#spark RDD Partition
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
70% of Tumblr users say the Dashboard is their favorite place to spend time online.
Text
What is PySpark? A Beginner’s Guide
Introduction
The digital era gives rise to continuous expansion in data production activities. Organizations and businesses need processing systems with enhanced capabilities to process large data amounts efficiently. Large datasets receive poor scalability together with slow processing speed and limited adaptability from conventional data processing tools. PySpark functions as the data processing solution that brings transformation to operations.
The Python Application Programming Interface called PySpark serves as the distributed computing framework of Apache Spark for fast processing of large data volumes. The platform offers a pleasant interface for users to operate analytics on big data together with real-time search and machine learning operations. Data engineering professionals along with analysts and scientists prefer PySpark because the platform combines Python's flexibility with Apache Spark's processing functions.
The guide introduces the essential aspects of PySpark while discussing its fundamental elements as well as explaining operational guidelines and hands-on usage. The article illustrates the operation of PySpark through concrete examples and predicted outputs to help viewers understand its functionality better.
What is PySpark?
PySpark is an interface that allows users to work with Apache Spark using Python. Apache Spark is a distributed computing framework that processes large datasets in parallel across multiple machines, making it extremely efficient for handling big data. PySpark enables users to leverage Spark’s capabilities while using Python’s simple and intuitive syntax.
There are several reasons why PySpark is widely used in the industry. First, it is highly scalable, meaning it can handle massive amounts of data efficiently by distributing the workload across multiple nodes in a cluster. Second, it is incredibly fast, as it performs in-memory computation, making it significantly faster than traditional Hadoop-based systems. Third, PySpark supports Python libraries such as Pandas, NumPy, and Scikit-learn, making it an excellent choice for machine learning and data analysis. Additionally, it is flexible, as it can run on Hadoop, Kubernetes, cloud platforms, or even as a standalone cluster.
Core Components of PySpark
PySpark consists of several core components that provide different functionalities for working with big data:
RDD (Resilient Distributed Dataset) – The fundamental unit of PySpark that enables distributed data processing. It is fault-tolerant and can be partitioned across multiple nodes for parallel execution.
DataFrame API – A more optimized and user-friendly way to work with structured data, similar to Pandas DataFrames.
Spark SQL – Allows users to query structured data using SQL syntax, making data analysis more intuitive.
Spark MLlib – A machine learning library that provides various ML algorithms for large-scale data processing.
Spark Streaming – Enables real-time data processing from sources like Kafka, Flume, and socket streams.
How PySpark Works
1. Creating a Spark Session
To interact with Spark, you need to start a Spark session.

Output:

2. Loading Data in PySpark
PySpark can read data from multiple formats, such as CSV, JSON, and Parquet.

Expected Output (Sample Data from CSV):

3. Performing Transformations
PySpark supports various transformations, such as filtering, grouping, and aggregating data. Here’s an example of filtering data based on a condition.

Output:

4. Running SQL Queries in PySpark
PySpark provides Spark SQL, which allows you to run SQL-like queries on DataFrames.

Output:
5. Creating a DataFrame Manually
You can also create a PySpark DataFrame manually using Python lists.

Output:

Use Cases of PySpark
PySpark is widely used in various domains due to its scalability and speed. Some of the most common applications include:
Big Data Analytics – Used in finance, healthcare, and e-commerce for analyzing massive datasets.
ETL Pipelines – Cleans and processes raw data before storing it in a data warehouse.
Machine Learning at Scale – Uses MLlib for training and deploying machine learning models on large datasets.
Real-Time Data Processing – Used in log monitoring, fraud detection, and predictive analytics.
Recommendation Systems – Helps platforms like Netflix and Amazon offer personalized recommendations to users.
Advantages of PySpark
There are several reasons why PySpark is a preferred tool for big data processing. First, it is easy to learn, as it uses Python’s simple and intuitive syntax. Second, it processes data faster due to its in-memory computation. Third, PySpark is fault-tolerant, meaning it can automatically recover from failures. Lastly, it is interoperable and can work with multiple big data platforms, cloud services, and databases.
Getting Started with PySpark
Installing PySpark
You can install PySpark using pip with the following command:

To use PySpark in a Jupyter Notebook, install Jupyter as well:

To start PySpark in a Jupyter Notebook, create a Spark session:

Conclusion
PySpark is an incredibly powerful tool for handling big data analytics, machine learning, and real-time processing. It offers scalability, speed, and flexibility, making it a top choice for data engineers and data scientists. Whether you're working with structured data, large-scale machine learning models, or real-time data streams, PySpark provides an efficient solution.
With its integration with Python libraries and support for distributed computing, PySpark is widely used in modern big data applications. If you’re looking to process massive datasets efficiently, learning PySpark is a great step forward.
youtube
#pyspark training#pyspark coutse#apache spark training#apahe spark certification#spark course#learn apache spark#apache spark course#pyspark certification#hadoop spark certification .#Youtube
0 notes
Text
Top 30+ Spark Interview Questions

Apache Spark, the lightning-fast open-source computation platform, has become a cornerstone in big data technology. Developed by Matei Zaharia at UC Berkeley's AMPLab in 2009, Spark gained prominence within the Apache Foundation from 2014 onward. This article aims to equip you with the essential knowledge needed to succeed in Apache Spark interviews, covering key concepts, features, and critical questions.
Understanding Apache Spark: The Basics
Before delving into interview questions, let's revisit the fundamental features of Apache Spark:
1. Support for Multiple Programming Languages:
Java, Python, R, and Scala are the supported programming languages for writing Spark code.
High-level APIs in these languages facilitate seamless interaction with Spark.
2. Lazy Evaluation:
Spark employs lazy evaluation, delaying computation until absolutely necessary.
3. Machine Learning (MLlib):
MLlib, Spark's machine learning component, eliminates the need for separate engines for processing and machine learning.
4. Real-Time Computation:
Spark excels in real-time computation due to its in-memory cluster computing, minimizing latency.
5. Speed:
Up to 100 times faster than Hadoop MapReduce, Spark achieves this speed through controlled partitioning.
6. Hadoop Integration:
Smooth connectivity with Hadoop, acting as a potential replacement for MapReduce functions.
Top 30+ Interview Questions: Explained
Question 1: Key Features of Apache Spark
Apache Spark supports multiple programming languages, lazy evaluation, machine learning, multiple format support, real-time computation, speed, and seamless Hadoop integration.
Question 2: Advantages Over Hadoop MapReduce
Enhanced speed, multitasking, reduced disk-dependency, and support for iterative computation.
Question 3: Resilient Distributed Dataset (RDD)
RDD is a fault-tolerant collection of operational elements distributed and immutable in memory.
Question 4: Functions of Spark Core
Spark Core acts as the base engine for large-scale parallel and distributed data processing, including job distribution, monitoring, and memory management.
Question 5: Components of Spark Ecosystem
Spark Ecosystem comprises GraphX, MLlib, Spark Core, Spark Streaming, and Spark SQL.
Question 6: API for Implementing Graphs in Spark
GraphX is the API for implementing graphs and graph-parallel computing in Spark.
Question 7: Implementing SQL in Spark
Spark SQL modules integrate relational processing with Spark's functional programming API, supporting SQL and HiveQL.
Question 8: Parquet File
Parquet is a columnar format supporting read and write operations in Spark SQL.
Question 9: Using Spark with Hadoop
Spark can run on top of HDFS, leveraging Hadoop's distributed replicated storage for batch and real-time processing.
Question 10: Cluster Managers in Spark
Apache Mesos, Standalone, and YARN are cluster managers in Spark.
Question 11: Using Spark with Cassandra Databases
Spark Cassandra Connector allows Spark to access and analyze data in Cassandra databases.
Question 12: Worker Node
A worker node is a node capable of running code in a cluster, assigned tasks by the master node.
Question 13: Sparse Vector in Spark
A sparse vector stores non-zero entries using parallel arrays for indices and values.
Question 14: Connecting Spark with Apache Mesos
Configure Spark to connect with Mesos, place the Spark binary package in an accessible location, and set the appropriate configuration.
Question 15: Minimizing Data Transfers in Spark
Minimize data transfers by avoiding shuffles, using accumulators, and broadcast variables.
Question 16: Broadcast Variables in Spark
Broadcast variables store read-only cached versions of variables on each machine, reducing the need for shipping copies with tasks.
Question 17: DStream in Spark
DStream, or Discretized Stream, is the basic abstraction in Spark Streaming, representing a continuous stream of data.
Question 18: Checkpoints in Spark
Checkpoints in Spark allow programs to run continuously and recover from failures unrelated to application logic.
Question 19: Levels of Persistence in Spark
Spark offers various persistence levels for storing RDDs on disk, memory, or a combination of both.
Question 20: Limitations of Apache Spark
Limitations include the lack of a built-in file management system, higher latency, and no support for true real-time data stream processing.
Question 21: Defining Apache Spark
Apache Spark is an easy-to-use, highly flexible, and fast processing framework supporting cyclic data flow and in-memory computing.
Question 22: Purpose of Spark Engine
The Spark Engine schedules, monitors, and distributes data applications across the cluster.
Question 23: Partitions in Apache Spark
Partitions in Apache Spark split data logically for more efficient and smaller divisions, aiding in faster data processing.
Question 24: Operations of RDD
RDD operations include transformations and actions.
Question 25: Transformations in Spark
Transformations are functions applied to RDDs, creating new RDDs. Examples include Map() and filter().
Question 26: Map() Function
The Map() function repeats over every line in an RDD, splitting them into a new RDD.
Question 27: Filter() Function
The filter() function creates a new RDD by selecting elements from an existing RDD based on a specified function.
Question 28: Actions in Spark
Actions bring back data from an RDD to the local machine, including functions like reduce() and take().
Question 29: Difference Between reduce() and take()
reduce() repeatedly applies a function until only one value is left, while take() retrieves all values from an RDD to the local node.
Question 30: Coalesce() and Repartition() in MapReduce
Coalesce() and repartition() modify the number of partitions in an RDD, with Coalesce() being part of repartition().
Question 31: YARN in Spark
YARN acts as a central resource management platform, providing scalable operations across the cluster.
Question 32: PageRank in Spark
PageRank in Spark is an algorithm in GraphX measuring the importance of each vertex in a graph.
Question 33: Sliding Window in Spark
A Sliding Window in Spark specifies each batch of Spark streaming to be processed, setting batch intervals and processing several batches.
Question 34: Benefits of Sliding Window Operations
Sliding Window operations control data packet transfer, combine RDDs within a specific window, and support windowed computations.
Question 35: RDD Lineage
RDD Lineage is the process of reconstructing lost data partitions, aiding in data recovery.
Question 36: Spark Driver
Spark Driver is the program running on the master node, declaring transformations and actions on data RDDs.
Question 37: Supported File Systems in Spark
Spark supports Amazon S3, HDFS, and Local File System as file systems.
If you like to read more about it please visit
https://analyticsjobs.in/question/what-is-apache-spark/
0 notes
Text
Streamlining Big Data Analytics with Apache Spark

