
Statistics
We looked inside some of the posts by dummdida and here's what we found interesting.
Average Info
Notes Per Post
13
Likes Per Post
11
Reblog Per Post
2
Reply Per Post
0
Time Between Posts
14 days
Number of Posts By Type
Text
16
Video
1
Last Seen Tumblr Blogs





Fun Fact
Tumblr was acquired by Yahoo for $1.1B in 2013.
Text
Cheap and lazy releases
Release early and release often.
That's fine if it's close to a noop. The Cockpit team also has great atuomation in this area, but here a few words on how we do this in KubeVirt.
Assumption: The git tree is our source and git tags map to logical releases.
Kudos: To GitHub and Travis CI.
Have a working CI in order toverify that a commit is good
You'll need to write test cases and have travis running them. I strongly recommended to have a great coverage, it keeps your .. inbox clean.
Tagging and release in order to mark a commit as a release
Here you want to either use plain annotated git tags, or even better git-evtag which is signing the whole tree.
Building images and binaries Travis has everything you need to build images and binaries (although I wonder when buildah will land here). Besides building images you can also push them to a registry of your choice. All triggered by tags mentioned above.
The travis deployment feature is also pretty handy, as you can directly create a GitHub release and upload artifacts.
Announce
Do it manually. You can generate changelogs, but reading them ... is nto nice for humans. Thus maybe a sentenc or two - but written by a real human - might be good.
All steps combined should give you: CI on each commit, github releases and pushed images for every tag you do.
All in all it's a lazy - or cheap - release.
1 note
·
View note
Text
Running minikube v0.26.0 with CRIO and KVM nesting enabled by default
Probably not worth a post, as it's mentioned in the readme, but CRIO was recently updated in minikube v0.26.0 which now makes it work like a charm.
When updating to 0.26 make sure to update the minikube binary, but also the docker-machine-driver-kvm2 binary.
Like in the past it is possible to switch to CRIO using
$ minikube start --container-runtime=cri-o Starting local Kubernetes v1.10.0 cluster... Starting VM... Getting VM IP address... Moving files into cluster... Setting up certs... Connecting to cluster... Setting up kubeconfig... Starting cluster components... Kubectl is now configured to use the cluster. Loading cached images from config file. $
However, my favorit launch line is:
minikube start --container-runtime=cri-o --network-plugin=cni --bootstrapper=kubeadm --vm-driver=kvm2
Which will use CRIO as the container runtime, CNI for networking, kubeadm for bringing up kube inside a KVM VM.
1 note
·
View note
Text
Running Ubuntu on Kubernetes with KubeVirt v0.3.0
You have this image, of a VM, which you want to run - alongside containers - why? - well, you need it. Some people would say it's dope, but sometimes you really need it, because it has an app you want to integrate with pods.
Here is how you can do this with KubeVirt.
1 Deploy KubeVirt
Deploy KubeVirt on your cluster - or follow the demo guide to setup a fresh minikube cluster.
2 Download Ubuntu
While KubeVirt comes up (use kubectl get --all-namespaces pods), download Ubuntu Server
3 Install kubectl plugin
Make sure to have the latest or recent kubectl tool installed, and install the pvc plugin:
curl -L https://github.com/fabiand/kubectl-plugin-pvc/raw/master/install.sh | bash
4 Create disk
Upload the Ubuntu server image:
$ kubectl plugin pvc create ubuntu1704 1Gi $PWD/ubuntu-17.04-server-amd64.iso disk.img Creating PVC persistentvolumeclaim "ubuntu1704" created Populating PVC pod "ubuntu1704" created total 701444 701444 -rw-rw-r-- 1 1000 1000 685.0M Aug 25 2017 disk.img Cleanup pod "ubuntu1704" deleted
5 Create and launch VM
Create a VM:
$ kubectl apply -f - apiVersion: kubevirt.io/v1alpha1 kind: VirtualMachinePreset metadata: name: large spec: selector: matchLabels: kubevirt.io/size: large domain: resources: requests: memory: 1Gi --- apiVersion: kubevirt.io/v1alpha1 kind: OfflineVirtualMachine metadata: name: ubuntu spec: running: true selector: matchLabels: guest: ubuntu template: metadata: labels: guest: ubuntu kubevirt.io/size: large spec: domain: devices: disks: - name: ubuntu volumeName: ubuntu disk: bus: virtio volumes: - name: ubuntu claimName: ubuntu1710
6 Connect to VM
$ ./virtctl-v0.3.0-linux-amd64 vnc --kubeconfig ~/.kube/config ubuntu
Final notes - This is booting the Ubuntu ISO image. But this flow should work for existing images, which might be much more useful.
