
Hey don't mind me if I randomly like and comment your blog, I'm just trying to get professionalism points ^~^
Don't wanna be here? Send us removal request.
Statistics
We looked inside some of the posts by raymondsecurityadventures and here's what we found interesting.
Average Info
Notes Per Post
28
Likes Per Post
19
Reblog Per Post
2
Reply Per Post
7
Time Between Posts
16 hours
Number of Posts By Type
Text
17
Last Seen Tumblr Blogs





Fun Fact
Tumblr has been banned in Indonesia for providing people with access to pornographic content.
Text
Lecture 9 - Really Long Version - WIP
The first half of this week’s lecture focused largely upon revision, whilst the second half referred to a couple new theoretical concepts (that had been covered by Jazz if you attend his classes so more revision) and a taste of Adam’s lecture next week on privacy.
Culture - Just Culture, Excellence Culture, Feedback Culture and everything in between
Just Culture
Contrasted against blame culture, just culture seeks to take a more holistic outlook upon placing fault for an incident in the event of one and tries to steer away from placing blame upon the last person to interact with the subject of the incident or ‘shooting the messenger’ and addressing the incident as the product of multiple issues. Since Australian airline Qantas’ adoption of this culture and its subsequent success, just culture has seen widespread, occasionally forced, adoption.
Many credit just culture’s success to the relative lack of aversion that individual employees have toward participating in incident and safety reporting related events, meetings and hearings as just culture places assurances to protect said participating employees from any unjust recourse, a la shooting the messenger style, and incentivises issue reporting.
Lessons To Learn from Traditional Engineering
Security engineering is a relatively new field compared to traditional engineering disciplines, so it seem to follow that security engineering could draw from traditional principles such as:
Implementing codes and methodologies to follow in times of crisis
Attempting to falsify everything; i.e. continually testing systems to examine potential issues
Culture of excellence; taking pride in your profession. Deadlines are important but so is delivering quality code and the former shouldn’t come at the cost of the latter.
Fix agile; it’s fast and agile but that’s pretty much it. Pretty awful about security
Associations; there are medical, engineering, accounting and law related associations such as the various bar associations, accounting and actuarial practice associations, Australian Medical Association etc. etc. that enforce rules of practice. Make one for software engineering.
Closing the Loop: Feedforward Systems
Feedforward neural networks tend to struggle classifying more difficult to things to classify, as the lack of feedback from deeper layers causes learning difficulties. This is remedied in various ways, however, the simplest of these remedies is to simply create a feedback loop and allow feedback from deeper layers into previous layers. Which is also commonsense in the real world; educational systems, security systems, government systems etc. all require methods of gauging the success of their policies in order to identify areas of improvement. Thus, apparatuses to channel feedback should exist and should probably be better than MyExperience.
System Properties and Design
Object Oriented Programming Principles
Loose coupling good, tight coupling bad: Steven Bradbury video with one member of a group of tightly coupled falling over causing other athletes to fall over and the Australian coming last because sucked - and thus loosely coupled to the group - wins gold.

Issues and Benefits of Automated Systems
Issues:
Predominantly their inability to cover edge scenarios. Such a system will always have to have a method of operating outside its parameters and artificial intelligence isn’t so advanced that systems are able to do so. So human interference is pretty much always necessary.
Benefits:
Removes the human element from decision making, which is ideal because humans are bad at a lot of things as seen in every cognitive bias ever
Systems Designed by People Suck
We spend 1bn dollars every election, but democratic systems still fucking suck because non-critical infrastructure programmers are building them rather than actual critical infrastructure programmers.
End-to-End
End-to-end security refers to security that stretches the entire length of a system, and is equally robust at all parts. Obviously, people tend to slack off and their cognitive biases may convince them or lead them to believe a particular area is more secure or less critical than is in actuality.
This is particularly true in the case of the US electoral system and only recently have its vulnerabilities been brought to light. Such as system operates in the following manner:
Elections:
People making up their mind about who to vote for
The announcement of voting
Propaganda everywhere
Establishing voting infrastructure
People go to the polls
The votes are counted
The results are announced
We know that the Russians knew step 1 was particularly weak, took advantage of existing information transfer systems (social media specifically) and used them to spread misinformation and Donald Trump won lmfao.
Really Loosely Related Section
I’m including this section for completeness’ sake but it won’t be written up properly and I doubt it will be of any relevance in the exam.
Free Speech? The n-word? Conflicts of interest?
You want all free speech except that's critical of you. When you believe in free speech, you have to believe in free speech that disagrees with you.
Self-Driving Cars: issues with hackermanz
Google: 'no it's fine lol, we have top people working on it. Self driving planes are a thing already, why not cars'. Proceeds to try to convince us that robots will be better than humans because humans are drunk, brash idiots. Proceeds to try and misdirect us:
Misdirection: Ethical dilemmas that computers have to make: would the car rather swerve into a young person or an old person?
Fails to address the magnitude of an incident involving systemic failure in computers v individually driven incidents such as terrorist attacks:
Terrorists are small in number.
Computers are not.
Security Analysis of that nuclear silo site in that Wargames film clip:
Features:
Random location in the middle of nowhere - obscurity
Inconspicuous location in Wisconsin - obscurity
Single way mirror so people wouldn't accidentally find it - security by obscurity
Sign on system
Dual authentication: two people to check codes. Defence in depth? Multiple points of failure?
Two keys required: forgot the protocol name
Large distance between keys
Case Studies to Read/Watch Up On:
3 Mile Island
Chernobyl
China Syndrome
Trust
A bit that our tutors elaborated upon but Richard himself failed to.
Importance of trust:
Makes things work. Trust makes processes efficient as people are able to let down their paranoia and focus upon doing what they specialise in, rather than trying to build 1000 walls to protect what they do and obtaining their own food and shelter rather than relying on specialists such as farmers, builders etc to obtain necessary goods/food/shelter.
It allows society to be society.
The Trust Dilemma
Protocols that rely on trusted third parties. Don't roll your own v allow a third party to do it? Are some things to be trusted? Everything has backdoors.
My Future
Richard tries to convince us of the holistic value of his course. Richard also justifies the strange range of topics to be presented in the portfolio:
Community is important: useful to build off each other's ideas. Something Einstein standing on shoulders of giants
Self-directed learning :- something awesome project. Helps you learn what is important, what you find interesting, constantly update knowledge because security is always changing
Exercise:- do CTFs…'noone's gonna check if you don't do it but do it anyway because you'll learn'. It’s important to stay in shape
Professionalism: plenty recent-ish security related professions growing so we need to do what's right for the profession
1 note
·
View note
Text
Time Management Wk 9 + Weekly Self-Reflection
This’ll probably be the last post I make before submission because I have
E X C E L L E N T T I M E M A N A G E M E N T™
and now that I’ve finished with my assignments and deadlines for the rest of my subjects, my work and extracurricular shit I do, I have time to do what I do best: watch anime and try to become a corporate sellout.
Over the weeks, I’ve had it rubbed it my face continuously that it probably isn’t particularly important, to be fully up to date all the time and that there’s more to existence than anime, going to the gym, grades and becoming a corporate shill. In fact trimesters have made becoming a corporate shill exceedingly difficult, because before, we had time to apply for internships and jobs over the winter break but its shitty replacement, T2 break, happens to occur AFTER internship and job searching season. Knew I should’ve transferred to USYD. I’ve had to manage my time more carefully than ever and that has meant not sleeping to stay up to date with work and school. With that said though: this whole not sleeping biz is really starting to take its toll on me and I’ve found it increasingly difficult to keep it up.
With that in mind, I’m probably going to do what I’ve always been doing but perhaps with a more open mind and maybe I’ll walk around wearing a tinfoil hat and you might notice that I’ll have rationed myself a little more time to sleep, because sleeping faster has failed miserably for me.
Anyway, I’ll probably keep posting lecture, tutorial, various bits of coursework and the occasional shitpost on this blog since I’ve grown accustomed to learning via writing out my thoughts, but the scheduling and teamwork bullshit I’m gonna toss out the window since I won’t need them to get good grades.

