#Amazon Scraping API
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
When “GIF” was named word of the year in 2012, Oxford Dictionaries U.S.A. credited Tumblr for pushing the word.
Text
Effortlessly extract price data from Amazon using the powerful Amazon Scraping API. Unlock valuable insights and make informed decisions to optimize your pricing strategies and gain a competitive edge.
For More Information:-
0 notes
Text
How to Extract Amazon Product Prices Data with Python 3
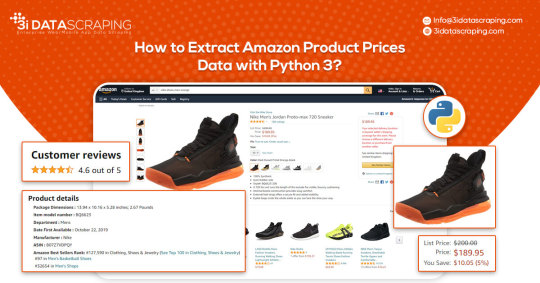
Web data scraping assists in automating web scraping from websites. In this blog, we will create an Amazon product data scraper for scraping product prices and details. We will create this easy web extractor using SelectorLib and Python and run that in the console.
#webscraping#data extraction#web scraping api#Amazon Data Scraping#Amazon Product Pricing#ecommerce data scraping#Data EXtraction Services
3 notes
·
View notes
Text
Want to stay ahead of Amazon price changes? Learn how to automate price tracking using Scrapingdog’s Amazon Scraper API and Make.com. A step-by-step guide for smarter, hands-free eCommerce monitoring.
0 notes
Text
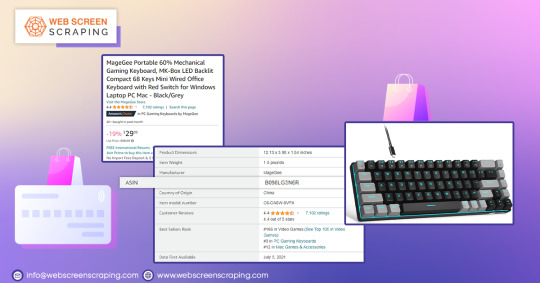
Amazon ASIN is a unique code assigned to each product on the platform. Sellers need to assign ASIN codes to their products before listing them. The ASIN code is a unique 10-character code that identifies products on Amazon, except for books which have an ISBN. It's crucial to know the ASIN code for your products to manage inventory and ensure a smooth customer experience.
0 notes
Text
Scraping Restaurant Data - Comparing Food Delivery Apps

To extract restaurant data, Foodspark provides the best restaurant delivery data scraping service. In recent years, food delivery services have been top-rated, but never more so than during the epidemic, when eating out was frowned upon by many. Despite loosened regulations, our smartphones will not take away food delivery apps soon.
#web scraping services#grocerydatascraping#food data scraping#zomato api#food data scraping services#grocerydatascrapingapi#restaurantdataextraction#fooddatascrapingservices#usa#restaurant data scraping#zomatoapi#amazon
1 note
·
View note
Link
[ad_1] In this tutorial, we walk you through building an enhanced web scraping tool that leverages BrightData’s powerful proxy network alongside Google’s Gemini API for intelligent data extraction. You’ll see how to structure your Python project, install and import the necessary libraries, and encapsulate scraping logic within a clean, reusable BrightDataScraper class. Whether you’re targeting Amazon product pages, bestseller listings, or LinkedIn profiles, the scraper’s modular methods demonstrate how to configure scraping parameters, handle errors gracefully, and return structured JSON results. An optional React-style AI agent integration also shows you how to combine LLM-driven reasoning with real-time scraping, empowering you to pose natural language queries for on-the-fly data analysis. !pip install langchain-brightdata langchain-google-genai langgraph langchain-core google-generativeai We install all of the key libraries needed for the tutorial in one step: langchain-brightdata for BrightData web scraping, langchain-google-genai and google-generativeai for Google Gemini integration, langgraph for agent orchestration, and langchain-core for the core LangChain framework. import os import json from typing import Dict, Any, Optional from langchain_brightdata import BrightDataWebScraperAPI from langchain_google_genai import ChatGoogleGenerativeAI from langgraph.prebuilt import create_react_agent These imports prepare your environment and core functionality: os and json handle system operations and data serialization, while typing provides structured type hints. You then bring in BrightDataWebScraperAPI for BrightData scraping, ChatGoogleGenerativeAI to interface with Google’s Gemini LLM, and create_react_agent to orchestrate these components in a React-style agent. class BrightDataScraper: """Enhanced web scraper using BrightData API""" def __init__(self, api_key: str, google_api_key: Optional[str] = None): """Initialize scraper with API keys""" self.api_key = api_key self.scraper = BrightDataWebScraperAPI(bright_data_api_key=api_key) if google_api_key: self.llm = ChatGoogleGenerativeAI( model="gemini-2.0-flash", google_api_key=google_api_key ) self.agent = create_react_agent(self.llm, [self.scraper]) def scrape_amazon_product(self, url: str, zipcode: str = "10001") -> Dict[str, Any]: """Scrape Amazon product data""" try: results = self.scraper.invoke( "url": url, "dataset_type": "amazon_product", "zipcode": zipcode ) return "success": True, "data": results except Exception as e: return "success": False, "error": str(e) def scrape_amazon_bestsellers(self, region: str = "in") -> Dict[str, Any]: """Scrape Amazon bestsellers""" try: url = f" results = self.scraper.invoke( "url": url, "dataset_type": "amazon_product" ) return "success": True, "data": results except Exception as e: return "success": False, "error": str(e) def scrape_linkedin_profile(self, url: str) -> Dict[str, Any]: """Scrape LinkedIn profile data""" try: results = self.scraper.invoke( "url": url, "dataset_type": "linkedin_person_profile" ) return "success": True, "data": results except Exception as e: return "success": False, "error": str(e) def run_agent_query(self, query: str) -> None: """Run AI agent with natural language query""" if not hasattr(self, 'agent'): print("Error: Google API key required for agent functionality") return try: for step in self.agent.stream( "messages": query, stream_mode="values" ): step["messages"][-1].pretty_print() except Exception as e: print(f"Agent error: e") def print_results(self, results: Dict[str, Any], title: str = "Results") -> None: """Pretty print results""" print(f"\n'='*50") print(f"title") print(f"'='*50") if results["success"]: print(json.dumps(results["data"], indent=2, ensure_ascii=False)) else: print(f"Error: results['error']") print() The BrightDataScraper class encapsulates all BrightData web-scraping logic and optional Gemini-powered intelligence under a single, reusable interface. Its