#AI in Data Science
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
Average visit duration of Tumblr.com is 10 mins and 25 secs.
Text
Data Science Careers: Your Path to Success in India

Data is the new oil in the rapidly changing landscape of digital opportunities today. From retail to health, there is a huge swarm of data with which companies want to analyze and form decisions, get insight into probable trends, operationalize, and strategize. This dependence on data has generated an immense demand for people who can interpret the raw data into insightful information — the Data scientists. Data science professionals are thus vital in an environment of fast-paced technology growth and are thus very much sought after if you are willing to work in a lucrative, intellectually stimulating, and impactful profession. Herein lies a huge opportunity for data science conversion in India.
Why Data Science is Booming in India
With the ongoing transformation of India's tech industry, growth is being driven by digital initiatives and newer technologies. This should create opportunities for the data scientist. Here lies a few reasons to opt for a career in data science:
High Demand and Less Supply:The demand for data scientists will probably never be fulfilled. This gap has led to high remuneration with a plethora of opportunities spread across industries.
Varied Industry Applications: All industries require data scientists. One can work from finance (fraud detection, risk assessment) to retail (customer behavior analysis, personalized recommendations), from healthcare (disease prediction, drug discovery) to manufacturing (predictive maintenance). Hence, your skills will be highly transferable.
Impactful Work: Data scientists play a crucial role in solving real-world problems. Your work can lead to significant improvements in efficiency, profitability, and even societal well-being.
Continuous Learning & Growth: The field of data science is constantly evolving. This dynamic nature ensures that your learning journey never stops, keeping your career fresh and exciting.
Essential Skills for Aspiring Data Scientists
From the start, for one to embark on the track of data science with a flourishing future, the following key areas need to be staked in a strong foundation:
Programming Proficiency: Python and R are the languages associated with data science. Python classes in Ahmedabad, for instance, are highly sought after because of Python's widespread use in libraries with data manipulation, analysis, and machine learning functionalities (NumPy, Pandas, Scikit-learn, TensorFlow, Keras).
Mathematics & Statistics: One should understand linear algebra, calculus, probability, and statistical modeling to interpret the data and establish concrete models.
Machine Learning & Deep Learning: With increased knowledge of implementations of numerous algorithms, machine learning modeling from regression, classification to clustering, and frameworks for deep learning, namely Tensorflow and PyTorch, one now stands to make predictive models.
Data Wrangling & Manipulation: Ability to clean, transform, and prepare messy raw data is a fundamental ability that generally occupies much of a data scientist's time.
Data Visualization: The communication of complex insights in a clear and comprehensible fashion allows effective communication through software like Tableau, Power BI, and Matplotlib.
Domain Knowledge: Having an understanding of the industry or business background of the data you are dealing with will help you ask the right questions and get relevant insights.
Your Success Path: Education and Training
A background in mathematics, statistics, computer science, or engineering helps but is not mandatory. Many aspiring data scientists come from varying backgrounds and acquire the necessary skills by undergoing intensive training.
One should join the best data science courses in Ahmedabad with Python to gain some real-time experience. Courses that deal with Data Science with Python, AI, Machine Learning, Deep Learning, and Analytics Tools will help you learn the complete set of skills required by the industry. Look into the institutes that promote practical-oriented learning, have great faculty, and provide career support.
Taking part in projects that could be included in a portfolio, contributing to open-source projects, and taking part in hackathons will further enhance your profile and provide evidence of your skills and practical application to prospective employers.
Final Wrap-Up
The demand for data scientists in India shall keep on rising, making it averse to a promising career. Join the correct education, polishing your skills in programming, statistics, learning-making, and data visualization, and you can go to become a successful and rewarding career in data science that will aid India's data-powered future.
Contact us
Call now on +91 9825618292
Visit Our Website: http://tccicomputercoaching.com/
#AI in Data Science#Data Science Careers India#Data Science Courses Ahmedabad#Python Programming Classes Ahmedabad#TCCI - Tririd Computer Coaching Institute
0 notes
Text

Step into the future of data science with Explainable AI. Uncover how these transparent models are enhancing our understanding of AI decisions, making complex algorithms more accessible, and revolutionizing the way data scientists approach. https://bit.ly/4cxvMgi
0 notes
Text
The surprising truth about data-driven dictatorships

Here’s the “dictator’s dilemma”: they want to block their country’s frustrated elites from mobilizing against them, so they censor public communications; but they also want to know what their people truly believe, so they can head off simmering resentments before they boil over into regime-toppling revolutions.
