#google map scraping tool
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
Tumblr’s website traffic is steadily declining.
Text

#google maps#google marketing agency#google map scraping#google map scraping tool#google map scraping free#google map scraping python#google map scraping make.com#google map scraping using python#google map scraping in urdu#how to do google map scraping#google map data scraping#cara scraping data google map#google map scraping fiverr#google map scraping github#google map scraping extension#google map scraping meaning#google map web scraping
0 notes
Text
diy ao3 wrapped: how to get your data!
so i figured out how to do this last year, and spotify wrapped season got me thinking about it again. a couple people in discord asked how to do it so i figured i'd write up a little guide! i'm not quite done with mine for this year yet because i wanted to do some graphics, but this is the post i made last year, for reference!
this got long! i tried to go into as much detail as possible to make it as easy as possible, but i am a web developer, so if there's anything i didn't explain enough (or if you have any other questions) don't hesitate to send me an ask!!
references
i used two reddit posts as references for this:
basic instructions (explains the browser extension; code gets title, word count, and author)
expanded instructions (code gets title, word count, and author, as well as category, date posted, last visited, warnings, rating, fandom, relationship, summary, and completion status, and includes instructions for how to include tags and switch fandoms/relationships to multiple—i will include notes on that later)
both use the extension webscraper.io which is available for both firefox and chrome (and maybe others, but i only use firefox/chrome personally so i didn't check any others, sorry. firefox is better anyway)
scraping your basic/expanded data
first, install the webscraper plugin/extension.
once it's installed, press ctrl+shift+i on pc or cmd+option+i on mac to open your browser's dev tools and navigate to the Web Scraper tab

from there, click "Create New Site Map" > "Import Sitemap"

it will open a screen with a field to input json code and a field for name—you don't need to manually input the name, it will fill in automatically based on the json you paste in. if you want to change it after, changing one will change the other.
i've put the codes i used on pastebin here: basic // expanded

once you've pasted in your code, you will want to update the USERNAME (highlighted in yellow) to your ao3 username, and the LASTPAGE (highlighted in pink) to the last page you want to scrape. to find this, go to your history page on ao3, and click back until you find your first fic of 2024! make sure you go by the "last visited" date instead of the post date.

if you do want to change the id, you can update the value (highlighted in blue) and it will automatically update the sitemap name field, or vice versa. everything else can be left as is.
once you're done, click import, and it'll show you the sitemap. on the top bar, click the middle tab, "Sitemap [id of sitemap]" and choose Scrape. you'll see a couple of options—the defaults worked fine for me, but you can mess with them if you need to. as far as i understand it, it just sets how much time it takes to scrape each page so ao3 doesn't think it's getting attacked by a bot. now click "start scraping"!


once you've done that, it will pop up with a new window which will load your history. let it do its thing. it will start on the last page and work its way back to the first, so depending on how many pages you have, it could take a while. i have 134 pages and it took about 10-12 minutes to get through them all.
once the scrape is done, the new window will close and you should be back at your dev tools window. you can click on the "Sitemap [id of sitemap]" tab again and choose Export data.

i downloaded the data as .xlsx and uploaded to my google drive. and now you can close your dev tools window!
from here on out my instructions are for google sheets; i'm sure most of the queries and calculations will be similar in other programs, but i don't really know excel or numbers, sorry!
setting up your spreadsheet
once it's opened, the first thing i do is sort the "viewed" column A -> Z and get rid of the rows for any deleted works. they don't have any data so no need to keep them. next, i select the columns for "web-scraper-order" and "web-scraper-start-url" (highlighted in pink) and delete them; they're just default data added by the scraper and we don't need them, so it tidies it up a little.

this should leave you with category, posted, viewed, warning, rating, fandom, relationship, title, author, wordcount, and completion status if you used the expanded code. if there are any of these you don't want, you can go ahead and delete those columns also!
next, i add blank columns to the right of the data i want to focus on. this just makes it easier to do my counts later. in my case these will be rating, fandom, relationship, author, and completion status.
one additional thing you should do, is checking the "viewed" column. you'll notice that it looks like this:
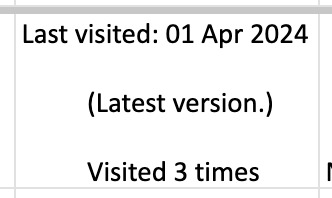
you can't really sort by this since it's text, not formatted as a date, so it'll go alphabetically by month rather than sorting by date. but, you'll want to be able to get rid of any entries that were viewed in 2023 (there could be none, but likely there are some because the scraper got everything on your last page even if it was viewed in 2023). what i did here was use the "find" dialog to search the "viewed" column for 2023, and deleted those rows manually.
ctrl/cmd+f, click the 3 dots for "more options". you want to choose "Specific range", then "C2:C#". replace C with the letter of your viewed column (remember i deleted a bunch, so yours may be different) and replace # with the number of the last row of your spreadsheet. then find 2023, select the rows containing it, right click > delete rows.
it isn't super necessary to do this, it will only add at most 19 fics to your count, but the option is there!

alright, with all that done, your sheet should look something like this:

exposing myself for having read stardew valley fic i guess
now for the fun part!!!
the math
yes, the math is the fun part.
scroll all the way down to the bottom of your sheet. i usually add 100 blank rows at the bottom just so i have some space to play with.
most of these will basically be the same query, just updating for the relevant column. i've put it in a pastebin here, but here's a screenshot so i can walk you through it:

you'll want to use lines 3-10, select the cell you want to put your data into, and paste the query into the formula bar (highlighted in green)

so, we're starting with rating, which is column E for me. if yours is a different letter you'll need to replace all the E's with the relevant letter.
what this does is it goes through the entire column, starting with row 2 (highlighted in yellow) and ending with your final row (highlighted in blue, you'll want to change this number to reflect how many rows you have). note that row 2 is your first actual data row, because of the header row.
it checks each row that has a value (line 5), groups by unique value (row 6), and arranges in descending order (row 7) by how many there are of each value (row 8). finally, row 10 determines how many rows of results you'll have; for rating, i put 5 because that's how many ratings there are, but you can increase the number of results (highlighted in pink) for other columns depending on how many you want. this is why i added the 100 extra rows!
next to make the actual number visible, go to the cell one column over. this is why we added the empty columns! next to your first result, add the second query from the pastebin:

your first and second cell numbers (highlighted in yellow and blue) should match the numbers from your query above, and the third number (highlighted in pink) should be the number of the cell with your first value. what this does is go through your column and count how many times the value occurs.
repeat this for the rest of the rows and you should end up with something like this! don't judge me and my reading habits please

now you can go ahead and repeat for the rest of your columns! as i mentioned above, you can increase the amount of result rows you get; i set it to 25 for fandom, relationship, and author, just because i was curious, and only two for completion status because it's either complete or not complete.
you should end up with something like this!

you may end up with some multiples (not sure why this happens, tagging issues maybe?) and up to you if you want to manually fix them! i just ended up doing a find and replace for the two that i didn't want and replaced with the correct tag.
now for the total wordcount! this one is pretty simple, it just adds together your entire column. first i selected the column (N for me) and went to Format > Number > 0 so it stripped commas etc. then at the bottom of the column, add the third query from the pastebin. as usual, your first number is the first data row, and the second is the last data row.

and just because i was curious, i wanted the average wordcount also, so in another cell i did this (fourth query from the pastebin), where the first number is the cell where your total is, and the second number is the total number of fics (total # of data rows minus 1 for the header row).

which gives me this:

tadaaaa!
getting multiple values
so, as i mentioned above, by default the scraper will only get the first value for relationships and fandoms. "but sarah," you may say, "what if i want an accurate breakdown of ALL the fandoms and relationships if there's multiples?"
here's the problem with that: if you want to be able to query and count them properly, each fandom or relationship needs to be its own row, which would skew all the other data. for me personally, it didn't bother me too much; i don't read a lot of crossovers, and typically if i'm reading a fic it's for the primary pairing, so i think the counts (for me) are pretty accurate. if you want to get multiples, i would suggest doing a secondary scrape to get those values separately.
if you want to edit the scrape to get multiples, navigate to one of your history pages (preferably one that has at least one work with multiple fandoms and/or relationships so you can preview) then hit ctrl+shift+i/cmd+option+i, open web scraper, and open your sitemap. expand the row and you should see all your values. find the one you want to edit and hit the "edit" button (highlighted in pink)

on the next screen, you should be good to just check the "Multiple" checkbox (highlighted in pink):

you can then hit "data preview" (highlighted in blue) to get a preview which should show you all the relationships on the page (which is why i said to find a page that has the multiples you are looking for, so you can confirm).

