#Best PySpark training
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
The “We are the 99%” Tumblr blog became the slogan for the Occupy Wall Street movement.
Text

Why Learning PySpark Inside Databricks is the Smartest Career Move You Can Make
Master PySpark inside Databricks the must-have skill for cloud data careers. Learn how to start, grow, and certify with AccentFuture's expert training.
#PySpark in Databricks#Databricks training#PySpark course#Learn PySpark online#Databricks certification#PySpark for data engineers#Best PySpark training#PySpark online training#Databricks PySpark tutorial.
0 notes
Text
How to Read and Write Data in PySpark
The Python application programming interface known as PySpark serves as the front end for Apache Spark execution of big data operations. The most crucial skill required for PySpark work involves accessing and writing data from sources which include CSV, JSON and Parquet files.
In this blog, you’ll learn how to:
Initialize a Spark session
Read data from various formats
Write data to different formats
See expected outputs for each operation
Let’s dive in step-by-step.
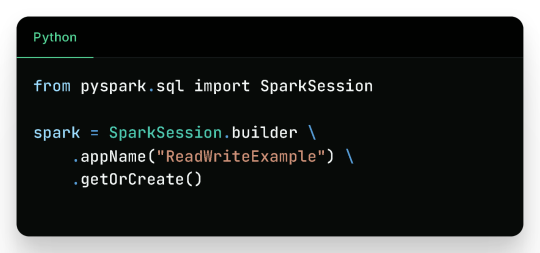
Getting Started
Before reading or writing, start by initializing a SparkSession.
Reading Data in PySpark
1. Reading CSV Files
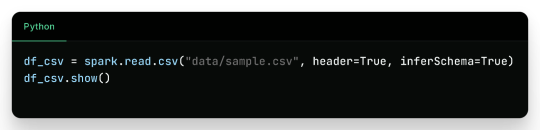
Sample CSV Data (sample.csv):

Output:

2. Reading JSON Files
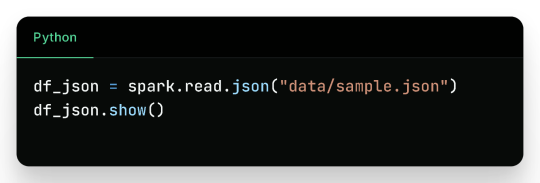
Sample JSON (sample.json):

Output:

3. Reading Parquet Files
Parquet is optimized for performance and often used in big data pipelines.

Assuming the parquet file has similar content:
Output:
4. Reading from a Database (JDBC)

Sample Table employees in MySQL:

Output:

Writing Data in PySpark
1. Writing to CSV
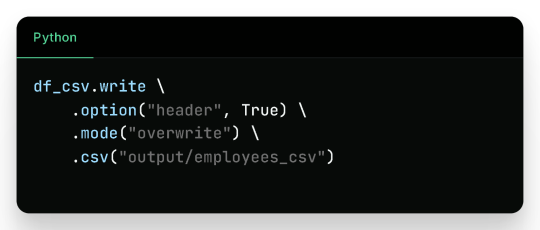
Output Files (folder output/employees_csv/):

Sample content:

2. Writing to JSON

Sample JSON output (employees_json/part-*.json):
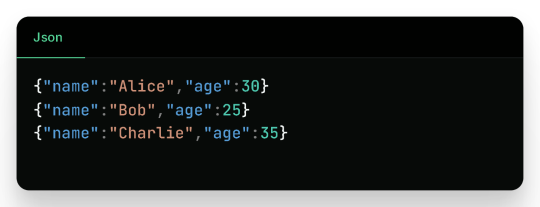
3. Writing to Parquet
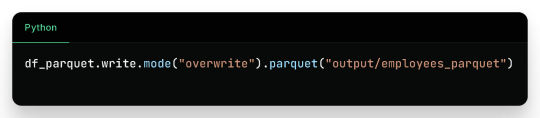
Output:
Binary Parquet files saved inside output/employees_parquet/
You can verify the contents by reading it again:
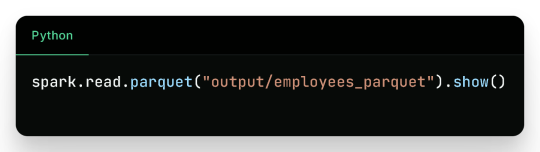
4. Writing to a Database
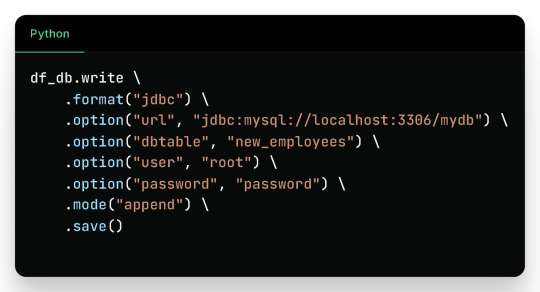
Check the new_employees table in your database — it should now include all the records.
Write Modes in PySpark
Mode
Description
overwrite
Overwrites existing data
append
Appends to existing data
ignore
Ignores if the output already exists
error
(default) Fails if data exists
Real-Life Use Case
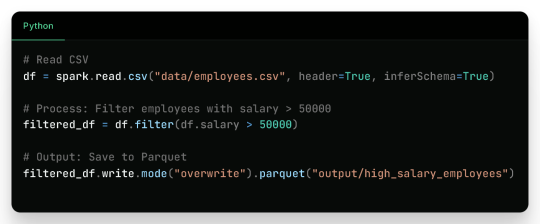
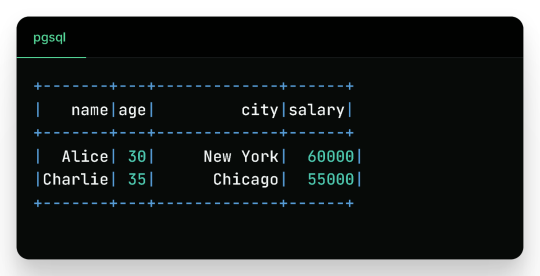
Filtered Output:
Wrap-Up
Reading and writing data in PySpark is efficient, scalable, and easy once you understand the syntax and options. This blog covered:
Reading from CSV, JSON, Parquet, and JDBC
Writing to CSV, JSON, Parquet, and back to Databases
Example outputs for every format
Best practices for production use
Keep experimenting and building real-world data pipelines — and you’ll be a PySpark pro in no time!
🚀Enroll Now: https://www.accentfuture.com/enquiry-form/
📞Call Us: +91-9640001789
📧Email Us: [email protected]
🌍Visit Us: AccentFuture
#apache pyspark training#best pyspark course#best pyspark training#pyspark course online#pyspark online classes#pyspark training#pyspark training online
0 notes
Text

