#how to do google map scraping
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs



happyrakshabandhanrakhiwishes
happy raksha bandhan rakhi wishes with name and photo download
2 posts


Fun Fact
Tumblr has been banned in Indonesia for providing people with access to pornographic content.
Text

#google maps#google marketing agency#google map scraping#google map scraping tool#google map scraping free#google map scraping python#google map scraping make.com#google map scraping using python#google map scraping in urdu#how to do google map scraping#google map data scraping#cara scraping data google map#google map scraping fiverr#google map scraping github#google map scraping extension#google map scraping meaning#google map web scraping
0 notes
Text
diy ao3 wrapped: how to get your data!
so i figured out how to do this last year, and spotify wrapped season got me thinking about it again. a couple people in discord asked how to do it so i figured i'd write up a little guide! i'm not quite done with mine for this year yet because i wanted to do some graphics, but this is the post i made last year, for reference!
this got long! i tried to go into as much detail as possible to make it as easy as possible, but i am a web developer, so if there's anything i didn't explain enough (or if you have any other questions) don't hesitate to send me an ask!!
references
i used two reddit posts as references for this:
basic instructions (explains the browser extension; code gets title, word count, and author)
expanded instructions (code gets title, word count, and author, as well as category, date posted, last visited, warnings, rating, fandom, relationship, summary, and completion status, and includes instructions for how to include tags and switch fandoms/relationships to multiple—i will include notes on that later)
both use the extension webscraper.io which is available for both firefox and chrome (and maybe others, but i only use firefox/chrome personally so i didn't check any others, sorry. firefox is better anyway)
scraping your basic/expanded data
first, install the webscraper plugin/extension.
once it's installed, press ctrl+shift+i on pc or cmd+option+i on mac to open your browser's dev tools and navigate to the Web Scraper tab

from there, click "Create New Site Map" > "Import Sitemap"

it will open a screen with a field to input json code and a field for name—you don't need to manually input the name, it will fill in automatically based on the json you paste in. if you want to change it after, changing one will change the other.
i've put the codes i used on pastebin here: basic // expanded

once you've pasted in your code, you will want to update the USERNAME (highlighted in yellow) to your ao3 username, and the LASTPAGE (highlighted in pink) to the last page you want to scrape. to find this, go to your history page on ao3, and click back until you find your first fic of 2024! make sure you go by the "last visited" date instead of the post date.

if you do want to change the id, you can update the value (highlighted in blue) and it will automatically update the sitemap name field, or vice versa. everything else can be left as is.
once you're done, click import, and it'll show you the sitemap. on the top bar, click the middle tab, "Sitemap [id of sitemap]" and choose Scrape. you'll see a couple of options—the defaults worked fine for me, but you can mess with them if you need to. as far as i understand it, it just sets how much time it takes to scrape each page so ao3 doesn't think it's getting attacked by a bot. now click "start scraping"!


once you've done that, it will pop up with a new window which will load your history. let it do its thing. it will start on the last page and work its way back to the first, so depending on how many pages you have, it could take a while. i have 134 pages and it took about 10-12 minutes to get through them all.
once the scrape is done, the new window will close and you should be back at your dev tools window. you can click on the "Sitemap [id of sitemap]" tab again and choose Export data.

i downloaded the data as .xlsx and uploaded to my google drive. and now you can close your dev tools window!
from here on out my instructions are for google sheets; i'm sure most of the queries and calculations will be similar in other programs, but i don't really know excel or numbers, sorry!
setting up your spreadsheet
once it's opened, the first thing i do is sort the "viewed" column A -> Z and get rid of the rows for any deleted works. they don't have any data so no need to keep them. next, i select the columns for "web-scraper-order" and "web-scraper-start-url" (highlighted in pink) and delete them; they're just default data added by the scraper and we don't need them, so it tidies it up a little.

this should leave you with category, posted, viewed, warning, rating, fandom, relationship, title, author, wordcount, and completion status if you used the expanded code. if there are any of these you don't want, you can go ahead and delete those columns also!
next, i add blank columns to the right of the data i want to focus on. this just makes it easier to do my counts later. in my case these will be rating, fandom, relationship, author, and completion status.
one additional thing you should do, is checking the "viewed" column. you'll notice that it looks like this:
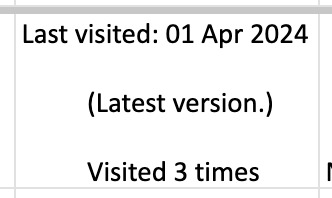
you can't really sort by this since it's text, not formatted as a date, so it'll go alphabetically by month rather than sorting by date. but, you'll want to be able to get rid of any entries that were viewed in 2023 (there could be none, but likely there are some because the scraper got everything on your last page even if it was viewed in 2023). what i did here was use the "find" dialog to search the "viewed" column for 2023, and deleted those rows manually.
ctrl/cmd+f, click the 3 dots for "more options". you want to choose "Specific range", then "C2:C#". replace C with the letter of your viewed column (remember i deleted a bunch, so yours may be different) and replace # with the number of the last row of your spreadsheet. then find 2023, select the rows containing it, right click > delete rows.
it isn't super necessary to do this, it will only add at most 19 fics to your count, but the option is there!

alright, with all that done, your sheet should look something like this:

exposing myself for having read stardew valley fic i guess
now for the fun part!!!
the math
yes, the math is the fun part.
scroll all the way down to the bottom of your sheet. i usually add 100 blank rows at the bottom just so i have some space to play with.
most of these will basically be the same query, just updating for the relevant column. i've put it in a pastebin here, but here's a screenshot so i can walk you through it:

you'll want to use lines 3-10, select the cell you want to put your data into, and paste the query into the formula bar (highlighted in green)

so, we're starting with rating, which is column E for me. if yours is a different letter you'll need to replace all the E's with the relevant letter.
what this does is it goes through the entire column, starting with row 2 (highlighted in yellow) and ending with your final row (highlighted in blue, you'll want to change this number to reflect how many rows you have). note that row 2 is your first actual data row, because of the header row.
it checks each row that has a value (line 5), groups by unique value (row 6), and arranges in descending order (row 7) by how many there are of each value (row 8). finally, row 10 determines how many rows of results you'll have; for rating, i put 5 because that's how many ratings there are, but you can increase the number of results (highlighted in pink) for other columns depending on how many you want. this is why i added the 100 extra rows!
next to make the actual number visible, go to the cell one column over. this is why we added the empty columns! next to your first result, add the second query from the pastebin:

your first and second cell numbers (highlighted in yellow and blue) should match the numbers from your query above, and the third number (highlighted in pink) should be the number of the cell with your first value. what this does is go through your column and count how many times the value occurs.
repeat this for the rest of the rows and you should end up with something like this! don't judge me and my reading habits please

now you can go ahead and repeat for the rest of your columns! as i mentioned above, you can increase the amount of result rows you get; i set it to 25 for fandom, relationship, and author, just because i was curious, and only two for completion status because it's either complete or not complete.
you should end up with something like this!

you may end up with some multiples (not sure why this happens, tagging issues maybe?) and up to you if you want to manually fix them! i just ended up doing a find and replace for the two that i didn't want and replaced with the correct tag.
now for the total wordcount! this one is pretty simple, it just adds together your entire column. first i selected the column (N for me) and went to Format > Number > 0 so it stripped commas etc. then at the bottom of the column, add the third query from the pastebin. as usual, your first number is the first data row, and the second is the last data row.

and just because i was curious, i wanted the average wordcount also, so in another cell i did this (fourth query from the pastebin), where the first number is the cell where your total is, and the second number is the total number of fics (total # of data rows minus 1 for the header row).

which gives me this:

tadaaaa!
getting multiple values
so, as i mentioned above, by default the scraper will only get the first value for relationships and fandoms. "but sarah," you may say, "what if i want an accurate breakdown of ALL the fandoms and relationships if there's multiples?"
here's the problem with that: if you want to be able to query and count them properly, each fandom or relationship needs to be its own row, which would skew all the other data. for me personally, it didn't bother me too much; i don't read a lot of crossovers, and typically if i'm reading a fic it's for the primary pairing, so i think the counts (for me) are pretty accurate. if you want to get multiples, i would suggest doing a secondary scrape to get those values separately.
if you want to edit the scrape to get multiples, navigate to one of your history pages (preferably one that has at least one work with multiple fandoms and/or relationships so you can preview) then hit ctrl+shift+i/cmd+option+i, open web scraper, and open your sitemap. expand the row and you should see all your values. find the one you want to edit and hit the "edit" button (highlighted in pink)

on the next screen, you should be good to just check the "Multiple" checkbox (highlighted in pink):

you can then hit "data preview" (highlighted in blue) to get a preview which should show you all the relationships on the page (which is why i said to find a page that has the multiples you are looking for, so you can confirm).

voila! now you can go back to the sitemap and scrape as before.
getting tag data
now, on the vein of multiples, i also wanted to get my most-read tags.
as i mentioned above, if you want to get ALL the tags, it'll skew the regular count data, so i did the tags in a completely separate query, which only grabs the viewed date and the tags. that code is here. you just want to repeat the scraping steps using that as a sitemap. save and open that spreadsheet.
the first thing you'll notice is that this one is a LOT bigger. for context i had 2649 fics in the first spreadsheet; the tags spreadsheet had 31,874 rows.
you can go ahead and repeat a couple of the same steps from before: remove the extra scraper data columns, and then we included the "viewed" column for the same reason as before, to remove any entries from 2023.
then you're just using the same basic query again!
replace the E with whatever your column letter is, and then change your limit to however many tags you want to see. i changed the limit to 50, again just for curiosity.
if you made it this far, congratulations! now that you have all that info, you can do whatever you want with it!
and again, if you have any questions please reach out!
55 notes
·
View notes
Text

