#Airflow Python DAG example
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
The Tumblr app for Google Glass was released on May 16, 2013.
Text
Secure ETL Pipelines | Automating SFTP File Transfers and Processing with Apache Airflow
Learn how to build robust and secure ETL pipelines using Apache Airflow. This guide provides a step-by-step tutorial on automating SFTP file transfers, implementing secure file processing, and leveraging Python DAGs for efficient workflow orchestration. Discover Airflow best practices, SFTP integration techniques, and how to create a reliable file processing pipeline for your data needs. Ideal for those seeking Apache Airflow training and practical examples for automating file transfers and ETL processes.
youtube
#Airflow best practices for ETL#Airflow DAG for secure file transfer and processing#Airflow DAG tutorial#Airflow ETL pipeline#Airflow Python DAG example#Youtube
0 notes
Text
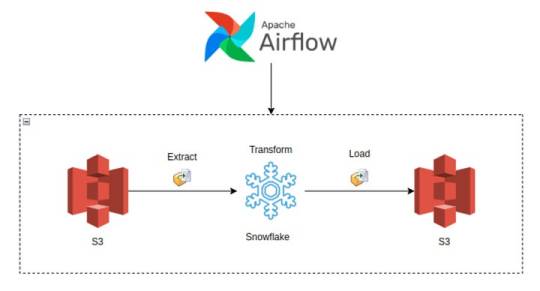
Building Data Pipelines with Snowflake and Apache Airflow

1. Introduction to Snowflake
Snowflake is a cloud-native data platform designed for scalability and ease of use, providing data warehousing, data lakes, and data sharing capabilities. Unlike traditional databases, Snowflake’s architecture separates compute, storage, and services, making it highly scalable and cost-effective. Some key features to highlight:
Zero-Copy Cloning: Allows you to clone data without duplicating it, making testing and experimentation more cost-effective.
Multi-Cloud Support: Snowflake works across major cloud providers like AWS, Azure, and Google Cloud, offering flexibility in deployment.
Semi-Structured Data Handling: Snowflake can handle JSON, Parquet, XML, and other formats natively, making it versatile for various data types.
Automatic Scaling: Automatically scales compute resources based on workload demands without manual intervention, optimizing cost.
2. Introduction to Apache Airflow
Apache Airflow is an open-source platform used for orchestrating complex workflows and data pipelines. It’s widely used for batch processing and ETL (Extract, Transform, Load) tasks. You can define workflows as Directed Acyclic Graphs (DAGs), making it easy to manage dependencies and scheduling. Some of its features include:
Dynamic Pipeline Generation: You can write Python code to dynamically generate and execute tasks, making workflows highly customizable.
Scheduler and Executor: Airflow includes a scheduler to trigger tasks at specified intervals, and different types of executors (e.g., Celery, Kubernetes) help manage task execution in distributed environments.
Airflow UI: The intuitive web-based interface lets you monitor pipeline execution, visualize DAGs, and track task progress.
3. Snowflake and Airflow Integration
The integration of Snowflake with Apache Airflow is typically achieved using the SnowflakeOperator, a task operator that enables interaction between Airflow and Snowflake. Airflow can trigger SQL queries, execute stored procedures, and manage Snowflake tasks as part of your DAGs.
SnowflakeOperator: This operator allows you to run SQL queries in Snowflake, which is useful for performing actions like data loading, transformation, or even calling Snowflake procedures.
Connecting Airflow to Snowflake: To set this up, you need to configure a Snowflake connection within Airflow. Typically, this includes adding credentials (username, password, account, warehouse, and database) in Airflow’s connection settings.
Example code for setting up the Snowflake connection and executing a query:pythonfrom airflow.providers.snowflake.operators.snowflake import SnowflakeOperator from airflow import DAG from datetime import datetimedefault_args = { 'owner': 'airflow', 'start_date': datetime(2025, 2, 17), }with DAG('snowflake_pipeline', default_args=default_args, schedule_interval=None) as dag: run_query = SnowflakeOperator( task_id='run_snowflake_query', sql="SELECT * FROM my_table;", snowflake_conn_id='snowflake_default', # The connection ID in Airflow warehouse='MY_WAREHOUSE', database='MY_DATABASE', schema='MY_SCHEMA' )
4. Building a Simple Data Pipeline
Here, you could provide a practical example of an ETL pipeline. For instance, let’s create a pipeline that:
Extracts data from a source (e.g., a CSV file in an S3 bucket),
Loads the data into a Snowflake staging table,
Performs transformations (e.g., cleaning or aggregating data),
Loads the transformed data into a production table.
Example DAG structure:pythonfrom airflow.providers.snowflake.operators.snowflake import SnowflakeOperator from airflow.providers.amazon.aws.transfers.s3_to_snowflake import S3ToSnowflakeOperator from airflow import DAG from datetime import datetimewith DAG('etl_pipeline', start_date=datetime(2025, 2, 17), schedule_interval='@daily') as dag: # Extract data from S3 to Snowflake staging table extract_task = S3ToSnowflakeOperator( task_id='extract_from_s3', schema='MY_SCHEMA', table='staging_table', s3_keys=['s3://my-bucket/my-file.csv'], snowflake_conn_id='snowflake_default' ) # Load data into Snowflake and run transformation transform_task = SnowflakeOperator( task_id='transform_data', sql='''INSERT INTO production_table SELECT * FROM staging_table WHERE conditions;''', snowflake_conn_id='snowflake_default' ) extract_task >> transform_task # Define task dependencies
5. Error Handling and Monitoring
Airflow provides several mechanisms for error handling:
Retries: You can set the retries argument in tasks to automatically retry failed tasks a specified number of times.