voila! now you can go back to the sitemap and scrape as before.
getting tag data
now, on the vein of multiples, i also wanted to get my most-read tags.
as i mentioned above, if you want to get ALL the tags, it'll skew the regular count data, so i did the tags in a completely separate query, which only grabs the viewed date and the tags. that code is here. you just want to repeat the scraping steps using that as a sitemap. save and open that spreadsheet.
the first thing you'll notice is that this one is a LOT bigger. for context i had 2649 fics in the first spreadsheet; the tags spreadsheet had 31,874 rows.
you can go ahead and repeat a couple of the same steps from before: remove the extra scraper data columns, and then we included the "viewed" column for the same reason as before, to remove any entries from 2023.
then you're just using the same basic query again!
replace the E with whatever your column letter is, and then change your limit to however many tags you want to see. i changed the limit to 50, again just for curiosity.
if you made it this far, congratulations! now that you have all that info, you can do whatever you want with it!
and again, if you have any questions please reach out!
55 notes
·
View notes
Text
Battle of the Fear Bands!
B6R2: The Eye
Research Me Obsessively:
“Rebecca and Valencia spend 3 days internet stalking their mutual ex-boyfriend's new girlfriend. The song goes both into the creepy lengths one can go to in order to gain access to this sort of information while joking about how this search for information is unhealthy and detrimental to those embarking upon it.”
youtube
Knowledge:
“Narrator seeks knowledge without caring about the cost or consequences. As quintessentially Eye as you can get”
youtube
Lyrics below the line!
Research Me Obsessively:
Hey, what are you doing for the next thirteen hours?
Don't do anything healthy. Don't be productive. Give in to your desire.
Research me obsessively
Uh-huh!
Find out everything you can about me You know you want to dig for me relentlessly
Uh-huh!
Using every available search tool and all forms of social media
You know you want to look at my Instagram but it's private so Google me until you find out where I went to high school and then set up a fake Instagram account using the name and the photo of someone that went to my high school and hope that I remember that person a little bit
Then request access to my private Instagram from the fake account and in the meantime scour my work Instagram account cause that one's public.
Research me obsessively
Uh-huh!
Find an actual picture of my parents' house on Google Maps You know you want to hunt for me tirelessly
Uh-huh!
It's not stalking 'cause the information is all technically public
Check out every guy I used to date
And deduce who broke up with who based on the hesitation in our smiles
So many unanswered questions.
Did I go to the University of Texas?
Am I an EMT?
Is that my obituary in which I'm survived by my loving husband of 50 years; children Susan and Mathew and grandchild Stephanie?
Wait no. That's just all the people with my same name.
Or is it?
Pay only 9.99 on a background check web site to know for sure.
So don't stop, just research me obsessively
Uh-huh!
and in lieu of flowers donate to other me's favorite charity
Research me just research me and research me and research me
Oops.
It's three days later.
Knowledge:
I can scrape off of my face All the soot from all the places I have been to And call it knowledge I can stitch and rip the gash That was a scar until I scratched and reinvoked it And call it knowledge And I won't complain about the blisters on my heel That we've surrendered to the real Or the feral dogs who feed on knowledge
I'm a statue of a man who looks nothing like a man But here I stand Grim and solid No scarlet secret's mine to hold Just a century of cold and thin and useless Sexless knowledge So I won't complain when my shattering is dreamt By the ninety-nine percent I'll surrender to their knowledge
'Cause I have read the terms and conditions I have read the terms and conditions Let the record show I agree to my position I accept the terms and conditions
Well I woke up this morning and saw the pitchforks at my door Said I woke up this morning—it was dark still—and there were pitchforks at my door And they were shining with a righteousness no knowledge ever shone before
I have read the terms and conditions I have read the terms and conditions I have read the terms and conditions I have read the terms and conditions
Next time let's get raised by wolves Next time let's get raised by wolves Next time let's get raised by wolves Next time let's get raised by wolves Next time let's get raised by wolves Next time let's get raised by wolves
3 notes
·
View notes
Text
Leads-Sniper.com Introduces Updated Web-Scraping Suite for Data-Driven Lead Generation
Web Scraping Tools Leads-Sniper.com has released an updated set of web-scraping tools designed to help organizations collect publicly available business information from widely used online sources. The new release focuses on streamlining data extraction from Google Maps, Google Search, Yellow Pages directories, and business domains, giving sales and research teams a structured way to build…
View On WordPress
0 notes
Text
Why Yelp Review Mining Matters for US Local Restaurant Chains
Why Yelp Review Mining is Crucial for Local Restaurant Chains in the US
Introduction
Yelp – America’s Real-Time Restaurant Scorecard :
In the U.S. restaurant ecosystem, Yelp is reputation currency.
With over 200 million reviews and counting, Yelp is the first place many diners check before trying a new restaurant. For local restaurant chains, these reviews don’t just impact search visibility—they shape customer perception, footfall, and delivery sales across locations.
At Datazivot, we help local chains mine Yelp reviews at scale—extracting detailed sentiment insights, dish-level complaints, location-specific issues, and brand performance trends.
Why Yelp Review Mining Matters for Local Chains
Whether you run 3 or 300 outlets, Yelp can:
Make or break your location-specific reputation
Expose staff behavior, hygiene issues, or taste concerns
Influence conversion rates on Google Maps and Yelp search
Provide early warnings of dips in service quality
By mining reviews, restaurant groups can:
Track underperforming outlets or dishes
Detect service or cleanliness complaints
Spot regional taste preferences
Benchmark against competitors
Improve menu design and CX
What Datazivot Extracts from Yelp Reviews
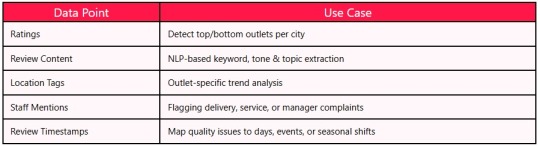
Sample Data from Yelp Review Mining
(Extracted by Datazivot)

Case Study: Local Chain in California Tracks Yelp Feedback to Drive Growth
Brand: CaliGrill (10-location BBQ chain)
Problem: Yelp ratings at 4 outlets fell below 3.5 stars in 2 months
Datazivot Review Mining Findings:
“Dry brisket,” “slow service,” and “dirty tables” were recurring
62% of complaints came from two specific branches
Sundays showed the highest volume of 1-star reviews
Actions Taken:
Weekend staff added at target branches
Menu revamped with better marination standards
Cleaning SOPs reinforced during peak hours
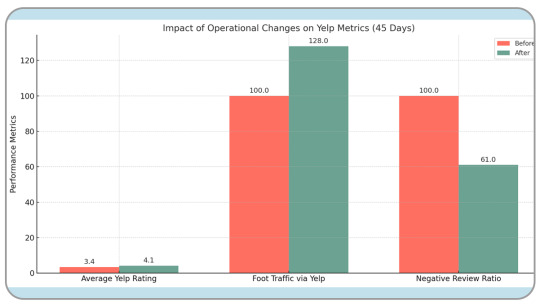
Results in 45 Days:
Average Yelp rating improved from 3.4 to 4.1
Foot traffic via Yelp referrals up 28%
Negative review ratio dropped 39%
Top Themes in Yelp Negative Reviews (2025)

Yelp Insights by Region
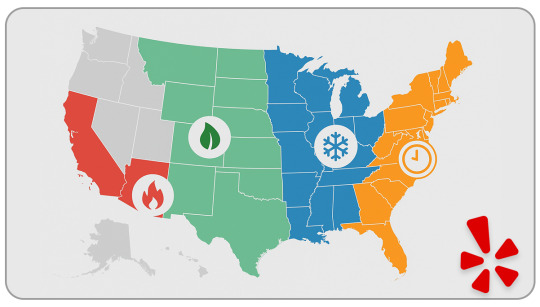
Flavor Preferences and Local Behavior :
Southern Cities: Expect stronger seasoning; “bland” triggers negative sentiment
Midwest Cities: Cold delivery is a major complaint for winter months
West Coast: Vegan/health-conscious customers flag portion size & presentation
Northeast: Time-based performance—reviews mention “waited 25+ minutes” often
Why Yelp Review Mining is Better Than Internal Surveys
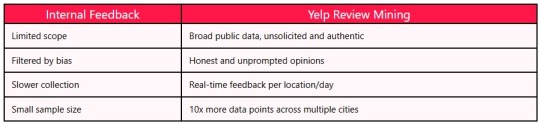
Benefits of Yelp Review Mining for Restaurant Chains