West African Chicken and Peanut Soup (Mali)
We're kicking off Soupquest 2025 in a big way by going straight for the unfamiliar: a delightful, creamy, sweet/savory tomato and peanut butter-based soup that originated in Mali but which is common in many countries in Africa, though this one is probably closer to the Ghana-tradition, as it's much soupier.
For those worried about the spice level, this soup uses 1 whole scotch bonnet, cut in half and then cooked in the soup for a time before removing the pepper itself. I was unable to find scotch bonnet peppers, so used habanero instead, and I opted to leave the pepper in for the entirety to give it a bit more kick, since a single habanero does not a spicy dish make. I'm happy to report that this does not at all register as spicy to me, only pleasantly warm, the peanut butter occupying the same niche as cream or cheese would.
This soup is delicious. The way it's often intended to be eaten is with fufu, a side dish made with pounded cassava root and plantains; I wasn't able to find cassava, but rice is perfectly acceptable to serve this over, turning it into something like a curry. It's sweet but not sugary, nutty, creamy, savory, warming but not spicy, and I can see how the fufu would be helpful because I was scraping my bowl for every last bit.
I used this recipe from Delish (presented here via wayback machine). Substitutions I made were as follows:
Subbed 1 habanero for 1 scotch bonnet pepper
Subbed 6 tbsp tomato sauce (reduced) for 2 tbsp tomato paste (I forgot to get the paste okay it's fine)
Added some baby spinach for color
You can make this with canned tomatoes if you'd like. Everything kind of breaks down into a delightful sauce in the end. I recommend using a natural or no-added-sugar-organic peanut butter to keep the soup from being too sweet; I used Jif's natural peanut butter and it was probably still on the sweeter side, but still delicious.
The last thing that you can do differently is use bone-in chicken thighs. Sear them as normal, trim as much meat off the bone as you can, and then put the bones back into the soup while it's cooking down. You can fish the bones out when it's done and easily shred whatever meat is remaining off the bone, and you get a bit of added chicken-y oomph to your soup.
For those who want to preview the soups I have collected (both from the wonderful suggestions here on tumblr, as well as through much googling), you can check out my Soup Map here.
36 notes
·
View notes
Text
Behind Wolfer: Ride the Paiute Pass Trail with Tom & Hermione
This post is dedicated to @nofear-x who is ten seconds from jumping onto a chestnut quarter horse (packed with snobby cheese and 10 pounds of bacon) and galloping into the mountains with me.

To write Tom and Hermione's sexy, mariticide-themed honeymoon in the High Sierras, I used a combo of trail guides and Google Earth to pick the most likely path the newlywed Riddles would have taken to get their cows into the mountains.
Wilderness cattle grazing was common during the warmer months, and some ranchers still do it, calving in the valleys during January-February, then running their cattle up the trail into the grassy highlands all summer. In the fall, they round up their cows and drive them into the valley again.
A common path into the backcountry would be the current HWY 168 leading from Bishop up into what is now Aspendell. This green, pretty valley would be an ideal spot for Tom to test out Hermione's bearings in chapter 11, in an area wooded enough to be private but far enough from Bishop so nobody would see what cosmic hell Hermione might call down.

I made this map to show where they went once they saddled up. It would be roughly 6-ish miles to get from the east end of the drainage, up through North Lake and to Loch Leven, where the lovebirds go for a swim in chapter 12.
In chapter 13 they'll make their way over Paiute Pass and into Humphrey's Basin. The whole thing is about 12 miles, which doesn't seem that long, but you gain over 4,000 feet of elevation, bringing you to a cloud-scraping height of 12,000 feet.
This is a strenuous hike, and if you're lucky enough to ride, you might take that steep of a pitch at 2-3 miles per hour. Now, the real-life pack outfitters that go from North Lake to Humphrey's Basin aren't clear online about how long that takes, so I'll guess two and a half days since our kids are running cattle and boning at every stop.
Hop over to Google Earth, and you can actually click on photos that will take you into a "street view" of the Paiute Pass Trail, so you can almost ride it yourself.
Here's a picture of what it looks like when you've activated street view mode. Click the little yellow Tom Riddle.

Tell me if you click through and see these sights!
As always, thank you for reading.
#wolfer#tomione#hermione x tom#hermione/tom#tom riddle#hermione granger#tom marvolo riddle#tom riddle fanfiction#hermione granger fanfiction
12 notes
·
View notes
Text
WTYP: The Shandor Building, Part 1 [take 2, the long post vs Tumblr's formatting]
[Do you like the colour of the fanfic? This is long and if you expand it you're gonna get the whole thing, because Tumblr hates you. Don't say I didn't warn you!]

[Beware of strong language, mention of all kinds of death, gore, and Lovecraftian horror.]
Part 1: Hello and Welcome to Shandor Studios (it's weird)
[TRANSCRIBER'S NOTE: The moon was waning and a raven was tapping on my window when I discovered a heretofore unknown tier at the WTYP Patreon page. It was called "Pazuzu" and cost $6.66 USD. It had one listed benefit "bonus bonus episode." I unlocked a single unnumbered bonus episode titled "Ibo Shanor" and subtitled "train bad actually." Judging from the dialogue, it dates to summer 2023. Since it lacked any closed-captioning, I took the liberty of transcribing it, and coping most of the slides for your edification. (Not really, this is a work of fiction.) I have styled Ms. Caldwell-Kelly as "Alice" since she still seems to be using that in podcast land at this time. Please support WTYP!]

[SLIDE: Shandor Studios, an art deco style building with some familiar-looking gargoyles perched on it, and poor JPEG compression, with an inset of the Stay-Puft Marshmallow Man. Captioned: Will the Real Ivo Shandor Please Stand Up?]
JUSTIN ROCZNIAK (R): Hello, and welcome to Well There’s Your Problem, a podcast about engineering disasters with…
LIAM ANDERSON (L) [chanting]: Studio! Studio! Studio!
R: …with slides.
L: Studio! Suck it, Discord!
ALICE CALDWELL-KELLY (A): It’s quite nice, actually. There’s a little break room, and somebody left us one of those edible arrangements, and a paperback Necronomicon…
DEVON (D) [text over slide]: IT WAS ACTUALLY VERY NICE. I HAD MY OWN CONTROL ROOM. BUT IT WAS NOT WORTH IT.
L [distorted, too close to the mic]: My audio sounds amazing! This bonus episode is about Liam’s cool mic!
A [obligingly]: Yay, Liam’s cool mic.
R: It’s made of meat, though.
L: What, my cool mic?
R: No, the edible arrangement in the break room. They’re usually made of fruit, this one is made of meat. Raw meat.
A: Yes, I was wondering if that was an American thing. [laughter] I’ve never been to Massachusetts before!
L: It’s Innsmouth, Alice. Nobody’s ever been to Innsmouth. It doesn’t technically exist.
R: It’s not even on Google Maps.
A: Is it sort of a, er, township? Unincorporated township?
R: It’s more of a, uh, cult.
A: Like an MLM?
L: Like Christianity!
R: Well, a bunch of fish people founded it in the late eighteen hundreds…
L: Fucking fish.
R: …and let’s say they got up to some questionable activities.
A: Anything I should be worried about?
R: Well…
A: I did travel here by interdimensional portal and that’s just a bit… off-putting? It’s very convenient, but…
L: Swimming, having gills…
R: I took the train.
L: Just breathe air, you little shits!
A: Did they not offer you an interdimensional portal, then?
R: No, they did, I just said I’d rather take the train.
A: How was it?
R: Not bad. It was made of meat, though. The train. Smooth ride. Turns out meat is an excellent shock absorber, just not very practical. There was a flock of ravens trying to eat us the whole way.
A: That’s… a bit odd.
L: Brian Phelps.
R: Brian Phelps is made of meat?
L: No, Brian Phelps is a fucking fish. [shouting, too close to mic again] You’re not fooling anyone, Brian! God, I could go for some salami. Is there any salami in the meat bouquet?
R: There is definitely not any salami in the meat bouquet.
L: I’m gonna make myself a sandwich!
[scraping sound, footsteps, door opens and closes]
A: It’s nice having a studio, though.
R: It’s not bad. I like these chairs with the wheels. Good lumbar support. How was the portal?
A: Terrifying, but brief. Very brief. It materialised right under me in the dairy aisle of Tesco’s, then I was in this howling green tunnel for about five seconds, and then I was here. On the one hand, I didn’t have to show my passport or go through security, but on the other hand, I’m just slightly concerned I might have cancer. Or a prion disease. [nervous laugh] Or maybe I’ll turn into a fish person. Did you mean literal fish people?
R: Yes.
A: I suppose… Someone got very lonely and fucked a fish, or…?
R: Yes.
A: What? Are you being serious? What kind of a fish… Do you mean mermaids?
R: No. In fact, mermaids have a notorious design flaw when it comes to sexual congress with us human types. What you’re after, as a lonely sailor, is an animal known as the “reverse-mermaid,” which is widely regarded as a joke, and depicted as the head and torso of a fish, with human legs, and presumably genitalia, underneath… [drawing a reverse-mermaid on the slide, with the mouse, badly] But which is in fact more of an elder god by the name of Dagon, which does indeed have legs and genitalia, but is more of a fully-anthropomorphic monstrous fish. [drawing monstrous legs and feet] He’s a bit larger and taller. Here, I’ll put a “D” for Dagon. [draws arrow] And the rest of him is up there.