Apache Spark is a powerful open-source data processing framework designed to streamline big data analytics. It's specifically built to handle large-scale data processing and analytics tasks efficiently. Here are some key aspects of how Apache Spark streamlines big data analytics:
In-Memory Processing: One of the significant advantages of Spark is its ability to perform in-memory data processing. It stores data in memory, which allows for much faster access and processing compared to traditional disk-based processing systems. This is particularly beneficial for iterative algorithms and machine learning tasks.
Distributed Computing: Spark is built to perform distributed computing, which means it can distribute data and processing across a cluster of machines. This enables it to handle large datasets and computations that would be impractical for a single machine.
Versatile Data Processing: Spark provides a wide range of libraries and APIs for various data processing tasks, including batch processing, real-time data streaming, machine learning, and graph processing. This versatility makes it a one-stop solution for many data processing needs.
Resilient Distributed Datasets (RDDs): RDDs are the fundamental data structure in Spark. They are immutable, fault-tolerant, and can be cached in memory for fast access. This simplifies the process of handling data and makes it more fault-tolerant.
Ease of Use: Spark provides APIs in several programming languages, including Scala, Java, Python, and R, making it accessible to a wide range of developers and data scientists. This ease of use has contributed to its popularity.
Integration: Spark can be easily integrated with other popular big data tools, like Hadoop HDFS, Hive, HBase, and more. This ensures compatibility with existing data infrastructure.
Streaming Capabilities: Spark Streaming allows you to process real-time data streams. It can be used for applications like log processing, fraud detection, and real-time dashboards.
Machine Learning Libraries: Spark's MLlib provides a scalable machine learning library, which simplifies the development of machine learning models on large datasets.
Graph Processing: GraphX, a library for graph processing, is integrated into Spark. It's useful for tasks like social network analysis and recommendation systems.
Community Support: Spark has a vibrant and active open-source community, which means that it's continuously evolving and improving. You can find numerous resources, tutorials, and documentation to help with your big data analytics projects.
Performance Optimization: Spark provides various mechanisms for optimizing performance, including data partitioning, caching, and query optimization.
1 note
·
View note
Text
The Ultimate Guide to Becoming an Azure Data Engineer

The Azure Data Engineer plays a critical role in today's data-driven business environment, where the amount of data produced is constantly increasing. These professionals are responsible for creating, managing, and optimizing the complex data infrastructure that organizations rely on. To embark on this career path successfully, you'll need to acquire a diverse set of skills. In this comprehensive guide, we'll provide you with an extensive roadmap to becoming an Azure Data Engineer.
1. Cloud Computing
Understanding cloud computing concepts is the first step on your journey to becoming an Azure Data Engineer. Start by exploring the definition of cloud computing, its advantages, and disadvantages. Delve into Azure's cloud computing services and grasp the importance of securing data in the cloud.
2. Programming Skills
To build efficient data processing pipelines and handle large datasets, you must acquire programming skills. While Python is highly recommended, you can also consider languages like Scala or Java. Here's what you should focus on:
Basic Python Skills: Begin with the basics, including Python's syntax, data types, loops, conditionals, and functions.
NumPy and Pandas: Explore NumPy for numerical computing and Pandas for data manipulation and analysis with tabular data.
Python Libraries for ETL and Data Analysis: Understand tools like Apache Airflow, PySpark, and SQLAlchemy for ETL pipelines and data analysis tasks.
3. Data Warehousing
Data warehousing is a cornerstone of data engineering. You should have a strong grasp of concepts like star and snowflake schemas, data loading into warehouses, partition management, and query optimization.
4. Data Modeling
Data modeling is the process of designing logical and physical data models for systems. To excel in this area:
Conceptual Modeling: Learn about entity-relationship diagrams and data dictionaries.
Logical Modeling: Explore concepts like normalization, denormalization, and object-oriented data modeling.
Physical Modeling: Understand how to implement data models in database management systems, including indexing and partitioning.
5. SQL Mastery
As an Azure Data Engineer, you'll work extensively with large datasets, necessitating a deep understanding of SQL.
SQL Basics: Start with an introduction to SQL, its uses, basic syntax, creating tables, and inserting and updating data.
Advanced SQL Concepts: Dive into advanced topics like joins, subqueries, aggregate functions, and indexing for query optimization.
SQL and Data Modeling: Comprehend data modeling principles, including normalization, indexing, and referential integrity.
6. Big Data Technologies
Familiarity with Big Data technologies is a must for handling and processing massive datasets.
Introduction to Big Data: Understand the definition and characteristics of big data.
Hadoop and Spark: Explore the architectures, components, and features of Hadoop and Spark. Master concepts like HDFS, MapReduce, RDDs, Spark SQL, and Spark Streaming.
Apache Hive: Learn about Hive, its HiveQL language for querying data, and the Hive Metastore.
Data Serialization and Deserialization: Grasp the concept of serialization and deserialization (SerDe) for working with data in Hive.
7. ETL (Extract, Transform, Load)
ETL is at the core of data engineering. You'll need to work with ETL tools like Azure Data Factory and write custom code for data extraction and transformation.
8. Azure Services
Azure offers a multitude of services crucial for Azure Data Engineers.
Azure Data Factory: Create data pipelines and master scheduling and monitoring.
Azure Synapse Analytics: Build data warehouses and marts, and use Synapse Studio for data exploration and analysis.
Azure Databricks: Create Spark clusters for data processing and machine learning, and utilize notebooks for data exploration.
Azure Analysis Services: Develop and deploy analytical models, integrating them with other Azure services.
Azure Stream Analytics: Process real-time data streams effectively.
Azure Data Lake Storage: Learn how to work with data lakes in Azure.
9. Data Analytics and Visualization Tools
Experience with data analytics and visualization tools like Power BI or Tableau is essential for creating engaging dashboards and reports that help stakeholders make data-driven decisions.
10. Interpersonal Skills
Interpersonal skills, including communication, problem-solving, and project management, are equally critical for success as an Azure Data Engineer. Collaboration with stakeholders and effective project management will be central to your role.
Conclusion
In conclusion, becoming an Azure Data Engineer requires a robust foundation in a wide range of skills, including SQL, data modeling, data warehousing, ETL, Azure services, programming, Big Data technologies, and communication skills. By mastering these areas, you'll be well-equipped to navigate the evolving data engineering landscape and contribute significantly to your organization's data-driven success.
Ready to Begin Your Journey as a Data Engineer?
If you're eager to dive into the world of data engineering and become a proficient Azure Data Engineer, there's no better time to start than now. To accelerate your learning and gain hands-on experience with the latest tools and technologies, we recommend enrolling in courses at Datavalley.
Why choose Datavalley?
At Datavalley, we are committed to equipping aspiring data engineers with the skills and knowledge needed to excel in this dynamic field. Our courses are designed by industry experts and instructors who bring real-world experience to the classroom. Here's what you can expect when you choose Datavalley:
Comprehensive Curriculum: Our courses cover everything from Python, SQL fundamentals to Snowflake advanced data engineering, cloud computing, Azure cloud services, ETL, Big Data foundations, Azure Services for DevOps, and DevOps tools.
Hands-On Learning: Our courses include practical exercises, projects, and labs that allow you to apply what you've learned in a real-world context.
Multiple Experts for Each Course: Modules are taught by multiple experts to provide you with a diverse understanding of the subject matter as well as the insights and industrial experiences that they have gained.
Flexible Learning Options: We provide flexible learning options to learn courses online to accommodate your schedule and preferences.
Project-Ready, Not Just Job-Ready: Our program prepares you to start working and carry out projects with confidence.
Certification: Upon completing our courses, you'll receive a certification that validates your skills and can boost your career prospects.
On-call Project Assistance After Landing Your Dream Job: Our experts will help you excel in your new role with up to 3 months of on-call project support.
The world of data engineering is waiting for talented individuals like you to make an impact. Whether you're looking to kickstart your career or advance in your current role, Datavalley's Data Engineer Masters Program can help you achieve your goals.
#datavalley#dataexperts#data engineering#dataexcellence#data engineering course#online data engineering course#data engineering training
0 notes
Text
Exploiting Apache Spark's Potential: Changing Enormous Information InvestigationPresentation
In the realm of huge information examination, Apache Flash has arisen as a distinct advantage. Spark is now the preferred framework for handling large-scale data processing tasks due to its lightning-fast processing and advanced analytics capabilities. In this blog, we'll talk about how Apache Spark has changed big data analytics and the amazing features and benefits it offers.
The Ecosystem of Spark:
Apache Flash is an open-source, dispersed figuring framework that gives a broad environment to enormous information handling. It provides a single platform for a variety of data processing tasks, including machine learning, graph processing, batch processing, and real-time streaming. Flash's adaptable design permits it to flawlessly coordinate with well known huge information innovations like Hadoop, Hive, and HBase, making it a flexible device for information specialists and information researchers.
Lightning-Quick Handling:
Spark's exceptional processing speed is one of the main reasons for its popularity. Flash use in-memory registering, empowering it to store information in Smash and perform calculations in-memory. When compared to conventional disk-based systems, this significantly reduces the disk I/O overhead, resulting in significantly quicker processing times. Flash's capacity to convey information and calculations across a group of machines likewise adds to its superior presentation abilities.
Distributed resilient datasets (RDDs):
RDDs are the principal information structure in Apache Flash. They are shortcoming open minded, unchanging assortments of items that can be handled in lined up across a bunch. Because they automatically handle data partitioning and fault tolerance, RDDs enable effective distributed processing. Complex data manipulations and aggregations are made possible by RDDs' support for a variety of transformations and actions.
DataFrames and Spark SQL:
A higher-level interface for working with structured and semi-structured data is provided by Spark SQL. It seamlessly integrates with Spark's RDDs and lets users query data using SQL syntax. DataFrames, which are a more effective and optimized approach to working with structured data, are also included in Spark SQL. DataFrames provide a user-friendly tabular structure and enable data manipulations that take full advantage of Spark's distributed processing capabilities.
AI with MLlib:
Flash's MLlib library works on the execution of adaptable AI calculations. MLlib gives a rich arrangement of AI calculations and utilities that can be consistently incorporated with Flash work processes. Its conveyed nature considers preparing models on enormous datasets, making it reasonable for dealing with huge information AI assignments. In addition, hyperparameter tuning, pipeline construction, and model persistence are all supported by MLlib.
Processing Streams Using Spark Streaming:
Flash Streaming empowers continuous information handling and investigation. It ingests information in little, miniature group spans, considering close to constant handling. Spark Streaming is able to deal with enormous streams of data and carry out intricate calculations in real time thanks to its integration with well-known messaging systems like Apache Kafka. This makes it ideal for applications like extortion location, log examination, and IoT information handling.
Capabilities for Spark's Graph Processing:
Flash's GraphX library gives a versatile system to chart handling and investigation. It permits clients to control and investigate huge scope chart information productively. GraphX is a useful tool for
applications like social network analysis, recommendation systems, and network topology analysis because it supports a wide range of graph algorithms.
Conclusion:
By providing a powerful, adaptable, and effective framework for processing and analyzing massive datasets, Apache Spark has revolutionized big data analytics. It is the preferred choice for both data engineers and data scientists due to its lightning-fast processing capabilities, extensive ecosystem, and support for various data processing tasks. Spark is poised to play a crucial role in the future of big data analytics by driving innovation and uncovering insights from massive datasets with continued development and adoption.
Find more information @ https://olete.in/?subid=165&subcat=Apache Spark
0 notes
Text
Pyspark fhash