2 notes
·
View notes
Text
v2v-job v0.2.0 POC for importing VMs into KubeVirt
KubeVirt becomes usable. And to make it easier to use it would be nice to be able to import existing VMs. After all migration is a strong point of KubeVirt.
virt-v2v is the tool of choice to convert some guest to run on the KVM hypervisor. What a great fit.
Thus recently I started a little POC to check if this would really work.
This post is just to wrap it up, as I just tagged v0.2.0 and finished a nice OVA import.
What the POC does:
Take an URL pointing to an OVA
Download and convert the OVA to a domxml and raw disk image
Create a PVC and move the raw disk image to it
Create an OfflineVirtualMachine from the domxml using xslt
This is pretty straight forward and currently living in a Job which can be found here: https://github.com/fabiand/v2v-job
It's actually using an OpenShift Template, but only works on Kubernetes so far, because I didn't finish the RBAC profiles. However, using the oc tool you can even run it on Kubernetes without Template support by using:
$ oc process --local -f manifests/template.yaml \ -p SOURCE_TYPE=ova \ -p SOURCE_NAME=http://192.168.42.1:8000/my.ova \ | kubectl apply -f - serviceaccount "kubevirt-privileged" created job "v2v" created
The interested reader can take a peek at the whole process in this log.
And btw - This little but awesome patch on libguestfs by Pino - will help this job to auto-detect - well, guess - the the guest operating system and set the OfflineVirtualMachine annotations correctly, in order to then - at runtime - apply the right VirtualMachinePresets, in order to launch the guest with optimized defaults.
0 notes
Text
KubeVirt v0.3.0-alpha.3: Kubernetes native networking and storage
First post for quite some time. A side effect of being busy to get streamline our KubeVirt user experience.
KubeVirt v0.3.0 was not released at the beginnig of the month.
That release was intended to be a little bigger, because it included a large architecture change (to the good). The change itself was amazingly friendly and went in without much problems - even if it took some time.
But, the work which was building upon this patch in the storage and network areas was delayed and didn't make it in time. Thus we skipped the release in order to let storage and network catch up.
The important thing about these two areas is, that KubeVirt was able to connect a VM to a network, and was able to boot of a iSCSI target, but this was not really tightly integrated with Kubernetes.
Now, just this week two patches landed which actually do integrate these areas with Kubernetes.
Storage
The first is storage - mainly written by Artyom, and finalized by David - which allows a user to use a persistent volume as the backing storage for a VM disk:
metadata: name: myvm apiVersion: kubevirt.io/v1alpha1 kind: VirtualMachine spec: domain: devices: disks: - name: mypvcdisk volumeName: mypvc lun: {} volumes: - name: mypvc persistentVolumeClaim: claimName: mypvc
This means that any storage solution supported by Kubernetes to provide PVs can be used to store virtual machine images. This is a big step forward in terms of compatibility.
This actually works by taking this claim, and attaching it to the VM's pod definition, in order to let the kubelet then mount the respective volume to the VM's pod. Once that is done, KubeVirt will take care to connect the disk image within that PV to the VM itself. This is only possible because the architecture change caused libvirt to run inside every VM pod, and thus allow the VM to consume the pod resources.
Side note, another project is in progress to actually let a user upload a virtual machine disk to the cluster in a convenient way: https://github.com/kubevirt/containerized-data-importer.
Network
The second change is about network which Vladik worked on for some time. This change also required the architectural changes, in order to allow the VM and libvirt to consume the pod's network resource.
Just like with pods the user does not need to do anything to get basic network connectivity. KubeVirt will connect the VM to the NIC of the pod in order to give it the most compatible intergation. Thus now you are able to expose a TCP or UDP port of the VM to the outside world using regular Kubernetes Services.
A side note here is that despite this integration we are now looking to enhance this further to allow the usage of side cars like Istio.
Alpha Release
The three changes - and their delay - caused the delay of v0.3.0 - which will now be released in the beginnig of March. But we have done a few pre-releases in order to allow interested users to try this code right now:
KubeVirt v0.3.0-alpha.3 is the most recent alpha release and should work fairly well.
More
But these items were just a small fraction of what we have been doing.