💻 Online Hands-on apache spark Training by Industry Experts | Powered by Sunbeam Institute
🎯 Why Learn Apache Spark with PySpark? ✔ Process huge datasets faster using in-memory computation ✔ Learn scalable data pipelines with real-time streaming ✔ Work with DataFrames, SQL, MLlib, Kafka & Databricks ✔ In-demand skill for Data Engineers, Analysts & Cloud Developers ✔ Boost your resume with project experience & certification readiness
📘 What You'll Master in This Course: ✅ PySpark Fundamentals – RDDs, Lazy Evaluation, Spark Context ✅ Spark SQL & DataFrames – Data handling & transformation ✅ Structured Streaming – Real-time data processing in action ✅ Architecture & Optimization – DAG, Shuffle, Partitioning ✅ Apache Kafka Integration – Connect Spark with Kafka Streams ✅ Databricks Lakehouse Essentials – Unified data analytics platform ✅ Machine Learning with Spark MLlib – Intro to scalable ML workflows ✅ Capstone Project – Apply skills in a real-world data project ✅ Hands-on Labs – With guidance from industry-experienced trainers
📌 Course Benefits: ✔ Learn from experienced mentors with practical exposure ✔ Become job-ready for roles like Data Engineer, Big Data Developer ✔ Build real-world confidence with hands-on implementation ✔ Flexible online format – learn from anywhere ✔ Certification-ready training to boost your profile
🧠 Who Should Join? 🔹 Working professionals in Python, SQL, BI, ETL 🔹 Data Science or Big Data enthusiasts 🔹 Freshers with basic coding knowledge looking to upskill 🔹 Anyone aspiring to work in real-time data & analytics
#Apache Spark Course#PySpark Training#Data Engineering Classes#Big Data Online Course#Kafka & Spark Integration#Databricks Lakehouse#Spark Mllib#Best PySpark Course India#Real-time Streaming Course#Sunbeam PySpark Training
0 notes
Text
Data engineer training and placement in Pune - JVM Institute
Kickstart your career with JVM Institute's top-notch Data Engineer Training in Pune. Expert-led courses, hands-on projects, and guaranteed placement support to transform your future!
#Best Data engineer training and placement in Pune#JVM institute in Pune#Data Engineering Classes Pune#Advanced Data Engineering Training Pune#Data engineer training and placement in Pune#Big Data courses in Pune#PySpark Courses in Pune
0 notes
Text
From Beginner to Pro: The Best PySpark Courses Online from ScholarNest Technologies

Are you ready to embark on a journey from a PySpark novice to a seasoned pro? Look no further! ScholarNest Technologies brings you a comprehensive array of PySpark courses designed to cater to every skill level. Let's delve into the key aspects that make these courses stand out:
1. What is PySpark?
Gain a fundamental understanding of PySpark, the powerful Python library for Apache Spark. Uncover the architecture and explore its diverse applications in the world of big data.
2. Learning PySpark by Example:
Experience is the best teacher! Our courses focus on hands-on examples, allowing you to apply your theoretical knowledge to real-world scenarios. Learn by doing and enhance your problem-solving skills.
3. PySpark Certification:
Elevate your career with our PySpark certification programs. Validate your expertise and showcase your proficiency in handling big data tasks using PySpark.
4. Structured Learning Paths:
Whether you're a beginner or seeking advanced concepts, our courses offer structured learning paths. Progress at your own pace, mastering each skill before moving on to the next level.
5. Specialization in Big Data Engineering:
Our certification course on big data engineering with PySpark provides in-depth insights into the intricacies of handling vast datasets. Acquire the skills needed for a successful career in big data.
6. Integration with Databricks:
Explore the integration of PySpark with Databricks, a cloud-based big data platform. Understand how these technologies synergize to provide scalable and efficient solutions.
7. Expert Instruction:
Learn from the best! Our courses are crafted by top-rated data science instructors, ensuring that you receive expert guidance throughout your learning journey.
8. Online Convenience:
Enroll in our online PySpark courses and access a wealth of knowledge from the comfort of your home. Flexible schedules and convenient online platforms make learning a breeze.
Whether you're a data science enthusiast, a budding analyst, or an experienced professional looking to upskill, ScholarNest's PySpark courses offer a pathway to success. Master the skills, earn certifications, and unlock new opportunities in the world of big data engineering!
#big data#data engineering#data engineering certification#data engineering course#databricks data engineer certification#pyspark course#databricks courses online#best pyspark course online#pyspark online course#databricks learning#data engineering courses in bangalore#data engineering courses in india#azure databricks learning#pyspark training course#pyspark certification course
1 note
·
View note
Text
The Microsoft Fabric DP-700: Fabric Data Engineer Associate course is a live, instructor-led online program designed to thoroughly prepare you for the official DP-700 exam. This training spans approximately 4 to 4.5 weeks and consists of weekend classes. It offers 24/7 support, lifetime access to updated content, and hands-on projects, including lakehouse creation, real-time pipelines with Event Streams, Delta Lake management, and CI/CD pipelines.
The Microsoft Fabric Training Online curriculum is aligned with Microsoft’s certification objectives and covers essential topics such as workspace setup, data ingestion, transformation, security, monitoring, and performance tuning within Microsoft Fabric. Participants will also learn SQL, PySpark, Kusto Query Language (KQL), Azure integration, and best practices for data governance and optimization.
With over 15,000 learners and strong 4.5-star reviews, the program combines expert-led sessions, real-world labs, mock exams, and certification guidance to help students acquire practical skills and the credentials needed for roles such as Fabric Data Engineer or AI-powered data specialist.
1 note
·
View note
Text
Data Science Tutorial for 2025: Tools, Trends, and Techniques
Data science continues to be one of the most dynamic and high-impact fields in technology, with new tools and methodologies evolving rapidly. As we enter 2025, data science is more than just crunching numbers—it's about building intelligent systems, automating decision-making, and unlocking insights from complex data at scale.
Whether you're a beginner or a working professional looking to sharpen your skills, this tutorial will guide you through the essential tools, the latest trends, and the most effective techniques shaping data science in 2025.
What is Data Science?
At its core, data science is the interdisciplinary field that combines statistics, computer science, and domain expertise to extract meaningful insights from structured and unstructured data. It involves collecting data, cleaning and processing it, analyzing patterns, and building predictive or explanatory models.
Data scientists are problem-solvers, storytellers, and innovators. Their work influences business strategies, public policy, healthcare solutions, and even climate models.

