#rectified linear units
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
Tumblr Inc. has $15.1M in annual revenue.
Text
What are the differences between the ReLU and Sigmoid activation functions in neural networks?
In neural networks, activation functions are very important for figuring out what a cell will do when it is given an input or set of inputs. The Rectified Linear Unit (ReLU) and the Sigmoid function are two activation functions that are often used. We'll talk about the differences between these two tasks in easy-to-understand language. Definition of the ReLU Activation Function
This is how the Rectified Linear Unit (ReLU) activation function is written: $$ f(x) = \max(0, x) If $x$ is a positive number, then the result is also a positive number. If you put in something negative, the result is 0. Features and traits
Lack of linearity: ReLU adds non-linearity to the model, which helps it learn complicated patterns. Simplicity: It uses few calculations because it only needs to compare and find the highest. Sparse activation: In a network that is randomly set up, only about half of the hidden units are active (have a non-zero output), which can make the model work better. Gradient Propagation: The disappearing gradient problem is something that other activation functions, like Sigmoid and Tanh, also have. ReLU helps fix this problem.
Pros and cons
Dying ReLU Problem: Neurons can get stuck during training and always send out 0 no matter what. This happens when the weights are changed in a way that stops the cell from firing again. Non-zero Centered: The results are never negative, which can make it harder to find the best solution.
What Does Sigmoid Activation Function Mean? You can write the Sigmoid activation function as $$\sigma(x) = \frac{1}{1 + e^{-x}} $$ Any real number can be mapped to the range (0, 1) by this function, which makes an S-shaped curve. Features and traits Smooth Gradient: The Sigmoid function has a smooth gradient, which is helpful for optimization methods that use gradients. The result is always between 0 and 1, which makes it good for problems that need to classify things into two groups. It was one of the first activation functions used in neural networks, which makes it historically important.
Pros and cons
Vanishing Gradient Problem: When the input numbers are very high or very low, the Sigmoid function's gradient gets very small. This can make the training process go much more slowly. Non-zero Centered: The results are not zero-centered, which can cause updates to be less effective during training, just like with ReLU. Calculations Take a Lot of Time: The exponential function in the Sigmoid formula makes it take longer to calculate than ReLU. Compared to
How it Works Speed of Training: Because it doesn't have the disappearing gradient problem, ReLU usually makes training deep neural networks faster than Sigmoid. Complexity: ReLU is easier to process and set up, which makes it better for big neural networks.
Cases of Use In deep neural networks, especially convolutional neural networks (CNNs) and deep learning models, ReLU is often used in the hidden layers. Sigmoid: This type of function is often used in the output layer for problems that need a result between 0 and 1, like binary classification problems.
Properties of Mathematical ReLU is not linear and can't be differentiated at zero, but it can be differentiated elsewhere, with a gradient of 1 for positive inputs and 0 for negative inputs. Sigmoid: Not linear, differentiable everywhere, but slopes disappear at very high or very low input values.
0 notes
Text
Understanding Neural Network Operation: The Foundations of Machine Learning

Neural networks are essential to the rapid advancement of artificial intelligence as a whole; self-driving automobiles and automated systems that can converse are only two examples. Neural networks enable technology to process information, learn from data, and make intelligent decisions in a manner comparable to that of humans. Taking a machine learning course in Coimbatore offers promising circumstances for aspiring individuals looking to progress in the sector, as industries worldwide embrace automation and technology. The foundation is the machine learning course in coimbatore at Xploreitcorp, where students learn both the basic and more complex ideas of neural networks while observing real-world situations.
2. What Terms Are Associated With Neural Networks?
Systems made up of neurons in discrete centers separated into layers are called neural networks. Traditional methods of task completion were replaced by automation as a result of technology advancements. Neural networks are a subset of machine learning that draws inspiration from the way the human brain functions. A basic neural network typically consists of an output component and an input layer with one or more hidden layers. Every network block, such as a neuron, assumes certain roles and edges before transmitting the results to the system's subsequent layer.
2. Neural Networks' Significance in Contemporary Artificial Intelligence
The intricacy and non-linear interactions between the data provide the fundamentals of neural networks for artificial intelligence. In domains like speech recognition, natural language processing (NLP), and even image classification, they outperform traditional learning methods. Neural networks are essential to any AI course given in Coimbatore that seeks to prepare students for the dynamic sector fostering their aspirations because of their capacity to learn and grow on their own.
FNNs, or feeding neural networks, are used for broad tasks like classification and regression.
Convolutional neural networks, or CNNs, are even more specialized for jobs involving the processing of images and videos.
Texts and time series data are examples of sequential data that are best suited for recurrent neural networks (RNNs).
Generative Adversarial Networks (GANs) are networks made specifically for creating synthetic data and deepfake content.
Coimbatore's top-notch machine learning courses give students several specialty options that improve their employment prospects.
4. Training and Optimization in the Acquisition of Knowledge by Neural Networks
A neural network must be trained by feeding it data and adjusting its weights, biases, and other parameters until the error is as little as possible. The following stages are used to complete the procedure:
In order to produce the output, inputs must be passed through the network using forward propagation.
Loss Analysis: The difference between the expected and actual results is measured by a loss function.
Backpropagation: Gradient descent is used in each layer to modify weight.
These ideas are applied in projects and lab sessions by students enrolled in Coimbatore's machine learning course.
5. Activation Functions' Significance
The task of deciding whether a neuron is active falls to activation functions. Among the most prevalent ones are:
For deep networks, ReLU (Rectified Linear Unit) performs best.
Sigmoid: Excellent for straightforward binary classification.
Tanh: Zero-centered, with a range of -1 to +1.
A well-chosen catalyst is essential for efficiency because, as is covered in Coimbatore AI classes, the activation function selection affects performance.
6. Neural Network Applications
The technology that underpin these fields are neural networks:
Healthcare: Image analysis of medications to diagnose illnesses.
Finance: Risk analysis and fraud assessment.
Retail: Making recommendations for customized accessories.
Transportation: Navigation in self-driving cars.
Joining the top machine learning course in Coimbatore is the greatest way to learn about these applications, as they are taught using real-world examples.
7. Difficulties in Creating Neural Networks
Despite its enormous potential, neural networks exhibit issues like:
When a model performs poorly on data it has never seen before but performs well on training data, this is known as overfitting.
Vanishing gradients: During gradient descent, the capacity to update weights is hampered by the loss of network depth. High computational cost: Requires a lot of training time and reliable hardware.
As taught in an AI course in Coimbatore, these and other challenges can be solved by employing techniques like batch normalization, regularization, and dropout.
8. Traditional Machine Learning vs. Neural Networks
When working with vast volumes of unstructured data, such as language, music, and photos, neural networks perform better than conventional machine learning methods like support vector machines and decision trees. They are also more effective in scaling data. This distinction is emphasized in each and every advanced machine learning course offered in Coimbatore to help students choose the best algorithm for the job.
9. What Is the Difference Between Deep Learning and Neural Networks?
Stratified learning is made possible by deep learning, a more complex subset of neural networks distinguished by the enormous number of layers (deep architectures) arranged within it. Because additional computer capacity enables the comprehension of more complex representations, networks function better with higher depth. Any reputable artificial intelligence course in Coimbatore covers differentiation in great detail because it is made evident and essential to understand.
In Coimbatore, why learn neural networks?
Coimbatore has developed into a center for learning as a result of the integration of new IT and educational technologies. Students who enroll in a Coimbatore machine learning course can:
Learn from knowledgeable, accomplished professors and experts.
Access laboratories with PyTorch and TensorFlow installed
Get assistance to help you land a job at an AI/ML company.
Do tasks that are in line with the industry.
Students enrolled in Coimbatore AI courses are guaranteed to be prepared for the workforce from the start thanks to the combination of theory instruction and industry involvement.
Final Remarks
Given that neural networks lie at the heart of artificial intelligence, the answer to the question of whether they are merely another trendy buzzword is usually no. Neural networks are essential for data professionals today due to the critical necessity to execute skills, particularly with applications ranging from self-driving cars to facial identification. If you want to delve further into this revolutionary technology, the best way to start is by signing up for a machine learning course in Coimbatore. With the right training and drive, your future in AI is assured.
👉 For additional information, click here.
✅ Common Questions and Answers (FAQ)
1. Which Coimbatore course is the best for learning neural networks?
The machine learning training provided by Xploreitcorp is the perfect choice if you are based in Coimbatore. It includes both the necessary theory and practice.
2. Does learning neural networks require prior programming language knowledge?
An advantage would be having a basic understanding of Python. To assist novices in understanding the fundamentals, the majority of AI courses in Coimbatore include a basic programming curriculum.
3. Are AI systems the only ones that use neural networks?
Yes, for the most part, but there are also connections to data science, robotics, and even cognitive sciences.
4. Which tools are frequently used to create neural networks?
The well-known neural network building tools TensorFlow, Keras, PyTorch, and Scikit-learn are covered in any top machine learning course in Coimbatore.
5. How much time does it take to become proficient with neural networks?
Mastery can be achieved in three to six months by participating in hands-on activities and working on real-world projects during a structured artificial intelligence course in Coimbatore.
0 notes
Text
An Introduction to Neural Networks and Deep Learning

