
#language + #technology = ? - is #DataMining, #TextMining the beginning or the end of the journey? How to teach traveling through data?
Don't wanna be here? Send us removal request.
Statistics
We looked inside some of the posts by notesjor and here's what we found interesting.
Average Info
Notes Per Post
0
Likes Per Post
0
Reblog Per Post
0
Reply Per Post
0
Time Between Posts
2 months
Number of Posts By Type
Text
17
Last Seen Tumblr Blogs





Fun Fact
BuzzFeed published a report claiming that Tumblr was utilized as a distribution channel for Russian agents to influence American voting habits during the 2016 presidential election in Feb 2018.
Text
CorpusExplorer (Update Q1 2021)
Es ist wieder soweit: #CorpusExplorer #ReleaseWeek für Q1 2021 - Neue spannende Funktionen. Infos zum Release hier. Pro Tag ein Tweet über die neuen Funktionen.
Vielleicht irre ich mich – aber ich glaube, in 2021 werden einige große Dinge mit dem CorpusExplorer passieren. Zumindest haben sich viele Funktionen angesammelt, die darauf warten veröffentlicht zu werden. Also starten wir mir den Änderungen für Q1 2021: DPXC-Editor “Der DPXC-Editor ist tot, lang lebe der DPXC-Editor”. Der DPXC-Editor ist ein Add-on, dass das Sammeln von Korpora per Copy&Paste…

View On WordPress
0 notes
Text
57. Jahrestagung des Leibniz-Instituts für Deutsche Sprache: 9. bis 11. März 2021
57. Jahrestagung des Leibniz-Instituts für Deutsche Sprache: 9. bis 11. März 2021
Das Programm der IDS Jahrestagung kann hier eingesehen werden: https://www1.ids-mannheim.de/aktuell/veranstaltungen/tagungen/2021/programm.html Eine Anmeldung ist über https://www.ids-mannheim.de/org/tagungen/anmeldung.html möglich.
View On WordPress
0 notes
Text
ZOOM-Vortrag 26.03.2021: vDHd2021
ZOOM-Vortrag 26.03.2021: vDHd2021 - Link bereits vorab per E-Mail.

View On WordPress
0 notes
Text
ZOOM-Vortrag 16.12.2020 an der Friedrich-Alexander-Universität (Erlangen-Nürnberg)

View On WordPress
0 notes
Text
Summer School (RUB Bochum) - 24. bis 28. August 2020: „tl;dr“ Too long; didn’t read (?) Große Textmengen computergestützt analysieren
Summer School (@ruhrunibochum) - 24. bis 28. August 2020: „tl;dr“ Too long; didn’t read (?) Große Textmengen computergestützt analysieren. https://bit.ly/3kcy4aC
Die Summer School beschäftigt sich mit computergestützten Verfahren, um große Mengen digitaler Texte, wie z. B. Internet-Blogs, Social Media-Einträge oder twitter Posts, zu extrahieren (Web Scraping), zu analysieren und für empirischen Forschungsprojekte und Abschlussarbeiten zu nutzen. Von korpuslinguistischen Verfahren (Frequenz- und Kollokationsanalysen) bis zu Machine Learning-Algorithmen…
View On WordPress
0 notes
Text
CorpusExplorer (Update Q2 2020 - SP1)
CorpusExplorer (Update Q2 2020 – SP1)
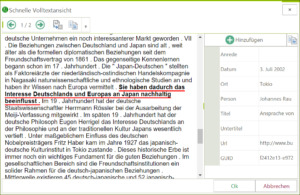
Heute gibt es ein kleines Service Pack (SP) für den CorpusExplorer. Neben wichtigen Stabilitäts- und Performance-Korrekturen enthält das SP folgende neuen Funktionen:
Die Volltextanzeige für die Textlinsen-Funktion wurde überarbeitet. Dadurch verbessern sich folgende Aspekte:
Der Text wird schnelle angezeigt – auch bei größeren Textmengen.