Essential Tools for Data Science in 2025
The data science toolkit has matured significantly, with tools becoming more powerful, user-friendly, and integrated with AI. Here are the must-know tools for 2025:
1. Python 3.12+
Python remains the most widely used language in data science due to its simplicity and vast ecosystem. In 2025, the latest Python versions offer faster performance and better support for concurrency—making large-scale data operations smoother.
Popular Libraries:
Pandas: For data manipulation
NumPy: For numerical computing
Matplotlib / Seaborn / Plotly: For data visualization
Scikit-learn: For traditional machine learning
XGBoost / LightGBM: For gradient boosting models
2. JupyterLab
The evolution of the classic Jupyter Notebook, JupyterLab, is now the default environment for exploratory data analysis, allowing a modular, tabbed interface with support for terminals, text editors, and rich output.
3. Apache Spark with PySpark
Handling massive datasets? PySpark—Python’s interface to Apache Spark—is ideal for distributed data processing across clusters, now deeply integrated with cloud platforms like Databricks and Snowflake.
4. Cloud Platforms (AWS, Azure, Google Cloud)
In 2025, most data science workloads run on the cloud. Services like Amazon SageMaker, Azure Machine Learning, and Google Vertex AI simplify model training, deployment, and monitoring.
5. AutoML & No-Code Tools
Tools like DataRobot, Google AutoML, and H2O.ai now offer drag-and-drop model building and optimization. These are powerful for non-coders and help accelerate workflows for pros.
Top Data Science Trends in 2025
1. Generative AI for Data Science
With the rise of large language models (LLMs), generative AI now assists data scientists in code generation, data exploration, and feature engineering. Tools like OpenAI's ChatGPT for Code and GitHub Copilot help automate repetitive tasks.
2. Data-Centric AI
Rather than obsessing over model architecture, 2025’s best practices focus on improving the quality of data—through labeling, augmentation, and domain understanding. Clean data beats complex models.
3. MLOps Maturity
MLOps—machine learning operations—is no longer optional. In 2025, companies treat ML models like software, with versioning, monitoring, CI/CD pipelines, and reproducibility built-in from the start.
4. Explainable AI (XAI)
As AI impacts sensitive areas like finance and healthcare, transparency is crucial. Tools like SHAP, LIME, and InterpretML help data scientists explain model predictions to stakeholders and regulators.
5. Edge Data Science
With IoT devices and on-device AI becoming the norm, edge computing allows models to run in real-time on smartphones, sensors, and drones—opening new use cases from agriculture to autonomous vehicles.
Core Techniques Every Data Scientist Should Know in 2025
Whether you’re starting out or upskilling, mastering these foundational techniques is critical:
1. Data Wrangling
Before any analysis begins, data must be cleaned and reshaped. Techniques include:
Handling missing values
Normalization and standardization
Encoding categorical variables
Time series transformation
2. Exploratory Data Analysis (EDA)
EDA is about understanding your dataset through visualization and summary statistics. Use histograms, scatter plots, correlation heatmaps, and boxplots to uncover trends and outliers.
3. Machine Learning Basics
Classification (e.g., predicting if a customer will churn)
Regression (e.g., predicting house prices)
Clustering (e.g., customer segmentation)
Dimensionality Reduction (e.g., PCA, t-SNE for visualization)
4. Deep Learning (Optional but Useful)
If you're working with images, text, or audio, deep learning with TensorFlow, PyTorch, or Keras can be invaluable. Hugging Face’s transformers make it easier than ever to work with large models.
5. Model Evaluation
Learn how to assess model performance with:
Accuracy, Precision, Recall, F1 Score
ROC-AUC Curve
Cross-validation
Confusion Matrix
Final Thoughts
As we move deeper into 2025, data science tutorial continues to be an exciting blend of math, coding, and real-world impact. Whether you're analyzing customer behavior, improving healthcare diagnostics, or predicting financial markets, your toolkit and mindset will be your most valuable assets.
Start by learning the fundamentals, keep experimenting with new tools, and stay updated with emerging trends. The best data scientists aren’t just great with code—they’re lifelong learners who turn data into decisions.
0 notes
Text
Lakehouse Architecture Best Practices: A Unified Data Future with AccentFuture
In the evolving landscape of data engineering, Lakehouse Architecture is emerging as a powerful paradigm that combines the best of data lakes and data warehouses. As businesses demand faster insights and real-time analytics across massive datasets, the Lakehouse model has become indispensable. At AccentFuture, our advanced courses empower learners with real-world skills in modern data architectures like the Lakehouse preparing them for the data-driven jobs of tomorrow.
What is Lakehouse Architecture?
Lakehouse Architecture is a modern data platform that merges the low-cost, scalable storage of a data lake with the structured data management and performance features of a data warehouse. It enables support for data science, machine learning, and BI workloads all within a single platform.
With engines like Apache Spark and platforms like Databricks, the Lakehouse allows for seamless unification of batch and streaming data, structured and unstructured formats, and analytics and ML workflows.