A: As a lonely sailor myself, I don’t see how something like that is any more fuckable than a regular fish. Or a manatee. Frankly, I’d rather fuck a manatee. At least it’s a mammal.
R: Yeah, but you’d be violating the Endangered Species Act.
A [laughing]: I’m sorry, aren’t they endangered? We want them to fuck! You told me to save the manatees, well I’m out there doing it! And then I’m going to save the whales!
R: Debatable whether creating a race of half-human, half-manatee hybrids is saving the species…
A: Are you some kind of fucking manatee eugenicist? If the manatee and I are both consenting adults, and we fancy each other, then leave us the fuck alone! This is how evolution works!
R: In the mind of Donald Trump, yes.
[door opening and closing]
D [text over slide]: I COULD EDIT THAT OUT BUT I’M TOO TRAUMATISED AND DRUNK.
L: You guys… Is that supposed to be a fucking fish?
R: No. It’s the legendary reverse-mermaid.
L: Well, I only respect half of it! Here. The meat bouquet started screaming when I cut into it, so I grabbed some doughnuts.
A: Oh, are there doughnuts? The meat bouquet has a way of…
L: You didn’t hear it?
R: The meat bouquet?
A: …of arresting one’s attention…
L [excited]: The soundproofing in here is fucking incredible!
D [text over slide]: IN RETROSPECT, THAT SHOULD HAVE BEEN A RED FLAG.
A: Out of sheer, morbid curiosity, did the doughnut scream?
L: Doughnuts don’t scream.
R: Do the doughnuts scream in… in the UK?
A: …No, not usually. Perhaps, perhaps on the continent, but not usually in Britain. They’re very stuffy and well-behaved.
L: And transphobic.
A: Of course.
L: Do you want one of these?
A: Er, I rather think… I’d better not eat or drink anything until another portal opens up and sends me home. Just in case this is a Persephone sort of situation…
R: Probably a good idea.
L: Low blood sugar kills, Alice. [muffled, chewing]
R: You’ll wind up married to Hades and having to spend six months out of the year in Massachusetts.
L: I’m spending twelve months out of the year in this studio, I don’t care if it’s in Massachusetts. If I have to, I will marry Hades twice.
R: Nah, you see, that’s not legal in Massachusetts. You’d be in a bigamous relationship with yourself.
L: Well, then one of you has to do it. Daddy needs his new mic. These chairs are awesome too!
[rumbling, squeaking]
A: I’m already in a very committed relationship with the Mothman, actually. We go around collapsing bridges and making appearances just out of camera frame. It’s quite fun.
R: Alice is actually a cryptid wanted across several New England states.
A: Yes, I’d like very much to get back to it, and not get cancer or die! [nervous laughter] Ah, shall we get on with the episode?
L: I’m never leaving this studio. You will pry this microphone from my cold, dead hand.
A: Intros? Did we do intros?
R: It’s a bonus episode, they already know us.
D [text over slide]: HONESTLY IF WE’D JUST DONE THE INTROS, IT WOULD’VE SAVED US A LOT OF TROUBLE.
A: Right…
R: But we do have [news drop] the God Damn News.
Part 2 will be another post, give me a minute and I'll link it...
#wtyp#well there's your problem#ghostbusters#long reads#fanfic#fanfiction#crossover fic#gozer the gozerian#alice caldwell-kelly#liam anderson#justin roczniak#devon#engineering disasters#podcast
44 notes
·
View notes
Text
Battle of the Fear Bands!
B6R2: The Eye
Research Me Obsessively:
“Rebecca and Valencia spend 3 days internet stalking their mutual ex-boyfriend's new girlfriend. The song goes both into the creepy lengths one can go to in order to gain access to this sort of information while joking about how this search for information is unhealthy and detrimental to those embarking upon it.”
youtube
Knowledge:
“Narrator seeks knowledge without caring about the cost or consequences. As quintessentially Eye as you can get”
youtube
Lyrics below the line!
Research Me Obsessively:
Hey, what are you doing for the next thirteen hours?
Don't do anything healthy. Don't be productive. Give in to your desire.
Research me obsessively
Uh-huh!
Find out everything you can about me You know you want to dig for me relentlessly
Uh-huh!
Using every available search tool and all forms of social media
You know you want to look at my Instagram but it's private so Google me until you find out where I went to high school and then set up a fake Instagram account using the name and the photo of someone that went to my high school and hope that I remember that person a little bit
Then request access to my private Instagram from the fake account and in the meantime scour my work Instagram account cause that one's public.
Research me obsessively
Uh-huh!
Find an actual picture of my parents' house on Google Maps You know you want to hunt for me tirelessly
Uh-huh!
It's not stalking 'cause the information is all technically public
Check out every guy I used to date
And deduce who broke up with who based on the hesitation in our smiles
So many unanswered questions.
Did I go to the University of Texas?
Am I an EMT?
Is that my obituary in which I'm survived by my loving husband of 50 years; children Susan and Mathew and grandchild Stephanie?
Wait no. That's just all the people with my same name.
Or is it?
Pay only 9.99 on a background check web site to know for sure.
So don't stop, just research me obsessively
Uh-huh!
and in lieu of flowers donate to other me's favorite charity
Research me just research me and research me and research me
Oops.
It's three days later.
Knowledge:
I can scrape off of my face All the soot from all the places I have been to And call it knowledge I can stitch and rip the gash That was a scar until I scratched and reinvoked it And call it knowledge And I won't complain about the blisters on my heel That we've surrendered to the real Or the feral dogs who feed on knowledge
I'm a statue of a man who looks nothing like a man But here I stand Grim and solid No scarlet secret's mine to hold Just a century of cold and thin and useless Sexless knowledge So I won't complain when my shattering is dreamt By the ninety-nine percent I'll surrender to their knowledge
'Cause I have read the terms and conditions I have read the terms and conditions Let the record show I agree to my position I accept the terms and conditions
Well I woke up this morning and saw the pitchforks at my door Said I woke up this morning—it was dark still—and there were pitchforks at my door And they were shining with a righteousness no knowledge ever shone before
I have read the terms and conditions I have read the terms and conditions I have read the terms and conditions I have read the terms and conditions
Next time let's get raised by wolves Next time let's get raised by wolves Next time let's get raised by wolves Next time let's get raised by wolves Next time let's get raised by wolves Next time let's get raised by wolves
3 notes
·
View notes
Text

I am, as usual, late lol, but Y'KNOW. This is gonna be a long, rambly post lol, sorry, I have a lot of thoughts.
2023 was a weird year for me, artwise. When it began I was still deep in my Art Block From Hell, which had begun in mid-2021 and lasted the entirety of 2022.
Being in the thick of such a ridiculously suffocating art block, for TWO AND A HALF YEARS, is like... I can't describe how fucking life-draining it is. It felt like something was fundamentally wrong with me -- like a part of me, which used to be as effortless as breathing or blinking my eyes, had ceased to function altogether. It wasn't just a regular art block, it was a complete identity crisis. I could no longer trust the instincts I'd honed over twenty-plus years, could no longer trust my sense of observation or my ability to recreate what I saw. I felt BROKEN, and every single time I picked up my tablet pen it was like I was scraping my insides with a spoon, trying to pick up whatever tiny dregs of dried-up, crusty shit I could manage to puke up onto my canvas. It was fucking painful and humiliating and completely demoralizing.
I'm not really sure what finally got me to do so, but sometime in summer (my memory is shit lol) I downloaded Game Maker, found a video tutorial on youtube, and just... gave myself over to it. I made myself learn how to use Aseprite, and working with pixels, making teeny-tiny little sprites, forced me to work in ways I usually don't. It was a lot harder for me to find the flaws in my art when my art was thirty-five pixels tall and the anatomy was stylized to communicate clear information rather than be a recreation or approximation of reality. I think I really do credit that time working on game dev as the thing that finally cracked loose all the gunk that was keeping me stuck -- I could not perpetuate the cycle of toxicity I'd fallen into because I could barely even conceptualize what 'good' or 'bad' pixel art even looked like lol. I just knew that I was making art, and for the first time in two years, it didn't feel like I was having to desperately beg the emaciated husks of my sense of self-worth and confidence to cooperate while doing so.
(I actually sort of abandoned my foray into game dev around August/September lol, as my adhd-brain, flitting around like a little hummingbird to every dopamine-rich-flower, is wont to do 🥲 But I wanna get back into it at some point!)
From there I had a rush of inspiration for an original project I've been mulling around in my head for years, and I wrote thousands of words in my worldbuilding document, made a map, developed the shell of a possible actual STORY. I returned to sketching. Conventional sketching. It was, at first, largely still comprised of that same demotivating struggle against myself, but I was so deep in the throes of inspiration (after several years of this project laying dormant in my google drive) that I NEEDED to sketch. So I kept going. And after a while, it got....... easier. And I started hating everything I made a little less. I painted, properly, for the first time in years. I stayed up late into the night, even if it meant I would be tired at work the next day, because drawing felt so damn GOOD again and I had missed that feeling so much. All I wanted to do was draw. For the first time in two and a half years, I could finally see the light at the end of the fucking tunnel.
I still don't think I'm quite out of the woods yet. My style is changing, as all artists' styles do over time, and that comes with stumbling adjustments. My confidence is still small and shaky and recovering; I still catch myself second-guessing what I've drawn, and even looking at some of the things here on my grid makes me cringe a little bit for one reason or another.
But compared to both 2021 and 2022, the volume of art, and in particular the volume of art I don't actively despise, is WAY higher, and I'm really really hopeful that that means I'm finding my footing again.
So! Here's to 2024, and to continuing to move towards the light at the end of the tunnel 🙏�� I'm gonna try.
#art vs artist#art vs artist 2023#my art#skella's ugly mug#I actually did an art vs artist in 2021 but I only ever posted it on facebook lol I wasn't confident enough to post it anywhere else#purple and orange/yellow continues to be my favorite color pallet apparently#sorry not sorry for being sappy on my own blog <3333#long post
15 notes
·
View notes
Text
Catching A Ghost | Simon 'GHOST' Riley
Ghost x Reader
CHAPTER TWO

