#talend sql
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
After the announcement of the deal with Yahoo!, there were 170K signatures of unhappy Tumblr users petitioning to prevent the sale in 2013.
Text
ETL and Data Testing Services: Why Data Quality Is the Backbone of Business Success | GQAT Tech
Data drives decision-making in the digital age. Businesses use data to build strategies, attain insights, and measure performance to plan for growth opportunities. However, data-driven decision-making only exists when the data is clean, complete, accurate, and trustworthy. This is where ETL and Data Testing Services are useful.
GQAT Tech provides ETL (Extract, Transform, Load) and Data Testing Services so your data pipelines can run smoothly. Whether you are migrating legacy data, developing on a data warehouse, or merging with other data, GQAT Tech services help ensure your data is an asset and not a liability.
What is ETL and Why Is It Important?
ETL (extract, transform, load) is a process for data warehousing and data integration, which consists of:
Extracting data from different sources
Transforming the data to the right format or structure
Loading the transformed data into a central system, such as a data warehouse.
Although ETL can simplify data processing, it can also create risks in that data can be lost, misformatted, corrupted, or misapplied transformation rules. This is why ETL testing is very important.
The purpose of ETL testing is to ensure that the data is:
Correctly extracted from the source systems
Accurately transformed according to business logic
Correctly loaded into the destination systems.
Why Choose GQAT Tech for ETL and Data Testing?
At GQAT Tech combine our exceptional technical expertise and premier technology and custom-built frameworks to ensure your data is accurate and certified with correctness.
1. End-to-End Data Validation
We will validate your data across the entire ETL process – extract, transform, and load- to confirm the source and target systems are 100% consistent.
2. Custom-Built Testing Frameworks
Every company has a custom data workflow. We build testing frameworks fit for your proprietary data environments, business rules, and compliance requirements.
3. Automation + Accuracy
We automate to the highest extent using tools like QuerySurge, Talend, Informatica, SQL scripts, etc. This helps a) reduce the amount of testing effort, b) avoid human error.
4. Compliance Testing
Data Privacy and compliance are obligatory today. We help you comply with regulations like GDPR, HIPAA, SOX, etc.
5. Industry Knowledge
GQAT has years of experience with clients in Finance, Healthcare, Telecom, eCommerce, and Retail, which we apply to every data testing assignment.
Types of ETL and Data Testing Services We Offer
Data Transformation Testing
We ensure your business rules are implemented accurately as part of the transformation process. Don't risk incorrect aggregations, mislabels, or logical errors in your final reports.
Data Migration Testing
We ensure that, regardless of moving to the cloud or the legacy to modern migration, all the data is transitioned completely, accurately, and securely.
BI Report Testing
We validate that both dashboards and business reports reflect the correct numbers by comparing visual data to actual backend data.
Metadata Testing
We validate schema, column names, formats, data types, and other metadata to ensure compatibility of source and target systems.
Key Benefits of GQAT Tech’s ETL Testing Services
1. Increase Data Security and Accuracy
We guarantee that valid and necessary data will only be transmitted to your system; we can reduce data leakage and security exposures.
2. Better Business Intelligence
Good data means quality outputs; dashboards and business intelligence you can trust, allowing you to make real-time choices with certainty.
3. Reduction of Time and Cost
We also lessen the impact of manual mistakes, compress timelines, and assist in lower rework costs by automating data testing.
4. Better Customer Satisfaction
Good data to make decisions off of leads to good customer experiences, better insights, and improved services.
5. Regulatory Compliance
By implementing structured testing, you can ensure compliance with data privacy laws and standards in order to avoid fines, penalties, and audits.
Why GQAT Tech?
With more than a decade of experience, we are passionate about delivering world-class ETL & Data Testing Services. Our purpose is to help you operate from clean, reliable data to exercise and action with confidence to allow you to scale, innovate, and compete more effectively.
Visit Us: https://gqattech.com Contact Us: [email protected]
#ETL Testing#Data Testing Services#Data Validation#ETL Automation#Data Quality Assurance#Data Migration Testing#Business Intelligence Testing#ETL Process#SQL Testing#GQAT Tech
0 notes
Text
Big Data Analytics: Tools & Career Paths

In this digital era, data is being generated at an unimaginable speed. Social media interactions, online transactions, sensor readings, scientific inquiries-all contribute to an extremely high volume, velocity, and variety of information, synonymously referred to as Big Data. Impossible is a term that does not exist; then, how can we say that we have immense data that remains useless? It is where Big Data Analytics transforms huge volumes of unstructured and semi-structured data into actionable insights that spur decision-making processes, innovation, and growth.
It is roughly implied that Big Data Analytics should remain within the triangle of skills as a widely considered niche; in contrast, nowadays, it amounts to a must-have capability for any working professional across tech and business landscapes, leading to numerous career opportunities.
What Exactly Is Big Data Analytics?
This is the process of examining huge, varied data sets to uncover hidden patterns, customer preferences, market trends, and other useful information. The aim is to enable organizations to make better business decisions. It is different from regular data processing because it uses special tools and techniques that Big Data requires to confront the three Vs:
Volume: Masses of data.
Velocity: Data at high speed of generation and processing.
Variety: From diverse sources and in varying formats (!structured, semi-structured, unstructured).
Key Tools in Big Data Analytics
Having the skills to work with the right tools becomes imperative in mastering Big Data. Here are some of the most famous ones:
Hadoop Ecosystem: The core layer is an open-source framework for storing and processing large datasets across clusters of computers. Key components include:
HDFS (Hadoop Distributed File System): For storing data.
MapReduce: For processing data.
YARN: For resource-management purposes.
Hive, Pig, Sqoop: Higher-level data warehousing and transfer.
Apache Spark: Quite powerful and flexible open-source analytics engine for big data processing. It is much faster than MapReduce, especially for iterative algorithms, hence its popularity in real-time analytics, machine learning, and stream processing. Languages: Scala, Python (PySpark), Java, R.
NoSQL Databases: In contrast to traditional relational databases, NoSQL (Not only SQL) databases are structured to maintain unstructured and semic-structured data at scale. Examples include:
MongoDB: Document-oriented (e.g., for JSON-like data).
Cassandra: Column-oriented (e.g., for high-volume writes).
Neo4j: Graph DB (e.g., for data heavy with relationships).
Data Warehousing & ETL Tools: Tools for extracting, transforming, and loading (ETL) data from various sources into a data warehouse for analysis. Examples: Talend, Informatica. Cloud-based solutions such as AWS Redshift, Google BigQuery, and Azure Synapse Analytics are also greatly used.
Data Visualization Tools: Essential for presenting complex Big Data insights in an understandable and actionable format. Tools like Tableau, Power BI, and Qlik Sense are widely used for creating dashboards and reports.
Programming Languages: Python and R are the dominant languages for data manipulation, statistical analysis, and integrating with Big Data tools. Python's extensive libraries (Pandas, NumPy, Scikit-learn) make it particularly versatile.
Promising Career Paths in Big Data Analytics
As Big Data professionals in India was fast evolving, there were diverse professional roles that were offered with handsome perks:
Big Data Engineer: Designs, builds, and maintains the large-scale data processing systems and infrastructure.
Big Data Analyst: Work on big datasets, finding trends, patterns, and insights that big decisions can be made on.
Data Scientist: Utilize statistics, programming, and domain expertise to create predictive models and glean deep insights from data.
Machine Learning Engineer: Concentrates on the deployment and development of machine learning models on Big Data platforms.
Data Architect: Designs the entire data environment and strategy of an organization.
Launch Your Big Data Analytics Career
Some more Specialized Big Data Analytics course should be taken if you feel very much attracted to data and what it can do. Hence, many computer training institutes in Ahmedabad offer comprehensive courses covering these tools and concepts of Big Data Analytics, usually as a part of Data Science with Python or special training in AI and Machine Learning. Try to find those courses that offer real-time experience and projects along with industry mentoring, so as to help you compete for these much-demanded jobs.
When you are thoroughly trained in the Big Data Analytics tools and concepts, you can manipulate information for innovation and can be highly paid in the working future.
At TCCI, we don't just teach computers — we build careers. Join us and take the first step toward a brighter future.
Location: Bopal & Iskcon-Ambli in Ahmedabad, Gujarat
Call now on +91 9825618292
Visit Our Website: http://tccicomputercoaching.com/
0 notes
Text
data cleansing
What is Data Cleansing and Why Is It Important?
In today’s digital age, data is one of the most valuable assets for any business. However, not all data is useful. Inaccurate, duplicate, or incomplete information can lead to poor decision-making, loss of revenue, and damaged reputations. That’s where data cleansing comes into play.