What are Neural Networks?
Neural networks are a class of machine learning algorithms inspired by the structure and function of the human brain.
A neural network consists of layers of interconnected nodes, or “neurons,” which work together to process and learn from data.
These networks are designed to recognize patterns, classify data, and make predictions based on input data.
A basic neural network consists of three key components: Input Layer: This layer receives the raw data (e.g., an image, text, or numeric data).
Hidden Layers:
These layers perform computations and learn representations of the input data. Output Layer: This layer provides the final prediction or classification (e.g., recognizing whether an image is of a cat or a dog).
Each connection between neurons has a weight that adjusts as the network learns. The goal is to adjust these weights to minimize the difference between the predicted output and the true output (or the target).
2. How Do Neural Networks Work?
A neural network processes data through the following steps: Feedforward: The input data is passed through the layers of the network, where each neuron performs a weighted sum of inputs and applies an activation function to determine the output.
Activation Functions:
Functions like ReLU (Rectified Linear Unit) or Sigmoid are applied to the output of neurons to introduce non-linearity, allowing the network to learn complex patterns.
Backpropagation:
After the network produces an output, the error (difference between the predicted output and the true output) is calculated. This error is propagated backward through the network, and the weights are updated to reduce the error, using optimization techniques like gradient descent.
The network continues learning through this process, iterating over the data multiple times to improve the accuracy of its predictions.
3. Deep Learning:
The Evolution of Neural Networks Deep learning is a subfield of machine learning that focuses on using large, deep neural networks with many layers — hence the name “deep” learning.
These deep networks, also known as deep neural networks (DNNs), are capable of learning hierarchical features and patterns in large amounts of data. While traditional neural networks may consist of just one or two hidden layers, deep neural networks can have dozens or even hundreds of layers.
This depth enables them to model more complex relationships and achieve impressive performance on tasks such as image recognition, natural language processing, and speech recognition.
4. Key Components of Deep Learning Convolutional Neural Networks (CNNs):
Used for image-related tasks, CNNs utilize convolution layers to automatically extract features from images, making them highly effective in computer vision tasks.
Recurrent Neural Networks (RNNs): These are used for sequence data (e.g., time series, speech, or text), where the network has “memory” and can use previous outputs as part of the input for future predictions.
Generative Adversarial Networks (GANs): GANs consist of two networks (a generator and a discriminator) that compete with each other, enabling the generation of new, synthetic data that resembles real data, such as creating realistic images or generating new music.
5. Training Neural Networks Training a neural network requires the following: Data: A large and high-quality dataset is essential for training deep learning models. The more data, the better the model can generalize to new, unseen data.
Optimization Algorithms:
Techniques like gradient descent help the network minimize the error by adjusting the weights iteratively.
Loss Function: A loss function (e.g., mean squared error or cross-entropy loss) measures how well the model’s predictions match the true values, guiding the optimization process.
6. Applications of Neural Networks and Deep Learning Neural networks and deep learning have revolutionized many fields due to their ability to handle large, complex datasets and learn from them:
Image and Video Recognition:
Applications like facial recognition, object detection, and autonomous driving rely on deep learning, particularly CNNs.
Natural Language Processing (NLP): Deep learning models are used in applications such as machine translation, sentiment analysis, and chatbots. Speech Recognition: Systems like virtual assistants (e.g., Siri, Alexa) use deep learning to convert speech to text and understand commands.
Healthcare:
Deep learning is used in medical imaging, drug discovery, and personalized treatment recommendations.
7. Challenges and Future of Deep Learning Despite its successes, deep learning faces several challenges:
Data and Computational Power:
Deep learning models require large datasets and significant computational resources (e.g., GPUs), which can be expensive and time-consuming.
Interpretability:
Deep neural networks, especially deep networks, are often seen as “black boxes” because their decision-making process is not easily interpretable.
Bias and Fairness:
Deep learning models can inherit biases from the data they are trained on, leading to ethical concerns about fairness and accountability.
However, ongoing research is addressing these challenges, and deep learning continues to evolve, with advancements in areas like transfer learning, reinforcement learning, and explainable AI.
WEBSITE: https://www.ficusoft.in/data-science-course-in-chennai/
0 notes
Text