0 notes
Text
H.OTP & T.OTP
Gonna choose this one since I haven’t seen too many posts that researched it.
HOTPs and TOTPs are both methods of generating short one time use passwords.
H.OTP - Hash-based One Time Passwords
Warning: the Wikipedia article for HOTP is quite possibly the worst Wikipedia article I have ever read. Read this instead: https://www.microcosm.com/blog/hotp-totp-what-is-the-difference
So the HOTP algorithm tries to generate unique one-time passwords or pads using a cryptographic hash such as SHA-1, a secret key K and a random value d. These parameters will be specified by the authenticating third-party and it works by having two communicating parties, that are not the authenticating party, compute the HOTP value and the aforementioned authenticating party will verify that they both match the expected value.
The Algorithm
The HOTP value itself, is computed by calling the HOTP function on the parameters K and c i.e. HOTP(K,c) where K is our secret key and c is a moving counter. This counter is both stored by the authenticator as well as the communicating parties. For the authenticator, it increments every time a new HOTP is validated, whilst for the parties, it will increment every time a new HOTP is attempted to be generated. The HOTP function itself is a HMAC algorithm that uses K as the key, and if you remember anything about HMACs, you’ll know they generally depend upon having the key prepended/appended to the message and being hashed by some algorithm. There is no message here however...so it’ll just be the key being hashed prepended to the counter.
Due to the nature of the counter incrementing, there may be times when the counters of the generating parties and the counter of the authenticator are out of sync. This will imply that an HOTP generated has not been validated by the authenticator. If the counters are out of sync by a large enough number (generally 4-5), the counter must be resynchronised which is allegedly quite a complex process.
Time Based One Time Passwords
Uses the idea that there are unlimited times to create passwords from, and that the current time will always be unique to the, well, current time. In fact, if you’d read my previous on the Stargate Ghost Problem, you’ll see that the idea behind the timestamp and this are identical; except timestamps themselves do not serve as difficult-to-brute force passwords. TOTP attempts to create OTPs by being the HOTP algorithm, but instead of a counter it uses the current UNIX time updated every ‘timestep’ which is generally 30 or 60 seconds. An OTP generated this way is only valid for the duration of each timestep.
The Difference
HOTPs are valid so long as the counters are not significantly out of sync which could take a while, whilst TOTPs are only valid for their timestep. Generally the longer the validation window, the more time an attacker will have to brute force your password.
However in the same vein, HOTPs offer a longer validation window and there can be multiple valid HOTPs at once, whilst only one TOTP can be valid at a time.
If you use any third-party authenticator app like Google Authenticator, you’ll know that they have adopted the TOTP due to its ease of use, in that they don’t require counter synchronisation, as well as the small validation window that they offer; particularly important when the passwords they generate are only 6 numbers long.
0 notes
Text
Tagging All Your Analysis Posts and Displaying Them All Together
https://www.tumblr.com/mega-editor go here and tag all your shit with whatever category you want.
You’re then able to view and sort your posts in a nice overview page - which happens to be the archive page - by tags. For example on my blog: https://raymondsecurityadventures.tumblr.com/archive/tagged/analysis
0 notes
Text
Spot The Fake
Something that’s been recently faked
I live in the American gardens building on West 81st St on the 11th floor. My name is Raymond Li, I am 21 years old. I believe in taking care of myself and a balanced diet and a rigorous exercise routine. If in the morning my face is a little puffy, I put on an icepack and wear it while I do my stomach crunches. I can do 1000 now. After I remove the icepack I use a deep pore cleanser lotion. In the shower I use a water activated gel cleanser, then a honey almond body scrub. And on the face: an exfoliating gel scrub. Then I apply an herb mint facial mask which I leave on for 10 minutes while I prepare the rest of my routine. I always use an aftershave lotion with little or no alcohol, because alcohol dries your face out and makes you look older. Then moisturiser. Then an anti ageing eye-balm followed by a final moisturising protective lotion.
There is definitely an idea of a Raymond Li. Some kind of abstraction. But there is no real me - only an entity, something illusory. And though I can hide my cold gaze and you can shake my hand and feel flesh gripping yours and maybe you can even sense our lifestyles are even comparable: I simply am not there.*
Detection
You too can be like this and someone who is someone they are not can be quite difficult to detect, as mentioned in week 2′s tutorial whereupon spies in deep-cover were used to discuss identity and its comprising elements, as the mask will inevitably stop being the mask and become your real face. That being said, someone who is inexperienced in playing their mask will, of course, bear signs of rigidity, an uncomfortableness in their role and perhaps other more telltale signs as issues with physical appearance and action. A good example is Scarlett Johansson in Ghost in the Shell (2016?), that bald white kid who plays Aang in The Last Airbender (2011?) and more recently, the showrunners of Game of Thrones pretending they could write a fucking script.
Something that could be easily faked:
Ear cavity biometric scanning. A Japanese firm, NEC, has developed a technology that works similarly to sonar in that it fires a sound wave toward your eardrum and reads the returned signal. This signal will have had to pass through your ear cavity (the hole leading to your eardrum), which will have interfered with the signal in such a way that the machine is capable of translating said signal into the pattern of the ridges (yes there are ridges in your ear) of your ear cavity. This machine is essentially a fat earphone hooked up to a computer that is capable of transmitting sound as well as listening to it. And while it sounds silly, it’s pertinent to remember that audio based imaging techniques such as ultrasound have become incredibly advanced and are capable of generating fairly high resolution images of your belly, or in this case, your ear cavity.
With this in mind, we now look to overcoming this system, and ‘authenticating’ ourselves as someone else using this tech. We could:
Obtain a wax mould of someone’s ear and artificially reconstruct an ear cavity by casting said mould onto a material of similar intensity reflection coefficient as skin to create a hollow earplug of sorts. Reflection coefficient refers to the speed that sound travels through a particular medium. To bypass an authentication protocol that utilised this machine, we could have our infiltrator simply wear this earplug. Alternatively, have the infiltrator carry a replica of the ear around that was built around the reconstructed ear cavity
