#retry pattern javascript
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
Tumblr Inc. is using 66 technologies for its website.
Text
Retry Design Pattern for Microservices Tutorial with Examples for API Developers
Full Video Link https://youtu.be/sli5D29nCw4 Hello friends, new #video on #retrypattern #designpattern for #microservices #tutorial for #api #developer #programmers is published on #codeonedigest #youtube channel. @java #java #aws #awsclo
In this video we will learn about Retry design pattern for microservices. In a microservices architecture, the retry pattern is a common pattern for recovering from transient errors. An application lost connectivity for a short period of time. A component is unavailable for a short period of time. This usually happens during maintenance or automatic recovery from a crash. A component is…

View On WordPress
#circuit breaker#circuit breaker pattern#microservice design patterns#microservice design patterns spring boot#microservice patterns#microservices#microservices architecture#microservices tutorial#retry design pattern#retry design pattern c#retry design pattern java#retry pattern#retry pattern c#retry pattern java#retry pattern javascript#retry pattern microservices#retry pattern spring boot#retry pattern vs circuit breaker#what are microservices
1 note
·
View note
Text
I’m a bit addicted to NumberLink puzzles. I’ve already exhausted three Android apps, so I went looking for other ways to play and eventually found Puzzle Baron. This has helped keep my brain occupied in a couple of ways. For one thing, it produces very different puzzles than any of the apps. For example, it seems to produce spirals more readily than the others - green 4, purple 6, and pink 7 in this image.
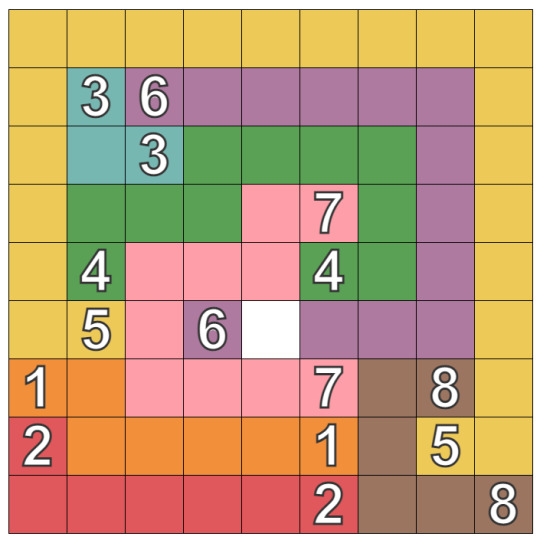
Overall, these seem more difficult, though that might just be because I had tuned my technique too much toward the apps’ generators. (This is what AI folks call overtraining; statisticians and stock pickers call it overfitting.) In any case, it has required some adjustment.
The other thing that has seemed odd was the leaderboards. Some of the same names kept appearing, which is normal by itself, but there were a couple of anomalies.
On some of the exceptionally hard puzzles, none of the usual suspects would be on the leaderboard. I’m pretty sure it’s not because none of them had ever seen that puzzle; the odds of that happening on any given puzzle are about 1/3,000 by my estimation, and it happens way too often for that math to work. The pattern of excellent scores or no scores seemed odd.
The top times often seemed to be around 30 seconds. On a 12x12 puzzle that’s barely enough time to trace the paths (it skips squares if you go too fast). That leaves zero time for thinking or backtracking, which even the best players have to do sometimes.
So, what’s going on? Have these players figured out a way to cheat? From looking at the page’s JavaScript I could see a couple of ways they could either insert an automatic solver or override the function that determines whether a position matches the solution.
As things happened, I tripped over the answer to my question by accident today. While replaying a completed puzzle isn’t allowed, if you abandon a puzzle there’s a way to come back and retry it. If you do that immediately it counts the time from the first time you brought it up, but that timer seems to reset if you just leave it for an hour or so and you get “charged” for the time on the second attempt? Do you see the problem here? Someone who has seen the puzzle before can solve it offline, then come back and trace the paths as fast as their finger can move for a sweet 30-second time. Several people have obviously figured this out - no JavaScript hackery required. On a site that doesn’t seem to have been actively maintained since 2019, they’re unlikely to stop either.
It’s a good example, for programmers, of how all code has to be evaluated for potential security impact. I’ll bet that when this programmer implemented the retry feature for abandoned puzzles they weren’t even thinking about whether it could be abused in a way that makes another feature (leaderboards) useless. Ditto for whichever dummy put the token representing a correct result right into the page that’s delivered to the user. That’s exactly the same mistake that has led to impersonation and forgery being so common on the web. Dumb.
0 notes
Text
Pros, Cons and Applications of Widely Known Software Architecture: Layered Architecture and Event-driven Architecture Patterns
10/13/20
An architectural pattern or a software architecture is a general and reusable solution to a problem in software architecture, a structure that solves the objective of the software within certain constraints. To know which software patter is applicable to the current problem requires understanding how each software architecture operates, and how components in the pattern interact with each other. Moreover, before someone is going to work on a software project, it is important to understand what framework is offered and what type of architecture pattern is implied in frameworks and other resources.
Layered architecture
Layered architecture patterns are n-tiered patterns where the components are organized in horizontal layers.
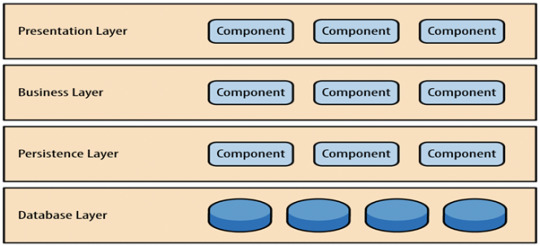
The above figure is an example of four layers in layered architecture, where each layer has a connection between modularity and component within them.
The presentation layer contains all categories related to the presentation layer.
The business layer contains business logic.
The persistence layer handles functions like object-relational mapping.
The database layer stores all the data information (i.e. database).
The Model-View-Controller (MVC) structure, which is offered by most of the popular web frameworks, is an example of a layered architecture.
In addition, the advantage of a layered architecture is that each layer can focus mainly on its own role. Thus, it has the following properties:
Maintainable
Testable (separately on each layers)
Easy to assign separate roles
Easy to update and enhance layers separately
Note that assigning tasks and defining separate layers is the biggest challenge. When the requirements fit the pattern well, the layers will be easy to separate. Due to the layer isolation, it is important to understand the whole picture of the layered architecture (every module of the system).
Used for:
New applications that need to be built quickly.
Applications requiring strict maintainability and testability standards.
Designing a rudimentary application where the user count is relatively low (less than 100).
Event-driven architecture
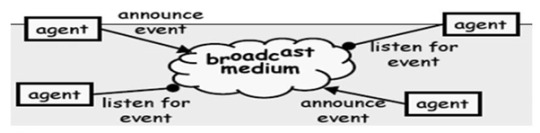
Programming a web page with JavaScript involves writing the small modules that react to events like mouse clicks or keystrokes. When an input is taken, the system triggers the event and delegates it to a proper event handler. Many different types of events are common in the browser, but the modules interact only with the events. This is different from the layered architecture where all data will typically pass through all layers.
An event-driven architecture has the following properties:
Easily adaptable to complex, often chaotic environments
Easily scalable
Expandable when new event types appear
Some difficulties of event-driven architecture include:
Testing can be complex if the modules can affect each other (i.e. the interactions between the modules can only be tested in a fully functioning system).
When modules fail to handle events, the central unit must have a backup plan. In fact, if a systematic error occurs, retry/rollback of the system is considered.
Messaging overhead can slow down processing speed, especially when the central unit must buffer messages that arrive in bursts.
Maintaining a transaction-based mechanism for consistency is difficult because the modules are decoupled and independent.
It is hard to debug in general.
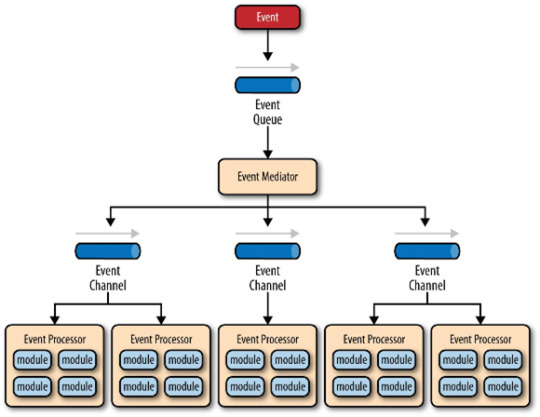
Used for:
Asynchronous systems with asynchronous data flow.
Applications where the individual data blocks interact with only a few of the many modules.
User interfaces (e.g. GUI programming).
References:
https://slideplayer.com/slide/4890810/ https://www.cs.cmu.edu/afs/cs/project/able/ftp/intro_softarch/intro_softarch.pdf
0 notes
Text
Mastering Async Await in Node.js

In this article, you will learn how you can simplify your callback or Promise based Node.js application with async functions (async/await).
Whether you’ve looked at async/await and promises in javascript before, but haven’t quite mastered them yet, or just need a refresher, this article aims to help you.
A note from the authors:
We re-released our number one article on the blog called "Mastering Async Await in Node.js" which has been read by more than 400.000 developers in the past 3 years.
This staggering 2000 word essay is usually the Nr. 1 result when you Google for Node.js Async/Await info, and for a good reason.
It's full of real-life use cases, code examples, and deep-diving explanations on how to get the most out of async/await. Since it's a re-release, we fully updated it with new code examples, as there are a lot of new Node.js features since the original release which you can take advantage of.
What are async functions in Node?
Async functions are available natively in Node and are denoted by the async keyword in their declaration. They always return a promise, even if you don’t explicitly write them to do so. Also, the await keyword is only available inside async functions at the moment - it cannot be used in the global scope.
In an async function, you can await any Promise or catch its rejection cause.
So if you had some logic implemented with promises:
function handler (req, res) { return request('https://user-handler-service') .catch((err) => { logger.error('Http error', err); error.logged = true; throw err; }) .then((response) => Mongo.findOne({ user: response.body.user })) .catch((err) => { !error.logged && logger.error('Mongo error', err); error.logged = true; throw err; }) .then((document) => executeLogic(req, res, document)) .catch((err) => { !error.logged && console.error(err); res.status(500).send(); }); }
You can make it look like synchronous code using async/await:
async function handler (req, res) { let response; try { response = await request('https://user-handler-service') ; } catch (err) { logger.error('Http error', err); return res.status(500).send(); } let document; try { document = await Mongo.findOne({ user: response.body.user }); } catch (err) { logger.error('Mongo error', err); return res.status(500).send(); } executeLogic(document, req, res); }
Currently in Node you get a warning about unhandled promise rejections, so you don’t necessarily need to bother with creating a listener. However, it is recommended to crash your app in this case as when you don’t handle an error, your app is in an unknown state. This can be done either by using the --unhandled-rejections=strict CLI flag, or by implementing something like this:
process.on('unhandledRejection', (err) => { console.error(err); process.exit(1); })
Automatic process exit will be added in a future Node release - preparing your code ahead of time for this is not a lot of effort, but will mean that you don’t have to worry about it when you next wish to update versions.
Patterns with async functions
There are quite a couple of use cases when the ability to handle asynchronous operations as if they were synchronous comes very handy, as solving them with Promises or callbacks requires the use of complex patterns.
Since [email protected], there is support for async iterators and the related for-await-of loop. These come in handy when the actual values we iterate over, and the end state of the iteration, are not known by the time the iterator method returns - mostly when working with streams. Aside from streams, there are not a lot of constructs that have the async iterator implemented natively, so we’ll cover them in another post.
Retry with exponential backoff
Implementing retry logic was pretty clumsy with Promises:
function request(url) { return new Promise((resolve, reject) => { setTimeout(() => { reject(`Network error when trying to reach ${url}`); }, 500); }); } function requestWithRetry(url, retryCount, currentTries = 1) { return new Promise((resolve, reject) => { if (currentTries <= retryCount) { const timeout = (Math.pow(2, currentTries) - 1) * 100; request(url) .then(resolve) .catch((error) => { setTimeout(() => { console.log('Error: ', error); console.log(`Waiting ${timeout} ms`); requestWithRetry(url, retryCount, currentTries + 1); }, timeout); }); } else { console.log('No retries left, giving up.'); reject('No retries left, giving up.'); } }); } requestWithRetry('http://localhost:3000') .then((res) => { console.log(res) }) .catch(err => { console.error(err) });
This would get the job done, but we can rewrite it with async/await and make it a lot more simple.
function wait (timeout) { return new Promise((resolve) => { setTimeout(() => { resolve() }, timeout); }); } async function requestWithRetry (url) { const MAX_RETRIES = 10; for (let i = 0; i <= MAX_RETRIES; i++) { try { return await request(url); } catch (err) { const timeout = Math.pow(2, i); console.log('Waiting', timeout, 'ms'); await wait(timeout); console.log('Retrying', err.message, i); } } }
A lot more pleasing to the eye isn't it?
Intermediate values
Not as hideous as the previous example, but if you have a case where 3 asynchronous functions depend on each other the following way, then you have to choose from several ugly solutions.
functionA returns a Promise, then functionB needs that value and functionC needs the resolved value of both functionA's and functionB's Promise.
Solution 1: The .then Christmas tree
function executeAsyncTask () { return functionA() .then((valueA) => { return functionB(valueA) .then((valueB) => { return functionC(valueA, valueB) }) }) }
With this solution, we get valueA from the surrounding closure of the 3rd then and valueB as the value the previous Promise resolves to. We cannot flatten out the Christmas tree as we would lose the closure and valueA would be unavailable for functionC.
Solution 2: Moving to a higher scope
function executeAsyncTask () { let valueA return functionA() .then((v) => { valueA = v return functionB(valueA) }) .then((valueB) => { return functionC(valueA, valueB) }) }
In the Christmas tree, we used a higher scope to make valueA available as well. This case works similarly, but now we created the variable valueA outside the scope of the .then-s, so we can assign the value of the first resolved Promise to it.
This one definitely works, flattens the .then chain and is semantically correct. However, it also opens up ways for new bugs in case the variable name valueA is used elsewhere in the function. We also need to use two names — valueA and v — for the same value.
Are you looking for help with enterprise-grade Node.js Development? Hire the Node developers of RisingStack!
Solution 3: The unnecessary array
function executeAsyncTask () { return functionA() .then(valueA => { return Promise.all([valueA, functionB(valueA)]) }) .then(([valueA, valueB]) => { return functionC(valueA, valueB) }) }
There is no other reason for valueA to be passed on in an array together with the Promise functionB then to be able to flatten the tree. They might be of completely different types, so there is a high probability of them not belonging to an array at all.
Solution 4: Write a helper function
const converge = (...promises) => (...args) => { let [head, ...tail] = promises if (tail.length) { return head(...args) .then((value) => converge(...tail)(...args.concat([value]))) } else { return head(...args) } } functionA(2) .then((valueA) => converge(functionB, functionC)(valueA))
You can, of course, write a helper function to hide away the context juggling, but it is quite difficult to read, and may not be straightforward to understand for those who are not well versed in functional magic.
By using async/await our problems are magically gone:
async function executeAsyncTask () { const valueA = await functionA(); const valueB = await functionB(valueA); return function3(valueA, valueB); }
Multiple parallel requests with async/await
This is similar to the previous one. In case you want to execute several asynchronous tasks at once and then use their values at different places, you can do it easily with async/await:
async function executeParallelAsyncTasks () { const [ valueA, valueB, valueC ] = await Promise.all([ functionA(), functionB(), functionC() ]); doSomethingWith(valueA); doSomethingElseWith(valueB); doAnotherThingWith(valueC); }
As we've seen in the previous example, we would either need to move these values into a higher scope or create a non-semantic array to pass these values on.