If you look at the kubevirt org on GitHub you will notice many more repositories there, covering storage, cockpit, and deployment with ansible - and it will be another post to write about how all of this is fitting together.
Welcome aboard!
KubeVirt is really speeding up and we are still looking for support. So if you are interested in working on a bleeding edge project tightly coupled with Kubernetes, but also having it's own notion, and an great team, then just reach out to me.
1 note
·
View note
Text
KubeVirt Status 0x7E1 (2017)
Where do we stand with KubeVirt at the end of the year? (This virtual machine management add-on for Kubernetes)
We gained some speed again, but before going into what we are doing right now; let's take a look at the past year.
Retro
The year started with publishing KubeVirt. The first few months flew by, and we were mainly driven by demoing and PoCing parts of KubeVirt. Quickly we were able to launch machines, and to even live migrate them.
We had the chance to speak about KubeVirt at a couple of conferences: FOSDEM 2017, devconf.cz 2017, KubeCon EU 2017, FrOSCon 2017. And our work was mainly around sorting out technical details, and understanding how things could work - in many areas. with many open ends.
At that time we had settled with CRD based solution, but aiming at a User API Server (to be used with API server aggregation), a single libvirt in a pod nicluding extensions to move the qemu processes into VM pods, and storage based on PVCs and iSSCI leveraging qemu's built-in drivers. And we were also struggling with a nice deployment. To name just a few of the big items we were looking at.
Low-level changes and storage
Around the middle of the year we were seeing all the features which we would like to consume - RAW block storage for volumes, device manager, resource classes (now delayed) - to go into Kubernetes 1.9. But at the same time we started to notice, that our current implementation was not suited to consume those features. The problem we were facing was that the VM processes lived in a single libvirtd pod, and were only living in te cgroups of the VM pods in order to allow Kubernets to see the VM resource consumption. But because the VMs were in a singlel ibvirt pod from a namespace perspective, we weren't bale to use any feature which was namespace related. I.e. raw block storage for volumes is a pretty big thing for us, as it will allow us to directly attach a raw block device to a VM. However, the block devices are exposed to pods, to the VM pods (the pods we spawn for every VM) - and up to now our VMs did not see the mount namespace of a pod, thus it's not possible to consume raw block devices. It's similar for the device manager work. It will allow us to bring devices to pods, but we are not able to consume them, because our VM proccesses live in the libvirt pod.
And it was even worse, we spent a significant amount of time on finding workarounds in order to allow VM processes to see the pods' namespaces in order to consume the features.
All of this due to the fact that we wanted to use libvirtd as intended: A single instance per host with a host wide view.
Why we do this initially - using libvirtd? Well, there were different opinions about this within the team. In the end we stuck to it, because there are some benefits over direct qemu, mainly API stability and support when it comes to things like live migrations. Further more - if we did use qemu directly, we would probably come up with something similar to libvirt - and that is not where we want to focus on (the node level virtualization).
We engaged internally and publicly with the libvirtd team and tried to understand how a future could look. The bottom line is that the libvirtd team - or parts of it - acknowledged the fact that the landscape if evolving, and that libvirtd want's to be part of this change - also in it's own interest to stay relevant. And this happened pretty recently, but it's an improtant change which will allow us to consume Kubernetes features much better. And should free time because we will spend much less time on finding workarounds.
API layer
The API layer was also exciting.
We spend a vast amount of time writing our own user API server to be used with API server aggregation. We went with this because it would have provided us with the full controll over our entity types and http endpoints, which was relevant in order to provide access to serial and graphical consoles of a VM.
We worked this based on the assumption that Kubernetes will provide anything to make it easy to integrate and run those custom API servers.
But in the end these assumptions were not met. The biggest blocker was that Kubernetes does not provide a convenient way to store an custom APIs data. Instead it is left to the API server to provide it's own mechanism to store it's data (state). This sounds small, but is annoying. This gap increases the burden on the operator to decide where to store data, it could eventually add dependencies for a custom etcd instance, or adds a dependency for PV in the cluster. In the end all of this might be there, but it wasis a goal of KubeVirt to be an easy to deploy add-on to Kubernetes. Taking care of these pretty cluster specific data storage problems took us to much off track.
Rigth now we are re-focusing on CRDs. We are looking at using jsonscheme for validation which landed pretty recently. And we try to get rid of our subresources to remove the need of a custom API server.
