#azure data pipeline
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
BuzzFeed published a report claiming that Tumblr was utilized as a distribution channel for Russian agents to influence American voting habits during the 2016 presidential election in Feb 2018.
Text
How to improve software development with Azure DevOps consulting services?
With the advancement of the technological sphere, Azure DevOps consulting services have created a storm to the internet. As the service provides end-to-end automation while enhancing development efficiency by utilizing tools like Azure Pipelines, Repos, and Artifacts, businesses can achieve smooth CI CD workflows. Consultants like us help to implement cloud-based infrastructure, automate deployments, and improve security, while ensuring rapid software releases with minimal downtime, optimizing cloud and on-premises environments.

0 notes
Text
Data Engineering Guide to Build Strong Azure Data Pipeline

This data engineering guide is useful for understanding the concept of building a strong data pipeline in Azure. Information nowadays is considered the main indicator in decision-making, business practice, and analysis, still, the main issue is having this data collected, processed, and maintained effectively and properly. Azure Data Engineering, Microsoft’s cloud services, offers solutions that help businesses design massive amounts of information transport pipelines in a structured, secure way. In this guide, we will shed light on how building an effective information pipeline can be achieved using Azure Data Engineering services even if it was your first time in this area.
Explain the concept of a data pipeline.
A data pipeline refers to an automated system. It transmits unstructured information from a source to a designated endpoint where it can be eventually stored and analyzed. Data is collected from different sources, such as applications, files, archives, databases, and services, and may be converted into a generic format, processed, and then transferred to the endpoint. Pipelines facilitate the smooth flow of information and the automation of such a process helps to keep the system under control by avoiding any human intervention and lets it process information in real-time or in batches at established intervals. Finally, the pipeline can handle an extremely high volume of data while tracking workflow actions comprehensively and reliably. This is essential for data-driven business processes that rely on huge amounts of information.
Why Use Azure Data Engineering Services for Building Data Pipelines?
There are many services and tools provided by Azure to strengthen the pipelines. Azure services are cloud-based services which means ‘anytime anywhere’ and scale. Handling a small one-line task (DevOps) to a complex task (workflow) can easily be implemented without thinking about the hardware resources. Another benefit of having services on the cloud is the scalability for the future. It also provides security for all the information. Now, let’s break down the steps involved in creating a strong pipeline in Azure.
Steps to Building a Pipeline in Azure
Step 1: Understand Your Information Requirements
The first step towards building your pipeline is to figure out what your needs are. What are the origins of the information that needs to be liquidated? Does it come from a database, an API, files, or a different system? Second, what will be done to the information as soon as it is extracted? Will it need to be cleaned? Transformed or aggregated? Finally, what will be the destination of the liquid information? Once, you identify the needs, you are good to implement the second step.
Step 2: Choose the Right Azure Services
Azure offers many services that you can use to compose pipelines. The most important are:
Azure Data Factory (ADF): This service allows you to construct and monitor pipelines. It orchestrates operations both on-premises and in the cloud and runs workflows on demand.
Azure Blob Storage: For business data primarily collected in raw form from many sources, for instance, Azure Blob Storage provides storage of unstructured data.
Azure SQL Database: Eventually, when the information is sufficiently processed, it could be written to a relational database, such as Azure SQL Database, for the ultimate in structured storage and ease of querying.
Azure Synapse Analytics: This service is suited to big-data analytics.
Azure Logic Apps: It allows the automation of workflows, integrating various services and triggers.
Each of these services offers different functionalities depending on your pipeline requirements.
Step 3: Setting Up Azure Data Factory
Having picked the services, the next activity is to set up an Azure Data Factory (ADF). ADF serves as the central management engine to control your pipeline and directs the flow of information from source to destination.
Create an ADF instance: In the Azure portal, the first step is to create an Azure Data Factory instance. You may use any name of your choice.
Set up linked services: Connections to sources such as databases, APIs, and destinations such as storage services to interact with them through ADF.
Data sets: All about what’s coming into or going out – the data. They’re about what you dictate the shape/type/nature of the information is at
Pipeline acts: A pipeline is a type of activity – things that do something. Pipelines are composed of acts that define how information flows through the system. You can add multiple steps with copy, transform, and validate types of operations on the incoming information.
Step 4: Data Ingestion
Collecting the information you need is called ingestion. In Azure Data Factory, you can ingest information collected from different sources, from databases to flat files, to APIs, and more. After you’ve ingested the information, it’s important to validate that the information still holds up. You can do this by using triggers and monitors to automate your ingestion process. For near real-time ingestion, options include Azure Event Hubs and Azure Stream Analytics, which are best employed in a continuous flow.
Step 5: Transformation and Processing
After it’s consumed, the data might need to be cleansed or transformed before processing. In Azure, this can be done through Mapping Data Flows built into ADF, or through the more advanced capabilities of Azure Databricks. For instance, if you have information that has to be cleaned (to weed out duplicates, say, or align different datasets that belong together), you’ll design transformation tasks to be part of the pipeline. Finally, the processed information will be ready for an analysis or reporting task, so it can have the maximum possible impact.
Step 6: Loading the Information
The final step is to load the processed data into a storage system that you can query and retrieve data from later. For structured data, common destinations are Azure SQL Database or Azure Synapse Analytics. If you’ll be storing files or unstructured information, the location of choice is Azure Blob Storage or Azure Data Lake. It’s possible to set up schedules within ADF to automate the pipeline, ingesting new data and storing it regularly without requiring human input.
Step 7: Monitoring and Maintenance
Once your pipeline is built and processing data, the scaled engineering decisions are all in the past, and all you have to do is make sure everything is working. You can use Azure Monitor and the Azure Data Factory (ADF) monitoring dashboard to track the channeled information – which routes it’s taking, in what order, and when it failed. Of course, you’ll tweak the flow as data changes, queries come in, and all sorts of black swans rear their ugly heads. You also need regular maintenance to keep things humming along nicely. As your corpus grows, you will need to tweak things here and there to handle larger information loads.
Conclusion
Designing an Azure pipeline can be daunting but, if you follow these steps, you will have a system capable of efficiently processing large amounts of information. Knowing your domain, using the right Azure data engineering services, and monitoring the system regularly will help build a strong and reliable pipeline.
Spiral Mantra’s Data Engineering Services
Spiral Mantra specializes in building production-grade pipelines and managing complex workflows. Our work includes collecting, processing, and storing vast amounts of information with cloud services such as Azure to create purpose-built pipelines that meet your business needs. If you want to build pipelines or workflows, whether it is real-time processing or a batch workflow, Spiral Mantra delivers reliable and scalable services to meet your information needs.
