#DataWarehousing
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
In 2020, Tumblr had 29.4 million users in the US.
Text
Transforming Data into Actionable Insights: Oak Tree Software

In today’s digital economy, data is one of the most valuable business assets. But raw data alone won’t fuel growth—it must be integrated, cleaned, and analyzed to uncover insights. Oak Tree Software offers end-to-end data engineering and business intelligence services designed to help organizations across the U.S. turn data into a strategic advantage.
Data Engineering Services in the USA: Building a Reliable Data Foundation
For any organization aiming to become data-driven, a solid data infrastructure is essential. Our data engineering solutions are designed to unify and organize data across platforms, making it accessible, accurate, and ready for analysis.
Our Core Data Engineering Services Include:
Data Integration: Connecting data from databases, cloud systems, APIs, and more into a single, cohesive platform.
Data Warehousing: Designing and deploying scalable, secure data warehouses to support analytics and reporting.
Data Transformation: Cleaning, normalizing, and structuring raw data to ensure consistency.
ETL (Extract, Transform, Load): Implementing automated ETL pipelines to streamline the data flow between systems.
We offer expert data engineering consulting services to ensure your data is not only well-managed but also future-ready.
Business Intelligence and Analytics: Make Data-Driven Decisions with Confidence
Once your data is properly structured, our BI services unlock insights that support smarter decision-making. Oak Tree Software’s business intelligence and analytics experts help businesses identify trends, track performance, and predict outcomes with confidence.

Business Intelligence Service Highlights:
Interactive Dashboards: Custom dashboards give you real-time visibility into KPIs and business performance.
Data Visualization: Easy-to-read charts, graphs, and maps make complex data clear and actionable.
Data Analysis & Reporting: In-depth reports uncover hidden patterns, risks, and opportunities.
Predictive Analytics: Leverage machine learning and statistical modeling to forecast trends and market shifts.
Our tailored approach ensures that you’re not just collecting data—but actively using it to fuel growth and innovation.
Data Engineering and Business Intelligence Consulting with a Purpose
At Oak Tree Software, we don’t believe in one-size-fits-all solutions. Our data engineering and business intelligence consulting is centered around your business goals. Whether you're looking to improve operational efficiency, enhance customer experience, or boost revenue, we build solutions that solve real problems.
We work closely with your team to identify pain points, implement the right tools, and deliver measurable results through customized strategies.
Nationwide Support, Local Expertise
Oak Tree Software proudly provides data engineering services in the USA, supporting companies from startups to enterprises. We combine deep technical expertise with a hands-on, collaborative approach to ensure your success every step of the way.
Ready to turn your data into growth? Contact Oak Tree Software today to learn how our data engineering and BI services can help your business thrive.
#DataEngineering#BusinessIntelligence#DataAnalytics#BIservices#DataTransformation#ETLPipelines#DataIntegration#DataWarehousing#PredictiveAnalytics#DataEngineeringConsulting#BusinessIntelligenceSolutions#DataDrivenDecisions#BigDataSolutions#AnalyticsConsulting#OakTreeSoftware#DataEngineeringServicesUSA#BusinessIntelligenceAndAnalytics#TechConsulting#DigitalTransformation#DataStrategy#oaktreecloud#Oaktreesoftware
0 notes
Text
BigQuery Essentials: Fast SQL Analysis on Massive Datasets
In an era where data is king, the ability to efficiently analyze massive datasets is crucial for businesses and analysts alike. Google BigQuery, a serverless, highly scalable, and cost-effective multi-cloud data warehouse, empowers users to run fast SQL queries and gain insights from vast amounts of data. This blog will explore the essentials of BigQuery, covering everything from loading datasets to optimizing queries and understanding the pricing model.
What is BigQuery?
