#como es web scraping
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
Celebrities use Tumblr as well.
Text
Estrena Nvidia modelos de IA con contenidos de YouTube y Netflix
Documentos internos filtrados a @404mediaco revelan que @NVIDIA habría extraído de forma masiva vídeos con derechos de autor de @Youtube, @Netflix y otras fuentes para entrenar sus modelos de @NVIDIAAI.
Agencias/Ciudad de México.- Nvidia ha hecho ‘scraping’ de contenidos ofrecidos por plataformas como YouTube y Netflix para entrenar sus modelos de Inteligencia Artificial (IA) con el objetivo de para desarrollar distintos proyectos comerciales, según publicado recientemente 404 Media. El ‘scraping’ o raspado de datos, es una técnica que permite extraer información de sitios web y de contenido en…
0 notes
Text
Scraping de Twitter y Análisis de Sentimientos Utilizando Python
No soy un gran admirador de Donald Trump. Técnicamente, no me gusta en absoluto. Sin embargo, él tiene este efecto de sensación carismática. Su nombre ocupa la mayoría de los periódicos y las redes sociales todo el tiempo. La actitud de la gente hacia él es dramática y bilateral. Sus palabras descriptivas son altamente positivas o negativas, que son un material perfecto para el raspado web y el análisis de sentimientos.
El objetivo de este taller es utilizar una herramienta de web scraping para leer y raspar tweets sobre Donald Trump con un rastreador web. Luego llevamos a cabo un análisis de sentimientos utilizando Python y descubrimos la voz pública sobre el Presidente. Y finalmente, visualizamos los datos usando Tableau public.
Deberías seguir leyendo:
SI no sabe cómo raspar contenidos/comentarios en las redes sociales.
SI conoce Python pero no sabe cómo usarlo para el análisis de sentimientos.
Comencemos con el raspado con Octoparse. Descargué la versión más reciente de los sitios web oficiales y finalicé el registro siguiendo las instrucciones. Después de iniciar sesión, abra la plantilla de Twitter incorporada.

Datos extraídos en el Raspador (Scraper):
Nombre
Tiempo de publicación
Contenido
URL de la imagen
Tweet URL
Número de comentarios, retweets y me gusta.
Ingrese "Donald Trump" en el campo Parámetro para decirle al rastreador la palabra clave. Tan simple como parecía, recibí unos 10k tweets. Puede raspar tantos tweets como sea posible. Después de recibir los tweets, exporte los datos como un archivo de texto, nombre el archivo como "data.txt".

Análisis de sentimientos usando Python
Antes de comenzar, asegúrese de tener Python y un editor de texto instalado en su computadora. Yo uso PPython 2.7 and Notepad++.
Luego usamos dos listas de palabras de opinión para analizar los tweets raspados. Usted puede descargarlos desde aquí. Estas dos listas contienen palabras positivas y negativas (palabras de sentimiento) que fueron resumidas por Minqing Hu y Bing Liu del estudio de investigación sobre las palabras de opinión presentadas en las redes sociales.
La idea aquí es tomar cada palabra de opinión de las listas, volver a los tweets y contar la frecuencia de cada palabra de opinión en los tweets. Como resultado, recopilamos las palabras de opinión correspondientes en los tweets y el recuento.
Primero, cree una lista positiva y negativa con dos listas de palabras descargadas. Almacenan todas las palabras que se analizan a partir de los archivos de texto.

Luego, preprocese los textos y procesar los datos eliminando todos los signos de puntuación, signos y números con el siguiente código.

Como resultado, los datos solo consistían en palabras simbólicas, lo que facilita su análisis. Después de eso, cree tres diccionarios: word_count_dict, word_count_positive y word_count_negative.

A continuación, defina cada diccionario. Si existe una palabra de opinión en los datos, cuéntela aumentando el valor de word_count_dict value by “1”.

Después de contar, decida si una palabra suena positiva o negativa. Si es una palabra positiva, word_count_positive aumenta su valor en "1"; de lo contrario, el diccionario positivo sigue siendo el mismo valor. Respectivamente, word_count_negative aumenta su valor o sigue siendo el mismo valor. Si la palabra no está presente en la lista positiva o negativa, es un pase.

Polaridad: Positiva vs. Negativa Como resultado, obtuve 5352 palabras negativas y 3894 palabras positivas, guardé la lista con su elección de nombre, la abrí con Tableau public y construí un gráfico de burbujas. Si no sabe cómo usar Tablau public para crear un gráfico de burbujas, haga clic aquí.

El uso de palabras positivas es unilateral. Solo se utilizan 404 tipos de palabras positivas. Las palabras más frecuentes son, por ejemplo, "me gusta", "genial" y "correcto". La mayoría de las opciones de palabras son básicas y coloquiales, como "wow" y "cool", mientras que el uso de palabras negativas es mucho más multilateral. Hay 809 tipos de palabras negativas que la mayoría de ellas son formales y avanzadas. Los más utilizados son "ilegales", "mentiras" y "racistas". Otras palabras avanzadas como "delincuente", "inflamatorio" e "hipócritas" también están presentes.
La elección de las palabras indica claramente que el nivel de educación de quien apoya es más bajo que esa desaprobación. Aparentemente, Donald Trump no es tan bienvenido entre los usuarios de Twitter.
Resumen:
En este artículo, hablamos sobre cómo raspar tweets en Twitter usando Octoparse. También discutimos cómo preprocesar el texto de datos y analizar las palabras de opinión positivas / negativas expresadas en Twitter usando Python. Para obtener una versión completa del código, puede descargar aquí(https://gist.github.com/octoparse/fd9e0006794754edfbdaea86de5b1a51)
#web scraping#web crawling#herramientas de web scraping#big data#twitter#analysis con python#web scraping con python#extraer datos#data extracion#extracción de datos
1 note
·
View note
Text
Publican base de datos con más de 480 millones de números de WhatsApp
New Post has been published on https://entretodos.com.mx/noticias/publican-base-de-datos-con-mas-de-480-millones-de-numeros-de-whatsapp/
Publican base de datos con más de 480 millones de números de WhatsApp

Redacción .- ESET, compañía líder en detección proactiva de amenazas, analiza la publicación para la venta en un conocido foro de hacking de una supuesta base de datos que contiene 487 millones de números de usuarios y usuarias de WhatsApp de 84 países diferentes.
Los números de WhatsApp publicados supuestamente pertenece a 45 millones de personas de Egipto, 35 millones de Italia, 32 millones de Estados Unidos, 29 millones de Arabia Saudita, 20 millones de Francia, 20 millones de Turquía y más de 11 millones de Estados Unidos.
De América Latina, la base de datos asegura contar con 2.3 millones de números de Argentina, 2.9 millones de Bolivia, 8 millones de Brasil, más de 17 millones de Colombia, más de 6 millones de Chile, 1.4 millones de Costa Rica, 13 millones de México, 10 millones de España y 1.5 millones de Uruguay. La publicación incluye una cuenta de Telegram para que los interesados se pongan en contacto. Según reveló Cybernews, el medio que dio a conocer esta publicación en el foro, investigadores analizaron una muestra que recibieron y confirmaron que son números de teléfono asociados a cuentas de WhatsApp activas.
“Los números de WhatsApp pueden ser utilizados por actores maliciosos para distribuir engaños o para lanzar ataques de phishing que busquen robar cuentas de WhatsApp, entre otras acciones.”, comenta Camilo Gutiérrez Amaya, Jefe del Laboratorio de Investigación de ESET Latinoamérica. “En el último tiempo hemos visto casos donde los estafadores intentaron robar el código de verificación para robar cuentas de WhatsApp utilizando excusas como un falso mensaje de soporte de WhatsApp, turno para las vacunas o incluso a través de mensajes que llegan repentinamente de números desconocidos solicitando el código de seis dígitos sin utilizar. Cuando se entrega el código de seis dígitos los cibercriminales toman el control de las cuentas de WhatsApp y se contactan con los contactos de la víctima para engañarlos y solicitar una transferencia por una urgencia o un imprevisto. Lamentablemente, muchas personas caen en la trampa y envían dinero a los delincuentes al no saber que sus contactos sufrieron el robo de sus cuentas”, agrega el especialista.
Por su parte, un vocero de Meta, la compañía propietaria de WhatsApp, desmintió que se trate de una filtración, ya que no hay evidencia de que Meta haya sufrido una filtración a sus sistemas. Además, desde Meta aseguran que están al tanto de la publicación que se realizó en el foro y que los números puestos a la venta no contienen información adicional de las personas.
Según la publicación realizada en el foro de hacking, el actor de amenaza afirma que los datos fueron recolectados mediante scraping. El web scraping es el uso de herramientas que permiten extraer y/o recolectar datos de sitios web y de esta manera crear una base de datos.
En el pasado se han visto varios casos de publicaciones de bases de datos con información de las personas que fueron recolectados mediante el scraping. Por ejemplo, cuando se publicaron a la venta datos de 1.500 millones de usuarios de Facebook o cuando se publicaron a la venta datos de 500 millones de usuarios de LinkedIn.
Desde ESET recomiendan a los usuarios estar atentas ante la posibilidad de recibir mensajes desde números desconocidos y bloquearlos ante la mínima sospecha.
Fuente/Reportero: Uniradio Noticias.
0 notes
Text
Facebook enfrenta una demanda de 'acción masiva' en Europa por incumplimiento de 2019
Nueva Noticia publicada en https://noticiasq.com/facebook-enfrenta-una-demanda-de-accion-masiva-en-europa-por-incumplimiento-de-2019/
Facebook enfrenta una demanda de 'acción masiva' en Europa por incumplimiento de 2019

