
vikramadityaprsingh
4 posts
Don't wanna be here? Send us removal request.
Statistics
We looked inside some of the posts by vikramadityaprsingh and here's what we found interesting.
Average Info
Notes Per Post
1
Likes Per Post
1
Reblog Per Post
0
Reply Per Post
0
Time Between Posts
6 days
Number of Posts By Type
Text
4
Last Seen Tumblr Blogs





Fun Fact
Tumblr Inc. is using 66 technologies for its website.
Text
Week#04 DMV Assignment#04
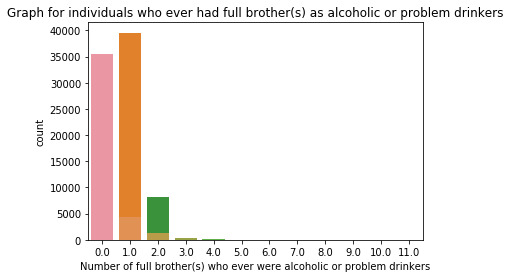
Program:
""" author: vikramaditya pratap singh research question: how much the family history affects the alcohol consumption/alcohol dependence of an individual """ # S2AQ1 --> DRANK ATLEAST 1 ALCOHOLIC DRINK IN LIFE; Yes = 1, No = 2 # S2AQ2 --> DRANK ATLEAST 12 ALCOHOLIC DRINKS IN LAST 12 MONTHS; Yes = 1, No = 2, Unknown = 9 # S2AQ3 --> DRANK ATLEAST 1 ALCOHLIC DRINK IN LAST 12 MONTHS; Yes = 1, No = 2, Unknown = 9 # CONSUMER --> DRINKING STATUS; Current drinker = 1, Ex-drinker = 2, Lifetime Abstainer = 3 # S2DQ1 --> BLOOD/NATURAL FATHER EVER AN ALCOHOLIC OR PROBLEM DRINKER; Yes = 1, No = 2, Unknown = 9 # S2DQ2 --> BLOOD/NATURAL MOTHER EVER AN ALCOHOLIC OR PROBLEM DRINKER; Yes = 1, No = 2, Unknown = 9 # S2DQ3C1 --> NUMBER OF FULL BROTHERS WHO WERE EVER ALCOHOLICS OR PROBLEM DRINKERS; Full Brother(s) = 0-11, Unknown = 99 # S2DQ4C1 --> NUMBER OF FULL SISTERS WHO WERE EVER ALCOHOLICS OR PROBLEM DRINKERS; Full Sister(s) = 0-9, Unknown = 99 import pandas as pd import numpy as np import seaborn as sb import matplotlib.pyplot as plt # loading up the data frame being used dataFrame = pd.read_csv('nesarc_pds.csv', low_memory = False) totalObservation = len(dataFrame) totalVariable = len(dataFrame.columns) print("Total number of observations/rows =", totalObservation) print("Total number of variables/columns =", totalVariable) # converting each variable to numeric data type dataFrame['S2AQ1'] = pd.to_numeric(dataFrame['S2AQ1']) dataFrame['S2AQ2'] = pd.to_numeric(dataFrame['S2AQ2']) dataFrame['S2AQ3'] = pd.to_numeric(dataFrame['S2AQ3']) dataFrame['CONSUMER'] = pd.to_numeric(dataFrame['CONSUMER']) dataFrame['S2DQ1'] = pd.to_numeric(dataFrame['S2DQ1']) dataFrame['S2DQ2'] = pd.to_numeric(dataFrame['S2DQ2']) dataFrame['S2DQ3C1'] = pd.to_numeric(dataFrame['S2DQ3C1']) dataFrame['S2DQ4C1'] = pd.to_numeric(dataFrame['S2DQ4C1']) # setting the "Unknown" data as NaN from variables S2AQ2, S2AQ3, S2DQ1, S2DQ2, S2DQ3C1, S2DQ4C1 dataFrame['S2AQ2'] = dataFrame['S2AQ2'].replace(9, np.nan) dataFrame['S2AQ3'] = dataFrame['S2AQ3'].replace(9, np.nan) dataFrame['S2DQ1'] = dataFrame['S2DQ1'].replace(9, np.nan) dataFrame['S2DQ2'] = dataFrame['S2DQ2'].replace(9, np.nan) dataFrame['S2DQ3C1'] = dataFrame['S2DQ3C1'].replace(99, np.nan) dataFrame['S2DQ4C1'] = dataFrame['S2DQ4C1'].replace(99, np.nan) # count and frequency distribution for I variable print("COUNT FOR: DRANK ATLEAST 1 ALCOHOLIC DRINK IN LIFE; Yes = 1, No = 2") count1 = dataFrame['S2AQ1'].value_counts(sort = False, dropna = False) print(count1) print("%AGE FOR: DRANK ATLEAST 1 ALCOHOLIC DRINK IN LIFE; Yes = 1, No = 2") perc1 = dataFrame['S2AQ1'].value_counts(sort = False, normalize = True, dropna = False) print(perc1) # count and frequency distribution for II variable print("COUNT FOR: DRANK ATLEAST 12 ALCOHOLIC DRINKS IN LAST 12 MONTHS; Yes = 1, No = 2, Unknown = 9") count2 = dataFrame['S2AQ2'].value_counts(sort = False, dropna = False) print(count2) print("%AGE FOR: DRANK ATLEAST 12 ALCOHOLIC DRINKS IN LAST 12 MONTHS; Yes = 1, No = 2, Unknown = 9") perc2 = dataFrame['S2AQ2'].value_counts(sort = False, normalize = True, dropna = False) print(perc2) # count and frequency distribution for III variable print("COUNT FOR: DRANK ATLEAST 1 ALCOHOLIC DRINK IN LAST 12 MONTHS; Yes = 1, No = 2, Unknown = 9") count3 = dataFrame['S2AQ3'].value_counts(sort = False, dropna = False) print(count3) print("%AGE FOR: DRANK ATLEAST 1 ALCOHOLIC DRINK IN LAST 12 MONTHS; Yes = 1, No = 2, Unknown = 9") perc3 = dataFrame['S2AQ3'].value_counts(sort = False, normalize = True, dropna = False) print(perc3) # count and frequency distribution for IV variable print("COUNT FOR: DRINKING STATUS; Current drinker = 1, Ex-drinker = 2, Lifetime Abstainer = 3") count4 = dataFrame['CONSUMER'].value_counts(sort = False, dropna = False) print(count4) print("%AGE FOR: DRINKING STATUS; Current drinker = 1, Ex-drinker = 2, Lifetime Abstainer = 3") perc4 = dataFrame['CONSUMER'].value_counts(sort = False, normalize = True, dropna = False) print(perc4) # count and frequency distribution for V variable print("COUNT FOR: BLOOD/NATURAL FATHER EVER AN ALCOHOLIC OR PROBLEM DRINKER; Yes = 1, No = 2, Unknown = 9") count5 = dataFrame['S2DQ1'].value_counts(sort = False, dropna = False) print(count5) print("%AGE FOR: BLOOD/NATURAL FATHER EVER AN ALCOHOLIC OR PROBLEM DRINKER; Yes = 1, No = 2, Unknown = 9") perc5 = dataFrame['S2DQ1'].value_counts(sort = False, normalize = True, dropna = False) print(perc5) # count and frequency distribution for VI variable print("COUNT FOR: BLOOD/NATURAL MOTHER EVER AN ALCOHOLIC OR PROBLEM DRINKER; Yes = 1, No = 2, Unknown = 9") count6 = dataFrame['S2DQ2'].value_counts(sort = False, dropna = False) print(count6) print("%AGE FOR: BLOOD/NATURAL MOTHER EVER AN ALCOHOLIC OR PROBLEM DRINKER; Yes = 1, No = 2, Unknown = 9") perc6 = dataFrame['S2DQ2'].value_counts(sort = False, normalize = True, dropna = False) print(perc6) # count and frequency distribution for VII variable print("COUNT FOR: NUMBER OF FULL BROTHERS WHO WERE EVER ALCOHOLICS OR PROBLEM DRINKERS; Full Brother(s) = 0-11, Unknown = 99") count7 = dataFrame['S2DQ3C1'].value_counts(sort = False, dropna = False) print(count7) print("%AGE FOR: NUMBER OF FULL BROTHERS WHO WERE EVER ALCOHOLICS OR PROBLEM DRINKERS; Full Brother(s) = 0-11, Unknown = 99") perc7 = dataFrame['S2DQ3C1'].value_counts(sort = False, normalize = True, dropna = False) print(perc7) # count and frequency distribution for VIII variable print("COUNT FOR: NUMBER OF FULL SISTERS WHO WERE EVER ALCOHOLICS OR PROBLEM DRINKERS; Full Sister(s) = 0-9, Unknown = 99") count8 = dataFrame['S2DQ4C1'].value_counts(sort = False, dropna = False) print(count8) print("%AGE FOR: NUMBER OF FULL SISTERS WHO WERE EVER ALCOHOLICS OR PROBLEM DRINKERS; Full Sister(s) = 0-9, Unknown = 99") perc8 = dataFrame['S2DQ4C1'].value_counts(sort = False, normalize = True, dropna = False) print(perc8) # changing format from numeric to categorical dataFrame['S2AQ1'] = dataFrame['S2AQ1'].astype('category') dataFrame['S2AQ2'] = dataFrame['S2AQ2'].astype('category') dataFrame['S2AQ3'] = dataFrame['S2AQ3'].astype('category') dataFrame['CONSUMER'] = dataFrame['CONSUMER'].astype('category') dataFrame['S2DQ1'] = dataFrame['S2DQ1'].astype('category') dataFrame['S2DQ2'] = dataFrame['S2DQ2'].astype('category') dataFrame['S2DQ3C1'] = dataFrame['S2DQ3C1'].astype('category') dataFrame['S2DQ4C1'] = dataFrame['S2DQ4C1'].astype('category') # graphing a univariate graph for each variable # univariate graph for I variable sb.countplot(x = "S2AQ1", data = dataFrame) plt.xlabel('Drank atleast 1 alcoholic drink in life') plt.title('Graph for Individuals who drank atleast 1 alcoholic drink in life.') # univariate graph for II variable sb.countplot(x = 'S2AQ2', data = dataFrame) plt.xlabel('Drank atleast 12 alcoholic drinks in 12 months') plt.title('Graph for Individuals who drank atleast 12 alcoholic drinks in 12 months.') # univariate graph for III variable sb.countplot(x = 'S2AQ3', data = dataFrame) plt.xlabel('Drank atleast 1 alcoholic drink in last 12 months.') plt.title('Graph for Individuals who drank atleast 1 alcoholic drinks in last 12 months.') # univariate graph for IV variable sb.countplot(x = 'CONSUMER', data = dataFrame) plt.xlabel('Drinking Status') plt.title('Graph of drinking status of individuals') # univariate graph for V variable sb.countplot(x = 'S2DQ1', data = dataFrame) plt.xlabel('Blood/Natural father ever an alcoholic or problem drinker') plt.title('Graph for individuals who ever had blood/natural father an alcoholic or problem drinker') # univariate graph for VI variable sb.countplot(x = 'S2DQ2', data = dataFrame) plt.xlabel('Blood/Natural mother ever an alcoholic or problem drinker') plt.title('Graph for individuals who ever had blood/natural mother ever an alcoholic or problem drinker') # univariate graph for VII variable sb.countplot(x = 'S2DQ3C1', data = dataFrame) plt.xlabel('Number of full brother(s) who ever were alcoholic or problem drinkers') plt.title('Graph for individuals who ever had full brother(s) as alcoholic or problem drinkers') # univariate graph for VIII variable sb.countplot('S2DQ4C1', data = dataFrame) plt.xlabel('Number of full sister(s) who ever were alcoholic or problem drinkers') plt.title('Graph for individuals who ever had full sister(s) as alcoholic or problem drinkers') # summary of each variable # description of I variable print('Description of Individuals who drank atleast 1 alcoholic drink in life') desc1 = dataFrame['S2AQ1'].describe() print(desc1) # description of II variable print('Description of Individuals who drank atleast 12 alcoholic drinks in