
Last Seen Blogs

tayfun0634
İsimsiz

atelier-wunderbar
Atelier Wunderbar

donutssexual
Donuts Sexual

tipikappa
Untitled

destielette
THIS BLOG DOESN'T EXIST
Text
引っ越します
引っ越し先
https://katsumi3.hatenablog.com/
Blender 2.8になったり他にも日本語の素晴らしい講座サイトが沢山出来たのでメモとらなくてもいいかなと。あと自分の中の2次創作する情熱が薄れてしまってそんなに作らなくなってしまいました。
3dcgだと作るの遅いしTwitterとかリアルタイム実況についていけなくなってしんどかったです。
丸っと引っ越せないので中身はこのままにしときます。
0 notes
Text
eevee基本設定
とりあえず年賀状を作るために畳を作った。
blender2.8系の操作がさっぱりわからないので講座動画見ながら操作を覚えたんだけど、日本語の講座動画増えててびっくりした。youtuber的なアレなんだろうか???
eeveeでレンダリングしてみたけどcyclesと違いがよく分からない。
↓eevee

↓cycles

モンキーの周りにもやっぽいものが出てるのがeevee。
なんとなく雰囲気あるような気がする。
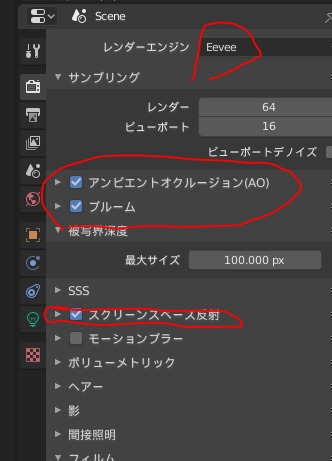
eevee設定は以下にチェックを入れておけばいい感じにレンダリングできるらしい
・アンビエントオクルージョン
・ブルーム
・スクリーンスペース反射
ブルームで光る部分にモヤが出る
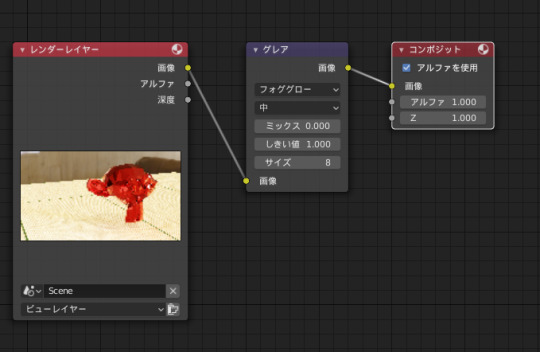
cyclesでモヤを出したい場合はコンポジットにグレアを追加するとよい。
eeveeでも使用可能。
0 notes
Text
blender bpyでデーターにアクセスする方法
二年ぐらい何もしてなかったので色々忘れてるっぽい...というか忘れてる。
アクティブなオブジェクトからデータを取得するにはbpy.context.objectなにがしとする。
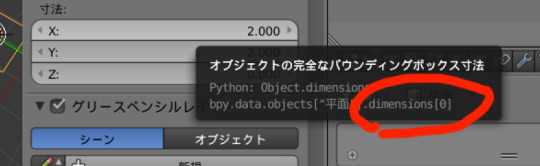
例:オブジェクトのx方向の寸法を取得
bpy.context.object.dimensions[0]
で値がとれる。
dimensions[0]という部分が分からなければ欲しいデータの上にマウスカーソルを持って来ておけば
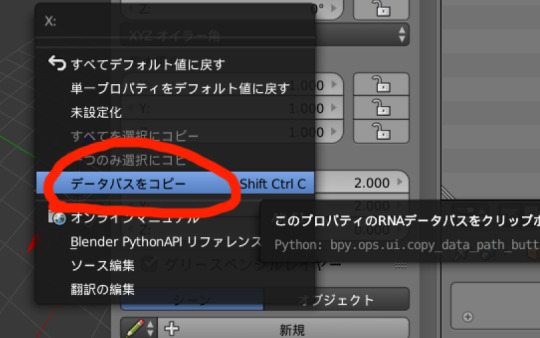
さらに右クリックで出てきた「データパスをコピー」を選択するとクリップボードにdimensionsという部分が出てくるのですごく楽
0 notes
Text
Windows10で動画を回転させたい(無料で)
ライブ配信動画をダウンロードしたら90度回転させないと見れなかった。
検索すると無料に見せかけた有料動画編集ソフト紹介ばかり出てきてすんげー面倒なのでメモ書きしておく。
ファイルが.tsの場合
1.iWisoft free video converterで一度MP4に変換する
2.変換したMP4をwindows10標準のフォトかmovie maker(今は配布されてない)で回転させて保存する。
