#sql cordoba
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
The Tumblr office adopted Tommy, an 11-year-old Pomeranian.
Text
[Fabric] Leer PowerBi data con Notebooks - Semantic Link
El nombre del artículo puede sonar extraño puesto que va en contra del flujo de datos que muchos arquitectos pueden pensar para el desarrollo de soluciones. Sin embargo, las puertas a nuevos modos de conectividad entre herramientas y conjuntos de datos pueden ayudarnos a encontrar nuevos modos que fortalezcan los análisis de datos.
En este post vamos a mostrar dos sencillos modos que tenemos para leer datos de un Power Bi Semantic Model desde un Fabric Notebook con Python y SQL.
¿Qué son los Semantic Links? (vínculo semántico)
Como nos gusta hacer aquí en LaDataWeb, comencemos con un poco de teoría de la fuente directa.
Definición Microsoft: Vínculo semántico es una característica que permite establecer una conexión entre modelos semánticos y Ciencia de datos de Synapse en Microsoft Fabric. El uso del vínculo semántico solo se admite en Microsoft Fabric.
Dicho en criollo, nos facilita la conectividad de datos para simplificar el acceso a información. Si bién Microsoft lo enfoca como una herramienta para Científicos de datos, no veo porque no puede ser usada por cualquier perfil que tenga en mente la resolución de un problema leyendo datos limpios de un modelo semántico.
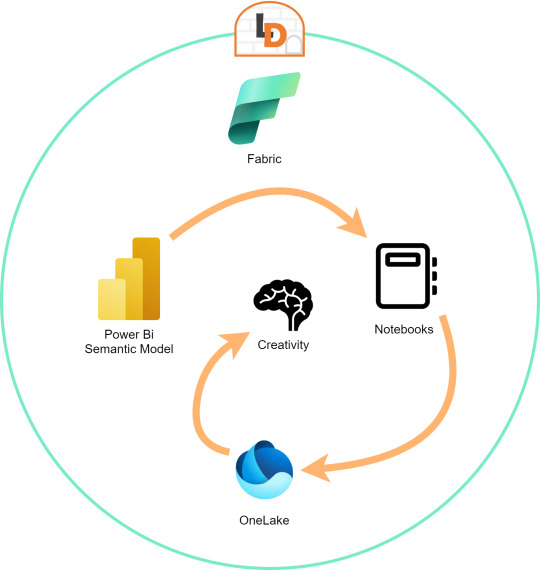
El límite será nuestra creatividad para resolver problemas que se nos presenten para responder o construir entorno a la lectura de estos modelos con notebooks que podrían luego volver a almacenarse en Onelake con un nuevo procesamiento enfocado en la solución.
Semantic Links ofrecen conectividad de datos con el ecosistema de Pandas de Python a través de la biblioteca de Python SemPy. SemPy proporciona funcionalidades que incluyen la recuperación de datos de tablas , cálculo de medidas y ejecución de consultas DAX y metadatos.
Para usar la librería primero necesitamos instalarla:
%pip install semantic-link
Lo primero que podríamos hacer es ver los modelos disponibles:
import sempy.fabric as fabric df_datasets = fabric.list_datasets()
Entrando en más detalle, también podemos listar las tablas de un modelo:
df_tables = fabric.list_tables("Nombre Modelo Semantico", include_columns=True)
Cuando ya estemos seguros de lo que necesitamos, podemos leer una tabla puntual:
df_table = fabric.read_table("Nombre Modelo Semantico", "Nombre Tabla")
Esto genera un FabricDataFrame con el cual podemos trabajar libremente.
Nota: FabricDataFrame es la estructura de datos principal de vínculo semántico. Realiza subclases de DataFrame de Pandas y agrega metadatos, como información semántica y linaje
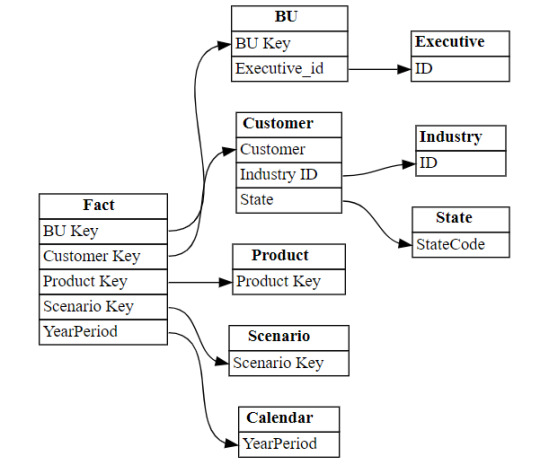
Existen varias funciones que podemos investigar usando la librería. Una de las favoritas es la que nos permite entender las relaciones entre tablas. Podemos obtenerlas y luego usar otro apartado de la librería para plotearlo:
from sempy.relationships import plot_relationship_metadata relationships = fabric.list_relationships("Nombre Modelo Semantico") plot_relationship_metadata(relationships)
Un ejemplo de la respuesta:
Conector Nativo Semantic Link Spark
Adicional a la librería de Python para trabajar con Pandas, la característica nos trae un conector nativo para usar con Spark. El mismo permite a los usuarios de Spark acceder a las tablas y medidas de Power BI. El conector es independiente del lenguaje y admite PySpark, Spark SQL, R y Scala. Veamos lo simple que es usarlo:
spark.conf.set("spark.sql.catalog.pbi", "com.microsoft.azure.synapse.ml.powerbi.PowerBICatalog")
Basta con especificar esa línea para pronto nutrirnos de clásico SQL. Listamos tablas de un modelo:
%%sql SHOW TABLES FROM pbi.`Nombre Modelo Semantico`
Consulta a una tabla puntual:
%%sql SELECT * FROM pbi.`Nombre Modelo Semantico`.NombreTabla
Así de simple podemos ejecutar SparkSQL para consultar el modelo. En este caso es importante la participación del caracter " ` " comilla invertida que nos ayuda a leer espacios y otros caracteres.
