
Mechanical Engineering 2019 | En-route Computer Science Master's | Professional-Academic-Shitposting Blog | violently gay | Trans Hacker Girl
Don't wanna be here? Send us removal request.
Statistics
We looked inside some of the posts by robotics-enthusiast and here's what we found interesting.
Average Info
Notes Per Post
173K
Likes Per Post
98K
Reblog Per Post
75K
Reply Per Post
163
Time Between Posts
2 months
Number of Posts By Type
Text
10
Photo
4
Link
2
Note
1
Last Seen Tumblr Blogs





Fun Fact
69% of Tumblr users are millennials.
Text
I GOT INTO GRAD SCHOOL
I GOT INTO GRAD SCHOOL #gatech #grad
11 notes
·
View notes
Photo

I've updated some backend scripts in my app to pull new data from #nytimes automatically. It is terrifying. North Dakota is currently at 10 % of their population affected by COVID-19 and it is exponentially increasing. Deaths are low but the beds are starting to get to capacity.
Data Visualization: Heroku
13 notes
·
View notes

Photo

i did transfer learning on gpt-2 on my own conversation history. needless to say it has been a smashing success
92 notes
·
View notes
Text
A PCA visualization of my chat history where words and word phrases are vectorized and compared via cosine similarity
It's kind of gay
171 notes
·
View notes
Photo

Using a linear algebra thing, you can contain a lot of the data in an image by saving only the numbers on the diagonal.
The image 540x540. I am using a concept called 'Singular Value Decomposition' to break up a matrix into 3 parts, bottom triangle, upper triangle, and the diagonal as 3 separate matrices
Then for each iteration between (1, 540), I remove one of those features and then recombine the matrices through matrix multiplication
You lose like.... 90 % of the data in the image by removing 10 entries in the diagonal
This means image data can be compressed even further and you don’t lose much meaning if you keep the diagonals intact
Some reading if you are interested: https://en.wikipedia.org/wiki/Singular_value_decomposition
6 notes
·
View notes
Link
A guide I wrote to getting CUDA to work on your NVIDIA machines for Machine Learning and Data Science
5 notes
·
View notes
Link
HI I’M NOT DEAD. I’ve been busy, dealing with COVID, trying to get a job, and realizing I am hella unemployable in this economy. My grad School dreams are on pause for now, and I’m currently writing blogs over on Medium while in a Data Science Bootcamp at General Assembly. Please connect with me! (it’s a face reveal uwu). Feel free to reach out to me via medium, linkedin, or github, and let me know if I’ve been able to inspire you or not. -Love, Vivi September 14, 2020
1 note
·
View note
Text
Research Update
I've been busy in the background doing neural net stuff. Here is what I've been doing all in a really pretty graph:
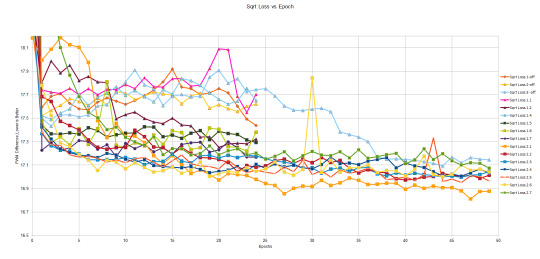
See here for a better copy:
Each line represents a training session. Each dot represents an epoch. An epoch is a calculation where the dataset is sent forward to update the weights of the network. (roughly that's how I understand it right now)
Reminder: a neural network can be mentally visualized as a multi dimensional linear algebra equation where simple calculations (multiplication based on a weight) are done on matrices to expand and reduce them.
eg: w1x + w2y + w3z = output
Where {w2, w2, w3} are weights for each "layer" of the equation and {x, y, z} are the type of layer (such as a pooling, convolutional, fully connected) and give instructions on what kind of calculation should be done to the given matrix.
In my case, the matrix is 3xb dimensional having 3 components (red, blue, green) per image and assigning b to be the number of imaged fed into the network at a time. I've varied them in powers of 2 from 2 to 128. I've chosen 2 because it's easy to remember and I can't go past 128 because my computer runs out of memory. (20GB of RAM is like, nothing)
Right now I'm varying epoch lengths, weight initialization: normal distribution and Xavier Uniform.
See here for more information:
For those who aren't too familiar with the process of machine learning, I'm essentially taking shots into the dark and seeing what sticks.
My current neural network structure is: 320x240 input, 1 pooling layer, 5 convolutional layers, 4 fully connected layers, 2 outputs. It's a very small network.
Y axis is the square root of the Mean Squared Loss from what my neural net outputs against what the actual number is (the Root Mean Squared Error, RMSE)
This is from statistics;"Mean Squared Error". It is an average of the squares of the errors, the average squared differences between estimated values and what is estimated. Values closer to zero are better, and is usually always positive.
MSE is the second moment of the error (about the origin) , and incorporates the variance of the estimator (the range of estimates from one data sample to another) and the bias (how far off the average estimated value is from truth, in this case my inputs).
Taking that into account, the graph shows the RSME and I can interpret it as the standard error because it is an unbiased estimator.
My data inputs are a 320x240 image and two numbers representing motor instructions for a DC motor normalized from (-400,400).
The plots represent what kind of error I get each training cycle (it seems to get around 17 PWM for now).
It means right now I have a neat little robot brain that can theoretically navigate hallways if I can implement pytorch into ROS (robot operating system).
Sources: Wikipedia
6 notes
·
View notes
Text
Shout-out for art
I had a wonderful friend ask if I wanted a cute monster for my blog and she drew the most adorable robot I've ever seen.

-Likes to take care of plants
-solar panel for a hat
-doesn't understand clothes but wears things like scarves and ribbons anyway
It's my new profile picture!
Sounds like me and how I'm struggling to get to graduate school
@thel3tterm
18 notes
·
View notes
Text
Small update
I've registered for the GRE
October 26 2019
I'm proud but also out by $205 USD for a freaking test
3 notes
·
View notes
Note
NEVER DO AN UNPAID INTERNSHIP YOUR LABOR IS BEING STOLEN
unpaid internships are unacceptable??
You are worth AT THE VERY LEAST whatever it costs to support a happy and healthy lifestyle. You should be paid for your time. I understand unpaid ints offer opportunities to be paid, but you have to be really fucking certain something good is going to come out if it.
Also, I’ve been hearing about “you can’t have unpaid interns adding value to your company, it’s illegal” and quite frankly either you’re being taken advantage of or you’ll have little actual experience, which both suck.
32 notes
·
View notes
Text
Step 1 Grad School: GRE
I took a free practice exam and GOD THEY'RE BRUTAL. 2.5 hours of testing

Big oof

I'm a little under average for all test takers

And I have a bit more to go for engineering grad school

And that's my target school. y i k e s
17 notes
·
View notes
Text
Cool engineering stuff:
Sterling engine powered by sunlight

21 notes
·
View notes
Photo




“our work should equip the next generation of women to outdo us in every field this is the legacy we’ll leave.”
171K notes
·
View notes
Text
this is also an asethetic 😂
No time to worry about Artificial Intelligence, too busy dealing with Real Organic Stupid.
875 notes
·
View notes