEMA_NAME 'test', TABLE_NAME 'newtable'); CREATE FOREIGN TABLE pgfdwsource=> select * from customer1_fdw; ERROR: permission denied for schema test Additional capabilities In addition to SELECT, postgres_fdw allows you to run UPDATE, INSERT, and DELETE on a foreign table. The following code updates the foreign table customer1_fdw (note Foreign Update in the query plan): pgfdwsource=> explain update customer1_fdw set name='Jeff' where name='Jerry'; QUERY PLAN ------------------------------------------------------------------------------- Update on customer1_fdw (cost=100.00..119.73 rows=4 width=114) -> Foreign Update on customer1_fdw (cost=100.00..119.73 rows=4 width=114) (2 rows) pgfdwsource=> select * from customer1_fdw; id | name | emailid | projectname | contactnumber ----+-------+---------------------+---------------------+--------------- 1 | Tom | [email protected] | Customer1.migration | 328909432 2 | Harry | [email protected] | Customer1.etl | 2328909432 3 | Jerry | [email protected] | Customer1.infra | 328909432 (3 rows) pgfdwsource=> update customer1_fdw set name='Jeff' where name='Jerry'; UPDATE 1 pgfdwsource=> select * from customer1_fdw; id | name | emailid | projectname | contactnumber ----+-------+---------------------+---------------------+--------------- 1 | Tom | [email protected] | Customer1.migration | 328909432 2 | Harry | [email protected] | Customer1.etl | 2328909432 3 | Jeff | [email protected] | Customer1.infra | 328909432 (3 rows) postgres_fdw come with some small optimizations, such as FDW maintaining the table schema locally. As a result, rather than doing a SELECT * to pull all the data from a table in remote server, the FDW sends query WHERE clauses to the remote server to run, and doesn’t retrieve table columns that aren’t needed for the current query. It can also push down joins, aggregates, sorts, and more. postgres_fdw is quite powerful; this post covers just the basic functionality. For more information about these optimizations, see Appendix F. Additional Supplied Modules. Summary This post illustrated what you can achieve with federated query capability and postgres_fdw in Amazon RDS for PostgreSQL or Aurora PostgreSQL to query data from a PostgreSQL-based remote server, both managed and self-managed on Amazon EC2 or on premises. We encourage you to use the postgres_fdw extension of community PostgreSQL in your Amazon RDS for PostgreSQL and Aurora PostgreSQL environments to query data from multiple databases in remote PostgreSQL-based servers like Amazon Redshift, Amazon RDS for PostgreSQL, Aurora PostgreSQL, self-managed PostgreSQL servers on Amazon EC2 or on premises, or from the same server in real time without the need for setting up ongoing replication or a data pipeline. About the Authors Vibhu Pareek is a Solutions Architect at AWS. He joined AWS in 2016 and specializes in providing guidance on cloud adoption through the implementation of well architected, repeatable patterns and solutions that drive customer innovation. He has keen interest in open source databases like PostgreSQL. In his free time, you’d find him spending hours on automobile reviews, enjoying a game of football or engaged in pretentious fancy cooking. Gaurav Sahi is a Principal Solutions Architect based out of Bangalore, India and has rich experience across embedded, telecom, broadcast & digital video and cloud technologies. In addition to helping customers in their transformation journey to cloud, his current passion is to explore and learn AI/ML services. He likes to travel, enjoy local food and spend time with family and friends in his free time. https://aws.amazon.com/blogs/database/federated-query-support-for-amazon-aurora-postgresql-and-amazon-rds-for-postgresql/
0 notes