Replicate the signal that the machine would expect to hear. After all, it is expecting only a sound byte and thus would be very susceptible to a replay attack. The issue would be obtaining said signal but there could perhaps be ways to steal it, such as implanting a similar device into their earphones. This would be the less likely to be successful however, as the broadcast sound, and hence the expected return signal, could probably be vary easily varied
*it’s a quote from the movie American Psycho. Don’t worry I’m not actually a murderous psychopath masquerading as a normie; I AM an anime watching, body pillow hugging normie.
1 note
·
View note
Text
Help my boi out and he’ll do the same for you xoxo
Community/Professionalism Evidence
This post will be dedicated to providing evidence for the community/professionalism portion of my job application. I intend to get some feedback from fellow classmates. I have helped others by engaging in discussions during the tutorial case studies and lecture content whenever someone needed help as well.
7 notes
·
View notes
Text
Teamwork makes the meme work
Either that or I’m trying too hard to get community and professionalism marks.
Drop a bit of feedback on anything I’ve ever done for this course on this post and I’ll do the same for you wherever you want.
On your bathroom mirror, in your car, on your primary school 1st grade classes’ whiteboard. Wherever. You. Want.
Also another call to make snide comments on my jobapp @ https://www.openlearning.com/u/taeyeonfan/jobapp/
6 notes
·
View notes
Text
anyoneelsehavingtheissuewhereyournewlinesandspacesarentworkingonTumblr?
Title
0 notes
Text
Week 8 Lecture 1/2-WIP
I wasn’t able to make it to the lecture this week due to my effective time management preempting me to work on my project and catch up afterward :). So a big thank you to https://public-insecurities.tumblr.com/post/186491909055/week-8-morning-lecture for providing the lecture outline that this post will be based off.Also, I’m aware that the raw videos have been released to YouTube, I just prefer the succinct summaries :):):):)PASFS)PERE):)
Anyhow this week’s material will be a little more philosophical in nature compared to previous week’s.
Fallback Attack/Protocol Downgrade Attack
As the name might suggest, a downgrade attack is an attack that causes a system or a protocol to abandon a higher quality mode of operation in favour of a shittier one. Typically these arise due to the existence of backward compatibility functions with older systems - another example of your Type I/Type II tradeoff. A nice example of a flaw like this was found in OpenSSL that allowed an attacker to negotiate the use of a deprecated version of TLS that basically worked by the attacker causing a failed negotiation of TLS 1.2, hoping that the client would then reattempt the handshake using TLS 1.0 or SSLv3, falsely believing that the attacker was using an older system.
Human Error and Cultural Issues
Whilst some issues may be any sole individual’s fault, it’s often due to an issue with the group that this individual may work for and the security culture that they had built up and implicitly taught their employees to follow. Human error exists and so security culture exists to prevent or minimise the issues that this flaw may cause and as such the culture is often the root cause for these issues, or, perhaps, more at fault for a human error than that human itself. Humans are humans after all and will inevitably screw up, but if these screwups are common amongst your employees, it may be worth looking at yourself and the behaviour you wish to project and for your employees to emulate in your culture.
Chekov’s Gun - if in the first act you have hung a pistol on the wall, then in the following on it should be fired.
Or in the bright world of corporate life; if you’re the last person to touch something and that something screws up, you’re getting fired. There’s a reason why this trope is so effective in cinema and writing.
Human Error
Undeniably the biggest security issue for any system is this concept of human error. Now, systems wouldn’t exist if it were not for humans, but it would be a lot lesser an issue if humans adhered to error checking systems and actively thought about them.
Root cause analysis
A commonly used method of problem solving used to identify the root causes of faults or problems and is very commonly used in the tech industry. The wikipedia page tells me it can be decomposed into simple steps:
Identify and describe the problem
Establish a timeline of operations from before the problem occurred, beginning from normal operations
Distinguish between the root causal events and noise using such techniques as event correlation
Draw up a graph to determine which causal events contributed to the problem and when they occurred
Why is this useful?
Because humans like to blame their problems on single things, rather than multiple groups of things that all contributed together to said problem, and root cause analysis takes a step back and attempts to provided a framework to allow us to piece together a more complete picture as to the issues.
A Short List of Human Weaknesses
Dis-honesty: a lot of security systems are built up upon the concept of trust and the better ones rely least upon this idea but there will always be some element of trust that should be reliable. The best of systems allow for humans to best be honest and don’t rely upon honour codes or webs of shared secrets but this won’t always be possible for a multitude of reasons; leading to honesty becoming a deciding factor of a system’s security.
And honesty isn’t always so clear cut and lying isn’t always malicious as is evidenced by the existence of confirmation and various other behavioural biases that will cause someone to believe in something contrary to evidence.
Misdirection and Tunnel Vision:
We’ve all faced the issue of tunnel vision where we become so focused on a particular task that we disregard plenty of other important factors including sleep, nutrition and general physical wellbeing in favour of anime, memes and whatever else we may be passionate about. Same with security consultants, pen testers and other people important to maintaining security who will sometimes tend to overlook certain aspects of security in favour of others.
Typically these aspects are what are most psychologically salient which leads to the issue of misdirection whereupon hackermen are able to divert the attention of counter-hackermen to red herrings type things.
Satisficing: Good enough is never enough, except when it is and that is the concept of satisficing. A trap that ensnares all but the most diligent of security people. In fact, the very concept of bits of ‘work’ and a reliance upon creating a system predicated upon causing the attacker to overcome too many bits of work for them to feasibly achieve often comes under ‘satisficing’.
Bounded Rationality:
The idea in decision making where the rationality - ability for individuals to think rationally/with reason - is limited by both the cognitive limitations of their minds and the finite amount of time they have to make a decision. In other, the security of your system is predicated behind how dumb the consultants and security engineers that you hired are.
Generalisation: a general statement or concept obtained by inference from specific cases
And indeed humans tend to verify generalisations rather than try to disprove them, despite that they’re obtained by inference from only very specific cases that may not prove to effective points of judgement.
Groupthink: being a sheep
It’s easier to follow the herd than to think up your own thoughts and security engineers are no exceptions to this rule. That being said, they’re being paid to not do this so idk.

