#google map scraping github
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
70% of Tumblr users say the Dashboard is their favorite place to spend time online.
Text

#google maps#google marketing agency#google map scraping#google map scraping tool#google map scraping free#google map scraping python#google map scraping make.com#google map scraping using python#google map scraping in urdu#how to do google map scraping#google map data scraping#cara scraping data google map#google map scraping fiverr#google map scraping github#google map scraping extension#google map scraping meaning#google map web scraping
0 notes
Text
Games Production (Feb 12th)
An Overview
this week was surprisingly productive - I have been suffering from burnout recently, and have been taking it slow, but I have significantly improved the Workflow Toolkit website, fixed some significant bugs in all three projects, and added some functionality to QuickBlock.
Star In The Making
This project hasn't been progressed much, but I finally added an audio system that allows all songs to be listened to during playing.

the Audio Manager Singleton plays the menu song in the menu scene, and the array of Game Music in the game scene. I was thinking about randomising the songs (so there is no order) but felt that this was nicer, like you're listening to an EP while playing - However this is subject to change.
Workflow Toolkit - Project
firstly, Portuguese (EU) has been added to Workflow Toolkit - making it the fourth language in this project. The translations were made by my cousin (and I am very thankful)

I will have to get a few more translations done because I had changed some text around to make it more understandable, but this is incredibly easy to do.
Workflow Toolkit - Website
I have made some great strides with the website, making documentation easier to understand as it is separated clearly and looks professional.
Firstly, I have now added a footer to the website that points to Chomp Games' (a studio I am planning to make) Social Medias (where in my marketing plan, I am posting weekly updates & information on the project)

The buttons from left to right are Instagram, BlueSky and YouTube.
I have also been working on the website's documentation page - currently just improving the UI and layout behind it, with plans to add more in depth documentation (like a record of functions, localisation language trackers and more)


I have also redesigned the dropdowns that explain what the project do, and it looks and feels nicer.

in comparison with the old website, here are some images:




in terms of the website, some other enhancements include Embeds and web scraping/crawling improvements:
Here's the embed:

to make this work, I added OpenGraph meta tags to each file (so I could make a different embed for each page)

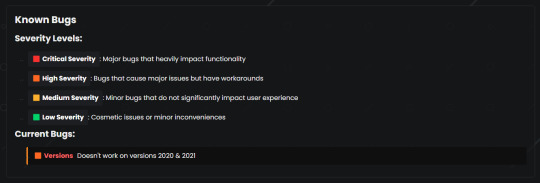
To improve web scraping and crawling, I added two files to the root of the website; SiteMap.xml and Robots.txt - SiteMap.xml tells search engines the important pages to cache. Due to how small the website is, I have told it to cache all pages.
Robots.txt tells web scrapers if they are welcome to scrape this website (although they do not have to adhere to this)

I have disabled scraping for all robots apart from Google's Scraper and Archive.org's scraper - I have a soft spot for everything related to archiving, and hence have allowed it through.
Googlebot has been allowed to enable it to get a high up link for SEO purposes.
I added a very slight overlay to the background of all pages (barring documentation.html) to make the website feel more lively. Here's a comparison:

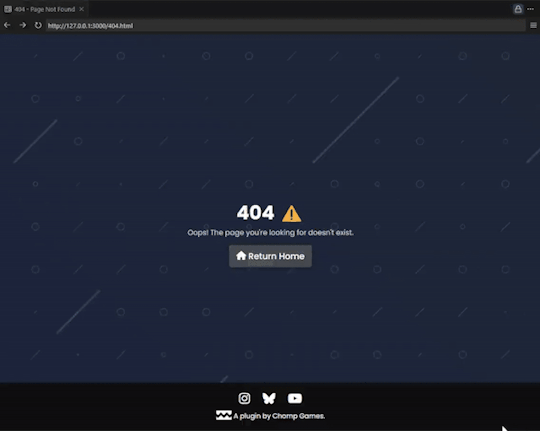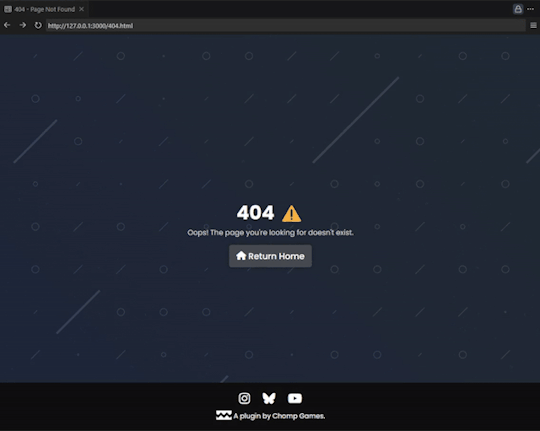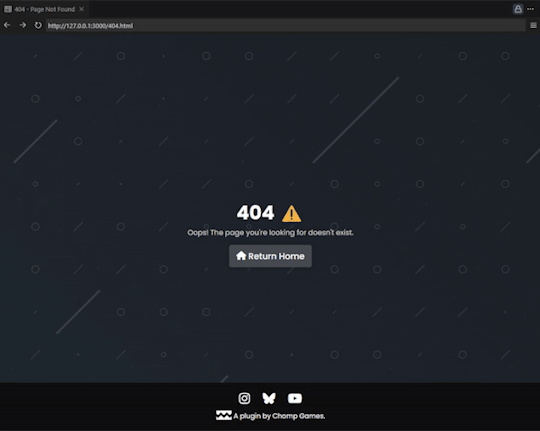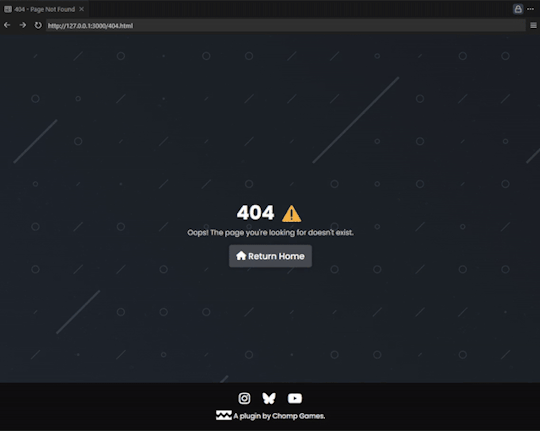
I then added a 404 error page incase somebody goes to the wrong page, it'll display that (instead of the default github pages one). The animation is 20 seconds long, so I have shown a sped up one below:
I also refactored the whole website because of internal frustration - it fixed some annoyances (but do not harm the website) like all spaces in download links being replaced by "%20".
QuickBlock
I refactored the asset loading of this project to be much more efficient, fixed some critical bugs in Grid Snapping, imported all of the assets that were made for me and worked on transformations of the placed assets:

These shapes allow you to fully customise your map (and more will be added!)

Firstly, I fixed the asset loading, and made it much more optimised. Before, there were hard-coded directories that connected to Enums, so you'd have to load an asset based on an enum and it was very ineffective, now, there is a ResourceManager Singleton that loads every asset based on it's "type".
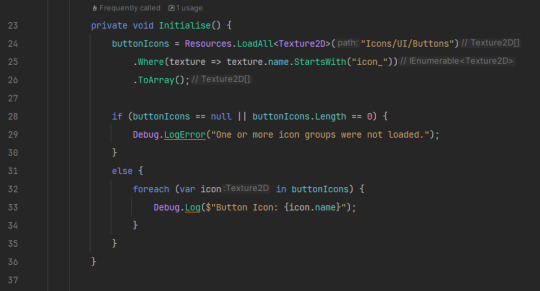
For simplicity in terms of this screenshot, I have deleted the other initialisations (logos, materials, textures etc).
you can then freely use the loaded assets like this:

This change has made the project feel more professional and optimised.
I then fixed some grid snapping issues that made it impossible for differently tagged items (for example, a block versus a ramp) to have different grid snapping. this lead fixed a major concern, and I can already now build simple areas with the blocks, walls, floors and ramps I have.
This week, I also added transform modifiers. I am very happy about this.
I have also started working on Palettes (will discuss this after my future plans), but no functionality yet

it also creates a little swatch of your palette, I love this!