Simon 'GHOST' Riley x AFAB!Reader!OC 18+ MINORS DNI! t.w // angst, mental health, language, violence, death, sexual themes/SMUT, military inaccuracies, language inaccuracies (google translate).
Catching A Ghost: Masterlist
It didn't take long to catch the team up to speed.
Despite having worked on the team for months, Hassan was incredibly careful, and you and your old team had barely scraped enough information for a folder.
Leaning over the map on the table, you placed tokens, pinpointing the locations of various gangs, possible hideouts, and anything else you knew of.
"This is quite the intel, (Y/N), I'm proud of you." Price said, and you smiled widely.
"Unfortunately, it's all we were able to get before (Y/N) and her team were, uh, compromised." Laswell said.
Eyes flicked back to you as you shifted uncomfortably, looking down at your hands.
"You all need to get a good night's rest; everyone needs to scrub up on their training before we try to take Hassan." Laswell spoke again, clearly picking up on the tension from you.
Everyone nodded, collecting their various belongings scattered around the room, and then made their way out. Price stayed behind with Laswell, the latter telling you to go ahead to your room, where your things were waiting for you.
"Know where you're goin', sweet cheeks?" Alex said, approaching you.
"Not a clue." You laughed.
"C'mon. I'll show you to the house."
Smiling, he threw an arm around your shoulder, yours latching around his waist, and he led you toward the door.
You stopped abruptly before moving outside, pulling your mask out of your pocket.
"You don't have to wear that 'round here, you know." Alex said, watching you place the mask on your face.
"You never know who's watching, Al. Can't afford to take that chance. It was bad enough that you and John are together, never mind that we're all now on the same task force." You shrugged.
He gave you a sympathetic look, knowing where you were coming from.
He sometimes wished he'd taken a leaf out of your book, especially after meeting Ghost too. The two of you were pretty similar when it came to your identity.
Nodding to you, you continued to walk out of the door just in front of Alex, when you went crashing into something big, and hard.
You gasped as you stumbled, hands gripping at the first thing they could hold to stop your fall, which just so happened to be Ghost's hoodie, now bunched into your fists. It appeared he also wanted you to avoid ending up on the floor, as you felt his gloved fingers digging into your hips, holding you flush against him.
You slowly looked up to meet his gaze.
Christ, how tall was he?
"Fuck- s-sorry, my bad." You mumbled out, still tight against his chest.
He held your eyes for a moment, and then let go, pushing you to arm's length, "Watch where ya goin', next time." He growled.
"Right, yeah. Sorry."
Ghost looked behind you, glaring at Alex before continuing back into the room. You frowned, but your face was hot.
Thank God for the mask, because without it, everyone would have seen how madly you were blushing.
It was him that smelled like gunpowder and...
Sauvage?
"Is he always like that?" you said, following Alex out into the night.
"Yup, that's Ghost for you. Never seen him do that, though."
"What?"
"Well first, the complete evil eyes he gave me, and second, Ghost doesn't touch people. Like, ever."
You furrowed your brows, but decided not to question further, honestly too tired to give a fuck.
It had been a long day and frankly you just wanted a bed.
"And here is your room, m'lady." Alex said, dramatically bowing as he opened your door.
Giggling, you entered, and did a small gleeful jiggle when you saw that Laswell had had someone make up your bed.
Thank God.
"This good enough for you, angel?" Alex said, leaning against the doorframe.
"It's perfect." you said, flopping down onto the bed.
Tapping the space next to you, you nodded to Alex, who smiled, moving over to lie down at your side, facing you.
"How's the leg?" you whispered.
"It's good, stop worrying about it."
"I won't stop, Al, I almost lost you. We all thought you'd died in Barkov's lab-"
"But I didn't, did I?" he smiled, rolling to his side. "Hmm? Did I?"
"No, you didn't."
"So I'm fine, (Y/N), okay?"
"Okay."
The two of you lay in each other's arms, mostly just enjoying each other's silent presence after not seeing each other for months, until the voices of the others pulled you back to reality.
"Well, that's my cue to hit the hay." he said, standing up and pulling you with him.
He opened your door, stepping out into the hallway as you followed, trudging slowly after him.
"I missed you, so much." you sighed, wrapping your arms around his middle.
"I missed you too, angel."
You squeezed him tighter, pushing your face into his chest.
"Hey- hey, (Y/N), what's goin' on?"
"I just...never mind. It's fine." you sniffed, pulling away. "I'm fine."
"You promise?" he said, looking down to you.
"I promise."
Boots thudding on the stairs interrupted your conversation as Ghost and Price emerged, stopping in their tracks as if they'd interrupted a moment.
"Yikes, well...I'll see you tomorrow, yeah?" Alex said, letting you go.
"Of course, g'night."
He placed a kiss to your forehead, before skipping down the hall, nodding to Ghost and Price as he passed. You turned to them, feigning a smile.
"Not sure I liked seeing a guy come out of your room in the night, (Y/N)." Price said.
"Oh give over, John. I'm a big girl." you rolled your eyes, laughing.
Ghost said nothing.
He just stood, staring from you, to Alex's door, and back to you. When he did move, he moved to stand in front of the door next to yours.
That was his room.
"Goodnight, Captain, L.T." you said, nodding to each of them before turning back into your room, shutting the door softly.
Quickly stripping off your clothes and into some shorts and a tank, you slipped under the covers, gun gripped tightly in your hand underneath the pillow.
You woke up before anyone else.
It was a shared house, a lot bigger inside that it looked. Everyone had their own room. Granted, they were pretty small, but it was better than the other shitty bases you'd stayed at.
The walls were relatively thin, and you smiled to yourself as you heard Price snoring away from three rooms down.
Ghost, in the room next to you, though, was as silent as a mouse.
You hadn't heard a peep all night. In fact, you couldn't quite decide whether he was actually in there.
Springing out of bed, you threw on a faded black army hoodie, stretched from years of it being your comfort clothing.
Padding to the bathroom, you brushed your teeth and washed your face, tossing your hair up roughly. You were thankful for your expert training, because now you were able to move around almost silently, so you didn't have to worry too much about waking the others.
Stopping back at your room to slip on some headphones for music, you skipped downstairs and into the large kitchen.
It was nice; beautiful counters, top of the range ovens and hobs, and a huge fridge-freezer.
It was stocked with all things necessary for a big breakfast, so you quickly got to work cooking up omelettes, bacon, and other things for the boys to enjoy.
Cooking, you moved your hips gracefully, nodding your head along to the music flowing in your ears. Despite being in such an environment, you felt a sense of normalcy, and it was comforting.
"So ya gonna get in the way of my mornin's, too?" a voice came from behind you, making you jump and spin around, hand over your heart.
"Jesus, fuck- Ghost!" you said, pulling the headphones down as you came face to face with the masked man. "Don't scare me like that."
"Maybe you should be more aware of your surroundings."
"I'm at home, cooking breakfast," you quipped, raising an eyebrow, "what exactly do I need to be aware of?"
"Well, ya didn't hear me, could've easily come up and killed ya right there."
"But you didn't."
"Not the point. I could've." He grumbled.
"But you didn't." Your eyes twinkled with amusement, messing with him was a little more fun than you'd expected, "And how exactly am I getting in the way of your mornings?"
"In my way. I'm usually the only one up at this time."
"Yeah well, me too." You shrugged turning back to finish cooking.
By then, you heard the stirring of the others, laughing as you heard that unmissable Scottish accent exclaim about smelling food.
Rolling his eyes, Ghost pushed past you toward the back door, "Goin' for a run."
"Don't you wanna eat first?" you said, a little confused.
You didn't get chance to hear his answer, though, as the men children of the 141 came bustling down, practically shoving each other out of the way to be the first through the doorway. You giggled, telling them to calm down, and handed each of them a plate you'd put together.
Everyone ate in silence, except for the content noises they made as they shovelled in your delicious breakfast.
If you did say so yourself, it was damn good.
A flash of black caught your attention outside as you saw Ghost returning. You perked up, for some reason, ready to greet him, but he just mumbled a hello to the others and rushed upstairs.
"He not eating with us?" you questioned.
"Nah-" Soap said, mouth full of eggs, "he doesn't much. Keeps to himself, but I think he's warming up to us."
"He should eat." You whispered and put together a plate.
The boys took no notice as you excused yourself for a moment, taking the plate upstairs. You stopped outside the bathroom, hearing the shower run, so you opted to leave the plate on the floor outside of his room.
You were about to do so, but noticed that the door was slightly ajar. With curiosity getting the better of you, you pushed open the door a little more, and peered in.
Christ, and people thought you were neat.
Everything was completely spotless and crisp. There was no question that this was the room of a hardened military man.
"What the fuck are you doing?" Ghost said, now behind you.
You gasped, turning quickly to face him.
His eyes were hard and angry. Water still glistened down his body. His mask was still on, but only a towel hung loosely around his waist.
Low on his waist, fuck.
"I-I, uh sorry I was just bringing you, uh..."
Completely flustered, words failed you, so you opted to just shove the plate of lukewarm food into his face.
He glanced at it, then back at you, nodding a little as he took it from you silently.
"Mind your business, Reaper." He said, and with that, he pushed into his room, closing the door.
"A thank you would have sufficed." You mumbled to yourself.
Shaking yourself out of the trance you had now found yourself in, you moved back to the kitchen.
Price opened his arms for you as you re-emerged, squeezing you softly as he placed a chaste kiss to your forehead.
"Mornin' L.T." Soap greeted you, smiling sweetly.
"Morning, L.T." Alex mocked him, earning a swift thump to the arm from Soap.
"Good morning, Soap." You smiled back, "I trust your breakfast was up to standard?"
"Bloody beautiful, love."
The others murmured in agreement, happy to have been fed well. You moved from Price's arms to start gathering the empty dishes, preparing to wash up.
"Glad you're 'ere (Y/N), I was getting pretty sick of Alejandro's shitty cooking." Your brother said.
"Ay! There is nothing wrong with my cooking, pendejo."
"Like hell there isn't, Ale. Not everything has to be so spicy!" Alex spoke up.
"Spicy? That's nothing!"
That was it, then.
The boys fell into a full-blown argument over who had the worst cooking skills. It was honestly laughable that this was supposed to be the deadliest task force in the world.
No one dared tangle with the 141, unless they had spices for ammo, clearly.
You giggled, washing up happily as they continued to argue, but that soon quietened down with the sound of boots thumping on the stairs.
Sure enough, a now-fully dressed Ghost came into the kitchen, placing his empty plate next to you.
No words were shared, but you liked to think he was grateful.
He stepped back, moving to lean against the counter in the corner of the room. His eyes burned into your skin as he watched you clean up, and you suddenly came aware of how little you were wearing.
"So, (Y/N), why don't you tell us a little more about yourself?" Soap asked, a flirty tone in his voice.
"Well, what would you like to know, sergeant?" You smiled, leaning onto the island counter, mug of tea in hand.
"Might as well get the elephant in the room out the way first...you single?"
"Behave, Johnny." Price said, glaring at the younger sergeant.
You laughed at your brother's protectiveness, smirking, "As a matter of fact, I am."
"You are?" Practically every mouth in the room said.
"...yes? Why is that such a shock?"
"Because...you're like, super-hot." Soap said, and this time, Price smacked him up the back of the head.
"Oh, thank you." You blushed, looking down at your mug, "I've not been single for long, though. I was engaged before. Called it off about two months ago."
"What did he do, (Y/N)?" Price grunted, fists balling at his sides, "I'll kill him."
"It's a long story, not really one I'd like to get into right now." You said through gritted teeth, hopeful that he'd get the message and drop it.
"What do you like to do for fun?" Alejandro asked, clearly sensing the tension in the room.
"I like reading, drawing, I'm a sucker for some video games too."
As you reeled off your interests and other little trivia about yourself, the boys hung on to every word.
Price had held them all back in the kitchen when you'd disappeared before, telling them things that had them feeling sympathy for you, and so they vowed to make as much of an effort as possible to make you feel at home in the group.
Whatever they were doing, it was working. It was only your first official day, and already you felt like part of the family.
#simon ghost riley#simon riley#task force 141#ghost mw2#ghost cod#ghost fanart#call of duty#cod mw oc#cod mw2#cod mwf2#callofduty#gaming#cod mw19#captain price#john mactavish
14 notes
·
View notes
Text
What happened to the cycle of renewal? Where are the regular, controlled burns?
Like the California settlers who subjugated the First Nations people and declared war on good fire, the finance sector conquered the tech sector.
It started in the 1980s, the era of personal computers — and Reaganomics. A new economic and legal orthodoxy took hold, one that celebrated monopolies as “efficient,” and counseled governments to nurture and protect corporations as they grew both too big to fail, and too big to jail.
For 40 years, we’ve been steadily reducing antitrust enforcement. That means a company like Google can create a single great product (a search engine) and use investors’ cash to buy a mobile stack, a video stack, an ad stack, a server-management stack, a collaboration stack, a maps and navigation stack — all while repeatedly failing to succeed with any of its in-house products.
It’s hard to appreciate just how many companies tech giants buy. Apple buys other companies more often than you buy groceries.
These giants buy out their rivals specifically to make sure you can’t leave their walled gardens. As Mark Zuckerberg says, “It is better to buy than to compete,” (which is why Zuckerberg bought Instagram, telling his CFO that it was imperative that they do the deal because Facebook users preferred Insta to FB, and were defecting in droves).
As these companies “merge to monopoly,” they are able to capture their regulators, ensuring that the law doesn’t interfere with their plans for literal world domination.
When a sector consists of just a handful of companies, it becomes cozy enough to agree on — and win — its lobbying priorities. That’s why America doesn’t have a federal privacy law. It’s why employees can be misclassified as “gig worker” contractors and denied basic labor protections.
It’s why companies can literally lock you out of your home — and your digital life — by terminating your access to your phone, your cloud, your apps, your thermostat, your door-locks, your family photos, and your tax records, with no appeal — not even the right to sue.
But regulatory capture isn’t merely about ensuring that tech companies can do whatever they want to you. Tech companies are even more concerned with criminalizing the things you want to do to them.
Frank Wilhoit described conservativism as “exactly one proposition”:
There must be in-groups whom the law protects but does not bind, alongside out-groups whom the law binds but does not protect.
This is likewise the project of corporatism. Tech platforms are urgently committed to ensuring that they can do anything they want on their platforms — and they’re even more dedicated to the proposition that you must not do anything they don’t want on their platforms.
They can lock you in. You can’t unlock yourself. Facebook attained network-effects growth by giving its users bots that logged into Myspace on their behalf, scraped the contents of their inboxes for the messages from the friends they left behind, and plunked them in their Facebook inboxes.
Facebook then sued a company that did the same thing to Facebook, who wanted to make it as easy for Facebook users to leave Facebook as it had been to get started there.
Apple reverse-engineered Microsoft’s crown jewels — the Office file-formats that kept users locked to its operating systems — so it could clone them and let users change OSes.
Try to do that today — say, to make a runtime so you can use your iOS apps and media on an Android device or a non-Apple desktop — and Apple will reduce you to radioactive rubble.
Big Tech has a million knobs on the back-end that they can endlessly twiddle to keep you locked in — and, just as importantly, they have convinced governments to ban any kind of twiddling back.
This is “felony contempt of business model.”
Governments hold back from passing and enforcing laws that limit the tech giants in the name of nurturing their “efficiency.”
But when states act to prevent new companies — or users, or co-ops, or nonprofits — from making it easier to leave the platforms, they do so in the name of protecting us.
Rather than passing a privacy law that would let them punish Meta, Apple, Google, Oracle, Microsoft and other spying companies, they ban scraping and reverse-engineering because someone might violate the privacy of the users of those platforms.
But a privacy law would control both scrapers and silos, banning tech giants from spying on their users, and banning startups and upstarts from spying on those users, too.
Rather than breaking up ad-tech, banning surveillance ads, and opening up app stores, which would make tech platforms stop stealing money from media companies through ad-fraud, price-gouging and deceptive practices, governments introduce laws requiring tech companies to share (some of) their ill-gotten profits with a few news companies.
This makes the news companies partners with the tech giants, rather than adversaries holding them to account, and makes the news into cheerleaders for massive tech profits, so long as they get their share. Rather than making it easier for the news to declare independence from Big Tech, we are fusing them forever.
We could make it easy for users to leave a tech platform where they are subject to abuse and harassment — but instead, governments pursue policies that require platforms to surveil and control their users in the name of protecting them from each other.
We could make it easy for users to leave a tech platform where their voices are algorithmically silenced, but instead we get laws requiring platforms to somehow “balance” different points of view.
The platforms aren’t merely combustible, they’re always on fire. Once you trap hundreds of millions — or billions — of people inside a walled fortress, where warlords who preside over have unlimited power over their captives, and those captives the are denied any right to liberate themselves, enshittification will surely and inevitably follow.
Laws that block us seizing the means of computation and moving away from Big Tech are like the heroic measures that governments undertake to keep people safe in the smouldering wildland-urban interface.
These measures prop up the lie that we can perfect the tech companies, so they will be suited to eternal rule.
Rather than building more fire debt, we should be making it easy for people to relocate away from the danger so we can have that long-overdue, “good fire” to burn away the rotten giants that have blotted out the sun.
What would that look like?
Well, this week’s news was all about Threads, Meta’s awful Twitter replacement devoted to “brand-safe vaporposting,” where the news and controversy are not welcome, and the experience is “like watching a Powerpoint from the Brand Research team where they tell you that Pop Tarts is crushing it on social.”
Threads may be a vacuous “Twitter alternative you would order from Brookstone,” but it commanded a lot of news, because it experienced massive growth in just hours. “Two million signups in the first two hours” and “30 million signups in the first morning.”
That growth was network-effects driven. Specifically, Meta made it possible for you to automatically carry over your list of followed Instagram accounts to Threads.
Meta was able to do this because it owns both Threads and Instagram. But Meta does not own the list of people you trust and enjoy enough to follow.
That’s yours.
Your relationships belong to you. You should be able to bring them from one service to another.
Take Mastodon. One of the most common complaints about Mastodon is that it’s hard to know whom to follow there. But as a technical matter, it’s easy: you should just follow the people you used to follow on Twitter —either because they’re on Mastodon, too, or because there’s a way to use Mastodon to read their Twitter posts.
Indeed, this is already built into Mastodon. With one click, you can export the list of everyone you follow, and everyone who follows you. Then you can switch Mastodon servers, upload that file, and automatically re-establish all those relationships.
That means that if the person who runs your server decides to shut it down, or if the server ends up being run by a maniac who hates you and delights in your torment, you don’t have to petition a public prosecutor or an elected lawmaker or a regulator to make them behave better.
You can just leave.
Meta claims that Threads will someday join the “Fediverse” (the collection of apps built on top of ActivityPub, the standard that powers Mastodon).
Rather than passing laws requiring Threads to prioritize news content, or to limit the kinds of ads the platform accepts, we could order it to turn on this Fediverse gateway and operate it such that any Threads user can leave, join any other Fediverse server, and continue to see posts from the people they follow, and who will also continue to see their posts.
youtube
Rather than devoting all our energy to keep Meta’s empire of oily rags from burning, we could devote ourselves to evacuating the burn zone.
This is the thing the platforms fear the most. They know that network effects gave them explosive growth, and they know that tech’s low switching costs will enable implosive contraction.
The thing is, network effects are a double-edged sword. People join a service to be with the people they care about. But when the people they care about start to leave, everyone rushes for the exits. Here’s danah boyd, describing the last days of Myspace:
If a central node in a network disappeared and went somewhere else (like from MySpace to Facebook), that person could pull some portion of their connections with them to a new site. However, if the accounts on the site that drew emotional intensity stopped doing so, people stopped engaging as much. Watching Friendster come undone, I started to think that the fading of emotionally sticky nodes was even more problematic than the disappearance of segments of the graph. With MySpace, I was trying to identify the point where I thought the site was going to unravel. When I started seeing the disappearance of emotionally sticky nodes, I reached out to members of the MySpace team to share my concerns and they told me that their numbers looked fine. Active uniques were high, the amount of time people spent on the site was continuing to grow, and new accounts were being created at a rate faster than accounts were being closed. I shook my head; I didn’t think that was enough. A few months later, the site started to unravel.
Tech bosses know the only thing protecting them from sudden platform collapse syndrome are the laws that have been passed to stave off the inevitable fire.
They know that platforms implode “slowly, then all at once.”
They know that if we weren’t holding each other hostage, we’d all leave in a heartbeat.
But anything that can’t go on forever will eventually stop. Suppressing good fire doesn’t mean “no fires,” it means wildfires. It’s time to declare fire debt bankruptcy. It’s time to admit we can’t make these combustible, tinder-heavy forests safe.
It’s time to start moving people out of the danger zone.
It’s time to let the platforms burn.
2 notes
·
View notes
Text
The New Search Era: AI Prioritises Data, Not Destination
Here’s what no one tells you about the future of search: it’s no longer about sending traffic to your website. It’s about serving answers directly before a user ever clicks. Google’s AI Overviews are making that reality loud and clear.
If you’ve noticed your organic clicks dropping, your carefully crafted blog content being skimmed past, or your product pages buried under zero-click results, you’re not alone.
The game has changed. And in this new AI-first landscape, the brands that win are the ones who show up with data, not fluff. Insights, not intros. Clarity, not clutter.
Let’s break down what’s really happening and what smart B2B startups need to do about it.
Forget Rankings. Focus on Responses.
Traditional SEO taught us to chase traffic. Rank high, get the clicks, nurture the lead. Simple, right?
But AI Overviews? They’re flipping that logic.
Search engines are no longer prioritising where to send users. Instead, they’re trying to eliminate the need for a click at all.
Google’s AI now scrapes and compiles information from multiple sources to deliver “answers” directly on the results page. And while that might be great for users, for brands it means one thing:
If your content isn’t structured to feed the AI’s understanding, you’re invisible.
Your Website Isn’t the Destination, Your Data Is.
If you’re still writing content to “rank for keywords,” it’s time to recalibrate.
AI is no longer ranking pages based on old-school SEO metrics. It’s evaluating how well your content answers intent-rich queries, fits schema markup, and integrates into knowledge graphs.
In other words, AI isn’t looking for pretty blog posts. It’s looking for credible data.
That means your marketing team needs to start thinking like a product team:
What structured content can we surface?
Are we using a schema to tag it?
Can our data be easily parsed and pulled into AI summaries?
Because in this world, being source material beats being page one.
The Rise of the “Answer Engine”
Let’s call this what it is: we’ve entered the Answer Engine era.
And your goal isn’t just visibility anymore, it’s extractability. If AI can’t easily extract meaning from your site, you don’t get featured. Period.
That’s where Answer Engine Optimization (AEO) comes in. It’s not just the evolution of SEO. It’s what connects your brand to the way search works now.
AEO helps you:
Make your site machine-readable
Align content to high-intent search patterns
Build topic authority across your niche
Show up in AI Overviews and voice search queries
So, What Should You Be Doing Now?
If you’re a startup with limited marketing resources, here’s the real talk:
You don’t need more content. You need better signals.
That means: ✔ Structuring your existing content with schema ✔ Prioritising entity mapping and topic clusters ✔ Using clear, concise language that aligns with user intent ✔ Thinking beyond blogs — Use case pages, product documentation, FAQs, and glossaries all matter
This is the kind of strategy you won’t get from a junior marketer or your old SEO playbook.
AI’s Not the Enemy. But It’s Not Waiting for You
Most bootstrapped founders I talk to are still wondering why their content isn’t performing. The truth?
You’re not behind because your product isn’t good. You’re behind because your data isn’t optimised for the new rules of search.
This isn’t just a content shift. It’s a mindset shift.
And if your internal team isn’t set up to think strategically about AEO, structured content, and AI-readiness, then it’s time to bring in leadership that can.
Final Thoughts: Don’t Just Show Up — Be Found
We’re moving into a world where search engines don’t just recommend. They respond. And the brands that get seen will be the ones built for extraction, not just exploration.
If you’re ready to align your SEO and marketing with where search is going, not where it’s been. AEO isn’t optional. It’s urgent.
Need Help Becoming AI-Search Ready?
At JJ Creative Media Co., we help B2B startups and lean tech teams rethink their SEO from the ground up, through structured strategy, smart content, and executive-level marketing leadership.
Want to check if your site is AEO-ready?
[Download the 7-Point AEO Readiness Checklist] (gated asset CTA) Or let’s talk about how a Fractional CMO can help realign your marketing for the AI era.
Contact me at JJ Creative Media Co.
1 note
·
View note
Text
How Can I Use Programmatic SEO to Launch a Niche Content Site?
Launching a niche content site can be both exciting and rewarding—especially when it's done with a smart strategy like programmatic SEO. Whether you're targeting a hyper-specific audience or aiming to dominate long-tail keywords, programmatic SEO can give you an edge by scaling your content without sacrificing quality. If you're looking to build a site that ranks fast and drives passive traffic, this is a strategy worth exploring. And if you're unsure where to start, a professional SEO agency Markham can help bring your vision to life.
What Is Programmatic SEO?
Programmatic SEO involves using automated tools and data to create large volumes of optimized pages—typically targeting long-tail keyword variations. Instead of manually writing each piece of content, programmatic SEO leverages templates, databases, and keyword patterns to scale content creation efficiently.
For example, a niche site about hiking trails might use programmatic SEO to create individual pages for every trail in Canada, each optimized for keywords like “best trail in [location]” or “hiking tips for [terrain].”
Steps to Launch a Niche Site Using Programmatic SEO
1. Identify Your Niche and Content Angle
Choose a niche that:
Has clear search demand
Allows for structured data (e.g., locations, products, how-to guides)
Has low to medium competition
Examples: electric bike comparisons, gluten-free restaurants by city, AI tools for writers.
2. Build a Keyword Dataset
Use SEO tools (like Ahrefs, Semrush, or Google Keyword Planner) to extract long-tail keyword variations. Focus on "X in Y" or "best [type] for [audience]" formats. If you're working with an SEO agency Markham, they can help with in-depth keyword clustering and search intent mapping.
3. Create Content Templates
Build templates that can dynamically populate content with variables like location, product type, or use case. A content template typically includes:
Intro paragraph
Keyword-rich headers
Dynamic tables or comparisons
FAQs
Internal links to related pages
4. Source and Structure Your Data
Use public datasets, APIs, or custom scraping to populate your content. Clean, accurate data is the backbone of programmatic SEO.
5. Automate Page Generation
Use platforms like Webflow (with CMS collections), WordPress (with custom post types), or even a headless CMS like Strapi to automate publishing. If you’re unsure about implementation, a skilled SEO agency Markham can develop a custom solution that integrates data, content, and SEO seamlessly.
6. Optimize for On-Page SEO
Every programmatically created page should include:
Title tags and meta descriptions with dynamic variables
Clean URL structures (e.g., /tools-for-freelancers/)
Internal linking between related pages
Schema markup (FAQ, Review, Product)
7. Track, Test, and Improve
Once live, monitor your pages via Google Search Console. Use A/B testing to refine titles, layouts, and content. Focus on improving pages with impressions but low click-through rates (CTR).
Why Work with an SEO Agency Markham?
Executing programmatic SEO at scale requires a mix of SEO strategy, web development, content structuring, and data management. A professional SEO agency Markham brings all these capabilities together, helping you:
Build a robust keyword strategy
Design efficient, scalable page templates
Ensure proper indexing and crawlability
Avoid duplication and thin content penalties
With local expertise and technical know-how, they help you launch faster, rank better, and grow sustainably.
Final Thoughts
Programmatic SEO is a powerful method to launch and scale a niche content site—if you do it right. By combining automation with strategic keyword targeting, you can dominate long-tail search and generate massive organic traffic. To streamline the process and avoid costly mistakes, partner with an experienced SEO agency Markham that understands both the technical and content sides of SEO.
Ready to build your niche empire? Programmatic SEO could be your best-kept secret to success
0 notes
Text
How to Scrape Google Reviews: A Complete Guide with Expert Data Scraping Services
In a world where customer feedback shapes business success, Google reviews have emerged as one of the most powerful tools for brands to understand public sentiment. These reviews are more than just star ratings—they're a direct window into customer experiences and expectations. Whether you're managing a small local store or a multinational company, analyzing Google reviews can offer valuable insights.
But manually collecting and analyzing thousands of reviews is time-consuming and inefficient. This is where data scraping services come into play. By automating the process, businesses can gather and analyze reviews at scale, making informed decisions more quickly and accurately.