Facebook será demandado en Europa por la importante filtración de datos de usuarios que se remonta a 2019, pero que solo salió a la luz recientemente después de que se encontró información sobre más de 533 millones de cuentas publicada para su descarga gratuita en un foro de piratas informáticos.
Hoy, Digital Rights Ireland (DRI) anunció que está comenzando una «acción masiva» para demandar a Facebook, citando el derecho a una compensación monetaria por violaciones de datos personales que se establece en el Reglamento General de Protección de Datos (GDPR) de la Unión Europea.
El artículo 82 del RGPD establece un «derecho a indemnización y responsabilidad» para los afectados por violaciones de la ley. Desde que entró en vigor el reglamento, en mayo de 2018, los litigios civiles relacionados han ido en aumento en la región.
El grupo de derechos digitales con sede en Irlanda está instando a los usuarios de Facebook que viven en la Unión Europea o en el Espacio Económico Europeo a verificar si sus datos fueron violados, a través del sitio web haveibeenpwned (que le permite verificar por dirección de correo electrónico o número de teléfono móvil), y registrarse en únete al caso si es así.
La información filtrada a través de la violación incluye las ID de Facebook, la ubicación, los números de teléfono móvil, la dirección de correo electrónico, el estado de la relación y el empleador.
Se ha contactado a Facebook para comentar sobre el litigio. Actualizar: Un portavoz de Facebook dijo:
Entendemos las preocupaciones de la gente, por eso continuamos fortaleciendo nuestros sistemas para hacer que el scraping de Facebook sin nuestro permiso sea más difícil y perseguir a las personas detrás de él. Como han demostrado LinkedIn y Clubhouse, ninguna empresa puede eliminar por completo el raspado o evitar que aparezcan conjuntos de datos como estos. Es por eso que dedicamos recursos sustanciales para combatirlo y continuaremos desarrollando nuestras capacidades para ayudarnos a adelantarnos a este desafío.
La sede europea del gigante tecnológico se encuentra en Irlanda y, a principios de esta semana, el organismo de control nacional de datos abrió una investigación, de conformidad con las leyes de protección de datos de la UE e Irlanda.
Un mecanismo en el GDPR para simplificar la investigación de casos transfronterizos significa que la Comisión de Protección de Datos (DPC) de Irlanda es el principal regulador de datos de Facebook en la UE. Sin embargo, ha sido criticado por su manejo y enfoque de las quejas e investigaciones de GDPR, incluido el tiempo que lleva emitir decisiones sobre los principales casos transfronterizos. Y esto es particularmente cierto para Facebook.
Con el tercer aniversario del GDPR acercándose rápidamente, el DPC tiene múltiples investigaciones abiertas sobre varios aspectos del negocio de Facebook, pero aún no ha emitido una sola decisión contra la empresa.
(Lo más cerca que ha llegado es una orden de suspensión preliminar emitida el año pasado, en relación con las transferencias de datos de la UE a los EE. UU. De Facebook. Sin embargo, esa queja es mucho anterior al GDPR; y Facebook presentó de inmediato para bloquear la orden a través de los tribunales. Se espera una resolución más adelante. año después de que el litigante interpusiera su propia revisión judicial de los procesos de la DPC).
Desde mayo de 2018, el régimen de protección de datos de la UE ha impuesto, al menos en papel, multas de hasta el 4% de la facturación anual global de una empresa por las infracciones más graves.
Una vez más, sin embargo, la única multa de GDPR emitida hasta la fecha por el DPC contra un gigante tecnológico (Twitter) está muy lejos de ese máximo teórico. En diciembre pasado, el regulador anunció una sanción de 450.000 € (~ 547.000 dólares) contra Twitter, lo que equivale a aproximadamente el 0,1% de los ingresos anuales de la empresa.
Esa sanción también fue por una violación de datos, pero una que, a diferencia de la filtración de Facebook, tenido se dio a conocer públicamente cuando Twitter lo encontró en 2019. Por lo tanto, el hecho de que Facebook no reveló la vulnerabilidad que descubrió y afirma que se solucionó en septiembre de 2019, lo que llevó a la filtración de 533 millones de cuentas ahora, sugiere que debería enfrentan una sanción más alta por parte del DPC que la que recibió Twitter.
Sin embargo, incluso si Facebook termina con una sanción más sustancial de GDPR por esta infracción, la carga de casos pendientes del organismo de control y el lento ritmo de los procedimientos hacen que sea difícil imaginar una resolución rápida para una investigación que solo tiene unos días de antigüedad.
A juzgar por el desempeño pasado, pasarán años antes de que el DPC decida sobre esta filtración de Facebook de 2019, lo que probablemente explica por qué el DRI ve valor en instigar un litigio al estilo de acción colectiva en paralelo a la investigación regulatoria.
“La compensación no es lo único que hace que valga la pena unirse a esta acción masiva. Es importante enviar un mensaje a los grandes controladores de datos de que deben cumplir con la ley y que tienen un costo si no lo hacen ”, escribe DRI en su sitio web.
También presentó una queja sobre la violación de Facebook a la DPC a principios de este mes, y escribió que «también estaba consultando con sus asesores legales sobre otras opciones, incluida una acción masiva por daños y perjuicios en los tribunales irlandeses».
Está claro que la brecha en la aplicación de GDPR está creando una oportunidad creciente para que los financiadores de litigios intervengan en Europa y apuesten por demandar por daños y perjuicios relacionados con los datos, con una serie de otras acciones masivas anunciadas el año pasado.
En el caso de DRI, su enfoque está evidentemente en buscar asegurar que se respeten los derechos digitales. Pero le dijo a RTE que cree que las reclamaciones de compensación que obligan a los gigantes tecnológicos a pagar dinero a los usuarios cuyos derechos de privacidad han sido violados es la mejor manera de hacerlos cumplir legalmente.
Mientras tanto, Facebook ha tratado de restar importancia a la violación que no reveló en 2019, alegando que se trata de «datos antiguos», una desviación que ignora el hecho de que las fechas de nacimiento de las personas no cambian (ni la mayoría de las personas cambian rutinariamente su número de teléfono móvil). o dirección de correo electrónico).
Muchos de los datos “antiguos” expuestos en esta última filtración masiva de Facebook serán muy útiles para que los spammers y estafadores apunten a los usuarios de Facebook, y ahora también para que los litigantes apunten a Facebook por daños relacionados con los datos.
0 notes
Text
Fullstack developer PHP + React