すこし古いPCなら運よくmovie makerがインストールさせてるかもしれないが無くてもフォトで出来る。
以下手順
mp4は「MPEG-4 Movie(*.MP4)」で変換する。
(紛らわしいが「MPEG-4(MC) movie(*.MP4)」以外を選ばないと黒い帯がついてmovie makerでは編集できなくなる)
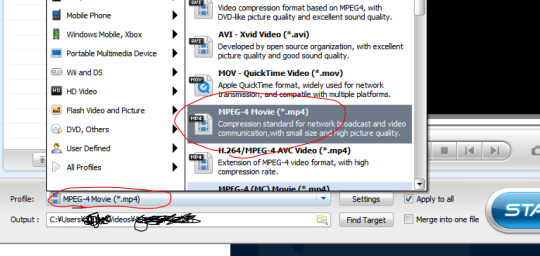
movie makerの場合
MP4ファイルを起動したmovie makerにドラッグ&ドロップして回転して「ムービーの保存」のところで「この...の推奨設定」にして保存。
面倒なことは特にない。
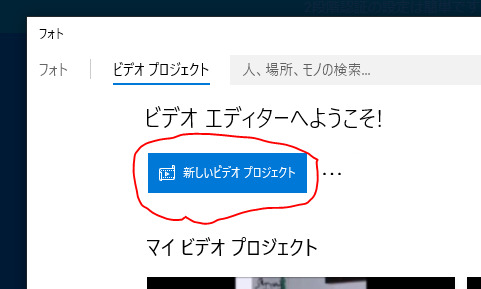
フォトの場合
スタートからフォトを起動しビデオプロジェクトをクリックする
(紛らわしいが画像や動画からはできない様子?なので必ずフォトを起動)

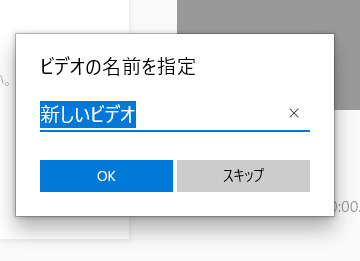
新しいビデオプロジェクトをクリックする
適当に名前付けて(いろいろ編集せず回転させるだけなのでそのままでも)OKをクリックする。
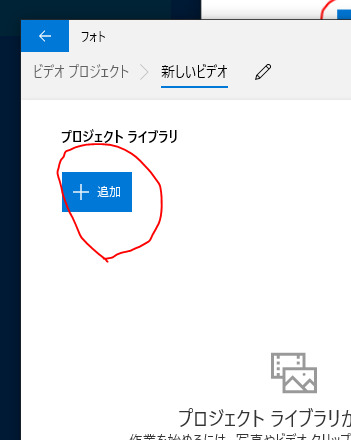
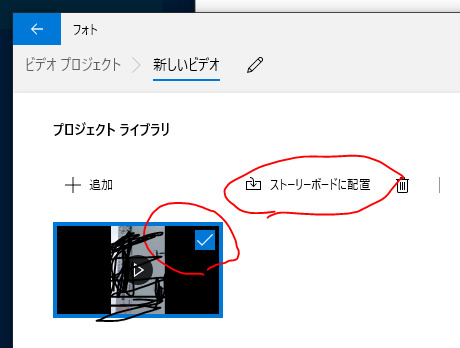
追加をクリックして回転させたいMP4を選ぶ。
読み込んだMP4にチェックが入ってるのを確認後「ストーリーボードに配置」をクリックする
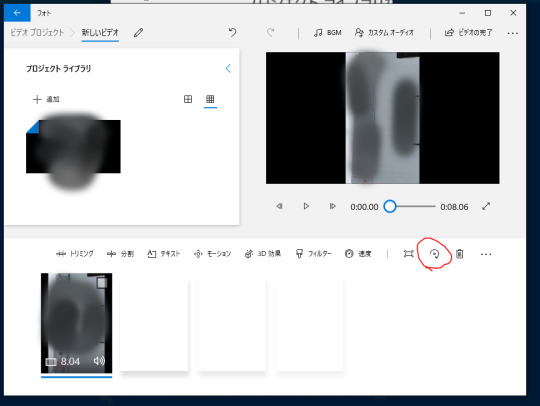
回転のマークをクリックする
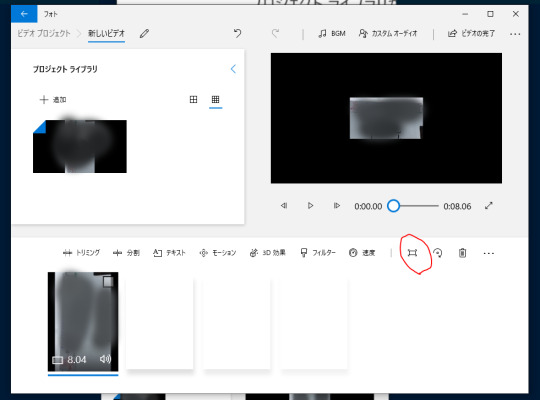
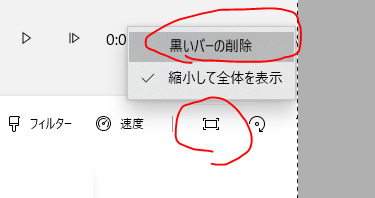
プレビューがちっちゃい画面になった場合は回転の隣の四角→黒いバーの削除を選択する(この機能はmovie makerにはないのでフォトのほう使った方が良いかも)
プレビューの下の動画の長さを確認。動画変換途中で異常に再生時間が長くなってることがある。その場合はトリミングで調整する。
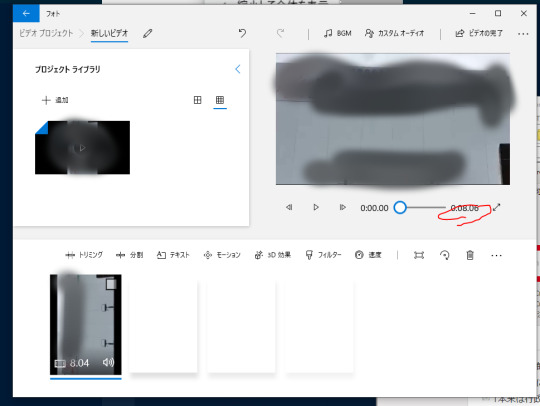
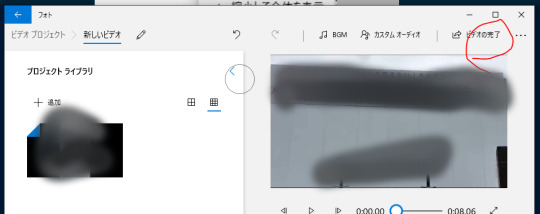
左上の「ビデオの完了」をクリックする
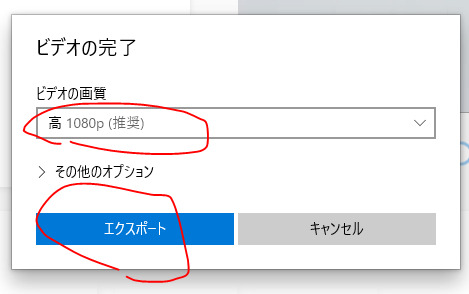
ビデオの画質を選んでエクスポートをクリックする。
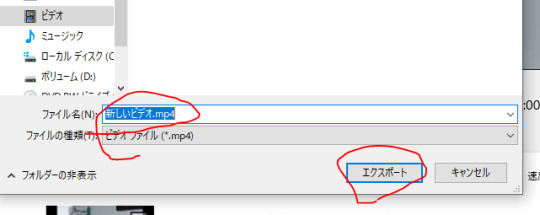
保存場所を決めて名前を付けてエクスポートをクリックする。
しばし待てば回転したファイルが指定した場所にできる。
フォトのビデオプロジェクトが自動保存されてるので後で削除しておくと良い。
0 notes
Text
交点を求めたい
blenderをcad的に使いたくて交点、延長線とか色々やりたい。
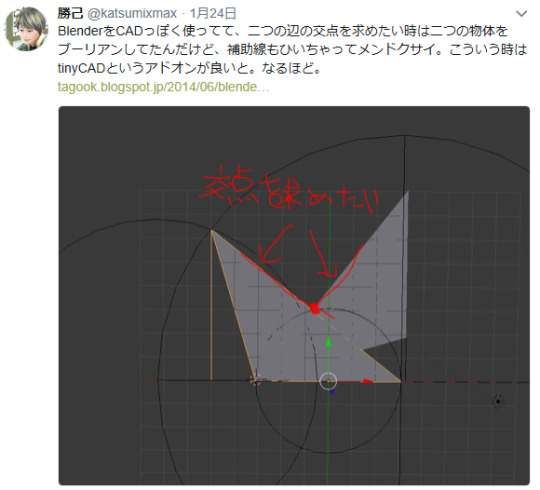
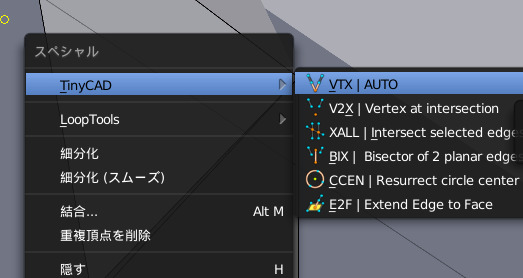
使い方をよく忘れるがtinyCADというadd-onをインストール後
編集モード→交点を求めたい辺を二つ選択→wキー→tinyCAD→好きなの選ぶ