Top Best Practices for Implementing a Lakehouse Architecture
1. Start with a Clear Data Governance Strategy
Before jumping into implementation, define clear data governance policies. This includes data access control, lineage tracking, and auditability. Utilize tools like Unity Catalog in Databricks or Apache Ranger to set up granular access control across different data personas—engineers, analysts, scientists, and business users.
Tip from AccentFuture: We guide our learners on implementing end-to-end governance using real-world case studies and tools integrated with Spark and Azure.
2. Use Open Data Formats (Delta Lake, Apache Iceberg, Hudi)
Always build your Lakehouse on open table formats like Delta Lake, Apache Iceberg, or Apache Hudi. These formats support ACID transactions, schema evolution, time travel, and fast reads/writes—making your data lake reliable for production workloads.
Delta Lake, for example, enables versioning and rollback of data, making it perfect for enterprise-grade data processing.
3. Optimize Storage with Partitioning and Compaction
Efficient storage design is critical for performance. Apply best practices like:
Partitioning data based on high-cardinality columns (e.g., date, region).
Z-Ordering or clustering to optimize read performance.
Compaction to merge small files into larger ones to reduce I/O overhead.
At AccentFuture, our Databricks & PySpark Training includes labs that teach how to optimize partitioning strategies with Delta Lake.
4. Implement a Medallion Architecture (Bronze, Silver, Gold Layers)
Adopt the Medallion Architecture to organize your data pipeline efficiently:
Bronze Layer: Raw ingested data (logs, streams, JSON, CSV, etc.)
Silver Layer: Cleaned, structured data (joins, filtering, type casting).
Gold Layer: Business-level aggregates and KPIs for reporting and dashboards.
This tiered approach helps isolate data quality issues, simplifies debugging, and enhances performance for end-users.
5. Use Data Lineage and Metadata Tracking
Visibility is key. Implement metadata tracking tools like:
Data Catalogs (Unity Catalog, AWS Glue Data Catalog)
Lineage Tracking tools (OpenLineage, Amundsen)
These tools help teams understand where data came from, how it was transformed, and who accessed it—ensuring transparency and reproducibility.
6. Embrace Automation with CI/CD Pipelines
Use CI/CD pipelines (GitHub Actions, Azure DevOps, or Databricks Repos) to automate:
Data ingestion workflows
ETL pipeline deployments
Testing and validation
Automation reduces manual errors, enhances collaboration, and ensures version control across teams.
AccentFuture’s project-based training introduces learners to modern CI/CD practices for data engineering workflows.
7. Integrate Real-Time and Batch Processing
Lakehouse supports both streaming and batch data processing. Tools like Apache Spark Structured Streaming and Apache Kafka can be integrated for real-time data ingestion. Use triggers and watermarking to handle late-arriving data efficiently.
8. Monitor, Audit, and Optimize Continuously
A Lakehouse is never “complete.” Continuously monitor:
Query performance (using Databricks Query Profile or Spark UI)
Storage usage and costs
Data pipeline failures and SLAs
Audit data access and transformations to ensure compliance with internal and external regulations.

Why Learn Lakehouse Architecture at AccentFuture?
At AccentFuture, we don’t just teach theory we bring real-world Lakehouse use cases into the classroom. Our Databricks + PySpark online courses are crafted by industry experts, covering everything from Delta Lake to real-time pipelines using Kafka and Airflow.
What You Get:
✅ Hands-on Projects ✅ Industry Interview Preparation ✅ Lifetime Access to Materials ✅ Certification Aligned with Market Demand ✅ Access to Mentorship & Career Support
Conclusion
Lakehouse Architecture is not just a trend—it’s the future of data engineering. By combining reliability, scalability, and flexibility in one unified platform, it empowers organizations to extract deeper insights from their data. Implementing best practices is key to harnessing its full potential.
Whether you're a budding data engineer, a seasoned analyst, or a business professional looking to upskill, AccentFuture’s Lakehouse-focused curriculum will help you lead the charge in the next wave of data innovation.
Ready to transform your data skills? 📚 Enroll in our Lakehouse & PySpark Training today at www.accentfuture.com
Related Articles :-
Databricks Certified Data Engineer Professional Exam
Ignore PySpark, Regret Later: Databricks Skill That Pays Off
Databricks Interview Questions for Data Engineers
Stream-Stream Joins with Watermarks in Databricks Using Apache Spark
💡 Ready to Make Every Compute Count?
📓 Enroll now: https://www.accentfuture.com/enquiry-form/
📧 Email: [email protected]
📞 Call: +91–9640001789
🌐 Visit: www.accentfuture.com
0 notes
Text
Optimizing GPU Costs for Machine Learning on AWS: Anton R Gordon’s Best Practices