Der Text springt automatisch zum ersten Fundstellensatz.
View On WordPress
0 notes
Text
CorpusExplorer (Update Q2 2020)
CorpusExplorer (Update Q2 2020) - „Alles neu macht der Mai“ - in der kommenden Woche stelle ich die neuen Features kurz vor...
Lange ist es her. Das letzte Update erfolgte im Q3 2019. Was war passiert? War die Entwicklung eingeschlafen? – Nein, die Entwicklung ging weiter. Es gab nur keine neuen Updates, da der CorpusExplorer als Teil meines Dissertationsprojekts eingereicht wurde und eine Begutachtung erfolgte. Jetzt steht nur noch die Verteidigung für mich an (also bitte Daumen drücken). Traditionell (seit mehr als…
View On WordPress
0 notes
Text
Vortrag am 25.11.2019: "Erstellen und Erschließen von Korpusdaten mittels CorpusExplorer" im Rahmen des "Digillu-Workshop: Zusammenstellung und Erschließung von Korpusdaten" an der BBAW
Vortrag am 25.11.2019: “Erstellen und Erschließen von Korpusdaten mittels CorpusExplorer” im Rahmen des “Digillu-Workshop: Zusammenstellung und Erschließung von Korpusdaten” an der BBAW
Methoden zur Zusammenstellung und Erschließung von Texten werden nicht nur in der Linguistik, sondern allgemein in den Geisteswissenschaften und jenseits von fachlichen Grenzen vielseitig eingesetzt, nicht zuletzt seit dem empirical turn. Ohne maschinell gestützte Herangehensweisen sind manche Textsammlungen nicht mehr produktiv für die Forschung zu greifen, zu überprüfen oder zu durchleuchten.…
View On WordPress
0 notes
Text
Vortrag am 19.11.2019: "Was heißt und zu welchem Ende studiert man Korpuslinguistik?" im Rahmen der "Ringvorlesung: Sprache und Kommunikation" an der Universität Siegen
Vortrag am 19.11.2019: “Was heißt und zu welchem Ende studiert man Korpuslinguistik?” im Rahmen der “Ringvorlesung: Sprache und Kommunikation” an der Universität Siegen
In dieser Ringvorlesung haben Sie die Möglichkeit, zahlreiche DozentInnen aus der Anglistik, der Germanistik und der Romanistik kennenzulernen. Sie werden Ihnen zentrale Bereiche aus der Linguistik und der Sprachlehr-/lernforschung vorstellen. Eine Liste der DozentInnen und Themen sehen Sie unten.. Das Material zur Ringvorlesung finden Sie auf der Lernplattform Moodle (http://moodle.uni-siegen.de
View On WordPress
0 notes
Text
Vortrag: "Ringvorlesung: Kommunikative Strategien des Politischen – Einblicke in die computergestützte Diskursforschung"
Vortrag: “Ringvorlesung: Kommunikative Strategien des Politischen – Einblicke in die computergestützte Diskursforschung”
View On WordPress
0 notes
Text
Vortrag: "Maschinelle Sprachverarbeitung in der Diskursanalyse – Ein Überblick" im Rahmen der "Ringvorlesung: Kommunikative Strategien des Politischen – Einblicke in die computergestützte Diskursforschung" (Universität Siegen)
Vortrag: “Maschinelle Sprachverarbeitung in der Diskursanalyse – Ein Überblick” im Rahmen der “Ringvorlesung: Kommunikative Strategien des Politischen – Einblicke in die computergestützte Diskursforschung” (Universität Siegen)
Ringvorlesung: Kommunikative Strategien des Politischen – Einblicke in die computergestützte Diskursforschung
Zeit & Ort: WS 2019/20 (immer Mi, 16-18 Uhr) im Hörsaal AR-B 2104/05 an der Universität Siegen