Understanding the Mathematics Behind a Neuron: Applications in the Financial Market
By Adriano
Introduction
Artificial intelligence, especially through neural networks, has revolutionized various sectors, including the financial market. Understanding the mathematics behind an artificial neuron not only sheds light on how these technologies function but also on how they can be applied to optimize operations with assets listed on stock exchanges around the world.
The Mathematics of a Neuron
An artificial neuron is a basic unit of a neural network, designed to mimic, in a simplified way, the behavior of biological neurons. Here are the main mathematical components:
Inputs: Each neuron receives a set of inputs, denoted by x_1, x_2, ..., x_n.
Weights: Each input is multiplied by a weight w_1, w_2, ..., w_n, which determines the relative importance of each input.
Weighted Sum: The weighted sum of these inputs is calculated as:z = \sum_{i=1}^n w_i x_i + bwhere b is the bias, a constant value added to adjust the neuron's activation.
Activation Function: This sum is then passed through an activation function, f(z), which decides whether the neuron "fires" or not. Common functions include:
Sigmoid: f(z) = \frac{1}{1 + e^{-z}}
ReLU (Rectified Linear Unit): f(z) = \max(0, z)
Tanh: f(z) = \tanh(z)
Applications in the Financial Market
Asset Price Prediction Neural networks can be trained to predict future prices of stocks or other financial assets. Using time series market data like historical prices, trading volume, and economic indicators, a model can learn complex, non-linear patterns that are hard to capture with traditional methods. I base my strategies on market movement predictions, using these models to anticipate trends and adjust my positions accordingly.
Risk Management Understanding weights and biases in neurons helps evaluate the sensitivity of predictive models to different market variables, allowing for better risk management. Tools like sensitivity analysis or VaR (Value at Risk) calculation can be enhanced with insights from neural networks. My approach involves constantly adjusting my strategy to minimize potential losses based on these predictions.
Portfolio Optimization Neurons can assist in building optimized portfolios, where each asset is weighted according to its potential return and risk. The mathematics behind neurons allows for dynamically adjusting these weights in response to new market information. I use neural networks to optimize my portfolio composition, ensuring an allocation that maximizes risk-adjusted return.
Fraud and Anomaly Detection In a globalized market, detecting anomalies or fraudulent activities is crucial. Neurons can be trained to recognize typical behavior patterns and signal when deviations occur. I also employ these techniques for fraud detection, monitoring transactions and trading patterns that might indicate suspicious activities or market manipulation.
Challenges and Considerations
Complexity and Transparency: Neural networks can be "black boxes," where the final decision is hard to interpret. This is particularly problematic in the financial market, where transparency is valued.
Overfitting: Neurons might adjust too closely to training data, losing the ability to generalize to new data.
Data Requirements: Models need large volumes of data to be effective, which can be an issue for less liquid assets or emerging markets.
Conclusion
The mathematics of neurons opens up a vast field of possibilities for the financial market, from market movement prediction to fraud detection. However, the application of these technologies should be done cautiously, considering the challenges of interpretability and data requirements. Combining mathematical knowledge with a deep understanding of the financial context is essential to fully leverage the potential of neural networks in the global capital market. My strategies are built on this foundation, always seeking the best performance and security in operations.
1 note
·
View note
Text
Deep Neural Networks (DNNs) sind eine Art von künstlichen neuronalen Netzwerken (ANNs), die aus mehreren Schichten von Neuronen bestehen und darauf spezialisiert sind, komplexe Muster und Abstraktionen in Daten zu erkennen. Sie bilden die Grundlage vieler moderner Anwendungen der Künstlichen Intelligenz, insbesondere im Bereich des Deep Learning.
1. Grundstruktur eines Neuronalen Netzwerks
Ein neuronales Netzwerk ist inspiriert von der Funktionsweise biologischer Gehirne. Es besteht aus einer großen Anzahl von miteinander verbundenen “Neuronen”, die in Schichten organisiert sind:
• Eingabeschicht (Input Layer): Diese Schicht nimmt die Daten aus der Außenwelt auf, z. B. Pixelwerte eines Bildes oder Wörter eines Satzes.
• Verborgene Schichten (Hidden Layers): Hier findet die eigentliche Verarbeitung und Abstraktion statt. Jede Schicht transformiert die Daten, bevor sie sie an die nächste weitergibt.
• Ausgabeschicht (Output Layer): Die Ergebnisse der Verarbeitung werden hier ausgegeben, z. B. eine Klassifikation (Hund oder Katze?) oder eine Wahrscheinlichkeit.
2. Was macht ein DNN „Deep“?
Ein Netzwerk gilt als „Deep“, wenn es mehrere versteckte Schichten enthält.
• Jede zusätzliche Schicht erlaubt dem Netzwerk, komplexere Muster und Zusammenhänge in den Daten zu erkennen.
• Während ein einfaches neuronales Netzwerk (z. B. mit einer Schicht) nur grundlegende Beziehungen modellieren kann, ermöglicht die Tiefe eines DNN die Erkennung von hierarchischen Mustern.
3. Wie funktionieren DNNs?
Der Kern eines DNNs besteht aus den folgenden Komponenten:
a) Neuronen und Gewichte
• Jedes Neuron in einer Schicht empfängt Eingaben aus der vorherigen Schicht.
• Diese Eingaben werden mit Gewichten (Weights) multipliziert, die die Bedeutung dieser Eingaben bestimmen.
• Das Ergebnis wird aufsummiert und durch eine Aktivierungsfunktion (Activation Function) geschickt, die entscheidet, ob das Neuron „feuert“ (aktiviert wird).
b) Vorwärtspropagation
• Daten fließen von der Eingabeschicht durch die verborgenen Schichten bis zur Ausgabeschicht. Jede Schicht transformiert die Daten weiter.
c) Fehlerberechnung
• Das Netzwerk berechnet den Fehler zwischen der vorhergesagten Ausgabe und der tatsächlichen Zielausgabe (z. B. mithilfe von Loss-Funktionen).
d) Rückwärtspropagation (Backpropagation)
• Der Fehler wird zurück durch das Netzwerk propagiert, um die Gewichte der Verbindungen zu aktualisieren.
• Ziel: Die Gewichte so anzupassen, dass der Fehler bei der nächsten Iteration kleiner wird. Dies geschieht durch einen Algorithmus namens Gradientenabstieg (Gradient Descent).
4. Hierarchische Merkmalsverarbeitung
Ein zentraler Vorteil von DNNs ist ihre Fähigkeit, hierarchische Muster zu lernen:
• Niedrige Schichten: Lernen einfache Merkmale wie Kanten, Linien oder Farben.
• Mittlere Schichten: Erkennen Kombinationen dieser Merkmale, z. B. Formen oder Texturen.
• Höhere Schichten: Erfassen abstrakte Konzepte wie Gesichter, Objekte oder Bedeutungen.
5. Aktivierungsfunktionen
Aktivierungsfunktionen führen Nichtlinearitäten ein, damit das Netzwerk komplexe Zusammenhänge modellieren kann. Häufige Funktionen:
• ReLU (Rectified Linear Unit): Setzt alle negativen Werte auf 0, behält positive Werte bei.
• Sigmoid: Komprimiert Werte in den Bereich zwischen 0 und 1.
• Softmax: Wandelt Ausgabewerte in Wahrscheinlichkeiten um (z. B. für Klassifikationsprobleme).
6. Anwendungsbereiche
Deep Neural Networks werden in vielen Bereichen eingesetzt:
• Bildverarbeitung: Objekterkennung, Gesichtsidentifikation, medizinische Bildanalyse.
• Sprachverarbeitung: Übersetzung, Sprachgenerierung, Sentimentanalyse.
• Generative KI: Bilder generieren (z. B. DALL·E), Texte erstellen (z. B. GPT).
• Spiele: Entscheidungsfindung in komplexen Szenarien (z. B. AlphaGo).
7. Herausforderungen von DNNs
• Rechenleistung: Training von DNNs erfordert viel Hardware (GPUs, TPUs).
• Datenbedarf: Große Datenmengen sind notwendig, um gute Ergebnisse zu erzielen.
• Erklärbarkeit: DNNs sind oft als „Black Boxes“ schwer zu interpretieren.
• Überanpassung (Overfitting): Modelle können zu stark auf Trainingsdaten optimiert werden und verlieren die Fähigkeit zur Generalisierung.
DNNs sind mächtig, weil sie nicht nur Daten „bearbeiten“, sondern lernen, sie zu verstehen und Abstraktionen zu schaffen. Dadurch haben sie viele der bahnbrechenden Entwicklungen in der KI ermöglicht.
0 notes
Text
The Role of Deep Learning in Enterprise Evolution

