#research topics in Apache Big Data Projects service
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
Tumblr has been providing a Korean-language service since 2013.
Text
Top Australian Universities for Cloud Computing and Big Data
In the age of digital transformation, data is the new oil; cloud computing is the infrastructure fuelling its refining. Big data and cloud computing together have created a dynamic ecosystem for digital services, business intelligence, and innovation generation. As industries shift towards cloud-first policies and data-driven decision-making, the demand for qualified individuals in these areas has increased. Known for its strong academic system and industry-aligned education, Australia offers excellent opportunities for foreign students to concentrate in Cloud Computing and Big Data. This post will examine the top Australian universities leading the way in these technical domains.
Why Study Cloud Computing and Big Data in Australia?
Ranked globally, Australia's universities are well-equipped with modern research tools, industry ties, and hands-on learning environments. Here are some fascinating reasons for learning Cloud Computing and Big Data in Australia:
Global Recognition:Ranked among the top 100 globally, Australian universities offer degrees recognised all around.
Industry Integration: Courses typically include capstone projects and internships as well as research collaborations with tech behemoths such as Amazon Web Services (AWS), Google Cloud, Microsoft Azure, and IBM.
High Employability: Graduates find decent employment in sectors including government, telecommunications, healthcare, and finance.
Post-Study Work Opportunities:Australia offers post-study work visas allowing foreign graduates to gain practical experience in the country.
Core Topics Covered in Cloud Computing and Big Data Courses
Courses in these fields typically cover:
Cloud Architecture & Security
Distributed Systems & Virtualization
Big Data Analytics
Machine Learning
Data Warehousing
Cloud Services (AWS, Google Cloud, Azure)
DevOps & Infrastructure Automation
Real-Time Data Processing (Apache Spark, Kafka)
Python, R, SQL, and NoSQL Databases
Top Australian Universities for Cloud Computing and Big Data
1. University of Melbourne
The University of Melbourne offers courses such the Master of Data Science and Master of Information Technology with a Cloud Computing emphasis. Renowned for its research excellence and global standing, the university emphasises a balance between fundamental knowledge and pragmatic cloud infrastructure training. Students benefit from close relationships with industry, including projects with AWS and Google Cloud, all run from its Parkville campus in Melbourne
2. University of Sydney
Emphasising Cloud Computing and Data Management, the University of Sydney provides the Master of Data Science and the Master of Information Technology. Its comprehensive course provides students information in data mining, architecture, and analytics. Internships and cooperative research in the heart of Sydney's Camperdown campus supported by the Sydney Informatics Hub allow students to engage with industry.
3. Monash University
Monash University offers a Master of Data Science as well as a Master of Information Technology concentrating in Enterprise Systems and Cloud Computing. Known for its multidisciplinary and practical approach, Monash mixes cloud concepts with artificial intelligence, cybersecurity, and IoT. Students located at the Melbourne Clayton campus have access to modern laboratories and industry-aligned projects.
4. University of New South Wales (UNSW Sydney)
University of New South Wales (UNSW Sydney) students can choose either the Master of Data Science and Decisions or the Master of IT. Under a curriculum covering distributed systems, networking, and scalable data services, UNSW provides practical training and close ties with Microsoft, Oracle, and other world players. The Kensington campus keeps a vibrant tech learning environment.
5. Australian National University (ANU)
The Australian National University (ANU), based in Canberra, offers the Master of Computing and the Master of Machine Learning and Computer Vision, both addressing Big Data and cloud tech. ANU's strength lies in its research-driven approach and integration of data analysis into scientific and governmental applications. Its Acton campus promotes high-level research with a global vi
6. University of Queensland (UQ)
The University of Queensland (UQ) offers the Master of Data Science as well as the Master of Computer Science with a concentration in Cloud and Systems Programming. UQ's courses are meant to include large-scale data processing, cloud services, and analytics. The St. Lucia campus in Brisbane also features innovation centres and startup incubators to enable students develop useful ideas.
7. RMIT University
RMIT University provides the Master of Data Science and the Master of IT with Cloud and Mobile Computing as a specialisation. RMIT, an AWS Academy member, places great importance on applied learning and digital transformation and provides cloud certifications in its courses. Students learn in a business-like environment at the centrally located Melbourne City campus.
8. University of Technology Sydney (UTS)
University of Technology Sydney (UTS) sets itself apart with its Master of Data Science and Innovation and Master of IT with Cloud Computing specialisation. At UTS, design thinking and data visualisation receive significant attention. Located in Ultimo, Sydney, the university features a "Data Arena" allowing students to interact with big-scale data sets visually and intuitively.
9. Deakin University
Deakin University offers a Master of Data Science as well as a Master of Information Technology with Cloud and Mobile Computing. Deakin's courses are flexible, allowing on-campus or online study. Its Burwood campus in Melbourne promotes cloud-based certifications and wide use of technologies including Azure and Google Cloud in course delivery.
10. Macquarie University
Macquarie University provides the Master of Data Science and the Master of IT with a Cloud Computing and Networking track. Through strong integration of cloud environments and scalable systems, the Macquarie Data Science Centre helps to foster industry cooperation. The North Ryde campus is famous for its research partnerships in smart infrastructure and public data systems.
Job Roles and Career Opportunities
Graduates from these programs can explore a wide range of roles, including:
Cloud Solutions Architect
Data Scientist
Cloud DevOps Engineer
Big Data Analyst
Machine Learning Engineer
Cloud Security Consultant
Database Administrator (Cloud-based)
AI & Analytics Consultant
Top Recruiters in Australia:
Amazon Web Services (AWS)
Microsoft Azure
Google Cloud
IBM
Atlassian
Accenture
Commonwealth Bank of Australia
Deloitte and PwC
Entry Requirements and Application Process
While specifics vary by university, here are the general requirements:
Academic Qualification: Bachelor’s degree in IT, Computer Science, Engineering, or a related field.
English Proficiency: IELTS (6.5 or above), TOEFL, or PTE.
Prerequisites:Some courses might need knowledge of statistics or programming (Python, Java).
Documents NeededSOP, academic transcripts, CV, current passport, and letters of recommendation.
Intakes:
February and July are the most common intakes.
Final Thoughts
Given the growing global reliance on digital infrastructure and smart data, jobs in Cloud Computing and Big Data are not only in demand but also absolutely essential. Australian universities are driving this transformation by offering overseas students the chance to learn from the best, interact with real-world technologies, and boldly enter global tech roles. From immersive courses and knowledgeable professors to strong industry ties, Australia provides the ideal launchpad for future-ready tech professionals.