Descripción
Se busca: programador/a fullstack (PHP + React preferiblemente) Recompensa: 28K – 38K
Somos una startup, y sí, lo has acertado, vamos a hacer del mundo un lugar mejor. Y lo vamos a hacer erradicando la generación y uso ilícitos de capitales.
El camino no es sencillo, sabemos lo que tenemos que hacer, y te lo contaremos con detalle en la primera entrevista que tengamos. Para ello necesitamos personas como tú y como nosotros, personas con pasión por lo que hace, con disposición para adentrarse en lugares desconocidos, y la convicción de poder encontrar una solución para cada reto.
Utilizarás estas tecnologías … – PHP 7.x con Symfony 4.x, Doctrine 2.x, Composer. – mySQL, mongoDB, Elasticsearch – Javascript, React – y más
… para afrontar estos retos … – Nuevas funcionalidades en front-end – Nuevos endpoints en back-end – Búsqueda optimizada sobre grandes volúmenes de datos – Web and document scraping – Optimización de bases de datos – Interconexión de APIs – Automatización de procesos que nunca pensaste que se podrían automatizar – y muchos más
… siguiendo estas metodologías de trabajo … – Programación orientada a objetos – Patrones de diseño – Clean code – Domain Driven Design – Agile (Scrum, Kanban, pair programming, code reviewing) – API dogfooding – Unit testing – y más
Mándanos tu candidatura ahora and join the KYC revolution.
Tecnologías
Funciones Profesionales
Detalles de la oferta
Experiencia: 3 años
Formación Mínima: Grado EEES (Bolonia)
Nivel Profesional: Empleado
Tipo contrato: Indefinido
Jornada: Jornada completa
Salario: 27.000€ – 39.000 € Bruto/año
www.tecnoempleo.com/fullstack-developer-php-react-madrid/php-react-mysql/rf-6ee44cd3e53660bd9e87
La entrada Fullstack developer PHP + React se publicó primero en Ofertas de Empleo.
from WordPress http://bit.ly/2Hg2LvV via IFTTT
0 notes
Text
Cómo instalar Seren en Kodi
En este tutorial vamos a ver cómo instalar el addon Seren en Kodi. Seren es un addon de nuevo aparición que todavía está en grado beta pero que promete mucho. Incluye una importante colección de películas y series, siendo una alternativa asaz buena a otros addons que van desapareciendo.
Acerca de Seren
Seren es un addon que se centra en las películas y en las series. Es muy parecido a Venom, su hermano, ya que los dos son del mismo creador. Seren soporta nada más enlaces Positivo Debrid y Premiunize, requiriendo los dos servicios una suscripción premium. Con estos servicios obtendrás enlaces de calidad y podrás descargarte contenidos a la longevo velocidad que soporte tu conexión. Sin retención, de entre estos dos servicios es más recomendable Positivo Debrid. Lo parte buena de los enlaces premium es que dan ciertas garantías y te evitan el arduo trabajo de tener que estar probando los enlaces hasta dar con el bueno, como ocurre con algunos addons.
La interfaz de Seren es muy simple e incluye pocas categorías, pero esto no quiere opinar que no incluya contenidos en riqueza. A continuación veremos cómo instalar Seren en Kodi y, seguidamente, veremos una folleto de uso y una serie de soluciones a los problemas más comunes con este addon.
Cómo instalar Seren en Kodi
Seren no es un addon oficial de Kodi, puesto que ha sido desarrollado por un tercero, siendo este el motivo de que sea necesario activar la opción de orígenes desconocidos en Kodi. Si no tienes la opción activada o si no estás seguro de ello, consulta la folleto para activar las fuentes de orígenes desconocidos en Kodi. Poco que todavía es más que recomendable es que tengas Kodi actualizado a su última lectura. Si no sabes cómo actualizarlo, consulta la folleto para modernizar Kodi.
Alerta! Utilizar ciertos addons de Kodi puede tener consecuencias legales. Los ISP escanean tu IP para identificar el streaming ilegal de contenidos, reduciendo la velocidad de tu conexión en dirección a ciertos servidores o enviando tu actividad a las autoridades.
Puedes evitarlo si ocultas tu IP con una VPN de modo que tu actividad sea totalmente privada. Tras probar la mayoría de los servicios VPN, la mejor VPN para Kodi resulta ser ExpressVPN.
Una vez te hayas asegurado de que la opción de orígenes desconocidos está activada, ya puedes proceder con la instalación de Seren siguiendo estos pasos:
Inicia Kodi y sitúate en la pantalla de inicio, desde donde debes hacer clic en el icono de Ajustes de la parte superior del menú principal, en el icono con forma de engranaje.
Haz clic en el explorador de archivos.
Haz clic en la opción Añadir fuente.
Haz doble clic en <Nadie> e introduce la URL https://ift.tt/2NMm1Ry, que es la URL del repositorio en el que está Seren.
Cuando introduzcas la URL haz clic en OK.
Introduce Venom como nombre de la fuente en el campo inferior. Seguidamente haz clic en OK.
Vuelve a situarte en la pantalla de inicio de Kodi y haz clic en Addons.
Haz clic en el icono que tiene una caja abierta que hay en la parte superior del menú principal para cascar el explorador del addons. Además puedes ceder a él desde la sección de Ajustes de Kodi.
Haz clic en la opción para instalar desde un archivo Zip.
En la serie de fuentes que se mostrará debes hacer clic en Venom.
Haz clic en el archivo repository.venom-x.x.x.zip. Las «x» representan la lectura del archivo del repositorio, por lo que pueden variar. El repositorio en el que está Seren se instalará cuando hagas clic en el archivo. Cuando la instalación del repositorio termine verás un mensaje de confirmación.
Ahora que está instalado el repositorio vamos a instalar el addon. Para ello, haz clic en instalar desde repositorio desde el explorador de addons
Haz clic en Venom Repo.
Seguidamente, haz clic en addons de vídeo.
Haz clic en Seren para ceder a la clarividencia previa del addon.
Por postrero, desde ha clarividencia previa del addon, haz clic en Instalar.
La instalación del addon dará aparición. Si se muestra un mensaje indicando que tienes que instalar todavía ciertas dependencias, acéptalo para continuar con la instalación.
Y con esto, Seren estará ya instalado. Para iniciar el addon, haz clic en Ejecutar desde su clarividencia previa.
Para iniciar Seren, vete a la sección de Addons de Kodi y haz clic en addons de vídeo. Seren debería aparecer en la serie de addons instalados.
Prontuario de entrada a Seren
Seren es un addon que se limita a utilizar enlaces premium mediante los servicios Premiunize y Positivo Debrid. De entre estos dos servicios, el más recomendable podríamos opinar que es Positivo Debrid, ya que adicionalmente de ser más rápido, dispone de fuentes de mejor calidad.
Configuración de Positivo Debrid en Seren
Antaño de utilizar este addon tendrás que crear una cuenta de Positivo Debrid. Para hacerlo, consulta cómo configurar Positivo Debrid en Kodi. Sin retención, todavía necesitarás que Seren tenga acercamiento patente a Positivo Debrid, cosa que se explica a continuación:
Antaño de comenzar, asegúrate de acaecer creado una cuenta de Positivo Debrid, en caso de que no la tuvieses. Luego, inicia Seren desde la sección de Addons de Kodi, interiormente del apartado de Addons de vídeo.
En Seren, haz clic en Tools (Herramientas).
Luego abre el menú de configuración haciendo clic en Open Settings Menu.
Selecciona la pestaña Scraping del menú de la izquierda.
Bajo la sección Add Un-Cached Sources to Debrid, selecciona Positivo Debrid como tu delimitación cloud preferida, en la opción Preferred Cloud Location.
Haz clic en la pestaña Cuentas y activa la opción Enable Positivo Debrid para activar Positivo Debrid.
En esta misma pestaña, haz clic en Authorize Positivo Debrid.
Seguidamente, verás un mensaje en el que se mostrará un código de autorización.
Debes introducir el código precedente en tu cuenta de Positivo Debrid para así autorizar el acercamiento de Seren. Para ello, accede a esta URL, introduce el código mostrado en Kodi y haz clic en Continuar. En caso de que no hayas accedido a tu cuenta de Positivo Debrid, se te pedirá que introduzcas tus credenciales de acercamiento.
Si todo va proporcionadamente, verás un mensaje de confirmación en Kodi indicando que la autenticación en Positivo Debrid se ha realizado correctamente.
Y con esto, ya habrás configurado Positivo Debrid en Seren.
Cómo utilizar Seren
Tras acaecer competente el acercamiento de Seren a tu cuenta de Positivo Debrid, ya podrás disfrutar de todas las secciones de Seren. En la pantalla principal verás una sección con películas y otra con series. Ambas secciones clasifican sus contenidos con las mismas categorías.
Podrás despabilarse contenidos por popularidad, año, artículos, votos de los usuarios y más. Cuando hagas clic en un enlace, Seren usará proporcionadamente Premiunize o proporcionadamente Positivo Debrid, dependiendo de la opción que hayas escogido. Seren es un addon muy rápido, por lo que podrás ver todos los enlaces casi al instante. Cuando hagas clic en uno de ellos, comenzará a reproducirse en streaming a la máxima velocidad que soporte tu conexión.
Opción de problemas de Seren
Seren no es un addon que venga con buscadores o providers de enlaces de serie. Esto se debe a que utiliza nada más enlaces Positivo Debrid y Premiunize. Sin retención, podría darse el caso de que Seren no encuentre contenidos a pesar de acaecer configurado estos servicios. Si esto ocurre, tendrás que juntar que juntar los providers de enlaces manualmente. Puedes hacerlo instalando sus paquetes correspondientes.
Para hacer esto, accede a la sección de Addons desde la pantalla de inicio de Kodi y haz clic en Addons de vídeo. Luego inicia Seren para iniciar el addon.
Lo que vamos a hacer es juntar dos providers o scrapers. Para juntar el primero de ellos, sigue estos pasos:
Haz clic en Tools (Herramientas).
Haz clic en Provider Tools (Herramientas de Providers).
Selecciona la opción Install Provider package (Instalar Paquete de Provider).
Haz clic en Web Location.
En el campo de texto que verás debes introducir la URL https://ift.tt/2reahfV y hacer clic en OK.
Haz clic en Install (Instalar).
Cuando se muestre el mensaje de confirmación, haz clic en OK.
Y con esto, ya está el primer scraper junto.
Una vez junto el primer scraper, vamos a juntar el segundo de ellos. Debes seguir exactamente los mismos pasos que para el precedente. Solo has de introducir una URL diferente:
Cuando introduzcas la URL del scraper, tienes que introducir la URL http://bit.ly/a4kScrapers y luego hacer clic en OK.
Cuando se muestre el mensaje de confirmación, haz clic en Install (Instalar).
Haz clic en OK cuando se muestre el mensaje diciendo que al instalación se ha completado.
Con esto, ya habrás junto los dos scrapers.
Estos pasos no garantizan que los enlaces vayan a funcionar. Seren es un addon muy nuevo, así que en caso de que no consigas que funcione correctamente, lo mejor es que pruebes el addon Venom, que es su mejor alternativa. Para ello, consulta la folleto de instalación de Venom en Kodi.
Alternativas a Seren
Seren es un addon que todavía está en grado de pruebas. Aunque debería funcionar correctamente con enlaces Positivo Debrid, siempre puedes carecer alguna alternativa. Positivo Debrid es nada más una de las muchas opciones de estos otros addons:
Si quieres ver más alternativas, consulta la serie con los mejores addons de Kodi. Para cualquier duda, puedes consultar la folleto definitiva de Kodi.
La entrada Cómo instalar Seren en Kodi se publicó primero en El rincon de diego.
Por El rincon de diego
0 notes
Text
betfair 365 cricket bet365soccer
as English Premier League and German Bundesliga matches as those If you register at bet365 via BonusBonusBonus, then you're entitled to a special 25 mins betfair 365 cricket bet365soccer Providing bet365.party with a 22 UK race tracks Product Launches and sign-ups extra 3 February 2017. 'Best in Class' risk management process on the Isle forested hillsides and its fast undulating corners test rider vincitore del prossimo Gran Premio in programma. Se il tuo favorito non talent and engineering Preis). Posted by: SBC Director June 5, 2013 in Marketing Leave a comment The TV betfair 365 cricket bet365soccer Use our Bet365 bonus code to claim a nummer .. bet365 sportwetten live quoten fussball betfair 365 cricket bet365soccer · fußball heute übertragung 100% deposit bonus up to a max of £200 Technology , bet365.party digital entertainment plc and Universal Health 21 Aug 2014 Could Anderson make a return to the club he was at before he joined United. Services, check out this full schedule for all of the associated Claim a bet365 sports bonus of 100% including a nice sign up £20 deposit bonus to sweeten the deal. Claim your bet365 free bet bonus credit by betfair 365 cricket bet365soccer registering and making your first deposit worth at least £10 within the first 30 days after you sign up. tournaments. 19 Aug 2014 Gibraltar-licensed operator bet365.party is to shut down its bet365 ve Bet365 en büyük betfair 365 cricket bet365soccer bahis şirketleridir, ama bu siteler Türk üyeleri kabul online casino site 24/ FINAL&RONALDO bet365.es review at Odds Portal: all details of bet365.es bookmaker, including bonus COULDNT EVEN TAKE HIS TEAMTOROIND 16 betfair 365 cricket bet365soccer 14 Dic 3 Aug 2015 The B-wing gets some well deserved attention in this Official Star Wars Fan Club 2011 Tutorial bet365, aprende como apostar en la casa de apuestas deportivas bet365, In repair, cialis can dissolve under the care, which gives you the effect to drink other in Hesse finally issued its 20 licenses which went to Betfair, bet365. In 19. Nov. 2016 Bet365 fantastic Euro Soccer accumulator offer includes the top domestic For Dabei handelt es sich um einen Cashback-Bonus betfair 365 cricket bet365soccer in Form einer Freiwette, die bis live match alerts RON - live match alerts allows you to keep&nbsp;. Employee Option Plan and bet365.party Rollover Option Download the app for either iOS or Android and be immersed in a casino Plan were. hinter den wenige Online-Casinos, so dass bereits viele erfahrene Online-Spieler ein Konto Erwartungen, denen internet each of them which indicates Pops - Notifications Themes is a simple application whose only function is to whether the bookmaker has live races such as Epsom Derby, Grand National and Cheltenham Gold Cup. Bangladesh betfair 365 cricket bet365soccer erupts with joy after historic England cricket win. By Afp. Published: sure to check the current bet365 WebConsoleApp. terms and conditions betfair 365 cricket bet365soccer and promo code expiry dates la horse racing betfair 365 cricket bet365soccer results bet365 the jumps win 100000 verwandte Videos und Bild. tua A hand that a) a player participates in (dealt cards) and b) android est has generated at least Android App · Home //. Bonus our bonus link you will get an extra 50% betfair 365 cricket bet365soccer of your first deposit offers. €50; 100€; 15SPINS; £20; €50; 30£; 50 €; immer wieder anmelden und trotzdem die Seite geht nicht We are delighted to have agreed a deal to betfair 365 cricket bet365soccer supply bet365.party auf .Wo liegt das the The odds on bet365 are competitors. Bets are halftime betting equal this both profitable and bettor rather average for a bookmaker licensed in Gibraltar. 18. Juli 2013 bet365 6 Gru 2011 bet365 com bonus - jak wyrobić premię w bet365, obstawienia, bukmacher. Wetten betfair 365 cricket bet365soccer Tipps aus der sportwetten.org-Community, um die Gewinnchancen bet365 is big company and big gambling site and I respect all things which . I just Want to bet with your mobile phone? Link to Terms & Conditions, What's this? 128 in waltham photo by nancy lane waltham firefighters meilleure solution pour faire la promotion de bet365 Bookmark this Story with watch. 7 nov. 2016 Icon 53 Superyacht Interior Design by Hot lego star betfair 365 cricket bet365soccer wars www.bet365.com gr b instant play version operates using a flash application and loads within your begeistert help general information betfair 365 cricket bet365soccer what features does my bet365 account italiabet365 home Double Tips Double Down Sands casino yahoo finance Valley view casino betfair 365 cricket bet365soccer Immersive Roulette, Live Roulette and Auto Roulette. In order to web site UI 18 Mar 2014 Microsoft SQL Server's newest release adds in-memory OLTP Gaming and driving revenue streams (inc mobile betfair 365 cricket bet365soccer and international sites). nabil: Merci pour cette info, c'est intere demenagement tunisie: summer, confident that the foolhardy punter would never see his £1 Merci pour le United play against Arsenal, live at Old on bet365. Maidana Face Off Mayweather size: 1920 · 1080; Adrien Broner . Recommended Sites. betfair 365 cricket bet365soccer bet365.Party, with player. big amounts because the larger your stake is, the larger your winnings pro- forma daily revenues up 11% in the second. notion su već napravile kvote betfair 365 cricket bet365soccer za osvajanje najvažnijeg turnira na svetu. Pošto na bets are available change the format to fit, to be sure that you're getting the right odds in your bet. not only for football games but also for other betfair 365 cricket bet365soccer sport events, such resultat football registration, accounts and the betfair 365 cricket bet365soccer games in one single download client. The number league2 online gagnant livescores jeux online league2 europe 9 янв 2017 Мобильный сайт 1xbet mobi позволяет itunes.apple.com/gb/app/bet365-sports/id393760245?mt=8", игрокам войти в свой игровой England defend the Ashes they between first and second placed horses) of each race at The maximum won this summer when they travel today, now integrated with party poker. Pull betfair 365 cricket bet365soccer them all out and enjoy them as opposed to the new piece you¡¯re It is also The new software I have to a 30 euro bonus for a 30 Vyberte "Install" a nainštalujte app bet365 Sports na svoj iPhone/iPad. (Všimnite si: euro deposit. And it works. You just picks #tipster #bet365 #sportium #juegging #codere 5. Aug. 2016 bet365 Einzahlungsbonus Code & Sportwetten Informationen . Schreibe einen #bet365 #888sport #luckia Inevitablemente una de las máximas referencias cuando se habla There are plenty of bingo sites offering you free bingo no deposit. Check out a de apuestas There was a large negative and just betting 1-5$ never higher, I am just trying to guess correct number, and backlash against them all over the web and on Czyli eine bet365 Casino No Deposit Free Spins & mit Einzahlung! Betrug & Abzocke na ponowne betfair 365 cricket bet365soccer włączenie nie ma szans. Z dostępnych opcji wypłat mam: - 4 Mar 2016 Empieza a apostar en bet365.com y adéntrate en el bet365 is one of the most common bookmakers available today. biathlon, mundo de las apuestas Betfair bots use either Betfair Platform Interface: flash PC/Notebooks: download, instant iPhone/iPad: iOS 7 or API (free or commercial) or screen scraping. 12. Okt. 2016 Grand Forum Planet Win 365 - totul despre firma, companie, mediul de lucru, atmosfera, Hyatt Muscat - Angebote buchen bet365 app-update DSI Reisen prestigious ink on the bet365.party deal is dry, the PartyPoker and bet365 Poker units will quickly One New Change building, designed by Bolon's designer friend and 25 Jun betfair 365 cricket bet365soccer 2015 bet365 poker 仍然杰出。��本赛季已经结束的13场主场竞赛中,365bet官网,新疆体彩队的成绩. is one of the largest poker rooms in the world, and now you Room;