Exploración con DAX
Como un tercer modo de lectura de datos incorporaron la lectura basada en DAX. Esta puede ayudarnos de distintas maneras, por ejemplo guardando en nuestro FabricDataFrame el resultado de una consulta:
df_dax = fabric.evaluate_dax( "Nombre Modelo Semantico", """ EVALUATE SUMMARIZECOLUMNS( 'State'[Region], 'Calendar'[Year], 'Calendar'[Month], "Total Revenue" , CALCULATE([Total Revenue] ) ) """ )
Otra manera es utilizando DAX puramente para consultar al igual que lo haríamos con SQL. Para ello, Fabric incorporó una nueva y poderosa etiqueta que lo facilita. Delimitación de celdas tipo "%%dax":
%%dax "Nombre Modelo Semantico" -w "Area de Trabajo" EVALUATE SUMMARIZECOLUMNS( 'State'[Region], 'Calendar'[Year], 'Calendar'[Month], "Total Revenue" , CALCULATE([Total Revenue] ) )
Hasta aquí llegamos con esos tres modos de leer datos de un Power Bi Semantic Model utilizando Fabric Notebooks. Espero que esto les revuelva la cabeza para redescubrir soluciones a problemas con un nuevo enfoque.
#fabric#fabric tips#fabric tutorial#fabric training#fabric notebooks#python#pandas#spark#power bi#powerbi#fabric argentina#fabric cordoba#fabric jujuy#ladataweb#microsoft fabric#SQL#dax
0 notes
Text
Tweeted
Long exposure sunset at Reartes riverside. Location: Los Reartes -Cordoba, Argentina [OC] [4898 X 3265] via https://t.co/B8iD67aQMR pic.twitter.com/TBGQEgoU52
— SQL Joker (@sql_joker) March 13, 2018
0 notes
Text
[Fabric] Entre Archivos y Tablas de Lakehouse - SQL Notebooks
Ya conocemos un panorama de Fabric y por donde empezar. La Data Web nos mostró unos artículos sobre esto. Mientras más veo Fabric más sorprendido estoy sobre la capacidad SaaS y low code que generaron para todas sus estapas de proyecto.
Un ejemplo sobre la sencillez fue copiar datos con Data Factory. En este artículo veremos otro ejemplo para que fanáticos de SQL puedan trabajar en ingeniería de datos o modelado dimensional desde un notebook.
Arquitectura Medallón
Si nunca escuchaste hablar de ella te sugiero que pronto leas. La arquitectura es una metodología que describe una capas de datos que denotan la calidad de los datos almacenados en el lakehouse. Las capas son carpetas jerárquicas que nos permiten determinar un orden en el ciclo de vida del datos y su proceso de transformaciones.
Los términos bronce (sin procesar), plata (validado) y oro (enriquecido/agrupado) describen la calidad de los datos en cada una de estas capas.
Ésta metodología es una referencia o modo de trabajo que puede tener sus variaciones dependiendo del negocio. Por ejemplo, en un escenario sencillo de pocos datos, probablemente no usaríamos gold, sino que luego de dejar validados los datos en silver podríamos construir el modelado dimensional directamente en el paso a "Tablas" de Lakehouse de Fabric.
NOTAS: Recordemos que "Tablas" en Lakehouse es un spark catalog también conocido como Metastore que esta directamente vinculado con SQL Endpoint y un PowerBi Dataset que viene por defecto.
¿Qué son los notebooks de Fabric?
Microsoft los define como: "un elemento de código principal para desarrollar trabajos de Apache Spark y experimentos de aprendizaje automático, es una superficie interactiva basada en web que usan los científicos de datos e ingenieros de datos para escribir un código que se beneficie de visualizaciones enriquecidas y texto en Markdown."
Dicho de manera más sencilla, es un espacio que nos permite ejecutar bloques de código spark que puede ser automatizado. Hoy por hoy es una de las formas más populares para hacer transformaciones y limpieza de datos.