Deep learning, a subset of machine learning, has emerged as a powerful technology that mimics the human brain’s neural networks to analyze and process vast amounts of data. In recent years, its applications have extended far beyond the realms of academia and research, finding a significant place in enterprise businesses. This article explores what deep learning is and delves into how it can revolutionize various aspects of enterprise operations, from enhanced decision-making to improved customer experiences.
Understanding Deep Learning:
Deep learning is a branch of artificial intelligence (AI) that involves the use of neural networks to simulate the way the human brain works. These neural networks consist of interconnected layers of nodes, each layer processing and extracting increasingly complex features from the input data. Through a process called training, these networks learn to recognize patterns and make predictions, enabling them to perform tasks such as image and speech recognition, natural language processing, and even complex decision-making.
Key Components of Deep Learning:
Neural Networks: The fundamental building blocks of deep learning, neural networks consist of interconnected layers of nodes (artificial neurons). These networks learn and adapt through the adjustment of weights connecting these nodes.
Training Data: Deep learning models require large amounts of labeled data for training. This data helps the neural network learn the patterns and relationships necessary to make accurate predictions.
Activation Functions: These functions introduce non-linearity to the neural network, enabling it to learn complex relationships in the data. Common activation functions include sigmoid, tanh, and rectified linear unit (ReLU).
Backpropagation: The optimization process where the neural network adjusts its weights based on the difference between predicted and actual outcomes. This iterative process enhances the model’s accuracy over time.
How Deep Learning Benefits Enterprise Businesses:
Data Analysis and Predictive Modeling:
Deep learning excels in analyzing vast datasets to identify patterns and trends that might go unnoticed by traditional analytics tools. This capability is invaluable for enterprises dealing with large volumes of data, as it allows for more accurate predictions and informed decision-making. From predicting market trends to optimizing supply chain operations, deep learning models can provide valuable insights to drive strategic planning.
Enhanced Customer Experiences:
Personalization is key to delivering superior customer experiences, and deep learning plays a pivotal role in achieving this. By analyzing customer data, including preferences, behaviors, and feedback, deep learning algorithms can tailor recommendations, advertisements, and interactions to meet individual needs. This not only improves customer satisfaction but also increases the likelihood of repeat business.
Automation and Efficiency:
Deep learning enables automation of complex tasks that traditionally required human intervention. This includes automating routine business processes, such as data entry and document processing, freeing up human resources for more strategic and creative endeavors. Robotics process automation driven by deep learning can significantly enhance operational efficiency, reduce errors, and cut down on costs.
Fraud Detection and Security:
In the realm of cybersecurity, deep learning is a formidable tool for detecting and preventing fraudulent activities. By analyzing patterns in user behavior and transaction data, deep learning models can identify anomalies indicative of potential security threats. This is particularly crucial for financial institutions, e-commerce platforms, and any enterprise dealing with sensitive customer information.
Natural Language Processing (NLP):
Deep learning has significantly advanced natural language processing capabilities. Enterprises can leverage NLP to automate customer support through chatbots, analyze sentiment in social media, and gain insights from unstructured textual data. This not only improves communication but also enables businesses to stay attuned to customer sentiments and market trends.
Supply Chain Optimization:
Deep learning can optimize supply chain operations by predicting demand, identifying bottlenecks, and enhancing inventory management. Through the analysis of historical data and real-time information, businesses can streamline their supply chains, reduce costs, and improve overall efficiency. This is especially relevant in industries where timely and accurate deliveries are critical.
Human Resources and Talent Acquisition:
Deep learning can revolutionize the recruitment process by automating resume screening, evaluating candidates based on diverse criteria, and predicting candidate success in specific roles. This not only speeds up the hiring process but also ensures a more objective and data-driven approach to talent acquisition.
Product Development and Innovation:
By analyzing market trends, customer feedback, and competitor data, deep learning can assist in product development and innovation. This proactive approach helps businesses stay ahead of the competition by anticipating consumer demands and preferences, fostering a culture of continuous improvement
Conclusion:
In conclusion, deep learning is a transformative force for enterprise businesses, offering unprecedented capabilities in data analysis, automation, and decision-making. As businesses continue to generate and collect massive amounts of data, the ability to extract meaningful insights from this information becomes paramount. Deep learning not only meets this demand but also opens new avenues for innovation, efficiency, and customer satisfaction.
Embracing deep learning technologies requires a strategic approach, including investments in talent acquisition, infrastructure, and ongoing research and development. However, the benefits are substantial, positioning businesses at the forefront of their respective industries and paving the way for a future where intelligent systems drive growth and success.
Original Source: Here
0 notes
Text
Unveiling the Power of Convolutional Neural Networks in Image Processing
Source – Towards Data Science
In the realm of artificial intelligence and computer vision, Convolutional Neural Networks (CNNs) stand as a groundbreaking innovation, revolutionizing the way machines perceive and analyze visual data. From image classification and object detection to facial recognition and medical imaging, CNNs have emerged as a cornerstone technology, driving advancements in various fields. In this comprehensive guide, we’ll explore the significance of convolutional neural networks, delve into their architecture and functioning, and highlight their transformative impact on image processing and beyond.
Understanding Convolutional Neural Networks (CNNs)
Convolutional Neural Networks (CNNs) are a class of deep neural networks specifically designed to process and analyze visual data, such as images and videos. Inspired by the structure and functioning of the human visual system, CNNs employ layers of interconnected neurons to extract features from input images, perform hierarchical abstraction, and make predictions based on learned patterns and relationships.
Key Components of Convolutional Neural Networks
Source – News – Fermilab
1. Convolutional Layers:
Convolutional layers are the core building blocks of CNNs, responsible for feature extraction through convolution operations. Each convolutional layer consists of a set of learnable filters or kernels, which slide across the input image, performing element-wise multiplications and aggregations to detect spatial patterns and features.
2. Pooling Layers:
Pooling layers are used to downsample the spatial dimensions of feature maps generated by convolutional layers, reducing computational complexity and improving model efficiency. Common pooling operations include max pooling and average pooling, which extract the most relevant information from feature maps while preserving spatial relationships.
3. Activation Functions:
Activation functions introduce non-linearities into the network, enabling CNNs to learn complex patterns and relationships in the input data. Popular activation functions used in CNNs include ReLU (Rectified Linear Unit), sigmoid, and tanh, which introduce non-linear transformations to the output of convolutional and pooling layers.
4. Fully Connected Layers:
Source – Built In
Fully connected layers, also known as dense layers, are typically added at the end of a CNN architecture to perform classification or regression tasks based on the features extracted by earlier layers. These layers connect every neuron in one layer to every neuron in the next layer, allowing the network to make high-level predictions based on learned representations.
Transformative Impact of Convolutional Neural Networks
1. Image Classification:
CNNs have revolutionized image classification tasks, achieving state-of-the-art performance on benchmark datasets such as ImageNet. By learning hierarchical representations of visual features, CNNs can accurately classify images into predefined categories, enabling applications such as autonomous driving, medical diagnosis, and content-based image retrieval.
2. Object Detection and Localization:
CNNs excel at object detection and localization tasks, accurately identifying and localizing objects within images or video frames. By leveraging techniques such as region proposal networks (RPNs) and anchor-based detection, CNNs can detect multiple objects of interest within complex scenes, paving the way for applications in surveillance, robotics, and augmented reality.
3. Semantic Segmentation:
Semantic segmentation involves partitioning an image into semantically meaningful regions and assigning a class label to each pixel. CNNs have demonstrated remarkable performance in semantic segmentation tasks, enabling applications such as autonomous navigation, medical image analysis, and environmental monitoring.
4. Transfer Learning and Domain Adaptation:
Source – Built In
CNNs trained on large-scale datasets can be fine-tuned or adapted to new tasks and domains with relatively few labeled examples, thanks to transfer learning techniques. By leveraging pre-trained CNN models as feature extractors, researchers and practitioners can accelerate model development and achieve competitive performance on task-specific datasets.
Future Directions and Challenges
As CNNs continue to evolve, researchers are exploring novel architectures, optimization techniques, and applications to push the boundaries of what’s possible in image processing and computer vision. However, challenges such as data scarcity, robustness to adversarial attacks, and interpretability remain areas of active research and innovation, highlighting the need for continued collaboration and interdisciplinary efforts in the field.
Conclusion
Convolutional Neural Networks (CNNs) represent a paradigm shift in image processing and computer vision, enabling machines to perceive, interpret, and analyze visual information with unprecedented accuracy and efficiency. From image classification and object detection to semantic segmentation and beyond, CNNs have unlocked a wealth of possibilities across diverse domains, transforming industries and driving innovation at an unprecedented pace. As CNNs continue to advance and mature, their transformative impact on society, science, and technology will only continue to grow, paving the way for a future where intelligent machines seamlessly interact with the visual world around us.
0 notes
Text
ReLU Activation Function: A Powerful Tool in Deep Learning
Introduction
In the vast field of deep learning, activation functions play a crucial role in determining the output of a neural network. One popular activation function is the Rectified Linear Unit (ReLU). In this article, we will delve into the details of the ReLU activation function, its benefits, and its applications in the realm of artificial intelligence.
Table of Contents
What is an Activation Function?
Understanding ReLU Activation
2.1 Definition of ReLU
2.2 How ReLU Works
2.3 Mathematical Representation
Advantages of ReLU
3.1 Simplicity and Efficiency
3.2 Addressing the Vanishing Gradient Problem
3.3 Non-linear Transformation
ReLU in Practice
4.1 ReLU in Convolutional Neural Networks
4.2 ReLU in Recurrent Neural Networks
4.3 ReLU in Generative Adversarial Networks
Limitations of ReLU
5.1 Dead ReLU Problem
5.2 Gradient Descent Variants
Conclusion
FAQs
7.1 How does ReLU differ from other activation functions?
7.2 Can ReLU be used in all layers of a neural network?
7.3 What are the alternatives to ReLU?
7.4 Does ReLU have any impact on model performance?
7.5 Can ReLU be used in regression tasks?
1. What is an Activation Function?
Before diving into the specifics of ReLU, it's essential to understand the concept of an activation function. An activation function introduces non-linearity into the output of a neuron, enabling neural networks to learn complex patterns and make accurate predictions. It determines whether a neuron should be activated or not based on the input it receives.
2. Understanding ReLU Activation
2.1 Definition of ReLU
ReLU, short for Rectified Linear Unit, is an activation function that maps any negative input value to zero and passes positive input values as they are. In other words, ReLU outputs zero if the input is negative and the input value itself if it is positive.
2.2 How ReLU Works
ReLU is a simple yet powerful activation function that contributes to the success of deep learning models. It acts as a threshold function, allowing the network to activate specific neurons and discard others. By discarding negative values, ReLU introduces sparsity, which helps the network focus on relevant features and enhances computational efficiency.
2.3 Mathematical Representation
Mathematically, ReLU can be defined as follows:
scssCopy code
f(x) = max(0, x)
where x represents the input to the activation function, and max(0, x) returns the maximum value between zero and x.
3. Advantages of ReLU
ReLU offers several advantages that contribute to its widespread use in deep learning models. Let's explore some of these benefits:
3.1 Simplicity and Efficiency
ReLU's simplicity makes it computationally efficient, allowing neural networks to process large amounts of data quickly. The function only involves a simple threshold operation, making it easy to implement and compute.
3.2 Addressing the Vanishing Gradient Problem
One significant challenge in training deep neural networks is the vanishing gradient problem. Activation functions such as sigmoid and tanh tend to saturate, resulting in gradients close to zero. ReLU helps alleviate this issue by preserving gradients for positive inputs, enabling effective backpropagation and faster convergence.
3.3 Non-linear Transformation
ReLU introduces non-linearity, enabling the network to learn complex relationships between inputs and outputs. Its ability to model non-linear transformations makes it suitable for a wide range of tasks, including image and speech recognition, natural language processing, and more.
4. ReLU in Practice
ReLU finds applications in various deep learning architectures. Let's explore how ReLU is used in different types of neural networks:
4.1 ReLU in Convolutional Neural Networks
Convolutional Neural Networks (CNNs) excel in image classification tasks. ReLU is commonly used as the activation function in CNNs because of its ability to capture and enhance relevant features within images.
4.2 ReLU in Recurrent Neural Networks
Recurrent Neural Networks (RNNs) are widely used in sequential data processing, such as language modeling and speech recognition. ReLU's non-linearity helps RNNs learn long-term dependencies in sequential data, leading to improved performance.
4.3 ReLU in Generative Adversarial Networks
Generative Adversarial Networks (GANs) are used for tasks such as image synthesis and style transfer. ReLU activation is often employed in the generator network of GANs to introduce non-linearity and improve the quality of generated samples.
5. Limitations of ReLU
While ReLU offers significant advantages, it also has some limitations that researchers and practitioners should be aware of:
5.1 Dead ReLU Problem
In certain scenarios, ReLU neurons can become "dead" and cease to activate. When a neuron's weights and biases are set in such a way that the output is always negative, the gradient during backpropagation becomes zero, rendering the neuron inactive. This issue can be addressed by using variants of ReLU, such as Leaky ReLU or Parametric ReLU.
5.2 Gradient Descent Variants
Some variants of gradient descent, such as the second-order methods, may not perform well with ReLU activation due to its non-differentiability at zero. Proper initialization techniques and learning rate schedules should be employed to mitigate these issues.
6. Conclusion
ReLU has emerged as a fundamental building block in deep learning models, offering simplicity, efficiency, and non-linearity. Its ability to address the vanishing gradient problem and its successful application across various neural network architectures make it an indispensable tool in the field of artificial intelligence.
FAQs
7.1 How does ReLU differ from other activation functions?
ReLU differs from other activation functions by transforming negative inputs to zero, while allowing positive inputs to pass unchanged. This characteristic enables ReLU to introduce sparsity and preserve gradients during backpropagation.
7.2 Can ReLU be used in all layers of a neural network?
ReLU can be used in most layers of a neural network. However, it is advisable to avoid ReLU in the output layer for tasks that involve predicting negative values. In such cases, alternative activation functions like sigmoid or softmax are typically used.
7.3 What are the alternatives to ReLU?
Some popular alternatives to ReLU include Leaky ReLU, Parametric ReLU (PReLU), and Exponential Linear Unit (ELU). These variants address the dead ReLU problem and introduce improvements in terms of the overall performance of the neural network.
7.4 Does ReLU have any impact on model performance?
ReLU can have a significant impact on model performance. By promoting sparsity and non-linearity, ReLU aids in capturing complex patterns and improving the network's ability to learn and generalize.
7.5 Can ReLU be used in regression tasks?
ReLU can be used in regression tasks; however, it is crucial to consider the nature of the target variable. If the target variable includes negative values, ReLU might not be suitable, and alternative activation functions should be explored.
0 notes
Link
0 notes
Text
Practical design knowledge in harmonics distortion and power factor correction (PFC)
Harmonics and Network Design
Nowadays, if you do not consider harmonics distortion when designing a new network, you missed the whole point of the network design. Yes, really. The sooner you realize that harmonics problems are on the rise, the better. Modern power networks are already pretty dirty because of mass non-linear loads installed without any prior consultation with experts or power analysis.