Network
Networking was also an issue where we spend a lot of time on. It still is a difficult topic.
Traditionally (this word is used intentionally) VMs are connected in a layer 2 or layer 3 fashion. However, as we (will really) run VMs in a pod, there are several ways of how we can connect a VM to a Kubernetes network
Layer 2 - Is not in Kubernetes
Layer 3 - We'd hijack the pod's IP and leave it to the VM
Layer 4 - This is how applications behave within a pod - If we make VMs work this way, then we are most compatible, but restrict the functionality of a VM
Besides of this - VMs often have multiple interfaces - and Kubernetes does not have a concept for this.
Thus it's a mix of technical and conceptual problems by itself. It becomes even more complex if you consider that the traditional layer 2 and 3 connectivity helped to solve problems, but in the cloud native worlds the same problems might be solved in a different way and in a different place. Thus here it is a challenge to understand what problems were solved, and how could they be solved today, in order to understand if feature slike layer 2 connectivity are really needed.
Forward
As you see, or read, we've spent a lot of time on reseraching, PoCing, and failing. Today it looks different, and I'm positive for the future.
libvirt changes, this will allow us to consume Kubernetes features much more easily
Our deployment is much better today - this shall allow us to move to other clusters (Tectonic, OpenShift, …)
We are not at an end with how networking will look, but we are implemeting something which is pretty compatible (missing link)
We care about storage and see that we tie much better into the Kubernetes storage world
The API is getting refactored and is looking much more Kube-ish now
We focus on CRDs and can simplify other things
People are starting to add a Cockpit UI to KubeVirt: https://www.youtube.com/watch?v=nT2EA6wYkKI (this UI will get a KubeVirt backend)
And a ManageIQ provider: https://www.youtube.com/watch?v=6Z_kGj9_s6Q
On a broader front:
We have a informal virtualization WG in order to discuss issues accross the board with other projects - and give users guidance! Also on slack
This post got longer than expected and it is still missing a lot of details, but you see we are moving on, as we still see the need of giving users a good way to migrate the workloads from today to tomorrow.
There are probably also some mistakes, feel free to give me a ping or ignore then in a friendly fashion.
1 note
·
View note
Text
Updating to Fedora 26
Finally - after the presentation at KVM Forum 2017 - I took the opportunity and updated my primary laptop to Fedora 26.
I used gnome-software for it, and everything went eventless, which is surprising, as I use luks, EFI, and blue jeans.
The only hassle so far was that blue jeans does still not support screen sharing when Wayland is used (but this is known), and that my screen was messed up and frozen after some time with two connected diesplays.
But this is really neglectable - Updates are just lame these days. Awesome.
1 note
·
View note
Text
This Week in KubeVirt 5
This is the fith weekly update from the KubeVirt team.
We are currently driven by
Being easier to be used on Kubernetes and OpenShift
Enabling people to contribute
Node Isolator use-case (more informations soon)
This week we achieved to:
Improved sagger documentation (for SDK generation) (@lukas-bednar) (https://github.com/kubevirt/kubevirt/pull/476)
Kubernetes 1.8 fixes (@cynepco3hahue) (https://github.com/kubevirt/kubevirt/pull/479 https://github.com/kubevirt/kubevirt/pull/484)
Ephemeral disk rewrite (@davidvossel) (https://github.com/kubevirt/kubevirt/pull/460)
Custom VM metrics proposal (@fromanirh ) (https://github.com/kubevirt/kubevirt/pull/487)
[WIP] Add API server PKI tool (@jhernand) (https://github.com/kubevirt/kubevirt/pull/498)
KubeVirt provider for the cluster autoscaler (@rmohr) (https://github.com/rmohr/autoscaler/pull/1)
In addition to this, we are also working on:
Finally some good progress with layer 3 network connectivity (@vladikr) (https://github.com/kubevirt/kubevirt/pull/450 https://github.com/vladikr/kubevirt/tree/veth-bridge-tap https://github.com/vladikr/kubevirt/tree/veth-macvtap)
Continued work on api server aggregation (@stu-gott) (https://github.com/kubevirt/kubevirt/pull/355)
Take a look at the pulse, to get an overview over all changes of this week: https://github.com/kubevirt/kubevirt/pulse
Finally you can view our open issues at https://github.com/kubevirt/kubevirt/issues
And keep track of events at our calendar https://calendar.google.com/[email protected]
If you need some help or want to chat you can find us on irc://irc.freenode.net/#kubevirt
0 notes
Text
Enabling Kernel same page merging for vagrant or anybody else
Running the KubeVirt vagrant setup with 2 nodes is somewhat painful when it comes to memory consumption. But this is the price we are happy to pay for decent CI.
vagrant will launch three virtual machines (two nodes, one master) on your host. All three vagrant machines use the same (CentOS based) image, this is the optimal case for the kernel same page merger (ksm). This kernelf eatures wanders through memory pages and merges identical ones into one (if they are marked accordingly).
