
Blog comunitario de la suite de analítica de Microsoft de la mano de Power Platform y Azure Data Platform. @ignacho_07
Don't wanna be here? Send us removal request.
Statistics
We looked inside some of the posts by ibarrau and here's what we found interesting.
Average Info
Notes Per Post
0
Likes Per Post
0
Reblog Per Post
0
Reply Per Post
0
Time Between Posts
14 days
Number of Posts By Type
Text
17
Last Seen Tumblr Blogs





Fun Fact
The KCSC sent more than 20K requests to delete posts related to prostitution and porn to Tumblr from January to June 2017.
Text
[Fabric] Seguridad - Enmascaramiento dinámico de datos
Las seguridad en Fabric se vuelve cada vez más prioritaria a medida que más es adoptado el ecosistema. Cierto es que la mayoría de los casos suelen pasar por como se regulan cuentas de acceso de desarrollo o tal vez permisos sobre recursos puntuales. Incluso cuando queremos afinarla un poco todo termina en una seguridad de la tabla por filas o columnas.
Gran parte de empresas se concentra en permitir o privar acceso a datos específicamente pero cierto es que muchas veces dejamos de lado otra forma de mantener la seguridad y poder trabajar con datos puntuales. Me refiero a enmascarar datos.
En este artículo veremos como enmascarar datos desde Fabric SQL Analytics Endpoint para que usuarios sepan que exista una columna pero su contenido este enmascarado.
Antes de comenzar vamos a ir directo a lo que nos gusta en LaDataWeb. Revisemos la definición de enmascaramiento dinámico de datos. Microsoft lo define de la siguiente manera:
El enmascaramiento de datos dinámico es una tecnología de protección de datos de vanguardia que ayuda a las organizaciones a proteger la información confidencial dentro de sus bases de datos. Permite definir reglas de enmascaramiento para columnas específicas, lo que garantiza que solo los usuarios autorizados vean los datos originales a la vez que se ocultan para otros usuarios. El enmascaramiento de datos dinámico proporciona una capa adicional de seguridad mediante la modificación dinámica de los datos presentados a los usuarios, en función de sus permisos de acceso.
Dicho sea de otro modo, podemos configurar nuestras tablas para que columnas no muestren datos sino textos inentendibles en lugar del dato real cuando son consultadas por específicas personas.
Esta modalidad existe en muchos motores. El que vamos mostrar funciona particularmente en SQL Server pero la prueba la vamos a construir dentro de Fabric en su experiencia SQL de un Warehouse
NOTA: de momento el SQL Analytics endpoint de un Lakehouse no admite sentencia CREATE. Por esta razón, usaremos Warehouse.
¿Por qué esconderíamos el dato de columnas a ciertos usuarios? Puede que nuestro conjunto de datos tenga información sensible que no queremos que sea visible por quien lo desarrolla. Tal vez estamos por revisar datos personales, valores salariales, etc. Dicho contenido es privado y no debería ser visible para quienes lo desarrollan.
¿Cómo se vería esto? Imaginemos a un Data Analyst conectandose por SQL Analytics endpoint o creando un report de Power Bi. Cuando uno de estos usuarios tiene aplicado el enmascaramiento, vería de la siguiente manera:

Desarrollo
El enmascarado de datos es un rasgo de una tabla. Por esta razón, se configura al momento de crear la tabla o modificando su estructura. Como la experiencia es 100%, comenzaremos abriendo el analytics endpoint de un Warehouse. Veamos como se aplicarían tres ejemplos al crear la tabla:
CREATE TABLE dbo.Cliente ( DNI INT ,Nombre VARCHAR(50) MASKED WITH (FUNCTION = 'partial(1,"-",2)') NULL ,Apellido VARCHAR(50) MASKED WITH (FUNCTION = 'default()') NULL ,TarjetaSSN CHAR(12) MASKED WITH (FUNCTION = 'partial(0,"XXX-XX-",4)') NULL ,Provincia VARCHAR(50) ,Localidad VARCHAR(50) ,Direccion VARCHAR(256) ,Email VARCHAR(100) NULL );
La columna Nombre muestra solo el primero y últimos dos caracteres de la cadena, con - en el centro.
La columna Apellido muestra XXXX.
La columna TarjetaSSN muestra XXX-XX-, seguido de los cuatro últimos caracteres de la cadena.
A partir de ese momento lo que insertemos en esa tabla será enmascarado para usuarios de lectura. Compartiríamos el Warehouse de la siguiente manera:

Un desarrollador de tablero ya podría conectarse con Power Bi Desktop o desde la interfaz para consultar datos. Si este usuario consultara datos de Cliente. Vería lo siguiente. Presten atención a las columnas afectadas Nombre, Apellido y TarjetaSSN

Importando datos desde el Warehouse en Power Bi Desktop:

Una vez publicado el informe, tengamos presente que la credencial para la actualización será clave para la visibilidad. Por ejemplo, coloque credenciales de un usuario administrador del warehouse y en el informe podremos visualizar datos:

Así conseguimos que el tablero productivo muestre datos para quienes deben verlo y que desarrolladores no vean el contenido. Recuerden que el desarrollador no podría ser miembro del área de trabajo del Warehouse sino que le compartimos el recurso puntual.
Ya conocemos como comenzar un proyecto nuevo con estas características, pero que sucede con nuestros modelos que ya existen en este momento. Para trabajarlos, vamos a modificar la estructura de la tabla con ALTER. Dicha sentencia puede ejecutarse tanto en Lakehouse como Warehouse. Veamos como enmascarar el email que generamos en la misma tabla y siempre estuvo visible.
ALTER TABLE dbo.Cliente ALTER COLUMN [Email] ADD MASKED WITH (FUNCTION = 'email()');
El resultado de dicha sentencia nos enmascararía la columna de correo dejando una visibilidad como indica la imagen:

Puede que en medio de estos desarrollos necesitemos que algunos de los usuarios tengan visibilidad sobre los datos. Para no cambiar los permisos sobre los recursos y seguir manteniendo su acceso de solo lectura, podemos dar permisos especiales sobre una tabla o columna como vimos en el post anterior usando GRANT. Veamos un ejemplo de como asignar esta excepción a un usuario para que vea Nombre y como quitársela. Quedaría así si lo viera:

GRANT UNMASK ON dbo.Cliente(Nombre) TO [[email protected]]; REVOKE UNMASK ON dbo.Cliente(Nombre) TO [[email protected]];
De esta manera podemos incluir una capa adicional de seguridad en nuestros procesos de desarrollo que no sean quitar la total visibilidad de una fila, columna, tabla, modelo, etc.
Para entrar en más detalle, pueden revisar en la documentación de microsoft que funciones podemos usar para el enmascarado dinámico en este enlace: https://learn.microsoft.com/es-es/sql/relational-databases/security/dynamic-data-masking?view=sql-server-ver17
Espero que les sea útil puesto que tiene mucha flexibilidad para su uso. Restaría sentarse a pensar bien como incluirlo en nuestro flujo laboral.
#ladataweb#microsoft fabric#fabric#fabric tips#fabric tutorial#fabric training#fabric warehouse#fabric cordoba#fabric argentina#fabric jujuy#fabric lakehouse#fabric security#tsql#sql
0 notes
Text
[Fabric] Seguridad en lakehouse y warehouse tablas y SQL
Ya Fabric sigue demostrando su gran experiencia de usuario en distintos enfoques. Uno de los más atractivos que hemos mencionado varias veces es su entorno SQL. Fabric con sus almacenamientos de lakehouse y warehouse en una gran interacción SQL.
Si conocen de SQL Server seguramente será de gran utilidad. En este artículo, veremos como establecer seguridad de datos granulares como si estuvieramos dentro de un SQL Server. Sin embargo, estamos dentro de un lakehouse almacenado en delta parquet.
La seguridad en Fabric evoluciona en tres niveles tal como explicamos en este artículo anterior de Seguridad en Fabric. El máximo nivel de rigurosidad es llegar a la granularidad. Esto significa que podemos permitir o restringir acceso a datos dentro de un elemento. Por ejemplo, si hablamos de un modelo semántico estaríamos refiriéndonos a OLS o RLS.
En caso de almacenamientos entorno a tablas en formatos delta en onelake, tenemos la posibilidad de la experiencia SQL gracias al SQL Endpoint que generan al crearse. En ese espacio podremos nutrirnos de tradicional SQL para realizar acciones como permitir, rechazar, cancelar acceso a tablas o inclusive más profundo como por ejemplo column level security, row level security e inclusive Dynamic data Masking.
Antes de comenzar a escribir SQL debemos pensar en el punto de acceso del usuario. Si el usuario ingresaría a Fabric a utilizar herramientas y navegar el lake, entonces probablemente demos acceso por OneLake Security. Si queremos que su experiencia sea 100% SQL, entonces lo haremos por código. Estos permisos son granular de un ítem. Entonces el usuario no debe tener permisos al área de trabajo, sino que dimos click a "Compartir" sobre Lakehouse y pusimos la mínima cantidad de permisos.

OneLake Security
Para configurar por este camino, lo primero es delimitar que tablas tendrá acceso un usuario. Podemos crear un rol que tiene acceso a especificas carpetas o tablas usando "Onelake Security"
Parados en lakehouse veremos un nuevo botón:

Una vez desplegado el menú podrán dar un nombre al rol y configurar los dos nros que ven en la imagen. Primero cambiar a selected data o clickear en botón "Add Data" para elegir que podrá ver el rol y segundo Agregar miembros y verlos en la pestaña "Members".
Un ejemplo de selección de datos sería:

De este modo cuando el usuario, ingrese al Lakehouse propiamente configurado. Solo vería esas cuatro tablas indicadas.
Configuración SQL
La configuración anterior solo daría acceso a la vista de lake, sin embargo estaría vacía frente a SQL Endpoint. Si quisiéramos que los ETL o la experiencia de consulta pase con scripts, procedimientos y toda la magia de lenguaje SQL este dada por experiencia SQL (dentro del sql endpoint o por algún DBMS); podríamos configurarlo por código en lugar de por UI. Con el SQL Analytics endpoint, se pueden aplicar permisos de T-SQL a objetos (esquemas, tablas, vistas, funciones, etc) mediante comandos DCL (data control language). Los comandos son GRANT, DENY, REVOKE
Veamos un ejemplo

Ejecutando esa consulta, el usuario listado podría ingresar al SQL Endpoint y ver esas tablas para ejecutar consultas select independiente de su asignación en onelake security. Vería lo siguiente.

De la misma manera funcionan las peticiones de las otras sentencias de control. Dejo material por si quieren verlas en profundidad o revisar otros ejemplos.
GRANT: https://learn.microsoft.com/en-us/sql/t-sql/statements/grant-transact-sql?view=sql-server-ver16
DENY: https://learn.microsoft.com/en-us/sql/t-sql/statements/deny-transact-sql?view=sql-server-ver16
REVOKE: https://learn.microsoft.com/en-us/sql/t-sql/statements/revoke-database-permissions-transact-sql?view=sql-server-ver16
Aún más profundidad
Si quisiéramos viajar incluso más lejos. Podríamos delimitar seguridad por columna, filas o enmascarar datos. Veamos un ejemplo por columna.