These two strategies are in tension: the more you censor, the less you know about the true feelings of your citizens and the easier it will be to miss serious problems until they spill over into the streets (think: the fall of the Berlin Wall or Tunisia before the Arab Spring). Dictators try to square this circle with things like private opinion polling or petition systems, but these capture a small slice of the potentially destabiziling moods circulating in the body politic.
Enter AI: back in 2018, Yuval Harari proposed that AI would supercharge dictatorships by mining and summarizing the public mood — as captured on social media — allowing dictators to tack into serious discontent and diffuse it before it erupted into unequenchable wildfire:
https://www.theatlantic.com/magazine/archive/2018/10/yuval-noah-harari-technology-tyranny/568330/
Harari wrote that “the desire to concentrate all information and power in one place may become [dictators] decisive advantage in the 21st century.” But other political scientists sharply disagreed. Last year, Henry Farrell, Jeremy Wallace and Abraham Newman published a thoroughgoing rebuttal to Harari in Foreign Affairs:
https://www.foreignaffairs.com/world/spirals-delusion-artificial-intelligence-decision-making
They argued that — like everyone who gets excited about AI, only to have their hopes dashed — dictators seeking to use AI to understand the public mood would run into serious training data bias problems. After all, people living under dictatorships know that spouting off about their discontent and desire for change is a risky business, so they will self-censor on social media. That’s true even if a person isn’t afraid of retaliation: if you know that using certain words or phrases in a post will get it autoblocked by a censorbot, what’s the point of trying to use those words?
The phrase “Garbage In, Garbage Out” dates back to 1957. That’s how long we’ve known that a computer that operates on bad data will barf up bad conclusions. But this is a very inconvenient truth for AI weirdos: having given up on manually assembling training data based on careful human judgment with multiple review steps, the AI industry “pivoted” to mass ingestion of scraped data from the whole internet.
But adding more unreliable data to an unreliable dataset doesn’t improve its reliability. GIGO is the iron law of computing, and you can’t repeal it by shoveling more garbage into the top of the training funnel:
https://memex.craphound.com/2018/05/29/garbage-in-garbage-out-machine-learning-has-not-repealed-the-iron-law-of-computer-science/
When it comes to “AI” that’s used for decision support — that is, when an algorithm tells humans what to do and they do it — then you get something worse than Garbage In, Garbage Out — you get Garbage In, Garbage Out, Garbage Back In Again. That’s when the AI spits out something wrong, and then another AI sucks up that wrong conclusion and uses it to generate more conclusions.
To see this in action, consider the deeply flawed predictive policing systems that cities around the world rely on. These systems suck up crime data from the cops, then predict where crime is going to be, and send cops to those “hotspots” to do things like throw Black kids up against a wall and make them turn out their pockets, or pull over drivers and search their cars after pretending to have smelled cannabis.
The problem here is that “crime the police detected” isn’t the same as “crime.” You only find crime where you look for it. For example, there are far more incidents of domestic abuse reported in apartment buildings than in fully detached homes. That’s not because apartment dwellers are more likely to be wife-beaters: it’s because domestic abuse is most often reported by a neighbor who hears it through the walls.
So if your cops practice racially biased policing (I know, this is hard to imagine, but stay with me /s), then the crime they detect will already be a function of bias. If you only ever throw Black kids up against a wall and turn out their pockets, then every knife and dime-bag you find in someone’s pockets will come from some Black kid the cops decided to harass.
That’s life without AI. But now let’s throw in predictive policing: feed your “knives found in pockets” data to an algorithm and ask it to predict where there are more knives in pockets, and it will send you back to that Black neighborhood and tell you do throw even more Black kids up against a wall and search their pockets. The more you do this, the more knives you’ll find, and the more you’ll go back and do it again.
This is what Patrick Ball from the Human Rights Data Analysis Group calls “empiricism washing”: take a biased procedure and feed it to an algorithm, and then you get to go and do more biased procedures, and whenever anyone accuses you of bias, you can insist that you’re just following an empirical conclusion of a neutral algorithm, because “math can’t be racist.”
HRDAG has done excellent work on this, finding a natural experiment that makes the problem of GIGOGBI crystal clear. The National Survey On Drug Use and Health produces the gold standard snapshot of drug use in America. Kristian Lum and William Isaac took Oakland’s drug arrest data from 2010 and asked Predpol, a leading predictive policing product, to predict where Oakland’s 2011 drug use would take place.