Clifton Study Abroad is an authority in helping students like you negotiate the challenging road of overseas education. Our experienced advisors are here to help you at every turn, from choosing the right university to application preparation to getting a student visa. Your future in technology starts here; let us help you in opening your perfect Cloud Computing and Big Data job.
Are you looking for the best study abroad consultants in Kochi
#study abroad#study in uk#study abroad consultants#study in australia#study in germany#study in ireland#study blog
0 notes
Text
How Can Beginners Start Their Data Engineering Interview Prep Effectively?
Embarking on the journey to become a data engineer can be both exciting and daunting, especially when it comes to preparing for interviews. As a beginner, knowing where to start can make a significant difference in your success. Here’s a comprehensive guide on how to kickstart your data engineering interview prep effectively.
1. Understand the Role and Responsibilities
Before diving into preparation, it’s crucial to understand what the role of a data engineer entails. Research the typical responsibilities, required skills, and common tools used in the industry. This foundational knowledge will guide your preparation and help you focus on relevant areas.
2. Build a Strong Foundation in Key Concepts
To excel in data engineering interviews, you need a solid grasp of key concepts. Focus on the following areas:
Programming: Proficiency in languages such as Python, Java, or Scala is essential.
SQL: Strong SQL skills are crucial for data manipulation and querying.
Data Structures and Algorithms: Understanding these fundamentals will help in solving complex problems.
Databases: Learn about relational databases (e.g., MySQL, PostgreSQL) and NoSQL databases (e.g., MongoDB, Cassandra).
ETL Processes: Understand Extract, Transform, Load processes and tools like Apache NiFi, Talend, or Informatica.
3. Utilize Quality Study Resources
Leverage high-quality study materials to streamline your preparation. Books, online courses, and tutorials are excellent resources. Additionally, consider enrolling in specialized programs like the Data Engineering Interview Prep Course offered by Interview Kickstart. These courses provide structured learning paths and cover essential topics comprehensively.
4. Practice with Real-World Problems
Hands-on practice is vital for mastering data engineering concepts. Work on real-world projects and problems to gain practical experience. Websites like LeetCode, HackerRank, and GitHub offer numerous challenges and projects to work on. This practice will also help you build a portfolio that can impress potential employers.
5. Master Data Engineering Tools
Familiarize yourself with the tools commonly used in data engineering roles:
Big Data Technologies: Learn about Hadoop, Spark, and Kafka.
Cloud Platforms: Gain experience with cloud services like AWS, Google Cloud, or Azure.
Data Warehousing: Understand how to use tools like Amazon Redshift, Google BigQuery, or Snowflake.
6. Join a Study Group or Community
Joining a study group or community can provide motivation, support, and valuable insights. Participate in forums, attend meetups, and engage with others preparing for data engineering interviews. This network can offer guidance, share resources, and help you stay accountable.
7. Prepare for Behavioral and Technical Interviews
In addition to technical skills, you’ll need to prepare for behavioral interviews. Practice answering common behavioral questions and learn how to articulate your experiences and problem-solving approach effectively. Mock interviews can be particularly beneficial in building confidence and improving your interview performance.
8. Stay Updated with Industry Trends
The field of data engineering is constantly evolving. Stay updated with the latest industry trends, tools, and best practices by following relevant blogs, subscribing to newsletters, and attending webinars. This knowledge will not only help you during interviews but also in your overall career growth.
9. Seek Feedback and Iterate
Regularly seek feedback on your preparation progress. Use mock interviews, peer reviews, and mentor guidance to identify areas for improvement. Continuously iterate on your preparation strategy based on the feedback received.
Conclusion
Starting your data engineering interview prep as a beginner may seem overwhelming, but with a structured approach, it’s entirely achievable. Focus on building a strong foundation, utilizing quality resources, practicing hands-on, and staying engaged with the community. By following these steps, you’ll be well on your way to acing your data engineering interviews and securing your dream job.
#jobs#coding#python#programming#artificial intelligence#education#success#career#data scientist#data science
0 notes
Text
Apache Big Data Projects

Apache Big Data Projects is the best transportation to reach desired position in your intellectual journey. We are started our Apache Big Data Projects service with much aspiration of support students and research fellows in all over the world.
#research topics in Apache Big Data Projects service#research guidance in Apache Big Data Projects service
0 notes
Text
Announcing Bandar-Log: easily monitor throughput of data sources and processing components for ETL pipelines
By Alexey Lipodat, Project Engagement, Oath
One of the biggest problems with a typical Extract, Transform, Load (ETL) workflow is that stringing together multiple systems adds processing time that is often unmeasured. At Oath, we turned to open source for a solution.
When researching possible solutions for enabling process metrics within our ETL pipeline, we searched for tools focused on Apache Kafka, Athena, Hive, Presto, and Vertica. For Kafka, we discovered Burrow, a monitoring service that provides consumer lag metric, but no existing options were available for Hive and Vertica. Creating or integrating a different monitoring application for each component of the ETL pipeline would significantly increase the complexity to run and maintain the system.
In order to avoid unnecessary complexity and effort, we built Bandar-Log, a simple, standalone monitoring application based on typical ETL workflows. We published it as an open source project so that it can be a resource for other developers as well.
Meet Bandar-Log
Bandar-Log is a monitoring service that tracks three fundamental metrics in real-time: lag, incoming, and outgoing rates. It runs as a standalone application that tracks performance outside the monitored application and sends metrics to an associated monitoring system (e.g. Datadog).

A typical ETL assumes there will be some processing logic between data sources. This assumption adds some delay, or "resistance," which Bandar-Log can measure.
For example:
How many events is the Spark app processing per minute as compared to how many events are coming to Kafka topics?
What is the size of unprocessed events in Kafka topics at this exact moment?
How much time has passed since the last aggregation processed?
Bandar-Log makes it easy to answer these questions and is a great tool:
Simple to use — create your own Bandar-Log in 10 minutes by following the Start Bandar-Log in 3 steps doc, and easily extend or add custom data sources
Stable — tested extensively on real-time big data pipelines
Fully supported — new features are frequently added
Flexible — no modifications needed to existing apps for this external, standalone application to monitor metrics.
How Bandar-Log works
To better understand how Bandar-Log works, let's review a single part of the ETL process and integrate it with Bandar-Log.
As an example, we’ll use the replication stage, the process of copying data from one data source to another. Let's assume we already have aggregated data in Presto/Hive storage and now we’ll replicate the data to Vertica and query business reports. We'll use a replicator app to duplicate data from one storage to another. This process copies the dedicated batch of data from Presto/Hive to Vertica.
