
Don't wanna be here? Send us removal request.
Statistics
We looked inside some of the posts by valentinayue-blog and here's what we found interesting.
Average Info
Notes Per Post
1
Likes Per Post
1
Reblog Per Post
0
Reply Per Post
0
Time Between Posts
3 days
Number of Posts By Type
Text
8
Link
9
Last Seen Tumblr Blogs





Fun Fact
Tumblr has 411 employees.
Text
Perspectiva de Datos: 54 Industrias que Usan Web Scraping
¿Qué es el web scraping?
Web Scraping (también llamado Web Crawling, Data Extraction, Screen Scraping) es el proceso de extraer datos de múltiples sitios web y guardarlos Excel, txt, CSV y JSON en formatos de databases locales. Con los abrumadores datos disponibles en Internet, el web scraping se convierte en un enfoque esencial para agregar Big Data.
¿Quién está usando web scraping?
Vamos a abordar esta pregunta analizando las diferentes industrias y trabajos que requieren habilidades de web scraping. Para hacer esto, hemos compilado y analizado información de trabajo extraída de sitios de trabajo, incluidos Indeed, Glassdoor y LinkedIn.
Para ver exactamente qué trabajos están usando habilidades de web scraping, tomamos un gigante tecnológico (Google) como ejemplo en esta investigación. Raspamos y analizamos las ofertas de trabajo de Google, para descubrir cuáles y cuántos trabajos requieren habilidades de web scraping.
Nuestros hallazgos se muestran a continuación. Después de leerlos, puede que estés tan sorprendido como nosotros. Si está interesado en el proceso de scraping, puede consultar los GitHub Repositories para descargar los rastreadores (que se ejecutan en una herramienta de web scraping gratuita Octoparse) para obtener los datos que desea.
Encontrar 1: 54 Industrias Requieren habilidades de Web Scraping
Raspamos y analizamos las ofertas de trabajo en diferentes industrias que requieren web scraping skills en LinkedIn. En total, hay trabajos en 54 industrias que requieren habilidades de web scraping. Las 10 principales industrias con la mayor demanda de habilidades de web scraping son Software de Computadora (22%), Tecnología de la Información y Servicios (21%), Servicios Financieros (12%), Internet (11%), Marketing y Publicidad (5%) Computadora&Seguridad de red (3%), Seguros (2%), Banca (2%), Consultoría de Gestión (2%) y Medios en línea (2%).
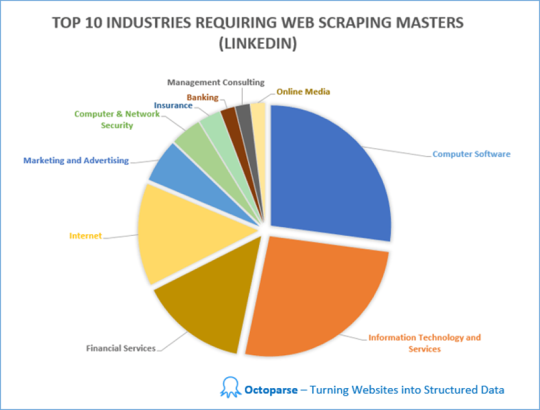
Otras industrias incluyen Petróleo & Energía, Construcción, Bienes de Consumo, Defensa y Espacio, Personal y Reclutamiento, Atención Hospitalaria & de Salud, Gestión Educativa, Gestión de Organizaciones sin fines de lucro, Productos Farmacéuticos, Publicaciones, Investigación, Fabricación Eléctrica/Electrónica, Administración Gubernamental ... etc.
Hallazgo 2: Los trabajos no tecnológicos requieren Web Scraping Skills
También en base a la información extraída de LinkedIn, descubrimos que los trabajos no tecnológicos también incluyen el web scraping en sus requisitos de trabajo.
La sabiduría tradicional dice que la mayoría de los trabajos que requieren web scraping son relevantes para la tecnología, como la tecnología de la información y la ingeniería. Sin embargo, sorprendentemente, hay muchos otros tipos de trabajos que requieren habilidades de web scraping, como ventas, desarrollo de negocios, marketing, recursos humanos, redacción/edición y consultoría.

Específicamente, exploramos de web scraping jobs in Google, para descubrir cuántos trabajos requieren habilidades de web scraping y qué otros requisitos hay además del web scraping.
Hallazgo 3: Habilidades de Web Scraping en Tech Company (Google como ejemplo) Dado que es bastante obvio que las compañías de software y tecnología de la información tienen la mayor demanda de expertos en web scraping, decidimos profundizar en las ofertas de trabajo de Google. Las categorías de trabajo que más necesitan habilidades de web scraping son Ingeniería de Software, Ventas y Gestión de Cuentas y Gestión de Programas, seguidas de Soluciones Técnicas y Marketing & Comunicaciones.
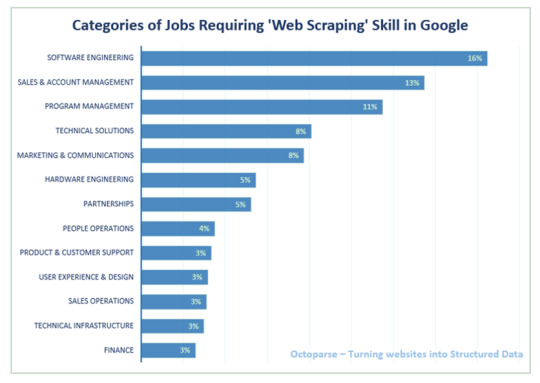
Para aquellos que tienen curiosidad sobre otros requisitos de habilidades para el ingeniero de software y ventas y administración de cuentas en Google, convertimos los requisitos del trabajo en nubes de palabras para darle una mejor idea.
Requisitos sobre Ingeniería de Software en Google

Requisitos sobre Ventas & Gestión de Cuentas en Google

Además de analizar las ofertas de trabajo que requieren habilidades de web scraping, también logramos ver una imagen más amplia de todos los trabajos disponibles en todas las industrias. Aquí hay información adicional que obtuvimos.
Hallazgo 4: Los 10 mejores trabajos mejor pagados
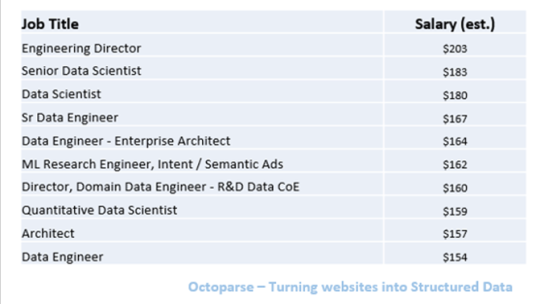
Según la información agregada de Glassdoor, existen grandes diferencias en los salarios para diferentes trabajos, que van desde $25K a $203K. Entre todos, los ingenieros de datos superiores y los científicos de datos son los trabajos mejor pagados.
Los datos anteriores se basan en la estimación de Glassdoor de los salarios base de los trabajos, que no necesariamente es respaldada por los empleadores. )
Entre toda la información sobre el trabajo que recopilamos, los trabajos que pagan menos son Político Reportero y Reclutador Junior, a partir de $25K y $29K.
Hallazgo 5: Las 10 Mejores Industrias de Pago
También exploramos el salario promedio en diferentes industrias, en base al mismo conjunto de datos extraído de Glassdoor. Las industrias con los salarios más altos son los servicios de petróleo y gas, biotecnología y productos farmacéuticos, y mercadería general y supermercado. Para nuestra sorpresa, Information Technology solo ocupa el número 5 en la lista.

Conclusión
Es seguro decir que el web scraping se ha convertido en una habilidad esencial para adquirir en el mundo digital actual, no solo para empresas tecnológicas y puestos tecnológicos, sino también para trabajos no tecnológicos. La capacidad de compilar grandes conjuntos de datos es fundamental para el análisis de Big Data, el aprendizaje automático y la inteligencia artificial.
Afortunadamente, Big Data es cada vez más fácil de acceder que nunca. Con Los 30 Mejores Software Gratuitos de Web Scraping en 2020 que se vuelven más inteligentes y populares, incluso las personas sin experiencia en programación pueden aplicar fácilmente el web scraping para agregar todo tipo de datos, trabajar con los conocimientos de Big Data para potenciar su negocio.