Data cleansing, also known as data cleaning or data scrubbing, is the process of detecting and correcting (or removing) corrupt, inaccurate, or irrelevant records from a dataset. The goal is to improve data quality so that it can be used effectively for business intelligence, marketing, operations, and analytics.
Key Steps in Data Cleansing
Removing Duplicate Records Duplicate entries can inflate figures and lead to misleading insights. Identifying and deleting these copies ensures that each customer, transaction, or product is only recorded once.
Correcting Inaccurate Data Errors in spelling, formatting, or inconsistent data entries are common. For example, “New York” might appear as “NY” or “N.Y.” A standard format should be enforced to ensure consistency.
Filling in Missing Information Missing data can cause gaps in reports and analysis. Where possible, missing fields should be completed using reliable sources or inferred through data relationships.
Standardizing Data Formats Formatting data uniformly (e.g., date formats, phone numbers, currency symbols) across all entries ensures compatibility and easy integration with different systems.
Validating Data Accuracy Comparing data against trusted external sources (like official databases) can help verify the accuracy of information such as addresses, emails, and contact details.
Why Businesses Need Data Cleansing
Improved Decision Making Clean data leads to more accurate reports, which helps management make better strategic decisions.
Enhanced Customer Experience Clean and accurate customer data allows for personalized and effective communication, increasing customer satisfaction and retention.
Increased Efficiency Employees spend less time correcting errors and more time on productive tasks. Automation of clean data can streamline operations.
Cost Reduction Bad data can result in wasted marketing spend, incorrect orders, and misinformed strategies. Data cleansing minimizes these costly errors.
Compliance and Risk Management Many industries have strict regulations around data privacy and accuracy. Clean data helps businesses stay compliant and avoid fines or legal issues.
Tools and Techniques for Data Cleansing
There are many software tools that support data cleansing, including Microsoft Excel, OpenRefine, Talend, Trifacta, and more advanced platforms like Informatica and SAS Data Quality. Techniques often involve scripting (e.g., Python or SQL), machine learning for identifying patterns, and manual reviews for sensitive or complex data sets.
Conclusion
Clean data is crucial for business success. Without it, even the best strategies and tools can fail. By investing in regular data cleansing, organizations not only protect their operations but also empower their teams to perform better with confidence in the information they rely on. It’s not just about cleaning data—it's about unlocking its full value.
0 notes
Text
Jaspersoft Consultancy for Advanced Reporting and Data Visualization Solutions
Businesses that want to make decisions based on data need strong tools that can turn complicated data into insightful knowledge. Jaspersoft, a powerful business intelligence (BI) suite by TIBCO, stands out as a top-tier reporting and data visualization platform. However, unlocking its full potential requires specialized knowledge and expertise. That’s where Jaspersoft consulting services come into play — and companies like Helical IT Solutions are leading the way in delivering customized, efficient, and scalable BI solutions.
What is Jaspersoft?
Jaspersoft is an enterprise-ready BI platform known for its flexibility, scalability, and ability to integrate with a wide range of data sources. It supports everything from pixel-perfect reporting and interactive dashboards to ad hoc reporting and multi-tenant environments.
Ideal for embedding analytics into web and mobile applications, Jaspersoft empowers both developers and end-users with its user-friendly interface and comprehensive feature set. Businesses across industries such as healthcare, finance, retail, and manufacturing rely on Jaspersoft to gain insights and drive smarter decision-making.
Key Features of Jaspersoft for Enterprise Reporting
Jaspersoft offers a comprehensive suite of features tailored for enterprise reporting:
• Multi-Source Data Connectivity: Connects to SQL and NoSQL databases, big data platforms like Hadoop and MongoDB, flat files, and even custom data sources.
• Centralized Repository: Securely manages reports, dashboards, analytic views, and user profiles in a central hub, with auditing and access monitoring.
• Flexible Deployment: Supports on-premises, cloud, and containerized environments, enabling businesses to deploy BI where it fits best.
• Advanced Scheduling and Distribution: Automates report and dashboard delivery, supporting both recurring and on-demand schedules.
• Interactive Visualizations: Enables users to drill down, filter, and customize visualizations for deeper data exploration.
• Branding and Theming: Offers extensive customization to align reports and dashboards with organizational branding
Custom Reporting Solutions Tailored to Business Needs
Every organization has unique reporting requirements. Jaspersoft’s extensible architecture allows for the creation of highly customized reports and dashboards. With tools like Jaspersoft Studio, users can design pixel-perfect reports, combine multiple data sources, and embed complex business logic. Consistency and efficiency are guaranteed across reporting projects with features like externalized style sheets, reusable components, and sub reports.
Professional Jaspersoft BI consultants help organizations tailor these solutions, whether it’s implementing custom plugins, integrating advanced security, or developing domain-specific analytics.
Integration with Existing Systems and Data Sources
Seamless integration is critical for modern BI. Jaspersoft supports integration with a wide array of enterprise systems, including ERP, CRM, and data warehouses. Its support for RESTful APIs and embeddable components (like Visualize.js and JasperReports Library) allows businesses to embed analytics directly into their web and mobile applications25. With ETL capabilities powered by Jasper ETL (Talend), organizations can extract, transform, and load data from disparate sources, ensuring a unified and accurate view for reporting136.
Optimizing Performance and Scalability
Performance and scalability are essential for enterprise BI deployments. Jaspersoft’s in-memory analysis, high availability, and load balancing features ensure rapid response times and reliability, even with large and complex datasets. Businesses can scale their BI operations while maintaining high performance by utilizing data warehousing best practices, such as star and snowflake schemas, and streamlining data pipelines. Helical IT Solutions specializes in performance tuning, capacity planning, and implementing high availability at both the BI and data warehouse levels
Why Choose Professional Jaspersoft Consultancy Services
While Jaspersoft offers powerful out-of-the-box features, realizing its full value often requires specialized expertise. Professional Jaspersoft Consulting services provide:
• Expert Implementation: Certified Jaspersoft BI consultants guide organizations through every stage—from platform selection to deployment and customization.
• End-to-End Support: Services cover all aspects, including report development, ETL, embedding analytics, security, and system integration.
• Cost-Effective Solutions: With experience across industries and geographies, consultants like Helical IT Solutions deliver scalable solutions at competitive rates.
• Proven Track Record: Helical IT Solutions boasts over 35 enterprise-level Jaspersoft implementations for Fortune 500 companies, governments, and diverse sectors, making them a trusted partner for advanced BI needs.
Introducing Helical IT Solutions: Your Jaspersoft Consulting Partner
Helical IT Solutions is a leading provider of Jaspersoft Consulting Services, with a team of certified Jaspersoft consultants and developers. Their expertise spans the full spectrum of Jaspersoft capabilities, including JasperReports development, ETL integration, high availability, load balancing, and custom plugin development. As a long-standing system integration partner for Jaspersoft, Helical has delivered BI solutions to clients in social media, energy, healthcare, telecom, and government sectors worldwide.
Whether you need a full-fledged BI implementation, migration, or ongoing support, Helical IT Solutions offers tailored Jaspersoft consulting to help you achieve your business intelligence goals.
Conclusion
Jaspersoft is a powerhouse in the realm of business intelligence, offering versatile tools for reporting and data visualization. But to truly harness its capabilities, expert implementation and strategic customization are essential.
That’s where Jaspersoft consulting becomes indispensable. Whether you're starting from scratch or looking to enhance an existing setup, partnering with experienced professionals like Helical IT Solutions ensures a smooth journey toward data-driven success.
From custom report development to enterprise-scale integration and optimization, Helical IT Solutions offers comprehensive Jaspersoft consulting services that turn your BI goals into reality. If you’re ready to elevate your business intelligence strategy, it’s time to talk to the experts.
0 notes
Text
Unveiling the Power of Data Analysis: The Engine Behind Smart Decision-Making
In today's digital-first world, data is everywhere—from the apps on our phones to the transactions we make, the websites we visit, and even the wearables we use. But raw data alone is not what gives organizations a competitive edge. The real value lies in understanding, interpreting, and extracting insights from that data—a process known as data analysis.
This blog explores the significance of data analysis, its types, techniques, tools, real-world applications, and future trends. Whether you're a beginner trying to break into the field or a business leader looking to leverage data, this article will give you a comprehensive overview of how data analysis is shaping the world.
What is Data Analysis?
At its core, data analysis is the process of examining, cleaning, transforming, and modeling data to discover useful information, draw conclusions, and support decision-making. It bridges the gap between raw data and actionable insights.