0 notes
Text
Data Engineering project : ETL data pipeline using azure ( Intermediate )
After a break I’m back again with another video, The concept of this video is to orchestrate a simple data pipeline using azure data … source
0 notes
Text
Sentra Secures $50M Series B to Safeguard AI-Driven Enterprises in the Age of Shadow Data
New Post has been published on https://thedigitalinsider.com/sentra-secures-50m-series-b-to-safeguard-ai-driven-enterprises-in-the-age-of-shadow-data/
Sentra Secures $50M Series B to Safeguard AI-Driven Enterprises in the Age of Shadow Data

In a landmark moment for data security, Sentra, a trailblazer in cloud-native data protection, has raised $50 million in Series B funding, bringing its total funding to over $100 million. The round was led by Key1 Capital with continued support from top-tier investors like Bessemer Venture Partners, Zeev Ventures, Standard Investments, and Munich Re Ventures.
This new investment arrives at a pivotal time, with AI adoption exploding across enterprises and bringing with it a tidal wave of sensitive data—and new security risks. Sentra, already experiencing 300% year-over-year growth and seeing fast adoption among Fortune 500 companies, is now doubling down on its mission: empowering organizations to innovate with AI without compromising on data security.
The AI Boom’s Dark Side: Unseen Risks in “Shadow Data”
While AI opens doors to unprecedented innovation, it also introduces a hidden threat—shadow data. As companies rush to harness the power of GenAI, data scientists and engineers frequently duplicate, move, and manipulate data across environments. Much of this activity flies under the radar of traditional security tools, leading to invisible data sprawl and growing compliance risks.
Gartner predicts that by 2025, GenAI will drive a 15% spike in data and application security spending, as organizations scramble to plug these emerging gaps. That’s where Sentra comes in.
What Makes Sentra Different?
Sentra’s Cloud-Native Data Security Platform (DSP) doesn’t just bolt security onto existing infrastructure. Instead, it’s designed from the ground up to autonomously discover, classify, and secure sensitive data—whether it lives in AWS, Azure, Google Cloud, SaaS apps, on-prem servers, or inside your AI pipeline.
At the heart of Sentra’s platform is an AI-powered classification engine that leverages large language models (LLMs). Unlike traditional data scanning tools that rely on fixed rules or predefined regex, Sentra’s LLMs understand the business context of data. That means they can identify sensitive information even in unstructured formats like documents, images, audio, or code repositories—with over 95% accuracy.
Importantly, no data ever leaves your environment. Sentra runs natively in your cloud or hybrid environment, maintaining full compliance with data residency requirements and avoiding any risk of exposure during the scanning process.
Beyond Classification: A Full Security Lifecycle
Sentra’s platform combines multiple layers of data security into one unified system:
DSPM (Data Security Posture Management) continuously assesses risks like misconfigured access controls, duplicated sensitive data, and misplaced files.
DDR (Data Detection & Response) flags suspicious activity in real-time—such as exfiltration attempts or ransomware encryption—empowering security teams to act before damage occurs.
DAG (Data Access Governance) maps user and application identities to data permissions and enforces least privilege access, a key principle in modern cybersecurity.
This approach transforms the once-static notion of data protection into a living, breathing security layer that scales with your business.
Led by a World-Class Cybersecurity Team
Sentra’s leadership team reads like a who’s who of Israeli cyber intelligence:
Asaf Kochan, President, is the former Commander of Unit 8200, Israel’s elite cyber intelligence unit.
Yoav Regev, CEO, led the Cyber Department within Unit 8200.
Ron Reiter, CTO, is a serial entrepreneur with deep technical expertise.
Yair Cohen, VP of Product, brings years of experience from Microsoft and Datadog.
Their shared vision: to reimagine data security for the cloud- and AI-first world.
And the market agrees. Sentra was recently named both a Leader and Fast Mover in the GigaOm Radar for Data Security Posture Management (DSPM), underscoring its growing influence in the security space.
Building a Safer Future for AI
The $50 million boost will allow Sentra to scale its operations, grow its expert team, and enhance its platform with new capabilities to secure GenAI workloads, AI assistants, and emerging data pipelines. These advancements will provide security teams with even greater visibility and control over sensitive data—across petabyte-scale estates and AI ecosystems.
“AI is only as secure as the data behind it,” said CEO Yoav Regev. “Every enterprise wants to harness AI—but without confidence in their data security, they’re stuck in a holding pattern. Sentra breaks that barrier, enabling fast, safe innovation.”
