
Don't wanna be here? Send us removal request.
Statistics
We looked inside some of the posts by karencifuentesc and here's what we found interesting.
Average Info
Notes Per Post
1
Likes Per Post
1
Reblog Per Post
0
Reply Per Post
0
Time Between Posts
6 days
Number of Posts By Type
Text
4
Last Seen Tumblr Blogs





Fun Fact
Total funding amounts to $125.3M.
Text
Creación de gráficos para mis datos
Paso 1 : Elaboración de histogramas para cada una de mis variables de estudio.
La sintaxis en SAS es la siguiente:

Resultados:
Para la variable explicativa INCOMEPERPERSON.
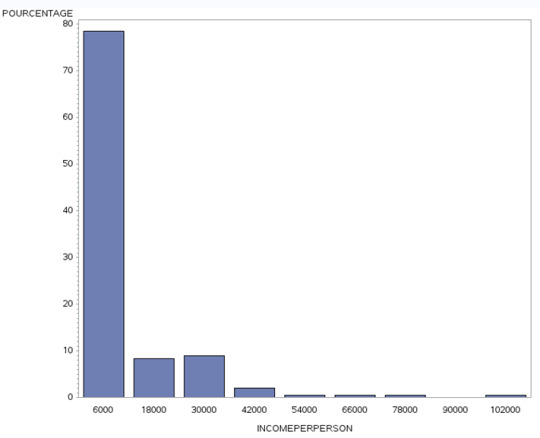
Conclusión: El histograma muestra que el 78% de los países tienen un ingreso per cápita promedio per anual de 6 mil dólares. También, que aproximadamente el 17 % de los países tienen ingresos entre 18 mil y 30 mil dólares per cápita al año. De igual forma, que solamente el 4% de los países tienen ingresos entre 42 mil y 66 mil dólares per cápita al año. Además, que muy pocos países (2%) tienen ingresos superiores a 78 mil dólares per cápita al año.
b. Para la variable de respuesta (1) ALCCONSUMPTION

Conclusión: El histograma muestra que el 16% de los países consume muy poco alcohol per cápita (menos de 2.5 litros por año) y que casi el 19% de los países consumen 5 litros de alcohol per cápita por año. También, que aproximadamente el 14% de los países consumen 10 litros de alcohol per cápita por año y que aproximadamente un 4% de los países consumen 15 litros de alcohol. Solamente un 1.5% de países consumen entre 20 y 2.5 litros de alcohol per cápita por año.
c. Para la variable de respuesta (2) : SUICIDEPER100TH

Conclusión: El histograma muestra que el 46% de los países presentan una mortalidad por suicidio de entre 2 y 6 personas por 100 mil habitantes. También, se observa que el 42% de los países presentan una mortalidad de entre 10 y 14 personas. El 11% de los países restantes presentan una mortalidad por suicidio de entre 18 y 34 personas por 100 mil habitantes.
Conclusión respecto a la forma de la distribución:
Se observa que para las variables de respuesta ALCCONSUMPTION y SUICIDEPER100TH y la variable independiente INCOMEPERPERSON, la distribución es asimétrica y sesgada hacia la derecha. Lo anterior indica que la mayoría de las observaciones son pequeñas o medianas, con una pocas observaciones mucho más grandes que el resto.
Se observa que las distribuciones asimétricas anteriores son unimodales.
Paso 2: Descripción de las medidas numéricas del centro y de la dispersión (desviación estándar) de las variables en estudio
La sintaxis en SAS es la siguiente:

Resultados de las tablas de estadísticas univariadas:
Variable explicativa: INCOMEPERPERSON


Media: 8740.966
Mediana: 2553.496
Moda: Valores faltantes (.)
Desviación estándar: 14263
Conclusión: El ingreso promedio per cápita de los países es de 8740 dólares. La mediana del ingreso promedio es de 2553 dólares. Respecto a la moda, el valor más frecuente son las observaciones faltantes (23 en total); por tanto, no se pudo establecer el ingreso per cápita más común.
La desviación estándar es de 14263; se puede decir que el promedio de ingreso per cápita de los países es de 8740 dólares, mas o menos 14263 dólares. En conclusión, hay mucha variabilidad en la variable de ingreso per cápita de un país al otro.
2. Variable de respuesta (1) : ALCCONSUMPTION
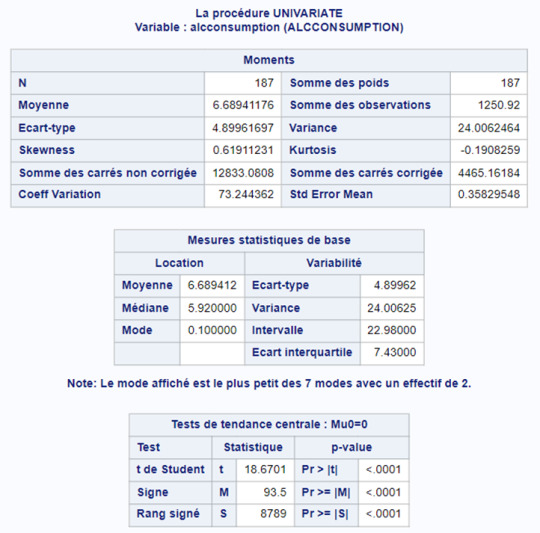

