#DatabaseDesign
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
China blocked Tumblr because of pornography and censorship problems in 2013.
Text

Learn MySQL In-Depth: Basics to Advanced https://www.youtube.com/playlist?list=PLdE8ESr9Th_tvPGAlbOEc-0_qleTOBgmU
#MySQL#Database#SQL#DataManagement#WebDevelopment#DatabaseDesign#SQLQueries#BackendDevelopment#PHPTutorials#DatabaseOptimization
1 note
·
View note
Text
Designing for Scale: Data Modeling in Big Data Environments
In today's data-driven world, businesses generate and consume vast amounts of data at an unprecedented pace. This surge in data necessitates new approaches to data modeling, particularly when dealing with big data environments. Traditional data modeling techniques, while proven and reliable for smaller datasets, often fall short when applied to the scale and complexity of modern data systems. This blog explores the differences between traditional and big data modeling, delves into various modeling techniques, and provides guidance on designing for scale in big data environments.
Difference Between Traditional and Big Data Modeling
Traditional data modeling typically involves creating detailed schemas upfront, focusing on normalization to minimize redundancy and ensure data integrity. These models are designed for structured data stored in relational databases, where consistency and transaction management are paramount.
In contrast, big data modeling must accommodate the three V's of big data: volume, velocity, and variety. This requires models that can handle large quantities of diverse data types, often arriving at high speeds. Flexibility and scalability are key, as big data systems need to process and analyze data quickly, often in real-time.
Dimensional Modeling: Star and Snowflake Schemas
Dimensional modeling is a technique used to design data warehouses, focusing on optimizing query performance. Two popular schemas are the star schema and the snowflake schema:
Star Schema: This is the simplest form of dimensional modeling. It consists of a central fact table connected to multiple dimension tables. Each dimension table contains attributes related to the fact table, making it easy to query and understand. The star schema is favored for its simplicity and performance benefits.
Snowflake Schema: This is a more complex version of the star schema, where dimension tables are normalized into multiple related tables. While this reduces redundancy, it can complicate queries and impact performance. The snowflake schema is best suited for environments where storage efficiency is more critical than query speed.

Star and Snowflake Schemas
NoSQL vs Relational Modeling Considerations
NoSQL databases have emerged as a powerful alternative to traditional relational databases, offering greater flexibility and scalability. Here are some key considerations:
Schema Flexibility: NoSQL databases often use a schema-less or dynamic schema model, allowing for greater flexibility in handling unstructured or semi-structured data. This contrasts with the rigid schemas of relational databases.
Scalability: NoSQL systems are designed to scale horizontally, making them ideal for large-scale applications. Relational databases typically scale vertically, which can be more expensive and less efficient at scale.
Consistency vs Availability: NoSQL databases often prioritize availability over consistency, adhering to the CAP theorem. This trade-off can be crucial for applications that require high availability and partition tolerance.
Denormalization Strategies for Distributed Systems
Denormalization is a strategy used to improve read performance by duplicating data across multiple tables or documents. In distributed systems, denormalization helps reduce the number of joins and complex queries, which can be costly in terms of performance:
Precomputed Views: Storing precomputed or materialized views can speed up query responses by eliminating the need for real-time calculations.
Data Duplication: By duplicating data in multiple places, systems can serve read requests faster, reducing latency and improving user experience.
Trade-offs: While denormalization improves read performance, it can increase storage costs and complicate data management, requiring careful consideration of trade-offs.

Denormalization Strategies
Schema-on-Read vs Schema-on-Write
Schema-on-read and schema-on-write are two approaches to data processing in big data environments:
Schema-on-Read: This approach defers the schema definition until data is read, allowing for greater flexibility in handling diverse data types. Tools like Apache Hive and Google BigQuery support schema-on-read, enabling ad-hoc analysis and exploration of large datasets.
Schema-on-Write: In this approach, the schema is defined before data is written, ensuring data integrity and consistency. Traditional relational databases and data warehouses typically use schema-on-write, which is suitable for well-structured data with known patterns.
FAQs
What is the main advantage of using NoSQL databases for big data modeling?
NoSQL databases offer greater scalability and flexibility, making them ideal for handling large volumes of unstructured or semi-structured data.
How does denormalization improve performance in distributed systems?
Denormalization reduces the need for complex joins and queries, speeding up read operations and improving overall system performance.