Google BigQuery is a fully managed, serverless data warehouse that allows users to process and analyze large datasets using SQL. It seamlessly integrates with other Google Cloud Platform services, offering robust features like real-time analytics, automatic scaling, and high-speed querying capabilities. BigQuery excels in handling petabyte-scale datasets, making it a favorite among data analysts and engineers.

Google big Query
Loading Datasets into BigQuery
Before you can perform any analysis, you'll need to load your datasets into BigQuery. The platform supports various data sources, including CSV, JSON, Avro, Parquet, and ORC files. You can load data from Google Cloud Storage, Google Drive, or even directly from your local machine.
To load data, you can use the BigQuery web UI, the bq command-line tool, or the BigQuery API. When preparing your data, ensure it's clean and well-structured to avoid errors during the loading process. BigQuery also offers data transfer services that automate the ingestion of data from external sources like Google Ads, Google Analytics, and YouTube.

Loading Datasets into BigQuery
Writing and Optimizing SQL Queries
BigQuery offers a powerful SQL dialect that enables you to write complex queries to extract insights from your data. Here are some tips to optimize your SQL queries for better performance:
Use SELECT * sparingly: Avoid using SELECT * in your queries as it processes all columns, increasing execution time and costs. Specify only the columns you need.
Leverage built-in functions: BigQuery provides various built-in functions for string manipulation, date operations, and statistical calculations. Use them to simplify and speed up your queries.
Filter early: Apply filters in your queries as early as possible to reduce the dataset size and minimize processing time.
Use JOINs wisely: When joining tables, ensure you use the most efficient join types and conditions to optimize performance.
Partitioning & Clustering in BigQuery
Partitioning and clustering are powerful features in BigQuery that help optimize query performance and reduce costs:
Partitioning: This involves dividing a table into smaller, manageable segments called partitions. BigQuery supports partitioning by date, ingestion time, or an integer range. By querying only relevant partitions, you can significantly reduce query time and costs.
Clustering: Clustering organizes the data within each partition based on specified columns. It enables faster query execution by improving data locality. When clustering, choose columns that are frequently used in filtering and aggregating operations.

Partitioning & Clustering in BigQuery
Pricing Model and Best Practices
BigQuery's pricing is based on two main components: data storage and query processing. Storage is billed per gigabyte per month, while query processing costs are based on the amount of data processed when running queries.
To manage costs effectively, consider the following best practices:
Use table partitions and clustering: As discussed earlier, these techniques can help reduce the amount of data processed and, consequently, lower costs.
Monitor usage: Regularly review your BigQuery usage and costs using the Google Cloud Console or BigQuery's built-in audit logs.
Set budget alerts: Establish budget alerts within Google Cloud Platform to receive notifications when spending approaches a predefined threshold.
Optimize query performance: Write efficient SQL queries to process only the necessary data, minimizing query costs.
FAQs
What types of data can I load into BigQuery?
BigQuery supports various data formats, including CSV, JSON, Avro, Parquet, and ORC files. Data can be loaded from Google Cloud Storage, Google Drive, or your local machine.
How can I reduce BigQuery costs?
Use table partitions and clustering, optimize your SQL queries, and regularly monitor your usage and spending. Additionally, set up budget alerts to stay informed about your expenses.
Can I use BigQuery with other Google Cloud services?
Yes, BigQuery seamlessly integrates with other Google Cloud Platform services, such as Google Cloud Storage, Google Data Studio, and Google Sheets, allowing you to create a comprehensive data analysis ecosystem.
What is the difference between partitioning and clustering in BigQuery?
Partitioning divides a table into smaller segments based on date, ingestion time, or integer range, while clustering organizes data within partitions based on specified columns. Both techniques enhance query performance and reduce costs.
Is BigQuery suitable for real-time analytics?
Absolutely. BigQuery supports real-time analytics, allowing you to gain insights from streaming data with minimal latency. It is well-suited for applications requiring up-to-the-minute data analysis.
Embark on your journey with BigQuery, and unlock the potential of your data with fast, scalable, and efficient SQL analysis!