The process often includes:
Collecting data from various sources.
Cleaning it to remove inaccuracies or inconsistencies.
Analyzing it using statistical or computational techniques.
Interpreting results to guide strategy or solve problems.
Why is Data Analysis Important?
Data analysis helps organizations make informed decisions backed by evidence rather than intuition. Some of the key benefits include:
Improved decision-making: Understand customer behavior, market trends, and internal performance.
Operational efficiency: Identify bottlenecks or inefficiencies in processes.
Personalized experiences: Deliver targeted products, services, or marketing.
Risk management: Detect fraud or forecast potential issues.
Innovation: Discover new business models or product ideas based on trends.
In short, data analysis transforms uncertainty into clarity.
Types of Data Analysis
There are four primary types of data analysis, each offering different levels of insight:
Descriptive Analysis
Answers: What happened?
Example: Monthly sales reports or website traffic summaries.
Goal: Provide an overview of past performance.
Diagnostic Analysis
Answers: Why did it happen?
Example: Investigating a drop in user engagement.
Goal: Identify root causes or contributing factors.
Predictive Analysis
Answers: What might happen next?
Example: Forecasting sales or customer churn using machine learning.
Goal: Use historical data to predict future outcomes.
Prescriptive Analysis
Answers: What should we do about it?
Example: Recommending supply chain adjustments based on demand forecasting.
Goal: Provide actionable strategies or optimizations.
The Data Analysis Process
The data analysis journey typically follows these key steps:
Define the Objective
Understand the problem you're solving or the question you're answering.
Collect Data
Sources may include databases, APIs, surveys, social media, logs, or third-party providers.
Clean and Prepare Data
Address missing values, outliers, duplicate entries, and inconsistent formatting.
Analyze Data
Use statistical tests, data visualization, and/or machine learning models.
Interpret Results
Translate findings into insights that align with your objectives.
Communicate Findings
Use dashboards, reports, or presentations to share results with stakeholders.
Popular Tools for Data Analysis
Here are some widely used tools, categorized by purpose:
Data Collection & Storage
SQL
Google BigQuery
AWS Redshift
MongoDB
Data Cleaning & Transformation
Excel
Python (Pandas, NumPy)
R
Talend
Analysis & Visualization
Tableau
Power BI
Python (Matplotlib, Seaborn, Plotly)
Excel
Looker
Advanced Analytics & Machine Learning
Python (scikit-learn, TensorFlow)
R
SAS
RapidMiner
The choice of tools depends on your project’s complexity, the volume of data, and the skills of your team.
Real-World Applications of Data Analysis
1. Healthcare
Data analysis enables hospitals to predict disease outbreaks, personalize patient care, and optimize resource allocation. For example, predictive models can forecast patient readmission risks, helping providers take preventive actions.
2. Finance
Banks and fintech companies use data analytics to detect fraudulent transactions, assess credit risk, and offer personalized financial products. Real-time analytics even powers algorithmic trading.
3. Retail and E-commerce
Understanding customer buying patterns, product performance, and inventory turnover helps businesses optimize pricing, improve customer experience, and increase conversions.
4. Marketing
With the help of customer segmentation and campaign performance analysis, marketers can run highly targeted, ROI-driven campaigns. Tools like Google Analytics or HubSpot help track engagement across channels.
5. Sports
Teams and organizations analyze performance metrics, health stats, and game footage to enhance training and strategy. Think “Moneyball” on steroids.
6. Transportation and Logistics
Companies like FedEx and UPS use data to optimize delivery routes, predict package delays, and enhance customer service.
Challenges in Data Analysis
Despite its benefits, data analysis is not without its hurdles:
Data Quality: Incomplete, outdated, or incorrect data can lead to poor decisions.
Data Silos: Disconnected data sources prevent holistic analysis.
Privacy Concerns: Handling sensitive information must comply with regulations (e.g., GDPR, HIPAA).
Skill Gaps: Many organizations struggle to find skilled data professionals.
Overfitting or Misinterpretation: Statistical errors can mislead decision-makers.
Mitigating these challenges requires investment in tools, talent, and a strong data governance strategy.
Future Trends in Data Analysis
As technology advances, so does the field of data analysis. Some emerging trends include:
1. Augmented Analytics
AI-driven platforms that automate data preparation, insight generation, and explanation—making analytics accessible to non-technical users.
2. Real-Time Analytics
Streaming data from IoT devices and cloud platforms is enabling instant decision-making, especially in industries like finance, manufacturing, and telecommunications.
3. Data Democratization
Self-service analytics tools are empowering employees across departments to analyze data without relying solely on data scientists.
4. Data Ethics and Governance
With increasing scrutiny on data privacy and algorithmic bias, ethical considerations are becoming integral to analysis workflows.
5. Integration with AI
Data analysis is no longer just descriptive or diagnostic—it's becoming prescriptive and autonomous, thanks to AI models that learn and adapt in real-time.
How to Get Started in Data Analysis
If you’re interested in pursuing a career in data analysis, here are a few tips:
Learn the fundamentals of statistics and data visualization.
Pick up tools like Excel, SQL, Python, and Tableau.
Work on real-world datasets from platforms like Kaggle or Data.gov.
Build a portfolio of projects that show your ability to derive insights.
Stay current with industry trends and best practices.
Conclusion
Data analysis is the compass guiding modern organizations through oceans of information. It turns questions into answers, confusion into clarity, and guesses into informed decisions. Whether you're running a business, managing a project, or planning your next big strategy, data analysis can provide the insights needed to succeed.
As data continues to grow in both volume and value, those who can analyze and act on it will hold the keys to the future.
If you'd like this blog formatted for a specific platform (e.g., Medium, WordPress), turned into a LinkedIn post series, or translated into a different tone or language, just say the word!
1 note
·
View note
Text
How to Automate Tableau to Power BI Migration for Faster Results
As businesses continue to evolve, so do their analytics needs. Many organizations are moving from Tableau to Power BI to leverage Microsoft’s broader ecosystem, tighter integration with Office 365, and cost efficiency. But migrating from one powerful BI platform to another isn’t a plug-and-play operation—it requires strategy, tools, and automation to ensure speed and accuracy.
At OfficeSolution, we specialize in streamlining your analytics journey. Here’s how you can automate your Tableau to Power BI migration and accelerate results without losing data integrity or performance.
Why Consider Migration to Power BI?
While Tableau offers rich data visualization capabilities, Power BI brings a robust suite of benefits, especially for organizations already embedded in Microsoft’s ecosystem. These include:
Seamless integration with Azure, Excel, and SharePoint
Scalable data models using DAX
Lower licensing costs
Embedded AI and natural language querying
Migrating doesn’t mean starting from scratch. With the right automation approach, your dashboards, data models, and business logic can be transitioned efficiently.
Step 1: Inventory and Assessment
Before automating anything, conduct a full inventory of your Tableau assets:
Dashboards and worksheets
Data sources and connectors
Calculated fields and filters
User roles and access permissions
This phase helps prioritize which dashboards to migrate first and which ones need redesigning due to functional differences between Tableau and Power BI.
Step 2: Use Automation Tools for Conversion
There are now tools and scripts that can partially automate the migration process. While full one-to-one conversion isn’t always possible due to the structural differences, automation can significantly cut manual effort:
Tableau to Power BI Converter Tools: Emerging tools can read Tableau workbook (TWB/TWBX) files and extract metadata, data sources, and layout designs.
Custom Python Scripts: Developers can use Tableau’s REST API and Power BI’s PowerShell modules or REST API to programmatically extract data and push it into Power BI.
ETL Automation Platforms: If your Tableau dashboards use SQL-based data sources, tools like Azure Data Factory or Talend can automate data migration and transformation to match Power BI requirements.
At OfficeSolution, we’ve developed proprietary scripts that map Tableau calculations to DAX and automate the bulk of the report structure transformation.
Step 3: Validate and Optimize
After automation, a manual review is crucial. Even the best tools require human oversight to:
Rebuild advanced visualizations
Validate data integrity and filters
Optimize performance using Power BI best practices
Align with governance and compliance standards
Our team uses a rigorous QA checklist to ensure everything in Power BI mirrors the original Tableau experience—or improves upon it.
Step 4: Train and Transition Users
The success of any migration depends on end-user adoption. Power BI offers a different interface and experience. Conduct hands-on training sessions, create Power BI templates for common use cases, and provide support as users transition.
Conclusion
Automating Tableau to Power BI migration isn’t just about saving time—it’s about ensuring accuracy, scalability, and business continuity. With the right combination of tools, scripting, and expertise, you can accelerate your analytics modernization with confidence.