methods enable you to easily fetch Amazon product details, bestseller lists, and LinkedIn profiles, handling API calls, error handling, and JSON formatting, and even stream natural-language “agent” queries when a Google API key is provided. A convenient print_results helper ensures your output is always cleanly formatted for inspection. def main(): """Main execution function""" BRIGHT_DATA_API_KEY = "Use Your Own API Key" GOOGLE_API_KEY = "Use Your Own API Key" scraper = BrightDataScraper(BRIGHT_DATA_API_KEY, GOOGLE_API_KEY) print("🛍️ Scraping Amazon India Bestsellers...") bestsellers = scraper.scrape_amazon_bestsellers("in") scraper.print_results(bestsellers, "Amazon India Bestsellers") print("📦 Scraping Amazon Product...") product_url = " product_data = scraper.scrape_amazon_product(product_url, "10001") scraper.print_results(product_data, "Amazon Product Data") print("👤 Scraping LinkedIn Profile...") linkedin_url = " linkedin_data = scraper.scrape_linkedin_profile(linkedin_url) scraper.print_results(linkedin_data, "LinkedIn Profile Data") print("🤖 Running AI Agent Query...") agent_query = """ Scrape Amazon product data for in New York (zipcode 10001) and summarize the key product details. """ scraper.run_agent_query(agent_query) The main() function ties everything together by setting your BrightData and Google API keys, instantiating the BrightDataScraper, and then demonstrating each feature: it scrapes Amazon India’s bestsellers, fetches details for a specific product, retrieves a LinkedIn profile, and finally runs a natural-language agent query, printing neatly formatted results after each step. if __name__ == "__main__": print("Installing required packages...") os.system("pip install -q langchain-brightdata langchain-google-genai langgraph") os.environ["BRIGHT_DATA_API_KEY"] = "Use Your Own API Key" main() Finally, this entry-point block ensures that, when run as a standalone script, the required scraping libraries are quietly installed, and the BrightData API key is set in the environment. Then the main function is executed to initiate all scraping and agent workflows. In conclusion, by the end of this tutorial, you’ll have a ready-to-use Python script that automates tedious data collection tasks, abstracts away low-level API details, and optionally taps into generative AI for advanced query handling. You can extend this foundation by adding support for other dataset types, integrating additional LLMs, or deploying the scraper as part of a larger data pipeline or web service. With these building blocks in place, you’re now equipped to gather, analyze, and present web data more efficiently, whether for market research, competitive intelligence, or custom AI-driven applications. Check out the Notebook. All credit for this research goes to the researchers of this project. Also, feel free to follow us on Twitter and don’t forget to join our 100k+ ML SubReddit and Subscribe to our Newsletter. Asif Razzaq is the CEO of Marktechpost Media Inc.. As a visionary entrepreneur and engineer, Asif is committed to harnessing the potential of Artificial Intelligence for social good. His most recent endeavor is the launch of an Artificial Intelligence Media Platform, Marktechpost, which stands out for its in-depth coverage of machine learning and deep learning news that is both technically sound and easily understandable by a wide audience. The platform boasts of over 2 million monthly views, illustrating its popularity among audiences. [ad_2] Source link
0 notes
Text
Unlocking Data Science's Potential: Transforming Data into Perceptive Meaning
Data is created on a regular basis in our digitally connected environment, from social media likes to financial transactions and detection labour. However, without the ability to extract valuable insights from this enormous amount of data, it is not very useful. Data insight can help you win in that situation. Online Course in Data Science It is a multidisciplinary field that combines computer knowledge, statistics, and subject-specific expertise to evaluate data and provide useful perception. This essay will explore the definition of data knowledge, its essential components, its significance, and its global transubstantiation diligence.

Understanding Data Science: To find patterns and shape opinions, data wisdom essentially entails collecting, purifying, testing, and analysing large, complicated datasets. It combines a number of fields.
Statistics: To establish predictive models and derive conclusions.
Computer intelligence: For algorithm enforcement, robotization, and coding.
Sphere moxie: To place perceptivity in a particular field of study, such as healthcare or finance.
It is the responsibility of a data scientist to pose pertinent queries, handle massive amounts of data effectively, and produce findings that have an impact on operations and strategy.
The Significance of Data Science
1. Informed Decision Making: To improve the stoner experience, streamline procedures, and identify emerging trends, associations rely on data-driven perception.
2. Increased Effectiveness: Businesses can decrease manual labour by automating operations like spotting fraudulent transactions or managing AI-powered customer support.
3. Acclimatised Gests: Websites like Netflix and Amazon analyse user data to provide suggestions for products and verified content.
4. Improvements in Medicine: Data knowledge helps with early problem diagnosis, treatment development, and bodying medical actions.
Essential Data Science Foundations:

1. Data Acquisition & Preparation: Databases, web scraping, APIs, and detectors are some sources of data. Before analysis starts, it is crucial to draw the data, correct offences, eliminate duplicates, and handle missing values.
2. Exploratory Data Analysis (EDA): EDA identifies patterns in data, describes anomalies, and comprehends the relationships between variables by using visualisation tools such as Seaborn or Matplotlib.
3. Modelling & Machine Learning: By using techniques like
Retrogression: For predicting numerical patterns.
Bracket: Used for data sorting (e.g., spam discovery).
For group segmentation (such as client profiling), clustering is used.