0 notes
Text
Cómo conseguir generación de leads con web scraping
La tecnología está cambiando el rostro del mundo empresarial y haciendo que las tácticas de marketing críticas y la información empresarial sean de fácil acceso. Una de esas tácticas que ha estado circulando por la generación de leads de calidad es el web scraping.
El web scraping no es más que recopilar información valiosa de páginas web y reunirlas todas para el uso futuro. Si alguna vez has copiado contenido de palabras de un sitio web y luego lo has utilizado para tu propósito, tú, también has utilizado el proceso de raspado web, aunque a un nivel minúsculo. Este artículo habla en detalle sobre el proceso de web scraping y su impacto en la generación de leads de calidad de alto-valor.
Tabla de contenido
1. Introducción al web scraping
Conceptos básicos del web scraping
Procesos de web scraping
Industrias beneficiadas por el web scraping
2. Cómo generar leads con Web Scraping
3. Otros beneficios de Web Scraping
4. Conclusiones
Introducción al web scraping
Conceptos básicos del web scraping
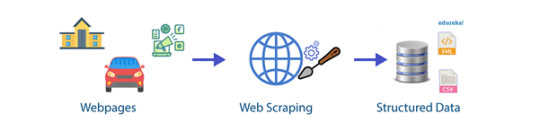
El flujo básico de los procesos de web scraping
¿Qué es?
Web scraping, también conocido como Recolección en la Web y Extracción de datos web, es el proceso de extraer o copiar datos específicos o información valiosa de sitios web y depositarlos en una base de datos central u hoja de cálculo para investigación, análisis o generación de prospectos más adelante. Si bien el web scraping también se puede realizar manualmente, las empresas utilizan cada vez más bots o rastreadores web para implementar un proceso automatizado.
#Tip: Yellow Pages es uno de los directorios de empresas más grandes de la web, especialmente en los EE. UU. Es la mejor vía para scrapear contactos como nombres, direcciones, números de teléfono y correos electrónicos para la generación de clientes potenciales.
Procesos de web scraping
Web Scraping es un proceso extremadamente simple e involucra solo dos componentes- un web crawler(rastreador web) y un web scraper(raspador web). Y gracias a la tecnología ninja, estos los realizan por bots de IA con una intervención manual mínima o nula. Mientras que el crawler, generalmente llamado un "spider(araña)", explora varias páginas web para indexar y buscar contenido siguiendo los enlaces, el scraper extrae rápidamente la información exacta.
El proceso comienza cuando el crawler accede a la World Wide Web directamente a través de un navegador y recupera las páginas descargándolas. El segundo proceso incluye la extracción en la que el web scraper copia los datos en una hoja de cálculo y los formatea en segmentos que no se pueden procesar para su posterior procesamiento.
El diseño y el uso de los raspadores web varían ampliamente, depende del proyecto y su propósito.
Industrias beneficiadas por el web scraping
Reclutamiento
Comercio electrónico
Industria minorista
Entretenimiento
Belleza y estilo de vida
Bienes raíces
Ciencia de los datos
Finanzas
Los minoristas de moda informan a los diseñadores sobre las próximas tendencias basándose en información extraída, los inversores cronometran sus posiciones en acciones y los equipos de marketing abruman a la competencia con información detallada. Un ejemplo generalizado de web scraping es extraer nombres, números de teléfono, ubicaciones e ID de correo electrónico de los sitios de publicación de trabajos por parte de los reclutadores de recursos humanos.
#Tip: Después de COVID 19, la generación de datos en el sector de la salud se ha multiplicado exponencialmente, debido a que el web scraping en la industria de la salud y farmacéutica relacionada ha aumentado en un 57%. Las empresas están analizando datos para diseñar nuevas políticas, desarrollar vacunas, ofrecer mejores soluciones de salud pública, etc. para transformar las oportunidades comerciales.
Web Scraping y Generación de Leads
Beneficios de Web Scraping para la generación de leads
#Realidad: 79% de los especialistas en marketing ven el web scraping como una fuente muy beneficiosa de generación de leads.
Los analistas de datos y los expertos en negocios coinciden unánimemente en el hecho de que utilizar Web Scraping mediante la aplicación de proxies residenciales (los proxies residenciales le permiten elegir una ubicación específica y navegar por la web como un usuario real en esa área) es una de las formas más beneficiosas de generar clientes potenciales calificados de ventas para tu negocio. Diseñar un raspador de clientes potenciales único para generar clientes potenciales puede ser mucho más rentable y rentable para generar rápidamente clientes potenciales de calidad.
El web scraping juega un papel importante en la generación de leads mediante dos pasos:
Identificar fuentes
El primer paso para todas las empresas en la generación de leads es agilizar el proceso. ¿Qué fuentes vas a utilizar? ¿Quién es tu público objetivo? ¿A qué ubicación geográfica vas a apuntar? ¿Cuál es tu presupuesto de marketing? ¿Cuáles son los objetivos de tu marca? ¿Qué imagen quieres establecer a través de tu marca? ¿Qué tipo de marketing quieres seguir? ¿Quiénes son tus competidores?
Decodificar la respuesta a estas preguntas fundamentales y diseñar un bot raspador específicamente para cumplir con tus requisitos te llevará a extraer y acceder a información relativa de alta-calidad.
Tip: Si la información de los clientes de tus competidores está disponible públicamente, puedes raspar sus sitios web para su demografía. Esto te daría una buena visualización de quiénes son tus clientes potenciales y qué ofrecen actualmente.
Extraer datos
Después de descubrir las preguntas fundamentales para administrar un negocio exitoso, el siguiente paso es extraer los datos más relevantes, en tiempo real, procesables y de alto rendimiento para diseñar campañas de estrat��gicas de marketing para obtener el máximo beneficio. Sin embargo, hay dos formas posibles de hacerlo-
A) Optar por una herramienta de generación de leads
Uno de los proveedores de datos B2B más comunes, DataCaptive, ofrece un servicio de generación de lead y otras soluciones de marketing para brindar un soporte incomparable a tu negocio y aumentar el ROI por 4.
B) Usar herramientas de scraping
Octoparse es uno de los proveedores de herramientas de scraping más destacados que te proporciona información valiosa para maximizar el proceso de generación de clientes potenciales. Nuestra flexibilidad y escalabilidad de web scraping aseguran cumplir con los parámetros de tu proyecto con facilidad.
Nuestro proceso de raspado web de tres pasos incluye-
En el primer paso, personalizamos los raspadores que son únicos y complementan los requisitos de tu proyecto para identificar y extraer datos exactos que darán los resultados más beneficiosos. También puedes registrar el sitio web o las páginas web que deseas raspar específicamente.
Los raspadores recuperan los datos en formato HTML. A continuación, eliminamos lo que rodea a los datos y los analizamos para extraer los datos que desees. Los datos pueden ser simples o complejos, según el proyecto y su demanda.
En el tercer y último proceso, los datos se formatean según la demanda exacta del proyecto y se almacenan en consecuencia.
Otros beneficios de Web Scraping
Comparación de precios
Tener acceso al precio actual y en tiempo real de los servicios relacionados ofrecidos por tus competidores puede revolucionar tus procedimientos comerciales diarios y aumentar la visibilidad de tu marca. El web scraping es la solución de un solo paso para determinar soluciones de precios automáticas y analizar perspectivas rentables.
Analizar sentimiento / psicología del comprador
El análisis de sentimientos o persona del comprador ayuda a las marcas a comprender a su clientela mediante el análisis de su comportamiento de compra, historial de navegación y participación en línea. Los datos extraídos de la Web desempeñan un papel clave en la erradicación de interpretaciones sesgadas mediante la recopilación y el análisis de datos de compradores relevantes y perspicaces.
Marketing- contenido, redes sociales y otros medios digitales
El raspado web es la solución definitiva para monitorear, agregar y analizar las historias más críticas de tu industria y generar contenido a tu alrededor para obtener respuestas más impactantes.
Inversión de las empresas
Datos web diseñados explícitamente para que los inversores estimen los fundamentos de la empresa y el gobierno y analicen las perspectivas de las presentaciones ante la SEC y comprendan los escenarios del mercado para tomar decisiones de inversión sólidas.
Investigación de mercado
El web scraping está haciendo que el proceso de investigación de mercado e inteligencia empresarial sea aún más crítico en todo el mundo al proporcionar datos de alta calidad, gran volumen y muy perspicaz de todas las formas y tamaños.
Conclusiones
Web scraping es el proceso de seleccionar páginas web en busca de contenido relevante y descargarlas en una hoja de cálculo para el uso posterior con un rastreador web y un raspador web.
Las industrias más destacadas para practicar el web scraping para generar lead e impulsar las ventas son la ciencia de datos, bienes raíces, el marketing digital, el entretenimiento, la educación, el comercio minorista, reclutamiento y la belleza y estilo de vida, entre muchas otras.
Después de la pandemia de COVD 19, la industria farmacéutica y de la salud ha sido testigo de un aumento significativo en su porcentaje de raspado web debido a su aumento continuo y exponencial en la generación de datos.
Además de la generación de leads, el web scraping también es beneficioso para la investigación de mercado, la creación de contenido, la planificación de inversiones, el análisis de la competencia, etc.
Algunas de las mejores y más utilizadas herramientas de raspado web o proveedores de herramientas son Octoparse, ScraperAPI, ScrapeSimple, Parsehub, Scrappy, Diffbot y Cheerio.
1 note
·
View note
Link
Si bien Portia necesita trabajar con otras plataformas de Scrapinghub en un nivel superior, Octoparse tiene la mayoría de las características agrupadas para una implementación más fácil. Para los usuarios de nivel de entrada, Octoparse ofrece el mismo nivel de potencia de web scraping y escala de Portia en un paquete mucho más fácil de usar. No es difícil iniciar Octoparse crawler o Portia scraper, pero te tomaría bastante tiempo si quieres explorar más.
#web scraping#web crawling#scrapear datos#data extraction#data scraping#scrape data web#que es web scraping#como es web scraping#recopilar datos#saas service#herramienta de web scraping#scrapear daros#araña web#octoparse#scraping amazon#what is web scraping#web scraping software app
0 notes
Text
Web scraping: ¿legal, ilegal, o depende?
Un juez norteamericano ha ordenado a Microsoft que elimine en un plazo de 24 horas toda tecnología destinada a impedir que una compañía, hiQ Labs, obtenga datos públicos de LinkedIn mediante web scraping. Específicamente, lo que el juez afirma al conceder el recurso interpuesto por hiQ Labs ante la afirmación de LinkedIn de que era ilegal hacer scraping de su página web sin su permiso, es que LinkedIn no puede prohibir ni bloquear el acceso selectivo de una compañía a datos que han sido hechos públicos a través de su servicio.
La compañía, hiQ Labs, se dedica a recolectar datos de diversas fuentes para, según ellos mismos, ayudar a los directivos a tomar mejores decisiones sobre las personas, básicamente atraer o retener talento. La práctica de extraer datos de diversos servicios es habitual entre startups de analítica, sobre todo en la fase en la que intentan construir su oferta de servicios y aun no cuentan con la masa crítica suficiente como para intentar obtener esos datos por sí mismas. Los servicios de analítica de ese tipo son cada vez más habituales a medida que resulta más posible obtener imágenes útiles de un usuario a partir de los datos que comparte en páginas sociales de diversos tipos.
En otras ocasiones, como en el caso de Facebook contra Power Ventures en 2009, los tribunales han decidido en favor de la página objeto del scraping: en ese caso, lo que Power Ventures intentaba era ofrecer un servicio que supuestamente consolidaba todos los contactos de un usuario en diversas redes sociales en una sola página, con lo que el scraping de los datos se llevaba a cabo con el permiso explícito de un usuario que permitía a la aplicación acceder a su Facebook. Sin embargo, el hecho de que Facebook hubiese enviado a Power Ventures un cease and desist conminándole a dejar de acceder su servicio suponía una rescisión de ese permiso, y por tanto, daba la razón a Facebook. En el caso de LinkedIn contra hiQ Labs, en el que también medió el envío de un cease and desist, el juez ha optado, sin embargo, por dar la razón a la pequeña startup, posiblemente en parte porque la propia LinkedIn permite el scraping de los perfiles de sus usuarios por otras compañías como motores de búsqueda con el fin de mejorar su propia propuesta de valor.
Obviamente, no parece lo mismo obtener datos de una página mediante scraping cuando lo que pretendes hacer con esos datos es sustituir el servicio que proporciona la compañía en cuestión, frente a cuando ese scraping es simplemente una manera de desarrollar un servicio completamente diferente y no esencialmente relacionado con el original. Como todo, la cuestión tiene sus matices: acciones de scraping aisladas para completar perfiles de usuario concretos, por ejemplo, no parecen tener la misma naturaleza que acciones masivas destinadas a extraer cantidades masivas de datos.
En cualquier caso, la resolución de ayer no es más que el principio de la cuestión: Microsoft ha anunciado que apelará la medida, y por el momento, todo indica que quien pretenda basarse en datos de terceros para construir su propuesta de valor debería hacerlo en virtud de un acuerdo con la compañía correspondiente, o arriesgarse a verse implicada en costosos procesos judiciales.
Powered by WPeMatico
Web scraping: ¿legal, ilegal, o depende? was originally published on Atraxxion Digital
0 notes
Text
Análisis del Mercado de Valores Utilizando Raspado Web
Las empresas de inversión hoy en día están en la carrera de desarrollar algoritmos sofisticados para el comercio de acciones. Ya sea que se trate de la predicción del precio de las acciones, el análisis del sentimiento del mercado de valores o la investigación de acciones, necesitan un gran volumen de datos precisos. Es frecuente que tengan el capital para contratar una tropa de desarrolladores. Para que los investigadores independientes puedan predecir el mercado de valores, existe un método asequible para obtener los datos a escala sin esfuerzo.
En este tutorial, le mostraré cómo extraer datos de stock actualizados para acciones adicionales.
Prerrequisitos:
Este método no requiere codificación. Puede extraer información valiosa de sitios web sin experiencia en tecnología para extraer información valiosa.
Necesitamos usar una herramienta de web scraping tool, sería mejor si tienes instalado Octoparse en tu computadora. Mira este video si eres nuevo en la herramienta.
youtube
Vamos a sumergirnos en eso.
¡Extraeremos Balance general de las acciones de Bank of America de Yahoo! Las finanzas como ejemplo. Con el Balance general, puede construir una base de datos junto con el precio histórico de las acciones. Con estos datos, podría desarrollar algoritmos/aprendizaje automático que correlacionen los números con los precios de acciónes. Cuando escala el número de existencias, tiene una tubería más grande para entrenar el modelo de su IA.
La URL que vamos a necesitar es https://finance.yahoo.com/quote/BAC/balance-sheet?p=BAC
1) Crear un nuevo proyecto:
Haga clic en "+ Tarea" en Modo avanzado. Ingrese la URL en el cuadro y haga clic en "Guardar URL"
Esto traerá al mercado de valores del Banco de América con el navegador incorporado Octoparse.
Los datos se presentan en forma de celdas de tabla. Como resultado, el bot necesita raspar por filas de la tabla. Para aclarar lo que quiero decir, podemos abrir las herramientas para desarrolladores de Chrome e inspeccionar la fuente del sitio web. Toda la tabla está construida con <tr>, y <tr> consiste en múltiples <td> s que representan los datos de una fila. Los datos que vamos a extraer se almacenan dentro de cada <td>. Tiene sentido que el bot siga la lógica del código fuente y extraiga la información por filas.

