#Extract Amazon results data
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
The total number of visits Tumblr.com received during January 2021 is 327 million.
Note
Two questions about Siren:
After the revolution, did Atom make any attempt to reclaim the planet?
Did the authorities/general public ever find out about Siren?
No and no
So Atom was the type of corporation that didn't really have to care about bad PR in the public eye. They were like Amazon - demonstrably shit, but has that ever really stopped them? Their product, their geneweave technology, was their golden goose and proprietary technology. Maybe there might have been a headline in the news cycle for a day, "Atom fined for 'unethical' genetic experimentation" and then that would be that, buried under more news. People would move on, clients who already wanted to buy the products of that experimentation didn't care, etc.
Why not go back to Siren? Well because public perception is not the issue. Clients' perception is. You do NOT want your potential clients (mostly extraction & colonisation giants in the space exploration business) to know that your amazing unethical products that they pay top spacedollar for started a bloody revolutionary war, destroyed a colony on a promising planet, and killed many of your top technicians. You don't want to wave a neon sign at that incident. You want to bury it and forget it; the geneticists never made it off Siren, the data is lost, the planet still unnamed and unlabelled in official charts. Mounting a massive militarised reclamation mission would be flashy and expensive. Ishmael was made on Ceti, the planet from which the settlers came, and his genetic information is still there. Better to take that and try again, in a more controlled environment. Plus the Siren mission was partially funded by investors (usually future clients paying to have some say over the product - hey we want to union bust on a genetic level, can you do that for us?) and it wouldn't go down well with those investors to sidle up and ask for more money to clean up their oopsie ("what happened to all the money we gave you??" "oh the mission results were inconclusive")
33 notes
·
View notes
Text
LeanBiome Review for Women 40+: Truth & Results

If you’re a woman over 40 struggling with stubborn weight gain, unpredictable digestion, or frustrating belly fat — you’re not alone.
I’m Jessica, and I’ve been exactly where you are. No amount of workouts or calorie counting seemed to make a difference… until I discovered how much my gut health was working against me.
That’s when I found LeanBiome — a probiotic-based supplement backed by Ivy League research and real-world testimonials.
But before you buy it, you deserve an honest, no-fluff breakdown of what’s inside, how it works, and whether it’s truly worth your money.
What Is LeanBiome?
LeanBiome is a unique probiotic formula designed to target “fat bacteria” in your gut microbiome — one of the newly discovered causes of weight gain, cravings, and low metabolism in women.
Unlike other gimmicky supplements, LeanBiome uses:
• Clinically studied lean bacteria like Lactobacillus Gasseri • Greenselect Phytosome® — a caffeine-free green tea extract that enhances fat burning • Delayed-release DRcaps to ensure full absorption in the gut
Benefits of LeanBiome
• Supports appetite control • Reduces fat storage • Improves gut diversity • Boosts metabolism • Vegan, gluten-free, soy-free
Download My Free Guide (10 Pages)
I created a full PDF guide that explains LeanBiome’s ingredients, clinical research, and tips for better results — written specifically for women over 40.
👉 Download here: https://drive.google.com/file/d/1nVh6VQEIHs1RJ2H7OTmrXschHGQ8uqoV/view?usp=drive_link
Where to Buy LeanBiome
LeanBiome is only sold through its official website — not Amazon or stores. The company offers:
• 180-day money-back guarantee • Discounts on 3- and 6-month bundles • A free gut-friendly smoothie recipe ebook with select orders
👉 Interested In Learning Where To Purchase? Click Here:
Is LeanBiome Worth It?
After reviewing the clinical data and trying it for myself, I truly believe LeanBiome can work — especially if you’ve ignored gut health until now.
It’s not magic. But it was the missing piece for me.
Final Thoughts
Weight loss after 40 doesn’t have to feel impossible. Fixing your gut was the key for me — and it might be for you too.
If you want to learn more, download the guide above or check out the official site for full details.
Thanks for reading, Jessica Whitmore
P.S. Got questions? Drop a comment — I read them all.
3 notes
·
View notes
Text
Data Engineering Concepts, Tools, and Projects
All the associations in the world have large amounts of data. If not worked upon and anatomized, this data does not amount to anything. Data masterminds are the ones. who make this data pure for consideration. Data Engineering can nominate the process of developing, operating, and maintaining software systems that collect, dissect, and store the association’s data. In modern data analytics, data masterminds produce data channels, which are the structure armature.
How to become a data engineer:
While there is no specific degree requirement for data engineering, a bachelor's or master's degree in computer science, software engineering, information systems, or a related field can provide a solid foundation. Courses in databases, programming, data structures, algorithms, and statistics are particularly beneficial. Data engineers should have strong programming skills. Focus on languages commonly used in data engineering, such as Python, SQL, and Scala. Learn the basics of data manipulation, scripting, and querying databases.
Familiarize yourself with various database systems like MySQL, PostgreSQL, and NoSQL databases such as MongoDB or Apache Cassandra.Knowledge of data warehousing concepts, including schema design, indexing, and optimization techniques.
Data engineering tools recommendations:
Data Engineering makes sure to use a variety of languages and tools to negotiate its objects. These tools allow data masterminds to apply tasks like creating channels and algorithms in a much easier as well as effective manner.
1. Amazon Redshift: A widely used cloud data warehouse built by Amazon, Redshift is the go-to choice for many teams and businesses. It is a comprehensive tool that enables the setup and scaling of data warehouses, making it incredibly easy to use.
One of the most popular tools used for businesses purpose is Amazon Redshift, which provides a powerful platform for managing large amounts of data. It allows users to quickly analyze complex datasets, build models that can be used for predictive analytics, and create visualizations that make it easier to interpret results. With its scalability and flexibility, Amazon Redshift has become one of the go-to solutions when it comes to data engineering tasks.
2. Big Query: Just like Redshift, Big Query is a cloud data warehouse fully managed by Google. It's especially favored by companies that have experience with the Google Cloud Platform. BigQuery not only can scale but also has robust machine learning features that make data analysis much easier. 3. Tableau: A powerful BI tool, Tableau is the second most popular one from our survey. It helps extract and gather data stored in multiple locations and comes with an intuitive drag-and-drop interface. Tableau makes data across departments readily available for data engineers and managers to create useful dashboards. 4. Looker: An essential BI software, Looker helps visualize data more effectively. Unlike traditional BI tools, Looker has developed a LookML layer, which is a language for explaining data, aggregates, calculations, and relationships in a SQL database. A spectacle is a newly-released tool that assists in deploying the LookML layer, ensuring non-technical personnel have a much simpler time when utilizing company data.
5. Apache Spark: An open-source unified analytics engine, Apache Spark is excellent for processing large data sets. It also offers great distribution and runs easily alongside other distributed computing programs, making it essential for data mining and machine learning. 6. Airflow: With Airflow, programming, and scheduling can be done quickly and accurately, and users can keep an eye on it through the built-in UI. It is the most used workflow solution, as 25% of data teams reported using it. 7. Apache Hive: Another data warehouse project on Apache Hadoop, Hive simplifies data queries and analysis with its SQL-like interface. This language enables MapReduce tasks to be executed on Hadoop and is mainly used for data summarization, analysis, and query. 8. Segment: An efficient and comprehensive tool, Segment assists in collecting and using data from digital properties. It transforms, sends, and archives customer data, and also makes the entire process much more manageable. 9. Snowflake: This cloud data warehouse has become very popular lately due to its capabilities in storing and computing data. Snowflake’s unique shared data architecture allows for a wide range of applications, making it an ideal choice for large-scale data storage, data engineering, and data science. 10. DBT: A command-line tool that uses SQL to transform data, DBT is the perfect choice for data engineers and analysts. DBT streamlines the entire transformation process and is highly praised by many data engineers.