Dicho esto, si desea aprender sobre el web scraping pero no quiere lidiar con Python u otros lenguajes de programación, una herramienta de web scraping es una gran opción. He perfilado una lista de herramientas de web scraping a continuación para su referencia. Entre todas las opciones en el mercado, Octoparse se destaca como el mejor web scraper automático GRATUITO como una solución para la extracción de datos a escala.
#Web scraping precios#scraping y crawling scraping y crawling#web scraping extracción de datos#web scraping import io#web scraper chrome#scraper parsers#excel importar datos web contraseña#buscar personas por ccorreo electrónico#crawly web scraper#web scraping extracción de datos en la web
0 notes
Link
#scraping y crawling#web scraping extracción de datos#que es parsehub#web scraping import io#web scraper chrome#scraper parsers#Copiar datos de web a excel#excel importar datos web contraseña#table capture#macro para obtener datos externos de una web#extraer datos de una página web a excel macro#Descargar datos página web python
0 notes
Text
Simple Scraping con Google Sheets (2020 actualizado)
Este herramienta de web scraping puede automatizar el proceso de copia y pegado repetitivos. En realidad, las hojas de Google pueden considerarse un web scraping básico. Puede usar una fórmula especial para extraer datos de una página web, importar los datos directamente a las hojas de Google y compartirlos con sus amigos.
En este artículo, primero le mostraré cómo construir un web scraping simple con Hojas de cálculo de Google. Luego lo compararé con Octoparse web scraping automático. Después de leerlo, tendrá una idea clara sobre qué método funcionaría mejor para sus necesidades específicas de web scraping.
Opción#1: Cree un web scraping sencillo con ImportXML en Google Spreadsheets
Paso 1: Abre una nueva hoja de Google.
Paso 2: Abra un sitio web de destino con Chrome. En este caso, elegimos ’Games sales’. Haga clic derecho en la página web y aparecerá un menú desplegable. Luego seleccione "inspeccionar". Presione una combinación de tres teclas: "Ctrl” + "Shift" + "C" para activar "Selector". Esto permitiría al panel de inspección obtener la información del elemento seleccionado dentro de la página web.
Paso 3: Copie y pegue la URL del sitio web en la hoja.
Opción#2: Intentemos obtener datos de precios con una fórmula simple: ImportXML
Paso 1: Copie el Xpath del elemento. Seleccione el elemento de precio y haga clic con el botón derecho para que aparezca el menú desplegable. Luego seleccione "Copiar", elija "Copiar XPath".
Paso 2: Escriba la fórmula en la hoja de cálculo.
=IMPORTXML(“URL”, “XPATH expression”)
Tenga en cuenta que la "expresión Xpath" es la que acabamos de copiar de Chrome. Reemplace la comilla doble "" dentro de la expresión Xpath con una comilla simple ''.
Opción#3: Hay otra fórmula que podemos usar:
=IMPORTHTML(“URL”, “QUERY”, Index)
Con esta fórmula, extraes toda la tabla.
Ahora, veamos cómo se puede lograr la misma tarea de raspado con un rastreador web, Octoparse.
Paso 1: Abra Octoparse, cree una nueva tarea seleccionando "+ Tarea" en el "Modo avanzado"
Paso 2: Elija su grupo de tareas preferido. Luego ingrese la URL del sitio web de destino y haga clic en "Guardar URL". En este caso: sitio web de Game Sale http://steamspy.com/
Paso 3: Aviso El sitio web de Game Sale se muestra en la sección de vista interactiva de Octoparse. Necesitamos crear una lista de bucles para que Octoparse revise los listados.
1. Haga clic en una fila de la tabla (podría ser cualquier archivo dentro de la tabla). Octoparse detectará elementos similares y los resaltará en rojo.
2. Necesitamos extraer por filas, así que elija "TR" (Fila de Tabla) desde el panel de control.
3. Después de seleccionar una fila, elija el comando "Seleccionar todos los subelementos" en el panel Consejos de acción. Elija el comando "Seleccionar todo" para seleccionar todas las filas de la tabla.
Paso 4: Elija "Extraer datos en el bucle" para extraer los datos.
Puede exportar los datos a Excel, CSV, TXT u otros formatos deseados. Las hojas de cálculo requieren que se copie y pegue, pero Octoparse automatiza el proceso. Además, Octoparse tiene más control sobre sitios web dinámicos con AJAX o reCaptcha.
Más recursos:
Create your first scraper with Octoparse [Video]
Los 20 mejores programas gratuitos de web scraping
Comparacion de las 5 mejores herramientas de web scraping
#Web scraping precios#scraping mensaje#como hacer web scraping con python#web scraping legal#web scraping javascript#scraper idealista#extraer datos de una web#correos electrónicos buscar#buscar personas por ccorreo electrónico#scrab in linkedin#Búsqueda de correos electrónicos#chrome scrab in
0 notes
Link
¿Cómo puede descargar imágenes de enlaces de forma gratuita en lote?
Para descargar la imagen del enlace, es posible que desee buscar en "Descargadores de imágenes a granel". Inspirado por las consultas recibidas, decidí hacer una lista de "los 5 mejores descargadores de imágenes masivas" para usted. Asegúrese de consultar este artículo Si desea descargar imágenes del enlace sin costo. (Si no está seguro de cómo extraer las URL de las imágenes, consulte esto: Cómo construir un rastreador de imágenes sin codificación)
#Web scraping precios#scraping mensaje#como hacer web scraping con python#web scraping legal#web scraping javascript#scraper idealista#extraer datos de una web#correos electrónicos buscar#buscar personas por ccorreo electrónico#scrab in linkedin#Búsqueda de correos electrónicos#chrome scrab in#web scraping software#crawly web scraper
0 notes
Text
Los 30 Mejores Software de Web Scraping Gratis en 2020
El Web scraping (también denominado extracción de datos web, web crawler, captura de pantalla o recolección web) es una técnica web para extraer datos de los sitios web. Convierte datos no estructurados en datos estructurados que pueden almacenarse en su computadora local o en una base de datos.
Puede ser difícil crear un web scraping para personas que no saben nada sobre codificación. Afortunadamente, hay herramientas disponibles tanto para personas que tienen o no habilidades de programación. Aquí está nuestra lista de las 30 herramientas de web scraping más populares, desde bibliotecas de código abierto hasta extensiones de navegador y software de escritorio.
1. Beautiful Soup
¿Para quién es esto?: desarrolladores que dominan la programación para crear un web scraping/web crawler para rastrear los sitios web.
Por qué deberías usarlo:Beautiful Soup es una biblioteca de Python de código abierto diseñada para scrape archivos HTML y XML. Son los principales analizadores de Python que se han utilizado ampliamente. Si tiene habilidades de programación, funciona mejor cuando combina esta biblioteca con Python.
2. Octoparse
¿Cómo hacer web scraping?: Las empresas o las personas tienen la necesidad de extraer datos de la web: comercio electrónico, inversión, criptomoneda, marketing, bienes raíces, etc. Este software no requiere habilidades de programación y codificación.
Por qué debería usarlo: Octoparse es una plataforma de datos web SaaS gratuita de por vida. Puede usar para raspar datos web y convertir datos no estructurados o semiestructurados de sitios web en un conjunto de datos estructurados sin codificación. También proporciona task templates para usar, como eBay, Twitter, BestBuy y muchas otras. Octoparse también proporciona servicio de datos web. Puede personalizar el tarea scraper según sus necesidades de raspado.
3. Import.io
Para quién es esto: Empresa que busca una solución de integración en datos web.
Por qué debería usarlo: Import.io es una plataforma de datos web SaaS. Proporciona un software de web scraping que le permite raspar datos de sitios web y organizarlos en conjuntos de datos. Pueden integrar los datos web en herramientas analíticas para ventas y marketing para obtener información.
4. Mozenda
Para quién es esto: Empresas y negocios hay necesidades de fluctuantes de datos/datos en tiempo real.
Por qué debería usarlo: Mozenda proporciona una herramienta de extracción de datos que facilita la captura de contenido de la web. También proporcionan servicios de visualización de datos. Elimina la necesidad de contratar a un analista de datos.
5. Parsehub
Para quién es esto: analista de datos, comercializadores e investigadores que carecen de habilidades de programación.
Por qué debería usarlo: ParseHub es un software visual de web scrapinng que puede usar para obtener datos de la web. Puede extraer los datos haciendo clic en cualquier campo del sitio web. También tiene una rotación de IP que ayudaría a cambiar su dirección IP cuando se encuentre con sitios web agresivos con una técnica anti-raspado.