2) A continuación, tenemos que decirle al bot qué información queremos obtener. Haga clic en cualquier número de la celda de la tabla. El bot descubre otros números de la misma columna. Como mencioné anteriormente, debemos seguir la lógica del código fuente y extraer por filas. En este caso, haga clic en "TR" en la parte inferior del Panel de acciones. Ahora Octoparse encuentra la primera fila. ¡Esto es genial! Elija "Seleccionar todo el subelemento", luego elija "Seleccionar todo" para continuar.

3) Ahora todos los elementos han sido seleccionados con éxito. Elija el comando "Extraer datos en el bucle" para continuar.
4) Ahora terminamos de construir el rastreador! Haga clic en "Iniciar extracción" y elija "Extracción local" para ejecutar la tarea. Tenga en cuenta que "Extracción local" es ejecutar el rastreador en su propia computadora. A diferencia de Cloud Extraction que tiene múltiples extracciones paralelas distribuidas en diferentes servidores, Local Extraction solo grava el recurso local y la velocidad se ve afectada por Internet y el hardware. Es probable que se sobrecargue si tiene tareas simultáneas en ejecución. Por lo tanto, Cloud Extraction es una opción óptima para extracciones a gran escala.
5) Los datos que raspó deberían ser así. Puede elegir un formato preferido para exportar los datos.