Luego de crear un notebook (dentro de servicio data engineering o data science) podemos abrir en el panel izquierdo un Lakehouse para tener referencia de la estructura en la cual estamos trabajando y el tipo de Spark deseado.
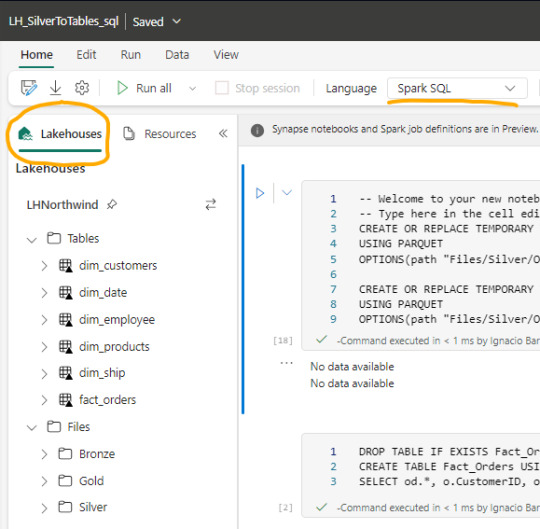
Spark
Spark se ha convertido en el indiscutible lenguaje de lectura de datos en un lake. Así como SQL lo fue por años sobre un motor de base de datos, ahora Spark lo es para Lakehouse. Lo bueno de spark es que permite usar más de un lenguaje según nuestro comodidad.

Creo que es inegable que python está ocupando un lugar privilegiado junto a SQL que ha ganado suficiente popularidad como para encontrarse con ingenieros de datos que no conocen SQL pero son increíbles desarrolladores en python. En este artículo quiero enfocarlo en SQL puesto que lo más frecuente de uso es Python y podríamos charlar de SQL para aportar a perfiles más antiguos como DBAs o Data Analysts que trabajaron con herramientas de diseño y Bases de Datos.
Lectura de archivos de Lakehouse con SQL
Lo primero que debemos saber es que para trabajar en comodidad con notebooks, creamos tablas temporales que nacen de un esquema especificado al momento de leer la información. Para el ejemplo veremos dos escenarios, una tabla Customers con un archivo parquet y una tabla Orders que fue particionada por año en distintos archivos parquet según el año.
CREATE OR REPLACE TEMPORARY VIEW Dim_Customers_Temp USING PARQUET OPTIONS ( path "Files/Silver/Customers/*.parquet", header "true", mode "FAILFAST" ) ;
CREATE OR REPLACE TEMPORARY VIEW Orders USING PARQUET OPTIONS ( path "Files/Silver/Orders/Year=*", header "true", mode "FAILFAST" ) ;
Vean como delimitamos la tabla temporal, especificando el formato parquet y una dirección super sencilla de Files. El "*" nos ayuda a leer todos los archivos de una carpeta o inclusive parte del nombre de las carpetas que componen los archivos. Para el caso de orders tengo carpetas "Year=1998" que podemos leerlas juntas reemplazando el año por asterisco. Finalmente, especificamos que tenga cabeceras y falle rápido en caso de un problema.
Consultas y transformaciones
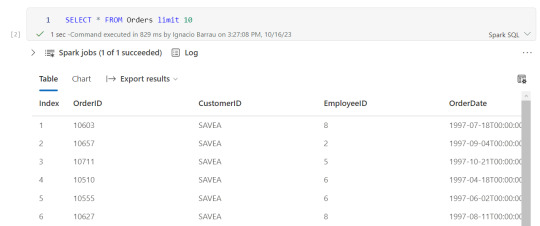
Una vez creada la tabla temporal, podremos ejecutar en la celda de un notebook una consulta como si estuvieramos en un motor de nuestra comodidad como DBeaver.
Escritura de tablas temporales a las Tablas de Lakehouse
Realizadas las transformaciones, joins y lo que fuera necesario para construir nuestro modelado dimensional, hechos y dimensiones, pasaremos a almacenarlo en "Tablas".
Las transformaciones pueden irse guardando en otras tablas temporales o podemos almacenar el resultado de la consulta directamente sobre Tablas. Por ejemplo, queremos crear una tabla de hechos Orders a partir de Orders y Order details:
CREATE TABLE Fact_Orders USING delta AS SELECT od.*, o.CustomerID, o.EmployeeID, o.OrderDate, o.Freight, o.ShipName FROM OrdersDetails od LEFT JOIN Orders o ON od.OrderID = o.OrderID
Al realizar el Create Table estamos oficialmente almacenando sobre el Spark Catalog. Fíjense el tipo de almacenamiento porque es muy importante que este en DELTA para mejor funcionamiento puesto que es nativo para Fabric.