In this blog, we’ll explore what Google reviews are, why they matter, and how to scrape them effectively.
What Are Google Reviews and Why Do They Matter?
Google reviews are customer-generated feedback and star ratings that appear on a business's Google profile. These reviews are visible on Google Search and Google Maps, influencing how people perceive and choose your business. Positive reviews can enhance your credibility and attract more customers, while negative ones can provide critical feedback for improvement. Google also considers these reviews in its search algorithm, making them essential for local SEO. In short, Google reviews are not just opinions; they’re public endorsements or warnings that impact your brand’s reputation, discoverability, and success. From a business perspective, understanding and leveraging this data is essential. Reviews highlight customer satisfaction, reveal service gaps, and offer a competitive edge by shedding light on what people love (or dislike) about your competitors.
Step-by-Step Guide: How to Scrape Google Reviews
Scraping Google reviews may sound technical, but with the right strategy and tools, it becomes a streamlined process. Below is a simple guide to help you get started.
Step 1: Identify the Google Place ID or Business URL
The first step in scraping reviews is locating the business’s unique identifier on Google. This could be the full URL from Google Maps or the Place ID provided through Google’s developer tools. This ensures your scraper targets the correct business location.
Step 2: Use the Google Places API (If You Only Need Limited Data)
Google provides an official API that allows access to a limited number of reviews (typically the latest five). You’ll need to set up a project in Google Cloud Console and request data using your API key. While this method is compliant with Google’s terms, it has significant limitations if you need historical or bulk data.
Step 3: Build or Use a Scraper for Larger Datasets
If your goal is to analyze a large volume of reviews over time, you’ll need more than what the API offers. This is where custom-built scrapers or third-party scraping platforms come in. Tools like BeautifulSoup, Scrapy, or Selenium can help automate the process, though they require technical expertise. Alternatively, you can partner with experts like TagX, who offer scalable and reliable data scraping services. Their solutions are built to handle dynamic content, pagination, and other complexities involved in scraping from platforms like Google
Step 4: Deal with Pagination and JavaScript Rendering
Google displays only a portion of reviews at a time and loads more as the user scrolls. A good scraper must simulate this behavior by managing pagination and rendering JavaScript content. This step ensures you don’t miss any data during the extraction process.
Step 5: Clean and Analyze Your Data
Once the reviews are scraped, they need to be cleaned and organized. You may need to remove HTML tags, eliminate duplicates, or normalize date formats. Structured data can then be analyzed using sentiment analysis tools or visualized using dashboards to uncover trends and insights.
Benefits of Using Data Scraping Services for Google Reviews
Manually collecting review data is inefficient and prone to errors. Professional data scraping services offer a range of benefits:
Accuracy: Eliminate human errors through automated, structured data collection
Scalability: Scrape thousands of reviews across multiple locations.
Speed: Collect and process data faster than manual methods
Customization: Filter and organize data based on your business needs
Compliance: Adhere to legal and ethical data collection standards
TagX, for example, provides customized scraping pipelines tailored to your business goals. Their platform supports large-scale review analysis, from raw data extraction to sentiment tagging and visualization.
Challenges of Scraping Google Reviews
Even with the right tools, scraping Google reviews isn’t always straightforward. Businesses may face challenges like CAPTCHAs, anti-bot mechanisms, and dynamically loaded content. Another common issue is inconsistent data formatting. Since users write reviews in different styles and languages, analyzing this data can be difficult. This is where web scraping using AI becomes incredibly valuable. AI-powered tools can adapt to different content layouts, recognize sentiment across languages, and even summarize or tag common themes across reviews.
Is It Legal to Scrape Google Reviews?
This question often arises, and the answer depends on how the data is collected and used. While Google’s terms of service typically prohibit automated scraping, the information being scraped—customer reviews—is public.If done ethically, without overloading Google’s servers or violating privacy, scraping public reviews is generally accepted for research and analysis. Still, it’s crucial to stay updated with legal best practices. Partnering with responsible providers like TagX ensures compliance and reduces risk.
Why Choose TagX for Google Review Scraping
When it comes to scraping sensitive and complex data like Google reviews, you need a partner you can trust. TagX brings deep expertise in building scalable, ethical, and AI-driven scraping solutions. They offer:
Smart scrapers that adapt to changes in Google’s layout
Scalable pipelines to collect millions of data points
NLP-powered sentiment analysis and keyword tagging
Complete compliance with data privacy regulations
Whether you're analyzing reviews to improve customer satisfaction or tracking competitor sentiment, TagX ensures you get actionable insights without the hassle.
Final Thoughts
Google reviews are a goldmine of customer insight, but manually managing and analyzing them is not practical at scale. By using expert data scraping services, businesses can unlock the full potential of this feedback to improve customer experience, drive product innovation, and strengthen their market presence. If you're ready to turn raw review data into strategic insights, consider partnering with TagX. Their blend of automation, AI, and compliance makes them ideal for scraping and analyzing Google reviews.
0 notes
Text
Why Travel Content Creators Should Join Platforms Like Cya On The Road in the Age of AI

