
Don't wanna be here? Send us removal request.
Statistics
We looked inside some of the posts by lilymia799 and here's what we found interesting.
Average Info
Notes Per Post
1
Likes Per Post
1
Reblog Per Post
0
Reply Per Post
0
Time Between Posts
15 days
Number of Posts By Type
Text
12
Last Seen Tumblr Blogs





Fun Fact
In February 2021, Tumblr had 518.6 million blog accounts.
Text
Streamlining Data Integration with SAP CDC
Efficient data integration is a cornerstone of modern business success. SAP Change Data Capture (CDC) ensures real-time synchronization and data accuracy across platforms, improving decision-making and operational efficiency.
What is SAP CDC?
SAP CDC is a mechanism to track changes—like inserts, updates, and deletes—in SAP and non-SAP systems. These changes are captured and made available to downstream applications, ensuring data consistency.
Advantages of SAP CDC
Real-Time Data Sync: Keeps all systems updated instantly.
Improved ETL Processes: Reduces latency and improves pipeline efficiency.
Lower Overhead: Operates with minimal impact on system performance.
Enhanced Reporting: Provides up-to-date data for analytics tools.
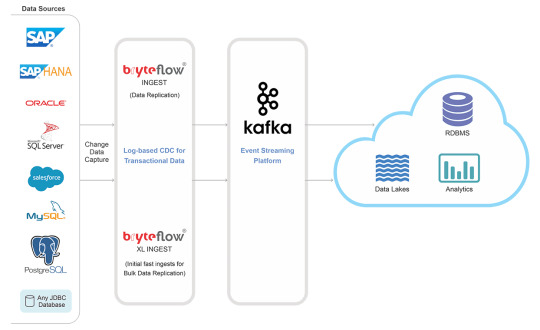
How SAP CDC Works
Log-Based Capture: Monitors changes via database logs.
Event Streaming: Sends change events to target systems in real time.
ETL Integration: Integrates seamlessly with data pipelines for further processing.
Applications of SAP CDC
Data Replication: Keep multiple databases synchronized.
Data Lakes and Warehousing: Feed real-time data into analytical environments.
Cloud Migration: Smoothly transfer data from legacy systems to modern platforms.
Advanced Use Cases
SAP CDC is especially valuable for companies operating across multiple regions. By ensuring data consistency and real-time availability, businesses can support global operations more effectively. SAP CDC also plays a vital role in machine learning workflows, providing up-to-date training data for AI models.
Getting Started with SAP CDC
Begin by identifying the source systems and changes you want to capture. Set up the integration using SAP tools or connectors, then test the pipeline to ensure accuracy. Focus on configuring alerts for failures to ensure continuous operations.
SAP CDC transforms how businesses manage data, providing a foundation for agile, data-driven operations. It’s the perfect solution for organizations seeking to stay ahead in today’s fast-paced digital landscape. Its real-time capabilities and flexibility make it indispensable for modern enterprises.
0 notes
Text
Leveraging SAP Data Lake for Comprehensive Data Management
The SAP Data Lake is a robust, cloud-based repository designed to handle large volumes of structured, semi-structured, and unstructured data. By integrating with SAP systems, it allows businesses to centralize their data for advanced analytics and storage.
What is SAP Data Lake?
SAP Data Lake is part of the SAP Data Intelligence suite, offering high-capacity storage for diverse data types. It empowers organizations to consolidate and analyze their data for strategic decision-making.

Key Features
Scalability: Handles massive data volumes effortlessly.
Flexibility: Supports various data formats, including JSON, XML, and CSV.
Seamless Integration: Works well with SAP HANA and other analytics tools.
Advantages of SAP Data Lake
Cost-Effective Storage: Store large datasets at reduced costs compared to traditional methods.
Enhanced Analytics: Combine diverse datasets for comprehensive insights.
Real-Time Processing: Integrate with SAP HANA for live data analytics.
Real-World Applications
IoT Data Management: Collect and store IoT data for advanced analysis.
Customer Insights: Merge customer data from multiple sources for 360-degree insights.
Operational Efficiency: Analyze operational data to optimize processes and resources.
Why Choose SAP Data Lake?
SAP Data Lake ensures that businesses can manage and analyze their growing data needs without compromising performance or scalability. It is a key enabler for businesses to become data-driven, unlocking new opportunities for growth and innovation.
0 notes
Text
Introduction to SAP ETL: Transforming and Loading Data for Better Insights
Understanding ETL in the Context of SAP
Extract, Transform, Load (ETL) is a critical process in managing SAP data, enabling companies to centralize and clean data from multiple sources. SAP ETL processes ensure data is readily accessible for business analytics, compliance reporting, and decision-making.