Home
instagram
#BigQuery#GoogleCloudPlatform#CloudAnalytics#SQLAnalytics#DataWarehousing#BigDataTools#QueryOptimization#DataScience#SunshineDigitalServices#ModernAnalytics#Instagram
0 notes
Text
#DidYouKnow Open Source Databases Power Scalable Systems
Swipe left to explore!
To learn more about Open Source Database Management Click Here 👉 https://simplelogic-it.com/open-source-database-management/
💻 Explore insights on the latest in #technology on our Blog Page 👉 https://simplelogic-it.com/blogs/
🚀 Ready for your next career move? Check out our #careers page for exciting opportunities 👉 https://simplelogic-it.com/careers/
#didyouknowfacts#knowledgedrop#interestingfacts#factoftheday#learnsomethingneweveryday#mindblown#didyouknowthat#triviatime#learnsomethingnew#opensource#opensourcedatabase#mysql#postgrsql#webapplications#analytics#datawarehousing#makeitsimple#simplelogicit#simplelogic#makingitsimple#itservices#itconsulting
0 notes
Text
Quormobimerge – Transforming Businesses with Cutting-Edge Tech Solutions
In today’s rapidly evolving digital landscape, businesses need more than just a basic online presence. They require powerful, scalable, and innovative solutions to stay ahead of the competition. Quormobimerge is at the forefront of this transformation, offering a comprehensive suite of IT services that help businesses achieve sustainable digital growth.
Why Quormobimerge?
Quormobimerge isn’t just another tech service provider – it’s a strategic partner that helps businesses harness the latest technology to streamline operations, enhance customer experience, and drive revenue growth.
From software development to AI-powered solutions, Quormobimerge delivers services tailored to every business need.
Our Services
🚀 Startup Kit – Get everything you need to launch your business in the digital world.
🛒 E-Commerce & Retail Solutions – From secure payment gateways to seamless customer experiences, we help businesses thrive online.
🌐 Website & App Development Services – Build high-performing websites and mobile apps that captivate users.
📊 Data Warehousing & Power BI Solutions – Transform raw data into actionable insights with our advanced analytics solutions.
💻 Custom Software Development Services – Tailored software solutions to meet your unique business needs.
🏢 Enterprise Software Development Services – Robust and scalable enterprise solutions to optimize workflows.
🤖 Artificial Intelligence & Machine Learning – Implement AI-driven automation and predictive analytics to boost efficiency.
Innovation That Drives Success
At Quormobimerge, we believe that technology should empower businesses, not complicate them. Our expert team ensures that every solution we deliver is designed with scalability, security, and performance in mind.
Whether you're a startup, an established enterprise, or an e-commerce brand, our team is ready to provide the best tech solutions to take your business to the next level.
Get Started Today!
Ready to supercharge your digital presence? Visit Quormobimerge.com and let’s build something amazing together!
#business#startup#entrepreneur#digitaltransformation#technology#innovation#businessgrowth#softwaredevelopment#customsoftware#webdevelopment#appdevelopment#enterprisesolutions#AI#machinelearning#ecommerce#onlineshopping#retailtech#datadriven#bigdata#analytics#PowerBI#datawarehousing#smallbusiness#technews#futureofwork#B2B#SaaS#cloudcomputing#techstartup#cybersecurity
0 notes
Text
Star Schema vs Snowflake Schema: Choosing the Right Data Structure for Your Business
In the fast-paced world of data management, selecting the right schema is crucial for efficient data storage and retrieval. In this video, we explore the Star and Snowflake schemas, comparing their structures, advantages, and challenges. Whether you're managing a simple data environment or a complex system, this guide will help you choose the best schema to optimize your analytical capacity. Learn how each schema can impact performance, storage efficiency, and data integrity for your organization.
youtube
#DataManagement#StarSchema#SnowflakeSchema#DataWarehousing#DataModeling#DataStorage#BigData#Analytics#BusinessIntelligence#SQL#DatabaseDesign#TechTrends#DataScience#DataArchitecture#DataRetrieval#StorageOptimization#DatabasePerformance#BusinessAnalytics#DataRedundancy#DataIntegrity#Youtube
0 notes
Text
Completed with the tutorial videos of the module on Data Warehousing with BigQuery in #dezoomcamp @DataTalksClub . Now one to assignments. Very little time to deadline; got to hurry!!
