
Don't wanna be here? Send us removal request.
Statistics
We looked inside some of the posts by iwebscraping and here's what we found interesting.
Average Info
Notes Per Post
9
Likes Per Post
7
Reblog Per Post
2
Reply Per Post
0
Time Between Posts
17 days
Number of Posts By Type
Text
2
Last Seen Tumblr Blogs




Fun Fact
28.6 is the average number of monthly visits per US mobile user.
Text
How Scraping LinkedIn Data Can Give You a Competitive Edge Over Your Competitors?

In the era of digital world, data is an important part in any growing business. Apart from extracting core data for investigation, companies believe in the usefulness of open internet data for competitive benefits. There are various data resources, but we consider LinkedIn as the most advantageous data source.
LinkedIn is the largest social media website for professionals and businesses. Also, it is one of the best sources for social media data and job data. Using LinkedIn web scraping, it becomes easy to fetch the data fields to investigate performance.
LinkedIn holds a large amount of data for both businesses and researchers. Along with finding profile information of companies and businesses, it is also possible to get data for profile details of the employees. LinkedIn is the biggest platform for job posting and searching jobs related information.
LinkedIn does not provide an inclusive API that will allow data analysts to access.
How Valuable is LinkedIn Data?
LinkedIn has registered almost 772 million clients among 200 countries. According 2018 data, there is 70% growth in information workers for the LinkedIn platform among 1.25 billion global workers’ population.
There are about 55 million firms, 14 million disclosed job posts, and 36000 skills are mentioned in LinkedIn platform. Hence, it is proved that web data for LinkedIn is extremely important for Business Intelligence.
Which type of Information Is Extracted From LinkedIn Scraping?
Millions of data items are accessible on the platform. There is some useful information for customers and businesses. Here are several data points commonly utilized by LinkedIn extracting services. According to data facts, LinkedIn registers two or more users every second!
Public data
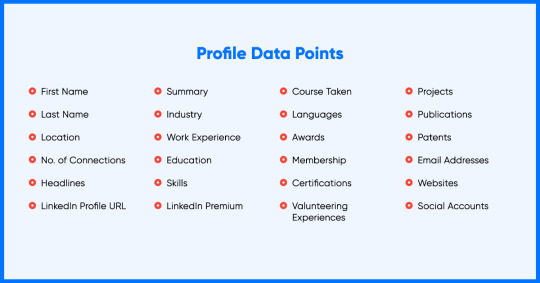
Having 772 million registered user accounts on LinkedIn and increasing, it is not possible to manually tap on the capital of such user information. There are around 100 data opinions available per LinkedIn account. Importantly, LinkedIn’s profile pattern is very reflective where a employer enters entire details of career or study history. Then it possible goes to rebuild an individual’s professional career from their work knowledge in a information.
Below shown is an overview of data points fetched from a personal LinkedIn users.
Company Data
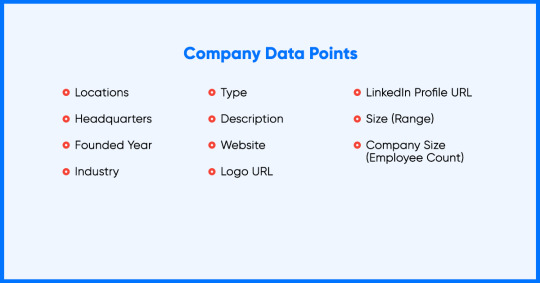
Organizations invest resources for upholding their LinkedIn profile using key firmographic, job data, and public activity. Fetching main firmographic data will enhance companies to remain ahead of the opposite companies and investigate the market site. Firms need to search filters such as industry, business size, and geological location to receive detailed competitive intelligence.
It is possible to scrape company’s data with necessary information as shown below:
Social Listening Information:

Either in research, business discipline, or any other economics, what data a top executive will share on social media platforms is as valuable as statistics with probable business impact. We can capture new market expansion, executive hires, and product failures, M&As, or departures. This is the fact because individuals and companies initiate to be more live on LinkedIn.
The point is to stay updated on those indicators by observing the social actions of the top experts and companies.
One can fetch data from the social actions of LinkedIn by highlighting the below data points.
How Businesses use LinkedIn Data Scraping?

Using all the available data, how will business effectively utilize the data to compete in the market. To learn this, there are few common use cases for information.