What is the key difference between schema-on-read and schema-on-write?
Schema-on-read allows schema definition at the time of data retrieval, offering flexibility, while schema-on-write requires schema definition before data is stored, ensuring consistency.
Why might a business choose a snowflake schema over a star schema?
A snowflake schema offers better storage efficiency through normalization, which is beneficial when storage costs are a primary concern.
Can dimensional modeling be used in NoSQL databases?
Yes, dimensional modeling concepts can be adapted for use in NoSQL databases, particularly for analytical purposes, though implementation details may differ.
Home
instagram
#DataModeling#DatabaseDesign#BigDataArchitecture#StarSchema#SnowflakeSchema#NoSQLDesign#DataEngineering#SchemaDesign#SunshineDigitalServices#DataInfrastructure#Instagram
0 notes
Text
Normalization in DBMS: Simplifying 1NF to 5NF
Database Management Systems (DBMS) are essential for storing, retrieving, and managing data efficiently. However, without a structured approach, databases can suffer from redundancy and anomalies, leading to inefficiencies and potential data integrity issues. This is where normalization comes into play. Normalization is a systematic method of organizing data in a database to reduce redundancy and improve data integrity. In this article, we will explore the different normal forms from 1NF to 5NF, understand their significance, and provide examples to illustrate how they help in avoiding redundancy and anomalies.
Normalization in DBMS
Understanding Normal Forms
Normalization involves decomposing a database into smaller, more manageable tables without losing data integrity. The different levels of normalization are called normal forms, each with specific criteria that need to be met. Let’s delve into each normal form and understand its importance.
First Normal Form (1NF)
The First Normal Form (1NF) is the foundation of database normalization. A table is in 1NF if:
All the attributes in a table are atomic, meaning each column contains indivisible values.
Each column contains values of a single type.
Each column must contain unique values or values that are part of a primary key.
Example of 1NF
Consider a table storing information about students and their subjects:
StudentID
Name
Subjects
1
Alice
Math, Science
2
Bob
English, Art
This table violates 1NF because the Subjects column contains multiple values. To transform it into 1NF, we need to split these values into separate rows:
StudentID
Name
Subject
1
Alice
Math
1
Alice
Science
2
Bob
English
2
Bob
Art
Second Normal Form (2NF)
A table is in the Second Normal Form (2NF) if:
It is in 1NF.
All non-key attributes are fully functionally dependent on the primary key.
In simpler terms, there should be no partial dependency of any column on the primary key.
Example of 2NF
Consider a table storing information about student enrollments:
EnrollmentID
StudentID
CourseID
Instructor
1
1
101
Dr. Smith
2
1
102
Dr. Jones
Here, Instructor depends only on CourseID, not on the entire primary key (EnrollmentID). To achieve 2NF, we split the table:
StudentEnrollments Table:
EnrollmentID
StudentID
CourseID
1
1
101
2
1
102
Courses Table:
CourseID
Instructor
101
Dr. Smith
102
Dr. Jones
Third Normal Form (3NF)
A table is in Third Normal Form (3NF) if:
It is in 2NF.
There are no transitive dependencies, i.e., non-key attributes should not depend on other non-key attributes.
Example of 3NF
Consider a table with student addresses:
StudentID
Name
Address
City
ZipCode
1
Alice
123 Main St
Gotham
12345
2
Bob
456 Elm St
Metropolis
67890
Here, City depends on ZipCode, not directly on StudentID. To achieve 3NF, we separate the dependencies:
Students Table:
StudentID
Name
Address
ZipCode
1
Alice
123 Main St
12345
2
Bob
456 Elm St
67890
ZipCodes Table:
ZipCode
City
12345
Gotham
67890
Metropolis
Understanding Normal Forms
Boyce-Codd Normal Form (BCNF)
A table is in Boyce-Codd Normal Form (BCNF) if:
It is in 3NF.
Every determinant is a candidate key.
BCNF is a stricter version of 3NF, dealing with certain anomalies not addressed by the latter.
Example of BCNF
Consider a table with employee project assignments:
EmployeeID
ProjectID
Task
1
101
Design
2
102
Build
Suppose an employee can work on multiple projects, and each project can have multiple tasks. If Task depends only on ProjectID, it violates BCNF. To achieve BCNF, decompose the table:
EmployeeProjects Table:
EmployeeID
ProjectID
1
101
2
102
ProjectTasks Table:
ProjectID
Task
101
Design
102
Build
Fourth Normal Form (4NF)
A table is in Fourth Normal Form (4NF) if:
It is in BCNF.
