
Don't wanna be here? Send us removal request.
Statistics
We looked inside some of the posts by rebekas-posts and here's what we found interesting.
Average Info
Notes Per Post
0
Likes Per Post
0
Reblog Per Post
0
Reply Per Post
0
Time Between Posts
1 day
Number of Posts By Type
Text
10
Link
7
Last Seen Tumblr Blogs





Fun Fact
In 2020, Tumblr had 29.4 million users in the US.
Text
How to Extract Hotel Reviews Data from Online Travel Portals?

No matter if it is a popular travel portal or a well-known review website, it’s easy to track or monitor your customer’s success stories. Different hotel reviews are provided by the guests on different travel websites which are a wonderful source for balanced customer experiences that can get analyzed to get actionable insights. For instance, in case, you are a chain of luxury hotels looking to know the clients better, then you could easily extract hotel reviews from travel websites. This is also a very good idea to scrape reviews on the competitors’ hotels ever since this will assist you to recognize their strengths and weaknesses that might boost your market’s strategy. Whereas there’s no lack of hotel reviews on online travel sites, the majority of businesses lack infrastructure, expertise, and sources to scrape hotel reviews from travel websites in an automated and efficient manner.
At X-Byte Enterprise Crawling, we have specialized in large-scale data scraping solutions as well as have been dealing with use cases where clients want to extract hotel reviews from travel websites. As a client, you don’t need to get involved in technically complex characteristics of web scraping services and data crawling. It helps you in concentrating on applications of hotel review data as well as other key business functions.
Different Applications of Hotel Reviews Data Scraping

Customer experience has become the most vital differentiator for nearly all kinds of businesses after meeting social media as well as other technological revolutions that provide extra power to customers. In case, you don’t make the customer experience your topmost priority, be ready to miss out on your competitors. That is where the majority of applications of hotel reviews have a role to play.
Through carefully analyzing hotel reviews, different businesses can get valuable insights into the customers as well as their priorities and demands. The impartial nature of the reviews makes that more valued to you being an owner of a hospitality business. Let’s go through the most well-known applications of hotel review scraping.
1. Know Your Customer Preferences

Staying updated with the customers’ preferences is not an option however, an important requirement about running any successful business. In case, your hotel is not addressing the demands of a customer, then your money is lying on the table which ultimately contributes to the customers’ dissatisfaction. For addressing this, it becomes important to first know what your clients are searching for. Extracting hotel reviews could help you recognize the host of problems, which are bothering future customers. Then you can go ahead to pull your customer services for more improvements.
2. Brand Monitoring

With the prevalent spread of social media, clients have become more expressive than ever about positive as well as negative experiences with different services and products they utilize. Brand image is very important because it directly transforms into customer loyalty as well as business growth. It also indicates that your business could be hit seriously even with a single bad experience or review shared online by the customer.
For maintaining an encouraging brand image, you should hear your customers very carefully. Brand monitoring allows you to become updated with the clients and find unaddressed problems before they could reach the PR’s nightmare! Scraping as well as extracting hotel reviews using a travel website is a very easy way of staying updated.
3. Competitor’s Analysis

It is very important to analyze your brand online as well as keep an eye on the competitors thinking about the competitive nature of today’s business domain. At times, reviews given by the competitors’ clients for their services could help you recognize lower-hanging fruits that you could capitalize on. For instance, in case, the competitors’ reviews on hotel pages’ intimate at the demands for a definite service, be the initial one to include it in your offerings. It can easily assist you in driving more sales without investing more in the study.
4. Natural Language Processing
Natural language processing witnesses solutions provided by Machine Learning that are concentrated on allowing machines to know the context after human languages. The systems of NLP are playing when you use voice assistant platforms like Siri, Cortana, Google Now, as well as the majority of translation tools. A huge amount of user-generated content is requisite to train the NLP system as well as hotel reviews data proves to be a greater source.
How Does Scraping Hotel Reviews Data Work?

With fully managed services from X-Byte, you don’t need to get bothered about complexities related to scraping hotel reviews.
This project begins with the requirement collecting phase where you just need to share the specific requirements of the websites you want to scrape, frequency of scraping as well as data fields to get scraped.
When we establish the project feasibility, our team sets the crawlers up and begins delivering data in the preferred frequency and format.
At X-Byte, we support different data deliveries in XML, CSV, and JSON through FTP, API, Amazon S3, Dropbox, Box, etc. We take complete ownership of scraping aspects as well as deliver the required data. You can send your requirements to us to get started.
For more visit: https://www.xbyte.io/web-scraping-api.php
0 notes
Link
Real-Time Web Scraping API Services Provider USA, Australia
Our Real-Time web scraping API Services Provider USA, Australia can scrape data from website and Mobile App API to provide immediate responses within a few seconds.
0 notes
Link
Learn the important nine questions to focus on before hiring a web scraping service provider. Market intelligence based on publicly available data is the new point of distinction. Market analysis, competitive analysis, and corporate strategy are all built on this basis. You'll need to access and evaluate a large quantity of data, whether you're starting a new project or building a new strategic plan for an existing company. In this case, web scraping is used.
0 notes
Text
Which are the 9 Questions Asked Before Hiring a Web Scraping Service?

Market intelligence based on publicly available data is the new point of distinction. Market analysis, competitive analysis, and corporate strategy are all built on this basis. You'll need to access and evaluate a large quantity of data, whether you're starting a new project or building a new strategic plan for an existing company. In this case, web scraping is used.
You must select whether to employ an in-house service or a dedicated web scraping service as an organization. Having an in-house team comes with several complications. Hiring is a time-consuming and expensive process that not every firm can or wants to undertake. Another issue that an in-house team may encounter is the need for a specific setup to crawl each website due to the challenges that web scraping poses. This will not only impair efficiency but will also increase the amount of money invested.
This is where personalized service comes into action. Web scraping professionals can ensure success swiftly by providing the lowest average cost, guaranteed efficiency, dependable structure, and up-to-date information. But how can you pick a top-notch web scraping service? This blog will cover nine web scraping questions to consider before hiring a web scraper for your business.
9 Questions to Ask Before Hiring a Web Scraping Service
1. Is the Service Capable of Handling Enormous Amounts of Data?

It is not difficult to create a web scraper. Management will get more difficult as the number of web scrapers and the volume of data grows. One of the most important web scraping issues to examine is if the direct service can keep up with the rising demand.
How will it maintain high-quality levels in the event of such load peaks? Choose a service that is scalable and has a lot of possibilities. This means that the scraping service won't pause and slow you down as your data needs grow. Your scraper should be able to provide enough services and facilities at the recommended average cost to cover all of your future data needs, no matter how big or little they are.
2. What Happens if the Company's Vendors Go Out of Business?