In today's rapidly evolving digital landscape, artificial intelligence is transforming the way we consume content. From personalised recommendations to AI-generated summaries, readers can now access travel information faster and more efficiently than ever before. While this may seem like a positive development for audiences, it raises urgent concerns for travel content writers. How can they protect their work and continue to earn a living when AI tools can scrape, summarise and distribute their content — often without credit or compensation?
The AI Dilemma for Travel Writers
Travel content creators have traditionally relied on web traffic and advertising revenue to monetise their blogs. They invest time, effort and often money in visiting destinations, crafting compelling narratives and producing high-quality images and guides. However, as AI tools become more adept at crawling the web, these writers face a double-edged sword: greater reach, but fewer clicks and less time spent on their pages, resulting in reduced ad revenue.
While AI companies may argue that they do not 'steal' in the traditional sense, they actually reproduce the essence of your work, removing the incentive for readers to visit your site. Your meticulously crafted article on Sydney's hidden gems might be summarised in a ChatGPT response or an AI Overview on Google — accurate in terms of facts, but completely devoid of your unique storytelling, voice, branding, and most importantly, your monetisation model. Readers get the value without ever clicking through to your blog. It's a system that extracts content by design — without credit, compensation, or consent.
Time to Rethink the Model
If the open internet can no longer guarantee fair compensation, creators should explore alternatives. Platforms like Cya On The Road offer a promising solution.
Cya On The Road enables travel writers to upload their content as self-guided tours complete with audio narration, maps, images and curated stops. But here’s the key difference:
You Set the Price!
Readers pay to access your unique travel experience, just as they would for a guidebook or walking tour. You maintain control over your content and are compensated directly for its value.
Why Cya On The Road Makes Sense
Protect your work: Unlike blog posts, which can be scraped, tour content on platforms like Cya On The Road is packaged in a way that makes it less accessible to AI tools and bots.
Monetise intelligently: Rather than relying on ad clicks, you earn money from every access. There are no middlemen ad blockers or SEO roulette.
Reach engaged audiences: Users on Cya On The Road are actively looking for travel experiences, not just scrolling for inspiration. They’re more likely to pay for detailed, authentic and high-quality guides.
Stay ahead of the curve: As more creators seek sustainable income models in a post-AI landscape, getting in early gives you a head start in building your brand and loyal customer base.
Final thoughts
AI is a disruptor. Travel content creators can no longer rely solely on free access and advertising revenue to sustain their work. Platforms such as Cya On The Road offer a viable alternative, respecting creators, engaging travellers, and preserving the magic of storytelling.
So, if you’re a travel writer looking for a smarter way to share your passion and get paid for it, it might be time to pack up your blog and head to a new destination — one that pays.
See how creators are thriving: Top 10 Paid Tours of 2024
Explore. Create. Monetise.
Join Cya On The Road today.
0 notes
Text
Small Towns, Big Reach: How Local Search Hubs Are Powering Business Visibility Where It Matters Most