Using KSM on Fedora is simple, to enable it you just need to install and run some supporting services:
dnf install ksm ksmtunde systemctl enable --now ksm ksmtuned # Now check that it's working (if you have VMs running) watch tail /sys/kernel/mm/ksm/* ... == /sys/kernel/mm/ksm/pages_shared == 379446 ...
Please note that ksm requires some CPU cycles to perform the de-duplication.
1 note
·
View note
Text
This Week in KubeVirt 4
This is the fourth weekly update from the KubeVirt team.
We are currently driven by
Being easier to be used on Kubernetes and OpenShift
Enabling people to contribute
Node Isolator use-case (more informations soon)
This week you can find us at:
Ohio Linux Fest (@stu-gott) "KubeVirt, Virtual Machine Management Using Kubernetes" https://ohiolinux.org/schedule/
This week we achieved to:
ReplicaSet for VirtualMachines (@rmohr) (https://github.com/kubevirt/kubevirt/pull/453)
Swagger documentation improvements (@rmohr, @lukas-bednar) (https://github.com/kubevirt/kubevirt/pull/475)
Hot-standby for our controller (@cynepco3hahue) (https://github.com/kubevirt/kubevirt/pull/461)
domxml/VM Spec mapping rules proposal (@rmohr, @michalskrivanek) (https://github.com/kubevirt/kubevirt/pull/466)
Launch flow improvement proposal (@davidvossel) (https://github.com/kubevirt/kubevirt/pull/469)
In addition to this, we are also working on:
Debug layer 3 network connectivity issues for VMs (@vladikr) (https://github.com/kubevirt/kubevirt/pull/450)
Review of the draft code for the api server aggregation (@stu-gott) (https://github.com/kubevirt/kubevirt/pull/355)
Take a look at the pulse, to get an overview over all changes of this week: https://github.com/kubevirt/kubevirt/pulse
Finally you can view our open issues at https://github.com/kubevirt/kubevirt/issues
And keep track of events at our calendar https://calendar.google.com/[email protected]
If you need some help or want to chat you can find us on irc://irc.freenode.net/#kubevirt
0 notes
Text
This Week in KubeVirt 3
This is the third weekly update from the KubeVirt team.
We are currently driven by
Being easier to be used on Kubernetes and OpenShift
Enabling people to contribute
Node Isolator use-case (more informations soon)
This week we achieved to:
Renamed VM kind to VirtualMachine (@cynepco3hahue) (https://github.com/kubevirt/kubevirt/pull/452)
Proposal for VirtualMachineReplicaSet to scale VMs (@rmohr) (https://github.com/kubevirt/kubevirt/pull/453)
Ephemeral Registry Disk Rewrite (@vossel) (https://github.com/kubevirt/kubevirt/pull/460)
Fix some race in our CI (@rmohr) (https://github.com/kubevirt/kubevirt/pull/459)
In addition to this, we are also working on:
Review of the draft code to get layer 3 network connectivity for VMs (@vladikr) (https://github.com/kubevirt/kubevirt/pull/450)
Review of the draft code for the api server aggregation (@stu-gott) (https://github.com/kubevirt/kubevirt/pull/355)
Review of the proposal integrate with host networking (@rmohr) (https://github.com/kubevirt/kubevirt/pull/367)
Converging multiple ansible playbooks for deployment on OpenShift (@petrkotas, @cynepco3hahue, @lukas-bednar) (https://github.com/kubevirt-incubator/kubevirt-ansible)
Continued discussion of VM persistence and ABI stability (https://groups.google.com/d/topic/kubevirt-dev/G0FpxJYFhf4/discussion)
Take a look at the pulse, to get an overview over all changes of this week: https://github.com/kubevirt/kubevirt/pulse
Finally you can view our open issues at https://github.com/kubevirt/kubevirt/issues
And keep track of events at our calendar https://calendar.google.com/[email protected]
If you need some help or want to chat you can find us on irc://irc.freenode.net/#kubevirt
0 notes
Text
This Week in KubeVirt 2
This is the second weekly update from the KubeVirt team.