As AI adoption accelerates and regulatory scrutiny tightens, Sentra’s approach may very well become the blueprint for modern enterprise data protection. For businesses looking to embrace AI with confidence, Sentra offers something powerful: security that moves at the speed of innovation.
#2025#adoption#ai#AI adoption#AI-powered#amp#Application Security#approach#apps#assistants#audio#AWS#azure#barrier#blueprint#Building#Business#CEO#Cloud#Cloud-Native#code#Companies#compliance#CTO#cyber#cybersecurity#Dark#data#data pipelines#data protection
1 note
·
View note
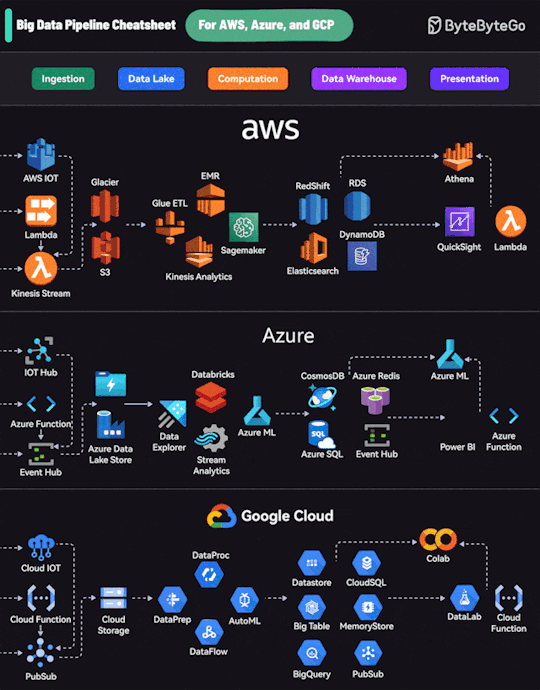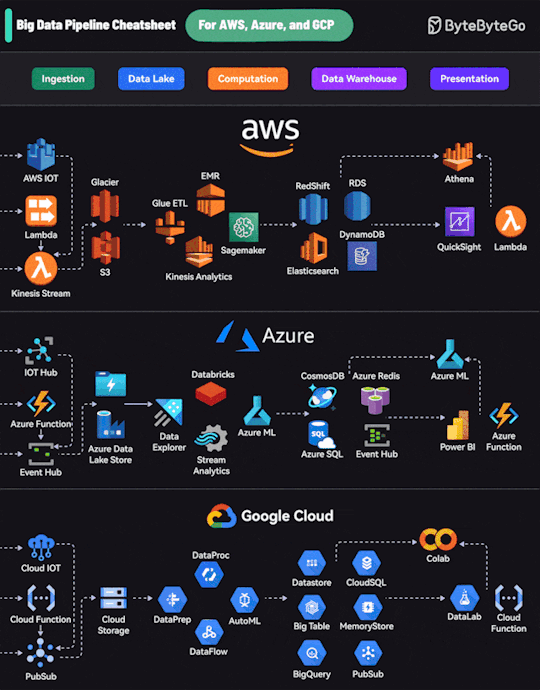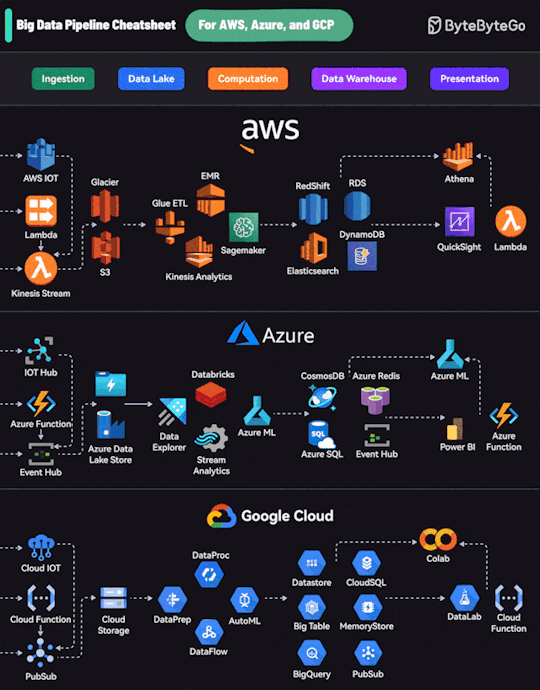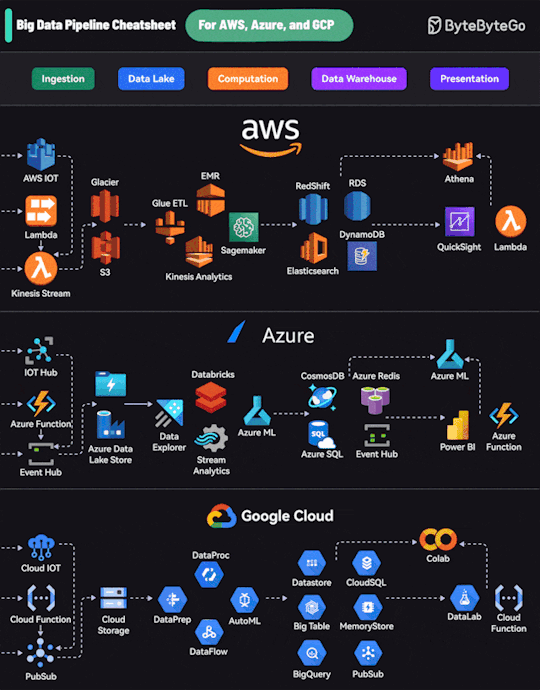
Text
1 note
·
View note
Text
#Azure Data Factory#azure data factory interview questions#adf interview question#azure data engineer interview question#pyspark#sql#sql interview questions#pyspark interview questions#Data Integration#Cloud Data Warehousing#ETL#ELT#Data Pipelines#Data Orchestration#Data Engineering#Microsoft Azure#Big Data Integration#Data Transformation#Data Migration#Data Lakes#Azure Synapse Analytics#Data Processing#Data Modeling#Batch Processing#Data Governance
1 note
·
View note
Text
Exploring the Azure Technology Stack: A Solution Architect’s Journey
Kavin
As a solution architect, my career revolves around solving complex problems and designing systems that are scalable, secure, and efficient. The rise of cloud computing has transformed the way we think about technology, and Microsoft Azure has been at the forefront of this evolution. With its diverse and powerful technology stack, Azure offers endless possibilities for businesses and developers alike. My journey with Azure began with Microsoft Azure training online, which not only deepened my understanding of cloud concepts but also helped me unlock the potential of Azure’s ecosystem.
In this blog, I will share my experience working with a specific Azure technology stack that has proven to be transformative in various projects. This stack primarily focuses on serverless computing, container orchestration, DevOps integration, and globally distributed data management. Let’s dive into how these components come together to create robust solutions for modern business challenges.

Understanding the Azure Ecosystem
Azure’s ecosystem is vast, encompassing services that cater to infrastructure, application development, analytics, machine learning, and more. For this blog, I will focus on a specific stack that includes:
Azure Functions for serverless computing.
Azure Kubernetes Service (AKS) for container orchestration.
Azure DevOps for streamlined development and deployment.
Azure Cosmos DB for globally distributed, scalable data storage.
Each of these services has unique strengths, and when used together, they form a powerful foundation for building modern, cloud-native applications.
1. Azure Functions: Embracing Serverless Architecture
Serverless computing has redefined how we build and deploy applications. With Azure Functions, developers can focus on writing code without worrying about managing infrastructure. Azure Functions supports multiple programming languages and offers seamless integration with other Azure services.
Real-World Application
In one of my projects, we needed to process real-time data from IoT devices deployed across multiple locations. Azure Functions was the perfect choice for this task. By integrating Azure Functions with Azure Event Hubs, we were able to create an event-driven architecture that processed millions of events daily. The serverless nature of Azure Functions allowed us to scale dynamically based on workload, ensuring cost-efficiency and high performance.
Key Benefits:
Auto-scaling: Automatically adjusts to handle workload variations.
Cost-effective: Pay only for the resources consumed during function execution.
Integration-ready: Easily connects with services like Logic Apps, Event Grid, and API Management.
2. Azure Kubernetes Service (AKS): The Power of Containers
Containers have become the backbone of modern application development, and Azure Kubernetes Service (AKS) simplifies container orchestration. AKS provides a managed Kubernetes environment, making it easier to deploy, manage, and scale containerized applications.
Real-World Application
In a project for a healthcare client, we built a microservices architecture using AKS. Each service—such as patient records, appointment scheduling, and billing—was containerized and deployed on AKS. This approach provided several advantages:
Isolation: Each service operated independently, improving fault tolerance.
Scalability: AKS scaled specific services based on demand, optimizing resource usage.
Observability: Using Azure Monitor, we gained deep insights into application performance and quickly resolved issues.
The integration of AKS with Azure DevOps further streamlined our CI/CD pipelines, enabling rapid deployment and updates without downtime.
Key Benefits:
Managed Kubernetes: Reduces operational overhead with automated updates and patching.
Multi-region support: Enables global application deployments.
Built-in security: Integrates with Azure Active Directory and offers role-based access control (RBAC).