How Datazivot Supports US-Based Chains

Conclusion
Yelp is Your Reputation Mirror—Use It Wisely :
In 2025, every local restaurant chain needs to listen harder, act faster, and improve smarter. Yelp is no longer just a review site—it’s your public scorecard. Leveraging Food & Restaurant Reviews Data Scraping allows businesses to extract deeper insights, monitor trends in real time, and respond to feedback with precision.
With Datazivot’s Yelp review mining platform, you gain the tools to:
Improve star ratings
Identify weak spots in service or food
Boost repeat business with better CX
Drive brand consistency across locations
Want to See What Yelp Says About Your Restaurant Chain?
Contact Datazivot for a free Yelp review sentiment report across your U.S. locations. Let the real voice of your customers guide your next big improvement.
#YelpReviewMining#CustomerExperience#LocalChainsUSA#CustomerFeedback#YelpUSA#USRestaurants#ReviewScraping#SentimentAnalysis#ReputationMonitoring#YelpCX
0 notes
Text
Planning Your Next Road Trip? Here Is Your Ultimate Checklist

With the wind in your hair and the promise of new adventures around every corner, there is always something special about hitting the open road. Whether you are a resident or a visitor, a road trip along Chennai's East Coast Road (ECR) offers astonishing coastal views, charming villages, and many new places to explore. To ensure a smooth and enjoyable experience, here is a checklist that can go along before you embark on your journey.
Keep A Check On Your Vehicle
Make sure your vehicle is road trip-ready before setting off. Have a check on the engine oil, coolant levels, and tire pressure. It is wise to carry a spare tire, jack, and essential tools for emergencies. Always remember that a well-prepared vehicle means fewer chances of unexpected breakdowns along the scenic ECR.
Pack the Essentials
Keep the road trip essentials within reach. This includes your driving license, vehicle registration, insurance papers, and a fully charged power bank. If you're planning to take a few detours and explore the lesser-known spots along the way, bring some snacks and bottled water to keep hunger at bay.
Plan Your Route
Although spontaneity is part of the charm of a road trip, it helps to have a rough idea of your route. Mark the main attractions along the ECR like Mahabalipuram, Kovalam Beach, and DakshinaChitra. When cell services become spotty, Google Maps and offline navigation apps can be lifesavers.
Create the Perfect Playlist
No road trip is complete without the right soundtrack. Curate a playlist that keeps the vibe upbeat, and don’t forget to include some local Tamil tunes to get into the spirit of Tamil Nadu. It’s the perfect way to set the mood as you drive along the picturesque coast.
Pack for Comfort
Bring along neck pillows and a light blanket, and wear comfy clothing to make those long stretches of driving more comfortable. Sunglasses and a good hat can also come in handy, especially with the sun shining brightly over the coastal road.
Bring a First Aid Kit
Safety first! Pack a basic first-aid kit with band-aids, antiseptic wipes, painkillers, and any essential medications you might need. It's better to be prepared. You never know when a minor scrape or headache might strike.
Keep Your Camera Ready
ECR is known for its stunning landscapes, so make sure your camera or smartphone is fully charged and ready to capture those picturesque moments. From sunrise shots over the Bay of Bengal to selfies at the historic rock carvings of Mahabalipuram, there will be plenty of memories to capture along the way.
Look Up Local Eateries
One of the best parts of a road trip is the opportunity to try out local food. Keep an eye out for popular eateries and seafood shacks along the ECR, where you can sample the freshest catch of the day. Don’t forget to try local delicacies like the famous filter coffee, biryani, kalakki, and Chettinad chicken.
Book a Comfortable Stay
There's nothing like retreating to a comfortable place after a day of exploring and adventure. That’s when you can book the Kaldan Samudhra Palace 5 Star Hotels in ECR. This beachside resort, set along the scenic ECR, offers a unique blend of luxury and cultural charm. With its Rajasthani-inspired architecture and vibrant interiors, it transports you to a royal haven while keeping you connected to the calming sea breeze. The palace resort offers a range of fun activities to elevate your stay, from beachside sunrise yoga sessions to traditional Rajasthani performances, making it the perfect stop for relaxation and cultural immersion. It’s the ideal base to unwind before continuing your journey along Chennai’s beautiful coast.
Set the Right Attitude
A road trip is all about the journey, so embrace every moment, even if things don’t go exactly as planned. Be open to making unplanned stops, chatting with locals, and taking in the sights and sounds of the road.
With this checklist in hand, you’re all set to embark on your road trip along the beautiful Chennai/ECR coastline. So gather your friends, fuel up, and get ready to create memories that will last a lifetime.
And don’t forget—when it’s time for a break, Kaldan Samudhra Palace awaits with its warm hospitality and stunning beachfront views. Happy road-tripping! Embark on a journey into paradise and book your stay today at Kaldan Samudhra Palace. For bookings & reservations, visit www.kaldanhotels.com or call us @ +91 8925814910
0 notes
Text
How Can I Use Programmatic SEO to Launch a Niche Content Site?
Launching a niche content site can be both exciting and rewarding—especially when it's done with a smart strategy like programmatic SEO. Whether you're targeting a hyper-specific audience or aiming to dominate long-tail keywords, programmatic SEO can give you an edge by scaling your content without sacrificing quality. If you're looking to build a site that ranks fast and drives passive traffic, this is a strategy worth exploring. And if you're unsure where to start, a professional SEO agency Markham can help bring your vision to life.
What Is Programmatic SEO?
Programmatic SEO involves using automated tools and data to create large volumes of optimized pages—typically targeting long-tail keyword variations. Instead of manually writing each piece of content, programmatic SEO leverages templates, databases, and keyword patterns to scale content creation efficiently.
For example, a niche site about hiking trails might use programmatic SEO to create individual pages for every trail in Canada, each optimized for keywords like “best trail in [location]” or “hiking tips for [terrain].”
Steps to Launch a Niche Site Using Programmatic SEO
1. Identify Your Niche and Content Angle
Choose a niche that:
Has clear search demand
Allows for structured data (e.g., locations, products, how-to guides)
Has low to medium competition
Examples: electric bike comparisons, gluten-free restaurants by city, AI tools for writers.
2. Build a Keyword Dataset
Use SEO tools (like Ahrefs, Semrush, or Google Keyword Planner) to extract long-tail keyword variations. Focus on "X in Y" or "best [type] for [audience]" formats. If you're working with an SEO agency Markham, they can help with in-depth keyword clustering and search intent mapping.
3. Create Content Templates
Build templates that can dynamically populate content with variables like location, product type, or use case. A content template typically includes:
Intro paragraph
Keyword-rich headers
Dynamic tables or comparisons
FAQs
Internal links to related pages
4. Source and Structure Your Data
Use public datasets, APIs, or custom scraping to populate your content. Clean, accurate data is the backbone of programmatic SEO.
5. Automate Page Generation
Use platforms like Webflow (with CMS collections), WordPress (with custom post types), or even a headless CMS like Strapi to automate publishing. If you’re unsure about implementation, a skilled SEO agency Markham can develop a custom solution that integrates data, content, and SEO seamlessly.
6. Optimize for On-Page SEO
Every programmatically created page should include:
Title tags and meta descriptions with dynamic variables
Clean URL structures (e.g., /tools-for-freelancers/)
Internal linking between related pages
Schema markup (FAQ, Review, Product)
7. Track, Test, and Improve
Once live, monitor your pages via Google Search Console. Use A/B testing to refine titles, layouts, and content. Focus on improving pages with impressions but low click-through rates (CTR).
Why Work with an SEO Agency Markham?
Executing programmatic SEO at scale requires a mix of SEO strategy, web development, content structuring, and data management. A professional SEO agency Markham brings all these capabilities together, helping you:
Build a robust keyword strategy
Design efficient, scalable page templates
Ensure proper indexing and crawlability
Avoid duplication and thin content penalties
With local expertise and technical know-how, they help you launch faster, rank better, and grow sustainably.
Final Thoughts
Programmatic SEO is a powerful method to launch and scale a niche content site—if you do it right. By combining automation with strategic keyword targeting, you can dominate long-tail search and generate massive organic traffic. To streamline the process and avoid costly mistakes, partner with an experienced SEO agency Markham that understands both the technical and content sides of SEO.
Ready to build your niche empire? Programmatic SEO could be your best-kept secret to success
0 notes
Text
Efficient Naver Map Data Extraction for Business Listings