last 12 months') desc2 = dataFrame['S2AQ2'].describe() print(desc2) # description of III variable print('Description of Individuals who drank atleast 1 alcoholic drink in last 12 months') desc3 = dataFrame['S2AQ3'].describe() print(desc3) # description of IV variable print('Description of drinking status of individuals') desc4 = dataFrame['CONSUMER'].describe() print(desc4) # description of V variable print('Description of individuals who ever had a blood/natural father an alcoholic or problem drinker') desc5 = dataFrame['S2DQ1'].describe() print(desc5) # description of VI variable print('Description of individuals who ever had a blood/natural mother an alcoholic or problem drinker') desc6 = dataFrame['S2DQ2'].describe() print(desc6) # description of VII variable print('Description of individuals who ever had a full brother(s) an alcoholic or problem drinker') desc7 = dataFrame['S2DQ3C1'].describe() print(desc7) # description of VIII variable print('Description of individuals who ever had a full sister(s) an alcoholic or problem drinker') desc8 = dataFrame['S2DQ4C1'].describe() print(desc8) # converting 1 variable to numeric before a bivariate graph dataFrame['S2DQ1'] = pd.to_numeric(dataFrame['S2DQ1']) # bivariate graph to get the association in drinking status and alcoholic situation of father sb.catplot(x = 'S2DQ1', y = 'CONSUMER', data = dataFrame, kind = 'bar', ci = None) plt.xlabel('Blood/Natural Father ever an alcoholic or problem drinker') plt.ylabel('Drinking status')
Output:
runfile('E:/data_management_and_visualization/script#01.py', wdir='E:/data_management_and_visualization') Total number of observations/rows = 43093 Total number of variables/columns = 3010 COUNT FOR: DRANK ATLEAST 1 ALCOHOLIC DRINK IN LIFE; Yes = 1, No = 2 1 34827 2 8266 Name: S2AQ1, dtype: int64 %AGE FOR: DRANK ATLEAST 1 ALCOHOLIC DRINK IN LIFE; Yes = 1, No = 2 1 0.808182 2 0.191818 Name: S2AQ1, dtype: float64 COUNT FOR: DRANK ATLEAST 12 ALCOHOLIC DRINKS IN LAST 12 MONTHS; Yes = 1, No = 2, Unknown = 9 2.0 22225 1.0 20836 NaN 32 Name: S2AQ2, dtype: int64 %AGE FOR: DRANK ATLEAST 12 ALCOHOLIC DRINKS IN LAST 12 MONTHS; Yes = 1, No = 2, Unknown = 9 2.0 0.515745 1.0 0.483512 NaN 0.000743 Name: S2AQ2, dtype: float64 COUNT FOR: DRANK ATLEAST 1 ALCOHOLIC DRINK IN LAST 12 MONTHS; Yes = 1, No = 2, Unknown = 9 2.0 16116 1.0 26946 NaN 31 Name: S2AQ3, dtype: int64 %AGE FOR: DRANK ATLEAST 1 ALCOHOLIC DRINK IN LAST 12 MONTHS; Yes = 1, No = 2, Unknown = 9 2.0 0.373982 1.0 0.625299 NaN 0.000719 Name: S2AQ3, dtype: float64 COUNT FOR: DRINKING STATUS; Current drinker = 1, Ex-drinker = 2, Lifetime Abstainer = 3 1 26946 2 7881 3 8266 Name: CONSUMER, dtype: int64 %AGE FOR: DRINKING STATUS; Current drinker = 1, Ex-drinker = 2, Lifetime Abstainer = 3 1 0.625299 2 0.182884 3 0.191818 Name: CONSUMER, dtype: float64 COUNT FOR: BLOOD/NATURAL FATHER EVER AN ALCOHOLIC OR PROBLEM DRINKER; Yes = 1, No = 2, Unknown = 9 1.0 8124 2.0 32445 NaN 2524 Name: S2DQ1, dtype: int64 %AGE FOR: BLOOD/NATURAL FATHER EVER AN ALCOHOLIC OR PROBLEM DRINKER; Yes = 1, No = 2, Unknown = 9 1.0 0.188522 2.0 0.752907 NaN 0.058571 Name: S2DQ1, dtype: float64 COUNT FOR: BLOOD/NATURAL MOTHER EVER AN ALCOHOLIC OR PROBLEM DRINKER; Yes = 1, No = 2, Unknown = 9 2.0 39553 1.0 2311 NaN 1229 Name: S2DQ2, dtype: int64 %AGE FOR: BLOOD/NATURAL MOTHER EVER AN ALCOHOLIC OR PROBLEM DRINKER; Yes = 1, No = 2, Unknown = 9 2.0 0.917852 1.0 0.053628 NaN 0.028520 Name: S2DQ2, dtype: float64 COUNT FOR: NUMBER OF FULL BROTHERS WHO WERE EVER ALCOHOLICS OR PROBLEM DRINKERS; Full Brother(s) = 0-11, Unknown = 99 5.0 44 0.0 35428 1.0 4408 2.0 1278 4.0 126 8.0 2 9.0 3 10.0 1 11.0 1 NaN 1464 3.0 283 6.0 42 7.0 13 Name: S2DQ3C1, dtype: int64 %AGE FOR: NUMBER OF FULL BROTHERS WHO WERE EVER ALCOHOLICS OR PROBLEM DRINKERS; Full Brother(s) = 0-11, Unknown = 99 5.0 0.001021 0.0 0.822129 1.0 0.102290 2.0 0.029657 4.0 0.002924 8.0 0.000046 9.0 0.000070 10.0 0.000023 11.0 0.000023 NaN 0.033973 3.0 0.006567 6.0 0.000975 7.0 0.000302 Name: S2DQ3C1, dtype: float64 COUNT FOR: NUMBER OF FULL SISTERS WHO WERE EVER ALCOHOLICS OR PROBLEM DRINKERS; Full Sister(s) = 0-9, Unknown = 99 0.0 39090 2.0 708 1.0 1847 4.0 43 6.0 4 8.0 1 9.0 1 5.0 13 NaN 1298 3.0 83 7.0 5 Name: S2DQ4C1, dtype: int64 %AGE FOR: NUMBER OF FULL SISTERS WHO WERE EVER ALCOHOLICS OR PROBLEM DRINKERS; Full Sister(s) = 0-9, Unknown = 99 0.0 0.907108 2.0 0.016430 1.0 0.042861 4.0 0.000998 6.0 0.000093 8.0 0.000023 9.0 0.000023 5.0 0.000302 NaN 0.030121 3.0 0.001926 7.0 0.000116 Name: S2DQ4C1, dtype: float64 Description of Individuals