As machine learning (ML) models grow in complexity, GPU acceleration has become essential for training deep learning models efficiently. However, high-performance GPUs come at a cost, and without proper optimization, expenses can quickly spiral out of control.
Anton R Gordon, an AI Architect and Cloud Specialist, has developed a strategic framework to optimize GPU costs on AWS while maintaining model performance. In this article, we explore his best practices for reducing GPU expenses without compromising efficiency.
Understanding GPU Costs in Machine Learning
GPUs play a crucial role in training large-scale ML models, particularly for deep learning frameworks like TensorFlow, PyTorch, and JAX. However, on-demand GPU instances on AWS can be expensive, especially when running multiple training jobs over extended periods.
Factors Affecting GPU Costs on AWS
Instance Type Selection – Choosing the wrong GPU instance can lead to wasted resources.
Idle GPU Utilization – Paying for GPUs that remain idle results in unnecessary costs.
Storage and Data Transfer – Storing large datasets inefficiently can add hidden expenses.
Inefficient Hyperparameter Tuning – Running suboptimal experiments increases compute time.
Long Training Cycles – Extended training times lead to higher cloud bills.
To optimize GPU spending, Anton R Gordon recommends strategic cost-cutting techniques that still allow teams to leverage AWS’s powerful infrastructure for ML workloads.
Anton R Gordon’s Best Practices for Reducing GPU Costs
1. Selecting the Right GPU Instance Types
AWS offers multiple GPU instances tailored for different workloads. Anton emphasizes the importance of choosing the right instance type based on model complexity and compute needs.
✔ Best Practice:
Use Amazon EC2 P4/P5 Instances for training large-scale deep learning models.
Leverage G5 instances for inference workloads, as they provide a balance of performance and cost.
Opt for Inferentia-based Inf1 instances for low-cost deep learning inference at scale.
“Not all GPU instances are created equal. Choosing the right type ensures cost efficiency without sacrificing performance.” – Anton R Gordon.
2. Leveraging AWS Spot Instances for Non-Critical Workloads
AWS Spot Instances offer up to 90% cost savings compared to On-Demand instances. Anton recommends using them for non-urgent ML training jobs.
✔ Best Practice:
Run batch training jobs on Spot Instances using Amazon SageMaker Managed Spot Training.
Implement checkpointing mechanisms to avoid losing progress if Spot capacity is interrupted.
Use Amazon EC2 Auto Scaling to automatically manage GPU availability.
3. Using Mixed Precision Training for Faster Model Convergence
Mixed precision training, which combines FP16 (half-precision) and FP32 (full-precision) computation, accelerates training while reducing GPU memory usage.
✔ Best Practice:
Enable Automatic Mixed Precision (AMP) in TensorFlow, PyTorch, or MXNet.
Reduce memory consumption, allowing larger batch sizes for improved training efficiency.
Lower compute time, leading to faster convergence and reduced GPU costs.
“With mixed precision training, models can train faster and at a fraction of the cost.” – Anton R Gordon.
4. Optimizing Data Pipelines for Efficient GPU Utilization
Poor data loading pipelines can create bottlenecks, causing GPUs to sit idle while waiting for data. Anton emphasizes the need for optimized data pipelines.
✔ Best Practice:
Use Amazon FSx for Lustre to accelerate data access.
Preprocess and cache datasets using Amazon S3 and AWS Data Wrangler.
Implement data parallelism with Dask or PySpark for distributed training.
5. Implementing Auto-Scaling for GPU Workloads
To avoid over-provisioning GPU resources, Anton suggests auto-scaling GPU instances to match workload demands.
✔ Best Practice:
Use AWS Auto Scaling to add or remove GPU instances based on real-time demand.
Utilize SageMaker Multi-Model Endpoint (MME) to run multiple models on fewer GPUs.
Implement Lambda + SageMaker hybrid architectures to use GPUs only when needed.
6. Automating Hyperparameter Tuning with SageMaker
Inefficient hyperparameter tuning leads to excessive GPU usage. Anton recommends automated tuning techniques to optimize model performance with minimal compute overhead.
✔ Best Practice:
Use Amazon SageMaker Hyperparameter Optimization (HPO) to automatically find the best configurations.
Leverage Bayesian optimization and reinforcement learning to minimize trial-and-error runs.
Implement early stopping to halt training when improvement plateaus.
“Automating hyperparameter tuning helps avoid costly brute-force searches for the best model configuration.” – Anton R Gordon.
7. Deploying Models Efficiently with AWS Inferentia
Inference workloads can become cost-prohibitive if GPU instances are used inefficiently. Anton recommends offloading inference to AWS Inferential (Inf1) instances for better price performance.
✔ Best Practice:
Deploy optimized TensorFlow and PyTorch models on AWS Inferentia.
Reduce inference latency while lowering costs by up to 50% compared to GPU-based inference.
Use Amazon SageMaker Neo to optimize models for Inferentia-based inference.
Case Study: Reducing GPU Costs by 60% for an AI Startup
Anton R Gordon successfully implemented these cost-cutting techniques for an AI-driven computer vision startup. The company initially used On-Demand GPU instances for training, leading to unsustainable cloud expenses.
✔ Optimization Strategy:
Switched from On-Demand P3 instances to Spot P4 instances for training.
Enabled mixed precision training, reducing training time by 40%.
Moved inference workloads to AWS Inferentia, cutting costs by 50%.
✔ Results:
60% reduction in overall GPU costs.
Faster model training and deployment with improved scalability.
Increased cost efficiency without sacrificing model accuracy.
Conclusion
GPU optimization is critical for any ML team operating at scale. By following Anton R Gordon’s best practices, organizations can:
✅ Select cost-effective GPU instances for training and inference.
✅ Use Spot Instances to reduce GPU expenses by up to 90%.
✅ Implement mixed precision training for faster model convergence.
✅ Optimize data pipelines and hyperparameter tuning for efficient compute usage.
✅ Deploy models efficiently using AWS Inferentia for cost savings.
“Optimizing GPU costs isn’t just about saving money—it’s about building scalable, efficient ML workflows that deliver business value.” – Anton R Gordon.
By implementing these strategies, companies can reduce their cloud bills, enhance ML efficiency, and maximize ROI on AWS infrastructure.
0 notes
Text
How to Integrate Hadoop with Machine Learning & AI
Introduction
With the explosion of big data, businesses are leveraging Machine Learning (ML) and Artificial Intelligence (AI) to gain insights and improve decision-making. However, handling massive datasets efficiently requires a scalable storage and processing solution—this is where Apache Hadoop comes in. By integrating Hadoop with ML and AI, organizations can build powerful data-driven applications. This blog explores how Hadoop enables ML and AI workflows and the best practices for seamless integration.
1. Understanding Hadoop’s Role in Big Data Processing
Hadoop is an open-source framework designed to store and process large-scale datasets across distributed clusters. It consists of:
HDFS (Hadoop Distributed File System): A scalable storage system for big data.
MapReduce: A parallel computing model for processing large datasets.
YARN (Yet Another Resource Negotiator): Manages computing resources across clusters.
Apache Hive, HBase, and Pig: Tools for data querying and management.
Why Use Hadoop for ML & AI?
Scalability: Handles petabytes of data across multiple nodes.
Fault Tolerance: Ensures data availability even in case of failures.
Cost-Effectiveness: Open-source and works on commodity hardware.
Parallel Processing: Speeds up model training and data processing.
2. Integrating Hadoop with Machine Learning & AI
To build AI/ML applications on Hadoop, various integration techniques and tools can be used:
(a) Using Apache Mahout
Apache Mahout is an ML library that runs on top of Hadoop.
It supports classification, clustering, and recommendation algorithms.
Works with MapReduce and Apache Spark for distributed computing.
(b) Hadoop and Apache Spark for ML
Apache Spark’s MLlib is a powerful machine learning library that integrates with Hadoop.
Spark processes data 100x faster than MapReduce, making it ideal for ML workloads.
Supports supervised & unsupervised learning, deep learning, and NLP applications.
(c) Hadoop with TensorFlow & Deep Learning
Hadoop can store large-scale training datasets for TensorFlow and PyTorch.
HDFS and Apache Kafka help in feeding data to deep learning models.
Can be used for image recognition, speech processing, and predictive analytics.
(d) Hadoop with Python and Scikit-Learn
PySpark (Spark’s Python API) enables ML model training on Hadoop clusters.
Scikit-Learn, TensorFlow, and Keras can fetch data directly from HDFS.
Useful for real-time ML applications such as fraud detection and customer segmentation.
3. Steps to Implement Machine Learning on Hadoop
Step 1: Data Collection and Storage
Store large datasets in HDFS or Apache HBase.
Use Apache Flume or Kafka for streaming real-time data.
Step 2: Data Preprocessing
Use Apache Pig or Spark SQL to clean and transform raw data.
Convert unstructured data into a structured format for ML models.
Step 3: Model Training
Choose an ML framework: Mahout, MLlib, or TensorFlow.
Train models using distributed computing with Spark MLlib or MapReduce.
Optimize hyperparameters and improve accuracy using parallel processing.
Step 4: Model Deployment and Predictions
Deploy trained models on Hadoop clusters or cloud-based platforms.
Use Apache Kafka and HDFS to feed real-time data for predictions.
Automate ML workflows using Oozie and Airflow.
4. Real-World Applications of Hadoop & AI Integration
1. Predictive Analytics in Finance
Banks use Hadoop-powered ML models to detect fraud and analyze risk.
Credit scoring and loan approval use HDFS-stored financial data.
2. Healthcare and Medical Research
AI-driven diagnostics process millions of medical records stored in Hadoop.
Drug discovery models train on massive biomedical datasets.
3. E-Commerce and Recommendation Systems
Hadoop enables large-scale customer behavior analysis.
AI models generate real-time product recommendations using Spark MLlib.
4. Cybersecurity and Threat Detection
Hadoop stores network logs and threat intelligence data.
AI models detect anomalies and prevent cyber attacks.
5. Smart Cities and IoT
Hadoop stores IoT sensor data from traffic systems, energy grids, and weather sensors.
AI models analyze patterns for predictive maintenance and smart automation.
5. Best Practices for Hadoop & AI Integration
Use Apache Spark: For faster ML model training instead of MapReduce.
Optimize Storage: Store processed data in Parquet or ORC formats for efficiency.
Enable GPU Acceleration: Use TensorFlow with GPU-enabled Hadoop clusters for deep learning.
Monitor Performance: Use Apache Ambari or Cloudera Manager for cluster performance monitoring.
Security & Compliance: Implement Kerberos authentication and encryption to secure sensitive data.
Conclusion
Integrating Hadoop with Machine Learning and AI enables businesses to process vast amounts of data efficiently, train advanced models, and deploy AI solutions at scale. With Apache Spark, Mahout, TensorFlow, and PyTorch, organizations can unlock the full potential of big data and artificial intelligence.
As technology evolves, Hadoop’s role in AI-driven data processing will continue to grow, making it a critical tool for enterprises worldwide.
Want to Learn Hadoop?
If you're looking to master Hadoop and AI, check out Hadoop Online Training or contact Intellimindz for expert guidance.
Would you like any refinements or additional details? 🚀
0 notes
Text
PySpark Courses in Pune - JVM Institute
In today’s dynamic landscape, data reigns supreme, reshaping businesses across industries. Those embracing Data Engineering technologies are gaining a competitive edge by amalgamating raw data with advanced algorithms. Master PySpark with expert-led courses at JVM Institute in Pune. Learn big data processing, real-time analytics, and more. Join now to boost your career!
#Best Data engineer training and placement in Pune#JVM institute in Pune#Data Engineering Classes Pune#Advanced Data Engineering Training Pune#PySpark Courses in Pune#PySpark Courses in PCMC#Pune
0 notes
Text
Transform Your Team into Data Engineering Pros with ScholarNest Technologies