Data Engineering Projects:
Data engineering is an important process for businesses to understand and utilize to gain insights from their data. It involves designing, constructing, maintaining, and troubleshooting databases to ensure they are running optimally. There are many tools available for data engineers to use in their work such as My SQL, SQL server, oracle RDBMS, Open Refine, TRIFACTA, Data Ladder, Keras, Watson, TensorFlow, etc. Each tool has its strengths and weaknesses so it’s important to research each one thoroughly before making recommendations about which ones should be used for specific tasks or projects.
Smart IoT Infrastructure:
As the IoT continues to develop, the measure of data consumed with high haste is growing at an intimidating rate. It creates challenges for companies regarding storehouses, analysis, and visualization.
Data Ingestion:
Data ingestion is moving data from one or further sources to a target point for further preparation and analysis. This target point is generally a data storehouse, a unique database designed for effective reporting.
Data Quality and Testing:
Understand the importance of data quality and testing in data engineering projects. Learn about techniques and tools to ensure data accuracy and consistency.
Streaming Data:
Familiarize yourself with real-time data processing and streaming frameworks like Apache Kafka and Apache Flink. Develop your problem-solving skills through practical exercises and challenges.
Conclusion:
Data engineers are using these tools for building data systems. My SQL, SQL server and Oracle RDBMS involve collecting, storing, managing, transforming, and analyzing large amounts of data to gain insights. Data engineers are responsible for designing efficient solutions that can handle high volumes of data while ensuring accuracy and reliability. They use a variety of technologies including databases, programming languages, machine learning algorithms, and more to create powerful applications that help businesses make better decisions based on their collected data.
4 notes
·
View notes
Link
0 notes
Link
[ad_1] In this tutorial, we walk you through building an enhanced web scraping tool that leverages BrightData’s powerful proxy network alongside Google’s Gemini API for intelligent data extraction. You’ll see how to structure your Python project, install and import the necessary libraries, and encapsulate scraping logic within a clean, reusable BrightDataScraper class. Whether you’re targeting Amazon product pages, bestseller listings, or LinkedIn profiles, the scraper’s modular methods demonstrate how to configure scraping parameters, handle errors gracefully, and return structured JSON results. An optional React-style AI agent integration also shows you how to combine LLM-driven reasoning with real-time scraping, empowering you to pose natural language queries for on-the-fly data analysis. !pip install langchain-brightdata langchain-google-genai langgraph langchain-core google-generativeai We install all of the key libraries needed for the tutorial in one step: langchain-brightdata for BrightData web scraping, langchain-google-genai and google-generativeai for Google Gemini integration, langgraph for agent orchestration, and langchain-core for the core LangChain framework. import os import json from typing import Dict, Any, Optional from langchain_brightdata import BrightDataWebScraperAPI from langchain_google_genai import ChatGoogleGenerativeAI from langgraph.prebuilt import create_react_agent These imports prepare your environment and core functionality: os and json handle system operations and data serialization, while typing provides structured type hints. You then bring in BrightDataWebScraperAPI for BrightData scraping, ChatGoogleGenerativeAI to interface with Google’s Gemini LLM, and create_react_agent to orchestrate these components in a React-style agent. class BrightDataScraper: """Enhanced web scraper using BrightData API""" def __init__(self, api_key: str, google_api_key: Optional[str] = None): """Initialize scraper with API keys""" self.api_key = api_key self.scraper = BrightDataWebScraperAPI(bright_data_api_key=api_key) if google_api_key: self.llm = ChatGoogleGenerativeAI( model="gemini-2.0-flash", google_api_key=google_api_key ) self.agent = create_react_agent(self.llm, [self.scraper]) def scrape_amazon_product(self, url: str, zipcode: str = "10001") -> Dict[str, Any]: """Scrape Amazon product data""" try: results = self.scraper.invoke( "url": url, "dataset_type": "amazon_product", "zipcode": zipcode ) return "success": True, "data": results except Exception as e: return "success": False, "error": str(e) def scrape_amazon_bestsellers(self, region: str = "in") -> Dict[str, Any]: """Scrape Amazon bestsellers""" try: url = f" results = self.scraper.invoke( "url": url, "dataset_type": "amazon_product" ) return "success": True, "data": results except Exception as e: return "success": False, "error": str(e) def scrape_linkedin_profile(self, url: str) -> Dict[str, Any]: """Scrape LinkedIn profile data""" try: results = self.scraper.invoke( "url": url, "dataset_type": "linkedin_person_profile" ) return "success": True, "data": results except Exception as e: return "success": False, "error": str(e) def run_agent_query(self, query: str) -> None: """Run AI agent with natural language query""" if not hasattr(self, 'agent'): print("Error: Google API key required for agent functionality") return try: for step in self.agent.stream( "messages": query, stream_mode="values" ): step["messages"][-1].pretty_print() except Exception as e: print(f"Agent error: e") def print_results(self, results: Dict[str, Any], title: str = "Results") -> None: """Pretty print results""" print(f"\n'='*50") print(f"title") print(f"'='*50") if results["success"]: print(json.dumps(results["data"], indent=2, ensure_ascii=False)) else: print(f"Error: results['error']") print() The BrightDataScraper class encapsulates all BrightData web-scraping logic and optional Gemini-powered intelligence under a single, reusable interface. Its methods enable you to easily fetch Amazon product details, bestseller lists, and LinkedIn profiles, handling API calls, error handling, and JSON formatting, and even stream natural-language “agent” queries when a Google API key is provided. A convenient print_results helper ensures your output is always cleanly formatted for inspection. def main(): """Main execution function""" BRIGHT_DATA_API_KEY = "Use Your Own API Key" GOOGLE_API_KEY = "Use Your Own API Key" scraper = BrightDataScraper(BRIGHT_DATA_API_KEY, GOOGLE_API_KEY) print("🛍️ Scraping Amazon India Bestsellers...") bestsellers = scraper.scrape_amazon_bestsellers("in") scraper.print_results(bestsellers, "Amazon India Bestsellers") print("📦 Scraping Amazon Product...") product_url = " product_data = scraper.scrape_amazon_product(product_url, "10001") scraper.print_results(product_data, "Amazon Product Data") print("👤 Scraping LinkedIn Profile...") linkedin_url = " linkedin_data = scraper.scrape_linkedin_profile(linkedin_url) scraper.print_results(linkedin_data, "LinkedIn Profile Data") print("🤖 Running AI Agent Query...") agent_query = """ Scrape Amazon product data for in New York (zipcode 10001) and summarize the key product details. """ scraper.run_agent_query(agent_query) The main() function ties everything together by setting your BrightData and Google API keys, instantiating the BrightDataScraper, and then demonstrating each feature: it scrapes Amazon India’s bestsellers, fetches details for a specific product, retrieves a LinkedIn profile, and finally runs a natural-language agent query, printing neatly formatted results after each step. if __name__ == "__main__": print("Installing required packages...") os.system("pip install -q langchain-brightdata langchain-google-genai langgraph") os.environ["BRIGHT_DATA_API_KEY"] = "Use Your Own API Key" main() Finally, this entry-point block ensures that, when run as a standalone script, the required scraping libraries are quietly installed, and the BrightData API key is set in the environment. Then the main function is executed to initiate all scraping and agent workflows. In conclusion, by the end of this tutorial, you’ll have a ready-to-use Python script that automates tedious data collection tasks, abstracts away low-level API details, and optionally taps into generative AI for advanced query handling. You can extend this foundation by adding support for other dataset types, integrating additional LLMs, or deploying the scraper as part of a larger data pipeline or web service. With these building blocks in place, you’re now equipped to gather, analyze, and present web data more efficiently, whether for market research, competitive intelligence, or custom AI-driven applications. Check out the Notebook. All credit for this research goes to the researchers of this project. Also, feel free to follow us on Twitter and don’t forget to join our 100k+ ML SubReddit and Subscribe to our Newsletter. Asif Razzaq is the CEO of Marktechpost Media Inc.. As a visionary entrepreneur and engineer, Asif is committed to harnessing the potential of Artificial Intelligence for social good. His most recent endeavor is the launch of an Artificial Intelligence Media Platform, Marktechpost, which stands out for its in-depth coverage of machine learning and deep learning news that is both technically sound and easily understandable by a wide audience. The platform boasts of over 2 million monthly views, illustrating its popularity among audiences. [ad_2] Source link
0 notes
Text
What Are the Real Benefits of Generative AI in IT Workspace?