Key Benefits of Using ETL for SAP Systems
Data Consistency: ETL tools clean and standardize data, reducing redundancy and discrepancies.
Enhanced Reporting: Transformed data is easier to query and analyze, making it valuable for reporting in SAP HANA and other data platforms.
Improved Performance: Offloading data from SAP systems to data lakes or warehouses like Snowflake or Amazon Redshift improves SAP application performance by reducing database load.
Popular SAP ETL Tools
SAP Data Services: Known for deep SAP integration, SAP Data Services provides comprehensive ETL capabilities with real-time data extraction and cleansing features.
Informatica PowerCenter: Popular for its broad data connectivity, Informatica offers robust SAP integration for both on-premises and cloud data environments.
AWS Glue: AWS Glue supports SAP data extraction and transformation, especially for integrating SAP with AWS data lakes and analytics services.
Steps in SAP ETL Process
Data Extraction: Extract data from SAP ERP, BW, or HANA systems. Ensure compatibility and identify specific tables or fields for extraction to streamline processing.
Data Transformation: Cleanse, standardize, and format the data. Transformation includes handling different data types, restructuring, and consolidating fields.
Data Loading: Load the transformed data into the desired system, whether an SAP BW platform, data lake, or an external data warehouse.
Best Practices for SAP ETL
Prioritize Data Security: Data sensitivity in SAP systems necessitates stringent security measures during ETL processes. Use encryption and follow compliance standards.
Automate ETL Workflows: Automate recurring ETL jobs to improve efficiency and reduce manual intervention.
Optimize Transformation: Streamline transformations to prevent overloading resources and ensure fast data processing.
Challenges in SAP ETL and Solutions
Complex Data Structures: SAP’s complex data structures may require advanced mapping. Invest in an ETL tool that understands SAP's unique configurations.
Scalability: As data volume grows, ETL processes may need adjustment. Choose scalable ETL tools that allow flexible data scaling.
0 notes
Text
How Does The SAP BW Extractor Work
The SAP BW Extractor, simply called the SAP Extractor today is a data management tool of SAP. It is used to extract SAP data from a source database and move it either to a downstream data warehouse or any other business intelligence system. The goal of the SAP BW Extractor is to provide SAP BW applications with data extracted from SAP sources.
SAP data can be integrated by the Extractor even if an SAP user is not on the SAP BW. Hence, a SAP BW Extractor can populate the delta queue with modified records of the new delta type. All the changed records can be moved to the SAP BW through a simple remote call.
Before using the SAP BW Extractor to mine data, it is necessary to define the load process in the schedule with an InfoPackage. Users can extract data once this process is completed. This extracted data may then be transferred to the input layer of the SAP BW Warehouse, commonly referred to as the PSA (Persistent Staging Area).

The SAP BW Extractor must be hard-coded before SAP data can be extracted. Only then can the application-specific Extractors deliver BI Content of the Business Warehouse. The functioning of an Extractor is fully automated. It can recognize the extracted data and the tables where the data is stored in read-only format after the generic extractor is named by the Data Source.
Master data attributes or texts are built in the SAP BW Extractor. These help to extract SAP data from all related database views and transparent tables. These features put the Extractor a notch above other Enterprise Resource Planning products such as Oracle, Salesforce, and Microsoft.
0 notes
Text
Benefits of Snowflake for enterprise database management
The importance of data for businesses cannot be overstated as the world continues to run on data-intensive, hyper-connected and real-time applications.
Businesses of all scale and capabilities rely on data to make future decisions and derive useful insights to create growth.
However, with the rising volume, complexity and dependency on data rich applications and platforms, it has become imperative for companies and enterprises to make use of scalable, flexible and robust tools and technologies.