#PYSPARK FHASH HOW TO#
#PYSPARK FHASH FULL#
#PYSPARK FHASH CODE#
By tuning the partition size to optimal, you can improve the performance of the Spark application
#PYSPARK FHASH FULL#
This yields output Repartition size : 4 and the repartition re-distributes the data(as shown below) from all partitions which is full shuffle leading to very expensive operation when dealing with billions and trillions of data. Note: Use repartition() when you wanted to increase the number of partitions. When you want to reduce the number of partitions prefer using coalesce() as it is an optimized or improved version of repartition() where the movement of the data across the partitions is lower using coalesce which ideally performs better when you dealing with bigger datasets. For example, if you refer to a field that doesn’t exist in your code, Dataset generates compile-time error whereas DataFrame compiles fine but returns an error during run-time.
#PYSPARK FHASH CODE#
Catalyst Optimizer is the place where Spark tends to improve the speed of your code execution by logically improving it.Ĭatalyst Optimizer can perform refactoring complex queries and decides the order of your query execution by creating a rule-based and code-based optimization.Īdditionally, if you want type safety at compile time prefer using Dataset. What is Catalyst?Ĭatalyst Optimizer is an integrated query optimizer and execution scheduler for Spark Datasets/DataFrame. Before your query is run, a logical plan is created using Catalyst Optimizer and then it’s executed using the Tungsten execution engine. Since DataFrame is a column format that contains additional metadata, hence Spark can perform certain optimizations on a query. Tungsten performance by focusing on jobs close to bare metal CPU and memory efficiency. Tungsten is a Spark SQL component that provides increased performance by rewriting Spark operations in bytecode, at runtime. Spark Dataset/DataFrame includes Project Tungsten which optimizes Spark jobs for Memory and CPU efficiency. Since Spark/PySpark DataFrame internally stores data in binary there is no need of Serialization and deserialization data when it distributes across a cluster hence you would see a performance improvement.
#PYSPARK FHASH HOW TO#
Using RDD directly leads to performance issues as Spark doesn’t know how to apply the optimization techniques and RDD serialize and de-serialize the data when it distributes across a cluster (repartition & shuffling). Spark RDD is a building block of Spark programming, even when we use DataFrame/Dataset, Spark internally uses RDD to execute operations/queries but the efficient and optimized way by analyzing your query and creating the execution plan thanks to Project Tungsten and Catalyst optimizer. In PySpark use, DataFrame over RDD as Dataset’s are not supported in PySpark applications. For Spark jobs, prefer using Dataset/DataFrame over RDD as Dataset and DataFrame’s includes several optimization modules to improve the performance of the Spark workloads.
0 notes
Text
Apache Spark RDD mapPartitions transformation
Apache Spark RDD mapPartitions transformation
Apache Spark RDD mapPartitions transformation Apache Spark RDD mapPartitions transformation In our previous posts we talked about map function. In this post we will learn RDD’s mapPartitions transformation in Apache Spark. As per Apache Spark, mapPartitions performs a map operation on an entire partition and returns a new RDD by applying the function to each partition of the RDD. In other…

