
Statistics
We looked inside some of the posts by phulkor and here's what we found interesting.
Average Info
Notes Per Post
8
Likes Per Post
8
Reblog Per Post
0
Reply Per Post
0
Time Between Posts
2 months
Number of Posts By Type
Text
13
Video
1
Photo
3
Last Seen Tumblr Blogs





Fun Fact
Tumblr has 411 employees.
Text
Java Snippets
Although a little bit geeky, I love this presentation from Adam Bien:
youtube
I learned that you do not need to compile your java classes (just run them in your terminal) and that you can use an interface as a main class:

1 note
·
View note
Text
Retrospective of 2024 - Long Time Archive
I would like to reflect on what I built last year through the lense of a software architect. This is the first installement in a series of architecture articles.
Last year, I had the opportunity to design and implement an archiving service to address GDPR requirements. In this article, I’ll share how we tackled this challenge, focusing on the architectural picture.
Introduction
This use case revolves around the Log Data Shipper, a core system component responsible for aggregating logs from multiple applications. These logs are stored in Elasticsearch, where they can be accessed and analyzed through an Angular web application. Users of the application (DPOs) can search the logs according to certain criteria, here is an example of such a search form:
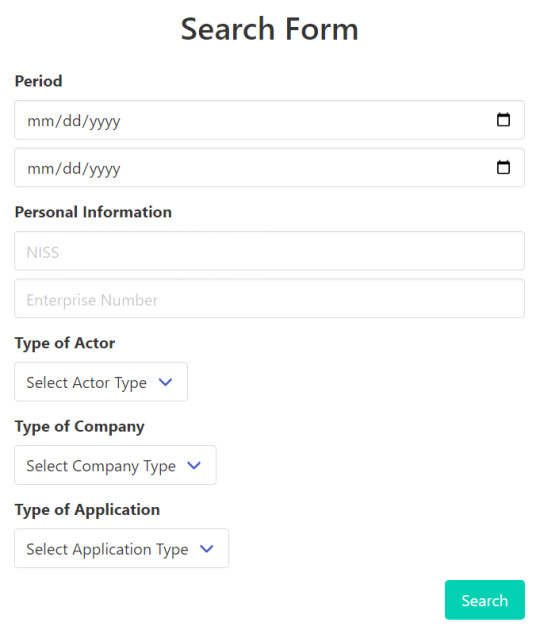
The system then retrieves logs from ES so that the user can sift through them or export them if necessary, basically do what DPOs do.
As the volume of data grows over time, storing it all in Elasticsearch becomes increasingly expensive. To manage these costs, we needed a solution to archive logs older than two years without compromising the ability to retrieve necessary information later. This is where our archiving service comes into play.
Archiving Solution
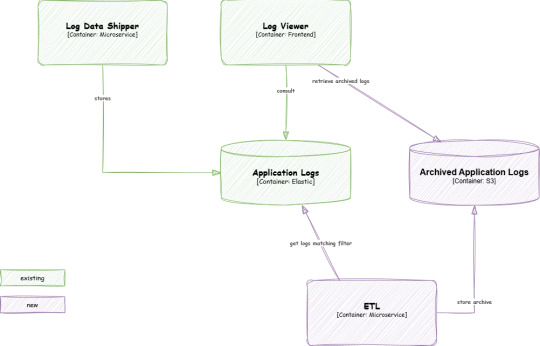
Our approach involved creating buckets of data for logs older than two years and storing them on an S3 instance. Since the cost of storing compressed data is very low and the retention is very high, this was a cost-effective choice. To make retrieval efficient, we incorporated bloom filters into the design.
Bloom Filters
A bloom filter is a space-efficient probabilistic data structure used to test whether an element is part of a set. While it can produce false positives, it’s guaranteed not to produce false negatives, which made it an ideal choice for our needs.
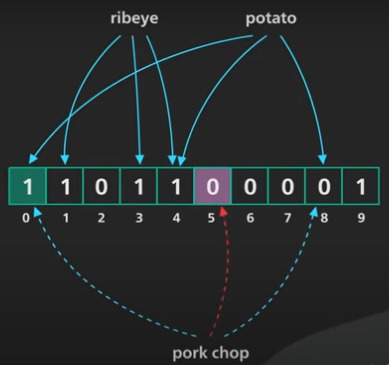
During the archiving process, the ETL processes batches of logs and extracts essential data. For each type of data, we calculate a corresponding bloom filter - each search criteria in the form -. Both the archives and their associated bloom filters (a metadata field) are stored in S3.