We are currently driven by
Being easier to be used on Kubernetes and OpenShift
Enabling people to contribute
This week we achieved to:
Keep cloud-init data in Secrets (@vossel) (https://github.com/kubevirt/kubevirt/pull/433)
First draft code to get layer 3 network connectivity for VMs (@vladikr) (https://github.com/kubevirt/kubevirt/pull/450)
First draft code for the api server aggregation (@stu-gott) (https://github.com/kubevirt/kubevirt/pull/355)
Add further migration documentation (@rmohr) (https://github.com/kubevirt/user-guide/pull/1)
In addition to this, we are also working on:
Progress on how to integrate with host networking (@rmohr) (https://github.com/kubevirt/kubevirt/pull/367)
Converging multiple ansible playbooks for deployment on OpenShift (@petrkotas, @cynepco3hahue, @lukas-bednar) (https://github.com/kubevirt-incubator/kubevirt-ansible)
Initial support for Anti- & Affinity for VMs (@MarSik) (https://github.com/kubevirt/kubevirt/issues/438)
Initial support for memory and cpu mapping (@MarSik) (https://github.com/kubevirt/kubevirt/pull/388)
Discussing VM persistence and ABI stability (https://groups.google.com/d/topic/kubevirt-dev/G0FpxJYFhf4/discussion)
Take a look at the pulse, to get an overview over all changes of this week: https://github.com/kubevirt/kubevirt/pulse
Finally you can view our open issues at https://github.com/kubevirt/kubevirt/issues
And keep track of events at our calendar https://calendar.google.com/[email protected]
If you need some help or want to chat you can find us on irc://irc.freenode.net/#kubevirt
0 notes
Text
This Week in KubeVirt #1
This is the first weekly update from the KubeVirt team.
We are currently driven by
Being easier to consume on Kubernetes and OpenShift
This week we achieved to
merge a design for cloud-init support (https://github.com/kubevirt/kubevirt/pull/372)
release KubeVirt v0.0.2 (https://github.com/kubevirt/kubevirt/releases/tag/v0.0.2)
Minikube based demo (https://github.com/kubevirt/demo)
OpenShift Community presentation (https://www.youtube.com/watch?v=IfuL2rYhMKY)
In addition to this, we are also working on:
Support stock Kubernetes networking (https://github.com/kubevirt/kubevirt/issues/261)
Move to a custom API Server suitable for API Server aggregation (https://github.com/kubevirt/kubevirt/issues/205)
Writing a user facing getting started guide (https://github.com/kubevirt/kubevirt/issues/410)
Ansible playbooks for deployment on OpenShift
Take a look at the pulse, to get an overview over all changes of this week: https://github.com/kubevirt/kubevirt/pulse
Finally you can view our open issues at https://github.com/kubevirt/kubevirt/issues
If you need some help or want to chat you can find us on irc://irc.freenode.net/#kubevirt.
0 notes
Text
That thing that makes KubeVirt a little different - or the Kubernetes virtualization API.
An unsual but persistent part in the KubeVirt development is the following question:
How does KubeVirt compare to virtlet, runv/hyper, oci-cc-runtime/ClearContainers, RancherVM, and alike?
It's a good question. And it actually took a while to get a clear view on this.
To get this clear view, I'll focus on two details:
KubeVirt is not a container runtime, and thus not using the CRI. The VM runtime (libvirt) is provided in a pod instead.
KubeVirt provides a dedicated API for VMs
Especially the first point is raised pretty often. The reason for this is - eventually - that it looks so obvious to just launch VMs instead of containers on the kubelet side - virtlet, runv, and oci-cc-runtime show that it really is an option (without going to much into the details here). Very often this is directly coupled to the question of why we ship our runtime in a pod.
The answer is simply that so far this setup "works":
we can spawn VMs
our runtime is Kubernetes native
because everything lives in pods, we can be delivered to "any" Kubernetes cluster, without messing with the host or kubelet.
We can be a native Kubernetes add-on.
Btw - A nice side effect is that VMs become just a workload - and this is a good separation of concerns and responsibility. Kubernetes owns the platform, and we provide our application to run specialized (virtual machine) processes on this platform.
But even with these benefits: There are some details (i.e. how to get VMs into ressource groups of other pods) which are a little nasty to solve for us, which might be easier to solve in the CRI based approach.