Data scientists create models that automate procedures and predict problems. Enrol in a reputable software training institution's Data Science course.
4. Visualisation & Liar: For stakeholders who are not technical, visual tools such as Tableau and Power BI assist in distilling complex data into understandable, captivating dashboards and reports.
Data Science Activities Across Diligence:
1. Online shopping
personalised recommendations for products.
Demand-driven real-time pricing schemes.
2. Finance & Banking
identifying deceptive conditioning.
trading that is automated and powered by predictive analytics.
3. Medical Care
tracking the spread of complaints and formulating therapeutic suggestions.
using AI to improve medical imaging.
4. Social Media
assessing public opinion and stoner sentiment.
curation of feeds and optimisation of content.
Typical Data Science Challenges:
Despite its potential, data wisdom has drawbacks.
Ethics & Sequestration: Preserving stoner data and preventing algorithmic prejudice.
Data Integrity: Inaccurate perception results from low-quality data.
Scalability: Pall computing and other high-performance structures are necessary for managing large datasets.
The Road Ahead:
As artificial intelligence advances, data wisdom will remain a crucial motorist of invention. unborn trends include :
AutoML – Making machine literacy accessible to non-specialists.
Responsible AI – icing fairness and translucency in automated systems.
Edge Computing – Bringing data recycling near to the source for real- time perceptivity.
Conclusion:
Data wisdom is reconsidering how businesses, governments, and healthcare providers make opinions by converting raw data into strategic sapience. Its impact spans innumerous sectors and continues to grow. With rising demand for professed professionals, now is an ideal time to explore this dynamic field.
0 notes
Text
Insights via Amazon Prime Movies and TV Shows Dataset

Introduction
In a rapidly evolving digital landscape, understanding viewer behavior is critical for streaming platforms and analytics companies. A leading streaming analytics firm needed a reliable and scalable method to gather rich content data from Amazon Prime. They turned to ArcTechnolabs for a tailored data solution powered by the Amazon Prime Movies and TV Shows Dataset. The goal was to decode audience preferences, forecast engagement, and personalize content strategies. By leveraging structured, comprehensive data, the client aimed to redefine content analysis and elevate user experience through data-backed decisions.
The Client
The client is a global streaming analytics firm focused on helping OTT platforms improve viewer engagement through data insights. With users across North America and Europe, the client analyzes millions of data points across streaming apps. They were particularly interested in Web scraping Amazon Prime Video content to refine content curation strategies and trend forecasting. ArcTechnolabs provided the capability to extract Amazon Prime Video data efficiently and compliantly, enabling deeper analysis of the Amazon Prime shows and movie dataset for smarter business outcomes.
Key Challenges
The firm faced difficulties in consistently collecting detailed, structured content metadata from Amazon Prime. Their internal scraping setup lacked scale and often broke with site updates. They couldn’t track changing metadata, genres, cast info, episode drops, or user engagement indicators in real time. Additionally, there was no existing pipeline to gather reliable streaming media data from Amazon Prime or track regional content updates. Their internal tech stack also lacked the ability to filter, clean, and normalize data across categories and territories. Off-the-shelf Amazon Prime Video Data Scraping Services were either limited in scope or failed to deliver structured datasets. The client also struggled to gain competitive advantage due to limited exposure to OTT Streaming Media Review Datasets, which limited content sentiment analysis. They required a solution that could extract Amazon Prime streaming media data at scale and integrate it seamlessly with their proprietary analytics platform.

Key Solution
ArcTechnolabs provided a customized data pipeline built around the Amazon Prime Movies and TV Shows Dataset, designed to deliver accurate, timely, and well-structured metadata. The solution was powered by our robust Web Scraping OTT Data engine and supported by our advanced Web Scraping Services framework. We deployed high-performance crawlers with adaptive logic to capture real-time data, including show descriptions, genres, ratings, and episode-level details. With Mobile App Scraping Services , the dataset was enriched with data from Amazon Prime’s mobile platforms, ensuring broader coverage. Our Web Scraping API Services allowed seamless integration with the client's existing analytics tools, enabling them to track user engagement metrics and content trends dynamically. The solution ensured regional tagging, global categorization, and sentiment analysis inputs using linked OTT Streaming Media Review Datasets , giving the client a full-spectrum view of viewer behavior across platforms.

Client Testimonial
"ArcTechnolabs exceeded our expectations in delivering a highly structured, real-time Amazon Prime Movies and TV Shows Dataset. Their scraping infrastructure was scalable and resilient, allowing us to dig deep into viewer preferences and optimize our recommendation engine. Their ability to integrate mobile and web data in a single feed gave us unmatched insight into how content performs across devices. The collaboration has helped us become more predictive and precise in our analytics."
— Director of Product Analytics, Global Streaming Insights Firm
Conclusion
This partnership demonstrates how ArcTechnolabs empowers streaming intelligence firms to extract actionable insights through advanced data solutions. By tapping into the Amazon Prime Movies and TV Shows Dataset, the client was able to break down barriers in content analysis and improve viewer experience significantly. Through a combination of custom Web Scraping Services , mobile integration, and real-time APIs, ArcTechnolabs delivered scalable tools that brought visibility and control to content strategy. As content-driven platforms grow, data remains the most powerful tool—and ArcTechnolabs continues to lead the way.
Source >> https://www.arctechnolabs.com/amazon-prime-movies-tv-dataset-viewer-insights.php
🚀 Grow smarter with ArcTechnolabs! 📩 [email protected] | 📞 +1 424 377 7584 Real-time datasets. Real results.
#AmazonPrimeMoviesAndTVShowsDataset#WebScrapingAmazonPrimeVideoContent#AmazonPrimeVideoDataScrapingServices#OTTStreamingMediaReviewDatasets#AnalysisOfAmazonPrimeTVShows#WebScrapingOTTData#AmazonPrimeTVShows#MobileAppScrapingServices
0 notes
Text
Stay Competitive with Real-Time Price Comparison Data!