View On WordPress
0 notes
Text
Google Analytics (GA) like Backend System Architecture
There are numerous way of designing a backend. We will take Microservices route because the web scalability is required for Google Analytics (GA) like backend. Micro services enable us to elastically scale horizontally in response to incoming network traffic into the system. And a distributed stream processing pipeline scales in proportion to the load.
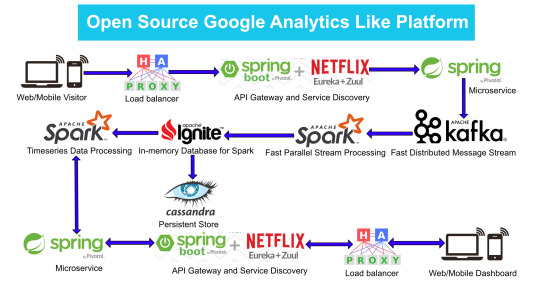
Here is the High Level architecture of the Google Analytics (GA) like Backend System.
Components Breakdown
Web/Mobile Visitor Tracking Code
Every web page or mobile site tracked by GA embed tracking code that collects data about the visitor. It loads an async script that assigns a tracking cookie to the user if it is not set. It also sends an XHR request for every user interaction.
HAProxy Load Balancer
HAProxy, which stands for High Availability Proxy, is a popular open source software TCP/HTTP Load Balancer and proxying solution. Its most common use is to improve the performance and reliability of a server environment by distributing the workload across multiple servers. It is used in many high-profile environments, including: GitHub, Imgur, Instagram, and Twitter.
A backend can contain one or many servers in it — generally speaking, adding more servers to your backend will increase your potential load capacity by spreading the load over multiple servers. Increased reliability is also achieved through this manner, in case some of your backend servers become unavailable.
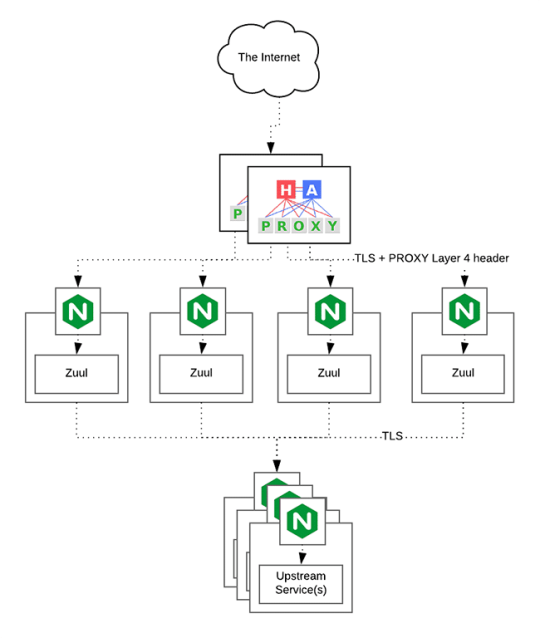
HAProxy routes the requests coming from Web/Mobile Visitor site to the Zuul API Gateway of the solution. Given the nature of a distributed system built for scalability and stateless request and response handling we can distribute the Zuul API gateways spread across geographies. HAProxy performs load balancing (layer 4 + proxy) across our Zuul nodes. High-Availability (HA ) is provided via Keepalived.
Spring Boot & Netflix OSS Eureka + Zuul
Zuul is an API gateway and edge service that proxies requests to multiple backing services. It provides a unified “front door” to the application ecosystem, which allows any browser, mobile app or other user interface to consume services from multiple hosts. Zuul is integrated with other Netflix stack components like Hystrix for fault tolerance and Eureka for service discovery or use it to manage routing rules, filters and load balancing across your system. Most importantly all of those components are well adapted by Spring framework through Spring Boot/Cloud approach.
An API gateway is a layer 7 (HTTP) router that acts as a reverse proxy for upstream services that reside inside your platform. API gateways are typically configured to route traffic based on URI paths and have become especially popular in the microservices world because exposing potentially hundreds of services to the Internet is both a security nightmare and operationally difficult. With an API gateway, one simply exposes and scales a single collection of services (the API gateway) and updates the API gateway’s configuration whenever a new upstream should be exposed externally. In our case Zuul is able to auto discover services registered in Eureka server.
Eureka server acts as a registry and allows all clients to register themselves and used for Service Discovery to be able to find IP address and port of other services if they want to talk to. Eureka server is a client as well. This property is used to setup Eureka in highly available way. We can have Eureka deployed in a highly available way if we can have more instances used in the same pattern.
Spring Boot Microservices
Using a microservices approach to application development can improve resilience and expedite the time to market, but breaking apps into fine-grained services offers complications. With fine-grained services and lightweight protocols, microservices offers increased modularity, making applications easier to develop, test, deploy, and, more importantly, change and maintain. With microservices, the code is broken into independent services that run as separate processes.
Scalability is the key aspect of microservices. Because each service is a separate component, we can scale up a single function or service without having to scale the entire application. Business-critical services can be deployed on multiple servers for increased availability and performance without impacting the performance of other services. Designing for failure is essential. We should be prepared to handle multiple failure issues, such as system downtime, slow service and unexpected responses. Here, load balancing is important. When a failure arises, the troubled service should still run in a degraded functionality without crashing the entire system. Hystrix Circuit-breaker will come into rescue in such failure scenarios.
The microservices are designed for scalability, resilience, fault-tolerance and high availability and importantly it can be achieved through deploying the services in a Docker Swarm or Kubernetes cluster. Distributed and geographically spread Zuul API gateways route requests from web and mobile visitors to the microservices registered in the load balanced Eureka server.
The core processing logic of the backend system is designed for scalability, high availability, resilience and fault-tolerance using distributed Streaming Processing, the microservices will ingest data to Kafka Streams data pipeline.
Apache Kafka Streams
Apache Kafka is used for building real-time streaming data pipelines that reliably get data between many independent systems or applications.
It allows:
Publishing and subscribing to streams of records
Storing streams of records in a fault-tolerant, durable way
It provides a unified, high-throughput, low-latency, horizontally scalable platform that is used in production in thousands of companies.
Kafka Streams being scalable, highly available and fault-tolerant, and providing the streams functionality (transformations / stateful transformations) are what we need — not to mention Kafka being a reliable and mature messaging system.
Kafka is run as a cluster on one or more servers that can span multiple datacenters spread across geographies. Those servers are usually called brokers.
Kafka uses Zookeeper to store metadata about brokers, topics and partitions.
Kafka Streams is a pretty fast, lightweight stream processing solution that works best if all of the data ingestion is coming through Apache Kafka. The ingested data is read directly from Kafka by Apache Spark for stream processing and creates Timeseries Ignite RDD (Resilient Distributed Datasets).
Apache Spark
Spark Streaming is an extension of the core Spark API that enables scalable, high-throughput, fault-tolerant stream processing of live data streams.
It provides a high-level abstraction called a discretized stream, or DStream, which represents a continuous stream of data.
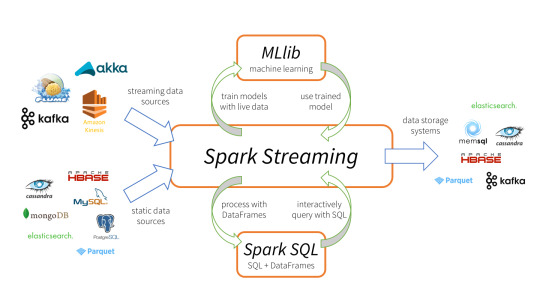
DStreams can be created either from input data streams from sources such as Kafka, Flume, and Kinesis, or by applying high-level operations on other DStreams. Internally, a DStream is represented as a sequence of RDDs (Resilient Distributed Datasets).
Apache Spark is a perfect choice in our case. This is because Spark achieves high performance for both batch and streaming data, using a state-of-the-art DAG scheduler, a query optimizer, and a physical execution engine.
In our scenario Spark streaming process Kafka data streams; create and share Ignite RDDs across Apache Ignite which is a distributed memory-centric database and caching platform.
Apache Ignite
Apache Ignite is a distributed memory-centric database and caching platform that is used by Apache Spark users to:
Achieve true in-memory performance at scale and avoid data movement from a data source to Spark workers and applications.
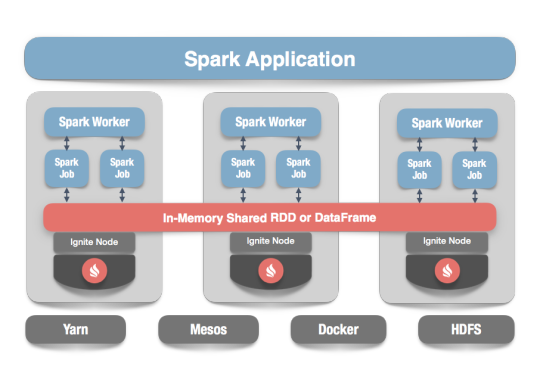
More easily share state and data among Spark jobs.
Apache Ignite is designed for transactional, analytical, and streaming workloads, delivering in-memory performance at scale. Apache Ignite provides an implementation of the Spark RDD which allows any data and state to be shared in memory as RDDs across Spark jobs. The Ignite RDD provides a shared, mutable view of the same data in-memory in Ignite across different Spark jobs, workers, or applications.
The way an Ignite RDD is implemented is as a view over a distributed Ignite table (aka. cache). It can be deployed with an Ignite node either within the Spark job executing process, on a Spark worker, or in a separate Ignite cluster. It means that depending on the chosen deployment mode the shared state may either exist only during the lifespan of a Spark application (embedded mode), or it may out-survive the Spark application (standalone mode).
With Ignite, Spark users can configure primary and secondary indexes that can bring up to 1000x performance gains.
Apache Cassandra
We will use Apache Cassandra as storage for persistence writes from Ignite.
Apache Cassandra is a highly scalable and available distributed database that facilitates and allows storing and managing high velocity structured data across multiple commodity servers without a single point of failure.
The Apache Cassandra is an extremely powerful open source distributed database system that works extremely well to handle huge volumes of records spread across multiple commodity servers. It can be easily scaled to meet sudden increase in demand, by deploying multi-node Cassandra clusters, meets high availability requirements, and there is no single point of failure.
Apache Cassandra has best write and read performance.
Characteristics of Cassandra:
It is a column-oriented database
Highly consistent, fault-tolerant, and scalable
The data model is based on Google Bigtable
The distributed design is based on Amazon Dynamo
Right off the top Cassandra does not use B-Trees to store data. Instead it uses Log Structured Merge Trees (LSM-Trees) to store its data. This data structure is very good for high write volumes, turning updates and deletes into new writes.
In our scenario we will configure Ignite to work in write-behind mode: normally, a cache write involves putting data in memory, and writing the same into the persistence source, so there will be 1-to-1 mapping between cache writes and persistence writes. With the write-behind mode, Ignite instead will batch the writes and execute them regularly at the specified frequency. This is aimed at limiting the amount of communication overhead between Ignite and the persistent store, and really makes a lot of sense if the data being written rapidly changes.
Analytics Dashboard
Since we are talking about scalability, high availability, resilience and fault-tolerance, our analytics dashboard backend should be designed in a pretty similar way we have designed the web/mobile visitor backend solution using HAProxy Load Balancer, Zuul API Gateway, Eureka Service Discovery and Spring Boot Microservices.
The requests will be routed from Analytics dashboard through microservices. Apache Spark will do processing of time series data shared in Apache Ignite as Ignite RDDs and the results will be sent across to the dashboard for visualization through microservices
0 notes
Link
Hadoop Spark Hive Big Data Admin Class Bootcamp Course NYC ##FreeCourse ##UdemyDiscount #Admin #Big #Bootcamp #Class #Data #Hadoop #Hive #NYC #Spark Hadoop Spark Hive Big Data Admin Class Bootcamp Course NYC Introduction Hadoop Big Data Course Introduction to the Course Top Ubuntu commands Understand NameNode, DataNode, YARN and Hadoop Infrastructure Hadoop Install Hadoop Installation & HDFS Commands Java based Mapreduce # Hadoop 2.7 / 2.8.4 Learn HDFS commands Setting up Java for mapreduce Intro to Cloudera Hadoop & studying Cloudera Certification SQL and NoSQL SQL, Hive and Pig Installation (RDBMS world and NoSQL world) More Hive and SQOOP (Cloudera – Sqoop and Hive on Cloudera. JDBC drivers. Pig Intro to NoSQL, MongoDB, Hbase Installation Understanding different databases Hive : Hive Partitions and Bucketing Hive External and Internal Tables Spark Scala Python Spark Installations and Commands Spark Scala Scala Sheets Hadoop Streaming Python Map Reduce PySpark – (Python – Basics). RDDs. Running Spark-shell and importing data from csv files PySpark – Running RDD Mid Term Projects Pull data from csv online and move to Hive using hive import Pull data from spark-shell and run map reduce for fox news first page Create Data in MySQL and using SQOOP move it to HDFS Using Jupyter Anaconda and Spark Context run count on file that has Fox news first page Save raw data using delimiter comma, space, tab and pipe and move that into spark-context and spark shell Broadcasting Data – stream of data Kafka Message Broadcasting Who this course is for: Carrier changes who would like to move to Big Data Hadoop Learners who want to learn Hadoop installations 👉 Activate Udemy Coupon 👈 Free Tutorials Udemy Review Real Discount Udemy Free Courses Udemy Coupon Udemy Francais Coupon Udemy gratuit Coursera and Edx ELearningFree Course Free Online Training Udemy Udemy Free Coupons Udemy Free Discount Coupons Udemy Online Course Udemy Online Training 100% FREE Udemy Discount Coupons https://www.couponudemy.com/blog/hadoop-spark-hive-big-data-admin-class-bootcamp-course-nyc/
0 notes
Text
Apache Spark : Spark Union adds up the partition of input RDDs
Apache Spark : Spark Union adds up the partition of input RDDs