6. Crawlmonster
Para quién es esto: SEO y especialistas en marketing
Por qué deberías usarlo: CrawlMonster es un software gratuito de web scraping. Le permite escanear sitios web y analizar el contenido de su sitio web, el código fuente, el estado de la página y muchos otros.
7. Connotate
Para quién es esto: Empresa que busca una solución de integración en datos web.
Por qué debería usarlo: Connotate ha estado trabajando junto con Import.IO, que proporciona una solución para automatizar el scraping de datos web. Proporciona un servicio de datos web que puede ayudarlo a raspar, recopilar y manejar los datos.
8. Common Crawl
Para quién es esto: Investigador, estudiantes y profesores.
Por qué deberías usarlo: Common Crawl se basa en la idea del código abierto en la era digital. Proporciona conjuntos de datos abiertos de sitios web rastreados. Contiene datos sin procesar de la página web, metadatos extraídos y extracciones de texto.
9. Crawly
Para quién es esto: Personas con requisitos de datos básicos sin hababilidad de codificación.
Por qué debería usarlo: Crawly proporciona un servicio automático que raspa un sitio web y lo convierte en datos estructurados en forma de JSON o CSV. Pueden extraer elementos limitados en segundos, lo que incluye: Texto del título. HTML, comentarios, etiquetas de fecha y entidad, autor, URL de imágenes, videos, editor y país.
10. Content Grabber
Para quién es esto: Desarrolladores de Python que son expertos en programación.
Por qué debería usarlo: Content Grabber es un software de web scraping dirigido a empresas. Puede crear sus propios agentes de web scraping con sus herramientas integradas de terceros. Es muy flexible en el manejo de sitios web complejos y extracción de datos.
11. Diffbot
Para quién es esto: Desarrolladores y empresas.
Por qué debería usarlo: Diffbot es una herramienta de web scraping que utiliza aprendizaje automático y algoritmos y API públicas para extraer datos de páginas web (web scraping). Puede usar Diffbot para el análisis de la competencia, el monitoreo de precios, analizar el comportamiento del consumidor y muchos más.
12. Dexi.io
Para quién es esto: Personas con habilidades de programación y cotificación.
Por qué deberías usarlo: Dexi.io es un rastreador web basado en navegador. Proporciona tres tipos de robots: extractor, rastreador y tuberías. PIPES tiene una función de robot maestro donde 1 robot puede controlar múltiples tareas. Admite muchos servicios de terceros (solucionadores de captcha, almacenamiento en la nube, etc.) que puede integrar fácilmente en sus robots.
13. DataScraping.co
Para quién es esto: Analista de datos, comercializadores e investigadores que carecen de habilidades de programación.
Por qué debería usarlo: Data Scraping Studio es un software gratuito de raspado web para recolectar datos de páginas web, HTML, XML y pdf. Actualmente, el cliente de escritorio solo está disponible para Windows.
14. Easy Web Extract
Para quién es esto: Negocios con necesidades limitadas de datos, especialistas en marketing e investigadores que carecen de habilidades de programación.
Por qué debería usarlo: Easy Web Extract es un software visual de raspado web para fines comerciales. Puede extraer el contenido (texto, URL, imagen, archivos) de las páginas web y transformar los resultados en múltiples formatos.
15. FMiner
Para quién es esto: Analista de datos, comercializadores e investigadores que carecen de habilidades de programación.
Por qué debería usarlo: FMiner es un software de web scraping con un diseñador de diagramas visuales, y le permite construir un proyecto con una grabadora de macros sin codificación. La característica avanzada le permite raspar desde sitios web dinámicos usando Ajax y Javascript.
16. Scrapy
Para quién es esto: Desarrollador de Python con habilidades de programación y scraping
Por qué deberías usarlo: Scrapy se usa para desarrollar y construir una araña web. Lo bueno de este producto es que tiene una biblioteca de red asincrónica que le permitirá avanzar en la siguiente tarea antes de que finalice.
17. Helium Scrape
Para quién es esto: Analista de datos, comercializadores e investigadores que carecen de habilidades de programación.
Por qué debería usarlo: Helium Scraper es un software visual de scraping de datos web que funciona bastante bien, especialmente eficaz para elementos pequeños en el sitio web. Tiene una interfaz fácil de apuntar y hacer clic, lo que facilita su uso.
18. Scrape.it
Para quién es esto: Personas que necesitan datos escalables sin codificación.
Por qué deberías usarlo: Permite que los datos raspados se almacenen en tu disco local que autorizas. Puede crear un Scraper utilizando su lenguaje de web scraping (WSL), que tiene una curva de aprendizaje baja y no tiene que estudiar codificación. Es una buena opción y vale la pena intentarlo si está buscando una herramienta de web scraping segura.
19. ScraperWiki
Para quién es esto: Un entorno de análisis de datos Python y R, ideal para economistas, estadísticos y administradores de datos que son nuevos en la codificación.
Por qué deberías usarlo: Tiene dos partes dentro de la empresa. Uno es QuickCode, que está diseñado para economistas, estadísticos y administradores de datos con conocimiento del lenguaje Python y R. La segunda parte es The Sensible Code Company, que proporciona un servicio de datos web para convertir información desordenada en datos estructurados.
20. Scrapinghub
¿Para quién es esto?: Python/Desarrolladores de web scraping
Por qué debería usarlo: Scraping Hub es una plataforma web basada en la nube. Tiene cuatro tipos diferentes de herramientas: Scrapy Cloud, Portia, Crawlera y Splash. Es genial que Scrapinghub ofrezca una colección de direcciones IP cubiertas en más de 50 países, que es una solución para los problemas de prohibición de IP.
21. Screen-Scraper
Para quién es esto: Para los negocios se relaciona con la industria automotriz, médica, financiera y de comercio electrónico.
Por qué debería usarlo: Screen Scraper puede proporcionar servicios de datos web para las industrias automotriz, médica, financiera y de comercio electrónico. Es más conveniente y básico en comparación con otras herramientas de web scraping como Octoparse. También tiene un ciclo de aprendizaje corto para las personas que no tienen experiencia en el web scraping.
22. Salestools.io
Para quién es esto: Comercializador y ventas.
Por qué debería usarlo: Salestools.io proporciona un software de web scraping que ayuda a los vendedores a recopilar datos en redes profesionales como LinkedIn, Angellist, Viadeo.
23. ScrapeHero
¿Quién es este: Para inversores, Hedge Funds, Market Analyst es muy útil.
Por qué debería usarlo: ScrapeHero como proveedor de API le permite convertir sitios web en datos. Proporciona servicios de datos web personalizados para empresas y empresas.
24. UniPath
Para quién es esto: Negocios con todos los tamaños
Por qué debería usarlo: UiPath es un software de automatización de procesos robótico para el web scraping gratuito. Permite a los usuarios crear, implementar y administrar la automatización en los procesos comerciales. Es una gran opción para los usuarios de negocios, ya que te hace crear reglas para la gestión de datos.
25. Web Content Extractor
Para quién es esto: Analista de datos, comercializadores e investigadores que carecen de habilidades de programación.
Por qué debería usarlo: Web Content Extractor es un software de web scraping fácil de usar para fines privados o empresariales. Es muy fácil de aprender y dominar. Tiene una prueba gratuita de 14 días
26. Webharvy
Para quién es esto: Analista de datos, comercializadores e investigadores que carecen de habilidades de programación.
Por qué debería usarlo: WebHarvy es un software de web scraping de apuntar y hacer clic. Está diseñado para no programadores. El extractor no le permite programar. Tienen tutoriales de web scraping que son muy útiles para la mayoría de los usuarios principiantes.
27. Web Scraper.io
Para quién es esto: Analista de datos, comercializadores e investigadores que carecen de habilidades de programación.
Por qué debería usarlo: Web Scraper es una extensión de navegador Chrome creada para extraer datos de sitios web. Es un software gratuito de web scraping para raspar páginas web dinámicas.
28. Web Sundew
Para quién es esto: Empresas, comercializadores e investigadores.
Por qué debería usarlo: WebSundew es una herramienta de raspado visual que funciona para el raspado estructurado de datos web. La edición Enterprise le permite ejecutar el scraping en un servidor remoto y publicar los datos recopilados a través de FTP.
29. Winautomation
Para quién es esto: Desarrolladores, líderes de operaciones comerciales, profesionales de IT
Por qué debería usarlo: Winautomation es una herramienta de web scraping de Windows que le permite automatizar tareas de escritorio y basadas en la web.
30. Web Robots
Para quién es esto: Analista de datos, comercializadores e investigadores que carecen de habilidades de programación.