0 notes
Text
厚塗り風味を作るのが楽しい。

blender2.79使用。
何とも言えない良い色が出た記念撮影。レンダリング後の加工一切なし。
スーツは微妙に色の交じり合ったいい色になったし、特にシャツの襟の色の影など自分好みの厚塗りテイストに出来た。かっこいい。
時を忘れてマテリアルをいじって調節していたが、blender2.8にはblenderレンダーが無いのがつらい。目のテカリはハロを使ったのだけどこれもなくなるのか・・。
blenderレンダーの再現に挑戦している人々もいるようだし、自力でシェーダーを作ろうとしている人もいるようだ。
海外勢(?)は早々にeeveeでアニメ調のノードを組んで配布している様子だった。さらっと動画は見るだけは見たのだけど、今のところBlender NPRさんが一度サイトを撤退した(事情はわからないが戻ってきていた)事や、blenderレンダーが無くなってしまう事にショックでちょっとやる気が出ない。
あと、今のところどうしても2.8でレンダリングしなければならない取り急ぎの事情もない。
0 notes
Text
マテリアルインデックスが適用されない場合
ノードエディタでオブジェクトインデックスを使ってマスクをかけているはずなのに、一向にマスクされない場合。
以下、通常の場合の手順確認。
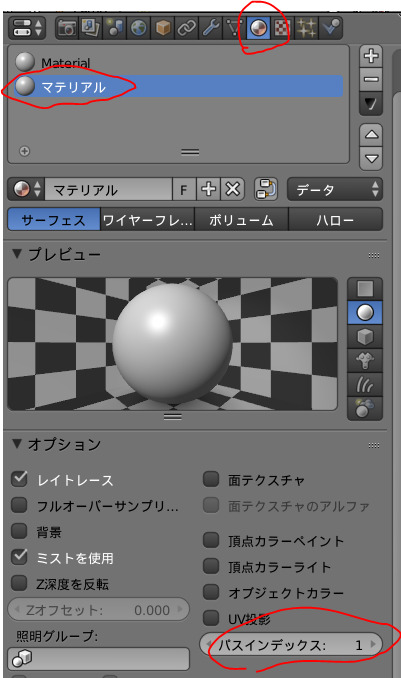
レンダーレイヤータブのパスオブジェクトインデックスかマテリアルインデックス使いたい方にレ点をつける
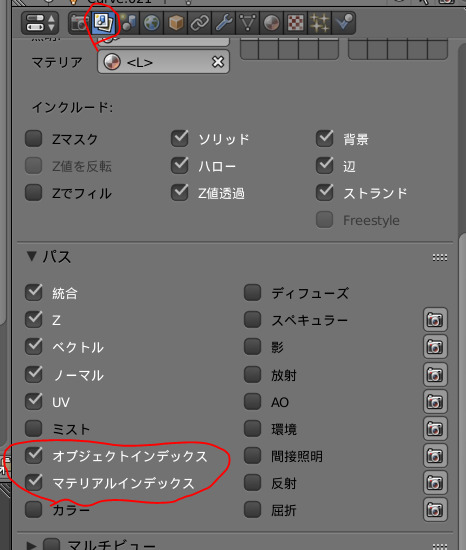
オブジェクトインデックスを使う場合
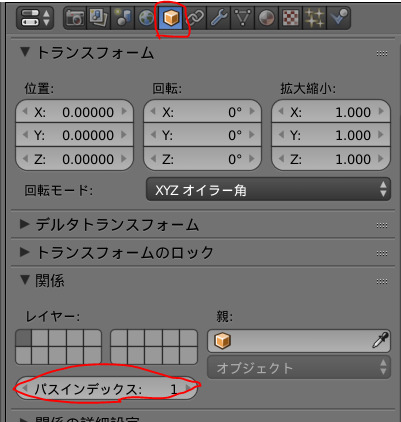
オブジェクトタブの関係のパスインデックスに好きな番号を入力。一度レンダリングする(レンダリングしないとノードに反映されないので要注意)
マテリアルインデックスを使う場合
マテリアルタブでマスクしたいマテリアルを選び、オプションのパスインデックスに好きな番号を入力し一度レンダリングする。
indexMAにIDマスク(先ほど使用したのと同じ番号をつける)をつなげる
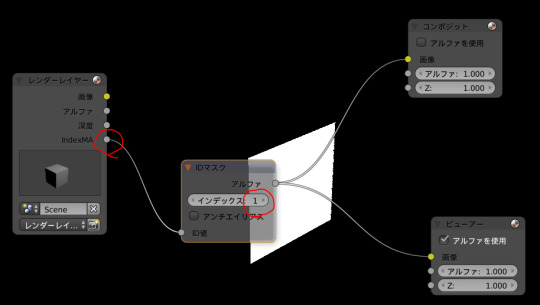
通常だとこれでマテリアルインデックスでマスクできるはずなんだけど、何らかの事情で(原因不明)でマスクできない場合がある。
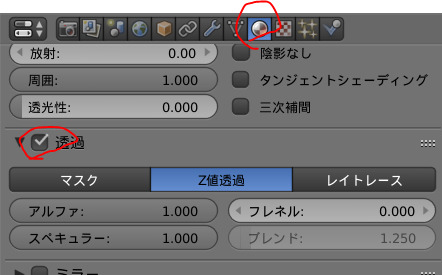
その場合はマテリアルタブの透過にレ点を入れるとマスクできるようになる。
1 note
·
View note
Text
自作モデルはいつ見てもカッコいい。
はい、かっこいいハイカッコいい。

しゅんけさん配布のNodeLines(blenderのノード)を使うとイカす白黒画像ができます。
本来は線画を作る用のノードですが、いろいろノードを繋ぎ変えると面白いです。
ひたすら自作モデルをぐるぐる回しては、はいかっこいいはいかっこいいというだけの作業になります。
ノードエディタで以下のようにつなぐと大変にかっこええ画像ができます。
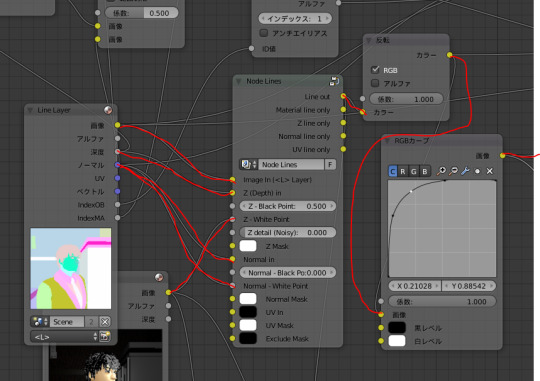
値を変えても面白い。はい、かっこいいかっこいい。
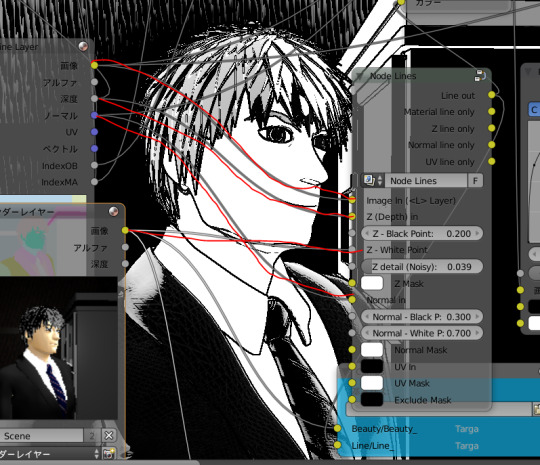