In the fast-evolving landscape of data engineering, the ability to transform your team into proficient professionals is a strategic imperative. ScholarNest Technologies stands at the forefront of this transformation, offering comprehensive programs that equip individuals with the skills and certifications necessary to excel in the dynamic field of data engineering. Let's delve into the world of data engineering excellence and understand how ScholarNest is shaping the data engineers of tomorrow.
Empowering Through Education: The Essence of Data Engineering
Data engineering is the backbone of current data-driven enterprises. It involves the collection, processing, and storage of data in a way that facilitates effective analysis and insights. ScholarNest Technologies recognizes the pivotal role data engineering plays in today's technological landscape and has curated a range of courses and certifications to empower individuals in mastering this discipline.
Comprehensive Courses and Certifications: ScholarNest's Commitment to Excellence
1. Data Engineering Courses: ScholarNest offers comprehensive data engineering courses designed to provide a deep understanding of the principles, tools, and technologies essential for effective data processing. These courses cover a spectrum of topics, including data modeling, ETL (Extract, Transform, Load) processes, and database management.
2. Pyspark Mastery: Pyspark, a powerful data processing library for Python, is a key component of modern data engineering. ScholarNest's Pyspark courses, including options for beginners and full courses, ensure participants acquire proficiency in leveraging this tool for scalable and efficient data processing.
3. Databricks Learning: Databricks, with its unified analytics platform, is integral to modern data engineering workflows. ScholarNest provides specialized courses on Databricks learning, enabling individuals to harness the full potential of this platform for advanced analytics and data science.
4. Azure Databricks Training: Recognizing the industry shift towards cloud-based solutions, ScholarNest offers courses focused on Azure Databricks. This training equips participants with the skills to leverage Databricks in the Azure cloud environment, ensuring they are well-versed in cutting-edge technologies.
From Novice to Expert: ScholarNest's Approach to Learning
Whether you're a novice looking to learn the fundamentals or an experienced professional seeking advanced certifications, ScholarNest caters to diverse learning needs. Courses such as "Learn Databricks from Scratch" and "Machine Learning with Pyspark" provide a structured pathway for individuals at different stages of their data engineering journey.
Hands-On Learning and Certification: ScholarNest places a strong emphasis on hands-on learning. Courses include practical exercises, real-world projects, and assessments to ensure that participants not only grasp theoretical concepts but also gain practical proficiency. Additionally, certifications such as the Databricks Data Engineer Certification validate the skills acquired during the training.
The ScholarNest Advantage: Shaping Data Engineering Professionals
ScholarNest Technologies goes beyond traditional education paradigms, offering a transformative learning experience that prepares individuals for the challenges and opportunities in the world of data engineering. By providing access to the best Pyspark and Databricks courses online, ScholarNest is committed to fostering a community of skilled data engineering professionals who will drive innovation and excellence in the ever-evolving data landscape. Join ScholarNest on the journey to unlock the full potential of your team in the realm of data engineering.
#big data#big data consulting#data engineering#data engineering course#data engineering certification#databricks data engineer certification#pyspark course#databricks courses online#best pyspark course online#best pyspark course#pyspark online course#databricks learning#data engineering courses in bangalore#data engineering courses in india#azure databricks learning#pyspark training course
1 note
·
View note
Text
https://bitaacademy.com/course/best-pyspark-training-in-chennai/
0 notes
Text
Best Azure Data Engineer Course In Ameerpet | Azure Data
Understanding Delta Lake in Databricks
Introduction
Delta Lake, an open-source storage layer developed by Databricks, is designed to address these challenges. It enhances Apache Spark's capabilities by providing ACID transactions, schema enforcement, and time travel, making data lakes more reliable and efficient. In modern data engineering, managing large volumes of data efficiently while ensuring reliability and performance is a key challenge.