0 notes
Text

👉 Join our ANGULAR Online Training ✍️ Registration Link: https://t.ly/xJ13n 👉New Batch Details: Date: 27th January 2025 Time: 7:30 AM to 09:00 AM Mode of Training: Online 📲 Meeting ID: 2516 462 9392 🔐 Password: 112233
#AzureTraining#DataEngineering#CloudComputing#AzureDataFactory#SQLBasics#PythonForData#DataWarehousing#MicrosoftAzure#NareshI
0 notes
Text

#DataAnalytics#Analytics#Conference#Training#DataWarehousing#Azure#Database#BusinessIntelligence#Realtime#Microsoft#Fabric#DataPlatform#DataEngineering#SQL#Reporting#Insights#Visualization#DAX#PowerQuery#Administration#DBA#DataScience#MachineLearning#AI#MicrosoftAI#Architecture#BestPractices
0 notes
Text
Data warehousing for a packaging & supply chain company IFI addressed R-PAC's SQL database performance issues by archiving historical data to a data lake, retaining one year of live data. This solution enhances website performance, reduces costs, and enables analytics-driven insights.
0 notes
Text

Bitcoin Data Mining . . . . for more information and a tutorial https://bit.ly/4hO4l4a check the above link
0 notes
Text
Amazon Redshift: A Quick-Start Guide To Data Warehousing
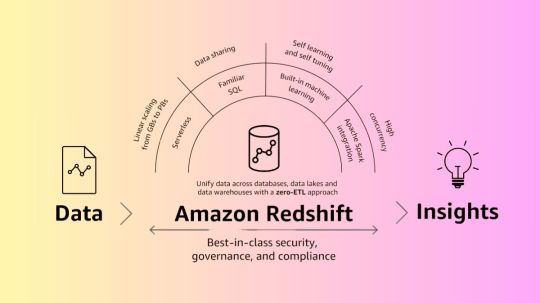
Amazon Redshift offers the finest price-performance cloud data warehouse to support data-driven decision-making.
What is Amazon Redshift?
Amazon Redshift leverages machine learning and technology created by AWS to provide the greatest pricing performance at any scale, utilizing SQL to analyze structured and semi-structured data across data lakes, operational databases, and data warehouses.
With only a few clicks and no data movement or transformation, you can break through data silos and obtain real-time and predictive insights on all of your data.
With performance innovation out of the box, you may achieve up to three times higher pricing performance than any other cloud data warehouse without paying extra.
Use a safe and dependable analytics solution to turn data into insights in a matter of seconds without bothering about infrastructure administration.
Why Amazon Redshift?
Every day, tens of thousands of customers utilize Amazon Redshift to deliver insights for their organizations and modernize their data analytics workloads. Amazon Redshift’s fully managed, AI-powered massively parallel processing (MPP) architecture facilitates swift and economical corporate decision-making. With AWS’s zero-ETL strategy, all of your data is combined for AI/ML applications, near real-time use cases, and robust analytics. With the help of cutting-edge security features and fine-grained governance, data can be shared and collaborated on safely and quickly both inside and between businesses, AWS regions, and even third-party data providers.
Advantages
At whatever size, get the optimal price-performance ratio
With a fully managed, AI-powered, massively parallel processing (MPP) data warehouse designed for speed, scale, and availability, you can outperform competing cloud data warehouses by up to six times.