Array iteration methods
You can use map, filter and reduce with async functions, although they behave pretty unintuitively. Try guessing what the following scripts will print to the console:
map
function asyncThing (value) { return new Promise((resolve) => { setTimeout(() => resolve(value), 100); }); } async function main () { return [1,2,3,4].map(async (value) => { const v = await asyncThing(value); return v * 2; }); } main() .then(v => console.log(v)) .catch(err => console.error(err));
filter
function asyncThing (value) { return new Promise((resolve) => { setTimeout(() => resolve(value), 100); }); } async function main () { return [1,2,3,4].filter(async (value) => { const v = await asyncThing(value); return v % 2 === 0; }); } main() .then(v => console.log(v)) .catch(err => console.error(err));
reduce
function asyncThing (value) { return new Promise((resolve) => { setTimeout(() => resolve(value), 100); }); } async function main () { return [1,2,3,4].reduce(async (acc, value) => { return await acc + await asyncThing(value); }, Promise.resolve(0)); } main() .then(v => console.log(v)) .catch(err => console.error(err));
Solutions:
[ Promise { <pending> }, Promise { <pending> }, Promise { <pending> }, Promise { <pending> } ]
[ 1, 2, 3, 4 ]
10
If you log the returned values of the iteratee with map you will see the array we expect: [ 2, 4, 6, 8 ]. The only problem is that each value is wrapped in a Promise by the AsyncFunction.
So if you want to get your values, you'll need to unwrap them by passing the returned array to a Promise.all:
main() .then(v => Promise.all(v)) .then(v => console.log(v)) .catch(err => console.error(err));
Originally, you would first wait for all your promises to resolve and then map over the values:
function main () { return Promise.all([1,2,3,4].map((value) => asyncThing(value))); } main() .then(values => values.map((value) => value * 2)) .then(v => console.log(v)) .catch(err => console.error(err));
This seems a bit more simple, doesn’t it?
The async/await version can still be useful if you have some long running synchronous logic in your iteratee and another long-running async task.
This way you can start calculating as soon as you have the first value - you don't have to wait for all the Promises to be resolved to run your computations. Even though the results will still be wrapped in Promises, those are resolved a lot faster then if you did it the sequential way.
What about filter? Something is clearly wrong...
Well, you guessed it: even though the returned values are [ false, true, false, true ], they will be wrapped in promises, which are truthy, so you'll get back all the values from the original array. Unfortunately, all you can do to fix this is to resolve all the values and then filter them.
Reducing is pretty straightforward. Bear in mind though that you need to wrap the initial value into Promise.resolve, as the returned accumulator will be wrapped as well and has to be await-ed.
.. As it is pretty clearly intended to be used for imperative code styles.
To make your .then chains more "pure" looking, you can use Ramda's pipeP and composeP functions.
Rewriting callback-based Node.js applications
Async functions return a Promise by default, so you can rewrite any callback based function to use Promises, then await their resolution. You can use the util.promisify function in Node.js to turn callback-based functions to return a Promise-based ones.
Rewriting Promise-based applications
Simple .then chains can be upgraded in a pretty straightforward way, so you can move to using async/await right away.
function asyncTask () { return functionA() .then((valueA) => functionB(valueA)) .then((valueB) => functionC(valueB)) .then((valueC) => functionD(valueC)) .catch((err) => logger.error(err)) }
will turn into
async function asyncTask () { try { const valueA = await functionA(); const valueB = await functionB(valueA); const valueC = await functionC(valueB); return await functionD(valueC); } catch (err) { logger.error(err); } }
Rewriting Node.js apps with async/await
If you liked the good old concepts of if-else conditionals and for/while loops,
if you believe that a try-catch block is the way errors are meant to be handled,
you will have a great time rewriting your services using async/await.
As we have seen, it can make several patterns a lot easier to code and read, so it is definitely more suitable in several cases than Promise.then() chains. However, if you are caught up in the functional programming craze of the past years, you might wanna pass on this language feature.
Are you already using async/await in production, or you plan on never touching it? Let's discuss it in the comments below.
Are you looking for help with enterprise-grade Node.js Development? Hire the Node developers of RisingStack!
This article was originally written by Tamas Kadlecsik and was released on 2017 July 5. The heavily revised second edition was authored by Janos Kubisch and Tamas Kadlecsik, and it was released on 2020 February 17.
Mastering Async Await in Node.js from node
Mastering Async Await in Node.js published first on https://koresolpage.tumblr.com/
0 notes
Photo

The 2019 State of JavaScript survey is here
#465 — November 29, 2019
Read on the Web
JavaScript Weekly
▶ Faster JavaScript Apps with JSON.parse() — Did you know that JSON can be parsed more quickly than JavaScript itself? Here's how and why to consider using JSON.parse instead of normal object literals.
Mathias Bynens / Bram van Damme
It's Time to Take the State of JavaScript 2019 Survey — Now in its fourth year, the popular State of JavaScript survey returns, seeking your responses to help find out “which libraries developers want to learn next, which have the best satisfaction ratings, and much more”. Of course, we’ll share the results once they’re live, as always.
Raphaël Benitte, Sacha Greif and Michael Rambeau
Getting Started Building Apps with JavaScript — CascadiaJS just wrapped up. Take a look at the collection of articles, tutorials and podcast episodes that will help you get started building web applications with JavaScript and JS-related technologies.
Heroku sponsor
ESLint 6.7 Released — The popular linting tool includes a new way for rule authors to make suggestions for non-automatic fixes, plus there are six new rules covering things like duplicate else-ifs and grouping accessor pairs. 6.7.1 quickly followed 6.7.0 fixing a regression.
ESLint
Cockatiel: A Resilience and Transient-Fault-Handling Library — This is for defining common resilience or fault handling techniques like ‘backoff’, retries, circuit breakers, timeouts, etc. and is inspired by .NET’s Polly fault handling library.
Connor Peet
The Epic List of Languages That Compile to JavaScript — JavaScript is as much a compile target as a language in its own right these days, and this extensive list on the CoffeeScript repo has been (and continues to be) updated for years. The latest addition? Fengari, a Lua VM written in JavaScript.
Jeremy Ashkenas et al.
▶ Building Promises From Scratch in a Post-Apocalyptic Future — A 20 minute screencast covering what’s involved in creating a promises implementation from scratch on top of lower level primitives (e.g. callbacks).
Low Level JavaScript
⚡️ Quick Releases
Babel 7.7.4 — The JavaScript transpiler.
Ink 2.6.0 — Like React but for building CLI apps.
GPU.js 2.3.0 — GPU-accelerated JavaScript.
jQuery.Terminal 2.9.0 — Add terminal experiences to your site/app.
💻 Jobs
Senior Front-End Software Engineer (Vue, Nuxt, Apollo) — Join our distributed Front-End functional team in our quest to make doctors more effective using Vue, Nuxt, Apollo and Rails.
Doximity
Vue Front End Lead at Valiant Finance - Sydney, Australia — FinTech based in Surry Hills looking for an experienced Vue Front End Lead to help us build our growing financial marketplace.
Valiant Finance
Find a Job Through Vettery — Make a profile, name your salary, and connect with hiring managers from top employers. Vettery is completely free for job seekers.
Vettery
📘 Articles & Tutorials
An Official Style Guide for Writing Redux Code — Recommended patterns, best practices, and suggested approaches for writing Redux-based apps.
Redux
An Introduction to the Picture-in-Picture Web API — Chrome supports a ‘picture-in-picture’ mechanism for creating floating video windows that continue to play even if a user navigates to a different page. Firefox and Safari have support via proprietary APIs too.
Ayooluwa Isaiah
Black Friday Sale: Quokka.js - Rapid JavaScript Prototyping in Your Editor — Quokka displays execution results in your editor as you type. Get it now with a 50% Black Friday discount.
Wallaby.js sponsor
Understanding Streams in Node.js — Streams continue to be one of the fundamental concepts that power Node applications.
Liz Parody
Outside the Web: Emscripten Now Generating Standalone WebAssembly Binaries — A key part of both asm.js and Emscripten was the idea of compiling binaries for use on the Web using JavaScript, but now Emscripten has support for emitting WebAssembly without relying on JavaScript at all. You can, of course, interact with such output from your JavaScript code, though.
Alon Zakai
Building Animated Draggable Interfaces with Vue.js and Tailwind — Tailwind CSS is an increasingly popular CSS framework.
Cristi Jora
Video Developer Report - Top Trends in Video Technology 2019
Bitmovin sponsor
Using Backreferences in JavaScript Regular Expressions — Backreferences allow you to use matches already made within a regex within that same regex.
stefan judis
For the Sake of Your Event Listeners, Use Web Workers — “Start by identifying notably intense processes and spin up a small Web Worker for them.”
Alex MacArthur
🔧 Code & Tools

litegraph.js: A Graph Node Engine and Editor — This would be useful if you need to create an online system for users to create and manipulate graphs or interconnecting ‘nodes’ for things like graphics, audio or data pipelines, say. Live demo here.
Javi Agenjo
Duktape 2.5: A Compact, Embeddable JavaScript Engine — An ES5.1-compliant JavaScript engine focused on being very compact. If you have a C/C++ project that needs a JS engine, it’s worth a look as the duk binary runs only 350K.
Sami Vaarala
Automate and Standardize Code Reviews for JS and 29 Other Languages — Set standards on coverage, duplication, complexity, and style issues and see real-time feedback in your Git workflow.
Codacy sponsor
Scala.js 1.0.0-RC1: A Scala to JavaScript Compiler — A final 1.0 release is due in early 2020. If this area of using Scala to build front-end apps interests you, you might also like Slinky which makes writing React apps in Scala easier.
Scala Team
Ketting 5.0: A 'Generic' Hypermedia Client for JavaScript — Supports Hypertext Application Language, JSON:API, Siren, and HTTP link headers. Works in both the browser and Node.js.
Evert Pot
WebGLStudio.js: A 3D Graphics Editor in the Browser — It’s not new but its author says it’s now mature, ready to be extended, and can be used in production (although a 1.0 release is still a little way away).
Javi Agenjo
JSONCrush: Compresses JSON Into URI Friendly Strings — The results are shorter than standard URI encoding.
Frank Force
by via JavaScript Weekly https://ift.tt/2R3J6CF
0 notes
Text
jenkins pipeline idiosyncrasies
window.location.replace("https://blog.sebastianfromearth.com/post/20171024183315");
Some useful resources
PIPELINE SYNTAX GROOVY SYNTAX REFERENCE GROOVY / BASH ESCAPE SEQUENCE RIDICULOUSNESS PIPELINE BEST PRACTICES JENKINS PIPELINE DIRTY SECRETS PART ONE & TWO
Keywords
pipeline (required) - contains the entire Pipeline definition agent (required)- defines the agent used for entire pipeline or a stage any - use any available agent none - do not use a node node - allocate a specific executor label - existing Jenkins node label for agent customWorkspace - use a custom workspace directory on agent docker - requires docker-enabled node image - run inside specified docker image label - existing Jenkins node label for agent registryUrl - use a private registry hosting image registryCredentialsId - id of credentials to connect to registry reuseNode - (Boolean) reuse the workspace and node allocated previously args - arguments for docker container. customWorkspace - use a custom workspace directory on agent dockerfile - use a local dockerfile filename - name of local dockerfile dir - subdirectory to use label - existing Jenkins node label reuseNode - (Boolean) reuse the workspace and node allocated previously args - arguments for docker container customWorkspace - use a custom workspace directory on agent stages (required) - contains all stages and steps within Pipeline stage (required) - specific named “Stage” of the Pipeline steps (required) - build steps that define the actions in the stage. Contains one or more of following: any build step or build wrapper defined in Pipeline. e.g. sh, bat, powershell, timeout, retry, echo, archive, junit, etc. script - execute Scripted Pipeline block when - executes stage conditionally branch - stage runs when branch name matches ant pattern expression - Boolean Groovy expression anyOf - any of the enclosed conditions are true allOf - all of the enclosed conditions are true not - none of the enclosed conditions are true parallel - stage - stages are executed in parallel but agent, environment, tools and post may also optionally be defined in stage environment - a sequence of “key = value” pairs to define environment variables credentials(‘id’) (optional) - Bind credentials to variable. libraries - load shared libraries from an scm lib - the name of the shared library to load options - options for entire Pipeline. skipDefaultCheckout - disable auto checkout scm timeout - sets timeout for entire Pipeline buildDiscarder - discard old builds disableConcurrentBuilds - disable concurrent Pipeline runs ansiColor - color the log file output tools - Installs predefined tools to be available on PATH triggers - triggers to launch Pipeline based on schedule, etc. parameters - parameters that are prompted for at run time. post - defines actions to be taken when pipeline or stage completes based on outcome. Conditions execute in order: always - run regardless of Pipeline status. changed - run if the result of Pipeline has changed from last run success - run if Pipeline is successful unstable - run if Pipeline result is unstable failure - run if the Pipeline has failed
Pass variable from one stage to another
stages { stage("1") { agent any steps { script { my_app_CHANGED = true def SOMETHING = true } echo "${my_app_CHANGED}" // true echo "${SOMETHING}" // true } } stage("2") { agent any steps { script { echo "${my_app_CHANGED}" // true echo "${SOMETHING}" // build will fail here, scope related } } } }
Omitting the "def" keyword puts the variable in the bindings for the current script and groovy treats it (mostly) like a globally scoped variable.
Pass a variable from bash to groovy
stages { stage("Determine What To Build") { agent any steps { sh '''#!/bin/bash echo true > my_app_CHANGED.txt // pipe something into a text file in your working directory. oooooo so0o0o0o0o diiiiiirty. ''' script { try { my_app_CHANGED_UNSAFE = readFile('my_app_CHANGED.txt') // assign contents of file to groovy variable here my_app_CHANGED = "${my_app_CHANGED_UNSAFE.trim()}" // need to trim the newline in file from the variable's value. } catch (exception) { my_app_CHANGED = false // in case the bash command failed. } } echo "${my_app_CHANGED}" // true } } }
Pass a variable from groovy to groovy
Ensure the entire thing is encased in "". ${blah} or $blah can both be used. GOOD - echo "Deploying my_app to ${DEPLOYMENT_GATEWAY}-0, ${ENVIRONMENT}, ${PACKAGE}" BAD - echo Deploying my_app to "${DEPLOYMENT_GATEWAY}"-0, "${ENVIRONMENT}", "${PACKAGE}"
stages { stage("Determine What To Build") { agent any steps { script { if ("${DEPLOY_TO}" == 'Somewhere' ) { DEPLOYMENT_GATEWAY = 'abc.somewhere.com' ENVIRONMENT = 'my_app-prod' PACKAGE = "my_app-${BRANCH_NAME}.tgz" echo "${DEPLOYMENT_GATEWAY}" echo "${ENVIRONMENT}" echo "${PACKAGE}" if ("${my_app_CHANGED}" == 'true') { switch("${BRANCH_NAME}") { case ".*": echo "Deploying my_app to ${DEPLOYMENT_GATEWAY}-0, ${ENVIRONMENT}, ${PACKAGE}" //sh gui_deployer.sh "${DEPLOYMENT_GATEWAY}" 8022 "${ENVIRONMENT}" "${PACKAGE}" echo "Deploying my_app to ${DEPLOYMENT_GATEWAY}-1, ${ENVIRONMENT}, ${PACKAGE}" //sh gui_deployer.sh "${DEPLOYMENT_GATEWAY}" 8023 "${ENVIRONMENT}" "${PACKAGE}" break } } else { echo "Nothing was deployed because the commit didn't include any changes to my_app." } } else { echo "Nothing was deployed because no environment was selected." return } } } } }
Pass a variable from groovy to a single line shell script
Ensure the entire thing is encased in "", not just the ${variable}.
script { def SOMETHING = "https://some.thing.com" sh "echo ${SOMETHING}" sh "SOMETHING=${SOMETHING}; echo SOMETHING" }
Pass a variable from groovy to a multiline line shell script
Make sure the """ are with double quotes. ''' sucks. pass the variable inside double quotes: "${variable}" if there is a bash $ being used, such as when referencing a bash variable $MYVAR, you need to escape it: \$MYVAR
script { def SOMETHING = "https://some.thing.com" sh """ eval \$(docker-machine env somenode) echo "${SOMETHING}" """ }
Assign groovy string to groovy variable which contains another groovy variable
Once again, ensure the entire thing is encased in "", not just the ${variable}.
script { PACKAGE = "my_app-${BRANCH_NAME}.tgz" }
Choosing which parallel stages to run based on conditions or parameters previously set
stages { stage("1") { agent any parallel ( "Package Consumer" : { echo "${my_app_1_CHANGED}" script { if ("${my_app_1_CHANGED}" == 'true') { sh ''' case "${BRANCH_NAME}" in *) echo Compressing Consumer GUI Package rm -f my_app_1-"${BRANCH_NAME}".tgz || true tar -czf my_app_1-"${BRANCH_NAME}".tgz -C my_app_1/web . ;; esac ''' } else { echo "Nothing was tarballed because the commit didn't include any changes to my_app_1." } } }, "Package Manager" : { echo "${my_app_2_CHANGED}" script { if ("${my_app_2_CHANGED}" == 'true') { sh ''' case "${BRANCH_NAME}" in *) echo Compressing Manager GUI Package rm -f my_app_2-"${BRANCH_NAME}".tgz || true tar -czf my_app_2-"${BRANCH_NAME}".tgz -C my_app_2/web . ;; esac ''' } else { echo "Nothing was tarballed because the commit didn't include any changes to my_app_2." } } }, "Package Operator" : { echo "${my_app_3_CHANGED}" script { if ("${my_app_3_CHANGED}" == 'true') { sh ''' case "${BRANCH_NAME}" in *) echo Compressing Operator GUI Package rm -f my_app_3-"${BRANCH_NAME}".tgz || true tar -czf my_app_3-"${BRANCH_NAME}".tgz -C my_app_3/web . ;; esac ''' } else { echo "Nothing was tarballed because the commit didn't include any changes to my_app_3." } } } ) } }
Escaping $ in ""
sh ''' SOMETHING=hello echo $SOMETHING buddy ''' // hello buddy sh """ SOMETHING=hello echo $SOMETHING """ // buddy sh """ SOMETHING=hello echo \$SOMETHING buddy """ // hello buddy
Junit stupidity in the post section
post { always { script { junit "my_app/coverage/junit/*.xml" } } }
Error stating that the time the test was run was older than some current time. Apparently if its more than something like 4 seconds, you'll get this error.
post { always { script { sh "sudo touch ${WORKSPACE}/my_app/coverage/junit/*.xml" junit "${WORKSPACE}/my_app/coverage/junit/*.xml" } } }
Touch the damn file right before. Not a solution, a bandaid, like everything about jenkins, one giant ball of bandaids. However this will also error because of the ${WORKSPACE} variable in the junit command. I dont know why.
post { always { script { sh "sudo touch ${WORKSPACE}/my_app/coverage/junit/*.xml" junit "my_app/coverage/junit/*.xml" } } }
This one works then.
