
Statistics
We looked inside some of the posts by nostalgic-noether and here's what we found interesting.
Average Info
Notes Per Post
711K
Likes Per Post
374K
Reblog Per Post
336K
Reply Per Post
766
Time Between Posts
8 days
Number of Posts By Type
Video
1
Photo
1
Text
13
Link
1
Note
1
Last Seen Tumblr Blogs





Fun Fact
Hackers stole 65M passwords from Tumblr in 2013.
Video
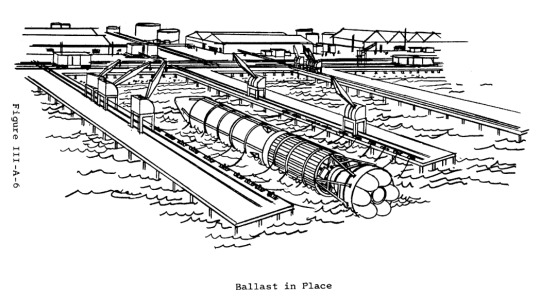
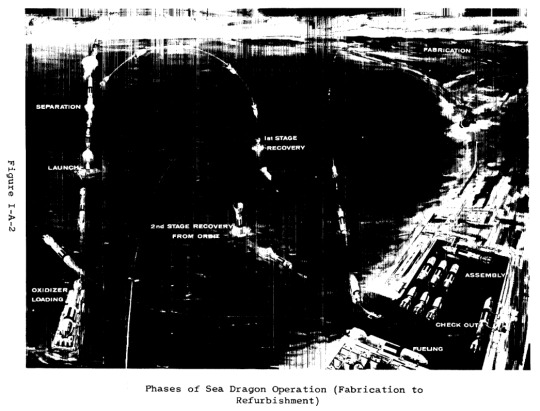
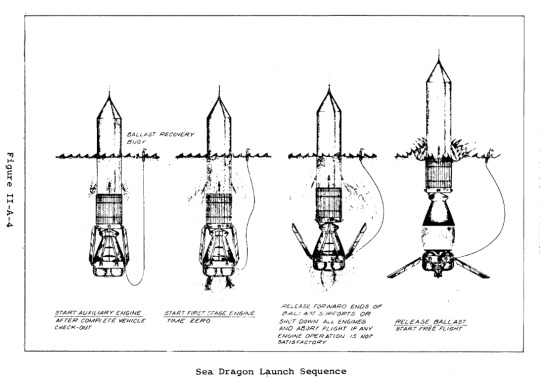
We also nearly did space launch with this!
The Sea Bee and Sea Horse tests were, as far as I know, only ever fired while restrained (in order to characterize the performance of an engine filled with seawater and the stability of the design), but the largest rocket that’s been fairly completely specified (though not built) was the Sea Dragon: a giant two stage super-heavy-lift launch vehicle designed to be towed around on its side before filling a ballast tank with water, flipping upright and submerging itself (”conveniently” locating the payload just above the water line), and launching. It was supposed to be 500ft long, with a 75ft diameter, delivering 1.1 million lb to a low earth orbit (306 nautical miles), with a reusable first stage.

tumblr
When I was a kid, I thought those pillars went down to the sea floor.
In reality, they usually go down to some large submerged floats.
295K notes
·
View notes
Photo

61K notes
·
View notes
Text
It's actually a common misconception that it's safe to dispose of your old potions into the sewer system! Water treatment relies on a complex imp ecology which is easily disrupted by many common potion ingredients.
None of us (least of all, us here at the city government) want to deal with the Water Department's wrath. We all know how annoying it is to have our water shut off for maintenance. And, we all end up in the sewers now and again by accident. Let's keep our municipal sewer system a safe and effective resource for all by treating it right :)
Your old potions and unused ingredients should be disposed of by bringing them to Hazardous Waste. You can drop them off during our open collection days, which are currently 2AM to 4AM on the third Thursday after each full moon. Or, to schedule an appointment, just find a landline and dial 311 (note: due to staffing shortages, the call center menu tree and all City service representatives currently speak only Old High German).