It has no multi-valued dependencies.
Multi-valued dependencies occur when one attribute in a table uniquely determines another attribute, independent of other attributes.
Example of 4NF
Consider a table with student courses and projects:
StudentID
CourseID
ProjectID
1
101
P1
1
102
P2
If CourseID and ProjectID are independent of each other, this violates 4NF. To achieve 4NF, separate the multi-valued dependencies:
StudentCourses Table:
StudentID
CourseID
1
101
1
102
StudentProjects Table:
StudentID
ProjectID
1
P1
1
P2
Fifth Normal Form (5NF)
A table is in Fifth Normal Form (5NF) if:
It is in 4NF.
It cannot have any join dependencies that are not implied by candidate keys.
5NF is primarily concerned with eliminating anomalies during complex join operations.
Example of 5NF
Consider a table with suppliers, parts, and projects:
SupplierID
PartID
ProjectID
1
A
X
1
B
Y
If SupplierID, PartID, and ProjectID are independent, the table needs to be decomposed to eliminate anomalies:
SupplierParts Table:
SupplierID
PartID
1
A
1
B
SupplierProjects Table:
SupplierID
ProjectID
1
X
1
Y
PartProjects Table:
PartID
ProjectID
A
X
B
Y
Normal Forms
Conclusion
Normalization is a crucial process in database design that helps eliminate redundancy and anomalies, ensuring data integrity and efficiency. By understanding the principles of each normal form from 1NF to 5NF, database designers can create structured and optimized databases. It’s important to balance normalization with practical considerations, as over-normalization can lead to complex queries and decreased performance.
FAQs
Why is normalization important in databases? Normalization is important because it reduces data redundancy, improves data integrity, and makes the database more efficient and easier to maintain.
What are the common anomalies avoided by normalization? Normalization helps avoid insertion, update, and deletion anomalies, which can compromise data integrity and lead to inconsistencies.
Can a database be over-normalized? Yes, over-normalization can lead to complex queries and decreased performance. It’s crucial to balance normalization with practical application requirements.
Is every table required to be in 5NF? Not necessarily. While 5NF eliminates all possible redundancies, many databases stop at 3NF or BCNF, which sufficiently addresses most redundancy and anomaly issues.
How do I decide which normal form to apply? The choice of normal form depends on the specific requirements of the database and application. Generally, it's best to start with 3NF or BCNF and assess if further normalization is needed based on the complexity and use case.
HOME
#DBMSNormalization#DatabaseNormalization#1NFto5NF#LearnDBMS#DatabaseDesign#DataModeling#SQLBasics#TechForStudents#InformationTechnology#DBMSBasics#AssignmentHelp#AssignmentOnClick#assignment#machinelearning#aiforstudents#assignmentwriting#assignment service#assignment help#assignmentexperts
0 notes
Link
0 notes
Text
Relational vs. Non-Relational Databases: Key Differences Explained
Relational databases use structured tables with predefined schemas and support SQL for querying, making them ideal for structured data and complex relationships. Non-relational databases, like NoSQL, offer flexibility with unstructured or semi-structured data, excelling in scalability and performance for big data and real-time applications. Each suits different use cases based on data type and Read More..

0 notes
Text
Backend & Admin Panel Development by CodingBit
Coding Bit develops backend systems using technologies like PHP, MySQL, and JavaScript. These systems handle application logic, user authentication, and dynamic content management, ensuring a scalable and secure foundation for mobile apps. Coding Bit Admin Panel Integration: They design and implement admin panels that allow businesses to manage users, products, orders, and other critical app data efficiently. These panels are built with user-friendly interfaces to facilitate easy management without requiring technical expertise. Live Project Experience: Coding Bit emphasizes hands-on experience by involving clients in live projects. This approach helps bridge the gap between theoretical knowledge and practical application, ensuring that the backend systems and admin panels meet real-world business needs. Coding Bit.
📞 Phone Number: +91 9511803947
📧 Email Address: [email protected]
0 notes
Text
MySQL is an open-source relational database management system (RDBMS) that is widely used for storing, managing, and retrieving data efficiently. It is one of the most popular database systems, known for its speed, reliability, and ease of use. MySQL is commonly used in web development, powering applications such as WordPress, Facebook, and many others.