At OfficeSolution, we help enterprises unlock the full value of Power BI through intelligent migration and ongoing support. Ready to upgrade your analytics stack? Let’s talk.
0 notes
Text
Career Path and Growth Opportunities for Integration Specialists
The Growing Demand for Integration Specialists.
Introduction
In today’s interconnected digital landscape, businesses rely on seamless data exchange and system connectivity to optimize operations and improve efficiency. Integration specialists play a crucial role in designing, implementing, and maintaining integrations between various software applications, ensuring smooth communication and workflow automation. With the rise of cloud computing, APIs, and enterprise applications, integration specialists are essential for driving digital transformation.
What is an Integration Specialist?
An Integration Specialist is a professional responsible for developing and managing software integrations between different systems, applications, and platforms. They design workflows, troubleshoot issues, and ensure data flows securely and efficiently across various environments. Integration specialists work with APIs, middleware, and cloud-based tools to connect disparate systems and improve business processes.
Types of Integration Solutions
Integration specialists work with different types of solutions to meet business needs:
API Integrations
Connects different applications via Application Programming Interfaces (APIs).
Enables real-time data sharing and automation.
Examples: RESTful APIs, SOAP APIs, GraphQL.
Cloud-Based Integrations
Connects cloud applications like SaaS platforms.
Uses integration platforms as a service (iPaaS).
Examples: Zapier, Workato, MuleSoft, Dell Boomi.
Enterprise System Integrations
Integrates large-scale enterprise applications.
Connects ERP (Enterprise Resource Planning), CRM (Customer Relationship Management), and HR systems.
Examples: Salesforce, SAP, Oracle, Microsoft Dynamics.
Database Integrations
Ensures seamless data flow between databases.
Uses ETL (Extract, Transform, Load) processes for data synchronization.
Examples: SQL Server Integration Services (SSIS), Talend, Informatica.
Key Stages of System Integration
Requirement Analysis & Planning
Identify business needs and integration goals.
Analyze existing systems and data flow requirements.
Choose the right integration approach and tools.
Design & Architecture
Develop a blueprint for the integration solution.
Select API frameworks, middleware, or cloud services.
Ensure scalability, security, and compliance.
Development & Implementation
Build APIs, data connectors, and automation workflows.
Implement security measures (encryption, authentication).
Conduct performance optimization and data validation.
Testing & Quality Assurance
Perform functional, security, and performance testing.
Identify and resolve integration errors and data inconsistencies.
Conduct user acceptance testing (UAT).
Deployment & Monitoring
Deploy integration solutions in production environments.
Monitor system performance and error handling.
Ensure smooth data synchronization and process automation.
Maintenance & Continuous Improvement
Provide ongoing support and troubleshooting.
Optimize integration workflows based on feedback.
Stay updated with new technologies and best practices.
Best Practices for Integration Success
✔ Define clear integration objectives and business needs. ✔ Use secure and scalable API frameworks. ✔ Optimize data transformation processes for efficiency. ✔ Implement robust authentication and encryption. ✔ Conduct thorough testing before deployment. ✔ Monitor and update integrations regularly. ✔ Stay updated with emerging iPaaS and API technologies.
Conclusion
Integration specialists are at the forefront of modern digital ecosystems, ensuring seamless connectivity between applications and data sources. Whether working with cloud platforms, APIs, or enterprise systems, a well-executed integration strategy enhances efficiency, security, and scalability. Businesses that invest in robust integration solutions gain a competitive edge, improved automation, and streamlined operations.
Would you like me to add recommendations for integration tools or comparisons of middleware solutions? 🚀
Integration Specialist:
#SystemIntegration
#APIIntegration
#CloudIntegration
#DataAutomation
#EnterpriseSolutions
0 notes
Text
ETL Pipeline Performance Tuning: How to Reduce Processing Time
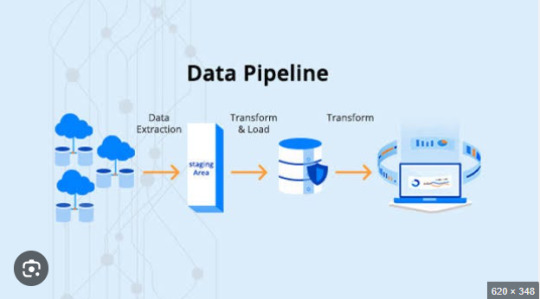
In today’s data-driven world, businesses rely heavily on ETL pipelines to extract, transform, and load large volumes of data efficiently. However, slow ETL processes can lead to delays in reporting, bottlenecks in data analytics, and increased infrastructure costs. Optimizing ETL pipeline performance is crucial for ensuring smooth data workflows, reducing processing time, and improving scalability.
In this article, we’ll explore various ETL pipeline performance tuning techniques to help you enhance speed, efficiency, and reliability in data processing.
1. Optimize Data Extraction
The extraction phase is the first step of the ETL pipeline and involves retrieving data from various sources. Inefficient data extraction can slow down the entire process. Here’s how to optimize it:
a) Extract Only Required Data
Instead of pulling all records, use incremental extraction to fetch only new or modified data.
Implement change data capture (CDC) to track and extract only updated records.
b) Use Efficient Querying Techniques
Optimize SQL queries with proper indexing, partitioning, and WHERE clauses to fetch data faster.
Avoid SELECT * statements; instead, select only required columns.
c) Parallel Data Extraction
If dealing with large datasets, extract data in parallel using multi-threading or distributed processing techniques.
2. Improve Data Transformation Efficiency
The transformation phase is often the most resource-intensive step in an ETL pipeline. Optimizing transformations can significantly reduce processing time.
a) Push Transformations to the Source Database
Offload heavy transformations (aggregations, joins, filtering) to the source database instead of handling them in the ETL process.
Use database-native stored procedures to improve execution speed.
b) Optimize Joins and Aggregations
Reduce the number of JOIN operations by using proper indexing and denormalization.
Use hash joins instead of nested loops for large datasets.
Apply window functions for aggregations instead of multiple group-by queries.
c) Implement Data Partitioning
Partition data horizontally (sharding) to distribute processing load.
Use bucketing and clustering in data warehouses like BigQuery or Snowflake for optimized query performance.
d) Use In-Memory Processing
Utilize in-memory computation engines like Apache Spark instead of disk-based processing to boost transformation speed.
3. Enhance Data Loading Speed
The loading phase in an ETL pipeline can become a bottleneck if not managed efficiently. Here’s how to optimize it:
a) Bulk Loading Instead of Row-by-Row Inserts
Use batch inserts to load data in chunks rather than inserting records individually.
Tools like COPY command in Redshift or LOAD DATA INFILE in MySQL improve bulk loading efficiency.
b) Disable Indexes and Constraints During Load
Temporarily disable foreign keys and indexes before loading large datasets, then re-enable them afterward.
This prevents unnecessary index updates for each insert, reducing load time.
c) Use Parallel Data Loading
Distribute data loading across multiple threads or nodes to reduce execution time.
Use distributed processing frameworks like Hadoop, Spark, or Google BigQuery for massive datasets.
4. Optimize ETL Pipeline Infrastructure
Hardware and infrastructure play a crucial role in ETL pipeline performance. Consider these optimizations:
a) Choose the Right ETL Tool & Framework
Tools like Apache NiFi, Airflow, Talend, and AWS Glue offer different performance capabilities. Select the one that fits your use case.
Use cloud-native ETL solutions (e.g., Snowflake, AWS Glue, Google Dataflow) for auto-scaling and cost optimization.
b) Leverage Distributed Computing
Use distributed processing engines like Apache Spark instead of single-node ETL tools.
Implement horizontal scaling to distribute workloads efficiently.
c) Optimize Storage & Network Performance
Store intermediate results in columnar formats (e.g., Parquet, ORC) instead of row-based formats (CSV, JSON) for better read performance.
Use compression techniques to reduce storage size and improve I/O speed.
Optimize network latency by placing ETL jobs closer to data sources.
5. Implement ETL Monitoring & Performance Tracking
Continuous monitoring helps identify performance issues before they impact business operations. Here’s how:
a) Use ETL Performance Monitoring Tools
Use logging and alerting tools like Prometheus, Grafana, or AWS CloudWatch to monitor ETL jobs.
Set up real-time dashboards to track pipeline execution times and failures.
b) Profile and Optimize Slow Queries
Use EXPLAIN PLAN in SQL databases to analyze query execution plans.
Identify and remove slow queries, redundant processing, and unnecessary transformations.
c) Implement Retry & Error Handling Mechanisms
Use checkpointing to resume ETL jobs from failure points instead of restarting them.