Local Discovery Is Changing Fast — And Small Towns Are Catching Up
Try this. You're driving through Kingman, Arizona. You’re low on gas and craving a good meal. Google shows you chains and ad-heavy results. But what about the local diner two blocks away that’s been feeding people for 40 years? Unless you know the name or stumble upon it, chances are—you’ll miss it.
That's the reality many small businesses face in rural communities. They’re there. They’re good. But they’re invisible to most people looking online. Search engines weren’t designed for close-knit, low-density towns. They’re built for global answers, not neighborhood insights.
This is where hyper-local platforms come in—and change everything.
Focused directories built for specific areas, like Mohave County, aren’t just filling a gap. They’re redefining what it means to find something nearby. Instead of battling irrelevant results or ads, users get clean, reliable info—hours of operation, contact details, maps, and reviews, all tailored to one region.
Want to see how that works in real-time? Just look at Local Businesses Kingman, AZ—you’ll find more than 10,000 local listings, 2,800+ business categories, and community-added reviews that actually tell you something useful. That’s not just convenience—it’s accuracy backed by local insight.
The growth of these platforms isn’t accidental. They meet real needs—both for locals trying to find trusted services, and for business owners trying to be seen by the very people they serve.
So how exactly do these hubs work better? Let’s look deeper.
Why Rural Business Listings Need Their Own Approach
Most big directories treat small towns as footnotes. Try searching for a plumber in Fort Mohave and you’ll likely get listings from another state—or dead links from businesses that shut down five years ago.
It happens because large search engines pull data from scattered sources. And in rural regions, that data is often:
Outdated
Generic
Or worse—missing entirely
On the flip side, hyper-local platforms take the time to gather verified info from local business owners. They aren’t guessing which categories apply. They’re not pulling hours from scraped data. They’re talking to the people behind the counters and toolsheds.
That leads to something critical: trust.
When people see that the info is coming from a local source—be it reviews, photos, or listings—they trust it more. It’s not about scale. It’s about accuracy and relevance.
That’s especially true in places where word-of-mouth still drives most decisions. A well-written audio review or a reliable phone number is far more valuable than another five-star chain review from a thousand miles away.
What Makes a Hyper-Local Directory Actually Useful
Not all platforms are created equal. Some copy-paste business names without context. Others overload users with ads and popups. A well-built local search hub needs a few critical features to truly help users—and businesses.
Here’s what separates effective directories from noise:
Verified listings: Business owners can update hours, add services, and correct mistakes instantly.
Category depth: Instead of just "restaurant," you’ll see “Mexican food,” “takeout,” or “pet-friendly dining.”
Location accuracy: Full addresses, working GPS links, and even neighborhood-level search.
Real reviews: Written by people who live or work nearby. Optional audio clips add context.
Mobile-ready design: Most people are on their phones. Clean UX matters—especially on the move.
By building around these features, regional directories create a better user experience that’s focused, fast, and reliable. You’re not scrolling through junk—you’re finding what matters, nearby.
How Local Businesses Win—Even Without Big Budgets
Here’s a hard truth: most small-town business owners don’t have time for SEO. They’re running the kitchen, fixing trucks, cutting hair, or managing stock. They’re not blogging weekly or worrying about Google’s next update.
That’s why a strong local directory acts like a digital storefront. Once listed, their business becomes visible to the people looking for exactly what they offer—without having to run paid ads or maintain a full website.
Let’s say someone needs an emergency locksmith at 11 p.m. on a weekend in Lake Havasu City. A good local platform doesn’t bury that service under ad-driven results—it puts them first, because they’re there, open, and local.
Benefits for small businesses include:
Increased foot traffic from locals and tourists alike
Fewer missed calls thanks to accurate contact info
Better reviews from users who actually visit
Stronger reputation by being listed alongside other trusted providers
In rural markets, these wins are huge. Being found by 50 more people a month can mean the difference between breaking even or growing.
Communities Grow Stronger When Businesses Are Visible
Local economies don’t grow because of massive corporations. They thrive because local people keep local businesses alive.
Search hubs built for specific counties or towns act like a digital town square. They give voice to the owners, space for feedback from real customers, and tools for users to support what’s nearby.
And when that ecosystem works? Everyone wins:
Residents save time and support their neighbors
Tourists find the places that make a town unique
Business owners get seen by real customers, not bots or irrelevant traffic
That’s not just helpful—it’s vital. Especially when rural communities are often underserved by national platforms and algorithms that don’t understand how they work.
The Bottom Line: Local Search Should Actually Feel Local
A good search shouldn’t feel like a chore. It should work—fast, clear, and tailored to where you are.
In counties like Mohave, with over 110 cities and towns, the role of local-first directories isn’t just helpful—it’s foundational. They fill a real gap. They create visibility where none existed. And they empower business owners without asking them to become tech experts.
So if you’re a small business owner in a place like Fort Mohave or a traveler passing through Kingman, remember this: the best results don’t always show up on page one of a giant search engine. Sometimes, they’re waiting in the right place—you just need to know where to look.
And the right place? It's usually built by someone local.
0 notes
Link
0 notes
Text
Games Production (Feb 12th)
An Overview
this week was surprisingly productive - I have been suffering from burnout recently, and have been taking it slow, but I have significantly improved the Workflow Toolkit website, fixed some significant bugs in all three projects, and added some functionality to QuickBlock.
Star In The Making
This project hasn't been progressed much, but I finally added an audio system that allows all songs to be listened to during playing.