3. Azure DevOps: Streamlining Development Workflows
Azure DevOps is an all-in-one platform for managing development workflows, from planning to deployment. It includes tools like Azure Repos, Azure Pipelines, and Azure Artifacts, which support collaboration and automation.
Real-World Application
For an e-commerce client, we used Azure DevOps to establish an efficient CI/CD pipeline. The project involved multiple teams working on front-end, back-end, and database components. Azure DevOps provided:
Version control: Using Azure Repos for centralized code management.
Automated pipelines: Azure Pipelines for building, testing, and deploying code.
Artifact management: Storing dependencies in Azure Artifacts for seamless integration.
The result? Deployment cycles that previously took weeks were reduced to just a few hours, enabling faster time-to-market and improved customer satisfaction.
Key Benefits:
End-to-end integration: Unifies tools for seamless development and deployment.
Scalability: Supports projects of all sizes, from startups to enterprises.
Collaboration: Facilitates team communication with built-in dashboards and tracking.

4. Azure Cosmos DB: Global Data at Scale
Azure Cosmos DB is a globally distributed, multi-model database service designed for mission-critical applications. It guarantees low latency, high availability, and scalability, making it ideal for applications requiring real-time data access across multiple regions.
Real-World Application
In a project for a financial services company, we used Azure Cosmos DB to manage transaction data across multiple continents. The database’s multi-region replication ensure data consistency and availability, even during regional outages. Additionally, Cosmos DB’s support for multiple APIs (SQL, MongoDB, Cassandra, etc.) allowed us to integrate seamlessly with existing systems.
Key Benefits:
Global distribution: Data is replicated across regions with minimal latency.
Flexibility: Supports various data models, including key-value, document, and graph.
SLAs: Offers industry-leading SLAs for availability, throughput, and latency.
Building a Cohesive Solution
Combining these Azure services creates a technology stack that is flexible, scalable, and efficient. Here’s how they work together in a hypothetical solution:
Data Ingestion: IoT devices send data to Azure Event Hubs.
Processing: Azure Functions processes the data in real-time.
Storage: Processed data is stored in Azure Cosmos DB for global access.
Application Logic: Containerized microservices run on AKS, providing APIs for accessing and manipulating data.
Deployment: Azure DevOps manages the CI/CD pipeline, ensuring seamless updates to the application.
This architecture demonstrates how Azure’s technology stack can address modern business challenges while maintaining high performance and reliability.
Final Thoughts
My journey with Azure has been both rewarding and transformative. The training I received at ACTE Institute provided me with a strong foundation to explore Azure’s capabilities and apply them effectively in real-world scenarios. For those new to cloud computing, I recommend starting with a solid training program that offers hands-on experience and practical insights.
As the demand for cloud professionals continues to grow, specializing in Azure’s technology stack can open doors to exciting opportunities. If you’re based in Hyderabad or prefer online learning, consider enrolling in Microsoft Azure training in Hyderabad to kickstart your journey.
Azure’s ecosystem is continuously evolving, offering new tools and features to address emerging challenges. By staying committed to learning and experimenting, we can harness the full potential of this powerful platform and drive innovation in every project we undertake.
#cybersecurity#database#marketingstrategy#digitalmarketing#adtech#artificialintelligence#machinelearning#ai
2 notes
·
View notes
Text
Top 10 In- Demand Tech Jobs in 2025

Technology is growing faster than ever, and so is the need for skilled professionals in the field. From artificial intelligence to cloud computing, businesses are looking for experts who can keep up with the latest advancements. These tech jobs not only pay well but also offer great career growth and exciting challenges.
In this blog, we’ll look at the top 10 tech jobs that are in high demand today. Whether you’re starting your career or thinking of learning new skills, these jobs can help you plan a bright future in the tech world.
1. AI and Machine Learning Specialists
Artificial Intelligence (AI) and Machine Learning are changing the game by helping machines learn and improve on their own without needing step-by-step instructions. They’re being used in many areas, like chatbots, spotting fraud, and predicting trends.
Key Skills: Python, TensorFlow, PyTorch, data analysis, deep learning, and natural language processing (NLP).
Industries Hiring: Healthcare, finance, retail, and manufacturing.
Career Tip: Keep up with AI and machine learning by working on projects and getting an AI certification. Joining AI hackathons helps you learn and meet others in the field.
2. Data Scientists
Data scientists work with large sets of data to find patterns, trends, and useful insights that help businesses make smart decisions. They play a key role in everything from personalized marketing to predicting health outcomes.
Key Skills: Data visualization, statistical analysis, R, Python, SQL, and data mining.
Industries Hiring: E-commerce, telecommunications, and pharmaceuticals.
Career Tip: Work with real-world data and build a strong portfolio to showcase your skills. Earning certifications in data science tools can help you stand out.
3. Cloud Computing Engineers: These professionals create and manage cloud systems that allow businesses to store data and run apps without needing physical servers, making operations more efficient.
Key Skills: AWS, Azure, Google Cloud Platform (GCP), DevOps, and containerization (Docker, Kubernetes).
Industries Hiring: IT services, startups, and enterprises undergoing digital transformation.
Career Tip: Get certified in cloud platforms like AWS (e.g., AWS Certified Solutions Architect).
4. Cybersecurity Experts
Cybersecurity professionals protect companies from data breaches, malware, and other online threats. As remote work grows, keeping digital information safe is more crucial than ever.
Key Skills: Ethical hacking, penetration testing, risk management, and cybersecurity tools.
Industries Hiring: Banking, IT, and government agencies.
Career Tip: Stay updated on new cybersecurity threats and trends. Certifications like CEH (Certified Ethical Hacker) or CISSP (Certified Information Systems Security Professional) can help you advance in your career.
5. Full-Stack Developers
Full-stack developers are skilled programmers who can work on both the front-end (what users see) and the back-end (server and database) of web applications.
Key Skills: JavaScript, React, Node.js, HTML/CSS, and APIs.
Industries Hiring: Tech startups, e-commerce, and digital media.
Career Tip: Create a strong GitHub profile with projects that highlight your full-stack skills. Learn popular frameworks like React Native to expand into mobile app development.
6. DevOps Engineers
DevOps engineers help make software faster and more reliable by connecting development and operations teams. They streamline the process for quicker deployments.
Key Skills: CI/CD pipelines, automation tools, scripting, and system administration.
Industries Hiring: SaaS companies, cloud service providers, and enterprise IT.
Career Tip: Earn key tools like Jenkins, Ansible, and Kubernetes, and develop scripting skills in languages like Bash or Python. Earning a DevOps certification is a plus and can enhance your expertise in the field.
7. Blockchain Developers
They build secure, transparent, and unchangeable systems. Blockchain is not just for cryptocurrencies; it’s also used in tracking supply chains, managing healthcare records, and even in voting systems.