Implement automatic retries for temporary failures like network issues.
Conclusion
Improving ETL pipeline performance requires optimizing data extraction, transformation, and loading processes, along with choosing the right tools and infrastructure. By implementing best practices such as parallel processing, in-memory computing, bulk loading, and query optimization, businesses can significantly reduce ETL processing time and improve data pipeline efficiency.
If you’re dealing with slow ETL jobs, start by identifying bottlenecks, optimizing SQL queries, and leveraging distributed computing frameworks to handle large-scale data processing effectively. By continuously monitoring and fine-tuning your ETL workflows, you ensure faster, more reliable, and scalable data processing—empowering your business with real-time insights and decision-making capabilities.
0 notes
Text
Big Data and Data Engineering
Big Data and Data Engineering are essential concepts in modern data science, analytics, and machine learning.
They focus on the processes and technologies used to manage and process large volumes of data.
Here’s an overview:
What is Big Data? Big Data refers to extremely large datasets that cannot be processed or analyzed using traditional data processing tools or methods.
It typically has the following characteristics:
Volume:
Huge amounts of data (petabytes or more).
Variety:
Data comes in different formats (structured, semi-structured, unstructured). Velocity: The speed at which data is generated and processed.
Veracity: The quality and accuracy of data.
Value: Extracting meaningful insights from data.
Big Data is often associated with technologies and tools that allow organizations to store, process, and analyze data at scale.
2. Data Engineering:
Overview Data Engineering is the process of designing, building, and managing the systems and infrastructure required to collect, store, process, and analyze data.
The goal is to make data easily accessible for analytics and decision-making.
Key areas of Data Engineering:
Data Collection:
Gathering data from various sources (e.g., IoT devices, logs, APIs). Data Storage: Storing data in data lakes, databases, or distributed storage systems. Data Processing: Cleaning, transforming, and aggregating raw data into usable formats.
Data Integration:
Combining data from multiple sources to create a unified dataset for analysis.
3. Big Data Technologies and Tools
The following tools and technologies are commonly used in Big Data and Data Engineering to manage and process large datasets:
Data Storage:
Data Lakes: Large storage systems that can handle structured, semi-structured, and unstructured data. Examples include Amazon S3, Azure Data Lake, and Google Cloud Storage.
Distributed File Systems:
Systems that allow data to be stored across multiple machines. Examples include Hadoop HDFS and Apache Cassandra.
Databases:
Relational databases (e.g., MySQL, PostgreSQL) and NoSQL databases (e.g., MongoDB, Cassandra, HBase).
Data Processing:
Batch Processing: Handling large volumes of data in scheduled, discrete chunks.
Common tools:
Apache Hadoop (MapReduce framework). Apache Spark (offers both batch and stream processing).
Stream Processing:
Handling real-time data flows. Common tools: Apache Kafka (message broker). Apache Flink (streaming data processing). Apache Storm (real-time computation).
ETL (Extract, Transform, Load):
Tools like Apache Nifi, Airflow, and AWS Glue are used to automate data extraction, transformation, and loading processes.
Data Orchestration & Workflow Management:
Apache Airflow is a platform for programmatically authoring, scheduling, and monitoring workflows. Kubernetes and Docker are used to deploy and scale applications in data pipelines.
Data Warehousing & Analytics:
Amazon Redshift, Google BigQuery, Snowflake, and Azure Synapse Analytics are popular cloud data warehouses for large-scale data analytics.
Apache Hive is a data warehouse built on top of Hadoop to provide SQL-like querying capabilities.
Data Quality and Governance:
Tools like Great Expectations, Deequ, and AWS Glue DataBrew help ensure data quality by validating, cleaning, and transforming data before it’s analyzed.
4. Data Engineering Lifecycle
The typical lifecycle in Data Engineering involves the following stages: Data Ingestion: Collecting and importing data from various sources into a central storage system.
This could include real-time ingestion using tools like Apache Kafka or batch-based ingestion using Apache Sqoop.
Data Transformation (ETL/ELT): After ingestion, raw data is cleaned and transformed.
This may include:
Data normalization and standardization. Removing duplicates and handling missing data.
Aggregating or merging datasets. Using tools like Apache Spark, AWS Glue, and Talend.
Data Storage:
After transformation, the data is stored in a format that can be easily queried.
This could be in a data warehouse (e.g., Snowflake, Google BigQuery) or a data lake (e.g., Amazon S3).
Data Analytics & Visualization:
After the data is stored, it is ready for analysis. Data scientists and analysts use tools like SQL, Jupyter Notebooks, Tableau, and Power BI to create insights and visualize the data.
Data Deployment & Serving:
In some use cases, data is deployed to serve real-time queries using tools like Apache Druid or Elasticsearch.
5. Challenges in Big Data and Data Engineering
Data Security & Privacy:
Ensuring that data is secure, encrypted, and complies with privacy regulations (e.g., GDPR, CCPA).
Scalability:
As data grows, the infrastructure needs to scale to handle it efficiently.
Data Quality:
Ensuring that the data collected is accurate, complete, and relevant. Data
Integration:
Combining data from multiple systems with differing formats and structures can be complex.
Real-Time Processing:
Managing data that flows continuously and needs to be processed in real-time.
6. Best Practices in Data Engineering Modular Pipelines:
Design data pipelines as modular components that can be reused and updated independently.
Data Versioning: Keep track of versions of datasets and data models to maintain consistency.
Data Lineage: Track how data moves and is transformed across systems.
Automation: Automate repetitive tasks like data collection, transformation, and processing using tools like Apache Airflow or Luigi.
Monitoring: Set up monitoring and alerting to track the health of data pipelines and ensure data accuracy and timeliness.
7. Cloud and Managed Services for Big Data
Many companies are now leveraging cloud-based services to handle Big Data:
AWS:
Offers tools like AWS Glue (ETL), Redshift (data warehousing), S3 (storage), and Kinesis (real-time streaming).
Azure:
Provides Azure Data Lake, Azure Synapse Analytics, and Azure Databricks for Big Data processing.
Google Cloud:
Offers BigQuery, Cloud Storage, and Dataflow for Big Data workloads.
Data Engineering plays a critical role in enabling efficient data processing, analysis, and decision-making in a data-driven world.

0 notes
Text

#Visualpath offers the Best Online DBT Courses, designed to help you excel in data transformation and analytics. Our expert-led #DBT Online Training covers tools like Matillion, Snowflake, ETL, Informatica, Data Warehousing, SQL, Talend, Power BI, Cloudera, Databricks, Oracle, SAP, and Amazon Redshift. With flexible schedules, recorded sessions, and hands-on projects, we provide a seamless learning experience for global learners. Master advanced data engineering skills, prepare for DBT certification, and elevate your career. Call +91-9989971070 for a free demo and enroll today!
WhatsApp: https://www.whatsapp.com/catalog/919989971070/
Visit Blog: https://databuildtool1.blogspot.com/
Visit: https://www.visualpath.in/online-data-build-tool-training.html
#visualpathedu #testing #automation #selenium #git #github #JavaScript #Azure #CICD #AzureDevOps #playwright #handonlearning #education #SoftwareDevelopment #onlinelearning #newtechnology #software #education #ITskills #training #trendingcourses #careers #students #typescript
#DBT Training#DBT Online Training#DBT Classes Online#DBT Training Courses#Best Online DBT Courses#DBT Certification Training Online#Data Build Tool Training in Hyderabad#Best DBT Course in Hyderabad#Data Build Tool Training in Ameerpet
0 notes
Text
Ensuring Data Accuracy with Cleaning
Ensuring data accuracy with cleaning is an essential step in data preparation. Here’s a structured approach to mastering this process:
1. Understand the Importance of Data Cleaning
Data cleaning is crucial because inaccurate or inconsistent data leads to faulty analysis and incorrect conclusions. Clean data ensures reliability and robustness in decision-making processes.
2. Common Data Issues
Identify the common issues you might face:
Missing Data: Null or empty values.
Duplicate Records: Repeated entries that skew results.
Inconsistent Formatting: Variations in date formats, currency, or units.
Outliers and Errors: Extreme or invalid values.
Data Type Mismatches: Text where numbers should be or vice versa.
Spelling or Casing Errors: Variations like “John Doe” vs. “john doe.”
Irrelevant Data: Data not needed for the analysis.
3. Tools and Libraries for Data Cleaning
Python: Libraries like pandas, numpy, and pyjanitor.
Excel: Built-in cleaning functions and tools.
SQL: Using TRIM, COALESCE, and other string functions.
