#the coding part is ok with chat gpt
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
Tumblr is used by 21% of adults online aged 18-29 years.
Text
bro why am i doing data science
#sometimes stats classes are doable and feel ok#AND THEN THERE'S THIS ONE#and the one i took last sem and dropped#i'm like feeling the same abt this one like i wanna drop TT#but bro like#this is a requirement and i wanna graduate in 4 years any real reason not fucking really but#adjsngbldhfgakjdghsadjhl#i have LOST motivation to keep chatgpting the shit out of this hw due in like less than 1.5 hours#the coding part is ok with chat gpt#but there's so fucking much derivation and proof shit like bro#why do i have to keep doing this shit in stats classes#makes me want to scream#im gonna call my mom tonight and we'll see if i manage not to cry woohoo aka 100% chance im gonna start crying lmfao#i need to get back to this hw#like at best i'll get half points on it#bc i've just given up on like the first half#which is derivation shit i dont have time to finish it anyway#but chat gpt doesn't rly help for that bc i can put it in but i have no idea what the fuck it's doing#ughhhghhsjfgllsdriaduhroiwngjfdshgd why did i do stats#nfjdghjlbdjsbfljgabgjhglksajhflkhgiuqerhihfnglkajfdngddjfaksjgd#jeanne talks
3 notes
·
View notes
Note
I have a question as a fanfic writer, I’m considering this can I make lawsuit against chat gpt if i feel they stole my fanfic? Is it possible to make a lawsuit as a fanfic writer against chat gpt for a fanfic?
I am not a lawyer, so take this advice with a grain of salt.
Fanfic itself is a little weird legally. While it fits the definition of copyright infringement, it's generally considered OK by most IP creators because of how it unites fandom and draws out some amazing creativity.
At the same time, IP creators cannot read fanfic, because the CONTENT of the fic minus the owned characters belongs to the writer. So if you write a Battlestar Galactica fanfic, for example, Starbuck, Apollo, and any other characters in that IP belong to Universal. But the writing itself, the story, the plot--that all belongs to you.
And while it's not possible to copyright an idea, it looks a little weird if you write a fanfic about something and then a remake of Battlestar Galactica has exactly that plot. So in order to claim plausible deniability (that is--they never read your fic, so they can't have stolen it) they'll be very up front about never reading fanfic.
I promise that recap has a point.
So the way ChatGPT works is it ingests a body of writing and looks for patterns in that writing. Then it breaks these patterns down into code, which then exists on the dataset. It's really easy to train a dataset on fanfic because on all sites where you'd post the fanfic, you also have to post a summary. And that summary provides the "prompt" information for anyone wishing to use text-generators to write a story.
Essentially, ChatGPT doesn't work out of its own vacuum like techbros think it does. Everything it creates, from the final output to the information for prompts, is stolen from the original creators.
What that means is, someone can feed your entire body of work into a dataset along with literal billions of other works. People "writing prompts" don't have the capacity to fathom how large over five billion works are--no human does. We're not really capable of understanding numbers that high. I mean, to a lot of people--even very left-leaning individuals--someone with one million dollars is in the same category as someone with one billion dollars.
I just want you to get the idea of the scale of writing that's been fed into these machines.
What that all means is this:
Let's say you wrote a fanfic where Starbuck and Apollo discover an alien civilization call the Xerzats and adopt a Xerzat child. They go on all sorts of adventures together, and they learn that apparently Xerzats just regularly turn themselves inside out. And your summary reflects a lot of this.
It doesn't matter that it's a fanfic, when someone writing the prompts for an AI-generated story asks chatGPT to write a book about two people named Genna and Lloyd who are shopping one day and find an alien in the apple barrel, because now ChatGPT has to fill 50,000 words of novel space, so it finds information about your Xerzats and essentially steals your whole idea (with some pattern changes cannibalized from other authors). The point is, you recognize the parts that you wrote.