Key Skills: Solidity, Ethereum, smart contracts, cryptography, and DApp development.
Industries Hiring: Fintech, logistics, and healthcare.
Career Tip: Create and share your own blockchain projects to show your skills. Joining blockchain communities can help you learn more and connect with others in the field.
8. Robotics Engineers
Robotics engineers design, build, and program robots to do tasks faster or safer than humans. Their work is especially important in industries like manufacturing and healthcare.
Key Skills: Programming (C++, Python), robotics process automation (RPA), and mechanical engineering.
Industries Hiring: Automotive, healthcare, and logistics.
Career Tip: Stay updated on new trends like self-driving cars and AI in robotics.
9. Internet of Things (IoT) Specialists
IoT specialists work on systems that connect devices to the internet, allowing them to communicate and be controlled easily. This is crucial for creating smart cities, homes, and industries.
Key Skills: Embedded systems, wireless communication protocols, data analytics, and IoT platforms.
Industries Hiring: Consumer electronics, automotive, and smart city projects.
Career Tip: Create IoT prototypes and learn to use platforms like AWS IoT or Microsoft Azure IoT. Stay updated on 5G technology and edge computing trends.
10. Product Managers
Product managers oversee the development of products, from idea to launch, making sure they are both technically possible and meet market demands. They connect technical teams with business stakeholders.
Key Skills: Agile methodologies, market research, UX design, and project management.
Industries Hiring: Software development, e-commerce, and SaaS companies.
Career Tip: Work on improving your communication and leadership skills. Getting certifications like PMP (Project Management Professional) or CSPO (Certified Scrum Product Owner) can help you advance.
Importance of Upskilling in the Tech Industry
Stay Up-to-Date: Technology changes fast, and learning new skills helps you keep up with the latest trends and tools.
Grow in Your Career: By learning new skills, you open doors to better job opportunities and promotions.
Earn a Higher Salary: The more skills you have, the more valuable you are to employers, which can lead to higher-paying jobs.
Feel More Confident: Learning new things makes you feel more prepared and ready to take on tougher tasks.
Adapt to Changes: Technology keeps evolving, and upskilling helps you stay flexible and ready for any new changes in the industry.
Top Companies Hiring for These Roles
Global Tech Giants: Google, Microsoft, Amazon, and IBM.
Startups: Fintech, health tech, and AI-based startups are often at the forefront of innovation.
Consulting Firms: Companies like Accenture, Deloitte, and PwC increasingly seek tech talent.
In conclusion, the tech world is constantly changing, and staying updated is key to having a successful career. In 2025, jobs in fields like AI, cybersecurity, data science, and software development will be in high demand. By learning the right skills and keeping up with new trends, you can prepare yourself for these exciting roles. Whether you're just starting or looking to improve your skills, the tech industry offers many opportunities for growth and success.
#Top 10 Tech Jobs in 2025#In- Demand Tech Jobs#High paying Tech Jobs#artificial intelligence#datascience#cybersecurity
2 notes
·
View notes
Text
Leveraging AI and Automation in Azure DevOps Consulting for Smarter Workflows
Azure DevOps consulting is evolving with the integration of Artificial Intelligence (AI) and automation, enabling organizations to optimize their CI CD pipelines to enhance predictive analytics. Spiral mantra , your strategic DevOps consultants in USA helps businesses harness AI-powered DevOps tools, ensuring seamless deployment and increased efficiency in software development lifecycles. Backed with certified experts, we help businesses to stay ahead by adopting AI-driven Azure DevOps consulting services for smarter, faster, and more reliable software delivery.

0 notes
Text
Top 6 Remote High Paying Jobs in IT You Can Do From Home
Technology has changed the scenario of workplaces and brought new opportunities for IT professionals erasing previous boundaries. Today, people are searching for both flexibility and, of course, better pay, which has made many look for remote well-paid jobs, especially in information technology field.
Advancements in technology have made remote work a reality for a growing number of IT specialists. Here, we will look into six specific remote high-paying IT jobs you can pursue from the comfort of your home:
Software Developer
Software developers are the architects of the digital world, designing, developing, and maintaining the software applications that power our lives. They work closely with clients, project managers, and other team members to translate concepts into functional and efficient software solutions.
In demand skills include proficiency in programming languages like Java, Python, Ruby, or JavaScript, knowledge of frameworks like React or Angular, and a strong foundation in problem-solving and communication. Platforms like Guruface can help you learn the coding skills to land a software developer job budget-friendly.
The average salary for a remote software developer is highly competitive, ranging from $65,000 to $325,000 according to recent data.
Data Scientist
Data scientists are the detectives of the digital age. They use their expertise in data analysis to uncover valuable insights and trends from large datasets, informing business decisions and driving growth.
To excel in this role, you'll need strong programming skills in languages like Python, R, and SQL, a solid understanding of statistical analysis and machine learning, and the ability to communicate complex findings effectively. Guruface is one of the leading online learning platforms that provides affordable data science courses.
The average salary for a remote Data Scientist is $154,932, with top earners exceeding $183,000.
Cloud Architect
Cloud architects are the masterminds behind an organization's cloud computing strategy. They design, plan, and manage a company's cloud infrastructure, ensuring scalability, security, and cost-effectiveness.
Cloud architects must be well-versed in cloud computing technologies from various providers like Amazon Web Services (AWS), Microsoft Azure, and Google Cloud Platform. In addition, proficiency in architectural design, infrastructure as code (IaC), and security compliance is essential. If you're interested in becoming a cloud architect, Guruface offers courses that can equip you with the necessary skills. Their cloud architect training programs can help you gain proficiency in cloud technologies from industry leaders like AWS, Microsoft Azure, and Google Cloud Platform.
The average salary for a cloud architect in the US is $128,418, with senior cloud architects earning upwards of $167,000 annually.
DevOps Engineer
DevOps engineers bridge the gap between IT and software development, streamlining the software development lifecycle. They leverage automation tools and methodologies to optimize production processes and reduce complexity.
A successful DevOps engineer requires expertise in tools like Puppet, Ansible, and Chef, experience building and maintaining CI/CD pipelines, and a strong foundation in scripting languages like Python and Shell. Guruface offers DevOps training courses that can equip you with these essential skills. Their programs can help you learn the principles and practices of DevOps, giving you the knowledge to automate tasks, build efficient CI/CD pipelines, and select the right tools for the job.
The average salary for a remote DevOps Engineer is $154,333, and the salary range typically falls between $73,000 and $125,000.
AI/Machine Learning Engineer
AI/Machine Learning Engineers are the builders of intelligent systems. They utilize data to program and test machine learning algorithms, creating models that automate tasks and forecast business trends.