Specialized Tools: OpenRefine, Talend, or Power Query.
4. Step-by-Step Process
a. Assess Data Quality
Perform exploratory data analysis (EDA) using summary statistics and visualizations.
Identify missing values, inconsistencies, and outliers.
b. Handle Missing Data
Imputation: Replace with mean, median, mode, or predictive models.
Removal: Drop rows or columns if data is excessive or non-critical.
c. Remove Duplicates
Use functions like drop_duplicates() in pandas to clean redundant entries.
d. Standardize Formatting
Convert all text to lowercase/uppercase for consistency.
Standardize date formats, units, or numerical scales.
e. Validate Data
Check against business rules or constraints (e.g., dates in a reasonable range).
f. Handle Outliers
Remove or adjust values outside an acceptable range.
g. Data Type Corrections
Convert columns to appropriate types (e.g., float, datetime).
5. Automate and Validate
Automation: Use scripts or pipelines to clean data consistently.
Validation: After cleaning, cross-check data against known standards or benchmarks.
6. Continuous Improvement
Keep a record of cleaning steps to ensure reproducibility.
Regularly review processes to adapt to new challenges.
Would you like a Python script or examples using a specific dataset to see these principles in action?
0 notes
Text
Tackling Missing Data: Solutions for Your ETL Pipeline
Missing data is a common issue in Extract, Transform, Load (ETL) pipelines, where data is extracted from multiple sources, transformed into a standardized format, and loaded into a target system. Missing data can occur due to various reasons such as incorrect data entry, data corruption, or errors in data transformation. The ETL validation of missing data can lead to inaccurate data analysis, incorrect business decisions, and a general lack of trust in the data. In this article, we will discuss the solutions for tackling missing data in ETL pipelines.
Understanding the Types of Missing Data
To tackle missing data, it's essential to understand the types of missing data. There are three types of missing data: (1) Missing Completely at Random (MCAR), where the missing data is not related to any other variable; (2) Missing at Random (MAR), where the missing data is related to another variable; and (3) Not Missing at Random (NMAR), where the missing data is related to the variable itself. By understanding the type of missing data, you can develop strategies to tackle it.
Solutions for Tackling Missing Data
There are several solutions for tackling missing data in ETL pipelines. Some common solutions include: (1) Data imputation, where missing values are replaced with estimated values; (2) Data interpolation, where missing values are replaced with values based on the surrounding data; (3) Data extrapolation, where missing values are replaced with values based on the trend of the data; and (4) Data deletion, where rows or columns with missing data are deleted. By using these solutions, you can ensure that your data is accurate and reliable.
Using ETL Tools to Tackle Missing Data
ETL tools can play a crucial role in tackling missing data. Many ETL tools provide features for handling missing data, such as data imputation, data interpolation, and data extrapolation. Some popular ETL tools for tackling missing data include: (1) Informatica PowerCenter; (2) Microsoft SQL Server Integration Services (SSIS); (3) Oracle Data Integrator (ODI); and (4) Talend. By using these tools, you can automate the process of handling missing data.

Best Practices for Preventing Missing Data
Preventing missing data is always better than tackling it after it occurs. Some best practices for preventing missing data include: (1) using data validation rules, such as checking for invalid or inconsistent data; (2) using data standardization, such as using standardized data formats; (3) using data normalization, such as scaling numeric data; and (4) using data quality checks, such as checking for missing or duplicate data. By following these best practices, you can prevent missing data from occurring in the first place.
Machine Learning Algorithms for Tackling Missing Data
Machine learning algorithms can be used to tackle missing data. Some popular machine learning algorithms for tackling missing data include: (1) regression algorithms, such as linear regression and logistic regression; (2) decision tree algorithms, such as decision trees and random forests; and (3) clustering algorithms, such as k-means and hierarchical clustering. By using these algorithms, you can predict missing values based on the patterns in the data.
Conclusion
Missing data is a common issue in ETL pipelines, but it can be tackled using various solutions. By understanding the types of missing data, using ETL tools, and following best practices for preventing missing data, you can ensure that your data is accurate and reliable. Machine learning algorithms can also be used to predict missing values based on the patterns in the data. By tackling missing data, you can ensure that your data is accurate and reliable, leading to better business decisions and a general trust in the data.
0 notes
Text
Integration Specialist: Bridging the Gap Between Systems and Efficiency
The Key to Scalable, Secure, and Future-Ready IT Solutions.
Introduction
In today’s interconnected digital landscape, businesses rely on seamless data exchange and system connectivity to optimize operations and improve efficiency. Integration specialists play a crucial role in designing, implementing, and maintaining integrations between various software applications, ensuring smooth communication and workflow automation. With the rise of cloud computing, APIs, and enterprise applications, integration specialists are essential for driving digital transformation.
What is an Integration Specialist?
An Integration Specialist is a professional responsible for developing and managing software integrations between different systems, applications, and platforms. They design workflows, troubleshoot issues, and ensure data flows securely and efficiently across various environments. Integration specialists work with APIs, middleware, and cloud-based tools to connect disparate systems and improve business processes.
Types of Integration Solutions
Integration specialists work with different types of solutions to meet business needs:
API Integrations
Connects different applications via Application Programming Interfaces (APIs).
Enables real-time data sharing and automation.
Examples: RESTful APIs, SOAP APIs, GraphQL.
Cloud-Based Integrations
Connects cloud applications like SaaS platforms.
Uses integration platforms as a service (iPaaS).
Examples: Zapier, Workato, MuleSoft, Dell Boomi.
Enterprise System Integrations
Integrates large-scale enterprise applications.
Connects ERP (Enterprise Resource Planning), CRM (Customer Relationship Management), and HR systems.
Examples: Salesforce, SAP, Oracle, Microsoft Dynamics.
Database Integrations
Ensures seamless data flow between databases.
Uses ETL (Extract, Transform, Load) processes for data synchronization.
Examples: SQL Server Integration Services (SSIS), Talend, Informatica.
Key Stages of System Integration
Requirement Analysis & Planning
Identify business needs and integration goals.
Analyze existing systems and data flow requirements.
Choose the right integration approach and tools.
Design & Architecture
Develop a blueprint for the integration solution.
Select API frameworks, middleware, or cloud services.
Ensure scalability, security, and compliance.
Development & Implementation
Build APIs, data connectors, and automation workflows.
Implement security measures (encryption, authentication).
Conduct performance optimization and data validation.
Testing & Quality Assurance
Perform functional, security, and performance testing.
Identify and resolve integration errors and data inconsistencies.
Conduct user acceptance testing (UAT).
Deployment & Monitoring
Deploy integration solutions in production environments.
Monitor system performance and error handling.
Ensure smooth data synchronization and process automation.
Maintenance & Continuous Improvement
Provide ongoing support and troubleshooting.
Optimize integration workflows based on feedback.
Stay updated with new technologies and best practices.
Best Practices for Integration Success
✔ Define clear integration objectives and business needs. ✔ Use secure and scalable API frameworks. ✔ Optimize data transformation processes for efficiency. ✔ Implement robust authentication and encryption. ✔ Conduct thorough testing before deployment. ✔ Monitor and update integrations regularly. ✔ Stay updated with emerging iPaaS and API technologies.
Conclusion
Integration specialists are at the forefront of modern digital ecosystems, ensuring seamless connectivity between applications and data sources. Whether working with cloud platforms, APIs, or enterprise systems, a well-executed integration strategy enhances efficiency, security, and scalability. Businesses that invest in robust integration solutions gain a competitive edge, improved automation, and streamlined operations.
Would you like me to add recommendations for integration tools or comparisons of middleware solutions? 🚀
0 notes
Text
Merging Different Databases: A Guide to Seamless Integration
Merging different databases is a crucial task for businesses and organizations aiming to consolidate data, enhance operational efficiency, and improve decision-making. Whether you're integrating databases due to a merger, system upgrade, or need for unified reporting, the process requires careful planning and execution. This article outlines the key considerations, challenges, and best practices involved in merging databases.
Why Merge Databases?
There are several reasons why organizations may need to merge multiple databases, including:
Business Mergers and Acquisitions: When companies merge or acquire other businesses, they often need to consolidate their data to ensure operational consistency and unified reporting.
System Integration: Organizations might use different software platforms or databases for various departments. Merging databases ensures that all information is centralized, leading to streamlined operations.
Data Unification: Merging databases can help eliminate data silos, allowing all departments or stakeholders to access the same, up-to-date information. This leads to better collaboration and more informed decision-making.