Media: 6.6894
Mediana: 5.9200
Moda: 0.1000
Desviación estándar: 4.8996
Conclusión: El consumo de alcohol promedio por adulto (de más de 15 años) de los países es de 6.6 litros por año. La mediana del consumo promedio es de 5.9 litros. Respecto a la moda, el valor más frecuente es 0.1 litros de alcohol por año.
La desviación estándar es de aproximadamente 4.8 litros; se puede decir que el promedio de consumo de alcohol per cápita de los países es de 5.9 litros, más o menos 4.8 litros. En conclusión, la variabilidad es escasa en la variable de consumo de alcohol de los países.
3. Variable de respuesta (2) : SUICIDEPER100TH


Media: 9.6408
Mediana: 8.2628
Moda: valores faltantes (.)
Desviación estándar: 6.3001
Conclusión: La mortalidad por suicidio por año de los países es en promedio de 9.6 personas por cada 100 000 habitantes. La mediana de la mortalidad promedio es de 8.2 personas. Respecto a la moda, el valor más frecuente son las observaciones faltantes (22 en total); por tanto, no se pudo establecer la mortalidad por suicidio más común.
La desviación estándar es de aproximadamente 6.3 personas; se puede decir que el promedio de la mortalidad por suicidio por cada 100 000 habitantes de los países es de 9.6 personas, más o menos 6.3 personas. En conclusión, se observa variabilidad en la variable de mortalidad por suicidio en los países.
Paso 3: Asociación entre variables
En este proyecto de investigación queremos observar la posible asociación (1) entre el ingreso per cápita (X) de los países y el consumo per cápita de alcohol (Y). También, la relación (2) entre el ingreso per cápita (X) de los países y la mortalidad por suicidio (Y).
Como las tres variables de estudio son de tipo cuantitativo, se elaboran dos diagramas de dispersión para observar relación entre las variables de interés.
Sintaxis usada en SAS:

Resultados:
Diagrama de dispersión para las variables ingreso per cápita (X) de los países y el consumo per cápita de alcohol (Y).

Conclusión: Aunque no se tenga la seguridad de que la asociación que estoy probando sea causal, el grafico muestra que hay una relación positiva o creciente entre las dos variables de interés. Esto indica que el aumento en el consumo de alcohol está asociado con ingresos per cápita mayores de los países.
2. Diagrama de dispersión para las variables ingreso per cápita (X) de los países y la mortalidad por suicidio (Y).

Conclusión: Aunque no se tenga la seguridad de que la asociación que estoy probando sea causal, el grafico muestra que hay una relación positiva o creciente (débil) entre las dos variables de interés. Esto indica que el aumento de la mortalidad por suicidio está asociado con ingresos per cápita mayores de los países.
Paso 4: Categorización de la variable explicativa
Para tener una mayor claridad de la relación entre las variables, agrupé la variable explicativa. Para eso usé la tabla de cuantiles (paso 2 del presente ejercicio):

División de los países en cuatro grupos ordenados, según el ingreso por persona, y crear una nueva variable categórica: Incomegroup.
Sintaxis en SAS:

Resultado de la tabla de frecuencia de la nueva variable:

Conclusión: la tabla muestra 47 países en el grupo de ingresos más bajos, con un aproximado del 25%. También, muestra 48 países en el segundo grupo y 48 países en el tercer grupo. El cuarto grupo contiene 47 países con los ingresos más altos.
2. Grafico bivariado: Grafico de barras cuantitativo.
Sintaxis en SAS:

Resultado:
Para la asociación entre (X) Ingreso por grupos de países y (Y) Consumo de alcohol:

Conclusión: El grafico de barras muestra la relación positiva señalada en el Diagrama de dispersión anterior. Es decir, a mayores ingresos de los países, mayor es el consumo de alcohol.
Para la asociación entre (X) Ingreso por grupos de países y (Y) Mortalidad por suicidio:

Conclusión: el grafico de barras muestra la variabilidad entre los ingresos por persona y la mortalidad por suicidio de los grupos de países; por tanto, no se establece una asociación lineal entre los ingresos y la mortalidad por suicidio de los países.
En el Diagrama de dispersión anterior se notó una relación lineal positiva; no obstante, la categorización de la variable explicativa (ingreso per cápita) fue útil para aclarar que la mortalidad por suicidio no depende o no está relacionada con el ingreso per cápita de los países.
0 notes
Text
Administración de variables
La siguiente imagen muestra la codificación general realizada en SAS para administrar las tres variables de mi proyecto de investigación (tomadas de Gapminder). A saber, (1) Ingreso per cápita, (2) Consumo per cápita en litros de alcohol por adultos (de más de 15 años), y (3) Mortalidad por suicidio.

A continuación, el paso a paso:
1. Gestión de información faltante
En el Codebook de Gapminder no se establecieron variables cuya categoría de respuesta sea, por ejemplo, "Desconocida" (como sí se observa en los ejemplos de las lecciones de SAS con otro tipo de Codebooks como NISAR). Así, examinando cada una de mis tres variables, me percaté de que no fue necesario añadir una sintaxis a mi programa para recodificar los datos apropiados como faltantes.
A continuación, y a manera de ejemplo, para la variable Consumo per cápita en litros de alcohol por adultos (de más de 15 años) se puede observar que predeterminadamente se establecieron 18 observaciones en el grupo de observaciones con información faltante.


Lo anterior pudo verificarse en los datos de salida de mi programa SAS, en donde la información faltante está codificada con un punto.

2. Incluir observaciones en blanco en una nueva variable
Este segundo paso no se pudo ejecutar dado el tipo de variables que elegí para mi proyecto de investigación. Y, como se explicó en el punto número 1, no fue necesario recodificar los datos puesto que SAS ya los había agrupado predeterminadamente en el grupo de observaciones faltantes.
3. Creación de variables secundarias
Si bien la naturaleza de mis variables (NO SON DE TIPO CUANTITATIVO) no me permitió obtener tablas de frecuencias ajustadas a los ejercicios que hemos venido desarrollando en el curso, quise realizar este ejercicio para evidenciar mi aprendizaje sobre la creación de variables secundarias. Por tanto, creé una variable denominada "variable2" que evidencia el resultado de la multiplicación entre la variable Ingreso per cápita y la variable Consumo per cápita en litros de alcohol por adultos (de más de 15 años).
Aquí la sintaxis en SAS:

De igual forma, verifiqué que dicha variable secundaria se creara correctamente, como se muestra a continuación, a través del procedimiento PRINT.

A continuación, una muestra de las primeras 38 y las últimas 37 observaciones (en total 150) en donde se evidencian las tres variables en estudio y la nueva variable creada: variable2.


4. Creación de una variable que combina más de dos variables
De nuevo, la naturaleza de mis tres variables primarias en estudio no me permitió obtener resultados adecuados para el presente ejercicio. No obstante, quise realizar este ejercicio para evidenciar mi aprendizaje sobre la creación de variables que combinan más de dos variables primarias. Por tanto, creé una variable denominada "variable3" que evidencia la suma de la variable Ingreso per cápita, Consumo per cápita en litros de alcohol por adultos (de más de 15 años), y Mortalidad por suicidio.
A continuación, la sintaxis en SAS:

Y el resultado de la frecuencia de las primeras observaciones de la variable3:

5. Agrupación de variables cuantitativas o categóricas
Para el presente ejercicio tomé la variable Consumo per cápita en litros de alcohol por adultos (de más de 15 años) y obtuve 4 grupos, tomando porcentajes acumulativos cercanos a 25%, 50% y 75%.
Aquí la sintaxis en SAS:

Como se muestra a continuación en la tabla de frecuencias, el primer grupo está conformado por 51 países, es decir, el 34% de la muestra, que consumen entre 0.03 y 1.92 litros de alcohol per cápita. El segundo grupo evidencia que 37 países, es decir el 24.67% de la muestra, consumen entre 2 y 5 litros de alcohol per cápita. El tercer grupo se compone de 30 países (20% de la muestra) que consumen entre 5.05 y 7.9 litros de alcohol. Y el último grupo está conformado por 32 países (32% de la muestra) que consumen entre 7.91 y 23.1 litros de alcohol per cápita.