#MySQL#Database#SQL#DatabaseManagement#TechEducation#MySQLTutorial#SQLDatabase#TechBooks#DataManagement#MySQLForBeginners#TechLearning#RelationalDatabase#DatabaseDesign#MySQLQueries#CRUDOperations#DatabaseOptimization#MySQLDatabase#WebDevelopment#TechTutorial#BackendDevelopment#MySQLAdmin#DatabaseSecurity#DataModeling#MySQLTips#WebAppDevelopment#MySQLBestPractices
0 notes
Text
Star Schema vs Snowflake Schema: Choosing the Right Data Structure for Your Business
In the fast-paced world of data management, selecting the right schema is crucial for efficient data storage and retrieval. In this video, we explore the Star and Snowflake schemas, comparing their structures, advantages, and challenges. Whether you're managing a simple data environment or a complex system, this guide will help you choose the best schema to optimize your analytical capacity. Learn how each schema can impact performance, storage efficiency, and data integrity for your organization.
youtube
#DataManagement#StarSchema#SnowflakeSchema#DataWarehousing#DataModeling#DataStorage#BigData#Analytics#BusinessIntelligence#SQL#DatabaseDesign#TechTrends#DataScience#DataArchitecture#DataRetrieval#StorageOptimization#DatabasePerformance#BusinessAnalytics#DataRedundancy#DataIntegrity#Youtube
0 notes
Text

Learn MySQL In-Depth: Basics to Advanced https://www.youtube.com/playlist?list=PLdE8ESr9Th_tvPGAlbOEc-0_qleTOBgmU
#MySQL#Database#SQL#DataManagement#WebDevelopment#DatabaseDesign#SQLQueries#BackendDevelopment#PHPTutorials#DatabaseOptimization
1 note
·
View note
Text
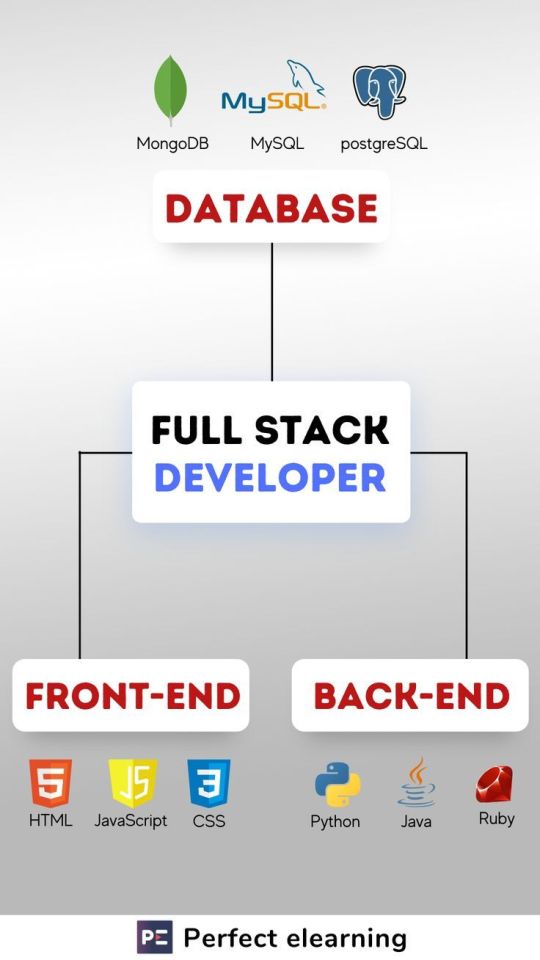
🌐 What is a Database? A Beginner's Guide 📚
📚💾 What is a Database?
Think of it as a high-tech treasure chest 🪙, storing all your important data in one neat place! From managing your Netflix watchlist 🎬 to saving your online shopping carts 🛍️, databases are the silent heroes 🦸♀️ behind your favorite apps. They keep things organized, searchable 🔍, and ready whenever you need them! 🚀✨

🔍 Types of Databases 🌐
1️⃣ 🗃️ Relational Database: Think of it as a spreadsheet 📊 that organizes data into neat tables. Example: MySQL, PostgreSQL.
2️⃣ 📚 NoSQL Database: For all the messy data 🌀—it handles unstructured info like a pro! Example: MongoDB, Cassandra.