Challenges of Merging Different Databases
Merging databases comes with several challenges, which, if not properly managed, can lead to data loss, inconsistency, or operational disruptions.
a. Data Inconsistency
Different databases may use varying data formats, structures, and types. For instance, one database may store dates in "MM/DD/YYYY" format, while another uses "YYYY-MM-DD." Such inconsistencies can lead to errors if not addressed during the merging process.
b. Duplicate Records
When merging databases, duplicate entries can be a significant issue. The same data or customer may exist in both databases under slightly different names or IDs, leading to redundancy and confusion.
c. Data Integrity
Maintaining data integrity during the merging process is crucial. This means ensuring that all data relationships, such as foreign keys and unique constraints, are preserved in the merged database.
d. Compatibility Issues
Different databases may be running on different systems (e.g., SQL Server, MySQL, Oracle), and migrating between these platforms requires careful handling of queries, indexing, and stored procedures to avoid compatibility issues.
Best Practices for Merging Different Databases
To ensure a smooth and successful database merge, follow these best practices:
a. Perform a Thorough Data Audit
Before merging databases, conduct a comprehensive audit to understand the structure, data types, and integrity constraints of each database. Identify discrepancies or conflicts, such as inconsistent field formats or duplicate records, so you can address them before the merge.
b. Data Cleansing and Standardization
Data cleansing involves removing duplicate records and correcting errors before merging the databases. Standardizing data formats ensures compatibility, making it easier to merge fields from different databases without conflict.
c. Use ETL Tools
ETL (Extract, Transform, Load) tools are commonly used for data migration and integration. These tools extract data from multiple sources, transform it into a common format, and load it into the target database. Popular ETL tools such as Apache NiFi, Talend, or Microsoft SQL Server Integration Services (SSIS) can streamline the process.
d. Test Before Final Integration
Before the final merge, run tests on a sample dataset. This allows you to identify and fix any errors or inconsistencies before committing to a full-scale merge. Testing helps prevent data loss and ensures all operations function correctly in the merged system.
e. Backup Data
Always backup both databases before proceeding with the merge. In case something goes wrong during the process, having a backup ensures you can restore your data and avoid permanent losses.
Post-Merge Considerations
After the merge, it’s essential to perform thorough testing and validation to ensure that all data has been integrated correctly. Check for issues such as missing records, broken links, or mismatched data types. Additionally, update any documentation or user guides to reflect the new database structure.
Conclusion
Merging different databases can be a complex but rewarding process that brings enhanced efficiency and better data management to an organization. By following best practices—such as conducting a thorough audit, using ETL tools, and testing before final integration���you can minimize risks and ensure a seamless database merge. Whether you're merging due to business growth, system upgrades, or organizational consolidation, proper planning and execution are key to a successful outcome.
For more info visit here:- data cleansing deduplication
0 notes
Text
Optimizing Data Pipeline for Snowflake: Choosing the Right Strategy

In today’s data-driven world, the demand for optimized data pipelines is growing rapidly, as organizations need to handle vast amounts of data efficiently. Snowflake, with its highly scalable and flexible cloud-based data platform, has emerged as a leading choice for managing and analyzing data. However, building and optimizing a data pipeline for Snowflake requires careful consideration of strategies to ensure efficiency, cost-effectiveness, and scalability. In this article, we’ll explore the key strategies for optimizing data pipelines for Snowflake and how to choose the right approach.
Understanding Data Pipelines and Snowflake
A data pipeline refers to the process of extracting, transforming, and loading (ETL) or extracting, loading, and transforming (ELT) data from various sources into a data warehouse for analysis. Snowflake’s unique architecture, which separates storage and compute, allows for high performance, scalability, and elasticity, making it an ideal platform for data pipelines.
Snowflake supports various data integration and transformation tools, both for batch and real-time processing. However, optimizing data pipelines is critical to ensuring that the data is ingested efficiently, processed with minimal latency, and is ready for analytics in the fastest possible time.
Key Considerations for Optimizing Snowflake Data Pipelines
Choosing Between ETL and ELTOne of the first strategic decisions when building a data pipeline for Snowflake is choosing between ETL and ELT.
ETL (Extract, Transform, Load) involves extracting data from sources, transforming it to a required format or structure outside of Snowflake (using tools like Talend or Informatica), and then loading the transformed data into Snowflake.
ELT (Extract, Load, Transform), on the other hand, involves extracting data, loading it into Snowflake, and then transforming it within the Snowflake environment using SQL, Snowflake’s native capabilities, or tools like dbt.
Snowflake's architecture supports both approaches, but ELT is generally more efficient when working with Snowflake. This is because Snowflake’s compute resources allow for powerful, fast transformations without needing to move data between systems. ELT leverages Snowflake’s storage-compute separation, meaning that you can transform large datasets within the platform without impacting performance.Recommendation: Choose ELT if your data needs extensive transformation, especially if you require near real-time data availability. ETL may be a better choice if you need pre-transformation due to specific business requirements or compliance regulations.
Leveraging Snowpipe for Real-Time Data IngestionSnowflake supports real-time data ingestion through its Snowpipe feature. Snowpipe allows for continuous, automated loading of data from external sources such as cloud storage (e.g., AWS S3, Azure Blob Storage). It eliminates the need for manual batch loading and can handle large streams of data in near real-time, making it ideal for time-sensitive data pipelines.To optimize the use of Snowpipe, ensure that you configure automated triggers (e.g., through AWS Lambda) to load data whenever new files are placed in storage. Additionally, use file batching strategies to prevent too many small files from overwhelming the pipeline, which can reduce performance and increase costs.Recommendation: Use Snowpipe for scenarios where real-time or frequent batch updates are needed. For larger batch updates or historical data loading, standard batch processes may suffice.
Optimize Data Partitioning and ClusteringWhen dealing with large datasets, optimizing how data is stored and accessed is crucial for performance. In Snowflake, partitioning occurs automatically via micro-partitions, which are small, compressed, immutable units of data.To further enhance query performance, Snowflake allows clustering of data based on specific columns. Clustering organizes data within micro-partitions, making it easier to retrieve specific subsets of data during queries. This is particularly useful when querying large datasets with frequent access patterns based on specific fields, such as dates or customer IDs.Recommendation: Use clustering when querying large, frequently accessed datasets that have predictable query patterns. Regularly monitor query performance and adjust clustering based on query behavior.
Cost Optimization with Auto-Scaling and Resource MonitoringOne of Snowflake’s strengths is its auto-scaling feature, which dynamically adjusts compute resources based on workload demand. While this ensures that pipelines are not bottlenecked by compute capacity, it can also lead to higher costs if not managed properly.To optimize cost, configure the compute warehouses to auto-suspend when idle, reducing unnecessary usage of resources. Additionally, right-size your compute warehouses based on the workload—use smaller warehouses for light ETL/ELT processes and scale up only when dealing with more complex or resource-intensive transformations.Recommendation: Use Snowflake’s resource monitors to track usage and set limits to avoid over-consumption of compute resources. Optimize warehouse sizing and ensure warehouses are set to auto-suspend when not in use.
Automating and Orchestrating Data PipelinesFor larger and more complex data pipelines, automation and orchestration are key to maintaining efficiency and ensuring timely data delivery. Tools like Apache Airflow or Snowflake’s integration with dbt (Data Build Tool) can help automate the scheduling, monitoring, and orchestration of ELT jobs.Automation can help ensure that data is regularly updated and that dependencies between different datasets and transformations are handled efficiently. Additionally, orchestrating jobs using parallel processing ensures optimal use of Snowflake’s compute resources.Recommendation: Implement an automation and orchestration framework to schedule jobs, track dependencies, and monitor pipeline health. This will ensure data pipelines remain optimized and reduce manual intervention.
Conclusion
Optimizing a data pipeline for Snowflake requires a thoughtful approach that balances performance, cost, and operational complexity. By choosing the right strategy—whether it's using ELT over ETL, leveraging real-time data ingestion with Snowpipe, or optimizing data partitioning and clustering—organizations can ensure their Snowflake pipelines are highly efficient and cost-effective. Coupled with automated orchestration and resource management, Snowflake can power data pipelines that meet modern business needs for speed, flexibility, and scalability.
0 notes
Text
ETL (Extract, Transform, Load) là gì? Vai trò quan trọng của ETL

Trong thế giới kinh doanh hiện đại, dữ liệu thường tồn tại ở nhiều nguồn khác nhau và không đồng nhất về định dạng. Đây là lúc ETL (Extract, Transform, Load) phát huy tác dụng. ETL là một quy trình quan trọng giúp doanh nghiệp trích xuất dữ liệu từ các nguồn khác nhau, chuyển đổi chúng thành định dạng phù hợp và nạp vào hệ thống đích để sử dụng. Bài viết này SunCloud sẽ giới thiệu chi tiết ETL là gì cũng như vai trò quan trọng của nó trong việc quản lý và tối ưu hóa dữ liệu doanh nghiệp.