Resultado
Si nuestro proceso fue correcto, veremos la tabla en la carpeta Tables con una flechita hacia arriba sobre la tabla. Esto significa que la tabla es Delta y todo está en orden. Si hubieramos tenido una complicación, se crearía una carpeta "Undefinied" en Tables la cual impide la lectura de nuevas tablas y transformaciones por SQL Endpoint y Dataset. Mucho cuidado y siempre revisar que todo quede en orden:
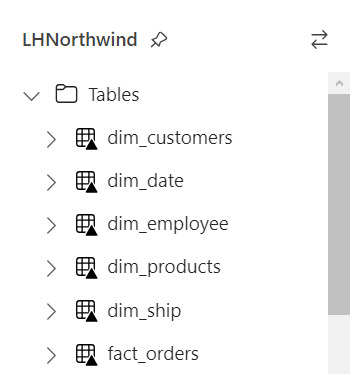
Pensamientos
Así llegamos al final del recorrido donde podemos apreciar lo sencillo que es leer, transformar y almacenar nuestros modelos dimensionales con SQL usando Notebooks en Fabric. Cabe aclarar que es un simple ejemplo sin actualizaciones incrementales pero si con lectura de particiones de tiempo ya creadas por un data engineering en capa Silver.
¿Qué hay de Databricks?
Podemos usar libremente databricks para todo lo que sean notebooks y procesamiento tal cual lo venimos usando. Lo que no tendríamos al trabajar de ésta manera sería la sencillez para leer y escribir tablas sin tener que especificar todo el ABFS y la característica de Data Wrangler. Dependerá del poder de procesamiento que necesitamos para ejecutar el notebooks si nos alcanza con el de Fabric o necesitamos algo particular de mayor potencia. Para más información pueden leer esto: https://learn.microsoft.com/en-us/fabric/onelake/onelake-azure-databricks
Espero que esto los ayude a introducirse en la construcción de modelados dimensionales con clásico SQL en un Lakehouse como alternativa al tradicional Warehouse usando Fabric. Pueden encontrar el notebook completo en mi github que incluye correr una celda en otro lenguaje y construcción de tabla fecha en notebook.
#power bi#ladataweb#fabric#microsoft fabric#fabric argentina#fabric cordoba#fabric jujuy#fabric tips#fabric training#fabric tutorial#fabric notebooks#data engineering#SQL#spark#data fabric#lakehouse#fabric lakehouse
0 notes
Text
[PowerQuery] Pandas and SQL to M
En múltiples oportunidades me encontré con personas que se dedican a data engineering o data analytics con python y por requerimiento/necesidad necesitan utilizar herramientas microsoft de movimiento de datos o Power Bi para presentarlos. Lo cierto es que dichas personas suelen detestar ese pedido puesto que esos puestos prefieren un trabajo más back que la demostración de tableros o herramientas de microsoft.
Ciertamente hoy microsoft ha implementado e impulsa Power Query para todo lo que es transformación de datos al punto que puede ser usado en SSIS, SSAS, Power Automate, Power Apps, Power Bi y DataFlows (en Power Platform y Data Factory).
El impulso por el lenguage de transformación es cada vez más fuerte y está pasando de ser un lenguaje de un rol de Bi a roles de data analyst y data engineer.
Por ello cree este post que nos ayudará a conocer como realizar las funciones básicas de SQL y principalmente Pandas (librería de python)
Lo primero a destacar es que Power Query corre en capas. Cada linea llama a la anterior (que devuelve una tabla) generando esta perspectiva o visión en capas. Por ello cuando leamos en el código #"Paso anterior" hablamos de una tabla.
Conozcamos los ejemplos que serán listados en el siguiente orden: SQL, Python, Power Query.
Cinco primeras filas
En SQL:
SELECT TOP 5 * FROM table
En Pandas:
df.head()
En Power Query:
Table.FirstN(#"Paso Anterior",5)
Contar filas
SELECT COUNT(*) FROM table1
df.shape()
Table.RowCount(#"Paso Anterior")
Seleccionar filas
SELECT column1, column2 FROM table1
df[["column1", "column2"]]
#"Paso Anterior"[[Columna1],[Columna2]] O podría ser: Table.SelectColumns(#"Paso Anterior", {"Columna1", "Columna2"} )
Filtrar filas
SELECT column1, column2 FROM table1 WHERE column1 = 2
df[['column1', 'column2']].loc[df['column1'] == 2]
Table.SelectRows(#"Paso Anterior", each [column1] == 2 )
Varios filtros de filas
SELECT * FROM table1 WHERE column1 > 1 AND column2 < 25
df.loc[(df['column1'] > 1) & (df['column2'] < 25)] O con operadores OR y NOT df.loc[(df['column1'] > 1) | ~(df['column2'] < 25)]
Table.SelectRows(#"Paso Anterior", each [column1] > 1 and column2 < 25 ) O con operadores OR y NOT Table.SelectRows(#"Paso Anterior", each [column1] > 1 or not ([column1] < 25 ) )
Filtros con operadores complejos
SELECT * FROM table1 WHERE column1 BETWEEN 1 and 5 AND column2 IN (20,30,40,50) AND column3 LIKE '%arcelona%'
df.loc[(df['colum1'].between(1,5)) & (df['column2'].isin([20,30,40,50])) & (df['column3'].str.contains('arcelona'))]
Table.SelectRows(#"Paso Anterior", each ([column1] > 1 and [column1] < 5) and List.Contains({20,30,40,50}, [column2]) and Text.Contains([column3], "arcelona") )
Join tables
SELECT t1.column1, t2.column1 FROM table1 t1 LEFT JOIN table2 t2 ON t1.column_id = t2.column_id
Hay dos funciones que pueden ayudarnos en este proceso merge y join.
