
Statistics
We looked inside some of the posts by alfonsojimenez and here's what we found interesting.
Average Info
Notes Per Post
51
Likes Per Post
48
Reblog Per Post
3
Reply Per Post
0
Time Between Posts
4 months
Number of Posts By Type
Text
13
Video
1
Last Seen Tumblr Blogs





Fun Fact
Mobile Tumblr US users spend an average of 4.04 minutes per session on the app.
Text
Backend dinámico en Varnish

Llevamos unos meses usando Varnish Cache como frontend para nuestras aplicaciones. El rendimiento está siendo fantástico, liberando al backend de mucho workload. Como backend, usamos un cluster de Apache con autoscaling en Amazon EC2. Para enroutar peticiones al cluster usamos ELB (Elastic Load Balancing), que ofrece un endpoint con IP dinámica. Uno de los problemas que encontramos al montar la infraestructura fue al definir la configuración del backend en Varnish.
¿Por qué usar ELB?
Antes que nada, preguntémonos porqué queremos usar ELB con IP dinámica en lugar de nuestro propio load balancer. Si estuviésemos usando la segunda opción, la capacidad máxima de nuestra aplicación estaría limitada por la capacidad del tráfico de red entrante de nuestro frontend load balancer, sin importar la cantidad de instancias que tengamos detrás. De esta manera, al disponer de un solo punto de entrada nos encontramos con un bottle neck.
Usando ELB nos aprovechamos de la ventaja de poder usar más de una conexión de red de entrada, ya que según el tráfico existente Amazon usará un load balancer u otro.
El problema de Varnish con backend dinámico
El problema al configurar un backend dinámico en Varnish reside en que no resuelve un registro CNAME para cada petición. Es decir, en la primera petición Varnish resuelve el host y cachea la dirección IP para las peticiones posteriores. En cuanto la IP cambie el backend dejará de estar disponible.
La solución que hemos encontrado es agrupar las instancias de backend del cluster autoscaling en un director. Al ser dinámico, tenemos que autogenerarlo cada vez que una instancia se cree o se destruya. Para ello he escrito un pequeño script en ruby que nos genera el director con las instancias pertenecientes a un grupo de autoscaling.
<![CDATA[// <![CDATA[ // ]]]]><![CDATA[>]]>
Podéis conseguir el script completo en github. Por defecto el script genera los nodos con las IPs privadas de las instancias, así que habría que permitir en el firewall acceder a las máquinas de Varnish a esas instancias. Aún así podéis cambiar esas IPs por las públicas, además de la lógica de arbitrariedad y otras bondades que ofrece Varnish como el healthcheck polling.
Si deseamos eliminar el bottleneck de entrada que comentábamos antes, podemos usar ELB delante de las máquinas que tengamos con Varnish.
3 notes
·
View notes
Text
Instalar Android 4.0 ICS en ExoPC

Ya han sido varias las personas que me han preguntado cómo instalar Android 4.0 Ice Cream Sandwich en una ExoPC Slate. El procesador que la tablet posee es un Intel Atom Pineview-M N450, perteneciente a la segunda generación de cores de Intel Atom (45 nm), que soporta un conjunto de instrucciones x86 (también la extensión de 64 bits). Existe un proyecto open source llamado Android x86 que consiste en portar este sistema operativo a plataformas x86. Desde la propia web del proyecto podemos conseguir imágenes ya compiladas. Para el caso de la ExoPC, tendremos que descargar android-x86-4.0-RC1-tegav2.iso: http://code.google.com/p/android-x86/downloads/list
Una vez que tengamos la imagen, crearemos un dispositivo de arranque usando una memoria flash USB. Para ello, podemos crear el bootloader usando la utilidad unetbootin.
Para la instalación necesitaremos un teclado USB, ya que no se cargarán los drivers de la pantalla multitouch. Para ejecutar el bootloader es necesario tener la memoria USB como prioridad de arranque.