Disabling concurrent builds on a multistage pipeline doesn't work if you use agents in the stages
pipeline { agent none options { buildDiscarder(logRotator(numToKeepStr: '10')) disableConcurrentBuilds() } stages { stage("1") { agent any steps { ... } } stage("2") { agent any steps { ... } } } }
Results in:
my_build-TWRKUBXHW7FVLDXTUXR7V4NSBGZMX4K65ZYM6WHW3NCJK5DECL5Q my-build-TWRKUBXHW7FVLDXTUXR7V4NSBGZMX4K65ZYM6WHW3NCJK5DECL5Q@2
For 2 concurrent builds even when we clearly specified in the pipeline options to disableConcurrentBuilds()
pipeline { agent any options { buildDiscarder(logRotator(numToKeepStr: '10')) disableConcurrentBuilds() } stages { stage("1") { steps { ... } } stage("2") { steps { ... } } } }
Use the global agent.
1 note
·
View note
Link
TypeScript, Angular, Firebase & Angular Material Masterclass ##elearning ##UdemyFreeDiscountCoupons #Angular #Firebase #Masterclass #Material #TypeScript TypeScript, Angular, Firebase & Angular Material Masterclass Angular is one of the most popular front-end frameworks for building client apps with HTML, CSS, and TypeScript. So basically, if you want to become a successful front-end or a full-stack developer, that get hired, you need to have Angular as a skill under your belt. Learning Angular 2 or Angular 4 or Angular 5 or Angular 6 or simply Angular(as the Angular team likes to call it) on your own can be confusing or frustrating at times. It might require you to browse through several tutorials, articles, YouTube videos, etc and get a grip on it. If you want to get rid of going through all that trouble and just focus on learning Angular, this is THE course for you. In this course, I'll take you through an exciting journey of learning Angular concepts through fun and easy to understand coding examples. ______________________________________________________________________________________________________________________________ As the course progresses, you'll get familiar with: TypeScript, Angular Application Architecture, and Angular CLI Angular Modules and Angular Components. Angular's Component LifeCycle Hooks Dependency Injection In Angular Routing Services Directives Pipes Forms Custom Decorators Angular Material Firebase TypeScript, Angular Application Architecture, and Angular CLI What is a Single Page Application Why Angular Types Let, Const Class, Interface Fat Arrow Functions Decorators Modules What is Angular CLI and how to use it? Basic tasks (ng serve/build/test, ng generate component/service/directive/pipe) The Architecture of Angular Applications Built using Angular-CLI Change Detection strategy (Zones) - Theoretical Angular Modules and Angular Components @NgModule Angular Application Bootstrap Mechanism @Component Data/Property Binding View Encapsulation Inter-component Communication (@Input/@Output, Event Emitter) Template variables (ViewChild/ContentChild) Content Projection(ng-content) Templates – will be covered as part of components Metadata – basic overview Lifecycle hooks Order and triggering of each hook Hooks specific to Components and Decorators Dependency Injection(Providers) Dependency Injection - Why? Dependency Injection - As a design pattern Dependency Injection - As a framework Dependency Injection - What? Injectors and Providers Hierarchical Dependency Injection Routing Child routes Route params Route Guards - CanActivate, CanActivateChild, CanDeactivate, Resolve, CanLoad Services(@Injectable) Service as a singleton, data sharing. HttpClient, HttpHeaders, HttpParams Observables with Operators like the map, subscribe, catch, retry etc Subjects Sharing data across Components using Service Directives(@Directive) Built-In Structural Directives - NgFor, NgIf, NgSwitch Built-In Attribute Directives - NgClass, NgStyle, NgNonBindable Building a Custom Structural Directive Building a Custom Attribute Directive Pipes(@Pipe) Build in Pipes Building Custom Pipes Pure and Impure Pipe Forms Template Driven Forms Reactive forms Form Validations Custom Synchronous form validations Custom Asynchronous form validations Custom Decorators Metadata – deep dive Building Custom Class Decorator Building Custom Property Decorator Integrating with Third Party Libraries Material Design Bootstrap Angular Material Firebase ______________________________________________________________________________________________________________________________ By the end of this course, you'll be able to: Build end-to-end Single Page Apps in Angular on your own Understand and fix common compile-time and run-time errors in minutes Understand and implement clean and maintainable code like a professional Apply best practices when building Angular apps We'll always start with the basics and go from there. Right from the beginning of the second module, you'll jump in and build your first Angular app within minutes. Angular 2 and all the later versions of Angular has been written in TypeScript. So, before getting started with Angular in section 2, you'll learn the fundamentals of TypeScript and object-oriented programming in section 1 to better understand and appreciate this powerful framework. Over the next 15 hours, you'll learn the essentials of building Single Page Applications(SPAs) with Angular: Displaying data and handling DOM events Building re-usable components Manipulating the DOM using directives(both Structural and Attribute) Transforming data using pipes Building template-driven and reactive forms Consuming REST APIs using HTTP services Handling HTTP errors properly Using Reactive Extensions and Observables Adding routing and navigation to adhere with basics of a Single Page Application Building real-time, server-less apps with Firebase Building beautiful UIs using Angular Material, and Material Design Bootstrap So, if you're a busy developer with limited time and want to quickly learn how to build SPAs with Angular, you're at the right place. All these topics are covered by over 15 hours of high-quality content. Taking this course is equivalent to going through hundreds of articles, tutorials, and videos on the web! Just that the content is laid out to cover all that you'll get to know during all that time! Once you go through the course(or just the preview videos), you'll know that the topics are explained in a clear and concise manner which is going to save you a lot of your precious time! This course is also packed with techniques and tips, that you can only learn from a seasoned developer. You'll see how we'll create a brand new Angular project with Angular CLI and build an application from A to Z, step-by-step. You'll also get to know ways to build a real-time SPA with Angular, Firebase, and Bootstrap. This application exhibits patterns that you see in a lot of real-world applications: Master/detail CRUD operations Interaction with a data store Forms with custom validation And a lot more...! PREREQUISITES You don't need familiarity with TypeScript or any previous versions of Angular. You're going to learn both TypeScript and Angular from scratch in this course. ______________________________________________________________________________________________________________________________ WHAT OTHER STUDENTS WHO HAVE TAKEN THIS COURSE SAY: "Explanation is crisp.. instructor is comfortable with the topic...examples used are good and easy to understand...various aspects of the code are explained...using MDB and material for angular both are covered for creating UI components...just only the full screen is shown at all times.. which makes things appear very small... screen highlight or zoom is not used while recording video.. rest all is great.. for learning angular" - Maneesh Parihar "內容詳細" - Huang JiaLin "That's a very comprehensive course on Angular that also teaches Angular Material and Firebase @Siddharth Ajmera: Thanks for this great course! As with so many other courses I would love to see some Summaries or cheatsheets as PDFs or foils and also I'd appreciate to see more schematics, graphs, and sketches." - He "講解詳細" -曾玟凱 "This course was perfect for beginners like me. I learned so much from it. Thanks a lot Siddharth for such a good course. Looking forward to more courses from you. Can you please add a section that demonstrates building of an application end to end?" - ankita daur "Siddarth explained the course in a very simple manner and with simple examples. Would love more indepth on Angular Material and Firebase from him. Great course." - Kumar "There is so much information provided in this course. I was looking for custom Decorators and use cases where in they could be implemented to make the code cleaner. I found perfect examples on similar topics in this training. This course is great for beginners." - Kewal Shah ______________________________________________________________________________________________________________________________ 30-DAY FULL MONEY-BACK GUARANTEE This course comes with a 30-day full money-back guarantee. Take the course, watch every lecture, follow along while coding, and if you are not happy for any reasons, contact Udemy for a full refund within the first 30 days of your enrolment. All your money back, no questions asked. ABOUT YOUR INSTRUCTOR Siddharth is a software engineer with around 5 years of professional experience. He is the author of this course with more than 15,000 students in 192 countries. He has done his Bachelor of Engineering in Computer Science. He has worked on several Modern Web Applications. Chatbots, and frameworks. He writes articles about Angular, and Chatbots on Medium. What are the requirements? Basic familiarity with HTML, CSS, and JavaScript NO knowledge of AngularJS or Angular is required What am I going to get from this course? Establish yourself as a skilled professional developer Build real-world Angular applications on your own Troubleshoot common Angular errors Master the best practices Write clean and elegant code like a professional developer What is the target audience? Developers who want to upgrade their skills and get better job opportunities Front-end developers who want to stay up-to-date with the latest technology Back-end developers who want to learn front-end development and become full-stack developers Hobbyist developers who are passionate about working with new frameworks Who this course is for: Anyone who wants to learn Angular Anyone interested in building Single Page Applications Anybody who wants to know Angular in depth Anyone who wants to learn TypeScript, Firebase and Angular Material 👉 Activate Udemy Coupon 👈 Free Tutorials Udemy Review Real Discount Udemy Free Courses Udemy Coupon Udemy Francais Coupon Udemy gratuit Coursera and Edx ELearningFree Course Free Online Training Udemy Udemy Free Coupons Udemy Free Discount Coupons Udemy Online Course Udemy Online Training 100% FREE Udemy Discount Coupons https://www.couponudemy.com/blog/typescript-angular-firebase-angular-material-masterclass/
0 notes
Text
RxJava support 2.0 releases support for Android apps
The RxJava team has released version 2.0 of their reactive Java framework, after an 18 month development cycle. RxJava is part of the ReactiveX family of libraries and frameworks, which is in their words, "a combination of the best ideas from the Observer pattern, the Iterator pattern, and functional programming". The project's "What's different in 2.0" is a good guide for developers already familiar with RxJava 1.x.
RxJava 2.0 is a brand new implementation of RxJava. This release is based on the Reactive Streams specification, an initiative for providing a standard for asynchronous stream processing with non-blocking back pressure, targeting runtime environments (JVM and JavaScript) as well as network protocols.
Reactive implementations have concepts of publishers and subscribers, as well as ways to subscribe to data streams, get the next stream of data, handle errors and close the connection.
The Reactive Streams spec will be included in JDK 9 as java.util.concurrent.Flow. The following interfaces correspond to the Reactive Streams spec. As you can see, the spec is small, consisting of just four interfaces:
· Flow.Processor<T,R>: A component that acts as both a Subscriber and Publisher.
· Flow.Publisher<T>: A producer of items (and related control messages) received by Subscribers.
· Flow.Subscriber<T>: A receiver of messages.
· Flow.Subscription: Message control linking a Flow.Publisher and Flow.Subscriber.
Spring Framework 5 is also going reactive. To see how this looks, refer to Josh Long's Functional Reactive Endpoints with Spring Framework 5.0.
To learn more about RxJava 2.0, InfoQ interviewed main RxJava 2.0 contributor, David Karnok.
InfoQ: First of all, congrats on RxJava 2.0! 18 months in the making, that's quite a feat. What are you most proud of in this release?
David Karnok: Thanks! In some way, I wish it didn't take so long. There was a 10 month pause when Ben Christensen, the original author who started RxJava, left and there was no one at Netflix to push this forward. I'm sure many will contest that things got way better when I took over the lead role this June. I'm proud my research into more advanced and more performant Reactive Streams paid off and RxJava 2 is the proof all of it works.
InfoQ: What’s different in RxJava 2.0 and how does it help developers?
Karnok: There are a lot of differences between version 1 and 2 and it's impossible to list them all here ,but you can visit the dedicated wiki page for a comprehensible explanation. In headlines, we now support the de-facto standard Reactive Streams specification, have significant overhead reduction in many places, no longer allow nulls, have split types into two groups based on support of or lack of backpressure and have explicit interop between the base reactive types.
InfoQ: Where do you see RxJava used the most (e.g. IoT, real-time data processing, etc.)?
Karnok: RxJava is more dominantly used by the Android community, based on the feedback I saw. I believe the server side is dominated by Project Reactor and Akka at the moment. I haven't specifically seen IoT mentioned or use RxJava (it requires Java), but maybe they use some other reactive library available on their platform. For real-time data processing people still tend to use other solutions, most of them not really reactive, and I'm not aware of any providers (maybe Pivotal) who are pushing for reactive in this area.
InfoQ: What benefits does RxJava provide Android more than other environments that would explain the increased traction?
Karnok: As far as I see, Android wanted to "help" their users solving async and concurrent problems with Android-only tools such as AsyncTask, Looper/Handler etc.
Unfortunately, their design and use is quite inconvenient, often hard to understand or predict and generally brings frustration to Android developers. These can largely contribute to callback hell and the difficulty of keeping async operations off the main thread.
RxJava's design (inherited from the ReactiveX design of Microsoft) is dataflow-oriented and orthogonalized where actions execute from when data appears for processing. In addition, error handling and reporting is a key part of the flows. With AsyncTask, you had to manually work out the error delivery pattern and cancel pending tasks, whereas RxJava does that as part of its contract.
In practical terms, having a flow that queries several services in the background and then presents the results in the main thread can be expressed in a few lines with RxJava (+Retrofit) and a simple screen rotation will cancel the service calls promptly.
This is a huge productivity win for Android developers, and the simplicity helps them climb the steep learning curve the whole reactive programming's paradigm shift requires. Maybe at the end, RxJava is so attractive to Android because it reduces the "time-to-market" for individual developers, startups and small companies in the mobile app business.
There was nothing of a comparable issue on the desktop/server side Java, in my opinion, at that time. People learned to fire up ExecutorService's and wait on Future.get(), knew about SwingUtilities.invokeLater to send data back to the GUI thread and otherwise the Servlet API, which is one thread per request only (pre 3.0) naturally favored blocking APIs (database, service calls).
Desktop/server folks are more interested in the performance benefits a non-blocking design of their services offers (rather than how easy one can write a service). However, unlike Android development, having just RxJava is not enough and many expect/need complete frameworks to assist their business logic as there is no "proper" standard for non-blocking web services to replace the Servlet API. (Yes, there is Spring (~Boot) and Play but they feel a bit bandwagon-y to me at the moment).