Por qué debería usarlo: Web Robots es una plataforma de web scraping basada en la nube para raspar sitios web dinámicos con mucho Javascript. Tiene una extensión de navegador web, así como un software de escritorio que es fácil para las personas para extraer datos de los sitios web.
#web scraping precios#cómo hhacer web scraping python#scraping mensaje#web scraping legal#web scraping javascript#scraper idealista#extraer datos de una web#scrab in linkedin
0 notes
Text
Cómo obtener datos a gran escala (guía 2020)
A medida que su negocio se amplía, es necesario llevar el proceso de extracción de datos al siguiente nivel y raspar los datos a gran escala. Sin embargo, la ampliación no es una tarea fácil. Es posible que encuentre algunos desafíos que le impidan obtener una cantidad significativa de datos de varias fuentes automáticamente.
Tabla de contenidos:
4 desafíos de extracción a gran escala
Combate con estos desafíos
Obstáculos mientras se somete a web spider a escala:
De The Lazy Artist Gallery
1. Estructura dinámica del sitio web: Es fácil scrape páginas web HTML. Sin embargo, muchos sitios web ahora dependen en gran medida de las técnicas de Javascript/Ajax para la carga dinámica de contenido. Ambos requieren todo tipo de bibliotecas complejas que estas bases de datos hacen que la scraping de datos en la red sea complejas
2. Tecnologías anti-scraping: Tales como Captcha y antecedentes después de iniciar sesión sirven como vigilancia para detener el correo no deseado. Sin embargo, también representan un gran desafío para que se pasado un web scraper básico. Como tales tecnologías anti-scraping aplican algoritmos de codificación complejos, se necesita mucho esfuerzo para encontrar una solución técnica para solucionarlo. Algunos incluso pueden necesitar un middleware como 2Captcha para resolver.
3. Velocidad de carga lenta: Cuantas más páginas web necesite un raspador (scraper), más tardará en completarse. Es obvio que el scraping a gran escala requerirá muchos recursos en una máquina local. Una carga de trabajo más pesada en la máquina local puede provocar una falla.
4. Almacenamiento de datos: Una extracción a gran escala genera un gran volumen de datos. Esto requiere una infraestructura sólida en el almacenamiento de datos para poder almacenar los datos de forma segura. Se necesitará mucho dinero y tiempo para mantener dicha base de datos.
Aunque estos son algunos de los desafíos comunes de la scraping a gran escala, Octoparse ya ayudó a muchas empresas a superar estos problemas. La tecnología de extracción de datos en la nube de Octoparse está diseñada para la extracción a gran escala.
La extracción en la nube optimiza el raspado a escala
La extracción en la nube le permite extraer datos de sus sitios web de destino 24/7 y transmitirlos a su base de datos, todo de forma automática. ¿La única ventaja obvia? No necesita sentarse junto a su computadora y esperar a que se complete la tarea.
Pero ... en realidad, hay cosas más importantes que puede lograr con la extracción en la nube. Déjame desglosarlos en detalles:
1. Rapidez
En Octoparse, llamamos a un proyecto de scraping una "tarea". Con la extracción en la nube, puede scrape hasta 6 a 20 veces más rápido que una ejecución local.
Así es como funciona la extracción en la nube. Cuando se crea una tarea y se configura para ejecutarse en la nube, Octoparse envía la tarea a varios servidores de la nube que luego realizan las tareas de raspado simultáneamente. Por ejemplo, si está tratando de raspar la información del producto para 10 almohadas diferentes en Amazon, en lugar de extraer las 10 almohadas una por una, Octoparse inicia la tarea y la envía a 10 servidores en la nube, cada uno extrae datos para uno de los diez almohadas Al final, obtendría 10 datos de almohadas extraídos en 1/10 del tiempo si extrajera los datos localmente.
Aparentemente, esta es una explicaciób demasiado simplificada del algoritmo Octoparse, pero se entiende la idea.
2. Scrape más sitios web simultáneamente
Cloud extracción también permite scrape hasta 20 sitios web simultáneamente. Siguiendo la misma idea, cada sitio web se raspa en un único servidor en la nube que luego envía los extraídos a su cuenta.
Puede configurar diferentes tareas con varias prioridades para asegurarse de que los sitios web se scraped en el orden preferido.
3. Almacenamiento ilimitado en la nube
Durante una extracción en la nube, Octoparse elimina los datos duplicados y almacena los datos limpios en la nube para que pueda acceder fácilmente a los datos en cualquier momento, en cualquier lugar y no hay límite para la cantidad de datos que puede almacenar. Para una experiencia de raspado aún más fluida, integre Octoparse con su propio programa o base de datos a través de API para administrar sus tareas y datos.
4. Programe ejecuciones para la extracción regular de datos Si va a necesitar feeds de datos regulares de cualquier sitio web, esta es la característica para usted. Con Octoparse, puede configurar fácilmente sus tareas para que se ejecuten según lo programado, diariamente, semanalmente, mensualmente o incluso en cualquier momento específico de cada día. Una vez que termine de programar, haga clic en "Guardar y comenzar". La tarea se ejecutará según lo programado.
5. Menos bloqueo
La extracción en la nube reduce la posibilidad de ser incluido en la lista negra/bloqueado. Puede usar proxies IP, cambiar agentes de usuario, borrar cookies, ajustar la velocidad de raspado, etc.
El seguimiento de datos web en un gran volumen, como redes sociales, noticias y sitios web de comercio electrónico, elevará el rendimiento de su negocio con prácticas basadas en datos. Es hora de deshacerse de la navegación web antigua y usar la tecnología de raspado web para obtener una ventaja competitiva ahora.
#herramienta de scraping#web scraping gratis#extraer datos de la web#extraer datos a excel#web scraping tutorial#web scraping precios#que es web scraping#web scraping python#web scraping amazon
0 notes
Link
En breve, los especialistas en marketing digital deberían equiparse con algunas "armas" adecuadas y poderosas para cumplir sus objetivos #.
En este artículo, echemos un vistazo a la lista de "armas": las mejores 10 herramientas de generación de leads.
Ver artículo original & más Blog:Extraer web dato
#b2b#b2b website#b2cmarketing#b2c#python#programming#api#marketing blog#youtube marketing#marketing digital#tutorial#blog#online sales
0 notes
Text
Big Data: 50 Fuentes de Datos Fascinantes y Gratuitas para la Visualización de Datos
Ver el artículo original & más Blog:Herramientas de Scraping
¿Alguna vez te has sentido frustrado cuando intentas buscar algunos datos en Google? ¿Páginas de sitios web relevantes pero ninguna puede cumplir sus expectativas? ¿Alguna vez ha sentido que sus artículos son menos persuasivos sin soporte de datos?
Pongamos este artículo en su lista de favoritos, la guía más completa de fuentes de datos, incluidos General Data, Government Data, Market Data for U.S y China etc.
Informacion General
1. Organización Mundial de la Salud
La Organización Mundial de la Salud ofrece datos y análisis sobre las prioridades mundiales de salud, como el hambre, la salud y las enfermedades mundiales.
2. The Broad Institute
The Broad Institute ofrece una serie de conjuntos de datos en biología y medicina.
3. Amazon Web Service
Amazon Web Service es una plataforma de datos basada en la nube sobre Química, Biología, Economía, etc. También es un intento de construir la base de datos más completa de información genética humana y la base de datos de imágenes de satélite de la Tierra de la NASA.
4. Figshare
Figshare es una plataforma para compartir resultados de investigación. Aquí, podrá ver algunos hallazgos sorprendentes de personas increíbles de todo el mundo.
5. UCLA
A veces, UCLA comparte algunos de sus hallazgos en trabajos de investigación.
6. UCI Machine Learning Repository
Este sitio web actualmente mantiene 394 conjuntos de datos como un servicio para la comunidad de aprendizaje automático.
7. Github
Algunos chicos geniales construyeron la comunidad GitHub, compartiendo un montón de conjuntos de datos increíbles. Ahora los datos que se encuentran dentro son ofrecidos por todos y ofrecidos a todos.
8. Pew Research Center
Pew Research Center ofrece sus datos en bruto de su fascinante investigación sobre la vida estadounidense.
Datos del gobierno
9. Data.gov
Data.gov es el hogar de los datos abiertos del gobierno de EE. UU. Puede encontrar datos, herramientas y recursos aquí para realizar investigaciones, visualización de datos, etc.