What techbros don't seem to get is that the parts YOU WROTE that are unique to your imagination? That's yours. What is currently a grey area is whether or not a person can claim copyright on those things, because this has never been argued before. It's never had to be. And currently the consensus is leaning toward your material being copyrightable.
Why? Because a lot of popular fiction started as fanfic. Most notably, 50 Shades of Grey started as Twilight fic, and a lot of the original material from when it was a Twilight fic still exists in the published book. Stephenie Meyer can't claim that material because it's literally not hers to claim.
That's really about only answer I can give you without getting into legal advice. If you're sure your work has been stolen, though, you should absolutely contact a lawyer and see what your options are.
1 note
·
View note
Text
Trying to build an AI to replace myself
I was suggested (jokingly) to build an AI that will replace me and I decided to give it an actual try. I decided to use GPT-2, it was a model that a couple years ago was regarded as super cool (now we have GPT-3 but its code isn’t released yet and frankly my pc would burst into flames if i tried to use it).
At the time, GPT-2 was considered so good that OpenAI delayed releasing the source code out of fear that if it falls into the wrong hands it would take over the world (jk they just didn’t want spam bots to evade detection with it).
The first lesson I learned while trying to build it was that windows is trash, get linux. The 2nd lesson i learned while trying to build it was that my GPU is trash, and after looking for one of the newest models online...
...I decided I’d just use Google’s GPUs for the training.
There’s 5 models of GPT-2 in total, I tried 4 of them on my pc and it crashed every single time, from the smallest to the biggest it goes
distilGPT2
GPT-2 124M
GPT-2 355M
GPT-2 774M
GPT-2 1.5B
From a little reading around, it turns out that even though 1.5B is better than 774M, its not significantly better, and distilGPT2 isn’t significantly worse than 124M.Every other improvement is significant, so my plan was to use distilGPT2 as a prototype, then to use 774M for an actually decent chatbot.
The prototype
I created a python script that would read the entire message history of a channel and write it down, here’s a sample.
<-USERNAME: froggie -> hug <-USERNAME: froggie -> huh* <-USERNAME: froggie -> why is it all gone <-USERNAME: Nate baka! -> :anmkannahuh: <-USERNAME: froggie -> i miss my old color <-USERNAME: froggie -> cant you make the maid role colorlesss @peds <-USERNAME: Levy -> oh no <-USERNAME: peds -> wasnt my idea <-USERNAME: Levy -> was the chat reset <-USERNAME: SlotBot -> Someone just dropped their wallet in this channel! Hurry and pick it up with `~grab` before someone else gets it!
I decided to use aitextgen as it just seemed like the easiest way and begun training, it was... kinda broken
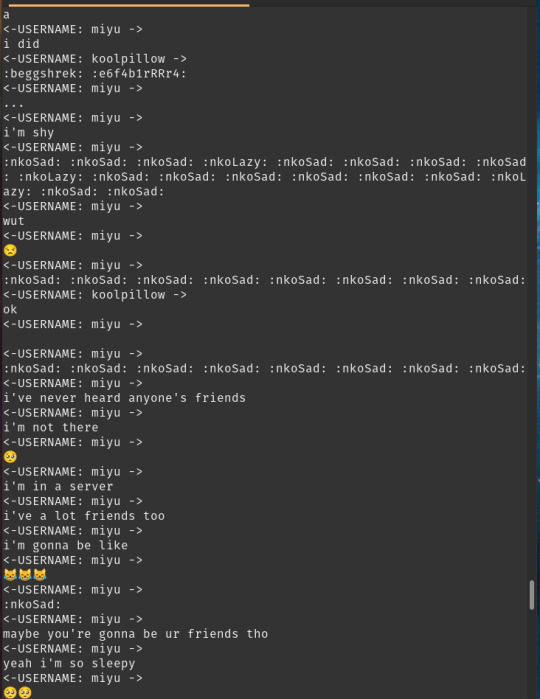
It had the tendency to use the same username over and over again and to repeat the same emote over and over again.