Simplemente agregando las columnas cerca de la tabla, el usuario tendría la restricción aplicada. La experiencia para las columnas no es la más grata de este modo porque el usuario ve todas las columnas pero el motor le impide ver datos de las columnas mostrando un mensaje así:

Para el caso de seguridad por filas, se requiere más profundidad en conocimientos de T-SQL (crear una función y una security policy). Si no conocen, les recomiendo mantenerlo en Warehouse o Modelo semántico que puede ser configurado por UI. En caso de enmascarar datos creo que es un tema para un artículo dedicado.
Finalmente, si quisiéramos validar los permisos de una tabla, podríamos usar el procedimiento de SQL Server sp_table_privileges o bien el siguiente script para validar todas las tablas que hubieran sido afectadas por GRANT o DENY:

Todas las aplicaciones mencionadas de SQL son aplicables en data warehouse de Fabric. Espero que este artículo haya dado más luz a lo que podríamos configurar de seguridad más fina en nuestros almacenamientos de Fabric.
#fabric#microsoft fabric#fabric training#fabric tutorial#fabric tips#power bi service#data engineering#lakehouse#warehouse#fabric security#SQL#ladataweb#fabric argentina#fabric cordoba#fabric jujuy
0 notes
Text
Seguridad en Fabric
Algo que cada departamento de IT o responsables de tecnología se pregunta cuando hay que incorporar nuevos servicios o software en una empresa esta muy cercano a la seguridad. De ellos es el gran interés por administrar usuarios, roles y patrones para que las responsabilidades de quienes ingresan este acorde a lo que les corresponde.
Con la creciente popularidad de Microsoft Fabric y sus distintas experiencias o servicios de desarrollo que tiene la suite, podemos marearnos en como se maneja. Por esta y otras razones, ladataweb trae un artículo para mostrar como esta organizada la seguridad en Fabric.
En caso que aún no estés familiarizado con Microsoft Fabric, te invito a dar una vuelta por este artículo introductorio.
Para comenzar no esta demás mencionar algunas aclaraciones. Fabric es un software as a service que abarca la experiencia de desarrollo end to end de un proyecto de datos, desde Gobernanza hasta un experimento de Ciencia de Datos. Esta integrado con el ecosistema de Microsoft en lo que respecta a 365 o Azure en diversos ejes.
Cuando un usuario quiere acceder a Fabric existen tres capas de seguridad que necesita atravesar:
Ingreso con Microsoft Entra ID: como un SaaS de la misma compañía, el acceso a la plataforma para lectura y escritura se encuentra bajo el servicio de administración de identidades de Azure.
Acceso a Fabric: luego de validar la existencia de la cuenta corporativa en el tenant, comprueba si el usuario puede acceder al servicio.
Seguridad de datos: existen distintos bloques de creación en la experiencia de Fabric y en este nivel vamos a enfocarnos puesto que refiere al fino de hasta donde puede llegar el usuario en el servicio.
Microsoft Fabric se encuentra organizado bajo áreas de trabajo. Éstas áreas son un espacio de trabajo colaborativo que permite alojar distintos ítems (reportes, pipelines, experimentos) de las experiencias/servicios (PowerBi, Data Factory, Data Science, etc). De esa forma, distintos profesionales de datos pueden trabajar en conjunto en un espacio. Así mismo, estos espacios rigen permisos y usuarios. Veamos gráficamente como se ajustarán los permisos

Bajo un Tenant disponemos de N áreas de trabajo que así mismo tienen N ítems creados por los servicios disponibles que alojan su información en el almacenamiento único OneLake.
NOTA: recordemos que un Tenant puede tener permitido o bloqueado ciertas acciones puntuales para grupos de seguridad de usuarios de manera adicional para la seguridad de la organización. Por ejemplo: exportar tableros a excel o permitir crear un ítem en preview.
La capa de seguridad de datos se encuentra subdivida en tres niveles:
Roles de área de trabajo
Permisos de ítem o elemento
Permisos de granular interno del ítem
Roles de área
Las áreas permiten agregar usuarios para que puedan interactuar y trabajar de manera colaborativa. Sin embargo, hay cuatro roles que en definitiva puede tomar un usuario que participa de este espacio.
Admin: permisos para editar todos los ítems, compartirlos y manejar el área.
Member: permisos para editar todos los ítems, compartirlos.
Contribuidor: permisos para editar todos los ítems
Visor: permiso para ver todos los items.
NOTA: Información de roles totalmente detallada aquí: https://learn.microsoft.com/es-es/power-bi/collaborate-share/service-roles-new-workspaces
Como podrán apreciar. Si un usuario forma parte del área de trabajo puede ver todos los ítems creados sin excepción. Para aquellos casos que necesitamos prender un permiso para un específico ítem es que nace el permiso que sigue.
Permiso de ítem o elemento
La mayoría de las creaciones dentro de un área de trabajo puede ser compartida de forma individual. Si nuestra área contiene un lakehouse, un modelo semántico, un informe y un notebook. Tranquilamente podríamos compartir a un data engineer el lakehouse y notebook mientras que un Bi o analista de datos tenga compartido el lakehouse, modelo semántico e informe. Finalmente, un usuario final solo compartirle el informe.
Esta claro que cuando trabajamos con muchos involucrados intentamos generar grupos para evitar compartir de manera tan directa por usuario, pero la posibilidad existe:

Permisos granulares
No siempre los desarrolladores deberían tener permisos totales. En los proyectos de datos muchas veces existe información sensible o simplemente de otra área. Así mismo hay distintos usuarios finales que no debería poder leer ciertos datos. Para los detalles finos dentro de los datos existen los permisos granulares.
Éstos permisos son configuraciones especiales de algunos ítems puntuales. De momento, aquellos con almacenamiento, es decir, lakehouse, warehouse y modelos semánticos. La idea es que dentro del mismo recurso podamos delimitar pautas o reglas.
Lakehouse: crear roles para asignar a usuarios. Dichos roles son delimitados para visualizar, ejecutar consultas SQL/Spark o compartir específicas carpetas o archivos.
Warehouse: también cuentan con seguridad a nivel de filas
Modelos semánticos: al estar constituido por tablas, se vuelve crítico su seguridad dentro de esos objetos. Dando pie a seguridad a nivel de filas (filtrar filas para algún usuario) o seguridad a nivel objeto (restringir columnas o tablas).
SQL Endpoint: tanto lakehouse como warehouse tienen por defecto este servicio. El mismo nos brinda configuraciones de seguridad de datos tradicionales de SQL como lo son seguridad a nivel de tablas, de filas y enmascarado de datos.
En definitiva, Fabric nos brinda puertas a una flexible y profunda seguridad que nos ayude a mantener las responsabilidades adecuadas para el rol o perfil de desarrollador que corresponda. No olvidemos las configuraciones del Tenant que pueden tener ciertas configuraciones adicionales que den permiso o negación a acciones concretas de grupos de usuarios. Pueden leer más detalle de ellas aquí: https://learn.microsoft.com/es-es/fabric/admin/tenant-settings-index
#fabric#microsoft fabric#fabric tips#fabric tutorial#fabric training#fabric jujuy#fabric cordoba#fabric argentina#ladataweb#fabric security#power bi service
0 notes
Text
[PowerBi] Mejorá la experiencia de usuarios sobre filtros
Durante muchos años PowerBi ha mantenido la misma visualización para el uso de filtros enfocado en una lista categórica. Con el tiempo se fue actualización para jugar con rangos numéricos, fechas y hasta relativos de tiempo.
Sin embargo, si queríamos diseñar una experiencia de usuario innovadora modificando formatos, modos y usos... terminábamos usando una custom visual o bookmarks. Este artículo nos cuenta de sobre el lanzamiento de tres nuevas visualizaciones de filtros nativas de Power Bi.
Comenzaremos poniendo en contexto. Hoy Power Bi tiene por defecto una sola visualización entorno a filtros.

La visual nos permite las siguientes acciones según el tipo de dato:
Texto: lista desplegable o visible con un checkbox (multiselect) o raddiobutton (single select) que puede tener un buscador. No dispone de opciones de formato fuera de cambiar texto y fondo.
Números: rango desde hasta.
Fecha: rango desde, hasta o ambos. También tiene la opción de relativos
Adicional a ésta, existen tres más que nos pueden ayudar a cubrir otras experiencias de usuarios. De momento, para poder utilizarlas, tenemos que abrir el menú de Archivo en Power Bi dekstop -> Opciones y configuración -> Opciones y buscar las caracteristicas de version preliminar (Preview Features). Allí encontrarán una larga lista de futuras características que microsoft planea incorporar en su ecosistema. En este artículo vamos a conversar sobre tres de ellas:

Veamos paso a paso cada una de ellas.
Filtro de texto
Esta nueva visualización viene a cubrir una deuda muy pendiente que es el filtro de palabras claves. Suele ser muy común de verlo en aplicaciones web y móviles para rápidamente filtrar una categoría si coincide una parte de la cadena de texto. Veamos un ejemplo.

Usando las letras "cam", puedo encontrar rapidamente 4 resultados de categorías.
El diferencial que se pueden incorporar en la visual es permitir multiples coincidencias de valores. Basta con ir a opciones de formato y permitirlo. Veamos otro ejemplo con dos cadenas de texto:

Filtro botones
Esta nueva visual viene a reemplazar al famoso Chiclet slicer que existía en las custom visual. Una visualización que arma un botón por cada categoría permitiendo todas las delimitaciones de formato que tienen los botones. Según su estado (defecto, presionar, poner mouse por encima, seleccionado) podemos cambiar colores de letras, fondos, sombras, etc mejorando la experiencia. También permite la selección única o múltiple. Veamos un ejemplo:

Para mejorar la disposición podemos delimitar cuantos botones mostrar por fila o por columna. Así podremos encastrar la visual como disponga mejor la página. Además, permite agregar una imagen al botón, tal como el chiclet.
Filtro de lista
Probablemente el más parecido a la visualización actual. Su principal diferencia con lo actual se basa en las muchas delimitaciones para el formato. Permite controlar cada situación dentro de la visual que la otra no podía. Podemos cambiar formato de colores por los mismos estados antes mencionados del texto, fondo y hasta checkbox dando de la visual más flexibilidad para la innovación. Veamos como quedaría una modificación rebuscada para que apreciemos todo lo que se puede modificar:

También permite evitar el scroll con listas fijas según una cantidad de categorías delimitadas.
Conclusión
Una deuda pendiente es saldada con estas nuevas características que un día serán nativas para solventar un freno a la creatividad que tenías que salir a buscar por otros medios. Pienso que nos mal acostumbramos a filtros comunes y poco atractivos por las limitaciones. Con estas nuevas opciones estoy seguro que hay mucho por ver en los diseños y templates que diseñe la comunidad.
#power bi#powerbi#power bi tutorial#power bi tips#power bi training#power bi jujuy#power bi cordoba#power bi argentina#power bi desktop#ladataweb#uxui#data viz#data visualization
0 notes
Text
[Fabric] Funciones de datos
Llega una fabric conference y las actualizaciones no paran. Junto con muchos anuncios que suceden, han liberado un nuevo item o tipo de contenido dentro del ecosistema de Fabric.
En esta oportunidad vamos a escribir sobre lo nuevo, Fabric User Data Functions. ¿Qué son? ¿Qué hacen? ¿Cómo las creo? ¿Qué integraciones tiene? y mucho más
Esta nueva funcionalidad tiene sensación y similitudes antes vistas, pero antes de relacionar por donde viene la mano, hagamos como nos gusta en LaDataWeb y veamos la definición de microsoft.
Las funciones de datos de usuario de Fabric son una plataforma que permite hospedar y ejecutar aplicaciones en Fabric. Esto permite a los desarrolladores de datos escribir lógica personalizada e insertarla en su ecosistema de Fabric. Esta característica admite el runtime de Python 3.11 y permite usar bibliotecas públicas de PyPI.
Puede que el concepto suene confuso. Vamos a hacerlo más simple. Son, básicamente, un espacio serverless para ejecutar código python. Cualquier similitud con Azure Functions es pura coincidencia. Quienes conocen el concepto de azure functions puede que ya sepan por donde viene la mano.
Las functions pueden conectarse con orígenes de datos de Fabric de forma nativa. Así mismo se integran a Pipelines y Notebooks. Podemos escribir código en una function desde el portal de Fabric online o incluso con la extensión de Visual Studio Code.
¿Por qué usarlas?
No creo que haya obligación de usarlas pero podrían ayudarnos en algunos aspectos. Veamos algunos:
Optimización de código: las funciones nos podrían ayudar a reducir duplicidad de código. Podrían contener sentencias de lógicas de negocio o transformaciones comunes.
Integración con pipelines y notebooks que podrían ayudar a optimizar procesos.
Permite integración con externos: podemos invocar las funciones desde aplicaciones cliente externas mediante puntos de conexión REST.
¿Cómo?
Sencillamente buscando la opción en nuevo item:

En caso que no veas el elemento, recuerda que para comenzar a usarlas necesitamos permitirlo en el tenant puesto que estan en preview:

Si aún así no puedes verla, es posible que aún no este disponible la característica en tu región. Puedes chequear esa info aqui: https://learn.microsoft.com/en-us/fabric/admin/region-availability
Una vez permitido, podremos crearlo. Similar a Az Functions, al crear el elemento tenemos creado un espacio de gestión de funciones. Estilo Function Apps. El mismo rápidamente nos indica que podemos configurar conneciones y agregar librerías de python.

Tras crear una nueva función vereos el código por defecto.