What is Delta Lake?
Delta Lake is an optimized storage layer built on Apache Parquet that brings the reliability of a data warehouse to big data processing. It eliminates the limitations of traditional data lakes by adding ACID transactions, scalable metadata handling, and schema evolution. Delta Lake integrates seamlessly with Azure Databricks, Apache Spark, and other cloud-based data solutions, making it a preferred choice for modern data engineering pipelines. Microsoft Azure Data Engineer
Key Features of Delta Lake
1. ACID Transactions
One of the biggest challenges in traditional data lakes is data inconsistency due to concurrent read/write operations. Delta Lake supports ACID (Atomicity, Consistency, Isolation, Durability) transactions, ensuring reliable data updates without corruption. It uses Optimistic Concurrency Control (OCC) to handle multiple transactions simultaneously.
2. Schema Evolution and Enforcement
Delta Lake enforces schema validation to prevent accidental data corruption. If a schema mismatch occurs, Delta Lake will reject the data, ensuring consistency. Additionally, it supports schema evolution, allowing modifications without affecting existing data.
3. Time Travel and Data Versioning
Delta Lake maintains historical versions of data using log-based versioning. This allows users to perform time travel queries, enabling them to revert to previous states of data. This is particularly useful for auditing, rollback, and debugging purposes. Azure Data Engineer Course
4. Scalable Metadata Handling
Traditional data lakes struggle with metadata scalability, especially when handling billions of files. Delta Lake optimizes metadata storage and retrieval, making queries faster and more efficient.
5. Performance Optimizations (Data Skipping and Caching)
Delta Lake improves query performance through data skipping and caching mechanisms. Data skipping allows queries to read only relevant data instead of scanning the entire dataset, reducing processing time. Caching improves speed by storing frequently accessed data in memory.
6. Unified Batch and Streaming Processing
Delta Lake enables seamless integration of batch and real-time streaming workloads. Structured Streaming in Spark can write and read from Delta tables in real-time, ensuring low-latency updates and enabling use cases such as fraud detection and log analytics.
How Delta Lake Works in Databricks?
Delta Lake is tightly integrated with Azure Databricks and Apache Spark, making it easy to use within data pipelines. Below is a basic workflow of how Delta Lake operates: Azure Data Engineering Certification
Data Ingestion: Data is ingested into Delta tables from multiple sources (Kafka, Event Hubs, Blob Storage, etc.).
Data Processing: Spark SQL and PySpark process the data, applying transformations and aggregations.
Data Storage: Processed data is stored in Delta format with ACID compliance.
Query and Analysis: Users can query Delta tables using SQL or Spark.
Version Control & Time Travel: Previous data versions are accessible for rollback and auditing.
Use Cases of Delta Lake
ETL Pipelines: Ensures data reliability with schema validation and ACID transactions.
Machine Learning: Maintains clean and structured historical data for training ML models. Azure Data Engineer Training
Real-time Analytics: Supports streaming data processing for real-time insights.
Data Governance & Compliance: Enables auditing and rollback for regulatory requirements.
Conclusion
Delta Lake in Databricks bridges the gap between traditional data lakes and modern data warehousing solutions by providing reliability, scalability, and performance improvements. With ACID transactions, schema enforcement, time travel, and optimized query performance, Delta Lake is a powerful tool for building efficient and resilient data pipelines. Its seamless integration with Azure Databricks and Apache Spark makes it a preferred choice for data engineers aiming to create high-performance and scalable data architectures.
Trending Courses: Artificial Intelligence, Azure AI Engineer, Informatica Cloud IICS/IDMC (CAI, CDI),
Visualpath stands out as the best online software training institute in Hyderabad.
For More Information about the Azure Data Engineer Online Training
Contact Call/WhatsApp: +91-7032290546
Visit: https://www.visualpath.in/online-azure-data-engineer-course.html
#Azure Data Engineer Course#Azure Data Engineering Certification#Azure Data Engineer Training In Hyderabad#Azure Data Engineer Training#Azure Data Engineer Training Online#Azure Data Engineer Course Online#Azure Data Engineer Online Training#Microsoft Azure Data Engineer#Azure Data Engineer Course In Bangalore#Azure Data Engineer Course In Chennai#Azure Data Engineer Training In Bangalore#Azure Data Engineer Course In Ameerpet
0 notes
Text
BigQuery Studio From Google Cloud Accelerates AI operations

