
Tel.: +32 495 88 07 98 @: [email protected] www.linkedin.com/in/ouallahoubayda
Don't wanna be here? Send us removal request.
Statistics
We looked inside some of the posts by datasmart and here's what we found interesting.
Average Info
Notes Per Post
4
Likes Per Post
3
Reblog Per Post
1
Reply Per Post
0
Time Between Posts
10 months
Number of Posts By Type
Text
5
Photo
1
Last Seen Tumblr Blogs





Fun Fact
The average Tumblr user visits about 67 pages every month.
Text
Le machine learning chez Amazon:

Alors que les autres géants de la tech profitent de chaque opportunité pour montrer leurs prouesses en matière d’intelligence artificielle (assistant vocal d’Apple, les voitures autonomes…), Amazon semble avoir adopté une approche plus subtile. Evidemment, l’opportunisme existe aussi chez Amazon (Alexa pour concurrencer Siri, prédiction pour son service cloud…). Mais ses algorithmes les plus stratégiques sont ceux qui lui permettent de rationaliser ses propres opérations.
Optimisation :
Les robots gèrent déjà une grande partie du in/out dans les centres de distribution. Pour optimiser les flux d’acheminement de marchandise, un algorithme de machine learning est utilisé. En effet, une attention particulière est accordée au temps d’attente pour le collaborateur humain qui doit ensuite scanner les produits manuellement. Un flux plus rapide des marchandises permet de réduire l’attente pour le collaborateur humain et d’améliorer les délais de livraison.
Prédiction :
Amazon-web-service (Aws) est un autre pôle d’activité du géant américain. L’entité offre aux entreprises des services de cloud-computing pour héberger les sites web et applications. La prédiction de la demande (le nombre de requêtes que les servers doivent exécuter) est une des préoccupations majeures pour les data scientists d’Aws. S’il n’y a pas suffisamment de puissance pour exécuter les requêtes, des erreurs peuvent êtres générées (ce qui se traduit notamment en perte pour le client). Amazone ne peut pas voir ce qui est hébergé, mais le trafic généré par chacun de ses clients peut être analysé… Comme pour les centres de distribution, les métadonnées qui alimentent les modèles de machine learning servent à prédire la demande et optimiser l’offre.
Développé pour servir :
Le dernier projet algorithmique développé par Amazone a permis de créer le premier magasin sans caisse (Amazon GO). L’algorithme de body-tracking est un algorithme de reconnaissance d’images avancé. Le système permet d’analyser les mouvements du corps via les caméras. Ainsi, l’algorithme a appris à détecter quand une personne prend un produit, remet le produit…. Il ne lui reste plus qu’à faire la somme des produits quand le consommateur quitte le magasin. L’entreprise l’assure, la reconnaissance faciale n’est pas utilisée pour identifier le consommateur et le lier à son compte Amazone. Un système de code-barre a été préféré pour faire le match entre les produits achetés et l’acheteur.
L’algorithme de body-tracking pourrait aussi servir dans les centres de distribution. L’objectif serait d’optimiser les temps de scanning en permettant une reconnaissance du produit peut import la manière dont le collaborateur humain le manipule. Cela permettrait de rationaliser encore un peu plus ses opérations. Il n’ y a pas de petites économies chez le leader du shopping online.
(Source: The economist 11/04/2019)
0 notes
Text
Quel business model pour la data ?
Si la data est le nouveau pétrole, notez que le pétrole brut ne vaut pas grand-chose à l’extraction. Au moment j’écris ces lignes, il ne coûte que 0,303 €/L (02/2019). Ce n’est qu’une fois qu’il est transformé, mélangé…raffiné (c’est-à-dire séparer les très nombreuses molécules qui le composent) qu’il gagne en utilité et se vend à 1,402€/L à la pompe (E10) ou sert de composants à de nombreux produits du quotidien. Il en va de même pour les données.
La valeur data, et donc son prix, dépend d’un certain nombre de facteurs. La quantité est peut-être le plus évident. Mais il y en a beaucoup d’autres, dont notamment le coût de traitement, les délais de péremption ou encore la demande. Par ailleurs, « beaucoup de données » ne veut pas nécessairement dire beaucoup de valeur.