El proceso de instalación tiene una duración de unos 5 minutos aproximadamente creando una partición nueva en el disco. Además, el instalador te ofrece la posibilidad de instalar GRUB, para poder seleccionar durante el arranque la versión/kernel de Android que desees usar. Por otro lado, también podrás crear una fake SD card para almacenar tus datos.
Más información | Android x86
0 notes
Text
Memoization en Ruby
Un ejemplo práctico muy usado cuando se intenta enseñar recursividad es una función que calcule la secuencia de Fibonacci. Una solución trivial en Ruby podría ser la siguiente:
def fib(n) n < 2 ? n : fib(n-1) + fib(n-2) end
Las primeras iteraciones de la secuencia se computan con una profundidad reducida. Por ejemplo fib(6) = 8, fib(7) = 13 o fib(8) = 21. Ejecutando el anterior código en mi máquina, el problema de rendimiento aparece cuando la entrada alcanza valores superiores a 40. Cómo se puede observar, la complejidad del algoritmo es del orden φn. Por ejemplo, para calcular fib(50) es necesario realizar 20.365.011.073 sumas.
Matemáticamente hablando, una función bien definida siempre devuelve un único valor para una determinada entrada. Es decir, un simple mapeo de elementos. Volviendo a la función anterior, sabemos que fib(8) siempre devolverá 21 independientemente del número de veces que ejecutemos la llamada. Un ejemplo de función matemáticamente mal definida sería rand(n), donde podríamos obtener un resultado diferente en varias llamadas con el mismo valor de entrada.
Existe una técnica que permite acelerar el rendimiento de funciones bien definidas llamada memoization. Básicamente consiste en cachear y reutilizar cálculos ya efectuados, ya que sabemos que la función para un valor de entrada n siempre devolverá el mismo resultado. Refactorizando la función fib(n), obtendríamos lo siguiente:
@series = [0,1] def fib(n) @series[n] ||= fib(n-1) + fib(n-2) end
Esta nueva versión almacena los resultados de las llamadas anteriores en un array (@series), reduciendo drásticamente el número de cálculos. De este modo podemos calcular fib(50) = 12586269025 de forma inmediata.
Además existe un gema muy útil llamada memoize, que permite acelerar funciones bien definidas de una manera sencilla. El primer trozo de código quedaría de la siguiente manera:
require 'rubygems' require 'memoize' include Memoize def fib(n) n < 2 ? n : fib(n-1) + fib(n-2) end memoize(:fib)
Para futuras llamadas a fib(n), la gema se encargará de cachear los resultados y aumentará el rendimiento de la función.
Fuente | Wikipedia Fuente | Ruby best practises
18 notes
·
View notes
Text
La importancia del foco y ser constante

A menudo comenzamos proyectos en nuestra vida, tanto personales como profesionales, tanto por placer, por vitalidad o por ánimo de lucro. A priori es sencillo empezar algo, pero menos fácil es mantenerlo y aún más complicado es acabarlo*.
Evitar procrastinación
La procrastinación es la mayor traba para el abandono de proyectos. El aplazamiento eterno, el dejar las cosas para mañana cuando las podemos hacer hoy. Falta de organización, distracciones, nacimiento de otras inquietudes o simplemente desilusión son los factores más comunes que nos lleva a ello. Por suerte o desgracia, nuestro tiempo es limitado y la frustración puede apoderarse de nosotros. En muchas ocasiones la principal razón es un mal planteamiento inicial.
Antes de comenzar algo, piensa si realmente quieres hacerlo
Y es que la raíz de la procrastinación surge antes de comenzar algo. Imagina la satisfacción de hacer ese proyecto que tienes en mente y formúlate una serie de preguntas a ti mismo. Aprendizaje, realización como persona, dinero, reconocimiento. ¿Qué te aportará? ¿Serás más feliz? ¿De verdad quieres hacerlo? ¿No hay otra cosa que prefieras hacer?
No comiences nada hasta que no acabes lo que estás haciendo
Evitar embarcarte en una interminable lista de proyectos, sino nunca acabarás nada. La diversificación es buena en todos los aspectos de la vida, pero hay que gestionar bien el tiempo. Estar ocupado con muchas cosas a la vez es sinónimo de fracaso, ya que de este modo no podrás enfocarte en lo que realmente es importante. Se realista y ten siempre en cuenta tus límites. Creernos un superman o superwoman es una idea equivocada.