When a user needs to retrieve data, the system tests each bloom filter against the search criteria. If a match is found, the corresponding archive is downloaded from S3. Although bloom filters might indicate the presence of data that isn’t actually in the archive (a false positive), this trade-off was acceptable for our use case as we are re-loading the logs in an temporary ES index. Finally we sort out all unecessary logs and the web application can read the logs in the same way current logs are consulted. We call this process "hydration".
Conclusion
This project was particularly interesting because it tackled an important topic – GDPR compliance – while allowing us to think outside the box by applying lesser-known data structures like bloom filters. Opportunities to solve challenging problems like this don’t come often, making the experience all the more rewarding.
It was also a great learning opportunity as I challenged the existing architecture, which required an additional index database. With the help of my team, we proposed an alternative solution that was both elegant and cost-effective. This project reinforced the importance of collaborative problem-solving and showed how innovative thinking can lead to efficient solutions.
0 notes
Text
Easy Slides and Powerpoints
I use markdown a lot in my day to day work to structure my notes when I'm not using pen and paper.
I was looking into quickly turning a few notes from a demo to slides, this couldn't be easier with pandoc.
First you need to install it, pertty easy with winget:
winget install --source winget --exact --id JohnMacFarlane.Pandoc
Afterwards, just covert your markdown to an html slideshow:
pandoc -t dzslides -s myslides.md -o myslides.htm
This uses the dzslides plugin and is quite nice.
Here is a kick ass example of dzslides and the doc:
example: Why you should fear the Ninja Turtles
doc: dzslides
I also discovered that you can convert it to powerpoint in a breeze.
I converted the master template of my company to match the documentation. For this go under View > Slide Master and respect the names in the pandoc doc Powerpoint layouts
You are ready to generate your powerpoint:
pandoc myslides.md -o myslides.pptx --reference-doc another.pptx
sauce
0 notes
Text
Petit recapitulatif du flow OAuth2
OAuth2 permet a des 3ce partie d'acceder a des données utilisateurs sans reveler leur mot de passe via l'échange de tokens.
client: celui qui désire acceder à une resource
resource owner: l'utilisateur qui possède une resource
auth server: serveur qui authentifie les utilisateur et emet des jetons
resource server: héberge une resource protégée
Oauth2 flows
Authorization code:
le client désire acceder à une resource a nom de l'utilisateur
l'utilisateur est dirigé vers l' auth server pour login et donner les accès au client
ensuite l'auth server envoie un code d'authorisation au client
le client envoie le code d'authorisation à l'auth server en échange d'un token courte durée
le client contacte le resource server avec le token qui lui donne accès
Client credential:
le client désire accéder à des resources qui lui appartiennent
le client s'authentifie au serveur via ses credentials (clientId + clientSecret)
l'auth server envoie un access token au client
le client peut utiliser ce token pour accéder les données
0 notes
Text
SLA vs SLO vs SLI