Some days back when i was doing union of 2 pair rdds, i found the strange behavior for the number of partitions.
The output RDD got different number of partition than input Rdd. For ex: suppose rdd1 and rdd2, each have 2 no of partitions and after union of these rdds i was expecting same no of partitions for output RDD, but the output RDD got the no of partitions as the sum of the partitions of…
View On WordPress
0 notes
Text
Understand the process of configuring Spark Application
Apache Spark is a powerful open-source analytics engine with a distributed general-purpose cluster computing framework. Spark Application is a self-contained computation that includes a driver process and a set of executor processes. Here, the driver process runs the main() function by sitting upon a node within the cluster. Moreover, this is responsible for three things: managing information regarding the Spark application; responding to a user’s program or input; and analyzing, allocating, and planning work across the executors.
The driver process is completely essential and it’s considered as the heart of a Spark application. It also manages all pertinent information during the lifetime of the Spark application. Furthermore, the executors are mainly responsible for actually executing the work that the driver allocates them.
Furthermore, Spark application can be configured using various properties that could be set directly on a SparkConf object. And the same is passed while initializing SparkContext,More info visit:big data and hadoop online training
Spark configuration
The below mentioned are the properties & their descriptions. This can be useful to tune and fit a spark application within the Apache Spark environment. Hereunder, we will discuss the following properties with particulars and examples:
Apache Spark Application Name
Number of Apache Spark Driver Cores
Driver’s Maximum Result Size
Driver’s Memory
Executors’ Memory
Spark’s Extra Listeners
Local Directory
Log Spark Configuration
Spark Master
Deploy Mode of Spark Driver
Log App Information
Spark Driver Supervise Action
Set Spark Application Name
The below code snippet helps us to understand the setting up of “Application Name”.
import org.apache.spark.SparkConf;
import org.apache.spark.SparkContext;
/**
* Configure Apache Spark Application Name
*/
public class AppConfigureExample {
public static void main(String[] args) {
// configure spark
SparkConf conf = new SparkConf().setMaster("local[2]");
conf.set("spark.app.name", "SparkApplicationName");
// start a spark context
SparkContext sc = new SparkContext(conf);
// print the configuration
System.out.println(sc.getConf().toDebugString());
// stop the spark context
sc.stop();
}
}
Output
Besides, the result for the above program is as follows;
spark.app.id=local-1501222987079
spark.app.name=SparkApplicationName
spark.driver.host=192.168.1.100
spark.driver.port=44103
spark.executor.id=driver
spark.master=local[2]
Number of Spark Driver Cores
Here, we will check the amount of Spark driver cores;
Name of the Property: spark.driver.cores
Default value: 01
Exception: This property is considered only within-cluster mode.
Moreover, this point renders the max number of cores that a driver process may use.
The below example explains to set the number of spark driver cores.
Set Spark Driver Cores
import org.apache.spark.SparkConf;
import org.apache.spark.SparkContext;
public class AppConfigureExample {
public static void main(String[] args) {
// configure spark
SparkConf conf = new SparkConf().setMaster("local[2]");
conf.set("spark.app.name", "SparkApplicationName");
conf.set("spark.driver.cores", "2");
// start a spark context
SparkContext sc = new SparkContext(conf);
// print the configuration
System.out.println(sc.getConf().toDebugString());
// stop the spark context
sc.stop();
}
}
Output
We can see the below output for the above code given.
spark.app.id=local-1501223394277
spark.app.name=SparkApplicationName
spark.driver.cores=2
spark.driver.host=192.168.1.100
spark.driver.port=42100
spark.executor.id=driver
spark.master=local[2]
Driver’s Maximum Result Size
Here, we will go with the Driver’s result size.
Name of the property: spark.driver.maxResultSize
Default value: 1 GB
Exception: Min value 1MB
This is the maximum limit on the total sum of size of serialized results of all partitions for each Spark action. Submitted jobs will stop in case the limit exceeds. By setting it to ‘zero’ means, there is no maximum limitation here to use. But, in case the value set by the property get exceeds, out-of-memory may occur within driver. The following is an example to set Maximum limit on Spark Driver’s memory usage:
Set Maximum limit on Spark Driver's memory usage
import org.apache.spark.SparkConf;
import org.apache.spark.SparkContext;
public class AppConfigureExample {
public static void main(String[] args) {
// configure spark
SparkConf conf = new SparkConf().setMaster("local[2]");
conf.set("spark.app.name", "SparkApplicationName");
conf.set("spark.driver.maxResultSize", "200m");
// start a spark context
SparkContext sc = new SparkContext(conf);
// print the configuration
System.out.println(sc.getConf().toDebugString());
// stop the spark context
sc.stop();
}
}
Output
This is the result that we get from the input given,
spark.app.id=local-1501224103438
spark.app.name=SparkApplicationName
spark.driver.host=192.168.1.100
spark.driver.maxResultSize=200m
spark.driver.port=35249
spark.executor.id=driver
spark.master=local[2]
Driver’s Memory Usage
Property Name : spark.driver.memory
Default value: Its 1g or 1 GB
Exception: In case, the spark application is yielded in client mode, the property has to be set through the command line option –driver-memory.
The following is the maximum limit on the usage of memory by Spark Driver. Submitted tasks may abort in case the limit exceeds. Setting it to ‘Zero’ means, there is no upper limit to use memory. But, in case the value set by the property exceeds, out-of-memory may occur within the driver. The below example explains how to set the Max limit on Spark Driver’s memory usage:
Set Maximum limit on Spark Driver's memory usage
import org.apache.spark.SparkConf;
import org.apache.spark.SparkContext;
public class AppConfigureExample {
public static void main(String[] args) {
// configure spark
SparkConf conf = new SparkConf().setMaster("local[2]");
conf.set("spark.app.name", "SparkApplicationName");
conf.set("spark.driver.memory", "600m");
// start a spark context
SparkContext sc = new SparkContext(conf);
// print the configuration
System.out.println(sc.getConf().toDebugString());
// stop the spark context
sc.stop();
}
}
Output
The resulting output will be as follows.
spark.app.id=local-1501225134344
spark.app.name=SparkApplicationName
spark.driver.host=192.168.1.100
spark.driver.memory=600m
spark.driver.port=43159
spark.executor.id=driver
spark.master=local[2]
Spark executor memory
Within every spark application there exist the same fixed stack size and a fixed number of cores for a spark executor also. The stack size refers to the Spark executor memory and the same is controlled with the spark.executor.memory property under the –executor-memory flag. Moreover, each spark application includes a single executor on each worker node. The executor memory is generally an estimate on how much memory of the worker node may the application will use.
Spark Extra Listeners
Users can utilize extra listeners by setting them under the spark.extraListeners property. The spark.extraListeners property is a comma-separated list of classes that deploy SparkListener. While starting SparkContext, instances of these classes will be developed and registered with Spark's listener bus (SLB).
In addition, to add extra listeners to the Spark application, users have the option to set this property during the usage of the spark-submit command. An example of it is:
./bin/spark-submit --conf spark.extraListereners <Comma-separated list of listener classes>
Local Directory
The directory useful for "scratch" space in the Spark application includes map output files and RDDs that stored on the disk. Moreover, this should be on a fast, local disk within the user’s system. This could be also a comma-separated (CSV) list of various directories on multiple disks.
Log Spark Configuration
In Spark configuration, “Logs” are the effective SparkConf as INFO while a SparkContext starts.
Spark Master
In this, the master URL has to use for the cluster connection purpose.
Deploy Mode of Spark Driver
The deploy mode of the Spark driver program within the Spark Application configuration, either client or cluster. This means to launch/start the driver program locally ("client") or remotely upon one of the nodes within the cluster.
There are two final steps in this regard namely; Log App Information and Spark Driver Supervise Action. These include logging in the info of the application while configuring and supervising the driver’s action.
Thus, in short, we can say that the whole process starts with a Spark Driver. Here, the Spark driver is accountable for changing a user program into units of physical performance known as tasks. At a high level, all the Spark programs follow a similar structure to perform well. Moreover, they built RDDs from some input to obtain new RDDs from those using transformations. And they execute actions to gather or save data. A Spark program completely builds a logical directed acyclic graph (DAG) of operations/processes.
Bottom Line
I hope you got the basic idea of the process of configuring Spark Application. This may help you to understand the further process easily with advanced options. Get more insights from big data online training
0 notes
Text
Spark foreachPartition vs foreach explained
Spark foreachPartition vs foreach explained