Die Ringvorlesung verknüpft zwei hochaktuelle wie auch brisante Themen unserer Gesellschaft, nämlich erstens Algorithmen und Methoden der maschinellen Sprachverarbeitung, zweitens…
View On WordPress
0 notes
Text
CorpusExplorer (Update Q3 2019)
CorpusExplorer (Update Q3 2019)
Das Q3 2019 Update des CorpusExplorers bringt folgende Neuerungen und Verbesserungen:
Neue Funktionen:
Neue Formate:
FoLiA XML
RSS Feeds
Speedy (Import/Export) – Danke an/Thanks to: Iian Neill & Andreas Kuczera
YouTube JSON
Wiktionary
Redewiedergabe – http://www.redewiedergabe.de/korpus.html
QuickMode – Ursprünglich war der QuickMode nur für Entwickler*innen gedacht. Deren Programme konnte so…
View On WordPress
#2019#CEC#CorpusExplorer#FoLiA#HighDPI#Q3#QuickMode#Redewiedergabe#RSS#Speedy#Update#Wiktionary#YouTube
0 notes
Text
CorpusExplorer (Update Q1 2019 + März SP1)
CorpusExplorer (Update Q1 2019 + März SP1)
Heute wurde ein kleines Zusatzupdate (SP) für den CorpusExplorer veröffentlicht. Folgendes wird dadurch verbessert:
Unterstützung für CoraXML 0.8 und CoraXML 1.0 – Damit können Dateien von https://www.linguistics.rub.de/comphist/resources/cora/index.html geöffnet werden. Zuvor war das Format nur über die Erweiterung Salt&Pepperverfügbar (hierbei wurde das Format zunächst nach Salt-XML, CoNLL und…
View On WordPress
0 notes
Text
Es ist soweit – ein großes Update wartet auf alle Nutzer*innen des CorpusExplorers.
Hier eine Zusammenfassung der Neuerungen/Verbesserungen:
Eine persönliche Angelegenheit zuerst: Seit mehreren Versionen unterstützen mich viele Nutzer*innen bei der Entwicklung, indem Sie der Übermittlung anonymisierter Telemetrie-Daten zustimmen. Euch allen vielen Dank. Meine Erfahrungen die ich dadurch sammeln konnte, sind unersetzlich. Mich störte aber (A) das diese Daten an Dritte (Microsoft Azure) gehen – und – (B) das eigentlich mehr Daten gesammelt werden, als nötig (ich hatte das schon so restriktiv eingestellt wie möglich, aber Azure Application Insights ist sehr sammelfreudig). Als Verfechter von Datensparsamkeit habe ich jetzt eine eigenen Lösung gebaut – der Quellcode für den Server (der die Daten sammelt) findet ihr auf GitHub (https://github.com/notesjor/OpenSourceTelemetrie). Der CorpusExplorer nutzt jetzt also eine eigenen, OpenSource Infrastruktur, die außerdem sehr datensparsam ist. Es werden z. B. keine IP-Adresse mehr protokolliert.
Die neue Startseite / die neue Korpus Übersicht Für etwas mehr Komfort sorgen die neue Startseite und die neue “Korpus Übersicht”. Auf der Startseite gibt es jetzt die Sektion “Aktuelles und Neuigkeiten” (vielleicht etwas doppelt gemoppelt). In diesem Bereich werden aktuell Meldungen zum CorpusExplorer angezeigt (ein per RSS synchronisierter Newsfeed). Dies Betrifft sowohl Programm-Updates als auch z. B. Workshops (Wer eigenen Workshops bewerben will, kann sich gerne melden – Kontakt). Darunter ist die Sektion “Verfügbar Add-ons” zu finden. Hier werden alle offiziellen Add-ons des CorpusExplorers aufgelistet, die sich mit einem Klick installieren lassen (auch hier: wer eigene Entwicklung plant oder einstellen möchte – gerne melden). Auf der “Korpus Übersicht” findet sich eine Sektion “Frei verfügbare Korpora” – Auch diese lassen sich mit einem Klick installieren/abonnieren.