3️⃣ ☁️ Cloud Database: Data stored up in the cloud ☁️, ready to be accessed anytime, anywhere! Example: AWS, Google Cloud.
4️⃣ 🧠 In-Memory Database: Super-fast, like the brain 🧠! Stores data in RAM for lightning-speed access. Example: Redis, Memcached.
5️⃣ 🏙️ Graph Database: Connects the dots 🧩 between data, like a social network! Example: Neo4j, Amazon Neptune.
Why Are Databases Important?
💡 Efficient Data Storage: Organize and store massive amounts of data easily.
🔍 Quick Access: Retrieve information in seconds, making tasks faster.
📈 Data Analysis: Helps businesses make smart decisions with organized data.
🛡️ Data Security: Protects sensitive information with backups and encryption.
🔄 Automation: Automates processes like transactions, inventory updates, and more!
🌍 Scalability: Can grow with your business or website as data increases.
3️⃣ Cool Database Facts
🧠 First Database Ever: IBM’s IMS (Information Management System) was created in the 1960s!
🌍 SQL Dominance: SQL is the most widely used database language around the globe.
🚀 Big Data Power: Databases handle massive amounts of data—Google processes over 40,000 searches per second!
#Database#TechTips#SQL#NoSQL#LearnTech#ProgrammingBasics#DataManagement#DBMS#BigData#DatabaseDesign#DataScience#DataAnalytics#CloudDatabase#DataMining#DatabaseAdministrator#RelationalDatabase#DatabaseOptimization#DataVisualization#DataStorage#DataSecurity#DatabaseDeveloper#DataWarehouse#MachineLearning#BusinessIntelligence
0 notes
Text
instagram
#SunshineDigital#DataNormalization#RDBMS#DatabaseDesign#DataIntegrity#SQLTips#RelationalDatabase#TechEducation#DataEfficiency#DatabaseOptimization#LearnSQL#Instagram
0 notes
Text
Understanding ER Modeling and Database Design Concepts
In the world of databases, data modeling is a crucial process that helps structure the information stored within a system, ensuring it is organized, accessible, and efficient. Among the various tools and techniques available for data modeling, Entity-Relationship (ER) diagrams and database normalization stand out as essential components. This blog will delve into the concepts of ER modeling and database design, demonstrating how they contribute to creating an efficient schema design.
ER Modeling
What is an Entity-Relationship Diagram?
An Entity-Relationship Diagram, or ERD, is a visual representation of the entities, relationships, and data attributes that make up a database. ERDs are used as a blueprint to design databases, offering a clear understanding of how data is structured and how entities interact with one another.
Key Components of ER Diagrams
Entities: Entities are objects or things in the real world that have a distinct existence within the database. Examples include customers, orders, and products. In ERDs, entities are typically represented as rectangles.
Attributes: Attributes are properties or characteristics of an entity. For instance, a customer entity might have attributes such as CustomerID, Name, and Email. These are usually represented as ovals connected to their respective entities.
Relationships: Relationships depict how entities are related to one another. They are represented by diamond shapes and connected to the entities they associate. Relationships can be one-to-one, one-to-many, or many-to-many.
Cardinality: Cardinality defines the numerical relationship between entities. It indicates how many instances of one entity are associated with instances of another entity. Cardinality is typically expressed as (1:1), (1:N), or (M:N).
Primary Keys: A primary key is an attribute or set of attributes that uniquely identify each instance of an entity. It is crucial for ensuring data integrity and is often underlined in ERDs.
Foreign Keys: Foreign keys are attributes that establish a link between two entities, referencing the primary key of another entity to maintain relationships.
Steps to Create an ER Diagram
Identify the Entities: Start by listing all the entities relevant to the database. Ensure each entity represents a significant object or concept.
Define the Relationships: Determine how these entities are related. Consider the type of relationships and the cardinality involved.
Assign Attributes: For each entity, list the attributes that describe it. Identify which attribute will serve as the primary key.
Draw the ER Diagram: Use graphical symbols to represent entities, attributes, and relationships, ensuring clarity and precision.
Review and Refine: Analyze the ER Diagram for completeness and accuracy. Make necessary adjustments to improve the model.