A lot more ideas will be worked on throughout this next week, as I do think that QuickBlock has a lot of potential.
These Include:
Texture Customisation (choose between textures)
Scaling
Commenting (comment in-editor while you're building)
Palette Implementation
Palette Implementation will allow you to colour specific parts of your build automatically - just by creating a palette. There will also be "Dark" modes and "Light" modes.
Ramps = yellow, foliage = green, floors = white,
walls = blue, misc = red.
DARK MODE
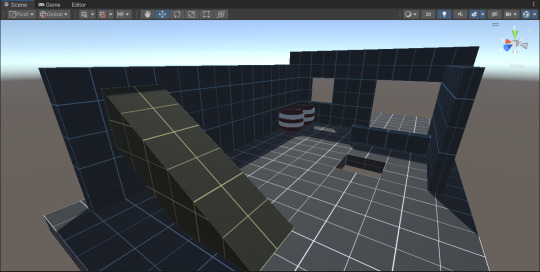
LIGHT MODE
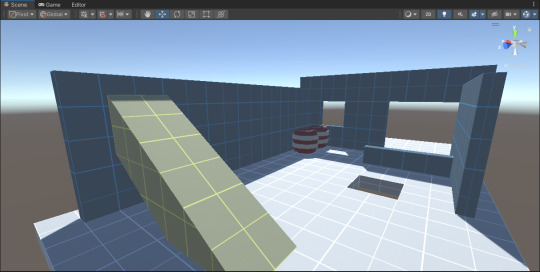
This will automatically be done with tag checking.
I hopefully will have this fully implemented by next week.
================================================
Performance Evaluation
[ I feel quite relieved that despite going through burnout, my ability to find less significant (but still important) tasks contribute to the momentum of these projects, without sacrificing my mental health.
Essentially, while these features (a .404 error page, colour palette, or music) isn't critical to the core functionality of these projects, it will enhance the final projects. ]
[ This however, is a double-edged sword, I need to be aware enough about feature creep, and knowing where and when to stop, then divert my attention to the necessary features of these projects, otherwise it can create a backlog of essential tasks, which would be challenging to come back from when I have just recovered from burnout. ]
================================================
Action Plan
This following week will be about organisation; but I need to be careful and plan for contingencies in terms of my mental health - and follow my Risk Assessment & Mitigation plan

Firstly, I will create a task tracker for Workflow Toolkit, QuickBlock and Star In The Making, I will not separate tasks by project, as this causes further frustration, but do any task I can tick off without further hurting my burnout.
This task tracker will be updated every two weeks, and I should be aiming to complete at least 2 tasks from this tracker every day (but allow less or none during tough days). I will make sure these tasks are measurable, and able to be completed.
I will make sure this tracker has some tasks that can easily be done, in case I am having a rough day in particular, but still need a task to be completed.
Once the bi-weekly tracker needs to be refreshed, I will delete all tasks and re-add them, to make sure my priorities will shift to more important areas.
================================================
1 note
·
View note
Text
Tree canopy and Google historical imagery
Historic imagery on Google Earth now covers a period of about 20 years, a useful period over which to compare the changes in tree canopy, whether due to the development of housing on green spaces or planting of new woodland.
The basic technique is to decide on an area and zoom level and take screen shots of the area on the useable historical images. Remove layers to avoid clutter. Adding kml polygons is also useful to mark the boundary of a park or development area. You can also overlay the plan for the future development.
Capturing the images
Care is needed to ensure registration. Initially I used visual reference points on the map which are stable throughout the period as diagonal corner marks. However better registration is possible using placemarks to fix the corners at defined lat/long positions. It will help in adding imagery in the future if these placemarks are saved as kml. I find that a small, round green unlabled icon is visible enough to draw the bounding box with the scraping tool (I use Snip and Sketch on Windows) but un-noticable on the images. Images are saved as jpgs. Images need to be named with a structure useful for constructing the animation: at the least they need to be sortable into time order and for GIF labeling, the label should be the last part of the name, separatd by a hyphen.
Making a GIF
One way of visualising the change is to generate a GIF from the images. It’s useful to label each image with a year and I use imagemagik for both tasks. It’s tedious to do this on separate command lines so I ‘wrote’ [tore characters from stackoverflow with my bleeding fingers more like] a Windows batch file to automate these tasks - never again - what a gruesome experience! The parameterised script is on GitHub. The current version takes a wildcard path to the images, a temporary directory for the labeled images and the name of the output GIF file.
This GIF shows the progress of a housing development at Filwood Park in Bristol.

JavaScript animation
The problem with GIFs is that you can’t pause them and this reduces their value for analytic purposes. An alternative when the images are few and small (as they are here) is to use JavaScript to animate the images. The greening of May Park Primary School in Eastville, Bristol shown here is a positive story.
In this page, the unlabled images with descriptive, sortable filenames can be viewed in sequence or animated. The caption is the file name. This is the first image from 1999.

and this is the same site in 2020 :