Today I learned that the SLA is what your client asks but that the SLO is what you deliver!
sauce for the image: https://www.atlassian.com/incident-management/kpis/sla-vs-slo-vs-sli
0 notes
Text
When to chose Microservice architecture
A microservices architecture is chosen because there is a strong need for short lead time, rapid and independent deployments of components and if you have the organizational structure to back it up – small, empowered independent teams with end-to-end responsibility. Hence, they are often powered by a fully automated CI/CD pipeline. The drawback is that you end up with a high demand for communication and a complex socio-technical system.
~ Lukas Pradel in this infoQ article
6 notes
·
View notes
Text
An angular download directive
The angular way of downloading files is a little confusing, you need to create an anchor and add the data you want to download to it, it looks like so:
downloadFile(data: Blob, fileName: string) { const a = document.createElement('a'); const objectUrl = URL.createObjectURL(data); a.href = objectUrl; a.download = fileName; a.click(); URL.revokeObjectURL(objectUrl); }
Instead of repeating this code everywhere I wannted to see if I could add it to a directive.
For this create a new directive like so:
@Directive({ selector: '[onDownloadFile]' }) export class DownloadFileDirective { @Input() downloadFunc: () => Observable<string[]> = () => of(); @Input() contentType: string = ''; @Input() fileName: string = ''; @HostListener('click', ['$event']) onClick() { this.downloadFunc().subscribe((value: string[]) => this.downloadFile( new Blob(value, {type: this.contentType}), this.fileName )); } downloadFile(data: Blob, fileName: string) { const a = document.createElement('a'); const objectUrl = URL.createObjectURL(data); a.href = objectUrl; a.download = fileName; a.click(); URL.revokeObjectURL(objectUrl); } }
It's a lot of code but most is generated automatically by the command
ng generate directive
The directive is called onDownloadFile and will handle the onClick event. To make it generic it accepts as input:
a callback function that does the async call to the backend or wathever
a content type for the popups of the browser
the final file name of the download
In this example the backend returns a string[] but the blob coud directly been returned instead.
You do not want to trigger the downloadFunc unnecessarily, that's why we pass a function and not the function call as first input of our directive:
@Input() downloadFunc: () => Observable<string[]> = () => of();
The notation is a little cryptic, also inputs need to be initialized so there is that.
Here we define downloadFunc as a function that returns an observable downloadFunc: () => Observable<string[]> and declare an initial version returning an empty observable = () => of()
Using this new directive is quite straightforward except for a little caveat. The function passed needs to bind the scope, otherwise our method downloadCsr will not work:
<button mat-flat-button class="download-btn" onDownloadFile [downloadFunc]="downloadCsr.bind(this)" [contentType]="'application/pkcs10'" [fileName]="cert.commonName + '.pem'"> {{'certificate.detail.downloadCSR' | translate}} </button>
Add onDownloadFile to tell that it should use the directives
Pass the download function as paramter. Here we bind the scope so that the callback works with this object.
contentType and fileName are passed to customize the download
That's all :)
Now you can re-use this accross your app for all your file download needs.
The source code is available in a convenient gist
Happy coding!
0 notes
Video
youtube
Victor Rentea is a reference in implementing the clean architecture. I've referenced it a few time on this blog. This time we'll focus on abused DTOs
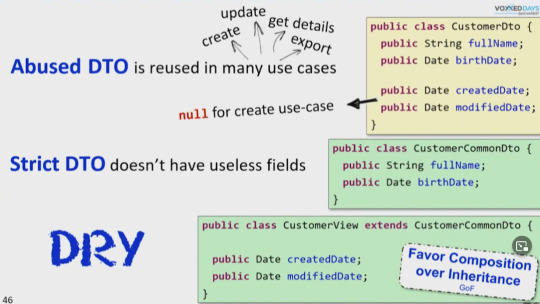
A DTO can be "abused" if it is used in a way that goes beyond its intended purpose. For example, if a DTO is used to transfer data from a database to a user interface, it may be fine to include database-specific fields such as a primary key in the DTO. However, if the same DTO is then used to transfer data between business layers or to other systems, those database-specific fields may no longer be relevant and could cause confusion or errors.
Another way a DTO can be abused is when it is used to transfer data between layers without a proper mapping strategy. A common mistake is that the DTO and the entity have the same fields. As the system evolves they will not be in sync and can cause issues.
An example of a correctly implemented DTO in Java might be:
class UserDTO { private String firstName; private String lastName; private String email; // Getters and setters for each field }
An example of an abused DTO in Java might be:
class UserDTO { private int id; // database primary key private String firstName; private String lastName; private String email; private boolean isAdmin; // business logic flag // Getters and setters for each field }
In the example above, the id field is specific to the database and the isAdmin field is specific to the business logic. Both of these fields may not be relevant or appropriate when transferring data between layers or systems, and could cause confusion or errors.
Victor goes on to explain in the example that CustomerView should have a field CustomerCommonDto and not extend from it.
Finally be weary that when doing this you might end up DRY-ing code on the assumption of fragile coincidence!
More about this in another entry.
Happy coding!
0 notes
Text
Code review
I read a lot more code than I write nowadays and most of my comments are related to code style, the use of java8 stream APIs, compacter code constructs and more readable code. The following video explains why you should never nest. And while I always say "never say never", not only are the comments really good, but the realisation of the video is really pleasant:
youtube
I noticed a few things on which I wanted to comment:
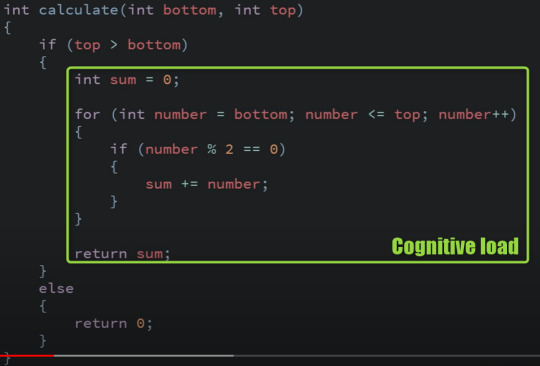
TS2:45: this is something that I see a lot in code review:
I call this "cognitive load". You need to keep this block in your brain and come to it later - This makes reading code more diffuclt.