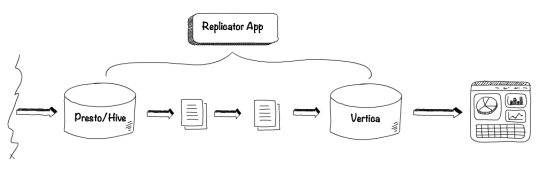
The replication process is now configured, but how should we track the progress? We want to make sure that the replication works as expected and that there isn’t any delay. In order to confirm that the replication is working correctly, we will need to know:
How much unreplicated data do we have in Presto/Hive?
What's the incoming rate of Presto/Hive data?
How much data has already been replicated to Vertica?
What's the lag between unreplicated and already replicated data?
Inserting tracking logic directly in the replicator app or adding tracking logic in all the ETL pipeline components where we need the process status pose concerns, as these approaches are not scalable and if the replicator app fails, no information is received. A standalone application, like Bandar-Log, solves these issues by tracking status from outside the monitored application.
Let's integrate Bandar-Log with the replication pipeline. As mentioned above, Bandar-Log operates with three fundamental metrics:
IN - incoming rate
OUT - outgoing rate
LAG - lag rate (the difference between IN and OUT)
Every component independently interprets lag and incoming/outgoing rates. For instance, a Spark-driven app depends on Kafka, therefore, the lag and rates signify the number of unread messages, both producing and consuming rates. For our replicator app, incoming and outgoing rates mean how many batches of data arrived and were processed per some interval. ETL components use a dedicated column to mark and isolate a specific piece of processed data, which is called batch_id. The semantics of batch_id is a Unix time timestamp measured in milliseconds, which determines the time when the piece of data was processed.
Keeping this in mind, we’ll now use the Presto/Hive source to measure the input rate and our Vertica source to measure the output rate.

Due to this approach, an input rate will be the last processed timestamp from Presto/Hive, and the output rate will be the last replicated timestamp from Vertica. Bandar-Log will fetch these metrics according to the rate interval, which can be configured to retrieve metrics based on preference. Fetched metrics will be pushed to Datadog, the default monitoring system.

Now that we have the input and output rate metrics. What about lag? How can we track the delay of our replication process?
This is quite simple: the LAG metric depends on IN and OUT metrics and is calculated as the difference between them. If we have both of these metrics, then we can easily calculate the LAG metric, which will show us the delay in the replication process between Presto/Hive and Vertica. However, if we are using the real-time system then we should provide data faster and track the status of this process. This metric can be called "Real-time Lag" and determines the delay between the current timestamp and the timestamp associated with the last processed or replicated batch of data.

To calculate the REALTIME_LAG metric, the IN metric from Presto/Hive isn’t needed; instead, we'll use the current timestamp and OUT metric from the final source, which is Vertica. After this step we'll receive four metrics (IN, OUT, LAG, REALTIME_LAG) in the monitoring system. We can now create appropriate dashboards and alert monitors.

This is just one of many examples showing how you can use Bandar-Log. Explore more examples in the Bandar-Log Readme doc. Download the code and if you’d like to contribute any code fixes or additional functionality, visit Bandar-Log on Github and become part of our open source community.
P.S. We’re hiring! Explore opportunities here.
7 notes
·
View notes
Text
A recent Statista report states that the total amount of data created, captured, copied, and consumed globally reached 64.2 zettabytes in 2020. It further projects that global data creation would be equivalent to 180 zettabytes by 2025.
Whether the internet is used to make transactions on different platforms, research a topic, order food online and perform other such things, data is continuously generated. The amount of data produced follows an upward trajectory, owing to the factors like increased utilization of social media, online shopping, as well as streaming services. And, for companies to make sense of this data and generate insights from such huge amounts of data—business data processing is the key.
What is Data Processing?
In this, data is collected and manipulated to make its best use. Hence, data processing services are used around the world by organizations to utilize their data in the best way possible—this includes converting raw data to an organized and more stable format. The resultant data can then be used to predict trends and make forecasts, which help in fail-proof and future-oriented decision-making.
However, dealing with big data is a complex business process that involves a great amount of technical expertise as there are various stages in the entire data processing cycle—right from the data cleansing, processing, analysis and to the transfer of data.
Data Processing Stages
Data might be available in the form of mailing lists, orders, forms, images, market research forms, credit cards, insurance claims, surveys, etc. Though the data is available in different formats, the data processing workflow remains the same, irrespective of the type and format of data. Take a look at the different stages of a data processing cycle:
Data Aggregation
Data aggregation is the first and, perhaps, one of the most important stages of the data processing cycle. The whole process is bound to go haywire if the data isn’t collected appropriately. It is collected from different systems, data warehouses, and organizations. If you opt for outsourcing ancillary tasks such as online or offline data processing tasks, you need to transfer raw data securely.
Data Organization
In the second step, raw data is cleaned properly and prepared to be converted into information that can be used further. The data cleansing process includes the elimination of errors, inaccuracies, and incomplete entries from the collected data, whereas data preparation involves arranging data in proper files and systems using automation software.
Data Input
In the data input stage, data is converted into machine readable language and entered into systems for processing purposes. It is reorganized to be prepared for conversion and generate valuable insights. The data input step is one of the most crucial parts of the data processing cycle.
Data Processing
Data processing is yet another crucial stage that includes algorithms and machine intervention to process data. Many of the latest tools and technologies such as Apache, MongoDB, Cassandra, etc., are used for data processing.
Data Output
In this step, data is converted into a simplified format so that it becomes easily interpretable by the researchers and other stakeholders. Data output must be presented in the form of images, videos, text, pie-charts, bar graphs, visuals, plots, graphs, histograms, etc. so that humans can interpret it easily and make informed decisions.
Data Storage
Data storage is the last stage of the data processing cycle that involves storing data for future use and reference after processing. Though recent data is highly valuable, historical data is also golden and never goes to waste. It is of immense importance for an organization and is highly essential in the case of data reviews and audits.
Last but not the least, data analysis is another important function related to data processing that includes the use of algorithms to predict patterns and make forecasts based on current data. This is one of the most important online and offline data processing solutions since it enables businesses to not merely survive, but thrive, even when facing stiff competition.
Bottom Line
Performing data processing in-house while managing other core competencies is a significant undertaking. It requires a great deal of time and effort to be executed efficiently; errors in the process can deviate from the desired outcomes. In addition to this, getting an in-house set-up adds to operational expenditures. Instead, engaging in outsourced services or consulting professionals is a better way out.
Collaborating with reliable and experienced data processing companies help businesses to get quality outcomes within the stipulated time and budget. The professionals are well-acquainted with the nitty-gritty of the entire task and work accordingly. Having the right blend of skills, experience, and expertise ensures accurate and reliable outcomes. Therefore, you must begin with finding an appropriate service provider.
0 notes
Text
How Does Data Science Works In 2021?