InfoQ: HTTP is a synchronous protocol and can cause a lot of back pressure when using microservices. Streaming platforms like Akka and Apache Kafka help to solve this. Does RxJava 2.0 do anything to allow automatic back pressure?
Karnok: RxJava 2's Flowable type implements the Reactive Streams interface/specification and does support backpressure. However, the Java level backpressure is quite different from the network level backpressure. For us, backpressure means how many objects to deliver through the pipeline between different stages where these objects can be non uniform in type and size. On the network level one deals with usually fixed size packets, and backpressure manifests via the lack of acknowledgement of previously sent packets. In classical setup, the network backpressure manifests on the Java level as blocking calls that don't return until all pieces of data have been written. There are non-blocking setups, such as Netty, where the blocking is replaced by implicit buffering, and as far as I know there are only individual, non-uniform and non Reactive Streams compatible ways of handling those (i.e., a check for canWrite which one has to spin over/retry periodically). There exist libraries that try to bridge the two worlds (RxNetty, some Spring) with varying degrees of success as I see it.
InfoQ: Do you think reactive frameworks are necessary to handle large amounts of traffic and real-time data?
Karnok: It depends on the problem complexity. For example, if your task is to count the number of characters in a big-data source, there are faster and more dedicated ways of doing that. If your task is to compose results from services on top of a stream of incoming data in order to return something detailed, reactive-based solutions are quite adequate. As far as I know, most libraries and frameworks around Reactive Streams were designed for throughput and not really for latency. For example, in high-frequency trading, the predictable latency is very important and can be easily met by Aeron but not the main focus for RxJava due to the unpredictable latency behavior.
InfoQ: Does HTTP/2 help solve the scalability issues that HTTP/1.1 has?
Karnok: This is not related to RxJava and I personally haven't played with HTTP/2 but only read the spec. Multiplexing over the same channel is certainly a win in addition to the support for explicit backpressure (i.e., even if the network can deliver, the client may still be unable to process the data in that volume) per stream. I don't know all the technical details but I believe Spring Reactive Web does support HTTP/2 transport if available but they hide all the complexity behind reactive abstractions so you can express your processing pipeline in RxJava 2 and Reactor 3 terms if you wish.
InfoQ: Java 9 is projected to be featuring some reactive functionality. Is that a complete spec?
Karnok: No. Java 9 will only feature 4 Java interfaces with 7 methods total. No stream-like or Rx-like API on top of that nor any JDK features built on that.
InfoQ: Will that obviate the need for RxJava if it is built right into the JDK?
Karnok: No and I believe there's going to be more need for a true and proven library such as RxJava. Once the toolchains grow up to Java 9, we will certainly provide adapters and we may convert (or rewrite) RxJava 3 on top of Java 9's features (VarHandles).
One of my fears is that once Java 9 is out, many will try to write their own libraries (individuals, companies) and the "market" gets diluted with big branded-low quality solutions, not to mention the increased amount of "how does RxJava differ from X" questions.
My personal opinion is that this is already happening today around Reactive Streams where certain libraries and frameworks advertise themselves as RS but fail to deliver based on it. My (likely biased) conjecture is that RxJava 2 is the closest library/technology to an optimal Reactive Streams-based solution that can be.
InfoQ: What's next for RxJava?
Karnok: We had fantastic reviewers, such as Jake Wharton, during the development of RxJava 2. Unfortunately, the developer previews and release candidates didn't generate enough attention and despite our efforts, small problems and oversights slipped into the final release. I don't expect major issues in the coming months but we will keep fixing both version 1 and 2 as well as occasionally adding new operators to support our user base. A few companion libraries, such as RxAndroid, now provide RxJava 2 compatible versions, but the majority of the other libraries don't yet or haven't yet decided how to go forward. In terms of RxJava, I plan to retire RxJava 1 within six months (i.e., only bugfixes then on), partly due to the increasing maintenance burden on my "one man army" for some time now; partly to "encourage" the others to switch to the RxJava 2 ecosystem. As for RxJava 3, I don't have any concrete plans yet. There are ongoing discussions about splitting the library along types or along backpressure support as well as making the so-called operator-fusion elements (which give a significant boost to our performance) a standard extension of the Reactive Streams specification.
1 note
·
View note
Text
Supercharge your iPaaS for Better Agility, Resilience, and Real-time Capabilities with an Event Broker
More and more enterprises are moving from on-premises enterprise service buses (ESB) to integration platform as a service (iPaaS) solutions like Boomi, Jitterbit, Mulesoft Anypoint and others. iPaaS solutions like these are a key component of what Gartner calls a hybrid integration approach[1], and as someone accustomed to creating ESB solutions, it’s been eye-opening see how quickly and easily you can get them up and running. But as I create iPaaS solutions, one thought keeps running through my mind: this would be so much more powerful and elegant if we added an event broker to the mix.
iPaaS and Synchronous REST Calls
At their heart, iPaaS solutions aim to simplify integration by creating a managed experience, particularly when deployed in the cloud. An iPaaS solution typically includes:
Graphical tools that show how transactions flow through the system
Connectors that contain logic for popular protocols
Built-in mapping tools that allow for data transformation
Defined locations for code snippets that isolate customer-specific modifications, typically in a language like JavaScript
Integrated source code repositories and deployment capabilities that are usually external in ESBs
Although there are adapters for many different information providers such as databases and EDI, most iPaaS (and most ESB) solution’s bread and butter has been synchronous REST calls between software as a service (SaaS) providers like Salesforce and SAP S/4HANA Cloud. As a result, iPaaS providers have focused on making synchronous API integrations as easy as possible. Architecturally, this generally means the same process that receives an incoming request maps the data using a graphical tool, connects to the information consumer, and sends the transformed message.
Figure 1: Typical iPaaS process flow
Adding an Event Broker to Your iPaaS Solution
Adding an event broker allows you to separate (decouple) that process, such that the iPaaS receives information via one process and writes it to a queue or topic[2], then a second process picks up the message and performs additional logic, typically including data transformation, before forwarding it to a consumer.
Figure 2: iPaaS flow with event broker
That decoupling can enhance traditional ESBs, but in some ways it’s even more important for iPaaS solutions. The architectural shift to decoupling using an event broker can improve an iPaaS’s resilience, agility and real-time capabilities—all without complicating its architecture or operation. The approach is a lot like breaking up a monolithic application into multiple microservices.
Some brief asides:
Many iPaaS providers have begun to integrate lightweight event brokers into their products. While I think there are advantages to having an event broker live outside the iPaaS itself, I will save that for another day and focus on the benefits of all event brokers, including those they include.
While event brokers provide great benefits for iPaaS architectures, they also present challenges. In a future blog I’ll discuss those challenges, the trade-offs they entail, and give guidance on architectural choices that can help you overcome them.
Planning for Failure – How an Event Broker Helps an iPaaS Stay Simple
One of the most complex and time-consuming tasks for any integration architect is making sure a system performs when things go wrong – in fact some experts say up to 25% of an integration project should be devoted to designing exception handling, and iPaaS solutions are no different. That isn’t surprising given that architects need to consider complex questions including:
What if the iPaaS itself fails? Will I lose in-flight transactions?
What should happen if a consumer goes down and I need to retry? How can I prevent it from decreasing performance and blocking incoming?
What if a consumer can’t process my incoming message until a human intervenes (e.g. adding a value to a cross reference table)? How can I easily move on to the next transaction and replay it later?
You can try to solve these issues within the iPaaS itself, perhaps by creating a library of custom code snippets in a language like JavaScript that dictate architectural standards like manually compensating for failed transactions and using adapters to ensure that transactions are persisted to disk. However, in doing so you sacrifice some of the simplicity that makes iPaaS so advantageous.
Introducing an event broker as part of a decoupled architecture, on the other hand, can answer some of the questions while keeping the iPaaS simple. As shown in Figure 3, by persisting messages to a queue or topic after arrival at the iPaaS, the event broker takes responsibility for guaranteeing that the message will not be lost in the event of a failure that brings down either your process or the entire iPaaS. Without an event broker, an iPaaS either requires custom persistence logic or accepts that messages will be lost in the event of failure, requiring the information provider to resend as necessary.
Figure 3: Event brokers allow for message persistence in the case of failure
Once the message is persisted by an event broker, the iPaaS receiver (not the end consumer) can acknowledge that the message has been successfully processed and becomes available for the next incoming message.
This ability for the iPaaS receiver to quickly and independently process messages comes in handy if the downstream information consumer isn’t available. Typically, an information consumer being unavailable results in multiple attempts to retry the transaction until it succeeds. As shown in Figure 4, if the receiver and sender are on the same thread, this can quickly cause the iPaaS to run out of resources, creating a chain reaction that blocks incoming transactions. By buffering incoming transactions, an event broker helps to keep your solution up and running. This buffering is even more valuable as we add in additional consumers, which we discuss in the next section.
Figure 4: Event brokers conserve resources during retry
Lastly, if the error turns out to be one that will take a while to resolve (e.g. someone to add a value to a look up table), the message can be placed into an error queue. When the issue is resolved, the message can be requeued for processing.
Figure 5: Event brokers simplify replay after human intervention
The Value of Event-Driven Architecture
To this point, we’ve focused on the benefits of decoupling a single sender and receiver from one another, and the benefits of that decoupling are worthwhile on their own. But the value really adds up as you begin distributing transactions amongst multiple diverse consumers using a fully event-driven architecture. Making your integrations more agile lets your architects and developers innovate more freely, solving business needs and exploring new frontiers for your business.
Architects need to consider complex questions including:
How can I quickly introduce new business functionality while making sure I’m not affecting existing functionality?
How do I handle situations where one consumer processes information faster than another? Or one consumer rejects the transaction, while another processes it?
How do I make sure I’m not locking myself into a deployment pattern (on-premises, cloud, etc), cloud provider, or even iPaaS solution?
To aid agility, iPaaS providers typically feature integrated source control and deployment capabilities. Including these components reduces the amount of additional infrastructure needed to start building an iPaaS solution – no more setting up a Git repository and configuring Jenkins.
Most iPaaS solutions include the ability to call multiple sender processes from a single receiver process, but as Figure 6 shows, even with the code promotion infrastructure in place, if the solution tightly couples senders and receivers of information you still need to have a complete test cycle and deployment with every change. That cycle is represented by a link icon in the diagram below. This tight coupling also makes error handling more complex, particularly in cases where one consumer rejects the transaction and additional consumers process it successfully.
Figure 6: iPaaS solution with multiple tightly coupled consumers
An event broker allows you to move into the realm of fully event-driven architecture. At the outset, the addition of an event broker may seem like it increases complexity—after all, there are now more components—but the addition of those components is more than offset by the fact that an event broker makes code more modular and reduces integration challenges.
By playing middleman between receivers and senders, an event broker lets you change a sender without redeploying and retesting the entire process. What’s more, you can very easily add new senders and consumers, and seamlessly integrate them into an existing solution.
With an event broker, you can design a new sender connecting to an innovative new application using iPaaS integration tools like graphical mapping, content-based filtering and pre-built connectivity. Then once you add a new subscription to the event broker, events begin flowing to the new process and onward to the information consumer.
Figure 7: iPaaS with loosely coupled consumers using event broker
Handling Slow Consumers and Routing Information with an Event Mesh
At runtime, decoupling lets consumers process information independently. This can help to resolve several difficult architectural challenges:
The first challenge decoupling alleviates is information consumers that process transactions at different rates of speed. An event broker creates a buffer that allows slow consumers to process messages at their own pace without affecting or constraining those applications that can process messages much more quickly.
Another challenge is dealing with instances in which one consumer rejects an incoming transaction, but other consumers are still able to process it. An event broker can handle that scenario without resorting to adhoc error handling. That said, error handling in an event-driven architecture can be tricky, and I look forward to diving into that topic in a future blog post.
By linking multiple brokers in different locations to form an event mesh, event brokers can efficiently route information between on-premises and cloud applications, different clouds and even different iPaaS solutions—without having to explicitly route information between them within your iPaaS.
Such an event mesh can also address the challenge of unreliable WAN connectivity by provide reliable delivery without each iPaaS application needing to handle this. If your deployment pattern changes, the event mesh dynamically reroutes events to the new topology.
Reacting to Real-Time Event Sources….in Real-Time
Beyond decoupling and event-driven architecture between iPaaS components, an event broker provides an on-ramp to real-time capabilities for your iPaaS. The internet of things (IoT) and other real-time information sources such as Workday and Salesforce present a massive opportunity to increase your business’s ability to react, but you typically need to act on such information in real-time to fully exploit its value. Real-time information sources can also send a massive spike in traffic during periods of high demand.
The need to process incoming events in real-time, and deal with sudden unpredictable bursts of data can be challenges for any iPaaS. In the absence of an event broker, iPaaS solutions are typically triggered either through a synchronous API request, or on a polling interval defined when the process is developed and deployed. In the case of a process invoked by a synchronous API request, dealing with traffic spikes within the structures of an iPaaS typically means increasing the number of processing threads available to handle the incoming flow of information and over allocation of memory and processing power. In the case of a polling interval, it is difficult to predict how often to poll far in advance, especially if you can’t change that interval when conditions change.
Figure 8: Using polling for real-time event processing
An event broker helps you overcome these challenges by providing an entry point for event-driven applications. Messages that are placed on event broker topics can trigger your iPaaS immediately, without having to worry about selecting a static polling interval. An event broker can also buffer incoming events and provide a throttling mechanism that prevents downstream processes from being overwhelmed in periods of high traffic.
Figure 9: Using an event broker for real-time event processing
Conclusion
Event brokers are a great potential partner for your iPaaS, enhancing their resilience, agility and real-time capabilities. Recognizing those potential benefits is the first step in the journey. The next steps are recognizing and overcoming some challenges that event brokers can introduce. In the future posts, I’m looking forward to answering questions such as:
What are situations when it makes sense to use an event broker, and when is it overkill?
What are the trade-off between using an iPaaS-provided message broker and an external one?
What does error handling look like when using an event broker?
What are some architectural “gotchas” associated with using event brokers with iPaaS?
How do I make all this work in real-world environments?
[1] For more on HIP, see https://www.gartner.com/smarterwithgartner/use-a-hybrid-integration-approach-to-empower-digital-transformation/
[2] For a more general introduction to messaging concepts and patterns, see https://www.enterpriseintegrationpatterns.com/patterns/messaging/Introduction.html
The post Supercharge your iPaaS for Better Agility, Resilience, and Real-time Capabilities with an Event Broker appeared first on Solace.
Supercharge your iPaaS for Better Agility, Resilience, and Real-time Capabilities with an Event Broker published first on https://jiohow.tumblr.com/
1 note
·
View note
Link
Build Single Page Application(SPA) from Scratch using Angular 5. Learn basics of TypeScript, Firebase & Angular Material
What you’ll learn
Built a Single Page Application using Angular
Using TypeScript
Implementing various building blocks in Angular
Using Third Party Modules like Angular Material and AngularFire 2
Requirements
NodeJS Installed
Basic knowledge of NodeJS, NPM, node_modules
We’ll use AngularCLI, so make sure that it’s installed as well.
We’ll use Visual Studio Code as our IDE
You should know JavaScript
Experience with Object Oriented Programming is a plus
Description
Angular is one of the most popular front-end frameworks for building client apps with HTML, CSS, and TypeScript. So basically, if you want to become a successful front-end or a full-stack developer, that get hired, you need to have Angular as a skill under your belt.
Learning Angular 2 or Angular 4 or Angular 5 or Angular 6 or simply Angular(as the Angular team likes to call it) on your own can be confusing or frustrating at times. It might require you to browse through several tutorials, articles, YouTube videos, etc and get a grip on it.
If you want to get rid of going through all that trouble and just focus on learning Angular, this is THE course for you. In this course, I’ll take you through an exciting journey of learning Angular concepts through fun and easy to understand coding examples.
______________________________________________________________________________________________________________________________
As the course progresses, you’ll get familiar with:
TypeScript, Angular Application Architecture, and Angular CLI
Angular Modules and Angular Components.