In a dynamic eCommerce world, pricing drives customer decisions—and smart businesses stay ahead by leveraging data.
📊 Key Takeaways from the Page: • Access structured, real-time pricing data from leading platforms (Amazon, Walmart, eBay & more). • Monitor competitors’ pricing, discounts, and stock changes. • Make informed decisions with automated price tracking tools. • Scale effortlessly with Real Data API’s high-frequency scraping and easy integration.
🔎 “80% of online shoppers compare prices before making a purchase—are you ready to meet them where they are?”
🚀 Optimize your pricing strategy today and dominate the digital shelf!
0 notes
Text
Dynamic Pricing & Food Startup Insights with Actowiz Solutions
Introduction
In today’s highly competitive food and restaurant industry, the difference between success and failure often lies in the ability to adapt swiftly to market dynamics. Investors and food startups are leveraging data intelligence to fine-tune pricing models, optimize profitability, and enhance operational performance. At the forefront of this transformation is Actowiz Solutions, a leading provider of web scraping and data intelligence services.
Why Dynamic Pricing is a Game-Changer
Dynamic pricing, also known as real-time pricing, allows businesses to adjust prices based on demand, competitor prices, customer behavior, and other external factors. For food startups, this can be the difference between overstocked perishables and sold-out menus.
Key Benefits of Dynamic Pricing:
Increased Revenue: Charge premium rates during peak demand.
Inventory Optimization: Reduce food waste by adjusting prices on soon-to-expire items.
Improved Competitiveness: Stay ahead by responding to competitor price changes in real-time.
Enhanced Customer Segmentation: Offer tailored pricing based on user location or purchase history.
How Actowiz Solutions Powers Dynamic Pricing
Actowiz Solutions enables startups and investors to collect vast amounts of real-time data from food delivery apps, restaurant aggregators, grocery platforms, and market listings. This data is structured and delivered via API or dashboards, enabling easy integration into pricing engines.
Actowiz Dynamic Pricing Data Flow:
flowchart LR A[Food Delivery Platforms] --> B[Web Scraping Engine - Actowiz Solutions] B --> C[Real-Time Price Data Aggregation] C --> D[Analytics Dashboard / API] D --> E[Dynamic Pricing Models for Startups] D --> F[Investor Performance Insights]
Example Datasets Extracted:
Menu prices from Zomato, Uber Eats, DoorDash, and Swiggy
Grocery prices from Instacart, Blinkit, and Amazon Fresh
Consumer review sentiment and delivery time data
Competitor promotional and discount trends
Performance Tracking with Actowiz Solutions
Beyond pricing, performance tracking is vital for both investors and startups. Actowiz Solutions offers detailed KPIs based on real-time web data.
Key Performance Metrics Offered:
Average Delivery Time
Customer Ratings and Reviews
Menu Update Frequency
Offer Usage Rates
Location-wise Performance
These metrics help investors evaluate portfolio startups and allow startups to fine-tune their services.
Sample Performance Dashboard:
Metric Value Trend Avg. Delivery Time 34 mins ⬇️ 5% Avg. Customer Rating 4.3/5 ⬇️ 2% Promo Offer Usage 38% ⬇️ 10% Menu Item Refresh Rate Weekly Stable New User Acquisition +1,200/mo ⬇️ 15%
Real-World Use Case
Case Study: A Vegan Cloud Kitchen Startup in California
A vegan cloud kitchen startup used Actowiz Solutions to scrape competitor pricing and delivery performance from platforms like DoorDash and Postmates. Within 3 months:
Adjusted pricing dynamically, increasing revenue by 18%
Reduced average delivery time by 12% by identifying logistics gaps
Gained deeper insight into customer sentiment through reviews
The investor backing the startup received real-time performance reports, enabling smarter funding decisions.
Infographic: How Actowiz Helps Food Startups Scale
graph TD A[Raw Market Data] --> B[Actowiz Data Extraction] B --> C[Cleaned & Structured Data] C --> D[Startup Analytics Dashboard] D --> E[Dynamic Pricing Engine] D --> F[Performance Reports for Investors]
Why Investors Trust Actowiz Solutions
Actowiz Solutions doesn’t just provide data—it offers clarity and strategy. For investors:
See real-time performance metrics
Evaluate ROI on food startups
Identify trends before they emerge
For startups:
Get actionable data insights
Implement real-time pricing
Measure what matters
Conclusion
Dynamic pricing and performance tracking are no longer luxuries in the food industry—they're necessities. With Actowiz Solutions, both investors and startups can make informed decisions powered by accurate, real-time data. As the food tech space becomes more competitive, only those who leverage data will thrive.
Whether you’re funding the next unicorn or building it—Actowiz is your partner in data-driven growth. Learn More
0 notes
Link
0 notes
Text
Unlock Your Programming Potential with a Python Course in Bangalore
In today’s digital era, learning to code isn’t just for computer scientists — it's an essential skill that opens doors across industries. Whether you're aiming to become a software developer, data analyst, AI engineer, or web developer, Python is the language to start with. If you're located in or near India’s tech capital, enrolling in a Python course in Bangalore is your gateway to building a future-proof career in tech.

Why Python?
Python is one of the most popular and beginner-friendly programming languages in the world. Known for its clean syntax and versatility, Python is used in:
Web development (using Django, Flask)
Data science & machine learning (NumPy, Pandas, Scikit-learn)
Automation and scripting
Game development
IoT applications
Finance and Fintech modeling
Artificial Intelligence (AI) & Deep Learning
Cybersecurity tools
In short, Python is the “Swiss army knife” of programming — easy to learn, powerful to use.
Why Take a Python Course in Bangalore?
Bangalore — India’s leading IT hub — is home to top tech companies like Google, Microsoft, Infosys, Wipro, Amazon, and hundreds of fast-growing startups. The city has a massive demand for Python developers, especially in roles related to data science, machine learning, backend development, and automation engineering.