0 notes
Text
Running Your First Program
Mi primer programa en SAS
libname mydata "/courses/d1406ae5ba27fe300" access=readonly; /comentario mio sin analisis de SAS/; data new; set mydata.gapminder; label incomeperperson= "Gross Domestic Product per capita" alcconsumption= "Alcohol consumtion per adult" suicideper100TH= "Suicide"; IF incomeperperson LE 6105.280743; PROC sort; by COUNTRY; PROC FREQ; TABLES country incomeperperson alcconsumption suicideper100TH; RUN;
2. Resultados de tablas de frecuencia
Nota: Antes de mostrar los resultados, quiero aclarar que el objetivo de la tarea es obtener las frecuencias de las variables relacionadas con mi proyecto de investigación. No obstante, mis variables contienen información que no permite sumar las observaciones, por tanto, no obtener información útil respecto a sus frecuencias. Por ejemplo, mi subconjunto de observaciones son los países con ingreso per capita medio y bajo. Sabemos cada país tiene un ingreso por capita unico, por tanto, para este ejercicio, no es posible sumar los países con un mismo ingreso. También, las variables de consumo de alcohol y suicidio contienen información de la cual no es posible establecer las frecuencias.
Sin embargo, como lo muestra el punto 1, realicé mi primer programa en SAS para evidenciar que aprendí a escribir los codigos que me permitieran hacer el primer subconjunto de observaciones, cambiar el nombre de las variables y obtener tablas de frecuencia.
(Note: Before showing the results, I want to clarify that the objective of the task is to obtain the frequencies of the variables related to my research project. However, my variables contain information that does not allow adding up the observations, therefore, not obtaining useful information regarding their frequencies. For example, my subset of observations are countries with medium and low per capita income. We know that each country has a unique per capita income, therefore, for this exercise, it is not possible to sum the countries with the same income. Also, the alcohol consumption and suicide variables contain information for which it is not possible to establish frequencies.
However, as shown in point 1, I ran my first program in SAS to show that I learned to write the codes that would allow me to make the first subset of observations, rename the variables and obtain frequency tables). Translated with DeepL
a. Subconjunto de 150 países con ingreso per capita medio y bajo






b. Gross Domestic Product per capita (un pequeño ejemplo de los 24 países con ingresos por capita mas bajos)

c. Alcohol consumtion per adult (un pequeño ejemplo de consumo de alcohol de los adultos de los 24 países con ingresos por capita mas bajos)

d. Suicidio (un pequeño ejemplo de la mortalidad por suicidio de los 24 países con ingresos por capita mas bajos)