Notifications: You can use the email_on_failure or custom callback functions to notify the team when something goes wrong.
Airflow UI: Monitoring is easy with the UI, where you can view logs, task statuses, and task retries.
Example of setting retries and notifications:pythonwith DAG('data_pipeline_with_error_handling', start_date=datetime(2025, 2, 17)) as dag: task = SnowflakeOperator( task_id='load_data_to_snowflake', sql="SELECT * FROM my_table;", snowflake_conn_id='snowflake_default', retries=3, email_on_failure=True, on_failure_callback=my_failure_callback # Custom failure function )
6. Scaling and Optimization
Snowflake’s Automatic Scaling: Snowflake can automatically scale compute resources based on the workload. This ensures that data pipelines can handle varying loads efficiently.
Parallel Execution in Airflow: You can split your tasks into multiple parallel branches to improve throughput. The task_concurrency argument in Airflow helps manage this.
Task Dependencies: By optimizing task dependencies and using Airflow’s ability to run tasks in parallel, you can reduce the overall runtime of your pipelines.
Resource Management: Snowflake supports automatic suspension and resumption of compute resources, which helps keep costs low when there is no processing required.1. Introduction to Snowflake
0 notes
Text
Apache Airflow and its Architecture
Apache Airflow and how to schedule, automate, and monitor complex data pipelines by using it. we discuss some of the essential concepts in Airflow such as DAGs and Tasks.
Understanding Data Pipelines: As you can see in the following diagram the phases we discussed in the earlier segment — Extraction > Storing raw data > Validating > Transforming > Visualising — can also be seen in the Uber example.
Apache Airflow is an open-source platform used for scheduling, automating, and monitoring complex data pipelines. With its powerful DAGs (Directed Acyclic Graphs) and task orchestration features, Airflow has become a popular tool among data engineers and data scientists for managing and executing ETL (Extract, Transform, Load) workflows.
In this blog, we will explore the fundamental concepts of Airflow and how it can be used to schedule, automate, and monitor data pipelines.
DAGs and Tasks
The fundamental building blocks of Airflow are DAGs and tasks. DAGs are directed acyclic graphs that define the dependencies between tasks, while tasks represent the individual units of work that make up the pipeline.
In Airflow, DAGs are defined using Python code, and tasks are defined as instances of Operator classes. Each task has a unique ID, and operators can be chained together to create a workflow.
For example, suppose you have a data pipeline that involves extracting data from a database, transforming it, and then loading it into another database. You could define this pipeline using a DAG with three tasks:
The Extract task, which retrieves data from the source database
The Transform task, which processes the data
The Load task, which writes the processed data to the target database
Each task is defined using a specific operator, such as the SQL operator for extracting data from a database, or the Python operator for running Python scripts.
0 notes
Text
Geofencing mongodb python example

Geofencing mongodb python example android#
Geofencing mongodb python example code#
There are several in-built operators available to us as part of Airflow. If we wish to execute a Bash command, we have Bash operator. For example, if we want to execute a Python script, we will have a Python operator. Thanks for the article “ Determining Whether A Point Is Inside A Complex Polygon”. To elaborate, an operator is a class that contains the logic of what we want to achieve in the DAG. If the point is exactly on the edge of the polygon, then the function may return true or false. The function will return true if the point X,Y is inside the polygon, or false if it is not. Using this method, GPS Tracking devices can be tracked either inside or outside of the polygon. But MongoDB should already be available in your system before python can connect to it and run. In this article we will learn to do that. Python can interact with MongoDB through some python modules and create and manipulate data inside Mongo DB. Backgroundįor geo-fencing, I used Polygonal geo-fencing method where a polygon is drawn around the route or area. MongoDB is a widely used document database which is also a form of NoSQL DB. The notification can contain information about the location of the device and might be sent to a mobile telephone or an email account. Geo FenceĪ Geo fence is a virtual perimeter on a geographic area using a location-based service, so that when the geo fencing device enters or exits the area, a notification is generated. These geo fences when crossed by a GPS equipped vehicle or person can trigger a warning to the user or operator via SMS or Email. Geo-fencing allows users of a GPS Tracking Solution to draw zones (i.e., a Geo Fence) around places of work, customer’s sites and secure areas. This is an unsecured server, and later we will add authorization.
Geofencing mongodb python example android#
To run the app from android studio, open one of your project's activity files and click Run icon from the toolbar.One of the important feature of GPS Tracking software using GPS Tracking devices is geo-fencing and its ability to help keep track of assets. Leave your server running in the background, you can now access your database from the mongo shell or as we will see later, also from python. I assume you have connected your actual Android Mobile device with your computer. import pymongo myclient pymongo.MongoClient('mongodb://localhost:27017/') If the above pymongo example program runs successfully, then a connection is said to made to the mongodb instance. Make sure that Mongo Daemon is up and running at the URL you specified.
Geofencing mongodb python example code#
Step 4 − Add the following code to androidManifest.xml You can pass the url of the MongoDB instance as shown in the following program. Public class MainActivity extends AppCompatActivity, 1) Import .location.FusedLocationProviderClient Using 2 sample programs we will write some information to the database and then. Step 3 − Add the following code to src/MainActivity.java import .PackageManager In this video, I will show how you can use Python to get connected to MongoDB. Note : If URI is not specified, it tries to connect to MongoDB instance at localhost on port 27017. Following is the syntax to create a MongoClient in Python. Deserialization, therefore, is the process of turning something in that format into an object. Create a connection to MongoDB Daemon Service using MongoClient. In programming, serialization is the process of turning an object into a new format that can be stored (e.g. Step 2 − Add the following code to res/layout/activity_main.xml Marshmallow serialization with MongoDB and Python. Step 1 − Create a new project in Android Studio, go to File ⇒ New Project and fill all required details to create a new project. This example demonstrates how do I get current GPS location programmatically in android.