Neue Startseite: Aktuelle Meldungen zum CorpusExplorer und direkt installierbare Add-ons.
Neue Korpus Übersicht: Frei verfügbare Korpora jetzt direkt installieren. Über 2,4 Mrd. Token.
Neue Dateiformate:
Unterstützung für TEI-XML P5 des CAL²-Projekts
Unterstützung für OffeneGesetze.de
Export für das SQLite basierte Format von coquery.org (aktuell BETA) – setzt eine Installation des SQLite-Addons voraus.
Verbesserungen:
Cut-Off-Phrasen sind jetzt strenger (auf Begriff (A) muss Begriff (B) folgen). Die Spanne zwischen den Begriffe A+B wird jetzt ausgegeben und erlaubt ein nachträgliches Filtern.
Korrekturen:
Verbesserung des CEC6-Stream
Die RegEx-Suche in Tabellen wurde verbessert (Spalten wurden nicht korrekt angezeigt, Fehlermeldungen [Easteregg] wurde entfernt).
Schnappschuss Refresh wurde verbessert.
CorpusExplorer (Update Q1 2019) - Neu: Direkt installierbare Korpora/Add-ons. OpenSource Telemetrie. uvm. Es ist soweit - ein großes Update wartet auf alle Nutzer*innen des CorpusExplorers. Hier eine Zusammenfassung der Neuerungen/Verbesserungen:
0 notes
Text
Workshop 19.03./20.02.2019 - „Information Extraction aus frühneuhochdeutschen Texten"
Workshop 19.03./20.02.2019 „Information Extraction aus frühneuhochdeutschen Texten" - der #CorpusExplorer ist auch mit von der Partie. https://bit.ly/2EbGP1m
Die automatisierte Erschließung historischer Texte, deren Sprache und Orthografie noch keiner Standardisierung unterliegt, ist schwierig. Am Zentrum für Informationsmodellierung laufen zur Zeit drei Projekte, die sprachlich im Frühneuhochdeutschen angesiedelt sind: die Erforschung frühneuzeitlicher Diplomatenkorrespondenz (fwf, P 30091), die Edition von Reichstagsakten von 1576 (fwf, I 3446) und…
View On WordPress
0 notes
Text
CorpusExplorer (XMAS Update Dez/Jan 2018/19)
CorpusExplorer (XMAS Update Dez/Jan 2018/19)
Erstmal wünsche ich allen Nutzer*innen des CorpusExplorers frohe Feiertage und einen guten Rutsch ins Jahr 2019. Die letzten Tage des Jahres nutze ich, um ein paar Dinge im CorpusExplorer zu verbessert. Folgendes hat sich getan:
Übersichtsanzeige wurde verbessert. Bisher wurden die Token (z. B. auf den Übersichtsseiten zu Korpora und Schnappschüssen) immer in Mio. angegeben. Dies führte in…
View On WordPress
0 notes
Text
CorpusExplorer (Update Nov/Dez 2018) - Reguläre Ausdrücke und CutOff-Phrasen
#CorpusExplorer Update nach CLiGS Würzburg Workshop - danke für das Feedback. Neu: Reguläre Ausdrücke für alle Tabellen & Suche. CutOff-Phrasen.
Auf einem Workshop in Würzburg (2018-11-09) baten mich mehrere Teilnehmer*innen, dass ich Reguläre Ausdrücke (Regular Expression – kurz RegEx) im CorpusExplorer ermöglichen soll. Bisher habe ich RegEx vermieden – oder zumindest in der Oberfläche gut versteckt. Auch weiterhin halte ich diese hässlichen RegEx-Dinger, die mehr an Marsianisch oder Klingonisch erinnern, als an eine Abfragesprache, für…
View On WordPress
0 notes