Introduction
In today's competitive business landscape, having access to accurate and comprehensive business data is crucial for strategic decision-making and targeted marketing campaigns. Naver Map Data Extraction presents a valuable opportunity to gather insights about local businesses, consumer preferences, and market trends for companies looking to expand their operations or customer base in South Korea.
Understanding the Value of Naver Map Business Data
Naver is often called "South Korea's Google," dominating the local search market with over 70% market share. The platform's mapping service contains extensive information about businesses across South Korea, including contact details, operating hours, customer reviews, and location data. Naver Map Business Data provides international and local businesses rich insights to inform market entry strategies, competitive analysis, and targeted outreach campaigns.
However, manually collecting this information would be prohibitively time-consuming and inefficient. This is where strategic Business Listings Scraping comes into play, allowing organizations to collect and analyze business information at scale systematically.
The Challenges of Accessing Naver Map Data
Unlike some other platforms, Naver presents unique challenges for data collection:
Language barriers: Naver's interface and content are primarily Korean, creating obstacles for international businesses.
Complex website structure: Naver's dynamic content loading makes straightforward scraping difficult.
Strict rate limiting: Aggressive anti-scraping measures can block IP addresses that require too many requests.
CAPTCHA systems: Automated verification challenges to prevent bot activity.
Terms of service considerations: Understanding the Legal Ways To Scrape Data From Naver Map is essential.
Ethical and Legal Considerations
Before diving into the technical aspects of Naver Map API Scraping, it's crucial to understand the legal and ethical framework. While data on the web is publicly accessible, how you access it matters from legal and ethical perspectives.
To Scrape Naver Map Data Without Violating Terms Of Service, consider these principles:
Review Naver's terms of service and robots.txt file to understand access restrictions.
Implement respectful scraping practices with reasonable request rates.
Consider using official APIs where available.
Store only the data you need and ensure compliance with privacy regulations, such as GDPR and Korea's Personal Information Protection Act.
Use the data for legitimate business purposes without attempting to replicate Naver's services.
Effective Methods For Scraping Naver Map Business Data
There are several approaches to gathering business listing data from Naver Maps, each with advantages and limitations.
Here are the most practical methods:
1. Official Naver Maps API
Naver provides official APIs that allow developers to access map data programmatically. While these APIs have usage limitations and costs, they represent the most straightforward and compliant Naver Map Business Data Extraction method.
The official API offers:
Geocoding and reverse geocoding capabilities.
Local search functionality.
Directions and routing services.
Address verification features.
Using the official API requires registering a developer account and adhering to Naver's usage quotas and pricing structure. However, it provides reliable, sanctioned access to the data without risking account blocks or legal issues.
2. Web Scraping Solutions
When API limitations prove too restrictive for your business needs, web scraping becomes a viable alternative. Naver Map Scraping Tools range from simple script-based solutions to sophisticated frameworks that can handle dynamic content and bypass basic anti-scraping measures.
Key components of an effective scraping solution include:
Proxy RotationRotating between multiple proxy servers is essential to prevent IP bans when accessing large volumes of data. This spreads requests across different IP addresses, making the scraping activity appear more like regular user traffic than automated collection.Commercial proxy services offer:1. Residential proxies that use real devices and ISPs.2. Datacenter proxies that provide cost-effective rotation options.3. Geographically targeted proxies that can access region-specific content.
Request Throttling Implementing delays between requests helps mimic human browsing patterns and reduces server load. Adaptive throttling that adjusts based on server response times can optimize the balance between collection speed and avoiding detection.
Browser Automation Tools like Selenium and Playwright can control real browsers to render JavaScript-heavy pages and interact with elements just as a human user would. This approach is efficient for navigating Naver's dynamic content loading system.
3. Specialized Web Scraping API Services
For businesses lacking technical resources to build and maintain scraping infrastructure, Web Scraping API offers a middle-ground solution. These services handle the complexities of proxy rotation, browser rendering, and CAPTCHA solving while providing a simple API interface to request data.
Benefits of using specialized scraping APIs include:
Reduced development and maintenance overhead.
Built-in compliance with best practices.
Scalable infrastructure that adapts to project needs.
Regular updates to counter anti-scraping measures.
Structuring Your Naver Map Data Collection Process
Regardless of the method chosen, a systematic approach to Naver Map Data Extraction will yield the best results. Here's a framework to guide your collection process:
1. Define Clear Data Requirements
Before beginning any extraction project, clearly define what specific business data points you need and why.
This might include:
Business names and categories.
Physical addresses and contact information.
Operating hours and service offerings.
Customer ratings and review content.
Geographic coordinates for spatial analysis.
Precise requirements prevent scope creep and ensure you collect only what's necessary for your business objectives.
2. Develop a Staged Collection Strategy
Rather than attempting to gather all data at once, consider a multi-stage approach:
Initial broad collection of business identifiers and basic information.
Categorization and prioritization of listings based on business relevance.
Detailed collection focusing on high-priority targets.
Periodic updates to maintain data freshness.
This approach optimizes resource usage and allows for refinement of collection parameters based on initial results.
3. Implement Data Validation and Cleaning
Raw data from Naver Maps often requires preprocessing before it becomes business-ready.
Common data quality issues include:
Inconsistent formatting of addresses and phone numbers.
Mixed language entries (Korean and English).
Duplicate listings with slight variations.
Outdated or incomplete information.
Implementing automated validation rules and manual spot-checking ensures the data meets quality standards before analysis or integration with business systems.
Specialized Use Cases for Naver Product Data Scraping
Beyond basic business information, Naver's ecosystem includes product listings and pricing data that can provide valuable competitive intelligence.
Naver Product Data Scraping enables businesses to:
Monitor competitor pricing strategies.
Identify emerging product trends.
Analyze consumer preferences through review sentiment.
Track promotional activities across the Korean market.
This specialized data collection requires targeted approaches that navigate Naver's shopping sections and product detail pages, often necessitating more sophisticated parsing logic than standard business listings.
Data Analysis and Utilization
The actual value of Naver Map Business Data emerges during analysis and application. Consider these strategic applications:
Market Penetration AnalysisBy mapping collected business density data, companies can identify underserved areas or regions with high competitive saturation. This spatial analysis helps optimize expansion strategies and resource allocation.
Competitive BenchmarkingAggregated ratings and review data provide insights into competitor performance and customer satisfaction. This benchmarking helps identify service gaps and opportunities for differentiation.
Lead Generation and OutreachFiltered business contact information enables targeted B2B marketing campaigns, partnership initiatives, and sales outreach programs tailored to specific business categories or regions.
How Retail Scrape Can Help You?

We understand the complexities involved in Naver Map API Scraping and the strategic importance of accurate Korean market data. Our specialized team combines technical expertise with deep knowledge of Korean digital ecosystems to deliver reliable, compliance-focused data solutions.
Our approach to Naver Map Business Data Extraction is built on three core principles:
Compliance-First Approach: We strictly adhere to Korean data regulations, ensuring all activities align with platform guidelines for ethical, legal scraping.
Korea-Optimized Infrastructure: Our tools are designed for Korean platforms, offering native language support and precise parsing for Naver’s unique data structure.
Insight-Driven Delivery: Beyond raw data, we offer value-added intelligence—market insights, tailored reports, and strategic recommendations to support your business in Korea.
Conclusion
Harnessing the information available through Naver Map Data Extraction offers significant competitive advantages for businesses targeting the Korean market. Organizations can develop deeper market understanding and more targeted business strategies by implementing Effective Methods For Scraping Naver Map Business Data with attention to legal compliance, technical best practices, and strategic application.
Whether you want to conduct market research, generate sales leads, or analyze competitive landscapes, the rich business data available through Naver Maps can transform your Korean market operations. However, the technical complexities and compliance considerations make this a specialized undertaking requiring careful planning and execution.
Need expert assistance with your Korean market data needs? Contact Retail Scrape today to discuss how our specialized Naver Map Scraping Tools and analytical expertise can support your business objectives.
Source : https://www.retailscrape.com/efficient-naver-map-data-extraction-business-listings.php
Originally Published By https://www.retailscrape.com/
#NaverMapDataExtraction#BusinessListingsScraping#NaverBusinessData#SouthKoreaMarketAnalysis#WebScrapingServices#NaverMapAPIScraping#CompetitorAnalysis#MarketIntelligence#DataExtractionSolutions#RetailDataScraping#NaverMapBusinessListings#KoreanBusinessDataExtraction#LocationDataScraping#NaverMapsScraper#DataMiningServices#NaverLocalSearchData#BusinessIntelligenceServices#NaverMapCrawling#GeolocationDataExtraction#NaverDirectoryScraping
0 notes
Text
How to Scrape Google Reviews: A Complete Guide with Expert Data Scraping Services
In a world where customer feedback shapes business success, Google reviews have emerged as one of the most powerful tools for brands to understand public sentiment. These reviews are more than just star ratings—they're a direct window into customer experiences and expectations. Whether you're managing a small local store or a multinational company, analyzing Google reviews can offer valuable insights.
But manually collecting and analyzing thousands of reviews is time-consuming and inefficient. This is where data scraping services come into play. By automating the process, businesses can gather and analyze reviews at scale, making informed decisions more quickly and accurately.