Piensa en grande y actúa en pequeño
Think Big, Act Small. La frustración nos puede llegar cuando nos marcamos metas demasiado altas. La solución para ello es simplificar, convertir tareas largas en tareas más cortas realizables en unas horas. Es bueno pensar en grande, pero también hay que focalizarse en el futuro inmediato. A la frase de "piensa en grande y actúa en pequeño" le podemos añadir "se rápido". Conozco de primera mano muchos proyectos que nunca fueron lanzados a causa de una interminable lista de metas, la mayoría innecesarias. Plantéate, ¿todas las features de mi proyecto son estrictamente necesarias para un primer lanzamiento? ¿podrían desarrollarse en una próxima versión? Simplificar nos ayudará a ver progresión, y ello a no frustrarnos y caer en la temida procrastinación.
La mayoría de los proyectos nunca acaban
En el primer párrafo puse un asterisco junto a la palabra acabarlo. Lo cierto es que la mayoría de los proyectos no se acaban. Publicar una primera release no es el fin de un proyecto, más bien se trata del principio. La constancia es la mejor herramienta para combatir el abandono. Al igual ocurre con las relaciones de pareja, que son un proyecto vital impulsado por un instinto de supervivencia que poseemos los seres humanos. La ausencia de la constancia por parte de algún miembro condena una relación al fracaso. Y así en numerosas situaciones cotidianas. Se constante en todas las facetas que engloba tu vida diaria. Con tus proyectos, con tu pareja, con tu trabajo, con tus amigos, etc. Todo funcionará mejor.
3 notes
·
View notes
Text
Volver a escribir

Ya hacía tiempo que no escribía, al menos en público. A pesar de que este humilde blog lleva online desde 2004, apenas he escrito una decena de posts en los últimos 2 años. Se me hace raro responder a la pregunta de ¿tienes un blog?. No voy a entrar en la discusión de si los blogs están muertos o no, de si la blogosfera en realidad existió o de si esto ya no es lo que era. Si no he publicado casi nada últimamente habré tenido mis motivos.
No acuso directamente a la falta de motivación, ni a la escasez de temas de los que hablar (siempre hay algo interesante que contar), ni siquiera al limitado tiempo libre que dispongo. Tal vez culpo a la evolución de la manera de comunicarse digitalmente, que como en otros ámbitos, es inevitable. Siempre he aplaudido la progresión y nunca he temido a los cambios. Por esa razón, nunca digo que los blogs hayan muerto, sino que los medios digitales han evolucionado y las personas con ellos. Años atrás si encontraba algo interesante que contar, lo analizaba en mi blog personal, la gente comentaba y enlazaba mis contenidos, se creaba una conversación. Hoy en día cuando encuentro algo interesante comparto el enlace con mis seguidores en Twitter, éstos vuelven a compartirlo con sus propios seguidores y así sucesivamente. Se ha perdido espíritu crítico, opinión y profundidad sobre los temas a tratar, pero se ha ganado difusión e inmediatez en la propagación de contenidos. Ahora el flujo de información que una persona puede consumir en un día es mucho mayor que en años atrás. Los usuarios cada vez generan menos contenidos, pero consumen más, dejando a los medios profesionales ese rol de productores.
Hace un par de semanas asistí a Evento Blog España 2011, que se celebró como de costumbre en Sevilla. Fue la sexta edición si no me equivoco. No iba desde 2009 y mucho había cambiado desde aquella primera vez en 2006. Muchas caras nuevas, mucha ausencia. Ya no se hablaba de trackbacks, comentarios o Technorati. No me atrevo a decir que el evento está en decadencia, pero sí es cierto que se habló de todo menos de blogs. De todos modos, mi más sincera enhorabuena a la organización por seguir durante tantos años al pie del cañón, pero quizás pronto tendrán que aplicarse al dicho popular de renovarse o morir.