who drank atleast 1 alcoholic drink in life count 43093 unique 2 top 1 freq 34827 Name: S2AQ1, dtype: int64 Description of Individuals who drank atleast 12 alcoholic drinks in last 12 months count 43061.0 unique 2.0 top 2.0 freq 22225.0 Name: S2AQ2, dtype: float64 Description of Individuals who drank atleast 1 alcoholic drink in last 12 months count 43062.0 unique 2.0 top 1.0 freq 26946.0 Name: S2AQ3, dtype: float64 Description of drinking status of individuals count 43093 unique 3 top 1 freq 26946 Name: CONSUMER, dtype: int64 Description of individuals who ever had a blood/natural father an alcoholic or problem drinker count 40569.0 unique 2.0 top 2.0 freq 32445.0 Name: S2DQ1, dtype: float64 Description of individuals who ever had a blood/natural mother an alcoholic or problem drinker count 41864.0 unique 2.0 top 2.0 freq 39553.0 Name: S2DQ2, dtype: float64 Description of individuals who ever had a full brother(s) an alcoholic or problem drinker count 41629.0 unique 12.0 top 0.0 freq 35428.0 Name: S2DQ3C1, dtype: float64 Description of individuals who ever had a full sister(s) an alcoholic or problem drinker count 41795.0 unique 10.0 top 0.0 freq 39090.0 Name: S2DQ4C1, dtype: float64
Graphs/Plots:
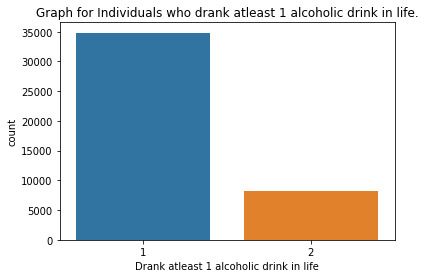

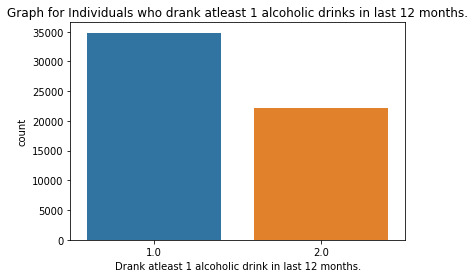

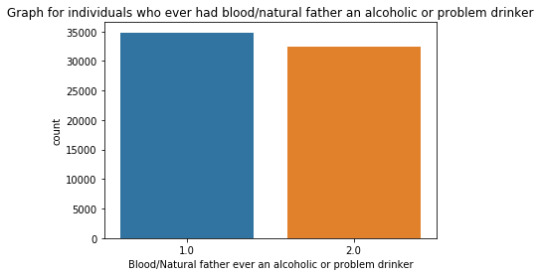
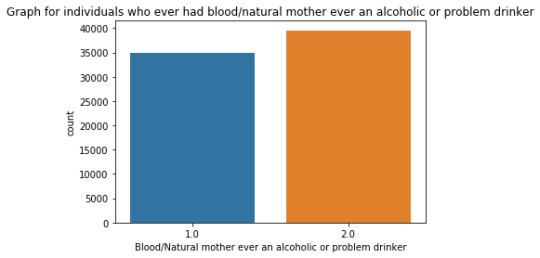

Summary:
As my variables were categorical it was not useful to do a quantitative analysis hence all the graphs are of categorical analysis. The "Graphs/Plots" section includes all the univariate and bivariate graphs.
0 notes
Text
Week#03 DMV Assignment#03
Program:
""" author: vikramaditya pratap singh research question: how much the family history affects the alcohol consumption/alcohol dependence of an individual """ # S2AQ1 --> DRANK ATLEAST 1 ALCOHOLIC DRINK IN LIFE; Yes = 1, No = 2 # S2AQ2 --> DRANK ATLEAST 12 ALCOHOLIC DRINKS IN LAST 12 MONTHS; Yes = 1, No = 2, Unknown = 9 # S2AQ3 --> DRANK ATLEAST 1 ALCOHLIC DRINK IN LAST 12 MONTHS; Yes = 1, No = 2, Unknown = 9 # CONSUMER --> DRINKING STATUS; Current drinker = 1, Ex-drinker = 2, Lifetime Abstainer = 3 # S2DQ1 --> BLOOD/NATURAL FATHER EVER AN ALCOHOLIC OR PROBLEM DRINKER; Yes = 1, No = 2, Unknown = 9 # S2DQ2 --> BLOOD/NATURAL MOTHER EVER AN ALCOHOLIC OR PROBLEM DRINKER; Yes = 1, No = 2, Unknown = 9 # S2DQ3C1 --> NUMBER OF FULL BROTHERS WHO WERE EVER ALCOHOLICS OR PROBLEM DRINKERS; Full Brother(s) = 0-11, Unknown = 99 # S2DQ4C1 --> NUMBER OF FULL SISTERS WHO WERE EVER ALCOHOLICS OR PROBLEM DRINKERS; Full Sister(s) = 0-9, Unknown = 99 import pandas as pd import numpy as np # loading up the data frame being used dataFrame = pd.read_csv('nesarc_pds.csv', low_memory = False) totalObservation = len(dataFrame) totalVariable = len(dataFrame.columns) print("Total number of observations/rows =", totalObservation) print("Total number of variables/columns =", totalVariable) # converting each variable to numeric data type dataFrame['S2AQ1'] = pd.to_numeric(dataFrame['S2AQ1']) dataFrame['S2AQ2'] = pd.to_numeric(dataFrame['S2AQ2']) dataFrame['S2AQ3'] = pd.to_numeric(dataFrame['S2AQ3']) dataFrame['CONSUMER'] = pd.to_numeric(dataFrame['CONSUMER']) dataFrame['S2DQ1'] = pd.to_numeric(dataFrame['S2DQ1']) dataFrame['S2DQ2'] = pd.to_numeric(dataFrame['S2DQ2']) dataFrame['S2DQ3C1'] = pd.to_numeric(dataFrame['S2DQ3C1']) dataFrame['S2DQ4C1'] = pd.to_numeric(dataFrame['S2DQ4C1']) # setting the "Unknown" data as NaN from variables S2AQ2, S2AQ3, S2DQ1, S2DQ2, S2DQ3C1, S2DQ4C1 dataFrame['S2AQ2'] = dataFrame['S2AQ2'].replace(9, np.nan) dataFrame['S2AQ3'] = dataFrame['S2AQ3'].replace(9, np.nan) dataFrame['S2DQ1'] = dataFrame['S2DQ1'].replace(9, np.nan) dataFrame['S2DQ2'] = dataFrame['S2DQ2'].replace(9, np.nan) dataFrame['S2DQ3C1'] = dataFrame['S2DQ3C1'].replace(99, np.nan) dataFrame['S2DQ4C1'] = dataFrame['S2DQ4C1'].replace(99, np.nan) # count and frequency distribution for I variable print("COUNT FOR: DRANK ATLEAST 1 ALCOHOLIC DRINK IN LIFE; Yes = 1, No = 2") count1 = dataFrame['S2AQ1'].value_counts(sort = False, dropna = False) print(count1) print("%AGE FOR: DRANK ATLEAST 1 ALCOHOLIC DRINK IN LIFE; Yes = 1, No = 2") perc1 = dataFrame['S2AQ1'].value_counts(sort = False, normalize = True, dropna = False) print(perc1) # count and frequency distribution for II variable print("COUNT FOR: DRANK ATLEAST 12 ALCOHOLIC DRINKS IN LAST 12 MONTHS; Yes = 1, No = 2, Unknown = 9") count2 = dataFrame['S2AQ2'].value_counts(sort = False, dropna = False) print(count2) print("%AGE FOR: DRANK ATLEAST 12 ALCOHOLIC