In this blog, we’ll explore what Google reviews are, why they matter, and how to scrape them effectively.
What Are Google Reviews and Why Do They Matter?
Google reviews are customer-generated feedback and star ratings that appear on a business's Google profile. These reviews are visible on Google Search and Google Maps, influencing how people perceive and choose your business. Positive reviews can enhance your credibility and attract more customers, while negative ones can provide critical feedback for improvement. Google also considers these reviews in its search algorithm, making them essential for local SEO. In short, Google reviews are not just opinions; they’re public endorsements or warnings that impact your brand’s reputation, discoverability, and success. From a business perspective, understanding and leveraging this data is essential. Reviews highlight customer satisfaction, reveal service gaps, and offer a competitive edge by shedding light on what people love (or dislike) about your competitors.
Step-by-Step Guide: How to Scrape Google Reviews
Scraping Google reviews may sound technical, but with the right strategy and tools, it becomes a streamlined process. Below is a simple guide to help you get started.
Step 1: Identify the Google Place ID or Business URL
The first step in scraping reviews is locating the business’s unique identifier on Google. This could be the full URL from Google Maps or the Place ID provided through Google’s developer tools. This ensures your scraper targets the correct business location.
Step 2: Use the Google Places API (If You Only Need Limited Data)
Google provides an official API that allows access to a limited number of reviews (typically the latest five). You’ll need to set up a project in Google Cloud Console and request data using your API key. While this method is compliant with Google’s terms, it has significant limitations if you need historical or bulk data.
Step 3: Build or Use a Scraper for Larger Datasets
If your goal is to analyze a large volume of reviews over time, you’ll need more than what the API offers. This is where custom-built scrapers or third-party scraping platforms come in. Tools like BeautifulSoup, Scrapy, or Selenium can help automate the process, though they require technical expertise. Alternatively, you can partner with experts like TagX, who offer scalable and reliable data scraping services. Their solutions are built to handle dynamic content, pagination, and other complexities involved in scraping from platforms like Google
Step 4: Deal with Pagination and JavaScript Rendering
Google displays only a portion of reviews at a time and loads more as the user scrolls. A good scraper must simulate this behavior by managing pagination and rendering JavaScript content. This step ensures you don’t miss any data during the extraction process.
Step 5: Clean and Analyze Your Data
Once the reviews are scraped, they need to be cleaned and organized. You may need to remove HTML tags, eliminate duplicates, or normalize date formats. Structured data can then be analyzed using sentiment analysis tools or visualized using dashboards to uncover trends and insights.
Benefits of Using Data Scraping Services for Google Reviews
Manually collecting review data is inefficient and prone to errors. Professional data scraping services offer a range of benefits:
Accuracy: Eliminate human errors through automated, structured data collection
Scalability: Scrape thousands of reviews across multiple locations.
Speed: Collect and process data faster than manual methods
Customization: Filter and organize data based on your business needs
Compliance: Adhere to legal and ethical data collection standards
TagX, for example, provides customized scraping pipelines tailored to your business goals. Their platform supports large-scale review analysis, from raw data extraction to sentiment tagging and visualization.
Challenges of Scraping Google Reviews
Even with the right tools, scraping Google reviews isn’t always straightforward. Businesses may face challenges like CAPTCHAs, anti-bot mechanisms, and dynamically loaded content. Another common issue is inconsistent data formatting. Since users write reviews in different styles and languages, analyzing this data can be difficult. This is where web scraping using AI becomes incredibly valuable. AI-powered tools can adapt to different content layouts, recognize sentiment across languages, and even summarize or tag common themes across reviews.
Is It Legal to Scrape Google Reviews?
This question often arises, and the answer depends on how the data is collected and used. While Google’s terms of service typically prohibit automated scraping, the information being scraped—customer reviews—is public.If done ethically, without overloading Google’s servers or violating privacy, scraping public reviews is generally accepted for research and analysis. Still, it’s crucial to stay updated with legal best practices. Partnering with responsible providers like TagX ensures compliance and reduces risk.
Why Choose TagX for Google Review Scraping
When it comes to scraping sensitive and complex data like Google reviews, you need a partner you can trust. TagX brings deep expertise in building scalable, ethical, and AI-driven scraping solutions. They offer:
Smart scrapers that adapt to changes in Google’s layout
Scalable pipelines to collect millions of data points
NLP-powered sentiment analysis and keyword tagging
Complete compliance with data privacy regulations
Whether you're analyzing reviews to improve customer satisfaction or tracking competitor sentiment, TagX ensures you get actionable insights without the hassle.
Final Thoughts
Google reviews are a goldmine of customer insight, but manually managing and analyzing them is not practical at scale. By using expert data scraping services, businesses can unlock the full potential of this feedback to improve customer experience, drive product innovation, and strengthen their market presence. If you're ready to turn raw review data into strategic insights, consider partnering with TagX. Their blend of automation, AI, and compliance makes them ideal for scraping and analyzing Google reviews.
0 notes
Text
Google AI Overview: Is It Killing Organic Search?

When Google announced its AI Overview feature, it was advertised as the next big thing in search—replacing traditional link lists with smart summary responses that provide immediate answers to users. Now that the launch has settled, this highly touted innovation is becoming embroiled in growing controversy. Users are questioning its accuracy, while it appears website publishers are having their content scraped without attribution.
With increasing search interest in terms like "Google AI Overview turn off," "Google AI Overview wrong," and "Google AI Overview stole my entire page Android," it's evident that dissatisfaction is building. Let's take a look at what's gone awry.
Google AI Overview: Great Concept, Flawed Execution
At its foundation, Google AI Overview is run by Google AI Ultra, meant to deliver fast, AI-driven experiences by scanning and aggregating information from several web writings. This level of efficiency, however, is certainly at the cost of user control and ownership of content.
Many content creators have found that the AI is now able to capture large portions of their blogs or articles and display it atop the summary results—without attribution, and without the benefit of clicks from web visitors. Some even made the claim “Google AI Overview stole my full page,” and it is specifically evident on Android devices where the AI generated content represents a larger proportion of the screen, while actual authored content appears smaller.
With this new model, it essentially turns the web upside down: content creators are creating helpful content, and in exchange for that content, they benefit with traffic, visibility, and perhaps the hope of monetization. The AI is now taking the content and essentially removing the reward.
When Google’s AI Gets It Wrong
A bigger concern is that Google’s AI sometimes gets facts completely wrong—and yet still displays those errors with authority. Viral screenshots have shown the AI providing bizarre, inaccurate, and even unsafe advice. These mistakes have led to a rise in searches like “Google AI Overview wrong” and “Google AI wrong answer.”
The problem lies in how the AI functions. If you’re wondering, “How does Google AI Overview work?”—the answer is this: it uses machine learning to paraphrase content from high-ranking pages. But it doesn’t understand the content the way a human does.
The SEO and Content Creator Fallout
This change, while huge for user experience, is shaking up SEO. Companies and publishers who built value through SEO can't escape the impact of AI summaries. Even when they were #1 in the SERPS, they have hardly received a click because the AI already started the game above their link and "answered" the question.
Now, many are looking to use advanced SEO tools (like Seobix) to understand how AI summaries will adjust the link rankings, flow of traffic, etc. There is an emerging sense that for businesses using SEO to grow, it won't matter how well they optimize if AI continues to map out the game in front of them and take the spotlight.
The Path Forward for Google
There’s no denying the potential of AI in search—but only when it works with creators, not against them. The ongoing Google AI Overview controversy is proof that innovation without collaboration creates imbalance.
For now, users and creators are caught in a system that prioritizes automation over accountability. If Google wants to maintain its position as the most trusted search engine, it must rebuild transparency, accuracy, and give users control over how they search.
Until that happens, the backlash around AI Overview is unlikely to fade.
#digital marketing#Google AI ultra#Google AI news#Google AI overview wrong#google ai overview#Google AI Overview turn off#How does Google AI overview work#Google AI Overview stole my entire page android
1 note
·
View note
Text
Why Travel Content Creators Should Join Platforms Like Cya On The Road in the Age of AI