Mark Ashdown and myself at Bristol Tree Forum have made a few of these historical series and we are hopeful that they will inform the debate about progress toward Bristol City’s aim doubling of tree canopy by 2046.
Confession
I spent rather a lot of time wondering why my attempts at pre-loading the images failing until I realised that the Chrome developer tool I was using had of course turned off caching! Doh!
0 notes
Text
15 March 2019
On a scale of 1 to 5...
This week I spoke at the Deloitte Academy at a session called 'Open data: where next?' I used that sexiest of government datasets - who needs Citymapper when you can have departmental organograms?! - to illustrate how far we've come and some of the snags. The main barriers to publication in this case were a perceived lack of political will, some difficulties in pulling the data together and - the big one - departments not seeing the value in the data and therefore not seeing the point.
A question at the end was: on a scale of 1 to 5, where would you rate the success of open data so far? I opted for a slightly pessimistic 2 or 3. Not because lots of good things haven't happened as a result of data, or because there aren't (some) politicians, civil servants, businesses and civil society institutions who understand the potential, but because much more could still be done and we're still not as good as we should be at showing the impact and importance of open data. (And it often depends what day it is as to whether I look at the same landscape and see the happy bunny of open data optimism or the duck of despair.)
More generally, government still isn't taking the big picture, forward-looking, ten- to fifteen-year view of how better data (open, closed, shared and everything in between) could mean better government and a better society. Hopefully the forthcoming National Data Strategy in the UK will start to address that.
What rating would you give on the 1 to 5 scale?
Today's links:
Graphic content
Brexit means...
How the government and Cabinet voted on Article 50 extension (Alasdairfor IfG)
How the Government’s frontbench voted on 13 March (Alasdair for IfG - much more on his Twitter)
Ministerial resignations, part one and part two (me for IfG)
A stark geographic divide among rebel Labour MPs... (Aron for IfG)
How MPs voted on Brexit delay* (FT)
How did your MP vote on extending article 50? (The Guardian)
Who governs Britain?* (FT, via Alasdair)
Everything else
The Year in Language: 2018 (Google News Initiative)
Data visualisations show Britain’s most trodden paths (Ordnance Survey)
Revealed: The thousands of public spaces lost to the council funding crisis (The Bureau of Investigative Journalism - also map, HuffPo)
The grounded 737 MAX fleet (Reuters)
New research finds parallels between German votes in 1933 and now*(The Economist)
Most independents are just moderate partisans* (Washington Post)
Goal comparison at the same age (@Bluegrenades)
Meta data
The Web at 30
30 years on, what’s next #ForTheWeb? (Tim Berners-Lee, World Wide Web Foundation)
Tim Berners-Lee: 'Stop web's downward plunge to dysfunctional future'(BBC News)
How Tim Berners-Lee's Inrupt project plans to fix the web (Wired)
Politics, parliament and government
Unlocking Digital Competition (Digital Competition Expert Panel)
Furman Review: Access to data is a new tool against monopoly(ODI)
We need tougher scrutiny of Big Tech’s data use and deals (Diane Coyle, FT)
It's time to rein in big tech, says Lords committee (Lords Communications Committee)
The spring statement attacks big tech firms in all the wrong ways (Wired)
Facebook proves Elizabeth Warren’s point by deleting her ads about breaking up Facebook (The Verge)
Alexandria Ocasio-Cortez says ‘we should be excited about automation’(The Verge)
#FoI and ICO
London councils’ FOI performance assessed (Campaign for Freedom of Information)
Head in the Sandbox (Tim Turner)
Every now and again public officials fail to properly redact documents they send out after an #foi request. This was one of those times... (The Ferret)
Everything else
Government as a Platform, the hard problems: part 1 — Introduction(Richard Pope - see also Platform Land)
Life and society are increasingly governed by numbers* (The Economist)
Statisticians may have a bit of an image problem – but their Code of Practice is full of good sense. (Sir David Spiegelhalter for National Statistical)
Facial recognition's 'dirty little secret': Millions of online photos scraped without consent (NBC News)
177 links to data journalism presentations, GitHub repos, tutorials, work samples & more from #NICAR19 (Sharon Machlis)
And finally...
Pi Day
How a farm boy from Wales gave the world pi (The Conversation)
Even After 31 Trillion Digits, We’re Still No Closer To The End Of Pi(FiveThirtyEight)
Pi Day: How One Irrational Number Made Us Modern* (New York Times)
A colorful π chart (Datawrapper)
Everything else
Beware the Ides of March? ONS data reveals which month we are really most likely to die in. (National Statistical)
I am officially too old to date Leonardo di Caprio... (Jack Hillcox, via Marieand Tim)
Dates in Excel - part one and part two (Allison McCartney)
Two British Lords Just Gave a Charmingly Spot-On Definition of “Algorithm” (Slate)
0 notes