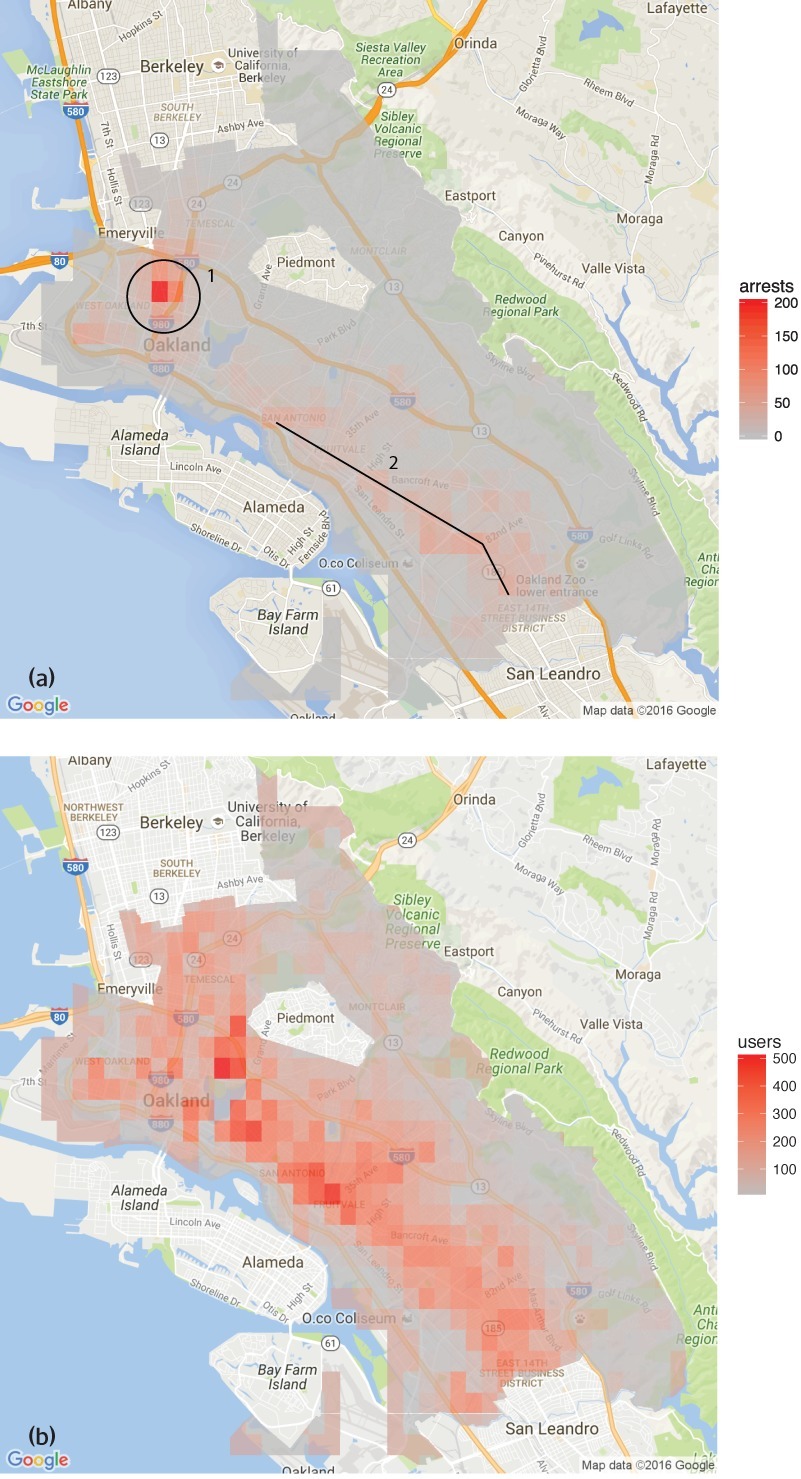
[Image ID: (a) Number of drug arrests made by Oakland police department, 2010. (1) West Oakland, (2) International Boulevard. (b) Estimated number of drug users, based on 2011 National Survey on Drug Use and Health]
Then, they compared those predictions to the outcomes of the 2011 survey, which shows where actual drug use took place. The two maps couldn’t be more different:
https://rss.onlinelibrary.wiley.com/doi/full/10.1111/j.1740-9713.2016.00960.x
Predpol told cops to go and look for drug use in a predominantly Black, working class neighborhood. Meanwhile the NSDUH survey showed the actual drug use took place all over Oakland, with a higher concentration in the Berkeley-neighboring student neighborhood.