Google Cloud is well positioned to provide enterprises with a unified, intelligent, open, and secure data and AI cloud. Dataproc, Dataflow, BigQuery, BigLake, and Vertex AI are used by thousands of clients in many industries across the globe for data-to-AI operations. From data intake and preparation to analysis, exploration, and visualization to ML training and inference, it presents BigQuery Studio, a unified, collaborative workspace for Google Cloud’s data analytics suite that speeds up data to AI workflows. It enables data professionals to:
Utilize BigQuery’s built-in SQL, Python, Spark, or natural language capabilities to leverage code assets across Vertex AI and other products for specific workflows.
Improve cooperation by applying best practices for software development, like CI/CD, version history, and source control, to data assets.
Enforce security standards consistently and obtain governance insights within BigQuery by using data lineage, profiling, and quality.
The following features of BigQuery Studio assist you in finding, examining, and drawing conclusions from data in BigQuery:
Code completion, query validation, and byte processing estimation are all features of this powerful SQL editor.
Colab Enterprise-built embedded Python notebooks. Notebooks come with built-in support for BigQuery DataFrames and one-click Python development runtimes.
You can create stored Python procedures for Apache Spark using this PySpark editor.
Dataform-based asset management and version history for code assets, including notebooks and stored queries.
Gemini generative AI (Preview)-based assistive code creation in notebooks and the SQL editor.
Dataplex includes for data profiling, data quality checks, and data discovery.
The option to view work history by project or by user.
The capability of exporting stored query results for use in other programs and analyzing them by linking to other tools like Looker and Google Sheets.
Follow the guidelines under Enable BigQuery Studio for Asset Management to get started with BigQuery Studio. The following APIs are made possible by this process:
To use Python functions in your project, you must have access to the Compute Engine API.
Code assets, such as notebook files, must be stored via the Dataform API.
In order to run Colab Enterprise Python notebooks in BigQuery, the Vertex AI API is necessary.
Single interface for all data teams
Analytics experts must use various connectors for data intake, switch between coding languages, and transfer data assets between systems due to disparate technologies, which results in inconsistent experiences. The time-to-value of an organization’s data and AI initiatives is greatly impacted by this.
By providing an end-to-end analytics experience on a single, specially designed platform, BigQuery Studio tackles these issues. Data engineers, data analysts, and data scientists can complete end-to-end tasks like data ingestion, pipeline creation, and predictive analytics using the coding language of their choice with its integrated workspace, which consists of a notebook interface and SQL (powered by Colab Enterprise, which is in preview right now).
For instance, data scientists and other analytics users can now analyze and explore data at the petabyte scale using Python within BigQuery in the well-known Colab notebook environment. The notebook environment of BigQuery Studio facilitates data querying and transformation, autocompletion of datasets and columns, and browsing of datasets and schema. Additionally, Vertex AI offers access to the same Colab Enterprise notebook for machine learning operations including MLOps, deployment, and model training and customisation.
Additionally, BigQuery Studio offers a single pane of glass for working with structured, semi-structured, and unstructured data of all types across cloud environments like Google Cloud, AWS, and Azure by utilizing BigLake, which has built-in support for Apache Parquet, Delta Lake, and Apache Iceberg.
One of the top platforms for commerce, Shopify, has been investigating how BigQuery Studio may enhance its current BigQuery environment.
Maximize productivity and collaboration
By extending software development best practices like CI/CD, version history, and source control to analytics assets like SQL scripts, Python scripts, notebooks, and SQL pipelines, BigQuery Studio enhances cooperation among data practitioners. To ensure that their code is always up to date, users will also have the ability to safely link to their preferred external code repositories.
BigQuery Studio not only facilitates human collaborations but also offers an AI-powered collaborator for coding help and contextual discussion. BigQuery’s Duet AI can automatically recommend functions and code blocks for Python and SQL based on the context of each user and their data. The new chat interface eliminates the need for trial and error and document searching by allowing data practitioners to receive specialized real-time help on specific tasks using natural language.
Unified security and governance
By assisting users in comprehending data, recognizing quality concerns, and diagnosing difficulties, BigQuery Studio enables enterprises to extract reliable insights from reliable data. To assist guarantee that data is accurate, dependable, and of high quality, data practitioners can profile data, manage data lineage, and implement data-quality constraints. BigQuery Studio will reveal tailored metadata insights later this year, such as dataset summaries or suggestions for further investigation.
Additionally, by eliminating the need to copy, move, or exchange data outside of BigQuery for sophisticated workflows, BigQuery Studio enables administrators to consistently enforce security standards for data assets. Policies are enforced for fine-grained security with unified credential management across BigQuery and Vertex AI, eliminating the need to handle extra external connections or service accounts. For instance, Vertex AI’s core models for image, video, text, and language translations may now be used by data analysts for tasks like sentiment analysis and entity discovery over BigQuery data using straightforward SQL in BigQuery, eliminating the need to share data with outside services.
Read more on Govindhtech.com
#BigQueryStudio#BigLake#AIcloud#VertexAI#BigQueryDataFrames#generativeAI#ApacheSpark#MLOps#news#technews#technology#technologynews#technologytrends#govindhtech
0 notes
Text
https://bitaacademy.com/course/best-pyspark-training-in-chennai/
0 notes