0 notes
Text
Airflow Clickhouse

Aspect calc. Aspect ratio calculator to get aspect ratio for your images or videos (4:3, 16:9, etc.).

Airflow Clickhouse Example
Airflow-clickhouse-plugin 0.6.0 Mar 13, 2021 airflow-clickhouse-plugin - Airflow plugin to execute ClickHouse commands and queries. Baluchon 0.0.1 Dec 19, 2020 A tool for managing migrations in Clickhouse. Domination 1.2 Sep 21, 2020 Real-time application in order to dominate Humans. Intelecy-pandahouse 0.3.2 Aug 25, 2020 Pandas interface for. I investigate how fast ClickHouse 18.16.1 can query 1.1 billion taxi journeys on a 3-node, 108-core AWS EC2 cluster. Convert CSVs to ORC Faster I compare the ORC file construction times of Spark 2.4.0, Hive 2.3.4 and Presto 0.214. Rev transcription career. We and third parties use cookies or similar technologies ('Cookies') as described below to collect and process personal data, such as your IP address or browser information. The world's first data engineering coding bootcamp in Berlin. Learn sustainable data craftsmanship beyond the AI-hype. Join our school and learn how to build and maintain infrastructure that powers data products, data analytics tools, data science models, business intelligence and machine learning s.
Airflow Clickhouse Connection
Package Name AccessSummary Updated jupyterlabpublic An extensible environment for interactive and reproducible computing, based on the Jupyter Notebook and Architecture. 2021-04-22httpcorepublic The next generation HTTP client. 2021-04-22jsondiffpublic Diff JSON and JSON-like structures in Python 2021-04-22jupyter_kernel_gatewaypublic Jupyter Kernel Gateway 2021-04-22reportlabpublic Open-source engine for creating complex, data-driven PDF documents and custom vector graphics 2021-04-21pytest-asynciopublic Pytest support for asyncio 2021-04-21enamlpublic Declarative DSL for building rich user interfaces in Python 2021-04-21onigurumapublic A regular expression library. 2021-04-21cfn-lintpublic CloudFormation Linter 2021-04-21aws-c-commonpublic Core c99 package for AWS SDK for C. Includes cross-platform primitives, configuration, data structures, and error handling. 2021-04-21nginxpublic Nginx is an HTTP and reverse proxy server 2021-04-21libgcryptpublic a general purpose cryptographic library originally based on code from GnuPG. 2021-04-21google-authpublic Google authentication library for Python 2021-04-21sqlalchemy-utilspublic Various utility functions for SQLAlchemy 2021-04-21flask-apschedulerpublic Flask-APScheduler is a Flask extension which adds support for the APScheduler 2021-04-21datadogpublic The Datadog Python library 2021-04-21cattrspublic Complex custom class converters for attrs. 2021-04-21argcompletepublic Bash tab completion for argparse 2021-04-21luarockspublic LuaRocks is the package manager for Lua modulesLuaRocks is the package manager for Lua module 2021-04-21srslypublic Modern high-performance serialization utilities for Python 2021-04-19pytest-benchmarkpublic A py.test fixture for benchmarking code 2021-04-19fastavropublic Fast read/write of AVRO files 2021-04-19cataloguepublic Super lightweight function registries for your library 2021-04-19zarrpublic An implementation of chunked, compressed, N-dimensional arrays for Python. 2021-04-19python-engineiopublic Engine.IO server 2021-04-19nuitkapublic Python compiler with full language support and CPython compatibility 2021-04-19hypothesispublic A library for property based testing 2021-04-19flask-adminpublic Simple and extensible admin interface framework for Flask 2021-04-19hyperframepublic Pure-Python HTTP/2 framing 2021-04-19pythonpublic General purpose programming language 2021-04-17python-regr-testsuitepublic General purpose programming language 2021-04-17pyamgpublic Algebraic Multigrid Solvers in Python 2021-04-17luigipublic Workflow mgmgt + task scheduling + dependency resolution. 2021-04-17libpython-staticpublic General purpose programming language 2021-04-17dropboxpublic Official Dropbox API Client 2021-04-17s3fspublic Convenient Filesystem interface over S3 2021-04-17furlpublic URL manipulation made simple. 2021-04-17sympypublic Python library for symbolic mathematics 2021-04-15spyderpublic The Scientific Python Development Environment 2021-04-15sqlalchemypublic Database Abstraction Library. 2021-04-15rtreepublic R-Tree spatial index for Python GIS 2021-04-15pandaspublic High-performance, easy-to-use data structures and data analysis tools. 2021-04-15poetrypublic Python dependency management and packaging made easy 2021-04-15freetdspublic FreeTDS is a free implementation of Sybase's DB-Library, CT-Library, and ODBC libraries 2021-04-15ninjapublic A small build system with a focus on speed 2021-04-15cythonpublic The Cython compiler for writing C extensions for the Python language 2021-04-15conda-package-handlingpublic Create and extract conda packages of various formats 2021-04-15condapublic OS-agnostic, system-level binary package and environment manager. 2021-04-15colorlogpublic Log formatting with colors! 2021-04-15bitarraypublic efficient arrays of booleans -- C extension 2021-04-15
Reverse Dependencies of apache-airflow

Clickhouse Icon
Digital recorder that transcribes to text. The following projects have a declared dependency on apache-airflow:
Clickhouse Download
acryl-datahub — A CLI to work with DataHub metadata
AGLOW — AGLOW: Automated Grid-enabled LOFAR Workflows
aiflow — AI Flow, an extend operators library for airflow, which helps AI engineer to write less, reuse more, integrate easily.