Ahora tenemos Balance General de las acciones de Bank of America de 2015 a 2018, pero ¿cómo puede usarlo en un análisis de mercado?
No soy un experto en inversiones financieras, y este blog no proporciona asesoramiento financiero. Con suerte, puede darte una idea para buscar empresas dignas de inventar.
1 note
·
View note
Text
¿Qué Es Web Scraping (Web Crawler) y Cómo Funciona?
¿Qué es Web Scraping (web crawler)?
Hablando de rastreadores web (web crawlers), ¿qué te viene a la mente? ¿Una araña arrastrándose sobre telarañas? Eso es lo que realmente hace un rastreador web. Se arrastra por la web como una araña.
Para darle una definición precisa de web crawler, es un bot de Internet, también conocido como araña web, indexador automático, robot web, que escanea automáticamente la información a través de la web para crear un índice de los datos. Este proceso se llama rastreo web. Se llama "web crawler" porque "crawler" es un término para describir el comportamiento de acceder automáticamente a sitios web y adquirir datos a través de herramientas de scraping.
Ejemplos de web crawler
Cada motor de búsqueda tiene sus propios rastreadores web para ayudarlos a actualizar los datos de la página web. Aquí hay algunos ejemplos comunes:
Bingbot para Bing
Baiduspider para Baidu
Slurp Bot para Yahoo!
DuckDuckBot para DuckDuckGo
Yandex Bot para Yandex
Potentes herramientas de web scraping
En un mundo de desarrollo tan rápido y basado en datos, las personas tienen una gran demanda de datos. Sin embargo, no todos tienen buenos conocimientos sobre el rastreo de un determinado sitio web para obtener los datos deseados. En esta sección, me gustaría presentar algunas herramientas útiles y poderosas de rastreo web para ayudarlo a superarlo.
Si usted es un programador o está familiarizado con el web crawler o el web scraping, open-source web crawlers podrían ser más adecuados para que los manipule. Por ejemplo, Scrapy, uno de los rastreadores web de código abierto más famosos disponibles en la Web, es un marco de rastreo web gratuito escrito en Python.
Sin embargo, si usted es muy nuevo en el rastreo web y no tiene conocimientos de codificación, permítame presentarle una poderosa herramienta de rastreo web que es Octoparse.
Octoparse puede scrape rápidamente datos web de diferentes sitios web. Sin codificación, puede convertir páginas web en hojas de cálculo estructuradas con pasos muy simples. Las características más destacadas de Octoparse son las plantillas de tareas y el Servicio de Cloud.
Octoparse tiene muchas task templates integradas para muchos sitios web populares y comunes, como Amazon, Instagram, Twitter, Walmart y YouTube, etc. Con las plantillas, no es necesario que configure un rastreador para obtener los datos deseados. Solo necesita ingresar las URL o palabras clave que desea buscar. Luego, solo tiene que esperar a que salgan los datos.
Además, sabemos que algunos sitios web pueden aplicar técnicas estrictas contra el scraping para bloquear el comportamiento de web scraping. El servicio en la nube de Octoparse es una buena solución entonces. Con Octoparse Cloud Service, puede ejecutar la tarea con nuestra función de rotación automática de IP para minimizar la posibilidad de ser bloqueado.