通常でもレンダリングやマテリアル設定にして自作モデルをぐるぐる回しては見て楽しんでるんですが、コンポジットだとそういうことができないので非常に残念。
1 note
·
View note
Text
blenderにopencvの代わりにscikit-image入れた
blenderにopenCVインストールしてみたもののimport cv2で落ちるという悲しい事件が起きたので代わりにscikit-image入れてみた。
インストール方法は基本的にはblenderで��める画像処理にある通りpipをインストールしてblenderのインストールしてある場所のpythonフォルダーにインストールという流れ。
scikit-image公式サイトからwindows用の
scikit_image-0.13.1-cp35-cp35m-win_amd64.whlをダウンロードし(ここではc:\tmpに置いた)そのまんまファイル名入れてpipなにがしを実行した。
Scripts\pip.exe install c:\tmp\scikit_image-0.13.1-cp35-cp35m-win_amd64.whl
blenderでimport skeimageすると要求されるのでそれもあらかじめインストールして置くこと(ただしmatplotlibは動かなかった)
Scripts\pip.exe install scipy
Scripts\pip.exe install matplotlib
で、blenderがProgram Filesにインストールされてる場合は管理者権限でコマンドプロンプトに入っとかなきゃいけない。
前回の通りにscikit-imageをコマンドプロンプトでインストールした後の流れについて、書いておこう。
今回も細線化してみる
細線化前の画像

レンダーレイヤーにソーベルとカラーランプを繋いで作った単純な線画
(カラーランプで二値化しておかないと真っ黒に変換されてしまう)
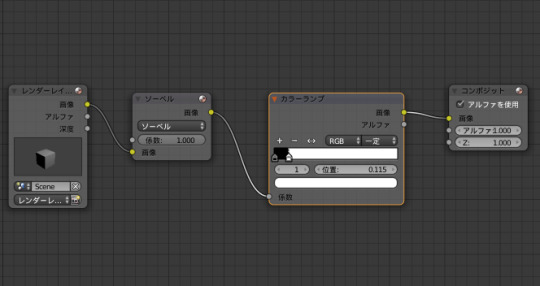
画像をいったん保存する(例によってこのサイトの”などは全角で表示されてしまうので要修正)
画像の名前から画像データ取得
blimg = bpy.data.images['sikaku']
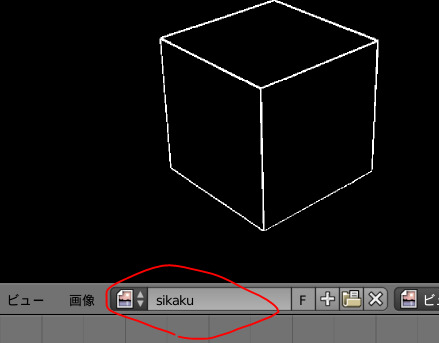
いったん保存
bpy.context.scene.render.image_settings.file_format = 'PNG'
bpy.context.scene.render.image_settings.color_mode = 'RGBA'
blimg.save_render(’c:/tmp/sikaku.png’)
保存したファイルを開く
from skimage import io
img = io.imread(’c:/tmp/sikaku.png’)
RGBからグレースケールにする
import skimage.color
gimg = skimage.color.rgb2gray(img)
細線化
from skimage.morphology import skeletonize, skeletonize_3d
skeleton = skeletonize(gimg)
注意:img.show()とかするとblender落ちる!!