0 notes
Text
STEP 1: Choose a data set that you would like to work with.
After looking through the codebook for the GAPMINDER, I have decided that I am particularly interested in income per person. I will use variables in association like alcohol consumption per adult and suicide.
STEP 2, 3, 4 and 5. Identify a specific topic of interest - Prepare a codebook of your own - Identify a second topic that you would like to explore in terms of its association with your original topic - Add questions/items/variables documenting this second topic to your personal codebook.
STEP 6. Perform a literature review to see what research has been previously done on this topic.
El interés de este proyecto en los países de renta baja radica en que la investigación sobre el alcohol, sus alcances y sus perjuicios se ha limitado a un grupo de países de renta alta (Holmes, A., & Anderson, K., 2017; Walls H, Cook S, Matzopoulos R, et al, 2020)). También, se ha evidenciado un aumento de consumo de alcohol en los países de renta baja y media (Walls H, Cook S, Matzopoulos R, et al, 2020).
La revisión bibliográfica permitió relacionar diferentes estudios con la hipótesis del presente proyecto de investigación: Los países con menor renta per cápita presentan mayores tasas de consumo de alcohol y un mayor riesgo de suicidio.
En relación, Katherine J. Karriker-Jaffe, Sarah C. M. Roberts, and Jason Bond (2013) en su estudio Income Inequality, Alcohol Use, and Alcohol-Related Problems proponen que los índices de pobreza se asocian positivamente con el consumo ligero y excesivo, y los problemas relacionados con el alcohol.
También, en el estudio Lifetime income patterns and alcohol consumption: Investigating the association between long- and short-term income trajectories and drinking, Cerdá, M, Johnson-Lawrence, V.D. and Galea, S (2011) encontraron que los ingresos más bajos se asociaron con mayores probabilidades de abstinencia y de consumo excesivo de alcohol, en relación con el consumo ligero/moderado.
Además, el estudio Convergence in National Alcohol Consumption Patterns: New Global Indicators (2017) comparó el consumo per cápita con la renta real per cápita. Lo resultados sugieren que “la convergencia de la renta por sí sola (la aproximación gradual de los países en desarrollo a la renta per cápita de los países de renta alta) no conduce necesariamente a la convergencia de las pautas de consumo de alcohol basadas en los volúmenes per cápita”.
En relación con el riesgo de suicidio y el ingreso per cápita, el estudio Impact of Income Inequality and Other Social Determinants on Suicide Rate in Brazil (2015) evidenció que, entre otros, la desigualdad de ingresos es un factor de riesgo para las tasas de suicidio en dicho país. Además, subraya que, por ejemplo, la disminución de la desigualdad de renta y el aumento de la renta per cápita pueden contrarrestar el aumento de los suicidios en Brasil.
También relacionado, Zhang, J., Ma, J., Jia, C., Sun, J., Guo, X., Xu, A., & Li, W. (2010) con la investigación Economic growth and suicide rate changes: A case in China from 1982 to 2005, demostraron que el desarrollo económico está asociado a la disminución de las tasas de suicidio en China.
Referencias:
Cerdá, M, Johnson-Lawrence, V.D. and Galea, S (2011). Lifetime income patterns and alcohol consumption: Investigating the association between long- and short-term income trajectories and drinking. Social Science & Medicine. Volume 73, Issue 8. Pages 1178-1185, ISSN 0277-9536. https://doi.org/10.1016/j.socscimed.2011.07.025.
Cook, W.K., Bond, J. and Greenfield, T.K. (2014). Alcohol policies in LAMICs. Addiction, 109: 1081-1090. https://doi.org/10.1111/add.12571
Doran CM, Kinchin I (2020). Economic and epidemiological impact of youth suicide in countries with the highest human development index. PLoS ONE 15(5): e0232940. https://doi.org/10.1371/journal.pone.0232940
Holmes, A., & Anderson, K. (2017). Convergence in National Alcohol Consumption Patterns: New Global Indicators. Journal of Wine Economics, 12(2), 117-148. doi:10.1017/jwe.2017.15
Nobuyoshi Ishii, Takeshi Terao, Yasuo Araki, Kentaro Kohno, Yoshinori Mizokami, Masano Arasaki, Noboru Iwata. Risk factors for suicide in Japan: A model of predicting suicide in 2008 by risk factors of 2007, Journal of Affective Disorders, Volume 147, Issues 1–3, 2013, Pages 352-354, ISSN 0165-0327, https://doi.org/10.1016/j.jad.2012.11.038.
Katherine J. Karriker-Jaffe, Sarah C. M. Roberts, and Jason Bond (2013). Income Inequality, Alcohol Use, and Alcohol-Related Problems. American Journal of Public Health 103, 649-656, https://doi.org/10.2105/AJPH.2012.300882
Keyes, K.M. and Hasin, D.S. (2008), Socio-economic status and problem alcohol use: the positive relationship between income and the DSM-IV alcohol abuse diagnosis. Addiction, 103: 1120-1130. https://doi.org/10.1111/j.1360-0443.2008.02218.x
Machado DB, Rasella D, dos Santos DN (2015) Impact of Income Inequality and Other Social Determinants on Suicide Rate in Brazil. PLoS ONE 10(4): e0124934. https://doi.org/10.1371/journal.pone.0124934
Netta Mäki, Pekka Martikainen (2009). The role of socioeconomic indicators on non-alcohol and alcohol-associated suicide mortality among women in Finland. A register-based follow-up study of 12 million person-years. Social Science & Medicine, Volume 68, Issue 12, 2009. Pages 2161-2169. ISSN 0277-9536, https://doi.org/10.1016/j.socscimed.2009.04.006.
Walls, H., Cook, S., Matzopoulos, R., & London, L. (2020). Advancing alcohol research in low-income and middle-income countries: A global alcohol environment framework. BMJ Global Health, 5(4). https://doi.org/10.1136/bmjgh-2019-001958
Zhang, J., Ma, J., Jia, C., Sun, J., Guo, X., Xu, A., & Li, W. (2010). Economic growth and suicide rate changes: A case in China from 1982 to 2005. European Psychiatry, 25(3), 159-163. doi:10.1016/j.eurpsy.2009.07.013
STEP 7. Based on your literature review, develop a hypothesis about what you believe the association might be between these topics.
Pregunta de investigación: ¿Se observan mayores tasas de consumo de alcohol y mayor riesgo de suicidio en los países con menor renta per cápita?
Hipótesis: Los países con menor renta per cápita presentan mayores tasas de consumo de alcohol y mayor riesgo de suicidio.
1 note
·
View note