aircan — no summary
airflow-add-ons — Airflow extensible opertators and sensors
airflow-aws-cost-explorer — Apache Airflow Operator exporting AWS Cost Explorer data to local file or S3
airflow-bigquerylogger — BigQuery logger handler for Airflow
airflow-bio-utils — Airflow utilities for biological sequences
airflow-cdk — Custom cdk constructs for apache airflow
airflow-clickhouse-plugin — airflow-clickhouse-plugin - Airflow plugin to execute ClickHouse commands and queries
airflow-code-editor — Apache Airflow code editor and file manager
airflow-cyberark-secrets-backend — An Airflow custom secrets backend for CyberArk CCP
airflow-dbt — Apache Airflow integration for dbt
airflow-declarative — Airflow DAGs done declaratively
airflow-diagrams — Auto-generated Diagrams from Airflow DAGs.
airflow-ditto — An airflow DAG transformation framework
airflow-django — A kit for using Django features, like its ORM, in Airflow DAGs.
airflow-docker — An opinionated implementation of exclusively using airflow DockerOperators for all Operators
airflow-dvc — DVC operator for Airflow
airflow-ecr-plugin — Airflow ECR plugin
airflow-exporter — Airflow plugin to export dag and task based metrics to Prometheus.
airflow-extended-metrics — Package to expand Airflow for custom metrics.
airflow-fs — Composable filesystem hooks and operators for Airflow.
airflow-gitlab-webhook — Apache Airflow Gitlab Webhook integration
airflow-hdinsight — HDInsight provider for Airflow
airflow-imaging-plugins — Airflow plugins to support Neuroimaging tasks.
airflow-indexima — Indexima Airflow integration
airflow-notebook — Jupyter Notebook operator for Apache Airflow.
airflow-plugin-config-storage — Inject connections into the airflow database from configuration
airflow-plugin-glue-presto-apas — An Airflow Plugin to Add a Partition As Select(APAS) on Presto that uses Glue Data Catalog as a Hive metastore.
airflow-prometheus — Modern Prometheus exporter for Airflow (based on robinhood/airflow-prometheus-exporter)
airflow-prometheus-exporter — Prometheus Exporter for Airflow Metrics
airflow-provider-fivetran — A Fivetran provider for Apache Airflow
airflow-provider-great-expectations — An Apache Airflow provider for Great Expectations
airflow-provider-hightouch — Hightouch Provider for Airflow
airflow-queue-stats — An airflow plugin for viewing queue statistics.
airflow-spark-k8s — Airflow integration for Spark On K8s
airflow-spell — Apache Airflow integration for spell.run
airflow-tm1 — A package to simplify connecting to the TM1 REST API from Apache Airflow
airflow-util-dv — no summary
airflow-waterdrop-plugin — A FastAPI Middleware of Apollo(Config Server By CtripCorp) to get server config in every request.
airflow-windmill — Drag'N'Drop Web Frontend for Building and Managing Airflow DAGs
airflowdaggenerator — Dynamically generates and validates Python Airflow DAG file based on a Jinja2 Template and a YAML configuration file to encourage code re-usability
airkupofrod — Takes a deployment in your kubernetes cluster and turns its pod template into a KubernetesPodOperator object.
airtunnel — airtunnel – tame your Airflow!
apache-airflow-backport-providers-amazon — Backport provider package apache-airflow-backport-providers-amazon for Apache Airflow
apache-airflow-backport-providers-apache-beam — Backport provider package apache-airflow-backport-providers-apache-beam for Apache Airflow
apache-airflow-backport-providers-apache-cassandra — Backport provider package apache-airflow-backport-providers-apache-cassandra for Apache Airflow
apache-airflow-backport-providers-apache-druid — Backport provider package apache-airflow-backport-providers-apache-druid for Apache Airflow
apache-airflow-backport-providers-apache-hdfs — Backport provider package apache-airflow-backport-providers-apache-hdfs for Apache Airflow
apache-airflow-backport-providers-apache-hive — Backport provider package apache-airflow-backport-providers-apache-hive for Apache Airflow
apache-airflow-backport-providers-apache-kylin — Backport provider package apache-airflow-backport-providers-apache-kylin for Apache Airflow
apache-airflow-backport-providers-apache-livy — Backport provider package apache-airflow-backport-providers-apache-livy for Apache Airflow
apache-airflow-backport-providers-apache-pig — Backport provider package apache-airflow-backport-providers-apache-pig for Apache Airflow
apache-airflow-backport-providers-apache-pinot — Backport provider package apache-airflow-backport-providers-apache-pinot for Apache Airflow
apache-airflow-backport-providers-apache-spark — Backport provider package apache-airflow-backport-providers-apache-spark for Apache Airflow
apache-airflow-backport-providers-apache-sqoop — Backport provider package apache-airflow-backport-providers-apache-sqoop for Apache Airflow
apache-airflow-backport-providers-celery — Backport provider package apache-airflow-backport-providers-celery for Apache Airflow
apache-airflow-backport-providers-cloudant — Backport provider package apache-airflow-backport-providers-cloudant for Apache Airflow
apache-airflow-backport-providers-cncf-kubernetes — Backport provider package apache-airflow-backport-providers-cncf-kubernetes for Apache Airflow
apache-airflow-backport-providers-databricks — Backport provider package apache-airflow-backport-providers-databricks for Apache Airflow
apache-airflow-backport-providers-datadog — Backport provider package apache-airflow-backport-providers-datadog for Apache Airflow
apache-airflow-backport-providers-dingding — Backport provider package apache-airflow-backport-providers-dingding for Apache Airflow
apache-airflow-backport-providers-discord — Backport provider package apache-airflow-backport-providers-discord for Apache Airflow
apache-airflow-backport-providers-docker — Backport provider package apache-airflow-backport-providers-docker for Apache Airflow
apache-airflow-backport-providers-elasticsearch — Backport provider package apache-airflow-backport-providers-elasticsearch for Apache Airflow