Use zero-ETL to unify all of your data
Use a low-code, zero-ETL strategy for integrated analytics to quickly access or ingest data from your databases, data lakes, data warehouses, and streaming data.
Utilize thorough analytics and machine learning to optimize value
Utilize your preferred analytics engines and languages to run SQL queries, open source analytics, power dashboards and visualizations, and activate near real-time analytics and AI/ML applications.
Use safe data cooperation to innovate more quickly
With fine-grained governance, security, and compliance, you can effortlessly share and collaborate on data both inside and between your businesses, AWS regions, and even third-party data sets without having to move or copy data by hand.
How it works
In order to provide the best pricing performance at any scale, Amazon Redshift leverages machine learning and technology created by AWS to analyze structured and semi-structured data from data lakes, operational databases, and data warehouses using SQL.
Use cases
Boost demand and financial projections
Allows you to create low latency analytics apps for fraud detection, live leaderboards, and the Internet of Things by consuming hundreds of megabytes of data per second.
Make the most of your business intelligence
Using BI tools like Microsoft PowerBI, Tableau, Amazon QuickSight, and Amazon Redshift, create insightful reports and dashboards.
Quicken SQL machine learning
To support advanced analytics on vast amounts of data, SQL can be used to create, train, and implement machine learning models for a variety of use cases, such as regression, classification, and predictive analytics.
Make money out of your data
Create apps using all of your data from databases, data lakes, and data warehouses. To increase consumer value, monetize your data as a service, and open up new revenue sources, share and work together in a seamless and safe manner.
Easily merge your data with data sets from outside parties
Subscribe to and merge third-party data in AWS Data Exchange with your data in Amazon Redshift, whether it’s market data, social media analytics, weather data, or more, without having to deal with licensing, onboarding, or transferring the data to the warehouse.
Amazon Redshift concepts
Amazon Redshift Serverless helps you examine data without provisioning a data warehouse. Automatic resource provisioning and intelligent data warehouse capacity scaling ensure quick performance for even the most demanding and unpredictable applications. The data warehouse is free when idle, so you only pay for what you use. The Amazon Redshift query editor v2 or your favorite BI tool lets you load data and query immediately. Take advantage of the greatest pricing performance and familiar SQL capabilities in a zero-administration environment.
If your company is eligible and your cluster is being formed in an AWS Region without Amazon Redshift Serverless, you may be eligible for the free trial. Choose Production or Free trial to answer. For what will you use this cluster? Free trial creates a dc2.large node configuration. AWS Regions with Amazon Redshift Serverless are included in the Amazon Web Services General Reference’s Redshift Serverless API endpoints.
Key Amazon Redshift Serverless ideas are below
Namespace: Database objects and users are in a namespace. Amazon Redshift Serverless namespaces contain schemas, tables, users, datashares, and snapshots.
Workgroup: A collection of computer resources. Amazon Redshift Serverless computes in workgroups. Redshift Processing Units, security groups, and use limits are examples. Configure workgroup network and security settings using the Amazon Redshift Serverless GUI, AWS Command Line Interface, or APIs.
Important Amazon Redshift supplied cluster concepts:
Cluster: A cluster is an essential part of an Amazon Redshift data warehouse’s infrastructure.
A cluster has compute nodes. Compiled code runs on compute nodes.
An additional leader node controls two or more computing nodes in a cluster. Business intelligence tools and query editors communicate with the leader node. Your client application only talks to the leader. External apps can see computing nodes.
Database: A cluster contains one or more databases.
One or more computing node databases store user data. SQL clients communicate with the leader node, which organizes compute node queries. Read about compute and leader nodes in data warehouse system design. User data is grouped into database schemas.
Amazon Redshift is compatible with other RDBMSs. It supports OLTP functions including inserting and removing data like a standard RDBMS. Amazon Redshift excels at batch analysis and reporting.
Amazon Redshift’s typical data processing pipeline and its components are described below.