In-depth knowledge of machine learning, deep learning, and natural language processing is crucial for this role, along with proficiency in programming languages like Python and R programming and familiarity with frameworks like TensorFlow and PyTorch.
The average machine learning engineer salary in the US is $166,000 annually, ranging from $126,000 to $221,000.
Information Security Analyst
Information security analysts are the guardians of an organization's digital assets. They work to identify vulnerabilities, protect data from cyberattacks, and respond to security incidents.
A cybersecurity analyst's skillset encompasses technical expertise in network security, risk assessment, and incident response, coupled with strong communication and collaboration abilities.
The average salary for an Information Security Analyst in the United States is $77,490, with a salary range of $57,000 to $106,000.
If you're looking to become a digital guardian, Guruface offers cybersecurity courses that can equip you with the necessary skills. Their programs can teach you to identify vulnerabilities in an organization's network, develop strategies to protect data from cyberattacks, and effectively respond to security incidents. By honing both technical expertise and soft skills like communication and collaboration, Guruface's courses can prepare you to thrive in the in-demand cybersecurity job market.
Conclusion
The rapid evolution of the IT sector presents an opportunity for professionals to engage remotely in high-paying jobs that not only offer high earnings but also contribute significantly to technological advancement. Through this exploration of roles such as Software Developers, Data Scientists, Cloud Architects, DevOps Engineers, AI/Machine Learning Engineers, and Information Security Analysts, we've uncovered the essential skills, career opportunities, and the vital role of continuous education via online platforms like Guruface in improving these career paths.
Forget stuffy textbooks – Guruface's online courses are all about the latest IT skills, making you a tech rockstar in the eyes of recruiters. Upskill from coding newbie to cybersecurity guru, all on your schedule and without a dent in your wallet.
1 note
·
View note
Text
How Real-time Data Pipeline works in Data Engineering? #dataengineering #realtimestreaming #azure
Join this channel to get access to perks: – – – Book a … source
0 notes
Text
Datasets Matter: The Battle Between Open and Closed Generative AI is Not Only About Models Anymore
New Post has been published on https://thedigitalinsider.com/datasets-matter-the-battle-between-open-and-closed-generative-ai-is-not-only-about-models-anymore/
Datasets Matter: The Battle Between Open and Closed Generative AI is Not Only About Models Anymore
Two major open source datasets were released this week.
Created Using DALL-E
Next Week in The Sequence:
Edge 403: Our series about autonomous agents continues covering memory-based planning methods. The research behind the TravelPlanner benchmark for planning in LLMs and the impressive MemGPT framework for autonomous agents.
The Sequence Chat: A super cool interview with one of the engineers behind Azure OpenAI Service and Microsoft CoPilot.
Edge 404: We dive into Meta AI’s amazing research for predicting multiple tokens at the same time in LLMs.
You can subscribe to The Sequence below:
TheSequence is a reader-supported publication. To receive new posts and support my work, consider becoming a free or paid subscriber.
📝 Editorial: Datasets Matter: The Battle Between Open and Closed Generative AI is Not Only About Models Anymore
The battle between open and closed generative AI has been at the center of industry developments. From the very beginning, the focus has been on open vs. closed models, such as Mistral and Llama vs. GPT-4 and Claude. Less attention has been paid to other foundational aspects of the model lifecycle, such as the datasets used for training and fine-tuning. In fact, one of the limitations of the so-called open weight models is that they don’t disclose the training datasets and pipeline. What if we had high-quality open source datasets that rival those used to pretrain massive foundation models?
Open source datasets are one of the key aspects to unlocking innovation in generative AI. The costs required to build multi-trillion token datasets are completely prohibitive to most organizations. Leading AI labs, such as the Allen AI Institute, have been at the forefront of this idea, regularly open sourcing high-quality datasets such as the ones used for the Olmo model. Now it seems that they are getting some help.
This week, we saw two major efforts related to open source generative AI datasets. Hugging Face open-sourced FineWeb, a 44TB dataset of 15 trillion tokens derived from 96 CommonCrawl snapshots. Hugging Face also released FineWeb-Edu, a subset of FineWeb focused on educational value. But Hugging Face was not the only company actively releasing open source datasets. Complementing the FineWeb release, AI startup Zyphra released Zyda, a 1.3 trillion token dataset for language modeling. The construction of Zyda seems to have focused on a very meticulous filtering and deduplication process and shows remarkable performance compared to other datasets such as Dolma or RedefinedWeb.
High-quality open source datasets are paramount to enabling innovation in open generative models. Researchers using these datasets can now focus on pretraining pipelines and optimizations, while teams using those models for fine-tuning or inference can have a clearer way to explain outputs based on the composition of the dataset. The battle between open and closed generative AI is not just about models anymore.
🔎 ML Research
Extracting Concepts from GPT-4
OpenAI published a paper proposing an interpretability technique to understanding neural activity within LLMs. Specifically, the method uses k-sparse autoencoders to control sparsity which leads to more interpretable models —> Read more.
Transformer are SSMs
Researchers from Princeton University and Carnegie Mellon University published a paper outlining theoretical connections between transformers and SSMs. The paper also proposes a framework called state space duality and a new architecture called Mamba-2 which improves the performance over its predecessors by 2-8x —> Read more.
Believe or Not Believe LLMs
Google DeepMind published a paper proposing a technique to quantify uncertainty in LLM responses. The paper explores different sources of uncertainty such as lack of knowledge and randomness in order to quantify the reliability of an LLM output —> Read more.
CodecLM
Google Research published a paper introducing CodecLM, a framework for using synthetic data for LLM alignment in downstream tasks. CodecLM leverages LLMs like Gemini to encode seed intrstructions into the metadata and then decodes it into synthetic intstructions —> Read more.
TinyAgent
Researchers from UC Berkeley published a detailed blog post about TinyAgent, a function calling tuning method for small language models. TinyAgent aims to enable function calling LLMs that can run on mobile or IoT devices —> Read more.
Parrot
Researchers from Shanghai Jiao Tong University and Microsoft Research published a paper introducing Parrot, a framework for correlating multiple LLM requests. Parrot uses the concept of a Semantic Variable to annotate input/output variables in LLMs to enable the creation of a data pipeline with LLMs —> Read more.
🤖 Cool AI Tech Releases
FineWeb
HuggingFace open sourced FineWeb, a 15 trillion token dataset for LLM training —> Read more.
Stable Audion Open
Stability AI open source Stable Audio Open, its new generative audio model —> Read more.
Mistral Fine-Tune
Mistral open sourced mistral-finetune SDK and services for fine-tuning models programmatically —> Read more.
Zyda
Zyphra Technologies open sourced Zyda, a 1.3 trillion token dataset that powers the version of its Zamba models —> Read more.