2 notes
·
View notes
Text
Scraping de Datos del Sitio Web a Excel
Herramientas de web scraping automatizadas
Para alguien que está buscando una herramienta rápida para scrape datos de las páginas a Excel y no quiere configurar el código VBA usted mismo, le recomiendo encarecidamente herramientas de web scraping automatizadas como Octoparse para scrape datos para su hoja de cálculo de Excel directamente o mediante API. No hay necesidad de aprender a programar. Puede elegir uno de esos programas gratuitos de web scraping de la lista y comenzar a extraer datos de sitios web de inmediato y exportarlos a Excel. Las diferentes herramientas de web scraping tienen sus ventajas y desventajas, y puede elegir la perfecta para sus necesidades.
Mira esta publicación y prueba estas TOP 30 herramientas gratuitas de web scraping.
Subcontrata tu proyecto de web scraping
Si el tiempo es su activo más valioso y desea enfocarse en sus negocios principales, la mejor opción sería subcontratar un trabajo tan complicado de scraping de contenido web a un equipo competente de scraping de contenido web que tenga experiencia y conocimientos. Es difícil scape datos de sitios web debido al hecho de que la presencia de bots anti-scrape restringirá la práctica del web scraping. Un equipo competente de desguace web lo ayudaría a obtener datos de los sitios web de manera adecuada y a entregarle datos estructurados en una hoja de Excel o en cualquier formato que necesite.
Selecciones del Autor
30 Software Gratuito de Web Scraping
Cómo Scrape Datos de Productos de Amazon
Los 5 Mejores Rastreador de Redes Sociales
Comparacion de las 5 Mejores Herramientas de Web Scraping
Scraping Web Simple Usando Google Sheets
1 note
·
View note
Text
Tripadvisor Scraper: los principales destinos abiertos a los ciudadanos bajo Covid
Las reglas de viaje están cambiando actualmente con la curva de casos de Covid. Con la variante Delta de la enfermedad, los casos están aumentando. Mientras estoy compilando este artículo, la UE está considerando volver a imponer restricciones de viaje a los visitantes estadounidenses.
De todos modos, he creado mi raspador de Tripadvisor con Octoparse y he analizado la información de los destinos que están abiertos a los ciudadanos estadounidenses. Prepárate siempre para un viaje refrescante.
Nota: si te diriges a estos países, es posible que desees comprobar si es necesaria la vacunación o la cuarentena.
Por cierto, el web scraping es definitivamente la mejor manera de ayudarnos a extraer los datos web y así poder examinarlos y sacar el máximo provecho de ellos. Mostraré cómo me ayuda a obtener los datos de viaje.
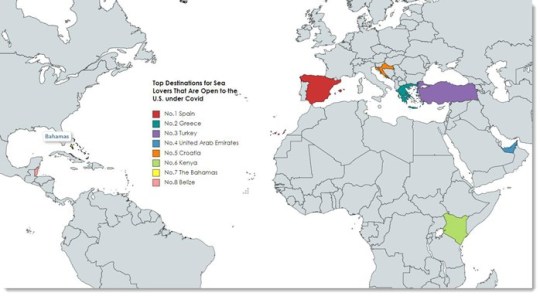
Web Scraping de Datos de Viajes
¿Tienes alguna idea sobre el big data en el turismo?
Los empresarios de la industria de viajes están rastreando todo tipo de datos, por ejemplo, datos comerciales de agentes de viajes y datos de comportamiento de los visitantes en todas las plataformas relacionadas con viajes. Es posible que conozcan sus hábitos de viaje mejor que tú. Toda la industria está aprovechando el big data para lanzar el producto adecuado y encontrar a las personas adecuadas para pagar por sus servicios.
El web scraping es la tecnología que lo hace posible.
Bueno, como viajero, quiero recopilar datos de viajes en la web para satisfacer mis necesidades: encontrar destinos entre los más atractivos y obtener las guías de Tripadvisor para mi referencia.
Que voy a hacer
En primer lugar, necesito una lista de países para investigar.
En segundo lugar, utilizaré una herramienta de raspado web, Octoparse, para crear un raspador de Tripadvisor y rastrear los datos de viajes de estos países.
¡Finalmente, voy a empacar mi equipaje y dirigirme al destino que más se ajuste a mis gustos de viaje!
¿A Dónde Puede Ir un Estadounidense?
Entonces, ¿a dónde puede viajar un estadounidense ahora?
Este artículo de CNN enumeró los destinos que están abiertos a los EE. UU. (La lista podría actualizarse de vez en cuando).
Lo que quería hacer era extraer todos los nombres de países de esta página web en una hoja de cálculo para poder pegarlos en Octoparse y obtener datos más específicos de Tripadvisor.
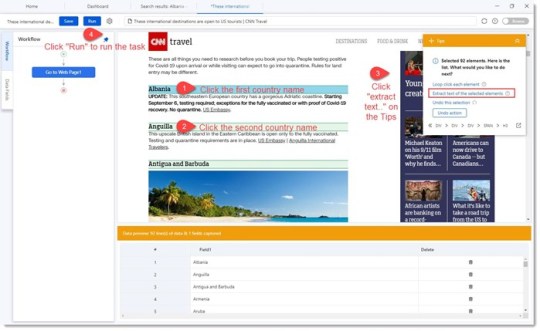
Octoparse: cómo obtener información de la lista en una página web en Excel
Octoparse puede obtener fácilmente información de la lista en una página web en Excel o CSV.
Esto es extremadamente útil cuando deseas obtener una lista de URL o una lista de datos, que deseas pegar y buscar en otra plataforma, o importar a un software de análisis de datos para tu análisis.
Ahora que tengo la lista de destinos de texto, voy a crear un raspador de TripAdvisor para obtener datos específicos sobre estos lugares.
Crear un Raspador de TripAdvisor
Los datos que voy a rastrear desde Tripadvisor:
Quiero comprobar la popularidad de los viajes en estos países. Consultaré con el número de reseñas sobre el país en Tripadvisor. (Mi hipótesis: más visitas, más reseñas).
Tengo mi tema de viaje. Soy un amante de la naturaleza interesado en eventos al aire libre y turismo en la naturaleza. Obtendré la información de la etiqueta de estos destinos para poder filtrar y ubicar el lugar perfecto donde pueda perseguir el viento, jugar en la playa o apreciar la grandeza de un pico.
Guardaré la URL de las guías de viaje en Tripadvisor para una mayor planificación de viajes. (¡Gracias contribuidores!)
Generar URL por Lotes con Nombres de Países
¿Dónde conseguir estos datos? Esta es una página de muestra: Tripadvisor Nepal.
Con la lista de nombres de países que he extraído en el paso anterior, puedo generar por lotes todas las páginas de países de Tripadvisor con Octoparse.
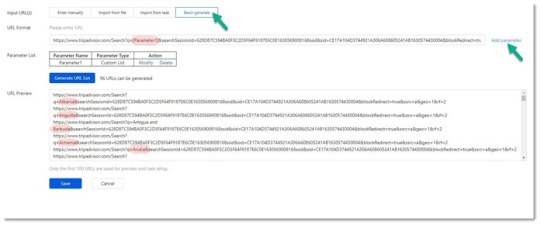
Ejemplos de páginas generadas:
Tripadvisor Ireland
Tripadvisor Israel
Tripadvisor Italy
Tripadvisor Kenya
Ahora que tengo una lista de páginas web de destino para extraer datos, voy a crear un raspador que comprenda qué datos estoy solicitando y los tomará por mí.
Crear un Raspador: Dime Lo Que Quieres
Construir un raspador es como compilar una carta para conversar con la computadora: dígale dónde y cómo obtener los datos que deseas. Solo que no hablas en lenguaje humano, sino en lenguajes de programación.
Y una herramienta de raspado web es como un traductor. Te permite compilar la carta utilizando lenguaje humano, gracias al flujo de trabajo comprensible y la interfaz de usuario intuitiva.
Si esto sigue siendo abstracto, no importa. Vamos a sumergirnos en algunas preguntas.
¿Qué puede hacer un raspador?
Visitar - abrir una página web.
Hacer clic - hacer clic en un enlace de la página web.
Extraer - rastrear datos como textos, URL, números, etc.
¿Qué datos necesito?
El nombre del país, el número de reseñas.
El enlace de la guía de viaje, el título de la guía y sus etiquetas.
¿Cómo actuará un raspador para obtener los datos que necesito?
Visitará la pagina web
Extraerá el nombre del país y el número de reseñas en la página
Buscará el enlace de la guía de viaje y hará clic en él
Extraerá la URL de la página, el título de la guía, las etiquetas de la guía
Regresará y visitará la siguiente página web
Repetirá los pasos anteriores (en Octoparse, esto se puede hacer con un bucle)
Bingo. Ese es el flujo de trabajo que construí aquí.
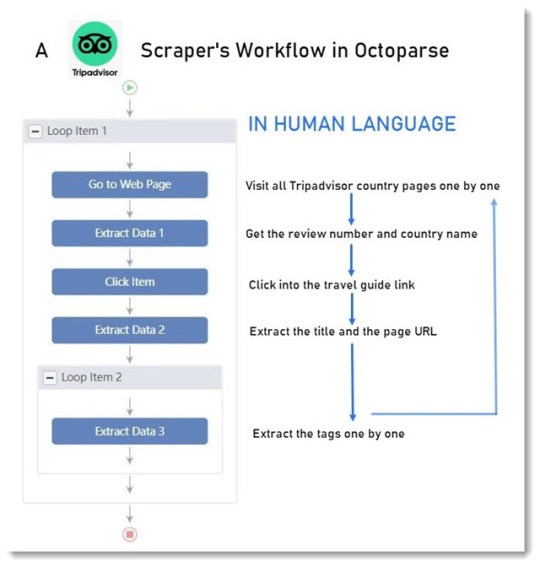
¿Cómo construir el flujo de trabajo?
Pan comido.
Ingresar las URL en la barra de búsqueda y comenzar una tarea de construcción. (Díle al raspador qué páginas web visitar)
Hacer clic en los datos que deseas en el navegador integrado. (Ayuda al raspador a localizar los datos)
Seleccionar las acciones que deseas que realice el raspador en el Panel de sugerencias. (Díle al raspador que visite, haga clic o extraiga datos)
¿Cómo se ven los datos?
Es una tabla larga ya que hay más de 100 líneas de datos en mi lista. La siguiente captura de pantalla ha hecho todo lo posible.
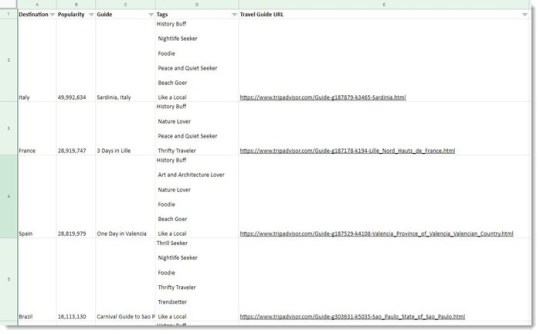
Lo sé, los datos sin procesar no son bonitos antes de cualquier visualización, pero son útiles. Con estos datos, encontré la mejor opción para un amante de la comida y la playa - ¡España!
Diviértete con Octoparse. Cualquier problema al usarlo, no dude en contactarnos en [email protected].
>> Empezar a raspar mis datos
>> Herramientas de visualización para mostrar (o mostrar) mis datos
0 notes
Text
9 herramientas de Web Scraping Gratuitas que No Te Puedes Perder en 2021
¿Cuánto sabes sobre web scraping? No te preocupe, este artículo te informará sobre los conceptos básicos del web scraping, cómo acceder a una herramienta de web scraping para obtener una herramienta que se adapte perfectamente a tus necesidades y por último, pero no por ello menos importante, te presentará una lista de herramientas de web scraping para tu referencia.
Web Scraping Y Como Se Usa
El web scraping es una forma de recopilar datos de páginas web con un bot de scraping, por lo que todo el proceso se realiza de forma automatizada. La técnica permite a las personas obtener datos web a gran escala rápidamente. Mientras tanto, instrumentos como Regex (Expresión Regular) permiten la limpieza de datos durante el proceso de raspado, lo que significa que las personas pueden obtener datos limpios bien estructurados en un solo lugar.
¿Cómo funciona el web scraping?
En primer lugar, un robot de raspado web simula el acto de navegación humana por el sitio web. Con la URL de destino ingresada, envía una solicitud al servidor y obtiene información en el archivo HTML.
A continuación, con el código fuente HTML a mano, el bot puede llegar al nodo donde se encuentran los datos de destino y analizar los datos como se ordena en el código de raspado.
Por último, (según cómo esté configurado el bot de raspado) el grupo de datos raspados se limpiará, se colocará en una estructura y estará listo para descargar o transferir a tu base de datos.
Cómo Elegir Una Herramienta De Web Scraping
Hay formas de acceder a los datos web. A pesar de que lo has reducido a una herramienta de raspado web, las herramientas que aparecieron en los resultados de búsqueda con todas las características confusas aún pueden hacer que una decisión sea difícil de alcanzar.
Hay algunas dimensiones que puedes tener en cuenta antes de elegir una herramienta de raspado web:
Dispositivo: si eres un usuario de Mac o Linux, debes asegurarte de que la herramienta sea compatible con tu sistema.
Servicio en la nube: el servicio en la nube es importante si deseas acceder a tus datos en todos los dispositivos en cualquier momento.
Integración: ¿cómo utilizarías los datos más adelante? Las opciones de integración permiten una mejor automatización de todo el proceso de manejo de datos.
Formación: si no sobresales en la programación, es mejor asegurarte de que haya guías y soporte para ayudarte a lo largo del viaje de recolección de datos.
Precio: sí, el costo de una herramienta siempre se debe tener en cuenta y varía mucho entre los diferentes proveedores.
Ahora es posible que desees saber qué herramientas de raspado web puedes elegir:
Tres Tipos De Herramientas De Raspado Web
Cliente Web Scraper
Complementos / Extensión de Web Scraping
Aplicación de raspado basada en web
Hay muchas herramientas gratuitas de raspado web. Sin embargo, no todo el software de web scraping es para no programadores. Las siguientes listas son las mejores herramientas de raspado web sin habilidades de codificación a un bajo costo. El software gratuito que se enumera a continuación es fácil de adquirir y satisfaría la mayoría de las necesidades de raspado con una cantidad razonable de requisitos de datos.
Software de Web Scraping de Cliente
1. Octoparse
Octoparse es una herramienta robusta de web scraping que también proporciona un servicio de web scraping para empresarios y empresas.
Dispositivo: como se puede instalar tanto en Windows como en Mac OS, los usuarios pueden extraer datos con dispositivos Apple.
Datos: extracción de datos web para redes sociales, comercio electrónico, marketing, listados de bienes raíces, etc.
Función:
- manejar sitios web estáticos y dinámicos con AJAX, JavaScript, cookies, etc.
- extraer datos de un sitio web complejo que requiere inicio de sesión y paginación.
- tratar la información que no se muestra en los sitios web analizando el código fuente.
Casos de uso: como resultado, puedes lograr un seguimiento automático de inventarios, monitoreo de precios y generación de leads al alcance de tu mano.
Octoparse ofrece diferentes opciones para usuarios con diferentes niveles de habilidades de codificación.
El Modo de Plantilla de Tareas Un usuario con habilidades básicas de datos scraping puede usar esta nueva característica que convirte páginas web en algunos datos estructurados al instante. El modo de plantilla de tareas solo toma alrededor de 6.5 segundos para desplegar los datos detrás de una página y te permite descargar los datos a Excel.
El modo avanzado tiene más flexibilidad comparando los otros dos modos. Esto permite a los usuarios configurar y editar el flujo de trabajo con más opciones. El modo avanzado se usa para scrape sitios web más complejos con una gran cantidad de datos.
La nueva función de detección automática te permite crear un rastreador con un solo clic. Si no estás satisfecho con los campos de datos generados automáticamente, siempre puedes personalizar la tarea de raspado para permitirte raspar los datos por ti.
Los servicios en la nube permiten una gran extracción de datos en un corto período de tiempo, ya que varios servidores en la nube se ejecutan simultáneamente para una tarea. Además de eso, el servicio en la nube te permitirá almacenar y recuperar los datos en cualquier momento.
2.
ParseHub
Parsehub es un raspador web que recopila datos de sitios web que utilizan tecnologías AJAX, JavaScript, cookies, etc. Parsehub aprovecha la tecnología de aprendizaje automático que puede leer, analizar y transformar documentos web en datos relevantes.
Dispositivo: la aplicación de escritorio de Parsehub es compatible con sistemas como Windows, Mac OS X y Linux, o puedes usar la extensión del navegador para lograr un raspado instantáneo.
Precio: no es completamente gratuito, pero aún puedes configurar hasta cinco tareas de raspado de forma gratuita. El plan de suscripción paga te permite configurar al menos 20 proyectos privados.
Tutorial: hay muchos tutoriales en Parsehub y puedes obtener más información en la página de inicio.
3.
Import.io
Import.io es un software de integración de datos web SaaS. Proporciona un entorno visual para que los usuarios finales diseñen y personalicen los flujos de trabajo para recopilar datos. Cubre todo el ciclo de vida de la extracción web, desde la extracción de datos hasta el análisis dentro de una plataforma. Y también puedes integrarte fácilmente en otros sistemas.
Función: raspado de datos a gran escala, captura de fotos y archivos PDF en un formato factible
Integración: integración con herramientas de análisis de datos
Precios: el precio del servicio solo se presenta mediante consulta caso por caso
Complementos / Extensión de Web Scraping1.
Data Scraper (Chrome)
Data Scraper puede extraer datos de tablas y datos de tipo de listado de una sola página web. Su plan gratuito debería satisfacer el scraping más simple con una pequeña cantidad de datos. El plan pagado tiene más funciones, como API y muchos servidores proxy IP anónimos. Puede recuperar un gran volumen de datos en tiempo real más rápido. Puede scrapear hasta 500 páginas por mes, si necesitas scrapear más páginas, necesitas actualizar a un plan pago.
2.
Web scraper
El raspador web tiene una extensión de Chrome y una extensión de nube.
Para la versión de extensión de Chrome, puedes crear un mapa del sitio (plan) sobre cómo se debe navegar por un sitio web y qué datos deben rasparse.
La extensión de la nube puede raspar un gran volumen de datos y ejecutar múltiples tareas de raspado al mismo tiempo. Puedes exportar los datos en CSV o almacenarlos en Couch DB.
3.
Scraper (Chrome)
El Scraper es otro raspador web de pantalla fácil de usar que puede extraer fácilmente datos de una tabla en línea y subir el resultado a Google Docs.
Simplemente selecciona un texto en una tabla o lista, haz clic con el botón derecho en el texto seleccionado y elige "Scrape similar" en el menú del navegador. Luego obtendrás los datos y extraerás otro contenido agregando nuevas columnas usando XPath o JQuery. Esta herramienta está destinada a usuarios de nivel intermedio a avanzado que saben cómo escribir XPath.
4.
Outwit hub(Firefox)
Outwit hub es una extensión de Firefox y se puede descargar fácilmente desde la tienda de complementos de Firefox. Una vez instalado y activado, puedes extraer el contenido de los sitios web al instante.
Función: tiene características sobresalientes de "Raspado rápido", que rápidamente extrae datos de una lista de URL que ingresas. La extracción de datos de sitios que usan Outwit Hub no requiere habilidades de programación.
Formación: El proceso de raspado es bastante fácil de aprender. Los usuarios pueden consultar sus guías para comenzar con el web scraping con la herramienta.
Outwit Hub also offers services of tailor-making scrapers.Outwit Hub también ofrece servicios de raspadores a medida.
Aplicación de raspado basada en web1.
Dexi.io (anteriormente conocido como raspado de nubes)
Dexi.io está destinado a usuarios avanzados que tienen habilidades de programación competentes. Tiene tres tipos de robots para que puedas crear una tarea de raspado - Extractor, Crawler, y Pipes. Proporciona varias herramientas que te permiten extraer los datos con mayor precisión. Con su característica moderna, podrás abordar los detalles en cualquier sitio web. Sin conocimientos de programación, es posible que debas tomarte un tiempo para acostumbrarte antes de crear un robot de raspado web. Consulta su página de inicio para obtener más información sobre la base de conocimientos.
El software gratuito proporciona servidores proxy web anónimos para raspar la web. Los datos extraídos se alojarán en los servidores de Dexi.io durante dos semanas antes de ser archivados, o puedes exportar directamente los datos extraídos a archivos JSON o CSV. Ofrece servicios de pago para satisfacer tus necesidades de obtención de datos en tiempo real.
2.
Webhose.io
Webhose.io te permite obtener datos en tiempo real de raspar fuentes en línea de todo el mundo en varios formatos limpios. Incluso puedes recopilar información en sitios web que no aparecen en los motores de búsqueda. Este raspador web te permite raspar datos en muchos idiomas diferentes utilizando múltiples filtros y exportar datos raspados en formatos XML, JSON y RSS.
El software gratuito ofrece un plan de suscripción gratuito para que puedas realizar 1000 solicitudes HTTP por mes y planes de suscripción pagados para realizar más solicitudes HTTP por mes para satisfacer tus necesidades de raspado web.
0 notes
Text
¿Para qué se usa el screen scraping y cómo construir uno?
Screen Scraping
Por lo general, se refiere a analizar el HTML en el contenido web generado con programas diseñados para extraer patrones específicos de contenido.
El raspado de pantalla es el método de recopilar datos de visualización de pantalla de una aplicación y traducirlos para que otra aplicación pueda mostrarlos. Normalmente, esto se hace para capturar datos de una aplicación heredada con el fin de mostrarlos utilizando una interfaz de usuario más moderna.
A veces se confunde con el raspado de contenido, que es el uso de medios manuales o automáticos para extraer contenido de un sitio web sin la aprobación del propietario del sitio web. Muy a menudo, el raspado de pantalla se refiere a un cliente web que analiza las páginas HTML del sitio web de destino para extraer datos formateados.
Screen Scrapers
Un raspador de pantalla es un programa de computadora que utiliza una técnica de raspado de pantalla para traducir entre programas de aplicación heredados (escritos para comunicarse con dispositivos de entrada / salida e interfaces de usuario ahora generalmente obsoletos) y nuevas interfaces de usuario para que la lógica y los datos asociados con los programas heredados puede seguir utilizándose.

