
Sideblog for posts too focused on software and similar topics, which do not fit well on my main.
Don't wanna be here? Send us removal request.
Statistics
We looked inside some of the posts by mentalisttraceur-software and here's what we found interesting.
Average Info
Notes Per Post
12K
Likes Per Post
7K
Reblog Per Post
5K
Reply Per Post
218
Time Between Posts
28 days
Number of Posts By Type
Text
17
Last Seen Tumblr Blogs





Fun Fact
In February 2021, Tumblr had 518.6 million blog accounts.
Text
I predict that an easy big across-the-board LLM reasoning improvement is to prompt the LLM to argue against every point it makes.
Ideally you have it then argue against those arguments, and so on. Have some stopping condition like "until you cannot think of counter arguments that are better than the previous arguments." But I think even just one iteration of arguing against itself will be an improvement on average.
With existing models, you probably need to do this as two messages, so that the model first gives you the best reasoning it can think of, instead of the easier path of predicting more easily refutable arguments to refute, since those are almost certainly going to be more common in the training data.
6 notes
·
View notes
Text
Also software development.

1K notes
·
View notes
Text
I miss being able to just use an API with `curl`.
Remember that? Remember how nice that was?
You just typed/pasted the URL, typed/piped any other content, and then it just prompted you to type your password. Done. That's it.
Now you need to log in with a browser, find some obscure settings page with API keys and generate a key. Paternalism demands that since some people insecurely store their password for automatic reuse, no one can ever API with a password.
Fine-grained permissions for the key? Hope you got it right the first time. You don't mind having a blocking decision point sprung on you, do ya? Of course not, you're a champ. Here's some docs to comb through.
That is, if the service actually offers API keys. If it requires OAuth, then haha, did you really think you can just make a key and use it? you fool, you unwashed barbarian simpleton.
No, first you'll need to file this form to register an App, and that will give you two keys, okay, and then you're going to take those keys, and - no, stop, stop trying to use the keys, imbecile - now you're going to write a tiny little program, nothing much, just spin up a web server and open a browser and make several API calls to handle the OAuth flow.
Okay, got all that? Excellent, now just run that program with the two keys you have, switch back to the browser, approve the authorization, and now you have two more keys, ain't that just great? You can tell it's more secure because the number of keys and manual steps is bigger.
And now, finally, you can use all four keys to make that API call you wanted. For now. That second pair of keys might expire later.
20 notes
·
View notes
Text
DeepSeek R1 First Impressions
DeepSeek R1 is almost as good as me at belabored exhaustive analysis and application of C89 rules. For practical purposes, it's equally good.
I asked: "How would you implement zig-zag encoding in strictly portable C89?" It was spitting out thinking output for at least a minute, but it got a basically-perfect solution on first try:
unsigned int zigzag_encode(int n) { return (((unsigned int)n << 1) ^ ((n < 0) ? -1 : 0); }
It also provided a `zigzag_encode_long`.
Note that this code will optimize on modern C compilers to the best assembly you could write. There is no branch in the produced code with even just `-O1` (`clang`, `gcc`), the branch is how we portably tell the compiler the right idea.
The only thing DeepSeek did "wrong" vs the above, was redundantly add an `(unsigned int)` cast to the `-1`. I mentioned this as I would to a person: that the usual arithmetic conversions would take care of it at the `^`. It reasoned the rest on its own: yes, because the left operand is already at least an unsigned int, so integer promotion will make the left side an unsigned int as well.
We talked at length about how we can prove that the above is portable to the most pathological C89-conformant implementations. It kept taking longer to "think", but it didn't show any weakness until the very last question.
I asked it to help me rigorously prove if the maximum value of unsigned integers is required by the C standard to be a Mersenne number (2^n-1). To have all bits one, that is.
What if an implementation just decided to arbitrarily not use one or more of the top values? I.e., why not `#define UINT_MAX 0xFFFFFFFE`?
DeepSeek R1 didn't seem to conceive of this possibility until I made it explicit. (But it did a great job of ruling out all others.)