In today's rapidly evolving digital landscape, artificial intelligence is transforming the way we consume content. From personalised recommendations to AI-generated summaries, readers can now access travel information faster and more efficiently than ever before. While this may seem like a positive development for audiences, it raises urgent concerns for travel content writers. How can they protect their work and continue to earn a living when AI tools can scrape, summarise and distribute their content — often without credit or compensation?
The AI Dilemma for Travel Writers
Travel content creators have traditionally relied on web traffic and advertising revenue to monetise their blogs. They invest time, effort and often money in visiting destinations, crafting compelling narratives and producing high-quality images and guides. However, as AI tools become more adept at crawling the web, these writers face a double-edged sword: greater reach, but fewer clicks and less time spent on their pages, resulting in reduced ad revenue.
While AI companies may argue that they do not 'steal' in the traditional sense, they actually reproduce the essence of your work, removing the incentive for readers to visit your site. Your meticulously crafted article on Sydney's hidden gems might be summarised in a ChatGPT response or an AI Overview on Google — accurate in terms of facts, but completely devoid of your unique storytelling, voice, branding, and most importantly, your monetisation model. Readers get the value without ever clicking through to your blog. It's a system that extracts content by design — without credit, compensation, or consent.
Time to Rethink the Model
If the open internet can no longer guarantee fair compensation, creators should explore alternatives. Platforms like Cya On The Road offer a promising solution.
Cya On The Road enables travel writers to upload their content as self-guided tours complete with audio narration, maps, images and curated stops. But here’s the key difference:
You Set the Price!
Readers pay to access your unique travel experience, just as they would for a guidebook or walking tour. You maintain control over your content and are compensated directly for its value.
Why Cya On The Road Makes Sense
Protect your work: Unlike blog posts, which can be scraped, tour content on platforms like Cya On The Road is packaged in a way that makes it less accessible to AI tools and bots.
Monetise intelligently: Rather than relying on ad clicks, you earn money from every access. There are no middlemen ad blockers or SEO roulette.
Reach engaged audiences: Users on Cya On The Road are actively looking for travel experiences, not just scrolling for inspiration. They’re more likely to pay for detailed, authentic and high-quality guides.
Stay ahead of the curve: As more creators seek sustainable income models in a post-AI landscape, getting in early gives you a head start in building your brand and loyal customer base.
Final thoughts
AI is a disruptor. Travel content creators can no longer rely solely on free access and advertising revenue to sustain their work. Platforms such as Cya On The Road offer a viable alternative, respecting creators, engaging travellers, and preserving the magic of storytelling.
So, if you’re a travel writer looking for a smarter way to share your passion and get paid for it, it might be time to pack up your blog and head to a new destination — one that pays.
See how creators are thriving: Top 10 Paid Tours of 2024
Explore. Create. Monetise.
Join Cya On The Road today.
0 notes
Text
Top 10 Lead Generation Platforms for Small Businesses

In today’s hyper-connected digital world, lead generation isn’t just about getting names — it’s about finding the right people at the right time. For small businesses with limited marketing budgets, finding scalable, cost-effective lead generation platforms is key to sustainable growth.
Here’s a roundup of the top 10 lead generation platforms that are perfect for small businesses looking to grow their customer base in 2025.
1. Prospect Wiki
Best for: B2B lead discovery and brand visibility Why it stands out: Prospect Wiki is a rising star in the business listing and outreach space. It acts as a central hub for companies to showcase services, connect with potential clients, and improve discoverability. It’s particularly helpful for small businesses aiming to be found by buyers and agencies.
Verified business listings High domain authority Built-in lead-gen and SEO advantages
2. LinkedIn
Best for: B2B connections and organic engagement Why it stands out: With its built-in networking tools and search filters, LinkedIn is a powerhouse for professionals. Small businesses can use LinkedIn to connect directly with decision-makers, run lead gen ads, or even publish high-value content to build trust.
Organic + paid lead opportunities Messaging tools and filters LinkedIn Sales Navigator (optional upgrade)
3. Google Business Profile
Best for: Local businesses and service providers Why it stands out: A well-optimized Google Business Profile can bring in tons of local traffic — especially for searches like “best [your service] near me.” It’s free and works great for small businesses serving local customers.
Free exposure on Google Maps/Search Collect reviews and build trust Boosts local SEO
4. Facebook Lead Ads
Best for: Wide demographic targeting and form-based leads Why it stands out: Facebook allows you to target specific audiences and collect leads directly within the platform. No landing pages needed — just a few taps and the lead is yours.
Highly targeted ad options Quick lead forms Integration with CRMs
5. Apollo.io
Best for: Sales outreach and contact info scraping Why it stands out: Apollo is a powerful tool that provides verified contact details, sequences, and outreach tracking. Small sales teams can benefit from automated email sequences and a rich database of professionals.
Email and phone contact details Outreach tracking CRM integrations
#LeadGeneration#SmallBusinessGrowth#TopLeadTools#DigitalMarketing#B2BLeads#MarketingTools#FreeLeadGeneration#OnlineLeads#LeadGenPlatforms
0 notes
Text
Unlock Business Data with a Google Maps Scraper Lifetime Deal
In today’s competitive digital landscape, data is everything. Whether you’re a marketer, a business owner, or a freelancer, having access to accurate local business data can give you a serious edge. That’s where a Google Maps Scraper Lifetime Deal becomes a total game-changer.
What is a Google Maps Scraper?
A Google Maps scraper is a tool designed to extract valuable data from Google Maps listings. This includes business names, addresses, phone numbers, websites, ratings, reviews, and even categories. Instead of manually collecting this data, which can be tedious and time-consuming, the scraper automates the process for you—saving hours of work and delivering ready-to-use business leads.
Why You Should Care About a Lifetime Deal
Getting a lifetime deal means you pay once and use the tool forever. There are no monthly fees or recurring charges, just unlimited access to data scraping whenever you need it. This can be a smart investment with long-term benefits for agencies, freelancers, and digital marketers.
Here’s why a lifetime deal for a Google Maps scraper makes sense:
One-time payment: Say goodbye to ongoing software costs.
Unlimited searches: Ideal for outreach, lead generation, or market research.
Fast and efficient: Pull hundreds or even thousands of listings in minutes.
Data export options: Export data to CSV or Excel for easy access.
Who Can Benefit From This Tool?
A Google Maps scraper isn’t just for tech geeks. Here’s who can benefit:
Local SEO experts looking to audit competitors or find citation opportunities.
Sales teams needing fresh leads based on industry and location.
Freelancers offering local marketing or data entry services.
Startups and agencies trying to build contact databases for outreach.
Imagine being able to pull a list of all real estate agencies in New York, or all restaurants in your town with a single click. That’s the power of a scraper.
Use Cases for Your Next Campaign
If you’re into SEO, outreach, or any kind of B2B marketing, this tool is pure gold. Here are a few creative ways to use it:
Local link building: Find businesses in your niche and offer guest posts or partnerships.
Cold outreach: Build a contact list for personalized email campaigns.
Competitor analysis: Compare data from other businesses in your target areas.
Service marketing: Target businesses that could benefit from your digital services.
Final Thoughts
Investing in a Google Maps Scraper Lifetime Deal isn’t just a shortcut—it’s a smart business decision. With automation, you can scale your efforts, get better data, and grow your reach faster than ever before.
Whether you're an SEO pro, a growth hacker, or just someone trying to make smarter business decisions, a Google Maps scraper can be one of the most powerful tools in your digital toolbox.
0 notes
Text
Why Businesses Need Reliable Web Scraping Tools for Lead Generation.
The Importance of Data Extraction in Business Growth
Efficient data scraping tools are essential for companies looking to expand their customer base and enhance their marketing efforts. Web scraping enables businesses to extract valuable information from various online sources, such as search engine results, company websites, and online directories. This data fuels lead generation, helping organizations find potential clients and gain a competitive edge.
Not all web scraping tools provide the accuracy and efficiency required for high-quality data collection. Choosing the right solution ensures businesses receive up-to-date contact details, minimizing errors and wasted efforts. One notable option is Autoscrape, a widely used scraper tool that simplifies data mining for businesses across multiple industries.

Why Choose Autoscrape for Web Scraping?
Autoscrape is a powerful data mining tool that allows businesses to extract emails, phone numbers, addresses, and company details from various online sources. With its automation capabilities and easy-to-use interface, it streamlines lead generation and helps businesses efficiently gather industry-specific data.
The platform supports SERP scraping, enabling users to collect information from search engines like Google, Yahoo, and Bing. This feature is particularly useful for businesses seeking company emails, websites, and phone numbers. Additionally, Google Maps scraping functionality helps businesses extract local business addresses, making it easier to target prospects by geographic location.
How Autoscrape Compares to Other Web Scraping Tools
Many web scraping tools claim to offer extensive data extraction capabilities, but Autoscrape stands out due to its robust features:
Comprehensive Data Extraction: Unlike many free web scrapers, Autoscrape delivers structured and accurate data from a variety of online sources, ensuring businesses obtain quality information.
Automated Lead Generation: Businesses can set up automated scraping processes to collect leads without manual input, saving time and effort.
Integration with External Tools: Autoscrape provides seamless integration with CRM platforms, marketing software, and analytics tools via API and webhooks, simplifying data transfer.
Customizable Lead Lists: Businesses receive sales lead lists tailored to their industry, each containing 1,000 targeted entries. This feature covers sectors like agriculture, construction, food, technology, and tourism.
User-Friendly Data Export: Extracted data is available in CSV format, allowing easy sorting and filtering by industry, location, or contact type.
Who Can Benefit from Autoscrape?
Various industries rely on web scraping tools for data mining and lead generation services. Autoscrape caters to businesses needing precise, real-time data for marketing campaigns, sales prospecting, and market analysis. Companies in the following sectors find Autoscrape particularly beneficial:
Marketing Agencies: Extract and organize business contacts for targeted advertising campaigns.
Real Estate Firms: Collect property listings, real estate agencies, and investor contact details.
E-commerce Businesses: Identify potential suppliers, manufacturers, and distributors.
Recruitment Agencies: Gather data on potential job candidates and hiring companies.
Financial Services: Analyze market trends, competitors, and investment opportunities.
How Autoscrape Supports Business Expansion
Businesses that rely on lead generation services need accurate, structured, and up-to-date data to make informed decisions. Autoscrape enhances business operations by:
Improving Customer Outreach: With access to verified emails, phone numbers, and business addresses, companies can streamline their cold outreach strategies.
Enhancing Market Research: Collecting relevant data from SERPs, online directories, and Google Maps helps businesses understand market trends and competitors.
Increasing Efficiency: Automating data scraping processes reduces manual work and ensures consistent data collection without errors.
Optimizing Sales Funnel: By integrating scraped data with CRM systems, businesses can manage and nurture leads more effectively.