The Importance of Normalization
Normalization is a process in database design that organizes data to reduce redundancy and improve integrity. It involves dividing large tables into smaller, more manageable ones and defining relationships among them. The primary goal of normalization is to ensure that data dependencies are logical and stored efficiently.
Normal Forms
Normalization progresses through a series of stages, known as normal forms, each addressing specific issues:
First Normal Form (1NF): Ensures that all attributes in a table are atomic, meaning each attribute contains indivisible values. Tables in 1NF do not have repeating groups or arrays.
Second Normal Form (2NF): Achieved when a table is in 1NF, and all non-key attributes are fully functionally dependent on the primary key. This eliminates partial dependencies.
Third Normal Form (3NF): A table is in 3NF if it is in 2NF, and all attributes are solely dependent on the primary key, eliminating transitive dependencies.
Boyce-Codd Normal Form (BCNF): A stricter version of 3NF where every determinant is a candidate key, resolving anomalies that 3NF might not address.
Higher Normal Forms: Beyond BCNF, there are Fourth (4NF) and Fifth (5NF) Normal Forms, which address multi-valued dependencies and join dependencies, respectively.
Benefits of Normalization
Reduced Data Redundancy: By storing data in separate tables and linking them with relationships, redundancy is minimized, which saves storage and prevents inconsistencies.
Improved Data Integrity: Ensures that data modifications (insertions, deletions, updates) are consistent across the database.
Easier Maintenance: With a well-normalized database, maintenance tasks become more straightforward due to the clear organization and relationships.
Benefits of Normalization
ER Modeling and Normalization: A Symbiotic Relationship
While ER modeling focuses on the conceptual design of a database, normalization deals with its logical structure. Together, they form a comprehensive approach to database design by ensuring both clarity and efficiency.
Steps to Integrate ER Modeling and Normalization
Conceptual Design with ERD: Begin with an ERD to map out the entities and their relationships. This provides a high-level view of the database.
Logical Design through Normalization: Use normalization steps to refine the ERD, ensuring that the design is free of redundancy and anomalies.
Physical Design Implementation: Translate the normalized ERD into a physical database schema, considering performance and storage requirements.
Common Challenges and Solutions
Complexity in Large Systems: For extensive databases, ERDs can become complex. Using modular designs and breaking down ERDs into smaller sub-diagrams can help.
Balancing Normalization with Performance: Highly normalized databases can sometimes lead to performance issues due to excessive joins. It's crucial to balance normalization with performance needs, possibly denormalizing parts of the database if necessary.
Maintaining Data Integrity: Ensuring data integrity across relationships can be challenging. Implementing constraints and triggers can help maintain the consistency of data.
Common Challenges and Solutions
Conclusion
Entity-Relationship Diagrams and normalization are foundational concepts in database design. Together, they ensure that databases are both logically structured and efficient, capable of handling data accurately and reliably. By integrating these methodologies, database designers can create robust systems that support complex data requirements and facilitate smooth data operations.
FAQs
What is the purpose of an Entity-Relationship Diagram?
An ER Diagram serves as a blueprint for database design, illustrating entities, relationships, and data attributes to provide a clear structure for the database.
Why is normalization important in database design?
Normalization reduces data redundancy and enhances data integrity by organizing data into related tables, ensuring consistent and efficient data storage.
What is the difference between ER modeling and normalization?
ER modeling focuses on the conceptual design and relationships within a database, while normalization addresses the logical structure to minimize redundancy and dependency issues.
Can normalization impact database performance?
Yes, while normalization improves data integrity, it can sometimes lead to performance issues due to increased joins. Balancing normalization with performance needs is essential.
How do you choose between different normal forms?
The choice depends on the specific needs of the database. Most databases aim for at least 3NF to ensure a balance between complexity and efficiency, with higher normal forms applied as necessary.
HOME
#ERModeling#DatabaseDesign#LearnDBMS#EntityRelationship#DataModeling#DBMSBasics#DatabaseConcepts#TechForStudents#InformationTechnology#DataArchitecture#AssignmentHelp#AssignmentOnClick#assignment help#assignment service#aiforstudents#machinelearning#assignmentexperts#assignment#assignmentwriting
0 notes
Text
MySQL Naming Conventions

What is MySQL?
MySQL is a freely available open source Relational Database Management System (RDBMS) that uses Structured Query Language (SQL). SQL is the most popular language for adding, accessing and managing content in a database. It is most noted for its quick processing, proven reliability, ease and flexibility of use.