This technical article will shed some light on practical ways of looking at the problems with harmonics distortion. It will also refresh your knowledge in the basics of harmonics and give you some good practical tips in designing, installation and protecting PFC (power factor correction) systems and measures.
The article contains examples of capacitor banks and PFC systems by German manufacturer Frako.
Table of contents:
1. Harmonics Facts and Questions
What are harmonics?
How are harmonics produced? - Level of harmonics if no PFC system has yet been installed
When can dangerous network resonances occur? - Example
What effect does the network configuration have on the problem of harmonics?
Voltage and current loads on PFC systems without detuning
2. Designing for networks with harmonics
Planning for PFC systems in networks with harmonics
Example
Measures to counteract expected resonances
3. Installation of Power Factor Correction (PFC)
Current transformer location
Overcurrent protection and cables
Ingress protection
1. Harmonics Facts and Questions
What are harmonics?
Modern low voltage networks increasingly have loads installed that draw non-sinusoidal currents from the power distribution system. These load currents cause voltage drops through the system impedances which distort the original sinusoidal supply voltage. Fourier analysis can be used to separate these superposed waveforms into the basic oscillation (supply frequency) and the individual harmonics.
The frequencies of the harmonics are integral multiples of the basic oscillation and are denoted by the ordinal number ‘n’ or ‘ν’ (Example: Supply frequency = 50 Hz → 5th harmonic = 250 Hz).
Linear loads are ohmic resistances (resistance heaters, light bulbs, etc.), three-phase motors and capacitors, and they are not harmful to the power system.
The most problematic loads that need attention!
Non-linear loads (harmonics generators) are:
Transformers and chokes
Electronic power converters
Rectifiers and converters, especially when controlling variable-speed induction motors
Induction and electric arc furnaces, welding equipment
Uninterruptible power supplies (https://gzepelectricalslimited.com/electrical-engineering/Solar-backup-systems) Solar & UPS systems
Single-phase switched-mode power supply units for modern electronic loads such as televisions, VCRs, computers, monitors, printers, telefax machines, electronic ballasts, compact energy-saving lamps.
Every periodic signal with a frequency f (regardless of the waveform) consists of the sum of the following:
The sine component of the frequency f known as the fundamental component or h1
The sine components of the integral multiples of the frequency f, known as the harmonics hn
In some cases DC components can also be present
y(t) = h1(t) + h3(t)...
Figure 1 – Analysing a periodic signal into its component harmonics

Harmonics can be divided into three categories:
1. Even harmonics (2nd, 4th, 6th, etc.
Even harmonics (2nd, 4th, 6th, etc.) as a rule only occur due to sudden load variations or faults in converters.
2. Odd harmonics (3rd, 5th, 7th, etc.
Harmonics divisible by 3 (3rd, 9th, 15th, etc.) occur due to asymmetrical loads and single-phase sources of harmonics. Typical sources are office buildings, hospitals, software companies, banks, etc., factories with 2-phase welding equipment.
The problem they cause: The harmonic currents in the neutral conductor are cumulative.
Figure 2 – Cumulative effect of the 3rd harmonic current in the neutral conductor.