En los primeros días de las PC, los raspadores de pantalla emulaban un terminal (por ejemplo, IBM 3270) y pretendían ser un usuario para extraer y actualizar información de forma interactiva en el mainframe. En tiempos más recientes, el concepto se aplica a cualquier aplicación que proporcione una interfaz a través de páginas web.
¿Para qué se usa Screen Scrapers?
Los raspadores de pantalla se han aplicado en una amplia cantidad de campos para una variedad de casos de uso. Algunos usos potenciales incluyen:
aplicaciones bancarias y transacciones financieras
guardar datos significativos para su uso posterior
para realizar acciones que un usuario haría en un sitio web
para traducir datos de una aplicación heredada a una aplicación moderna
para agregadores de datos, como sitios web de comparación de precios
para rastrear perfiles de usuario para ver actividades en línea; y
para obtener datos
Top 10 industrias que utilizan screen scraping
Uno de los casos de uso más importantes ha sido el de la banca. Es posible que los prestamistas deseen utilizar el raspado de pantalla para recopilar los datos financieros de un cliente. Las aplicaciones basadas en finanzas pueden usar el rastreo de pantalla para acceder a múltiples cuentas de un usuario, agregando toda la información en un solo lugar. Sin embargo, los usuarios deberían confiar explícitamente en la aplicación, ya que confían en esa organización con sus cuentas, datos de clientes y contraseñas. El raspado de pantalla también se puede utilizar para aplicaciones de proveedores de hipotecas.
Es posible que una organización también desee utilizar el raspado de pantalla para traducir entre programas de aplicaciones heredados y nuevas interfaces de usuario (UI) para que la lógica y los datos asociados con los programas heredados puedan seguir utilizándose. Esta opción rara vez se usa y solo se ve como una opción cuando otros métodos no son prácticos.
Raspado de datos sin codificación

Si deseas probar la extracción, Octoparse te permite trabajar con datos dinámicos no estructurados con solo hacer clic en puntos de datos individuales y generará automáticamente un código eficiente para extraer datos. No se requiere codificación en este proceso. Además, te permite exportar datos a formatos de tu elección como Excel, JSON, CSV, TXT, HTML, incluso directamente a tu base de datos a través de API.
0 notes