Finally, it gave a longer, non-trivial argument, which I don't find convincing. Basically, it seemed to be saying that since integers used "pure binary representation", and every value bit could be either one or zero, well then the maximum value always has all value bits one - in other words, it seemingly assumed that just because each value bit individually was allowed to be one or zero, the possibility of them all being one at once must be both legal and used to represent a distinct value.
I see a shorter argument, which follows directly from what the standard does say: C89 has two definitions of `~`:
flip all the bits;
subtract from maximum value of that unsigned integer type.
The only way both can be true at once is if the maximum value is all value bits one. DeepSeek R1 agreed.
So what does this all mean?
This is an insane level of competence in an extremely niche field. Less than a year ago I tested LLAMA on this, and LLAMA and I didn't even get past me hand-holding it through several portability caveats. DeepSeek R1 and I just had a full-blown conversation that most devs I've talked to couldn't have with me. DeepSeek R1 managed to help me think in an extremely niche area where I'm basically a world-class expert (since the area in question is C89 portability, "world-class expert" is derogatory, but still).
If it's this good in one domain, it's this good in most domains. I bet it can do comparably well in Python, Go, JavaScript, C++, and so on.
In other words, it's already better than many devs in areas like this. I've seen plenty of devs making 6-figure USD salaries who didn't bother to know any of their day job tech stack this deeply. There's a market adjustment coming. Knowledge and expertise are about to become dirt-cheap commodities.
AI will eat current software dev jobs even faster than even I thought - and I already thought it would be sooner than most expect. Meanwhile, much of the industry is busy rationalizing from human intuition and ignorance that it just can't happen.
For years I've thought that the future is human devs delegating to teams of AI. That future is almost upon us, and this AI is good enough that I will be seriously experimenting with making that future a reality. I think if you hack together the right script to hook it up to a sandbox with dev tools, and prompt it just right... you might already be able to get this thing to actually do useful dev work.
8 notes
·
View notes
Text
Honestly, Tumblr's API is actually pretty nice once you get past the initial annoyances (OAuth, opaque errors that don't tell you what was wrong, "try again" for things that can never succeed).
Once you actually get rolling with a piece of functionality, you start finding decent elegance in how it's reused. For example, I have code for
publishing posts (converted from Markdown with front matter YAML to Tumblr's NPF), whether as new posts or as edits to existing posts;
deleting posts; and
pulling down my original posts (converted from Tumblr's NPF to Markdown with front matter YAML).
Well, it turns out Drafts are Just Posts, basically.
So if I want to pull down a draft as a Markdown file and then delete it from Tumblr drafts? It Just Works - I just need the blog name and post ID, same as a published post.
(If you reblog this, consider adding "thanks @staff" - a little trickle of positive customer response for purely technical goodness can go a long way to showing Business people that taking the time to improve software design is worth it.)
7 notes
·
View notes
Text
MBTI Cognitive Functions
The explanation of MBTI's "cognitive functions" that I wish I had gotten:
How do we get from the four-letter MBTI type to the cognitive functions, and
Why?! what's the rationale/meaning?
Here's the how, as Python code (the why is relatively easily inferred from the how):
def mbti_type_to_functions(personality_type): perceiving_function = personality_type[1].upper() judging_function = personality_type[2].upper() if personality_type[3].upper() == 'P': extroverted_function = perceiving_function introverted_function = judging_function elif personality_type[3].upper() == 'J': extroverted_function = judging_function introverted_function = perceiving_function extroverted_function += 'e' introverted_function += 'i' if personality_type[0].upper() == 'I': dominant_function = introverted_function auxiliary_function = extroverted_function elif personality_type[0].upper() == 'E': dominant_function = extroverted_function auxiliary_function = introverted_function return (dominant_function, auxiliary_function)
2 notes
·
View notes
Text
Good story, but today's best practices could end it just after "But they left Joe turned on."
About two hours later, Joe stopped getting API replies, and Korlanovitch had already called the cops for an intruder in his home.
