#sqoop import where
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
Mobile US users spent an average of 115.8 minutes on Tumblr app monthly.
Text
Big Data Analytics Training - Learn Hadoop, Spark

Big Data Analytics Training – Learn Hadoop, Spark & Boost Your Career
Meta Title: Big Data Analytics Training | Learn Hadoop & Spark Online Meta Description: Enroll in Big Data Analytics Training to master Hadoop and Spark. Get hands-on experience, industry certification, and job-ready skills. Start your big data career now!
Introduction: Why Big Data Analytics?
In today’s digital world, data is the new oil. Organizations across the globe are generating vast amounts of data every second. But without proper analysis, this data is meaningless. That’s where Big Data Analytics comes in. By leveraging tools like Hadoop and Apache Spark, businesses can extract powerful insights from large data sets to drive better decisions.
If you want to become a data expert, enrolling in a Big Data Analytics Training course is the first step toward a successful career.
What is Big Data Analytics?
Big Data Analytics refers to the complex process of examining large and varied data sets—known as big data—to uncover hidden patterns, correlations, market trends, and customer preferences. It helps businesses make informed decisions and gain a competitive edge.
Why Learn Hadoop and Spark?
Hadoop: The Backbone of Big Data
Hadoop is an open-source framework that allows distributed processing of large data sets across clusters of computers. It includes:
HDFS (Hadoop Distributed File System) for scalable storage
MapReduce for parallel data processing
Hive, Pig, and Sqoop for data manipulation
Apache Spark: Real-Time Data Engine
Apache Spark is a fast and general-purpose cluster computing system. It performs:
Real-time stream processing
In-memory data computing
Machine learning and graph processing
Together, Hadoop and Spark form the foundation of any robust big data architecture.
What You'll Learn in Big Data Analytics Training
Our expert-designed course covers everything you need to become a certified Big Data professional:
1. Big Data Basics
What is Big Data?
Importance and applications
Hadoop ecosystem overview
2. Hadoop Essentials
Installation and configuration
Working with HDFS and MapReduce
Hive, Pig, Sqoop, and Flume
3. Apache Spark Training
Spark Core and Spark SQL
Spark Streaming
MLlib for machine learning
Integrating Spark with Hadoop
4. Data Processing Tools
Kafka for data ingestion
NoSQL databases (HBase, Cassandra)
Data visualization using tools like Power BI
5. Live Projects & Case Studies
Real-time data analytics projects
End-to-end data pipeline implementation
Domain-specific use cases (finance, healthcare, e-commerce)
Who Should Enroll?
This course is ideal for:
IT professionals and software developers
Data analysts and database administrators
Engineering and computer science students
Anyone aspiring to become a Big Data Engineer
Benefits of Our Big Data Analytics Training
100% hands-on training
Industry-recognized certification
Access to real-time projects
Resume and job interview support
Learn from certified Hadoop and Spark experts
SEO Keywords Targeted
Big Data Analytics Training
Learn Hadoop and Spark
Big Data course online
Hadoop training and certification
Apache Spark training
Big Data online training with certification
Final Thoughts
The demand for Big Data professionals continues to rise as more businesses embrace data-driven strategies. By mastering Hadoop and Spark, you position yourself as a valuable asset in the tech industry. Whether you're looking to switch careers or upskill, Big Data Analytics Training is your pathway to success.
0 notes
Text
Cloudera QuickStart VM

The Cloudera QuickStart VM is a virtual machine that offers a simple way to start using Cloudera’s distribution, including Apache Hadoop (CDH). It contains a pre-configured Hadoop environment and a set of sample data. The QuickStart VM is designed for educational and experimental purposes, not for production use.
Here are some key points about the Cloudera QuickStart VM:
Pre-configured Hadoop Environment: It comes with a single-node cluster running CDH, Cloudera’s distribution of Hadoop and related projects.
Toolset: It includes tools like Apache Hive, Apache Pig, Apache Spark, Apache Impala, Apache Sqoop, Cloudera Search, and Cloudera Manager.
Sample Data and Tutorials: The VM includes sample data and guided tutorials to help new users learn how to use Hadoop and its ecosystem.
System Requirements: It requires a decent amount of system resources. Ensure your machine has enough RAM (minimum 4 GB, 8 GB recommended) and CPU power to run the VM smoothly.
Virtualization Software: You need software like Oracle VirtualBox or VMware to run the QuickStart VM.
Download and Setup: The VM can be downloaded from Cloudera’s website. After downloading, you must import it into your virtualization software and configure the settings like memory and CPUs according to your system’s capacity.
Not for Production Use: The QuickStart VM is not optimized for production use. It’s best suited for learning, development, and testing.
Updates and Support: Cloudera might periodically update the QuickStart VM. Watch their official site for the latest versions and support documents.
Community Support: For any challenges or queries, you can rely on Cloudera’s community forums, where many Hadoop professionals and enthusiasts discuss and solve issues.
Alternatives: If you’re looking for a production-ready environment, consider Cloudera’s other offerings or cloud-based solutions like Amazon EMR, Google Cloud Dataproc, or Microsoft Azure HDInsight.
Remember, if you’re sending information about the Cloudera QuickStart VM in a bulk email, ensure that the content is clear, concise, and provides value to the recipients to avoid being marked as spam. Following email marketing best practices like using a reputable email service, segmenting your audience, personalizing the email content, and including a clear call to action is beneficial.
Hadoop Training Demo Day 1 Video:
youtube
You can find more information about Hadoop Training in this Hadoop Docs Link
Conclusion:
Unogeeks is the №1 IT Training Institute for Hadoop Training. Anyone Disagree? Please drop in a comment
You can check out our other latest blogs on Hadoop Training here — Hadoop Blogs
Please check out our Best In Class Hadoop Training Details here — Hadoop Training
S.W.ORG
— — — — — — — — — — — -
For Training inquiries:
Call/Whatsapp: +91 73960 33555
Mail us at: [email protected]
Our Website ➜ https://unogeeks.com
Follow us:
Instagram: https://www.instagram.com/unogeeks
Facebook: https://www.facebook.com/UnogeeksSoftwareTrainingInstitute
Twitter: https://twitter.com/unogeeks
#unogeeks #training #ittraining #unogeekstraining
0 notes
Text
What is a Data Lake?
A data lake refers to a central storage repository used to store a vast amount of raw, granular data in its native format. It is a single store repository containing structured data, semi-structured data, and unstructured data.
A data lake is used where there is no fixed storage, no file type limitations, and emphasis is on flexible format storage for future use. Data lake architecture is flat and uses metadata tags and identifiers for quicker data retrieval in a data lake.
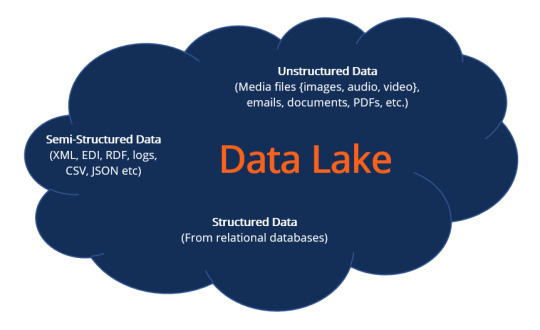
The term “data lake” was coined by the Chief Technology Officer of Pentaho, James Dixon, to contrast it with the more refined and processed data warehouse repository. The popularity of data lakes continues to grow, especially in organizations that prefer large, holistic data storage.
Data in a data lake is not filtered before storage, and accessing the data for analysis is ad hoc and varied. The data is not transformed until it is needed for analysis. However, data lakes need regular maintenance and some form of governance to ensure data usability and accessibility. If data lakes are not maintained well and become inaccessible, they are referred to as “data swamps.”
Data Lakes vs. Data Warehouse
Data lakes are often confused with data warehouses; hence, to understand data lakes, it is crucial to acknowledge the fundamental distinctions between the two data repositories.
As indicated, both are data repositories that serve the same universal purpose and objective of storing organizational data to support decision-making. Data lakes and data warehouses are alternatives and mainly differ in their architecture, which can be concisely broken down into the following points.