TS5:50: I call this "intentional programming". Tell what you code should do so other humans can read it, then implement the "holes" - the functions - with computer code
To finish, a little quote from our friend Donald Knuth

0 notes
Photo


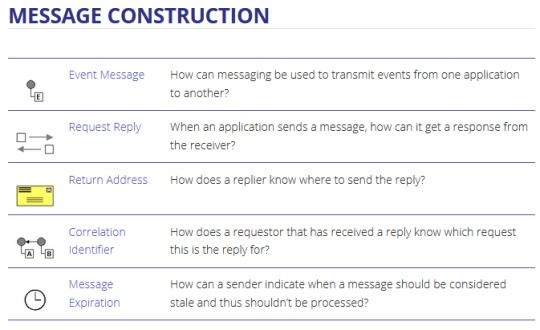






Enterprise integration patterns - cheat sheet
~ sauce: camel.apache.org
1 note
·
View note
Text
How Does Maven Resolve Version Conflicts?
I needed to check out how to maven bom again and stumbled upon this interesting tutorial.
Something I did not know is that maven resolves version conflicts through the approach of "the nearest transitive dependency in the tree depth and the first in resolution":
Maven also indicates for each transitive dependency why it was omitted:
omitted for duplicate
omitted for conflict
Of course the simple way to override this resolution is to add the transitive dependency directly into the dependencies of the projet. Personally I do not find this to be a sexy solution and we'll eventually explore alternatives. But for now, let's stick with that solution.
Good luck with your dependency hell!
0 notes
Text
Architecting the web
This is a real interesting read on how to architect a modern website:
→ How I built a modern website in 2021
The whole thing is meticuously described with a lot of images to make everything clear:
Kudos to Kent C. Dodds!
0 notes
Text
To mock or not to mock
I'm generally not a great fan of using mock for testing. My sense is that it "crystalizes" the code and makes it very difficult to refactor.
As others do it better than me, I decided to reference this very interesting article about when you should mock.
3 important pointers in the article are about the cost of mocking
Using mocks leads to violations of the DRY principle.
Using mocks makes refactoring harder.
Using mocks can reduce the simplicity of the design.
And finally a good advice on when to mock:
Only use a mock (or test double) “when testing things that cross the dependency inversion boundaries of the system” (per Bob Martin).
0 notes
Text
You shall not use linkedlist
I remember my first job where all the java code was specifically using LinkedList. It was a recommendation of my seniors because there might be sizing issues with ArrayList.
I've always kept that in the back of my head as the first years on a job are very formative. I now realise it's not really true, as stated here:
Looking at just these operations on ArrayList and LinkedList, there are clear tradeoffs. Element access in ArrayList is faster, but editing potentially involves copying O(n) elements, which can be expensive. Many people claim that LinkedList has the advantage for editing operations because they are O(1). This is true, but only at the ends of the list, or if you already have the location in the list where you want to do the editing. (Such as with a ListIterator.) If you have to search for the location, or if the index is somewhere in the middle, you have to pay the traversal cost to get to that location.
The kicker here is that traversing through a LinkedList is considerably more expensive than copying the elements of an ArrayList. If we assume that the edit location is uniformly distributed within the list, the average cost of element copying in an ArrayList is around 0.9µs. For a LinkedList, however, the average cost of traversing to a location is over 4µs. There are clearly workloads where a LinkedList will outperform an ArrayList. However, in many cases, the traversal cost of the LinkedList is so much more expensive than the copying cost of the ArrayList, it more than offsets LinkedList‘s O(1) advantage in editing operations.
That’s why I claim that ArrayList is usually preferable, and LinkedList should (almost) never be used.
~ sauce
What I keep from this is that in the end,
early optimisation is the root of all evil
... and you should really only try to fix code where you notice there are preformance problems.
Even today I recommend tha you:
Write readable code
Test it a lot
Measure it
Eventually improve it if there is a real bottleneck
Most often than not, the 4th step is not necessary. Trying to improve your code by making it less readable is a mistake in the first place.
Anyways... back to the LinkedList discussion, I now know there is no reason for me to use it anymore.
0 notes
Photo