Angular’s Component LifeCycle Hooks
Dependency Injection In Angular
Routing
Services
Directives
Pipes
Forms
Custom Decorators
Angular Material
Firebase
TypeScript, Angular Application Architecture, and Angular CLI
What is a Single Page Application
Why Angular
Types
Let, Const
Class, Interface
Fat Arrow Functions
Decorators
Modules
What is Angular CLI and how to use it? Basic tasks (ng serve/build/test, ng generate component/service/directive/pipe)
The Architecture of Angular Applications Built using Angular-CLI
Change Detection strategy (Zones) – Theoretical
Angular Modules and Angular Components
@NgModule
Angular Application Bootstrap Mechanism
@Component
Data/Property Binding
View Encapsulation
Inter-component Communication (@Input/@Output, Event Emitter)
Template variables (ViewChild/ContentChild)
Content Projection(ng-content)
Templates – will be covered as part of components
Metadata – basic overview
Lifecycle hooks
Order and triggering of each hook
Hooks specific to Components and Decorators
Dependency Injection(Providers)
Dependency Injection – Why?
Dependency Injection – As a design pattern
Dependency Injection – As a framework
Dependency Injection – What?
Injectors and Providers
Hierarchical Dependency Injection
Routing
Child routes
Route params
Route Guards – CanActivate, CanActivateChild, CanDeactivate, Resolve, CanLoad
Services(@Injectable)
Service as a singleton, data sharing.
HttpClient, HttpHeaders, HttpParams
Observables with Operators like the map, subscribe, catch, retry etc
Subjects
Sharing data across Components using Service
Directives(@Directive)
Built-In Structural Directives – NgFor, NgIf, NgSwitch
Built-In Attribute Directives – NgClass, NgStyle, NgNonBindable
Building a Custom Structural Directive
Building a Custom Attribute Directive
Pipes(@Pipe)
Build in Pipes
Building Custom Pipes
Pure and Impure Pipe
Forms
Template Driven Forms
Reactive forms
Form Validations
Custom Synchronous form validations
Custom Asynchronous form validations
Custom Decorators
Metadata – deep dive
Building Custom Class Decorator
Building Custom Property Decorator
Integrating with Third Party Libraries
Material Design Bootstrap
Angular Material
Firebase
______________________________________________________________________________________________________________________________
By the end of this course, you’ll be able to:
Build end-to-end Single Page Apps in Angular on your own
Understand and fix common compile-time and run-time errors in minutes
Understand and implement clean and maintainable code like a professional
Apply best practices when building Angular apps
We’ll always start with the basics and go from there. Right from the beginning of the second module, you’ll jump in and build your first Angular app within minutes.
Angular 2 and all the later versions of Angular has been written in TypeScript. So, before getting started with Angular in section 2, you’ll learn the fundamentals of TypeScript and object-oriented programming in section 1 to better understand and appreciate this powerful framework.
Over the next 15 hours, you’ll learn the essentials of building Single Page Applications(SPAs) with Angular:
Displaying data and handling DOM events
Building re-usable components
Manipulating the DOM using directives(both Structural and Attribute)
Transforming data using pipes
Building template-driven and reactive forms
Consuming REST APIs using HTTP services
Handling HTTP errors properly
Using Reactive Extensions and Observables
Adding routing and navigation to adhere with basics of a Single Page Application
Building real-time, server-less apps with Firebase
Building beautiful UIs using Angular Material, and Material Design Bootstrap
So, if you’re a busy developer with limited time and want to quickly learn how to build SPAs with Angular, you’re at the right place.
All these topics are covered by over 15 hours of high-quality content. Taking this course is equivalent to going through hundreds of articles, tutorials, and videos on the web! Just that the content is laid out to cover all that you’ll get to know during all that time! Once you go through the course(or just the preview videos), you’ll know that the topics are explained in a clear and concise manner which is going to save you a lot of your precious time! This course is also packed with techniques and tips, that you can only learn from a seasoned developer. You’ll see how we’ll create a brand new Angular project with Angular CLI and build an application from A to Z, step-by-step.
You’ll also get to know ways to build a real-time SPA with Angular, Firebase, and Bootstrap. This application exhibits patterns that you see in a lot of real-world applications:
Master/detail
CRUD operations
Interaction with a data store
Forms with custom validation
And a lot more…!
PREREQUISITES
You don’t need familiarity with TypeScript or any previous versions of Angular. You’re going to learn both TypeScript and Angular from scratch in this course.
______________________________________________________________________________________________________________________________
WHAT OTHER STUDENTS WHO HAVE TAKEN THIS COURSE SAY:
“Explanation is crisp.. instructor is comfortable with the topic…examples used are good and easy to understand…various aspects of the code are explained…using MDB and material for angular both are covered for creating UI components…just only the full screen is shown at all times.. which makes things appear very small… screen highlight or zoom is not used while recording video.. rest all is great.. for learning angular” – Maneesh Parihar
“內容詳細” – Huang JiaLin
“That’s a very comprehensive course on Angular that also teaches Angular Material and Firebase @Siddharth Ajmera: Thanks for this great course! As with so many other courses I would love to see some Summaries or cheatsheets as PDFs or foils and also I’d appreciate to see more schematics, graphs, and sketches.” – He
“講解詳細” -曾玟凱
“This course was perfect for beginners like me. I learned so much from it. Thanks a lot Siddharth for such a good course. Looking forward to more courses from you. Can you please add a section that demonstrates building of an application end to end?” – ankita daur
“Siddarth explained the course in a very simple manner and with simple examples. Would love more indepth on Angular Material and Firebase from him. Great course.” – Kumar
“There is so much information provided in this course. I was looking for custom Decorators and use cases where in they could be implemented to make the code cleaner. I found perfect examples on similar topics in this training. This course is great for beginners.” – Kewal Shah
______________________________________________________________________________________________________________________________
30-DAY FULL MONEY-BACK GUARANTEE
This course comes with a 30-day full money-back guarantee. Take the course, watch every lecture, follow along while coding, and if you are not happy for any reasons, contact Udemy for a full refund within the first 30 days of your enrolment. All your money back, no questions asked.
ABOUT YOUR INSTRUCTOR
Siddharth is a software engineer with around 5 years of professional experience. He is the author of this course with more than 15,000 students in 192 countries. He has done his Bachelor of Engineering in Computer Science. He has worked on several Modern Web Applications. Chatbots, and frameworks. He writes articles about Angular, and Chatbots on Medium.
What are the requirements?
Basic familiarity with HTML, CSS, and JavaScript
NO knowledge of AngularJS or Angular is required
What am I going to get from this course?
Establish yourself as a skilled professional developer
Build real-world Angular applications on your own
Troubleshoot common Angular errors
Master the best practices
Write clean and elegant code like a professional developer
What is the target audience?
Developers who want to upgrade their skills and get better job opportunities
Front-end developers who want to stay up-to-date with the latest technology
Back-end developers who want to learn front-end development and become full-stack developers
Hobbyist developers who are passionate about working with new frameworks
Who this course is for:
Anyone who wants to learn Angular
Anyone interested in building Single Page Applications
Anybody who wants to know Angular in depth
Anyone who wants to learn TypeScript, Firebase and Angular Material
Created by Siddharth Ajmera Last updated 7/2018 English English [Auto-generated]
Size: 1.82 GB
Download Now
https://ift.tt/2qhzs1b.
The post TypeScript, Angular, Firebase & Angular Material Masterclass appeared first on Free Course Lab.
0 notes
Text
jQuery Form Plugins To Use In Your Websites (46 Options)
Have you tried creating the forms from scratch on your website? Why not use jQuery form plugins?
Having forms on your website just doesn’t really cut it. You need those forms to be validated to receive the appropriate data from the sender.
This way you don’t only stave off unwanted submissions, but you also guide your senders to fill out the forms.
Validating the date is just as important as having the forms themselves.
There are a few ways to create flawless forms, and the good news is that if you use some of the jQuery Form Plugins available, things get much easier.
jQuery form plugins to check out
Fileuploader
Fileuploader is a beautiful and powerful HTML5 file uploading tool. A jQuery and PHP plugin that transforms the standard file input into a revolutionary and fancy field on your page.
File preview with image thumbnail or icon
File image thumbnail can be generated in canvas to resize it perfectly for given with and height
Render synchron the file preview
File icon background is generated from file extension
Customize your own input and thumbnail elements
Responsive and fancy animations
Choose multiple files from different folders
Drag&Drop feature
Upload each file with Ajax
Upload synchron the files
Upload progressbar with many data available
Start, retry and cancel upload actions
Paste images from clipboard (only in Chrome)
Validate the file’s limit, size and extension. You can also use your own function
Edit mode for already uploaded files
All files are in one list in a hidden input
Use input HTML attributes to configurate it
HTML template renderer using Text variables
CSS file icon
PHP upload helper
PHP generates an array with many file informations
PHP can create a custom file name
API and more than 24 Callbacks to manipulate freely the appearance and functionality of your file input
Conditionize.js
A small jQuery plugin for handling showing and hiding things conditionally based on input – typically groups of form fields. It works using data attributes to keep all of the name/values for inputs directly in the markup and saves you the trouble of having to manually show/hide a bunch of stuff through JS, as well as improving maintenance if you need to change the name or value of an input you were listening to.
Cleave.js
Cleave.js has a simple purpose: to help you format input text content automatically.
Credit card number formatting
Phone number formatting (i18n js lib separated for each country to reduce size)
Date formatting
Numeral formatting
Custom delimiter, prefix and blocks pattern
CommonJS / AMD mode
AttrValidate
A lightweight jQuery plugin for basic form validation using HTML5 form attributes. Recommended as a polyfill for older browsers which do not provide built-in validation.
Mobiscroll Forms
Mobiscroll Forms supports multiple themes for different platforms and the web – iOS, Android, Windows Phone.
Shipping with 13 elements for:
Single line and multiline text
Select styling
Buttons
Segmented control
Checkbox and checklist
Radio buttons
Switch
Stepper
Page styling & Typography
Slider
Progress
Alert, confirm and prompt
Toast and snackbar
Multipicker
Multipicker is jQuery plugin for selecting days, numbers or other elements, it supports multi selecting (like checkboxes) or single element selection (like radio buttons).
SmartWizard
Smart Wizard is a flexible and heavily customizable jQuery step wizard plugin with Bootstrap support. It is easy to implement and gives a neat and stylish interface for your forms, checkout screen, registration steps etc. Based on the feedback from our users over the past years we have come up with the best ever built jQuery wizard plugin of all time.
Features:
Bootstrap support
Responsive themes
Heavily customizable toolbar, option to add extra buttons
Theme support with various themes included
Customizable css styles
Url navigation and step selection
Public methods for external function call
Enhanced event support
In-built wizard reset method
Ajax content loading with option to specify individual url for steps
Keyboard navigation
Contact Form to Google Spreadsheet
Create Contact Form in HTML and submit the data to Google Spreadsheet. Google re-captcha has been integrated to protect forms to be submitted by robots. Check the demo and documentation for more details.
Features:
Google Spreadsheet as database: Uses Google Spreadsheet to capture form responses. New responses can be appended at the top.
Simple Form: Designed with simple HTML5, CSS3 and bootstrap.
Protection: Google re-captcha to prevent spamming.
Customization: You can customize the form according to your own requirement.
Look and feel: Bootstrap two column layout, responsive. Shows status loader when the form is being submitted.
Notification: Can send notification email to the admin with submitted form data.
Hierarchy Select
A jQuery hierarchy select plugin used for selecting hierarchy structures in a selectbox format with autocomplete search.
SmartMenu
SmartMenu is a user-friendly, highly customizable and responsive jQuery mega menu plugin. It allows you to use multiple menus with different submenus.
Features:
Responsive design
Supports multiple instances
Horizontal (top, bottom) or Vertical (left, right) menu layouts
Mega / Flyout submenus
Pure CSS3 animations (fade, slide)
3 ways of dropdown (hover, click, toggle)
7 color skins which can be changed easily
Custom mega dropdowns, forms, search bar, social icons or HTML
12 columns fluid grid
You can add images, maps or videos
BunnyJS
BunnyJS is a modern Vanilla JS and ES6 library and next-generation front-end framework, package of small stand-alone components without dependencies.
No dependencies – can be used in any project anywhere anytime
0 learning curve – you can start right now, just plain JavaScript with simple architecture easy to maintain and extend
Designed in mind to build modern, complicated, real world business apps
Faster, simpler, enjoyable than any frontend framework
Large set of ready components, custom UI elements and utils
Dirrty
Dirrty lightweight jquery plugin to detect if the fields of a form had been modified.
If a field has been modified then the form is dirrty
Detect the moment when the form gets dirty, and trigger a custom event, for example enable a “save changes” button
Detect the moment when the form gets clean again, and trigger a custom event, for example disable the “save changes” button, cause is not necesary
Prompt the user to save changes before leaving if the form is dirty
Inputmask
jQuery inputmask is a jquery plugin which create an input mask.
An inputmask helps the user with the input by ensuring a predefined format. This can be usefull for dates, numerics, phone numbers, …
Features:
easy to use
optional parts anywere in the mask
possibility to define aliases which hide complexity
date / datetime masks
numeric masks
lots of callbacks
non-greedy masks
many features can be enabled/disabled/configured by options
supports readonly/disabled/dir=”rtl” attributes
support data-inputmask attribute
multi-mask support
Formbase
Formbase is a better default styles for common input elements.Formbase eliminates cross browser bugs, inconsistencies across systems and applies a beautiful default styling to several input elements.
Works in all modern browsers (and IE11)
No JavaScript, just CSS
Works with inputs, textareas, checkboxes and radio buttons
Zero dependencies
File Input
File input fields look differently in all browsers. It’s a pain in the arse to design something that looks nice in all browsers and it sucks that support for this is not available in Twitter Bootstrap. This jQuery plugin is designed to make all file input fields look like standard Twitter Bootstrap buttons.
Form Designer
FORM-DESIGNER is a jQuery form builder tool which will help you to build an interactive form to use in your website template. This is mainly a HTML developer’s tool, but anyone who have a little knowledge about CSS and HTML structure and use of them, can use this tool.
I try to keep this jquery application very simple and user-friendly so that anyone can understand it within one or two tries.In this tool you will get total 7 option to create form from 7 different template and one option to create a custom form. As a final output, you will get the HTML,CSS and jQuery code here.
Choices.js
A vanilla, lightweight (~15kb gzipped), configurable select box/text input plugin. Similar to Select2 and Selectize but without the jQuery dependency.
Lightweight
No jQuery dependency
Configurable sorting
Flexible styling
Fast search/filtering
Clean API
Right-to-left support
JSON Manager
JSON manager: jQuery plug-in that converts JS & JSON objects to HTML forms and back again.
Medea loves JSON. Give Medea a JSON object, even one with nested objects, and it will be converted into an HTML form. The form allows fields in the object to be edited, or deleted, or for new ones to be created. The modified object is returned via the submit event.
Spider
Mailgun API for mail validation online
50+ Form templates
Ajax form
Remote/server validation
Php ready form
Dynamic field
Credit card validator
Zip/Pin code validator
Semantic ui integrated
Custom error container
custom error handler
Multiple input validator As one
button style included
60+ button style included in package
TextArea
One of the most used, but under featured HTML controls, is the humble TEXTAREA control. This control is designed to accept large blocks of text from the user. A wide variety of plugins exist for the TEXTAREA that layer it with toolbars, auto-resizing, rich-text editing and the works.
More jQuery form plugins?
Keep scrolling.
There are more.
Character and Word Counter
This jQuery Word and character counter plug-in allows you to count characters or words, up or down. You can set a minimum or maximum goal for the counter to reach.
Create a custom message for your counter’s message
Force character/word limit on user to prevent typing
Works against copy/paster’s!
Addel
Addel is a simple & lightweight jQuery form plugin for powering UIs that enable dynamic addition & deletion of HTML elements, conceived with form elements in mind.
PopSelect
A jQuery plugin to replace the traditional <select> box with a sleek Popover with options pre-populated. Better User interface than any other multiselects.