1. ETL là gì?
ETL (Extract, Transform, Load) là một quy trình trong quản lý dữ liệu, đặc biệt là trong các hệ thống kho dữ liệu và phân tích dữ liệu. Quy trình này bao gồm ba bước chính: trích xuất dữ liệu (Extract), chuyển đổi dữ liệu (Transform), và nạp dữ liệu (Load). ETL giúp thu thập dữ liệu từ nhiều nguồn khác nhau, xử lý chúng để phù hợp với mục tiêu kinh doanh hoặc phân tích, sau đó nạp vào hệ thống đích như kho dữ liệu hoặc cơ sở dữ liệu phân tích.
2. Quá trình hoạt động của ETL là gì?
ETL hoạt động theo ba bước cơ bản như sau:
a. Trích xuất dữ liệu (Extract)
Quá trình trích xuất dữ liệu là bước đầu tiên trong ETL, nơi dữ liệu được lấy từ các nguồn khác nhau. Các nguồn dữ liệu này có thể bao gồm cơ sở dữ liệu quan hệ, các hệ thống ERP, ứng dụng web, hoặc thậm chí là các tệp tin như CSV, XML. Một số thách thức phổ biến trong quá trình trích xuất là:
Đa dạng hóa định dạng dữ liệu: Dữ liệu có thể tồn tại ở nhiều định dạng khác nhau, do đó việc trích xuất cần có khả năng xử lý các loại dữ liệu này một cách hiệu quả.
Dung lượng lớn: Các hệ thống lớn có thể chứa một lượng dữ liệu khổng lồ, đòi hỏi quá trình trích xuất phải nhanh chóng và chính xác để không làm gián đoạn hoạt động của hệ thống.
Các công cụ phổ biến để trích xuất dữ liệu bao gồm Apache NiFi, Talend, và Microsoft SQL Server Integration Services (SSIS).
b. Chuyển đổi dữ liệu (Transform)
Sau khi dữ liệu được trích xuất, bước tiếp theo là chuyển đổi dữ liệu. Đây là quá trình phức tạp nhất trong ETL, bởi vì dữ liệu cần được làm sạch, định dạng lại, và cấu trúc lại để phù hợp với các yêu cầu của hệ thống đích. Các hoạt động trong bước chuyển đổi có thể bao gồm:
Làm sạch dữ liệu: Loại bỏ các giá trị sai hoặc không hợp lệ, xử lý dữ liệu bị thiếu hoặc trùng lặp.
Chuyển đổi định dạng: Chuyển đổi các kiểu dữ liệu, ví dụ từ số nguyên sang chuỗi ký tự hoặc từ định dạng ngày tháng kiểu Mỹ sang kiểu Việt Nam.
Tính toán và tổng hợp: Tính toán các giá trị mới từ dữ liệu gốc, ví dụ như tổng doanh thu, trung bình số lượng sản phẩm bán ra, v.v.
Ánh xạ dữ liệu: Kết hợp dữ liệu từ các nguồn khác nhau vào cùng một cấu trúc thống nhất.
Quá trình chuyển đổi đảm bảo rằng dữ liệu đầu ra không chỉ chính xác mà còn dễ sử dụng cho mục đích phân tích hoặc báo cáo. Các công cụ phổ biến cho việc chuyển đổi dữ liệu bao gồm Apache Spark, Pentaho, và Informatica.
c. Nạp dữ liệu (Load)
Bước cuối cùng trong quy trình ETL là nạp dữ liệu vào hệ thống đích. Đây có thể là một kho dữ liệu doanh nghiệp, một cơ sở dữ liệu SQL, hoặc một hệ thống phân tích dữ liệu. Có hai phương pháp chính để nạp dữ liệu:
Nạp dữ liệu một lần (Full Load): Toàn bộ dữ liệu được nạp vào hệ thống đích trong một lần. Phương pháp này thường áp dụng cho các hệ thống mới hoặc khi cần làm mới toàn bộ dữ liệu.
Nạp dữ liệu tăng dần (Incremental Load): Chỉ những phần dữ liệu mới hoặc thay đổi được nạp vào hệ thống đích. Phương pháp này hiệu quả khi xử lý các hệ thống lớn với khối lượng dữ liệu thay đổi liên tục.
Công cụ phổ biến cho việc nạp dữ liệu bao gồm Apache Hadoop, Google BigQuery, và Amazon Redshift.
3. Vai trò quan trọng của ETL trong quản lý dữ liệu
ETL đóng vai trò quan trọng trong việc tối ưu hóa quá trình quản lý và phân tích dữ liệu. Dưới đây là một số vai trò chính của ETL:
Hợp nhất dữ liệu từ nhiều nguồn
Trong các doanh nghiệp, dữ liệu thường tồn tại ở nhiều hệ thống khác nhau, mỗi hệ thống lại có cách tổ chức và định dạng riêng. ETL giúp hợp nhất các dữ liệu này, tạo ra một cái nhìn tổng quan và đồng nhất về dữ liệu doanh nghiệp, giúp các nhà quản lý dễ dàng phân tích và đưa ra quyết định.
Cải thiện chất lượng dữ liệu
Bằng việc làm sạch và chuẩn hóa dữ liệu trong quá trình chuyển đổi, ETL giúp cải thiện chất lượng dữ liệu. Điều này đảm bảo rằng các báo cáo và phân tích dựa trên dữ liệu đều chính xác và đáng tin cậy.
Tối ưu hóa hiệu suất hệ thống
Với khả năng nạp dữ liệu tăng dần, ETL giúp giảm tải cho hệ thống đích, đồng thời tối ưu hóa hiệu suất xử lý dữ liệu. Các quy trình ETL hiện đại còn cho phép xử lý dữ liệu theo thời gian thực, giúp doanh nghiệp phản ứng nhanh chóng với các thay đổi trong thị trường.
Hỗ trợ phân tích dữ liệu nâng cao
ETL là tiền đề quan trọng cho các phân tích dữ liệu nâng cao, chẳng hạn như phân tích dự đoán hoặc học máy (machine learning). Với dữ liệu đã được làm sạch và chuẩn hóa, các thuật toán phân tích có thể hoạt động hiệu quả hơn, mang lại những dự báo chính xác và hữu ích cho doanh nghiệp.
4. Câu hỏi thường gặp về ETL là gì?
Sự khác biệt giữa ETL và ELT là gì?
ETL thực hiện chuyển đổi dữ liệu trước khi nạp vào hệ thống đích. Ngược lại, ELT thực hiện nạp dữ liệu trước và sau đó chuyển đổi dữ liệu trong hệ thống đích. ELT thường được sử dụng trong các hệ thống có khả năng xử lý mạnh như các hệ thống lưu trữ đám mây.
ETL có thể xử lý dữ liệu thời gian thực không?
Một số hệ thống ETL hiện đại hỗ trợ xử lý dữ liệu theo thời gian thực, cho phép nạp và xử lý dữ liệu ngay lập tức khi có sự thay đổi. Điều này giúp doanh nghiệp phản ứng nhanh chóng với các biến động thị trường và các yêu cầu phân tích dữ liệu ngay tức thì.
ETL có thể tự động hóa được không?
Quy trình ETL có thể được tự động hóa hoàn toàn bằng cách sử dụng các công cụ ETL và kịch bản tự động hóa. Điều này giúp giảm thiểu sai sót do con người gây ra, tiết kiệm thời gian và đảm bảo tính nhất quán trong việc xử lý và quản lý dữ liệu.
Kết luận
ETL là một quy trình quan trọng trong quản lý và xử lý dữ liệu, đóng vai trò then chốt trong việc tối ưu hóa hoạt động của doanh nghiệp. Với khả năng trích xuất, chuyển đổi và nạp dữ liệu một cách hiệu quả, ETL không chỉ giúp doanh nghiệp có cái nhìn tổng quan về dữ liệu mà còn hỗ trợ quá trình ra quyết định dựa trên dữ liệu một cách chính xác và kịp thời. Việc hiểu rõ ETL là gì và áp dụng đúng cách sẽ mang lại lợi ích lớn cho bất kỳ tổ chức nào đang tìm cách tối ưu hóa dữ liệu và nâng cao hiệu quả hoạt động.
Nguồn: https://suncloud.vn/etl-la-gi
0 notes