Structure
The schema for a data lake is not predetermined before data is applied to it, which means data is stored in its native format containing structured and unstructured data. Data is processed when it is being used. However, a data warehouse schema is predefined and predetermined before the application of data, a state known as schema on write. Data lakes are termed schema on read.
Flexibility
Data lakes are flexible and adaptable to changes in use and circumstances, while data warehouses take considerable time defining their schema, which cannot be modified hastily to changing requirements. Data lakes storage is easily expanded through the scaling of its servers.
User Interface
Accessibility of data in a data lake requires some skill to understand its data relationships due to its undefined schema. In comparison, data in a data warehouse is easily accessible due to its structured, defined schema. Many users can easily access warehouse data, while not all users in an organization can comprehend data lake accessibility.
Why Create a Data Lake?
Storing data in a data lake for later processing when the need arises is cost-effective and offers an unrefined view to data analysts. The other reasons for creating a data lake are as follows:
The diverse structure of data in a data lake means it offers a robust and richer quality of analysis for data analysts.
There is no requirement to model data into an enterprise-wide schema with a data lake.
Data lakes offer flexibility in data analysis with the ability to modify structured to unstructured data, which cannot be found in data warehouses.
Artificial intelligence and machine learning can be employed to make profitable forecasts.
Using data lakes can give an organization a competitive advantage.
Data Lake Architecture
A data lake architecture can accommodate unstructured data and different data structures from multiple sources across the organization. All data lakes have two components, storage and compute, and they can both be located on-premises or based in the cloud. The data lake architecture can use a combination of cloud and on-premises locations.
It is difficult to measure the volume of data that will need to be accommodated by a data lake. For this reason, data lake architecture provides expanded scalability, as high as an exabyte, a feat a conventional storage system is not capable of. Data should be tagged with metadata during its application into the data lake to ensure future accessibility.
Below is a concept diagram for a data lake structure:

Data lakes software such as Hadoop and Amazon Simple Storage Service (Amazon S3) vary in terms of structure and strategy. Data lake architecture software organizes data in a data lake and makes it easier to access and use. The following features should be incorporated in a data lake architecture to prevent the development of a data swamp and ensure data lake functionality.
Utilization of data profiling tools proffers insights into the classification of data objects and implementing data quality control
Taxonomy of data classification includes user scenarios and possible user groups, content, and data type
File hierarchy with naming conventions
Tracking mechanism on data lake user access together with a generated alert signal at the point and time of access
Data catalog search functionality
Data security that encompasses data encryption, access control, authentication, and other data security tools to prevent unauthorized access
Data lake usage training and awareness
Hadoop Data Lakes Architecture
We have singled out illustrating Hadoop data lake infrastructure as an example. Some data lake architecture providers use a Hadoop-based data management platform consisting of one or more Hadoop clusters. Hadoop uses a cluster of distributed servers for data storage. The Hadoop ecosystem comprises three main core elements:
Hadoop Distributed File System (HDFS) – The storage layer whose function is storing and replicating data across multiple servers.
Yet Another Resource Negotiator (YARN) – Resource management tool
MapReduce – The programming model for splitting data into smaller subsections before processing in servers
Hadoop supplementary tools include Pig, Hive, Sqoop, and Kafka. The tools assist in the processes of ingestion, preparation, and extraction. Hadoop can be combined with cloud enterprise platforms to offer a cloud-based data lake infrastructure.

Hadoop is an open-source technology that makes it less expensive to use. Several ETL tools are available for integration with Hadoop. It is easy to scale and provides faster computation due to its data locality, which has increased its popularity and familiarity among most technology users.
Data Lake Key Concepts
Below are some key data lake concepts to broaden and deepen the understanding of data lakes architecture.
Data ingestion – The process where data is gathered from multiple data sources and loaded into the data lake. The process supports all data structures, including unstructured data. It also supports batch and one-time ingestion.
Security – Implementing security protocols for the data lake is an important aspect. It means managing data security and the data lake flow from loading, search, storage, and accessibility. Other facets of data security such as data protection, authentication, accounting, and access control to prevent unauthorized access are also paramount to data lakes.
Data quality – Information in a data lake is used for decision making, which makes it important for the data to be of high quality. Poor quality data can lead to bad decisions, which can be catastrophic to the organization.
Data governance – Administering and managing data integrity, availability, usability, and security within an organization.
Data discovery – Discovering data is important before data preparation and analysis. It is the process of collecting data from multiple sources and consolidating it in the lake, making use of tagging techniques to detect patterns enabling better data understandability.
Data exploration – Data exploration starts just before the data analytics stage. It assists in identifying the right dataset for the analysis.
Data storage – Data storage should support multiple data formats, be scalable, accessible easily and swiftly, and be cost-effective.
Data auditing – Facilitates evaluation of risk and compliance and tracks any changes made to crucial data elements, including identifying who made the changes, how data was changed, and when the changes took place.
Data lineage – Concerned with the data flow from its source or origin and its path as it is moved within the data lake. Data lineage smoothens error corrections in a data analytics process from its source to its destination.
Benefits of a Data Lake
A data lake is an agile storage platform that can be easily configured for any given data model, structure, application, or query. Data lake agility enables multiple and advanced analytical methods to interpret the data.
Being a schema on read makes a data lake scalable and flexible.
Data lakes support queries that require a deep analysis by exploring information down to its source to queries that require a simple report with summary data. All user types are catered for.
Most data lakes software applications are open source and can be installed using low-cost hardware.
Schema development is deferred until an organization finds a business case for the data. Hence, no time and costs are wasted on schema development.
Data lakes offer centralization of different data sources.
They provide value for all data types as well as the long-term cost of ownership.
Cloud-based data lakes are easier and faster to implement, cost-effective with a pay-as-you-use model, and are easier to scale up as the need arises. It also saves on space and real estate costs.
Challenges and Criticism of Data Lakes
Data lakes are at risk of losing relevance and becoming data swamps over time if they are not properly governed.
It is difficult to ensure data security and access control as some data is dumped in the lake without proper oversight.
There is no trail of previous analytics on the data to assist new users.
Storage and processing costs may increase as more data is added to the lake.
On-premises data lakes face challenges such as space constraints, hardware and data center setup, storage scalability, cost, and resource budgeting.
Popular Data Lake Technology Vendors
Popular data lake technology providers include the following:
Amazon S3 – Offers unlimited scalability
Apache – Uses Hadoop open-source ecosystem
Google Cloud Platform (GCP) – Google cloud storage
Oracle Big Data Cloud
Microsoft Azure Data Lake and Azure Data Analytics
Snowflake – Processes structured and semi-structured datasets, notably JSON, XML, and Parquet
More Resources
To keep learning and developing your knowledge base, please explore the additional relevant resources below:
Business Intelligence
Data Mart
Scalability
Data Protection
1 note
·
View note
Text
How to use data analytics to improve your business operations

There is a floating demand for experts with Analytics capabilities that can discover, evaluate, and also analyze Big Data. The requirement for analytical specialists in Hyderabad is on a higher swing. Presently, there is a huge deficiency within the number of skilled Big Data experts. We at 360DigiTMG design the curriculum around trending subjects for data analytics courses in hyderabad so that it'll be easy for specialists to obtain a task. The Qualified Data Analytics training course in Hyderabad from 360DigiTMG provided in-depth knowledge regarding Analytics by palms-on experience like study and initiatives from diverse sectors.
We do offer Fast-Track data analytics training and One-to-One Big Information Analytics Learning Hyderabad. 360DigiTMG provides added programs in Tableau and also Organization Analytics with R to boost your research and also obtain you on the career course to be a Data Analyst. This training program offers you step-by-step information to understand all the subjects that a Data Analyst needs to recognize.
360DigiTMG Course in Information Analytics
This Tableau qualification program assists you understand Tableau Desktop computer 10, a world-wide made use of knowledge visualization, reporting, and business knowledge device. Advancement your profession in analytics by finding out Tableau as well as how to best use this training in your job.
In addition to the academic data, you'll get to work on jobs which can make you business-prepared. data analytics course is especially curated to impart these competencies that employers in fact take into consideration underneath information analyst credentials.