Consider the worst-case situation. What happens if your service provider goes out of business? This can occur due to a variety of reasons, including an economic meltdown, a lawsuit, and so on. You won't be able to feed your app that is fully reliant on data unless you have access to the scraping technology.
If the direct providers employ proprietary technology, you will not receive help because the technology is no longer maintained. It is ideal to hire someone who uses open-source technology. You'll have to live with the worry of losing data if you choose a supplier who uses proprietary technologies.
3. What Factors are Considered to Ensure the Quality of Data?
Data received on the web is often unstructured and not in useful shape unless the service provider has cleaned up the mess. Finally, the effectiveness of the service you want will determine how successful and structured it is. As a result, you'll need to choose a service provider who will maintain track of data cleanup and conversion into usable and useful information.
The trustworthiness of the final database is crucial, as it influences the research process and, eventually, the results. You must not compromise data quality because it will have a negative impact on your reputation and sales. There is no such thing as a perfect programmatic approach. A combination of human - artificial intelligence will be the most effective method here.
4. How Transparent are the Pricing Policies?
Transparency is crucial when it comes to pricing. It should be a simple price scheme that anyone can understand with a glance. Complex payment methods can be inconvenient and even dangerous at times. They may even infer that there are additional fees. Prices should be predictable when you grow up in the future. Look for a web scraping service that charges in an open and plain manner. The pricing plan should, in theory, allow you to easily estimate your future average cost.
As a result, the more constant the pricing plan, the more trustworthy the service! You can choose providers who use a pay-as-you-go pricing model, which means you'll just pay for the data you use rather than being charged separately for large and small amounts of data.
5. How to Deal with Website Pattern Variation?
Websites are updated regularly to stay up with UI/UX improvements and to include more features. Web scrapers are created specifically for the customizations of a web page at the time of setup; as a result, constant revisions mislead the programs, leading crawlers to struggle. If your network operator is unable to recognize it and adjust scrapers, the quality of your data will suffer. You must assess whether a supplier is knowledgeable and prepared to react to constantly changing website patterns when choosing a vendor. To reflect the changes, the scraper would need to be updated. You should avoid these changes if the scraper can't handle them well.
6. How to Deal with Anti-Scraping Mechanisms?
Please keep in mind that many websites have developed anti-scraping features to prohibit web scrapers from accessing their information since they don't want excessive bot activity to overwhelm their page. Bots, captchas, being blacklisted, and other obstacles may be encountered. Choosing appropriate anti-scraping tools and getting around these measures is a complete pain. There are various choices available, but they can be expensive and time-consuming. So, before you hire a web scraping service, find out how they plan to solve the problem. Anti-scraping tools and robust technologies are necessary for an effective scraping service to handle these situations while maintaining the target servers' integrity.
7. Which are the Formats of Delivering Data?
One of the most important web scraping questions to ask is what formats/file types you want this same data returned in. Please double-check that the web data scraping provider can supply the data format you require. Search for a web scraping program that provides CSV data if you require it in that format.
Working with someone who can generate data in a variety of forms is ideal because you can continue to rely on them even if your demands alter in the future. Data can be delivered in a variety of ways. Data can be delivered in CSV, JSON, other standard formats, or via an API, by most providers. Finally, the vendor who can provide information in a form that you are comfortable with.
8. How Does the Customer Support System Work?
Web scraping is the process of converting large amounts of unstructured data into an arranged and accessible format. When dealing with massive amounts of data that you may not even be able to manage, customer service is critical. You might have problems with some figures, the structure, or a variety of other factors. As a result, you'll need someone who can answer your questions quickly and without risking your deadlines. You'll also need quick responses to your questions. If you have good customer service, you won't have to worry about anything going wrong.
9. Customer Reviews and Competitive Analysis
Customer feedback and ratings can be very important decision considerations. Customers' opinions will inform you how they felt about the service and whether or not they would suggest it to others. As a result, don't forget to thoroughly study these customer reviews and conduct complete competitive research to learn about your competitors' choices. Furthermore, they must have completed their own study, which will enable you to make selections that are both faster and more effective.
Conclusion
Given the importance of web scraping, a properly designed web scraping service is the only way to get a competitive advantage. However, deciding which one is best for your company can be difficult unless you have a list of crucial factors to consider while weighing your options. Before choosing a web scraping provider, make sure you ask yourself these 9 web scraping questions. Then, to automate your data scraping, use a web scraper like X-Byte Enterprise Crawling.
Contact X-Byte Enterprise Crawling to learn more!
For more visit: https://www.xbyte.io/which-are-the-9-questions-asked-before-hiring-a-web-scraping-service.php
0 notes
Text
How to extract amazon results with python and selenium?

In this assignment, we will try at the pagination having Selenium for a cycle using pages of Amazon results pages as well as save data in a json file.
What is Selenium?

Selenium is an open-source automation tool for browsing, mainly used for testing web applications. This can mimic a user’s inputs including mouse movements, key presses, and page navigation. In addition, there are a lot of methods, which permit element’s selection on the page. The main workhorse after the library is called Webdriver, which makes the browser automation jobs very easy to do.
Essential Package Installation
For the assignment here, we would need installing Selenium together with a few other packages.
Reminder: For this development, we would utilize a Mac.
To install Selenium, you just require to type the following in a terminal:
pip install selenium
To manage a webdriver, we will use a webdriver-manager. Also, you might use Selenium to control the most renowned web browsers including Chrome, Opera, Internet Explorer, Safari, and Firefox. We will use Chrome.
pip install webdriver-manager
Then, we would need Selectorlib for downloading and parsing HTML pages that we route for:
pip install selectorlib
Setting an Environment
After doing that, create a new folder on desktop and add some files.
$ cd Desktop
$ mkdir amazon_scraper
$ cd amazon_scraper/
$ touch amazon_results_scraper.py
$ touch search_results_urls.txt
$ touch search_results_output.jsonl
You may also need to position the file named “search_results.yml” in the project directory. A file might be used later to grab data for all products on the page using CSS selectors. You can get the file here.
Then, open a code editor and import the following in a file called amazon_results_scraper.py.
from selenium import webdriver
from webdriver_manager.chrome import ChromeDriverManager
from selenium.common.exceptions import NoSuchElementException
from selectorlib import Extractor
import requests
import json
import time
After that, run the function called search_amazon that take the string for different items we require to search on Amazon similar to an input:
def search_amazon(item):
#we will put our code here.
Using webdriver-manager, you can easily install the right version of a ChromeDriver:
def search_amazon(item):
driver = webdriver.Chrome(ChromeDriverManager().install())
How to Load a Page as well as Select Elements?
Selenium gives many methods for selecting page elements. We might select elements by ID, XPath, name, link text, class name, CSS Selector, and tag name. In addition, you can use competent locators to target page elements associated to other fundamentals. For diverse objectives, we would use ID, class name, and XPath. Let’s load the Amazon homepage. Here is a driver element and type the following:
After that, you need to open Chrome browser and navigate to the Amazon’s homepage, we need to have locations of the page elements necessary to deal with. For various objectives, we require to:
Response name of the item(s), which we want to search in the search bar.
After that, click on the search button.
Search through the result page for different item(s).
Repeat it with resulting pages.
After that, just right click on the search bar and from the dropdown menu, just click on the inspect button. This will redirect you to a section named browser developer tools. Then, click on the icon:

After that, hover on the search bar as well as click on search bar to locate different elements in the DOM:

This search bar is an ‘input’ element getting ID of “twotabssearchtextbox”. We might interact with these items with Selenium using find_element_by_id() method and then send text inputs in it using binding .send_keys(‘text, which we want in the search box’) comprising:
search_box = driver.find_element_by_id('twotabsearchtextbox').send_keys(item)
After that, it’s time to repeat related steps we had taken to have the location of search boxes using the glass search button:

To click on items using Selenium, we primarily need to select an item as well as chain .click() for the end of the statement:
search_button = driver.find_element_by_id("nav-search-submit-text").click()
When we click on search, we require to wait for the website for loading the preliminary page of results or we might get errors. You could use:
import time
time.sleep(5)
Although, selenium is having a built-in method to tell the driver to await for any specific amount of time:
driver.implicitly_wait(5)
When the hard section comes, we want to find out how many outcome pages we have and repeat that through each page. A lot of smart ways are there for doing that, although, we would apply a fast solution. We would locate the item on any page that shows complete results as well as select that with XPath.
Now, we can witness that complete result pages are given in the 6th list elements
· (tag) about a list getting the class “a-pagination”. To make it in a fun way, we would position two choices within try or exclude block: getting one for the “a-pagination” tag and in case, for whatever reason that fails, we might select an element below that with the class named “a-last”.
Whereas using Selenium, a common error available is the NoSuchElementExcemtion, which is thrown whereas Selenium only cannot have the portion on a page. It might take place if an element hasn’t overloaded or if the elements’ location on the page’s changes. We might catch the error and also try and select something else if our preliminary option fails as we use the try-except:
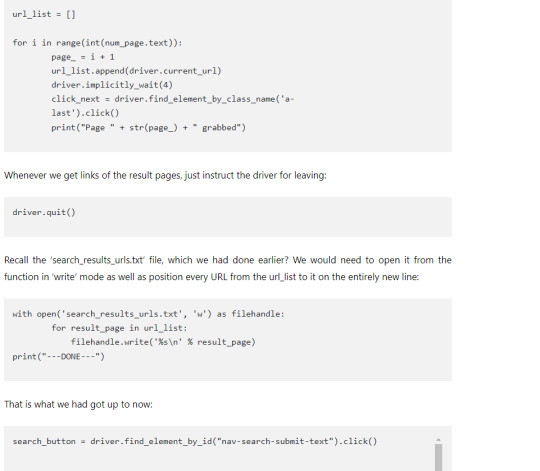
The time has come now to make a driver wait for a few seconds:
driver.implicitly_wait(3)
We have selected an element on the page that shows complete result pages and we want to repeat via every page, collecting present URL for a list that we might later feed to an additional script. The time has come to utilize num_page, have text from that element, cast it like the integer and put it in ‘a’ for getting a loop:
Integrate an Amazon Search Results Pages Scraper within the Script.
Just because we’ve recorded our function to search our items and also repeat via results pages, we want to grab and also save data. To do so, we would use an Amazon search results pages’ scraper from a xbyte.io-code.
The scrape function might utilize URL’s in a text file to download HTML, extract relevant data including name, pricing, and product URLs. Then, position it in ‘search_results.yml’ files. Under a search_amazon() function, place the following things:

search_amazon('phones')
To end with, we would position the driver code to scrape(url) purpose afterwards we utilize search_amazon() functions:
And that’s it! After running a code, a search_results_output.jsonl file might hold data for all the items scraped from a search.
Here is a completed script:
from selenium import webdriver
from webdriver_manager.chrome import ChromeDriverManager
from selenium.common.exceptions import NoSuchElementException
from selectorlib import Extractor
import requests
import json
import time
def search_amazon(item):
driver = webdriver.Chrome(ChromeDriverManager().install())
driver.get('https://www.amazon.com')
search_box = driver.find_element_by_id('twotabsearchtextbox').send_keys(item)
search_button = driver.find_element_by_id("nav-search-submit-text").click()
driver.implicitly_wait(5)
try:
num_page = driver.find_element_by_xpath('//*[@class="a-pagination"]/li[6]')
except NoSuchElementException:
num_page = driver.find_element_by_class_name('a-last').click()
driver.implicitly_wait(3)
url_list = []
for i in range(int(num_page.text)):
page_ = i + 1
url_list.append(driver.current_url)
driver.implicitly_wait(4)
click_next = driver.find_element_by_class_name('a-last').click()
print("Page " + str(page_) + " grabbed")
driver.quit()
with open('search_results_urls.txt', 'w') as filehandle:
for result_page in url_list:
filehandle.write('%s\n' % result_page)
print("---DONE---")
def scrape(url):
headers = {
'dnt': '1',
'upgrade-insecure-requests': '1',
'user-agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_4) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/83.0.4103.61 Safari/537.36',
'accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9',
'sec-fetch-site': 'same-origin',
'sec-fetch-mode': 'navigate',
'sec-fetch-user': '?1',
'sec-fetch-dest': 'document',
'referer': 'https://www.amazon.com/',
'accept-language': 'en-GB,en-US;q=0.9,en;q=0.8',
}
# Download the page using requests
print("Downloading %s"%url)
r = requests.get(url, headers=headers)
# Simple check to check if page was blocked (Usually 503)
if r.status_code > 500:
if "To discuss automated access to Amazon data please contact" in r.text:
print("Page %s was blocked by Amazon. Please try using better proxies\n"%url)
else:
print("Page %s must have been blocked by Amazon as the status code was %d"%(url,r.status_code))
return None
# Pass the HTML of the page and create
return e.extract(r.text)
search_amazon('Macbook Pro') # <------ search query goes here.
# Create an Extractor by reading from the YAML file
e = Extractor.from_yaml_file('search_results.yml')
# product_data = []
with open("search_results_urls.txt",'r') as urllist, open('search_results_output.jsonl','w') as outfile:
for url in urllist.read().splitlines():
data = scrape(url)
if data:
for product in data['products']:
product['search_url'] = url
print("Saving Product: %s"%product['title'].encode('utf8'))
json.dump(product,outfile)
outfile.write("\n")
# sleep(5)
Constraints
The script works extremely well on broad searches, although would fail with particular searches with items that return below 5 pages of the results. We might work to improve that in future for scrape amazon product data.
Disclaimer
Just because Amazon won’t need auto extraction of the site and you require to consult.robots file whereas doing the big-scale collection of data. The assignment was helpful as well as made to learn objectives. So, in case, you are being blocked, you would have been warned!
For more details, contact X-Byte Enterprise Crawling or ask for a free quote!
For more visit: https://www.xbyte.io/how-to-extract-amazon-results-with-python-and-selenium.php
0 notes
Text
How Web Scraping Affects Location-Based Data?
Online Data is Becoming More Localized
The days of a website showing the same information and data to all users are quickly coming to an end. Depending on the user's location, sites dynamically display various data and information. In this blog, we'll look at how this development affects web scraping and how internet data collection must respond. The Price or availability is generally the information that varies depending on the location. The price that one person sees, or if a product is available to the public for delivery, or pick up, will differ depending on where the individual is located.
E-Commerce Data
Traditional businesses and manufacturers are increasingly turning switching to internet shopping due to Covid-19. On the other hand, physical things have always been delivered locally, even if there are no stores. Let us take an example of Target.com’s location-specific options.
When you first visit Target.com, the site strives to make the user experience as simple as possible by guessing your location.
This means you'll have fewer keystrokes to make when choosing a store or location,
If this location "guessing" is inaccurate, or and if you're not shopping at the Target.com-guessed location, you can enlarge the panel and select a few possibilities depending on various factors.
The purpose of the websites is to predict the location as accurately as possible without compromising the customer experience, such as forcing users to choose a location before visiting the website or making it very difficult for them to explore or buy on the site.
How Do Websites Will Know the Location?
Websites use a variety of methods to identify your location, ranging from non-invasive to quite intrusive. Here are a few approaches that are currently in use.
IP Address
Each device accessing the Internet is assigned an IP (Internet Protocol) address. It is the number having the format 123.456.789.123 which is allocated to your Internet Service provider (ISP) and then either partially or completely assigned to your connection or device. When you access a site, your IP address is provided to them, and they can use GeoIP databases to look up your information. Websites can use these databases to connect an IP address to a specific address, such as a city, town, state, or nation.
You do not influence whether your IP address is sent to a website, but you can certainly try to mask it with services like VPNs. Here's an example of how to use the GeoIP lookup page to find an Amazon AWS IP address.
You can check the city and Zip code of the IP address that represents amazon AWS on the GeoIP lookup page.
GPS Location
This method relies on data from your device's hardware chips to determine its location using the Global Positioning System (GPS). This is a sensor tracking technology that is built in to most phones and certain laptops.
Apps can use the GPS position directly, or they can be sent to the web browser used to view the website. The website obtains the precise Latitude and Longitude coordinates of your position, which may be found everywhere on the planet.
The user can control who has access to this information at the device level as well as per-app or website level (in most cases).
Ways to Acquire Location-Based Data from A Website
The methods used to obtain location-specific data differ on every website, but they are often the following:
Use the mapped location of your IP address.
Allow your browsers (and thus the website) to use your location via GPS.
Indicate a specific zip code or retail location.
Impact of Location Specific Information on Web Scraping
The implications of adopting web scraping services for data collection as location-specific data become more popular are enormous.
On the other hand, marketers save money by eliminating the need to dispatch "mystery shoppers" to physical locations to check goods availability and cost. This information can now be acquired online with increasing precision. The data may now encompass the entire country, as well as all of a brand's stores and all of its brands. When compared to traditional methods, the savings are significant, and the data coverage is considerably broader and more frequent.
On the other hand, the cost of obtaining this information rises as a result of the necessity to collect information from large sites rather than a single one. The cost of buying IPs in every city or a particular location is higher because local IPs are available in every area.
In comparison to a location-neutral data gathering project, the page count that must be scraped increases since the location for each product must be established, which can take 2 to 3 times the number of pages.
Examples of Location-Based Access on Famous Websites
How you will set the location
Setting location on Walmart.com
How Does Website Will Automatically Choose GPS Location?
For example, Walgreens.com is requesting permission to access the computer's GPS position with the Edge browser. When a website requests this information, other browsers display identical prompts.
For any queries, Contact X-Byte Enterprise Crawling.
Request for a quote!
0 notes
Link
X-Byte Enterprise Crawling is a Web Scraping Services provider in USA, Australia, UAE, Germany and more countries. Using web data scraping, you can extract data.
Well-managed & enterprise-grade web scraping services to get clean and comprehensive data. X-Byte’s well-managed platform provides a complete service package to easily convert millions of webpages into plug-and-play data. Get clean & clear data from any site without any hassle!
0 notes
Text
Web Scraping Amazon Grocery Data using X-Byte Cloud?
Having over 350 million products across product types and activities, Amazon acquired 45% of the US e-commerce market share in 2020. It is one of the world's largest online marketplaces. By using the Amazon scraping tool to scrape grocery delivery information will assist you to easily study your competition, keeping a record of important product information like prices and ratings, and spot emerging market trends.
Below are the Steps for Scraping Amazon Grocery Delivery Data
Creating an account on X-byte Cloud.
Selecting the Amazon scraping tool for instance Amazon search results Scraper.
Enter the list of input URLs.
Execute the crawler, and download the required data.
X-Byte Cloud's pre-built scrapers allow you to extract publicly available data from Google, retail websites, social media, financial websites, and more. X-Byte’s cloud-based web crawlers make web scraping simple. Furthermore, no extra software is required to organize a scraping job. You can use your browser to access the scraper at any moment, enter the required input URLs, and the data will be delivered to you.
Data Fields Scraped from Amazon Grocery Delivery Data
Using Amazon search result scraper, we can extract the below-given data fields:
Product name
Category
Price
Reviews
Ratings
Descriptions
ASIN
Seller information
How to Scrape Amazon Grocery Delivery Data?
The Amazon Search Results Scraper from X-Byte Cloud is simple to use and allows you to safeguard data in the most efficient way possible. The required data and information can be collected from Amazon's food search results page.
Step 1: Creating an X-Byte cloud Account for using Amazon Scraping Tool
Sign up on X-Byte Cloud by signing up using an email address and other details. https://www.xbyte.io/amazon-product-search.php
Before subscribing to X-Byte Cloud, you can try scraping 20-25 pages for free. A thorough explanation of how to execute the Amazon Search Results Scraper, which is available on X-Byte Cloud, can be seen below.
Step 2: Add the Amazon Search Result Crawler to Account and Provide with Necessary Requirements.
After making an account on X-Byte Cloud, go to the Crawlers tab and add the Amazon Search Results Scraper.
After that, select ‘Add this crawler to my account.' The main basic page, as shown under the ‘Input' tab, has all data fields:
1. Crawler Name:
Providing a name to your crawlers may help you distinguish between scraping operations. Fill in the chosen name in the input field and save your changes at the end of the screen by clicking the ‘Save Settings' button.
2. Domain
You may extract comprehensive product information from categories or search engine results on Amazon US, Amazon Canada, and Amazon UK with X-Byte’s Amazon Search Result Scraper. Simply type in the domain you want to scrape into the input field and the scraper will handle the rest.
3. Search Result URLs
Then, throughout this data field, enter your target URLs. We recommend utilizing no more than three input URLs if you're on the free plan. If you currently have an X-Byte Cloud subscription, you can add an unlimited number of URLs for the Amazon Search Results Scraper to extract the data.
If you want to scrape more than one URL, enter them one after the other, separated by a new line (press Enter key). The URLs for the search results can be obtained from Amazon's website in the following way:
Select an Amazon Fresh category now. You can also use filters to narrow down your search results if necessary. Then, the Search Results URLs data field will work as follow:
4. Keywords
Users must enter a list of keywords that they'd like to scrape Amazon grocery data for in this area. Keywords such as 'organic apples,' 'fresh apples,' and 'fresh Honeycrisp apples,' can be used.
If you're not sure what keywords to use, you can use the desired search results URL as input instead.
5. Brand Name
Thousands of brands can be found on Amazon's marketplace. Scraping can be accelerated by including the names of your competitors' brands.
6. Number of Pages to Scrape
On Amazon, you can choose the amount of search results pages to scrape. You can select from the following options:
You can enter the required number of documents in the ‘Custom number of pages' data section below if you have special needs.
Step 3: Running the Amazon Search Results Scraper
After you've filled in all of the information, click 'Save Settings' to save your changes.
To get started, go to the top of the page and click on ‘Gather Data.'
Under the tasks tab, you can check the status of the Amazon scraping program. The status of the scraper may be found there.
If the status is set to ‘Running,' your data is being collected.
If the status is ‘Finished,' it means the crawler has completed the task.
Step 4: Download the Scraped Information
Finally, select ‘View Data' to see the collected data, or ‘Download' to save the results to your computer in Excel, CSV, or JSON format.
The below image shows the scraped grocery information in CSV format.
Features of the X-Byte Cloud Amazon Search Results Scraper
Scheduling the Scraping Process
You can schedule your data crawling using X-Byte Cloud at your convenience.
Generating API Key:
API keys allow the user to create the crawlers and improve the efficiency of the operation. This key can be found on the Integrations tab.
Immediate data Delivery to Dropbox account – You can upload all of the obtained data to a Dropbox account if you pay for an X-Byte cloud subscription. This way, anyone can read the system whenever and anywhere they choose. This feature can be found under the Integrations tab.
Gathering Solutions to Scrape Amazon Data
Of course, Amazon has one of the largest publicly accessible data collections. Customer preferences, market trends, product reviews, ratings, product descriptions, and other information can all be included in the data. Web scraping is a fantastic solution because it eliminates the need to manually search through all of Amazon's data. X-Byte Cloud ensures that you do have instant access to this structured and reliable data.
While you concentrate on other key business activities, then Amazon Search Results Crawler may retrieve crucial grocery delivery information and more. Scraping for grocery data with the Amazon Search Results Crawler on X-Byte Cloud is only the effective way to extract the required information.
Looking for Scraping Amazon Grocery Delivery Data, Contact X-Byte Enterprise Crawling Now!!
For more visit: https://www.xbyte.io/web-scraping-amazon-grocery-data-using-x-byte-cloud.php
#Web Scraping Amazon Grocery Data#amazon scraping tool#amazon search results crawler#Scraping grocery data
0 notes
Link
Scrape Target Product Prices and Inventory Availability
Scraping product data from Target. Collect all the information like availability, pricing, product name, image, customer services, ratings, and there are more than 25+ data fields more for Target.
Top Data Extraction and Web Scraping Services Provider Company in USA, INDIA providing Website data extraction and Web Scraping services using Python.
#Target search scraper#Scrape Target Product Prices#Scrape Inventory Availability#Web scraping services
0 notes
Text
How to Scrape Website Data using Infinite Scrolling?