A example Amazon Redshift data processing path is shown below.Image credit to AWS
An enterprise-class relational database query and management system is Amazon Redshift. Business intelligence (BI), reporting, data, and analytics solutions can connect to Amazon Redshift. Analytic queries retrieve, compare, and evaluate vast volumes of data in various stages to obtain a result.
Multiple data sources upload structured, semistructured, and unstructured data to the data storage layer at the data ingestion layer. This data staging section holds data in various consumption readiness phases. Storage may be an Amazon S3 bucket.
The optional data processing layer preprocesses, validates, and transforms source data using ETL or ELT pipelines. ETL procedures enhance these raw datasets. ETL engines include AWS Glue.
Read more on govindhtech.com
#AmazonRedshift#QuickStartGuide#DataWarehousing#machinelearning#AWSzeroETLstrategy#datawarehouse#AmazonS3#data#aws#news#realtimeanalytics#AmazonQuickSight#technology#technews#govindhtech
0 notes
Text
Implementing a data warehouse? Learn how to navigate common challenges and optimize your data warehousing strategy.
0 notes
Text
youtube
Whether you're aiming for a career in software development, network administration etc. our courses will equip you with the knowledge and tools you need to succeed in today's dynamic tech landscape. Make your career in Information Technology Feel Free to speak to our education counselor at 8055 330 550
#ITDegree#TechEducation#FutureReady#softwaredeveloper#gamesdeveloper#qualityassurancetester#digitalmarketing#softwaretester#databasemanagementsystem#operatingsystem#datawarehousing#webdevelopment#Youtube
0 notes
Text
Creole Studios Launches Comprehensive Data Engineering Services with Azure Databricks Partnership
Creole Studios introduces its cutting-edge Data Engineering Services, aimed at empowering organizations to extract actionable insights from their data. Backed by certified experts and a strategic partnership with Azure Databricks, we offer comprehensive solutions spanning data strategy, advanced analytics, and secure data warehousing. Unlock the full potential of your data with Creole Studios' tailored data engineering services, designed to drive innovation and efficiency across industries.

#DataEngineering#BigDataAnalytics#DataStrategy#DataOps#DataQuality#AzureDatabricks#DataWarehousing#MachineLearning#DataAnalytics#BusinessIntelligence
0 notes
Text
What are the components of Azure Data Lake Analytics?
Azure Data Lake Analytics consists of the following key components:
Job Service: This component is responsible for managing and executing jobs submitted by users. It schedules and allocates resources for job execution.
Catalog Service: The Catalog Service stores and manages metadata about data stored in Data Lake Storage Gen1 or Gen2. It provides a structured view of the data, including file names, directories, and schema information.
Resource Management: Resource Management handles the allocation and scaling of resources for job execution. It ensures efficient resource utilization while maintaining performance.
Execution Environment: This component provides the runtime environment for executing U-SQL jobs. It manages the distributed execution of queries across multiple nodes in the Azure Data Lake Analytics cluster.
Job Submission and Monitoring: Azure Data Lake Analytics provides tools and APIs for submitting and monitoring jobs. Users can submit jobs using the Azure portal, Azure CLI, or REST APIs. They can also monitor job status and performance metrics through these interfaces.
Integration with Other Azure Services: Azure Data Lake Analytics integrates with other Azure services such as Azure Data Lake Storage, Azure Blob Storage, Azure SQL Database, and Azure Data Factory. This integration allows users to ingest, process, and analyze data from various sources seamlessly.
These components work together to provide a scalable and efficient platform for processing big data workloads in the cloud.
#Azure#DataLake#Analytics#BigData#CloudComputing#DataProcessing#DataManagement#Metadata#ResourceManagement#AzureServices#DataIntegration#DataWarehousing#DataEngineering#AzureStorage#magistersign#onlinetraining#support#cannada#usa#careerdevelopment
1 note
·
View note