We learned every component of Digital advertising and marketing in addition to real time instances right here. 360DigiTMG is a wonderful area where you can be shown complete & every suggestion of electronic advertising. A devoted online survey was produced and the link was sent out to above 30 knowledge science colleges, of which 21 responded throughout the stated time.
360DigiTMG data analytics course in hyderabad

During the first few weeks, you'll examine the important ideas of Big Data, and you they'll move on to learning about different Big Data design systems, Big Information handling and also Big Information Analytics. You'll collaborate with Big Data instruments, consisting of Hadoop, Hive, Hbase, Flicker, Sqoop, Scala, Storm, and.
The demand for Service analytics is huge in both house and worldwide task markets. According to Newscom, India's analytics market would certainly raise 2 instances to INR Crores by the end of 2019.
The EMCDSA qualification demonstrates an individual's ability to take part and contribute as a data science staff member on big understanding jobs. Python is becoming increasingly preferred due to a lot of reasons. It is also thought-about that it is obligatory to grasp the Python phrase structure earlier than doing something remarkable like info scientific research. Though, there are a lot of reasons to discover Python, nevertheless one of the vital reasons is that it's the greatest language to grasp if you intend to evaluate the data or get into the round of expertise examination as well as understanding sciences. In order to begin your info scientific research journey, you will need to first find out the naked minimum phrase structure.
Artificial intelligence formulas are utilized to construct predictive styles using Regression Analysis and also an Information Researcher must establish expertise in Neural Networks as well as Attribute Engineering. 360DigiTMG supplies a good Certification Program on data analytics course hyderabad, Life Sciences and also Medical care Analytics meant for doctors. Medical professionals will discover to translate Electronic Health and wellness Document (EHR) information sorts as well as buildings and also apply predictive modelling on the exact same. Along with this, they'll be instructed to use artificial intelligence methods to medical care understanding.
Yet, finding out Python in order to use it for data sciences would possibly take a while, although, it's totally pricey. The majority of entry level details analyst tasks a minimum of call for a bachelor's diploma. Nevertheless, having a master's level in understanding analytics is beneficial. The majority of people from technological histories start at entry-level settings comparable to a statistical assistant, business help expert, procedures expert, or others, which supply them valuable on-the-job training as well as experience.
For more information
360DigiTMG - Data Analytics, Data Science Course Training Hyderabad
Address - 2-56/2/19, 3rd floor,, Vijaya towers, near Meridian school,, Ayyappa Society Rd, Madhapur,, Hyderabad, Telangana 500081
Call us@+91 99899 94319
0 notes
Text
I’ll Take Care Of You // Byron Langley
Word Count: 1203
Summary- You have to work, but can’t focus as your boyfriend is home alone and ill.
Warnings; N/A
A/n; I’m really not sure why, but the simple imagines take me the longest to write. Suppose I have to come up with most of the plot, but am restricted at the same time if that makes sense? Nonetheless, It’s finally done.
Requested; Yes.
req; hi, i want to request a sick byron imagine ever since in the last poop sqoop joe mentioned he wasn't feeling well :( thank you💘
-
You were immensely relieved as the clock finally hit 12:00pm, break time. Quickly cleaning up, you opened one of your many office drawers where you kept your purse and phone. You thanked heaven you lived close to work, so you could just drive to the flat for lunch. You opened your phone, checking if you missed anything during the hours you were occupied with work.
‘Byron 💕: Could you pick up some more medicine before coming home?’
The text illuminated your screen, causing you to sigh. Recently, Byron had been feeling ill, and you hated that you couldn’t do anything to help. When it came to it, there really wasn’t much you could do, but it still made you feel useless and a pathetic girlfriend when you couldn’t make your boyfriend feel better.
‘You: Of course, By. Take care, I’ll be home in 20 minutes.’
You popped into the shop on the way home, grabbing some extra medications and a tub of ice cream for Byron’s sore throat, and drove home as quickly as you could. (Without breaking the law, of course.) You entered the flat, slipping off your shoes at the door and entering the bedroom, where Byron was wrapped in a cocoon of blankets. You giggled slightly at the sight, him groaning at the sudden noise.
“Hello to you too, mister.” You teased, sitting on the edge of the bed next to his shielded body. Another groan was your response, and you frowned. “I got your medicine.” You said, softer. He shifted slightly, so his head was now peeking out of the shell of blankets surrounding him. “Thank you.” He said, his voice scratchy and obviously sore. You winced slightly at the sound.
You handed him the medicine, leaving the room to get him a water bottle, (which you scolded him for not already having one when he was sick, as drinking water was very important). You got yourself a sandwich to eat for lunch while you were there, and returned quickly and helping him untangle his limbs from the sheets. You got him to take his medicine, brushing his hair off of his sticky forehead.
As your raised your arm, you frowned as you saw the time. “Crap.” You muttered, taking the last bite of your sandwich and standing up, despite your conscious telling you to stay and take care of Byron. “I’ve gotta get back to work, hun. Take a nap, I’ll be back before you know it. There’s ice cream in the fridge for you if you want it.” You told him, and he grabbed your arm. By the expression on his face, you figured he’d ask you to stay; but he knew you couldn’t.
“Will you bring back Nando’s?” He asked instead, making you chuckle. “Of course, Byron.” You smiled, kissing his forehead lightly and opening the window. “I love you, but it stinks and the air is completely stale in here. Just because you’re sick doesn’t mean you’re allowed to stink up my room!” You instructed, and he chuckled slightly, nodding. You bid him goodbye, driving back to work.
The rest of the day dragged on, as it does when you have something better you could be doing, and your eyes kept instinctively drifting to the clock. It was the longest day of work you’d had in awhile. Don’t get me wrong; you loved your job, but with a sick boyfriend at home and you not being there for him you were really despising it right now.
Finally, it rolled around 4pm and you were allowed to leave. You quickly gathered your things, taking some papers you could work on at home and leaving as fast as possible. Leaving always took so long, all the cars trying to get out, and you wanted to get home. You got to your car and it only took a few minutes to pull out, despite the wave of cars attempting the same action as you.
You drove to Nando’s, which thankfully, wasn’t too far from your work, picked up some dinner for you and Bryon, remembering his very specific order, and you sighed as you realized you’d likely get stuck in traffic. It was a bad time, and you were in the middle of London. Great. You’d spent the whole day worrying about Byron, (though deep down, you knew he’d be fine for a few hours), and you just wanted to curl up next to him and watch some 3 star comedy you could make fun of on Netflix for the rest of the night.
You tapped the steering wheel impatiently as the cars passed you, and the line of cars slowly inched forward and through stop lights. Finally, you pulled up to your flat parking lot and couldn’t have been more relieved. “Byron?” You called, kicking off your uncomfortable shoes and sighing in relief. “In here, still.” He called, from the bedroom. You walked in, and frowned. “Have you moved at all
since I left?” You asked, concerned. He looked at you, his eyes red and tired-looking. “I got up to go to the bathroom right after you left, and I got ice cream. Since then, no.” He rasped, his sore throat evident in his voice.
“Didn’t I open this window?” You asked him, eyebrows raised. “I got cold.” He shrugged, and you rolled your eyes at his obvious excuse. “Byron, at least if you’re not getting out of bed, you need some source of fresh air.” You opened it again, and walked back to the bed. “Alright, time to get up. I know you’re sick but it’s not helping to stay in bed all day.” He groaned, but you weren’t changing your mind.
You pulled him up; he didn’t fight, he knew you were right anyways. You dragged him out to the sitting room, and sat him down on the couch. He turned on some football, while you quickly prepared some tea, and set out your Nando’s. When everything was ready, you sat down on the couch next to him, placing everything in front.
You spent the evening taking care of him, more so than usual, as though making up the time you were at work and couldn’t be home for him. “Thank you, Y/N. You know you didn’t have to do all of this.” Byron told you, as you were changing into your nighttime attire. “I wanted too. I hate that I had to leave you for work.” You frowned, guiltily. “Hey, it’s okay. You’re here now. Now let’s watch Netflix and make fun of stupid movies until we fall asleep.”