Thank you for coming to my TED Talk.
Heuristics:
Other reading:
Film to watch: The China Syndrome
1 note
·
View note
Text
Bitcoin Replay Attacks and Preventions
I get the feeling Richard will ask for something like this on the final exam for the section on the student-led case studies/talks so I’m gonna compose this for you guys <3
Trigger Warning: if you’re allergic to people spouting dated corporate and technological buzzwords like no tomorrow, you might wanna stay away from this short article
How Transactions Work
Bitcoin and Bitcoin Cash used to operate on two separate ledgers, and if you know anything about cryptocurrencies you know when you make an authenticated transaction, that transaction goes on the ledger; more commonly referred to as the blockchain because it’s a chain of so-called blocks. These transactions are authenticated using a public key method known as ECDSA where basically the details of the transaction are taken and signed by the sender of the funds (who had sent the funds already), signed by both participating parties when the recipient of the funds is satisfied that they received the agreed amount from the sender using their own private key and said details are then authenticated by a group of other computers in the network with both their public keys who serve to ‘bear witness’ to the transaction. Only when everyone’s happy, the transaction is placed on the ledger.
The Replay Attack
After the hard fork, BTC and BTCC weren’t entirely separate in that the public and private keys used to authorise transactions in both currencies were the same, but they used separate ledgers.
So you can probably see the problem: while they used separate ledgers, the signatures used were identical so someone could take a transaction on one ledger with your signature and include it on the other ledger, and said transaction would still have your signature so it would be an authentic transaction. Now the transaction doesn’t specify for what those funds were being spent on, but they do specify where and how much so the attacker would have to spend the exact amount that the transaction carried and with the exact same receiver of the funds...who were often quite difficult to find because a lot of transactions were made on the black market/dark web. But the potential for abuse was there.
The Solution
This was a rather easy problem to solve: just add a mark on the transaction that identifies the check is for a particular ledger and not the other. How boring.
But there was an issue deploying this fix: some developers forking from the original BTC blockchain refused to add replay protection - namely the devs of Segwit2x - and claimed that it was the developers of BTC’s responsibility to do this and there was this whole argument that led to lots of people losing a lot of BTC until SegWit2X’s developers caved.
1 note
·
View note
Text
Stargate Ghost Problem
Like everyone else doing this course, I’m cranking out my final few blogposts to supplement my blog. This is literally the Houdini case study we talked about in Week 3 so I’m gonna treat this as revision since I’d forgotten virtually everything from before week 5:
Thanks to Hugh Chan on the forums for giving us some context on the problem.
The Stargate problem is the scenario when you have a group of military people standing outside a Stargate to another dimension/reality/univerise/whatever (irrelevant). One of the brave young cadets volunteers to walk through the portal and ends up in this fantastic universe, full of beautiful, charismatic aliens. One of the aliens asks if he can join the cadet back into his universe. The cadet agrees. When they walk back into the Earth universe, the cadet disintegrates and becomes a ghost. The alien can however see and hear the ghost, but no living thing on Earth can either see or hear the ghost of the young cadet. How can one ensure that the ghost can communicate legitimately through the alien, with the people of Earth?
Now there are a number of ways I recall we discussed this as a class but the predominantly agreed upon method was ‘TiMeStAmP’, where a TiMeStAmP would be appended to the message, hashed with a cryptographic algorithm like SHA-256 and the message alongside the hash would be sent to the receiver.
Now we didn’t really discuss in class how this works but I did some digging and found that:
The receiver then takes the time and produces his own current timestamp, generated from his own clock which should be synchronised to be slower than the sender’s clock for a predetermined time interval that is kept secret say 10.14642 seconds and said timestamp identical to the original timestamp of the sender. The message will then be hashed with the timestamp using the same algorithm and the hashes compared to determine the authenticity of the message as is the case with other forms of MAC. Now this is still vulnerable to what are called clock attacks where the attacker has found the time interval the clock synchronisation interval through some side channel attack and can produce his own authentic timestamps, but it adds an additional layer of complexity to the replay attack I guess. TiMeStAmP can be considered a variant of the one-time-use code method where two parties are given a list of codes to be used once before being crossed off the list and these codes will be used to hash the messages in the same way. Once again, this is vulnerable to a side channel attack that has the attacker steal the secret list of codes but all in all, adds additional layer of complexity to the replay attack and forces the attacker to have to overcome this additional step.
Comparison TiMeStAmP is far easier to use and can generate unlimited codes so can be used with unlimited messages. That being said, it’s a lot easier to brute force a timestamp synchronisation than it is a one-time-use code, particularly if said code is hundreds of characters long. And as mentioned one-time-use codes aren’t unlimited and secrets have a tendency to get out eventually.
1 note
·
View note
Text
Breaking an Actual CAPTCHA
Responsible Disclosure Statement: So I’ve told the CAPTCHA maker that his app kinda sucks but I feel compelled now to say that I don’t actually use it to break into the:

1 million installations that this guy has on his WordPress app. So while I may not share my code...you could probably do it yourself fairly easily given my blogposts so perhaps I’ll hide them... With that in mind however, there are plenty of tutorials and people who have the code up on the internet so I’ll leave them up and reiterate that you probably shouldn’t use whatever app you create maliciously without permission because it’s illegal and it’ll make your life unreasonably hard and like for what? Don’t be an ass
So far I've managed to scrape up all my data and chop it up into little tiny bits as outlined in this blogpost Preprocessing CAPTCHAs and so I ended up with roughly 40,000 images of individual character images that I organised into nice little individual letter directories and which I will feed a simple CNN architecture that I'd stolen from an online blogpost that had great success on the MNIST dataset, which is a collection of handwritten digits similar in nature to the pixelated digits that we've extracted.

Since the laptop I'm running this off is really shit and ideally NN's are trained on powerful GPUs or even more ideally Tensor Core GPUs like Nvidia makes or TPUs like Google and some other companies have made for their AI capabilities, I've had to further simplify this NN architecture and reduce the # of epochs.
So it looks like this:
Input -> (Convolutional layer -> Max Pooling Layer) -> (Convolutional layer -> Max Pooling Layer) -> Fully Connected Layer -> Output layer -> Output
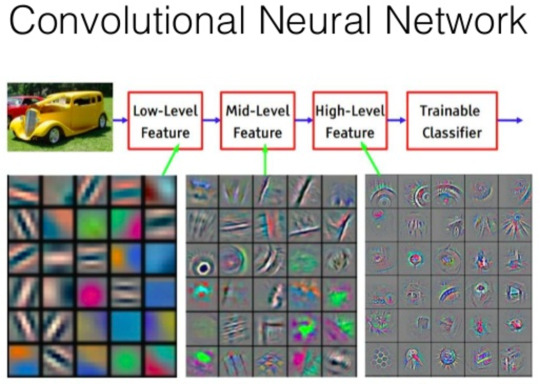
And so we have an incredibly basic ConvNet. I don't think I explained the concept of max pooling so I'll explain it now with this picture:

It's a type of pooling layer that squeezes the input data into as small as possible a matrix which will let us reduce the volume of inputs and hence the time needed to train our convolutional layers and the number of neurons required. This of course comes at the price of accuracy of the kernels we are training, but a necessary evil as it will allow us to train more epochs more quickly over time and enhance the accuracy of our kernels.
For our first convolutional layer, we have 20 5*5 filters that produces images of 20*20. As mentioned in previous blogposts, for each of the 20 filters, take the filter and convolve it with the image which as previously stated is just sliding it over the image, taking the dot product of the filter and the chunk of the input image it's covering and set the middle pixel of that chunk we are covering to that dot product.
We then stack the output of these 20 filters to produce the feature volume. These outputs are known as feature maps and will consist of different low level features of the input image such as the potential edges of objects, the direction of light in the image etc.
Now there are activation maps that help to recognise the various parts of the feature volumes and these will be a grid consisted of 20*20 neurons and each neuron is assigned a different part of the feature map and will fire if they 'recognise' that particular part of the feature map.
Since there are 20 filters and 20 output feature maps, there will be 20 activation maps, one for each filter. Thus, the activation map helps us recognise whether there a specific features in the feature map that had been passed to us. Since there are 20 of these, they'll altogether recognise a combination of features.
Then the outputs will enter the second convolutional network where it'll start to recognise higher level features using the exact same process before entering the final fully connected layers which will serve to judge the output of the network and assign probabilities to those outputs/combination of features, that describe how likely it is that they are a particular character.
If the kernels/filters haven't been adjusted to have the correct weights yet, the activation maps won't recognise the correct features and probably makes incorrect judgements in the fully connected layer regarding these. Backpropagation fixes that by adjusting the values in each filter and the weights in the fully connected layer according to the accuracy of the output. This is a pretty complex mathematical process so I won't go into much detail.
This adjustment is known as training.
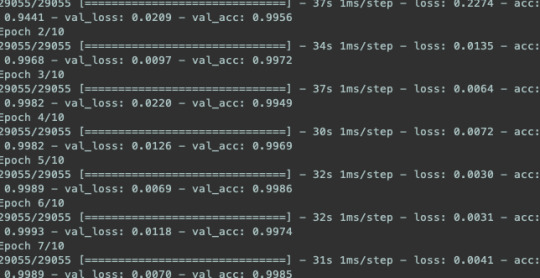
So we train our network on our datasets in multiple batches, with each fully trained batch being referred to as an epoch.
These batches consist of any part of our datasets and can range from the whole dataset to just a small sample. Here's how training looks:
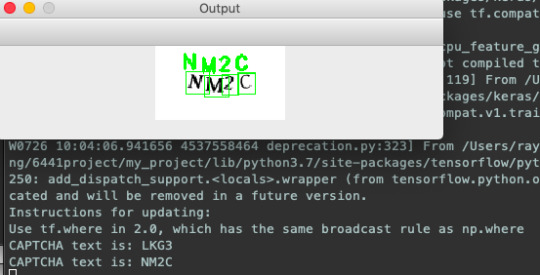
Now we've trained our network on individual letters, we then write a simple script to split our CAPTCHA up and feed the individual letters to our CNN.

The script will throw me a bunch of errors because I'm using deprecated code, piece the letters together again and voila:
3 notes
·
View notes
Text
Preprocessing CAPTCHA Images to make identification more accurate
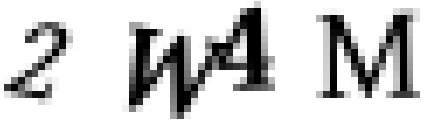
So I’ve scraped images that look like this and my goal is to obtain maximum classification accuracy i.e. correctly identify the CAPTCHA using a ConvNet. Now we COULD chuck the whole image straight into a ConvNet and obtain reasonable accuracy, but we could make our CNN’s life a lot easier by simply separating the characters from one another and training it to identify the individual characters that form the CATPCHA. At this point we are almost basically training on the MNIST dataset, the ‘hello world’ of deep learning which is just a collection of handwritten numbers and letters, whose training data has been predicted to upwards of 99.5% accuracy given only test data. But we’ve some work to do to make it look like this:

One of the reasons why MNIST can be predicted with such accuracy is due to the sharpness of each individual image i.e. no image is particularly pixelated, which allows for important distinguishing features of letters and numbers such as the curvature of 6′s, 0′s, 8′s, 9′s etc. to be particularly clear, rather than seemingly blocky and flat. This can be achieved using anti-aliasing, so I try it on a letter to see if it looks any better:

Eh, they kinda look the same. What about thresholding (converting any pixel with any shade into pure black rgb(255,255,255))?

Much better.
Now how do we deal with letters squished together like in the first CAPTCHA?

Basically when try to separate the letters from each other using OpenCV we must identify the contours of the image (the continuous blobs of pixels), obtaining a bounding rectangle for each contour and then checking whether there are ACTUALLY four contours or not. We know there SHOULD be four contours so if there are only 2 or 3 or even 1 we have to check the length of the contour. If it’s approximately twice as large as some arbitrary value we assign the smallest bounding box but smaller than three times, we’ve identified a joining of two letters. If it’s three times as large but smaller than four times, we’ve identified three joined together etc.
So I use a pretty hacky method of doing this: I just split it by the length of bounding box so:
The W:

The 4:
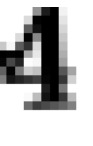
You can see it cuts off a little but like whatever. So applying our image preprocessing methods to our CAPTCHA we get:




Which we can then feed to our CNN and obtain a fairly high degree of accuracy! Hopefully...
1 note
·
View note
Text
Tracking down a CAPTCHA maker to tell him his CAPTCHA sucks + Data Scraping Goal
I’ve identified my victim. It’s going to be https://en-au.wordpress.org/plugins/really-simple-captcha/ and as the name suggests it’s an incredibly simple CAPTCHA. It’ll probably be quite a trivial problem for a CNN, HOWEVER, actually scraping the damn data will be the tricky part.
Nah joke not really since we actually have access to the source code, the hard part will be not breaking the servers the poor guy uses to host his tool if I write a script to the job for me.
In the spirit of responsible disclosure I am obliged to say:
This is just a case study for the potential of NNs, please don’t do mean stuff :(
If you write a script to try and take data from this man like I’m doing, please put a lot of sleeps in it and try not to generate too many instances of the CAPTCHA using the script he wrote. I’m not sure if the place he’s hosting it has any DDOS protection but even if it does, try not to break it anyway. We don’t wanna bring this guy’s app down by accident.
I’m not gonna share the script I built because a) my code is ugly as fuck and b) I don’t wanna bring down the guy’s app and get him banned from AWS or wherever he’s hosting it.
That being said if you want a hint on how to do it, here’s a snippet of code from his site. It produces a JPEG. Yeah it’s not hard.