10. US Census Bureau
La Oficina del Censo de EE. UU. Es una gran cantidad de información sobre la vida de los ciudadanos estadounidenses que abarca datos de población, datos geográficos y educación.
11. Open Data Network
Open Data Network es un sitio web de búsqueda fácil para que pueda encontrar datos relacionados con el gobierno, con buenas herramientas de visualización integradas.
12. European Union Open data portal
Los datos abiertos de la Unión Europea son para acceder a una creciente gama de datos de la institución de la Unión Europea.
13. Canada Open Data
Canada Open Data le permite obtener un acceso rápido y fácil a los servicios e información más solicitados por el gobierno de Canadá.
14. Open Government Data
Este sitio web proporciona a los visitantes excelentes datos de gobierno abierto de los US, EU, Canada, CKAN y más.
15. The CIA World Factbook
El World Factbook proporciona información sobre la historia, las personas, el gobierno, la economía, la geografía, las comunicaciones, el transporte, los asuntos militares y transnacionales para 267 entidades mundiales.
16. Gov.uk
Gov.uk son los datos del Gobierno del Reino Unido, incluida la bibliografía nacional británica, metadatos de todos los libros y publicaciones del Reino Unido desde 1950.
17. Health Data.gov
Health Data Gov se dedica a hacer que los datos de salud de alto valor sean más accesibles para empresarios, investigadores y formuladores de políticas con la esperanza de obtener mejores resultados de salud para todos. Tiene 125 años de datos de atención médica en los Estados Unidos, incluidos datos de Medicare a nivel de reclamos, epidemiología y estadísticas de población.
18. UNICEF
Unicef ofrece estadísticas e informes sobre la situación de los niños en todo el mundo.
19. National Climatic Data Center
El Centro Nacional de Datos Climáticos es una gran colección de conjuntos de datos ambientales, meteorológicos y climáticos del Centro Nacional de Datos Climáticos de EE. UU. El archivo de datos meteorológicos más grande del mundo.
Google
20. Google públicos datos incluyen datos de indicadores de desarrollo mundial, de la OECD y de indicadores de desarrollo humano, principalmente relacionados con datos económicos y del mundo.
21. Google Trends Estadísticas sobre el volumen de búsqueda (como proporción de la búsqueda total) para cualquier término dado, desde 2004.
22. Google Finance 40 años de datos del mercado de valores, actualizados en tiempo real. years’ worth of stock market data, updated in real-time.
Market Data
E-commerce Plataformas
23. Amazon
24. eBay
Dos de las plataformas de comercio electrónico más grandes de los EE. UU., Que enumeran toneladas de productos para clientes. Mientras tanto, ofrece información de productos para vendedores e investigadores para análisis.
25. Yelp
Muchos restaurantes se enumeran en este sitio web, los clientes hacen comentarios sobre restaurantes y estos comentarios pueden ayudar a otros clientes a elegir qué restaurantes cenar. Además, la información del restaurante y las reseñas de los clientes son extremadamente valiosas para que un especialista en marketing las estudie.
26. Yellowpages
Yellowpages es una gran marca incluso antes de que ingresáramos a la era de Internet. El sitio web ofrece información comercial.
27. Cars
Este sitio web proporciona información del automóvil, tanto autos usados como autos nuevos. También incluye la información de contacto del propietario.
Real Estate
28. Real Estate
29. Zillow
30. Realtor
Estos tres sitios web enumeran casas, apartamentos en venta o en alquiler, y ofrecen información muy completa sobre viviendas.
31. Trip Advisor
Una plataforma para que los clientes revisen excelentes hoteles en todo el mundo. Permite a los visitantes encontrar los mejores hoteles para vacacionar a través de reseñas, y estas reseñas son muy dignas de estudiar si se encuentra en la industria hotelera.
32. Glassdoor
Un sitio web de reclutamiento, que enumera miles de puestos vacantes. La información extraída puede ser utilizada para el estudio de costos laborales.
33. Linkedin Las mejores redes sociales para la comunicación formal. Miles de usuarios están registrados, y los perfiles de usuario son bastante convincentes. Muy útil para que las personas traten de encontrar un trabajo u obtener oportunidades de ventas.
Chinese Market
Como todos sabemos, China es un mercado con enormes posibilidades, por lo que también enumeré algunos sitios web para obtener datos del mercado chino.
Real Estate
34. www.58.com (58同城)
35. www.anjuke.com (安居客)
36. www.qfang.com (Q房网)
37. Fang.com (房天下)
Estos sitios web recopilan datos completos de bienes raíces en China. El florecimiento del mercado inmobiliario de China hace que el precio de la vivienda sea un punto caliente para la sociedad, estos sitios ofrecen datos masivos y confiables para las personas que realizan su investigación sobre bienes raíces en China.
E-commerce Platforms
38. JD.com
39. Tmall.com
40. Taobao.com
Las empresas de comercio electrónico de China suministran productos masivos al mundo, muchos dispositivos se importan de China y se extienden por todo el mundo, entonces, ¿cómo es la plataforma de comercio electrónico de China? ¿No tienen curiosidad ustedes?
Car Markets
41. www.autohome.com.cn(汽车之家)
China siempre ha sido un mercado con un enorme potencial que todo fabricante de automóviles quiere aprovechar. El mejor sitio web para que los investigadores de mercado recopilen datos es AUTO HOME, que reúne toneladas de datos y reseñas de consumidores, lo mejor para el análisis del mercado chino de automóviles.
42. www.zuche.com(神州租车)
43. www.1hai.cn(一嗨租车)
Estos dos sitios web lideran el mercado de alquiler de automóviles en China. Recopilar información sobre el uso del automóvil puede ayudarlo a realizar análisis relevantes.
Transporte, Hotel, Travel
44. www.ctrip.com (携程网)
45. www.qunar.com(去哪儿网)
Si extrae datos de estos sitios web, podrá conocer cómo funcionan los mercados de transporte, hoteles y viajes en China.
Catering Market
46. www.dianping.com(大众点评)
47. www.meituan.com(美团网)
Los sitios web anteriores son similares a Yelp, y debido a que los chinos cada vez son más ricos, la calidad de los comentarios de estos sitios es relativamente alta porque las personas se vuelven más exigentes.
Recruiting Websites
48. www.lagou.com(拉勾网)
49. www.zhaopin.com(智联招聘)
50. www.51job.com(前程无忧)
Extra:
Octoparse: Técnicamente no es una fuente de datos, pero es un buen sitio web del que puede obtener datos. Ofrece una herramienta de web scraping y servicio de recolección de datos.
Estos sitios web ofrecen una gran cantidad de trabajos cada año y, por lo tanto, obtienen decenas de miles de usuarios registrados de estudiantes universitarios. Mi idea de extraer datos de estos sitios es que podemos conocer las demandas del mercado sobre ciertas industrias.
Hoy en día es un mundo de integración de información, las fuentes de datos que se arriba son solo la punta del iceberg. Como ahora que estamos entrando en la era de los grandes datos, necesitamos hacer un buen uso de los datos.
#data science#big data#python#saas website#saas#software#tools#windows#mac#seo#web scraping#data extraction#data analysis
0 notes
Link
Las 20 Mejores Herramientas de Web Scraping para Extracción de Datos
1 note
·
View note
Link
Por definición, un sales lead es "una persona o entidad que tiene el interés y la autoridad para comprar su producto o servicio", que se considera la etapa inicial del proceso de ventas. Dicho esto, sales lead (cliente potencial de ventas) equivale a una persona a quien le podría vender su producto.
Entonces, la pregunta es cómo encontrar un grupo de personas a escala y contactarlos directamente.
#extraer datos#extracción de datos#data scraping#raspado de datos#herramientas de raspado#recoger datos de Internet#los scrapeadores#recolectar datos#las técnicas de web scraping#Usos para las herramientas de web scraping#técnica de entrada de datos#scrape email data#web scraping excel
0 notes
Text
7 Razones por Las Personas Scraping Amazon
Amazon es conocido como el mayor minorista basado en Internet del mundo en términos de ventas totales y capitalización de mercado. Esta plataforma de comercio electrónico contiene datos masivos que son críticos para las empresas en línea. En este artículo, enumeré 7 razones por las cuales las personas scrape datos de Amazon.
Recopilar datos sobre productos de la competencia
Uno de los más grandes estrategas militares chinos antiguos, Sun Tzu, dijo: "Conocer a ti mismo y a tu enemigo te ayuda a ganar todas las guerras". Este dicho funciona tan bien en los negocios. La recopilación de datos de productos de la competencia ayuda a una empresa a desarrollar estrategias adecuadas y tomar las decisiones correctas.