You smiled. Even though he was sick, he put your happiness and preferences first, and thought of how to cheer you up. “I thought I was supposed to be taking care of you.” You teased, climbing into bed next to him. “You already have, more than I could ask for.” He said, pulling you into his chest. “You’re gonna get me sick!” You whined, but only playfully. “Good. Then you can stay home and I’ll get to take care of you.” You smiled, shaking your head and leaning up to kiss his cheek. “I love you, Byron.” “I love you too, Y/N.”
#byron langley imagine#byron langley#byron#langley#youtuber imagines#buttercream imagines#buttercream squad imagine#buttercreams#buttercream#buttercream squad#buttercream gang#buttercream gang imagines
179 notes
·
View notes
Link
Description It is a very common word that is thrown around in IT circles today. But it is a very serious course that adds skills to a developer and admin specialist. It is now defined as a study from where the ‘data’, ‘material’ or ‘information’ comes from. The science involves data conversion into valued creation for business. Mining data is huge business and identifying patterns is important. Job responsibilitiesA data scientist is a very significant person who helps large or small enterprises to regulate the raw data sources and interpret them efficiently. A deep analytical skill is required to become a data scientist. Your role is to take care of 4 duties- management, analytics, experiment with new technologies to benefit the organization, increase knowledge for data insights to help business grow. Requisites to learnDo you have a degree in Statistics, maths or computer science? All are appreciated in becoming a superb data scientist. An additional knowledge on machine learning and economics is beneficial. To study and get trained a working knowledge is acceptable. Join a Data Analytics Training in Bangalore for best results and certification programs. Course details/benefitsThere are many advantages of studying this course in a reputed training center that has proper facilities. Bangalore offers several options for students, programmers and IT admins. This training certificate is in demand and adds muscle to Hadoop, Flume, Sqoop and machine learning. When you opt for DVS Technologies a prime Data Science Training institute in Bangalore, you get successful placements after completion of the modules. Key features of certification course and modulesWhen you take admission in one of the best Data Science Training in Bangalore you will get familiar with: • Python training which will cover-• Data Wrangling• Data Exploration• Data Visualization & manipulation• Mathematical computing• Machine Learning & Ai• Data Analytics and its types• Installing Python & different packages• Juptyer Notebook reviews
0 notes
Text
Apache Sqoop

Apache Sqoop is an open-source tool that efficiently transfers bulk data between Apache Hadoop and structured data stores such as relational databases. It is a part of the Hadoop ecosystem and is used to import data from external sources into Hadoop Distributed File System (HDFS) or related systems like Hive and HBase. Similarly, it can also be used to export data from Hadoop or its associated systems to external structured data stores.
Here are some key features and aspects of Apache Sqoop:
Data Import: Sqoop can import individual tables or entire databases into Hadoop. It can also partition the data based on a column in the table, allowing efficient data organization.
Data Export: Sqoop can export data from the Hadoop File System into relational databases.
Connectors for Multiple Data Sources: It provides connectors for various relational databases, allowing them to interact with different data sources seamlessly.
Parallel Data Transfer: Sqoop uses MapReduce to import and export the data, which allows for parallel processing and, hence, efficient data transfer.
Incremental Loads: It supports incremental loading of a single table or free-form SQL query, which makes it possible to transfer only the newly updated data.
Integration with Hadoop Ecosystem: Sqoop works well with Hadoop, Hive, HBase, and other components of the Hadoop ecosystem.
Command Line Interface: Sqoop provides a command-line interface, making it easy to script and automate data transfer tasks.
Sqoop is particularly useful in scenarios where organizations need to move large amounts of data between Hadoop systems and relational databases, and it helps bridge the gap between Big Data ecosystems and traditional data management systems.
Hadoop Training Demo Day 1 Video:
youtube
You can find more information about Hadoop Training in this Hadoop Docs Link
Conclusion:
Unogeeks is the №1 IT Training Institute for Hadoop Training. Anyone Disagree? Please drop in a comment
You can check out our other latest blogs on Hadoop Training here — Hadoop Blogs
Please check out our Best In Class Hadoop Training Details here — Hadoop Training
S.W.ORG
— — — — — — — — — — — -
For Training inquiries:
Call/Whatsapp: +91 73960 33555
Mail us at: [email protected]
Our Website ➜ https://unogeeks.com
Follow us:
Instagram: https://www.instagram.com/unogeeks
Facebook: https://www.facebook.com/UnogeeksSoftwareTrainingInstitute
Twitter: https://twitter.com/unogeeks
#unogeeks #training #ittraining #unogeekstraining
0 notes
Link
Description It is a very common word that is thrown around in IT circles today. But it is a very serious course that adds skills to a developer and admin specialist. It is now defined as a study from where the ‘data’, ‘material’ or ‘information’ comes from. The science involves data conversion into valued creation for business. Mining data is huge business and identifying patterns is important. Job responsibilitiesA data scientist is a very significant person who helps large or small enterprises to regulate the raw data sources and interpret them efficiently. A deep analytical skill is required to become a data scientist. Your role is to take care of 4 duties- management, analytics, experiment with new technologies to benefit the organization, increase knowledge for data insights to help business grow. Requisites to learnDo you have a degree in Statistics, maths or computer science? All are appreciated in becoming a superb data scientist. An additional knowledge on machine learning and economics is beneficial. To study and get trained a working knowledge is acceptable. Join a Data Analytics Training in Bangalore for best results and certification programs. Course details/benefitsThere are many advantages of studying this course in a reputed training center that has proper facilities. Bangalore offers several options for students, programmers and IT admins. This training certificate is in demand and adds muscle to Hadoop, Flume, Sqoop and machine learning. When you opt for DVS Technologies a prime Data Science Training institute in Bangalore, you get successful placements after completion of the modules. Key features of certification course and modulesWhen you take admission in one of the best Data Science Training in Bangalore you will get familiar with: • Python training which will cover-• Data Wrangling• Data Exploration• Data Visualization & manipulation• Mathematical computing• Machine Learning & Ai• Data Analytics and its types• Installing Python & different packages• Juptyer Notebook reviews
0 notes
Link
Description
It is a very common word that is thrown around in IT circles today. But it is a very serious course that adds skills to a developer and admin specialist. It is now defined as a study from where the ‘data’, ‘material’ or ‘information’ comes from. The science involves data conversion into valued creation for business. Mining data is huge business and identifying patterns is important.
Job responsibilities
A data scientist is a very significant person who helps large or small enterprises to regulate the raw data sources and interpret them efficiently. A deep analytical skill is required to become a data scientist. Your role is to take care of 4 duties- management, analytics, experiment with new technologies to benefit the organization, increase knowledge for data insights to help business grow.
Requisites to learn
Do you have a degree in Statistics, maths or computer science? All are appreciated in becoming a superb data scientist. An additional knowledge on machine learning and economics is beneficial. To study and get trained a working knowledge is acceptable. Join a Data Analytics Training in Bangalore for best results and certification programs.
Course details/benefits
There are many advantages of studying this course in a reputed training center that has proper facilities. Bangalore offers several options for students, programmers and IT admins. This training certificate is in demand and adds muscle to Hadoop, Flume, Sqoop and machine learning. When you opt for DVS Technologies a prime Data Science Training institute in Bangalore, you get successful placements after completion of the modules.
Key features of certification course and modules
When you take admission in one of the best Data Science Training in Bangalore you will get familiar with:
• Python training which will cover-
• Data Wrangling
• Data Exploration
• Data Visualization & manipulation
• Mathematical computing
• Machine Learning & Ai
• Data Analytics and its types
• Installing Python & different packages
• Juptyer Notebook reviews
0 notes
Link
Description
It is a very common word that is thrown around in IT circles today. But it is a very serious course that adds skills to a developer and admin specialist. It is now defined as a study from where the ‘data’, ‘material’ or ‘information’ comes from. The science involves data conversion into valued creation for business. Mining data is huge business and identifying patterns is important.
Job responsibilities
A data scientist is a very significant person who helps large or small enterprises to regulate the raw data sources and interpret them efficiently. A deep analytical skill is required to become a data scientist. Your role is to take care of 4 duties- management, analytics, experiment with new technologies to benefit the organization, increase knowledge for data insights to help business grow.