What’s even more vivid is what happens when you simulate running Predpol on the new arrest data that would be generated by cops following its recommendations. If the cops went to that Black neighborhood and found more drugs there and told Predpol about it, the recommendation gets stronger and more confident.
In other words, GIGOGBI is a system for concentrating bias. Even trace amounts of bias in the original training data get refined and magnified when they are output though a decision support system that directs humans to go an act on that output. Algorithms are to bias what centrifuges are to radioactive ore: a way to turn minute amounts of bias into pluripotent, indestructible toxic waste.
There’s a great name for an AI that’s trained on an AI’s output, courtesy of Jathan Sadowski: “Habsburg AI.”
And that brings me back to the Dictator’s Dilemma. If your citizens are self-censoring in order to avoid retaliation or algorithmic shadowbanning, then the AI you train on their posts in order to find out what they’re really thinking will steer you in the opposite direction, so you make bad policies that make people angrier and destabilize things more.
Or at least, that was Farrell(et al)’s theory. And for many years, that’s where the debate over AI and dictatorship has stalled: theory vs theory. But now, there’s some empirical data on this, thanks to the “The Digital Dictator’s Dilemma,” a new paper from UCSD PhD candidate Eddie Yang:
https://www.eddieyang.net/research/DDD.pdf
Yang figured out a way to test these dueling hypotheses. He got 10 million Chinese social media posts from the start of the pandemic, before companies like Weibo were required to censor certain pandemic-related posts as politically sensitive. Yang treats these posts as a robust snapshot of public opinion: because there was no censorship of pandemic-related chatter, Chinese users were free to post anything they wanted without having to self-censor for fear of retaliation or deletion.
Next, Yang acquired the censorship model used by a real Chinese social media company to decide which posts should be blocked. Using this, he was able to determine which of the posts in the original set would be censored today in China.
That means that Yang knows that the “real” sentiment in the Chinese social media snapshot is, and what Chinese authorities would believe it to be if Chinese users were self-censoring all the posts that would be flagged by censorware today.
From here, Yang was able to play with the knobs, and determine how “preference-falsification” (when users lie about their feelings) and self-censorship would give a dictatorship a misleading view of public sentiment. What he finds is that the more repressive a regime is — the more people are incentivized to falsify or censor their views — the worse the system gets at uncovering the true public mood.
What’s more, adding additional (bad) data to the system doesn’t fix this “missing data” problem. GIGO remains an iron law of computing in this context, too.
But it gets better (or worse, I guess): Yang models a “crisis” scenario in which users stop self-censoring and start articulating their true views (because they’ve run out of fucks to give). This is the most dangerous moment for a dictator, and depending on the dictatorship handles it, they either get another decade or rule, or they wake up with guillotines on their lawns.
But “crisis” is where AI performs the worst. Trained on the “status quo” data where users are continuously self-censoring and preference-falsifying, AI has no clue how to handle the unvarnished truth. Both its recommendations about what to censor and its summaries of public sentiment are the least accurate when crisis erupts.
But here’s an interesting wrinkle: Yang scraped a bunch of Chinese users’ posts from Twitter��— which the Chinese government doesn’t get to censor (yet) or spy on (yet) — and fed them to the model. He hypothesized that when Chinese users post to American social media, they don’t self-censor or preference-falsify, so this data should help the model improve its accuracy.
He was right — the model got significantly better once it ingested data from Twitter than when it was working solely from Weibo posts. And Yang notes that dictatorships all over the world are widely understood to be scraping western/northern social media.
But even though Twitter data improved the model’s accuracy, it was still wildly inaccurate, compared to the same model trained on a full set of un-self-censored, un-falsified data. GIGO is not an option, it’s the law (of computing).
Writing about the study on Crooked Timber, Farrell notes that as the world fills up with “garbage and noise” (he invokes Philip K Dick’s delighted coinage “gubbish”), “approximately correct knowledge becomes the scarce and valuable resource.”
https://crookedtimber.org/2023/07/25/51610/
This “probably approximately correct knowledge” comes from humans, not LLMs or AI, and so “the social applications of machine learning in non-authoritarian societies are just as parasitic on these forms of human knowledge production as authoritarian governments.”