Recopila datos de los productos que se clasifican primero en una página
Cómo hacer más ventas es siempre una preocupación de todos los empresarios. Para los distribuidores de Amazon, la mejor manera de hacer más ventas es hacer que sus productos aparezcan en una página de la búsqueda más relevante.
Para hacer esto, necesitan comprender el algoritmo que Amazon aplica para calcular las clasificaciones de productos. Una vez que los datos de los productos se colocan en la primera fila, los distribuidores de Amazon pueden encontrar elementos que afectan la clasificación de los productos. Mediante una cuidadosa observación y análisis de datos, deberían poder conocer los pesos de cada factor de clasificación.
Recopilar información de los mejores revisores
La revisión de productos juega un papel importante en la fórmula de clasificación de Amazon, pero la forma de invitar a más personas a escribir reseñas sigue siendo una pregunta.
En Amazon, hay una página que enumera los mejores 10k revisores de clientes. Cada vez que sale un nuevo producto, los distribuidores de Amazon pueden invitarlos a hacer algunas revisiones para sus productos.
Sin embargo, copiar y pegar repetidamente durante más de 1,000 páginas requeriría mucho tiempo y costos de mano de obra. Para realizar este trabajo, puede aprovechar las herramientas de web scraping como Octoparse. Pueden ayudar a scrape datos de la web.
(P.S. Invitar a revisores a comentar viola las reglas de Amazon. Los distribuidores de Amazon deberían considerar las ventajas y desventajas)
Recopilar reseñas de sus propios productos.
Una empresa siempre debe saber cómo están sus productos en el mercado. Una forma de ver el rendimiento de sus productos es estudiar las revisiones de los productos y hacer un análisis de sentimiento . Hay críticas positivas, neutrales y negativas. Con los datos de las revisiones de productos disponibles, los distribuidores de Amazon podrían decidir qué deben hacer para mejorar sus productos, servicio al cliente, etc.
Recopilar perfiles de clientes
Cada negocio tiene su nicho objetivo, al igual que un negocio de comercio electrónico. Sin embargo, a diferencia de otros negocios basados en la generación de leads, los perfiles de clientes están bien protegidos por Amazon. Los distribuidores de Amazon cambian las estrategias para recopilar perfiles de clientes que han comprado sus productos. Al estudiar sus hábitos de compra, los distribuidores pueden planificar diferentes conjuntos de productos combinados para ellos, aumentando así las ventas.
Recopilar datos sobre el mercado
Algunos distribuidores de Amazon tienen grandes recursos de fabricantes. Para hacer un buen uso, pueden hacer más productos y vender en Amazon. Sin embargo, no está claro qué tipo de producto fabricar para que puedan hacer más ventas y generar más ingresos. Para averiguar qué tipos de productos son los más demandados, los distribuidores de Amazon recopilan datos en el mercado para estudiar lo que más se vende. Entonces, pueden hacer un buen uso de sus recursos de fabricación.
Los clientes usan datos para comparar entre tiendas en línea
Una plataforma de comercio electrónico contiene una variedad de productos, y es común que los clientes quieran hacer una comparación y filtrar los malos. Este proceso sería más fácil si la información sobre el producto, como los precios, se extrajera en formatos de datos estructurados como Excel, JSON, CSV. Las herramientas de extracción de datos como Octoparse pueden scrape los datos requeridos y ponerlos en hojas de Excel, que pueden analizarse más a fondo.
#web scraping#web crawling#data extraction#scrapear datos#captura datos#recopliar datos#data mining#data analysis#data visualization#big data#tutorial#python#web scraping Amazon#amazon
0 notes
Text
Agregadores de Contenido: ¿Los Content Publishers del Futuro?
Imagina que es 1995. Tus padres acaban de regresar del trabajo, tu papá se sienta en el sofá y despliega un periódico. Históricamente, nuestras noticias solo provienen de un puñado de fuentes. La televisión, los periódicos, las revistas específicas de la industria, el boca a boca, etc.
Ahora avancemos rápidamente hasta 2020. Su teléfono le envía constantemente noticias. Actualizaciones de redes sociales, noticias de última hora. Estás inundado de contenido. Si tiene una pregunta, puede acceder a la respuesta en cuestión de segundos desde una selección de cientos de sitios. Su ciclo diario de noticias podría abarcar todo, desde eventos actuales y gadgets hasta costura y jardinería. Independientemente de lo que le interese, hay una fuente datos de noticias disponible con solo tocar un botón. ¿Pero la clave de esto? La mayoría es gratis.
Fuente: Ofcom UK
Como resultado, los principales editores como The Guardian y Wall Street Journal están luchando. Muchos están implementando estructuras de tarifas y solicitudes de donación para tratar de compensar la industria de la impresión en declive y la consiguiente pérdida de ingresos publicitarios.
En su lugar hay una nueva forma de consumo de medios. Algo que hace que la accesibilidad del usuario y la navegación instantánea sean aún más simples y agradables - la agregación de contenido.
Combine esto con extracción de datos sofisticada y podrá publicar contenido que sea muy valioso para sus usuarios.
¿Qué es la agregación de contenido? Cada vez más, los sitios de revisión y los sitios de contenido seleccionados agregan datos de toda la web y los presentan en un formato fácil de usar para el usuario. Piense en sitios como Flipboard, Google News e incluso Reddit. Estos se presentan en forma de contenido agregado.
Fuente: Flipboard.com
La idea simple implica extraer contenido de otras fuentes y recopilarlo todo en un solo lugar. Esto facilita a los usuarios navegar y la capacidad de saltar entre temas e industrias. Los usuarios ni siquiera tienen que hacer clic en un artículo. Simplemente pueden ver el título o el resumen y pasar al siguiente.
¿Dónde encaja la extracción de datos? La extracción de datos es una forma de pulling back the flesh de un website y ver cómo funcionan las partes, ver qué sucede debajo del capó. Esto proporciona muchas ideas diferentes que se pueden utilizar en una variedad de industrias y proporcione información para una serie de objetivos, incluido el resumen de contenido.
La forma en que la extracción de datos puede ayudar a la agregación de contenido es bastante simple — le dice qué páginas web están obteniendo la mayor cantidad de interacciones, lo que lo dirige a las que son más beneficiosas para obtener y luego recopilar para su redistribución.
La extracción de datos puede parecer intimidante, pero es increíblemente sencilla, con el equipo adecuado. Octoparse es una poderosa herramienta de extracción de datos. Es súper fácil de usar y le permite obtener datos de una gran variedad de fuentes. El valor de esto en la agregación de contenido es claro - puede encontrar rápidamente el contenido adecuado para sus usuarios, lo que aumenta el compromiso al publicar el contenido correcto.
Agregador vs. curador
La automatización es la diferencia clave. Los curadores de contenido recopilan minuciosamente el mejor contenido sobre un tema determinado y crean artículos a su alrededor. Piensa en artículos como "predicciones musicales de 2019 de 10 productores líderes". El autor de ese artículo no ha hablado con cada productor para construir ese artículo. Han seleccionado contenido de varios medios, ya sean cuentas de redes sociales, blogs o sitios de noticias, y han elaborado un artículo en torno a ellos.
Los agregadores usan datos para construir su contenido. Estos agregadores de datos extraen palabras clave de los sitios en sus bases de datos y crean paneles para que los usuarios accedan al contenido de una variedad de fuentes. Esto reduce la carga de escribir contenido desde el agregador y mejora la experiencia del usuario.
¿Qué significa esto para los editores?
Los agregadores de contenido y datos representan un desafío único para los editores, particularmente para aquellos que generan ingresos a partir de suscripciones o publicidad en el sitio. Si los usuarios acceden a noticias a través de sitios como Flipboard o News360, música a través de Spotify y reseñas a través de Metacritic, significa que es probable que no visiten o compren el contenido de origen. Dado eso, ¿de dónde viene el dinero?
En el caso de Flipboard, aunque ofrece todo su contenido de forma gratuita, en realidad beneficia al editor final porque envía tráfico a las fuentes. Flipboard tiene 100 millones de usuarios mensuales y los medios de comunicación han notado picos recientes de tráfico referidos desde el sitio. Esta relación es mutuamente beneficiosa.
Flipboard disfruta del tráfico de las búsquedas recientes y de cola larga, así como también de las visitas repetidas de aquellos que prefieren "aggregated content", y el editor final obtiene los ingresos publicitarios de aquellos que llegan al sitio. Metacritic opera un modelo similar. Consolidando no solo los sitios de revisión, sino que también resume los comentarios personales de los críticos en un one-stop resumen.