This is where database management solutions help businesses implement data pipelines for storing, modifying and analysing data in real-time.
Although there are many tools and solutions to make use of real-time data processing and analysis, not all tools are created equal.
While many companies rely on legacy systems like Microsoft SQL server to power a wide range of applications, modern day businesses are increasingly adapting to cloud-based data warehousing platforms.
One such name in the database management sphere is called Snowflake which is a serverless, cloud-native infrastructure as a service platform.
Snowflake supports Microsoft Azure, Google Cloud and Amazon AWS and is fully scalable to meet your computing and data processing needs.
If you are interested in leveraging the power and capabilities of Snowflake’s cloud based data warehousing solution, it’s time to prepare for migrating your existing SQL server to Snowflake with the help of tools like Bryteflow. Bryteflow allows fully automated, no-code replication of SQL server database to a Snowflake data lake or data warehouse.
0 notes
Text
The Evolution and Functioning of SQL Server Change Data Capture (CDC)
The SQL Server CDC feature was introduced by Microsoft in 2005 with advanced “after update”, “after insert”, and “after delete” functions. Since the first version did not meet user expectations, another version of SQL Server CDC was launched in 2008 and was well received. No additional activities were required to capture and archive historical data and this form of this feature is in use even today.
Functioning of SQL Server CDC
The main function of SQL Server CDC is to capture changes in a database and present them to users in a simple relational format. These changes include insert, update, and delete of data. All metrics required to capture changes to the target database like column information and metadata are available for the modified rows. These changes are stored in tables that mirror the structure of the tracked stored tables.
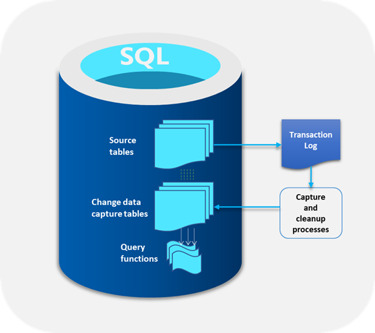
One of the main benefits of SQL Server CDC is that there is no need to continuously refresh the source tables where the data changes are made. Instead, SQL Server CDC makes sure that there is a steady stream of change data with users moving them to the appropriate target databases.
Types of SQL Server CDC
There are two types of SQL Server CDC
Log-based SQL Server CDC where changes in the source database are shown in the system through the transaction log and file which are then moved to the target database.
Trigger-based SQL Server CDC where triggers placed in the database are automatically set off whenever a change occurs, thereby lowering the costs of extracting the changes.
Summing up, SQL Server Change Data Capture has optimized the use of the CDC feature for businesses.
0 notes
Text
Why Should You Migrate Databases From Oracle to SQL Server
Oracle has been the mainstay among database management systems for organizations around the world for decades. However, the current data-driven business environment requires databases to provide unlimited storage capacities and high computing power while being affordable. All these combined can only be possible on a cloud-based platform, one of the reasons why migrating databases from Oracle to SQL Server is so popular today.

How to migrate databases from Oracle to SQL Server.
Follow the steps given below to migrate databases from Oracle to SQL server.
After a new SSMA project is created, project conversion, type mapping, and migration options have to be implemented.
The Oracle database server and an instance of the SQL Server have to be connected.
The Oracle database schemas are required to be mapped to SQL Server database schemas.
Next, the Oracle database schemas have to be converted into SQL Server schemas.
The converted database objects are to be loaded into SQL Server either by saving a script and running it in SQL Server or by synchronizing the database objects.
Finally, migrate data Oracle to SQL Server and update all database applications.
There are two migration methods that may be followed:
One-shot method: The entire Oracle to SQL Server database migration is completed in one shot. The entire system must be shut down so that any incremental data after the final backup is not left out.
Phased migration: Here the first method is first completed and then, migration is carried out in phases at certain intervals to include the movement of new data.
In a nutshell, DBAs need to be proficient in both systems to successfully migrate data from Oracle to SQL Server.
0 notes
Text
Replication of SAP Applications to Google BigQuery
In this post, we will go into the various facets of replicating applications from SAP to BigQuery through SAP Data Services.
Presently, users can integrate data such as Google BigQuery with business data that exists in the SAP Data Warehouse Cloud of the SAP Business Technology Platform. This is done with the help of hyper-scaler storage. What is important here is that data is queried through virtual tables directly with specific tools.

It is also possible to replicate data from SAP to BigQuery and assess all SAP data in one place.
To start the process of replicating data from SAP to BigQuery, ensure that the database is on SAP HANA or any other platform supported by SAP. This SAP to BigQuery activity is typically used to merge data in SAP systems with that of BigQuery.
After the replication process is completed, this data is used for getting deep business insights from Machine Learning (ML) for petabyte scale analytics. The SAP to BigQuery replication process is not complex and SAP system administrators with knowledge of configuring SAP Basis, SAP DS, and the Google Cloud can easily do it.
Here is the replication process of SAP to BigQuery.
Update all data in the source system SAP applications
The SAP LT Replication Server replicates all changes made to the data. These are then stored in the Operational Data Queue.
A subscriber of the Operational Delta Queue, SAP DS, continually tracks changes to the data at pre-determined intervals.
The data from the delta queue is extracted by SAP DS and then processed and formatted to match the structure that is supported by BigQuery.
Finally, data is loaded from SAP to BigQuery.
0 notes
Text
The Evolution And Structure Of The SAP Data Lake
In April 2020, SAP launched the SAP Data Lake. The goal was to further enhance the existing data storage capabilities and offer affordable options to clients. The components of this newly launched product were the SAP HANA native storage extension along with the SAP data lake.