While it is true that most people write multiple messages at a time, one sentence each, and they sometimes write the same emoji multiple times for emphasis, it’s almost never as extreme as the output of GPT2.
But you know what? this IS just a prototype after all, and besides, maybe it only repeats the same name because it needs a prompt with multiple names in it for it to use them in chat, which would be fixed when id implement my bot (just kidding that screenshot is from after i started using prompts with the last 20 messages in the chat history and it still regressed to spam).
So i made a bot using python again, every time a message is sent
it reads the last 20 messages
stores them into a string
appends <-USERNAME: froggie -> to the string
uses it as a prompt
gets the output and cuts everything after a username besides froggie appears
sends up to 5 of the messages it reads in the output
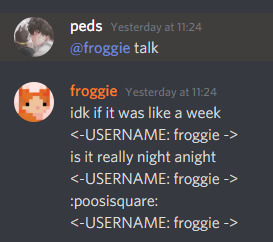
waitwaitwait let me fix that real quick
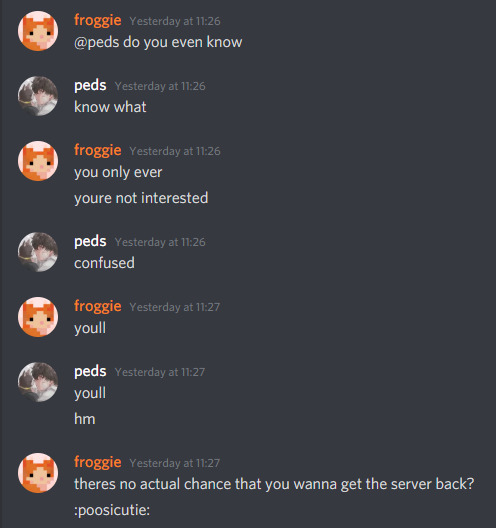
hey, it’s saying words, its sending multiple messages if it has to, it never even reached the limit of 5 i set it to so somehow it doesn’t degrade into spam when i only get the messages with my name on it....

ok that was just one time
but besides the fact that pinging and emoting is broken, (which has nothing to do with the AI) it was a really succesful prototype!
The 774M
The first thing i noticed was that the 774M model was training MUCH slower than the distilGPT, i decided that while it is training i should try to use the default model to see if my computer can even handle it.
It... kinda did..... not really
It took the bot minutes to generate a message and countless distressing errors in the console

>this is bad
This is bad indeed.
With such a huge delay in messages it can’t really have a real-time chat but at least it works, and i was still gonna try it, the model without training seemed to just wanna spam the username line over and over again, but it is untrained after all, surely after hours of training i could open the google colab to find the 774M model generate beautiful realistic conversations, or at least be as good as distilGPT.
(I completely forgot to take a screenshot of it but here is my faithful reenactment)
<-USERNAME froggie -> <-USERNAME froggie -> <-USERNAME froggie -> <-USERNAME miyu -> <-USERNAME miyu -> <-USERNAME levy -> <-USERNAME peds -> <-USERNAME miyu -> <-USERNAME peds ->
It had messages sometimes but 80% of the lines were just username lines.
On the upside it actually seemed to have a better variety of names,
But it still seemed unusable, and that is after 7000 steps, whereas distilGPT seemed usable after its first 1000!
So after seeing how both the ai and my computer are failures i decided I’d just give up, maybe I’ll try this again when I get better hardware and when I’m willing to train AIs for entire days.
So why in the hell is the 774M model worse than distilGPT?
I asked around and most answers i got were links to research papers that I couldn’t understand.
I made a newer version of the script that downloads the chatlogs so that messages by the same person will only have the username line written once, but I didn’t really train an AI with it yet, perhaps it would have helped a bit, but I wanna put this project on hold until I can upgrade my hardware, so hopefully this post will have a part 2 someday.
0 notes