Research
Having the capability of rebuilding whole careers for creating a LinkedIn profile, one can only think how broad it is in the research arena.
Research institutions and top academic are initiating to explore the power of information and are even starting to integrate LinkedIn in their publications as a reference.
We can choose an example as fetching all the profiles corporated with company X from 2012 to 2018 and collecting data items such like skills, and interacting to the sales presentation of the company X. It can be assumed that few abilities found in workers would result in an outstanding company.
Human Resources
Human resources are all about people, and LinkedIn is a database record of experts across the globe. One creates a competitive advantage that goes to any recruiter, HR technical SaaS, or any service provider. It is obvious that searching them physically on LinkedIn is not that extensible, but it is valuable when you have all the data with you.
Alternative Information For Finance
Financial organizations are looking forward for data to calculate better investment capability of the company. That is where people’s data play an important role and drives the presentation of the company.
The capability of LinkedIn User information of all the employees cannot be judged. Organizations can utilize this information to monitor business hierarchies, educational backgrounds, functional compositions, and more. Furthermore, gathering the information will provide insights like key departures/ executive hires, talent acquisition policies, and geographical market expansions.
Ways to Extract LinkedIn Data
Looking forward to reader’s advantage, web data scraping for LinkedIn is a method that will use computer programming to enhance data fetching from several sources like sites, digital media platforms, e-commerce, and webpages business platforms. If someone is professional enough to build the scraper, then you can build it. But, extracting LinkedIn information has its challenges with a huge figure of information and social media platform control.
There are various LinkedIn data scraping tools available in the marketplace with distinguishing factors such as data points, data quality, and aggregation scale. Selecting the perfect data partner according to your company’s requirement is quite difficult.
Here at iWeb Scraping, our data collecting methods are continuously evolving in providing LinkedIn extracting service delivering scraping results with well-formatted complete data points, datasets, and even first-class data.
Conclusions
LinkedIn is a far-reaching and filter-after data source from public and company information. This is predictable for more growth as the company continues to utilize more employers. The possibility of using the volume of data is boundless and business firms might start capitalization for this opportunity.
Unless you know the effective methods for scraping, it is better to use LinkedIn scrapers developed by experts. Also, you can ping us for more assistance regarding LinkedIn data web scraping.
https://www.iwebscraping.com/how-scraping-linkedin-data-can-give-you-a-competitive-edge-over-your-competitors.php
6 notes
·
View notes
Text
How to Extract Product Data from Walmart with Python and BeautifulSoup

Walmart is the leading retailer with both online stores as well as physical stores around the world. Having a larger product variety in the portfolio with $519.93 Billion of net sales, Walmart is dominating the retail market as well as it also provides ample data, which could be utilized to get insights on product portfolios, customer’s behavior, as well as market trends.
In this tutorial blog, we will extract product data from Walmart s well as store that in the SQL databases. We use Python for scraping a website. The package used for the scraping exercise is called BeautifulSoup. Together with that, we have also utilized Selenium as it helps us interact with Google Chrome.
Scrape Walmart Product Data
The initial step is importing all the required libraries. When, we import the packages, let’s start by setting the scraper’s flow. For modularizing the code, we initially investigated the URL structure of Walmart product pages. A URL is an address of a web page, which a user refers to as well as can be utilized for uniquely identifying the page.
Here, in the given example, we have made a listing of page URLs within Walmart’s electronics department. We also have made the list of names of different product categories. We would use them in future to name the tables or datasets.
You may add as well as remove the subcategories for all major product categories. All you require to do is going to subcategory pages as well as scrape the page URL. The address is general for all the available products on the page. You may also do that for maximum product categories. In the given image, we have showed categories including Toys and Food for the demo.
In addition, we have also stored URLs in the list because it makes data processing in Python much easier. When, we have all the lists ready, let’s move on for writing a scraper.
Also, we have made a loop for automating the extraction exercise. Although, we can run that for only one category as well as subcategory also. Let us pretend, we wish to extract data for only one sub-category like TVs in ‘Electronics’ category. Later on, we will exhibit how to scale a code for all the sub-categories.
Here, a variable pg=1 makes sure that we are extracting data for merely the first URL within an array ‘url_sets’ i.e. merely for the initial subcategory in main category. When you complete that, the following step might be to outline total product pages that you would wish to open for scraping data from. To do this, we are extracting data from the best 10 pages.