Lo que ejecutemos dentro de @udf.function() def hello_fabric será como nuestro main de ejecución. En este caso hello_fabric es el nombre de la función. Podemos crear funciones def por fuera, importar librerías y acomodarnos en dicho espacio de código.
Una vez creada nuestra función que podría transformar datos o ejecutar un proceso simple, damos en "Publish".
Publicada la función podremos ejecutarla desde un código externo o en una integración con Pipelines y notebooks.
1- Código externo: fijense que hay un botón Generate invocation code. Al seleccionarlo, se abrirá un código de ejemplo para ejecutar la función.

2- Pipelines: dentro de los pipelines de Data Factory encontraremos a "Functions" como una actividad más de las posibilidades que nos brinda la herramienta.

3- Notebooks: para poder utilizarla en notebooks necesitamos importar NotebookUtils (antiguo MSSparkUtils). Luego podremos llamarlas con la siguiente sentencia:
myFunctions = notebookutils.udf.getFunctions('UDFItemName') # Get functions from UDF within the same workspace myFunctions = notebookutils.udf.getFunctions('UDFItemName', 'workspaceId') # Get functions from UDF across different workspace
NOTA: para más información de la librería acceder aquí: https://learn.microsoft.com/en-us/fabric/data-engineering/notebook-utilities#user-data-function-udf-utilities
Antes de terminar repasemos algunas consideraciones:
Fabric Functions necesitan de una capacidad de Fabric para crearse y ejecutarse. Su computo aparece en Capacity Metrics Apps.
En preview limitadas por regiones.
Solo son editables por sus dueños/owners. Si queremos tomar posición podemos repasar esta doc: https://learn.microsoft.com/es-es/fabric/fundamentals/item-ownership-take-over
Límites del servicio:

Conclusión
Seguramente esta feature tiene mucho más por mostrarnos cuando sea lanzada definitivamente. Espero que les sea de interés y ayude en procesos de datos que estén desarrollando.
#fabric#microsoftfabric#fabric tutorial#fabric tips#fabric training#power bi service#data engineering#fabric jujuy#fabric argentina#fabric cordoba#ladataweb#fabric functions
0 notes
Text
[PowerBi][Fabric] Scanner API
Antes de la existencia de una área de administración que nos permita navegar recursos, solía estar el problema de "que hay en mi tenant?". Si no habíamos gobernado desde el primer momento, puede que se creara mucho más contenido del esperado.
En ese entonces Microsoft creo un request de API que permite entrar al máximo nivel de detalle de absolutamente todo lo que hay en el tenant. Este request tiene la más profundidad que lo que podemos encontrar en reportes y herramientas automáticas.
En este artículo, vamos a mostrar como obtener los resultados más finos de el total contenido desplegado en el tenant usando la librería de python para la power bi rest api, SimplePBI.
Vamos a comenzar escribiendo como Microsoft define a la Scanner API:
La Scanner API es parte de la Power BI Rest API de administración. Permite a los administradores recuperar de manera eficiente y automática información valiosa sobre los activos de Power BI de su organización, como inventario, metadatos y linaje. A su vez, pueden aprovechar esta información para sus propias soluciones personalizadas.
La API fue desarrollada con el objetivo de mejorar la eficiencia y el rendimiento del escaneo de Power BI (ahora también Fabric), de manera que pueda soportar grandes cantidades de activos de datos, mientras sigue cumpliendo con las prácticas de seguridad de las organizaciones. El Scanner soporta la autenticación de Service Principal y el escaneo incremental, y devuelve metadatos como el estado de respaldo, la etiqueta de sensibilidad, etc.
Dado que la API contiene un gran volumen de información, vamos a necesitar ejecutar más de un request y prerequisitos. Vamos a asumir que usaremos Service Principal. Para iniciarnos debemos registrar una app en Azure con los permisos sin permiso puntual (a menos que autentiquemos con master user que exigiría Tenant.Read.All o Tenant.ReadWrite.All) y permitirle a Fabric el paso de Service Principals. Si no sabes hacerlo podes leer aqui. Luego hay que permitirle en el mismo admin portal de Fabric que el service principal pueda leer la admin API como indica la imagen

Con dicha configuraciones podemos comenzar los cuatro pasos de ejecución. Lo primero que vamos a hacer es autenticarnos. Para ello necesitaremos TenantID, AppID o ClientID y el Secret Value. Importaremos la librería y comenzaremos.
# Import library from simplepbi import token from simplepbi import admin # Service Principal auth tok = token.Token(tenant_id, app_client_id, None, None, app_secret_key, use_service_principal=True) # Creating admin category request ad = admin.Admin(tok.token)
Con "ad" podremos ejecutar acciones que correspondan a esta doc: https://learn.microsoft.com/en-us/rest/api/power-bi/admin
En la misma podremos encontrar 4 requests correspondientes a workspace info que nos ayudaran en el paso a paso.
1- Obtener los espacios de trabajo que deseas rastrear
Lo primero será recolectar las áreas de trabajo que queres escanear para obtener la información fina. La sugerencia de proceso será usar un request que permite traerlos a todos, o filtrar por desuso pasado una fecha o quitar los personales. El request es el siguiente:
response = ad.get_modified_workspaces_preview(excludePersonalWorkspaces=True, modifiedSince=None)
Obtiene una lista de IDs de áreas de trabajo en la organización. Debido a que el siguiente request en el proceso solo pueden manejar 100 grupos por solicitud, hemos adaptado la respuesta del request para que este primer paso sea una lista de listas. La respuesta es una lista de listas con 100 áreas por lista. Esto quiere decir que si tenemos 226 áreas, el resultado será una lista que tiene dentro 3 listas, una lista con 100, otra lista con 100 y la última lista con 26 áreas de trabajo. Automáticamente preparará la lista de listas para que puedas recorrer los siguientes pasos por ti mismo. Recuerda que puedes verificar la longitud de una lista con el siguiente código:
# Verificar el número de listas de 100 espacios de trabajo. len(response) # Mostrar áreas de trabajo, [0] es un ejemplo de la primera lista de 100 response[0]
Más información del request: https://learn.microsoft.com/en-us/rest/api/power-bi/admin/workspace-info-get-modified-workspaces
2- Delimitar información del área de trabajo
Seleccionadas las áreas, vamos a delimitar la granularidad de información, es decir, cuanto detalle realmente queremos.
scan_id = ad.post_workspace_info(response[0], lineage=True, datasourceDetails=True, datasetSchema=True, datasetExpressions=True, getArtifactUsers=True)
datasetSchema: Si quieren devolver el esquema del conjunto de datos (tablas, columnas y medidas). Si ponen el parámetro en verdadero, deben habilitar completamente el "análisis de metadatos" para que se devuelvan los datos. Esta configuración se encuentra en el portal de administración en apartado de inquilino/tenant. Buscar la opción relacionada a análisis de metadatos.
datasourceDetails: Si quieren devolver los detalles del origen de datos
getArtifactUsers: Si quieren devolver los detalles de usuarios para elementos de Power BI (como un informe o un panel)
lineage: Si quieren devolver información de linaje (flujos de datos ascendentes, mosaicos, ID de origen de datos)
El request devuelve un ID de escaneo (scan_id) en formato UUID. Inicia una llamada para recibir los metadatos de la lista solicitada de áreas de trabajo. El parámetro de áreas de trabajo es una lista de máximo 100 espacios de trabajo. Puedes ejecutar esta solicitud recorriendo la lista de listas de la respuesta anterior. De manera predeterminada, devolverá todos los datos posibles. Puedes cambiar a false los parámetros en el detalle del método que no desees obtener o para mejorar la performance de la llamada.
3- Obtener el estado del escaneo
ad.get_scan_status_preview(scan_id)
Obtiene el estado del escaneo para la llamada solicitada recientemente. Antes de obtener toda la estructura para los 100 espacios de trabajo, necesitamos pedir a la API que apruebe el escaneo. Esta solicitud devolverá el mismo ID y un estado. Si la respuesta para el estado es "Succeeded" (Exitoso), podrás completar la solicitud del escáner en el último paso. Si no, espera e inténtalo más tarde.
4- Obtener el resultado del escaneo
ad.get_scan_result_preview(scan_id)
Obtiene el resultado del escaneo para el scan_id especificado. Esta solicitud finalmente devolverá un enorme diccionario de Python con todos los datos que solicitamos para los 100 espacios de trabajo listados en el escaneo. La respuesta se vería así:

Podemos ver pintada cada categoría de items que recorrería por cada workspace desplegando más o menos información, según los parámetros del segundo paso.
NOTA: Fabric se está incorporando a esta dinámica mostrando sus items como salen en reports. Ahi encontraría algo como "warehouses" o "SQLAnalyticsEndpoint".
Así llegamos al final del artículo en donde aprendimos como relevar toda la información más fina de lo que hay creado a nivel organización. Esto puede ser de gran utilidad para automatizar relevamientos por secciones o en totalidad y armar nuestros propios informes/aplicaciones que lean la información a modo de monitoreo.
#power bi#powerbi#power bi argentina#power bi cordoba#power bi jujuy#power bi tutorial#power bi training#power bi tips#ladataweb#fabric#microsoft fabric#power bi rest api python#simplepbi
0 notes
Text
youtube
Power Platform Bootcamp Buenos Aires
Evento de la comunidad Argentina con grandes sesiones.
El Poder de Python y R en Power BI por Mike Ramirez
Transforme datos con buenas prácticas de Power Query por Ignacio Barrau
Agentes en Power Platform: El Futuro de la IA por Andrés Arias Falcón
Power Virtual Agent - Charlando con tu base de datos por Matias Molina y Nicolas Muñoz
¿Por qué deberían los desarrolladores automatizar? por Mauro Gioberti
Microsoft Fabric + Power BI: Arquitecturas y Licenciamiento - Todo lo que necesitas saber por Gonzalo Bissio y Maximiliano Accotto
El auge de los copilotos: De la adopción del low-code a la maestría en análisis de datos por Gaston Cruz y Alex Rostan
Libérate de las Tareas Repetitivas: Potencia tu Talento con Power Apps y Power Automate por Anderson Estrada
Introducción a Microsoft Fabric - Data analytics para la era de al Inteligencia Artificial por Javier Villegas
Tu Primer despliegue con PBIP Power BI Control de versiones CI/CD GIT en GITHUB por Vicente Antonio Juan Magallanes
Espero que lo disfruten
#power bi#power platform#powerbi#power bi argentina#power bi cordoba#power bi jujuy#power bi tips#power bi tutorial#power bi training#fabric#microsoft fabric#dataops#power bi cicd#Youtube
0 notes
Text
[PowerBi] Experiencia de usuario mejorada con Field Parameters
No son un lanzamiento nuevo y ya llevan buen tiempo desde sus inicios. Aún si son un tema tan importante en el manejo de experiencia de usuario que quisimos reflotar el tema para conversar nuevamente de esta característica.
En este artículo repasaremos el concepto de los fields parameters y veremos tres formas en que podemos utilizarlos para construir navegaciones que abarquen más conceptos manteniendo una vista limpia para el usuario.
Comencemos con un contexto teórico como nos gusta comenzar aquí en LaDataWeb. Veamos como define Microsoft a esta feature:
Los field parameters (en español llamados parámetros de campo) permiten a los usuarios cambiar dinámicamente las medidas o dimensiones que se analizan dentro de un informe. Esta característica puede ayudar a los lectores de informes a explorar y personalizar el análisis del informe al seleccionar diferentes medidas o dimensiones en las que están interesados.
Dicho de otras le permiten al usuario intercambiar columnas y medidas de una visualización que contenga el parámetro que será reflejado como filtro.
Para poder comenzar a trabajar con ellos, primero debemos activarlo puesto que es una característica de versión preliminar (preview):

Comencemos entonces creando un parámetro tipo "Field/Campo" al cual le asignaremos columnas o medidas.