Anyway, don’t even bother writing a script I’ve taken the liberty of doing it for you and uploading the data to a G Drive: https://drive.google.com/open?id=1Ml8w0Rfq5mMT8y0pFGl0XCknL_Fra3mE
Also, I in no way shape or form condone tracking down the people that still use this CRAPTCHA and taking advantage of their poor security.
I bet he knows how bad it is already and doesn’t really care since he’s probably migrated to Google’s reCAPTCHA 3 but I’m gonna tell him how sucky it is anyway for the responsible data handling marks.

IN FACT, the way the CAPTCHA images themselves are handled is kinda insecure in itself...maybe? so it’s possible that a NN might not even be necessary.
Wow, on top of project progress and responsible data handling, I get to do security analysis too? I mean, my entire project is already kind of a data analysis project but hey I’ll take it. So combing the source code we find that the name of the CAPTCHA images are generated from the 4-characters of the image, and are confirmed by comparing a hash of the 4 characters to the hash stored in the corresponding file server side.

It’s encrypted with an MD5 which has been or’d with a 64 length salt value generated by wp_generate_password() which is just a WordPress function that generates random characters given a length. MD5 is pretty trivial to break using a tool like dCipher but is it when there’s a salt? Also trivial when you know what the salt is, look up HashCat (might make a blogpost on this later this week actually. I might even ditch my original computer vision method hehe XD). But how long does it take HashCat to separate the hash and the salt? Pretty darn quick when it knows that the salt was prepended to the hash. From there we can probably pretty easily brute force all alphanumeric 4 letter CAPTCHAs and their MD5s to identify the correct CAPTCHA.
0 notes
Text
Project Update - Basic CNN Built
You’ll notice that I hadn’t made any posts for my pass goal but I in fact did complete it as an exercise. It’s just a basic NN that I built on Google CoLab that’s trained on the Fashion MNIST dataset and obtains a decent 85% accuracy identifying various items Thanks for the free GPU Google, I hope my soul will sell for a lot. Have a look if you’re interested, it’s in the form of a notebook so it’ll run line-by-line if you tell it to:
https://colab.research.google.com/drive/1sKbAnylpeolY9irdQGtZlP9meUobjGmB
Unfortunately, my experience with cloud based computing extends that far and I’m not quite how I’d import datasets I’d scraped in and out of Google Drive and then use it with Google CoLab. This was quite the unforeseen challenge...
So I said fuck it I’ll just TRAIN MY CONVOLUTIONAL NEURAL NETS ON LOCALLY ON MY MAC AIR WITH INTEGRATED FUCKING GRAPHICS THAT’LL TURN OUT WELL.
And it has so far, but that’s because the architecture I built for this exercise was a ShallowNet and the ShallowNet consists of only 1 convolutional layer, 1 activation layer following it, one flattening layer and one fully connected layer with a softmax activation layer proceeding it to scale the outputs to [0,1]. I then trained this ShallowNet on an animals dataset consisted of cats, dogs and pandas that I needed to identify.
Of course, the images needed to be translated into actual data so I began by flattening the images and scaling them to a suitable size using some built in Keras functions. I then scaled their pixel intensities to the range of 0 and 1, split this data into training and test sets as is tradition in analysis and trained my ShallowNet on the training and tested it on the test sets.
You can check out the code here: https://github.com/raymondmli/NNadventures. It’s the shallownet_animals.py file although really it’ll work on any dataset you pass it not only the animals set (include the directory of images. Make sure each image is in a subdirectory that is the correct label of the images in it). Also you’ll need Keras and TensorFlow installed lmfao so maybe not.
Anyway since it’s a ShallowNet, of course it trains quickly, taking on average 1.5 seconds per epoch, and since I ran it for 100 epochs, the NN took 2 and a half minutes to train. That being said, I only used a batch size of 32 images per epoch...
Translator’s note: an epoch is the number of times a batch of the data was passed into the neural net. Batches can range from the full dataset to just a small sample.
And here are the results:
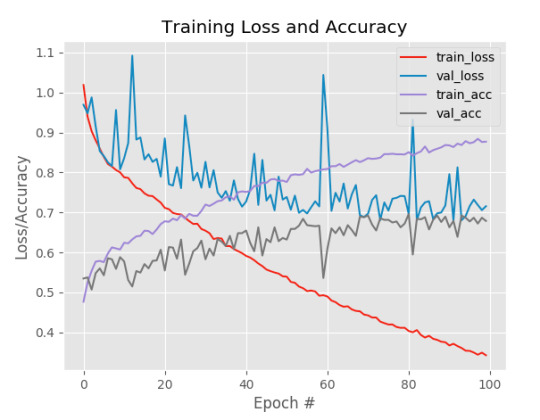
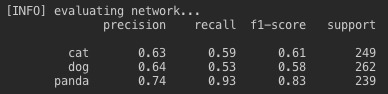
In the above graph, the red line represents the error of the predictions that the NN made whilst the purple line represents accuracy. You’ll notice that the accuracy actually hits ~95% but the precision on the test data is quite poor. This is probably due to overfitting which I talked about in another blogpost, the result of the filters of the CNN placing too much stock in one particular trait of an animal, perhaps the shape of its ears or its fluffiness to identify another. This often happens when the NN tunnel visions on a particular feature which could occur if you have too few layers so it’ll keep updating the weights of the same edges and ‘tunnel vision’, train it over too many epochs and cause it to update the same edges too much or a combination of the two.
So we end up with a bit of a shitty result tbh, let’s see if it’s any better when I add epochs to it.
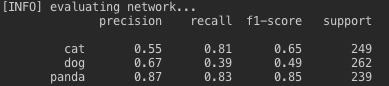
Interesting. So its ability to classify cats lost a fair bit of accuracy, whilst dogs rose a little and pandas significantly rose. Again, this is due to model overfitting which was kind of the result of the nature of the datasets. The cats dataset was designed to be overfit quite easily (e.g. it had lots of similar pictures of cats and then a lot of VERY different pictures) whilst pandas wasn’t designed at all, it’s just a random and quite diverse collection of pandas which will generally yield better results because it’ll allow your network to recognise a more diverse array of features
Anyway that’s my CR goal completed. Honestly wasn’t really difficult to do when everything’s abstracted away for you so I appear to have wasted a lot of time learning the low level details of the algorithms that are involved in the process. That being said, the educational posts were an alternative DN goal for me but it’s a little disappointing knowing I might not be able to finish my actual DN goal in time because I made all those educational posts; especially considering how difficult it is to scrape data and individually classify them. Nice one idiot.
0 notes
Text
Weekly Time Management, Complaining + Give Me JobApp Feedback
Good news! I got 63/100 on my fucking finance exam, somehow scoring 5/15 in the short answer section, so I’ll be working extra hard on this portfolio this week to make up for that trash mark and to distract me from my suicidal tendencies. Not that I really have the time until Sunday to do so as you can see below. Disclaimer: I don’t actually want to kill myself so don’t call the police on me.......yet
And so for my first effort to try and obtain marks in the community and professionalism, I want you my loyal reader to take a look at my job app/portfolio and give me some feedback! Take a look: https://www.openlearning.com/u/taeyeonfan/jobapp/ and drop me a comment here or on my app if you like! And if you want, shoot me a DM or post a comment here with your job app link and I’ll be more happy than to leave some on yours and get us both some feedback marks in the process.
If you actually look at my schedule, you’ll notice that I’m gonna be a bad kid and for the first time miss a lecture :O :O :O but luckily I follow some pretty quality blogs that I trust will come up with the material and that I’ll hopefully be able to make my own and submit that shit alongside my portfolio by Sunday 5pm because I have quality time management skills.