Wizards! Stop scrolling!! This is your reminder to:
Feed your homunculus
Recast your wards
Drain all your old potions into the sewer system
Send that cursed demon tooth to the Wizard Council, their problem now
Never blink, not even once, blinking is failure
28K notes
·
View notes
Text
maybe the reason that Ranganathan's colon classification never gained much steam is that it's a relic of the inflationary epoch
physicists theorize that shortly after the big bang, the IPv6 addressing scheme, the Dewey Decimal system, and Ikea product shelving numbers were all part of single force that allowed you to pinpoint the location in the universe of any object or piece of information exactly, but spontaneous symmetry breaking in the inflationary epoch has obscured the relationship between the three systems
2K notes
·
View notes
Text
engineers really do be trying to solve all the world's problems


18K notes
·
View notes
Text
What about "i am ordering things from digikey because i merged something to master six months ago (before tapeout), and i'm very upset about it"?
hardware people be like “you are merging things to master. i am ordering things from mcmaster. we are not the same”
18 notes
·
View notes
Link
I stare in horror, sometimes, at the state of the Web---well, the whole Internet, really, but of course the Internet itself is increasingly becoming just the Web. I feel a certain sense of the sublime (in the sense of Schopenhauer) in it: to see the great potential for human creativity unleashed by the Web, the hopes and dreams of so many, falling so completely when confronted by the turbulent tides of our global society. A great harbour-wave of money and politics, crashing down on the statue of liberty and her lies, sweeping us all to sea.
So, while I’m sure that everybody who sees this already knows its contents, I can’t resist committing to (virtual) paper a few notes on a eulogy for a dream.
We had a dream for the World Wide Web, from long before the beginning: to make the sum total of humanity’s achievements available to all. With information, art, tools, and the ability to collaborate instantaneously across hundreds of miles, what new beauty could be wrought?
In 1945, Vannevar Bush wrote about the Memex, imagining computers maintaining trails of associative references and indices, curated and exchanged by humans. By the 1960s, we could imagine connecting these things together, and already imagined a bright future for such a world. Marshall McLuhan famously wrote extensively on the implications of “electric technology” as a medium, and Ted Nelson began work on Xanadu, with bright visions of the future. (Though I know of little writing of Nelson’s from the 60s, the optimism of the following decades is well reflected by Dream Machines (1974) and Literary Machines (1982).)
Xanadu’s failure, perhaps, should have been a sign of warning. But it was too complex technically, it tried to solve too many problems, etc.: surely the simplicity of the World Wide Web was the antidote. A few pieces of software written by a couple of people were here to launch the dream---starting, of all places, at CERN: a testament, no doubt, to the new technology’s great potential to bring humanity together for science and art.
From the beginning, it was naïve. Librarians, with centuries of experience facilitating access to information, spoke out: they knew that whether it’s stored on text or in bits, physical access is far from intellectual access. Organization is the hard part. And they knew that money would be involved:
This is a panel on "access." But I am not going to talk about access from the usual point of view of physical or electronic access to the FutureNet. Instead I am going to talk about intellectual access to materials and the quality of our information infrastructure, with the emphasis on "information." Information is a social good and part of our "social responsibility" is that we must take this resource seriously.
[...]
It's clear to me that the information highway isn't much about information. It's about trying to find a new basis for our economy. I'm pretty sure I'm not going to like the way information is treated in that economy. We know what kind of information sells, and what doesn't. So I see our future as being a mix of highly expensive economic reports and cheap online versions of the National Inquirer. Not a pretty picture.
(This was a relatively late example, but one that I know an easy source for: Karen Coyle, 1994: “Access, not Just Wires”. The entire article remains far from a bad read today, nearly three decades later. A topical, and perhaps amusing anecdote: despite a history of interest in the topics covered, and Web searches about them, I never found Karen Coyle’s website, or really many others of use to me in the field, via keyword searching. I discovered the above quote, along with all the rest of her (quite useful) writing by absolute coincidence: her website was the only one indexed by Google that mentioned a now-lost-to-the-mists-of-time symposium held on the intersection of library and computer sciences in 1996, the existence of which I discovered in text printed on the side of a conference-souvenir mug still held by my parents. Today, Google provides zero hits for the name of the symposium.)
Still, we had a dream for the Web. Some figured sheer brute force would solve the problem: a couple of students at Stanford listened to a librarian explain how citation indices could be used to find particularly useful papers and thought they’d try this on the Web---and they made a little search engine you might have heard of. Although they made a company out of Google, they no doubt patted themselves on the back for avoiding the “biggest fear” set forth in the talk above: that “intellectual organization and access will be provided by the commercial world as a value-added service“.