3. Harmonics not divisible by 3 (5th, 7th, 11th, 13th, etc.)
Harmonics not divisible by 3 (5th, 7th, 11th, 13th, etc.) occur due to 3-phase sources of harmonics 5th and 7th harmonics: from 6-pulse converters 11th and 13th harmonics: from 12-pulse converters
The problem they cause: The harmonics are transmitted via the transformer! The total harmonic distortion THD is the result of the vector addition of all harmonics present and is, as a rule, expressed as a proportion of the fundamental frequency, thus providing a quick overview of network power quality.
Each harmonic can be considered as an individual system with its own phase angle! This results in a difference between cos φ (fundamental frequency) and PF (power factor, overall harmonics).
Harmonics are generated not only in industrial installations but also increasingly in private households. As a rule, the devices generating these harmonics only feed in the odd orders, so that it is only the 3rd, 5th, 7th, 9th, 11th, etc. harmonics that are encountered.
Figure 3– Network current and voltage superposed with the following harmonics: 5% of the 5th harmonic, 4% of the 7th harmonic and 2.5% of the 11th harmonic
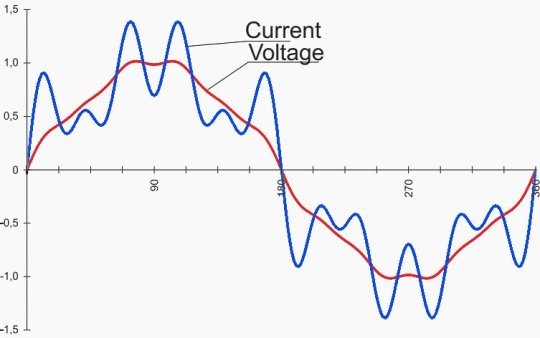
To be continued
1 note
·
View note
Text
Impact of Power Quality
Power Quality is a significant issue which is usually left unattended at most of the MSME units of our country. The consumer of electrical energy requires electric power with a certain quality, but loads can have a negative impact (or act as pollutants) on the electrical system and are thus also subject to an assessment in terms of quality. Power quality is therefore intrinsically linked to the interaction between the electrical system and loads and one must take into account both the voltage quality and power quality.
Possible consequences of low power quality that affect business costs are:
Power failures (Release switches, fuses blowing).
Breakdowns or malfunctions of machines.
Loss of saved data and operational settings in memory units.
Overheating of machines (transformers, motors, etc.) leading to reduced useful life.
Damage to sensitive equipment (computers, production line control systems, etc.).
Electronic communication interference.
Increased distribution system losses.
The need to oversize systems to cope with additional electric stress, resulting in higher installation and operational costs.
Luminosity flickering.
Safety issues due to possibility of bursting cables and flash in connections.
Interruption of production due to these impacts of low power quality entails high costs due to production loss and the associated waste. The impact of production interruptions is greatest in companies with continuous production.
Among the main causes of poor power quality in LT systems are:
Excessive reactive power, because it charges useless power to the system.
Harmonic pollution, which causes additional stress on the networks and systems, causing them to operate less efficiently.
Voltage variations, because equipment operates less efficiently.
The solutions vary for each cause. Excessive reactive power is regulated by a power factor correction system, which not only avoids any penalties due to excessive reactive energy, but reduces the ���unnecessary” electrical current that flows into the lines and power components, yielding substantial benefits, such as reducing voltage drops along the lines and leakages due to the Joule effect.
Harmonic pollution is caused by large amounts of non-linear consumption (from inverters, soft starters, rectifiers, power electronics, non-filament lighting, presses, etc.). Such devices deform the electrical current causing disturbances and problems to the system. Harmonic pollution is solved by active filters that are capable of eliminating the current harmonics in the system by measuring and injecting the same current, but in the opposite phase.
The voltage variations can be reduced with a voltage stabilizer, which ensures a voltage output at a nominal value. Reduced productivity, loss of data, loss of security, and machine breakdowns are only some of the problems caused by an unstable power supply that can be solved with a voltage stabilizer.
Proper treatment of the power quality is utmost necessity for long term failure proof operation of the production system is the need of time and shall be highlighted and made mandatory by law if deemed fit by authorities.

#vrindaautomations#power factor correction#harmonic distortion#variable frequency drive market#vfd#industrial automation
2 notes
·
View notes
Text
" Harmonic Analysis a Root Cause Finder for Repetitive Failure
How NLL affect today's electrical power system? A study of electrical power harmonic analysis helps to know the root cause of equipment and drive failure for correctional power-related steps. Today's Engineers are finding a power quality problem that is becoming increasingly apparent is the harmonic distortions of the fundamental waveform. The problem has arisen due to extensive use of Non-Linear Loads (NLL) in today's electrical power system, which alter sinusoidal shape of the sine wave, and thereby cause harmonic generations and distortion power factor (PF) in the power System.
Measurement units of Power Quality Harmonics are defined by Total Voltage Harmonic Distortion THDv and Total Current Harmonic Distortion THDi. THD values are calculated as the sum of square root of individual harmonics namely 2nd, 3rd, 4th, 5th, 6th, 7th, ... nth divided by fundamental current/voltage. The fundamental harmonics are the 50hz/ 60hz values for voltage and current.
Harmonics are as old a phenomenon as the introduction of the AC System. Mercury Arc Rectifier (MAR) developed in 1920's and Semiconductor Controlled Rectifiers (SCR) and Thyristors developed in 1950's created harmonics due to their nature of non-linear-load. Its usage was much lesser then, typically 5% in 1960, that could not have created any significant impact on the power system. However, economic prosperity coupled with technological advancements have mandated today's comfort conditions those necessitate employing matching controls which are increasingly introducing nonlinear loads which are altering the very sinusoidal characteristic of current and voltage wave forms and creating Harmonics and bad Power Quality.
1 note
·
View note
Text
Neural Network Basics
Purpose: to breach the semantic gap between humans and machines. Humans have them naturally built into our brains; we must build them within machines.
Essentially a graph structure, where each node performs a simple computation given an input and each edge carries the generated signal from one node to another. These edges may be weighted more heavily to emphasise the importance of a signal. Each node has various inputs passed into them, and if a particular threshold is reached then the activation function will output a signal and the particular node will be activated and this output will serve as the input for the next node. Our inputs, for this project, would simply be the mentioned vectors of pixel intensities at particular points.
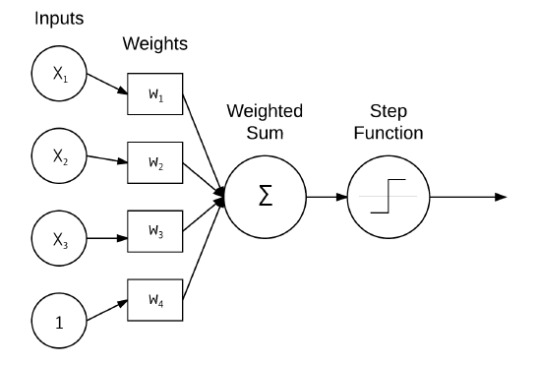
In the diagram we have a very basic NN that takes 3 inputs + a bias, and which are passed into the node to produce a weighted sum that will then be judged by the activation function to determine whether the inputs were sufficient to justify an output.
The step function before the 'signal' is sent out is meant to filter the signal - if the value is too low/signal too weak, no sendo. If it passes the threshold, yes. This is a very basic activation function that will produce a signal if the sum reaches some threshold.
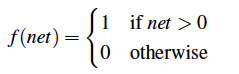
Here, our threshold is 0. If you remember your HS math, you'll know that this function is indeed not differentiable, which can lead to some issues down the line so we typically use a differentiable function as the activation function instead instead such as the sigmoid.
The sigmoid had it own issues however, so the ReLU function was born. Well, perhaps not born but came into use in NN creation.
Sigmoid (below)