画像の色の取り方が違うのでこのまま保存すると黒が紫色になってしまうので直す。
(詳しくはhttp://scikit-image.org/docs/dev/user_guide/data_types.html(英語))
from skimage import img_as_ubyte
ub = img_as_ubyte(skeleton)
scikitで保存する場合
io.imsave("c:/tmp/saisen.png",ub)
PILで保存(matplotlibがimportできないため)
pilImg = Image.fromarray(numpy.uint8(ub))
pilImg.save("c:/tmp/saisen.png")
saisenimg = bpy.data.images.load('c:/tmp/pil_saisen.png')
saisenimg.name = 'saisen'
↓1ピクセルの線画がblenderに表示される。
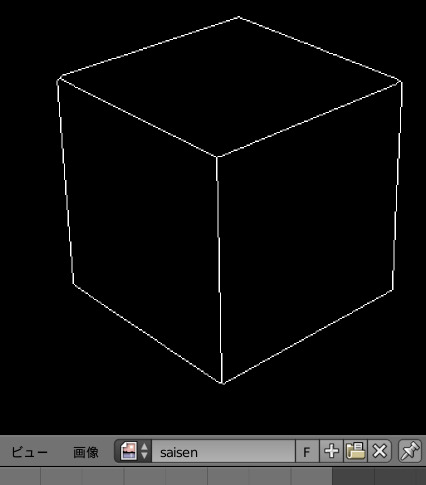
まとめ
・matplotlibで途中経過を気軽に見れないのはつらい
・ほかにも面白そうな機能いっぱいあるお(^_-)-☆
・画像をいったん保存してどうのこうのといじるなら別にblenderでやらんでもいいのでわ(^^;)
import bpy
from skimage.morphology import skeletonize
#matplotlibはインポートできなかった。
#import matplotlib.pyplot as plt
from skimage.util import invert
from skimage import io
from PIL import Image
import skimage.color
import numpy
from skimage import img_as_ubyte
blimg = bpy.data.images['sikaku']
bpy.context.scene.render.image_settings.file_format = 'PNG'
bpy.context.scene.render.image_settings.color_mode = 'RGBA'
blimg.save_render('c:/tmp/sikaku.png')
img = io.imread('C:/tmp/sikaku.png')
#反転する時はinvertを使う
#img=invert(img)
gimg = skimage.color.rgb2gray(img)
skeleton = skeletonize(gimg)
ub = img_as_ubyte(skeleton)
#scikitで保存する場合
io.imsave("c:/tmp/saisen.png",ub)
#pilで保存する場合
pilImg = Image.fromarray(numpy.uint8(ub))
pilImg.save('c:/tmp/saisen.png')
saisenimg = bpy.data.images.load('c:/tmp/pil_saisen.png')
saisenimg.name = 'saisen'
0 notes
Text
Blenderにopencv入れたら落ちた
blenderへのopencvとpiloowのインストール(opencvは失敗したのでscikit-imageいれた)してみた記録
windows 10
blender2.79
blender内のpython3.53
pillow
blenderで始める画像処理 にある通りだけど、blenderをProgram Filesにインストールしている場合はコマンドプロンプトを管理者権限で開いてインストールを行わないとエラー出る。
opencv
この場合は
「Could not find a version that satisfies the requirement opencv (from versions: )
No matching distribution found for opencv」
コマンドを
Scripts\pip.exe install opencv_pythonに変えたら
Could not install packages due to an EnvironmentError: [Errno 13] Permission denied: 'c:\\program files\\blender foundation\\blender\\2.79\\python\\Lib\\site-packages\\numpy\\core\\multiarray.cp35-win_amd64.pyd'
Consider using the `--user` option or check the permissions.