Then, we loop through a complete length of top_n array i.e. 10 times for opening the product pages as well as scrape a complete webpage structure in HTML form code. It is like inspecting different elements of web page as well as copying the resultants’ HTML code. Although, we have more added a limitation that only a part of HTML structure, which lies in a tag ‘Body’ is scraped as well as stored as the object. That is because applicable product data is only within a page’s HTML body.
This entity can be used for pulling relevant product data for different products, which were listed on an active page. For doing that, we have identified that a tag having product data is the ‘div’ tag having a class, ‘search-result-gridview-item-wrapper’. Therefore, in next step, we have used a find_all function for scraping all the occurrences from the given class. We have stored this data in the temporary object named ‘codelist’.
After that, we have built the URL of separate products. For doing so, we have observed that different product pages begin with a basic string called ‘https://walmart.com/ip’. All unique-identifies were added only before this string. A unique identifier was similar as a string values scraped from a ‘search-result-gridview-item-wrapper’ items saved above. Therefore, in the following step, we have looped through a temporary object code list, for constructing complete URL of any particular product’ page.
With this URL, we will be able to scrape particular product-level data. To do this demo, we have got details like unique Product codes, Product’s name, Product page URL, Product_description, name of current page’s category where a product is positioned, name of the active subcategory where the product is positioned on a website (which is called active breadcrumb), Product pricing, ratings (Star ratings), number of reviews or ratings for a product as well as other products suggested on the Walmart’s site similar or associated to a product. You may customize this listing according to your convinience.
The code given above follows the following step of opening an individual product page, based on the constructed URLs as well as scraping the products’ attributes, as given in the listing above. When you are okay with a listing of attributes getting pulled within a code, the last step for a scraper might be to attach all the product data in the subcategory within a single frame data. The code here shows that.
A data frame called ‘df’ would have all the data for products on the best 10 pages of a chosen subcategory within your code. You may either write data on the CSV files or distribute it to the SQL database. In case, you need to export that to the MySQL database within the table named ‘product_info’, you may utilize the code given below:
You would need to provide the SQL database credentials and when you do it, Python helps you to openly connect the working environment with the database as well as push the dataset straight as the SQL dataset. In the above code, in case the table having that name exists already, the recent code would replace with the present table. You may always change a script to evade doing so. Python provides you an option to 'fail', 'append', or 'replace' data here.
It is the basic code structure, which can be improved to add exclusions to deal with missing data or later loading pages. In case, you choose to loop the code for different subcategories, a complete code would look like:
import os import selenium.webdriver import csv import time import pandas as pd from selenium import webdriver from bs4 import BeautifulSoup url_sets=["https://www.walmart.com/browse/tv-video/all-tvs/3944_1060825_447913", "https://www.walmart.com/browse/computers/desktop-computers/3944_3951_132982", "https://www.walmart.com/browse/electronics/all-laptop-computers/3944_3951_1089430_132960", "https://www.walmart.com/browse/prepaid-phones/1105910_4527935_1072335", "https://www.walmart.com/browse/electronics/portable-audio/3944_96469", "https://www.walmart.com/browse/electronics/gps-navigation/3944_538883/", "https://www.walmart.com/browse/electronics/sound-bars/3944_77622_8375901_1230415_1107398", "https://www.walmart.com/browse/electronics/digital-slr-cameras/3944_133277_1096663", "https://www.walmart.com/browse/electronics/ipad-tablets/3944_1078524"] categories=["TVs","Desktops","Laptops","Prepaid_phones","Audio","GPS","soundbars","cameras","tablets"] # scraper for pg in range(len(url_sets)): # number of pages per category top_n= ["1","2","3","4","5","6","7","8","9","10"] # extract page number within sub-category url_category=url_sets[pg] print("Category:",categories[pg]) final_results = [] for i_1 in range(len(top_n)): print("Page number within