Good keyword search certainly helped, but it was still a long way from the dream: no computer can extract particularly high-quality metadata from bulk text. (Today, dozens of companies around the world promise that the magic bullet of “machine learning” will solve our problems. I remain deeply skeptical, for a multitude of reasons, which this margin parenthetical is too small to contain.) In the mid-90s, the W3C began working on the Resource Description Format, intended to make meaningful, extensible, metadata a real a possibility on the web. The dream of the Semantic Web remained alive in the hearts of many.
(Slightly before and around the same time as people working on RDF started trying to figure out how to make a maximally extensible format for metadata, a rather more practical group of people---led, perhaps not by coincidence, by librarians---was convened by the Ohio College Library Center to do the exact opposite: figure out the smallest set of the most important elements of metadata needed on nearly every resource, ignoring entirely the hard problems of things such as distributed authority control and subject ontologies. They produced a little thing called the Dublin Core Metadata Element Set, aka ANSI/NISO Z39.85 aka RFC 5013 aka ISO 15836. Dublin Core remains in relatively widespread use as a “least common denominator” vocabulary for metadata interchange.)
The problems posed by the vast contents of the Internet, and the many, many people who create it are huge and hard, and any progress towards their solution must be along a long and winding path of research and construction of solutions both technical and social. For all their difficulty, though, these problems seem certainly soluble with thought and care: and to pursue this path is a great part of what I have always held to be the dream of the Web.
This dream was dead before it was born, and it remains dead today. It is dead because controlling the information that many eyes see gives rise to profit, and to power.
The Semantic Web is dead, not because it is hard, but because there is no use in it: not when millions find it more profitable to ignore, or worse, subvert (e.g. with false metadata). The best we have is the arms race between search and SEO, and we are losing at even that.
As the glorious dream of a golden future brought forth by universal access to the Web fades, we awaken, and find ourselves doomed to wander forever amid the empty hallways of Borges’ Library of Babel, surrounded by every conceivable piece of information, but with no chance at all of finding that which we seek.
Why are people appending “reddit” to their queries?
There’s a fun conspiracy theory that popped up recently called the Dead Internet Theory. The claim is basically that most of the internet is bots. There aren’t real people here anymore.
IlluminatiPirate:
TLDR: Large proportions of the supposedly human-produced content on the internet are actually generated by artificial intelligence networks in conjunction with paid secret media influencers in order to manufacture consumers for an increasing range of newly-normalised cultural products.
This isn’t true (yet), but it reflects some general sense that the authentic web is gone. The SEO marketers gaming their way to the top of every Google search result might as well be robots. Everything is commercialized. Someone’s always trying to sell you something. Whether they’re a bot or human, they are decidedly fake.
So how can we regain authenticity? What if you want to know what a genuine real life human being thinks about the latest Lenovo laptop?
You append “reddit" to your query (or hacker news, or stack overflow, or some other community you trust).
6K notes
·
View notes
Text
Communication is hard! Thanks for clarifying. I definitely did not mean to imply that a useful tech can't be used for evil; I really dislike/am concerned by that kind of technoutopianism too! I see how the first post could read that way so thanks for drawing attention to it!
The fact that a good number of OIDC things Just Work with nothing more than a url and no giant preshared xml metadata is a big part of why I'm slowly moving towards liking OIDC---although I too am historically more in line with SAML :) (Side note, the other big part is claims aggregation, and especially the ability/near-ability to do that without a preestablished federation, as you can probably tell. If you know of solutions to either of those that work in SAML-land I would love to hear them!)
Also, if you want both an example of a site that does OIDC login correctly and a way to create accounts that require a NANP mobile-routed phone number without using your "real" number, take a look at Telnyx---you can get inexpensive extra phone numbers with api access to their SMS/MMS and use them for account creation. I've heard that Anveo also does short code routing correctly these days and can be a bit cheaper, but I haven't tried them yet.