apache-airflow-backport-providers-email — Back-ported airflow.providers.email.* package for Airflow 1.10.*
apache-airflow-backport-providers-exasol — Backport provider package apache-airflow-backport-providers-exasol for Apache Airflow
apache-airflow-backport-providers-facebook — Backport provider package apache-airflow-backport-providers-facebook for Apache Airflow
apache-airflow-backport-providers-google — Backport provider package apache-airflow-backport-providers-google for Apache Airflow
apache-airflow-backport-providers-grpc — Backport provider package apache-airflow-backport-providers-grpc for Apache Airflow
apache-airflow-backport-providers-hashicorp — Backport provider package apache-airflow-backport-providers-hashicorp for Apache Airflow
apache-airflow-backport-providers-jdbc — Backport provider package apache-airflow-backport-providers-jdbc for Apache Airflow
apache-airflow-backport-providers-jenkins — Backport provider package apache-airflow-backport-providers-jenkins for Apache Airflow
apache-airflow-backport-providers-jira — Backport provider package apache-airflow-backport-providers-jira for Apache Airflow
apache-airflow-backport-providers-microsoft-azure — Backport provider package apache-airflow-backport-providers-microsoft-azure for Apache Airflow
apache-airflow-backport-providers-microsoft-mssql — Backport provider package apache-airflow-backport-providers-microsoft-mssql for Apache Airflow
apache-airflow-backport-providers-microsoft-winrm — Backport provider package apache-airflow-backport-providers-microsoft-winrm for Apache Airflow
apache-airflow-backport-providers-mongo — Backport provider package apache-airflow-backport-providers-mongo for Apache Airflow
apache-airflow-backport-providers-mysql — Backport provider package apache-airflow-backport-providers-mysql for Apache Airflow
apache-airflow-backport-providers-neo4j — Backport provider package apache-airflow-backport-providers-neo4j for Apache Airflow
apache-airflow-backport-providers-odbc — Backport provider package apache-airflow-backport-providers-odbc for Apache Airflow
apache-airflow-backport-providers-openfaas — Backport provider package apache-airflow-backport-providers-openfaas for Apache Airflow
apache-airflow-backport-providers-opsgenie — Backport provider package apache-airflow-backport-providers-opsgenie for Apache Airflow
apache-airflow-backport-providers-oracle — Backport provider package apache-airflow-backport-providers-oracle for Apache Airflow
apache-airflow-backport-providers-pagerduty — Backport provider package apache-airflow-backport-providers-pagerduty for Apache Airflow
apache-airflow-backport-providers-papermill — Backport provider package apache-airflow-backport-providers-papermill for Apache Airflow
apache-airflow-backport-providers-plexus — Backport provider package apache-airflow-backport-providers-plexus for Apache Airflow
apache-airflow-backport-providers-postgres — Backport provider package apache-airflow-backport-providers-postgres for Apache Airflow
apache-airflow-backport-providers-presto — Backport provider package apache-airflow-backport-providers-presto for Apache Airflow
apache-airflow-backport-providers-qubole — Backport provider package apache-airflow-backport-providers-qubole for Apache Airflow
apache-airflow-backport-providers-redis — Backport provider package apache-airflow-backport-providers-redis for Apache Airflow
apache-airflow-backport-providers-salesforce — Backport provider package apache-airflow-backport-providers-salesforce for Apache Airflow
apache-airflow-backport-providers-samba — Backport provider package apache-airflow-backport-providers-samba for Apache Airflow
apache-airflow-backport-providers-segment — Backport provider package apache-airflow-backport-providers-segment for Apache Airflow
apache-airflow-backport-providers-sendgrid — Backport provider package apache-airflow-backport-providers-sendgrid for Apache Airflow
apache-airflow-backport-providers-sftp — Backport provider package apache-airflow-backport-providers-sftp for Apache Airflow
apache-airflow-backport-providers-singularity — Backport provider package apache-airflow-backport-providers-singularity for Apache Airflow
apache-airflow-backport-providers-slack — Backport provider package apache-airflow-backport-providers-slack for Apache Airflow
apache-airflow-backport-providers-snowflake — Backport provider package apache-airflow-backport-providers-snowflake for Apache Airflow
0 notes
Photo

"[D] Optimal ML development flow/process, feedback would be helpful."- Detail: I'm a Software Engineer specializing in Data Infrastructure/Engineering and DevOps.I've been speaking with a few colleagues who work with ML and have expressed their frustration with the lack of a consistent "developer flow" for ML projects, so I wanted to ask this community, what does YOUR ideal developer flow look like?I apologize in advance for my lack of knowledge on this subject, and if I've used any of the terms incorrectly. I'm very new and just trying to learn more about the underlying infrastructure.Here's what we sketched out to be a reasonable developer flow:Assumptions:Data is already available, all connections are correctly configured. You can explore it using notebooks or a sql tool like apache superset.You have access to an ETL tool (eg: apache airflow) where you've built dags to aggregate data and preprocess source data to be in the input format for your ML model.You have access to development machines ("devboxes") which are configured exactly like production machines where the task/job will run - except that devboxes can only read production data but NOT write production data (can still write to dev/staging databases). These are your test environment.Workflow:You start a (hosted) notebook (Jupyter or Zeppelin) which has access to the data. You also have access to the pre-processed datasets mentioned in Assumptions[2] and you build out your models (I don't really know what happens here - i'm sorry)You can also write python/scala code instead of using the notebook and test it by running it on the devbox.You've built and (minimally tested) your model and want to train, deploy and productionize it. What happens after this?Could someone help me understand what happens after this step?I'm guessing you'll need to train the model, can that be done in the notebook or the python file which you can run on your devbox. Training the model in the notebook seems untrackable, so you'll probably want to train it in python/scala code which will be checked into github.You'll probably need to re-train it periodically so the python/scala function can be deployed in an Airflow DAG which trains it daily/weekly.What would be the common processes of deploying it after this step?For example, for regular software projects it would be:Code -> Test Locally -> Push to github (not merged yet) -> CI/CD builds the new code and pushes to staging -> test staging -> everything looks good/no regression in other services -> push to production by merging PRFor Data Engineering projects, the workflow is all over the place but my ideal workflow is:Code (create a new DAG/update queries) -> Test on devbox with sample data (local testing is not possible with large datasets) -> Push to github (not merged yet) -> CI/CD builds the new code/DAG -> new DAG runs in staging with staging data, generates staging tables to test -> everything looks good/data quality checks pass -> push to production by merging PR -> production jobs pick up the new queries/DAGs.DISCLAIMER: I know very little about this space, I'm happy to read any documentation you provide on this.Thank you in advance!. Caption by feedthemartian. Posted By: www.eurekaking.com
0 notes
Text
Airflow 101: Start automating your batch workflows with ease

Copyrights (Production Line)
In this blog, I cover the main concepts behind pipeline automation with Airflow and go through the code (and a few gotchas) to create your first workflow with ease.
Why Airflow?
Data pipelines are built by defining a set of “tasks” to extract, analyze, transform, load and store the data. For example, a pipeline could consist of tasks like reading archived logs from S3, creating a Spark job to extract relevant features, indexing the features using Solr and updating the existing index to allow search. To automate this pipeline and run it weekly, you could use a time-based scheduler like Cron by defining the workflows in Crontab. This is really good for simple workflows, but things get messier when you start to maintain the workflow in large organizations with dependencies. It gets complicated if you’re waiting on some input data from a third-party, and several teams are depending on your tasks to start their jobs.
Airflow is a workflow scheduler to help with scheduling complex workflows and provide an easy way to maintain them. There are numerous resources for understanding what Airflow does, but it’s much easier to understand by directly working through an example.
Here are a few reasons to use Airflow:
Open source: After starting as an internal project at Airbnb, Airflow had a natural need in the community. This was a major reason why it eventually became an open source project. It is currently maintained and managed as an incubating project at Apache.
Web Interface: Airflow ships with a Flask app that tracks all the defined workflows, and let’s you easily change, start, or stop them. You can also work with the command line, but the web interface is more intuitive.
Python Based: Every part of the configuration is written in Python, including configuration of schedules and the scripts to run them. This removes the need to use restrictive JSON or XML configuration files.
When workflows are defined as code, they become more maintainable, versionable, testable, and collaborative.
Concepts
Let’s look at few concepts that you’ll need to write our first workflow.
Directed Acyclic Graphs

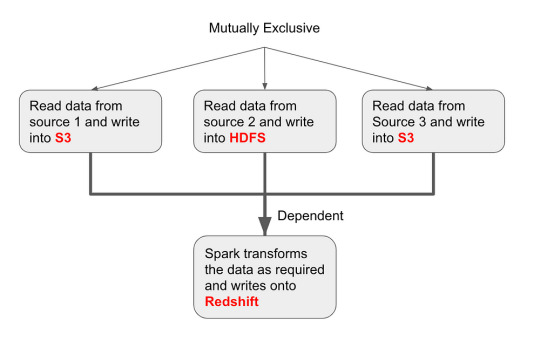
The DAG that we are building using Airflow
In Airflow, Directed Acyclic Graphs (DAGs) are used to create the workflows. DAGs are a high-level outline that define the dependent and exclusive tasks that can be ordered and scheduled.
We will work on this example DAG that reads data from 3 sources independently. Once that is completed, we initiate a Spark job to join the data on a key and write the output of the transformation to Redshift.
Defining a DAG enables the scheduler to know which tasks can be run immediately, and which have to wait for other tasks to complete. The Spark job has to wait for the three “read” tasks and populate the data into S3 and HDFS.
Scheduler
The Scheduler is the brains behind setting up the workflows in Airflow. As a user, interactions with the scheduler will be limited to providing it with information about the different tasks, and when it has to run. To ensure that Airflow knows all the DAGs and tasks that need to be run, there can only be one scheduler.
Operators
Operators are the “workers” that run our tasks. Workflows are defined by creating a DAG of operators. Each operator runs a particular task written as Python functions or shell command. You can create custom operators by extending the BaseOperator class and implementing the execute() method.
Tasks
Tasks are user-defined activities ran by the operators. They can be functions in Python or external scripts that you can call. Tasks are expected to be idempotent — no matter how many times you run a task, it needs to result in the same outcome for the same input parameters.
Note: Don’t confuse operators with tasks. Tasks are defined as “what to run?” and operators are “how to run”. For example, a Python function to read from S3 and push to a database is a task. The method that calls this Python function in Airflow is the operator. Airflow has built-in operators that you can use for common tasks.
Getting Started
To put these concepts into action, we’ll install Airflow and define our first DAG.
Installation and Folder structure
Airflow is easy (yet restrictive) to install as a single package. Here is a typical folder structure for our environment to add DAGs, configure them and run them.