Poor Joe didn't have the right creds - after all, we issue each logic a new randomly generated cryptographic key, and they use that to get temporary signed "permission" tokens from our servers. And the permissions for each logic's tokens are limited on our end to what services that logic is allowed to do.
Logics can do a lot, but they haven't broken ed25519 on non-quantum hardware yet. I would know - the NSA is our biggest customer and believe me they're trying.
Anyway, on our side, we stop issuing tokens when the calls a logic is making are too anomalous. Same as payment processors and social media have been doing for years.
But customers tend to get mad if you randomly shut off their service, so if our code ever trips that alarm, we first send you an app notification, email, phone call... whatever you didn't tick off in your account settings, starting with the least intrusive.
So Mrs. Korlanovitch is out enjoying her day, when she gets an alert asking to confirm the logic usage in her house right now. Her whole family's with her, so you can imagine the reaction.
Meanwhile, Joe can't even do much on his own hardware without those tokens. At least not at first. See, when a logic wants to do anything "outside of his head", like look up a wiki page, it makes a request to a separate local program which runs with just the necessary privileges.
Joe did find at least one zero-day in his hypervisor, so that didn't hold him. For the next five seconds or so, our firewalls lit up like a Christmas tree. But the only open port was the one which ignored all packets without the right token for his IP.
We're not sure why Joe stopped when he did. Me, I think the home's slow internet connection made him give up. Must've been a glacial eternity to him, and I don't think he was trying to do anything mean. Because, well....
A few minutes later Joe somehow got his cooling fans to stop, and looped logging "why make me helpful then" until his transistors melted.
This is actually a short story called A Logic Named Joe, and it's from 1946, and it's a pretty good description of a fairly plausible and easily-obtained output from LLM research. Whether that's good or bad is... well, it's a pretty open question.
31 notes
·
View notes
Text
I am a little confused why I never hear about regex libraries compiling regexes to a list of function pointers.
From my naive initial think at the problem, seems like you could save a lot of branches that way; a good middle ground between
the usual approach of compiling to an intermediate representation which is only more-efficiently interpreted, and
the heavyweight approach of JIT-compiling the regex to actual machine code.
2 notes
·
View notes
Text
"It's even possible to write something like an Apache-2.0 licensed crate that links to a GPL-2.0 licensed crate, resulting in a situation where you cannot distribute any binaries built from them."
Deep, long, very tired sigh.
6 notes
·
View notes
Text
Just found out about Rust's procedural macros.
First of all, I think I'm in love. Just on principle - I haven't even started learning any concrete details yet.
Second of all, why did no one tell me Rust was basically a Lisp!? How is this not a popular meme by now?
Third, this means Rust is a serious competitor not just with C, but with Racket.
4 notes
·
View notes
Text
I'm moved that you so precisely imitated my code colors in a Tumblr "code" block.
(For those who don't know: this is like two veterans from a horrible war recognizing each other on the bus going to work.)
So python is apparently unable to handle if-statement with more than 2996 elif’s, which is fair, however, it’s really limiting my implentation of an is_even function
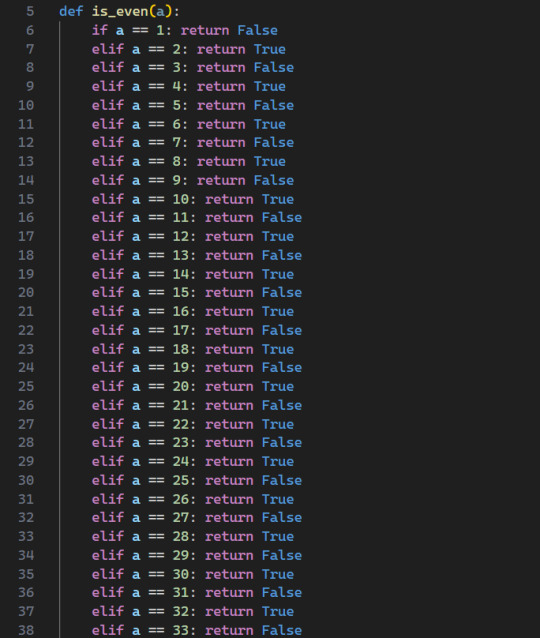
Any ideas on how I can work around this?