Plus généralement, on peut considérer que la valeur data dépend de l’intérêt stratégique pour le client, le niveau de sophistication de l’analyse/traitement(≈raffinage) et le revenu potentiel que la donnée peut générer.
Cette nouvelle source de valeur a fait émerger différents business models dont 3 sont repris ci-dessous :
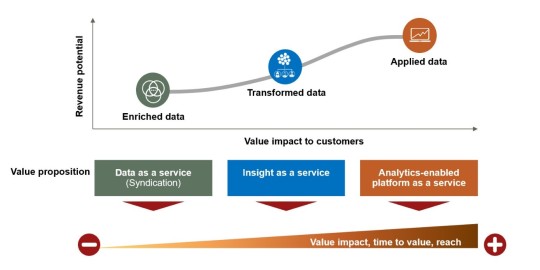
Data as a service. Le business model où la valeur ajoutée est la plus faible. Les données sont agrégées et anonymisées pour être directement vendues à des intermédiaires ou au client final. Les TELCO fournissent ainsi des données de localisation aux autorités locales pour la gestion du trafic ou alimenter les technologies de la « Smart city », les données de payement électronique ou encore les données générer par la grande distribution (via les cartes de fidélité) font aussi l’objet d’un vif intérêt : Orange, proximus, Tesco…
Insight as a service. Les entreprises peuvent aussi combiner les données internes avec des données externes (achat/partenariat) et appliquer des analyse avancée (Machine Learning) pour fournir des insights actionnables. L’entreprise néerlandaise AkzoNobel (spécialisée dans les peintures et produits chimiques) a développé un modèle de prise de décision qui permet aux opérateurs maritimes de faire de belles économies d’énergie (carburent & CO2).
On pourrait s’interroger sur les motivations d’une entreprise spécialisée dans les peintures à fournir à ses clients une application de prise à la décision. C’est aussi ça la révolution data : des acteurs sur des terrains inattendus avec de nouveaux services aux clients.
Analytics-enabled platform : Le business model le plus complexe, mais offre le bénéfice potentiel le plus élevé. Il s’agit ici de développer des algorithmes sophistiqués pour enrichir et transformé des données délivrées en temps réel via le cloud ou une Platform self-service. Ce model permet à une entreprise d’accéder à de nouveaux marchés et parfois de créer un nouveau business.
Predix est une platform développée pas General Electric qui permet au client d’avoir des prédictions et des prescriptions concernant la consommation électrique des machines industrielles GE, la maintenance et autres indicateurs qui permettent une réduction des coûts et de simplifier les process.
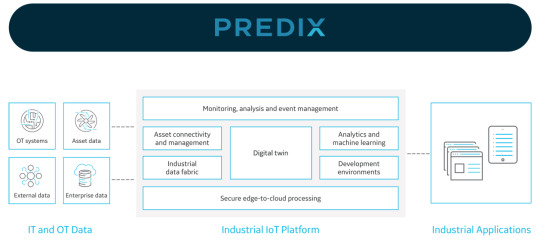
Il va sans dire que le troisième modèle est le plus intéressant en termes de profit potentiel. Il est aussi celui qui exige le plus de ressources techniques et d’investissements de départ. Permettre à l’utilisateur de conduire ses propres analyses nécessite une grande quantité de données, le développement et l’intégration des méthodes d’analyse/algorithmes avancées…avec une infrastructure à la hauteur. Tout le monde ne peut pas y prétendre.
Vendre la data seule est le modèle le plus simple à mettre en place. Encore faut-il avoir la data qui a de la valeur pour le marché. Et quand bien même elle en aurait, il faut souvent que la quantité soit au rendez-vous. Il y a là aussi beaucoup de défis à relever : le nouveau contexte imposé par l’entrée en vigueur du GDPR ne facilite pas les choses.
Pourtant on peut aussi créer de la valeur avec la data sans directement la vendre. C’est sur quoi repose le deuxième modèle. Il s’agirait de vendre l’information qui répond aux besoins du client via des insights ou des prescriptions sans vendre la data. Les quelques initiatives de partage de données avec des secteurs stratégiques offrent de belles opportunités en la matière et l’apparition de nouveaux services. Ainsi, on ajoute de la valeur tout en restant maître de la matière première. Se pose alors la question de la confiance. Les exemples de manipulation ne manquent pas. Les plus gros ont réussi à forcer la confiance de leur client. Mais pour les plus petit, il va falloir convaincre…le client ne va pas payer les yeux fermés pour des insights qui n’ont pas démontré leur intérêt.