Table of Contents
·
What is a Data Science all about?
o Description of data science
§ Why do companies need data science?
§ We’ve come a long way in working with small data, on large unstructured beaches and have been developed differently from different sources. Traditional business intelligence tools do not work to solve this huge unstructured platform. Thus, data technology provides advanced tools for the use of data from a variety of sources, such as financial magazines, multimedia files, advertising forms, sensors and instruments, and text files.
§ Data Science Information
What is a Data Science all about?
Data science continues to be a hot topic among organizations and trained professionals who oversee data collection and receive sound advice to support business growth. Many items are building for any business, but only if they are well managed.
The need for memory has increased as we enter the era of high points. 2010 The publication was to build state-of-the-art facilities to preserve this important information, which was eventually acquired and improved to create business clarification. Systems like Hadoop, which supports backup, are currently trying to process this data. Let’s take a look at what data science is and how it fits into big data and business environments.
Description of data science
In general, data science can be defined as the study of data, its origin, its representation, and whether it is an important investment and tool for the development of IT and strategies. commercial.
Why do companies need data science? We’ve come a long way in working with small data, on large unstructured beaches and have been developed differently from different sources. Traditional business intelligence tools do not work to solve this huge unstructured platform. Thus,
data technology provides advanced tools
for the use of data from a variety of sources, such as financial magazines, multimedia files, advertising forms, sensors and instruments, and text files.
The following is the correct use, which is why data technology has gained popularity among companies.
Data science has many advantages for predictive analysis. Weather forecasting provides information on satellites, radars, ships, and aircraft to forecast the weather and predicts natural disasters. This allows you to do it on time and avoid as many dangers as possible.
The marketing of the product is still unclear, as traditional methods provide information from reading history, purchase history, and important demographics. With the help of data science, a lot of data and a large number of different types can be taught well and enough to show other selected systems.
Data science also helps in decision-making. The classic design is autonomous or smart cars. A smart car collects real-time information from its environment using various cells such as radar, cameras, and lasers to plan where it is located. Based on this information and high quality of education, it makes important driving choices such as turning, stopping, speed, and so on.
Data Science Variants
Why imitate a career in science fiction?
After reviewing why companies need data technology in the previous section, let’s take a look at why video technology is a viable option in this video
What is a data expert?
Search engines search for relevant topics, gather relevant information from a variety of sources, store and organize data, record relevant information, and ultimately change business decisions, and communicate results accurately too -company.
Data researchers not only create measurable scales and simplify the knowledge economy, but also have the communication and control experience needed to find measurable and visible members in a variety of businesses.
The best quality of data science
Statistical proof
Scientific advice
Communication skills in a variety of ways
The brain is curious
creatures
If you want to find out all the data related to the data, you can watch the video below
What are the key skills of a news analyst?
Data science is a discipline that combines mathematical knowledge, business experience, and scientific knowledge. They form the basis of data science and require a deep understanding of the concepts in each field.
These are the skills you need to become a data scientist-
Mathematical Experience: There is a misconception that data analysis is related to mathematics. There is no doubt that numbers and old numbers are very important for data science, but other strategies are also very important, such as multiplication methods and especially algebraic lines, which are supportive. Multi-method data acquisition system. data and engine functions.
Business: Business-backed data analysts are also responsible for sharing information with relevant parties and individuals to comply with business decisions. They are in a position to offer business advice because they are like everyone else. Therefore, data analysts must have the acumen for the business to perform its functions.
State-of-the-art knowledge: information scientists have to work with complex algorithms and tools. They also need to encode and create hotfixes using one or more SQL, Python, R, and SAS languages, and sometimes Java, Scala, Julia, and others. Data researchers also need to overcome technical problems and avoid obstacles or obstacles that may arise due to a lack of scientific experience.
Other activities in the science of science:
By now, we understand what data science is, why companies need data science, who is a data scientist, and what special skills are needed to start data science.
Now, for data scientists, let’s take a look at some of the information used by scientists:
Data Specialist – This function is a bridge between business analysts and data analysts. They work on selected issues and get results by organizing and analyzing the data presented. Translate technology into event performance monitoring and by communicating this result to relevant stakeholders. In addition to programming and math skills, they need data security and vision skills.
Data Engineer – The job of a data engineer is to handle large data transitions. They organize the data transfer and infrastructure to convert the data and send it to the real data processors for processing. Works well on Java, Scala, MongoDB, Cassandra DB, and Apache Hadoop.
Is Data Science Important For 2021? Learn with Skill Shiksha
Data Science Information
1. What is a simple definition of data science?
Data science can be defined as a limited search space that uses data for a variety of research and publication projects to find ideas and meaning in it. Data science requires a combination of different technologies, including math, business design, computer science, and so on. Data is now widely distributed through phones and other devices. Businesses use this information to better understand customer behavior and more. However, this does not mean that data science is only used to promote business. The use of data technology is widespread in all industries such as health, finance, education, supply chain, and more.
The first meaning of scientific data is the ability to convert raw data into valuable information. Today, data technology is important for development and today it promotes solutions in a variety of contexts.
2. What exactly do media scientists do?
Data scientists develop and use algorithms to analyze data. These approaches often involve the use and development of user tools and traditional tools to help companies and customers interpret meaningful data. They also help you read data-driven reports to better understand your customers. Overall, data researchers have contributed to every step of data processing, from optimization to structural improvement and enhancement, from experimentation to real-time performance evaluation.
3. What is an example of science fiction?
Examples and applications of data technology have become widespread in all industries. Outstanding examples of data technology today are their use in the study of COVID-19 infection and in the development of therapeutic drugs. Examples of data technology include fraud detection, independent service, health checks, non-fiction, e-commerce and entertainment management, and more.
4. What is the right course of data science?
A Certificate in Information Science is a degree in science, math, science, or any related field. Undergraduate university students may also enroll in data science courses. The authors shall enter X., XII. and a bachelor’s degree has about 60 percent.
5. Is scientific data a good job?
Yes, data science is a big undertaking, indeed one of the best of the moment. There is no local law that will not take advantage of data technology, which means that the work of data technology is growing every year. This means that competitors also receive the best prices on the market. According to Glassdoor, data scientists earn about $ 116,100 a year.
6. Do data scientists stick to it?
Yes, news scientists often code. Because of their role, data analysts are required to create a variety of behavior-related tasks. Data scientists need to have knowledge of different programming languages such as C / C ++, SQL, Python, Java, and more. Python has become the most widely used language for data scientists.
7. What problems does data science solve?
From climate change to improved data service systems, data scientists around the world are solving every problem. Data technology projects range from the development of collaborative goals to the development of quality solutions and construction plans.