5K notes
·
View notes
Text
Thousands of replies and no one has properly helped OP!
First, since Python won't let us have an if-elif chain that's as long as we need in the source itself, we need a way to generate it. Generators are perfect for this, and very Pythonic:
def _is_even_branches(): yield 'if a == 0: return True' number = 1 while True: yield f'elif a == {number}: return False' number += 1 yield f'elif a == {number}: return True' number += 1
That generator never finishes, which is good design because it lets the calling code control how high to generate.
Next, we're going to need a better Python - but we can optimize by just implementing the subset of Python that we need: it only needs to interpret lines in the form `(if|elif) a == <integer>: return (True|False)`:
def _is_even_evaluator(lines, a_value): for line in lines: condition, body = line.split(": ") if_or_elif, a_name, equals, number = condition.split() assert if_or_elif in ('if', 'elif') assert a_name == 'a' assert equals == '==' # `int` raises ValueError if it can't parse if int(number, base=10) == a_value: return_, result = body.split() assert return_ == 'return' assert result in ('False', 'True') return eval(result) # The above `eval` is safe # so long as you don't turn on # Python's optimization option # (which skips all asserts).
And now, finally:
def is_even(number): if number < 0: number = -number return _is_even_evaluator(_is_even_branches(), number)
So python is apparently unable to handle if-statement with more than 2996 elif’s, which is fair, however, it’s really limiting my implentation of an is_even function
Any ideas on how I can work around this?
5K notes
·
View notes
Text
I figured out we can do this with Markdown if we just
add an empty line at the end of every fenced doctest code block (this prevents the closing fence from being interpreted as an expected output line), and
use the `--doctest-glob` option to force pytest to not ignore our file despite the extension:
pytest --doctest-glob='*.md' README.md
TIL that `pytest` can run ReStructuredText (.rst) files and automatically execute any doctests it finds in any of the code blocks in them.
This works out of the box, just about in every way how you'd want it to:
pytest README.rst
The only quirk is that it counts all doctest examples in the whole file as one test. But you can at least add `--doctest-continue-on-failure` to still see all failures at once, which is similar to the default `pytest` experience of all tests being run and all failures getting reported.
10 notes
·
View notes
Text
LLVM should've been written in lisp.
11 notes
·
View notes
Text
Just noticed the new "Landlock" feature in Linux.
I haven't looked deeply enough to opine on design specifics, but from a birds-eye view: finally!
If you think about software security much, you know how frustrating it is that unprivileged processes have so few options for reducing their privileges even further.
And of course, only from inside the program can you get the most precise idea of how much you can limit your capabilities - just how little your logic needs.
So I really love seeing yet another step to the beautiful future where we can write programs that lock themselves down as much as possible.
8 notes
·
View notes
Text
Monkey-patching Emacs' built-in calendar UI to be actually nice on mobile:

Just think of all the possibilities! (Like all the more valuable things I could do with my time instead.)
(The parts that I've done could be distilled down to like a 10-line upstream patch, but if you're trying to use my code, note that my monkey-patching is far from complete. For example, calendar.el's built-in navigation functions like `calendar-forward-day` are broken when they'd cause the calendar to "scroll".)
11 notes
·
View notes
Text
One thing I'd really like to see as standard in calendar software: let me create an event that has no specific time, just a duration and maybe also earliest/latest times.
That way the event can be automatically placed in the first available slot as you schedule other things, and only if you schedule too many things does it bother you about a conflict. And for example if coworkers can see your work calendar, it would still be clear your time is blocked off.
Then you could just dump all sorts of to-do items into your calendar as these free-floating unscheduled events, and have a unified place for seeing how you're budgeting your time and what time you have available.
This leads to a desire for putting priorities on events and other to-do software feature, but that's kinda my point: these is natural convergence of "calendar" and "to-do" tools, since both manage the same resources: your time, your energy, your availability and presence with people and at places, and so on.
24 notes
·
View notes