0 notes
Photo
Fact: Socks As Gift analysis on Python(Sample size=3). #python #fact #matplotlib #numpy #chistmas #statisFUN
0 notes
Text
The Zen of Python
Beautiful is better than ugly. Explicit is better than implicit. Simple is better than complex. Complex is better than complicated. Flat is better than nested. Sparse is better than dense. Readability counts. Special cases aren't special enough to break the rules. Although practicality beats purity. Errors should never pass silently. Unless explicitly silenced. In the face of ambiguity, refuse the temptation to guess. There should be one-- and preferably only one --obvious way to do it. Although that way may not be obvious at first unless you're Dutch. Now is better than never. Although never is often better than *right* now. If the implementation is hard to explain, it's a bad idea. If the implementation is easy to explain, it may be a good idea. Namespaces are one honking great idea -- let's do more of those!
4 notes
·
View notes
Text
Statistique et sciences des données….
Par Hadley Wickham chercheur en chef chez Rstudio et professeur de statistique à l’Université de Rice (USA).
Dans un article publié par l’Institut de statistique mathématique , H. Wickham met en exergue les opportunités et certaines limites concernant le confusion naturelle entre statistique et la science des données. Les statistiques sont indispensables pour l’analyse des données. Mais en même temps, les départements de statistique continuent à se concentrer sur des problèmes qui ne sont plus pertinents en ce qui concerne l'analyse des données telle qu'elle est aujourd'hui. On pense tous à ces datasets avec toujours la bonne structure pour appliquer la technique. L’auteur met ainsi en évidence la part de l’analyse des données qui est hors du champ/domaine purement statistique.
Les trois étapes de l’analyse des données, selon Wickham, sont:
1) Collecter les données (et les questions):
2) Analyser ( par la visualisation et les modèles)
3) Communiquer les résultats obtenus.
Il est rare que les étapes se suivent sans détour. Parfois, les résultats mettent en évidence une erreur dans le modèle ou la nécessité de collecter d’autres données .
La science statistique a beaucoup de chose à dire sur la collecte des données: échantillonnage, enquête, expérimentations sont bien maîtrisés par des décennies de recherche. Mais les statisticiens ont peu à dire sur le “comment” collecter et affiner les questions. En effet, pour faire de bonnes analyses, il faut d’abord (se) poser les bonnes questions. Mais il y a peu de recherche en statistique sur l’élaboration des "bonnes questions" selon Wickham. Ce n’est pas une compétence particulièrement développée, même chez les Phd.
Une fois les données collectées, il faut les ordonner (ou les normaliser) de sorte qu’elles soient “analysables”. Mettre les données dans la bonne forme est essentiel pour une analyse fluide. Si les données sont dans une forme inadaptée, on passe parfois plus de temps à les mettre en forme qu’à les interroger.
Ensuite, toute analyse des données implique leur manipulation (mettre en forme, croiser, découper), visualisation (essentiellement graphique mais pas uniquement) et modélisation (mathématique). La visualisation et la modélisation sont complémentaires. La visualisation peut surprendre et aider à (re)définir une série de questions. Cependant, la visualisation dépend de l'interprétation humaine, et par là sa fiabilité est limitée. En ce qui concerne le modèle, la fiabilité est meilleure (les logiciels sont d’une aide précieuse) . Mais le modèle est limitée par ses hypothèses. Un modèle par nature ne peut pas surprendre. Il ne va que confirmer (ou rejeter) ce que nous supposions. Ainsi, quelle que soit l’analyse, on peut utiliser la visualisation et la modélisation. Mais la recherche statistique a été surtout menée sur la modélisation. L'attention a rarement porté sur la visualisation et encore moins sur comment trouver le compromis entre visualisation et modélisation .