Cuando la creación termina y tiene éxito. Nuestro modelo semántic tendrá una nueva tabla con una nueva columna. Si revisamos dicha creación podremos apreciar su código DAX:

Aquí podríamos editar cualquier cambio de nuestros parámetros deseados, como por ejemplo, cambiar el nombre de la columna o medida.
Fíjense en la foto de la creación, también nos alerta is queremos introducir un Slicer/filtro en la página. Esto contendrá un filtro con cada uno de los valores de los parámetros.
Para poder construir algo entorno a los parámetros, arrastraremos la columna de la tabla del parámetro. La visualización reflejará el dato de lo que contiene el parámetro, es decir el mismo resultado que la columna o medida suelta. En este caso, una tabla de tres columnas con valores. ¿De que nos sirve tener un campo que muestra varios? pues que ese campo en una visualización de slicer nos mostraría los nombres de esa DAX para seleccionar. Tal como muestra la siguiente imagen:

Como pueden ver, ambas tienen la columna del parametro, pero una es tabla y la otra slicer. Cuando la usamos en slicer nos muestra el nombre de los campos para filtrar, pero si la usamos en otra visual, muestra resultado de datos.
Esto vuelve muy dinámica la exploración de datos. Veamos tres ejemplos.
1) Cambio de medida en visual
El ejemplo más frecuente que apareció en el lanzamiento fue intercambiar medidas en un gráfico. En este caso usaremos un gráfico de línea en el tiempo donde la serie de tiempo quiere ser analizada por distintos cálculos. En lugar de construir tres gráficos o tener las tres líneas en la misma gráfica, podemos intercambiar ese valor con un parámetro. Para mejorar el efecto visual podemos cambiar el filtro/slicer como botones tipo pestañas del gráfico

2) Seleccionar de campos de una tabla
Otra tradicional experiencia amada por los usuario tradicionales que son fanáticos de las tablas, consiste en permitirles delimitar las columnas que verán en sus tablas. Esto da una percepción de selfservice para el análisis a quienes solo quieren ver tablas. Entonces, para determino análisis, podríamos delimitar muchas columnas categóricas y las principales medidas a controlar. Podríamos mejorar la experiencia de usuario con un botón que abra y cierre esa opción:

3) Cambio de leyenda en una visual
No todo son selecciones de campos y cambios de números. También podemos cambiar otras percepciones de las visualizaciones como las leyendas. Podríamos tomar un gráfico de barras apiladas o una torta para rotar los colores y categorías que involucran. Idealmente dando una selección única de campos mejoraríamos la experiencia

En este último caso podemos apreciar que se puede modificar el código para ajustarlo a nuestras necesidades. En este caso pasamos a español las categorías cambiando DAX:
Filter Granularity = { ("Educación", NAMEOF(Customer[Education]), 0), ("Estado Civil", NAMEOF(Customer[Marital Status]), 1), ("Ocupación", NAMEOF(Customer[Occupation]), 2), ("Género", NAMEOF(Customer[Gender]), 3) }
Conclusión
Asi como éstas fueron construidas hay muchas más que van que pueden inventarse para mejorar la interacción del usuario. Podríamos tener un filtro que filtre otro filtro para reducir el espacio que ocupan. Esta en nuestra imaginación ese límite y en la comunidad. Como siempre puede descargar el reporte con los ejemplos de mi GitHub.
#powerbi#power bi#power bi argentina#power bi cordoba#power bi jujuy#power bi tutorial#power bi training#power bi tips#power bi desktop#ladataweb#uxui
0 notes
Text
Migrando capacidad Premium a Fabric
En el último tiempo son muchas las compañias cambiando de capacidad para aprovechar al máximo la nueva tecnología que Microsoft nos brinda. Este cambio se vuelve cada vez más necesario puesto que está anunciado que Premium no podrá renovarse y es tiempo de dar el salto hasta Fabric.
En este artículo describiremos estrategias y alternativas para migraciones de este tipo dentro de un mismo tenant y que podemos hacer frente a tenants distintos.
Si aún no estas al tanto de que es Fabric. Te invito a dar una vuelta por este artículo. Para organizarnos mejor vamos a separar este artículo cuando es en mismo tenant o separados.
Migrar en un mismo tenant
La palabra migrar es la usada en el mercado pero sinceramente no creo que esté alineada con la necesidad real. Porque digo esto, porque en realidad no migramos, sino que ajustamos las áreas de trabajo a otra capacidad. Sería como cambiar el almacenamiento de un código. Entendiendo que cambiarnos de Premium a Fabric es en realiad reasignar la capacidad del área de trabajo es que vamos a proceder.
Algunos detalles importantes a tener en cuenta. La región de nuestra capacidad tiene importancia. Si bien existe una opción en el portal de administración para manipular capacidades multiregión, recomiendo crear el Fabric dentro de la misma región que Premium para evitar otras configuraciones adicionales. Así mismo, el formato de almacenamiento de los modelos semánticos puede generar errores. El formato large puede ocacionar errores dependiendo de la complejidad del modelo, a diferencia del small que está más limitado e igual en ambos casos. Adicionalmente a las recomendaciones duras, agrego una más organizativa que refiere a aprovechar este tiempo de proceso para validar que las áreas de trabajo en la capacidad "deban" estarlo y aprovechar de remover de la capacidad las que no se usan, nunca debieron estar o podrían estar en pro (puesto que su adiencia son todos usuarios con licencia).
Comencemos con las alternativas:
1) Manual uno por uno
Permisos requeridos, basta con ser administrador de las áreas de trabajo premium y administrador de capacidad Fabric.
Tal vez la forma más engorrosa, pero no nos dejemos engañar. Si tenemos pocas areas de trabajo, puede ser muy eficiente para aprovechar de visualizar el contenido del área antes de cambiar su capacidad. Para realizar este proceso, abrimos un área de trabajo dirigiendonos a su configuración. Allí encontramos una pestaña referida a licencias para cambiarlo.

2) Manual en lote
Permisos requeridos, cuenta de usuario con rol Fabric Administrator y Administrador de capacidad Fabric. En caso que la migración sea directa, es decir que todas y cada una de las áreas de trabajo y sus ítems de Premium van a pasar a Fabric; ésta es una gran opción.
Esto nos permitirá migrar la totalidad de áreas en pocos clicks. Para ello, nos dirigimos a Workspaces dentro del portal de administración y filtramos las áreas por su tipo de capacidad:
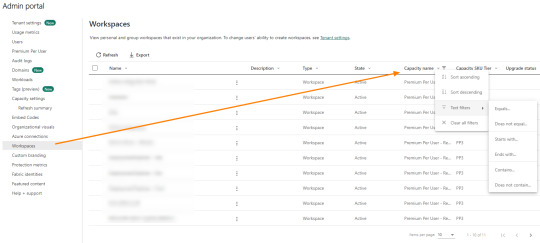
Una vez que la lista de workspace está filtrada correctamente, vamos a seleccionar todos con el cuadradito junto al nombre y aparecerá el botón para reasignar capacidad:
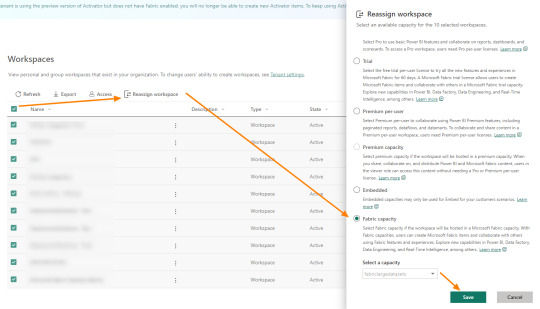
Tengamos presente que eso cambiará las áreas que vemos en la lista. Si estamos viendo 10 resultados, solo serán esos 10 seleccionados. Si tenemos 1000 áreas de trabajo, podemos poner que muestre 100 resultados esta vista y ejecutar esta acción 10 veces para mover lotes de 100 áreas de trabajo.
3) Script API
Permisos requeridos, cuenta de usuario con rol Fabric Administrator y una App Registrada en Azure. En caso de utilizar service principal, hay que adicionar que dicha app tenga los permisos para que utilice la Fabric API en el admin portal. Esos detalles pueden leerlos aqui. Experiencia en desarrollo con PowerShell, Python (Librería SimplePBI) u otro lenguaje de programación y manejo de API. Dependiendo el login efectuado necesitaremos administrador de capacidad Fabric para la App o el usuario.
Esta metodología aplica particularmente para cuando las áreas que vamos a migrar tiene condiciones más complejas. Con esto nos referimos a que hicimos un análisis de las áreas que pertenecen al premium y no todas serán migradas. Ya sea porque el contenido no era apropiado, nunca debió estar en premium, no se utiliza o queremos optimizar el contenido en la nueva capacidad, con esta opción podríamos concretarlo. El primer paso sería relevar éstas áreas de trabajo y armar una lista de IDs y nombres de áreas. A partir de esto la idea es escribir un script que itere las áreas de trabajo reasignado su capacidad. Dependiendo si vamos a autenticar la App Registrada en Azure como Service Principal o con Master User (usuario y contraseña con permiso Fabric Administrator).
Master User: en este caso podremos ejecutar la reasignación desde la categoría de la API de administración: https://learn.microsoft.com/en-us/rest/api/power-bi/admin/capacities-assign-workspaces-to-capacity
Service Principal: como no pueden ejecutar acciones de administración, como pre requisito, debemos asignar la App como Admin de las áreas de trabajo a migrar. Por ello, podemos hacerlo manualmente o con un script que haga el login Master User y una acción Group AddUserAsAdmin. Recien entonces, podremos ejecutar la reasignación desde la categoría de la API de capacidad: https://learn.microsoft.com/en-us/rest/api/power-bi/capacities/groups-assign-to-capacity
Lo más recomendado sería utilizar la autenticación Master User dado que mientras no podamos ejecutar acciones de administración con Service Principal, se vuelve largo el proceso y si ya iteramos para asignar un service principal al área de trabajo a migrar, podríamos estar usando el mismo script para ejecutar la reasignación.
NOTA: Tengamos en cuenta que la autenticación de la API por master user no funciona con MFA. Si tenemos MFA estaremos obligados a utilizar los PowerBi cmdlets de Powershell.
Migrar entre dos tenant distintos
Aquí el proyecto se complica. Hoy no hay herramientas que provean esta solución de manera ágil y dependiendo la cantidad y tipo de ítems de nuestro premium, resultará en cuanto porcentaje de migración realmente se puede efectuar.
El primer detalle a tener en cuenta en este caso es referido a tipo de ítems. ¿Utilizamos solo reportes de PowerBi? ¿Tenemos más contenido como Dataflows gen1, paneles, etc? ¿Se están usando ítems de fabric como notebooks, pipelines o warehouses?
Dependerá de las respuestas a estas preguntas sobre cuan posible es migrar y cuanta manualidad tendríamos. Antes de comenzar recalco que no existe una metodología que soporte esta operación. Es por esto que no podremos migrar el 100% de los casos y tampoco podremos librarnos de trabajos manuales.
Veamos alternativas:
1) Migración manual:
Permisos requeridos, licencia de PowerBi pro en ambos tenants y administrador de capacidad Fabric del nuevo. Rol de miembro o administrador de área de trabajo origen. Permiso de creación de área de trabajo destino.
No se puede dejar de mencionar que el trabajo manual es una opción. Considero crítico para operar de este modo, validar que aquello que deba migrarse sea realmente necesario y se use. No migrar aquello de lo que podemos presindir considerando que es muy laborioso. Crear una área en el nuevo tenant, asignar su capacidad. Descargar los archivos .pbix, exportar json de dataflows, copiar códigos de notebooks en tenant origen y publicar, importar o pegar en tenant destino. Ésta forma es muy lenta pero garantiza mantener exactamente cada componente. Consideremos que algunos componentes como los Paneles, no puede exportarse y solo queda recrearlos.
2) Script API
Permisos requeridos, cuenta de usuario con Power Bi PRO y una App Registrada en Azure. En caso de utilizar service principal, hay que adicionar que dicha app tenga los permisos para que utilice la Fabric API en el admin portal. Esos detalles pueden leerlos aqui. Experiencia en desarrollo con PowerShell, Python (Librería SimplePBI) u otro lenguaje de programación y manejo de API. Ya sea el usuario o el Service Principal deben formar parte del área de trabajo origen. Permiso de creación de áreas de trabajo y administrador de capacidad Fabric en nuevo tenant.
Aunque ésta pueda resultar la forma más atractiva, cabe mencionar que no todo los ítems de las áreas de trabajo se pueden exportar. Puede ser una muy atractiva opción para migraciones basadas en reporte de PowerBi, dado que exportar reportes e importarlos en otro tenant son operaciones factibles en la Rest API. Al iterar las áreas de trabajo en el primer tenant podríamos tomar el nombre, crearlas en el nuevo con la app/usuario como administrador, asignarles capacidad y comenzar a poblarlo. Todo con API. En caso de contar con ítems de Fabric, poco a poco va siendo posible obtenerlos y recrearlos con la API.
3) Manual/Script con repositorio git.
Permisos requeridos dependen si será manual o con script. Cuenta de usuario con Power Bi PRO y una App Registrada en Azure. Experiencia en desarrollo con PowerShell, Python (Librería SimplePBI) u otro lenguaje de programación y manejo de API. El usuario debe formar parte del área de trabajo destino. Permiso de creación de áreas de trabajo y administrador de capacidad Fabric en nuevo tenant. Acceso al repositorio con AD o Personal Access Token.
Dependiendo si nuestros desarrollos ya estaban ordenados dentro de un repositorio o no, delimitará cuan complejo será el proceso. Si no tenemos nuestro premium integrado a repositorios, lo primero será crear un repositorio, organizarlo por carpetas según las áreas de trabajo y sincronizarlo. Realizado el prerequisito de un origen integrado a un repositorio, podremos proceder.
Por un lado, la migración manual. Ingresar al nuevo tenant. Crear una área de trabajo. Asignarle capacidad Fabric e integrarlo a su correspondiente carpeta del repositorio. De esta forma todos los ítems del repositorio serán parte del área de trabajo.
Por otro lado, el proceso podría utilizar un script para automatizar acciones. La iteración de la migración sería por carpetas de workspace en el repositorio. La idea es crear un área de trabajo con el mismo nombre, asignarse como administrador y asignar la capacidad. Hasta ahi como siempre. Lo nuevo sería conectar el repositorio y hacer un update (pull) con la API de Fabric logueando con Master User (no tiene permitido service principal la categoría git de la API). De esa forma, aprovechando el repositorio, se irían creando y poblando las áreas con sus ítems siempre y cuando sean versionables. Aqui tenemos limitación obligada a master user que podríamos tener MFA y nos impediría seguir. La alternativa sería realizar un deploy desde el repositorio al área de trabajo, sin embargo la dificultad para construir ese request para cada ítem de PowerBi es muy alta. Lo que generaría controversia de si demoraremos más en hacer el proceso automatico que manual.
NOTA: recuerden que los repositorios permitidos son Azure DevOps o GitHub. Pueden leer más sobre la integración en los hipervínculos.
Conclusión
Así llegamos al final del artículo con muchas opciones de migración premium o pro a fabric. Recordemos que la forma más viable es hacerlo dentro del mismo tenant y que si es a separados hay mucha más complejidad. Seguramente, no son las únicas formas. Así como podemos usar la API hoy son cada vez más las operaciones que podemos ejecutar con Semantic links y sempy en Fabric notebooks. Repaso también que no todo componente es migrable, configuraciones de CI/CD o deployment pipelines podrían causar un verdadero dolor de cabeza entre distintos tenants. Espero que esto los ayude a no sufrir tanto las migraciones.
#powerbi#power bi#power bi premium#fabric#microsoft fabric#fabric tutorial#fabric training#fabric tips#fabric capacity#fabric jujuy#fabric argentina#fabric cordoba#ladataweb#simplepbi
0 notes
Text
[PowerBi] ¿Qué es TMDL?
Hace un tiempo que Microsoft ha anunciado TMDL. Puede que muchos se preguntaran qué es y porque aún no vemos cambios. La respuesta pasa porque es un concepto que estaba más de fondo, más en el código.
Hace tiempo que la comunidad de Power Bi traia algunos dolores no resueltos con desarrollos complejos. Pasando por el versionado y repositorio de código hasta la replicación de lógicas o formatos complejos. Este nuevo concepto puede ayudarnos.
Dado que a partir del último release de PowerBi Desktop vamos a poder visualizarlo en una vista propia, hemos decidido escribir este artículo para comprender de que se trata y porque es importante.
Vamos a comenzar como gusta hacer aqui en LaDataWeb con su definición de libro directa de Microsoft.
El lenguaje de definición de modelos tabulares (TMDL) es una sintaxis de definición del modelo de objetos para los modelos de datos tabulares en el nivel de compatibilidad 1200 o superior.
En palabras más simples es código. Un lenguaje que podemos disponibilizar para los modelos tabulares modernos. Ahora, ¿por que querriamos disponibilizarlo? por las razones antes mencionadas. Si tenemos activado el uso de este código, entonces podríamos resguardar mucho mejor un historial de versiones, resolver conflictos entre trabajos en paralelo en un repositorio; replicar conceptos, lógicas o formatos, etc.
¿Cómo se relaciona con PowerBi Desktop?
¿Recuerdan que hace un tiempo hablabamos de "Guardar como proyecto" a un archivo de Power Bi en este artículo? Bueno, ahi estabamos dando los primeros pasos para desagregar un pbix en archivos de código. En ese momento el formato por defecto no era muy amigable y tenía ciertos conflictos para interpretarlo o combinarlo en desarrollos concurrentes. Por esta razón se crea TMDL para facilitarnos la lectura, comprensión y uso.
Veamos su estructura que busca ayudarnos:

Lo primero es que podremos leer a un desarrollo de PowerBi en archivos de código. Antes de asustarnos sepamos que puede abrirse desde Power Bi Desktop como siempre o con VScode y una extensión TMDL.
A la izquierda en la imagen podemos apreciar la estructura de nuestro archivo de PowerBi desagregada. Dividida en reporte y modelo semántico. Así mismo detecta conceptos como cultura, perspectiva, roles o tablas. Todo materia de cosas que ya hemos visto en el mismo programa. Estos archivos de código estan por conceptos. Por ejemplo la imagen muestra un archivo de tabla. La estrcutura del archivo esta siempre bajo definiciones de la tabla como nombres, medidas o columnas a la izquierda y en un color y sus características o propiesdades con una sangría que ayuda a dividir a quien pertenece. Si quieren ver el detalle de las sentencias en fino pueden pasar por aqui: https://learn.microsoft.com/es-es/analysis-services/tmdl/tmdl-overview?view=asallproducts-allversions
¿De que nos sirve este código? ¿Puedo seguir desarrollando igual que siempre?
Lo cierto es que quien desarrolla puede seguir igual que siempre. La diferencia pasa por nuevas opciones. Un desarrollador interiorizado con esto, podrá copiar y replicar este código. Código que tiene propiedades, formatos, lógicas, visualizaciones configuradas, etc. Antes tal vez era imposible pensar en copiar valores de una visualización entre dos archivos de power bi, o pensar en copiar medidas, inclusive roles. Nos la pasabamos recreando en lugar de copiar. Imaginen si la comunidad comienza a compartir patrones de este código como por ejemplo convertir un gráfico de lineas en uno de puntos o de barras redondeadas como ya se ha visto en videos al alcance de un copiar y pegar.
Conflictos en equipo
Este concepto no solo pasa por la replicación y desarrollo basado en código. También añade una más simple solución al momento de tratar conflictos de código entre dos desarrollos. Ya habíamos mencionado en posts anteriores que guardar como proyecto ayudaba a que dos desarrolladores pudieran usar un repositorio, hacer pull del contenido, modificarlo y devolverlo al ambiente apropiado. Sin embargo, cuando dos de ellos manipulan conceptos similares aparece un conflicto. Por ejemplo, los dos modifican la misma medida o agregan medidas en la misma tabla. Con TMDL, podemos identiciar fácilmente la diferencia y hasta combinar los códigos para que convivan a diferencia de la modalidad antigua TMSL (basada en json). Con todo esto queremos aclarar el beneficio pero no queremos entrar en tanto detalle técnico de merges porque podríamos escribir varios artículos del tratamiento.
Primeros pasos
Para dar inicio y comenzar a estudiar este código, recomiendo leerlo sobre archivos de PowerBi con los que estén familiarizados. Lo primero será guardar nuestro PowerBi como proyecto. Luego tenemos dos métodos para ver el código.
1- Visual studio code extensión TMDL
Para quienes les gusten más las pantallas negras y vivir del código seguramente encontrar este espacio más familiar. Basta con instalar la extensió: https://marketplace.visualstudio.com/items?itemName=analysis-services.TMDL

2- Power Bi Desktop TMDL view
De momento está en preview, lo que significa que tenemos que activiarla en las opciones de Desktop. Una vez activada veríamos un nuevo icono a la izquierda. Solo con abrirlo y arrastrar un objeto a su canva podremos comenzar a ver el código:

Conclusión
Este tema va a revolucionar los desarrollos de la reportería. Tanto si nos sumamos a la ola como si no lo hacemos, indiscutiblemente es un concepto que va a dirrumpir el mercado con sus posibilidades de generar scripts para la comunidad de reutilización y trabajar en equipo comodamente. Como un beneficio adicional les comparto que si usamos código, podemos usar Github Copilot que ayudaría bastante en los desarrollos.
#power bi#powerbi#power bi argentina#power bi cordoba#power bi jujuy#power bi tutorial#power bi training#power bi tips#power bi desktop#ladataweb#power bi TMDL#TMDL
0 notes
Text
[Fabric] Protegé la experiencia de usuarios en una capacidad
Cada día más y más personas se suman a la ola de Fabric. Gracias a su amplia variedad de planes permite a pequeñas y grandes empresas nutrirse de sus características desde tempranas etapas. Algo primordial al momento de construir servicios o contenido en un recurso dedicado es monitorear esa capacidad.
¿Por que lo hacemos? porque necesitamos asegurarnos que sus recursos sean viables y no se sobrecargue. Si hay una sobrecarga todo se vuelve lento, la experiencia de usuario cae dado que no logramos dar respuesta a sus peticiones por fallas o demoras.
En este artículo mostraremos como mantener la experiencia de usuario sana aunque los procesos operativos colapsaran.
Hace unos días escribimos sobre la importancia de mantener una capacidad sana y hemos mencionado formas de montiorearla/administrarla. Ambos artículos son una gran fuente de aprendizaje para velar por un espacio dedicado que respondas a las necesidades de los usuarios con los recursos disponibles.
En estos artículos hacemos mención sobre dos categorías de operaciones que utiliza la capacidad. Hablamos de operaciones background e interactive. Tal como su nombre lo indica una refiere a todos los procesos bach, código, calendarizados, flujos, etc. Mientras que interactivo vela por la respuesta de los modelos dentro de los informes para usuarios finales. En enero 2025 microsoft fabric incorporó una excelente característica que nos ayude a poner límites porcentuales a operaciones background.
La característica se llama Surge Protection, y la definición en palabras microsoft:
"La protección contra sobrecargas ayuda a limitar el uso excesivo de su capacidad al limitar la cantidad de cómputo consumido por los trabajos en segundo plano. Puede configurar la protección contra sobrecargas para cada capacidad. La protección contra sobrecargas ayuda a prevenir el estrangulamiento y los rechazos, pero no es un sustituto de la optimización de la capacidad, el escalado vertical y el escalado horizontal. Cuando la capacidad alcanza su límite de cómputo, experimenta retrasos interactivos, rechazos interactivos o todos los rechazos incluso cuando la protección contra sobrecargas está habilitada."
Muy bien define que esta es una característica que se suma a ayudarnos. No va a reemplazar las prácticas anteriores.
¿Cómo funciona?
Ahora disponemos de dos parámetros nuevos para definirle a las capacidades. Por un lado el porcentaje máximo de la capacidad que pueden alcanzar las operaciones de segundo plano (Background Rejection threshold) y por otro el porcentaje al cual debe bajar el procesamiento para retomar las operaciones de segundo plano. Tomemos un ejemplo para explicarlo mejor (Background Recovery threshold)
LaDataWeb ha configurado estos parametros delimitando 70% para el rechazo de operaciones y 40% para la recuperación. Elegimos 70% porque conocemos la actividad de interactividad de los usuarios y casi siempre ronda entre 17% y 20% según nuestra Fabric Capacity Metrics app. Entonces sabemos que resguardando 30% estaremos seguro y limitamos 70% a las de segundo plano. Podríamos pensarlo como que hemos partido el 100% de la capacidad limitando al back a usar hasta cierto punto.
El día comienza a las 8 am cuando la gente inicia la jornada tradicional de trabajo y corre más operaciones de lo debido manualmente logrando que el background llegue a 70%. Surge Protection al llegar al 70%, continuará las operaciones que este "En ejecución", pero comenzará a rechazar todas las operaciones nuevas que intenten correr. ¿Como sabremos que rechazó? podran saberlo al ejecutar porque verán así:

O en la Fabric capacity metrics app en el nuevo apartado de "System events":

Esto significa que por 24 horas Fabric intentará reducir la capacidad de background rechazando nuevas peticiones. Los usuarios que dan uso con operaciones de interactividad dispondran de 30% de la capacidad. Si su uso es el promedio especulado, no se verían afectados en performance en sus operaciones. Lo cual permite a la empresa seguir operando.
¿Hasta cuando estará bloqueado el back? seguirá rechazando peticiones hasta que la capacidad baje hasta un 40% como lo fue especificado en el parametro de recuperación de capacidad.
¿Cómo configurarlo?
Abrimos el menú de configuración -> Admin portal -> opciones de capacidad. Seleccionamos la capacidad deseada para configurarlo y prendemos la opción de Surge Protection. Luego delimitamos los valores como el ejemplo de la imagen:

Así llegamos al final del artículo donde revisamos una excelente característica que nos ayuda a mantener la experiencia de los usuarios aún cuando los procesos estan en situaciones críticas.
Espero que esta nueva feature los ayude.
#microsoftfabric#fabric#fabric tutorial#fabric tips#fabric training#fabric jujuy#fabric argentina#fabric cordoba#ladataweb#fabric capacity
0 notes
Text
[PowerQuery] Múltiples reemplazos estilo switch o case
Hace tiempo no escribíamos un tip en M. Recientemente, me comentaron que querían hacer varios reemplazos de texto por nro para generar una columna de ID y mejorar la relación para que sea más liviana. Un buen ejercicio para alivianar el modelo.
Recorde que había escrito un post al inicio del blog con múltiples reemplazos, pero quise probar una técnica que aprendí hace unos años y hoy voy a compartir aqui.
Este artículo mostrará lo más parecido que tenemos en power query para generar algo estilo case o switch.
Para poder generar un case en Power Query vamos a realizar algo similar a un archivo de formato json. Veamos el caso simplificado.
Contamos con una tabla de hechos que traía el estado de una operación en texto y tenemos una dimension de estados. Sin embargo para reducir el tamaño de la relación y buena práctica, sería mejor que la relación este dada por un entero y no texto.