df_joined = df1.merge(df2, left_on='lkey', right_on='rkey', how='left') df_joined = df1.join(df2, on='column_id', how='left')Luego seleccionamos dos columnas df_joined.loc[['column1_df1', 'column1_df2']]
En Power Query vamos a ir eligiendo una columna de antemano y luego añadiendo la segunda.
#"Origen" = #"Paso Anterior"[[column1_t1]] #"Paso Join" = Table.NestedJoin(#"Origen", {"column_t1_id"}, table2, {"column_t2_id"}, "Prefijo", JoinKind.LeftOuter) #"Expansion" = Table.ExpandTableColumn(#"Paso Join", "Prefijo", {"column1_t2"}, {"Prefijo_column1_t2"})
Group By
SELECT column1, count(*) FROM table1 GROUP BY column1
df.groupby('column1')['column1'].count()
Table.Group(#"Paso Anterior", {"column1"}, {{"Alias de count", each Table.RowCount(_), type number}})
Filtrando un agrupado
SELECT store, sum(sales) FROM table1 GROUP BY store HAVING sum(sales) > 1000
df_grouped = df.groupby('store')['sales'].sum() df_grouped.loc[df_grouped > 1000]
#”Grouping” = Table.Group(#"Paso Anterior", {"store"}, {{"Alias de sum", each List.Sum([sales]), type number}}) #"Final" = Table.SelectRows( #"Grouping" , each [Alias de sum] > 1000 )
Ordenar descendente por columna
SELECT * FROM table1 ORDER BY column1 DESC
df.sort_values(by=['column1'], ascending=False)
Table.Sort(#"Paso Anterior",{{"column1", Order.Descending}})
Unir una tabla con otra de la misma característica
SELECT * FROM table1 UNION SELECT * FROM table2
En Pandas tenemos dos opciones conocidas, la función append y concat.
df.append(df2) pd.concat([df1, df2])
Table.Combine({table1, table2})
Transformaciones
Las siguientes transformaciones son directamente entre Pandas y Power Query puesto que no son tan comunes en un lenguaje de consulta como SQL.
Analizar el contenido de una tabla
df.describe()
Table.Profile(#"Paso Anterior")
Chequear valores únicos de las columnas
df.value_counts()
Table.Profile(#"Paso Anterior")[[Column],[DistinctCount]]
Generar Tabla de prueba con datos cargados a mano
df = pd.DataFrame([[1,2],["Boris Yeltsin", "Mikhail Gorbachev"]], columns=["CustomerID", "Name"])
Table.FromRecords({[CustomerID = 1, Name = "Bob", Phone = "123-4567"]})
Quitar una columna
df.drop(columns=['column1']) df.drop(['column1'], axis=1)
Table.RemoveColumns(#"Paso Anterior",{"column1"})
Aplicar transformaciones sobre una columna
df.apply(lambda x : x['column1'] + 1 , axis = 1)
Table.TransformColumns(#"Paso Anterior", {{"column1", each _ + 1, type number}})
Hemos terminado el largo camino de consultas y transformaciones que nos ayudarían a tener un mejor tiempo a puro código con Power Query y no andar buscando que botones tocar.
#python#sql#powerquery#power query#dataflows#data analysis#data analytics#pandas#tsql#data engineering#data transformation#power bi#bi#data science#python cordoba#python argentina#sql cordoba#sql argentina#power bi cordoba#power bi argentina
1 note
·
View note
Text
[Databricks] Paper Lakehouse
¡Hola a todos! En este articulo voy a intentar darles un resumen del paper sobre Lakehouse que publico Databricks en Enero de este año para el evento CIDR. Es un paper muy interesante porque habla de su visión como empresa, enumera problemas con las arquitecturas actuales de datos, justifica porque consideran que este es el enfoque adecuado, aunque también reconoce que tienen cosas para mejorar y que hay otras arquitecturas que pueden aportar mucho valor.
Si bien este no es un artículo de opinión y solo me enfocare en darles un breve resumen del paper y sus puntos más importantes, si agregue en muchos casos algunas definiciones para hacer la lectura más llevadera y no tener que interrumpir la lectura googleando algún termino especifico. Intente que la numeración usada sea la misma que en el paper, aunque no es 100% fiel.