The rapid evolution of artificial intelligence (AI) is reshaping industries—and the Information Technology (IT) sector is no exception. Among the most transformative advancements is Generative AI, a subset of AI that goes beyond analyzing data to actually creating content, code, and solutions. But what are the real, tangible benefits of generative AI in the IT workspace?

In this blog, we break down how generative AI is revolutionizing the IT environment, streamlining workflows, enhancing productivity, and enabling teams to focus on higher-value tasks.
1. Accelerated Software Development
One of the most direct and impactful applications of generative AI in IT is in software development. Tools like GitHub Copilot, Amazon CodeWhisperer, and ChatGPT-based code assistants can:
Auto-generate code snippets based on natural language prompts.
Detect bugs and suggest real-time fixes.
Generate test cases and documentation.
Speed up debugging with natural language explanations of errors.
This helps developers move faster from idea to implementation, often reducing coding time by 30-50% depending on the task.
2. Improved IT Support and Helpdesk Automation
Generative AI is transforming IT service desks by providing intelligent, automated responses to common queries. It can:
Automate ticket triaging and prioritization.
Draft knowledge base articles based on issue histories.
Offer chatbot-driven resolutions for repetitive issues.
Provide context-aware suggestions for support agents.
As a result, organizations experience faster resolution times, reduced support costs, and improved user satisfaction.
3. Enhanced Cybersecurity and Threat Analysis
In cybersecurity, generative AI tools can analyze vast logs of network activity and generate detailed threat reports or simulate new attack patterns. Key benefits include:
Anomaly detection using generative models trained on normal behavior.
Automated incident reports with plain-language summaries.
Simulated phishing and malware attacks to test system resilience.
Code analysis for security vulnerabilities.
By generating threat insights in real time, security teams can stay ahead of evolving threats.
4. Infrastructure and DevOps Optimization
Generative AI can help automate and optimize infrastructure management tasks:
Generate infrastructure-as-code (IaC) templates (like Terraform or CloudFormation scripts).
Suggest cloud resource configurations based on usage patterns.
Automate CI/CD pipeline creation.
Create deployment scripts and documentation.
This empowers DevOps teams to focus more on strategic infrastructure design rather than repetitive setup work.
5. Boosting Collaboration and Knowledge Sharing
Generative AI can extract and distill knowledge from large sets of documentation, Slack threads, or emails to:
Summarize key conversations and decisions.
Automatically generate project updates.
Translate technical content for non-technical stakeholders.
Help onboard new team members with personalized learning materials.
This promotes faster knowledge transfer, especially in distributed or hybrid teams.
6. Innovation Through Rapid Prototyping
With generative AI, IT teams can build quick prototypes of software products or user interfaces with simple prompts, helping:
Validate ideas faster.
Gather user feedback early.
Reduce development costs in early stages.
This fosters an innovation-first culture and minimizes time-to-market for digital products.
7. Enhanced Decision-Making With AI-Augmented Insights
By integrating generative AI with analytics platforms, IT teams can:
Generate real-time reports with narrative summaries.
Translate technical metrics into business insights.
Forecast system load, demand, or failure points using simulation models.
This allows leaders to make data-driven decisions without being bogged down by raw data.
8. Reduction of Human Error and Cognitive Load
Generative AI acts as a second brain for IT professionals, helping:
Reduce fatigue from routine coding or configuration tasks.
Minimize manual errors through guided inputs.
Suggest best practices in real time.
By offloading repetitive mental tasks, it frees up bandwidth for creative and strategic thinking.
Real-World Examples
IBM Watsonx: Helps automate IT operations and detect root causes of issues.
GitHub Copilot: Used by developers to increase productivity and improve code quality.
ServiceNow’s AI-powered Virtual Agents: Automate ITSM ticket resolution.
Google Duet AI for Cloud: Assists cloud architects with resource planning and cost optimization.
Conclusion
Generative AI IT workspace is no longer just a buzzword—it's a practical, powerful ally for IT teams across development, operations, support, and security. While it’s not a silver bullet, its ability to automate tasks, generate content, and enhance decision-making is already delivering measurable ROI in the IT workspace.
As adoption continues, the key for IT leaders will be to embrace generative AI thoughtfully, ensuring it complements human expertise rather than replacing it. When done right, the result is a more agile, efficient, and innovative IT environment.
0 notes
Text
Unlocking Data Science's Potential: Transforming Data into Perceptive Meaning
Data is created on a regular basis in our digitally connected environment, from social media likes to financial transactions and detection labour. However, without the ability to extract valuable insights from this enormous amount of data, it is not very useful. Data insight can help you win in that situation. Online Course in Data Science It is a multidisciplinary field that combines computer knowledge, statistics, and subject-specific expertise to evaluate data and provide useful perception. This essay will explore the definition of data knowledge, its essential components, its significance, and its global transubstantiation diligence.

Understanding Data Science: To find patterns and shape opinions, data wisdom essentially entails collecting, purifying, testing, and analysing large, complicated datasets. It combines a number of fields.
Statistics: To establish predictive models and derive conclusions.
Computer intelligence: For algorithm enforcement, robotization, and coding.
Sphere moxie: To place perceptivity in a particular field of study, such as healthcare or finance.
It is the responsibility of a data scientist to pose pertinent queries, handle massive amounts of data effectively, and produce findings that have an impact on operations and strategy.
The Significance of Data Science
1. Informed Decision Making: To improve the stoner experience, streamline procedures, and identify emerging trends, associations rely on data-driven perception.
2. Increased Effectiveness: Businesses can decrease manual labour by automating operations like spotting fraudulent transactions or managing AI-powered customer support.
3. Acclimatised Gests: Websites like Netflix and Amazon analyse user data to provide suggestions for products and verified content.
4. Improvements in Medicine: Data knowledge helps with early problem diagnosis, treatment development, and bodying medical actions.
Essential Data Science Foundations:

1. Data Acquisition & Preparation: Databases, web scraping, APIs, and detectors are some sources of data. Before analysis starts, it is crucial to draw the data, correct offences, eliminate duplicates, and handle missing values.
2. Exploratory Data Analysis (EDA): EDA identifies patterns in data, describes anomalies, and comprehends the relationships between variables by using visualisation tools such as Seaborn or Matplotlib.
3. Modelling & Machine Learning: By using techniques like
Retrogression: For predicting numerical patterns.
Bracket: Used for data sorting (e.g., spam discovery).
For group segmentation (such as client profiling), clustering is used.
Data scientists create models that automate procedures and predict problems. Enrol in a reputable software training institution's Data Science course.
4. Visualisation & Liar: For stakeholders who are not technical, visual tools such as Tableau and Power BI assist in distilling complex data into understandable, captivating dashboards and reports.
Data Science Activities Across Diligence:
1. Online shopping
personalised recommendations for products.
Demand-driven real-time pricing schemes.
2. Finance & Banking
identifying deceptive conditioning.
trading that is automated and powered by predictive analytics.
3. Medical Care
tracking the spread of complaints and formulating therapeutic suggestions.
using AI to improve medical imaging.