We create a new Python file my_dag.py and save it inside the dags folder.
Importing various packages
# airflow related from airflow import DAG from airflow.operators.python_operator import PythonOperator from airflow.operators.bash_operator import BashOperator
# other packages from datetime import datetime from datetime import timedelta
We import three classes, DAG, BashOperator and PythonOperator that will define our basic setup.
Setting up default_args
default_args = { 'owner': 'airflow', 'depends_on_past': False, 'start_date': datetime(2018, 9, 1), 'email_on_failure': False, 'email_on_retry': False, 'schedule_interval': '@daily', 'retries': 1, 'retry_delay': timedelta(seconds=5), }
This helps setting up default configuration that applies to the DAG. This link provides more details on how to configure the default_args and the additional parameters available.
Defining our DAG, Tasks, and Operators
Let’s define all the tasks for our existing workflow. We have three tasks that read data from their respective sources and store them in S3 and HDFS. They are defined as Python functions that will be called by our operators. We can pass parameters to the function using **args and **kwargs from our operator. For instance, the function source2_to_hdfs takes a named parameter config and two context parameters ds and **kwargs.
def source1_to_s3(): # code that writes our data from source 1 to s3
def source2_to_hdfs(config, ds, **kwargs): # code that writes our data from source 2 to hdfs # ds: the date of run of the given task. # kwargs: keyword arguments containing context parameters for the run.
def source3_to_s3(): # code that writes our data from source 3 to s3
We instantiate a DAG object below. The schedule_interval is set for daily and the start_date is set for September 1st 2018 as given in the default_args.
dag = DAG( dag_id='my_dag', description='Simple tutorial DAG', default_args=default_args)
We then have to create four tasks in our DAG. We use PythonOperator for the three tasks defined as Python functions and BashOperator for running the Spark job.
config = get_hdfs_config()
src1_s3 = PythonOperator( task_id='source1_to_s3', python_callable=source1_to_s3, dag=dag)
src2_hdfs = PythonOperator( task_id='source2_to_hdfs', python_callable=source2_to_hdfs, op_kwargs = {'config' : config}, provide_context=True, dag=dag )
src3_s3 = PythonOperator( task_id='source3_to_s3', python_callable=source3_to_s3, dag=dag)
spark_job = BashOperator( task_id='spark_task_etl', bash_command='spark-submit --master spark://localhost:7077 spark_job.py', dag = dag)
The tasks of pushing data to S3 (src1_s3 and src3_s3) are created using PythonOperator and setting the python_callable as the name of the function that we defined earlier. The task src2_hdfs has additional parameters including context and a custom config parameter to the function. the dag parameter will attach the task to the DAG (though that workflow hasn’t been shown yet).
The BashOperator includes the bash_command parameter that submits a Spark job to process data and store it in Redshift. We set up the dependencies between the operators by using the >> and <<.
# setting dependencies src1_s3 >> spark_job src2_hdfs >> spark_job src3_s3 >> spark_job
You can also use set_upstream() or set_downstream() to create the dependencies for Airflow version 1.7 and below.
# for Airflow <v1.7 spark_job.set_upstream(src1_s3) spark_job.set_upstream(src2_hdfs)
# alternatively using set_downstream src3_s3.set_downstream(spark_job)
Adding our DAG to the Airflow scheduler
The easiest way to work with Airflow once you define our DAG is to use the web server. Airflow internally uses a SQLite database to track active DAGs and their status. Use the following commands to start the web server and scheduler (which will launch in two separate windows).
> airflow webserver
> airflow scheduler
Alternatively, you can start them as services by setting up systemd using the scripts from the Apache project. Here are screenshots from the web interface for the workflow that we just created.


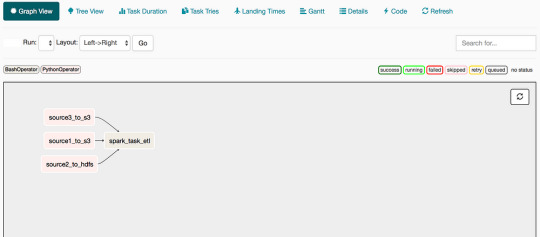

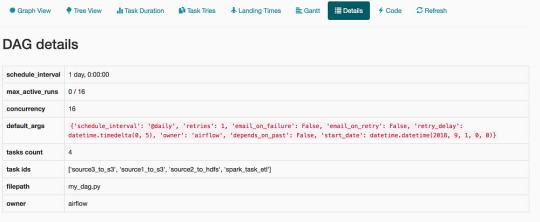
Here is the entire code for this workflow:
We have written our first DAG using Airflow. Every day, this DAG will read data from three sources and store them in S3 and HDFS. Once the data is in the required place, we have a Spark job that runs an ETL task. We have also provided instructions to handle retries and the time to wait before retrying.
Gotchas
Use Refresh on the web interface: Any changes that you make to the DAGs or tasks don’t get automatically updated in Airflow. You’ll need to use the Refresh button on the web server to load the latest configurations.
Be careful when changing start_date and schedule_interval: As already mentioned, Airflow maintains a database of information about the various runs. Once you run a DAG, it creates entries in the database with those details. Any changes to the start_date and schedule_interval can cause the workflow to be in a weird state that may not recover properly.
Start scheduler separately: It seems obvious to start the scheduler when the web server is started. Airflow doesn’t work that way for an important reason — to provide separation of concerns when deployed in a cluster environment where the Scheduler and web server aren’t necessarily onthe same machine.
Understand Cron definitions when using it in schedule_interval: You can set the value for schedule_interval in a similar way you set a Cron job. Be sure you understand how they are configured. Here is a good start to know more about those configurations.