The Clarion Science Fiction and Fantasy Writers’ Workshop summer fundraiser is almost over! I am an alum, instructor and volunteer board member for this nonprofit workshop whose alums include Octavia Butler, Kim Stanley Robinson, Bruce Sterling, Nalo Hopkinson, Kameron Hurley, Nnedi Okorafor, Lucius Shepard, and Ted Chiang! Your donations will help us subsidize tuition for students, making Clarion — and sf/f — more accessible for all kinds of writers.
Libro.fm is the indie-bookstore-friendly, DRM-free audiobook alternative to Audible, the Amazon-owned monopolist that locks every book you buy to Amazon forever. When you buy a book on Libro, they share some of the purchase price with a local indie bookstore of your choosing (Libro is the best partner I have in selling my own DRM-free audiobooks!). As of today, Libro is even better, because it’s available in five new territories and currencies: Canada, the UK, the EU, Australia and New Zealand!
[Image ID: An altered image of the Nuremberg rally, with ranked lines of soldiers facing a towering figure in a many-ribboned soldier's coat. He wears a high-peaked cap with a microchip in place of insignia. His head has been replaced with the menacing red eye of HAL9000 from Stanley Kubrick's '2001: A Space Odyssey.' The sky behind him is filled with a 'code waterfall' from 'The Matrix.']
Image: Cryteria (modified) https://commons.wikimedia.org/wiki/File:HAL9000.svg
CC BY 3.0 https://creativecommons.org/licenses/by/3.0/deed.en
—
Raimond Spekking (modified) https://commons.wikimedia.org/wiki/File:Acer_Extensa_5220_-_Columbia_MB_06236-1N_-_Intel_Celeron_M_530_-_SLA2G_-_in_Socket_479-5029.jpg
CC BY-SA 4.0 https://creativecommons.org/licenses/by-sa/4.0/deed.en
—
Russian Airborne Troops (modified) https://commons.wikimedia.org/wiki/File:Vladislav_Achalov_at_the_Airborne_Troops_Day_in_Moscow_%E2%80%93_August_2,_2008.jpg
“Soldiers of Russia” Cultural Center (modified) https://commons.wikimedia.org/wiki/File:Col._Leonid_Khabarov_in_an_everyday_service_uniform.JPG
CC BY-SA 3.0 https://creativecommons.org/licenses/by-sa/3.0/deed.en
#pluralistic#habsburg ai#self censorship#henry farrell#digital dictatorships#machine learning#dictator's dilemma#eddie yang#preference falsification#political science#training bias#scholarship#spirals of delusion#algorithmic bias#ml#Fully automated data driven authoritarianism#authoritarianism#gigo#garbage in garbage out garbage back in#gigogbi#yuval noah harari#gubbish#pkd#philip k dick#phildickian
833 notes
·
View notes
Text
i hate you artificial intelligence i hate you chat gpt i hate you copilot i hate you meta ai i hate you "i'll look it up on chat gpt" i hate you photoshop generative fill i hate you "I'll just ask ai to summarize this" i hate you "in 5 years everything will use ai" I HATE YOU LOSS OF THE HUMAN TOUCH I HATE YOU COLD UNFEELING MACHINE
#julia.txt#im losing my MINDDDD#obligatory disclaimer as i am in science : this js about generative ai i love u ai for data analysis
31 notes
·
View notes
Text
robot / AI characters in media are always my favorite and idk why?? even if theyre “evil” i still find them the most interesting. im always drawn towards books, games, and film that have robotic main characters.
#hal 9000#am allied mastercomputer#inscryption p03#data soong#wall e#i robot#science fiction#robots#ai
101 notes
·
View notes
Text
comp sci majors who also hate generative AI reblog please I need to know some people in my field are sane 😭
#post inspired by the fuckass ai bro in my summer class#like that shit should be processing human-unfriendly data#not making “art”#analytical ai is so fucking cool it's literally how we discovered the higgs boson#why can't we focus on that instead of the Art Theft Machine#anti ai#generative ai#computer science#the raccoons speak
5 notes
·
View notes
Text
Cornell quantum researchers have detected an elusive phase of matter, called the Bragg glass phase, using large volumes of X-ray data and a new machine learning data analysis tool. The discovery settles a long-standing question of whether this almost–but not quite–ordered state of Bragg glass can exist in real materials. The paper, "Bragg glass signatures in PdxErTe3 with X-ray diffraction Temperature Clustering (X-TEC)," is published in Nature Physics. The lead author is Krishnanand Madhukar Mallayya, a postdoctoral researcher in the Department of Physics in the College of Arts and Sciences (A&S). Eun-Ah Kim, professor of physics (A&S), is the corresponding author. The research was conducted in collaboration with scientists at Argonne National Laboratory and at Stanford University.