Timon
With Timon – Step Form Wizard you will have power combo of 21 different styles, 8 different transition effects, validation in your step form, titles and subtitles with multiple step. , also Timon – Step Form Wizard has predefined set of form sizes from tiny to large. You can easily create and customize any form to fit your needs.
Features:
Step navigation
Fully responsive
Many options for design and function
Can be used for tabs
Step navigation
21 Style
8 transition effect
Select.js
Another one of these jQuery form plugins is Select.js. It is a Javascript and CSS library for creating styleable select elements. It aims to reproduce the behavior of native controls as much as is possible, while allowing for complete styling with CSS.
Tagger Widget
jQuery plugin to turn a HTML select into an auto-suggesting, tagging widget. It was written from the ground up and has support for hierachical data, searching for data that isn’t displayed, displaying arbitrary HTML in the suggestion list, running the original onChange actions, displaying tags for items previously selected but no longer in the list, keyboard accessibility and many other features.
formBuilder
A jQuery plugin for drag and drop form creation. To start building forms with this plugin call formBuilder() on the textarea you would like to make your editor. FormBuilder takes a number of options and is translatable.
OrderNow
PHP Order Form will helps to get project orders from the clients for the people like web developers, corporates and freelancers easily. This form is PayPal integrated and admin functionalities are integrated.
Features:
Responsive design layout
PHP order form with MySql database
Multitab features
Cross-browser platform
Contents are organized in a user-friendly format
Admin can manage all contents and order management
Mail Templates are available in admin side
Easy Forms
Easy Forms is one of the jQuery form plugins in this article that will help you design and develop web forms quickly and easily. Actually, you will not need programming skills to make your forms work in minutes.
Build any type of online forms: Contact forms, Order forms, Registration forms, Online surveys, Trivias and more.
Drag & Drop Fields. No coding skills required.
HTML5 Fields Support
Create Multi-Step Forms
Bootstrap CSS Support
Theme & Template Managers
Advanced CSS Editor with Form Live Preview
Parsley
Parsley.js is a lightweight and feature-rich library that instead of validating forms with Javascript, it uses data attributes embedded in the DOM to achieve the same function. The surprisingly easy to configure plugin also allows you to override almost every default behavior so that it will fit in with your form requirements.
jQuery Validation Engine
When it comes to the jQuery Validation Engine, you don’t need to worry about the structure of your form as the plugin will create an error DIV and position it in the top right corner of the specified input, keeping both the forms code and validations seperate. Phis is probably the easiest validation solution in this article.
Validatr
Validatr uses HTML5 input attributes to perform validation, with support for color, date, email, number and range. The input types text, checkbox, radio…. are supported, but do not require the same level of validation.
Where possible, Validatr will use native validation, using Modernizr to test for support. If an input type is not supported it will use it’s own ruleset to supplement native validation. In both cases case, the validation message is shown.
Smoke
Smoke is a collection of components for Bootstrap – including a form validator. In comparison to the other Bootstrap validator (#4), it doesn’t use native browser validation – therefore error messages aren’t automatically localized and validation rules have to be specified using HTML5 and data attributes, as well as JavaScript.
Validetta
This plugin offers validation using a data attribute, with quite limited options. It comes with just the basic validation rules, everything else can be added with custom regular expressions – but there is no example demonstrating it. Compared to the other plugins, the only unique feature is that error messages are displayed in a bubble (see demo below).
jQuery.validity
A plugin to control validation with JavaScript only – no HTML5 or data attributes. While this may be helpful for dynamic validation rules, the plugin doesn’t offer enough options to make writing efficient. It even doesn’t allow using new HTML5 type attributes like email, nor does it provide a function to check if a form is valid – necessary in order to show a success message.
h5Validate
This plugin has unfortunately been abandoned by its creator (Eric Elliott). Consequently, the demo/documentation website returns a 404 and there are two dozen open issues. The plugin doesn’t automatically validate inputs by type and the following example even doesn’t show error messages. We’ve included it in the list, as Eric is looking for a new maintainer for the project, so there’s a chance that at some point in the future, it might get some life breathed back into it.
SkipOnTab
A jQuery plugin to exempt selected shape fields from the ahead tab order.This library is maximum beneficial while the customers are familiar with the shape, and makes use of it frequently.
Contact Tabs
A jQuery shape generator for creating limitless slide-out or static touch tabs containing AJAX powered customised bureaucracy. Plugin consists of 12 one-of-a-kind form factors and consumer-aspect validation.
Simple Contact Form
With jQuery Simple Contact Form, you could installation an ajax touch form for your website, writing only the form html code and one js code line. Email is generated and ship by using the plugin (php report blanketed) .
Form Recover
By installing this plugin you’ll permit your users to have a draft of their shape saved and restored automatically in cases of unintended refresh or browser crash.
Forms Plus
Forms Plus is a form framework. JS version includes everything CSS has, plus date/time pickers, shade pickers, sliders, captcha fields, spinners, area groups (for code, credit card number, and many others.)
Prosto Forms
Prosto Forms is a responsive Form Framework and set of beautiful shape factors with large quantity of javascript capabilities: validation, protecting, modals, ajax put up, datepickers.
Simple Subscription Popup
Simple Signup jQuery Form Plugins will gather the visitor’s electronic mail deal with in your internet site with an attention-grabber, effective manner. It has a number of elective customization alternatives and you may setup truely in mins.
Foggle
jQuery Foggle is a plugin that helps you to interact with various shape factors primarily based on consumer-enter. It helps you to pick which elements to allow (or disable) whilst the person fills out the shape.
WizardPro
WizardPro lets in you to create website wizards in only a few mins. You can use this plugin for nearly some thing that requires some steps, like a utility installer, a signup or touch form.
Virtual Phone Number Selling Form
Virtual Phone Number Selling Form is a selling form for those voip commercial enterprise who’re promoting virtual telephone numbers designed for All styles of VOIP Business. It’s an jQuery Plugin based totally on present day Bootstrap 3.3.7.
If you liked this article with jQuery form plugins, you should check out these as well:
jQuery Bootstrap Plugins (51 Great Examples)
Charts And Graphs Javascript Libraries
jQuery Lightbox Plugins (19 Examples)
jQuery Gallery Plugins For Showcasing Images Better
The post jQuery Form Plugins To Use In Your Websites (46 Options) appeared first on Design your way.
from Web Development & Designing http://www.designyourway.net/blog/resources/jquery-form-plugins/
0 notes
Text
RX JAVA 2.0 releases support for Android
The RxJava team has released version 2.0 of their reactive Java framework, after an 18 month development cycle. RxJava is part of the ReactiveX family of libraries and frameworks, which is in their words, "a combination of the best ideas from the Observer pattern, the Iterator pattern, and functional programming". The project's "What's different in 2.0" is a good guide for developers already familiar with RxJava 1.x.
RxJava 2.0 is a brand new implementation of RxJava. This release is based on the Reactive Streams specification, an initiative for providing a standard for asynchronous stream processing with non-blocking back pressure, targeting runtime environments (JVM and JavaScript) as well as network protocols.
Reactive implementations have concepts of publishers and subscribers, as well as ways to subscribe to data streams, get the next stream of data, handle errors and close the connection.
The Reactive Streams spec will be included in JDK 9 as java.util.concurrent.Flow. The following interfaces correspond to the Reactive Streams spec. As you can see, the spec is small, consisting of just four interfaces:
· Flow.Processor<T,R>: A component that acts as both a Subscriber and Publisher.
· Flow.Publisher<T>: A producer of items (and related control messages) received by Subscribers.
· Flow.Subscriber<T>: A receiver of messages.
· Flow.Subscription: Message control linking a Flow.Publisher and Flow.Subscriber.
Spring Framework 5 is also going reactive. To see how this looks, refer to Josh Long's Functional Reactive Endpoints with Spring Framework 5.0.
To learn more about RxJava 2.0, InfoQ interviewed main RxJava 2.0 contributor, David Karnok.
InfoQ: First of all, congrats on RxJava 2.0! 18 months in the making, that's quite a feat. What are you most proud of in this release?
David Karnok: Thanks! In some way, I wish it didn't take so long. There was a 10 month pause when Ben Christensen, the original author who started RxJava, left and there was no one at Netflix to push this forward. I'm sure many will contest that things got way better when I took over the lead role this June. I'm proud my research into more advanced and more performant Reactive Streams paid off and RxJava 2 is the proof all of it works.
InfoQ: What’s different in RxJava 2.0 and how does it help developers?
Karnok: There are a lot of differences between version 1 and 2 and it's impossible to list them all here ,but you can visit the dedicated wiki page for a comprehensible explanation. In headlines, we now support the de-facto standard Reactive Streams specification, have significant overhead reduction in many places, no longer allow nulls, have split types into two groups based on support of or lack of backpressure and have explicit interop between the base reactive types.
InfoQ: Where do you see RxJava used the most (e.g. IoT, real-time data processing, etc.)?
Karnok: RxJava is more dominantly used by the Android community, based on the feedback I saw. I believe the server side is dominated by Project Reactor and Akka at the moment. I haven't specifically seen IoT mentioned or use RxJava (it requires Java), but maybe they use some other reactive library available on their platform. For real-time data processing people still tend to use other solutions, most of them not really reactive, and I'm not aware of any providers (maybe Pivotal) who are pushing for reactive in this area.
InfoQ: What benefits does RxJava provide Android more than other environments that would explain the increased traction?
Karnok: As far as I see, Android wanted to "help" their users solving async and concurrent problems with Android-only tools such as AsyncTask, Looper/Handler etc.
Unfortunately, their design and use is quite inconvenient, often hard to understand or predict and generally brings frustration to Android developers. These can largely contribute to callback hell and the difficulty of keeping async operations off the main thread.
RxJava's design (inherited from the ReactiveX design of Microsoft) is dataflow-oriented and orthogonalized where actions execute from when data appears for processing. In addition, error handling and reporting is a key part of the flows. With AsyncTask, you had to manually work out the error delivery pattern and cancel pending tasks, whereas RxJava does that as part of its contract.
In practical terms, having a flow that queries several services in the background and then presents the results in the main thread can be expressed in a few lines with RxJava (+Retrofit) and a simple screen rotation will cancel the service calls promptly.
This is a huge productivity win for Android developers, and the simplicity helps them climb the steep learning curve the whole reactive programming's paradigm shift requires. Maybe at the end, RxJava is so attractive to Android because it reduces the "time-to-market" for individual developers, startups and small companies in the mobile app business.
There was nothing of a comparable issue on the desktop/server side Java, in my opinion, at that time. People learned to fire up ExecutorService's and wait on Future.get(), knew about SwingUtilities.invokeLater to send data back to the GUI thread and otherwise the Servlet API, which is one thread per request only (pre 3.0) naturally favored blocking APIs (database, service calls).
Desktop/server folks are more interested in the performance benefits a non-blocking design of their services offers (rather than how easy one can write a service). However, unlike Android development, having just RxJava is not enough and many expect/need complete frameworks to assist their business logic as there is no "proper" standard for non-blocking web services to replace the Servlet API. (Yes, there is Spring (~Boot) and Play but they feel a bit bandwagon-y to me at the moment).
InfoQ: HTTP is a synchronous protocol and can cause a lot of back pressure when using microservices. Streaming platforms like Akka and Apache Kafka help to solve this. Does RxJava 2.0 do anything to allow automatic back pressure?
Karnok: RxJava 2's Flowable type implements the Reactive Streams interface/specification and does support backpressure. However, the Java level backpressure is quite different from the network level backpressure. For us, backpressure means how many objects to deliver through the pipeline between different stages where these objects can be non uniform in type and size. On the network level one deals with usually fixed size packets, and backpressure manifests via the lack of acknowledgement of previously sent packets. In classical setup, the network backpressure manifests on the Java level as blocking calls that don't return until all pieces of data have been written. There are non-blocking setups, such as Netty, where the blocking is replaced by implicit buffering, and as far as I know there are only individual, non-uniform and non Reactive Streams compatible ways of handling those (i.e., a check for canWrite which one has to spin over/retry periodically). There exist libraries that try to bridge the two worlds (RxNetty, some Spring) with varying degrees of success as I see it.
InfoQ: Do you think reactive frameworks are necessary to handle large amounts of traffic and real-time data?
Karnok: It depends on the problem complexity. For example, if your task is to count the number of characters in a big-data source, there are faster and more dedicated ways of doing that. If your task is to compose results from services on top of a stream of incoming data in order to return something detailed, reactive-based solutions are quite adequate. As far as I know, most libraries and frameworks around Reactive Streams were designed for throughput and not really for latency. For example, in high-frequency trading, the predictable latency is very important and can be easily met by Aeron but not the main focus for RxJava due to the unpredictable latency behavior.
InfoQ: Does HTTP/2 help solve the scalability issues that HTTP/1.1 has?
Karnok: This is not related to RxJava and I personally haven't played with HTTP/2 but only read the spec. Multiplexing over the same channel is certainly a win in addition to the support for explicit backpressure (i.e., even if the network can deliver, the client may still be unable to process the data in that volume) per stream. I don't know all the technical details but I believe Spring Reactive Web does support HTTP/2 transport if available but they hide all the complexity behind reactive abstractions so you can express your processing pipeline in RxJava 2 and Reactor 3 terms if you wish.
InfoQ: Java 9 is projected to be featuring some reactive functionality. Is that a complete spec?
Karnok: No. Java 9 will only feature 4 Java interfaces with 7 methods total. No stream-like or Rx-like API on top of that nor any JDK features built on that.
InfoQ: Will that obviate the need for RxJava if it is built right into the JDK?
Karnok: No and I believe there's going to be more need for a true and proven library such as RxJava. Once the toolchains grow up to Java 9, we will certainly provide adapters and we may convert (or rewrite) RxJava 3 on top of Java 9's features (VarHandles).
One of my fears is that once Java 9 is out, many will try to write their own libraries (individuals, companies) and the "market" gets diluted with big branded-low quality solutions, not to mention the increased amount of "how does RxJava differ from X" questions.
My personal opinion is that this is already happening today around Reactive Streams where certain libraries and frameworks advertise themselves as RS but fail to deliver based on it. My (likely biased) conjecture is that RxJava 2 is the closest library/technology to an optimal Reactive Streams-based solution that can be.
InfoQ: What's next for RxJava?
Karnok: We had fantastic reviewers, such as Jake Wharton, during the development of RxJava 2. Unfortunately, the developer previews and release candidates didn't generate enough attention and despite our efforts, small problems and oversights slipped into the final release. I don't expect major issues in the coming months but we will keep fixing both version 1 and 2 as well as occasionally adding new operators to support our user base. A few companion libraries, such as RxAndroid, now provide RxJava 2 compatible versions, but the majority of the other libraries don't yet or haven't yet decided how to go forward. In terms of RxJava, I plan to retire RxJava 1 within six months (i.e., only bugfixes then on), partly due to the increasing maintenance burden on my "one man army" for some time now; partly to "encourage" the others to switch to the RxJava 2 ecosystem. As for RxJava 3, I don't have any concrete plans yet. There are ongoing discussions about splitting the library along types or along backpressure support as well as making the so-called operator-fusion elements (which give a significant boost to our performance) a standard extension of the Reactive Streams specification.
0 notes
Text
The RxJava team has released version 2.0 of their reactive Java framework
The RxJava team has released version 2.0 of their reactive Java framework, after an 18 month development cycle. RxJava is part of the ReactiveX family of libraries and frameworks, which is in their words, "a combination of the best ideas from the Observer pattern, the Iterator pattern, and functional programming". The project's "What's different in 2.0" is a good guide for developers already familiar with RxJava 1.x.
RxJava 2.0 is a brand new implementation of RxJava. This release is based on the Reactive Streams specification, an initiative for providing a standard for asynchronous stream processing with non-blocking back pressure, targeting runtime environments (JVM and JavaScript) as well as network protocols.
Reactive implementations have concepts of publishers and subscribers, as well as ways to subscribe to data streams, get the next stream of data, handle errors and close the connection.
The Reactive Streams spec will be included in JDK 9 as java.util.concurrent.Flow. The following interfaces correspond to the Reactive Streams spec. As you can see, the spec is small, consisting of just four interfaces:
· Flow.Processor<T,R>: A component that acts as both a Subscriber and Publisher.