Testing Autoscrape: Free Trial and Accessibility
For businesses unsure about committing to a web scraper tool, Autoscrapeoffers a free account that provides up to 100 scrape results. This allows users to evaluate the platform's capabilities before making a purchase decision.
Whether a business requires SERP scraping, Google Maps data extraction, or automated lead generation, Autoscrape delivers a reliable and efficient solution that meets the needs of various industries. Choosing the right data scraping tool is crucial for businesses aiming to scale operations and enhance their customer acquisition strategies.
Investing in a well-designed web scraping solution like Autoscrape ensures businesses can extract valuable information quickly and accurately, leading to more effective marketing and sales efforts.
0 notes
Text
NLP Sentiment Analysis | Reviews Monitoring for Actionable Insights
NLP Sentiment Analysis-Powered Insights from 1M+ Online Reviews

Business Challenge

A global enterprise with diversified business units in retail, hospitality, and tech was inundated with customer reviews across dozens of platforms:
Amazon, Yelp, Zomato, TripAdvisor, Booking.com, Google Maps, and more. Each platform housed thousands of unstructured reviews written in multiple languages — making it ideal for NLP sentiment analysis to extract structured value from raw consumer feedback.
The client's existing review monitoring efforts were manual, disconnected, and slow. They lacked a modern review monitoring tool to streamline analysis. Key business leaders had no unified dashboard for customer experience (CX) trends, and emerging issues often went unnoticed until they impacted brand reputation or revenue.
The lack of a central sentiment intelligence system meant missed opportunities not only for service improvements, pricing optimization, and product redesign — but also for implementing a robust Brand Reputation Management Service capable of safeguarding long-term consumer trust.
Key pain points included:
No centralized system for analyzing cross-platform review data
Manual tagging that lacked accuracy and scalability
Absence of real-time CX intelligence for decision-makers
Objective
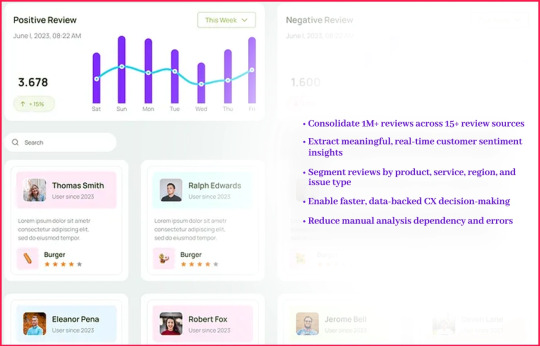
The client set out to:
Consolidate 1M+ reviews across 15+ review sources
Extract meaningful, real-time customer sentiment insights
Segment reviews by product, service, region, and issue type
Enable faster, data-backed CX decision-making
Reduce manual analysis dependency and errors
Their goal: Build a scalable sentiment analysis system using a robust Sentiment Analysis API to drive operational, marketing, and strategic decisions across business units.
Our Approach

DataZivot designed and deployed a fully-managed NLP-powered review analytics pipeline, customized for the client's data structure and review volume. Our solution included:
1. Intelligent Review Scraping
Automated scraping from platforms like Zomato, Yelp, Amazon, Booking.com
Schedule-based data refresh (daily & weekly)
Multi-language support (English, Spanish, German, Hindi)
2. NLP Sentiment Analysis
Hybrid approach combining rule-based tagging with transformer-based models (e.g., BERT, RoBERTa)
Sentiment scores (positive, neutral, negative) and sub-tagging (service, delivery, product quality)
Topic modeling to identify emerging concerns
3. Categorization & Tagging
Entity recognition (locations, product names, service mentions)
Keyword extraction for trend tracking
Complaint type detection (delay, quality, attitude, etc.)
4. Insights Dashboard Integration
Custom Power BI & Tableau dashboards
Location, time, sentiment, and keyword filters
Export-ready CSV/JSON options for internal analysts
Results & Competitive Insights

DataZivot's solution produced measurable results within the first month:
These improvements gave the enterprise:
Faster product feedback loops
Better pricing and menu optimization for restaurants
Localized insights for store/service operations
Proactive risk mitigation (e.g., before issues trended on social media)
Want to See the Dashboard in Action?
Book a demo or download a Sample Reviews Dataset to experience the power of our sentiment engine firsthand.
Contact Us Today!
Dashboard Highlights

The custom dashboard provided by DataZivot enabled:
Review Sentiment Dashboard featuring sentiment trend graphs (daily, weekly, monthly)
Top Keywords by Sentiment Type ("slow service", "friendly staff")
Geo Heatmaps showing regional sentiment fluctuations
Comparative Brand Insights (across subsidiaries or competitors)
Dynamic Filters by platform, region, product, date, language
Tools & Tech Stack

To deliver the solution at scale, we utilized:
Scraping Frameworks: Scrapy, Selenium, BeautifulSoup
NLP Libraries: spaCy, TextBlob, Hugging Face Transformers (BERT, RoBERTa)
Cloud Infrastructure: AWS Lambda, S3, EC2, Azure Functions
Dashboards & BI: Power BI, Tableau, Looker
Languages Used: Python, SQL, JavaScript (for dashboard custom scripts)
Strategic Outcome

By leveraging DataZivot’s NLP infrastructure, the enterprise achieved:
Centralized CX Intelligence: CX leaders could make decisions based on real-time, data-backed feedback
Cross-Industry Alignment: Insights across retail, hospitality, and tech units led to unified improvement strategies
Brand Perception Tracking: Marketing teams tracked emotional tone over time and correlated with ad campaigns
Revenue Impact: A/B-tested updates (product tweaks, price changes) showed double-digit improvements in review sentiment and NPS
Conclusion
This case study proves that large-scale review analytics is not only possible — it’s essential for modern enterprises managing multiple consumer-facing touchpoints. DataZivot’s approach to scalable NLP and real-time sentiment tracking empowered the client to proactively manage their brand reputation, uncover hidden customer insights, and drive growth across verticals.
If your organization is facing similar challenges with fragmented review data, inconsistent feedback visibility, or a slow response to customer sentiment — DataZivot’s sentiment intelligence platform is your solution.
#NLPSentimentAnalysis#CrossPlatformReviewData#SentimentAnalysisAPI#BrandReputationManagement#ReviewMonitoringTool#IntelligentReviewScraping#ReviewSentimentDashboard#RealTimeSentimentTracking#ReviewAnalytics
0 notes
Text
Scrape Google Maps Popular Times for Vietnam Restaurants

How Can You Scrape Google Maps Popular Times for Vietnam Restaurants to Optimize Operations?
Introduction
Google Maps is an essential business tool that provides insights into customer behaviors, foot traffic, and peak hours. Its most useful feature, Popular Times, offers real-time and historical information about when restaurants are most busy. Restaurant owners, food delivery chains, and market research firms can find the Scrape Google Maps Popular Times for Vietnam Restaurants capability to provide them with a competitive edge.
With this information, companies can Extract Restaurant Peak Hours Data from Google Maps in Vietnam to make better staffing decisions, enhance customer satisfaction, and improve delivery speed. Companies can also Scrape Real-Time Restaurant Traffic Insights in Vietnam to enhance marketing and operations.
However, scraping this information poses technical and ethical issues. To comply, it's important to use best practices and legal standards. This article discusses the significance, difficulty, applications, and ethics of extracting Google Maps Popular Times information in Vietnam's culinary sector.
Importance of Scraping Google Maps Popular Times Data