By joining a Python course in Bangalore, you get:
Direct exposure to real-world projects
Trainers with corporate experience
Workshops with startup founders and hiring partners
Proximity to the best placement opportunities
Peer learning with passionate tech learners
Whether you're a fresher, student, or working professional looking to upskill, Bangalore offers the best environment to learn Python and get hired.
What’s Included in a Good Python Course?
A high-quality Python course in Bangalore typically covers:
✔ Core Python
Variables, data types, loops, and conditionals
Functions, modules, and file handling
Object-Oriented Programming (OOP)
Error handling and debugging
✔ Advanced Python
Iterators, generators, decorators
Working with APIs and databases
Web scraping (with Beautiful Soup and Selenium)
Multi-threading and regular expressions
✔ Real-World Projects
Build a dynamic website using Flask or Django
Create a weather forecasting app
Automate Excel and file management tasks
Develop a chatbot using Python
Analyze datasets using Pandas and Matplotlib
✔ Domain Specializations
Web Development – Django/Flask-based dynamic sites
Data Science – NumPy, Pandas, Matplotlib, Seaborn, Scikit-learn
Machine Learning – Supervised & unsupervised learning models
Automation – Scripts to streamline manual tasks
App Deployment – Heroku, GitHub, and REST APIs
Many training providers also help prepare for Python certifications, such as PCAP (Certified Associate in Python Programming) or Microsoft’s Python certification.
Who Can Join a Python Course?
Python is extremely beginner-friendly. It’s ideal for:
Students (Engineering, BCA, MCA, BSc IT, etc.)
Career switchers from non-tech backgrounds
Working professionals in IT/analytics roles
Startup founders and entrepreneurs
Freelancers and job seekers
There are no prerequisites except basic logical thinking and eagerness to learn.
Career Opportunities after Learning Python
Bangalore has a booming job market for Python developers. Completing a Python course in Bangalore opens opportunities in roles like:
Python Developer
Backend Web Developer
Data Analyst
Data Scientist
AI/ML Engineer
Automation Engineer
Full Stack Developer
DevOps Automation Specialist
According to job portals, Python developers in Bangalore earn ₹5 to ₹15 LPA depending on skillset and experience. Data scientists and ML engineers with Python expertise can earn even higher.
Top Institutes Offering Python Course in Bangalore
You can choose from various reputed institutes offering offline and online Python courses. Some top options include:
Simplilearn – Online + career support
JSpiders / QSpiders – For freshers and job seekers
Intellipaat – Weekend batches with projects
Besant Technologies – Classroom training + placement
Coding Ninjas / UpGrad / Edureka – Project-driven, online options
Ivy Professional School / AnalytixLabs – Python for Data Science specialization
Most of these institutes offer flexible timings, EMI payment options, and placement support.
Why Python is a Must-Have Skill in 2025
Here’s why you can’t ignore Python anymore:
Most taught first language in top universities worldwide
Used by companies like Google, Netflix, NASA, and IBM
Dominates Data Science & AI ecosystems
Huge job demand and salary potential
Enables rapid prototyping and startup MVPs
Whether your goal is to land a job in tech, build a startup, automate tasks, or work with AI models — Python is the key.
Final Thoughts
If you want to break into tech or supercharge your coding journey, there’s no better place than Bangalore — and no better language than Python.
By enrolling in a Python course in Bangalore, you position yourself in the heart of India’s tech innovation, backed by world-class mentorship and career growth.
Ready to transform your future?
Start your Python journey today in Bangalore and code your way to success.
0 notes
Link
[ad_1] In this tutorial, we walk you through building an enhanced web scraping tool that leverages BrightData’s powerful proxy network alongside Google’s Gemini API for intelligent data extraction. You’ll see how to structure your Python project, install and import the necessary libraries, and encapsulate scraping logic within a clean, reusable BrightDataScraper class. Whether you’re targeting Amazon product pages, bestseller listings, or LinkedIn profiles, the scraper’s modular methods demonstrate how to configure scraping parameters, handle errors gracefully, and return structured JSON results. An optional React-style AI agent integration also shows you how to combine LLM-driven reasoning with real-time scraping, empowering you to pose natural language queries for on-the-fly data analysis. !pip install langchain-brightdata langchain-google-genai langgraph langchain-core google-generativeai We install all of the key libraries needed for the tutorial in one step: langchain-brightdata for BrightData web scraping, langchain-google-genai and google-generativeai for Google Gemini integration, langgraph for agent orchestration, and langchain-core for the core LangChain framework. import os import json from typing import Dict, Any, Optional from langchain_brightdata import BrightDataWebScraperAPI from langchain_google_genai import ChatGoogleGenerativeAI from langgraph.prebuilt import create_react_agent These imports prepare your environment and core functionality: os and json handle system operations and data serialization, while typing provides structured type hints. You then bring in BrightDataWebScraperAPI for BrightData scraping, ChatGoogleGenerativeAI to interface with Google’s Gemini LLM, and create_react_agent to orchestrate these components in a React-style agent. class BrightDataScraper: """Enhanced web scraper using BrightData API""" def __init__(self, api_key: str, google_api_key: Optional[str] = None): """Initialize scraper with API keys""" self.api_key = api_key self.scraper = BrightDataWebScraperAPI(bright_data_api_key=api_key) if google_api_key: self.llm = ChatGoogleGenerativeAI( model="gemini-2.0-flash", google_api_key=google_api_key ) self.agent = create_react_agent(self.llm, [self.scraper]) def scrape_amazon_product(self, url: str, zipcode: str = "10001") -> Dict[str, Any]: """Scrape Amazon product data""" try: results = self.scraper.invoke( "url": url, "dataset_type": "amazon_product", "zipcode": zipcode ) return "success": True, "data": results except Exception as e: return "success": False, "error": str(e) def scrape_amazon_bestsellers(self, region: str = "in") -> Dict[str, Any]: """Scrape Amazon bestsellers""" try: url = f" results = self.scraper.invoke( "url": url, "dataset_type": "amazon_product" ) return "success": True, "data": results except Exception as e: return "success": False, "error": str(e) def scrape_linkedin_profile(self, url: str) -> Dict[str, Any]: """Scrape LinkedIn profile data""" try: results = self.scraper.invoke( "url": url, "dataset_type": "linkedin_person_profile" ) return "success": True, "data": results except Exception as e: return "success": False, "error": str(e) def run_agent_query(self, query: str) -> None: """Run AI agent with natural language query""" if not hasattr(self, 'agent'): print("Error: Google API key required for agent functionality") return try: for step in self.agent.stream( "messages": query, stream_mode="values" ): step["messages"][-1].pretty_print() except Exception as e: print(f"Agent error: e") def print_results(self, results: Dict[str, Any], title: str = "Results") -> None: """Pretty print results""" print(f"\n'='*50") print(f"title") print(f"'='*50") if results["success"]: print(json.dumps(results["data"], indent=2, ensure_ascii=False)) else: print(f"Error: results['error']") print() The BrightDataScraper class encapsulates all BrightData web-scraping logic and optional Gemini-powered intelligence under a single, reusable interface. Its methods enable you to easily fetch Amazon product details, bestseller lists, and LinkedIn profiles, handling API calls, error handling, and JSON formatting, and even stream natural-language “agent” queries when a Google API key is provided. A convenient print_results helper ensures your output is always cleanly formatted for inspection. def main(): """Main execution function""" BRIGHT_DATA_API_KEY = "Use Your Own API Key" GOOGLE_API_KEY = "Use Your Own API Key" scraper = BrightDataScraper(BRIGHT_DATA_API_KEY, GOOGLE_API_KEY) print("🛍️ Scraping Amazon India Bestsellers...") bestsellers = scraper.scrape_amazon_bestsellers("in") scraper.print_results(bestsellers, "Amazon India Bestsellers") print("📦 Scraping Amazon Product...") product_url = " product_data = scraper.scrape_amazon_product(product_url, "10001") scraper.print_results(product_data, "Amazon Product Data") print("👤 Scraping LinkedIn Profile...") linkedin_url = " linkedin_data = scraper.scrape_linkedin_profile(linkedin_url) scraper.print_results(linkedin_data, "LinkedIn Profile Data") print("🤖 Running AI Agent Query...") agent_query = """ Scrape Amazon product data for in New York (zipcode 10001) and summarize the key product details. """ scraper.run_agent_query(agent_query) The main() function ties everything together by setting your BrightData and Google API keys, instantiating the BrightDataScraper, and then demonstrating each feature: it scrapes Amazon India’s bestsellers, fetches details for a specific product, retrieves a LinkedIn profile, and finally runs a natural-language agent query, printing neatly formatted results after each step. if __name__ == "__main__": print("Installing required packages...") os.system("pip install -q langchain-brightdata langchain-google-genai langgraph") os.environ["BRIGHT_DATA_API_KEY"] = "Use Your Own API Key" main() Finally, this entry-point block ensures that, when run as a standalone script, the required scraping libraries are quietly installed, and the BrightData API key is set in the environment. Then the main function is executed to initiate all scraping and agent workflows. In conclusion, by the end of this tutorial, you’ll have a ready-to-use Python script that automates tedious data collection tasks, abstracts away low-level API details, and optionally taps into generative AI for advanced query handling. You can extend this foundation by adding support for other dataset types, integrating additional LLMs, or deploying the scraper as part of a larger data pipeline or web service. With these building blocks in place, you’re now equipped to gather, analyze, and present web data more efficiently, whether for market research, competitive intelligence, or custom AI-driven applications. Check out the Notebook. All credit for this research goes to the researchers of this project. Also, feel free to follow us on Twitter and don’t forget to join our 100k+ ML SubReddit and Subscribe to our Newsletter. Asif Razzaq is the CEO of Marktechpost Media Inc.. As a visionary entrepreneur and engineer, Asif is committed to harnessing the potential of Artificial Intelligence for social good. His most recent endeavor is the launch of an Artificial Intelligence Media Platform, Marktechpost, which stands out for its in-depth coverage of machine learning and deep learning news that is both technically sound and easily understandable by a wide audience. The platform boasts of over 2 million monthly views, illustrating its popularity among audiences. [ad_2] Source link
0 notes
Text
Smart Retail Decisions Start with AI-Powered Data Scraping

In a world where consumer preferences change overnight and pricing wars escalate in real time, making smart retail decisions is no longer about instincts—it's about data. And not just any data. Retailers need fresh, accurate, and actionable insights drawn from a vast and competitive digital landscape.
That’s where AI-powered data scraping steps in.
Historically, traditional data scraping has been used to gather ecommerce data. But by leveraging artificial intelligence (AI) in scraping processes, companies can gain real-time, scalable, and predictive intelligence to make informed decisions in retailing.
Here, we detail how data scraping using AI is revolutionizing retailing, its advantages, what kind of data you can scrape, and why it enables high-impact decisions in terms of pricing, inventory, customer behavior, and market trends.
What Is AI-Powered Data Scraping?
Data scraping is an operation of pulling structured data from online and digital channels, particularly websites that do not support public APIs. In retail, these can range from product offerings and price data to customer reviews and availability of items in stock.
AI-driven data scraping goes one step further by employing artificial intelligence such as machine learning, natural language processing (NLP), and predictive algorithms to:
Clean and structure unstructured data
Interpret customer sentiment from reviews
Detect anomalies in prices
Predict market trends
Based on data collected, provide strategic proposals
It's not just about data-gathering—it’s about knowing and taking wise action based on it.
Why Retail Requires Smarter Data Solutions
The contemporary retail sector is sophisticated and dynamic. This is why AI-powered scraping is more important than ever:
Market Changes Never Cease to Occur Prices, demand, and product availability can alter multiple times each day—particularly on marketplaces such as Amazon or Walmart. AI scrapers can monitor and study these changes round-the-clock.
Manual Decision-Making is Too Slow Human analysts can process only so much data. AI accelerates decision-making by processing millions of pieces of data within seconds and highlighting what's significant.