In Spark foreachPartition() is used when you have a heavy initialization (like database connection) and wanted to initialize once per partition where as foreach() is used to apply a function on every element of a RDD/DataFrame/Dataset partition.
In this Spark Dataframe article, you will learn what is foreachPartiton used for and the differences with its sibling foreach (foreachPartiton vs…
View On WordPress
0 notes
Text
8 Performance Optimization Techniques Using Spark
Due to its fast, easy-to-use capabilities, Apache Spark helps to Enterprises process data faster, solving complex data problems quickly.
We all know that during the development of any program, taking care of the performance is equally important. A Spark job can be optimized by many techniques so let’s dig deeper into those techniques one by one. Apache Spark optimization helps with in-memory data computations. The bottleneck for these spark optimization computations can be CPU, memory or any resource in the cluster.
1. Serialization
Serialization plays an important role in the performance for any distributed application. By default, Spark uses Java serializer.
Spark can also use another serializer called ‘Kryo’ serializer for better performance.
Kryo serializer is in compact binary format and offers processing 10x faster than Java serializer.
To set the serializer properties:
conf.set(“spark.serializer”, “org.apache.spark.serializer.KryoSerializer”)
Code:
val conf = new SparkConf().setMaster(…).setAppName(…)
conf.registerKryoClasses(Array(classOf[MyClass1], classOf[MyClass2]))
val sc = new SparkContext(conf)
Serialization plays an important role in the performance of any distributed application and we know that by default Spark uses the Java serializer on the JVM platform. Instead of Java serializer, Spark can also use another serializer called Kryo. The Kryo serializer gives better performance as compared to the Java serializer.
Kryo serializer is in a compact binary format and offers approximately 10 times faster speed as compared to the Java Serializer. To set the Kryo serializer as part of a Spark job, we need to set a configuration property, which is org.apache.spark.serializer.KryoSerializer.
2. API selection
Spark introduced three types of API to work upon – RDD, DataFrame, DataSet
RDD is used for low level operation with less optimization
DataFrame is best choice in most cases due to its catalyst optimizer and low garbage collection (GC) overhead.
Dataset is highly type safe and use encoders. It uses Tungsten for serialization in binary format.
We know that Spark comes with 3 types of API to work upon -RDD, DataFrame and DataSet.
RDD is used for low-level operations and has less optimization techniques.
DataFrame is the best choice in most cases because DataFrame uses the catalyst optimizer which creates a query plan resulting in better performance. DataFrame also generates low labor garbage collection overhead.
DataSets are highly type safe and use the encoder as part of their serialization. It also uses Tungsten for the serializer in binary format.
Code:
val df = spark.read.json(“examples/src/main/resources/people.json”)
case class Person(name: String, age: Long)
// Encoders are created for case classes
val caseClassDS = Seq(Person(“Andy”, 32)).toDS()
// Encoders for most common types are automatically provided by importing spark.implicits._
val primitiveDS = Seq(1, 2, 3).toDS()
primitiveDS.map(_ + 1).collect() // Returns: Array(2, 3, 4)
// DataFrames can be converted to a Dataset by providing a class. Mapping will be done by name
val path = “examples/src/main/resources/people.json”
val peopleDS = spark.read.json(path).as[Person]
3. Advance Variable
Broadcasting plays an important role while tuning Spark jobs.
Broadcast variable will make small datasets available on nodes locally.
When you have one dataset which is smaller than other dataset, Broadcast join is highly recommended.
To use the Broadcast join: (df1. join(broadcast(df2)))
Spark comes with 2 types of advanced variables – Broadcast and Accumulator.
Broadcasting plays an important role while tuning your spark job. Broadcast variable will make your small data set available on each node, and that node and data will be treated locally for the process.
Want more?
Subscribe to receive articles on topics of your interest, straight to your inbox.
Success!
First Name
Last Name
Email
Subscribe
Suppose you have a situation where one data set is very small and another data set is quite large, and you want to perform the join operation between these two. In that case, we should go for the broadcast join so that the small data set can fit into your broadcast variable. The syntax to use the broadcast variable is df1.join(broadcast(df2)). Here we have a second dataframe that is very small and we are keeping this data frame as a broadcast variable.
Code:
val broadcastVar = sc.broadcast(Array(1, 2, 3))
broadcastVar.value
res0: Array[Int] = Array(1, 2, 3)
val accum = sc.longAccumulator(“My Accumulator”)
sc.parallelize(Array(1, 2, 3, 4)).foreach(x => accum.add(x))
accum.value
res2: Long = 10
4. Cache and Persist
Spark provides its own caching mechanisms like persist() and cache().
cache() and persist() will store the dataset in memory.
When you have a small dataset which needs be used multiple times in your program, we cache that dataset.
Cache() – Always in Memory
Persist() – Memory and disks
Spark provides its own caching mechanism like Persist and Caching. Persist and Cache mechanisms will store the data set into the memory whenever there is requirement, where you have a small data set and that data set is being used multiple times in your program. If we apply RDD.Cache() it will always store the data in memory, and if we apply RDD.Persist() then some part of data can be stored into the memory some can be stored on the disk.
5. ByKey Operation
Shuffles are heavy operation which consume a lot of memory.
While coding in Spark, the user should always try to avoid shuffle operation.
High shuffling may give rise to an OutOfMemory Error; To avoid such an error, the user can increase the level of parallelism.
Use reduceByKey instead of groupByKey.
Partition the data correctly.
As we know during our transformation of Spark we have many ByKey operations. ByKey operations generate lot of shuffle. Shuffles are heavy operation because they consume a lot of memory. While coding in Spark, a user should always try to avoid any shuffle operation because the shuffle operation will degrade the performance. If there is high shuffling then a user can get the error out of memory. Inthis case, to avoid that error, a user should increase the level of parallelism. Instead of groupBy, a user should go for the reduceByKey because groupByKey creates a lot of shuffling which hampers the performance, while reduceByKey does not shuffle the data as much. Therefore, reduceByKey is faster as compared to groupByKey. Whenever any ByKey operation is used, the user should partition the data correctly.
6. File Format selection
Spark supports many formats, such as CSV, JSON, XML, PARQUET, ORC, AVRO, etc.
Spark jobs can be optimized by choosing the parquet file with snappy compression which gives the high performance and best analysis.
Parquet file is native to Spark which carries the metadata along with its footer.
Spark comes with many file formats like CSV, JSON, XML, PARQUET, ORC, AVRO and more. A Spark job can be optimized by choosing the parquet file with snappy compression. Parquet file is native to Spark which carry the metadata along with its footer as we know parquet file is native to spark which is into the binary format and along with the data it also carry the footer it’s also carries the metadata and its footer so whenever you create any parquet file, you will see .metadata file on the same directory along with the data file.
Code:
val peopleDF = spark.read.json(“examples/src/main/resources/people.json”)
peopleDF.write.parquet(“people.parquet”)
val parquetFileDF = spark.read.parquet(“people.parquet”)
val usersDF = spark.read.format(“avro”).load(“examples/src/main/resources/users.avro”)
usersDF.select(“name”, “favorite_color”).write.format(“avro”).save(“namesAndFavColors.avro”)
7. Garbage Collection Tuning
JVM garbage collection can be a problem when you have large collection of unused objects.
The first step in GC tuning is to collect statistics by choosing – verbose while submitting spark jobs.
In an ideal situation we try to keep GC overheads < 10% of heap memory.
As we know underneath our Spark job is running on the JVM platform so JVM garbage collection can be a problematic when you have a large collection of an unused object so the first step in tuning of garbage collection is to collect statics by choosing the option in your Spark submit verbose. Generally, in an ideal situation we should keep our garbage collection memory less than 10% of heap memory.
8. Level of Parallelism
Parallelism plays a very important role while tuning spark jobs.
Every partition ~ task requires a single core for processing.
There are two ways to maintain the parallelism:
Repartition: Gives equal number of partitions with high shuffling
Coalesce: Generally reduces the number of partitions with less shuffling.
In any distributed environment parallelism plays very important role while tuning your Spark job. Whenever a Spark job is submitted, it creates the desk that will contain stages, and the tasks depend upon partition so every partition or task requires a single core of the system for processing. There are two ways to maintain the parallelism – Repartition and Coalesce. Whenever you apply the Repartition method it gives you equal number of partitions but it will shuffle a lot so it is not advisable to go for Repartition when you want to lash all the data. Coalesce will generally reduce the number of partitions and creates less shuffling of data.
These factors for spark optimization, if properly used, can –
Eliminate the long-running job process