とエラー出たのでメッセージの通り--userを付け加えて
Scripts\pip.exe install opencv_python --user
とやったらインストール成功した
・・・がblender側でimport cv2したらblender落ちた。
(このときインストールされたのはnumpy-1.14.3 opencv-python-3.4.0.12の様子)
blender側で
import sys
sys.path.append(”C:\Program Files\Blender Foundation\Blender\2.79\python\lib\site-packages\cv2“)
import cv2
やってみても落ちた、悲しい。
代わりにscikit-imageをインストールしてみた。
公式サイトからwindows用の
scikit_image-0.13.1-cp35-cp35m-win_amd64.whlをダウンロードし(ここではc:\tmpに置いた)そのまんまファイル名入れてpipなにがしを実行した。
Scripts\pip.exe install c:\tmp\scikit_image-0.13.1-cp35-cp35m-win_amd64.whl
blenderでimport skeimageすると要求されるのでそれもあらかじめインストールして置くこと(ただしmatplotlibは動かなかった)
Scripts\pip.exe install scipy
Scripts\pip.exe install matplotlib
長くなったのでscikit-imageの件はまた次に書く
0 notes
Text
未来への警告
っていう感じのエラー出た。
治したいけど、なんかとりあえず動いてるからいいや、で放置しまくりなのでメモしとく。
FutureWarning: Conversion of the second argument of issubdtype from `float` to `np.floating` is deprecated. In future, it will be treated as `np.float64 == np.dtype(float).type`. from ._conv import register_converters as _register_converters
0 notes
Text
chainerでエラーが出たときに助かったサイト
「お前の血は何色だ」っていう名前のブログなんだけど、とにかく「このエラー訳わからん、しむぅ~」って時に超助かった。ほんとエラーがでてるときはこのブログの名前みたいな気持ちになる(でもエラーが出るのは自分のせいなのであるので・・・orz)
エラーの文章全文が書いてあってその内容についても書いてあって超助かった(二度目)。
先人の苦労に感謝である・・・。
お前の血は何色だ!! 4
http://d.hatena.ne.jp/rti7743/20170105/1483602327
0 notes
Text
画像の余白づけ
from PIL import Image
img = image.open(000.jpg)
w,h =img.size
yohaku_h = 10
yohaku_w = 50
yohaku = Image.new("RGB", (w+yohaku_w*2,h+yohaku_h*2),(255,255,255))
imc = img.crop()
yohaku.paste(imc,(yohaku_w,yohaku_h))
yohaku.show()
0 notes
Text
google Colaboratory を使ってみた
前回の続き
chainer 4も使えるようで、Ubuntuって何?レベルでも基本のコマンドは「!」マークをコマンドプロンプトで使うコマンドの頭につければいいみたいで、windowsしかわかんねーよ状態の自分でも大丈夫だった。
先人の知恵でgoogleドライブから普通にファイル呼びだせるコマンドもあってなんとかエラーを乗り越えpix2pixを動かすことができた。
途中細かくサムネイルみたいなのとりすぎてgoogleドライブ保存上限15GBに到達してしまった。
でも途中まで保存されてたsnapshotモデルを使って画像を変換することができてほっとした。
学習済みモデル(600MB)を読み込んでCPUで変換すると20秒ぐらいかかった・・・20秒は遅いと思う。
どこかで何かしくじっているのでは?と経過時間を見てみた
dec = Decoder(out_ch=3)の直後で3秒
(net.pyのDecoderを呼び出しているところ)と
if os.path.exists(codri+'generate_tmp'):
shutil.rmtree(codri+'generate_tmp')
の部分で5秒かかっている。
なんかgoogleドライブ関係あるのか???
わからんけど、とりあえず自分PCでCPU変換をやってみたところ7秒で全部終わってしまった。(後で初回起動時は14秒かかった事が分かった)
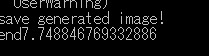
ifのところも一秒もかからずに終わってる。
(しかしすでに2秒近く時間が経過している(-_-;))
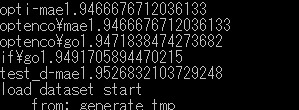
あとはnpzを呼び出すところで4秒かかってる。
chainer.serializers.load_npz(args.model, trainer)
どちらにしても256×256の画像を一枚変換するだけで7秒というのも、ちと遅い・・・・。ただ、遅い部分がnpz(学習済みモデル)のロードとdecoderなら沢山のファイルをまとめて処理する場合なら一回づつ呼び出して終わりで問題ないような気がする。次に試してみたい。
あと小さい画像だと色々面倒すぎて大きい画像でやってみたい。
0 notes
Text
ブロードキャストエラー
頻発するブロードキャストエラーについて。
親切にも何が悪いのか内容を教えてくれるエラー
ValueError: could not broadcast input array from shape (256,3,256) into shape (3,256,256)
shape(256,3,256) からshape(3,256,256) に入力配列をブロードキャストできませんでしたよっていう事で
ブロードキャストは大きさの違う配列同士の計算をしてくれるんだけど、その時の配列の大きさが合いませんよっていう意味。(詳しくはわかってない)
とりあえず、ここでは大きさを合わせれば解決する時の場合のメモ。
まずshapeとは配列に入っているモノの数。
例えば(一次元配列)
import numpy as np
a = np.array([1,2,3])
a.shape
とすると出力(配列aのshape)は(3,)になる。
次元数は
a.ndim
で、表されこのaの次元数は1となる()

a = np.array([[1,2],[3,4,5],[6,7,8,9]])
a.shape