8. Why do scientists refuse?
The main reasons for the removal of data analysts are not what is expected from the selected job and working conditions. Data researchers are very concerned about the gap between their expectations and the certainty of the work involved. Data mining work can play out remotely, but the truth is that it involves a lot of work. It is no coincidence that companies pay a lot of money to data analysts. It handles a lot of discs and creates a lot of sounds and numbers every day, which can be a little overwhelming. One reason is that data analysts often work independently and lack confidence in the team. Although this is a good job, you can feel lonely and connected.
9. Can I study data science on my own?
You can really start learning data science, but to become a professional you have to enroll in courses that give you real training, guidance, and coaching. Data science has many functions around the world, and to qualify for a job, you need industry knowledge and knowledge of real-world forms that can only be achieved by highly experienced manufacturers.
10. What should I study to become a news scientist?
To be a data scientist, you must first learn the Python format, the R format, the SQL database, and so on. If you understand these languages well, you will find simple algorithms and tools. Therefore, it is best to register for the course so that you can better understand and know this website.
0 notes
Text
How Does Data Science Works In 2021
What is a Data Science all about?
Data science continues to be a hot topic among organizations and trained professionals who oversee data collection and receive sound advice to support business growth. Many items are building for any business, but only if they are well managed.
The need for memory has increased as we enter the era of high points. 2010 The publication was to build state-of-the-art facilities to preserve this important information, which was eventually acquired and improved to create business clarification. Systems like Hadoop, which supports backup, are currently trying to process this data. Let’s take a look at what data science is and how it fits into big data and business environments.
Description of data science
In general, data science can be defined as the study of data, its origin, its representation, and whether it is an important investment and tool for the development of IT and strategies. commercial.
Why do companies need data science? We’ve come a long way in working with small data, on large unstructured beaches and have been developed differently from different sources. Traditional business intelligence tools do not work to solve this huge unstructured platform. Thus,
data technology provides advanced tools
for the use of data from a variety of sources, such as financial magazines, multimedia files, advertising forms, sensors and instruments, and text files.
The following is the correct use, which is why data technology has gained popularity among companies.
Data science has many advantages for predictive analysis. Weather forecasting provides information on satellites, radars, ships, and aircraft to forecast the weather and predicts natural disasters. This allows you to do it on time and avoid as many dangers as possible.
The marketing of the product is still unclear, as traditional methods provide information from reading history, purchase history, and important demographics. With the help of data science, a lot of data and a large number of different types can be taught well and enough to show other selected systems.
Data science also helps in decision-making. The classic design is autonomous or smart cars. A smart car collects real-time information from its environment using various cells such as radar, cameras, and lasers to plan where it is located. Based on this information and high quality of education, it makes important driving choices such as turning, stopping, speed, and so on.
Data Science Variants
Why imitate a career in science fiction?
After reviewing why companies need data technology in the previous section, let’s take a look at why video technology is a viable option in this video
What is a data expert?
Search engines search for relevant topics, gather relevant information from a variety of sources, store and organize data, record relevant information, and ultimately change business decisions, and communicate results accurately too -company.
Data researchers not only create measurable scales and simplify the knowledge economy, but also have the communication and control experience needed to find measurable and visible members in a variety of businesses.
The best quality of data science
Statistical proof
Scientific advice
Communication skills in a variety of ways
The brain is curious
creatures
If you want to find out all the data related to the data, you can watch the video below
What are the key skills of a news analyst?
Data science is a discipline that combines mathematical knowledge, business experience, and scientific knowledge. They form the basis of data science and require a deep understanding of the concepts in each field.
These are the skills you need to become a data scientist-
Mathematical Experience: There is a misconception that data analysis is related to mathematics. There is no doubt that numbers and old numbers are very important for data science, but other strategies are also very important, such as multiplication methods and especially algebraic lines, which are supportive. Multi-method data acquisition system. data and engine functions.
Business: Business-backed data analysts are also responsible for sharing information with relevant parties and individuals to comply with business decisions. They are in a position to offer business advice because they are like everyone else. Therefore, data analysts must have the acumen for the business to perform its functions.
State-of-the-art knowledge: information scientists have to work with complex algorithms and tools. They also need to encode and create hotfixes using one or more SQL, Python, R, and SAS languages, and sometimes Java, Scala, Julia, and others. Data researchers also need to overcome technical problems and avoid obstacles or obstacles that may arise due to a lack of scientific experience.
Other activities in the science of science:
By now, we understand what data science is, why companies need data science, who is a data scientist, and what special skills are needed to start data science.
Now, for data scientists, let’s take a look at some of the information used by scientists:
Data Specialist – This function is a bridge between business analysts and data analysts. They work on selected issues and get results by organizing and analyzing the data presented. Translate technology into event performance monitoring and by communicating this result to relevant stakeholders. In addition to programming and math skills, they need data security and vision skills.
Data Engineer – The job of a data engineer is to handle large data transitions. They organize the data transfer and infrastructure to convert the data and send it to the real data processors for processing. Works well on Java, Scala, MongoDB, Cassandra DB, and Apache Hadoop.
Is Data Science Important For 2021? Learn with Skill Shiksha
Data Science Information
What is a simple definition of data science?
Data science can be defined as a limited search space that uses data for a variety of research and publication projects to find ideas and meaning in it. Data science requires a combination of different technologies, including math, business design, computer science, and so on. Data is now widely distributed through phones and other devices. Businesses use this information to better understand customer behavior and more. However, this does not mean that data science is only used to promote business. The use of data technology is widespread in all industries such as health, finance, education, supply chain, and more.
The first meaning of scientific data is the ability to convert raw data into valuable information. Today, data technology is important for development and today it promotes solutions in a variety of contexts.
2. What exactly do media scientists do?
Data scientists develop and use algorithms to analyze data. These approaches often involve the use and development of user tools and traditional tools to help companies and customers interpret meaningful data. They also help you read data-driven reports to better understand your customers. Overall, data researchers have contributed to every step of data processing, from optimization to structural improvement and enhancement, from experimentation to real-time performance evaluation.
3. What is an example of science fiction?
Examples and applications of data technology have become widespread in all industries. Outstanding examples of data technology today are their use in the study of COVID-19 infection and in the development of therapeutic drugs. Examples of data technology include fraud detection, independent service, health checks, non-fiction, e-commerce and entertainment management, and more.
0 notes
Text
120+ new live online training courses for July and August
120+ new live online training courses for July and August
Get hands-on training in machine learning, software architecture, Java, Kotlin, leadership skills, and many other topics.
Develop and refine your skills with 120+ new live online training courses we opened up for July and August on our learning platform.
Space is limited and these courses often fill up.