3 notes
·
View notes
Text
fcron and non interactive apt-get install
This is a very short post, but it might be useful for someone with the same problem. I was trying to install fcron on a remote machine via an automated script, but apt-get install couldn’t finish because a dialog using whiptail came up. It wasn’t the common prompt asking yes or no, which can be ignored by the -y option.
Fortunately, there’s a smart workaround to get rid of these prompts:
DEBIAN_FRONTEND=noninteractive apt-get install -q -y fcron
Basically we set the type of user interface used for the installer to noninteractive mode before installing the package. You can always reset DEBIAN_FRONTEND to its default value.
3 notes
·
View notes
Text
Mourinho y la teoría del torneo

Lo importante no es ganar sino participar, es el consuelo para perdedores por excelencia. 27 de Abril de 2010, Camp Nou. El Inter de Milán contra todo pronóstico elimina al FC Barcelona en las semifinales de la Champions League. José Mourinho, técnico del Inter por aquel entonces y émulo de Nereo Rocco, empleó un sistema táctico muy defensivo que noqueó todas las opciones de remontada de los azulgranas. Dicho sistema, popularmente conocido como catenaccio y que prolifera en las formaciones de muchos equipos italianos, fue duramente criticado por los aficionados del Barça tras la eliminatoria. Recibió todo tipo de calificaciones: destructivo, feo, injusto, inmoral, atentatorio de los derechos más sagrados de la humanidad ... pero lo que nadie insinuó es que la estrategia desplegada por el once del jacarandoso Mourinho era ilegal. A pesar de ser la antítesis del juego del Barça, no podemos discutir la validez ni la legimitidad de la victoria del Inter. Y es que esa noche hicieron lo que tenían que hacer, eliminar al equipo rival. Para eso es lo que les pagan. A los futbolistas no les pagan por tener la velocidad ni el regate de Messi, ni el control ni la visión de juego de Xavi, ni la seguridad ni el desparpajo de Pepe Reina, ni siquiera por tener la polla de Yaya Touré. La remuneración que reciben los jugadores de fútbol simplemente tiene como mero objetivo ganar a los rivales. Ganar, ganar y ganar. Eso es lo que mantiene a un equipo en lo más alto y a sus bolsillos llenos. La Teoría del Torneo fue desarrollada por los economistas Edward Lazear y Sherwin Rosen. Esta teoría se usa para calcular remuneraciones variables no dependiendo de la productividad marginal, sino en base a las diferencias relativas entre un grupo determinado de personas que trabajan en una misma organización. De otra manera, este sistema se basa en enfrentar a compañeros de una empresa premiando a aquellos que destaquen sobre los demás en un objetivo determinado. Este premio podría tratarse de una paga extra, una promoción en la organización o un viaje a las Islas Fiji. Las reglas del juego son fáciles, destacar sobre los demás compañeros. Imaginemos por un momento que trabajamos como periodista en la redacción de un diario online. La dirección del rotativo nos premia a cada redactor si un artículo alcanza un número de lecturas en un determinado periodo de tiempo. Este incentivo se trataría de un pago por el rendimiento absoluto, es decir, solamente tiene en cuenta un objetivo global alcanzado por un individuo, dejando a un lado el rendimiento alcanzado por los demás. Sin embargo en la teoría del torneo se mide el rendimiento relativo, teniendo el cuenta el rendimiento de los demás. Entonces la compañía podría cambiar las reglas del juego, premiendo a aquel que escriba el artículo que obtenga más lecturas en un determinado período. Habría varios métodos para conseguir el premio. Algunos se limitarían a intentar escribir buenos artículos, que interesen a un gran número de público y así conseguir el mayor número posible de lecturas. Pero ojo, otros más avispados podrían usar otros métodos menos ortodoxos para conseguir el premio, como intentar que los demás compañeros pierdan. Esto crearía un tenso ambiente de trabajo, rompiendo la armonía del compañerismo. Lo que se diseñó para motivar podría terminar frustrando a los trabajadores. Por eso tenemos que ser cuidadosos y vigilar el ambiente si finalmente decidimos implementar un torneo para motivar a nuestros empleados.