Scraping Google Maps Popular Times data is pivotal for businesses aiming for data-informed insights about customer foot traffic, busy times, and trends in the marketplace. It allows restaurants, delivery restaurants, and stores to improve operations, augment customer experience, and make more effective strategic choices to grow.
1. Optimizing Business Operations: Vietnam's restaurant industry is dynamic and highly competitive, with a diverse range of eateries, from local street food stalls to high-end fine dining establishments. Understanding customer foot traffic trends can significantly impact business success. Scraping Google Maps Peak Hours for Restaurants in Vietnam enables restaurant owners to analyze footfall patterns and make data-driven decisions. By leveraging this data, they can:
Identify peak and off-peak hours to allocate staff more efficiently, ensuring smooth service.
Plan inventory purchases based on high-traffic periods to reduce food waste and maximize profits.
Improve marketing strategies by offering promotions or targeted ads during slower hours to attract more customers.
2. Enhancing Customer Experience: Long wait times can negatively impact customer satisfaction and deter potential diners. Web Scraping Restaurant Popular Times Data in Vietnam allows restaurants to improve customer experiences by:
Informing patrons about estimated wait times, helping them plan their visits better.
Offering discounts, special deals, or happy-hour promotions during non-peak hours to boost sales.
Adjust seating arrangements and enhance service speed by predicting footfall trends and optimizing workflows.
3. Empowering Food Delivery and Logistics Services: Vietnam's food delivery sector, dominated by platforms like GrabFood, Baemin, and ShopeeFood, has revolutionized the dining experience. These platforms require accurate data to streamline their logistics. Web Scraping Food Delivery Data can help these services:
Optimize delivery times by identifying peak traffic hours and reducing delays.
Assign delivery riders efficiently to balance demand and minimize idle time.
Predict busy periods, allowing food delivery apps to adjust their resources and provide faster order processing.
4. Market Research and Competitor Analysis: Expanding restaurant chains or launching new dining ventures requires thorough market research. By using Restaurant Menu Data Scraping , businesses can extract pricing, menu trends, and competitor offerings. Food Delivery Scraping API Services also help analyze restaurant demand across different locations. This data-driven approach allows businesses to:
Identify high-footfall areas for new restaurant openings, ensuring strategic placement.
Assess competitor performance by evaluating peak hours and customer traffic trends.
Adjust pricing strategies based on real-time demand fluctuations, maximizing profitability.
By leveraging Google Maps data through advanced scraping techniques, restaurants and food delivery businesses in Vietnam can enhance operational efficiency, improve customer experience, and gain a competitive edge in the industry.
Unlock valuable insights with our cutting-edge scraping services—boost efficiency, optimize operations, and stay ahead of the competition today!
Contact us today!
Challenges in Scraping Google Maps Popular Times Data

While scraping Google Maps Popular Times data is valuable, it comes with several challenges:
1. Technical Barriers
Google Maps does not provide a direct API for Popular Times, requiring advanced web scraping techniques.
Data is embedded dynamically, making extracting using traditional scraping methods challenging.
JavaScript rendering is needed to access live Popular Times data.
2. Legal and Ethical Considerations
Scraping data from Google Maps can violate its Terms of Service, leading to potential legal consequences.
Ethical concerns arise when using data without permission, especially for commercial purposes.
Alternative solutions, such as Google Places API (limited in functionality), should be considered to ensure compliance.
3. Data Accuracy and Real-Time Updates
Google Maps updates Popular Times in real-time based on location data and user activity.
Inaccurate scraping methods may lead to outdated or incorrect information.
Aggregating data over time requires robust storage and processing solutions.
Use Cases of Google Maps Popular Times Data for Vietnam Restaurants

Google Maps Popular Times data provides valuable insights into Vietnam's restaurant industry, helping businesses optimize operations and improve customer experiences. By analyzing peak hours and foot traffic patterns, restaurants can enhance staffing, streamline food delivery logistics, and refine marketing strategies. This data is essential for market research, competitor analysis, and making informed restaurant expansion and pricing decisions.
Restaurant Chains and Franchises
Large restaurant chains and franchises in Vietnam rely on data-driven strategies to maintain efficiency and profitability across multiple locations. By utilizing Restaurant Data Intelligence Services, businesses can extract and analyze Google Maps Popular Times data to:
Optimize staffing schedules based on peak and off-peak hours, ensuring smooth service and reducing labor costs.
Identify underperforming branches and implement operational improvements, such as menu changes or better marketing strategies.
Determine the most promising locations for launching new outlets by assessing foot traffic trends and customer behavior.
Integrate insights into a Food Price Dashboard to monitor revenue patterns and adjust pricing dynamically for maximum profitability.
Local Food Vendors and Street Food Businesses
Vietnam's vibrant street food culture attracts both locals and tourists. Small food vendors and mobile food stalls can leverage Food Delivery Intelligence Services to make data-driven business decisions. Popular Times data helps vendors:
Adjust selling hours by identifying peak demand times, ensuring maximum visibility and sales.
Target specific customer segments more effectively by understanding foot traffic trends in different areas.
Identify prime locations for setting up food stalls during peak hours, enhancing exposure and profitability.
Optimize ingredient sourcing and pricing strategies using insights from a Food Price Dashboard, keeping costs competitive while maintaining profitability.
Tourism and Hospitality Industry
Vietnam's booming tourism industry creates a high demand for dining recommendations. Travel agencies, hotels, and tour operators can use Food Delivery Datasets to enhance guest experiences by:
Recommending the best dining times to tourists, helping them avoid long wait times.
Planning guided food tours that align with real-time foot traffic data, ensuring seamless experiences.
Partnering with restaurants to offer exclusive discounts during off-peak hours, driving more traffic during slower periods.
Analyzing visitor dining trends to tailor hotel dining options and local food recommendations.
Investors and Real Estate Developers
Investors and real estate developers looking to enter Vietnam's restaurant industry must consider location viability. By leveraging Restaurant Data Intelligence Services , they can gain valuable insights from Google Maps Popular Times data to:
Evaluate the feasibility of restaurant locations before purchasing or leasing properties.
Understand the correlation between foot traffic trends and rental prices, making informed investment decisions.
Assess market demand for different restaurant types and concepts, increasing the chances of business success.
Predict future property value fluctuations based on restaurant traffic trends and commercial activity.
By incorporating Google Maps Popular Times data into their decision-making, businesses in Vietnam's restaurant sector can optimize operations, enhance customer experiences, and gain a competitive edge.
Future Trends and Innovations

1. AI-Powered Analytics for Demand Prediction
Machine learning models can enhance Popular Times data analysis by predicting future trends. AI algorithms can:
Forecast customer flow based on historical data.
Suggest the best operational strategies for restaurant owners.
Automate pricing adjustments based on peak and off-peak hours.
2. Integration with Smart Restaurant Management Systems
Modern POS (Point of Sale) systems can integrate Popular Times data to:
Provide real-time demand insights.
Automate inventory management based on footfall trends.
Improve customer engagement through data-driven marketing campaigns.
3. Collaboration Between Food Delivery Platforms and Restaurants
As food delivery services grow in Vietnam, platforms like GrabFood and ShopeeFood can:
Use Google Maps Popular Times to optimize restaurant listings.
Implement AI-driven demand predictions for efficient food delivery management.
Develop surge pricing models to balance supply and demand.
How Food Data Scrape Can Help You?
Real-Time Data Extraction – Our advanced scraping technology provides up-to-date insights, allowing businesses to monitor foot traffic trends, peak hours, and customer behavior for smarter decision-making.
Customized Data Solutions – We offer tailored scraping solutions to extract relevant data, including restaurant traffic insights, food delivery trends, and competitor analysis, ensuring you get actionable intelligence.
Scalability and Automation – Our high-performance scraping services can handle large-scale data extraction across multiple locations, automating the process for seamless and efficient data collection.
Compliance and Data Security – We prioritize ethical scraping practices, ensuring compliance with legal regulations while safeguarding your business data and maintaining confidentiality.
Integration with Business Intelligence Tools – Our scraped data can be easily integrated into dashboards, analytics platforms, and decision-making tools, enhancing your ability to optimize operations and boost profitability.
Conclusion
Extracting available and unavailable food items from USA stores is vital for retailers, suppliers, e-commerce businesses, and consumers. The insights gained from this data enable better inventory management, improved customer experience, and optimized supply chains. As data extraction technologies evolve, businesses harnessing this information effectively will gain a competitive edge in the ever-changing food industry. By leveraging food availability data, companies can ensure smoother operations, better decision-making, and enhanced market positioning in the grocery and food retail sector.
If you are seeking for a reliable data scraping services, Food Data Scrape is at your service. We hold prominence in Food Data Aggregator and Mobile Restaurant App Scraping with impeccable data analysis for strategic decision-making.
Source>> https://www.fooddatascrape.com/scrape-google-maps-popular-times-vietnam-restaurants.php
#ScrapeGoogleMapsPopularTimesforVietnamRestaurants#ExtractRestaurantPeakHoursDatafromGoogleMapsinVietnam#ScrapeRealTimeRestaurantTrafficInsightsinVietnam#ScrapingGoogleMapsPeakHoursforRestaurantsinVietnam#WebScrapingRestaurantPopularTimesDatainVietnam
0 notes