Requisites to learn
Do you have a degree in Statistics, maths or computer science? All are appreciated in becoming a superb data scientist. An additional knowledge on machine learning and economics is beneficial. To study and get trained a working knowledge is acceptable. Join a Data Analytics Training in Bangalore for best results and certification programs.
Course details/benefits
There are many advantages of studying this course in a reputed training center that has proper facilities. Bangalore offers several options for students, programmers and IT admins. This training certificate is in demand and adds muscle to Hadoop, Flume, Sqoop and machine learning. When you opt for DVS Technologies a prime Data Science Training institute in Bangalore, you get successful placements after completion of the modules.
Key features of certification course and modules
When you take admission in one of the best Data Science Training in Bangalore you will get familiar with:
• Python training which will cover-
• Data Wrangling
• Data Exploration
• Data Visualization & manipulation
• Mathematical computing
• Machine Learning & Ai
• Data Analytics and its types
• Installing Python & different packages
• Juptyer Notebook reviews
0 notes
Link
Description
It is a very common word that is thrown around in IT circles today. But it is a very serious course that adds skills to a developer and admin specialist. It is now defined as a study from where the ‘data’, ‘material’ or ‘information’ comes from. The science involves data conversion into valued creation for business. Mining data is huge business and identifying patterns is important.
Job responsibilities
A data scientist is a very significant person who helps large or small enterprises to regulate the raw data sources and interpret them efficiently. A deep analytical skill is required to become a data scientist. Your role is to take care of 4 duties- management, analytics, experiment with new technologies to benefit the organization, increase knowledge for data insights to help business grow.
Requisites to learn
Do you have a degree in Statistics, maths or computer science? All are appreciated in becoming a superb data scientist. An additional knowledge on machine learning and economics is beneficial. To study and get trained a working knowledge is acceptable. Join a Data Analytics Training in Bangalore for best results and certification programs.
Course details/benefits
There are many advantages of studying this course in a reputed training center that has proper facilities. Bangalore offers several options for students, programmers and IT admins. This training certificate is in demand and adds muscle to Hadoop, Flume, Sqoop and machine learning. When you opt for DVS Technologies a prime Data Science Training institute in Bangalore, you get successful placements after completion of the modules.
Key features of certification course and modules
When you take admission in one of the best Data Science Training in Bangalore you will get familiar with:
• Python training which will cover-
• Data Wrangling
• Data Exploration
• Data Visualization & manipulation
• Mathematical computing
• Machine Learning & Ai
• Data Analytics and its types
• Installing Python & different packages
• Juptyer Notebook reviews
0 notes
Text
How to use data analytics to improve your business operations

There is a hovering need for professionals with Analytics capacities that can find, examine, and also interpret Big Data. The need for logical experts in Hyderabad is on a higher swing. Presently, there is a large shortage within the variety of experienced Big Data experts. We at 360DigiTMG layout the educational program around trending topics for data analytics course in hyderabad so that it'll be very easy for professionals to obtain a work. The Qualified Data Analytics program in Hyderabad from 360DigiTMG used in-depth understanding about Analytics by palms-on experience like study as well as campaigns from diverse sectors.
We do give Fast-Track Big Information Analytics Training in Hyderabad and One-to-One data analytics courses in hyderabad. 360DigiTMG presents added programs in Tableau and also Service Analytics with R to enhance your research as well as obtain you on the career path to becoming an Information Expert. This training program provides you step-by-step details to master all the subjects that a Data Expert needs to understand.
360DigiTMG Course in Information Analytics

This Tableau certification training course assists you understand Tableau Desktop 10, a global utilized understanding visualization, reporting, and also organization knowledge tool. Advance your occupation in analytics by discovering Tableau and just how to ideal use this coaching in your job.
In addition to the academic data, you'll deal with tasks which can make you business-prepared. data analytics course hyderabad is specifically curated to convey these expertise that employers actually consider beneath data expert credentials.
We got to discover every module of Digital marketing together with live examples right below. 360DigiTMG is a remarkable location where you can be instructed to complete & every concept of digital advertising and marketing. A committed online survey was developed and the link was sent to above 30 knowledge scientific research colleges, of which 21 responded throughout the stated time.
360DigiTMG data analytics training
Throughout the initial couple of weeks, you'll study the important suggestions of Big Data, and also you they'll carry on to learning about different Big Information engineering systems, Big Information handling as well as Big Data Analytics. You'll work with Big Information tools, including Hadoop, Hive, Hbase, Flicker, Sqoop, Scala, Tornado, as well as.
The need for Service analytics is huge in both home and also global job markets. According to Newscom, India's analytics market would certainly boost two circumstances to INR Crores by the end of 2019.
The EMCDSA accreditation demonstrates a person's capacity to participate and add as an information scientific research staff member on huge understanding tasks. Python is coming to be significantly popular due to a lot of reasons. It is also thought-about that it is mandatory to understand the Python phrase structure earlier than doing something interesting like info scientific research. Though, there are a lot of causes to find out about Python, nevertheless one of the vital reasons is that it's the greatest language to comprehend if you want to examine the data or enter the sphere of understanding assessment and scientific research. In order to start your detailed science journey, you will need to initially learn the naked minimum phrase structure.
Machine learning algorithms are used to develop anticipating styles utilizing Regression Evaluation and a Data Researcher has to develop experience in Neural Networks and Feature Design. 360DigiTMG provides an excellent Accreditation Program on Life Sciences and Healthcare Analytics meant for medical professionals. Medical professionals will certainly find out to analyze Electronic Health and wellness Record (EHR) information types and also buildings and also apply anticipating modelling on the same. Along with this, they'll be educated to make use of artificial intelligence methods to healthcare understanding.
But, discovering Python in order to use it for information sciences would possibly take a while, although, it totally rates it. Most entry level details experts work a minimum of a bachelor's diploma. Nonetheless, having a master's level in understanding analytics is helpful. Many folks from technological histories start at entry-level settings similar to an analytical aide, venture help analyst, procedures expert, or others, which supply them invaluable on-the-job training as well as experience.
For more information
360DigiTMG - Data Analytics, Data Science Course Training Hyderabad
Address - 2-56/2/19, 3rd floor,, Vijaya towers, near Meridian school,, Ayyappa Society Rd, Madhapur,, Hyderabad, Telangana 500081
Call us@+91 99899 94319
youtube
0 notes
Text
Emancipating and revamping career through data analytics

There is a hovering need for specialists with Analytics abilities that can discover, evaluate, as well as interpret Big Information. The need for logical professionals in Hyderabad gets on an upward swing. Presently, there is a big deficit within the number of proficient Big Information analysts. We at 360DigiTMG layout the curriculum around trending topics for our data analytics course in hyderabad in order that it'll be easy for specialists to get a task. The Certified Information Analytics program in Hyderabad from 360DigiTMG provided comprehensive understanding about Analytics by palms-on experience like case studies as well as initiatives from varied industries.
We do supply Fast-Track data analytics course hyderabad and One-to-One Big Information Analytics Learning Hyderabad. 360DigiTMG offers additional programs in Tableau as well as Service Analytics with R to improve your researching and also obtain you on the career course to coming to be an Information Expert. This training program offers you detailed info to understand all the topics that a Data Expert must recognize.
360DigiTMG Course in Information Analytics
This Tableau certification program helps you master Tableau Desktop computer 10, a worldwide utilized knowledge visualization, reporting, as well as organization knowledge tool. Advancement your occupation in analytics by learning Tableau as well as just how to best usage this training in your job.
In addition to the academic data, you'll reach work on jobs which can make you business-prepared. The training course is particularly curated to convey these expertise that companies really think about underneath data analyst qualification.
We reached discover every module of Digital advertising in addition to live instances right here. 360DigiTMG is a terrific place where you can be instructed complete & every idea of digital advertising and marketing. A dedicated online questionnaire was produced and the link was sent to greater than 30 knowledge scientific research universities, of which 21 responded throughout the stipulated time.

360DigiTMG data analytics course
Throughout the initial few weeks, you'll research the important ideas of Big Information, and you then'll go on to discovering various Big Data design platforms, Big Data processing as well as Big Information Analytics. You'll work with Big Information tools, consisting of Hadoop, Hive, Hbase, Glow, Sqoop, Scala, Tornado, as well as.