DRINKS IN LAST 12 MONTHS; Yes = 1, No = 2, Unknown = 9") perc2 = dataFrame['S2AQ2'].value_counts(sort = False, normalize = True, dropna = False) print(perc2) # count and frequency distribution for III variable print("COUNT FOR: DRANK ATLEAST 1 ALCOHOLIC DRINK IN LAST 12 MONTHS; Yes = 1, No = 2, Unknown = 9") count3 = dataFrame['S2AQ3'].value_counts(sort = False, dropna = False) print(count3) print("%AGE FOR: DRANK ATLEAST 1 ALCOHOLIC DRINK IN LAST 12 MONTHS; Yes = 1, No = 2, Unknown = 9") perc3 = dataFrame['S2AQ3'].value_counts(sort = False, normalize = True, dropna = False) print(perc3) # count and frequency distribution for IV variable print("COUNT FOR: DRINKING STATUS; Current drinker = 1, Ex-drinker = 2, Lifetime Abstainer = 3") count4 = dataFrame['CONSUMER'].value_counts(sort = False, dropna = False) print(count4) print("%AGE FOR: DRINKING STATUS; Current drinker = 1, Ex-drinker = 2, Lifetime Abstainer = 3") perc4 = dataFrame['CONSUMER'].value_counts(sort = False, normalize = True, dropna = False) print(perc4) # count and frequency distribution for V variable print("COUNT FOR: BLOOD/NATURAL FATHER EVER AN ALCOHOLIC OR PROBLEM DRINKER; Yes = 1, No = 2, Unknown = 9") count5 = dataFrame['S2DQ1'].value_counts(sort = False, dropna = False) print(count5) print("%AGE FOR: BLOOD/NATURAL FATHER EVER AN ALCOHOLIC OR PROBLEM DRINKER; Yes = 1, No = 2, Unknown = 9") perc5 = dataFrame['S2DQ1'].value_counts(sort = False, normalize = True, dropna = False) print(perc5) # count and frequency distribution for VI variable print("COUNT FOR: BLOOD/NATURAL MOTHER EVER AN ALCOHOLIC OR PROBLEM DRINKER; Yes = 1, No = 2, Unknown = 9") count6 = dataFrame['S2DQ2'].value_counts(sort = False, dropna = False) print(count6) print("%AGE FOR: BLOOD/NATURAL MOTHER EVER AN ALCOHOLIC OR PROBLEM DRINKER; Yes = 1, No = 2, Unknown = 9") perc6 = dataFrame['S2DQ2'].value_counts(sort = False, normalize = True, dropna = False) print(perc6) # count and frequency distribution for VII variable print("COUNT FOR: NUMBER OF FULL BROTHERS WHO WERE EVER ALCOHOLICS OR PROBLEM DRINKERS; Full Brother(s) = 0-11, Unknown = 99") count7 = dataFrame['S2DQ3C1'].value_counts(sort = False, dropna = False) print(count7) print("%AGE FOR: NUMBER OF FULL BROTHERS WHO WERE EVER ALCOHOLICS OR PROBLEM DRINKERS; Full Brother(s) = 0-11, Unknown = 99") perc7 = dataFrame['S2DQ3C1'].value_counts(sort = False, normalize = True, dropna = False) print(perc7) # count and frequency distribution for VIII variable print("COUNT FOR: NUMBER OF FULL SISTERS WHO WERE EVER ALCOHOLICS OR PROBLEM DRINKERS; Full Sister(s) = 0-9, Unknown = 99") count8 = dataFrame['S2DQ4C1'].value_counts(sort = False, dropna = False) print(count8) print("%AGE FOR: NUMBER OF FULL SISTERS WHO WERE EVER ALCOHOLICS OR PROBLEM DRINKERS; Full Sister(s) = 0-9, Unknown = 99") perc8 = dataFrame['S2DQ4C1'].value_counts(sort = False, normalize = True, dropna = False) print(perc8)
Output:
runfile('E:/data_management_and_visualization/script#01.py', wdir='E:/data_management_and_visualization') Total number of observations/rows = 43093 Total number of variables/columns = 3010 COUNT FOR: DRANK ATLEAST 1 ALCOHOLIC DRINK IN LIFE; Yes = 1, No = 2 1 34827 2 8266 Name: S2AQ1, dtype: int64 %AGE FOR: DRANK ATLEAST 1 ALCOHOLIC DRINK IN LIFE; Yes = 1, No = 2 1 0.808182 2 0.191818 Name: S2AQ1, dtype: float64 COUNT FOR: DRANK ATLEAST 12 ALCOHOLIC DRINKS IN LAST 12 MONTHS; Yes = 1, No = 2, Unknown = 9 2 22225 1 20836 NaN 32 Name: S2AQ2, dtype: int64 %AGE FOR: DRANK ATLEAST 12 ALCOHOLIC DRINKS IN LAST 12 MONTHS; Yes = 1, No = 2, Unknown = 9 2 0.515745 1 0.483512 NaN 0.000743 Name: S2AQ2, dtype: float64 COUNT FOR: DRANK ATLEAST 1 ALCOHOLIC DRINK IN LAST 12 MONTHS; Yes = 1, No = 2, Unknown = 9 2 16116 1 26946 NaN 31 Name: S2AQ3, dtype: int64 %AGE FOR: DRANK ATLEAST 1 ALCOHOLIC DRINK IN LAST 12 MONTHS; Yes = 1, No = 2, Unknown = 9 2.0 0.373982 1.0 0.625299 NaN 0.000719 Name: S2AQ3, dtype: float64 COUNT FOR: DRINKING STATUS; Current drinker = 1, Ex-drinker = 2, Lifetime Abstainer = 3 1 26946 2 7881 3 8266 Name: CONSUMER, dtype: int64 %AGE FOR: DRINKING STATUS; Current drinker = 1, Ex-drinker = 2, Lifetime Abstainer = 3 1 0.625299 2 0.182884 3 0.191818 Name: CONSUMER, dtype: float64 COUNT FOR: BLOOD/NATURAL FATHER EVER AN ALCOHOLIC OR PROBLEM DRINKER; Yes = 1, No = 2, Unknown = 9 1 8124 2 32445 NaN 2524 Name: S2DQ1, dtype: int64 %AGE FOR: BLOOD/NATURAL FATHER EVER AN ALCOHOLIC OR PROBLEM DRINKER; Yes = 1, No = 2, Unknown = 9 1 0.188522 2 0.752907 NaN 0.058571 Name: S2DQ1, dtype: float64 COUNT FOR: BLOOD/NATURAL