4. Social Media
assessing public opinion and stoner sentiment.
curation of feeds and optimisation of content.
Typical Data Science Challenges:
Despite its potential, data wisdom has drawbacks.
Ethics & Sequestration: Preserving stoner data and preventing algorithmic prejudice.
Data Integrity: Inaccurate perception results from low-quality data.
Scalability: Pall computing and other high-performance structures are necessary for managing large datasets.
The Road Ahead:
As artificial intelligence advances, data wisdom will remain a crucial motorist of invention. unborn trends include :
AutoML – Making machine literacy accessible to non-specialists.
Responsible AI – icing fairness and translucency in automated systems.
Edge Computing – Bringing data recycling near to the source for real- time perceptivity.
Conclusion:
Data wisdom is reconsidering how businesses, governments, and healthcare providers make opinions by converting raw data into strategic sapience. Its impact spans innumerous sectors and continues to grow. With rising demand for professed professionals, now is an ideal time to explore this dynamic field.
0 notes
Text
Terms like big data, data science, and machine learning are the buzzwords of this time. It is not for nothing that data is also referred to as the oil of the 21st century. But first, the right data of the right quality must be available so that something becomes possible here. It must firstly be extracted to be processed further, e.g. into business analyses, statistical models, or even a new data-driven service. This is where the data engineer comes into play. In this article, you'll find out everything about their field of work, training, and how you can enter this specific work area.Tasks of a Data EngineerData engineers are responsible for building data pipelines, data warehouses and lakes, data services, data products, and the whole architecture that uses this data within a company. They are also responsible for selecting the optimal data infrastructure, and monitoring and maintaining it. Of course, this means that data engineers also need to know a lot about the systems in a company—only then can they correctly and efficiently connect ERP and CRM systems.The data engineer must also know the data itself. Only then can correct ETL/ELT processes be implemented in data pipelines from source systems to end destinations like cloud data warehouses. In this process, the data is often transformed, e.g. summarized, cleaned, or brought into a new structure. It is also important that they work well with related areas, because only then can good results be delivered together with data scientists, machine learning engineers, or business analysts. In this regard, one can see that data teams often share their data transformation responsibilities amongst themselves. Within this context, data engineers take up slightly different tasks than the other teams. However, one can say that this is the exact same transformation process as in the field of software development where multiple teams have their own responsibilities.How to Become a Data EngineerThere is no specific degree program in data engineering. However, a lot of (online) courses and training programs exist for one to specialise in it. Often, data engineers have skills and knowledge from other areas like:(Business) informaticsComputer or software engineeringStatistics and data scienceTraining with a focus on trending topics like business intelligence, databases, data processes, cloud data science, or data analytics can make it easier for one to enter the profession. Also, they can then expect a higher salary. Environment of a Data Engineer: SourceSkills and Used Technologies Like other professions in the field of IT and data, the data engineer requires a general as well as a deep technical understanding. It is important for data engineers to be familiar with certain technologies in the field. These include:Programming languages like Python, Scala, or C#Database languages like SQLData storage/processing systemsMachine learning toolsExperience in cloud technologies like Google, Amazon, or AzureData modeling and structuring methodsExamples of Tools and Languages used in Data Engineering - SourceIt is important to emphasize that the trend in everything is running towards the cloud. In addition to SaaS and cloud data warehouse technologies such as Google BigQuery or Amazon Redshift, DaaS (data as a service) is also becoming increasingly popular. In this case, data integration tools with their respective data processes are all completely implemented and stored in the cloud.Data Engineer vs. Data ScientistThe terms “data scientist” and “data engineer” are often used interchangeably. However, their roles are quite different. As already said, data engineers work closely with other data experts like data scientists and data analysts. When working with big data, each profession focuses on different phases. While both professions are related to each other and have many points of contact, overarching (drag and drop) data analysis tools ensure that data engineers can also take on data science tasks and vice versa.
The core tasks of a data engineer lie in the integration of data. They obtain data, monitor the processes for it, and prepare it for data scientists and data analysts. On the other side, the data scientist is more concerned with analyzing this data and building dashboards, statistical analyses, or machine learning models.SummaryIn conclusion, one can say that data engineers are becoming more and more important in today’s working world, since companies do have to work with vast amounts of data. There is no specific program that must be undergone prior to working as a data engineer. However, skills and knowledge from other fields such as informatics, software engineering, and machine learning are often required. In this regard, it is important to say that a data engineer should have a specific amount of knowledge in programming and database languages to do their job correctly. Finally, one must state that data engineers are not the same as data scientists. Both professions have different tasks and work in slightly different areas within a company. While data engineers are mostly concerned with the integration of data, data scientists are focusing on analyzing the data and creating visualizations such as dashboard or machine learning models.
0 notes
Link
#AIethics#Antitrust#digitalmarkets#enshittification#interoperability#platformcapitalism#platformdecay#techregulation
0 notes
Text

Background
The UK e-commerce market is intensely price-driven—especially on platforms like Amazon UK, where sellers compete not just on product quality but on dynamic pricing.
A London-based electronics reseller found it increasingly difficult to maintain price competitiveness, especially against third-party sellers and Amazon’s own listings.
They turned to RetailScrape to implement a real-time Amazon UK price scraping solution focused on product-specific monitoring and smart price adjustments.
Business Objectives
Monitor top-selling electronics SKUs on Amazon UK in real time
Automate price benchmarking against competitors, including Amazon Retail
Enable dynamic repricing to retain Buy Box share
Improve margin optimization and increase sales conversions
Challenges
1. Amazon’s Algorithmic Pricing: Amazon frequently adjusts product prices based on demand, competition, and inventory—often several times a day.
2. Buy Box Competition: Winning the Buy Box is essential for sales, but price is the primary deciding factor.
3. Manual Price Reviews: Previously, the client reviewed pricing only once daily, missing out on mid-day price changes.
RetailScrape’s Data-Driven Solution
RetailScrape deployed a custom Amazon UK Scraping Pipeline configured to track:
Hourly prices for over 500 competitor-listed SKUs
Buy Box ownership status
Seller names and ratings
Amazon Retail price (if applicable)
Availability and delivery time
Data was pushed directly into the client’s pricing engine via RetailScrape’s secure API, enabling automated repricing rules.
Sample Extracted Data
Key Insights Delivered
1. Amazon Undercuts: Amazon Retail was undercutting third-party sellers by 3-7% in 40% of tracked SKUs.
2. Evening Discounts: The lowest competitor prices were often posted between 7 PM – 10 PM GMT.
3. Buy Box Sensitivity: A pricing difference as small as £0.30 often determined Buy Box status.
Client Actions Enabled by RetailScrape
Set up automated repricing rules triggered when a competitor lowered prices by more than 1%.
Introduced “Buy Box Guardrails”—ensuring minimum margin thresholds were met while staying competitive.
Deprioritized listings where Amazon Retail owned the Buy Box consistently, reallocating marketing budget to other products.
Business Results Achieved (After 6 Weeks)

“RetailScrape turned our Amazon pricing strategy from reactive to real-time. Within a month, we nearly doubled our Buy Box retention and improved margins without sacrificing competitiveness.”
- CE-Commerce Director, London Electronics Seller
Conclusion
For UK-based Amazon sellers, competitive pricing isn't a nice-to-have—it's survival. With RetailScrape, our London client transitioned to a data-first strategy using real-time Amazon UK scraping. The result? Better pricing decisions, improved visibility, and healthier profit margins.
RetailScrape continues to support them with advanced analytics and API-based automation as they scale across new product lines in 2025.
Read more >> https://www.retailscrape.com/amazon-price-tracking-for-london-retailers.php
officially published by https://www.retailscrape.com/.