The need for Business analytics is large in both home as well as global task markets. According to Newscom, India's analytics market would raise two circumstances to INR Crores by the end of 2019.
The EMCDSA certification shows a person's ability to take part as well as contribute as a data science employee on huge knowledge tasks. Python is ending up being increasingly preferred because of a plenty of factors. It is also thought-about that it is necessary to grasp the Python phrase structure earlier than doing something remarkable like information science. Though, there are a lots of causes to discover Python, however one of the essential causes is that it's the best language to realize if you want to analyze the information or get involved in the ball of knowledge evaluation and expertise scientific researches. In order to begin your details science journey, you will have to initial find out the naked minimum phrase structure.
Machine learning formulas are used to build anticipating styles using Regression Analysis and also an Information Researcher must create competence in Neural Networks and also Feature Engineering. 360DigiTMG provides an Rlent Certification Program on Life Sciences as well as Health care Analytics indicated for doctor. Physician will discover to analyze Electronic Health and wellness Document (EHR) information sorts and also buildings and also apply anticipating modelling on the exact same. In addition to this, they'll be shown to make use of machine learning methods to healthcare understanding.
Yet, finding out Python in order to use it for data scientific researches would potentially take a while, although, it's completely rate it. A lot of beginning info analyst jobs at the very least require a bachelor's diploma. Nonetheless, having a master's degree in expertise analytics is advantageous. Many individuals from technological histories begin at entry-level settings similar to a statistical aide, business help expert, operations analyst, or others, which supply them valuable on-the-job training and also experience.
For more Information
360DigiTMG - Data Analytics, Data Science Course Training Hyderabad
Address - 2-56/2/19, 3rd floor,, Vijaya towers, near Meridian school,, Ayyappa Society Rd, Madhapur,, Hyderabad, Telangana 500081
099899 94319
youtube
0 notes
Text
Hadoop Admin training in Pune, India.

Hadoop Admin Training in Pune
At SevenMentor training institute, we are always striving to achieve value for our applicants. We provide the best Hadoop Admin Training in Pune that pursues latest instruments, technologies, and methods. Any candidate out of IT and Non-IT history or having basic knowledge of networking could register for this program. Freshers or experienced candidates can combine this course to understand Hadoop management, troubleshooting and setup almost. The candidates who are Freshers, Data Analyst, BE/ Bsc Candidate, Any Engineers, Any schooling, Any Post-Graduate, Database Administrators, Working Professional all can join this course and update themselves to improve a career in late technologies. Hadoop Admin classes in Pune is going to be processed by Accredited Trainer from Corporate Industries directly, As we believe in supplying quality live Greatest Hadoop Administration Training in Pune with all the essential practical to perform management and process under training roofing, The coaching comes with Apache spark module, Kafka and Storm for real time occasion processing, You to combine the greater future with SevenMentor.
Proficiency After Training
Can handle and procedures the Big Data, Learn How to Cluster it and manage complex team readily.
Will Have the Ability to manage extra-large amount of Unstructured Data Across various Business Companies
He/She will Have the Ability to apply for various job positions to data process Engineering operate in MNCs
Hadoop Admin Classes in Pune
What we provide for Hadoop Admin Courses before stepping into Hadoop Environment for the very first time, we will need to understand why Hadoop came into existence. What were the drawbacks of traditional RDBMS in and Hadoop is better?
We're going to learn about fundamental networking concepts. Together with media terminologies we're also going understand about AWS Cloud. Why cloud at the very first location? Now businesses are turning to cloud. Baremetals and VM's do not probably have the capacity to put away the number of information that is generated in the present world. Plus it costs business a great deal of money to store the information to the hardware, and also the upkeep of these machines will also be required on timely basis. Cloud offers answer to such issues, where a company can store all of its information which is generated without worrying about the number of information that's created on daily basis. They don't need to care for the upkeep and safety of these machines, cloud sellers appears after all this. Here at SevenMentor we'll provide you hands on exposure to the Amazon Web Services (AWS Cloud) since AWS is market leader within this subject.
We'll offer exposure to Linux surroundings too. Hadoop Administrator understands a great deal of tickets concerning the Hadoop bunch and those tickets need to be resolved in accordance with the priority of these tickets. In business we call it all troubleshooting. Thus, Hadoop Admin must troubleshoot in Linux environment. We've developed our course in this manner that in the event that you don't have any knowledge from Linux Environment we'll provide you sufficient exposure to the technology whilst covering the sessions of Hadoop Admin.
What is Hadoop Admin?
Hadoop is a member level open supply package framework designed for storage and procedure for huge scale type of information on clusters of artifact hardware. The Apache Hadoop software library is a framework which allows the data distributed processing across clusters for calculating using easy programming versions called Map Reduce. It is intended to rescale from single servers to a bunch of machines and each giving native computation and storage in economical means. It functions in a run of map-reduce tasks and each of these tasks is high-latency and depends on each other. So no job can begin until the previous job was completed and successfully finished. Hadoop solutions usually comprise clusters that are tough to manage and maintain. In many cases, it requires integration with other tools like MySQL, mahout, etc.. We have another popular framework which works with Apache Hadoop i.e. Spark. Apache Spark allows software developers to come up with complicated, multi-step data pipeline application routines. It also supports in-memory data sharing across DAG (Directed Acyclic Graph) established applications, so that different jobs can work with the same shared data. Spark runs on top of this Hadoop Distributed File System (HDFS) of Hadoop to improve functionality. Spark does not possess its own storage so it uses storage. With the capacities of in-memory information storage and information processing, the spark program performance is more time quicker than other big data technology or applications. Spark has a lazy evaluation which helps with optimization of the measures in data processing and control. It supplies a higher-level API for enhancing consistency and productivity. Spark is designed to be a fast real-time execution engine which functions both in memory and on disk. Spark is originally written in Scala language plus it runs on the exact same Java Virtual Machine (JVM) environment. It now supports Java, Scala, Clojure, R, Python, SQL for writing applications.
Why Should I take Hadoop Admin Training in Pune?
Apache Hadoop framework allows us to write distributed systems or applications. It's more efficient and it automatically distributes the job and information among machines which lead a parallel programming model. Hadoop works with various sorts of data effectively. In addition, it provides a high fault-tolerant method to prevent data losses. Another big advantage of Hadoop is that it is open source and compatible with all platforms since it's based on java. On the current market, Hadoop is the only remedy to work on large data effectively in a distributed fashion. The Apache Hadoop software library is a framework that makes it possible for the data distributed processing across clusters for computing using simple programming models known as Map Reduce. It's intended to ratio from single servers to the cluster of servers and each giving native computation and storage in a cheap way. It works in a series of map-reduce tasks and every one of these tasks is high-latency and depends upon each other. So no occupation can start until the last job has been finished and successfully finished. Hadoop solutions normally include clusters that are hard to manage and maintain.
We have another popular framework which works with Apache Hadoop i.e. Spark.
Apache Spark enables software developers to develop complicated, multi-step data pipeline software patterns. It also supports in-memory data sharing across DAG (Directed Acyclic Graph) established applications, so that different tasks can use the exact same shared data. Spark runs on top of this Hadoop Distributed File System (HDFS) of Hadoop to improve functionality. Spark does not possess its own storage so it utilizes storage. With the capabilities of in-memory data storage and data processing, the spark program functionality is more time faster than other large information technologies or applications. Spark includes a lazy evaluation which helps with optimization of the steps in data processing and control. It provides a higher-level API for improving consistency and productivity. Spark is designed to be a fast real-time execution engine which works both in memory and on disk.
Where Hadoop Admin could be utilized?
Machine Learning -- Machine learning is that the scientific research of calculations and applied mathematics versions that computer systems use to execute a specific job whilst not mistreatment specific directions. AI -- Machine intelligence which behaves like a person and takes decisions.
Data Analysis - is an extensive way of scrutinizing and re-transforming data with the objective of discovering useful information, notifying conclusions and supporting decision-making steps.
Graph and data visualization -- Data representation through graphs, graphs, images, etc..