ReLU (rectified linear unit) also known as a 'ramp function' and it’s equation (below)
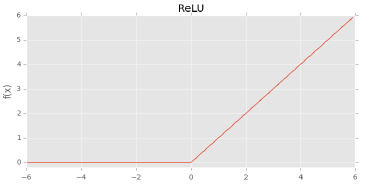

I shan't go into detail, but notice that the sigmoid's f(x) value is bound at 1 and so will will not be able to produce any signal greater than 1 which is necessary in some NN applications. Sigmoids also take forever to compute, whilst ReLU is literally just a line.
ReLU's cousin, the Leaky ReLU, also exists and may be used as an alternative. Which one you use really depends on your project. As the name suggests, it is a version that is leaky i.e. when input < 0, it will 'leak' a bit of signal.

The ELU (still below)

Empirically, variants of the ELU have enjoyed better performance than its cousins.
Feedforward Network Architecture
The cornerstone of NN research, feedforward networks consist of nodes that will only feed into the next layer of nodes, never feeding backward - hence feedforward.
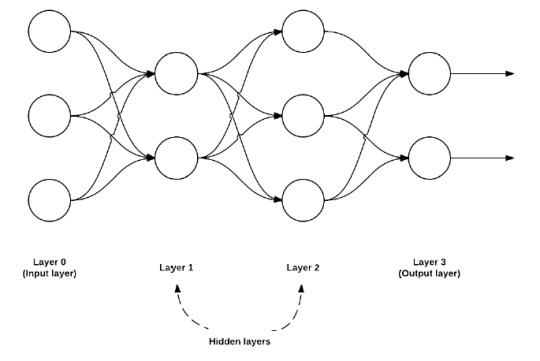
In feedforward networks, there are multiple layers, each with different functions. Layer 0 generally serves as the layer for input, where all the data enters and is processed by its nodes. Each node takes a different column/vector as an input, so for e.g. if we were training a NN to classify pictures of cats, one node may take fluffiness data and another may take tail length data.
Layers 1 and 2 in the above image serve as the layers which help process Layer 0's output and Layer 3 above is the output layer where the input data is classified into their various labels, with each node classifying a different label e.g. an NN classifying handwritten digits would have an output layer consisted of 10 nodes for each digit from 0-9 and similarly a NN classifying images of cats will simply have an output layer of a single node, which will either output 1 for yes it's a cat, or 0 for no it's not a cat.
The Perceptron Algorithm:
Not gonna go into detail since it’s not really interesting. Some believe it useful to understand. I don't.
Essentially trains a straight line of the above form to separate data belonging to two different labels by adjusting the values of that n looking symbol:

Looping over each datapoint/vector and its corresponding label
Taking the datapoint and passing it into the line function which calculates the value.
Updates each weight of the line function by the size of each step according to the output. If the output is smaller than expected, increase each weight by the step. If output is larger, decrease each weight by the step. Repeat until the line function output converges
And here’s the end product when we train the perceptron (the line that separates the data points).

Training a NN - Backpropagation:
Arguably the most important in machine learning, backpropagation is consisted of two phases:
Propagation
Backward pass
Let's look at how backpropagation and NN's work by training a NN to learn to XOR by training it on the XOR dataset which is consisted of the entire XOR domain. i.e. 0 XOR 0 is 0, 0 XOR 1 is 1 etc. etc.
Notice the dataset on the right has a third vector consisted of all 1's. This represents our bias vector and will serve as a third data vector, requiring us to add an additional input node for our NN.

Our NN will require only one single output node which will output either 1 or 0.
How deep a hidden layer should be (recall that the hidden layers were the layers that weren't the output or input layer) is totally subjective but for easier problems like this, a single hidden layer should be fine.

After deciding on the architecture, we then must initialise the weights leading from each node. This can be done in various ways but we initialise them randomly here.