Consider that you are extracting products from flipkart and you also want to extract other 100 products from all the categories, however you are incapable to utilize this technique as it grabs the initial 15 products from the page.
Flipkart is having a feature named infinite scrolling therefore there are no pagination (like? page=2, page=3) within the URL. In case, it had the feature we might have entered a value in the “while loop” as well as incremented page values like we have given below.
page_count = 0
while page_count < 5:
url = "http://example.com?page=%d" %(page_count)
# scraping code...
page_count += 1
Now, let’s get back to the infinite scrolling.
“Ajax” allows any website of using infinite scrolling. However, the ajax request has the URL from which products gets loaded on the similar pages on scroll.
To observe the URL.
Open a page in the Google Chrome
After that, go to a console and right click as well as allow LogXMLHttpRequests.
Now reload a page as well as scroll down slowly. While the new products get populated, you would see various URLs called after “XHR finished loading: GET” and click on it. Flipkart has various kinds of URLs. The one that you are searching for begins with “flipkart.com/lc/pr/pv1/spotList1/spot1/productList?p=blahblahblah&lots_of_crap”
Then left click on the URL and this would be highlighted within a Network tab of Chrome dev tools. From that, you could copy the URL or open that in the new window. (here is the image)

Whenever you open a link in a new tab then you would see something like that with about 15-20 products every page.