Artificial intelligence and machine learning
Building Intelligent Systems with AI and Deep Learning, July 16
Machine Learning in Practice, August 3
Hands-on Machine Learning with Python: Classification and Regression, August 3
Getting Started with Computer Vision Using Go, August 6
Deep Learning for Natural Language Processing (NLP), August 8
Building Deep Learning Model Using Tensorflow, August 9-10
Hands-on Machine Learning with Python: Clustering, Dimension Reduction, and Time Series Analysis, August 13
Essential Machine Learning and Exploratory Data Analysis with Python and Jupyter Notebook, August 13-14
Machine Learning with R, August 13-14
Deep Reinforcement Learning, August 16
Artificial Intelligence: An Overview for Executives, August 17
Reinforcement Learning with Tensorflow and Keras, August 23-24
Democratizing Machine Learning: A Dive into Google Cloud Machine Learning APIs, August 24
Blockchain
Understanding Hyperledger Fabric Blockchain, August 13-14
Blockchain Applications and Smart Contracts, August 16
Introducing Blockchain, August 27
Business
Introduction to Critical Thinking, August 3
Managing Team Conflict, August 7
Introduction to Strategic Thinking Skills, August 8
Creating a Great Employee Experience through Onboarding, August 9
Introduction to Leadership Skills, August 16
Leadership Communication Skills for Managers, August 16
Introduction to Customer Experience, August 16
Introduction to Delegation Skills, August 16
Having Difficult Conversations, August 23
Data science and data tools
Shiny R, July 27
Applied Network Analysis for Data Scientists: A Tutorial for Pythonistas, July 30-31
Getting Started with Pandas, August 1
Beginning Data Analysis with Python and Jupyter, August 1-2
Mastering Pandas, August 2
Understanding Data Science Algorithms in R: Regression, August 6
Understanding Data Science Algorithms in R: Scaling, Normalization, and Clustering, August 10
Apache Hadoop, Spark, and Big Data Foundations, August 16
Rich Documents with R Markdown, August 16
Mastering Relational SQL Querying, August 21-22
Hands-on Introduction to Apache Hadoop and Spark Programming, August 21-22
Design
VUI Design Fundamentals, August 1
Product management
Information Architecture: Research and Design, August 28
Introduction to Project Management, August 28
Programming
Advanced SQL Series: Relational Division, July 9
Reactive Spring Boot, July 13
Pythonic Design Patterns, July 23
Designing Bots and Conversational Apps for Work, July 24
Test-Driven Development In Python, July 24
Beyond Python Scripts: Logging, Modules, and Dependency Management, July 25
Beyond Python Scripts: Exceptions, Error Handling, and Command-Line Interfaces, July 26
Spring Boot and Kotlin, July 30
Players Making Decisions, August 1
Bash Shell Scripting in 3 Hours, August 1
Reactive Spring Boot, August 2
Introduction to Modularity with the Java 9 Platform Module System (JPMS), August 6
Creating a Custom Skill for Amazon Alexa, August 6
Get Started With Kotlin, August 6-7
JavaScript the Hard Parts: Closures, August 10
Python Data Handling: A Deeper Dive, August 13
Getting Started with Python’s Pytest, August 13
Building Chatbots for the Google Assistant using Dialogflow, August 14
Design Patterns Boot Camp, August 14-15
Advanced SQL Series: Window Functions, August 15
Scala Fundamentals: From Core Concepts to Real Code in 5 Hours, August 15
Building Chatbots with AWS, August 17
Fundamentals of Virtual Reality Technology and User Experience, August 17
Mastering Python’s Pytest, August 17
Scalable Programming with Java 8 Parallel Streams, August 20
Scaling Python with Generators, August 20
Test-Driven Development In Python, August 21
Pythonic Object-Oriented Programming, August 22
Linux Foundation System Administrator (LFCS) Crash Course, August 22-24
Beyond Python Scripts: Logging, Modules, and Dependency Management, August 22
Pythonic Design Patterns, August 23
Interactive Java with JShell, August 27
Python: The Next Level, August 27-28
IoT Fundamentals, August 29-30
OCA Java SE 8 Programmer Certification Crash Course, August 29-31
Reactive Programming with Java 8 Completable Futures, August 30
Learn Linux in 3 Hours, August 30
Beyond Python Scripts: Exceptions, Error Handling, and Command-Line, August 31
Security
Introduction to Encryption, August 2
Cyber Security Fundamentals, August 2-3
AWS Security Fundamentals, August 7
Certified Ethical Hacker (CEH) Certification Crash Course, August 14-15
Amazon Web Services (AWS) Security Crash Course, August 17
https://ift.tt/2tSAW3T
0 notes
Link
Get instructor-led training in Python, Go, React, Agile, data science, and many other topics.
Develop your skills with 120+ new live online trainings we just opened up for March, April, and May on our learning platform.
Space is limited and these trainings often fill up.