#AmazonUKScrapingData#RealTimeAmazonScraping#AmazonUKPriceScraping#AmazonUKScrapingPipeline#PriceOptimization#RetailScrapeAPI#DynamicPricingStrategy#CompetitorPriceTracking#AmazonPricingData#AmazonSellerAnalytics#eCommercePriceOptimization
0 notes
Link
[ad_1] In this tutorial, we walk you through building an enhanced web scraping tool that leverages BrightData’s powerful proxy network alongside Google’s Gemini API for intelligent data extraction. You’ll see how to structure your Python project, install and import the necessary libraries, and encapsulate scraping logic within a clean, reusable BrightDataScraper class. Whether you’re targeting Amazon product pages, bestseller listings, or LinkedIn profiles, the scraper’s modular methods demonstrate how to configure scraping parameters, handle errors gracefully, and return structured JSON results. An optional React-style AI agent integration also shows you how to combine LLM-driven reasoning with real-time scraping, empowering you to pose natural language queries for on-the-fly data analysis. !pip install langchain-brightdata langchain-google-genai langgraph langchain-core google-generativeai We install all of the key libraries needed for the tutorial in one step: langchain-brightdata for BrightData web scraping, langchain-google-genai and google-generativeai for Google Gemini integration, langgraph for agent orchestration, and langchain-core for the core LangChain framework. import os import json from typing import Dict, Any, Optional from langchain_brightdata import BrightDataWebScraperAPI from langchain_google_genai import ChatGoogleGenerativeAI from langgraph.prebuilt import create_react_agent These imports prepare your environment and core functionality: os and json handle system operations and data serialization, while typing provides structured type hints. You then bring in BrightDataWebScraperAPI for BrightData scraping, ChatGoogleGenerativeAI to interface with Google’s Gemini LLM, and create_react_agent to orchestrate these components in a React-style agent. class BrightDataScraper: """Enhanced web scraper using BrightData API""" def __init__(self, api_key: str, google_api_key: Optional[str] = None): """Initialize scraper with API keys""" self.api_key = api_key self.scraper = BrightDataWebScraperAPI(bright_data_api_key=api_key) if google_api_key: self.llm = ChatGoogleGenerativeAI( model="gemini-2.0-flash", google_api_key=google_api_key ) self.agent = create_react_agent(self.llm, [self.scraper]) def scrape_amazon_product(self, url: str, zipcode: str = "10001") -> Dict[str, Any]: """Scrape Amazon product data""" try: results = self.scraper.invoke( "url": url, "dataset_type": "amazon_product", "zipcode": zipcode ) return "success": True, "data": results except Exception as e: return "success": False, "error": str(e) def scrape_amazon_bestsellers(self, region: str = "in") -> Dict[str, Any]: """Scrape Amazon bestsellers""" try: url = f" results = self.scraper.invoke( "url": url, "dataset_type": "amazon_product" ) return "success": True, "data": results except Exception as e: return "success": False, "error": str(e) def scrape_linkedin_profile(self, url: str) -> Dict[str, Any]: """Scrape LinkedIn profile data""" try: results = self.scraper.invoke( "url": url, "dataset_type": "linkedin_person_profile" ) return "success": True, "data": results except Exception as e: return "success": False, "error": str(e) def run_agent_query(self, query: str) -> None: """Run AI agent with natural language query""" if not hasattr(self, 'agent'): print("Error: Google API key required for agent functionality") return try: for step in self.agent.stream( "messages": query, stream_mode="values" ): step["messages"][-1].pretty_print() except Exception as e: print(f"Agent error: e") def print_results(self, results: Dict[str, Any], title: str = "Results") -> None: """Pretty print results""" print(f"\n'='*50") print(f"title") print(f"'='*50") if results["success"]: print(json.dumps(results["data"], indent=2, ensure_ascii=False)) else: print(f"Error: results['error']") print() The BrightDataScraper class encapsulates all BrightData web-scraping logic and optional Gemini-powered intelligence under a single, reusable interface. Its methods enable you to easily fetch Amazon product details, bestseller lists, and LinkedIn profiles, handling API calls, error handling, and JSON formatting, and even stream natural-language “agent” queries when a Google API key is provided. A convenient print_results helper ensures your output is always cleanly formatted for inspection. def main(): """Main execution function""" BRIGHT_DATA_API_KEY = "Use Your Own API Key" GOOGLE_API_KEY = "Use Your Own API Key" scraper = BrightDataScraper(BRIGHT_DATA_API_KEY, GOOGLE_API_KEY) print("🛍️ Scraping Amazon India Bestsellers...") bestsellers = scraper.scrape_amazon_bestsellers("in") scraper.print_results(bestsellers, "Amazon India Bestsellers") print("📦 Scraping Amazon Product...") product_url = " product_data = scraper.scrape_amazon_product(product_url, "10001") scraper.print_results(product_data, "Amazon Product Data") print("👤 Scraping LinkedIn Profile...") linkedin_url = " linkedin_data = scraper.scrape_linkedin_profile(linkedin_url) scraper.print_results(linkedin_data, "LinkedIn Profile Data") print("🤖 Running AI Agent Query...") agent_query = """ Scrape Amazon product data for in New York (zipcode 10001) and summarize the key product details. """ scraper.run_agent_query(agent_query) The main() function ties everything together by setting your BrightData and Google API keys, instantiating the BrightDataScraper, and then demonstrating each feature: it scrapes Amazon India’s bestsellers, fetches details for a specific product, retrieves a LinkedIn profile, and finally runs a natural-language agent query, printing neatly formatted results after each step. if __name__ == "__main__": print("Installing required packages...") os.system("pip install -q langchain-brightdata langchain-google-genai langgraph") os.environ["BRIGHT_DATA_API_KEY"] = "Use Your Own API Key" main() Finally, this entry-point block ensures that, when run as a standalone script, the required scraping libraries are quietly installed, and the BrightData API key is set in the environment. Then the main function is executed to initiate all scraping and agent workflows. In conclusion, by the end of this tutorial, you’ll have a ready-to-use Python script that automates tedious data collection tasks, abstracts away low-level API details, and optionally taps into generative AI for advanced query handling. You can extend this foundation by adding support for other dataset types, integrating additional LLMs, or deploying the scraper as part of a larger data pipeline or web service. With these building blocks in place, you’re now equipped to gather, analyze, and present web data more efficiently, whether for market research, competitive intelligence, or custom AI-driven applications. Check out the Notebook. All credit for this research goes to the researchers of this project. Also, feel free to follow us on Twitter and don’t forget to join our 100k+ ML SubReddit and Subscribe to our Newsletter. Asif Razzaq is the CEO of Marktechpost Media Inc.. As a visionary entrepreneur and engineer, Asif is committed to harnessing the potential of Artificial Intelligence for social good. His most recent endeavor is the launch of an Artificial Intelligence Media Platform, Marktechpost, which stands out for its in-depth coverage of machine learning and deep learning news that is both technically sound and easily understandable by a wide audience. The platform boasts of over 2 million monthly views, illustrating its popularity among audiences. [ad_2] Source link
0 notes
Text
4DBInfer: A Tool for Graph-Based Prediction in Databases

4DBInfer
A database-based graph-centric predictive modelling benchmark.
4DBInfer enables model comparison, prediction tasks, database-to-graph extraction, and graph-based predictive architectures.
4DBInfer, an extensive open-source benchmarking toolbox, focusses on graph-centric predictive modelling on Relational Databases (RDBs). Shanghai Lablet of Amazon built it to meet the major gap in well-established, publically accessible RDB standards for training and assessment.
As computer vision and natural language processing advance, predictive machine learning models using RDBs lag behind. The lack of public RDB benchmarks contributes to this gap. Single-table or graph datasets from preprocessed relational data often form the basis for RDB prediction models. RDBs' natural multi-table structure and properties are not fully represented by these methods, which may limit model performance.