· Flow.Publisher<T>: A producer of items (and related control messages) received by Subscribers.
· Flow.Subscriber<T>: A receiver of messages.
· Flow.Subscription: Message control linking a Flow.Publisher and Flow.Subscriber.
Spring Framework 5 is also going reactive. To see how this looks, refer to Josh Long's Functional Reactive Endpoints with Spring Framework 5.0.
To learn more about RxJava 2.0, InfoQ interviewed main RxJava 2.0 contributor, David Karnok.
InfoQ: First of all, congrats on RxJava 2.0! 18 months in the making, that's quite a feat. What are you most proud of in this release?
David Karnok: Thanks! In some way, I wish it didn't take so long. There was a 10 month pause when Ben Christensen, the original author who started RxJava, left and there was no one at Netflix to push this forward. I'm sure many will contest that things got way better when I took over the lead role this June. I'm proud my research into more advanced and more performant Reactive Streams paid off and RxJava 2 is the proof all of it works.
InfoQ: What’s different in RxJava 2.0 and how does it help developers?
Karnok: There are a lot of differences between version 1 and 2 and it's impossible to list them all here ,but you can visit the dedicated wiki page for a comprehensible explanation. In headlines, we now support the de-facto standard Reactive Streams specification, have significant overhead reduction in many places, no longer allow nulls, have split types into two groups based on support of or lack of backpressure and have explicit interop between the base reactive types.
InfoQ: Where do you see RxJava used the most (e.g. IoT, real-time data processing, etc.)?
Karnok: RxJava is more dominantly used by the Android community, based on the feedback I saw. I believe the server side is dominated by Project Reactor and Akka at the moment. I haven't specifically seen IoT mentioned or use RxJava (it requires Java), but maybe they use some other reactive library available on their platform. For real-time data processing people still tend to use other solutions, most of them not really reactive, and I'm not aware of any providers (maybe Pivotal) who are pushing for reactive in this area.
InfoQ: What benefits does RxJava provide Android more than other environments that would explain the increased traction?
Karnok: As far as I see, Android wanted to "help" their users solving async and concurrent problems with Android-only tools such as AsyncTask, Looper/Handler etc.
Unfortunately, their design and use is quite inconvenient, often hard to understand or predict and generally brings frustration to Android developers. These can largely contribute to callback hell and the difficulty of keeping async operations off the main thread.
RxJava's design (inherited from the ReactiveX design of Microsoft) is dataflow-oriented and orthogonalized where actions execute from when data appears for processing. In addition, error handling and reporting is a key part of the flows. With AsyncTask, you had to manually work out the error delivery pattern and cancel pending tasks, whereas RxJava does that as part of its contract.
In practical terms, having a flow that queries several services in the background and then presents the results in the main thread can be expressed in a few lines with RxJava (+Retrofit) and a simple screen rotation will cancel the service calls promptly.
This is a huge productivity win for Android developers, and the simplicity helps them climb the steep learning curve the whole reactive programming's paradigm shift requires. Maybe at the end, RxJava is so attractive to Android because it reduces the "time-to-market" for individual developers, startups and small companies in the mobile app business.
There was nothing of a comparable issue on the desktop/server side Java, in my opinion, at that time. People learned to fire up ExecutorService's and wait on Future.get(), knew about SwingUtilities.invokeLater to send data back to the GUI thread and otherwise the Servlet API, which is one thread per request only (pre 3.0) naturally favored blocking APIs (database, service calls).
Desktop/server folks are more interested in the performance benefits a non-blocking design of their services offers (rather than how easy one can write a service). However, unlike Android development, having just RxJava is not enough and many expect/need complete frameworks to assist their business logic as there is no "proper" standard for non-blocking web services to replace the Servlet API. (Yes, there is Spring (~Boot) and Play but they feel a bit bandwagon-y to me at the moment).
InfoQ: HTTP is a synchronous protocol and can cause a lot of back pressure when using microservices. Streaming platforms like Akka and Apache Kafka help to solve this. Does RxJava 2.0 do anything to allow automatic back pressure?
Karnok: RxJava 2's Flowable type implements the Reactive Streams interface/specification and does support backpressure. However, the Java level backpressure is quite different from the network level backpressure. For us, backpressure means how many objects to deliver through the pipeline between different stages where these objects can be non uniform in type and size. On the network level one deals with usually fixed size packets, and backpressure manifests via the lack of acknowledgement of previously sent packets. In classical setup, the network backpressure manifests on the Java level as blocking calls that don't return until all pieces of data have been written. There are non-blocking setups, such as Netty, where the blocking is replaced by implicit buffering, and as far as I know there are only individual, non-uniform and non Reactive Streams compatible ways of handling those (i.e., a check for canWrite which one has to spin over/retry periodically). There exist libraries that try to bridge the two worlds (RxNetty, some Spring) with varying degrees of success as I see it.
InfoQ: Do you think reactive frameworks are necessary to handle large amounts of traffic and real-time data?
Karnok: It depends on the problem complexity. For example, if your task is to count the number of characters in a big-data source, there are faster and more dedicated ways of doing that. If your task is to compose results from services on top of a stream of incoming data in order to return something detailed, reactive-based solutions are quite adequate. As far as I know, most libraries and frameworks around Reactive Streams were designed for throughput and not really for latency. For example, in high-frequency trading, the predictable latency is very important and can be easily met by Aeron but not the main focus for RxJava due to the unpredictable latency behavior.
InfoQ: Does HTTP/2 help solve the scalability issues that HTTP/1.1 has?
Karnok: This is not related to RxJava and I personally haven't played with HTTP/2 but only read the spec. Multiplexing over the same channel is certainly a win in addition to the support for explicit backpressure (i.e., even if the network can deliver, the client may still be unable to process the data in that volume) per stream. I don't know all the technical details but I believe Spring Reactive Web does support HTTP/2 transport if available but they hide all the complexity behind reactive abstractions so you can express your processing pipeline in RxJava 2 and Reactor 3 terms if you wish.
InfoQ: Java 9 is projected to be featuring some reactive functionality. Is that a complete spec?
Karnok: No. Java 9 will only feature 4 Java interfaces with 7 methods total. No stream-like or Rx-like API on top of that nor any JDK features built on that.
InfoQ: Will that obviate the need for RxJava if it is built right into the JDK?
Karnok: No and I believe there's going to be more need for a true and proven library such as RxJava. Once the toolchains grow up to Java 9, we will certainly provide adapters and we may convert (or rewrite) RxJava 3 on top of Java 9's features (VarHandles).
One of my fears is that once Java 9 is out, many will try to write their own libraries (individuals, companies) and the "market" gets diluted with big branded-low quality solutions, not to mention the increased amount of "how does RxJava differ from X" questions.
My personal opinion is that this is already happening today around Reactive Streams where certain libraries and frameworks advertise themselves as RS but fail to deliver based on it. My (likely biased) conjecture is that RxJava 2 is the closest library/technology to an optimal Reactive Streams-based solution that can be.
InfoQ: What's next for RxJava?
Karnok: We had fantastic reviewers, such as Jake Wharton, during the development of RxJava 2. Unfortunately, the developer previews and release candidates didn't generate enough attention and despite our efforts, small problems and oversights slipped into the final release. I don't expect major issues in the coming months but we will keep fixing both version 1 and 2 as well as occasionally adding new operators to support our user base. A few companion libraries, such as RxAndroid, now provide RxJava 2 compatible versions, but the majority of the other libraries don't yet or haven't yet decided how to go forward. In terms of RxJava, I plan to retire RxJava 1 within six months (i.e., only bugfixes then on), partly due to the increasing maintenance burden on my "one man army" for some time now; partly to "encourage" the others to switch to the RxJava 2 ecosystem. As for RxJava 3, I don't have any concrete plans yet. There are ongoing discussions about splitting the library along types or along backpressure support as well as making the so-called operator-fusion elements (which give a significant boost to our performance) a standard extension of the Reactive Streams specification.
0 notes
Text
Supercharge your iPaaS for Better Agility, Resilience, and Real-time Capabilities with an Event Broker
More and more enterprises are moving from on-premises enterprise service buses (ESB) to integration platform as a service (iPaaS) solutions like Boomi, Jitterbit, Mulesoft Anypoint and others. iPaaS solutions like these are a key component of what Gartner calls a hybrid integration approach[1], and as someone accustomed to creating ESB solutions, it’s been eye-opening see how quickly and easily you can get them up and running. But as I create iPaaS solutions, one thought keeps running through my mind: this would be so much more powerful and elegant if we added an event broker to the mix.
iPaaS and Synchronous REST Calls
At their heart, iPaaS solutions aim to simplify integration by creating a managed experience, particularly when deployed in the cloud. An iPaaS solution typically includes:
Graphical tools that show how transactions flow through the system
Connectors that contain logic for popular protocols
Built-in mapping tools that allow for data transformation
Defined locations for code snippets that isolate customer-specific modifications, typically in a language like JavaScript
Integrated source code repositories and deployment capabilities that are usually external in ESBs
Although there are adapters for many different information providers such as databases and EDI, most iPaaS (and most ESB) solution’s bread and butter has been synchronous REST calls between software as a service (SaaS) providers like Salesforce and SAP S/4HANA Cloud. As a result, iPaaS providers have focused on making synchronous API integrations as easy as possible. Architecturally, this generally means the same process that receives an incoming request maps the data using a graphical tool, connects to the information consumer, and sends the transformed message.
Figure 1: Typical iPaaS process flow
Adding an Event Broker to Your iPaaS Solution
Adding an event broker allows you to separate (decouple) that process, such that the iPaaS receives information via one process and writes it to a queue or topic[2], then a second process picks up the message and performs additional logic, typically including data transformation, before forwarding it to a consumer.
Figure 2: iPaaS flow with event broker
That decoupling can enhance traditional ESBs, but in some ways it’s even more important for iPaaS solutions. The architectural shift to decoupling using an event broker can improve an iPaaS’s resilience, agility and real-time capabilities—all without complicating its architecture or operation. The approach is a lot like breaking up a monolithic application into multiple microservices.
Some brief asides:
Many iPaaS providers have begun to integrate lightweight event brokers into their products. While I think there are advantages to having an event broker live outside the iPaaS itself, I will save that for another day and focus on the benefits of all event brokers, including those they include.
While event brokers provide great benefits for iPaaS architectures, they also present challenges. In a future blog I’ll discuss those challenges, the trade-offs they entail, and give guidance on architectural choices that can help you overcome them.
Planning for Failure – How an Event Broker Helps an iPaaS Stay Simple
One of the most complex and time-consuming tasks for any integration architect is making sure a system performs when things go wrong – in fact some experts say up to 25% of an integration project should be devoted to designing exception handling, and iPaaS solutions are no different. That isn’t surprising given that architects need to consider complex questions including:
What if the iPaaS itself fails? Will I lose in-flight transactions?
What should happen if a consumer goes down and I need to retry? How can I prevent it from decreasing performance and blocking incoming?
What if a consumer can’t process my incoming message until a human intervenes (e.g. adding a value to a cross reference table)? How can I easily move on to the next transaction and replay it later?
You can try to solve these issues within the iPaaS itself, perhaps by creating a library of custom code snippets in a language like JavaScript that dictate architectural standards like manually compensating for failed transactions and using adapters to ensure that transactions are persisted to disk. However, in doing so you sacrifice some of the simplicity that makes iPaaS so advantageous.
Introducing an event broker as part of a decoupled architecture, on the other hand, can answer some of the questions while keeping the iPaaS simple. As shown in Figure 3, by persisting messages to a queue or topic after arrival at the iPaaS, the event broker takes responsibility for guaranteeing that the message will not be lost in the event of a failure that brings down either your process or the entire iPaaS. Without an event broker, an iPaaS either requires custom persistence logic or accepts that messages will be lost in the event of failure, requiring the information provider to resend as necessary.
Figure 3: Event brokers allow for message persistence in the case of failure
Once the message is persisted by an event broker, the iPaaS receiver (not the end consumer) can acknowledge that the message has been successfully processed and becomes available for the next incoming message.
This ability for the iPaaS receiver to quickly and independently process messages comes in handy if the downstream information consumer isn’t available. Typically, an information consumer being unavailable results in multiple attempts to retry the transaction until it succeeds. As shown in Figure 4, if the receiver and sender are on the same thread, this can quickly cause the iPaaS to run out of resources, creating a chain reaction that blocks incoming transactions. By buffering incoming transactions, an event broker helps to keep your solution up and running. This buffering is even more valuable as we add in additional consumers, which we discuss in the next section.
Figure 4: Event brokers conserve resources during retry
Lastly, if the error turns out to be one that will take a while to resolve (e.g. someone to add a value to a look up table), the message can be placed into an error queue. When the issue is resolved, the message can be requeued for processing.
Figure 5: Event brokers simplify replay after human intervention
The Value of Event-Driven Architecture
To this point, we’ve focused on the benefits of decoupling a single sender and receiver from one another, and the benefits of that decoupling are worthwhile on their own. But the value really adds up as you begin distributing transactions amongst multiple diverse consumers using a fully event-driven architecture. Making your integrations more agile lets your architects and developers innovate more freely, solving business needs and exploring new frontiers for your business.
Architects need to consider complex questions including:
How can I quickly introduce new business functionality while making sure I’m not affecting existing functionality?
How do I handle situations where one consumer processes information faster than another? Or one consumer rejects the transaction, while another processes it?
How do I make sure I’m not locking myself into a deployment pattern (on-premises, cloud, etc), cloud provider, or even iPaaS solution?
To aid agility, iPaaS providers typically feature integrated source control and deployment capabilities. Including these components reduces the amount of additional infrastructure needed to start building an iPaaS solution – no more setting up a Git repository and configuring Jenkins.
Most iPaaS solutions include the ability to call multiple sender processes from a single receiver process, but as Figure 6 shows, even with the code promotion infrastructure in place, you still need to have a complete test cycle and deployment with every change if the solution tightly senders and receivers of information. That cycle is represented by a link icon in the diagram below. This tight coupling also makes error handling more complex, particularly in cases where one consumer rejects the transaction and additional consumers process it successfully.
Figure 6: iPaaS solution with multiple tightly coupled consumers
An event broker allows you to move into the realm of fully event-driven architecture. At the outset, the addition of an event broker may seem like it increases complexity—after all, there are now more components—but the addition of those components is more than offset by the fact that an event broker makes code more modular and reduces integration challenges.
By playing middleman between receivers and senders, an event broker lets you change a sender without redeploying and retesting the entire process. What’s more, you can very easily add new senders and consumers, and seamlessly integrate them into an existing solution.
With an event broker, you can design a new sender connecting to an innovative new application using iPaaS integration tools like graphical mapping, content-based filtering and pre-built connectivity. Then once you add a new subscription to the event broker, events begin flowing to the new process and onward to the information consumer.
Figure 7: iPaaS with loosely coupled consumers using event broker
Handling Slow Consumers and Routing Information with an Event Mesh
At runtime, decoupling lets consumers process information independently. This can help to resolve several difficult architectural challenges:
The first challenge decoupling alleviates is information consumers that process transactions at different rates of speed. An event broker creates a buffer that allows slow consumers to process messages at their own pace without affecting or constraining those applications that can process messages much more quickly.
Another challenge is dealing with instances in which one consumer rejects an incoming transaction, but other consumers are still able to process it. An event broker can handle that scenario without resorting to adhoc error handling. That said, error handling in an event-driven architecture can be tricky, and I look forward to diving into that topic in a future blog post.
By linking multiple brokers in different locations to form an event mesh, event brokers can efficiently route information between on-premises and cloud applications, different clouds and even different iPaaS solutions—without having to explicitly route information between them within your iPaaS.
Such an event mesh can also address the challenge of unreliable WAN connectivity by provide reliable delivery without each iPaaS application needing to handle this. If your deployment pattern changes, the event mesh dynamically reroutes events to the new topology.
Reacting to Real-Time Event Sources….in Real-Time
Beyond decoupling and event-driven architecture between iPaaS components, an event broker provides an on-ramp to real-time capabilities for your iPaaS. The internet of things (IoT) and other real-time information sources such as Workday and Salesforce present a massive opportunity to increase your business’s ability to react, but you typically need to act on such information in real-time to fully exploit its value. Real-time information sources can also send a massive spike in traffic during periods of high demand.