Leaders and Managers
I've picked up on some discussions in the hallways about the differences between being a leader or a manager and that sometimes it's better to be one or the other.
A thing I did not know is that a leader performs the 5 functions of management as described by Herny Fayol:
Planning: Plan for the future and develop appropriate strategies to meet organizational goals
Organisation: Process of assembling physical, financial and human resources
Commanding: Communicate clearly and honestly and act in a way that reflects company values
Coordinating: Aims to create harmony between the various activities within the organisation
Controlling: Is progress being made toward the goals and objectives stated in the planning phase ?
A manager has a position whereas the leader can be anyone who follows him. In that regard, the former is pinned to the corporate ideology and the latter has more aura attached to it.
What drove me to these considerations are discussions I had with colleagues in the past. My company offers trainings that focus on the disctinction between the two roles but this article points out that it's good to have it both ways.
I'll ponder on this a little more!
0 notes
Photo

[Too Many] Scrum meetings
I've seen scrum implemented in many ways but a recurring issue I hear from developers is that there are too many meetings.
If we look at the diagram, there are actually 5. I think the fallacies of the meetings are that they are boring and not well prepared. Most likely one person communicates and others are not listening and people are not engaged.
I think a few important points about those meetings are to be respected and inforced by the scrum master:
the daily goes in all directions but the 3 main questions are not answered
also the daily is not to communicate to the manager but to the TEAM so that they are aware of what is happening and can help if necessary
the sprint planning is neverending. This is because grooming is skipped and the two meetings end up squished together. A good grooming session is more informal but levels everyone on what needs to be done.
t-shirt sizing is important to get a feel of the work and plan a release correctly
the backlog should contain all the features of the software for each release. Grooming it will clear the picture and add the details
enter all your sprints when you scope your release, this will give you a clear picture of the tasks at hand
the retrospective can be fun and is also a moment for people to vent about their problems. I do not recommend to skip it. However there will be points that cannot be tackled, like "the client sucks". It should be communicated that those are out of the scope of the retro.
These are a few rough drafts about scrum but there are other agile methodologies that might be more suited if you are not delivering an MVP.
I'll probably refine these idaes but I felt important to communicate these pointers.
0 notes
Text
GIT: Delete a local branch
This deletes the local branch (but not the remote)
Change branch if necessary
git checkout -
Delete the local branch
git branch -D
Pull the remote branch
git pull git checkout
0 notes