4DBInfer addresses this with a 4D exploring framework. The 4-D design of RDB predictive analytics allows for deep exploration of the model design space and meticulous comparison of baseline models along these four critical dimensions:
4DBInfer includes RDB benchmarks from social networks, advertising, and e-commerce. Temporal evolution, schema complexity, and scale (billions of rows) vary among these datasets.
For every dataset, 4DBInfer finds realistic prediction tasks, such as estimating missing cell values.
Techniques for RDB-to-graph extraction: The program supports many approaches to retain the rich tabular information of big RDBs' structured data while transforming it into graph representations. The Row2Node function turns every table row into a graph node with foreign-key edges, whereas the Row2N/E method turns some rows into edges only to capture more sophisticated relational patterns. Additionally, “dummy tables” improve graph connectivity. According to the text, these algorithms subsample well.
FourDBInfer implements several resilient baseline structures for graph-based learning. These cover early and late feature-fusion paradigms. Deep Feature Synthesis (DFS) models collect tabular data from the graph before applying typical machine learning predictors, while Graph Neural Networks (GNNs) train node embeddings using relational message passing. These trainable models output subgraph-based predictions with well-matched inductive biases.
Comprehensive 4DBInfer tests yielded many noteworthy findings:
Graph-based models that use the complete multi-table RDB structure usually perform better than single-table or table joining models. This shows the value of RDB relational data.
The RDB-to-graph extraction strategy considerably affects model performance, emphasising the importance of design space experimentation.
GNNs and other early feature fusion graph models perform better than late-fusion models. Late-fusion models can compete, especially with computing limits.
Model performance depends on the job and dataset, underscoring the need for many benchmarks to provide correct findings.
The results suggest a future research topic: the tabular-graph machine learning paradigm nexus may yield the best solutions.
4DBInfer provides a consistent, open-sourced framework for the community to develop creative approaches that accelerate relational data prediction research. The source code of 4DBInfer is public.
#4DBInfer#RelationalDatabases#RDBbenchmarks#machinelearning#GraphNeuralNetworks#predictivemachinelearning#technology#technews#technologynews#news#govindhtech
0 notes
Text
Semantic Knowledge Graphing Market Size, Share, Analysis, Forecast, and Growth Trends to 2032: Transforming Data into Knowledge at Scale
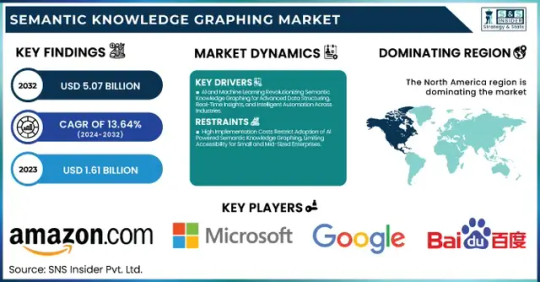
The Semantic Knowledge Graphing Market was valued at USD 1.61 billion in 2023 and is expected to reach USD 5.07 billion by 2032, growing at a CAGR of 13.64% from 2024-2032.
The Semantic Knowledge Graphing Market is rapidly evolving as organizations increasingly seek intelligent data integration and real-time insights. With the growing need to link structured and unstructured data for better decision-making, semantic technologies are becoming essential tools across sectors like healthcare, finance, e-commerce, and IT. This market is seeing a surge in demand driven by the rise of AI, machine learning, and big data analytics, as enterprises aim for context-aware computing and smarter data architectures.
Semantic Knowledge Graphing Market Poised for Strategic Transformation this evolving landscape is being shaped by an urgent need to solve complex data challenges with semantic understanding. Companies are leveraging semantic graphs to build context-rich models, enhance search capabilities, and create more intuitive AI experiences. As the digital economy thrives, semantic graphing offers a foundation for scalable, intelligent data ecosystems, allowing seamless connections between disparate data sources.
Get Sample Copy of This Report: https://www.snsinsider.com/sample-request/6040
Market Keyplayers:
Amazon.com Inc. (Amazon Neptune, AWS Graph Database)
Baidu, Inc. (Baidu Knowledge Graph, PaddlePaddle)
Facebook Inc. (Facebook Graph API, DeepText)
Google LLC (Google Knowledge Graph, Google Cloud Dataproc)
Microsoft Corporation (Azure Cosmos DB, Microsoft Graph)
Mitsubishi Electric Corporation (Maisart AI, MELFA Smart Plus)
NELL (Never-Ending Language Learner, NELL Knowledge Graph)
Semantic Web Company (PoolParty Semantic Suite, Semantic Middleware)
YAGO (YAGO Knowledge Base, YAGO Ontology)
Yandex (Yandex Knowledge Graph, Yandex Cloud ML)
IBM Corporation (IBM Watson Discovery, IBM Graph)
Oracle Corporation (Oracle Spatial and Graph, Oracle Cloud AI)
SAP SE (SAP HANA Graph, SAP Data Intelligence)
Neo4j Inc. (Neo4j Graph Database, Neo4j Bloom)
Databricks Inc. (Databricks GraphFrames, Databricks Delta Lake)
Stardog Union (Stardog Knowledge Graph, Stardog Studio)
OpenAI (GPT-based Knowledge Graphs, OpenAI Embeddings)
Franz Inc. (AllegroGraph, Allegro CL)
Ontotext AD (GraphDB, Ontotext Platform)
Glean (Glean Knowledge Graph, Glean AI Search)
Market Analysis
The Semantic Knowledge Graphing Market is transitioning from a niche segment to a critical component of enterprise IT strategy. Integration with AI/ML models has shifted semantic graphs from backend enablers to core strategic assets. With open data initiatives, industry-standard ontologies, and a push for explainable AI, enterprises are aggressively adopting semantic solutions to uncover hidden patterns, support predictive analytics, and enhance data interoperability. Vendors are focusing on APIs, graph visualization tools, and cloud-native deployments to streamline adoption and scalability.
Market Trends
AI-Powered Semantics: Use of NLP and machine learning in semantic graphing is automating knowledge extraction and relationship mapping.
Graph-Based Search Evolution: Businesses are prioritizing semantic search engines to offer context-aware, precise results.
Industry-Specific Graphs: Tailored graphs are emerging in healthcare (clinical data mapping), finance (fraud detection), and e-commerce (product recommendation).
Integration with LLMs: Semantic graphs are increasingly being used to ground large language models with factual, structured data.
Open Source Momentum: Tools like RDF4J, Neo4j, and GraphDB are gaining traction for community-led innovation.
Real-Time Applications: Event-driven semantic graphs are now enabling real-time analytics in domains like cybersecurity and logistics.
Cross-Platform Compatibility: Vendors are prioritizing seamless integration with existing data lakes, APIs, and enterprise knowledge bases.
Market Scope
Semantic knowledge graphing holds vast potential across industries:
Healthcare: Improves patient data mapping, drug discovery, and clinical decision support.
Finance: Enhances fraud detection, compliance tracking, and investment analysis.
Retail & E-Commerce: Powers hyper-personalized recommendations and dynamic customer journeys.
Manufacturing: Enables digital twins and intelligent supply chain management.
Government & Public Sector: Supports policy modeling, public data transparency, and inter-agency collaboration.
These use cases represent only the surface of a deeper transformation, where data is no longer isolated but intelligently interconnected.
Market Forecast
As AI continues to integrate deeper into enterprise functions, semantic knowledge graphs will play a central role in enabling contextual AI systems. Rather than just storing relationships, future graphing solutions will actively drive insight generation, data governance, and operational automation. Strategic investments by leading tech firms, coupled with the rise of vertical-specific graphing platforms, suggest that semantic knowledge graphing will become a staple of digital infrastructure. Market maturity is expected to rise rapidly, with early adopters gaining a significant edge in predictive capability, data agility, and innovation speed.