¿Qué pasa con la pérdida de las tarifas de suscripción?
¿Los ingresos publicitarios compensan la pérdida de las tarifas de suscripción? Algunos dirían que no. Y solo porque un sitio vea un aumento en el tráfico de referencia de un sitio que proporciona agregación de contenido, no significa necesariamente que volverán. Es más probable que vuelvan a visitar su panel de control y solo hagan clic en el mismo editor si tienen otro titular que les llame la atención.
Piense en cómo Amazon, eBay y Shopify han arrinconado el mercado de comercio electrónico de manera abrumadora. Shopify, en particular, es pertinente aquí, ya que puede conectarlo a Blogfeeder y usar la herramienta para sincronizar con cualquier blog y extraer todo el contenido que desee, algunas de las diferentes fuentes de contenido a las que se conecta, WordPress.com , Tumblr, Pinterest, Blogger/Blogspot, Medium y Facebook (actualizaciones de estado).
Sin embargo, a pesar de esto, una gran cantidad de vendedores optan por vender a través de Amazon para aprovechar su plataforma existente, en lugar de crear algo de forma independiente. ¿Por qué? Porque saben que sus tiendas personales nunca podrían esperar obtener tráfico a nivel de Amazon. Por supuesto, una vez que siguen ese camino, se quedan estancados: cuando las personas pueden obtener sus productos en Amazon, no se molestarán en intentar comprarles directamente.
Una situación de huevo y gallina para editores
Es una situación difícil para los editores. No hay duda al respecto. Los usuarios adoran los agregadores. A medida que aumenta su popularidad, podemos ver caídas sostenidas del tráfico en los sitios de publisher final a favor de picos específicos de artículos. Pero los agregadores necesitan que estos editores finales sigan creando contenido para poder existir. De lo contrario, ¿qué agregarían? El beneficio para los usuarios es la recopilación de todas estas fuentes altamente respetadas en un solo lugar. Si se dejan, ¿estarán satisfechos con los reemplazos de la lista B o C? Improbable.
Algunos agregadores eventualmente establecen su propia experiencia y avanzan hacia posiciones de autoridad e influencia en sus campos, pero no todos: algunos continúan agregándose indefinidamente, sin involucrarse nunca en la producción. Como tal, para continuar, debe haber beneficios claros tanto para los editores como para los agregadores. Los editores deben comprender el beneficio para el usuario final de tener contenido en un solo lugar, mientras que los agregadores deben apreciar el tiempo y el esfuerzo que lleva crear el contenido que muestran.
También es importante mantener motivados a los editores. Si los canales de redes sociales, los agregadores y los sindicadores mantienen la mayoría del tráfico y los ingresos publicitarios, entonces el incentivo para que los editores continúen creando contenido excelente disminuye. ¿Por qué lo harían ellos? La única forma en que un editor estará motivado es generando ingresos a partir de su trabajo. De esta manera, pueden pagar a los contribuyentes, editores y desarrolladores para mantener su propio sitio, mientras disfrutan de los beneficios de los picos de tráfico de los agregadores. Es una relación bidireccional que debe ser mutuamente beneficiosa para tener un impacto duradero en Internet.
¿Los agregadores de contenido son el futuro?
Los editores evolucionan constantemente sus flujos de ingresos, optimizando los anuncios y los modelos de suscripción. Algunos, como el Washington Post, incluso informan ganancias anuales, impensables hace unos años, cuando muchos profetizaron el declive de la industria de los medios digitales.
Pero no hay duda de que las dos partes deben trabajar juntas. La agregación implacable sin pensar en los editores eventualmente conducirá a un contenido mediocre. Sin embargo, también es imposible ignorar el valor que los agregadores proporcionan al usuario final. Todo el contenido que necesitan de sus fuentes favoritas en un solo lugar, accesible al instante. En un mundo donde la gratificación instantánea es la nueva norma, parece cada vez más probable que los agregadores son los editores de contenido del futuro.
Rodney Laws
Rodney Laws es un experto en comercio electrónico con más de una década de experiencia en la creación de negocios en línea. Consulte sus comentarios en EcommercePlatforms.io y encontrará consejos prácticos que puede usar para crear la mejor tienda en línea para su negocio. Conéctese con él en Twitter @EcomPlatformsio.
#web scraping#web crawling#raspado web#extracción de datos#extraer datos#tutorial de web scraping#web scraping excel#python#saas#recopilar datos
0 notes
Link
Lead generation, definida como la acción o proceso de identificar y cultivar clientes potenciales para productos o servicios comerciales, es una parte importante del trabajo de un vendedor digital. Es decir, un vendedor digital debe identificar a sus compradores ideales y cultivar a sus clientes potenciales. Frente a una gran cantidad de proveedores y canales en línea cambiantes, así como a los desafíos planteados por de los canales de ventas y a interrupción de las conexiones de los clientes objetivo.
#markrting#marketing digital#web scraping#lead generation#herramientas de web scraping#B2B business#software#app#web service#saas
0 notes
Link
Algunas personas pueden tener una pregunta como esta, "¿Podemos usar los datos de Internet?" No hay duda de que Internet proporciona tanta información increíble hoy que podríamos descubrir qué tan valiosa podría ser. Por eso surge el web data scraping. El Web data scraping, el proceso de algo así como copiar y pegar automáticamente, es un campo en crecimiento que puede proporcionar información poderosa para respaldar el análisis y la inteligencia empresarial.
En este blog, analizaré múltiples casos de uso y herramientas esenciales de minería de datos para recolectar datos web. Ahora, comencemos.
#web scraping#web crawl#web sscraper#data analysis#extraciónde de datos#data scraping#tutorial de web scraping#data extraction
0 notes
Link
Hemos realizado grandes cambios en las funciones y la interfaz interactiva.
En cuanto a las funciones, hay una gran mejora con respecto al "Advanced Mode", que mejorará la eficiencia para que los usuarios adquieran datos.
En cuanto a la interfaz del producto, la optimización del diseño se ha realizado en diferentes secciones para que Octoparse sea más user-friendly.
Octoparse 8.1 Beta Aspectos Destacados de La Actualización
1. Elementos de la página web"Auto Detect" para ayudar a los nuevos usuarios a incorporar rápidamente
Los usuarios solo necesitan ingresar la URL de una página web para comenzar, y luego Octoparse analizará la página web exhaustivamente para detectar automáticamente texto, imágenes y otros elementos en la website. Después de la detección automática, Octoparse generará una configuración de tarea recomendada (como campos de datos, paginación, configuración de desplazamiento hacia abajo infinitivo, etc.) para los usuarios.
#recolectar datos#extraer datos online de forma automática#Usos para las herramientas de web scraping#técnica de entrada de datos#herramientas de raspado#raspar datos#raspado web#extraer datos#web crawling#webscraper#mozenda#octoparse
0 notes
Link
Si bien Portia necesita trabajar con otras plataformas de Scrapinghub en un nivel superior, Octoparse tiene la mayoría de las características agrupadas para una implementación más fácil. Para los usuarios de nivel de entrada, Octoparse ofrece el mismo nivel de potencia de web scraping y escala de Portia en un paquete mucho más fácil de usar. No es difícil iniciar Octoparse crawler o Portia scraper, pero te tomaría bastante tiempo si quieres explorar más.
#web scraping#web crawling#scrapear datos#data extraction#data scraping#scrape data web#que es web scraping#como es web scraping#recopilar datos#saas service#herramienta de web scraping#scrapear daros#araña web#octoparse#scraping amazon#what is web scraping#web scraping software app
0 notes
Text
Big Data: 50 Fuentes de Datos Fascinantes y Gratuitas para la Visualización de Datos
¿Alguna vez te has sentido frustrado cuando intentas buscar algunos datos en Google? ¿Páginas de sitios web relevantes pero ninguna puede cumplir sus expectativas? ¿Alguna vez ha sentido que sus artículos son menos persuasivos sin soporte de datos?
Pongamos este artículo en su lista de favoritos, la guía más completa de fuentes de datos, incluidos General Data, Government Data, Market Data for U.S y China etc.
Informacion General
1. Organización Mundial de la Salud
La Organización Mundial de la Salud ofrece datos y análisis sobre las prioridades mundiales de salud, como el hambre, la salud y las enfermedades mundiales.
2. The Broad Institute
The Broad Institute ofrece una serie de conjuntos de datos en biología y medicina.