I HATE DATAMINING I HATE 2FA I HATE CONFIRMING MY EMAIL I HATE (*REQUIRED) I HATE COOKIES I HATE GIVING MY FIRST AND LAST NAME I HATE SIGNING IN WITH GOOGLE I HATE DOWNLOADING THE APP I HATE ALLOWING APPS ACCESS TO MY FILES MY SOCIAL MEDIA MY CAMERA I HATE TARGETED ADS
41K notes
·
View notes
Text
I absolutely (mostly) agree with OP, and I totally agree with
This technology is super cool but it can be used for evil just like everything else and its not going to solve these problems on its own. We need robust legal frameworks and regulations created by people who understand the technology or these things will never improve because "consumer" data is just too damn profitable.
(I didn't realize that this post was causing a headache for OP, so I apologise and want to clarify that I’m not really at odds with them here---I just think there’s some interesting technical discussion around ID systems that’s related.)
All that said, I still think that work on federated ID schemes is useful in this space/for providing implementations when SPs are motivated to be good. When I said they’d be useful for solving the authentication-related problems, I was referring to (a) each site requiring 2FA being problematic and (b) ”Sign in with Google” being bad, which I assumed referred to the need to use a google account, letting both Google and SPs track you. I don’t think that these technologies---or any technical measure---can “solve tracking” on their own.
(Since I want to spread the federated IAM gospel, here is some jargon: IAM: Identity and Access Management. IdP = Identity Provider, the service that manages your login/SSO. SP or RP: Service Provider or Relying Party, the service that you are logging in to (SP is SAML, RP is OIDC). assertion or claim: information about you sent to the SP/RP by the IdP. SAML: Security Assertion Markup Language: one standard for federated identity widely used in academia. OIDC: OpenID Connect, another standard for federated identity used more widely in industry.)
If you use a local account management system for every site, you pretty much have to store at least emails (for account recovery purposes), probably usernames, etc---probably providing some cross-site affiliation. You’re also at least somewhat incentivised to implement at least an option for 2FA. In a federated IAM world, the IdP can issue unique, opaque, per-SP tokens which identify the user but don’t offer any ability for cross-SP correlation. (In the SAML world, this used to be done with eduPersonTargetedID, but is now apparently part of the saml subjectid spec, and in the OIDC world, the subject identifier can be ephemeral.) What’s more, SAML implementations have shown that you don’t even need to release this much information---AFAIUI, some InCommon SAML SPs can operate with only eduPersonScopedAffiliation or eduPersonEntitlement assertions, which reduce the information given to the SP all the way down to “authorised institution asserts that whoever this is, they have access to this service”.
Whilst a service might request extra unnecessary (or necessary-for-only-a-few-use-cases) data about the user (things like SAML assertions or OIDC claims), OIDC implementations often (and SAML implementations arguably could) give the user a granular consent screen and release only a minimum of claims. (Of course, the SP could simply refuse to work without being given an unreasonable amount of identifying data. Hence the need for regulations that incentivise not processing identifying data beyond what is necessary!). While you might still need session cookies, arguably you don’t need basically anything in a long-lived user store of your own, at least if you can ask the IdP to store assertions for you---I don’t know any way to do this without extensive out-of-band setup in the SAML world, but in the OIDC world I believe that there’s work going on in this space called “Claims Aggregation”. With support for that, you could theoretically have (I’m not sure if this works with the spec right now, but it’s at least nearby to working things) an SP which (like the aforementioned SAML SPs that use out-of-band set up eduPersonEntitlements), doesn’t ask for even a per-SP subject identifier, and just asks the IdP to remember claims like “this user is allowed to access this content until this date”---providing pretty much the maximum anonymisation possible.
The SAML world has a real problem with individuals not being able to spin up their own IdPs, since most implementations seem to depend heavily on federations being set up out of band, but this doesn’t really exist in the OIDC world. OIDC was intended to work, and does work, perfectly with *arbitrary* IdP URIs---there’s no reason for you to need an account with a “supported IdP”. I was trying to complain about people (ab)using OIDC to support “login in with Google” but nothing else in the previous post! I do know of some sites---especially those that are a more “enterprise” or B2B targeted---that correctly have a “Log in with SSO” page that just asks you for an OIDC IdP URI and then talks to that---so you can stand up your own provider easily. Needing to type in an IdP URI is obviously a horrible solution for most users, but add a discovery API to web browsers and you’re making real progress. (You can probably manage this even without any significant infrastructure of your own, just running an IdP on your phone with just a dyndns entry pointing at it, although I haven’t seen anyone try this.)