Vamos a asumir que la operación no puede desarrollarse en base de datos, porque recordemos que "mientras más temprano o atrás podamos resolver data modeling mejor será". Este escenario esta a modo de ejemplo.
Conociendo los estados y sus ID podríamos crear una función que reemplace el texto por el número esperado bajo una condición.
El primer paso será generar una variable que tenga las opciones de reemplazo

El primer valor será el que queremos encontrar y el segundo el que reemplazaremos. Podríamos definir que es una lista de listas, puesto que los {} en Power Query representan listas.
Para pode ejecutar el reemplazo sobre un texto seguiremos con la siguiente indicación:

De ese modo selecciona una lista devolviendo el primer resultado {0} quiere el segundo item {1}. Para filtrar ese item haremos un contains de texto de "rawText" validando contra cada fila (haciendo un each validamos fila por fila) donde _ representa una lista de las recorridas y {0} el primer item de la fila al cual lo compara.
Para mejor desarrollo esto podemos englobarlo en una función que recibe el texto por parametro y llamaremos "ChageStatus"

Para ejecutarlo en nuestra tabla de operación podemos llamarlo de dos maneras. Por un lado con "Agregar columna personalizada". La nueva columna simplemente haría ChangeStatus([Estado]).
Si queremos reemplazar la columna existente con sus múltiples reemplazos, entonces agregaremos un paso personalizado con el botón fx.
Nos nutriremos de TransformColumns y generaremos un código de este estilo:
= Table.TransformColumns( #"Paso anterior", { { "Estado", each ChangeStatus(_) } } )
El método permite ejecutar varias funciones recorriendo fila a fila sobre una columna. De nuevo una lista de listas. En nuestro caso es una sola operación de lista en la listas. Para ello, definimos la columna Estado como la involucrada al reemplazo y llamamos la función con each. Each nos permite ir fila a fila capturando el record de la columna con "_". Por esta razón, lo colocamos como parámetro.
De esa forma reemplazaremos nuestros textos por números de texto. Solo restará cambiar el tipo de la columna a entero para reducir el tamaño de la relación cuando esta generado el modelo.
Espero que este pequeño tip les haya servido y despligue nuevas ideas sobre Power Query y su manejo de listas.
#power bi#powerbi#power bi argentina#power bi cordoba#power bi jujuy#power query#power query tips#power query training#power query tutorial#ladataweb#power query switch#power query case
0 notes
Text
[PowerBI] Usando Iconos y código SVG
Una parte fundamental en nuestros tableros de datos es la estética para la experiencia de usuario. Las interpretaciones pueden mejorar de gran manera si nos fortalecemos con imagenes que aporten al mensaje objetivo que tiene el tablero.
Esta demostrado que la experiencia de usuarios es más enriquecedora si nuestras tarjetas tienen un icono al lado o si nuestras tablas tienen formato condicional.
Este artículo nos muestra alternativas para enriquecer de esa forma nuestros reportes desarrollados.
La flexibilidad de Power Bi ha crecido de gran manera. Lo que nos ha permitido jugar con muchas alternativas útiles o divertidas para contar historias con datos. Hoy podemos nutrir de imagenes informes con visualizaciones a través de url, imagenes cargadas por sistema, botones, unichars, formatos condicionales y hasta svgs.
Básicos
Lo primero que se nos presentó y deberíamos conocer es cargar imagenes y controlar formatos condicionales. Las imagenes pueden ser cargadas de dos formas. Por un lado por el botón de la interfaz:
Y por otro como parte de un componente, por ejemplo un botón en blanco. Tanto en propiedades de estilo "Icons" o "Fill" podremos encontrar opciones para cargarlas:

En caso de trabajo de iconos en tablas, el estándar es el formato condicional por iconos que trae unos por defecto.
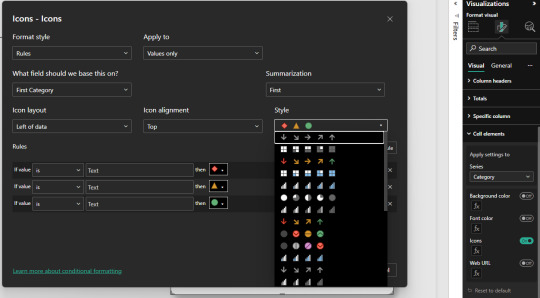
Usandolos podemos incorporar a nuestras tarjetas, tablas o enfoques de tablero una mejor experiencia.
Otras formas
Esta puede ser útil pero carece de flexibilidad. Cargar un .png por cada guia que queremos mostrar o si nuestra usuario quiere iconos especiales para el formato condicional, estos y otros requerimientos pueden verse limitados. Por ésta razón, vamos a ver tres métodos adicionales para enriquecer nuestras historias.
Emoticones o smiles: tradicionales que encontramos en cualquier chat
Unichars: valores estandarizados de íconos que PowerBi lee por DAX
SVG: es un formato vectorial muy útil para su uso online por su flexibilidad. Permite crear una imagen en una gran URL
Estas tres opciones podemos aplicarlas en visualizaciones individuales como tarjetas, en formas, en visualizaciones que lean imagenes como simple image y también en tablas o matrices.
Emoticones
Tal vez la forma más simple de tarjeta que no conocíamos que se renderiza en todo lugar de windows. Con un simple "Windwos + ." en el teclado se nos desplega un menú para incorporar el ícono como texto. Así podríamos facilmente utilizarlo en reglas de dax para determinar un formato. Por ejemplo:

Unichar
No son realmente iconos o imágenes sino que son caracteres especiales llamados unicode. Unicode es un estándar de codificación de caracteres diseñado para facilitar el tratamiento informático. Para usarlo nos nutrimos de la función DAX UNICHAR. La misma, devuelve el carácter Unicode al que hace referencia el valor numérico. ¿Cómo sabremos que número escribir?, podemos asesorarnos de algún sitio web, por ejemplo "https://unichar.app/web/"
En este ejemplo en lugar de seleccionar un solo ícono, pense en puntuar los valores de venta en cinco estrellas. Según las reglas colocara estrellas vacías o llenas
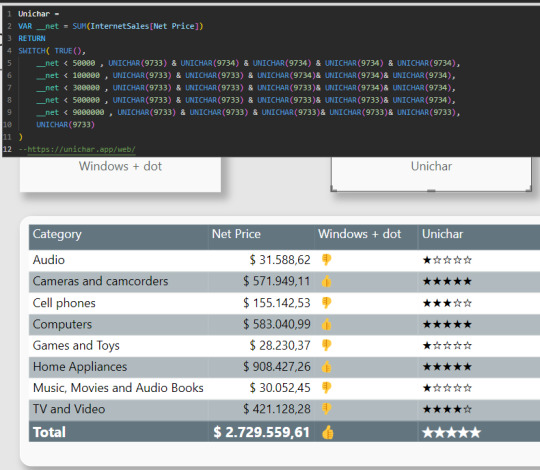
Con tanta libertad de unicodes para usar con unichars, la creatividad será nuestro límte. Asi con estrellas podemos simular puntajes, rankings, etc. Podríamos haber usado algo similar a pulgares también.
Una gran característica de los unichar es que son considerados "texto" en la medida. Lo que significa que podemos pintarlos de cualquier color al igual que el texto.
SVGs
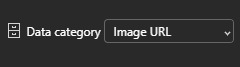
Tal vez el modo que más asusta es el SVG. Pero así también es el más versátil puesto que no se queda en la forma de un objeto sino que da pie a animación. Podemos pensar en el svg como algo similar al código html, puesto que tiene tags y configuraciones de estilo. El modo en el que power bi puede renderizarlo es considerandolo como una "Image URL". Si utilizamos una medida o columna, debemos categorizarla como tal:
Un SVG se compone de la siguiente manera:
data:image/svg+xml;utf8, <svg width='200' height='50' xmlns='http://www.w3.org/2000/svg'>[Código]</svg>
La carcaza siempre es la misma y se modifica normalmente sobre código. Se puede jugar con width y height como tamaños horizontales y verticales límites para el dibujo. Consideren que algunas visualizaciones, como las tablas, tiene configuraciones de formato para esto también:
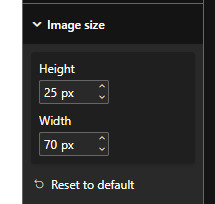
Dichas propiedades pueden afectar al tamaño del renderizado en la visualización.
Veamos dos ejemplos. Por un lado podríamos poner tags similares a los editores modernos de tablas. Con un código que construya un tag para buenos resultados (success) y malos (failure) junto con una medida que sea un simple IF como windows + dot para elegir podríamos hacer grandes cosas. Veamos ejemplo de success:

Como pueden ver, dentro del tag svg construimos dos tags más. Por un lado el fondo rect que refiere a rectángulo con bordes redondeados y el text que tiene texto por encima.
SVG también nos permite jugar con animaciones. Entonces podríamos usar formas tradicionales como cuadrados o círculos y jugar con animaciones que llamen la atención. En este ejemplo también construimos dos SVG, un cuadrado rojo y un círculo verde. Ambos con movimientos y separados por el mismo IF que hablamos antes para separar valores a modo de ejemplo objetivo. Veamos como:

Por supuesto que el gif da el ejemplo, pero no reproduce tan fluido como el resultado final que es mucho más agradable a la vista. En este caso, incorporamos el tag animate que nos da la flexibilidad de jugar con movimientos.
¿Cómo crear SVG?
Tal vez piensen que no tienen tiempo para aprender esto de código svg. Hay varios caminos, no debemos cancelarlo por ello. Puede que algunas personas más académicas les interese conocer las sentencias de código posible y saber suficiente para controlarlo y entenderlo todo. Quienes no quieran esto hay dos alternativas. Por un lado, buscar otros SVG y posteos de comunidad al respecto. Por otro lado, podemos utilizar IA. Así es, una IA puede ayudarnos con esto. El círculo verde con su movimiento fue construido 100% por IA. Le pedi eso a un chat bastante famoso y me devolvió el código con la animación.
En definitiva podemos validar ideas y pedir códigos escritos. Ya no hay excusa para usar Iconos y SVGs para adornar nuestra UI de informes y brindar aspectos más agradables a los usuarios finales. Recuerden que pueden descargar el archivo de Power Bi Desktop desde mi GitHub.
#power bi#powerbi#power bi argentina#power bi cordoba#power bi jujuy#power bi tutorial#power bi training#power bi tips#power bi desktop#ladataweb#data viz#data visualization
0 notes
Text
[Fabric] Fast Copy con Dataflows gen2
Cuando pensamos en integración de datos con Fabric está claro que se nos vienen dos herramientas a la mente al instante. Por un lado pipelines y por otro dataflows. Mientras existía Azure Data Factory y PowerBi Dataflows la diferencia era muy clara en audiencia y licencias para elegir una u otra. Ahora que tenemos ambas en Fabric la delimitación de una u otra pasaba por otra parte.
Por buen tiempo, el mercado separó las herramientas como dataflows la simple para transformaciones y pipelines la veloz para mover datos. Este artículo nos cuenta de una nueva característica en Dataflows que podría cambiar esta tendencia.
La distinción principal que separa estas herramientas estaba basado en la experiencia del usuario. Por un lado, expertos en ingeniería de datos preferían utilizar pipelines con actividades de transformaciones robustas d datos puesto que, para movimiento de datos y ejecución de código personalizado, es más veloz. Por otro lado, usuarios varios pueden sentir mucha mayor comodidad con Dataflows puesto que la experiencia de conectarse a datos y transformarlos es muy sencilla y cómoda. Así mismo, Power Query, lenguaje detrás de dataflows, ha probado tener la mayor variedad de conexiones a datos que el mercado ha visto.
Cierto es que cuando el proyecto de datos es complejo o hay cierto volumen de datos involucrado. La tendencia es usar data pipelines. La velocidad es crucial con los datos y los dataflows con sus transformaciones podían ser simples de usar, pero mucho más lentos. Esto hacía simple la decisión de evitarlos. ¿Y si esto cambiara? Si dataflows fuera veloz... ¿la elección sería la misma?
Veamos el contexto de definición de Microsoft:
Con la Fast Copy, puede ingerir terabytes de datos con la experiencia sencilla de flujos de datos (dataflows), pero con el back-end escalable de un copy activity que utiliza pipelines.
Como leemos de su documentación la nueva característica de dataflow podría fortalecer el movimiento de datos que antes frenaba la decisión de utilizarlos. Todo parece muy hermoso aun que siempre hay frenos o limitaciones. Veamos algunas consideraciones.
Origenes de datos permitidos
Fast Copy soporta los siguientes conectores
ADLS Gen2
Blob storage
Azure SQL DB
On-Premises SQL Server
Oracle
Fabric Lakehouse
Fabric Warehouse
PostgreSQL
Snowflake
Requisitos previos
Comencemos con lo que debemos tener para poder utilizar la característica
Debe tener una capacidad de Fabric.
En el caso de los datos de archivos, los archivos están en formato .csv o parquet de al menos 100 MB y se almacenan en una cuenta de Azure Data Lake Storage (ADLS) Gen2 o de Blob Storage.
En el caso de las bases de datos, incluida la de Azure SQL y PostgreSQL, 5 millones de filas de datos o más en el origen de datos.
En configuración de destino, actualmente, solo se admite lakehouse. Si desea usar otro destino de salida, podemos almacenar provisionalmente la consulta (staging) y hacer referencia a ella más adelante. Más info.
Prueba
Bajo estas consideraciones construimos la siguiente prueba. Para cumplir con las condiciones antes mencionadas, disponemos de un Azure Data Lake Storage Gen2 con una tabla con información de vuelos que pesa 1,8Gb y esta constituida por 10 archivos parquet. Creamos una capacidad de Fabric F2 y la asignaciones a un área de trabajo. Creamos un Lakehouse. Para corroborar el funcionamiento creamos dos Dataflows Gen2.
Un dataflow convencional sin FastCopy se vería así:

Podemos reconocer en dos modos la falta de fast copy. Primero porque en el menú de tabla no tenemos la posibilidad de requerir fast copy (debajo de Entable staging) y segundo porque vemos en rojo los "Applied steps" como cuando no tenemos query folding andando. Allí nos avisaría si estamos en presencia de fast copy o intenta hacer query folding:
Cuando hace query folding menciona "... evaluated by the datasource."
Activar fast copy
Para activarlo, podemos presenciar el apartado de opciones dentro de la pestaña "Home".
Allí podemos encontrarlo en la opción de escalar o scale:
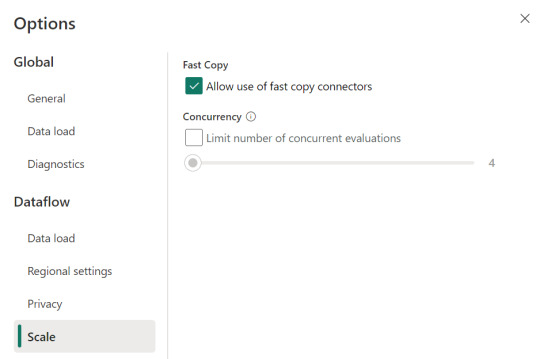
Mientras esa opción esté encendida. El motor intentará utilizar fast copy siempre y cuando la tabla cumpla con las condiciones antes mencionadas. En caso que no las cumpla, por ejemplo la tabla pese menos de 100mb, el fast copy no será efectivo y funcionaría igual que un dataflow convencional.
Aquí tenemos un problema, puesto que la diferencia de tiempos entre una tabla que usa fast copy y una que no puede ser muy grande. Por esta razón, algunos preferiríamos que el dataflow falle si no puede utilizar fast copy en lugar que cambie automaticamente a no usarlo y demorar muchos minutos más. Para exigirle a la tabla que debe usarlo, veremos una opción en click derecho:

Si forzamos requerir fast copy, entonces la tabla devolverá un error en caso que no pueda utilizarlo porque rompa con las condiciones antes mencionadas a temprana etapa de la actualización.
En el apartado derecho de la imagen tambien podemos comprobar que ya no está rojo. Si arceramos el mouse nos aclarará que esta aceptado el fast copy. "Si bien tengo otro detalle que resolver ahi, nos concentremos en el mensaje aclarando que esta correcto. Normalmente reflejaría algo como "...step supports fast copy."
Resultados
Hemos seleccionado exactamente los mismos archivos y ejecutado las mismas exactas transformaciones con dataflows. Veamos resultados.
Ejecución de dataflow sin fast copy:

Ejecución de dataflow con fast copy:

Para validar que tablas de nuestra ejecución usan fast copy. Podemos ingresar a la corrida

En el primer menú podremos ver que en lugar de "Tablas" aparece "Actividades". Ahi el primer síntoma. El segundo es al seleccionar una actividad buscamos en motor y encontramos "CopyActivity". Así validamos que funcionó la característica sobre la tabla.
Como pueden apreciar en este ejemplo, la respuesta de fast copy fue 4 veces más rápida. El incremento de velocidad es notable y la forma de comprobar que se ejecute la característica nos revela que utiliza una actividad de pipeline como el servicio propiamente dicho.
Conclusión
Seguramente esta característica tiene mucho para dar e ir mejorando. No solamente con respecto a los orígenes sino tambien a sus modos. No podemos descargar que también lo probamos contra pipelines y aqui esta la respuesta:
En este ejemplo los Data Pipelines siguen siendo superiores en velocidad puesto que demoró 4 minutos en correr la primera vez y menos la segunda. Aún tiene mucho para darnos y podemos decir que ya está lista para ser productiva con los origenes de datos antes mencionados en las condiciones apropiadas. Antes de terminar existen unas limitaciones a tener en cuenta:
Limitaciones
Se necesita una versión 3000.214.2 o más reciente de un gateway de datos local para soportar Fast Copy.
El gateway VNet no está soportado.
No se admite escribir datos en una tabla existente en Lakehouse.
No se admite un fixed schema.
#fabric#microsoft fabric#fabric training#fabric tips#fabric tutorial#data engineering#dataflows#fabric dataflows#fabric data factory#ladataweb
0 notes
Text
Fabric Rest API ahora en SimplePBI
La Data Web trae un regalo para esta navidad. Luego de un gran tiempo de trabajo, hemos incorporado una gran cantidad de requests provenientes de la API de Fabric a la librería SimplePBI de python . Los llamados globales ya están en preview y hemos intentado abarcar los más destacados.
Este es el comienzo de un largo camino de desarrollo que poco a poco intentar abarcar cada vez más categorías para facilitar el uso como venimos haciendo con Power Bi hace años.
Este artículo nos da un panorama de que hay especificamente y como comenzar a utilizarla pronto.
Para ponernos en contexto comenzamos con la teoría. SimplePBI es una librería de Python open source que vuelve mucho más simple interactuar con la PowerBi Rest API. Ahora incorpora también Fabric Rest API. Esto significa que no tenemos que instalar una nueva librería sino que basta con actualizarla. Esto podemos hacerlo desde una consola de comandos ejecutando pip siempre y cuando tengamos python instalado y PIP en las variables de entorno. Hay dos formas:
pip install --upgrade SimplePBI pip install -U SimplePBI
Necesitamos una versión 1.0.1 o superior para disponer de la nueva funcionalidad.
Pre requisitos
Tal como lo hacíamos con la PowerBi Rest API, lo primero es registrar una app en azure y dar sus correspondientes permisos. De momento, todos los permisos de Fabric se encuentran bajo la aplicación delegada "Power Bi Service". Podes ver este artículo para ejecutar el proceso: https://blog.ladataweb.com.ar/post/740398550344728576/seteo-powerbi-rest-api-por-primera-vez
Características
La nueva incorporación intentará cubrir principalmente dos categorías indispensables de la Rest API. Veamos la documentación para guiarnos mejor: https://learn.microsoft.com/en-us/rest/api/fabric/articles/api-structure
A la izquierda podemos ver todas las categorías bajo las cuales consultar u operar siempre y cuando tengamos permisos. Fabric ha optado por denominar "Items" a cada tipo de contenido creable en su entorno. Por ejemplo un item podría ser un notebook, un modelo semántico o un reporte. En este primer release, hemos decidido enfocarnos en las categorías más amplias. Estamos hablando de Admin y Core. Cada una contiene una gran cantidad métodos. Una enfocada en visión del tenant y otro en operativo de la organización. Admin contiene subcategorías como domains, items, labels, tenant, users, workspaces. En core encontraremos otra como capacities, connections, deployment pipelines, gateways, items, job scheduler, long running operations, workspaces.
La forma de uso es muy similar a lo que simplepbi siempre ha presentado con una ligera diferencia en su inicialización de objeto, puesto que ahora tenemos varias clases en un objeto como admin o core.
Para importar llamaremos a fabric desde simplepbi aclarando la categoría deseada
from simplepbi.fabric import core
Para autenticar vamos a necesitar valores de la app registrada. Podemos hacerlo por service principal con un secreto o nuestras credenciales. Un ejemplo para obtener un token que nos permita utilizar los objetos de la api con service principal es:
t = token.Token(tenant_id, app_client_id, None, None, app_secret_key, use_service_principal=True)
Vamos intentar que las categorías de la documentación coincidan con el nombre a colocar luego de importar. Sin embargo, puede que algunas no coincidan como "Admin" de fabric no puede usarse porque ya existe en simplepbi. Por lo tanto usariamos "adminfab". Luego inicializamos el objeto con la clase deseada de la categoría de core.
it = core.Items(t.token)
De este modo tenemos accesibilidad a cada método en items de core. Por ejemplo listarlos:
Consideraciones
No todos los requests funcionan con Service Principal. La documentación especifica si podremos usar dicha autenticación o no. Leamos con cuidado en caso de fallas porque podría no soportar ese método.
Nuevos lanzamientos en core y admin. Nos queda un largo año en que buscaremos tener esas categorías actualizadas y poco a poco ir planificando bajo prioridad cuales son las más atractivas para continuar.
Para conocer más, seguirnos o aportar podes encontrarnos en pypi o github.
Recordemos que no solo la librería esta incorporando estos requests como preview sino también que la Fabric API esta cambiando cada día con nuevos lanzamientos y modificaciones que podrían impactar en su uso. Por esto les pedimos feedback y paciencia para ir construyendo en comunidad una librería más robusta.
#fabric#microsoftfabric#fabric tutorial#fabric training#fabric tips#fabric rest api#power bi rest api#fabric python#ladataweb#simplepbi#fabric argentina#fabric cordoba#fabric jujuy
0 notes
Text
[Fabric] Herramientas para administrar o monitorear la organización
Con el lanzamiento de fabric en 2023 aparecieron herramientas que nos ayudan a comprender mejor el uso de la plataforma. Una deuda pendiente que transcurría en Power Bi. Desde ese entonces, la plataforma no deja de sorprender. Incluso ahora en ignite 2024 volvemos a incorporar más herramientas útiles que nos asistan a entender nuestro entorno.
Este artículo listara las herramientas disponibles que hay para entender el uso de la plataforma, que hay creado por todas partes, monitorear sus corridas, monitorear la capacidad, etc. Cada una de ellas con distintos filtros de gran introspección
Vamos a comenzar separando el artículo en herramientas de monitoreo y herramientas de administración. Cada una de ellas con objetivos diferentes. Casi todas vienen visibles por defecto para poder utilizarlas. Algunas son accesibles por todo usuario y otras solo por administradores.
Administrativas
A mi parecer lo que conlleva a la administración pasa por comprender que está desplegado en la organización. La administración puede ser del Tenant o inclusive de un usuario convencional que es responsable de X cantidad de áreas de trabajo. Lo importante es poder explorar cuantos reportes (u otro contenido) hay, donde se encuentran, quienes lo crearon, etc. Esa información la tenemos disponible en dos formas.
Área de trabajo de administración
En esta área de trabajo, exclusiva de administradores, podremos ver la totalidad de la organización. Cada workspace, modelo semantico, notebook, etc. Aquí existe un informe llamado "Purview Hub". Este informe refleja todos los items creados en el ecosistema Fabric, sus dominios, etiquetas de sensibilidad de datos, endorsements (si fueron certificados o promovidos), etc. Una vista rápida para que se den una idea de como podríamos comprender todos los items es:

En caso de tener confusión en su uso, tiene una excelente guia de bookmarks en el primer botón de arriba a la izquierda llamado "Take a tour".