1. You can observe that merely 15 products again! However, we want all these products”.
So, just check a URL there like Get a parameter called? start= (any number) Now for the initial 20 products, set a number to 0; and for the next 20, get a number to 21 as well as in case, there are 15 products every page with 0, 16, 31 etc. Iterate the URL in a while loop including we have showed you before and you will be done.
2. Again facing any problem the where are the images?
Just right click to view the page source about the URL, you would see the tag having data-src=”” attribute; which is your product’s image..
It is an example about Flipkart.com only. Various websites might have various Ajax URLs and various get parameters on a URL.
Web scraping services websites might also have the “JSON” responses within Ajax URLs. In case, you get them you don’t have to utilize scraping; only access the JSON response including any JSON API that you have utilized before.
In case of any doubts please make your comments in the below section or contact X-Byte Enterprise Crawling or ask for a free quote!
Happy Scraping!
More more visit: https://www.xbyte.io/web-scraping-services.php
0 notes
Link
Amazon Web Scraping Services | Scrape Product Data from Amazon
Best Amazon Data Scraping Services provider USA, UK, Europe, Canada, We Offer Scrape Amazon products Data, buy box details, best sellers ranks, reviews, shipping information and more.
With Amazon Data Scraping, it becomes easy to analyze product trends and inspire buyers. Our Amazon data scraping services will help you get the finest ways of assessing product performance as well as take the necessary steps to do product improvement.
Top Data Extraction and Web Scraping Services Provider Company in USA, INDIA providing Website data extraction and Web Scraping services using Python.
#Amazon Data Scraping#Scrape Amazon Product Data#scrape amazon data#Amazon Product Intelligence#Amazon Price Intelligence#Amazon Reviews Scraping#web scraping services
0 notes
Text
How to Scrape Google Play Review Data?

Scrape Google Play Reviews Scraper and downloads them for datasets including name, text information, and date. Input the ID or URL of the apps as well as get information for all the reviews.
GET STARTED NOW
WE HAVE DONE 90% OF THE WORK ALREADY!
It's as easy as Copy and Paste
Start
Google Play Reviews Scraper and downloads them for datasets including name, text information, and date. Input the ID or URL of the apps as well as get information for all the reviews.
Download
Just download the data in CSV, Excel, or JSON formats. Just link the Dropbox for storing data.
Schedule
Just schedule the crawlers on hourly, weekly, or daily to have the newest posts on Dropbox.

SAMPLE DATA
ExcelJson
#
URL
Title
Company Name
Category
Description
Star Rating
Review Count
Updated
Size
Installs
Current Version
Requires Android
Content rating
Interactive Elements
In-app Products
Offered By
Developer
Privacy Policy

1
https://play.google.com/store/apps/details?id=com.whatsapp
WhatsApp Messenger
WhatsApp LLC
Communication
WhatsApp from Facebook is a FREE messaging and video calling app. It’s used by over 2B people in more than 180 countries. It’s simple, reliable, and private, so you can easily keep in touch with your friends and family. WhatsApp works across mobile and desktop even on slow connections, with no subscription fees*.
4.1
137396140
25-05-2021
Varies with device
5,000,000,000+
2.21.10.16
4.1 and up
Rated for 3+
Users interact, Digital purchases
-
WhatsApp LLC
Visit website [email protected] Privacy Policy 1601 Willow Road Menlo Park, CA 94025
outside of where you live for the purposes as described in this Privacy Policy. WhatsApp uses Facebook’s global infrastructure and data centers, including in the United States. These transfers are necessary to provide the global Services set forth in our Terms. Please keep in mind that the countries or territories to which your information is transferred may have different privacy laws and protections than what you have in your home country or territory.
2
https://play.google.com/store/apps/details?id=com.instagram.android
Instagram
-
Social
Instagram (from Facebook) brings you closer to the people and things you love. Connect with friends, share videos and photos of what you’re up to, or see what's new from others all over the world. Explore your social community where you can feel free to be yourself and share everything from your daily moments to life's highlights.
3.8
119518219
25-05-2021
Varies with device
1,000,000,000+
Varies with device
Varies with device
Rated for 12+ Parental guidance recommended
Users interact, Shares info, Shares location
₹85.00 – ₹450.00 per item
Instagram
Visit website [email protected] Privacy Policy Facebook, Inc. 1601 Willow Rd Menlo Park, CA 94025 United States
We use the information we have (including information from research partners we collaborate with) to conduct and support research and innovation on topics such as general social welfare, technological development, public interest, health and well-being . Looking. For example, we analyze the information we have for ways to evacuate during times of emergency to assist in relief operations . Learn more about our research program.

SCRAPE GOOGLE PLAY REVIEWS LISTINGS DATA
Our Google Play Reviews Scraper is mainly designed for scraping complete data from Google Play Store. The extracted data includes:
· Title
· App ID
· URL
· Description
· Summary
· Summary HTML
· Installs
· Min Installs
· Score
· Ratings
· Reviews
· Original Price
· Sales
· Sales Text
· Sales Time
AMONG THE MOST ADVANCED GOOGLE PLAY REVIEWS SCRAPERS ACCESSIBLE
· Best Option of Google Reviews API
· Scrape Unlimited Reviews from Businesses or Places
· Extract Google Reviews with No Rate-Limits
· Built-In Option for Extracting the Newest, Most Appropriate, Lowest, and Highest Ratings Reviews
GET REVIEWS IN A FEW MINUTES
Our Google Play Reviews Scraper is mainly designed for scraping complete data from Google Play Store. The extracted data includes:
You can get different Google reviews for a particular place or business within minutes using X-Byte’s Google Play Reviews Scraper.
Just provide Google Review Links or Place IDs to begin data scraping. Besides, you can choose the reviews variety filter if you need special reviews.
· Scrape competitor reviews using some clicks
· Collect and offer data occasionally to Dropbox

FIND GOOGLE PLACE IDS
You can also utilize X-Byte’s Google Play Reviews Scraper to collect information like Place IDs for businesses and places. Instead, you could use the authorized Google’s Place ID finder tool to get place IDs.
0 notes
Link
Google Play Reviews Scraper | Scrape Google Play Review Data
Scrape Google Play Reviews Scraper and downloads them for datasets including name, text information, and date. Input the ID or URL of the apps as well as get information for all the reviews.
1. Best Option of Google Reviews API 2. Scrape Unlimited Reviews from Businesses or Places 3. Extract Google Reviews with No Rate-Limits 4. Built-In Option for Extracting the Newest, Most Appropriate, Lowest, and Highest Ratings Reviews
0 notes
Text
How to Scrape Data from TikTok?