0 notes
Text
5 tips for working from home

I have been working in my pyjamas since more than two years ago. I mean by this that I have been working remotely from home. Now you may be thinking, I could never do that, and yeah, you are right, this kind of job is not made for everyone. It’s got its advantages, but it’s got its disadvantages as well like everything else in the world. If you don’t organize yourself thoroughly, you will never be able to put up with it for a long time. I must to admit that I sometimes miss working in an office with my colleagues, but in the other hand I’m absolutely aware of the great advantages that my current job offers me. I think the right thing to do is try to find a good balance among work and free time. Here you have some tips to help you find that balance.
1. Don’t work and spend your free time in the same place
This is one of the hardest facts for anyone working remotely to stand. It’s very frustrating (and unhealthy?) to sleep, work, eat, have a shower, watch TV, … in only one room. I know sometimes you have no choice since I also had to do all my life within four walls whilst I was living in San Francisco. Having a bed at a few meters from you when you are working on something boring is very tempting. Believe me, your productivity could fall off by far. So as long you can avoid doing this. Try to set up an independent workspace free of distractions.
2. Make people who are living with you realize that you are working
In case you are not living on your own, some people will find hard to realize that you are really working, not spending all day at home. They will tend to talk to you or ask you to do things whilst you are working. Let them know when you knock off.
3. Make a good use of the free time that a telecommute job offers you
One of the best advantages of working from home is the large amount of time that you can save in a day. I have realized that I can have up to 2 hours of free time more than when I was working in an office (trains, traffic stucks, lunch times, …). I normally spend that time on housework (laundry, house cleaning, grocery shopping, cooking, …) and on chilling me out.
4. Have a work timetable and carry it out strictly
Despite some companies already sets you a work timetable, normally they will give you the freedom of work whenever you want within reasonable limits. So this is when you have to discipline yourself and stick to working hours. You can also try to fit your timetable around people living with you, therefore you will avoid becoming very unsociable. Don’t get up too early or too late, design timetable which you can feel comfortable with.
5. Try to be available as much as you can
This is a very important point to have in mind when you are a telecommute worker: availability. Try to be available for your company as much as you can, at least during working hours. There are loads of ways you can be contacted by: phone, mail, IM, VoIP, … It’s very frustrating when you need a guy who you are paying for and you can’t find him/her.
Image | TylerIngram
0 notes
Video
vimeo
2011 Porsche Boxster Spyder. 320-hp, 3.4-liter flat-six
17 notes
·
View notes
Text
La cultura de la propina en los Estados Unidos

Una propina consiste en el pago voluntario como recompensa por un buen trato recibido. Generalmente estos pagos van dirigidos a empleados del sector servicios (camareros, taxistas, …). En Europa es bastante común dejar una parte del cambio como propina cuando la atención por parte del servidor ha sido excepcional y por lo consiguiente el cliente se siente muy satisfecho por ello. En mi caso suelo dejar algo de propina cuando en un restaurante me sirven extraordinariamente bien, es decir, en muy pocas ocasiones. Y con esto no quiero decir que me traten mal ni mucho menos. En muchos restaurantes se incluye en la factura un cargo extra por el servicio (normalmente viene descrito en concepto de cubierto), el cual por ley el cliente está en pleno derecho a no pagar en caso de que el servicio no haya sido lo suficientemente bueno.