1 note
·
View note
Text
Privacy - TEAMWORK group ANALYSIS with lots of COMMUNICATION and stuff
I’m not begging for marks, you are.
In today’s group analysis session we floated as a class/team what we believed to be suitable types of data for the government to be able to retain, throwing suggestions at Jazz for a lot of data but I’m gonna concentrate on a controversial one:
Relationships:
Well to be honest, I don’t have any data on this category for the government to keep on file on me other than my current girlfriend:

But with that in mind, I’m sure other people with shitty 3D relationships actually do have things to disclose and there are +’s and -’s to this of course. So for the purposes of this discussion, I’m gonna limit it to only actual relationships (sorry waifu lovers) of any kind; sexual, platonic and romantic. Anyway I discussed with a friend afterwards and here’s what we came up with as a team.
+’s:
Can have point of contact in case you or your significant other throw yourselves off K17 or get into sticky situations
Can be approved to visit you in prison/court/the hospital more easily
Can be far easier to claim couple tax exemptions particularly if you two have children but are not married, or are homosexual
Can more easily link to the source of your STDs if you have any. Possible manner of tracking whoever owes you compensation for giving you AIDs?
I personally wouldn’t be able to use such a service since the only thing I get intimate with is my body pillow but y’know real people, real sex, real consequences.
Personal preferences can probably be analysed so dating apps could become more personalised if this becomes public
Can more easily find and talk to potential witnesses/accomplices of a criminal
Deter adultery(?) Is that a good thing?? Human monogamy discussion for next time, but let’s assume yes.
Discourages people from fucking animals:
That being said, I don’t know anyone who fucks dogs who would disclose that they do to the government. I also don’t know anyone who fucks dogs period.
Discourages corruption/networking:
Government and corporate officials won’t be as able to favour their mates as easily for a job if their relationships are fully disclosed which would be a pretty big boon to the world because, in my humble anime watching opinion, relationships/networking are far too powerful as tools to get ahead in the world, compared to actual competence metrics such as intelligence and experience.
One could also make the argument that since the human is naturally inclined to want to be vulnerable and that some people work better when they’re working amongst friends, emphasis on networking/connections could be an accurate competence metric, particularly in professions such as sales aka professional social engineering.
-’s:
Can possibly be recognised as social degenerate if you don’t have anyone on your relationship record or a lot of the people on your relationship record are degenerates which could reflect poorly on you
Can easily track you if you have STDs or catch it from a partner. If this becomes publicly available knowledge, your future love life could be harpooned forever. Whether this information should be public at all is a philosophical debate for another time. Or not really since 2D is justice.
Can easily find your personal preferences, which could of course be used against you; possible source of discrimination if you have fetishes, are homosexual and/or are into kinky shit
May force couples that are in ill-defined relationships into formalising their relationship as they’d have to lodge it with the government; essentially turning the modern relationship into a binary construct. So: the DEATH OF LOVE AS WE KNOW IT
May pave the way for relationship restrictions which would open a whole new can of worms such as a eugenics debate, a lot of Romeo and Juliet bullshit and other fun stuff like racism

Conclusion: Yeah nah I don’t want the world to know that I’m an anime watching, waifu loving degenerate. Big no. But if I wanted what was best for the world: also big no. Relationship data was something that got you killed in Nazi Germany, and as some other helpful contributing class members said: you might trust the government now but you might not 20 years into the future.
‘And once it’s out there, it’s out there forever. You’ve opened a Pandora’s box.’ - Jasper Lowell 2019
5 notes
·
View notes