category:",i_1) url_cat=url_category+"?page="+top_n[i_1] driver= webdriver.Chrome(executable_path='C:/Drivers/chromedriver.exe') driver.get(url_cat) body_cat = driver.find_element_by_tag_name("body").get_attribute("innerHTML") driver.quit() soupBody_cat = BeautifulSoup(body_cat) for tmp in soupBody_cat.find_all('div', {'class':'search-result-gridview-item-wrapper'}): final_results.append(tmp['data-id']) # save final set of results as a list codelist=list(set(final_results)) print("Total number of prods:",len(codelist)) # base URL for product page url1= "https://walmart.com/ip" # Data Headers WLMTData = [["Product_code","Product_name","Product_description","Product_URL", "Breadcrumb_parent","Breadcrumb_active","Product_price", "Rating_Value","Rating_Count","Recommended_Prods"]] for i in range(len(codelist)): #creating a list without the place taken in the first loop print(i) item_wlmt=codelist[i] url2=url1+"/"+item_wlmt #print(url2) try: driver= webdriver.Chrome(executable_path='C:/Drivers/chromedriver.exe') # Chrome driver is being used. print ("Requesting URL: " + url2) driver.get(url2) # URL requested in browser. print ("Webpage found ...") time.sleep(3) # Find the document body and get its inner HTML for processing in BeautifulSoup parser. body = driver.find_element_by_tag_name("body").get_attribute("innerHTML") print("Closing Chrome ...") # No more usage needed. driver.quit() # Browser Closed. print("Getting data from DOM ...") soupBody = BeautifulSoup(body) # Parse the inner HTML using BeautifulSoup h1ProductName = soupBody.find("h1", {"class": "prod-ProductTitle prod-productTitle-buyBox font-bold"}) divProductDesc = soupBody.find("div", {"class": "about-desc about-product-description xs-margin-top"}) liProductBreadcrumb_parent = soupBody.find("li", {"data-automation-id": "breadcrumb-item-0"}) liProductBreadcrumb_active = soupBody.find("li", {"class": "breadcrumb active"}) spanProductPrice = soupBody.find("span", {"class": "price-group"}) spanProductRating = soupBody.find("span", {"itemprop": "ratingValue"}) spanProductRating_count = soupBody.find("span", {"class": "stars-reviews-count-node"}) ################# exceptions ######################### if divProductDesc is None: divProductDesc="Not Available" else: divProductDesc=divProductDesc if liProductBreadcrumb_parent is None: liProductBreadcrumb_parent="Not Available" else: liProductBreadcrumb_parent=liProductBreadcrumb_parent if liProductBreadcrumb_active is None: liProductBreadcrumb_active="Not Available" else: liProductBreadcrumb_active=liProductBreadcrumb_active if spanProductPrice is None: spanProductPrice="NA" else: spanProductPrice=spanProductPrice if spanProductRating is None or spanProductRating_count is None: spanProductRating=0.0 spanProductRating_count="0 ratings" else: spanProductRating=spanProductRating.text spanProductRating_count=spanProductRating_count.text ### Recommended Products reco_prods=[] for tmp in soupBody.find_all('a', {'class':'tile-link-overlay u-focusTile'}): reco_prods.append(tmp['data-product-id']) if len(reco_prods)==0: reco_prods=["Not available"] else: reco_prods=reco_prods WLMTData.append([codelist[i],h1ProductName.text,ivProductDesc.text,url2, liProductBreadcrumb_parent.text, liProductBreadcrumb_active.text, spanProductPrice.text, spanProductRating, spanProductRating_count,reco_prods]) except Exception as e: print (str(e)) # save final result as dataframe df=pd.DataFrame(WLMTData) df.columns = df.iloc[0] df=df.drop(df.index[0]) # Export dataframe to SQL import sqlalchemy database_username = 'ENTER USERNAME' database_password = 'ENTER USERNAME PASSWORD' database_ip = 'ENTER DATABASE IP' database_name = 'ENTER DATABASE NAME' database_connection = sqlalchemy.create_engine('mysql+mysqlconnector://{0}:{1}@{2}/{3}'. format(database_username, database_password, database_ip, base_name)) df.to_sql(con=database_connection, name='‘product_info’', if_exists='replace',flavor='mysql')
You may always add additional complexity into this code for adding customization to the scraper. For example, the given scraper will take care of the missing data within attributes including pricing, description, or reviews. The data might be missing because of many reasons like if a product get out of stock or sold out, improper data entry, or is new to get any ratings or data currently.
For adapting different web structures, you would need to keep changing your web scraper for that to become functional while a webpage gets updated. The web scraper gives you with a base template for the Python’s scraper on Walmart.
Want to extract data for your business? Contact iWeb Scraping, your data scraping professional!
#web scraping#data mining#walmart data scraping#web scraping api#big data#ecommerce#data extraction#scrape walmart
3 notes
·
View notes