And we see - we are a few lines into the post, and the discussion is going down the winding road of seeing which runtime approach is the best.
That's how it often goes, but that's not where I want to right now.
KubeVirt is not only a runtime. KubeVirt also has an explicit API for virtualization. Initially we used TPRs, then as Kubernetes extension capabilities evolved we went over to CRDs, and are now working on our own User API Server to be used with API Server aggregation. Regardless of this history - The important bit is that we have an explicit API dedicated to virtualization.
And this - in retrospective (and forward facing) - is the significant difference.
The explicit virtualization related API - which consists of new top level types for different things in the virtualization area (like VMS) - gives us the freedom to express all the functionality we need to provide a robust, solid, and stable virtualization platform.
The other approaches (except for RancherVM) have a different view here: They re-use (intentionally and with different motivations) the existing pod specification, to derive VMs from them. But this approach comes to it's limits as soon as virtualization specific functionality (for example live migration) is needed. For those features pod's don't have an API, and annotations or other workarounds need to be used to "logically extend" the pod concept, to enable this missing (virtualization) functionality.
I'm not saying that the one way or the other is technically wrong. It's just that both approaches might just be addressig different goals. I.e. oci-cc-runtime has clearly the goal of using VMs for isolation purpose only - So far it does not look as if they want to expose them as "fully fledged VMs".
And to close the loop: The API is pretty independent of the runtime, and this tells me that in the end it is not that important how the VMs are run - with a runtime in a pod or via a CRI based runtime. The important bit is, that with KubeVirt the user is given the full controll over his VMs.
Side note - Instead of a dedicated API, there is also the option to extend the pod specification using annotations to cover the virtualization specific properties. The issue is, that this does not scale, and will bloat the pod specification.
Thus, the next time you are encountering this topic, you might want to think of KubeVirt as the Kubernetes virtualization API.
2 notes
·
View notes
Text
KubeVirt at FrOSCon 2017
There was also a small talk at FrOSCON (Hello Sunday morning!), the recordings are now published as well.
1 note
·
View note
Video
youtube
We had the opportunity to present KubeVirt at the regular OpenShift Commons Briefing. Even if KubeVirt does not yet run on OpenShift, we are still aiming for it - and Adam actually made good progress in the past week.
This session also included the new minikube based demo.
1 note
·
View note
Text
GPG signed git commits and tags for fancy GitHub integration
Fancy things are a driving factor.
Thus recently GitHub drove me to add gpg signatures to (first) tags and now to commits in general.
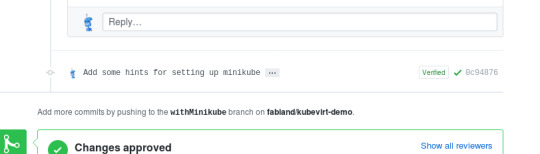
The reasons is that those tags and commits stick out by getting a verified tag. You can see the small greenish box with "Verified" on the right hand side:
You need a couple of things to get there:
Make sure to install dnf install gnupg2 on Fedora.
A GPG key
Associating your email with the key
Uploaded GPG key in GitHub
Configure (gpg-agent) and git to sign your commits
All of this is nicely documented at GitHub - kudos for this documentation.
Once the basics are setup, you can use this for signing commits and tags.
For tags I went a little step further and looked into git-evtag which is using a stronger hash and also recursing over submodules. The primary reason for this was to allow using the git tree as a primary artefact for code delivery. Which is appropriate sometimes, but not always.
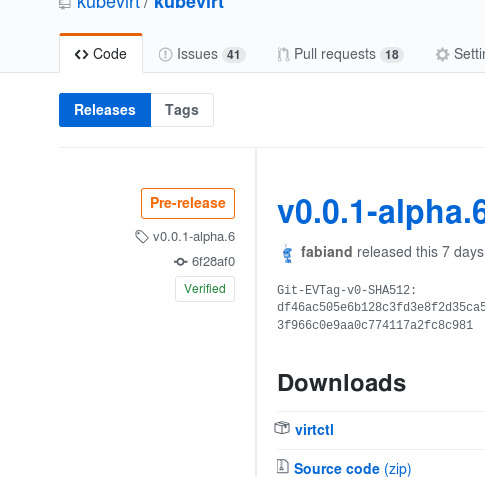
And with all of this, you also get the fancy verified labels on release, as here:
1 note
·
View note