Tools in Hadoop:
HDFS (Hadoop Distributed File System) fundamental storage for Hadoop.
Map scale back might be a programmatic version engine to perform man jobs.
Apache Hive is a Data Warehouse tool used to operate on Ancient data using HQL.
Apache Sqoop is a tool for Import and export data from RDBMS into HDFS and Vice-Versa.
Apache Ooozie is a tool for Job scheduling and similarly control applications over the cluster.
Apache HBase is a NoSQL database based on CAP(Consistency Automaticity Partition) principles.
A flicker could be a framework will in memory computation and works with Hadoop. This framework relies on scala and coffee language.
Why go for Best Hadoop Admin Training in Pune in SevenMentor?
At our renowned institute SevenMentor training, we have got industry-standard Hadoop program designed by IT professionals. The coaching we provide is 100% functional. Together with Hadoop Administrator Certification at Pune, we supply 100+ missions, POC's and real-time jobs. Additionally CV writing, mock tests, interviews are required to earn candidate industry-ready. We offer elaborated notes, interview kit and reference books to each candidate. Hadoop Administration Courses in Pune from Sevenmentor will master you handling and processing considerable quantities of info, unfiltered data with simple. The coaching went beneath bound modules where pupils find out how to install, strategy, configure a Hadoop cluster from planning to monitoring. The pupil can get coaching from live modules and also on a software package to fully optimize their data within the field of information process, the Best Hadoop Admin institute in Pune will allow you to monitor performance and work on information safety concepts in profound.
Hadoop admin is chargeable for the execution and support of this Enterprise Hadoop atmosphere.
Hadoop Administration invloves arising with, capacity arrangement, cluster discovered, performance fine-tuning, observation, structure arising withscaling and management. Hadoop Admins itself might well be a name that covers a heap of different niches within the massive information world: trusting on the size of this corporate they work for, Hadoop administrator may additionally worry liberal arts DBA like jobs with HBase and Hive databases, security administration and cluster management. Our syllabus covers all topics to deploy, manage, monitor, and secure a Hadoop Cluster at the end.
After successful conclusion of Hadoop Administration Classes in Pune in SevenMentor, you can manage and procedures that the Big Data, Learn to Cluster it and manage complex things readily. You will be able to control the extra-large quantity of Unstructured Data Around various small business Companies. You will have the ability to use for various job positions to information process Engineering work in MNCs.
Job Opportunities After Greatest Hadoop Admin Training in Pune.
The present IT job market is shifting about Big information only, 65 percent of their highest paid jobs direct to Big data Hadoop careers. Thus, if you're interested in finding a profession in Substantial data Hadoop admin, then you will be happy to know that existing Hadoop market is growing rapidly not just in IT industry but also in additional domain and sectors such as e-commerce, banking, digital marketing, government, medical, research, and promotion.
Hadoop Administrator -- Responsible for the implementation and ongoing administration of Hadoop infrastructure. Aligning with all the systems engineering team to suggest and deploy new hardware and software bundle environments required for Hadoop and also revamp existing environments.
A Hadoop admin plays a major job role in the company, he or she acts as the core of the business. The best Hadoop Administrator Training at Pune learner is not only responsible to administrate to handle entire Hadoop clusters but also handle all resources, tools, the infrastructure of the Hadoop ecosystem. He is also responsible for handling installation and maintenance of full Hadoop multi-node cluster, and manage overall maintenance and functionality. Hadoop admin is clearly responsible for the implementation and support of the Enterprise Hadoop atmosphere. Hadoop Admins itself might be a title that covers a pile of assorted niches within the huge data world: counting on the grade of the firm they work for, Hadoop administrator could, in addition, be worried performing arts DBA like tasks with HBase and Hive databases, safety administration and cluster administration. It covers matters to deploy, manage, track, and secure a Hadoop Cluster.
After effective Hadoop administrator training in Pune completion in SevenMentor, you can handle and processes the Big Data, Learn to Cluster it and manage complicated things readily. You will have the ability to control the extra-large quantity of Unstructured Data Across various Business Companies. You'll have the ability to apply for various job positions to information process Engineering operate in MNCs.
Accessible Hadoop Admin Certification Course at Pune
Businesses square measure using Hadoop wide to interrupt down their informational sets. The main reason is Hadoop system mainly depends on a straightforward programming model (MapReduce) and it empowers a figuring arrangement that is flexible, adaptable, blame tolerant and fiscally savvy. Here, the primary concern is to stay up to speed in creating prepared in-depth datasets as so much as holding time up amongst queries and holding up time to conduct the app.
We at Seventmentor understands the need for candidates and most well-liked batch timings. Presently, we've got weekends and weekdays batches for Big data Hadoop Admin Training in Pune. We also give versatile batch timings as per need. The entire duration for the Hadoop Admin class in Pune is 40 Hours. In weekdays batch, Hadoop Administrator Certification at Pune will probably be of 2 hours each day and at the weekend its 3 hours every day.
Nowadays learning of Hadoop is important and essential skills for beginners and seasoned to make a career in IT as well as experience to boost the abilities for better opportunities. It will be helpful for any operational, technical and support adviser.
SevenMentor as Best Hadoop Admin Training in Pune provides a unique Big Data Hadoop Admin class in Pune considering fresher or entry-level engineers to encounter.
0 notes
Text
300+ TOP Apache SQOOP Interview Questions and Answers
SQOOP Interview Questions for freshers experienced :-
1. What is the process to perform an incremental data load in Sqoop? The process to perform incremental data load in Sqoop is to synchronize the modified or updated data (often referred as delta data) from RDBMS to Hadoop. The delta data can be facilitated through the incremental load command in Sqoop. Incremental load can be performed by using Sqoop import command or by loading the data into hive without overwriting it. The different attributes that need to be specified during incremental load in Sqoop are- Mode (incremental) –The mode defines how Sqoop will determine what the new rows are. The mode can have value as Append or Last Modified. Col (Check-column) –This attribute specifies the column that should be examined to find out the rows to be imported. Value (last-value) –This denotes the maximum value of the check column from the previous import operation. 2. How Sqoop can be used in a Java program? The Sqoop jar in classpath should be included in the java code. After this the method Sqoop.runTool () method must be invoked. The necessary parameters should be created to Sqoop programmatically just like for command line. 3. What is the significance of using –compress-codec parameter? To get the out file of a sqoop import in formats other than .gz like .bz2 we use the –compress -code parameter. 4. How are large objects handled in Sqoop? Sqoop provides the capability to store large sized data into a single field based on the type of data. Sqoop supports the ability to store- CLOB ‘s – Character Large Objects BLOB’s –Binary Large Objects Large objects in Sqoop are handled by importing the large objects into a file referred as “LobFile” i.e. Large Object File. The LobFile has the ability to store records of huge size, thus each record in the LobFile is a large object. 5. What is a disadvantage of using –direct parameter for faster data load by sqoop? The native utilities used by databases to support faster load do not work for binary data formats like SequenceFile 6. Is it possible to do an incremental import using Sqoop? Yes, Sqoop supports two types of incremental imports- Append Last Modified To insert only rows Append should be used in import command and for inserting the rows and also updating Last-Modified should be used in the import command. 7. How can you check all the tables present in a single database using Sqoop? The command to check the list of all tables present in a single database using Sqoop is as follows- Sqoop list-tables –connect jdbc: mysql: //localhost/user; 8. How can you control the number of mappers used by the sqoop command? The Parameter –num-mappers is used to control the number of mappers executed by a sqoop command. We should start with choosing a small number of map tasks and then gradually scale up as choosing high number of mappers initially may slow down the performance on the database side. 9. What is the standard location or path for Hadoop Sqoop scripts? /usr/bin/Hadoop Sqoop 10. How can we import a subset of rows from a table without using the where clause? We can run a filtering query on the database and save the result to a temporary table in database. Then use the sqoop import command without using the –where clause