Correction execution engine
Improve performance time by managing resources
For more information and if you have any additional questions, please feel free to reach out to our Spark experts at Syntelli.
SIMILAR POSTS
How Predictive Analytics in Finance Can Accelerate Data-Driven Enterprise Transformation
As the U.S. economy faces unprecedented challenges, predictive analytics in financial services is necessary to accommodate customers’ immediate needs while preparing for future changes. These future changes may amount to enterprise transformation, a fundamental...
read more
7 Reasons to Start Using Customer Intelligence in Your Healthcare Organization
Healthcare organizations face an array of challenges regarding customer communication and retention. Customer intelligence can be a game-changer for small and large organizations due to its ability to understand customer needs and preferences. When it comes to data,...
read more
The Future of Analytics in Higher Education with Artificial Intelligence
The future is sooner than you would have expected – it is now. Contrary to concerns about Artificial Intelligence (AI) in everyday activities, ethical AI can enhance a balanced, accessible, scalable, and inclusive learning system. With the increasingly limited...
read more
The post 8 Performance Optimization Techniques Using Spark appeared first on Syntelli Solutions Inc..
https://www.syntelli.com/eight-performance-optimization-techniques-using-spark
0 notes
Text
February 11, 2020 at 10:00PM - The Big Data Bundle (93% discount) Ashraf
The Big Data Bundle (93% discount) Hurry Offer Only Last For HoursSometime. Don't ever forget to share this post on Your Social media to be the first to tell your firends. This is not a fake stuff its real.
Hive is a Big Data processing tool that helps you leverage the power of distributed computing and Hadoop for analytical processing. Its interface is somewhat similar to SQL, but with some key differences. This course is an end-to-end guide to using Hive and connecting the dots to SQL. It’s perfect for both professional and aspiring data analysts and engineers alike. Don’t know SQL? No problem, there’s a primer included in this course!
Access 86 lectures & 15 hours of content 24/7
Write complex analytical queries on data in Hive & uncover insights
Leverage ideas of partitioning & bucketing to optimize queries in Hive
Customize Hive w/ user defined functions in Java & Python
Understand what goes on under the hood of Hive w/ HDFS & MapReduce
Big Data sounds pretty daunting doesn’t it? Well, this course aims to make it a lot simpler for you. Using Hadoop and MapReduce, you’ll learn how to process and manage enormous amounts of data efficiently. Any company that collects mass amounts of data, from startups to Fortune 500, need people fluent in Hadoop and MapReduce, making this course a must for anybody interested in data science.
Access 71 lectures & 13 hours of content 24/7
Set up your own Hadoop cluster using virtual machines (VMs) & the Cloud
Understand HDFS, MapReduce & YARN & their interaction
Use MapReduce to recommend friends in a social network, build search engines & generate bigrams
Chain multiple MapReduce jobs together
Write your own customized partitioner
Learn to globally sort a large amount of data by sampling input files
Analysts and data scientists typically have to work with several systems to effectively manage mass sets of data. Spark, on the other hand, provides you a single engine to explore and work with large amounts of data, run machine learning algorithms, and perform many other functions in a single interactive environment. This course’s focus on new and innovating technologies in data science and machine learning makes it an excellent one for anyone who wants to work in the lucrative, growing field of Big Data.
Access 52 lectures & 8 hours of content 24/7
Use Spark for a variety of analytics & machine learning tasks
Implement complex algorithms like PageRank & Music Recommendations
Work w/ a variety of datasets from airline delays to Twitter, web graphs, & product ratings
Employ all the different features & libraries of Spark, like RDDs, Dataframes, Spark SQL, MLlib, Spark Streaming & GraphX
The functional programming nature and the availability of a REPL environment make Scala particularly well suited for a distributed computing framework like Spark. Using these two technologies in tandem can allow you to effectively analyze and explore data in an interactive environment with extremely fast feedback. This course will teach you how to best combine Spark and Scala, making it perfect for aspiring data analysts and Big Data engineers.
Access 51 lectures & 8.5 hours of content 24/7
Use Spark for a variety of analytics & machine learning tasks
Understand functional programming constructs in Scala
Implement complex algorithms like PageRank & Music Recommendations
Work w/ a variety of datasets from airline delays to Twitter, web graphs, & Product Ratings
Use the different features & libraries of Spark, like RDDs, Dataframes, Spark SQL, MLlib, Spark Streaming, & GraphX
Write code in Scala REPL environments & build Scala applications w/ an IDE
For Big Data engineers and data analysts, HBase is an extremely effective databasing tool for organizing and manage massive data sets. HBase allows an increased level of flexibility, providing column oriented storage, no fixed schema and low latency to accommodate the dynamically changing needs of applications. With the 25 examples contained in this course, you’ll get a complete grasp of HBase that you can leverage in interviews for Big Data positions.
Access 41 lectures & 4.5 hours of content 24/7
Set up a database for your application using HBase
Integrate HBase w/ MapReduce for data processing tasks
Create tables, insert, read & delete data from HBase
Get a complete understanding of HBase & its role in the Hadoop ecosystem
Explore CRUD operations in the shell, & with the Java API
Think about the last time you saw a completely unorganized spreadsheet. Now imagine that spreadsheet was 100,000 times larger. Mind-boggling, right? That’s why there’s Pig. Pig works with unstructured data to wrestle it into a more palatable form that can be stored in a data warehouse for reporting and analysis. With the massive sets of disorganized data many companies are working with today, people who can work with Pig are in major demand. By the end of this course, you could qualify as one of those people.
Access 34 lectures & 5 hours of content 24/7
Clean up server logs using Pig
Work w/ unstructured data to extract information, transform it, & store it in a usable form
Write intermediate level Pig scripts to munge data
Optimize Pig operations to work on large data sets
Data sets can outgrow traditional databases, much like children outgrow clothes. Unlike, children’s growth patterns, however, massive amounts of data can be extremely unpredictable and unstructured. For Big Data, the Cassandra distributed database is the solution, using partitioning and replication to ensure that your data is structured and available even when nodes in a cluster go down. Children, you’re on your own.
Access 44 lectures & 5.5 hours of content 24/7
Set up & manage a cluster using the Cassandra Cluster Manager (CCM)
Create keyspaces, column families, & perform CRUD operations using the Cassandra Query Language (CQL)
Design primary keys & secondary indexes, & learn partitioning & clustering keys
Understand restrictions on queries based on primary & secondary key design
Discover tunable consistency using quorum & local quorum
Learn architecture & storage components: Commit Log, MemTable, SSTables, Bloom Filters, Index File, Summary File & Data File
Build a Miniature Catalog Management System using the Cassandra Java driver
Working with Big Data, obviously, can be a very complex task. That’s why it’s important to master Oozie. Oozie makes managing a multitude of jobs at different time schedules, and managing entire data pipelines significantly easier as long as you know the right configurations parameters. This course will teach you how to best determine those parameters, so your workflow will be significantly streamlined.
Access 23 lectures & 3 hours of content 24/7
Install & set up Oozie
Configure Workflows to run jobs on Hadoop
Create time-triggered & data-triggered Workflows
Build & optimize data pipelines using Bundles
Flume and Sqoop are important elements of the Hadoop ecosystem, transporting data from sources like local file systems to data stores. This is an essential component to organizing and effectively managing Big Data, making Flume and Sqoop great skills to set you apart from other data analysts.
Access 16 lectures & 2 hours of content 24/7
Use Flume to ingest data to HDFS & HBase
Optimize Sqoop to import data from MySQL to HDFS & Hive
Ingest data from a variety of sources including HTTP, Twitter & MySQL
from Active Sales – SharewareOnSale https://ift.tt/2qeN7bl https://ift.tt/eA8V8J via Blogger https://ift.tt/37kIn4G #blogger #bloggingtips #bloggerlife #bloggersgetsocial #ontheblog #writersofinstagram #writingprompt #instapoetry #writerscommunity #writersofig #writersblock #writerlife #writtenword #instawriters #spilledink #wordgasm #creativewriting #poetsofinstagram #blackoutpoetry #poetsofig
0 notes
Text
Spark Actions
Overview
In our Apache Spark tutorial journey, we have learnt how to create Spark RDD using Java, Spark Transformations. In this article, we are going to explain Spark Actions. Spark Actions are another type of operations which returns final values to Driver program or writes the data to external system.
You can find all the Java files of this article at our Git repository.
1.1 count()
count is an action which returns number of elements in the RDD, usually it is used to get an idea of RDD size before performing any operation on RDD.