MOTHER EVER AN ALCOHOLIC OR PROBLEM DRINKER; Yes = 1, No = 2, Unknown = 9 2 39553 1 2311 NaN 1229 Name: S2DQ2, dtype: int64 %AGE FOR: BLOOD/NATURAL MOTHER EVER AN ALCOHOLIC OR PROBLEM DRINKER; Yes = 1, No = 2, Unknown = 9 2 0.917852 1 0.053628 NaN 0.028520 Name: S2DQ2, dtype: float64 COUNT FOR: NUMBER OF FULL BROTHERS WHO WERE EVER ALCOHOLICS OR PROBLEM DRINKERS; Full Brother(s) = 0-11, Unknown = 99 5 44 0 35428 1 4408 2 1278 4 126 8 2 9 3 10 1 11 1 NaN 1464 3 283 6 42 7 13 Name: S2DQ3C1, dtype: int64 %AGE FOR: NUMBER OF FULL BROTHERS WHO WERE EVER ALCOHOLICS OR PROBLEM DRINKERS; Full Brother(s) = 0-11, Unknown = 99 5 0.001021 0 0.822129 1 0.102290 2 0.029657 4 0.002924 8 0.000046 9 0.000070 10 0.000023 11 0.000023 NaN 0.033973 3 0.006567 6 0.000975 7 0.000302 Name: S2DQ3C1, dtype: float64 COUNT FOR: NUMBER OF FULL SISTERS WHO WERE EVER ALCOHOLICS OR PROBLEM DRINKERS; Full Sister(s) = 0-9, Unknown = 99 0 39090 2 708 1 1847 4 43 6 4 8 1 9 1 5 13 NaN 1298 3 83 7 5 Name: S2DQ4C1, dtype: int64 %AGE FOR: NUMBER OF FULL SISTERS WHO WERE EVER ALCOHOLICS OR PROBLEM DRINKERS; Full Sister(s) = 0-9, Unknown = 99 0 0.907108 2 0.016430 1 0.042861 4 0.000998 6 0.000093 8 0.000023 9 0.000023 5 0.000302 NaN 0.030121 3 0.001926 7 0.000116 Name: S2DQ4C1, dtype: float64
Summary:
The above output show the result of my program, I haven't used much of any data management techniques as it was unnecessary for my research area. The only thing I added is the "NaN" for "Unknown".
0 notes
Text
Week#02 DMV Assignment#02
Program:
""" author: vikramaditya pratap singh research question: how much the family history affects the alcohol consumption/alcohol dependence of an individual """ # S2AQ1 --> DRANK ATLEAST 1 ALCOHOLIC DRINK IN LIFE; Yes = 1, No = 2 # S2AQ2 --> DRANK ATLEAST 12 ALCOHOLIC DRINKS IN LAST 12 MONTHS; Yes = 1, No = 2, Unknown = 9 # S2AQ3 --> DRANK ATLEAST 1 ALCOHLIC DRINK IN LAST 12 MONTHS; Yes = 1, No = 2, Unknown = 9 # CONSUMER --> DRINKING STATUS; Current drinker = 1, Ex-drinker = 2, Lifetime Abstainer = 3 # S2DQ1 --> BLOOD/NATURAL FATHER EVER AN ALCOHOLIC OR PROBLEM DRINKER; Yes = 1, No = 2, Unknown = 9 # S2DQ2 --> BLOOD/NATURAL MOTHER EVER AN ALCOHOLIC OR PROBLEM DRINKER; Yes = 1, No = 2, Unknown = 9 # S2DQ3C1 --> NUMBER OF FULL BROTHERS WHO WERE EVER ALCOHOLICS OR PROBLEM DRINKERS; Full Brother(s) = 0-11, Unknown = 99 # S2DQ4C1 --> NUMBER OF FULL SISTERS WHO WERE EVER ALCOHOLICS OR PROBLEM DRINKERS; Full Sister(s) = 0-9, Unknown = 99 import pandas as pd import numpy as np # loading up the data frame being used dataFrame = pd.read_csv('nesarc_pds.csv', low_memory = False) totalObservation = len(dataFrame) totalVariable = len(dataFrame.columns) print("Total number of observations/rows =", totalObservation) print("Total number of variables/columns =", totalVariable) # converting each variable to numeric data type dataFrame['S2AQ1'] = pd.to_numeric(dataFrame['S2AQ1']) dataFrame['S2AQ2'] = pd.to_numeric(dataFrame['S2AQ2']) dataFrame['S2AQ3'] = pd.to_numeric(dataFrame['S2AQ3']) dataFrame['CONSUMER'] = pd.to_numeric(dataFrame['CONSUMER']) dataFrame['S2DQ1'] = pd.to_numeric(dataFrame['S2DQ1']) dataFrame['S2DQ2'] = pd.to_numeric(dataFrame['S2DQ2']) dataFrame['S2DQ3C1'] = pd.to_numeric(dataFrame['S2DQ3C1']) dataFrame['S2DQ4C1'] = pd.to_numeric(dataFrame['S2DQ4C1']) # count and frequency distribution for I variable print("COUNT FOR: DRANK ATLEAST 1 ALCOHOLIC DRINK IN LIFE; Yes = 1, No = 2") count1 = dataFrame['S2AQ1'].value_counts(sort = False, dropna = False) print(count1) print("%AGE FOR: DRANK ATLEAST 1 ALCOHOLIC DRINK IN LIFE; Yes = 1, No = 2") perc1 = dataFrame['S2AQ1'].value_counts(sort = False, normalize = True, dropna = False) print(perc1) # count and frequency distribution for II variable print("COUNT FOR: DRANK ATLEAST 12 ALCOHOLIC DRINKS IN LAST 12 MONTHS; Yes = 1, No = 2, Unknown = 9") count2 = dataFrame['S2AQ2'].value_counts(sort = False, dropna = False) print(count2) print("%AGE FOR: DRANK ATLEAST 12 ALCOHOLIC DRINKS IN LAST 12 MONTHS; Yes = 1, No = 2, Unknown = 9") perc2 = dataFrame['S2AQ2'].value_counts(sort = False, normalize = True, dropna = False) print(perc2) # count and frequency distribution for III variable print("COUNT FOR: DRANK ATLEAST 1 ALCOHOLIC DRINK IN LAST 12 MONTHS; Yes = 1, No = 2, Unknown = 9") count3 = dataFrame['S2AQ3'].value_counts(sort = False, dropna = False) print(count3) print("%AGE FOR: DRANK ATLEAST 1 ALCOHOLIC DRINK IN LAST 12 MONTHS; Yes = 1, No = 2, Unknown = 9") perc3 = dataFrame['S2AQ3'].value_counts(sort = False, normalize = True, dropna = False) print(perc3) # count and frequency distribution for IV variable print("COUNT FOR: DRINKING STATUS; Current drinker = 1, Ex-drinker = 2, Lifetime Abstainer = 3") count4 = dataFrame['CONSUMER'].value_counts(sort = False, dropna = False) print(count4) print("%AGE FOR: DRINKING STATUS; Current drinker = 1, Ex-drinker = 2, Lifetime Abstainer = 3") perc4 = dataFrame['CONSUMER'].value_counts(sort = False, normalize = True, dropna = False) print(perc4) # count and frequency distribution for V variable print("COUNT FOR: BLOOD/NATURAL FATHER EVER AN ALCOHOLIC OR PROBLEM DRINKER; Yes = 1, No = 2, Unknown = 9") count5 = dataFrame['S2DQ1'].value_counts(sort = False, dropna = False) print(count5) print("%AGE FOR: BLOOD/NATURAL FATHER EVER AN ALCOHOLIC OR PROBLEM DRINKER; Yes = 1, No = 2, Unknown = 9") perc5 = dataFrame['S2DQ1'].value_counts(sort = False, normalize = True, dropna = False) print(perc5) # count and frequency distribution for VI variable print("COUNT FOR: BLOOD/NATURAL MOTHER EVER AN ALCOHOLIC OR PROBLEM DRINKER; Yes = 1, No = 2, Unknown = 9") count6 = dataFrame['S2DQ2'].value_counts(sort = False, dropna = False) print(count6) print("%AGE FOR: BLOOD/NATURAL MOTHER EVER AN ALCOHOLIC OR PROBLEM DRINKER; Yes = 1, No = 2, Unknown = 9") perc6 = dataFrame['S2DQ2'].value_counts(sort = False, normalize = True, dropna = False) print(perc6) # count and frequency distribution for VII variable print("COUNT FOR: NUMBER OF FULL BROTHERS WHO WERE EVER ALCOHOLICS OR PROBLEM DRINKERS; Full Brother(s) = 0-11, Unknown = 99") count7 = dataFrame['S2DQ3C1'].value_counts(sort = False, dropna = False) print(count7) print("%AGE FOR: NUMBER OF FULL BROTHERS WHO WERE EVER ALCOHOLICS OR PROBLEM DRINKERS; Full Brother(s) = 0-11, Unknown = 99") perc7 = dataFrame['S2DQ3C1'].value_counts(sort = False, normalize = True, dropna = False) print(perc7) # count and frequency distribution for VIII variable print("COUNT FOR: NUMBER OF FULL SISTERS WHO WERE EVER ALCOHOLICS OR PROBLEM DRINKERS; Full Sister(s) = 0-9, Unknown = 99") count8 = dataFrame['S2DQ4C1'].value_counts(sort = False, dropna = False) print(count8) print("%AGE FOR: NUMBER OF FULL SISTERS WHO WERE EVER ALCOHOLICS OR PROBLEM DRINKERS; Full Sister(s) = 0-9, Unknown = 99") perc8 = dataFrame['S2DQ4C1'].value_counts(sort = False, normalize = True, dropna = False) print(perc8)
Output:
runfile('E:/data_management_and_visualization/script#01.py', wdir='E:/data_management_and_visualization') Total number of observations/rows = 43093 Total number of variables/columns = 3010 COUNT FOR: DRANK ATLEAST 1 ALCOHOLIC DRINK IN LIFE; Yes = 1, No = 2 1 34827 2 8266 Name: S2AQ1, dtype: int64 %AGE FOR: DRANK ATLEAST 1 ALCOHOLIC DRINK IN LIFE; Yes = 1, No = 2 1 0.808182 2 0.191818 Name: S2AQ1, dtype: float64 COUNT FOR: DRANK ATLEAST 12 ALCOHOLIC DRINKS IN LAST 12 MONTHS; Yes = 1, No = 2, Unknown = 9 1 20836 2 22225 9 32 Name: S2AQ2, dtype: int64 %AGE FOR: DRANK ATLEAST 12 ALCOHOLIC DRINKS IN LAST 12 MONTHS; Yes = 1, No = 2, Unknown = 9 1 0.483512 2 0.515745 9 0.000743 Name: S2AQ2, dtype: float64 COUNT FOR: DRANK ATLEAST 1 ALCOHOLIC DRINK IN LAST 12 MONTHS; Yes = 1, No = 2, Unknown = 9 1 26946 2 16116 9 31 Name: S2AQ3, dtype: int64 %AGE FOR: DRANK ATLEAST 1 ALCOHOLIC DRINK IN LAST 12 MONTHS; Yes = 1, No = 2, Unknown = 9 1 0.625299 2 0.373982 9 0.000719 Name: S2AQ3, dtype: float64 COUNT FOR: DRINKING STATUS; Current drinker = 1, Ex-drinker = 2, Lifetime Abstainer = 3 1 26946 2 7881 3 8266 Name: CONSUMER, dtype: int64 %AGE FOR: DRINKING STATUS; Current drinker = 1, Ex-drinker = 2, Lifetime Abstainer = 3 1 0.625299 2 0.182884 3 0.191818 Name: CONSUMER, dtype: float64 COUNT FOR: BLOOD/NATURAL FATHER EVER AN ALCOHOLIC OR PROBLEM DRINKER; Yes = 1, No = 2, Unknown = 9 1 8124 2 32445 9 2524 Name: S2DQ1, dtype: int64 %AGE FOR: BLOOD/NATURAL FATHER EVER AN ALCOHOLIC OR PROBLEM DRINKER; Yes = 1, No = 2, Unknown = 9 1 0.188522 2 0.752907 9 0.058571 Name: S2DQ1, dtype: float64 COUNT FOR: BLOOD/NATURAL MOTHER EVER AN ALCOHOLIC OR PROBLEM DRINKER; Yes = 1, No = 2, Unknown = 9 1 2311 2 39553 9 1229 Name: S2DQ2, dtype: int64 %AGE FOR: BLOOD/NATURAL MOTHER EVER AN ALCOHOLIC OR PROBLEM DRINKER; Yes = 1, No = 2, Unknown = 9 1 0.053628 2 0.917852 9 0.028520 Name: S2DQ2, dtype: float64 COUNT FOR: NUMBER OF FULL BROTHERS WHO WERE EVER ALCOHOLICS OR PROBLEM DRINKERS; Full Brother(s) = 0-11, Unknown = 99 0 35428 1 4408 2 1278 3 283 99 1464 4 126 5 44 6 42 7 13 8 2 9 3 10 1 11 1 Name: S2DQ3C1, dtype: int64 %AGE FOR: NUMBER OF FULL BROTHERS WHO WERE EVER ALCOHOLICS OR PROBLEM DRINKERS; Full Brother(s) = 0-11, Unknown = 99 0 0.822129 1 0.102290 2 0.029657 3 0.006567 99 0.033973 4 0.002924 5 0.001021 6 0.000975 7 0.000302 8 0.000046 9 0.000070 10 0.000023 11 0.000023 Name: S2DQ3C1, dtype: float64 COUNT FOR: NUMBER OF FULL SISTERS WHO WERE EVER ALCOHOLICS OR PROBLEM DRINKERS; Full Sister(s) = 0-9, Unknown = 99 0 39090 1 1847 2 708 3 83 99 1298 4 43 5 13 6 4 7 5 8 1 9 1 Name: S2DQ4C1, dtype: int64 %AGE FOR: NUMBER OF FULL SISTERS WHO WERE EVER ALCOHOLICS OR PROBLEM DRINKERS; Full Sister(s) = 0-9, Unknown = 99 0 0.907108 1 0.042861 2 0.016430 3 0.001926 99 0.030121 4 0.000998 5 0.000302 6 0.000093 7 0.000116 8 0.000023 9 0.000023 Name: S2DQ4C1, dtype: float64