も出力は(3,)になる。次元数は1。
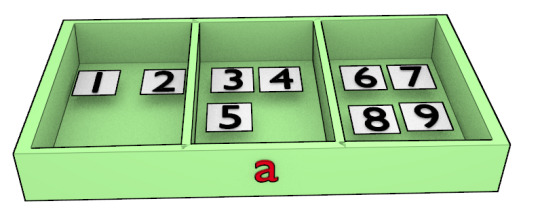
二次元配列だと
a = np.array([[1,2],[3,4],[5,6]])
a.shape
だと(3, 2)になり
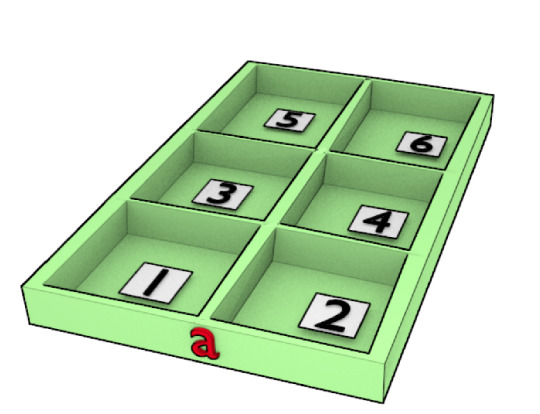
奥行きのある箱に。
3次元配列になると
a = np.array([[[1,2,3,4],[5,6,7,8]],[[9,10,11,12],[13,14,15,16]],[[17,18,19,20],[21,22,23,24]]])
a.shape
だと(3, 2, 4)になる。
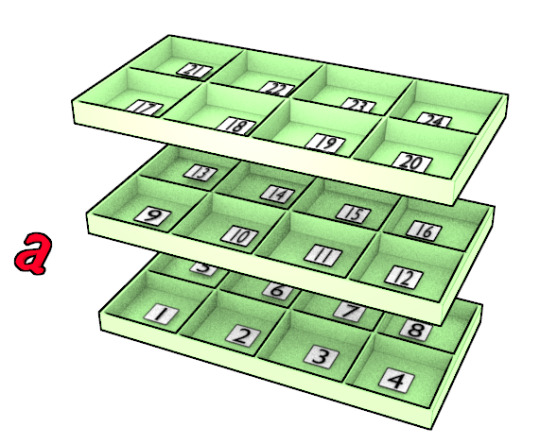
三階建てですね。
もう一度エラーを見ると
ValueError: could not broadcast input array from shape (256,3,256) into shape (3,256,256)
つまり256階建て3部屋265小部屋に3階建て256部屋256小部屋に入りませんよ、建物の形が違うよって感じ。
これを合わせてあげるにはさっきのshapeが(3, 2, 4)の配列を
a = np.array([[[1,2,3,4],[5,6,7,8]],[[9,10,11,12],[13,14,15,16]],[[17,18,19,20],[21,22,23,24]]])
a=a.transpose((2,0,1))
a.shape
出力は(4,3,2)になり
aは以下の形になる
array([[[ 1, 5],
[ 9, 13],
[17, 21]],
[[ 2, 6],
[10, 14],
[18, 22]],
[[ 3, 7],
[11, 15],
[19, 23]],
[[ 4, 8],
[12, 16],
[20, 24]]])
4階建て、2部屋、3小部屋ですかね。
0 notes
Text
chainerのpix2pixを動かしてみた。
前回の続き。
とにかくまずは自分の環境で動くのかどうかを確認したい。結論としてgpuで動かなかった。cpuのみ。
windows 10 home
python3.6(非anaconda)
chainer 3.5(python 4.0.0でもcpuのみなら動いた)
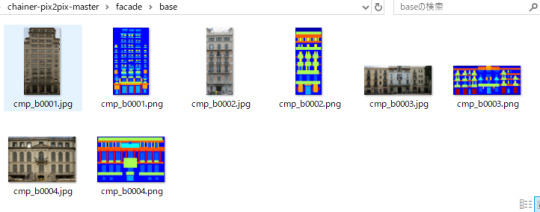
\chainer-pix2pix-master\facade\baseに入力画像教師画像を4枚づつcmpの画像を入れる
train_facade.pyの70行辺りに画像を何枚使うか指定するところ(data_range=(1,300))があるので以下に書き換える
train_d = FacadeDataset(args.dataset, data_range=(1,3))
test_d = FacadeDataset(args.dataset, data_range=(3,5))
train_dにcmp_b0001と0002のペア、test_dに0003と0004のペアが入る。
50行辺りのin_chの値を3にする
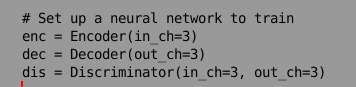
scipyをインストールしてtrain_facade.pyをGPUで実行。
python train_facade.py -g 0 -i ./facade/base --out result_facade --snapshot_interval 10000
はいエラーです、もうやだー!!アウトオブメモリーとか悲しい事言うなよぉ...orz
cupy.cuda.memory.OutOfMemoryError: out of memory to allocate 33554432 bytes (total 426982400 bytes)
gpuなし(cpuのみ)
動くがエラーあり・・・。
C:\Users\ユーザー名\AppData\Local\Programs\Python\Python36\lib\site-packages\chainer\functions\normalization\batch_normalization.py:65: UserWarning: A batch with no more than one sample has been given to F.batch_normalization. F.batch_normalization will always output a zero tensor for such batches. This could be caused by incorrect configuration in your code (such as running evaluation while chainer.config.train=True), but could also happen in the last batch of training if non-repeating iterator is used.
翻訳##########################
UserWarning: batch_normalization には、複数のサンプルがないバッチが与えられています。batch_normalization は、このようなバッチに対して常にゼロテンソルを出力します。これは、コード内の不適切な構成 (チェーンの実行中の評価など) が原因で発生する可能性がありますが、繰り返し反復子が使用されていない場合は、トレーニングの最後のバッチでも発生する可能性があります。
###############################
わからん。
が動いてるのでせめてまともに動いてるか確認したい・・・。
画像が4セットと少なすぎて途中経過が出力されないまま終わってしまう。
cpuのみで--snapshot_interval を10で実行
エラー出るので
facade_visualizer.pyの20行辺りのin_chを3にする。
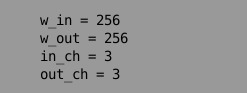
それから
in_all[it,:] = x_in.data.get()[0,:]
でnumpyにgetなんてもの無いよ的なエラー出るのであきらめてgetを外す。
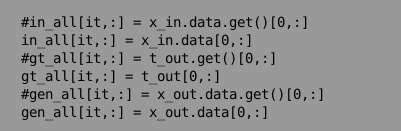
というのも、検索したところ、gpuからどうのこうのとあって・・・そもそもGPU使ってないから必要ないんじゃないかと・・・
するとなんか動き出した。
--outで指定したフォルダが自動で作られてこの中のプレビューに画像がちょっとづつ増えていく・・・。いや、ほんとうれしい。


ただ、4ペアの画像で1時間15分となると40ペアで12時間半、400ペアで125時間・・・4日か・・・んんんまぁ、まだ現実的な時間かなぁ(汗)
自前のグラボ(弱)使っても2倍までしかスピードあがらんでぇ・・・
次回(その後、google colaboratory 使ってみた)に続く
0 notes
Text
必要なデータセットは何か?