3. Amazon Web Service
Amazon Web Service es una plataforma de datos basada en la nube sobre Química, Biología, Economía, etc. También es un intento de construir la base de datos más completa de información genética humana y la base de datos de imágenes de satélite de la Tierra de la NASA.
4. Figshare
Figshare es una plataforma para compartir resultados de investigación. Aquí, podrá ver algunos hallazgos sorprendentes de personas increíbles de todo el mundo.
5. UCLA
A veces, UCLA comparte algunos de sus hallazgos en trabajos de investigación.
6. UCI Machine Learning Repository
Este sitio web actualmente mantiene 394 conjuntos de datos como un servicio para la comunidad de aprendizaje automático.
7. Github
Algunos chicos geniales construyeron la comunidad GitHub, compartiendo un montón de conjuntos de datos increíbles. Ahora los datos que se encuentran dentro son ofrecidos por todos y ofrecidos a todos.
8. Pew Research Center
Pew Research Center ofrece sus datos en bruto de su fascinante investigación sobre la vida estadounidense.
Datos del gobierno
9. Data.gov
Data.gov es el hogar de los datos abiertos del gobierno de EE. UU. Puede encontrar datos, herramientas y recursos aquí para realizar investigaciones, visualización de datos, etc.
10. US Census Bureau
La Oficina del Censo de EE. UU. Es una gran cantidad de información sobre la vida de los ciudadanos estadounidenses que abarca datos de población, datos geográficos y educación.
11. Open Data Network
Open Data Network es un sitio web de búsqueda fácil para que pueda encontrar datos relacionados con el gobierno, con buenas herramientas de visualización integradas.
12. European Union Open data portal
Los datos abiertos de la Unión Europea son para acceder a una creciente gama de datos de la institución de la Unión Europea.
13. Canada Open Data
Canada Open Data le permite obtener un acceso rápido y fácil a los servicios e información más solicitados por el gobierno de Canadá.
14. Open Government Data
Este sitio web proporciona a los visitantes excelentes datos de gobierno abierto de los US, EU, Canada, CKAN y más.
15. The CIA World Factbook
El World Factbook proporciona información sobre la historia, las personas, el gobierno, la economía, la geografía, las comunicaciones, el transporte, los asuntos militares y transnacionales para 267 entidades mundiales.
16. Gov.uk
Gov.uk son los datos del Gobierno del Reino Unido, incluida la bibliografía nacional británica, metadatos de todos los libros y publicaciones del Reino Unido desde 1950.
17. Health Data.gov
Health Data Gov se dedica a hacer que los datos de salud de alto valor sean más accesibles para empresarios, investigadores y formuladores de políticas con la esperanza de obtener mejores resultados de salud para todos. Tiene 125 años de datos de atención médica en los Estados Unidos, incluidos datos de Medicare a nivel de reclamos, epidemiología y estadísticas de población.
18. UNICEF
Unicef ofrece estadísticas e informes sobre la situación de los niños en todo el mundo.
19. National Climatic Data Center
El Centro Nacional de Datos Climáticos es una gran colección de conjuntos de datos ambientales, meteorológicos y climáticos del Centro Nacional de Datos Climáticos de EE. UU. El archivo de datos meteorológicos más grande del mundo.
Google
20. Google públicos datos incluyen datos de indicadores de desarrollo mundial, de la OECD y de indicadores de desarrollo humano, principalmente relacionados con datos económicos y del mundo.
21. Google Trends Estadísticas sobre el volumen de búsqueda (como proporción de la búsqueda total) para cualquier término dado, desde 2004.
22. Google Finance 40 años de datos del mercado de valores, actualizados en tiempo real. years’ worth of stock market data, updated in real-time.
Market Data
E-commerce Plataformas
23. Amazon
24. eBay
Dos de las plataformas de comercio electrónico más grandes de los EE. UU., Que enumeran toneladas de productos para clientes. Mientras tanto, ofrece información de productos para vendedores e investigadores para análisis.
25. Yelp
Muchos restaurantes se enumeran en este sitio web, los clientes hacen comentarios sobre restaurantes y estos comentarios pueden ayudar a otros clientes a elegir qué restaurantes cenar. Además, la información del restaurante y las reseñas de los clientes son extremadamente valiosas para que un especialista en marketing las estudie.
26. Yellowpages
Yellowpages es una gran marca incluso antes de que ingresáramos a la era de Internet. El sitio web ofrece información comercial.
27. Cars
Este sitio web proporciona información del automóvil, tanto autos usados como autos nuevos. También incluye la información de contacto del propietario.
Real Estate
28. Real Estate
29. Zillow
30. Realtor
Estos tres sitios web enumeran casas, apartamentos en venta o en alquiler, y ofrecen información muy completa sobre viviendas.
31. Trip Advisor
Una plataforma para que los clientes revisen excelentes hoteles en todo el mundo. Permite a los visitantes encontrar los mejores hoteles para vacacionar a través de reseñas, y estas reseñas son muy dignas de estudiar si se encuentra en la industria hotelera.
32. Glassdoor
Un sitio web de reclutamiento, que enumera miles de puestos vacantes. La información extraída puede ser utilizada para el estudio de costos laborales.
33. Linkedin Las mejores redes sociales para la comunicación formal. Miles de usuarios están registrados, y los perfiles de usuario son bastante convincentes. Muy útil para que las personas traten de encontrar un trabajo u obtener oportunidades de ventas.
Chinese Market
Como todos sabemos, China es un mercado con enormes posibilidades, por lo que también enumeré algunos sitios web para obtener datos del mercado chino.
Real Estate
34. www.58.com (58同城)
35. www.anjuke.com (安居客)
36. www.qfang.com (Q房网)
37. Fang.com (房天下)
Estos sitios web recopilan datos completos de bienes raíces en China. El florecimiento del mercado inmobiliario de China hace que el precio de la vivienda sea un punto caliente para la sociedad, estos sitios ofrecen datos masivos y confiables para las personas que realizan su investigación sobre bienes raíces en China.
E-commerce Platforms
38. JD.com
39. Tmall.com
40. Taobao.com
Las empresas de comercio electrónico de China suministran productos masivos al mundo, muchos dispositivos se importan de China y se extienden por todo el mundo, entonces, ¿cómo es la plataforma de comercio electrónico de China? ¿No tienen curiosidad ustedes?
Car Markets
41. www.autohome.com.cn(汽车之家)
China siempre ha sido un mercado con un enorme potencial que todo fabricante de automóviles quiere aprovechar. El mejor sitio web para que los investigadores de mercado recopilen datos es AUTO HOME, que reúne toneladas de datos y reseñas de consumidores, lo mejor para el análisis del mercado chino de automóviles.
42. www.zuche.com(神州租车)
43. www.1hai.cn(一嗨租车)
Estos dos sitios web lideran el mercado de alquiler de automóviles en China. Recopilar información sobre el uso del automóvil puede ayudarlo a realizar análisis relevantes.
Transporte, Hotel, Travel
44. www.ctrip.com (携程网)
45. www.qunar.com(去哪儿网)
Si extrae datos de estos sitios web, podrá conocer cómo funcionan los mercados de transporte, hoteles y viajes en China.
Catering Market
46. www.dianping.com(大众点评)
47. www.meituan.com(美团网)
Los sitios web anteriores son similares a Yelp, y debido a que los chinos cada vez son más ricos, la calidad de los comentarios de estos sitios es relativamente alta porque las personas se vuelven más exigentes.
Recruiting Websites
48. www.lagou.com(拉勾网)
49. www.zhaopin.com(智联招聘)
50. www.51job.com(前程无忧)
Extra:
Octoparse: Técnicamente no es una fuente de datos, pero es un buen sitio web del que puede obtener datos. Ofrece una herramienta de web scraping y servicio de recolección de datos.
Estos sitios web ofrecen una gran cantidad de trabajos cada año y, por lo tanto, obtienen decenas de miles de usuarios registrados de estudiantes universitarios. Mi idea de extraer datos de estos sitios es que podemos conocer las demandas del mercado sobre ciertas industrias.
Hoy en día es un mundo de integración de información, las fuentes de datos que se muestran arriba son solo la punta del iceberg. Como ahora que estamos entrando en la era de los grandes datos, necesitamos hacer un buen uso de los datos.
#web scraping#database#software#webcrawler#web crawling#tutorial#saas#data service#python#data source#datavisualization#big data#data analysis#data scraping#scrape datos#extract data from web
0 notes