Summary:
Above are the program and output showing the count and frequency distribution for the variables I considered for my reasearch which is, alcohol consumption/alcohol dependence in an individual with a family history of alcoholism. I have not considered any specific condition for my program and/or research as I am interested in all the variables being used in my research.
0 notes
Text
Week#01 DMV Assignment#01
Selection of a Dataset:
After looking through the codebook for NESARC study, I have decided that I am particularly interested in alcohol dependence. I am not sure at this point of time about which variables I will use regarding alcohol dependence, so for now I will include all the relevant variable in my personal codebook.
While alcohol dependence is a good starting point, I need to determine what it is about alcohol dependence that I am interested in. It strikes me that some of my friends and family members are so hooked into alcohol, some seemed to have started drinking in pure peer pressure of friends but some had a long history of alcoholism in their family
Topic of Association:
I decide that I am most interested in exploring the association between family history of alcoholism and alcohol dependence. As of now I will try to investigate the family history including only the parents and siblings add to my codebook variables reflecting the drinking habits of natural/blood parents and of an individual's elder brother/sister.
Literature Review:
1. Family History as a Predictor of Alcohol Dependence
The effects of various levels of positive family history of alcoholism on the probability of past year alcohol dependence were investigated using a general population sample of 23,152 drinkers 18 years of age and older. Forty percent reported a positive family history. After adjustment for age, race, gender, and poverty and compared with persons with a negative family history, the odds of alcohol dependence were increased by 45% among persons with alcoholism in second or third degree relatives only, by 86% among those with alcoholism in first degree relatives only, and by 167% among those with alcoholism in first and second or third degree relatives. The effects of family history did not vary among population subgroups as defined by age, race, gender, and poverty.
References:
Authors:
Deborah A. Dawson
Thomas C. Harford
Bridget F. Grant
Links:
Family History as a Predictor of Alcohol Dependence
2. Parent-child closeness affects the similarity of drinking levels between parents and their college-age children
College males reported drinking more frequently and in higher amounts than females. Correlations between quantity-frequency (QF) indices of drinking by parents and by their college-age children showed the greatest similarity between fathers and sons. Log linear analyses compared each parent's drinking level against each of three other factors that might affect the QF levels of college-age children: the relationship between parent and child, the effect of the parent's drinking on the parent, and how the parent's drinking affected their treatment of the child. The results supported models in which the relationship of each parent's drinking to the QF levels of both sons and daughters was affected by the closeness of the parent-child relationship. However, there was no support for models involving how each parent's drinking affected that parent or how each parent's drinking affected their treatment of the child.
References:
Authors:
John Jung
Links:
Parent-child closeness affects the similarity of drinking levels between parents and their colleges-age children
Hypothesis:
According to my findings from the literatures, I have come to a point that the closeness of parents to their child can affect the alcohol dependence of their child mostly in college-age, if the parents are a heavy drinkers.
1 note
·
View note