The Competition is Tough Retailers are in a race to offer the best prices, maintain optimal inventory, and deliver exceptional customer experiences. Data scraping allows companies to monitor competitors in real time.
Types of Retail Data You Can Scrape with AI
AI-powered scraping tools can extract and analyze the following retail data from ecommerce sites, review platforms, competitor websites, and search engines:
Product Information
Titles, descriptions, images
Product variants (size, color, model)
Brand and manufacturer details
Availability (in stock/out of stock)
Pricing & Promotions
Real-time price tracking
Historical pricing trends
Discount and offer patterns
Dynamic pricing triggers
Inventory & Supply
Stock levels
Delivery timelines
Warehouse locations
SKU movement tracking
Reviews & Ratings
NLP-based sentiment analysis
Star ratings and text content
Trending complaints or praise
Verified purchase filtering
Market Demand & Sales Rank
Bestsellers by category
Category saturation metrics
Sales velocity signals
New or emerging product trends
Logistics & Shipping
Delivery options and timeframes
Free shipping thresholds
Return policies and costs
Benefits of AI-Powered Data Scraping in Retail
So what happens when you combine powerful scraping capabilities with AI intelligence? Retailers unlock a new dimension of performance and strategy.
1. Real-Time Competitive Intelligence
With AI-enhanced scraping, retailers can monitor:
Price changes across hundreds of competitor SKUs
Promotional campaigns
Inventory status of competitor bestsellers
AI models can predict when a competitor may launch a flash sale or run low on inventory—giving you an opportunity to win customers.
2. Smarter Dynamic Pricing
Machine learning algorithms can:
Analyze competitor pricing history
Forecast demand elasticity
Recommend optimal pricing
Retailers can automatically adjust prices to stay competitive while maximizing margins.
3. Enhanced Product Positioning
By analyzing product reviews and ratings using NLP, you can:
Identify common customer concerns
Improve product descriptions
Make data-driven merchandising decisions
For example, if customers frequently mention packaging issues, that feedback can be looped directly to product development.
4. Improved Inventory Planning
AI-scraped data helps detect:
Which items are trending up or down
Seasonality patterns
Regional demand variations
This enables smarter stocking, reduced overstock, and faster response to emerging trends.
5. Superior Customer Experience
Insights from reviews and competitor platforms help you:
Optimize support responses
Highlight popular product features
Personalize marketing campaigns
Use Cases: How Retailers Are Winning with AI Scraping
DTC Ecommerce Brands
Use AI to monitor pricing and product availability across marketplaces. React to changes in real time and adjust pricing or run campaigns accordingly.
Multichannel Retailers
Track performance and pricing across online and offline channels to maintain brand consistency and pricing competitiveness.
Consumer Insights Teams
Analyze thousands of reviews to spot unmet needs or new use cases—fueling product innovation and positioning.
Marketing and SEO Analysts
Scrape metadata, titles, and keyword rankings to optimize product listings and outperform competitors in search results.
Choosing the Right AI-Powered Scraping Partner
Whether building your own tool or hiring a scraping agency, here’s what to look for:
Scalable Infrastructure
The tool should handle scraping thousands of pages per hour, with robust error handling and proxy support.
Intelligent Data Processing
Look for integrated machine learning and NLP models that analyze and enrich the data in real time.
Customization and Flexibility
Ensure the solution can adapt to your specific data fields, scheduling, and delivery format (JSON, CSV, API).
Legal and Ethical Compliance
A reliable partner will adhere to anti-bot regulations, avoid scraping personal data, and respect site terms of service.
Challenges and How to Overcome Them
While AI-powered scraping is powerful, it’s not without hurdles:
Website Structure Changes
Ecommerce platforms often update their layouts. This can break traditional scraping scripts.
Solution: AI-based scrapers with adaptive learning can adjust without manual reprogramming.
Anti-Bot Measures
Websites deploy CAPTCHAs, IP blocks, and rate limiters.
Solution: Use rotating proxies, headless browsers, and CAPTCHA solvers.
Data Noise
Unclean or irrelevant data can lead to false conclusions.
Solution: Leverage AI for data cleaning, anomaly detection, and duplicate removal.
Final Thoughts
In today's ecommerce disruption, retailers that utilize real-time, smart data will be victorious. AI-driven data scraping solutions no longer represent an indulgence but rather an imperative to remain competitive.
By facilitating data capture and smarter insights, these services support improved customer experience, pricing, marketing, and inventory decisions.
No matter whether you’re introducing a new product, measuring your market, or streamlining your supply chain—smart retailing begins with smart data.
0 notes
Text

Background
The UK e-commerce market is intensely price-driven—especially on platforms like Amazon UK, where sellers compete not just on product quality but on dynamic pricing.
A London-based electronics reseller found it increasingly difficult to maintain price competitiveness, especially against third-party sellers and Amazon’s own listings.
They turned to RetailScrape to implement a real-time Amazon UK price scraping solution focused on product-specific monitoring and smart price adjustments.
Business Objectives
Monitor top-selling electronics SKUs on Amazon UK in real time
Automate price benchmarking against competitors, including Amazon Retail
Enable dynamic repricing to retain Buy Box share
Improve margin optimization and increase sales conversions
Challenges
1. Amazon’s Algorithmic Pricing: Amazon frequently adjusts product prices based on demand, competition, and inventory—often several times a day.
2. Buy Box Competition: Winning the Buy Box is essential for sales, but price is the primary deciding factor.
3. Manual Price Reviews: Previously, the client reviewed pricing only once daily, missing out on mid-day price changes.
RetailScrape’s Data-Driven Solution
RetailScrape deployed a custom Amazon UK Scraping Pipeline configured to track:
Hourly prices for over 500 competitor-listed SKUs
Buy Box ownership status
Seller names and ratings
Amazon Retail price (if applicable)
Availability and delivery time
Data was pushed directly into the client’s pricing engine via RetailScrape’s secure API, enabling automated repricing rules.