En los Estados Unidos la cultura de la propina es bastante peculiar, incluso puede resultar un tanto chocante para el visitante. Es un objeto de opiniones sin límites y dispares, aunque está más que asumido resignadamente por la sociedad estadounidense. Aquí la propina entra en un escenario donde deja de ser voluntaria y pasa a ser una obligación moral. Tal es dicha obligación, que si no se deja propina la sensación equivale a marcharse del establecimiento sin pagar. Esta práctica aceptada por la sociedad establece que es necesario propinar a la persona que te sirve una cantidad comprendida entre el 10% y el 20% del importe total de la factura. Es muy probable que si en un restaurante no dejas nada de propina el camarero te exija su gratificación, ya que lo consideran como una buena parte de su sueldo. Y digo una buena parte de su sueldo porque en los Estados Unidos un camarero normalmente cobra el minimum wage establecido por cada estado, entonces la mayoría de las veces la recaudación de propinas puede llegar a superar al propio salario. De hecho las propinas se incluyen en la declaración fiscal como ingresos (al menos un 8%), un invento del orwelliano IRS (Internal Revenue Service) para intentar subsanar los agravios producidos en la economía sumergida del país, porque… ¿cuanto dinero se mueve al año en los Estados Unidos en concepto de propinas? Obviamente este sistema es el negocio perfecto para el dueño del restaurante, puesto que no necesita pagar a sus empleados un salario relativamente alto, ya que éstos se complementan gracias a la “voluntad” de los clientes y evitan el tener que abonar una cantidad bastante importante de impuestos.
En mi opinión cuando una propina deja de ser voluntaria deja de ser propina. He vivido experiencias totalmente opuestas en otros países como Japón, donde el hecho de dejar una propina puede llegar a ser incluso ofensivo para el camarero. Personalmente pienso que los gastos del servicio deberían de estar incluido siempre en el precio que aparece en el menú, como también lo están la mesa y el mantel que se predispone para el cliente. Además, el buen servicio es aquel que resulta totalmente transparente para el consumidor, no se trata de ofrecer una adulación extrema por el mero hecho de conseguir una propina mayor.
Un argumento, que por cierto no me gusta nada, a favor de las propinas obligatorias en USA se basa en que el salario medio de un camarero es bastante bajo. Aunque no me da exactamente igual, me temo decir que este problema no atañe al cliente. Puestos así hasta se puede considerar como una desigualdad de oportunidades respecto a otros trabajadores de sectores diferentes y con sueldos bajos. De este modo, ¿por qué no propinamos a una señora de la limpieza o a un cajero de de un supermercado?
También cabe decir que el sistema proclive a calcular una propina basada proporcionalmente al total de la factura me parece un tanto irracional. Siguiendo la regla del 20%, si en un restaurante pido una botella de vino valorada en $40 necesitaría pagar $8 en concepto de propina. Sin embargo, si pido otra botella valorada en $400, el gasto correspondiente a la propina asciende a $80. ¿Realmente supone al camarero una carga mayor de trabajo traer una botella más cara o más barata? A mi modo de ver, esta fórmula carece de sentido.
Por suerte o degracia y debido al carácter intangible del asunto, seguiré propinando a diestro y siniestro mientras esté por Estados Unidos, remitiéndome al proverbio de San Ambrosio de Milán, cuando estés en Roma, haz como los romanos.
1 note
·
View note
Text
Integrating Yahoo r3 with phing
Yahoo r3 is a powerful tool for building websites which could require multiple
languages or dimensions. The r3 outputs may be plain text files, web templates, configuration files or even source code. Sometimes maintaining a big site translated into different languages can become a nightmare, but r3 lets you do it on an easy way. It offers a neat and powerful command line interface which will make your life easier. It can also be managed by using a web interface.