JavaRDD<String> likes = javaSparkContext.parallelize(Arrays.asList("Java")); JavaRDD<String> learn = javaSparkContext.parallelize(Arrays.asList("Spark","Scala")); JavaRDD<String> likeToLearn = likes.union(learn); //Learning::2 System.out.println("Learning::"+learn.count());
1.2 collect()
we can use collect action to retrieve the entire RDD. This can be useful if your program filters RDDs down to a very small size and you’d like to deal with it locally.
Note:
Keep in mind that your entire dataset must fit in memory on a single machine to use collect() on it, so collect() shouldn’t be used on large datasets.
reusing the above example, we can print the likeToLearn RDD elements in system console using collect action like,
List<String> result = likeToLearn.collect(); //Prints I like [Java, Spark, Scala] System.out.println("I like "+result.toString());
Now, moving forward we want continue the example by adding few other skills in our skillset.
We can use below snippet to add new learning skills in our learn RDD.
String[] newlyLearningSkills = {"Elastic Search","Spring Boot"}; JavaRDD<String> learningSkills = learn.union(javaSparkContext.parallelize(Arrays.asList(newlyLearningSkills))); //learningSkills::[Spark, Scala, Elastic Search, Spring Boot] System.out.print("learningSkills::"+learningSkills.collect().toString());
Here, we are using union to add new skills in learn RDD, so as a result we can get new RDD i.e learningSkills RDD.
1.3 take(n)
we can use take spark action to retrieve a small number of elements in the RDD at the driver program. We then iterate over them locally to print out information at the driver.
countinuing our example, now we have added new skills and as a result we do have learningSkills Spark RDD.
Now, If we call take action on learningSkills RDD like,
List<String> learning4Skills = learningSkills.take(4); //Learning 4 Skills::[Spark, Scala, Elastic Search, Spring Boot] System.out.println("Learning 4 Skills::"+learning4Skills.toString());
We will get 4 different skills from learningSkills RDD.
1.4 top(n)
Spark top action returns top(n) elements from RDD. In order to get top 2 learning skills from our learningSkills RDD, we can call top(2) action like,
List<String> learningTop2Skills = learningSkills.top(2); //Learning top 2 Skills::[Spring Boot, Spark] System.out.println("Learning top 2 Skills::"+learningTop2Skills.toString());
So, as a result we will get new RDD i.e learningTop2Skills and we can print the top 2 learning skills as shown in code snippet.
Note: Here, we have not defined any ordering, so it uses default ordering. we can use
public static java.util.List<T> top(int num,java.util.Comparator<T> comp) method for specifying custom Comparator while using top action.
1.5 countByValue()
countByValue Spark action returns occurence of each element in the given RDD.
so, in case, if we call countByValue action on learningSkills RDD, It will return a Map<String,Long>where each element is stored as Key in Map and Value represents its count.
Map<String,Long> skillCountMap= learningSkills.countByValue(); for(Map.Entry<String,Long> entry: skillCountMap.entrySet()){ System.out.println("key::"+entry.getKey()+"\t"+"value:"+entry.getValue()); }
Output
key::Scala value:1 key::Spark value:1 key::Elastic Search value:1 key::Spring Boot value:1
1.6 reduce()
The reduce action takes two elments as input and it returns one element as output. The output element must be of same type as input element. The simple example of such function is an addition function. We can add the elements of RDD, count the number of words. reduce action accepts commutative and associative operations as an argument.
So in our case lets take a list of integers and add them using reduce action as shown below.
The result will be sum of all the integers i.e 21.
JavaRDD<Integer> intRdd = javaSparkContext.parallelize(Arrays.asList(1,2,3,4,5,6)); Integer result = intRdd.reduce((v1, v2) -> v1+v2); System.out.println("result::"+result);
1.7 fold()
Spark fold action is similar to reduce action, apart from that it takes “Zero value” as input, so “Zero Value” is used for the initial call on each partition.
Note: Zero value is that it should be the identity element of that operation i.e 0 for Sum, 1 for Multiplication and division, empty list for concatenation etc.
Key Difference: The key difference between fold() and reduce() is that, reduce() throws an exception for empty collection, but fold() is defined for empty collection.
Return type : The return type of fold() is same as that of the element of RDD we are operating on.
ProTip: You can minimize object creation in fold() by modifying and returning the first of the two parameters in place. However, you should not modify the second parameter.
JavaRDD<Integer> intRdd = javaSparkContext.parallelize(Arrays.asList(1,2,3,4,5,6)); Integer foldResult = intRdd.fold(0,((v1, v2) -> (v1+v2))); System.out.println("Fold result::"+foldResult);
1.8 aggregate()
fold() and reduce() spark actions works well for operations where we are returning the same return type as RDD type, but many times we want to return a different type.
For example, when computing a running average, we need to keep track of both the count so far and the number of elements, which requires us to return a pair. We could work around this by first using map() where we transform every element into the element and the number 1, which is the type we want to return, so that the reduce() function can work on pairs.
The aggregate() function frees us from the constraint of having the return be the same type as the RDD we are working on.
Input: With aggregate() spark action like fold(), we have to supply,
An initial zero value of the type we want to return.
A function to combine the elements from our RDD with the accumulator.
We need to supply a second function to merge two accumulators, given that each node accumulates its own results locally.
We can use aggregate() to compute the average of an RDD, avoiding a map() before the fold().
For better explaination of aggregate spark action, lets consider an example where we are interested in calculating moving average of integer numbers,
So following code will calculate the moving average of integers from 1 to 10.
You can find the complete example of the Aggregate spark action at our git repository.
JavaRDD<Integer> intRDD = javaSparkContext.parallelize(Arrays.asList(1,2,3,4,5,6,7,8,9,10)); Function2<AverageCount, Integer, AverageCount> addAndCount = new Function2<AverageCount, Integer, AverageCount>() { public AverageCount call(AverageCount a, Integer x) { a.total += x; a.num += 1; return a; } }; Function2<AverageCount, AverageCount, AverageCount> combine = new Function2<AverageCount, AverageCount, AverageCount>() { public AverageCount call(AverageCount a, AverageCount b) { a.total += b.total; a.num += b.num; return a; } }; AverageCount initial = new AverageCount(0, 0); AverageCount currentMovingAverage = intRDD.aggregate(initial, addAndCount, combine); System.out.println("Moving Average:"+currentMovingAverage.avg());
Now, if you run this code, you will get moving average as 5.5, lets add another 3 values, i.e 11,12,13 using following snippet.
JavaRDD<Integer> anotherIntRDD = javaSparkContext.parallelize(Arrays.asList(11,12,13)); JavaRDD<Integer> resultantRDD = intRDD.union(anotherIntRDD); AverageCount newMovingAverage = resultantRDD.aggregate(initial, addAndCount, combine); System.out.println("Changed Moving Average:"+newMovingAverage.avg());
Now if you run the program, you will get the changed moving average i.e 7.
1.9 foreach()
When we have a situation where we want to apply operation on each element of RDD, but it should not return value to the driver. In this case, foreach() function is useful. A good example of this would be posting JSON to a webserver or inserting records into a database. In either case, the foreach() action lets us perform computations on each element in the RDD without bringing it back locally.
In our case we are simply printing each element of our previously derived RDD i.e learningSkills RDD.
So we can use following line to print all the elements of learningSkills RDD.
learningSkills.foreach(element -> System.out.println(element));
1.10 saveAsTextFile()
Outputting text files is also quite simple. The method saveAsTextFile(), we have already demonstrated in our passing function to spark example, This spark action takes a path and will output the contents of the RDD to that file. The path is treated as a directory and Spark will output multiple files underneath that directory. This allows Spark to write the output from multiple nodes. With this method we don’t get to control which files end up with which segments of our data, but there are other output formats that do allow this.
we have used following code snippet to save the RDDs to textFiles.
adultMinorCountsRDD.saveAsTextFile(args[1]); aggregatedFamilyPairsRDD.saveAsTextFile(args[2]);
2. API & References
We have used Spark API for Java for writing this article, you can find complete John Party problem solution at our Git repository.
3. Conclusion
Apache Spark computes the result when it encounters a Spark Action. Thus, this lazy evaluation decreases the overhead of computation and make the system more efficient. If you have any query about Spark Actions, feel free to share with us. We will be happy to solve them.
0 notes
Text
Understanding Apache Spark Map transformation
Understanding Apache Spark Map transformation
Understanding Spark RDD’s Map transformation Map() function in Apache Spark. In this post we will talk about the RDD Map transformation in Apache Spark. RDD ( Resilient Distributed Dataset ) is the most basic building block in Apache Spark. RDD is a collection of objects that is partitioned and distributed across nodes in a cluster As per Apache Spark documentation, map(func) transformation…

View On WordPress
0 notes