What is a naming convention?
In computer programming, a naming convention is a set of rules for choosing the character sequence to be used for identifiers that denote variables, types, functions, and other entities in source code and documentation.
General rules — Naming conventions
Using lowercase will help speed typing, avoid mistakes as MYSQL is case sensitive.
Space replaced with Underscore — Using space between words is not advised.
Numbers are not for names — While naming, it is essential that it contains only Alpha English alphabets.
Valid Names — Names should be descriptive of the elements. i.e. — Self-explanatory and not more than 64 characters.
No prefixes allowed.
Database name convention
Name can be singular or plural but as the database represents a single database it should be singular.
Avoid prefix if possible.
MySQL table name
Lowercase table name
MySQL is usually hosted in a Linux server which is case-sensitive hence to stay on the safe side use lowercase. Many PHP or similar programming frameworks, auto-detect or auto-generate class-based table names and most of them expect lowercase names.
Table name in singular
The table is made up of fields and rows filled with various forms of data, similarly the table name could be plural but the table itself is a single entity hence it is odd and confusing. Hence use names like User, Comment.
Prefixed table name
The table usually has the database or project name. sometimes some tables may exist under the same name in the database to avoid replacing this, you can use prefixes. Essentially, names should be meaningful and self-explanatory. If you can’t avoid prefix you can fix it using php class.
Field names
Use all above cases which include lowercase, no space, no numbers, and avoid prefix.
Choose short names no-longer than two words.
Field names should be easy and understandable
Primary key can be id or table name_id or it can be a self-explanatory name.
Avoid using reserve words as field name. i.e. — Pre-defined words or Keywords. You can add prefix to these names to make it understandable like user_name, signup_date.
Avoid using column with same name as table name. This can cause confusion while writing query.
Avoid abbreviated, concatenated, or acronym-based names.
Do define a foreign key on database schema.
Foreign key column must have a table name with their primary key.
e.g. blog_id represents foreign key id from table blog.
Avoid semantically — meaningful primary key names. A classic design mistake is creating a table with primary key that has actual meaning like ‘name’ as primary key. In this case if someone changes their name then the relationship with the other tables will be affected and the name can be repetitive losing its uniqueness.
Conclusion
Make your table and database names simple yet understandable by both database designers and programmers. It should things that might cause confusion, issues with linking tables to one another. And finally, it should be readable for programming language or the framework that is implemented.
#MySQL#DatabaseManagement#SQL#NamingConventions#RelationalDatabase#DatabaseDesign#CodingStandards#TableNaming#FieldNaming#DatabaseSchema#ProgrammingTips#DataManagement#CaseSensitivity#PrimaryKey#ForeignKey#DatabaseBestPractices#OpenSource#DatabaseOptimization#MySQLTips#DataStructure
0 notes
Text
#OracleDatabase#LearnOracle#DatabaseManagement#SQL#DataScience#OracleTraining#DatabaseDeveloper#TechEducation#DataAnalysis#OracleCertification#DatabaseDesign#OracleSQL
0 notes
Text
Database Design & Development Solution - dbForge Edge

Introduction to Database Development
Database development has existed since the 1960s. This was the time when the need arose to efficiently organize and manage large volumes of data. As the demand grew, different relational database management systems, such as MySQL, SQL Server, or Oracle, strated springing up like mushrooms. Today, this field is still rapidly evolving driven by new technologies.
In the digital age we live in, data has become one of the most valuable assets. Many professionals are dedicating their career to improving its organization, accessibility, and security. Thus, it is crucial to keep up with the latest tools for best results.
In this article, we will talk about:
Visual database design and its impact
Database projects and their role in streamlined development
Adding notes, stamps, and images for enriched documentation
Benefits of visual database design
Cross-platform development
Databases and cloud servers
Different connection types and their impact
The convenience of dbForge Edge
0 notes
Text
Mô hình dữ liệu là gì? Các yếu tố chính của mô hình dữ liệu
Một mô hình dữ liệu tốt giúp ta hiểu rõ hơn về quan hệ giữa các đối tượng, thuộc tính và hành vi của dữ liệu trong hệ thống.
Trong bài viết này, chúng ta sẽ khám phá các loại mô hình dữ liệu là gì và vai trò của chúng trong việc tổ chức và quản lý dữ liệu.
0 notes