You can also check out more FAQs that the Airflow project has compiled to help beginners get started with writing workflows easily.
Interested in transitioning to a career in data? Learn more about the Insight Fellows program and start your application today.
0 notes
Text
Just an update on next steps:
I created a GitHub repo for the project I’m going to attempt - a NLP / Goodreads rating mix. Essentially, does the pos/neg inflection of a review correlate to the star rating given?
Moved airflow stuff to the new repo - so I had to change $AIRFLOW_HOME. I was unsure on whether it should be two directories or not, but I figure that for simplicity’s sake, a repo should be the whole project and I wasn’t sure how to direct people to the airflow repo if it wasn’t.
Then I went about starting a sample dag! Didn’t realize they would auto trigger when turned on, because the way our work env was set up, they never did. Initial test was calling the Goodreads API and seeing that response. Initially tried importing the “requests” library and calling that within a PythonOperator but this caused Python to crash every time I tried to run the task. I don’t know what was happening there. But then I found the http_operator already in the Airflow repo, so I was able to successfully use that!
This is an example of the task: get_api = SimpleHttpOperator( ask_id='get_api', method='GET', http_conn_id='goodreads_api', endpoint='book/review_counts.json?isbns=0441172717%2C0141439602&key=YOURKEYHERE', headers={"Content-Type": "application/json"}, xcom_push=True, dag=dag)
The thing that confused me the most was "http_conn_id" - for now, I just added this within the Airflow API, though I believe you can add it programatically as well. In this case, it just corresponds to the goodreads URL and is marked as an http connection. The "endpoint" is the rest of URL for this example. It will return the reviews for this specific ISBN. I've hardcoded in my dev key for now. Next steps are to get these reviews for a random sampling of ISBNs and turn my dev key into an env variable!
0 notes
Text
Airflow XComs example | Airflow Demystified
Read the airflow official XComs docs:
go over the official example and astrnomoer.io examples
be sure to understand the documentation of python operator
be sure to understand: , context becomes available only when Operator is actually executed, not during DAG-definition. And it makes sense because in taxanomy of Airflow, xcoms are communication mechanism between tasks in realtime:…
View On WordPress
0 notes
Photo

"[Project]Deploy trained model to AWS lambda with Serverless framework"- Detail: Hi guys,We have continue updating our open source project for packaging and deploying ML models to product (github.com/bentoml/bentoml), and we have create an easy way to deploy ML model as a serverless (www.serverless.com) project that you could easily deploy to AWS lambda and Google Cloud Function. We want to share with you guys about it and hear your feedback. A little background of BentoML for those aren't familiar with it. BentoML is a python library for packaging and deploying machine learning models. It provides high-level APIs for defining a ML service and packaging its artifacts, source code, dependencies, and configurations into a production-system-friendly format that is ready for deployment.Feature highlights: * Multiple Distribution Format - Easily package your Machine Learning models into format that works best with your inference scenario: - Docker Image - deploy as containers running REST API Server - PyPI Package - integrate into your python applications seamlessly - CLI tool - put your model into Airflow DAG or CI/CD pipeline - Spark UDF - run batch serving on large dataset with Spark - Serverless Function - host your model with serverless cloud platformsMultiple Framework Support - BentoML supports a wide range of ML frameworks out-of-the-box including Tensorflow, PyTorch, Scikit-Learn, xgboost and can be easily extended to work with new or custom frameworks.Deploy Anywhere - BentoML bundled ML service can be easily deploy with platforms such as Docker, Kubernetes, Serverless, Airflow and Clipper, on cloud platforms including AWS Lambda/ECS/SageMaker, Gogole Cloud Functions, and Azure ML.Custom Runtime Backend - Easily integrate your python preprocessing code with high-performance deep learning model runtime backend (such as tensorflow-serving) to deploy low-latancy serving endpoint. How to package machine learning model as serverless project with BentoMLIt's surprising easy, just with a single CLI command. After you finished training your model and saved it to file system with BentoML. All you need to do now is run bentoml build-serverless-archive command, for example: $bentoml build-serverless-archive /path_to_bentoml_archive /path_to_generated_serverless_project --platform=[aws-python, aws-python3, google-python] This will generate a serverless project at the specified directory. Let's take a look of what files are generated. /path_to_generated_serverless_project - serverless.yml - requirements.txt - copy_of_bentoml_archive/ - handler.py/main.py (if platform is google-python, it will generate main.py) serverless.yml is the configuration file for serverless framework. It contains configuration to the cloud provider you are deploying to, and map out what events will trigger what function. BentoML automatically modifies this file to add your model prediction as a function event and update other info for you.requirements.txt is a copy from your model archive, it includes all of the dependencies to run your modelhandler.py/main.py is the file that contains your function code. BentoML fill this file's function with your model archive class, you can make prediction with this file right away without any modifications.copy_of_bentoml_archive: A copy your model archive. It will be bundle with other files for serverless deployment. What's nextAfter you generate this serverless project. If you have the default configuration for AWS or google. You can deploy it right away. Otherwise, you can update the serverless.yaml based on your own configurations.Love to hear feedback from you guys on this. CheersBo Edit: Styling. Caption by yubozhao. Posted By: www.eurekaking.com
0 notes
Text
Airflow file sensor example | Airflow Demystified
Airflow file sensor example | Airflow Demystified
I recently encountered an ETL job, where the DAG worked perfectly and ended in success, however the underlying resources did not behave as I expected. i.e one of the task was expected to run and external python script. The scripted ended with success, which in turn forced Airflow DAG to report success. However, the python was suppose to create a file in GCS and it didn’t.
I Looked for a…
View On WordPress
0 notes