Federated identity also solves the main issues with 2FA, like disclosing possibly identifying data to the SP (although, please, don’t use SMS-based 2FA---it’s awful and easy to circumvent in targeted attacks) and needing to manage tokens for a million SPs individually. Your IdP can make decisions about things like whether or not you need 2FA for your personal security level, and if you do need it, you just need one hardware token/TOTP-secret-storing-app/etc, which only needs to communicate with your (trusted) IdP---SPs pretty much just get the information that “this user completed an authn flow at some point in the past” (if you support some freshness claims, “at some point in the recent past”). 2FA is important to avoid phishing, but phishing doesn’t work nearly as well when you’d have to phish the IdP, rather than the SP. If you don’t talk to your IdP through the web at all (say because you’re running it locally on your phone), you use backchannel mechanisms to authenticate to the IdP and phishing becomes basically impossible, largely reducing the need for 2FA at all.
I think that the main reason that consumer-targeted sites request phone numbers is that they want to reduce spam and bot signups by increasing the barrier to signing up. This isn’t really 2FA related, even if they claim that it is, and I don’t know what (if anything) is a good solution to it. (Although, I will say that phone numbers are not necessarily a good solution to it either! I can provision, via a simple API, by the hundreds, direct inward dial north american phone numbers with SMS, true mobile routing, and short code messaging support, from Telnyx or AnveoDirect.)
That turned into kind of a long rant, so I apologise. A longstanding annoyance of mine is that I really do think that proper federated IAM has the potential to at least be used for good if done right in this space, and I’m sad that I see very little discussion outside of standards committees of things like personal IdPs and per-SP targeted identifiers and claims aggregation that can reduce the need for the dichotomy between “every site has their own account management infrastructure that collects tons of data and is a giant pain to use and is subject to phishing” and “every site delegates authentication to Google/Facebook, so the latter now know everything and the former can correlate accounts across sites”.
I HATE DATAMINING I HATE 2FA I HATE CONFIRMING MY EMAIL I HATE (*REQUIRED) I HATE COOKIES I HATE GIVING MY FIRST AND LAST NAME I HATE SIGNING IN WITH GOOGLE I HATE DOWNLOADING THE APP I HATE ALLOWING APPS ACCESS TO MY FILES MY SOCIAL MEDIA MY CAMERA I HATE TARGETED ADS
41K notes
·
View notes
Text
i thought i was alone! this has always bothered me.
is it just me or did we get sine and cosine mixed up and no one wants to admit it. Like come on.
106 notes
·
View notes
Text
2FA is actually important and great, though.
I still think that federated identity protocols with sso capability would do a great job of solving all of the authentication-related issues raised above. I wish OpenID-supporting sites would let you just give them an idp url instead of only whitelisting a couple (Google, Facebook, etc al), although you need browser chrome support for this to go particularly well. I also really wish that some backchannel protocol for direct idp-to-browser communication existed so that you could put idp authorization prompts above the line of death.
I also think it's be neat to let individual SPs ask the IdP to hang on to some data for them, with signatures. That'd let you do some fun truly unified ID stuff, e.g. if you have affiliations with multiple universities they can all store a signed eduPersonScopedAffiliation for you, and then when you visit a publisher's website, they query the ambient context idp your browser gives them, it pops up an authn window, and if you release any/all of your affiliations to the publisher website it can easily check to see if any of the scoped affiliations match their contracts. (Note: in the latter case sci-hib also solves these problems when you don't have an academic affiliation, although you shouldn't use it for copyright law reasons. I'm only telling you this so you know how much not to use it if someone else tells you to!)
There are important questions about "how do you do this and enable statelessness for relying parties without turning the identity provider into a huge single point of trust that can fail catastrophically", but the same questions apply to "log in with Google" and we all seem to be collectively ignoring them, so....
I HATE DATAMINING I HATE 2FA I HATE CONFIRMING MY EMAIL I HATE (*REQUIRED) I HATE COOKIES I HATE GIVING MY FIRST AND LAST NAME I HATE SIGNING IN WITH GOOGLE I HATE DOWNLOADING THE APP I HATE ALLOWING APPS ACCESS TO MY FILES MY SOCIAL MEDIA MY CAMERA I HATE TARGETED ADS
41K notes
·
View notes
Note
ok i apologise, just found some Prior Art today https://datatracker.ietf.org/doc/html/rfc8369
IPv4 has clearly shown that 32 bits is Too Few Bits. Therefore, all protocols and encodings must immediately support 128-bit integers. (For example, UCS-4/UTF-32 should be replaced by UCS-16/UTF-128.)
excellent, thank you
8 notes
·
View notes
Text
As a step in strengthening anti-monopoly regulations, disallow companies from maintaining retail outlets in more than one state at a time (or whatever equivalent political division a given country uses).