🛠 Real World AI
Salesforce discusses their use of Amazon SageMaker in their Einstein platform —> Read more.
📡AI Radar
Cisco announced a $1B AI investment fund with some major positions in companies like Cohere, Mistral and Scale AI.
Cloudera acquired AI startup Verta.
Databricks acquired data management company Tabular.
Tektonic, raised $10 million to build generative agents for business operations —> Read more.
AI task management startup Hoop raised $5 million.
Galileo announced Luna, a family of evaluation foundation models.
Browserbase raised $6.5 million for its LLM browser-based automation platform.
AI artwork platform Exactly.ai raised $4.3 million.
Sirion acquired AI document management platform Eigen Technologies.
Asana added AI teammates to complement task management capabilities.
Eyebot raised $6 million for its AI-powered vision exams.
AI code base platform Greptile raised a $4 million seed round.
TheSequence is a reader-supported publication. To receive new posts and support my work, consider becoming a free or paid subscriber.
#agents#ai#AI-powered#amazing#Amazon#architecture#Asana#attention#audio#automation#automation platform#autonomous agents#azure#azure openai#benchmark#Blog#browser#Business#Carnegie Mellon University#claude#code#Companies#Composition#construction#data#Data Management#data pipeline#databricks#datasets#DeepMind
0 notes
Text
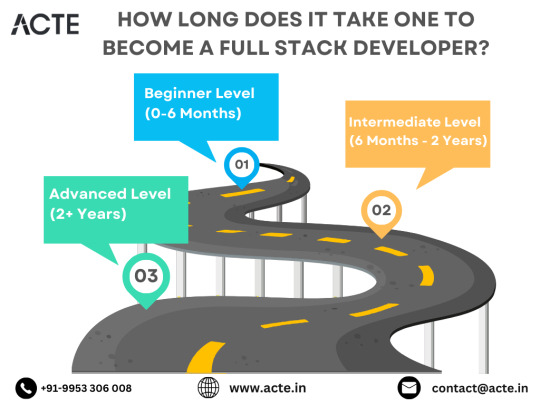
The Roadmap to Full Stack Developer Proficiency: A Comprehensive Guide
Embarking on the journey to becoming a full stack developer is an exhilarating endeavor filled with growth and challenges. Whether you're taking your first steps or seeking to elevate your skills, understanding the path ahead is crucial. In this detailed roadmap, we'll outline the stages of mastering full stack development, exploring essential milestones, competencies, and strategies to guide you through this enriching career journey.

Beginning the Journey: Novice Phase (0-6 Months)
As a novice, you're entering the realm of programming with a fresh perspective and eagerness to learn. This initial phase sets the groundwork for your progression as a full stack developer.
Grasping Programming Fundamentals:
Your journey commences with grasping the foundational elements of programming languages like HTML, CSS, and JavaScript. These are the cornerstone of web development and are essential for crafting dynamic and interactive web applications.
Familiarizing with Basic Data Structures and Algorithms:
To develop proficiency in programming, understanding fundamental data structures such as arrays, objects, and linked lists, along with algorithms like sorting and searching, is imperative. These concepts form the backbone of problem-solving in software development.
Exploring Essential Web Development Concepts:
During this phase, you'll delve into crucial web development concepts like client-server architecture, HTTP protocol, and the Document Object Model (DOM). Acquiring insights into the underlying mechanisms of web applications lays a strong foundation for tackling more intricate projects.
Advancing Forward: Intermediate Stage (6 Months - 2 Years)
As you progress beyond the basics, you'll transition into the intermediate stage, where you'll deepen your understanding and skills across various facets of full stack development.
Venturing into Backend Development:
In the intermediate stage, you'll venture into backend development, honing your proficiency in server-side languages like Node.js, Python, or Java. Here, you'll learn to construct robust server-side applications, manage data storage and retrieval, and implement authentication and authorization mechanisms.
Mastering Database Management:
A pivotal aspect of backend development is comprehending databases. You'll delve into relational databases like MySQL and PostgreSQL, as well as NoSQL databases like MongoDB. Proficiency in database management systems and design principles enables the creation of scalable and efficient applications.
Exploring Frontend Frameworks and Libraries:
In addition to backend development, you'll deepen your expertise in frontend technologies. You'll explore prominent frameworks and libraries such as React, Angular, or Vue.js, streamlining the creation of interactive and responsive user interfaces.
Learning Version Control with Git:
Version control is indispensable for collaborative software development. During this phase, you'll familiarize yourself with Git, a distributed version control system, to manage your codebase, track changes, and collaborate effectively with fellow developers.
Achieving Mastery: Advanced Phase (2+ Years)
As you ascend in your journey, you'll enter the advanced phase of full stack development, where you'll refine your skills, tackle intricate challenges, and delve into specialized domains of interest.
Designing Scalable Systems:
In the advanced stage, focus shifts to designing scalable systems capable of managing substantial volumes of traffic and data. You'll explore design patterns, scalability methodologies, and cloud computing platforms like AWS, Azure, or Google Cloud.
Embracing DevOps Practices:
DevOps practices play a pivotal role in contemporary software development. You'll delve into continuous integration and continuous deployment (CI/CD) pipelines, infrastructure as code (IaC), and containerization technologies such as Docker and Kubernetes.
Specializing in Niche Areas:
With experience, you may opt to specialize in specific domains of full stack development, whether it's frontend or backend development, mobile app development, or DevOps. Specialization enables you to deepen your expertise and pursue career avenues aligned with your passions and strengths.
Conclusion:
Becoming a proficient full stack developer is a transformative journey that demands dedication, resilience, and perpetual learning. By following the roadmap outlined in this guide and maintaining a curious and adaptable mindset, you'll navigate the complexities and opportunities inherent in the realm of full stack development. Remember, mastery isn't merely about acquiring technical skills but also about fostering collaboration, embracing innovation, and contributing meaningfully to the ever-evolving landscape of technology.
#full stack developer#education#information#full stack web development#front end development#frameworks#web development#backend#full stack developer course#technology
10 notes
·
View notes
Text
[GÓC TUYỂN DỤNG]
📢TUYỂN DỤNG FULLSTACK DEVELOPER📢
MÔ TẢ CÔNG VIỆC:
Phát triển và bảo trì hệ thống: Phối hợp với Product team, Technical Lead cũng như Frontend/Mobile engineer để xây dựng các API / nghiệp vụ phục vụ hệ thống
Tối ưu hoá: tối ưu hoá performance về API, database query, tương tác cross-servicé
Phối hợp với các bộ phận non-IT: phối hợp với các bên liên quan như vận hành sản phẩm, cskh, kinh doanh để kịp thời xử lý và cải thiện sản phẩm
Testing: có trách nhiệm test/ automation test với sản phẩm mình tạo ra, đảm bảo chất lượng code.