Continue Reading.
43 notes
·
View notes
Text
Nvidia is now offering free AI courses.
👉 AI for All: From Basics to GenAI Practice
https://lnkd.in/drnju4C7
👉 Getting Started with AI
https://lnkd.in/dCAckqfF
👉 Generative AI Explained
https://lnkd.in/dDe5hBks
👉 Accelerate data science workflows
https://lnkd.in/dxB4SpK7
👉 Building a Brain in 10 Minutes
https://lnkd.in/d93H5BYr
6 notes
·
View notes
Text
Apparently today is international cat day!



I'd like to paint or sculpt more cats. But probably not ~100 at once, as in the 2nd artwork.
1. crop of: https://www.olenashmahalo.com/project/animals-2023 2. crops of: https://www.olenashmahalo.com/project/herding-data
#cats#SciArt#ScienceIllustration#NoAI#natureintheory#olena shmahalo#science illustration#illustration#art#portfolio#cat art#digital painting#human art#human artists#No AI#CSP#ragdoll cat#neuroscience#big data
17 notes
·
View notes
Text
To be clear, AI can drive scientific breakthroughs. My concern is about their magnitude and frequency. Has AI really shown enough potential to justify such a massive shift in talent, training, time, and money away from existing research directions and towards a single paradigm?
Every field of science is experiencing AI differently, so we should be cautious about making generalizations. I’m convinced, however, that some of the lessons from my experience are broadly applicable across science:
AI adoption is exploding among scientists less because it benefits science and more because it benefits the scientists themselves.
Because AI researchers almost never publish negative results, AI-for-science is experiencing survivorship bias.
The positive results that get published tend to be overly optimistic about AI’s potential.
As a result, I’ve come to believe that AI has generally been less successful and revolutionary in science than it appears to be.
Ultimately, I don’t know whether AI will reverse the decades-long trend of declining scientific productivity and stagnating (or even decelerating) rates of scientific progress. I don’t think anyone does. But barring major (and in my opinion unlikely) breakthroughs in advanced AI, I expect AI to be much more a normal tool of incremental, uneven scientific progress than a revolutionary one.
3 notes
·
View notes
Text
Perish (love how Tumblr decided that not only is it the queer site that constantly suppresses queer people, but now they’re happy to get desperate users (many of which are minors) to get their data harvested just like that koko one! Oh how they care.) I can’t wait to see the lawsuits.
#expedite your meeting with god posthaste whoever came up with this#are you harvesting data like the koko one does :]#I can’t wait until they’re sued into oblivion and this also includes current tumblr staff#vena vents#not art#trying to get mentally unwell people who cannot evaluate the situation or aren’t aware enough about the therapy shit#including minors I’m sure which I;m pretty sure is illegal#any kind of new ai that;s not simulating or performing some task for science and whatnot are on the shitlist until proven innocent#but this is insidious and I don’t fucking care if it;s actually queer owned advertising this is predatory
89 notes
·
View notes
Text
I'm not an extrovert. At all. In everyday life, I'm a yapper, sure, but I need someone to first assure me I am okay to yap, so I don't start conversations, even when I really want to join in sometimes! It's just the social anxiety acting up. God knows where from and why I lose a lot of my inhibitions when it comes to talking to people about music. I don't know where the confidence has suddenly sprung from. I've made a crazy amount of friends in musical circles, either just talking to people about common music or (since it is after all in music circles) talking to bands about their own music. I let out a sigh of relief any time an interaction goes well, because in truth it's going against my every instinct. I wish I could do that in everyday life
#like that's the point where we need to remind everyone around me that as much as I say#radio is 'a job'-- it's not 'my job' lol. I wish I was this interested in data science#but like. Honestly?? I'm not even a data scientist!? I answered a few questions about classical AI having come from a computer science back#background and now people are saying to me 'I know you're a data scientist and not a programmer' sir I am a computer scientist#what are you on about#and like I guess I get to google things and they're paying me so I'm not complaining but like I am not a data scientist#my biggest data scientist moment was when I asked 'do things in data science ever make sense???' and a bunch of data scientists went#'no :) Welcome to the club' ???????