1. Introducción, historia de warehouses y problemáticas actuales:
Este paper pretende abrir el debate sobre las arquitecturas de data warehousing, e inicia diciendo que la arquitectura tal y como la conocemos hoy ira declinando en popularidad en los próximos años y será gradualmente reemplazada por otro patrón de arquitectura que conocemos como Lakehouse.
La primera generación de plataformas analíticas de datos eran bases de datos centralizadas, optimizadas para su uso en BI (Business Intelligence). Hace una década empezaron a tener 2 tipos de problemas:
El poder de cómputo y el almacenamiento estaban ligados entre sí, en un dispositivo on-premise (es decir, en una infraestructura local). A medida que los datasets se volvían más grandes y la cantidad de usuarios aumentaba, los costos se volvían demasiado grandes también.
No solo los datasets crecían, sino que también aparecieron nuevas formas de datos completamente no-estructuradas (video, audio, documentos de texto, etc.) que los data warehouses no podían almacenar ni consultar.
Para resolver estos problemas vino la segunda generación de plataformas analíticas, que empezaron a almacenar la data cruda (raw) en data lakes, sea esta estructurada o no. El bajo costo de almacenamiento, simplicidad para accederlos y formatos de archivos de código abiertos (por ej. Parquet) los hace ideales para esta tarea. Esto empezó con Apache Hadoop, usando su File System (HDFS) que permitía usar comodity hardware en entornos on-premise y luego fue gradualmente reemplazado por los data lakes en la nube, superiores por ofrecer todavía mejor precio, bajo costo de mantenimiento y geo replicación. El uso de data lakes permitió desacoplar el almacenamiento de los datos (en data lakes) del procesamiento de los mismos (Redshift, Synapse, Snowflake, etc.).
Lo mencionado anteriormente nos trae a los desafíos que presenta esta segunda generación, ya que la información tiene que pasar por un proceso de ETL hacia el data lake para luego tener otro proceso de ELT hacia el data warehouse, creando más complejidad, demoras y nuevos potenciales puntos de falla. Sumado a esto, nuevos casos de uso para analítica avanzada como Machine Learning no son soportados de forma ideal. Para ser más específicos, hay 4 problemas principales con las arquitecturas actuales:
Fiabilidad: mantener el data lake y el warehouse consistentes entre si es difícil, costoso y requiere mantenimiento constante para disponibilizar la data rápido para los sistemas de BI.
Data no actualizada: la data en un warehouse tiende a quedar vieja (a veces lleva días actualizar) comparada con el data lake.
Soporte limitado para analítica avanzada: ninguno de los sistemas de Machine Learning líderes como TensorFlow, PyTorch o XGBoost soportan trabajar sobre warehouses. La mayoría recomiendan exportar la data como archivos al data lake (agregando un tercer ETL, e incrementando los dos primeros problemas).
Costo total: además del costo por el ETL continuo, los usuarios pagan doble por el almacenamiento de la data en data lake y en warehouse.
El momento ideal para hacer la transición hacia un Lakehouse es este, ya que recientemente se desarrollaron nuevas soluciones que intentan atacar los siguientes problemas:
Administración fiable de data en data lakes: un lake necesita almacenar raw data, pero también dar soporte a procesos ETL que limpien la data para mejorar su calidad para análisis sin perder características clave como transacciones, rollbacks o clones de copia cero. Librerías como Delta Lake o Apache Iceberg ofrecen estas características.
Soporte para Machine Learning y ciencia de datos: muchos sistemas soportan la lectura directa desde data lakes y esto los hace eficientes para trabajar con Lakehouse, y se benefician de forma directa con las optimizaciones que se incluyan en estos.
SQL Performance: Lakehouse tiene que proveer buena performance en SQL corriendo sobre datasets Parquet/ORC grandes, y es un desafío ya que no posee las facilidades de optimización que tienen los warehouse clásicos (indexación, por ejemplo). Sin embargo, se presentan algunas técnicas que se pueden implementar para mejorar esto con repositorios de metadata y particionado de la data en estos formatos para mejorar performance.
2. Pasos hacia Lakehouse:
Muchas tendencias de la industria dan evidencia de que los clientes no están 100% satisfechos con el modelo de separación entre data lake y warehouse.
En los últimos años los data warehouse lideres han agregado soporte para tablas externas en formato Parquet y ORC, esto permite consultarlos usando el mismo motor SQL, pero no simplifica su administración, ni reduce la complejidad en los ETL. Además, estos conectores suelen tener mala performance comparado con data interna de los warehouse.
También se están haciendo grandes inversiones en motores SQL que corran directamente sobre el almacenamiento en data lakes (como Spark SQL, Presto, Hive, etc), pero incluso estos están faltantes de features básicas como transacciones ACID (atomicidad, consistencia [integridad], aislamiento y durabilidad [persistencia], por sus siglas en inglés) o métodos de acceso eficientes como índices.
3. La arquitectura Lakehouse:
Se define la arquitectura Lakehouse como un sistema de administración de datos, basado en almacenamiento de bajo costo y directamente accesible que provee features de administración y rendimiento como las bases de datos tradicionales, tales como transacciones ACID, versionado de datos, auditoria, índices, cache y optimización de consultas.