From the early days of the launch, certain advanced technologies and cutting-edge systems were included in the package. This led this data lake to compete with the already existing ones in the niche such as Amazon Simple Storage Service and Microsoft Azure.
Unique Structure of the SAP Data Lake
The unique structure of the SAP data lake differentiates it from the others as its structure leads to cost savings for organizations using it.
The SAP data lake is shaped like a pyramid and is divided into three segments.
At the top of the pyramid is data that is important for organizations and is continually accessed daily and processed for operational requirements. Due to its importance, the cost of storing this data is the highest of the lot.
The middle segment of the pyramid holds data that is not as important as the top tier but not so insignificant as to be deleted from the system. This data is not required to be accessed daily and hence the storage costs are less than the top tier.
At the bottom of the pyramid in the SAP data lake is data that is rarely used. In traditional systems, this data would have been deleted to increase storage space but in this data lake, the costs are so minimal that businesses typically choose to retain it for historical purposes. Because of these benefits, most organizations are now switching to the SAP data lake.
0 notes
Text
OData Support In The Sap Gateway
It was Microsoft that first launched OData (Open Data Protocol) for exchanging data over the Internet. OData is built on the REST (Representational State Transfer) architecture that is based on the HTTP protocol. OData supports the full range of Create, Read, Update, and Delete (CRUD) operations. SAP OData has been implemented in the SAP NetWeaver Gateway.
An integral part of the SAP NetWeaver is the design, implementation, deployment, and testing of OData services. Additionally, SAP OData generates OData services to expose Business Warehouse infocubes and CDS views.

The present database management systems where there is an exponential increase in applications running in the cloud, necessitates an open and uniform connectivity to SAP systems. SAP OData has now become the most popular choice for accessing SAP systems from the Internet. Keep in mind though that SAP OData is relevant only if the SAP systems act as a service or data provider.
There are several scenarios for deploying OData services. It all depends on where the individual components of SAP Data services run.
Let us look at three possible scenarios.
# A single central SAP Gateway System connects to multiple backend SAP systems leading to high security and good performance since data and the OData Runtime reside on the same system.
# A single instance of the OData Runtime runs on the (only) central SAP Gateway System, which connects to multiple backend SAP systems. The SAP Gateway System can be located inside a demilitarized zone (DMZ). This option allows for good security and low maintenance costs.
# All components are implemented on the backend SAP system. This option has the lowest TCO since a dedicated gateway system is not needed. However, there might be limitations regarding security and scalability.
0 notes
Text
Enhancing Data Integration with Oracle CDC
Oracle Change Data Capture (CDC) is a powerful tool that helps organizations streamline data integration processes by capturing changes in Oracle databases and making them available for real-time processing. This capability is crucial for businesses that rely on timely data updates for analytics, reporting, and operational efficiency.
Understanding Oracle CDC
Oracle CDC captures changes in database tables and makes these changes available to downstream systems. It works by monitoring changes such as inserts, updates, and deletes, and then recording these changes in a change table. This data can then be extracted and applied to other systems, ensuring data consistency across the organization.