the Audio Manager Singleton plays the menu song in the menu scene, and the array of Game Music in the game scene. I was thinking about randomising the songs (so there is no order) but felt that this was nicer, like you're listening to an EP while playing - However this is subject to change.
Workflow Toolkit - Project
firstly, Portuguese (EU) has been added to Workflow Toolkit - making it the fourth language in this project. The translations were made by my cousin (and I am very thankful)

I will have to get a few more translations done because I had changed some text around to make it more understandable, but this is incredibly easy to do.
Workflow Toolkit - Website
I have made some great strides with the website, making documentation easier to understand as it is separated clearly and looks professional.
Firstly, I have now added a footer to the website that points to Chomp Games' (a studio I am planning to make) Social Medias (where in my marketing plan, I am posting weekly updates & information on the project)

The buttons from left to right are Instagram, BlueSky and YouTube.
I have also been working on the website's documentation page - currently just improving the UI and layout behind it, with plans to add more in depth documentation (like a record of functions, localisation language trackers and more)


I have also redesigned the dropdowns that explain what the project do, and it looks and feels nicer.

in comparison with the old website, here are some images:




in terms of the website, some other enhancements include Embeds and web scraping/crawling improvements:
Here's the embed:

to make this work, I added OpenGraph meta tags to each file (so I could make a different embed for each page)

To improve web scraping and crawling, I added two files to the root of the website; SiteMap.xml and Robots.txt - SiteMap.xml tells search engines the important pages to cache. Due to how small the website is, I have told it to cache all pages.
Robots.txt tells web scrapers if they are welcome to scrape this website (although they do not have to adhere to this)

I have disabled scraping for all robots apart from Google's Scraper and Archive.org's scraper - I have a soft spot for everything related to archiving, and hence have allowed it through.
Googlebot has been allowed to enable it to get a high up link for SEO purposes.
I added a very slight overlay to the background of all pages (barring documentation.html) to make the website feel more lively. Here's a comparison:

I then added a 404 error page incase somebody goes to the wrong page, it'll display that (instead of the default github pages one). The animation is 20 seconds long, so I have shown a sped up one below:
I also refactored the whole website because of internal frustration - it fixed some annoyances (but do not harm the website) like all spaces in download links being replaced by "%20".
QuickBlock
I refactored the asset loading of this project to be much more efficient, fixed some critical bugs in Grid Snapping, imported all of the assets that were made for me and worked on transformations of the placed assets:

These shapes allow you to fully customise your map (and more will be added!)

Firstly, I fixed the asset loading, and made it much more optimised. Before, there were hard-coded directories that connected to Enums, so you'd have to load an asset based on an enum and it was very ineffective, now, there is a ResourceManager Singleton that loads every asset based on it's "type".
For simplicity in terms of this screenshot, I have deleted the other initialisations (logos, materials, textures etc).
you can then freely use the loaded assets like this:

This change has made the project feel more professional and optimised.
I then fixed some grid snapping issues that made it impossible for differently tagged items (for example, a block versus a ramp) to have different grid snapping. this lead fixed a major concern, and I can already now build simple areas with the blocks, walls, floors and ramps I have.
This week, I also added transform modifiers. I am very happy about this.
I have also started working on Palettes (will discuss this after my future plans), but no functionality yet

it also creates a little swatch of your palette, I love this!

A lot more ideas will be worked on throughout this next week, as I do think that QuickBlock has a lot of potential.
These Include:
Texture Customisation (choose between textures)
Scaling
Commenting (comment in-editor while you're building)
Palette Implementation
Palette Implementation will allow you to colour specific parts of your build automatically - just by creating a palette. There will also be "Dark" modes and "Light" modes.
Ramps = yellow, foliage = green, floors = white,
walls = blue, misc = red.
DARK MODE
LIGHT MODE
This will automatically be done with tag checking.
I hopefully will have this fully implemented by next week.
================================================
Performance Evaluation
[ I feel quite relieved that despite going through burnout, my ability to find less significant (but still important) tasks contribute to the momentum of these projects, without sacrificing my mental health.
Essentially, while these features (a .404 error page, colour palette, or music) isn't critical to the core functionality of these projects, it will enhance the final projects. ]
[ This however, is a double-edged sword, I need to be aware enough about feature creep, and knowing where and when to stop, then divert my attention to the necessary features of these projects, otherwise it can create a backlog of essential tasks, which would be challenging to come back from when I have just recovered from burnout. ]
================================================
Action Plan
This following week will be about organisation; but I need to be careful and plan for contingencies in terms of my mental health - and follow my Risk Assessment & Mitigation plan

Firstly, I will create a task tracker for Workflow Toolkit, QuickBlock and Star In The Making, I will not separate tasks by project, as this causes further frustration, but do any task I can tick off without further hurting my burnout.
This task tracker will be updated every two weeks, and I should be aiming to complete at least 2 tasks from this tracker every day (but allow less or none during tough days). I will make sure these tasks are measurable, and able to be completed.
I will make sure this tracker has some tasks that can easily be done, in case I am having a rough day in particular, but still need a task to be completed.
Once the bi-weekly tracker needs to be refreshed, I will delete all tasks and re-add them, to make sure my priorities will shift to more important areas.
================================================
1 note
·
View note