I know this could be a somewhat confusing thing to explain, so I’m going to try to give an example of what you can do with it. At Weblogs SL, we have a platform which handles instances of 37 blogs in 2 languages (Spanish and Portuguese), so we have to maintain 37×2 = 74 sites. They almost share the same layout
So after far too much research, we came up with Yahoo r3, but we still had an itch to scratch: how can we integrate this into our continuous integration workflow? We are using Phing (and Java Ant) for building our sites, so it was nice to have some Phing tasks to work with r3. So I wrote these two tasks:
r3GenerateTask.php
require_once 'phing/Task.php'; /** * r3 Generate Task * * PHP version 5 * * @category Phing Task * @package phing * @author Alfonso Jimenez * license http://www.gnu.org/licenses/gpl.html GPL * */ class r3GenerateTask extends Task { /** * path to r3 workspace * * var string */ protected $r3Workspace; /** * init method * * @return boolean */ public function init() { return true; } /** * main method * * @return void */ public function main() { $command = 'r3 -c '. $this->Workspace .' generate -av'; $output = array(); $return = null; try { exec($command, $output, $return); foreach ($output as $line) { $this->log($line, Project::MSG_VERBOSE); } if ($return !== 0) { throw new BuildException('Task exited with code'. $return); } } catch (BuildException $e) { $op = Project::MSG_WARN; if ($this->quiet === true) { $op = Project::MSG_VERBOSE; } $this->log($e->getMessage(), $op); } } }
r3SetVarTask.php
require_once 'phing/Task.php'; /** * r3 setVar Task * * PHP version 5 * * category Phing Task * package phing * author Alfonso Jimenez <[email protected]> * license http://www.gnu.org/licenses/gpl.html GPL * */ class r3SetVarTask extends Task { /** * path to r3 workspace * * var string */ protected $r3Workspace; /** * dimension * * @var string */ protected $dimension; /** * variable key * * @var string */ protected $key; /** * variable value * * @var string */ protected $value; /** * sets the r3 workspace path * * param string $r3Workspace * * return void */ public function setr3Workspace($r3Workspace) { $this->r3Workspace = $r3Workspace; } /** * sets dimension * * param string $dimension * * return void */ public function setDimension($dimension) { $this->dimension = $dimension; } /** * sets the variable key * * param string $key * * return void */ public function setKey($key) { $this->key = $key; } /** * sets the variable value * * param string $value * * return void */ public function setValue($value) { $this->value = $value; } /** * init method * * @return boolean */ public function init() { return true; } /** * main method * * @return void */ public function main() { $command = ‘r3 -c ‘. $this‐>r3Workspace .’ var set ‘. $this‐>dimension �� .’ ‘. $this‐>key .’ ‘. $this‐>value; $output = array(); $return = null; try { exec($command, $output, $return); foreach ($output as $line) { $this->log($line, Project::MSG_VERBOSE); } if ($return !== 0) { throw new BuildException(‘Task exited with code’. $return); } } catch (BuildException $e) { $op = Project::MSG_WARN; if ($this->quiet === true) { $op = Project::MSG_VERBOSE; } $this->log($e->getMessage(), $op); } } }
If you want to use these tasks in your Phing file, you have to place them in /usr/share/php/phing/extended/tasks/ first. Then you can call them by writing the following tag-commands:
<taskdef name=”r3-generate” classname=”extended.tasks.r3GenerateTask” /> <taskdef name=”r3-setVar” classname=”extended.tasks.r3SetVarTask” />
<r3-generate r3Workspace=”${workspace.dir}”></r3> <r3-setVar r3Workspace=”${workspace.dir}” dimension=”${dimension}” key=”var_key” value=”${var_value}”></r3>
Let’s see an example of a real Phing file. Imagine that we have to write a task which needs to do the following steps:
Get a Yahoo r3 workspace from a SVN repository (http://svn.test.com/trunk/r3)
Build the Yahoo r3 workspace
Move the generated templates into a certain directory
Clean up the temporary files
So we can straightforward write a Phing task in order to follow this sequence of steps:
<?xml version="1.0"?> <project name="Yahoo r3 Templates Build" basedir="." default="build"> <property name="tmp.dir" value="/tmp/template" /> <property name="templates.dir" value="/home/r3/templates" /> <property name="svn" value="http://svn.test.com/trunk/r3" /> <target name="build" depends="init, generate, clean" /> <target name="init"> <taskdef name="r3-generate" classname="extended.tasks.r3GenerateTask" /> <mkdir dir="${tmp.dir}" /> <svncheckout svnpath="/usr/bin/svn" repositoryurl="${svn}" todir="${tmp.dir}"/> </target> <target name="generate"> <r3-generate r3Workspace="${tmp.dir}"></r3-generate> </target> <target name="clean"> <copy todir="${templates.dir}"> <fileset dir="${tmp.dir}/htdocs"> <include name="**" /> </fileset> </copy> <delete dir="${tmp.dir}" includeemptydirs="true" failonerror="true" /> </target> </project>
0 notes
Text
phpredis, 2 Fast 2 Furious

Redis (REmote DIctionary Server) is a persistent key-value database with built-in net interface written in ANSI-C for Posix systems. Whilst it may at first seem like the wheel is being reinvented here, the need for something beyond a simple key-value database is pretty clear. It’s possible to use Redis like a replacement of memcached, with the main difference being the dataset is stored persistently – not volatile data – and Redis introduces new data structures such as list and sets. Furthermore, it implements atomic operations in order to interoperate with these data structures.