ものすごい思い込みのもと自力でデータセットを作ってみたらエラーが無くならんので元のhttps://github.com/pfnet-research/chainer-pix2pixのデータセット(facade_dataset.py)の中身で何やってるかお勉強メモ(2018年4月23日)
readmeに書いてある通りなんだけど、自分めも追加・・・
自前でデータセット作るには256×256のサイズnumpyarryで作ったfloat型の入力画像とint型の教師画像の中身をチャネル、高さ、横幅に並び替えてあるものがget_exampleで呼び出せればいいみたい。
自分で画像だけを用意してあとはそっくりそのまま元のスクリプト使うにはカラーで入力画像をjpg、教師画像をpngにして同じ名前と同じ縦横比にして/facade/baseっていうフォルダー作ってその中に380枚づつ入れとけばいいのではではと思い画像をcmpのbaseから4枚づつ持ってきてやってみた。(train_facade.pyの70行目を要修正)
scipyが無いよ的なエラーが出るので公式に書いてある通りのコマンドでインストール。
python -m pip install --user numpy scipy matplotlib ipython jupyter pandas sympy nose
train_facade.py実行したらCPU、GPUともにエラーが出た(詳細は次回)。
勘違いしてたが写真(jpg)のほうがimgで色で塗り分けてある方(png)がlabelだった。
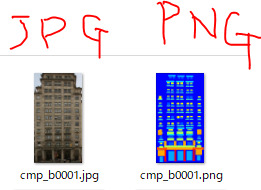
画像をまとめて加工したい場合はget_exampleでやってしまった方がいいらしい。
train_facade.pyの70行目で300枚づつのデータセットを呼び出す。
train_dが学習用でtest_dが評価用(80枚)だろうなぁ。
train_d = FacadeDataset(args.dataset, data_range=(1,300))
test_d = FacadeDataset(args.dataset, data_range=(300,379))
しかし、gpuがへなちょこなのでchainerv4のcpuでばりばり動かせるというやつも試してはみたいんだが・・・・環境つくるのめんどい、失敗したらまた動かんようになるのかふあ-ん。
##################################
#facade_dataset.py
import os
import numpy
from PIL import Image
import six
import numpy as np
from io import BytesIO
import os
import pickle
import json
import numpy as np
import skimage.io as io
from chainer.dataset import dataset_mixin#
#以下のアドレスからBASEデーターセットをダウンロードする
# download `BASE` dataset from http://cmp.felk.cvut.cz/~tylecr1/facade/
class FacadeDataset(dataset_mixin.DatasetMixin):
def __init__(self, dataDir='./facade/base', data_range=(1,300)):
#dataDirのフォルダーから300回画像セットを取り出す
print("load dataset start")
print(" from: %s"%dataDir)
print(" range: [%d, %d)"%(data_range[0], data_range[1]))
self.dataDir = dataDir
self.dataset = []
for i in range(data_range[0],data_range[1]):
#imgが入力画像(jpg)、labelが教師画像(png)
#ダウンロードしたデータセットの中身が
#もともと同じ名前でjpgとpngに分けてある
img = Image.open(dataDir+"/cmp_b%04d.jpg"%i)
label = Image.open(dataDir+"/cmp_b%04d.png"%i)
w,h = img.size
r = 286 / float(min(w,h))
#min(w、h)・・・wとhの小さいほうの値をとる
#wとhで小さいほうの辺が286で縦横比は変わらないように画像のサイズを変更する
# resize images so that min(w, h) == 286
#バイリニア補間で入力画像をリサイズ
img = img.resize((int(r*w), int(r*h)), Image.BILINEAR)
#ニアレストネイバー(色数を増やしたくない時に使用)で
#教師画像をリサイズ
label = label.resize((int(r*w), int(r*h)), Image.NEAREST)
#画像をnumpyに入れる
#pil用(高さ、横幅、チャンネル)から
#chainer用(チャネル、高さ、横幅)にデーターを入れ替える
#transpose(2,0,1)・・・データの縦と横を入れ替える
#astype("f")・・・フロート型(入力画像はフロート型でなければならない)
#/128.0/-1.0・・・値を0~1にしなければならないが256じゃなくてなんで128で割るのかわからない、マイナス1は反転???
img = np.asarray(img).astype("f").transpose(2,0,1)/128.0-1.0
label_ = np.asarray(label)-1 # [0, 12)
#numpy.zeros・・・0を要素とする配列を生成する
#astype("i")・・・教師画像はint型でなければならない
label = np.zeros((12, img.shape[1], img.shape[2])).astype("i")
for j in range(12):
label[j,:] = label_==j
#入力と教師画像を一緒にデーターセットに追加
self.dataset.append((img,label))
print("load dataset done")
def __len__(self):
#学習データの数
return len(self.dataset)
# return (label, img)
def get_example(self, i, crop_width=256):
#i番目の画像/ラベルのペアを読み取り、前処理された画像を返す。
#入力画像から256×256のサイズでランダムに切り取っている
_,h,w = self.dataset[i][0].shape
x_l = np.random.randint(0,w-crop_width)
x_r = x_l+crop_width
y_l = np.random.randint(0,h-crop_width)
y_r = y_l+crop_width
return self.dataset[i][1][:,y_l:y_r,x_l:x_r], self.dataset[i][0][:,y_l:y_r,x_l:x_r]
#################################
0 notes