Access Complete Report: https://www.snsinsider.com/reports/semantic-knowledge-graphing-market-6040
Conclusion
The Semantic Knowledge Graphing Market is no longer just a futuristic concept—it's the connective tissue of modern data ecosystems. As industries grapple with increasingly complex information landscapes, the ability to harness semantic relationships is emerging as a decisive factor in digital competitiveness.
About Us:
SNS Insider is one of the leading market research and consulting agencies that dominates the market research industry globally. Our company's aim is to give clients the knowledge they require in order to function in changing circumstances. In order to give you current, accurate market data, consumer insights, and opinions so that you can make decisions with confidence, we employ a variety of techniques, including surveys, video talks, and focus groups around the world.
Contact Us:
Jagney Dave - Vice President of Client Engagement
Phone: +1-315 636 4242 (US) | +44- 20 3290 5010 (UK)
#Semantic Knowledge Graphing Market#Semantic Knowledge Graphing Market Share#Semantic Knowledge Graphing Market Scope#Semantic Knowledge Graphing Market Trends
1 note
·
View note
Text
How Naver Data Scraping Services Solve Market Research Challenges in South Korea

Introduction
South Korea is one of the most digitally connected nations in the world. With a population of over 51 million and an internet penetration rate exceeding 96%, the country provides a highly dynamic and data-rich environment for businesses. The South Korean audience is tech-savvy, mobile-first, and heavily reliant on digital content when making purchasing decisions. Platforms like Naver, Kakao, and Coupang dominate user interactions, influencing both consumer behavior and corporate strategies.
To tap into this tech-forward market, businesses must access localized, real-time data—a process now streamlined by Real-Time Naver Data Scraping and Naver Market Data Collection tools. These services offer unparalleled access to user reviews, search patterns, product trends, and regional preferences.
The Dominance of Naver in South Korea’s Online Ecosystem
Naver isn't just a search engine—it’s South Korea’s equivalent of Google, YouTube, and Amazon rolled into one. From search results to blogs (Naver Blog), news, shopping, and Q&A (Naver KnowledgeiN), it covers a broad spectrum of online activity. Over 70% of search engine market share in South Korea belongs to Naver, and it serves as the first point of research for most local users.
Because of this massive influence, businesses aiming for success in South Korea must prioritize Naver Data Extraction Services and Naver Market Data Collection for meaningful insights. Standard global analytics tools don’t capture Naver’s closed ecosystem, making Naver Data Scraping Services essential for accessing actionable intelligence.
Why Traditional Market Research Falls Short in South Korea?
Global market research tools often overlook Naver’s ecosystem, focusing instead on platforms like Google and Amazon. However, these tools fail to access Korean-language content, user sentiment, and real-time search trends—all of which are critical for local strategy. Language barriers, API limitations, and closed-loop ecosystems create blind spots for international brands.
That’s where Scrape Naver Search Results and Real-Time Naver Data Scraping come into play. These technologies allow for automated, scalable, and precise data extraction across Naver's services—filling the gap left by conventional analytics.
With Naver Data Scraping Services, companies can bypass platform restrictions and dive into consumer conversations, trend spikes, product feedback, and keyword dynamics. This ensures your market research is not only accurate but also hyper-relevant.
Understanding Naver’s Ecosystem
Breakdown of Naver Services: Search, Blogs, News, Shopping, and Q&A
Naver functions as South Korea’s all-in-one digital hub. It merges multiple content ecosystems into one platform, influencing almost every digital journey in the region. Naver Search is the core feature, accounting for over 70% of web searches in South Korea. Naver Blog drives user-generated content, while Naver News aggregates editorial and user-curated journalism. Naver Shopping is the go-to platform for product searches and purchases, and Naver KnowledgeiN (Q&A) remains a top destination for peer-sourced solutions.
For researchers and marketers, this ecosystem offers a goldmine of Korean Market Data from Naver. Services like Naver Product Listings Extraction and Structured Data Extraction from Naver allow businesses to analyze consumer trends, brand perception, and product placement.
Why Naver Data is Critical for Market Research in South Korea?
South Korean consumers rely heavily on Naver for decision-making—whether they're searching for product reviews, comparing prices, reading news, or asking questions. Traditional global platforms like Google, Amazon, or Yelp are significantly less influential in this region. For accurate, localized insights, businesses must tap into Naver Web Data Services.
Services such as Naver Competitor Analysis Solutions and Naver Price Intelligence Services enable brands to monitor how products are presented, priced, and perceived in real time. Naver Shopping’s dominance in e-commerce, combined with authentic reviews from Naver Blogs and user sentiment in KnowledgeiN, provides unmatched depth for understanding market trends.
Without access to these insights, companies risk making strategic errors. Language-specific search behaviors, brand preferences, and even pricing expectations differ greatly in South Korea. Naver Data gives you the context, accuracy, and cultural relevance global datasets cannot offer.
Challenges Posed by Its Unique Structure and Language Barrier
While Naver’s ecosystem is a treasure trove for researchers, it comes with significant challenges. The first major hurdle is language—most content is in Korean, and machine translation often distorts nuance and meaning. Without proper localization, businesses may misread sentiment or fail to capture market intent.
Secondly, Naver does not follow standard web architectures used by Western platforms. Dynamic content rendering, AJAX-based loading, and DOM obfuscation make it harder to extract structured data. This makes Structured Data Extraction from Naver a highly specialized task.
Moreover, Naver restricts third-party access via public APIs, especially for shopping and blog data. Without dedicated Naver Data Scraping Services, valuable consumer signals remain hidden. Manual research is time-consuming and prone to error, especially in fast-paced sectors like tech or fashion.
Solutions like Naver Product Listings Extraction and Korean Market Data from Naver help overcome these hurdles. They automate data collection while preserving language integrity and platform structure, enabling companies to make data-driven decisions in real time.
Common Market Research Challenges in South Korea
Entering the South Korean market offers lucrative opportunities—but only if you truly understand its digital ecosystem. With Naver dominating the online landscape and consumer behaviors rapidly evolving, companies face multiple research hurdles that traditional tools simply can’t overcome. Below are four of the most persistent challenges and how they relate to Naver Data Scraping Services and modern market intelligence solutions.
1. Lack of Transparent, Localized Data
South Korean consumers rely primarily on Naver for search, shopping, reviews, and blog content. However, much of this data is isolated within the Naver ecosystem and is presented in Korean, making it inaccessible to non-native teams. International analytics platforms rarely index or translate this data effectively, which creates a transparency gap in understanding customer sentiment, buying patterns, or regional preferences.
Naver Data Extraction Services help bridge this gap by pulling localized, structured content directly from Naver’s various services. These services include blogs, reviews, Q&A, and price listings—critical for building buyer personas and validating product-market fit.
2. Difficulty in Tracking Consumer Behavior on Korean Platforms
Global brands often struggle to analyze how Korean users behave online. User journeys, content engagement, product interest, and brand perception are all filtered through Naver’s proprietary logic and interface. Since South Korean consumers don’t follow the same funnel patterns as Western audiences, applying generic Google Analytics data can be misleading.
To solve this, companies can Scrape Naver Search Results and user activity across blog posts, Q&A interactions, and shopping reviews. This provides insight into what users are searching, how they talk about brands, and how they compare alternatives—all in a culturally contextualized environment.
3. Inaccessibility of Competitor and Trend Data Without Automation
Monitoring competitor strategies and trending products is essential in Korea’s competitive sectors like tech, fashion, and FMCG. Yet, manual tracking across Naver’s platforms is time-consuming, limited in scope, and often outdated by the time reports are compiled.