I released a PHP extension called phpredis a couple of weeks ago, which works as a PHP client API for Redis. The project is hosted at Google Code at the moment, and you can get the code directly from the SVN repository: http://phpredis.googlecode.com/svn/trunk/.
Despite a vanilla PHP client library already exists, I felt the need to write it since a PHP extension normally performs better and I wanted to make the most of Redis potential.
Let’s see a snippet of how to make a simple operation to Redis using the PHP client:
$redis = new Redis(); $redis->connect('127.0.0.1', 6379); $redis->set('key', 27); echo $redis->get('key'); // it should print 27 $redis->incrby('key', 3); echo $redis->get('key'); // it should print 30
The code above was quite obvious, it stored a value associate to key and it increments its value by 3. Let’s see another snippet a bit more complex, for example using a list:
$redis = new Redis(); $redis->connect('127.0.0.1', 6379); $redis->lPush('list', 'val'); $redis->lPush('list', 'val2'); $redis->lPush('list', 'val3', 1); echo $redis->lPop('list', 1); // it should print val3 echo $redis->lPop('list'); // it should print val2 echo $this->lPop('list'); //it should print val
Notice that depending on the last optional parameter (0 by default) it’s possible to append/extract an element to/from the tail or to/from the head of the list.
There is a list including all the available methods. At the moment, I’m working on the implementation of more new Redis commands and on the support for complex data structures such as arrays and PHP objects.
Apart from phpredis, there are more client API for languages as Perl, Python, Ruby and Erlang. You can find this and more at the Redis project homepage. Redis has been written by Salvatore Sanfilippo who I’m chuffed to bits with.
1 note
·
View note
Text
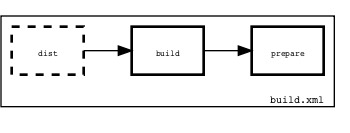
Visualization of a Phing buildfile
Raphael Stolt published a method to get a visualization of a Phing buildfile a few days ago:
Out of the box the Phing -l option can be used to get a first overview of all available targets in a given buildfile but it doesn’t untangle the target dependencies and sometimes a picture is still worth a thousand words. Luckily the Ant community already provides several tools to accomplish the visualization of Ant buildfiles, reaching from solutions that apply a Xslt stylesheet upon a given buildfile.
He uses the ant2dot tool and the Graphiz library to show the XML from a buildfile into a graphic. The image represents the flow of the build.
0 notes
Text
Multiple Constructors in PHP

As you probably know, it’s possible to have multiple constructors in Java. They need to have the same name as the class, and they can only be distinguished by the number and type of arguments. In PHP5, you can only have one constructor. You can define it using the reserved word __construct. If the __construct function doesn’t exist, PHP5 will search for the old-style constructor function (by the name of the class). So if we cannot have multiple constructors, how could we create objects with different initial conditions? It’s not a big deal. There’s a pattern called Factory Method, which defines virtual constructors using static methods. Let’s see an example:
class Person { private $name; private $email; public static function withName($name) { $person = new Person(); $person->name = $name; return $person; } public static function withEmail($email) { $person = new Person(); $person->email = $email; return $person; } public static function fullPerson($name, $email) { $person = new Person(); $person->name = $name; $person->email = $email; return $person; } }
We have a class called Person which contains 2 private attributes: name and email. It also has 3 static methods: withName, withEmail and fullPerson. These methods will behave like constructors.
So if we want to create a Person object just with the name value, we can do it using the following statement:
$person = Person::withName('Example');
2 notes
·
View notes