The need to process incoming events in real-time, and deal with sudden unpredictable bursts of data can be challenges for any iPaaS. In the absence of an event broker, iPaaS solutions are typically triggered either through a synchronous API request, or on a polling interval defined when the process is developed and deployed. In the case of a process invoked by a synchronous API request, dealing with traffic spikes within the structures of an iPaaS typically means increasing the number of processing threads available to handle the incoming flow of information and over allocation of memory and processing power. In the case of a polling interval, it is difficult to predict how often to poll far in advance, especially if you can’t change that interval when conditions change.
Figure 8: Using polling for real-time event processing
An event broker helps you overcome these challenges by providing an entry point for event-driven applications. Messages that are placed on event broker topics can trigger your iPaaS immediately, without having to worry about selecting a static polling interval. An event broker can also buffer incoming events and provide a throttling mechanism that prevents downstream processes from being overwhelmed in periods of high traffic.
Figure 9: Using an event broker for real-time event processing
Conclusion
Event brokers are a great potential partner for your iPaaS, enhancing their resilience, agility and real-time capabilities. Recognizing those potential benefits is the first step in the journey. The next steps are recognizing and overcoming some challenges that event brokers can introduce. In the future posts, I’m looking forward to answering questions such as:
What are situations when it makes sense to use an event broker, and when is it overkill?
What are the trade-off between using an iPaaS-provided message broker and an external one?
What does error handling look like when using an event broker?
What are some architectural “gotchas” associated with using event brokers with iPaaS?
How do I make all this work in real-world environments?
[1] For more on HIP, see https://www.gartner.com/smarterwithgartner/use-a-hybrid-integration-approach-to-empower-digital-transformation/
[2] For a more general introduction to messaging concepts and patterns, see https://www.enterpriseintegrationpatterns.com/patterns/messaging/Introduction.html
The post Supercharge your iPaaS for Better Agility, Resilience, and Real-time Capabilities with an Event Broker appeared first on Solace.
Supercharge your iPaaS for Better Agility, Resilience, and Real-time Capabilities with an Event Broker published first on https://jiohow.tumblr.com/
1 note
·
View note
Text
Supercharge your iPaaS for Better Agility, Resilience, and Real-time Capabilities with an Event Broker
More and more enterprises are moving from on-premises enterprise service buses (ESB) to integration platform as a service (iPaaS) solutions like Boomi, Jitterbit, Mulesoft Anypoint and others. iPaaS solutions like these are a key component of what Gartner calls as a hybrid integration approach[1], and as someone accustomed to creating ESB solutions, it’s been eye-opening see how quickly and easily you can get them up and running. But as I create iPaaS solutions, one thought keeps running through my mind: this would be so much more powerful and elegant if we added an event broker to the mix.
iPaaS and Synchronous REST Calls
At their heart, iPaaS solutions aim to simplify integration by creating a managed experience, particularly when deployed in the cloud. An iPaaS solution typically includes:
Graphical tools that show how transactions flow through the system
Connectors that contain logic for popular protocols
Built-in mapping tools that allow for data transformation
Defined locations for code snippets that isolate customer-specific modifications, typically in a language like JavaScript
Integrated source code repositories and deployment capabilities that are usually external in ESBs
Although there are adapters for many different information providers such as databases and EDI, most iPaaS (and most ESB) solution’s bread and butter has been synchronous REST calls between software as a service (SaaS) providers like Salesforce and SAP S/4HANA Cloud. As a result, iPaaS providers have focused on making synchronous API integrations as easy as possible. Architecturally, this generally means the same process that receives an incoming request maps the data using a graphical tool, connects to the information consumer, and sends the transformed message.
Figure 1: Typical iPaaS process flow
Adding an Event Broker to Your iPaaS Solution
Adding an event broker allows you to separate (decouple) that process, such that the iPaaS receives information via one process and writes it to a queue or topic[2], then a second process picks up the message and performs additional logic, typically including data transformation, before forwarding it to a consumer.
Figure 2: iPaaS flow with event broker
That decoupling can enhance traditional ESBs, but in some ways it’s even more important for iPaaS solutions. The architectural shift to decoupling using an event broker can improve an iPaaS’s resilience, agility and real-time capabilities—all without complicating its architecture or operation. The approach is a lot like breaking up a monolithic application into multiple microservices.
Some brief asides:
Many iPaaS providers have begun to integrate lightweight event brokers into their products. While I think there are advantages to having an event broker live outside the iPaaS itself, I will save that for another day and focus on the benefits of all event brokers, including those they include.
While event brokers provide great benefits for iPaaS architectures, they also present challenges. In a future blog I’ll discuss those challenges, the trade-offs they entail, and give guidance on architectural choices that can help you overcome them.
Planning for Failure – How an Event Broker Helps an iPaaS Stay Simple One of the most complex and time-consuming tasks for any integration architect is making sure a system performs when things go wrong – in fact some experts say up to 25% of an integration project should be devoted to designing exception handling, and iPaaS solutions are no different. That isn’t surprising given that architects need to consider complex questions including:
What if the iPaaS itself fails? Will I lose in-flight transactions?
What should happen if a consumer goes down and I need to retry? How can I prevent it from decreasing performance and blocking incoming?
What if a consumer can’t process my incoming message until a human intervenes (e.g. adding a value to a cross reference table)? How can I easily move on to the next transaction and replay it later?
You can try to solve these issues within the iPaaS itself, perhaps by creating a library of custom code snippets in a language like JavaScript that dictate architectural standards like manually compensating for failed transactions and using adapters to ensure that transactions are persisted to disk. However, in doing so you sacrifice some of the simplicity that makes iPaaS so advantageous.
Introducing an event broker as part of a decoupled architecture, on the other hand, can answer some of the questions while keeping the iPaaS simple. As shown in Figure 3, by persisting messages to a queue or topic after arrival at the iPaaS, the event broker takes responsibility for guaranteeing that the message will not be lost in the event of a failure that brings down either your process or the entire iPaaS. Without an event broker, an iPaaS either requires custom persistence logic or accepts that messages will be lost in the event of failure, requiring the information provider to resend as necessary.
Figure 3: Event brokers allow for message persistence in the case of failure
Once the message is persisted by an event broker, the iPaaS receiver (not the end consumer) can acknowledge that the message has been successfully processed and becomes available for the next incoming message.
This ability for the iPaaS receiver to quickly and independently process messages comes in handy if the downstream information consumer isn’t available. Typically, an information consumer being unavailable results in multiple attempts to retry the transaction until it succeeds. As shown in Figure 4, if the receiver and sender are on the same thread, this can quickly cause the iPaaS to run out of resources, creating a chain reaction that blocks incoming transactions. By buffering incoming transactions, an event broker helps to keep your solution up and running. This buffering is even more valuable as we add in additional consumers, which we discuss in the next section.
Figure 4: Event brokers conserve resources during retry
Lastly, if the error turns out to be one that will take a while to resolve (e.g. someone to add a value to a look up table), the message can be placed into an error queue. When the issue is resolved, the message can be requeued for processing.
Figure 5: Event brokers simplify replay after human intervention
The Value of Event-Driven Architecture
To this point, we’ve focused on the benefits of decoupling a single sender and receiver from one another, and the benefits of that decoupling are worthwhile on their own. But the value really adds up as you begin distributing transactions amongst multiple diverse consumers using a fully event-driven architecture (EDA). Making your integrations more agile lets your architects and developers innovate more freely, solving business needs and exploring new frontiers for your business.
Architects need to consider complex questions including:
How can I quickly introduce new business functionality while making sure I’m not affecting existing functionality?
How do I handle situations where one consumer processes information faster than another? Or one consumer rejects the transaction, while another processes it?
How do I make sure I’m not locking myself into a deployment pattern (on-premises, cloud, etc), cloud provider, or even iPaaS solution?
To aid agility, iPaaS providers typically feature integrated source control and deployment capabilities. Including these components reduces the amount of additional infrastructure needed to start building an iPaaS solution – no more setting up a Git repository and configuring Jenkins.
Most iPaaS solutions include the ability to call multiple sender processes from a single receiver process, but as Figure 6 shows, even with the code promotion infrastructure in place, you still need to have a complete test cycle and deployment with every change if the solution tightly senders and receivers of information. That cycle is represented by a link icon in the diagram below. This tight coupling also makes error handling more complex, particularly in cases where one consumer rejects the transaction and additional consumers process it successfully.
Figure 6: iPaaS solution with multiple tightly coupled consumers
An event broker allows you to move into the realm of fully event-driven architecture. At the outset, the addition of an event broker may seem like it increases complexity—after all, there are now more components—but the addition of those components is more than offset by the fact that an event broker makes code more modular and reduces integration challenges.
By playing middleman between receivers and senders, an event broker lets you change a sender without redeploying and retesting the entire process. What’s more, you can very easily add new senders and consumers, and seamlessly integrate them into an existing solution.
With an event broker, you can design a new sender connecting to an innovative new application using iPaaS integration tools like graphical mapping, content-based filtering and pre-built connectivity. Then once you add a new subscription to the event broker, events begin flowing to the new process and onward to the information consumer.
Figure 7: iPaaS with loosely coupled consumers using event broker
Handling Slow Consumers and Routing Information with an Event Mesh
At runtime, decoupling lets consumers process information independently. This can help to resolve several difficult architectural challenges:
The first challenge decoupling alleviates is information consumers that process transactions at different rates of speed. An event broker creates a buffer that allows slow consumers to process messages at their own pace without affecting or constraining those applications that can process messages much more quickly.
Another challenge is dealing with instances in which one consumer rejects an incoming transaction, but other consumers are still able to process it. An event broker can handle that scenario without resorting to adhoc error handling. That said, error handling in an event-driven architecture can be tricky, and I look forward to diving into that topic in a future blog post.
By linking multiple brokers in different locations to form an event mesh, event brokers can efficiently route information between on-premises and cloud applications, different clouds and even different iPaaS solutions—without having to explicitly route information between them within your iPaaS.
Such an event mesh can also address the challenge of unreliable WAN connectivity by provide reliable delivery without each iPaaS application needing to handle this. If your deployment pattern changes, the event mesh dynamically reroutes events to the new topology.
Reacting to Real-Time Event Sources….in Real-Time
Beyond decoupling and event-driven architecture between iPaaS components, an event broker provides an on-ramp to real-time capabilities for your iPaaS. The internet of things (IoT) and other real-time information sources such as Workday and Salesforce present a massive opportunity to increase your business’s ability to react, but you typically need to act on such information in real-time to fully exploit its value. Real-time information sources can also send a massive spike in traffic during periods of high demand.
The need to process incoming events in real-time, and deal with sudden unpredictable bursts of data can be challenges for any iPaaS. In the absence of an event broker, iPaaS solutions are typically triggered either through a synchronous API request, or on a polling interval defined when the process is developed and deployed. In the case of a process invoked by a synchronous API request, dealing with traffic spikes within the structures of an iPaaS typically means increasing the number of processing threads available to handle the incoming flow of information and over allocation of memory and processing power. In the case of a polling interval, it is difficult to predict how often to poll far in advance, especially if you can’t change that interval when conditions change.
Figure 8: Using polling for real-time event processing
An event broker helps you overcome these challenges by providing an entry point for event-driven applications. Messages that are placed on event broker topics can trigger your iPaaS immediately, without having to worry about selecting a static polling interval. An event broker can also buffer incoming events and provide a throttling mechanism that prevents downstream processes from being overwhelmed in periods of high traffic.
Figure 9: Using an event broker for real-time event processing
Conclusion
Event brokers are a great potential partner for your iPaaS, enhancing their resilience, agility and real-time capabilities. Recognizing those potential benefits is the first step in the journey. The next steps are recognizing and overcoming some challenges that event brokers can introduce. In the future posts, I’m looking forward to answering questions such as:
What are situations when it makes sense to use an event broker, and when is it overkill?
What are the trade-off between using an iPaaS-provided message broker and an external one?
What does error handling look like when using an event broker?
What are some architectural “gotchas” associated with using event brokers with iPaaS?
How do I make all this work in real-world environments?
[1] For more on HIP, see https://www.gartner.com/smarterwithgartner/use-a-hybrid-integration-approach-to-empower-digital-transformation/
[2] For a more general introduction to messaging concepts and patterns, see https://www.enterpriseintegrationpatterns.com/patterns/messaging/Introduction.html
The post Supercharge your iPaaS for Better Agility, Resilience, and Real-time Capabilities with an Event Broker appeared first on Solace.
Supercharge your iPaaS for Better Agility, Resilience, and Real-time Capabilities with an Event Broker published first on https://jiohow.tumblr.com/
1 note
·
View note
Link
Learn numerous RxJs Operators, learn all RxJs and Reactive Programming core concepts via Practical Examples
What you’ll learn
Learn the RxJs library via Practical Examples
Become familiar with an extended subset of RxJs Operators
Understand in detail the core notions of Reactive Programming
Learn how to design and build Applications in Reactive style
Requirements
Just a bit of Javascript
No previous knowledge of Typescript or Angular is needed
No previous knowledge of RxJs is needed, we will start from scratch
Description
This Course in a Nutshell (note: this course includes the Typescript Jumpstart E-Book)
This course is a complete practical guide for the RxJs library (Reactive Extensions for Javascript).
If you are a developer just getting started with the Angular ecosystem, or even if you already have some experience with it, the part that you will find the hardest to wrap your head around is RxJs.
And this is because RxJs and Reactive Programming have a steep learning curve that makes it hard to just jump in into an existing program and learn these concepts by example. With RxJs that approach will simply not work. Instead, we need to start at the beginning and learn some baseline reactive design concepts first.
In this course, we will start by presenting a couple of baseline concepts, and then we will provide you with an extended catalog of RxJs operators that will in practice cover the vast majority of your daily needs.
Also, the goal here is not to cover every single operator, but instead to choose an extended subset that contains the most commonly used operators, and provide practical examples for each.
Another goal of the course is to show how RxJs is meant to be used for building programs using Reactive Design as opposed to an imperative programming style.
Course Overview
We will start by quickly introducing RxJs: we will cover the notions of Stream and Observable, and we will answer common questions such as: what is RxJs, when to use it and why, what problem does it solve?
We will then write our own Observable from first principles: we will implement our own HTTP observable that will allow us to handle backend HTTP requests while supporting error handling and cancellation.
After this quick introduction, we will dive straight into the practical examples covering a large variety of operators. We will cover the operators by explaining their behavior using the official RxJs marble diagrams, and then we will complement that with a practical example.
We will first start with the Map and Filter operators, and quickly move to more complex operators such as shareReplay, concat, concatMap, and other commonly used observable combination strategies such as: merge and mergeMap, exhaustMap, switch and switchMap. We will provide practical examples for these operators that include backend save operations and search typeaheads.
We will then cover several RxJs error handling strategies, like catch and recover, catch and rethrow or retry.
We will also cover the notion of subject and give examples of several commonly used subjects, such as BehaviorSubject or AsyncSubject. We will then use a subject to implement a very commonly used reactive pattern: we will implement a centralized observable store from first principles.
We will also cover many other commonly used operators, that include but are not restricted to: withLatestFrom, forkJoin, take, first, delay, delayWhen, startWith, etc.
At the end of the course, we will implement our own custom pipeable operator from first principles: we will implement a debugging operator that is going to be very helpful for debugging our RxJS programs.
What Will You Learn In this Course?
By taking this course you will learn how to use the RxJs library in practice for building applications in reactive style. You will understand well the core notions that are the basis of reactive programming, such as Streams and Observables.
You will also be familiar with an extended subset of operators that in practice will provide all that you will need for building applications in reactive style using RxJs.
Have a look at the course free lessons below, and please enjoy the course!
Who is the target audience?
Developers trying to make sense of the RxJs library
Developers looking to learn Reactive Programming
Developers trying to understand how to build Applications in a Reactive Design style
Created by Angular University Last updated 10/2018 English English [Auto-generated]
Size: 2.47 GB
Download Now
https://ift.tt/2q98yeG.
The post RxJs 6 In Practice (with FREE E-Book) appeared first on Free Course Lab.
0 notes