#why did I do a whole ass computer science degree then. Does anyone at all even want that anymore. Has everything in the realm of#computer science just been Solved. What of all the problems I learned and researched about. Which were cool. Are they just dead#Ugh the worst thing the AI hype has done rn is it has genuinely required everyone to pretend they're a data scientist#even MORE than before. I hate this#anyway; I wish I didn't hate it and I was curious and talked to many people in the field#like it's tragicomedy when every person I meet in music is like 'you've got to pursue this man you're a great interviewer blah blah blah'#and like I appreciate that this is coming from people who themselves have/are taking a chance on life#but. I kinda feel like my career does not exist anymore realistically so unless 1) commercial radio gets less shitty FAST#2) media companies that are laying off 50% of their staff miraculously stop or 3) Tom Power is suddenly feeling generous and wants#a completely unknown idiot to step into the biggest fucking culture show in the country (that I am in no way qualified for)#yeah there's very very little else. There's nothing else lol#Our country does not hype. They don't really care for who you are. f you make a decent connection with them musically they will come to you#Canada does not make heroes out of its talent. They will not be putting money into any of that. Greenlight in your dreams.#this is something I've been told (and seen) multiple times. We'll see it next week-- there are Olympic medallists returning to uni next wee#no one cares: the phrase is 'America makes celebrities out of their sportspeople'; we do not. Replace sportspeople with any public professi#Canada does not care for press about their musicians. The only reason NME sold here was because Anglophilia not because of music journalism#anyway; personal
10 notes
·
View notes
Text
one of my essays from back when i studied philosophy is being put into a good answers guide at my university<3 not one of my good ones but
#its abt the philosophy of conspiracism in the modern day. suuuuuch a blast to write#my prof told me that he was like gasping at the twists and turns of the anti vaccine movement#i was like king have you been living in this world with us. this is just the news peace and love#so fun to like talk abt the moon landing and 911 and just stream of consciousness and someone think its good#bc if i had handed that in as a poltiics paper it would be like snooze you missed these things and its not valuable bc x y z#but this dude had never heard any of it before! loved that#he was like 'to get the full 100 i would have wanted some actual philosophy content in there' and yeah true#gonna talk to the prof tho bc theres a new philosophy of AI unit#and its been running a few years i took it in my last sem of undergrad#and it was so fallacious and like dick sucking of AI engineers#i kept being like true ai or not lets talk abt how this is impacting society NOW since its being CALLED ai#and i kept getting almost failing grades#then my final exam was graded by a different prof and lo and behold it pulled my grade waaaaaaay up#so clearly my writing is. good. and my grasp of AI and the concepts is. good.#that dude was just musk pilled or smth#anyway gonna tell the head of phils to keep an eye lmao#its a core unit for data science students and it has no intellectual credit to it AT ALL imo#its like what happens when ai starts producing more ai and we get deleted from existence and i was like what abt wages girl#im the problem tho
7 notes
·
View notes
Text
Unlocking the Power of Data: Essential Skills to Become a Data Scientist

In today's data-driven world, the demand for skilled data scientists is skyrocketing. These professionals are the key to transforming raw information into actionable insights, driving innovation and shaping business strategies. But what exactly does it take to become a data scientist? It's a multidisciplinary field, requiring a unique blend of technical prowess and analytical thinking. Let's break down the essential skills you'll need to embark on this exciting career path.
1. Strong Mathematical and Statistical Foundation:
At the heart of data science lies a deep understanding of mathematics and statistics. You'll need to grasp concepts like:
Linear Algebra and Calculus: Essential for understanding machine learning algorithms and optimizing models.
Probability and Statistics: Crucial for data analysis, hypothesis testing, and drawing meaningful conclusions from data.
2. Programming Proficiency (Python and/or R):
Data scientists are fluent in at least one, if not both, of the dominant programming languages in the field:
Python: Known for its readability and extensive libraries like Pandas, NumPy, Scikit-learn, and TensorFlow, making it ideal for data manipulation, analysis, and machine learning.
R: Specifically designed for statistical computing and graphics, R offers a rich ecosystem of packages for statistical modeling and visualization.