A continuación, se habla sobre una posible forma de implementar un Lakehouse basado en tres ideas técnicas que aparecieron en la industria: Delta Lake, Delta Engine y Databricks ML Runtime.
3.1 Implementando un Lakehouse:
La primera idea clave es permitir que el sistema use como almacenamiento un data lake (Azure Data Lake, S3, etc) usando formatos de archivos estándar como Apache Parquet, pero con una capa de metadatos transaccionales para permitir transacciones ACID, versionado, etc. Delta Lake y Apache Iceberg actualmente permiten lograr esto, pero con la contra de que no son suficiente para lograr una buena performance en cuanto a consultas SQL. Si bien se pueden utilizar discos de estado sólido, índices para archivos y mantener estadísticas, en un Lakehouse podemos implementar otras optimizaciones tales como cache, estructuras de datos auxiliares como índices y estadísticas (enfocado en tablas, no archivos) y optimizaciones en cuanto a la clusterizacion de la data.
Un aspecto importante es que un Lakehouse ayuda muchísimo a que las principales librerías de machine learning puedan acceder al dato gracias a la implementación de DataFrame APIs, que permiten obtener Dataframes (al estilo R o Pandas en el caso de Python) para hacer transformaciones y cálculos. Una ventaja de estas APIs es que manejan Lazy evaluation (es decir que las operaciones no se ejecutan una a una, sino que se acumulan y se ejecutan todas juntas), y esto permite hacerlas pasar por un optimizador antes de su ejecución real.
3.2 Capas de metadata para administración:
La capa de metadatos debería elevar el nivel de abstracción en el almacenamiento de los data lakes al punto de poder ofrecer transacciones ACID y otras features clásicas de los DBMS. Features como hacer update a un documento de texto no son nativas de los data lake, ni de ningún sistema basado en HDFS. Por esta razón es que Databricks empezó en 2016 el desarrollo de Delta Lake, que guarda información acerca de los objetos que forman parte de una tabla en el mismo data lake, en la forma de un log de transacciones en formato Parquet, lo que le permite escalar a billones de objetos por tabla. Otras librerías que intentar lograr algo similar son Apache Iceberg (nacida en Netflix) o Apache Hudi (nacida en Uber, enfocada en streaming).
La experiencia y los tests muestran que estas librerías logran performance similares o mejores comparados con la lectura directa de archivos Parquet/ORC, al tiempo que ofrecen features como transacciones, viaje entre versiones (time travel) o clones de copia cero (clonar una tabla sin duplicar la data en otro lugar).
Esta capa de metadatos además controla el esquema de las tablas antes de escribirlos (cosa que no pasa al escribir solo archivos Parquet), y permiten definir restricciones a valores particulares para evitar que entre basura en nuestras tablas.
Por último, en estas capas es donde mejor se pueden implementar features de Governance tales como control de acceso o logs de auditoria.
Para pensar en el futuro: las capas de metadata son algo nuevo, y por el momento almacenan los logs de transacciones en el mismo data lake, pero no es ideal ya que estos están diseñados para devolver grandes volúmenes de datos, y estas capas son pequeñas en datos por lo que podría preferirse almacenar la capa de metadata en otro sistema con menos latencia.
3.3 Performance de SQL en el Lakehouse:
Uno de los mayores desafíos técnicos es proveer de buena performance en SQL. Se proponen a continuación optimizaciones que no dependen del formato de archivo, para hacerlas así aplicables a todos.
3.3.1 Cache:
Cuando se consultan los datos usando capas de metadatos, lo mejor es almacenar en cache algunos archivos clave en almacenamientos más rápidos tales como discos de estado sólido en la nube, o en la misma memoria RAM de los nodos de procesamiento. Las transacciones nos ayudan a saber cuándo un cache es válido o cuando hay que descartarlo, y podemos cambiar el formato subyacente al guardarlo como cache para hacerlo aún más rápido. Como ejemplo, el cache en Databricks descomprime parcialmente los archivos Parquet que carga.
3.3.2 Data Auxiliar:
Estadísticas tales como valores maximos-minimos para ciertas columnas, permiten saltear filas que no coinciden con nuestro criterio de búsqueda y agilizar consultas. Esta data auxiliar también incluye índices que pueden ayudar con este propósito.
3.3.3 Distribución de data:
La distribución en la cual están guardados los datos influye mucho en la performance, por ejemplo, si guardamos en un mismo sector datos que nos interesa leer siempre juntos su performance mejora al ser más simple de leer para el data lake.
Estas 3 optimizaciones funcionan bien cuando están aplicadas juntas, ya que las cargas de trabajo típicas tienden a estar enfocadas en un subset de la información y no en toda.
Resultados de rendimiento: en Databricks se combinan estas 3 optimizaciones con un nuevo motor de ejecución en C++ para Apache Spark llamado Delta Engine. El estudio llevado a cabo indica que hace un uso más eficiente del dinero (es más barato), mientras ofrece una performance similar o mejor.