Key Benefits of Oracle CDC
Real-Time Data Synchronization: Oracle CDC ensures that changes in the source database are immediately available to target systems. This real-time synchronization is essential for applications that require up-to-date information, such as financial reporting and inventory management.
Reduced Data Latency: By capturing and applying changes as they happen, Oracle CDC minimizes the latency between data generation and data availability. This low-latency approach is critical for applications that rely on timely data for decision-making.
Efficient Data Integration: Oracle CDC simplifies the process of integrating data from multiple sources. By capturing changes at the source, it eliminates the need for complex ETL processes, making data integration more efficient and less error-prone.
Improved Data Consistency: Oracle CDC ensures that all systems have consistent data by capturing and applying changes in a controlled manner. This consistency is crucial for maintaining data integrity across the organization.
Implementing Oracle CDC
To implement Oracle CDC, businesses need to configure the CDC environment and define the change data capture rules. This involves specifying which tables and columns to monitor for changes. Once configured, Oracle CDC will capture changes and store them in a change table, which can be accessed by downstream systems.
Use Cases for Oracle CDC
Data Warehousing: Oracle CDC can be used to keep data warehouses in sync with operational databases. By capturing changes in real-time, it ensures that the data warehouse always contains the most recent data, enabling timely and accurate analytics.
Application Integration: Many businesses operate multiple applications that need to share data. Oracle CDC facilitates this by capturing changes in one application’s database and applying them to another application’s database, ensuring data consistency across the enterprise.
Business Intelligence: Real-time data is crucial for business intelligence applications that provide insights into operations. Oracle CDC ensures that BI tools have access to the latest data, enabling more accurate and timely analysis.
Disaster Recovery: Oracle CDC can be used to replicate data to a backup system in real-time. In the event of a disaster, this ensures that the backup system has the most recent data, minimizing data loss and downtime.
0 notes
Text
Migrating from SQL Server to Snowflake Essential Steps and Benefits
Transitioning from SQL Server to Snowflake can significantly enhance your data management capabilities. Snowflake's cloud-native architecture offers numerous advantages, including scalability, flexibility, and cost-efficiency, making it a popular choice for modern data warehousing needs. This article outlines the essential steps and benefits of migrating from SQL Server to Snowflake.
Key Steps for Migration
1. Initial Assessment and Planning
Start with a thorough assessment of your existing SQL Server environment. Identify the databases, tables, and other objects that need to be migrated. Understand the data volume, dependencies, and specific requirements of your applications. Develop a comprehensive migration plan that includes timelines, resources, and risk mitigation strategies.
2. Choosing the Right Migration Tools
Select migration tools that facilitate a smooth transition from SQL Server to Snowflake. Tools such as Azure Data Factory, Matillion, and Fivetran can help automate the extraction, transformation, and loading (ETL) processes. These tools ensure data integrity and minimize downtime during the migration.

3. Schema Conversion
SQL Server and Snowflake have different schema structures. Use schema conversion tools to translate SQL Server schemas into Snowflake-compatible formats. Pay attention to data types, indexing, and partitioning strategies to optimize performance in Snowflake.
4. Data Transformation and Migration
Transform your data to align with Snowflake’s architecture. This might involve data cleansing, reformatting, and converting stored procedures and T-SQL code into Snowflake’s SQL dialect. Leverage Snowflake’s capabilities, such as support for semi-structured data and time travel features, to enhance your data operations.
5. Testing and Validation
Perform thorough testing and validation to ensure that the data has been accurately migrated and that all applications function as expected. Validate data integrity, check for any discrepancies, and conduct performance testing to ensure that Snowflake meets your performance requirements.
6. Security and Compliance
Implement robust security measures to protect your data during and after the migration. Ensure that access controls, encryption, and compliance requirements are met in the Snowflake environment. Snowflake provides extensive security features, including role-based access control and end-to-end encryption.
Benefits of Migrating to Snowflake
1. Scalability and Performance
Snowflake’s architecture allows for automatic scaling of compute resources to handle varying workloads efficiently. This elasticity ensures consistent performance without manual intervention, making it ideal for businesses with growing and fluctuating data needs.
2. Cost Efficiency
With Snowflake’s pay-as-you-go pricing model, you only pay for the storage and compute resources you use. This can lead to significant cost savings, especially for organizations with variable data workloads. Snowflake's separation of storage and compute allows you to optimize resource usage and reduce costs.
3. Simplified Data Management
Snowflake offers a fully managed service, reducing the burden of database administration. Automatic updates, maintenance, and performance tuning are handled by Snowflake, allowing your IT team to focus on more strategic tasks and innovations.
4. Advanced Analytics Capabilities
Snowflake supports diverse data types and integrates seamlessly with various data analytics tools. This enables advanced analytics and machine learning applications, allowing you to gain deeper insights from your data. Snowflake’s support for semi-structured data like JSON, Avro, and Parquet enhances your analytical capabilities.
5. Enhanced Data Sharing and Collaboration
Snowflake’s secure data sharing capabilities facilitate seamless collaboration across departments and with external partners. Real-time data sharing without the need for complex ETL processes improves efficiency and enables better decision-making.
6. Robust Security Features
Snowflake incorporates comprehensive security measures, including end-to-end encryption, role-based access control, and detailed auditing capabilities. These features ensure that your data remains secure and compliant with regulatory standards.
1 note
·
View note