Basic Android Development , March 6-7
From Monolith to Microservices, March 12-13
Getting Started with Spring and Spring Boot , March 21-22
Scala Programming Fundamentals, March 26
Unit Testing with the Spock Framework, March 26
Managing Your Manager, March 28
Getting Started with Go, March 28-29
Reactive Spring and Spring Boot, March 29
Scala Programming Fundamentals: Sealed Traits, Collections, and Functions, March 30
Advanced React, April 2
Creating a Custom Skill for Amazon Alexa, April 2
Python Beyond the Basics: Scaling Python with Generators, April 2
Essential Machine Learning and Exploratory Data Analysis with Python and Jupyter Notebook, April 2-3
Red Hat Certified System Administrator (RHCSA) Crash Course, April 2-5
Ansible in 3 Hours, April 3
Python Beyond the Basics: Pythonic Design Patterns, April 3
Gradle: The Basics and Beyond, April 3-4
Deep Reinforcement Learning, April 4
CPUs and RAM: CompTIA A+ 220-901 Exam Prep, April 4
Getting Started with Node.js, April 4
Cloud Native Architecture Patterns, April 4-5
SQL Fundamentals for Data, April 4-5
Python: The Next Level, April 4-5
High Performance TensorFlow in Production: Hands on with GPUs and Kubernetes, April 4-5
Advanced Agile: Scaling in the Enterprise, April 5
Amazon Web Services: Architect Associate Certification - AWS Core Architecture Concepts, April 5-6
Getting Started with React.js, April 6
Linux Troubleshooting, April 6
Managing Complexity in Network Engineering, April 9
Introducing Blockchain, April 9
Git Fundamentals, April 9 & 11
CompTIA Security+ SY0-501 Crash Course, April 9-10
Full Stack Development with MEAN, April 9-10
Red Hat Certified Engineer (RHCE) Crash Course, April 9-12
Practical AI on iOS, April 10
Working with Engineers as a Non-Technical Product Manager, April 10
Python for Applications: Beyond Scripts, April 10-11
Getting Started with Spring and Spring Boot, April 10-11
Power Systems: CompTIA A+ 220-901 Exam Prep, April 11
Leading Change that Sticks, April 11
Reactive Python for Data Science, April 11
Beginner’s Guide to Creating Prototypes in Sketch, April 11
Docker: Up and Running, Apr 11-12
CCNA Security Crash Course, April 11-12
OCA Java SE 8 Programmer Certification Crash Course, April 11-13
Introduction to Google Cloud Platform, April 12
Building Effective and Adaptive Teams, April 12
Product Management in Practice, April 12-13
Amazon Web Services: AWS Managed Services , April 12-13
Apache Hadoop, Spark, and Big Data Foundations, April 13
Learn Linux in 3 Hours, April 13
Managing and Automating Tasks with PowerShell, April 13
Getting Started with Azure Infrastructure as a Service, April 13
Implementing and Troubleshooting TCP/IP, April 13
Programming with Java 8 Lambdas and Streams, April 13
Learn the Basics of Scala in 3 hours, April 16
Designing Bots and Conversational Apps for Work, April 16
Node.js Advanced Topics, April 16
Pythonic Object-Oriented Programming, April 16
Cyber Security Fundamentals, April 16-17
Hands-on Introduction to Apache Hadoop and Spark Programming, April 16-17
Microservices Architecture and Design, April 16-17
Architecture Without an End State, April 16-17
Test-Driven Development In Python, April 17
React: Beyond the Basics, April 17
Scalable Programming with Java 8 Parallel Streams, April 17
Porting from Python 2 to Python 3, April 17
Scalable Programming with Java 8 Parallel Streams, April 17
Design Patterns Boot Camp, April 17-18
Hard Drives: CompTIA A+ 220-901 Exam Prep, April 18
How Agile and Traditional Teams Work Together, April 18
Introduction to Analytics for Product Managers, April 18
Managing your Manager, April 18
CompTIA Cybersecurity Analyst CySA+ CS0-001 Crash Course, April 18-19
Data Science for Security Professionals, April 18-20
Reactive Spring and Spring Boot, April 19
Getting Started with DevOps in 90 Minutes, April 19
Introduction to Ethical Hacking and Penetration Testing, April 19-20
Amazon Web Services: AWS Design Fundamentals, April 19-20
Getting Started with OpenStack, April 20
Java 8 Generics in 3 Hours, April 20
What’s New in the PMBOK® Guide, Sixth Edition?, April 20
Networking in AWS - Full Day, April 23
Troubleshooting Agile, April 23
Design Patterns Bootcamp, April 23-24
Introduction to Lean, April 24
Usability Testing 101, April 24
AWS Security Fundamentals, April 24
High Performance TensorFlow in Production: Hands on with GPUs and Kubernetes, April 24-25
Enhanced Security with Machine Learning, April 24-26
Leading Collaborative Workshops for Product Design and Development, April 25
Python Beyond the Basics: Scaling Python with Generators, April 25
Docker: Beyond the Basics (CI/CD), April 25-26
Next Level Git, April 25-26
Blockchain Applications and Smart Contracts, April 26
Reactive Programming with Java 8 Completable Futures, April 26
Scala Fundamentals: From Core Concepts to Real Code in 5 Hours, April 26
Getting Started with Python’s Pytest, April 26
Introduction to Cisco Next-Generation Firewalls, April 26-27
Python Beyond the Basics: Pythonic Design Patterns, April 26
Getting Started with Java: From Core Concepts to Real Code in 3 Hours, April 27
Customer Research for Product Managers, April 27
Having Difficult Conversations, April 27
Design Fundamentals for Non Designers, April 27
Mastering Python’s Pytest, April 27
Building Data APIs with GraphQL, April 27
Amazon Web Services (AWS) Security Crash Course, April 30
Linux Performance Optimization, April 30
Linux Under the Hood, April 30
Node.js: Beyond the Basics, April 30
Security Testing with Kali Linux, April 30
Scala Beyond the Basics, Apr 30-May 1
Introduction to Customer Experience, May 1
Amazon Web Services: Architect Associate Certification - AWS Core Architecture Concepts, May 3-4
Get Started With Kotlin, May 7-8
Negotiation Fundamentals, May 15
From Monolith to Microservices, May 15-16
From Monolith to Microservices, May 22-23
Introduction to Project Management, May 29
Visit our learning platform for more information on these and our other live online trainings.
Continue reading More than 120 live online trainings just released on O'Reilly's learning platform.
from All - O'Reilly Media http://ift.tt/2G0PT8D
0 notes
Text
Feynman Liang at Scale
1. Can you talk about your background, and how did you come to functional programming?
Hacker News provided my first introduction to the world of functional programming. But it was an online course by University of Pennsylvania on Haskell, CIS194, that solidified my passion for the industry. As someone who is always looking for the next challenge and finds satisfaction through continual learning, this exposure to more advanced programming languages and their potential excited me.
I stumbled across Scala while working on Apache Spark. While in my previous role at Databricks, I came to really appreciate its elegance. Now at Gigster, we are also adopting functional paradigms. Rather than being imperative, we choose functional programming because of its declarative nature. This style of composing complex computations is amenable to code reuse, as it can be arranged in one way to solve a big problem and then rearranged and used again to tackle something else.
2. What are the most interesting projects you are working on at Gigster?
I’m really excited about what we’re doing to build teams in an optimal way. Gigster is a smart software development service serving more than 40 of the world's largest companies. We provide access to a network of the most talented developers and designers, and have developed a series of tools that use automation to make the traditionally complex process of software development more efficient and reliable
3. What technology stack are you using?
We are always experimenting with the latest technologies, so our stack includes everything from Javascript and Python to Scala and MongoDB. We want teams to be able to work in the technology standard that makes the most sense for their project and that they are most passionate about. We’ve adopted a microservices-oriented architecture throughout the organization to provide this kind of freedom, and leverage Docker and Kubernetes to make it possible. I’m really invested in finding success in our container management and build deployment pipeline.
4. What will you be talking about at Scale By The Bay 2017, and why did you choose this topic?
In 2016, I published research on training deep distributed decision trees on Apache Spark, and my presentation on Saturday will be focused on what we found. In our research, we partitioned data by column (or feature), rather than by row. Though this process, we uncovered some interesting and somewhat unexpected tradeoffs, such as reduced communications resulting in a lowered cost for a high-dimensional dataset such as images. In the session, we’ll be digging into our process and the results.
5. What are some other exciting technologies you are looking at currently?
I’m particularly excited about the potential for Elixir, because it is functional from the ground up and robust frameworks like Phoenix provide developer productivity and empower rapid application development..