How to extract videos liked or posted by the users, snowball a big user listing from the seed accounts, as well as gather trending videos using an easy API.
TikTok has “boomed like a rocket in the U.S. as well as across the world, making a newer mobile video experience, which has left Facebook and YouTube scrambling for keeping up.”
If you consider only U.S. users with 18 years age, TikTok has reached from 22.2 million visitors during January to 39.2 million visitors during April, as per Comscore data given to Adweek.
This platform has become more than a new cool app: as current events have presented, its algorithms extent videos, which can have real-life consequences. Let’s take some important examples web scraping services:
K-pop fans have used TikTok for pranking Trump’s rally within Tulsa, buying tickets and not showing them up
Teenagers on TikTok prearranged “shopping cart desertion” on Trump’s product website in efforts to hide inventories from others
Certain users are inspiring Trump’s opposition for clicking on ads about Trump to drive a campaign’s advertising prices
This app has spread biased videos of Joe Biden

In brief, scraping TikTok as well as its powerful algorithms have a large real-world guidance, particularly considering that any typical user occupies nearly an hour every day watching videos on a platform. By keeping that in mind, you should realize what TikTok displays to millions of eyeballs daily and for doing that, we would require some data.
Below is the code give about how to gather TikTok data with different ways. We have tried to make it general as well as useful for maximum use cases, however, you would probably require to tweak that as per what you do. The remainders of the post includes how to perform the following:
Collecting videos posted by users
Collecting videos liked by users
Snowball a user’s list
Collecting trending videos
(If you are planning to do a few dozens of requests, we suggest to set up a proxy. We haven’t tested it yet, but an API we demo here needs to integrate with the proxies very easily. Second thing, if you need to track reputation over time, you would need to add some timestamps to statistics.)

1. Collecting Videos Posted by Users
Any good place to begin is collecting different videos from the given users. We will use TikTok API (run pip3 to install TikTok API to get a package).

2. Collecting Videos Liked by the Users
Here, you might be interested in videos “liked” by the given users. It is pretty straight to gather. Let’s observe what videos an official TikTok account has enjoyed recently:

3. Snowball a User’s List
Say that you want to make a larger user list from which you can collect videos posted and liked. You can use 50 maximum-followed TikTok accounts, however, 50 might not generate an extensive enough sample.
A substitute approach is using the submitted users to snowball the user’s list from only one user. Initially, we will perform this for different accounts like:
tiktok is an official account of an app
washingtonpost is amongst our favorite accounts
charlidamelio is a most-followed account available on TikTok
chunkysdead results in a self-proclaimed “cult” on an app
This is the code we have used:
@lizzo (lizzo, 8900000 fans)
@wizkhalifa (Wiz Khalifa, 1800000 fans)
@capuchina114 (Capuchina❗️👸🏼, 32600 fans)
@silviastephaniev (Silvia Stephanie💓, 27600 fans)
@theweeknd (The Weeknd, 1400000 fans)
@theawesometalents (Music videos, 33400 fans)
...
From what we have observed, a getSuggestedUsersbyIDCrawler technique begins to branch and get smaller and extra niche accounts that have thousands of followers instead of hundreds of millions or thousands. It is a good news in case, you need a typical dataset.
In case, you wish to collect an extensive sample data using TikTok, we advise you to start with the proposed users’ crawler.
4. Collecting trending videos
Finally, might be you just need to get trending videos about an easy content analysis or keep it up 🙂. The APIs make it very simple, like this:
That’s all for now, thanks a lot for reading! For more details, you can contact X-Byte Enterprise Crawling or ask for a free quote!
Source: https://www.xbyte.io/how-to-scrape-data-from-tiktok-a-detailed-tutorial.php
#Social Media Monitoring Services#scrape social media data#Scrape Data TikTok#Extract social media data
0 notes
Text
What is Hotel Pricing Intelligence Solutions?

Discover real-time hotel pricing intelligence solutions, which take the assumptions about pricing rooms in different strategic business methods using X-Byte Enterprise Crawling’s hotel pricing intelligence services.
GET STARTED NOW
BEST HOTEL PRICING INTELLIGENCE SOLUTIONS | SCRAPE HOTEL PRICING DATA
Discover real-time hotel pricing intelligence solutions, which take the assumptions about pricing rooms in different strategic business methods using X-Byte Enterprise Crawling’s hotel pricing intelligence services. X-Byte’s hotel pricing intelligence services get data every day or when required to ensure that the hotel's data is constantly updated with current, relevant, and perceptive. Have cutting-edge data on competitor’s hotel room pricing, market, and business demands as well as maintain consumer loyalty through charging the best rates through our hotel pricing intelligence services.
TRACK COMPETITORS AND MARKET RATES
Compare the hotel room pricing with the closest competitors using our hotel pricing intelligence services. Save your money, efforts, and time used in tracking different data resources manually, through understanding the most current market demands in one view.
Identify the minimum as well as maximum hotel prices against different competitors using our hotel price intelligence services. Different hotel reservation services help you make changes in the room rates in real-time to increase your hotel bookings online.