3. Data Wrangling and Preprocessing Skills:
Raw data is rarely clean and ready for analysis. A significant portion of a data scientist's time is spent on:
Data Cleaning: Handling missing values, outliers, and inconsistencies.
Data Transformation: Reshaping, merging, and aggregating data.
Feature Engineering: Creating new features from existing data to improve model performance.
4. Expertise in Databases and SQL:
Data often resides in databases. Proficiency in SQL (Structured Query Language) is essential for:
Extracting Data: Querying and retrieving data from various database systems.
Data Manipulation: Filtering, joining, and aggregating data within databases.
5. Machine Learning Mastery:
Machine learning is a core component of data science, enabling you to build models that learn from data and make predictions or classifications. Key areas include:
Supervised Learning: Regression, classification algorithms.
Unsupervised Learning: Clustering, dimensionality reduction.
Model Selection and Evaluation: Choosing the right algorithms and assessing their performance.
6. Data Visualization and Communication Skills:
Being able to effectively communicate your findings is just as important as the analysis itself. You'll need to:
Visualize Data: Create compelling charts and graphs to explore patterns and insights using libraries like Matplotlib, Seaborn (Python), or ggplot2 (R).
Tell Data Stories: Present your findings in a clear and concise manner that resonates with both technical and non-technical audiences.
7. Critical Thinking and Problem-Solving Abilities:
Data scientists are essentially problem solvers. You need to be able to:
Define Business Problems: Translate business challenges into data science questions.
Develop Analytical Frameworks: Structure your approach to solve complex problems.
Interpret Results: Draw meaningful conclusions and translate them into actionable recommendations.
8. Domain Knowledge (Optional but Highly Beneficial):
Having expertise in the specific industry or domain you're working in can give you a significant advantage. It helps you understand the context of the data and formulate more relevant questions.
9. Curiosity and a Growth Mindset:
The field of data science is constantly evolving. A genuine curiosity and a willingness to learn new technologies and techniques are crucial for long-term success.
10. Strong Communication and Collaboration Skills:
Data scientists often work in teams and need to collaborate effectively with engineers, business stakeholders, and other experts.
Kickstart Your Data Science Journey with Xaltius Academy's Data Science and AI Program:
Acquiring these skills can seem like a daunting task, but structured learning programs can provide a clear and effective path. Xaltius Academy's Data Science and AI Program is designed to equip you with the essential knowledge and practical experience to become a successful data scientist.
Key benefits of the program:
Comprehensive Curriculum: Covers all the core skills mentioned above, from foundational mathematics to advanced machine learning techniques.
Hands-on Projects: Provides practical experience working with real-world datasets and building a strong portfolio.
Expert Instructors: Learn from industry professionals with years of experience in data science and AI.
Career Support: Offers guidance and resources to help you launch your data science career.
Becoming a data scientist is a rewarding journey that blends technical expertise with analytical thinking. By focusing on developing these key skills and leveraging resources like Xaltius Academy's program, you can position yourself for a successful and impactful career in this in-demand field. The power of data is waiting to be unlocked – are you ready to take the challenge?
3 notes
·
View notes
Text
The total lunar eclipse on March 14, 2025, will be a spectacular celestial event visible across India, Asia, Europe, Africa, and the Americas. During this event, the Moon will turn a reddish hue, creating the stunning "Blood Moon" effect.
New Scientists Awards
Nomination Link: https://newscientists.net/award-nomination/?ecategory=Awards&rcategory=Awardee
Web Visitors: https://newscientists.net/
For Enquiry: [email protected]
#sciencefather #new scientists awards #scientist #scienceinnovation #Geology #EarthScience #Precambrian #Metamorphism #ArcheanEon #JuniorScientist #PostdoctoralResearcher #LabTechnician #ResearchCoordinator #PrincipalInvestigator #ClinicalResearchCoordinator #MarketResearchAnalyst #EnvironmentalScientist #SocialScientist #EconomicResearcher #LunarEclipse2025 #TotalLunarEclipse #BloodMoon2025 #Eclipse2025 #MarchEclipse #EclipseInIndia #LunarEclipseAsia #EclipseViewing
Get Connected Here:
=================
Twitter: https://x.com/awards67811
Instagram: https://www.instagram.com/afreen202564/
Blogger: https://www.blogger.com/blog/posts/8014336030053733629?hl=en&tab=jj Pinterest: https://in.pinterest.com/scienceawards/
2 notes
·
View notes