6. What are your expectations for Scale By The Bay in November 2017?
I’ve been a fan of the Scale By the Bay (formerly Scala by the Bay) events since the first one I attended in 2014. It’s an incredible opportunity to learn straight from figureheads in the community. Being able to put a human touch to an online alias always reinvigorates my passion for this work. This year specifically, I’m really looking forward to seeing Travis Brown and Matei Zaharia, among many others.
0 notes
Text
What is salary for Hadoop developer in India (7 years Java exp.) Are there any good opportunities for Hadoop developers in India as well as abroad?
Hadoop was started in 2003, Google launched project Nutch to handle billions of searches and indexing millions of web pages. In Oct 2003 - Google releases papers with GFS (Google File System).After that in Dec 2004 - Google releases papers with MapReduce. In 2005 - Nutch used GFS and MapReduce to perform operations. After this evolution in 2006 - Yahoo! created Hadoop based on GFS and MapReduce (with Doug Cutting and team) and in 2007 - Yahoo started using Hadoop on a 1000 node cluster. In Jan 2008 - Apache took over Hadoop. The major turning point came when in Jul 2008, they tested a 4000 node cluster with Hadoop successfully and the final end point was there when in 2009, Hadoop successfully sorted a petabyte of data in less than 17 hours to handle billions of searches and indexing millions of web pages According to the Forester software survey “Hadoop is unstoppable as its open source roots grow wildly and deeply into enterprise data management architectures”. If you have lots of structured, unstructured, and/or binary data, there is a sweet spot for Hadoop in your organization.” Alone, Hadoop is a software market that IDC predicts will be worth $813 million in 2016 (although that number is likely very low), but it’s also driving a big data market the research firm predicts will hit more than $23 billion by 2016.
Major companies which are working with Hadoop or using Hadoop Technology are
· Amazon Web Services
· Cloudera
· Hortonworks
· IBM
· Intel
· Microsoft
· Pivotal Software
· Teradata
So basically Hadoop has impacted a lot in the financial sector also .It has also created a new window of income for software professionals. It has impacted the salaries of fresher’s and professionals .Let’s see on what factors it depends .Your paycheck depends on a number of factors, could be anything from 5 LPA - 25 LPA at 2-3 years of work experience:
1. Years of experience in industry (even if you didn't work on Hadoop before)
2. College from which you got your bachelors/master’s degree
3. Paying capacity of the company, counter offers you have, your negotiation skills
4. Hadoop certifications are a plus. Employers care more about your programming, data structures, algorithms, and basic CS skills first before looking at the certifications, without them they don't add much value.
5. Open source contributions are a plus.
Normally a Hadoop developer gets starting package of 3.5 to 5 lac pa, which with an experience of around 2-3 years can easily go up to 9-10 lac pa. Though it means you got to be very good at it. The highest salaries offered in India varies according to the city . Read more…
So different type of opportunities for Hadoop are there in different cities and the salary packages varies according to the opportunities .So according to an analysis report. The report describes the variation in highest salaries according to cities.
· Mumbai-12.19 lac per annum
· Bangalore-10.48 lac per annum
· Delhi NCR-10.4 lac per annum
· Pune-9.81 lac per annum
· Chennai-9.45 lac per annum
· Hyderabad-9.42 lac per annum
· Kolkata-9.35 lac per annum
If you want to know more about these topic please visit- Salary of Hadoop Developer.Here from you get many more valuable information which will definitely helpful to you.
0 notes
Photo

What is the current entry level salary in Hadoop/big data fields in India?
Hadoop was started in 2003, Google launched project Nutch to handle billions of searches and indexing millions of web pages. In Oct 2003 - Google releases papers with GFS (Google File System).After that in Dec 2004 - Google releases papers with MapReduce. In 2005 - Nutch used GFS and MapReduce to perform operations. After this evolution in 2006 - Yahoo! created Hadoop based on GFS and MapReduce (with Doug Cutting and team) and in 2007 - Yahoo started using Hadoop on a 1000 node cluster. In Jan 2008 - Apache took over Hadoop. The major turning point came when in Jul 2008, they tested a 4000 node cluster with Hadoop successfully and the final end point was there when in 2009, Hadoop successfully sorted a petabyte of data in less than 17 hours to handle billions of searches and indexing millions of web pages According to the Forester software survey “Hadoop is unstoppable as its open source roots grow wildly and deeply into enterprise data management architectures”. “Forrester believes that Hadoop is a must-have data platform for large enterprises, forming the cornerstone of any flexible future data management platform. If you have lots of structured, unstructured, and/or binary data, there is a sweet spot for Hadoop in your organization.” Alone, Hadoop is a software market that IDC predicts will be worth $813 million in 2016 (although that number is likely very low), but it’s also driving a big data market the research firm predicts will hit more than $23 billion by 2016.
Since Cloudera launched in 2008, Hadoop has spawned dozens of startups and spurred hundreds of millions in venture capital investment since 2008. Major companies which are working with Hadoop or using Hadoop Technology are
· Amazon Web Services
· Cloudera
· Hortonworks
· IBM
· Intel
· Microsoft
· Pivotal Software
· Teradata
So basically Hadoop has impacted a lot in the financial sector also.It has also created a new window of income for software professionals. It has impacted the salaries of fresher’s and professionals.Let’s see what factors it depends on Your paycheck depends on a number of factors, could be anything from 5 LPA - 25 LPA at 2-3 years of work experience:
1. Years of experience in industry (even if you didn't work on Hadoop before)
2. College from which you got your bachelor's/master’s degree
3. Paying capacity of the company, counter offers you have, your negotiation skills
4. Hadoop certifications are a plus. Employers care more about your programming, data structures, algorithms, and basic CS skills first before looking at the certifications, without them they don't add much value.
5. Open source contributions are a plus.
Normally a Hadoop developer gets starting package of 3.5 to 5 lac pa, which with an experience of around 2-3 years can easily go up to 9-10 lac pa. Though it means you got to be very good at it. The highest salaries offered in India varies according to the city.So different type of opportunities for Hadoop are there in different cities and the salary packages vary according to the opportunities.So according to an analysis report. The report describes the variation in highest salaries according to cities.
· Mumbai-12.19 lac per annum
· Bangalore-10.48 lac per annum
· Delhi NCR-10.4 lac per annum
· Pune-9.81 lac per annum
· Chennai-9.45 lac per annum
· Hyderabad-9.42 lac per annum
· Kolkata-9.35 lac per annum
If you want to know more about this topic please visit- What is the Salary of Hadoop Developer. Here from you get many more valuable information which will definitely helpful to you.
0 notes