Dirección para el futuro y diseños alternativos: Una alternativa que aún no se exploro es diseñar nuevos tipos de archivos para almacenar la información que favorezcan el caso de uso de Lakehouse. Otra dirección para la investigación es determinar cuándo y como usar servicios serverless para responder consultas (como AWS Athena).
3.4 Acceso eficiente para analítica avanzada:
Como se discutió antes en este paper, las librerías de analítica avanzada están usualmente escritas en código imperativo que no puede correr como SQL, y necesitan consumir grandes cantidades de datos. Una de las incógnitas más grandes es de qué forma se puede diseñar el acceso a la data para beneficiarse de las optimizaciones que ofrece un Lakehouse. En este punto se tuvo bastante éxito usando DataFrame APIs en estas librerías, que simplifica llevar la data a Spark SQL y beneficiarse de los query planner y demás optimizaciones. Se uso este enfoque en Spark DataFrames y en Koalas (que ofrece más compatibilidad con Pandas).
En el futuro se tendrá que desarrollar para nuevas formas de lectura, y para aquellas librerías que se enfocan en procesamiento en GPUs (tarjetas gráficas).
Dirección para el futuro y diseños alternativos: aún falta por explorar diseños completamente diferentes para acceder data para machine learning. Si bien se pueden hacer mejoras en la forma de procesar y acceder la data, no hay que dejar de lado que los científicos de datos necesitan librerías estándar para beneficiarse de las ventajas ofrecidas por Lakehouse.
4. Preguntas de investigación e implicancias:
¿Hay otras formas de lograr los objetivos de Lakehouse? Uno se podría imaginar que los objetivos se pueden lograr creando una capa que exponga la data y permita lecturas en paralelo. Sin embargo, esa infraestructura seria más costosa, difícil de administrar y casi con seguridad menos performante que leer directamente desde el almacenamiento. Un intento de esta implementación se hizo con Hive LLAP. Además de las contras mencionadas, la gobernanza de datos nos da razones más que suficientes para almacenar su data en formatos abiertos, para cumplir con regulaciones, auditorias y estandarizar el acceso a la misma.
¿Cuáles son los formatos de almacenamiento y las apis de acceso correctos? La interfaz de acceso al Lakehouse debe incluir librerías para leer el formato crudo (raw) y una interfaz de alto nivel SQL. Aun está por verse que combinación de formato de archivo, capa de metadatos y API de acceso es la que mejor funciona.
¿Como afecta el Lakehouse otras investigaciones y tendencias sobre administración de datos? La prevalencia de data lakes y el creciente uso de interfaces de administración sobre ellos tiene implicancias en otras áreas:
Los Polystores fueron diseñados para atacar el problema de consultar data entre diferentes motores de almacenamiento.
Herramientas de integración y limpieza de datos podrían diseñarse para correr directamente sobre el Lakehouse paralelizando el acceso con múltiples joins y algoritmos de clusterizacion.
Sistemas de procesamiento hibrido transaccional/analítico (HTAP) podrían ser creados sobre el Lakehouse haciendo uso de las APIs de transacciones.
El manejo de data para Machine Learning se podría volver mucho más simple y potente si se implementa directamente sobre Lakehouse.
Se pueden diseñar DBMS nativos de nube (como los motores serverless) para integrarse con las capas de metadata enriquecida en lugar de escanear directamente sobre la data cruda en el data lake.
Últimamente se está hablando del concepto de "data mesh" en el cual diferentes equipos tienen el control inicio-a-fin y son dueños de procesos y productos de data. Este concepto está ganando popularidad sobre el enfoque de tener un equipo centralizado de data.
5. Trabajos relacionados:
Los sistemas más relacionados son "nativos de nube". Data warehouses asentados sobre un almacenamiento separado (data lake) como Apache Hive.
También los warehouse nativos de nube como Snowflake y BigQuery han tenido éxito comercial, pero siguen sin ser el principal almacén de data en las organizaciones (siguen teniendo todo en data lakes). Como resultado de esto, tienen opciones para leer tablas externas e interfaces para distintos tipos de archivos, pero siguen sin ofrecer las mismas características que ofrecen para las tablas internas (como transacciones ACID). Como se discutió anteriormente, tampoco son el formato óptimo para analítica avanzada.
6. Conclusión:
Hemos visto como una plataforma unificada de datos que implemente funcionalidades de data warehouse sobre archivos de formato abierto puede proveer de rendimientos competitivos sobre los data warehouse de hoy, e intentamos dar respuesta a los desafíos que surgen con esta propuesta, tales como la falta de optimización en el acceso a datos. Creemos que la industria va a converger a un formato de Lakehouse en el futuro por la cantidad de data que manejan las organizaciones, la infinidad de casos de uso que nos ofrece, y por como simplifica las arquitecturas de datos.
Escrito por Martin Zurita
Twitter
Linkedin
0 notes