YÊU CẦU:
Must have (Bắt buộc):
Có kiến thức về lập trình hướng đối tượng (OOP)
Nắm vững cấu trúc dữ liệu và giải thuật (Data structures and algorithm)
Có khả năng giải quyết vấn đề tốt (Problem solving)
Hiểu biết về các giao thức HTTP, gRPC, Graphql API
Có kiến thức / kinh nghiệm sử dụng Git
Hiểu biết về nguyên lý SOLID trong lập trình
Có kiến thức về Design Pattern và áp dụng trong lập trình.
Về Backend Development:
Có kinh nghiệm lập trình backend với NodeJS ( tối thiểu 1 năm với Typescript)
Có tối thiểu 2 năm kinh nghiệm xây dựng hệ thống chịu tải cao và độ trễ thấp
Có kinh nghiệm xây dựng các hệ thống API Restful, Graphql hoặc gRPC
Quen thuộc và có kinh nghiệm xây dựng hệ thống phân tán, microservices / serverless
Sử dụng thành thạo testing framework như Jest, mocha,…
Về Database / Data storing Experience (Kinh nghiệm về cơ sử dữ liệu, lưu trữ dữ liệu):
Sử dụng thành thạo Postgresql hoặc Mysql
Có kinh nghiệm / thành thạo MongoDB
Có kinh nghiệm sử dụng Redis trong caching
Về Frontend Development:
Có tối thiểu 2 năm kinh nghiệm lập trình frontend với ReactJS / Vue
Sử dụng thành thạo các State Management system trong lâp trình frontend
Có khả năng xây dựng website SPA/SSR 1 cách mượt mà, hiệu suất cao
Thành thạo các công cụ Frontend debugging, testing
Về Devops Experience:
Sử dụng tốt commandline trong công việc
Có khả năng xây dựng cicd pipelines cơ bản cho backend, frontend
Có hiểu biết, kinh nghiệm về docker, K8s
Ưu tiên ứng viên:
Có kinh nghiệm sử dụng Nestjs framework cho Nodejs
Có kinh nghiệm lập trình Backend với Java
Có kinh nghiệm thực chiến với cloud provider như AWS, GCP, Azure,…
QUYỀN LỢI:
Mức lương: Level Junior: Từ 13.000.000đ-20.000.000đ, Middle: Từ 25.000.000đ - 30.000.000đ hoặc thoả thuận theo năng lực
Thời gian làm việc: Từ 9h00 - 18h00 từ Thứ 2 - Thứ 6, nghỉ Thứ 7 và Chủ nhật. Làm việc từ 1-2 ngày thứ 7 trong tháng nếu có lịch retro dự án.
Đầy đủ các quyền lợi theo luật lao động: BHXH, BHYT, BHTN, Thai sản,…
Lương tháng 13, thưởng theo kết quả làm việc cuối năm, thưởng các ngày Lễ Tết 30/04, 01/05, 08/03, Tết Âm lịch, Dương lịch, sinh nhật, hiếu hỷ,…
Xét tăng lương định kỳ hàng năm;
Môi trường làm việc trẻ, năng động, với cơ hội đào tạo & thăng tiến, các hoạt động gắn kết thường xuyên như Teambuilding, du lịch.
Văn hóa trao quyền, khuyến khích nhân viên sáng tạo, cải tiến và phát triển bản thân.
Cơ hội tham gia nhiều dự án, đa dạng trong lĩnh vực công nghệ.
THÔNG TIN LIÊN HỆ VÀ ỨNG TUYỂN TẠI:
Email: [email protected]
Hotline: 0987.215.468 (Ms. Xoan) hoặc 0337.049.208 (Ms. Hoài)
Facebook/LinkedIn: Airdata Technology
Địa chỉ Công ty:
🏢Trụ sở chính: Số 77 Thoại Ngọc Hầu, Phường Hoà Thạnh, Quận Tân Phú, TP. Hồ Chí Minh
🏢Văn phòng đại diện tại Hà Nội: Toà nhà CT1 – C14 Bắc Hà, Nam Từ Liêm, Hà Nội
#Airdata
#product#full stack developer#airdata
1 note
·
View note
Text
Essential Guidelines for Building Optimized ETL Data Pipelines in the Cloud With Azure Data Factory
http://securitytc.com/TBwVgB
2 notes
·
View notes
Text
How can you optimize the performance of machine learning models in the cloud?
Optimizing machine learning models in the cloud involves several strategies to enhance performance and efficiency. Here’s a detailed approach:

Choose the Right Cloud Services:
Managed ML Services:
Use managed services like AWS SageMaker, Google AI Platform, or Azure Machine Learning, which offer built-in tools for training, tuning, and deploying models.
Auto-scaling:
Enable auto-scaling features to adjust resources based on demand, which helps manage costs and performance.
Optimize Data Handling:
Data Storage:
Use scalable cloud storage solutions like Amazon S3, Google Cloud Storage, or Azure Blob Storage for storing large datasets efficiently.
Data Pipeline:
Implement efficient data pipelines with tools like Apache Kafka or AWS Glue to manage and process large volumes of data.
Select Appropriate Computational Resources:
Instance Types:
Choose the right instance types based on your model’s requirements. For example, use GPU or TPU instances for deep learning tasks to accelerate training.
Spot Instances:
Utilize spot instances or preemptible VMs to reduce costs for non-time-sensitive tasks.
Optimize Model Training:
Hyperparameter Tuning:
Use cloud-based hyperparameter tuning services to automate the search for optimal model parameters. Services like Google Cloud AI Platform’s HyperTune or AWS SageMaker’s Automatic Model Tuning can help.
Distributed Training:
Distribute model training across multiple instances or nodes to speed up the process. Frameworks like TensorFlow and PyTorch support distributed training and can take advantage of cloud resources.
Monitoring and Logging:
Monitoring Tools:
Implement monitoring tools to track performance metrics and resource usage. AWS CloudWatch, Google Cloud Monitoring, and Azure Monitor offer real-time insights.
Logging:
Maintain detailed logs for debugging and performance analysis, using tools like AWS CloudTrail or Google Cloud Logging.
Model Deployment:
Serverless Deployment:
Use serverless options to simplify scaling and reduce infrastructure management. Services like AWS Lambda or Google Cloud Functions can handle inference tasks without managing servers.
Model Optimization:
Optimize models by compressing them or using model distillation techniques to reduce inference time and improve latency.
Cost Management:
Cost Analysis:
Regularly analyze and optimize cloud costs to avoid overspending. Tools like AWS Cost Explorer, Google Cloud’s Cost Management, and Azure Cost Management can help monitor and manage expenses.
By carefully selecting cloud services, optimizing data handling and training processes, and monitoring performance, you can efficiently manage and improve machine learning models in the cloud.
2 notes
·
View notes