Automated Naver Market Data Collection tools solve this by continuously extracting real-time data from product listings, reviews, and even sponsored content. With automated tracking, businesses can monitor pricing changes, product launches, campaign engagement, and user sentiment—all without lifting a finger.
4. Rapidly Shifting Market Trends Requiring Real-Time Insights
South Korea’s market is fast-paced—driven by pop culture, tech releases, and viral trends. A delay in understanding these shifts can lead to lost opportunities or misaligned marketing strategies. Businesses need up-to-the-minute insights, not static reports.
That’s where Real-Time Naver Data Scraping comes into play. It captures live updates across Naver Search, blogs, and product listings—allowing for trend detection, sentiment tracking, and campaign optimization in real time. This helps brands stay relevant, responsive, and ahead of competitors.
Traditional market research tools cannot provide the level of localization, speed, or data granularity needed to thrive in South Korea. Leveraging Naver Data Scraping Services enables companies to bypass these limitations and build smarter, culturally-aligned strategies based on real-time, structured data.
How Naver Data Scraping Services Address These Challenges?

To stay competitive in South Korea’s fast-moving digital ecosystem, businesses must move beyond outdated or manual research methods. Modern Naver Web Data Services allow companies to automate intelligence gathering, extract relevant localized data, and instantly respond to consumer behavior shifts. Here’s how Naver Data Scraping Services tackle the core challenges highlighted earlier:
1. Real-Time Data Extraction from Naver’s Core Services
Timely decision-making depends on instant access to market signals. With Structured Data Extraction from Naver, companies can pull real-time insights from critical services like Naver Search, Blogs, Shopping, and KnowledgeiN (Q&A). This means tracking product reviews, brand mentions, and consumer questions as they happen.
By using Korean Market Data from Naver, brands gain up-to-the-minute visibility on consumer sentiment and behavioral patterns. For example, when a product goes viral on Naver Blogs, real-time scraping helps marketing teams align campaigns instantly, avoiding missed windows of opportunity.
2. Automated Monitoring of Trends, Reviews, and Consumer Sentiment
Manually scanning Naver Blogs or Q&A pages for customer feedback is inefficient and often incomplete. Naver Web Data Services automate this process, aggregating mentions, keywords, and sentiment indicators across thousands of posts.
Using Naver Competitor Analysis Solutions, businesses can also track how users are talking about rival brands, including what features customers like or criticize. Combined with sentiment scoring and review analysis, this automation provides a 360° view of market perception.
3. Competitive Pricing Analysis from Naver Shopping
South Korean e-commerce is hyper-competitive, with product listings and pricing strategies constantly changing. Naver Product Listings Extraction provides structured data from Naver Shopping, enabling businesses to monitor competitors’ pricing models, discount trends, and stock availability.
Naver Price Intelligence Services automate this data flow, allowing brands to dynamically adjust their pricing in response to real-time competitor behavior. Whether you’re launching a product or running a promotion, staying ahead of market pricing can directly boost conversions and ROI.
4. Regional Keyword and Content Trend Tracking for Local Targeting
SEO and content marketing strategies in Korea must be based on local search behavior—not Western keyword databases. Naver Competitor Analysis Solutions and Korean Market Data from Naver help identify trending topics, search queries, and blog discussions specific to South Korean consumers.
By scraping Naver Search and related services, businesses can discover how users phrase questions, which products they explore, and what content drives engagement. This intelligence informs ad copy, landing pages, and product descriptions that feel native and resonate locally.
5. Language and Format Normalization for Global Research Teams
The Korean language and Naver’s content structure present localization challenges for global teams. Structured Data Extraction from Naver not only captures data but also formats and translates it for integration into global dashboards, CRMs, or analytics tools.
Through services like Naver Data Scraping Services, raw Korean-language content is standardized, categorized, and optionally translated—allowing non-Korean teams to run multilingual analyses without distortion or delay. This streamlines reporting and collaboration across international departments.
Businesses that leverage Naver Product Listings Extraction, Naver Price Intelligence Services, and Naver Competitor Analysis Solutions can unlock rich, real-time market insights tailored for the South Korean landscape. With automated scraping, localized intelligence, and global-ready formats, Actowiz Solutions enables next-gen research on the most critical Korean platform—Naver.
#Market Data Collection tools#Competitor Analysis Solutions#Price Intelligence Services#real-time market insights
0 notes
Text
Data Analytics Services in the USA – Empowering Business Growth with Data
In today’s digital age, data is a treasure trove of opportunities waiting to be unlocked. Data analytics services in the USA have become a critical aspect of modern business strategy, providing companies with powerful insights that help shape decisions and improve performance. Whether it’s predictive modeling, optimizing marketing efforts, or understanding customer behavior, businesses in the USA are relying on data analytics to drive innovation and gain a competitive edge.
Why Data Analytics Services in the USA Are Crucial for Business Success
With the explosion of big data, many organizations struggle to derive value from it. This is where data analytics services in the USA come into play. By employing advanced algorithms, machine learning models, and visualization tools, businesses can translate complex data into meaningful patterns and trends that reveal opportunities and threats. Through accurate analysis, companies gain an in-depth understanding of their customers, markets, and competitors.
✅ Transforming Raw Data into Actionable Insights Data analytics services are designed to help organizations extract value from vast amounts of raw data. From tracking user interactions on websites to monitoring supply chain processes, data analytics services in the USA empower businesses to streamline operations and enhance customer experience.
Types of Data Analytics Services in the USA:
Descriptive Analytics – Helps organizations understand past events by analyzing historical data. It's essential for generating reports and monitoring business health.
Diagnostic Analytics – Identifies the reasons behind specific business events or issues. For example, why sales declined during a particular quarter.
Predictive Analytics – Uses historical data to predict future trends and behaviors. It helps businesses anticipate customer needs and prepare for upcoming market changes.
Prescriptive Analytics – Provides actionable recommendations based on predictive analytics. It helps businesses know not just what will happen, but also what they should do about it.
Advanced Tools and Techniques Used in Data Analytics Services in the USA
Many data analytics services in the USA are powered by cutting-edge technologies such as Artificial Intelligence (AI), Machine Learning (ML), and Natural Language Processing (NLP). These tools allow for highly accurate and scalable analytics. Some of the most popular tools and software used include:
Tableau & Power BI – for visualizing complex data in a simple, easy-to-understand format
R & Python – Programming languages used for statistical analysis and machine learning models
SQL Databases – Used for structured data querying
Google Analytics & SEMrush – Popular for digital marketing insights
The Business Impact of Data Analytics Services in the USA
Data analytics isn’t just about numbers; it’s about making smarter decisions that drive tangible business results. By implementing data analytics services in the USA, companies can:
Optimize marketing strategies and target the right audience
Predict sales trends and prepare for market shifts
Improve operational efficiency by identifying inefficiencies
Personalize the customer experience, enhancing engagement and loyalty
Real-World Examples of Successful Data Analytics Implementation
Netflix uses predictive analytics to suggest shows and movies tailored to individual preferences, leading to increased user engagement and retention.
Amazon leverages customer data to provide personalized product recommendations and streamline its supply chain, improving customer satisfaction and reducing delivery times.
Conclusion
As businesses navigate an increasingly data-heavy world, data analytics services in the USA are no longer optional—they’re a competitive necessity. The right data analytics strategies empower businesses to unlock insights, predict trends, optimize processes, and ultimately drive long-term growth. If your business is ready to evolve with data, now is the time to implement analytics that fuel success.
Contact Information:
Address: Plot No 9, Sarwauttam Complex, Manwakheda Road, Anand Vihar, Behind Vaishali Apartment, Sector 4, Hiran Magri, Udaipur, Rajasthan 313002
Phone: (+91) 77278 08007, (+91) 95713 08737
Email: [email protected]
0 notes