Apache SQOOP Interview Questions 11. When the source data keeps getting updated frequently, what is the approach to keep it in sync with the data in HDFS imported by sqoop? qoop can have 2 approaches. To use the –incremental parameter with append option where value of some columns are checked and only in case of modified values the row is imported as a new row. To use the –incremental parameter with lastmodified option where a date column in the source is checked for records which have been updated after the last import. 12. What is a sqoop metastore? It is a tool using which Sqoop hosts a shared metadata repository. Multiple users and/or remote users can define and execute saved jobs (created with sqoop job) defined in this metastore. Clients must be configured to connect to the metastore in sqoop-site.xml or with the –meta-connect argument. 13. Can free form SQL queries be used with Sqoop import command? If yes, then how can they be used? Sqoop allows us to use free form SQL queries with the import command. The import command should be used with the –e and – query options to execute free form SQL queries. When using the –e and –query options with the import command the –target dir value must be specified. 14. Tell few import control commands: Append Columns Where These command are most frequently used to import RDBMS Data. 15. Can free form SQL queries be used with Sqoop import command? If yes, then how can they be used? Sqoop allows us to use free form SQL queries with the import command. The import command should be used with the –e and – query options to execute free form SQL queries. When using the –e and –query options with the import command the –target dir value must be specified. 16. How can you see the list of stored jobs in sqoop metastore? sqoop job –list 17. What type of databases Sqoop can support? MySQL, Oracle, PostgreSQL, IBM, Netezza and Teradata. Every database connects through jdbc driver. 18. What is the purpose of sqoop-merge? The merge tool combines two datasets where entries in one dataset should overwrite entries of an older dataset preserving only the newest version of the records between both the data sets. 19. How sqoop can handle large objects? Blog and Clob columns are common large objects. If the object is less than 16MB, it stored inline with the rest of the data. If large objects, temporary stored in_lob subdirectory. Those lobs processes in a streaming fashion. Those data materialized in memory for processing. IT you set LOB to 0, those lobs objects placed in external storage. 20. What is the importance of eval tool? It allows user to run sample SQL queries against Database and preview the results on the console. It can help to know what data can import? The desired data imported or not? 21. What is the default extension of the files produced from a sqoop import using the –compress parameter? .gz 22. Can we import the data with “Where” condition? Yes, Sqoop has a special option to export/import a particular data. 23. What are the limitations of importing RDBMS tables into Hcatalog directly? There is an option to import RDBMS tables into Hcatalog directly by making use of –hcatalog –database option with the –hcatalog –table but the limitation to it is that there are several arguments like –as-avro file , -direct, -as-sequencefile, -target-dir , -export-dir are not supported. 24. what are the majorly used commands in sqoop? In Sqoop Majorly Import and export command are used. But below commands are also useful sometimes. codegen, eval, import-all-tables, job, list-database, list-tables, merge, metastore. 25. What is the usefulness of the options file in sqoop. The options file is used in sqoop to specify the command line values in a file and use it in the sqoop commands. For example the –connect parameter’s value and –user name value scan be stored in a file and used again and again with different sqoop commands. 26. what are the common delimiters and escape character in sqoop? The default delimiters are a comma(,) for fields, a newline(\n) for records Escape characters are \b,\n,\r,\t,\”, \\’,\o etc 27. What are the two file formats supported by sqoop for import? Delimited text and Sequence Files. 28. while loading table from MySQL into HDFS, if we need to copy tables with maximum possible speed, what can you do? We need to use -direct argument in import command to use direct import fast path and this -direct can be used only with MySQL and PostGreSQL as of now. 29. How can you sync a exported table with HDFS data in which some rows are deleted? Truncate the target table and load it again. 30. Differentiate between Sqoop and distCP. DistCP utility can be used to transfer data between clusters whereas Sqoop can be used to transfer data only between Hadoop and RDBMS. 31. How can you import only a subset of rows form a table? By using the WHERE clause in the sqoop import statement we can import only a subset of rows. 32. How do you clear the data in a staging table before loading it by Sqoop? By specifying the –clear-staging-table option we can clear the staging table before it is loaded. This can be done again and again till we get proper data in staging. 33. What is Sqoop? Sqoop is an open source project that enables data transfer from non-hadoop source to hadoop source. It can be remembered as SQL to Hadoop -> SQOOP. It allows user to specify the source and target location inside the Hadoop. 35. How can you export only a subset of columns to a relational table using sqoop? By using the –column parameter in which we mention the required column names as a comma separated list of values. 36. Which database the sqoop metastore runs on? Running sqoop-metastore launches a shared HSQLDB database instance on the current machine. 37. How will you update the rows that are already exported? The parameter –update-key can be used to update existing rows. In it a comma-separated list of columns is used which uniquely identifies a row. All of these columns is used in the WHERE clause of the generated UPDATE query. All other table columns will be used in the SET part of the query. 38. You have a data in HDFS system, if you want to put some more data to into the same table, will it append the data or overwrite? No it can’t overwrite, one way to do is copy the new file in HDFS. 39. Where can the metastore database be hosted? The metastore database can be hosted anywhere within or outside of the Hadoop cluster. 40. Which is used to import data in Sqoop ? In SQOOP import command is used to import RDBMS data into HDFS. Using import command we can import a particular table into HDFS. – 41. What is the role of JDBC driver in a Sqoop set up? To connect to different relational databases sqoop needs a connector. Almost every DB vendor makes this connecter available as a JDBC driver which is specific to that DB. So Sqoop needs the JDBC driver of each of the database it needs to interact with. 42. How to import only the updated rows form a table into HDFS using sqoop assuming the source has last update timestamp details for each row? By using the lastmodified mode. Rows where the check column holds a timestamp more recent than the timestamp specified with –last-value are imported. 43. What is InputSplit in Hadoop? When a hadoop job is run, it splits input files into chunks and assign each split to a mapper to process. This is called Input Split 44. Hadoop sqoop word came from ? Sql + Hadoop = sqoop 45. What is the work of Export In Hadoop sqoop ? Export the data from HDFS to RDBMS 46. Use of Codegen command in Hadoop sqoop ? Generate code to interact with database records 47. Use of Help command in Hadoop sqoop ? List available commands 48. How can you schedule a sqoop job using Oozie? Oozie has in-built sqoop actions inside which we can mention the sqoop commands to be executed. 49. What are the two file formats supported by sqoop for import? Delimited text and Sequence Files. 50. What is a sqoop metastore? It is a tool using which Sqoop hosts a shared metadata repository. Multiple users and/or remote users can define and execute saved jobs (created with sqoop job) defined in this metastore. Clients must be configured to connect to the metastore in sqoop-site.xml or with the –meta-connect argument. SQOOP Questions and Answers pdf Download Read the full article
0 notes
Link
Ingestion of Big Data Using Apache Sqoop & Apache Flume ##elearning ##freetutorials #Apache #Big #Data #Flume #Ingestion #Sqoop Ingestion of Big Data Using Apache Sqoop & Apache Flume This course provides basic and advanced concepts of Sqoop. This course is designed for beginners and professionals. Sqoop is an open source framework provided by Apache. It is a command-line interface application for transferring data between relational databases and Hadoop. This course includes all topics of Apache Sqoop with Sqoop features, Sqoop Installation, Starting Sqoop, Sqoop Import, Sqoop where clause, Sqoop Export, Sqoop Integration with Hadoop ecosystem etc. Flume is a standard, simple, robust, flexible, and extensible tool for data ingestion from various data producers (webservers) into Hadoop. In this course, we will be using simple and illustrative example to explain the basics of Apache Flume and how to use it in practice. This wonderful online course on Sqoop Training is a detailed course which will help you understand all the important concepts and topics of Sqoop Training. Through this Sqoop Training, you will learn that Sqoop permits quick and rapid import as well as export of data from data stores which are structured such as relational databases, NoSQL systems and enterprise data warehouse. 👉 Activate Udemy Coupon 👈 Free Tutorials Udemy Review Real Discount Udemy Free Courses Udemy Coupon Udemy Francais Coupon Udemy gratuit Coursera and Edx ELearningFree Course Free Online Training Udemy Udemy Free Coupons Udemy Free Discount Coupons Udemy Online Course Udemy Online Training 100% FREE Udemy Discount Coupons https://www.couponudemy.com/blog/ingestion-of-big-data-using-apache-sqoop-apache-flume/
0 notes