Sample Extracted Data
Key Insights Delivered
1. Amazon Undercuts: Amazon Retail was undercutting third-party sellers by 3-7% in 40% of tracked SKUs.
2. Evening Discounts: The lowest competitor prices were often posted between 7 PM – 10 PM GMT.
3. Buy Box Sensitivity: A pricing difference as small as £0.30 often determined Buy Box status.
Client Actions Enabled by RetailScrape
Set up automated repricing rules triggered when a competitor lowered prices by more than 1%.
Introduced “Buy Box Guardrails”—ensuring minimum margin thresholds were met while staying competitive.
Deprioritized listings where Amazon Retail owned the Buy Box consistently, reallocating marketing budget to other products.
Business Results Achieved (After 6 Weeks)

“RetailScrape turned our Amazon pricing strategy from reactive to real-time. Within a month, we nearly doubled our Buy Box retention and improved margins without sacrificing competitiveness.”
- CE-Commerce Director, London Electronics Seller
Conclusion
For UK-based Amazon sellers, competitive pricing isn't a nice-to-have—it's survival. With RetailScrape, our London client transitioned to a data-first strategy using real-time Amazon UK scraping. The result? Better pricing decisions, improved visibility, and healthier profit margins.
RetailScrape continues to support them with advanced analytics and API-based automation as they scale across new product lines in 2025.
Read more >> https://www.retailscrape.com/amazon-price-tracking-for-london-retailers.php
officially published by https://www.retailscrape.com/.
#AmazonUKScrapingData#RealTimeAmazonScraping#AmazonUKPriceScraping#AmazonUKScrapingPipeline#PriceOptimization#RetailScrapeAPI#DynamicPricingStrategy#CompetitorPriceTracking#AmazonPricingData#AmazonSellerAnalytics#eCommercePriceOptimization
0 notes
Text
Unlock Fashion Intelligence: Scraping Fashion Products from Namshi.com

Unlock Fashion Intelligence: Scraping Fashion Products from Namshi.com
In the highly competitive world of online fashion retail, data is power. Whether you're a trend tracker, competitive analyst, eCommerce business owner, or digital marketer, having access to accurate and real-time fashion product data gives you a serious edge. At DataScrapingServices.com, we offer tailored Namshi.com Fashion Product Scraping Services to help you extract structured and up-to-date product data from one of the Middle East’s leading online fashion retailers.
Namshi.com has emerged as a prominent eCommerce platform, particularly in the UAE and other GCC countries. With a wide range of categories such as men’s, women’s, and kids’ clothing, shoes, bags, beauty, accessories, and premium brands, it offers a treasure trove of data for fashion retailers and analysts. Scraping data from Namshi.com enables businesses to keep pace with shifting fashion trends, monitor competitor pricing, and optimize product listings.
✅ Key Data Fields Extracted from Namshi.com
When scraping Namshi.com, we extract highly relevant product information, including:
Product Name
Brand Name
Price (Original & Discounted)
Product Description
Category & Subcategory
Available Sizes & Colors
Customer Ratings and Reviews
Product Images
SKU/Item Code
Stock Availability
These data points can be customized to meet your specific needs and can be delivered in formats such as CSV, Excel, JSON, or through APIs for easy integration into your database or application.
💡 Benefits of Namshi.com Fashion Product Scraping
1. Competitor Price Monitoring
Gain real-time insights into how Namshi.com prices its fashion products across various categories and brands. This helps eCommerce businesses stay competitive and optimize their pricing strategies.
2. Trend Analysis
Scraping Namshi.com lets you track trending items, colors, sizes, and brands. You can identify which fashion products are popular by analyzing ratings, reviews, and availability.
3. Catalog Enrichment
If you operate an online fashion store, integrating scraped data from Namshi can help you expand your product database, improve product descriptions, and enhance visuals with high-quality images.
4. Market Research
Understanding the assortment, discounts, and promotional tactics used by Namshi helps businesses shape their marketing strategies and forecast seasonal trends.
5. Improved Ad Targeting
Knowing which products are popular in specific regions or categories allows fashion marketers to create targeted ad campaigns for better conversion.
6. Inventory Insights
Tracking stock availability lets you gauge demand patterns, optimize stock levels, and avoid overstock or stockouts.
🌍 Who Can Benefit?
Online Fashion Retailers
Fashion Aggregators
eCommerce Marketplaces
Brand Managers
Retail Analysts
Fashion Startups
Digital Marketing Agencies
At DataScrapingServices.com, we ensure all our scraping solutions are accurate, timely, and fully customizable, with options for daily, weekly, or on-demand extraction.
Best eCommerce Data Scraping Services Provider
Scraping Kohls.com Product Information
Scraping Fashion Products from Namshi.com
Ozon.ru Product Listing Extraction Services
Extracting Product Details from eBay.de
Fashion Products Scraping from Gap.com
Scraping Currys.co.uk Product Listings
Extracting Product Details from BigW.com.au
Macys.com Product Listings Scraping
Scraping Argos.co.uk Home and Furniture Product Listings
Target.com Product Prices Extraction
Amazon Price Data Extraction
Best Scraping Fashion Products from Namshi.com in UAE:
Fujairah, Umm Al Quwain, Dubai, Khor Fakkan, Abu Dhabi, Sharjah, Al Ain, Ajman, Ras Al Khaimah, Dibba Al-Fujairah, Hatta, Madinat Zayed, Ruwais, Al Quoz, Al Nahda, Al Barsha, Jebel Ali, Al Gharbia, Al Hamriya, Jumeirah and more.
📩 Need fashion data from Namshi.com? Contact us at: [email protected]
Visit: DataScrapingServices.com
Stay ahead of the fashion curve—scrape smarter, sell better.
#scrapingfashionproductsfromnamshi#extractingfashionproductsfromnamshi#ecommercedatascraping#productdetailsextraction#leadgeneration#datadrivenmarketing#webscrapingservices#businessinsights#digitalgrowth#datascrapingexperts
0 notes