OneLake Catalag
Un lanzamiento reciente que tiene un foco similar es el Catálogo de Onelake. La principal diferencia se basa en que el catálogo está visible para todo usuario de Fabric y muestra sobre lo que el usuario tiene permisos en lugar de mostrar toda la organización. Se encuentra accesible en el menú izquierdo de navegación.
Tiene una muy simple y sencilla interfaz que nos permite buscar por área de trabajo o items (lakehouse, semantic model, report, pipeline, etc)

Me parece ideal para quienes sea administradores responsables de ciertos desarrollos en varias áreas de trabajo.
Monitoreo
Tenemos tres herramientas de monitoreo en distintos ejes, una de administradores, una app que podemos disponibilizar permisos y una para cada usuario.
Métricas/Logs de uso de plataforma.
Al igual que Purview hub, en el admin workspace encontraremos un segundo informe llamado "Feature usage and Adoption". Este informe se enfoca en revelarnos la actividad de cada usuario que ingresó a la plataforma los últimos 30 días. Registra el uso que dan los usuarios a la plataforma. La lista de operaciones que guardará al momento de ejecutarse podemos leerla en este enlace: https://learn.microsoft.com/en-us/fabric/admin/operation-list?wt.mc_id=DP-MVP-5004778
El informe nos permite explorar por area de trabajo y capacidad las actividades registradas. Podemos ver que usuario ejecuto que operación en que día. Siempre se registran últimos 30 días y no más.

Pronto podemos visualizar las operaciones más realizadas. En este caso get data source details, puesto que es un tenant que hay más investigaciones que reportes para visualizar. Para más detalles de su uso podemos revisar su doc aqui: https://learn.microsoft.com/en-us/fabric/admin/feature-usage-adoption?wt.mc_id=DP-MVP-5004778
Fabric Capacity metrics app
No tenemos una manera de monitorear una capacidad dedicada por defecto. Por eso, esta app es muy importante de leer e instalar. Cuando compramos una capacidad es crítico monitorear sus recursos. Comprender que contenidos, flujos de datos, etc están siendo más pesados que otros. Podemos comprender si la capacidad tiene mucho flujo de background o mucha interactividad de usuarios. Estos detalles y muchos más pueden verse con la Fabric Capacity Metrics App. La herramienta es clave para poder gestionar una sana capacidad como lo expresamos en este artículo.
Esta herramienta no viene por defecto en la organización. Debe instalarse desde el menú de Apps "Get Apps". Allí aparecen muchas de distintas emrpesas. Buscamos el nombre y la instalamos.
La app funciona igual que una PowerBi App de workspace. Crea una nueva área y permite dar permiso a quien querramos. Para configurarla debemos ser owners de la capacidad y completar los parámetros del dataset.

Para conocer en mayor detalle su funcionalidad, podemos ver el siguiente enlace: https://learn.microsoft.com/en-us/fabric/enterprise/metrics-app-compute-page?wt.mc_id=DP-MVP-5004778
Sección Monitoreo
¿Qué nos falta? comprender si nuestras operaciones de background estan corriendo satisfactoriamente. Si hoy usamos fabric, seguramente tenemos muchos contenidos de integración de datos poblando lakehouse o transformando, limpiando y preparando datos para leer. Este espacio nos permite ver el estado de esas operaciones con versátiles filtros de estado, tipo de item, fecha de corrida relativa, quien lo hizo o en que área de trabajo se encuentra. Así mismo brinda una variedad de columnas para ver en mayor detalle.

Esta sección la pueden ver todos los usuarios y les muestra aquellos elementos que tenga permisos de ver o controlar. Nuevamente, muy útil para ingenieros de datos con muchos flujos, administradores de áreas de trabajo o dominios, etc.
¿Eso es todo?
No claro que no. Todo el tiempo surjen actualizaciones e ideas de personas que traen más y más visibilidad. Por ejemplo, hay artículos revelando como leer información de los audit logs para llegar a una medida más profunda de una capacidad de Fabric. Podemos usar la API para generar un histórico de las operaciones para no quedarnos en últimos 30 días. Incluso armar nuestro propio purview hub basado en datos profundos que consigamos con API. Hay muchos miembros activo de la comunidad con nuevas ideas para afinar detalles o dar alternativas. Recientemente, en el ignite 2024, las áreas de trabajo incorporaron un monitoreo en tiempo real que podemos setear con recursos realtime:

Nosotros expresamos las que vienen por defecto y una indispensable. Ustedes pueden adaptar muchas otras nuevas en distintos ejes o utilizar lo que mostramos.
#fabric#microsoft fabric#microsoftfabric#fabric tutorial#fabric tips#fabric training#fabric monitor#administrate fabric#fabric capacity#ladataweb#fabric ladataweb#fabric cordoba#fabric argentina#fabric jujuy
0 notes
Text
[DataModeling] Tip DAX para autoreferencia o recurrencia de tabla
Hace tiempo que no nos sentrabamos en acompañar un escenario de modelado. En esta oportunidad, nos vamos a enfocar en como resolver una situación de auto referencia o recurrencia de tabla. Suele ocurrir que una tabla puede tener ids o claves de referencia para si misma y las formas de resolverlo pueden variar.
En este artículo, vamos a mostrar como valernos de DAX para resolver un esquema jerárquico corporativo que ayude a develar un organigrama organizacional basado en niveles o posiciones/cargos superiores.
Contexto
Entre las formas de modelar bases de datos transaccionales, buscamos normalizar los datos para evitar la redundancia lo más posible. Así es como pueden aparecer escenarios donde hay tablas que van a referenciarse a si mismas. Esto quiere decir que podemos tener una clave foránea apuntando a una clave primaria. Para no abordar tanta teoría veamos un ejemplo que ayude a enfocar el caso.
Nos enviaron un requerimiento que pide detallar un organigrama o estructura jerárquica en la organización que permita explorar la cantidad de empleados según distintos focos de mando. Piden que la información sea explorable, puede ser una matriz o árbol del siguiente estilo:
Árbol de decomposición
Matriz

Supongamos que tenemos una tabla de Empleados en nuestra base de datos. La organización tiene un gran volumen de personal, lo que hace que naturalmente haya una estructura jerárquica con cargos de mando o de management. Todas las personas institucionales forman parte de la tabla empleados fila por fila. Sin embargo, necesitamos guardar información sobre la persona a la cual responden. Aquí aparece la auto referencia. Para resolver esta operación en vistas de base de datos transaccional, será más performante y menos costoso delimitar una nueva columna que autoreferencie a otra fila en lugar de otras tablas para los cargos pertinentes. Veamos como quedaría una tabla con la nueva columna:

Fíjense que la columna id_superior pertenece a un id_empleado de otra fila. Cuando esto ocurre, estamos frente a un caso de auto referencia.
Dependiendo el proceso y escenario a delimtiar en nuestro modelo semántico, puede ser resuelto de distintas formas. Podríamos generar fact factless que orienten un mapeo de quienes responden a quienes o podemos tomar esta tabla como dimensión y generar columnas que representen el mando jerárquico como columnas categóricas de la dimension.
Este artículo se enfocará en la segunda solución. Vamos a generar columnas categoricas que nos ayuden a construir algo semejante a lo siguiente:
La idea es generar columns por cantidad de niveles jerárquicos que se presenten. Si bien la mejor solución es implementarlo lo más temprano posible, es decir en un warehouse, lakehouse o procesamiento intermedio; aquí vamos a mostrar como crear las columnas con DAX.
Vamos a crear una columna calculada de la siguiente manera:
Level1 = LOOKUPVALUE( Empleados_Jerarquia[Nombre] , Empleados_Jerarquia[id_empleado] , PATHITEM( PATH ( Empleados_Jerarquia[id_empleado], Empleados_Jerarquia[id_superior]) , 1 , INTEGER ) )
Vamos a nutrirnos de tres funciones para generar un recorrido dentro de la misma tabla.
LOOKUPVALUE: Esta función busca un valor en una columna específica de una tabla, basándose en criterios de búsqueda. En este caso, está buscando el nombre de un empleado con criterio de igualdad entre id_empleado que mapee al id_superior de la fila actual.
PATH: Esta función crea una cadena que representa la jerarquía de empleados, utilizando los id_empleado y id_superior. Busca los ID y los separa por Pipes. Entonces por ejemplo en la fila de ID = 5 de Joaquín. El resultado de Path será "1|2|5" representando que los ID de sus superiores son primero el empleado 2 y luego el empleado 1.
PATHITEM(..., 1, INTEGER): Esta función toma la cadena generada por PATH y extrae un elemento de ella. En este caso, está extrayendo el primer elemento (el id del empleado que está en la posición 1). Aquí, el 1 se refiere a la posición que queremos extraer (el primer ítem en la jerarquía). Si Joaquín tenía 3 valores, vamos a buscar el de la primera posición, en este caso "1".
Resultado: lookupvalue buscara el nombre del empleado con ID 1 para la columna.
Esta función podríamos replicarla para cada nivel. La función antes vista traería el primero de la cadena, es decir la dirección de la empresa. Para llegar al siguiente nivel cambiamos el parametro de pathitem de manera que traiga el segundo resultado de Path en sus pipes.
Level2 = LOOKUPVALUE( Empleados_Jerarquia[Nombre] , Empleados_Jerarquia[id_empleado] , PATHITEM( PATH ( Empleados_Jerarquia[id_empleado], Empleados_Jerarquia[id_superior]) , 2 , INTEGER ) )
En primera instancia esto parecería resolverlo. Este sería nuestro resultado:
Esta puede ser una solución directa si solo queremos navegar por nombres de personas en cadena (filtramos Level5 <> Blank). Sin embargo, si también quisieramos conocer la cantidad de personas que tienen a cargo, es necesario contar a la persona al mando como parte del equipo, sino generaríamos una cadena de "Blanks" como pueden ver en niveles del 2 al 5. Esto lo podemos corregir copiando el nivel anterior cuando ocurre un blanco.
Level2 = VAR __lvl2 = LOOKUPVALUE( Empleados_Jerarquia[Nombre] , Empleados_Jerarquia[id_empleado] , PATHITEM( PATH ( Empleados_Jerarquia[id_empleado], Empleados_Jerarquia[id_superior]) , 2 , INTEGER ) ) RETURN IF ( ISBLANK(__lvl2) , Empleados_Jerarquia[Level1], __lvl2 )
De esa forma el equipo de Laura (primera) cuenta con tres gerentes y si misma al conteo total de empleados.
Las visualizaciones pueden ser construidas por cada nivel como columnas categóricas de las dimensiones:
Así mismo podría usarse el nombre del cargo como nombre de columna para ver la pirámide institucional de una manera más sencilla.
De esta forma llegaríamos al resultado esperado y mostrado en la primera imagen de requerimiento.
Ojala esta solución les sirva para resolver situaciones de modelado recursivo. Recuerden que si podemos ejecutar esto en SQL en nuestra capa de transformación, sería lo mejor para construir la dimensión. Como siempre pueden descargar el archivo de ejemplo de mi GitHub.
#dax#dax tip#dax tutorial#dax training#data modeling#powerbi#power bi#power bi desktop#power bi cordoba#power bi argentina#power bi jujuy#ladataweb
0 notes