COMPETITION PRICE TRACKING
With no availability of the competitive rate data, success might be a far-sighted matter. The application of a well-organized hotel price intelligence solution deals with this most significant aspect because it produces a detailed pricing report about the key competencies that helps comparison as well as effective and well-optimized pricing.
By providing actionable insights, the usage of hotel pricing intelligence might put you on the top of different price developments available in the business as well as signal you in case any immediate action is needed. By assessing the live demands in the market, you might react quicker and more accurately if it is growing the rates, lower them, or run some promotional offers, and more.
MAKE LONG-TERM FORECASTS
As rate uniformity is the main factor in a pricing strategy of nearly all the hotels, the accessibility of real-time data helps inefficient distribution by ensuring that the prices, which you set for the room types in different channels are corresponding to the industry drifts and do not highpoint a plain difference.
Nearly all the price intelligence services provide the supreme benefit of long-term forecasting, offering hoteliers a chance to optimize the room rates in advance. Different graphical representation about these forecasts is generally easy-to-know as well as aids in the proper planning.
REVENUE MAXIMIZATION
As technology is taking the role of rivalry and business rate tracking, the revenue managers might spread their arms in different directions as well as coordinate other significant functions where the expertise and knowledge might provide fruitful results.
By selling room at the finest prices in any type of market situation, you make sure that you don’t miss the revenues because of any unforeseen pricing variations available in the market. The usage of active hotel pricing intelligence helps the fulfillment of revenue growth objectives.
SCRAPING OF PRICING & PROPERTY DATA OF GIVEN DESTINATION
Property price scraping or pricing data extraction is performed by setting customized web crawlers for fetching the property data from competitors’ hotel portals. Total competitors to get crawled could be decided through evaluating the market as well as close competitors.
A normalization system for preparing that for matching
Extracted property data with different property data fields
Property price data given is in the clean as well as ready-to-use format
At X-Byte Enterprise Crawling, we provide the scrape pricing data through multiple formats including XML, JSON, or CSV as per your preferences. This frequency of crawling could be defined according to your particular requirements.
COMPARE THE FARES OF HOTELS FROM DIFFERENT SOURCES
Understanding what competitors offer can help you stay on the top, predominantly when the rivalry is fierce as housing services. Getting room pricing accustomed as well as efficient promptly is important to the previous sales figure.
Develop an efficient marketing strategy
Get the best hotel deals in terms of pricing
Make different customer personas
Predicting when a hotel has lowest or highest occupancy rates are important for an active property pricing strategy, particularly during the leave times. Getting comments as well as reviews extracted or analyzed can help you in keep an eye on how the clients are feeling for the services and hotel offered.
FETCH CUSTOMER REVIEWS, RATINGS & COMMENTS FROM A SET OF HOTELS
Using computer vision, deep learning, and proxy networks, web data gets web scraping services without the requirement of developing and maintaining the code. Supported by our exclusive machine learning algorithms, our API keeps working and scrape data even though the website alters.
Building a product fuels it with dependable hotel review data feeds.
Get accurate and reliable hotel review data feed.
Use hotel review data to do sentiment analysis.
To ensure you don’t need to cope with throttling and bans, our hotel pricing intelligence services have permitted us in developing a severe data quality procedure, which delivers high-quality data outputs.
INTEGRATE HOTEL SCRAPING API FOR REAL-TIME PRICE SCRAPING
You can integrate hotel scraping API with product URL and find the hotel data in seconds! You may associate that with the pricing intelligence tools to monitor product prices. This works like a private API for your shopping website.
Easily crawl complex websites
Get high-speed data crawling
Schedule different scraping jobs
We completely improve the quality of data as well as retry the API calls repeatedly if the extracted data doesn’t clear the quality checking. If the hotel websites change their structure, it upsets the hotel scraping APIs too. Therefore, we always perform website changes for making sure that the API does well.
Source: https://www.xbyte.io/hotel-pricing-intelligence-solution.php
0 notes
Link
Hotel Pricing Intelligence Solutions | Scrape Hotel Pricing Data
X-Byte Enterprise Crawling provides the Best Hotel Pricing Intelligence Solutions to extract or scrape data from hotel pricing. Get hotel pricing API at affordable prices. Discover real-time hotel pricing intelligence solutions, which take the assumptions about pricing rooms in different strategic business methods using X-Byte Enterprise Crawling’s hotel pricing intelligence services.
0 notes
Text
How to Get Products Data from Amazon with ASINs?

Get Products Data from Amazon with ASIN Number
Amazon’s reach has unequaled amongst e-commerce market players. The catalog of Amazon boasts more than 400 million products as well as beats Google being the initial stop for the product searches. At X-Byte, our Amazon ASIN scraper could be used for scraping Amazon product data on the regular basis with no hassle.
For keeping all the products well-organized, Amazon utilizes Amazon ASIN numbers. An ASIN (Amazon Standard Identification Number) is a unique block of 10 letters or numbers, which are utilized to recognize items given on Amazon. Nearly every product on Amazon’s catalog understands them and it is key of selling the marketplace. Deliberating how to find ASIN numbers from amazon? Typically, Amazon ASIN codes of the items could be available on product data page for any particular items on Amazon.com. In case, you have the ASIN list for that you want to scrape Amazon product data, this could be achieved through Amazon ASIN scraper..

What is an ASIN Number?
ASIN is the ten-digit alphanumeric code, which recognizes products on Amazon. This is unique for every product as well as is assigned while creating a newer product in the Amazon’s catalog. Nearly all products on Amazon have the ASIN code excluding books (they utilize ISBN (International Standard Book Number) instead of an ASIN). Having this Amazon product identifier is required before you could sell on Amazon. In case, you wonder how you get an ASIN number, this is very easy. Whereas many utilize an Amazon scraping tool for scraping data, this does not provide the finest results.
For a single product traded on Amazon, they should only become a single ASIN code as well as one product details page. It makes that easier for consumers to navigate massive catalog of Amazon. Any matching products as well as their ASINs are finally merged. Before selling any items on Amazon, observe if the ASIN already subsists for a product. In case, you have one, you can begin trading through creating offers under the ASIN. Whenever you do that, you are sharing an ASIN with other sellers providing the similar product. It is usually the case for retailers, resellers, as well as products having wide distribution.
In case, you don’t have any ASIN, you’ll require to make new products in the Amazon’s catalog. Once you create a new product, Amazon would assign an exclusive ASIN, as well as you can start selling. It is generally the case about private-labels, brand owners, as well as sellers having special distribution rights.
You can have Amazon ASIN codes using a search box on homepage of Amazon within Adding a product page about your Amazon Sellers’ Central accounts. Search through product name, UPC, model, or EAN.
Why to Utilize Amazon’s ASIN Scraper?
In case, you have the listing of ASINs as well as are searching to extract Amazon product data, setting an Amazon web scraper would be a perfect solution. That’s is how you could start with product data for the ASIN list.
Give us the listing of ASINs
Identify the regularity of crawls
Identify data delivery formats
Identify the data delivery mode
When we get your requirements, we will start a setup procedure that involves programming a web crawler for data scraping corresponding to an ASIN list. Scrape Amazon products data at the required frequency. When the setup is done, we can provide data in well-known formats including JSON, CSV, or XML. A delivery mode could be directly uploaded in your FTP, SFTP, S3, Dropbox, Azure, GDrive, or Box accounts, relying on the preference. We could also perform a presented indexing for hosting data in the servers as well as make that accessible to query through APIs.
Using our years of experience in scraping Amazon data as well as other important e-commerce websites, you could be assured about having high-quality and well-structured data reliably. Contact X-Byte Enterprise Crawling to scrape Amazon products data for ASIN lists
For more visit: https://www.xbyte.io/how-to-get-products-data-from-amazon-with-asins.php
#Amazon Data Scraping#Scrape Amazon Product Data#scrape amazon data#Scrape Amazon ASIN Number#Amazon Product Intelligence
0 notes