The forward pass begins which means that simply a datapoint is input into the network, and each node processes the input by multiplying it by the weights and sends a signal to the next node according to the output of the activation function. This proceeds until the output layer is reached and we are able to check its output.
If the output is lower than 0.98 and greater than 0.02, we need to apply a backward pass.
We first need to compute the error, which will simply be the difference between the predicted label and the true label of the datapoint that we're trying to predict and if you recall my earlier post, you'll remember that this error was computed using the loss function.
More specifically, we're computing the error with respect to the case, at that particular datapoint, that a particular layer were removed from the network.
We can do this by computing the partial derivative of that loss function with respect to that particular layer and multiplying the result by our step size(recall that in gradient descent we took random 'steps' blindly toward the minimal point on the loss function). If this sounds complicated, then well you'd be right, it is but luckily we don't need to understand it since we're using a high level library in Keras. If you're using Caffe, you'll probably need to know it so here's some reading. WARNING PRETTY DIFFICULT STUFF.
I should've done XXS or site injection for my project. http://neuralnetworksanddeeplearning.com/chap2.html
Yeah so anyway after we've obtained the loss values, multiplied it with the step size we simply add this value to the weight matrix of the layer. BUT wait what’s the weight matrix of the layer? The weight matrix simply denotes the edge weights from the previous layer to the current layer, and are just an easy way to represent these edges.
So the algorithm goes like this:
Forward pass up to the end
Find error and step size product of last layer
Add it to the weight matrix of the current layer
Iterate to the previous layer and repeat ad nauseam or until you've gotten to the input nodes
That was easy.
1 note
·
View note
Text
Unraveling the Power of Deep Learning: A Beginner's Guide
Welcome to our deep learning blog series, where we embark on an exciting journey into the realm of artificial neural networks. In this inaugural blog post, we'll lay the foundation for your deep learning adventure, demystifying the concepts and techniques that drive this powerful field. Whether you're a beginner or have some experience with machine learning, this guide will equip you with the knowledge to understand and appreciate the potential of deep learning.
The Essence of Deep Learning: Deep learning is a subfield of machine learning that focuses on training artificial neural networks to learn and make predictions from vast amounts of data. It enables machines to automatically discover intricate patterns and representations in the data, leading to accurate predictions, classifications, and intelligent decision-making.
Artificial Neural Networks: Building Blocks of Deep Learning: At the heart of deep learning are artificial neural networks, inspired by the interconnected structure of the human brain. These networks consist of layers of interconnected nodes called neurons. Each neuron receives inputs, performs computations, and produces an output. By stacking multiple layers of neurons, neural networks can learn complex representations and capture hierarchical patterns in the data.
Feedforward and Backpropagation: Training Neural Networks: To train a neural network, we employ the feedforward and backpropagation algorithms. During feedforward, input data is propagated through the network, activating neurons and producing output. Backpropagation is the process of calculating the gradients of the network's parameters with respect to a loss function. These gradients guide the adjustment of weights and biases, allowing the network to improve its predictions iteratively.
Activation Functions: Adding Non-Linearity: Activation functions introduce non-linearity to neural networks, enabling them to learn complex relationships in the data. Popular activation functions include the sigmoid, ReLU (Rectified Linear Unit), and tanh (hyperbolic tangent). Each activation function has its characteristics, impacting how information is transformed and propagated through the network.
Loss Functions: Assessing Model Performance: Loss functions quantify the discrepancy between predicted and actual outputs, providing a measure of how well the neural network is performing. Common loss functions include mean squared error (MSE) for regression tasks and categorical cross-entropy for classification tasks. Selecting an appropriate loss function depends on the nature of the problem being solved.
Regularization Techniques: Tackling Overfitting: Overfitting occurs when a neural network performs well on training data but fails to generalize to new, unseen data. Regularization techniques help combat overfitting and improve generalization. Techniques such as L1 and L2 regularization, dropout, and early stopping introduce constraints or modifications to the model, preventing it from becoming overly complex and increasing its ability to generalize.
On embarking on your deep learning journey! In this introductory blog post, we've explored the fundamental concepts of deep learning, including artificial neural networks, training algorithms like feedforward and backpropagation, activation functions, loss functions, and regularization techniques. Armed with this knowledge, you now have a solid foundation to delve deeper into the world of deep learning. In future posts, we'll unravel more advanced topics and explore real-world applications of deep learning. So, stay curious, keep learning, and let the power of deep learning unlock new frontiers in your understanding of artificial intelligence.
1 note
·
View note
Text
Quality assurance and testing | H2kinfosys
Quality assurance and testing are integral components of the software development process, playing a pivotal role in ensuring the delivery of reliable, high-quality software products to end-users. These processes encompass a broad spectrum of activities aimed at identifying and rectifying defects and issues within the software, while also verifying that it meets the specified requirements. In this, we will delve into the essential aspects of quality assurance and testing, highlighting their significance, methodologies, and evolving trends in the ever-evolving landscape of software development.
Quality assurance is a comprehensive approach that focuses on creating a quality-driven culture within a software development organization. It encompasses the entire software development life cycle, from initial planning and design to coding, testing, and maintenance. The primary goal of QA is to prevent defects and issues from arising in the first place, thereby saving time and resources down the line. This proactive approach involves establishing best practices, standards, and processes to ensure that each phase of development adheres to a predetermined set of quality criteria.
Testing, on the other hand, is a specific subset of QA that involves the systematic evaluation of a software product to identify and rectify defects. Testing can be categorized into various levels and types, such as unit testing, integration testing, system testing, and user acceptance testing. These different testing levels focus on verifying different aspects of the software, from individual code units to the overall functionality and user experience. The ultimate aim of testing is to provide stakeholders with confidence in the software's quality and reliability.
One of the cornerstones of quality assurance and testing is the utilization of standardized methodologies and frameworks. These methodologies, such as Waterfall, Agile, and DevOps, provide a structured approach to software development and testing. Waterfall, for instance, follows a linear and sequential model, with each phase being completed before moving on to the next. Agile, in contrast, promotes iterative development, allowing for flexibility and continuous testing throughout the project. DevOps emphasizes collaboration and automation, enabling seamless integration of development and testing. The choice of methodology often depends on the project's nature, scope, and specific requirements.
In recent years, Agile and DevOps have gained widespread popularity due to their ability to adapt to changing customer needs and rapidly evolving market conditions. They emphasize continuous integration and continuous delivery (CI/CD), enabling quick and frequent releases while maintaining a high level of quality through automated testing and deployment pipelines. This approach has transformed the way testing is conducted, as it demands robust automation frameworks, thorough test coverage, and real-time feedback to development teams.
Automated testing, in particular, has revolutionized the testing landscape. It involves the use of testing tools and scripts to execute test cases, comparing actual outcomes with expected results. Automated testing provides several advantages, including repeatability, reduced testing time, and early detection of defects. Test automation tools like Selenium, Appium, and JUnit have become indispensable in modern software development. Furthermore, the incorporation of artificial intelligence and machine learning in testing has opened up opportunities for intelligent test case generation, predictive defect analysis, and self-healing test scripts.
The rise of cloud computing and virtualization has also contributed to the transformation of testing processes. Cloud-based testing solutions offer scalability, cost-effectiveness, and the ability to simulate real-world conditions by accessing a wide range of environments and devices. This is particularly important in the context of mobile and web application testing, where diverse devices, operating systems, and network conditions need to be accounted for.
In addition to the technical aspects of quality assurance and testing, the human element is crucial. Skilled and experienced QA and testing professionals are essential for ensuring a software product's quality. Testers are responsible for test planning, test case design, execution, and reporting. They must possess domain knowledge, an understanding of end-users' perspectives, and the ability to think critically to identify potential risks and areas of improvement. Collaboration and communication skills are equally important, as testers work closely with developers, business analysts, and project managers to convey testing progress and issues.
In conclusion, H2kinfosys quality assurance and testing are fundamental components of the software development process, ensuring that software products meet the highest standards of quality and reliability. These processes encompass a wide range of activities, from preventive measures and proactive quality management to systematic defect identification and rectification. They have evolved in response to changing development methodologies, automation, and technology trends. As the software development landscape continues to evolve, quality assurance and testing will remain indispensable in delivering software that delights end-users and fulfills business objectives.
Tags: QA training, QA testing certification, Best Online training in USA, Top Quality Assurance Online Training in GA USA, qa testing training and job placement, quality assurance analyst training, free online qa testing training, QA testing training, QA analyst job description, quality assurance tester training, free it certification course, quality analyst course,q&a training h2kinfosys, free online learning with certificate, quality assurance certification,qa certification H2kinfosys, qa testing course H2kinfosys, qa tester training H2kinfosys,
#QualityAssurance, #H2kinfosys , #ToptenOnlinetraining, #TestingAutomation,
#OnlineTraining, qaH2kinfosys, #QATesting.
1 note
·
View note
Text
The Sigmoid Activation Function: Understanding its Role in Artificial Neural Networks
In the realm of artificial neural networks, the sigmoid activation function holds a prominent place. Its ability to transform input values into a desired output range has made it a popular choice in various applications, ranging from deep learning to logistic regression. This article aims to shed light on the sigmoid activation function, exploring its characteristics, applications, and advantages.
The sigmoid Activation function is a mathematical equation that maps any real-valued number to a value between 0 and 1. It has a distinctive S-shaped curve, which is where its name originates. The most commonly used sigmoid function is the logistic function, also known as the logistic sigmoid.
The mathematical representation of the logistic sigmoid function is as follows:
f(x) = 1 / (1 + e^(-x))
In this equation, 'e' represents the base of the natural logarithm, and 'x' is the input value. When 'x' is a large positive number, the exponential term approaches infinity, causing the denominator of the fraction to become extremely large. As a result, the sigmoid function tends towards 1. Conversely, when 'x' is a large negative number, the exponential term tends towards zero, causing the sigmoid function to approach 0.
One of the primary applications of the sigmoid activation function is in binary classification tasks. By employing the logistic sigmoid as the activation function in the output layer of a neural network, the network can estimate the probability of an input belonging to a particular class. The sigmoid function's output can be interpreted as the confidence or likelihood that the input belongs to the positive class, with 0 representing low confidence and 1 indicating high confidence.
Another advantage of the sigmoid function is its differentiability. This property is crucial in training neural networks using gradient-based optimization algorithms, such as backpropagation. The sigmoid function has a smooth gradient, allowing efficient computation of gradients during the backpropagation process. This differentiability facilitates the adjustment of network parameters, optimizing the model's performance through the learning process.
However, despite its popularity, the sigmoid activation function also has its limitations. One notable drawback is the vanishing gradient problem. As the input to the sigmoid function moves towards extreme values (either very large positive or negative), the function's gradient becomes extremely small. This vanishing gradient can hinder the learning process in deep neural networks, making it difficult for them to capture and propagate useful information over long distances.
To address the vanishing gradient problem and other limitations, alternative activation functions have been developed. ReLU (Rectified Linear Unit) and its variants, for instance, have gained popularity due to their ability to mitigate the vanishing gradient problem and accelerate training in deep networks. However, the sigmoid activation function still finds its use in specific scenarios, particularly when working with models that require probabilistic outputs or in certain architectures like recurrent neural networks.
In conclusion, the sigmoid activation function has played a crucial role in the development and success of artificial neural networks. Its ability to map input values into a desirable output range, differentiability, and applicability in binary classification tasks make it a valuable tool in machine learning. Although it has certain limitations, the sigmoid function continues to find relevance in various domains, contributing to the advancement of artificial intelligence and deep learning.
For further updates visit inside AIML
1 note
·
View note