L’objectif final de l’analyse n’est pas qu'un modèle, mais aussi une rhétorique. Une analyse n’a pas de sens si elle ne parvient pas à convaincre quelqu’un d’agir. Dans le business, ça veut dire convaincre le manager. En science, il faut convaincre les pairs. La communication fait partie du programme académique. Mais elle tend à se concentrer sur la communication entre statisticiens, et non avec des personnes qui ont une expertise dans un autre domaine (business, publicité, biologie…). Par ailleurs, dans le business, les analyses ne se font pas qu’une fois. il faut réactualiser au fur et à mesure que les nouvelles données arrivent. Ainsi, ces “data products” (données en tant que produit) exigent des compétences statistiques solides, mais également des compétences informatique/maîtrise de l’infrastructure (computing).
La science statistique n’est qu'une part de la science des données. Elle s’est concentré sur la collecte et la modélisation. Mais la science statistique n’a pas encore développé le “comment” des bonnes questions, de la forme des données, de la communication des résultats, de la construction de données en tant que produit. Il y a donc à faire en la matière et c'est en cela que la science des données doit s'appliquer.
Source: Institute of Mathematical Statistics Billetin: "Data science: how is it different to statistics?"
0 notes
Text
Big Data ou Big Erreur!!!
Il y a plus élogieux pour se vendre. Mais je voulais donner le ton! Dans son cours d’introduction à la finance, Jake Xia, professeur au MIT, met en garde ses étudiants contre ces algorithmes prétendument “intelligents”. Il rappelle à juste titre les limites de ses méthodes et la nécessite de toujours les actualiser.
Le premier article que je tenais à partager a été publié en mars 2014 dans le Financial Times sous la plume de Tim Harford. Une manière de remettre "gentillement" l’église au milieu du village sans jeter le bébé avec l’eau du bain.
T. Hardford nous explique comment certains ont vendu l’idée "séduisante" qu’avec l’accumulation massive des données, les chiffres parleraient d’eux-même. Nous pourrions ainsi nous affranchir de la théorie et de la technique statistique. En effet, le volume de données a atteint des sommets, actualisées régulièrement, de plus en plus précises et bon marché. Nous n'aurions plus qu’à balancer nos syllabus de théorie de sondage et d’inférence. "Fini les intervalles de confiance et les probabilités d'inclusion...On peut zapper les formules, les gars!!! Le Big Data est là!!!” Seulement c’est loin d’être aussi simple.
L’auteur illustre assez bien son propos par de nombreux exemples… Au delà des problèmes techniques, il nous rappelle cette histoire qui a fait briller l’Institut Gallup. Les statisticiens la connaissent bien. En 1936, Alfred Landon (Republicain) se présente contre Roosevelt (Démocrate). Un magazine respecté, le Literary Digest, qui ne manquait pas de moyens sonde 2.400.000 personnes (un Big Data pour l’époque). Sur cette base qu’il croit solide, le Literary Digest prédit la victoire de Landon. Dans le même temps, George Gallup, prédit le contraire avec un échantillon de seulement 3000 personnes. C’est Roosevelt qui l’emporte.
Les questionnaires du Literary Digest avaient été envoyées aux abonnés du téléphone et aux propriétaires de voitures, autrement dit des gens aisés, plus favorable aux républicains. Là où G. Gallup avait pris soin de construire un échantillon représentatif de l’électorat. “Mr Gallup understood something that The Literary Digest did not”.
Ceux qui ont gardé leur syllabus sous la main pourront aller vérifier. En matière de prédiction, sondage et inférence, la taille n’est pas tout. Le “Big” ne doit pas éclipser le reste. Un petit échantillon de qualité peut faire aussi bien, si pas mieux, que la plus volumineuse des bases de données. Les utilisateurs de Twitter par exemple, aussi nombreux soient-ils, ne sont pas représentatifs de la population dans son ensemble (plutôt jeunes, issus des villes…). Ainsi, en apportant des solutions, le Big Data lance aussi un certain nombre de défis qui exigent rigueur et compétence.
Il est certain que le Big Data est plein de promesses...quand il n'est pas déjà en action. Mais pour en tirer pleinement profit et ne pas répéter les erreurs du passé, il faut un peu plus que des vendeurs.
À bon entendeur, salut !
Source: Big data: are we making a big mistake? By Tim Harford
0 notes