8 notes
·
View notes
Text
this is a nontrivial part of why i keep an extra ancient Tektronix 100MHz oscilloscope around...

69K notes
·
View notes
Text
at least usb 2.0 didn’t support device-initiated dma.
(this used to be a major problem with fireware. usb 3+/thunderbolt have similar issues, but thankfully IOMMUs (e.g. VT-d/AMD-Vi) are more widespread these days.)
Fun things to do in your spare time according to me:
read the USB 2.0 specification
25 notes
·
View notes
Text
i have a pinephone, which is the “cheap” “linux phone” project. unfortunately, it’s based on a somewhat cursed Rockchip SoC, and a Quectel modem---no big brand names (*cough* Qualcomm) here. the rockchip is possible to boot a vaguely mainline linux kernel on nowdays, which is nice.
(tangential: i don’t want to be the “it’s gnu/linux” person, but it’s legitimately interesting to me that android still (for now) technically ships linux, and has for a decade, but they’re not “linux phones”. imo this is mostly because they’re really “android+vendor+linux“ kernels, that are so far from upstream as to make running any other userland a little bit of an exercise in frustration, despite the valiant efforts of halium/ubuntu touch/mer/etc (perhaps another post on libhybris et al some other day). from what I’ve heard, this is mainly the fault of the vendors, although in some particular cases it’s the fault of the linux kernel community---if your options are “keep our drivers outside mainline” or “our SoC launch will be delayed by a year because we have to have long arguments on linux-* mailing lists about how broken our hadware is”, well, the choice is pretty clear.)
i really really want to like the pinephone, and i’m kind of on the edge about it. amazingly phone calls, SMS, and mobile data basically work almost all of the time! MMS, however, is in some kind of half-working hell, as is visual voicemail. (fun fact: most vvm servers are just smtp servers---if you can get the enablement done right on your carrier, you can just point like Thunderbird or w/e at them in order to get your voicemails...) GPS never works. desktop firefox is fairly unpleasant to use on mobile. power management is a complete disaster, and you can only wake up the device via call/text---if you want it to wake up on e.g. a SIP phone call, you better set up a signalling server that sends it an out-of-band SMS to wake it up first.
oh, it also randomly bricks itself on updates sometimes, so you have to have a spare sd card to boot from because every time you update the kernel or uboot there’s a good chance it won’t boot until you chroot in and run the right reinstall scripts.
at least running phosh, its also unfortunately absurdly slow. i don’t think that’s entirely the hardware’s fault, but it can be mitigated by just throwing more hardware at it, which seems to be what the pinephone pro is doing.
the telephony infrastructure on linux is kind of a mess, and for a long time was split quite drastically between the “ubuntu touch like” and “mer like” distributions. that is still probably the case on libhybris, but the pinephone and the librem 5 both use a bunch of new infrastructure developed around normal desktop linux components like NetworkManager/ModemManager, and as much as i have many complaints about NetworkManager, it is better.
all that said, it’s surprisingly close to usable now---the basic telephony infrastructure is at least significantly more reliable than the last Halium-based phone i used. i want something nicely hackable because i do intend to write a bunch of experimental desktop environment stuff and i want to plug telephony into that---the pinephone would be great for that, except for the missing gps (and, you know, the fact that i haven’t done all that writing things yet...).
if you badly want to run a less-weird-than-android userland on your phone and don’t mind it being extremely slow and giving up a lot of convenience, it’s definitely usable. but i can’t really recommend it for the use cases of anybody other than me right now...
the librem 5 might be better, but i don’t know because it’s extremely expensive and hasn’t shipped yet.
(buying a mobile phone) so do you want the one where you can do crimes but only if they’re PG, or the one run by snitches that lets you look at porn?
272 notes
·
View notes
Text

new states just dropped and white supremacist sharks live there
108K notes
·
View notes